Baseball Player Behavior Classification System Using Long Short-Term Memory with Multimodal Features

 ,
,  and
and
Abstract
:1. Introduction
2. Related Work
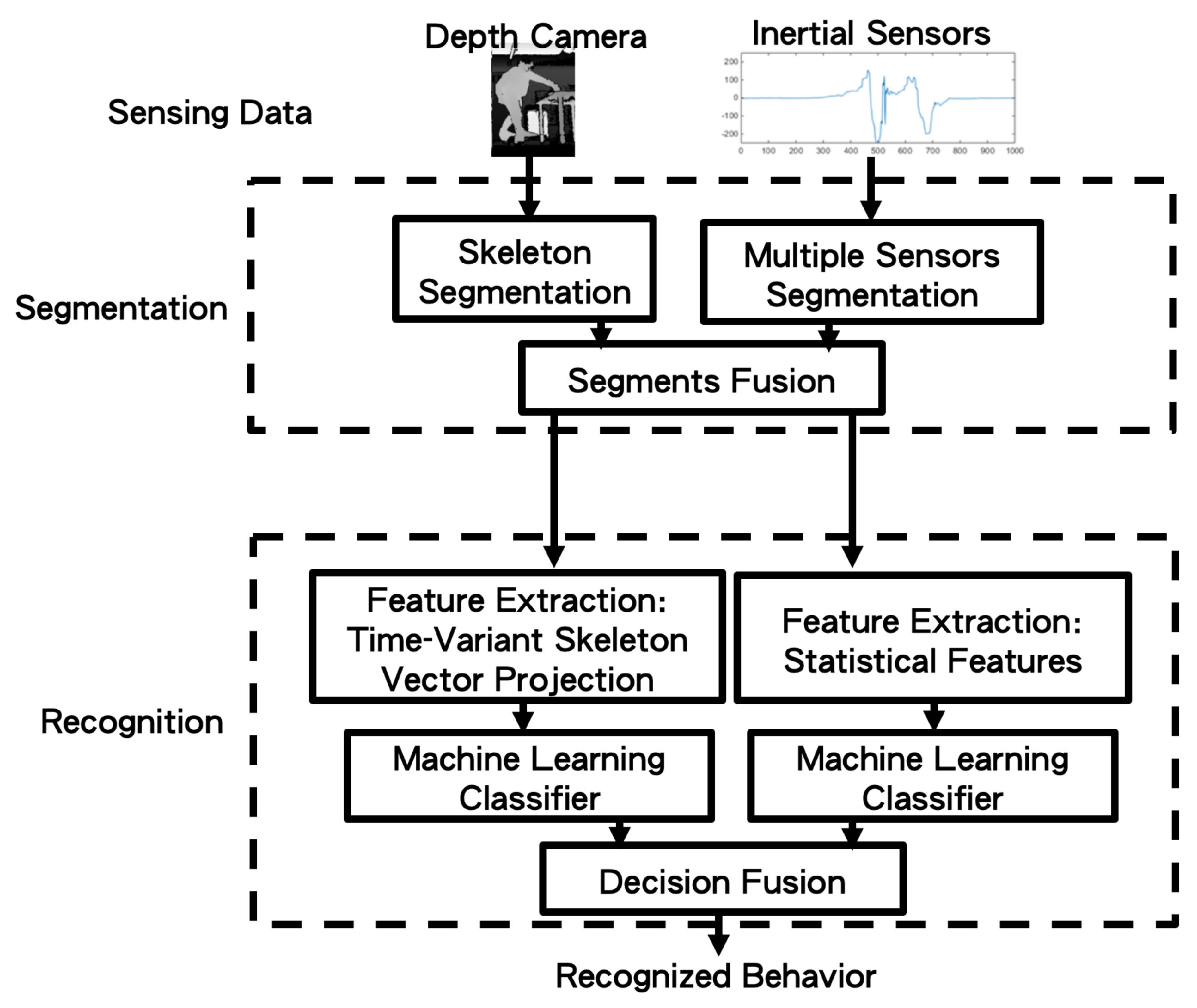
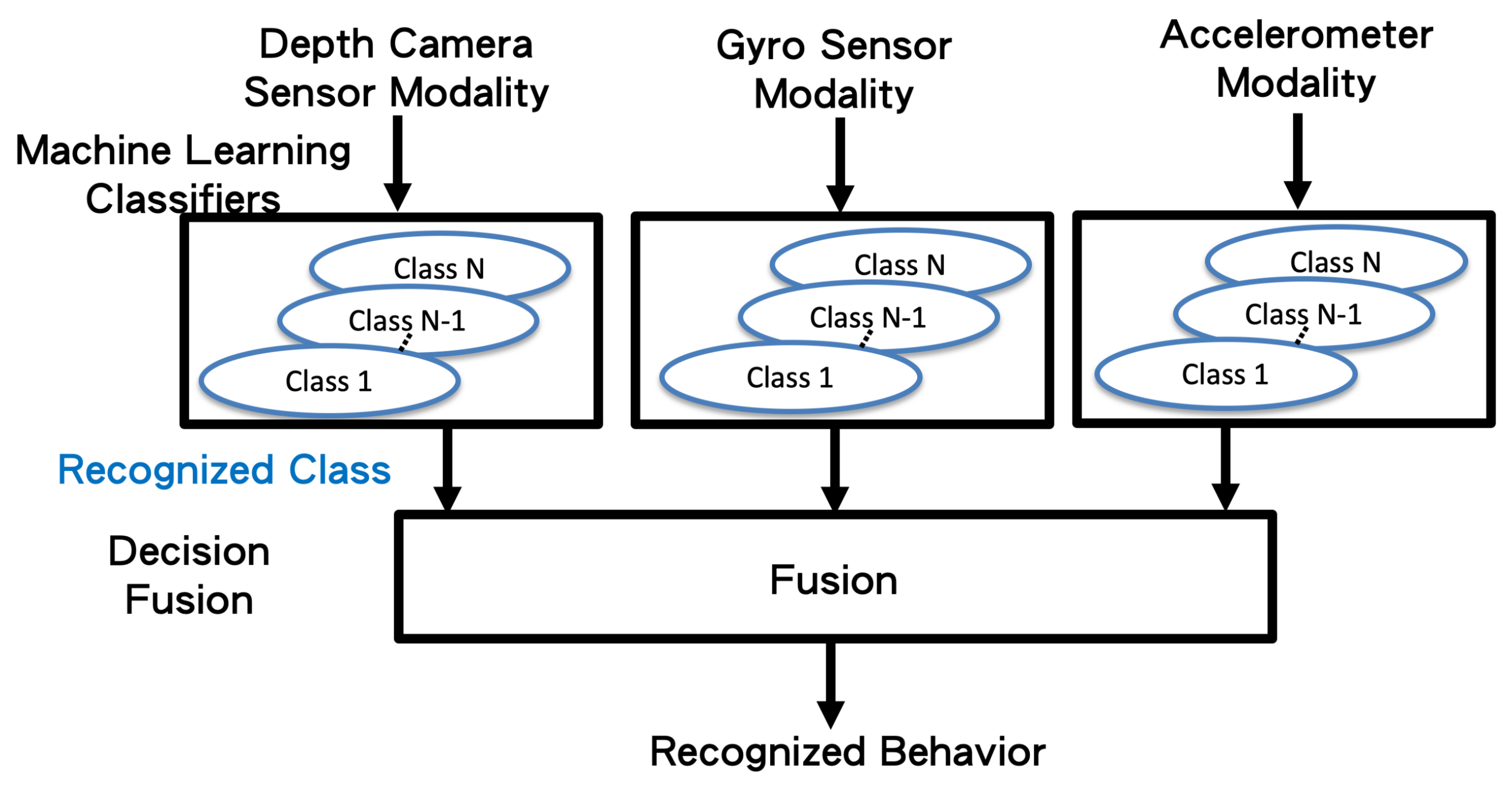
3. Proposed Machine Learning Based Behavior Recognition Fusion System
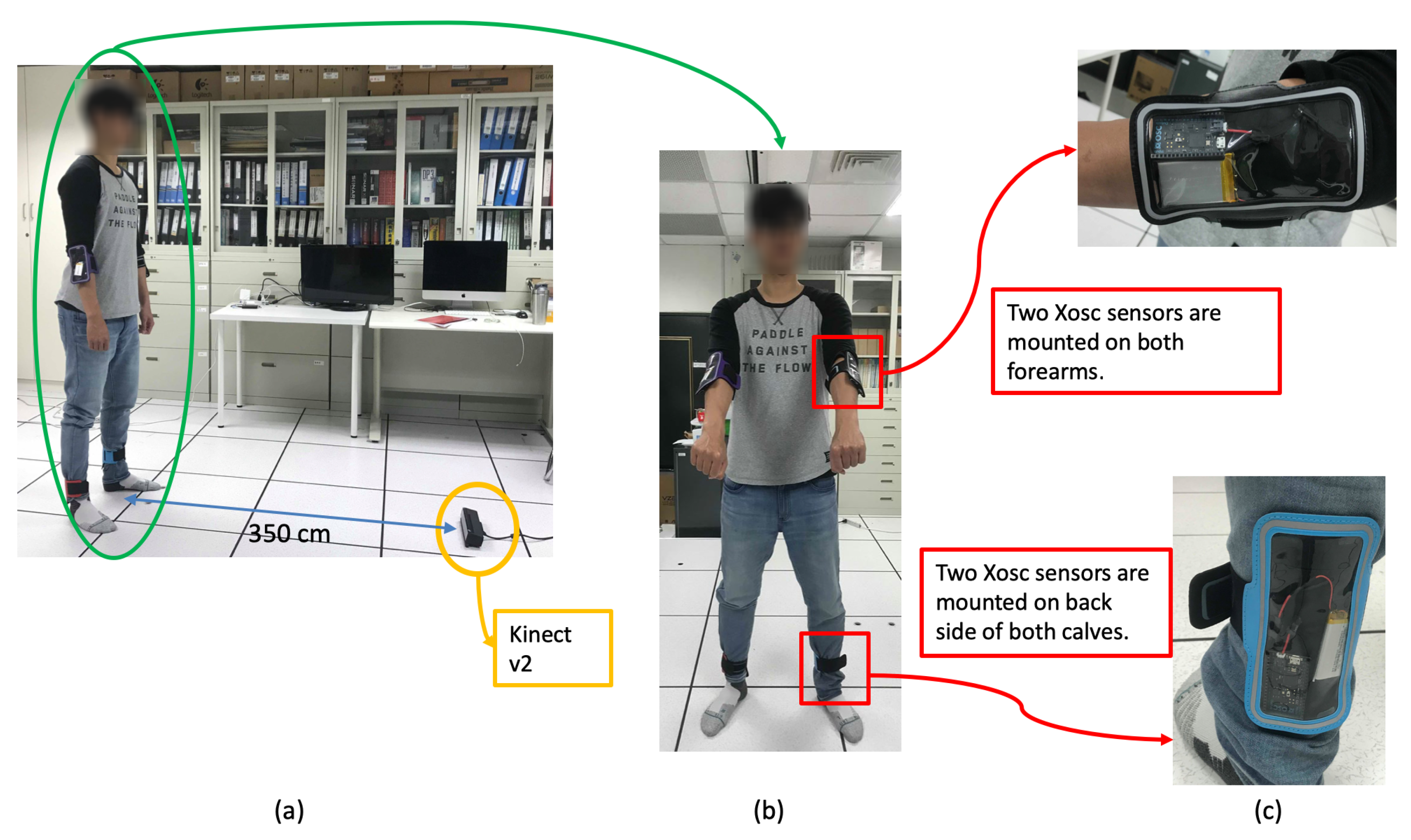
3.1. Segmentation from Multimodal Sensors
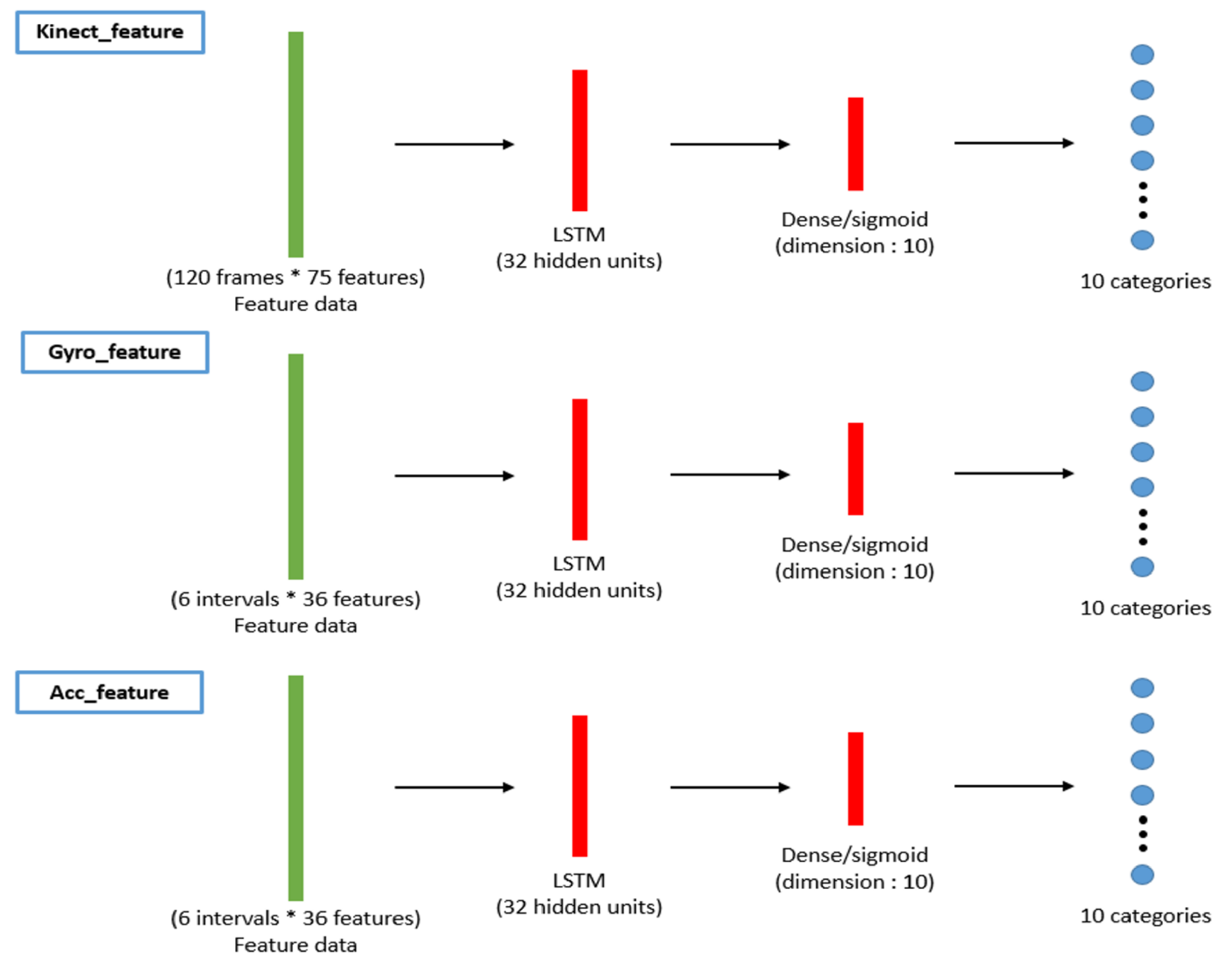
3.2. Behavior Recognition
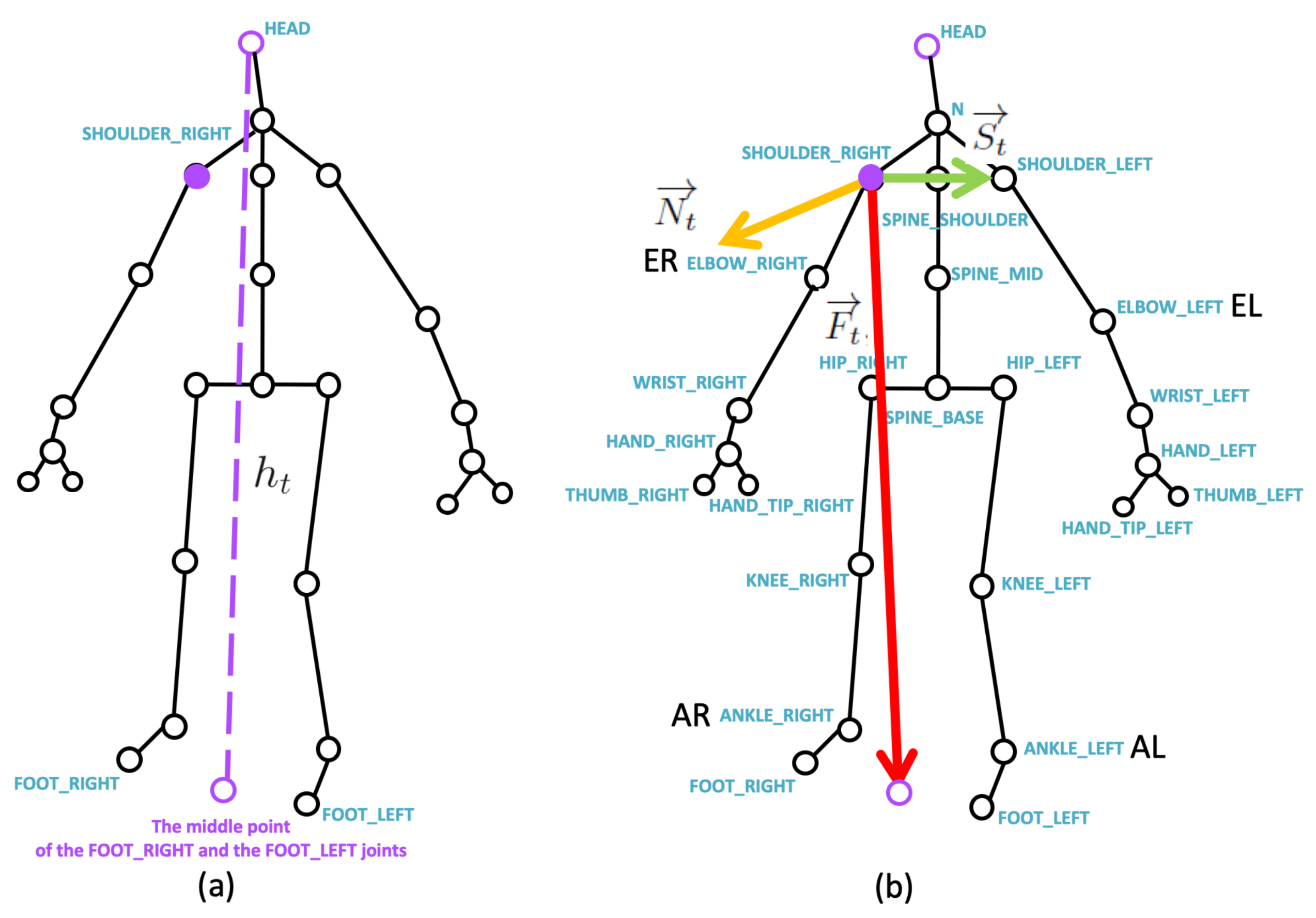
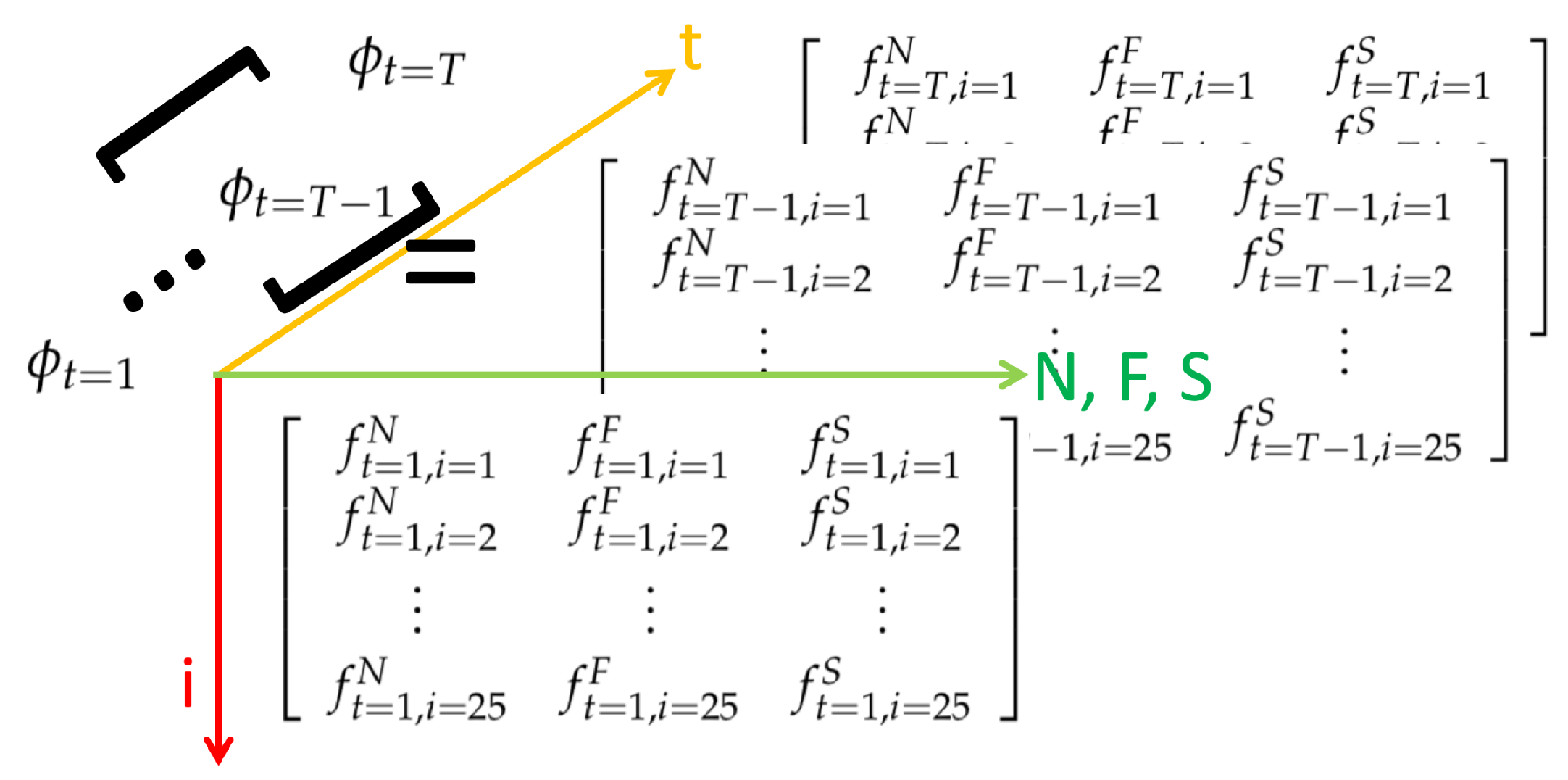
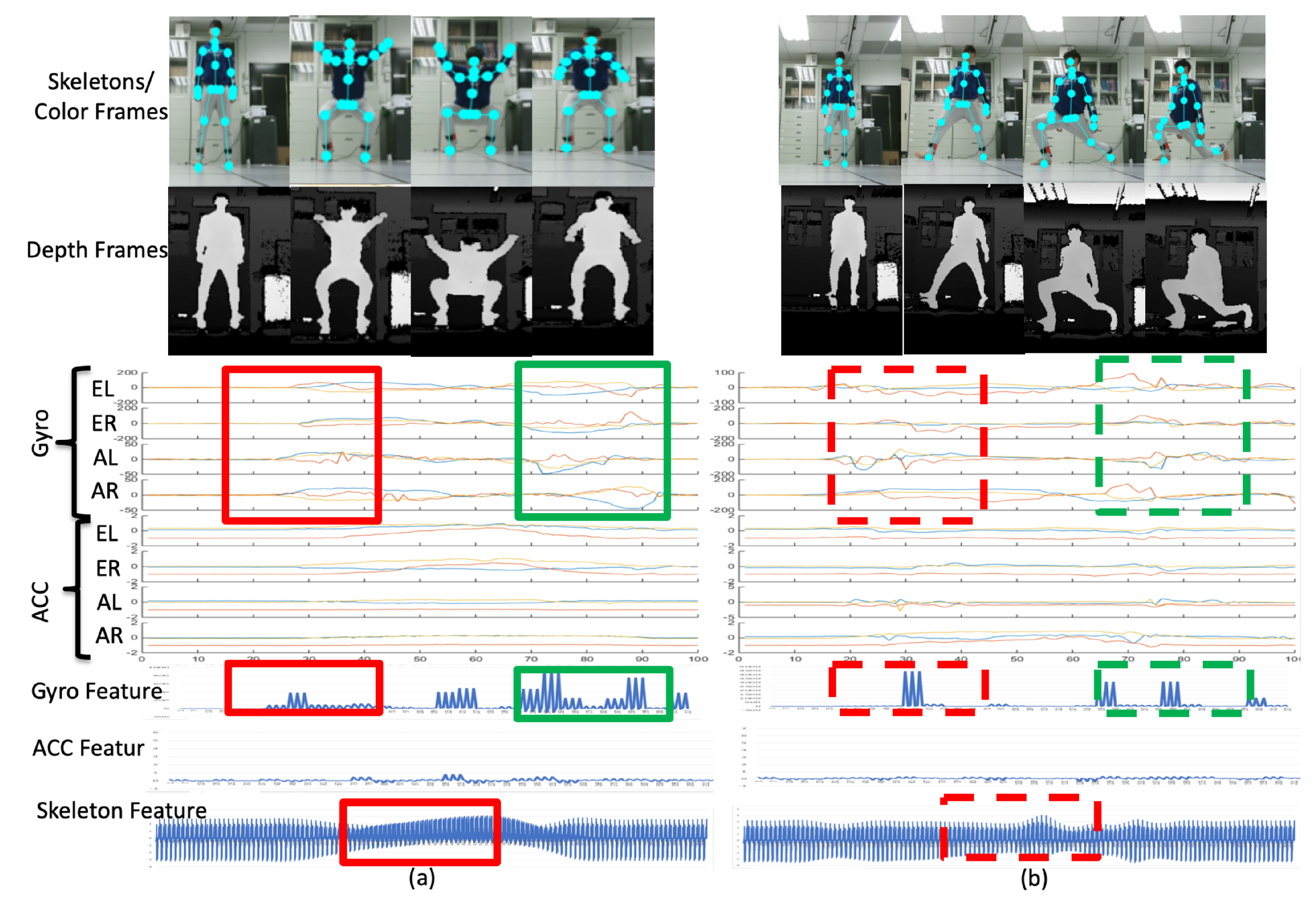
3.2.1. Features from a Depth Camera: Time-Variant Skeleton Vector Projection
3.2.2. Features from the Inertial Sensors: Statistical Features
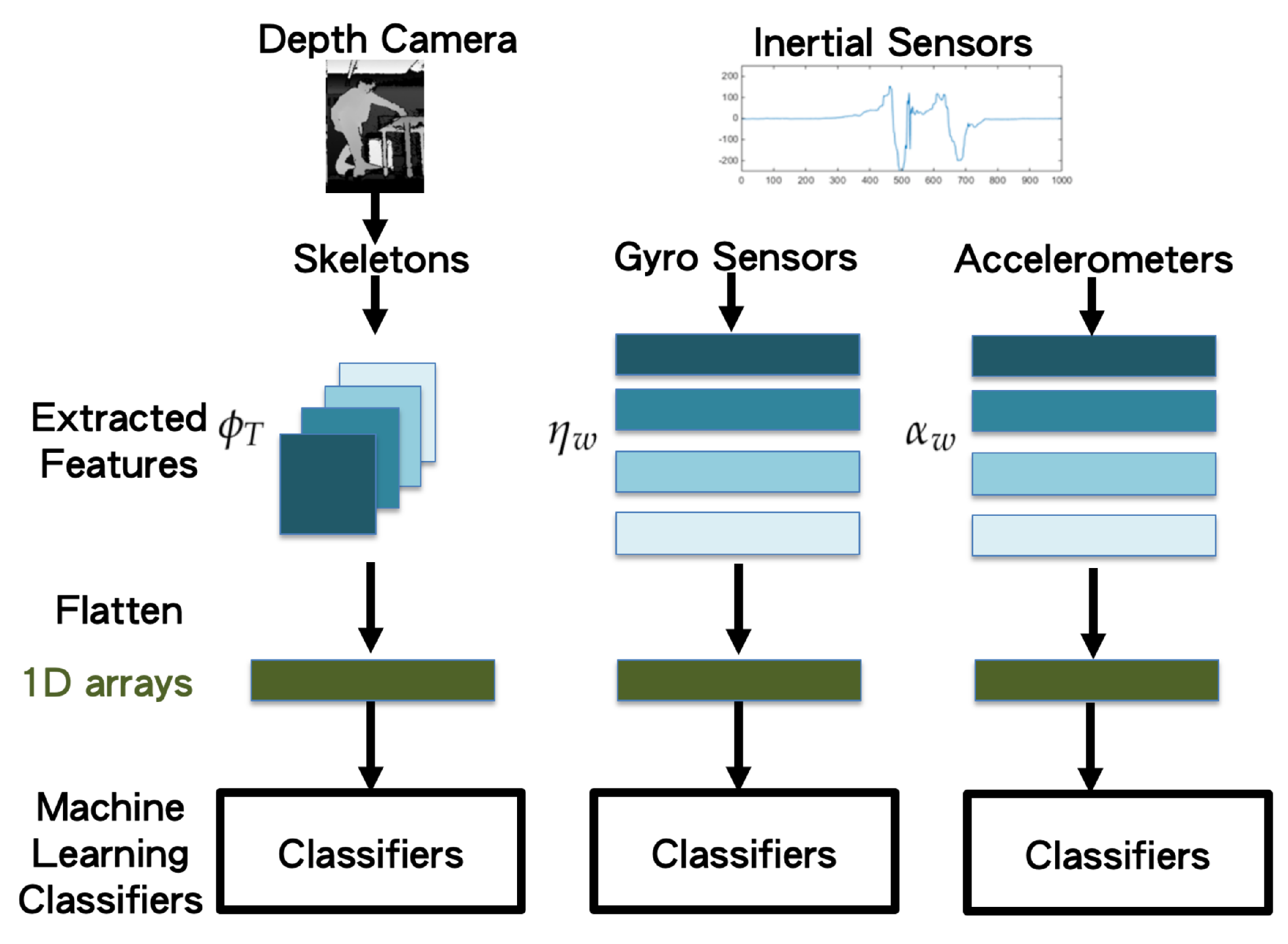
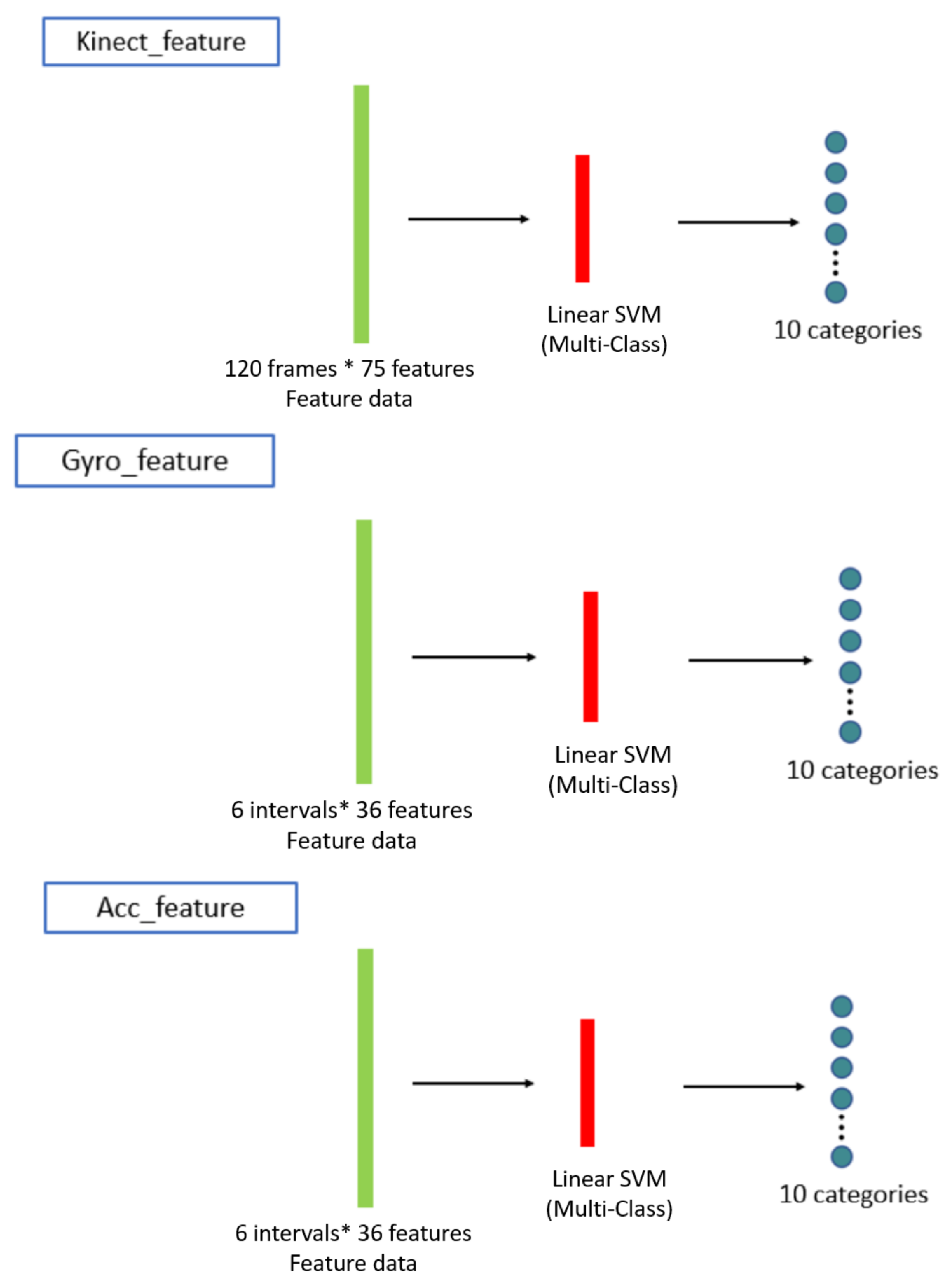
3.3. Machine Learning Classifiers with Decision Fusion
4. Experimental Results
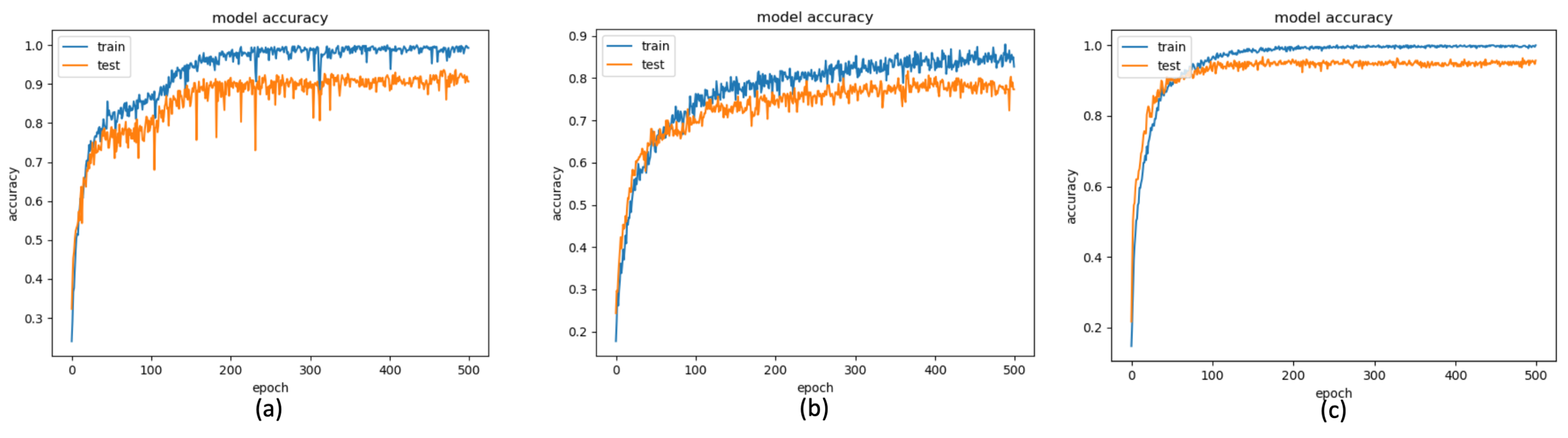
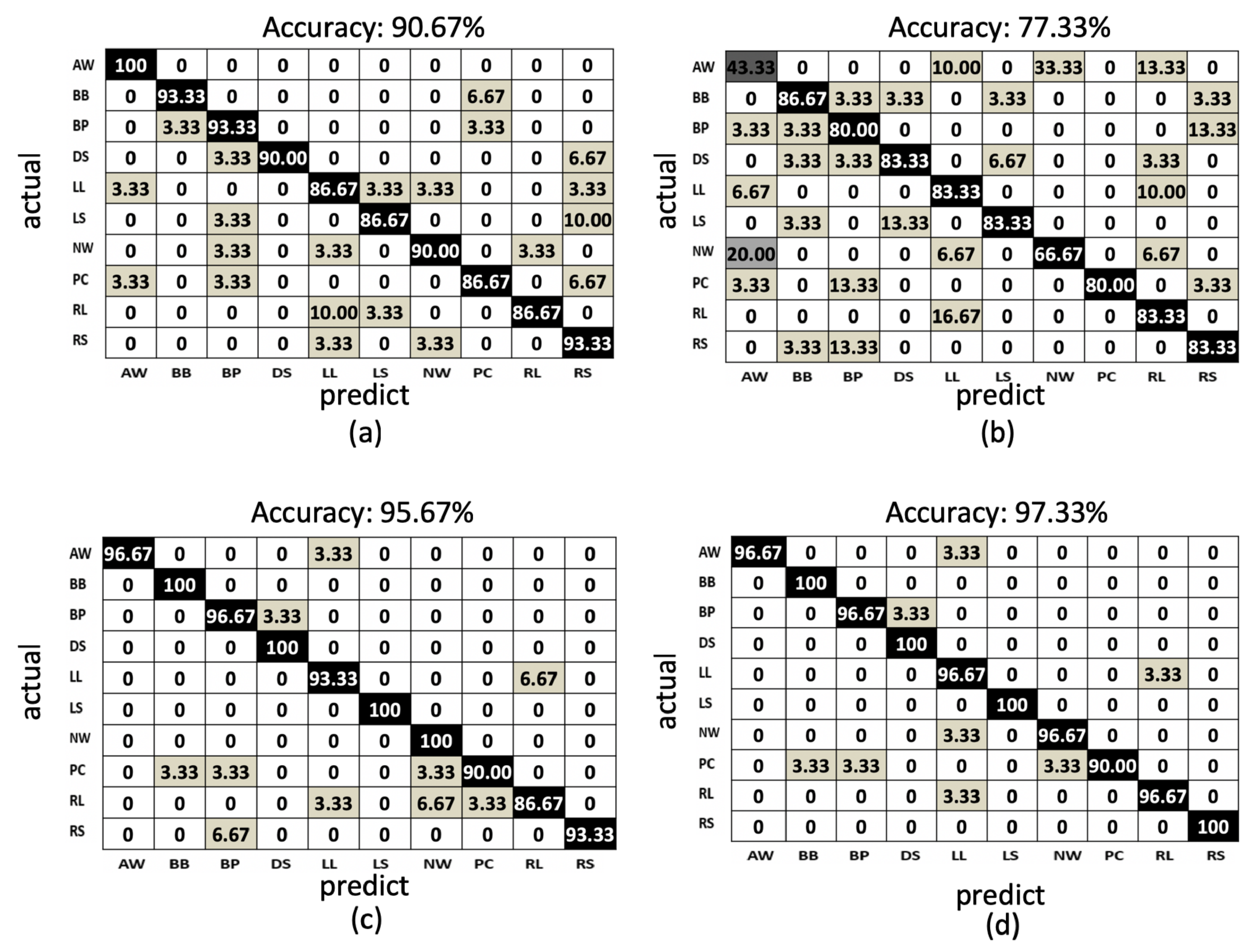
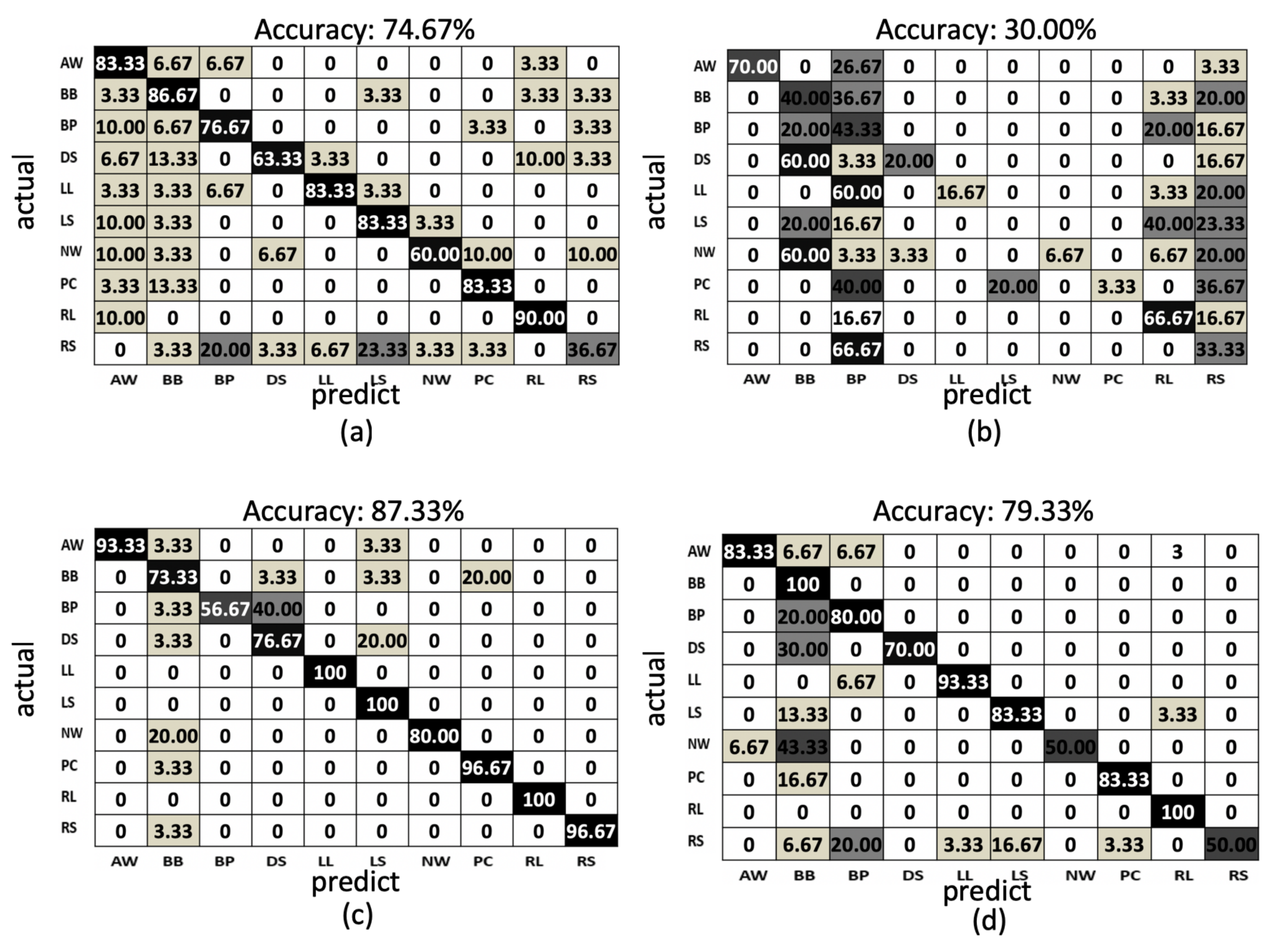
4.1. Quantitative Evaluation
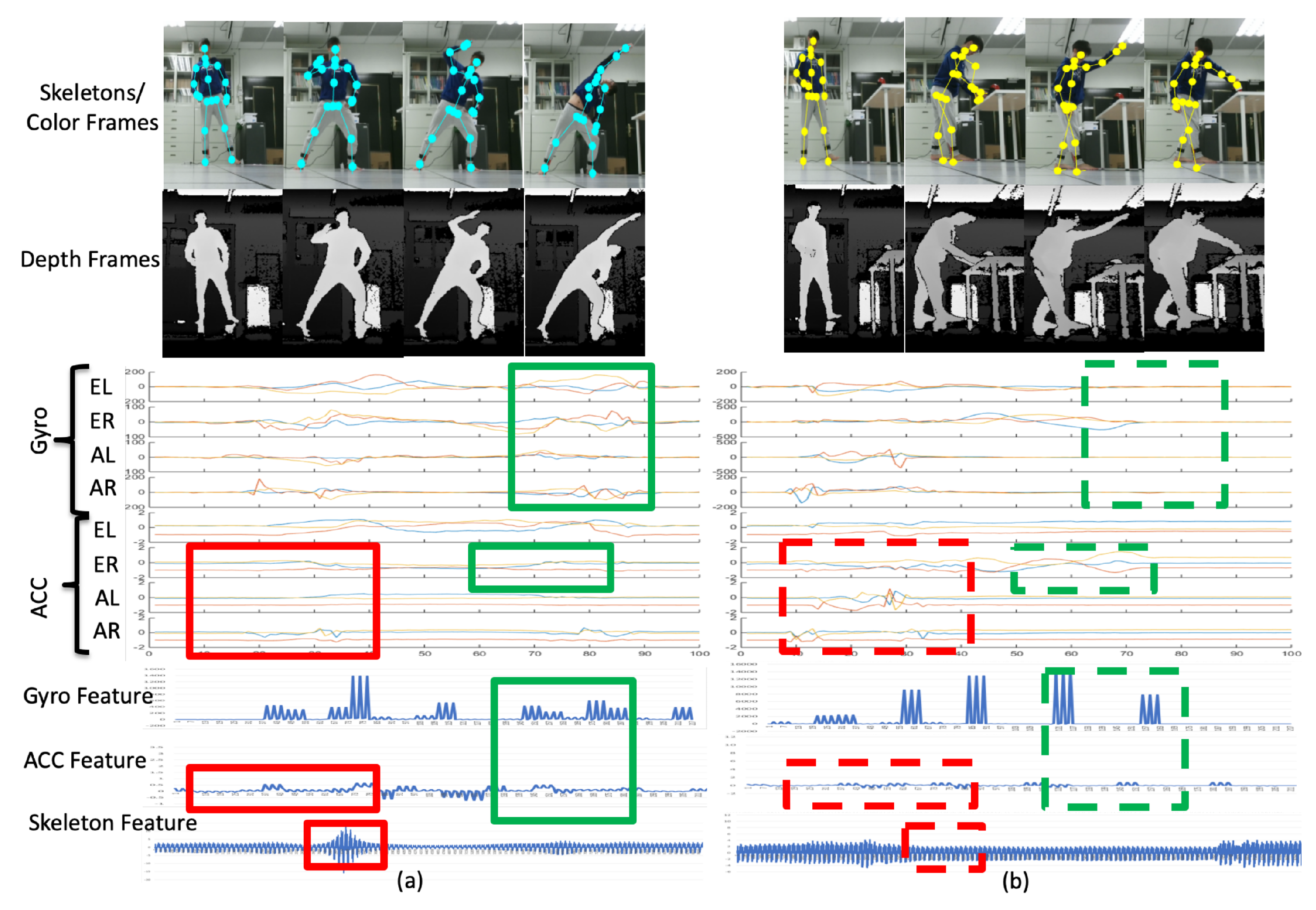
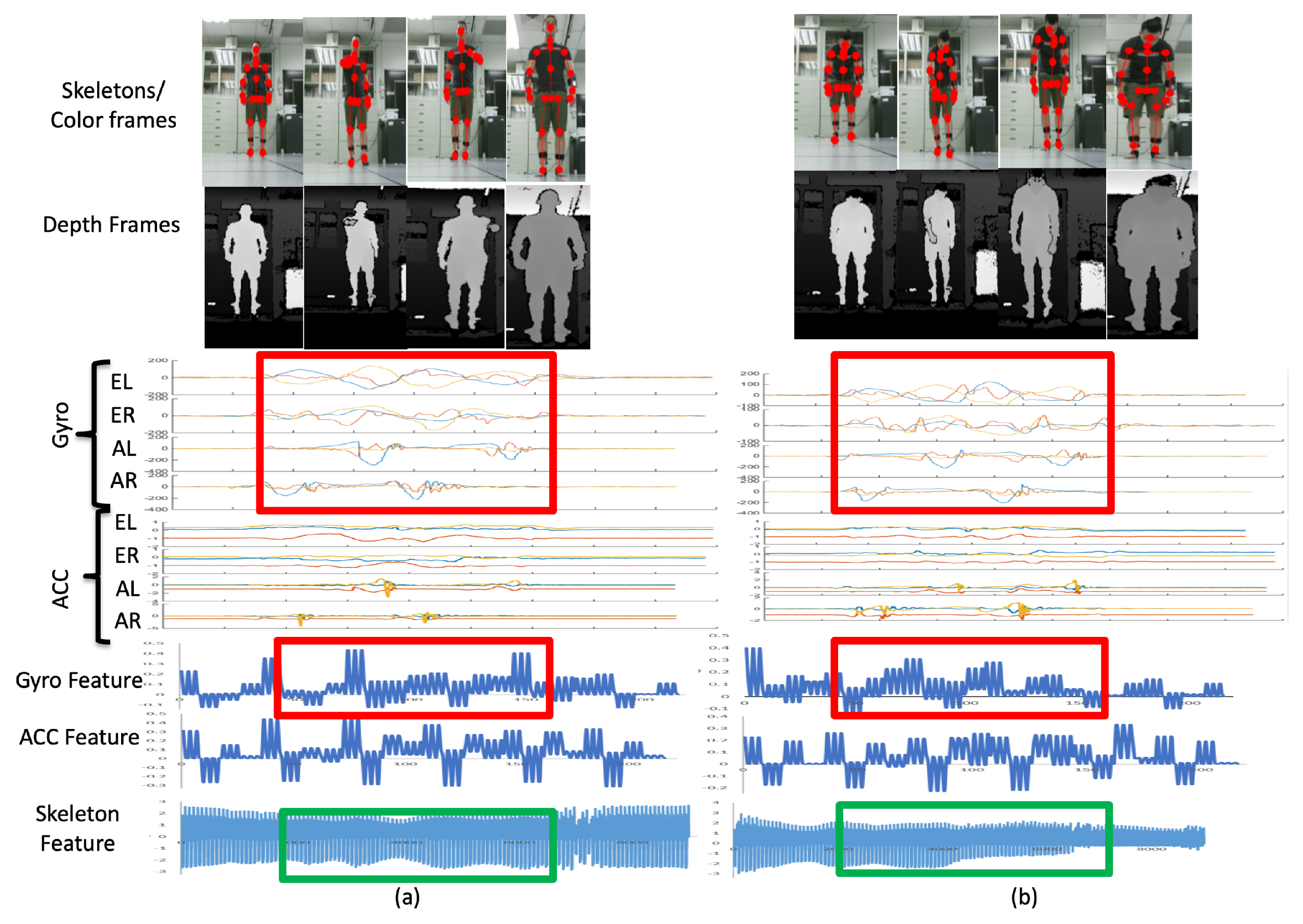
4.2. Qualitative Evaluation
4.3. Complexity Comparison
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zelnik-Manor, L.; Irani, M. Statistical analysis of dynamic actions. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1530–1535. [Google Scholar] [CrossRef] [PubMed]
- Khan, Z.; Sohn, W. Abnormal human activity recognition system based on R-transform and kernel discriminant technique for elderly home care. IEEE Trans. Consum. Electron. 2011, 57, 1843–1850. [Google Scholar] [CrossRef]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Mehta, D.; Sridhar, S.; Sotnychenko, O.; Rhodin, H.; Shafiei, M.; Seidel, H.P.; Xu, W.; Casas, D.; Theobalt, C. VNect: Real-time 3D human pose estimation with a single RGB camera. ACM Trans. Graph. 2017, 36, 44. [Google Scholar] [CrossRef]
- Shotton, J.; Fitzgibbon, A.; Cook, M.; Sharp, T.; Finocchio, R.; Moore, M.; Kipman, A.; Blake, A. Real-time human pose recognition in parts from single depth images. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar]
- Luber, M.; Spinello, L.; Arras, K.O. People tracking in RGB-D data with on-line boosted target models. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, San Francisco, CA, USA, 25–30 September 2011. [Google Scholar]
- Zollhofer, M.; Niebner, M.; Izadi, S.; Rhemann, C.; Zach, C.; Fisher, M.; Wu, C.; Fitzgibbon, A.; Loop, C.; Theobalt, C.; et al. Real-time non-rigid reconstruction using an RGB-D camera. ACM Trans. Gr. 2014, 33, 156. [Google Scholar] [CrossRef]
- Dou, M.; Khamis, S.; Degtyarev, Y.; Davidson, P.; Fanello, S.R.; Kowdle, A.; Escolano, S.O.; Rhemann, C.; Kim, D.; Taylor, J.; et al. Fusion4D: Real-time performance capture of challenging scenes. ACM Trans. Graph. 2016, 35, 114. [Google Scholar] [CrossRef]
- Newcombe, R.A.; Fox, D.; Seitz, S.M. DynamicFusion: Reconstruction and tracking of non-rigid scenes in real-time. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Orts-Escolano, S.; Rhemann, C.; Fanello, S.; Chang, W.; Kowdle, A.; Degtyarev, Y.; Kim, D.; Davidson, P.L.; Khamis, S.; Dou, M.; et al. Holoportation: Virtual 3D teleportation in real-time. In Proceedings of the ACM Symposium on User Interface Software and Technology, Tokyo, Japan, 16–19 October 2016. [Google Scholar]
- Xu, R.; Zhou, S.; Li, W.J. MEMS accelerometer based nonspecific-user hand gesture recognition. IEEE Sens. J. 2012, 12, 1166–1173. [Google Scholar] [CrossRef]
- Gupta, H.P.; Chudgar, H.S.; Mukherjee, S.; Dutta, T.; Sharma, K. A continuous hand gestures recognition technique for human-machine interaction using accelerometer and gyroscope sensors. IEEE Sens. J. 2016, 16, 6425–6432. [Google Scholar] [CrossRef]
- Xie, R.; Cao, J. Accelerometer-based hand gesture recognition by neural network and similarity matching. IEEE Sens. J. 2016, 16, 4537–4545. [Google Scholar] [CrossRef]
- Available online: https://support.xbox.com/en-US/xbox-on-windows/accessories/kinect-for-windows-v2-info (accessed on 1 February 2019).
- Available online: https://www.microsoft.com/en-us/download/details.aspx?id=44561 (accessed on 1 February 2019).
- Dawar, N.; Kehtarnavaz, N. Action detection and recognition in continuous action streams by deep learning-based sensing fusion. IEEE Sens. J. 2018, 18, 9660–9668. [Google Scholar] [CrossRef]
- Kuo, C.H.; Chang, P.C.; Sun, S.W. Behavior recognition using multiple depth cameras based on a time-variant skeleton vector projection. IEEE Trans. Emerg. Top. Comput. Intell. 2017, 1, 294–304. [Google Scholar] [CrossRef]
- Chen, C.; Jafari, R.; Kehtarnavaz, N. A real-time human action recognition system using depth and inertial sensor fusion. IEEE Sens. J. 2016, 16, 773–781. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Peppoloni, L.; Satler, M.; Luchetti, E.; Avizzano, C.A.; Tripicchio, P. Stacked generalization for scene analysis and object recognition. In Proceedings of the IEEE 18th International Conference on Intelligent Engineering Systems INES 2014, Tihany, Hungary, 3–5 July 2014; pp. 215–220. [Google Scholar]
- Available online: http://x-io.co.uk/x-osc/ (accessed on 1 February 2019).
- Available online: https://www.tensorflow.org/ (accessed on 1 February 2019).
- Fan, R.E.; Chen, P.H.; Lin, C.J. Working set selection using second order information for training support vector machines. J. Mach. Learn. Res. 2005, 6, 1889–1918. [Google Scholar]
- Kim, H.; Lee, S.; Lee, D.; Choi, S.; Ju, J.; Myung, H. Real-time human pose estimation and gesture recognition from depth images using superpixels and SVM classifier. Sensors 2015, 15, 12410–12427. [Google Scholar] [CrossRef] [PubMed]
- Pei, L.; Guinness, R.; Chen, R.; Liu, J.; Kuusniemi, H.; Chen, Y.; Chen, L.; Kaistinen, J. Human behavior cognition using smartphone sensors. Sensors 2013, 13, 1402–1424. [Google Scholar] [CrossRef] [PubMed]
- Available online: https://www.mathworks.com/help/stats/svmtrain.html (accessed on 1 February 2019).
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin, Germany, 2009; p. 222. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| LSTM | SVM | |
|---|---|---|
| Depth Sensor | ||
| Gyro Sensor | ||
| Accelerometer | ||
| Decision Fusion |
| LSTM | SVM | |
|---|---|---|
| Depth Sensor Training Time | ||
| Gyro Sensor Training Time | ||
| Accelerometer Training Time | ||
| Decision Fusion Testing Time |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, S.-W.; Mou, T.-C.; Fang, C.-C.; Chang, P.-C.; Hua, K.-L.; Shih, H.-C. Baseball Player Behavior Classification System Using Long Short-Term Memory with Multimodal Features. Sensors 2019, 19, 1425. https://doi.org/10.3390/s19061425
Sun S-W, Mou T-C, Fang C-C, Chang P-C, Hua K-L, Shih H-C. Baseball Player Behavior Classification System Using Long Short-Term Memory with Multimodal Features. Sensors. 2019; 19(6):1425. https://doi.org/10.3390/s19061425
Chicago/Turabian StyleSun, Shih-Wei, Ting-Chen Mou, Chih-Chieh Fang, Pao-Chi Chang, Kai-Lung Hua, and Huang-Chia Shih. 2019. "Baseball Player Behavior Classification System Using Long Short-Term Memory with Multimodal Features" Sensors 19, no. 6: 1425. https://doi.org/10.3390/s19061425
APA StyleSun, S. -W., Mou, T. -C., Fang, C. -C., Chang, P. -C., Hua, K. -L., & Shih, H. -C. (2019). Baseball Player Behavior Classification System Using Long Short-Term Memory with Multimodal Features. Sensors, 19(6), 1425. https://doi.org/10.3390/s19061425