Semantic Segmentation of Building Roof in Dense Urban Environment with Deep Convolutional Neural Network: A Case Study Using GF2 VHR Imagery in China



Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Sets and Study Areas
2.1.1. Image Preprocessing and Training Data Collection
2.1.2. Collection of Sample Images
2.2. Methodology
2.2.1. Design of DCNN
2.2.2. DCNN Model Training and Inference
2.2.3. Post-Processing with Conditional Random Field (CRF)
3. Results and Discussion
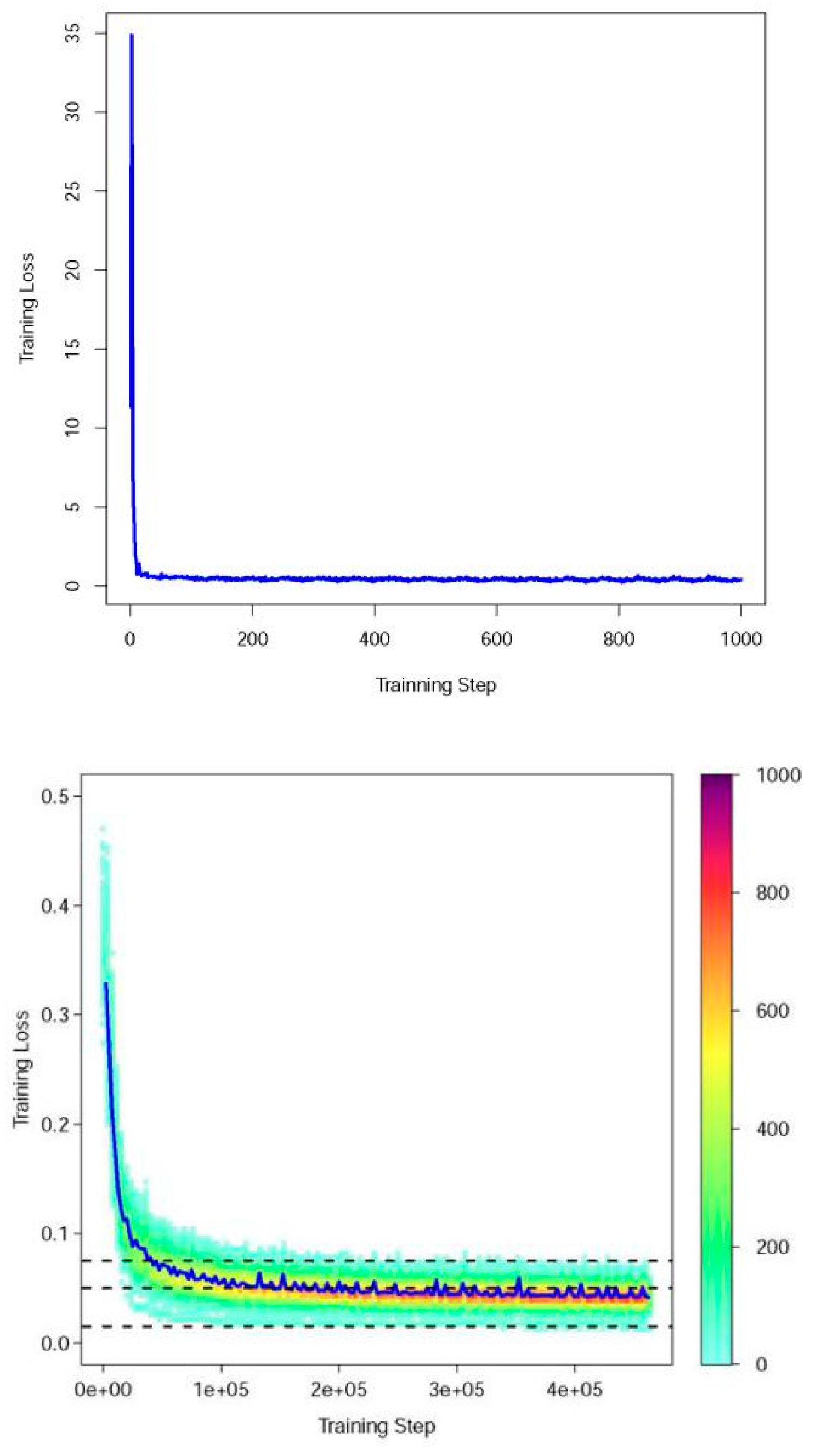
3.1. Training of the DCNN Model
3.2. Qualitative Assessment
3.3. Quantitative Assessment
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- United Nations, Department of Economic and Social Affairs, Population Division. World Urbanization Prospects: The 2014 Revision. Available online: https://population.un.org/wup/Publications/Files/WUP2014 -Report.pdf (accessed on 2 March 2019).
- Alshehhi, R.; Marpu, P.R.; Wei, L.W.; Mura, M.D. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Xie, Y.; Weng, Q. Updating urban extents with nighttime light imagery by using an object-based thresholding method. Remote Sens. Environ. 2016, 187, 1–13. [Google Scholar] [CrossRef]
- Seto, K.C.; Golden, J.S.; Alberti, M.; Nd, T.B. Sustainability in an urbanizing planet. Proc. Natl. Acad. Sci. USA 2017, 114, 8935–8938. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sohn, G.; Dowman, I. Data fusion of high-resolution satellite imagery and lidar data for automatic building extraction. ISPRS J. Photogramm. Remote Sens. 2007, 62, 43–63. [Google Scholar] [CrossRef]
- Awrangjeb, M.; Zhang, C.; Fraser, C.S. Automatic extraction of building roofs using lidar data and multispectral imagery. ISPRS J. Photogramm. Remote Sens. 2013, 83, 1–18. [Google Scholar] [CrossRef]
- Zhang, Y. Optimisation of building detection in satellite images by combining multispectral classification and texture filtering. ISPRS J. Photogramm. Remote Sens. 1999, 54, 50–60. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef] [Green Version]
- Ok, A.O. Automated detection of buildings from single VHR multispectral images using shadow information and graph cuts. ISPRS J. Photogramm. Remote Sens. 2013, 86, 21–40. [Google Scholar] [CrossRef]
- Ngo, T.T.; Mazet, V.; Collet, C.; Fraipont, P.D. Shape-based building detection in visible band images using shadow information. IEEE J. Select. Topics Appl. Earth Obs. Remote Sens. 2016, 99, 1–13. [Google Scholar] [CrossRef]
- Kim, T.; Muller, J.P. Development of a graph-based approach for building detection. Image Vision Comput. 1999, 17, 3–14. [Google Scholar] [CrossRef]
- Sirmacek, B.; Unsalan, C. Urban-area and building detection using sift keypoints and graph theory. IEEE Trans. Geosci. Remote Sens. 2009, 47, 1156–1167. [Google Scholar] [CrossRef]
- Grinias, I.; Panagiotakis, C.; Tziritas, G. MRF-based segmentation and unsupervised classification for building and road detection in peri-urban areas of high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2016, 122, 145–166. [Google Scholar] [CrossRef]
- San, A.D.K.; Turker, M. Support vector machines classification for finding building patches from ikonos imagery: The effect of additional bands. J. Appl. Remote Sens. 2014, 8, 6836–6894. [Google Scholar]
- Sumer, E.; Turker, M. An adaptive fuzzy-genetic algorithm approach for building detection using high-resolution satellite images. Comput. Environ Urban Syst. 2013, 39, 48–62. [Google Scholar] [CrossRef]
- Huang, X.; Yuan, W.; Li, J.; Zhang, L. A new building extraction postprocessing framework for high-spatial-resolution remote-sensing imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 654–668. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- LeCun, Y.; Kavukvuoglu, K.; Farabet, C. Convolutional Networks and Applications in Vision. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS’10), Paris, France, 30 May–2 June 2010; pp. 253–256. [Google Scholar]
- Ross, G.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intel. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 21 June–1 July 2016; pp. 770–778. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Yuan, J. Automatic building extraction in aerial scenes using convolutional networks. arXiv, 2016; arXiv:1602.06564. [Google Scholar]
- Bittner, K.; Cui, S.; Reinartz, P. Building Extraction from Remote Sensing Data using fully convolutional Networks. Int. Arch. Photogram. Remote Sens. Spatial Inf. Sci. 2017, XLII-1/W1, 481–486. [Google Scholar] [CrossRef]
- Sun, L.; Tang, Y.; Zhang, L. Rural building detection in high-resolution imagery based on a two-stage cnn model. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1998–2002. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional neural networks for large-scale remote-sensing image classification. IEEE Trans. Geosci. Remote Sens. 2016, 55, 645–657. [Google Scholar] [CrossRef]
- Microsoft. Building Footprints for the United States. Available online: https://github.com/Microsoft/USBuildingFootprints (accessed on 2 March 2019).
- Ilke, D.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raska, R. Deepglobe 2018: A challenge to parse the earth through satellite images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; 2018; pp. 1721–1781. [Google Scholar]
- Tong, X.; Zhao, W.; Xing, J.; Fu, W. Status and development of China High-Resolution Earth Observation System and application. In Proceedings of the IEEE Symposium on Geoscience and Remote Sensing, Beijing, China, 10–15 July 2016; pp. 3738–3741. [Google Scholar]
- Ian, G.; Yoshua, B.; Aaron, C. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Efficient inference in fully connected crfs with gaussian edge potentials. Adv. Neural Inf. Process. Syst. 2011, 24, 109–117. [Google Scholar]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Salk, C.; Fritz, S.; See, L.; Dresel, C.; McCallum, I. An Exploration of Some Pitfalls of Thematic Map Assessment Using the New Map Tools Resource. Remote Sens. 2018, 10, 376. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor | Spatial Resolution (m) | Spectral Bands (µm) |
|---|---|---|
| PMS-panromatic | 0.8 | 0.45–0.90 |
| PMS-multispectral | 3.2 | 0.45–0.52; 0.52–0.59; 0.63–0.69; 0.77–0.89 |
| City | Region of China | Acquisition Date |
|---|---|---|
| Beijing | North | 20160827 |
| Shenyang | Northeast | 20160612 |
| Chengdu | Southwest | 20160711 |
| Guangzhou | South | 20160723 |
| Wuhan | Central China | 20160901 |
| Shanghai | Southeast | 20160602 |
| Urumqi | Northwest | 20160625 |
| Methods | OA | mIOU |
|---|---|---|
| DCNN | 94.67% | 0.83 |
| DCNN-CRF | 94.69% | 0.83 |
| Ground Truth | Building (DCNN) | NotBuilding (DCNN) | Building (CRF) | NotBuilding (CRF) | |
|---|---|---|---|---|---|
| Segmentation | |||||
| 9968092 | 1902330 | 9447704 | 1399396 | ||
| NotBuilding | 2158790 | 62516836 | 2679178 | 63019770 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, Y.; Wu, Y.; Li, B.; Gao, S.; Liu, M.; Zhan, Y. Semantic Segmentation of Building Roof in Dense Urban Environment with Deep Convolutional Neural Network: A Case Study Using GF2 VHR Imagery in China. Sensors 2019, 19, 1164. https://doi.org/10.3390/s19051164
Qin Y, Wu Y, Li B, Gao S, Liu M, Zhan Y. Semantic Segmentation of Building Roof in Dense Urban Environment with Deep Convolutional Neural Network: A Case Study Using GF2 VHR Imagery in China. Sensors. 2019; 19(5):1164. https://doi.org/10.3390/s19051164
Chicago/Turabian StyleQin, Yuchu, Yunchao Wu, Bin Li, Shuai Gao, Miao Liu, and Yulin Zhan. 2019. "Semantic Segmentation of Building Roof in Dense Urban Environment with Deep Convolutional Neural Network: A Case Study Using GF2 VHR Imagery in China" Sensors 19, no. 5: 1164. https://doi.org/10.3390/s19051164
APA StyleQin, Y., Wu, Y., Li, B., Gao, S., Liu, M., & Zhan, Y. (2019). Semantic Segmentation of Building Roof in Dense Urban Environment with Deep Convolutional Neural Network: A Case Study Using GF2 VHR Imagery in China. Sensors, 19(5), 1164. https://doi.org/10.3390/s19051164