Context Definition and Query Language: Conceptual Specification, Implementation, and Evaluation

 ,
, 

Abstract
:1. Introduction
- analysing the existing Context Query Languages proposed in the literature and deriving a refined set of functional requirements for CQL.
- proposing a refined version of CDQL and presenting a formal specification of its syntax using Extended Backus-Naur Form (EBNF) statements.
- demonstrating the feasibility and applicability of CDQL by presenting exemplary queries for each of the use cases discussed in the paper.
- conducting multiple experiments based on real-world and synthetic dataset to evaluate the performance of an implementation of the proposed language in the CoaaS platform.
2. Motivating Use Cases
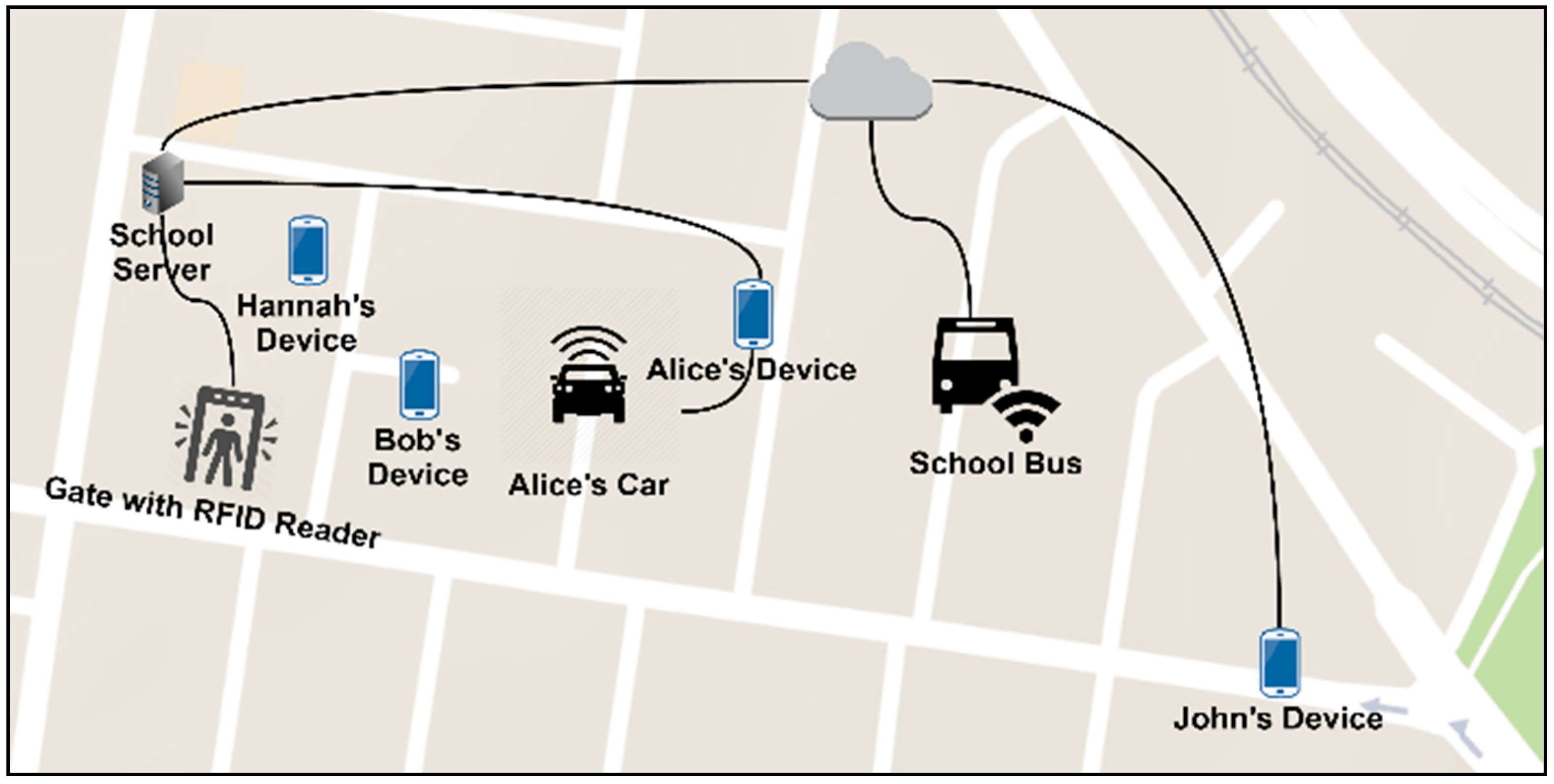
2.1. Use Case 1: School Safety
- The selected parent(s) for picking up Hannah should be trusted by John;
- The selected parent(s) should have a car with an extra seat for Hanna;
- The selected parent(s) should be close enough to the school;
- The child of the selected parent(s) should finish the school at the same time as Hannah;
- The child of the selected parent(s) should be currently at school.
2.2. Use Case 2: Smart Parking Recommender
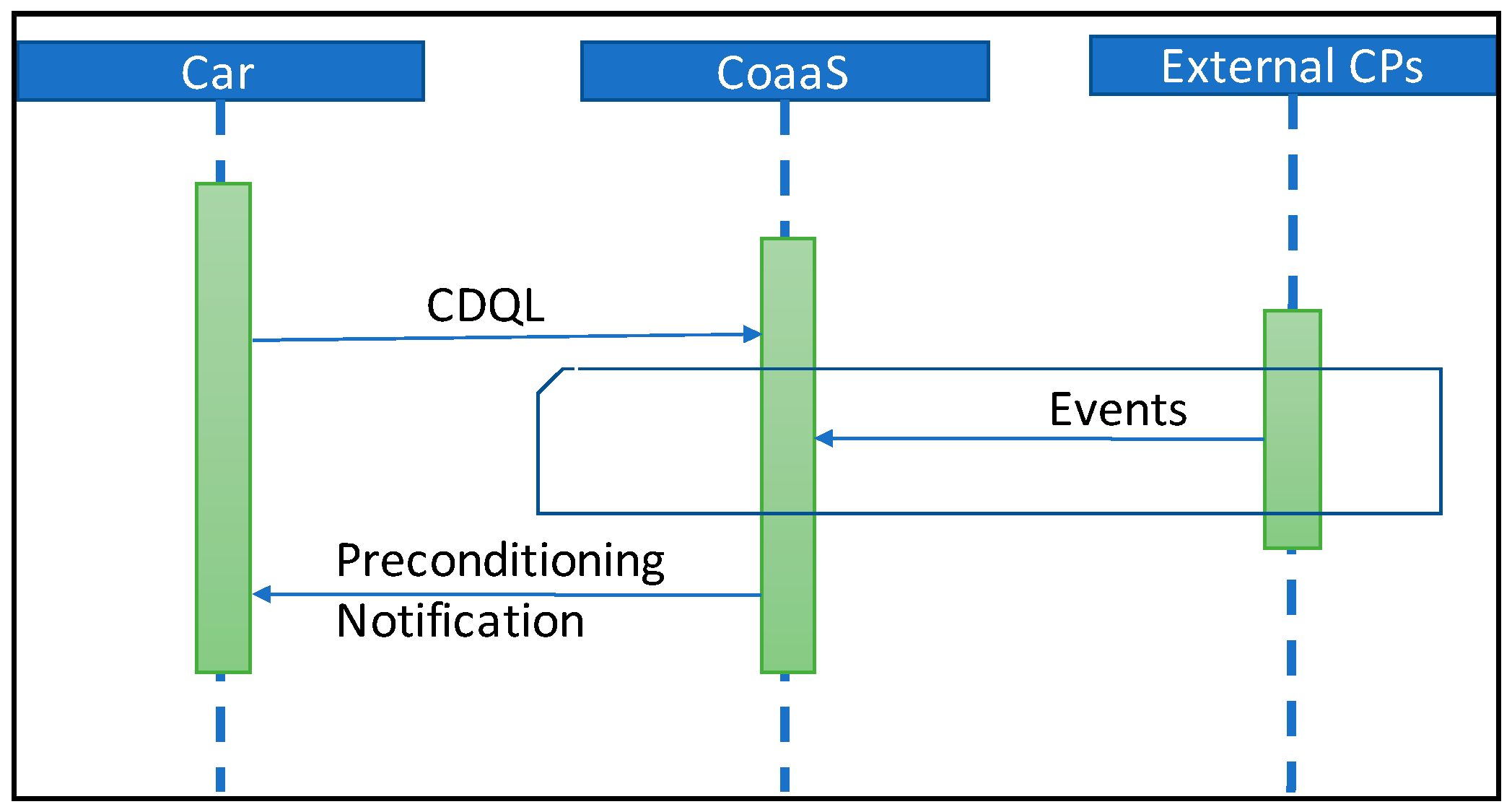
2.3. Use Case 3: Vehicle Pre-Conditioning
- Support for complex context queries concerning various contexts entities and constraints (e.g., join queries);
- Support for domain-based standards (e.g., ontologies) and facilitate interoperability.
- Support for both pull-based and push-based queries;
- Support for aggregating and reasoning functions to query high-level context and also mitigate the privacy issues of sharing sensitive providers’ data with external consumers;
- Support for continuous and situation/event-based queries;
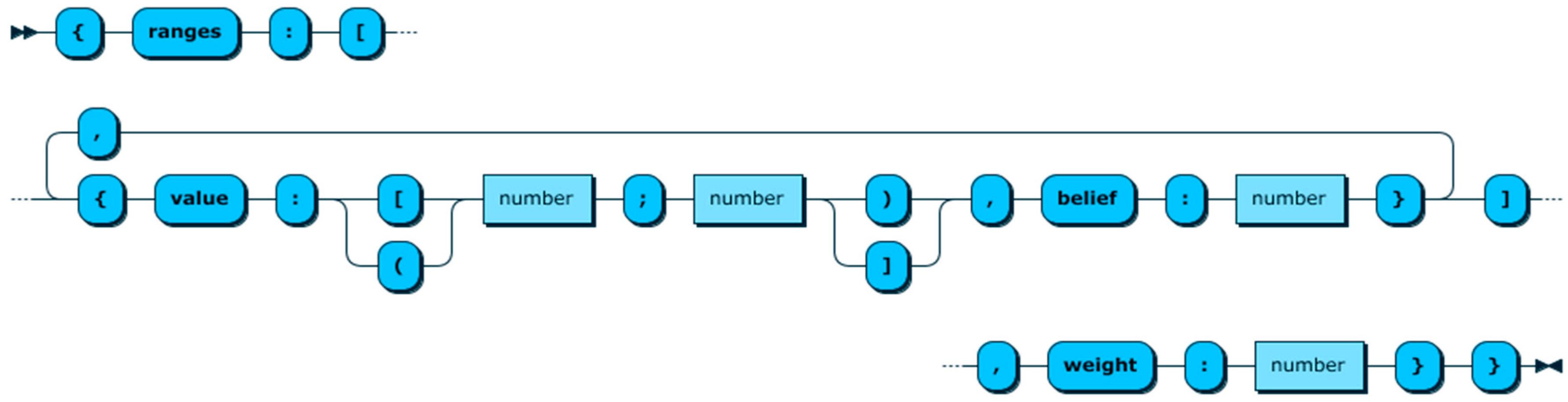
- Support for different aspects of context such as imperfectness, uncertainty, Quality of Context (QoC), and Cost of Context (CoC).
3. Related Works
3.1. Definition of Context and Context-Awareness
3.2. Context Management and Provisioning
- ‘Sensor Data Acquisition ‘deals with how raw information about any context is fetched and used as input to the middleware. It is vital that the system can cope with a variety of heterogeneous sources and sensors simultaneously. Sensors may be physical, virtual, or logical. Depending on the intelligence and computational power, pre-processing and filtering may be performed by the sensor nodes themselves or as part of the middleware functionality. Both synchronous and asynchronous sources are generally supported.
- ‘Context Storage’ refers to the mechanism of persisting contextual information in the middleware. Having a proper context storage technique has two main benefits. Caching strategies allow for faster provisioning of the necessary context since repeated processing stages may be omitted. Moreover, the storage of expired context in a history database enables the analysis of previous situations. Such information can be used to determine habits and long-term intentions taking successive sequences of activities towards the desired goal into account.
- ‘Context Lookup & Discovery’ provide means for an application, service or actuator to identify the available context and how to acquire and query for it. Commonly used approaches include lookup tables, semantic queries or legacy web service mechanisms such as SOAP (Simple Object Access Protocol) and WSDL (Web Services Description Language).
- ‘Context Diffusion & Distribution’ are related to the output of a middleware system, i.e., how context information is made available to the consumers. This encompasses not only the definition of query models (e.g., key-value based, or SQL based) but also the mode of communication. Communication protocols may support event-driven asynchronous publish/subscribe mechanisms to notify the application layer about context changes of interest. Additionally, synchronous on-demand queries may be supported by the middleware.
- ‘Privacy, Security, and Access Control’ are considered as vital tasks in context management middleware’s since they might expose users’ sensitive information to untrusted external systems.
- ‘Context Processing & Reasoning’ refer to the capability of inferring context from raw sensor data or existing primitive low-level context. The middleware may apply feature extraction, description logic, rule-based reasoning or probabilistic inference on behalf of the application layer, hence saving battery consumption on mobile resource-constrained devices. A powerful middleware should support modularity so that numerous processing mechanisms and algorithms can be plugged in.
3.3. Semantic Web for Internet of Things
3.4. Context Query Languages
- Can be dynamic or static.
- Can be continuous data streams.
- Can be temporal, erroneous, ambiguous, unavailable or incomplete.
- Can be spatial.
- Can be unstructured.
- Can be a situation that is derived and reasoned from other context.
3.5. Discussions
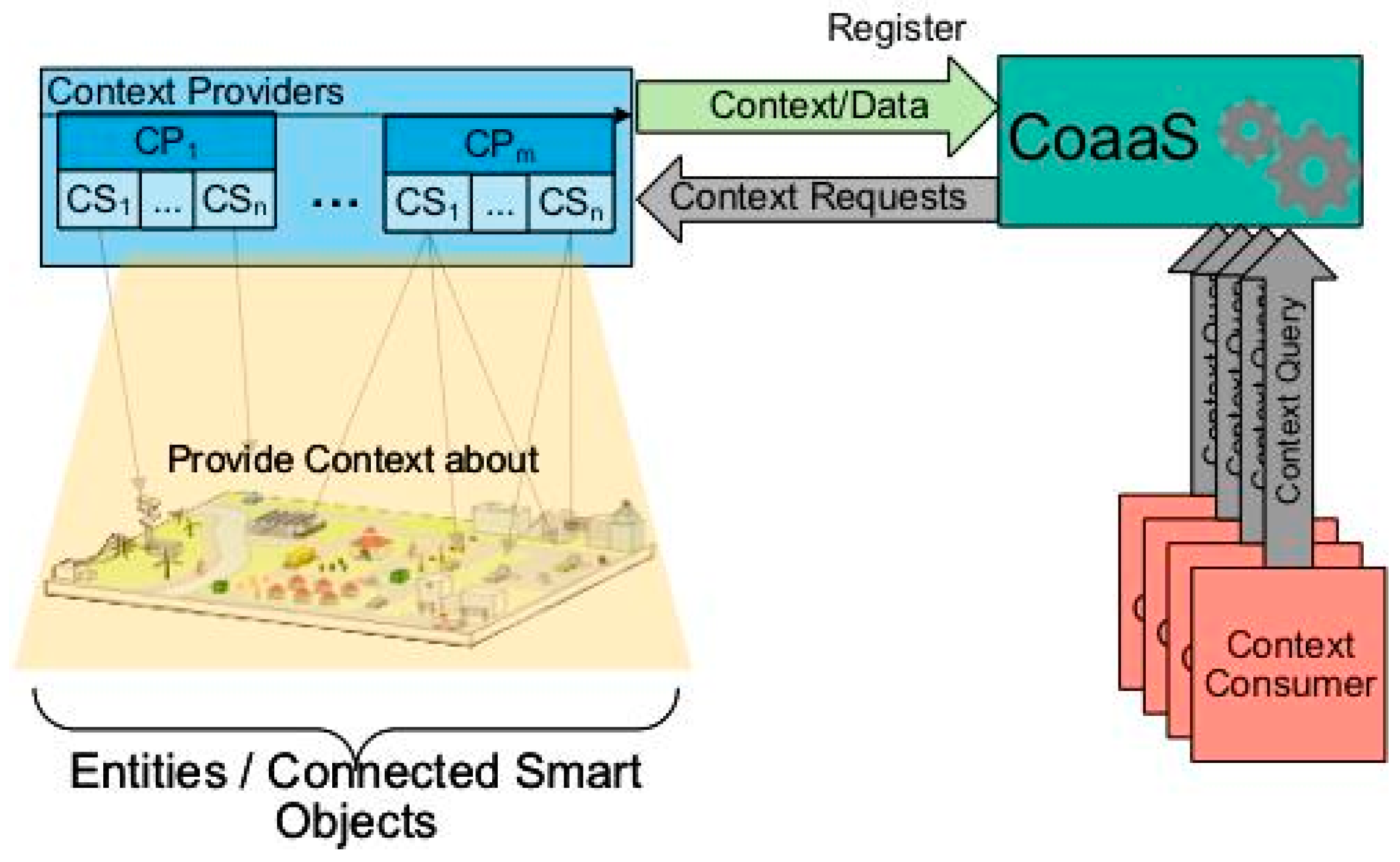
4. Context-as-a-Service (CoaaS)
4.1. CoaaS Vision and Definition
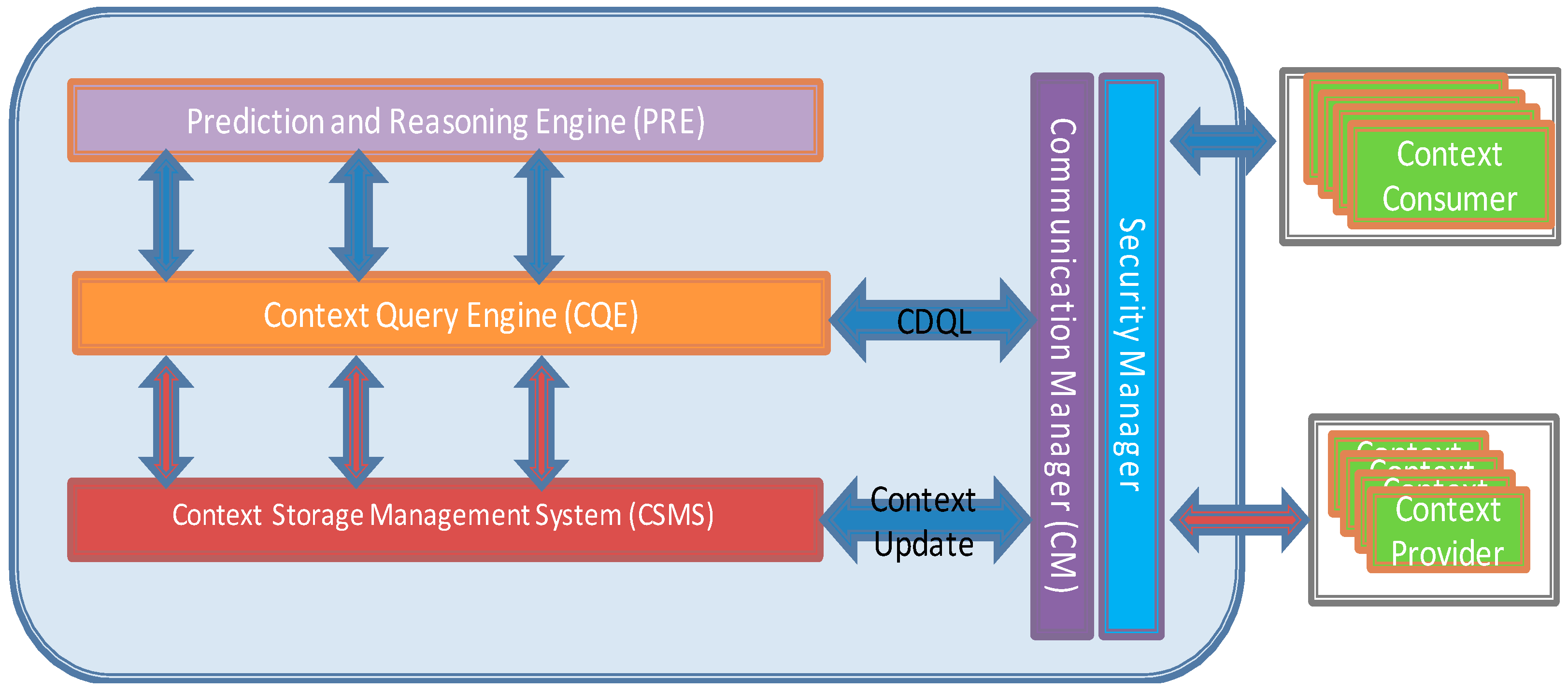
4.2. CoaaS Reference Architecture
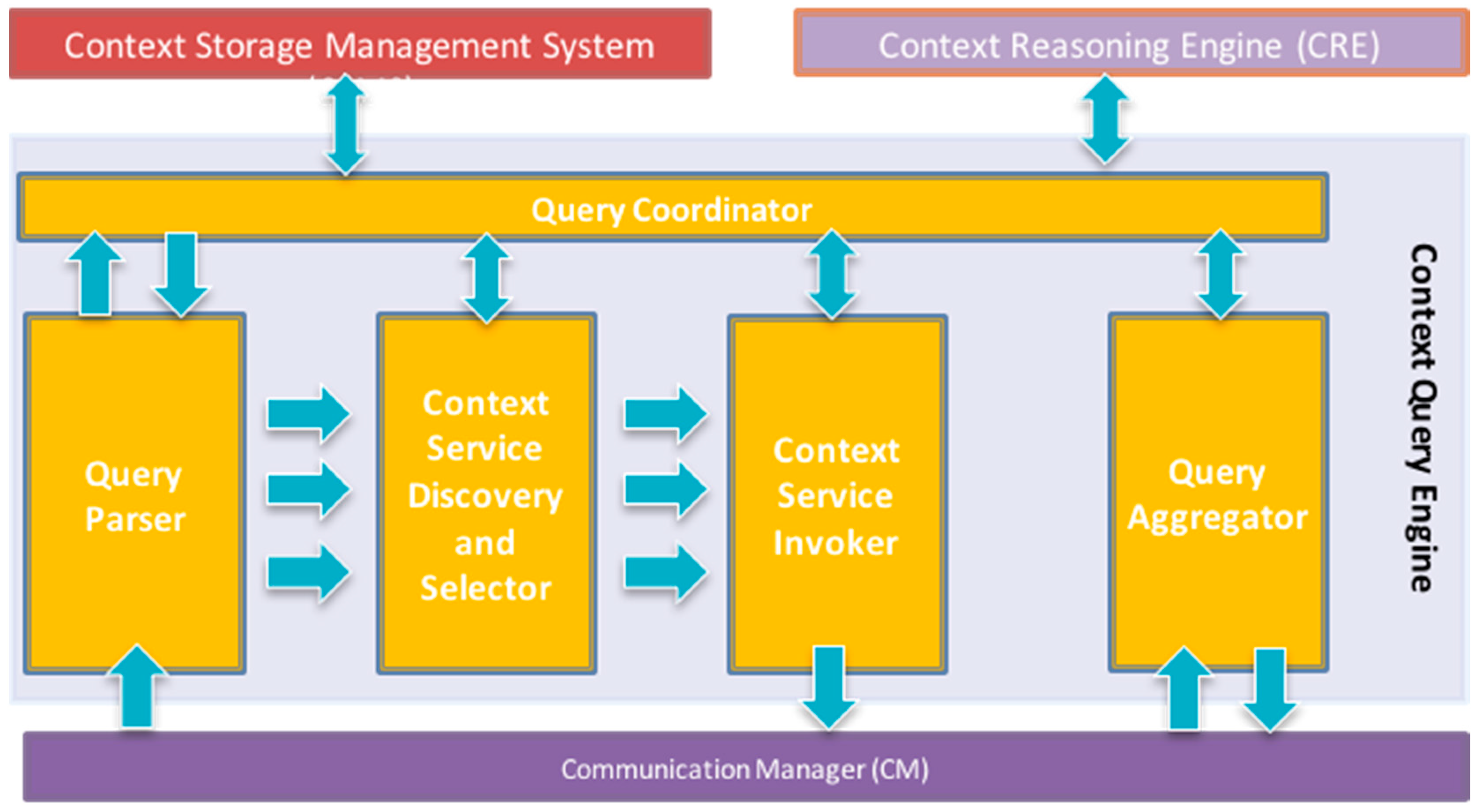
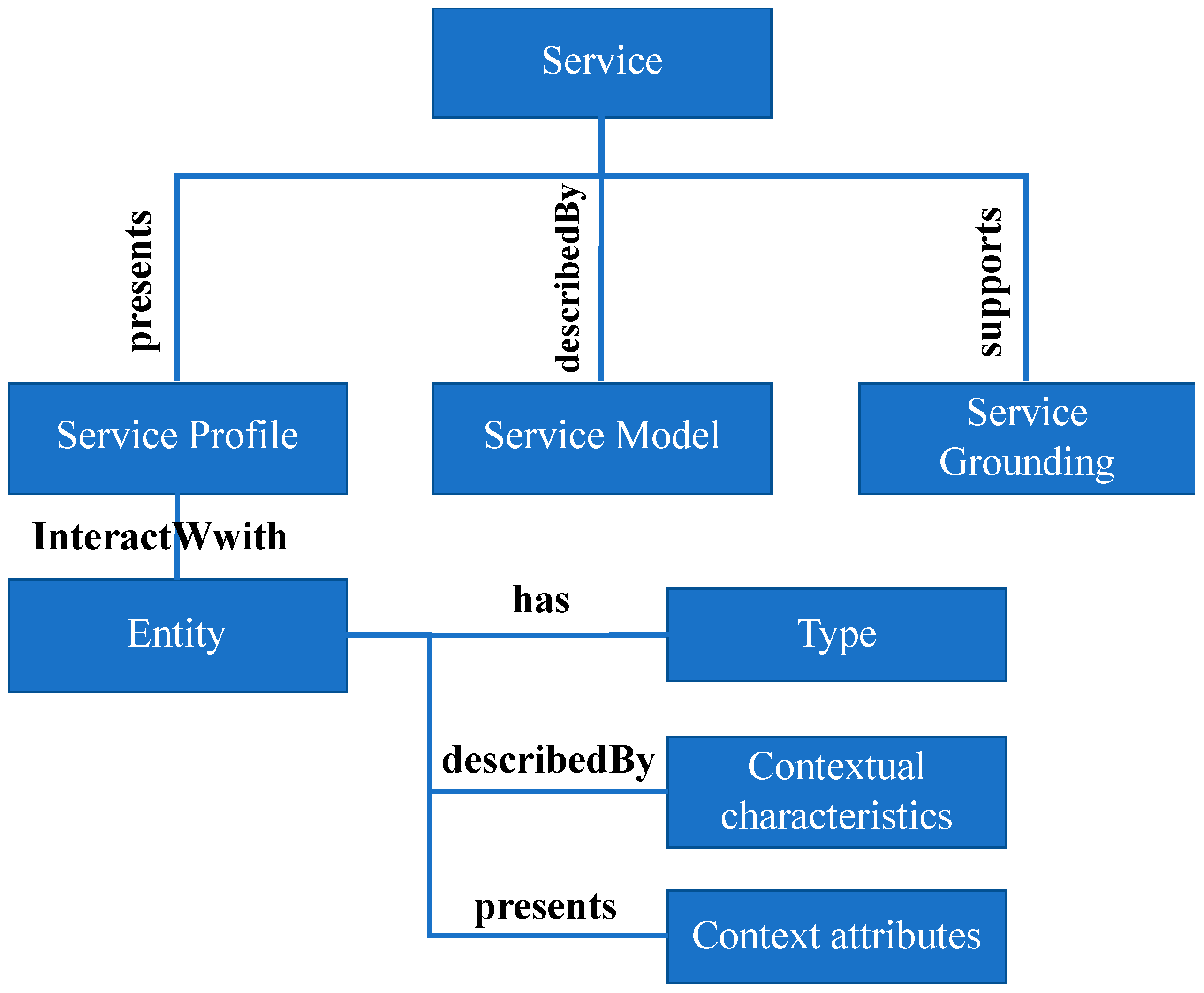
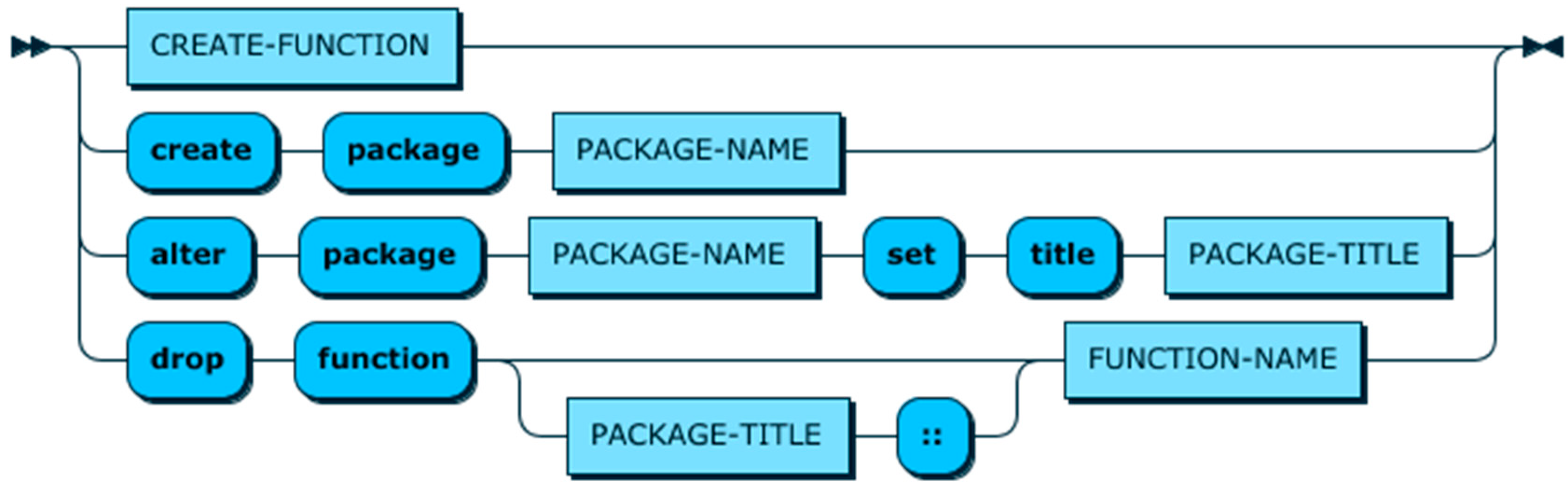
5. Context Service Description Language
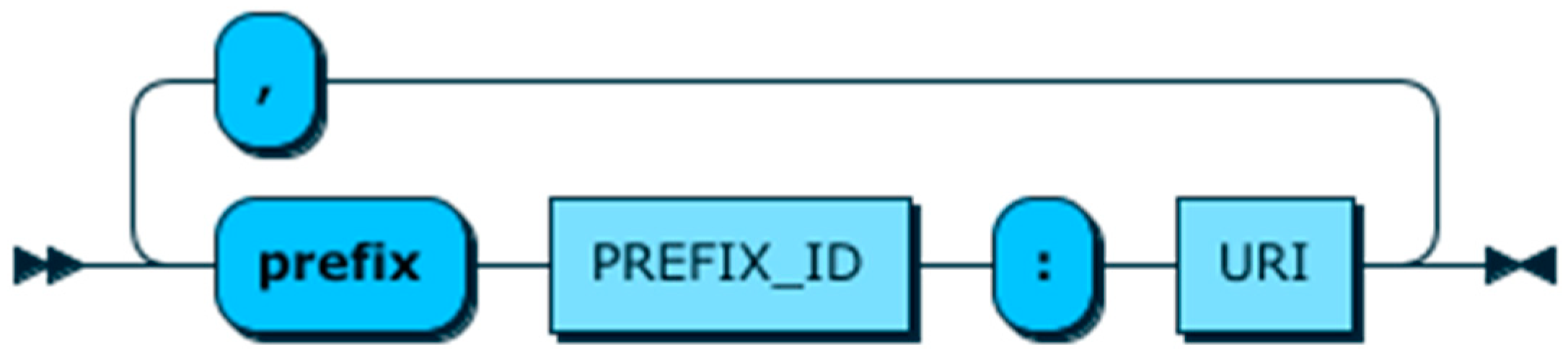
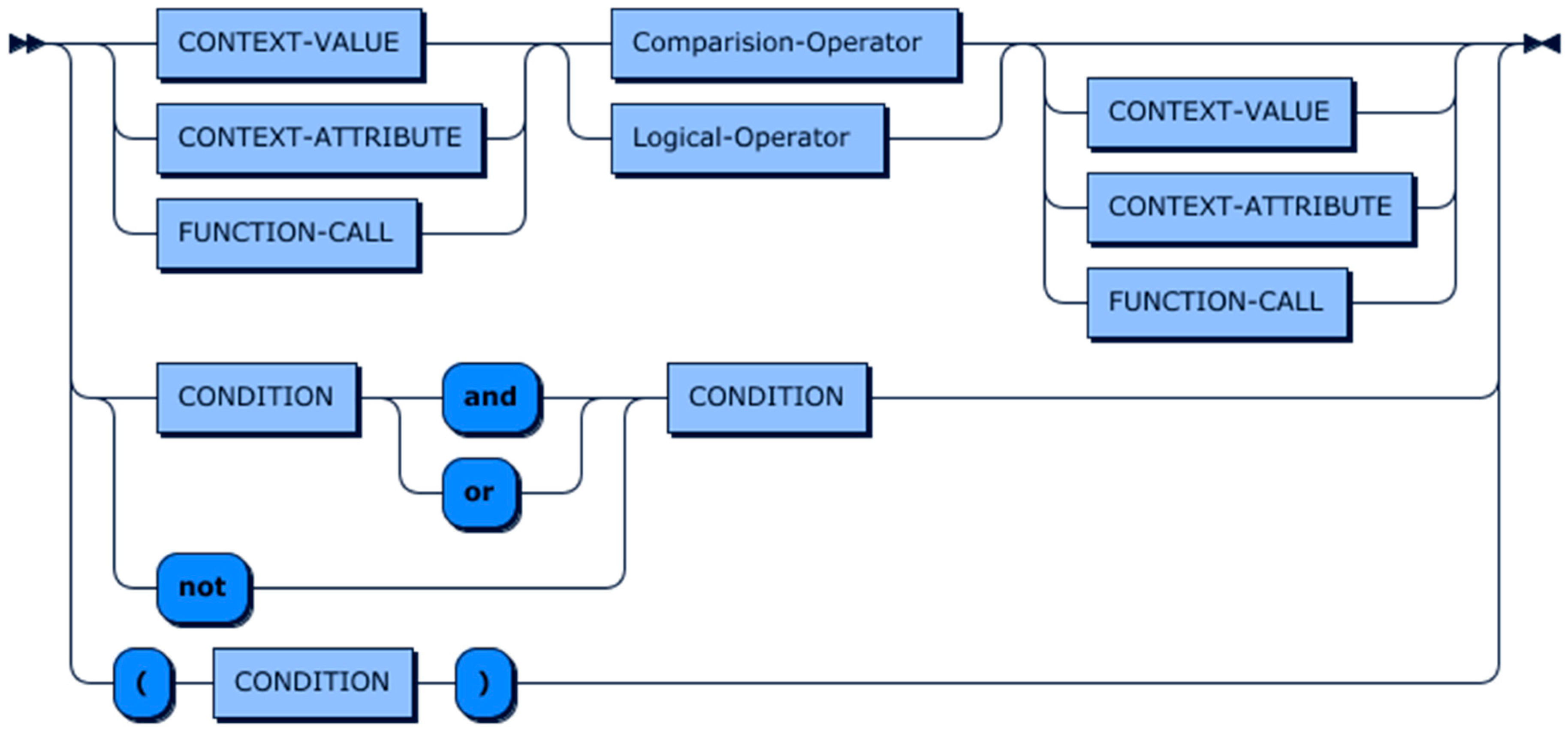
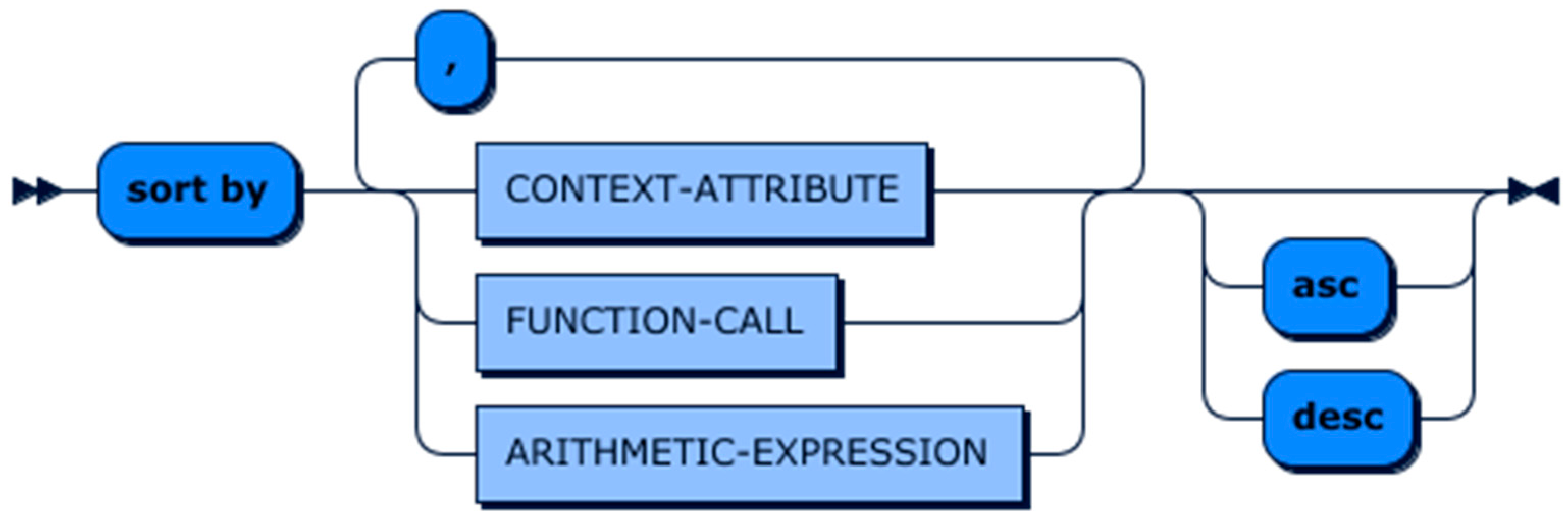
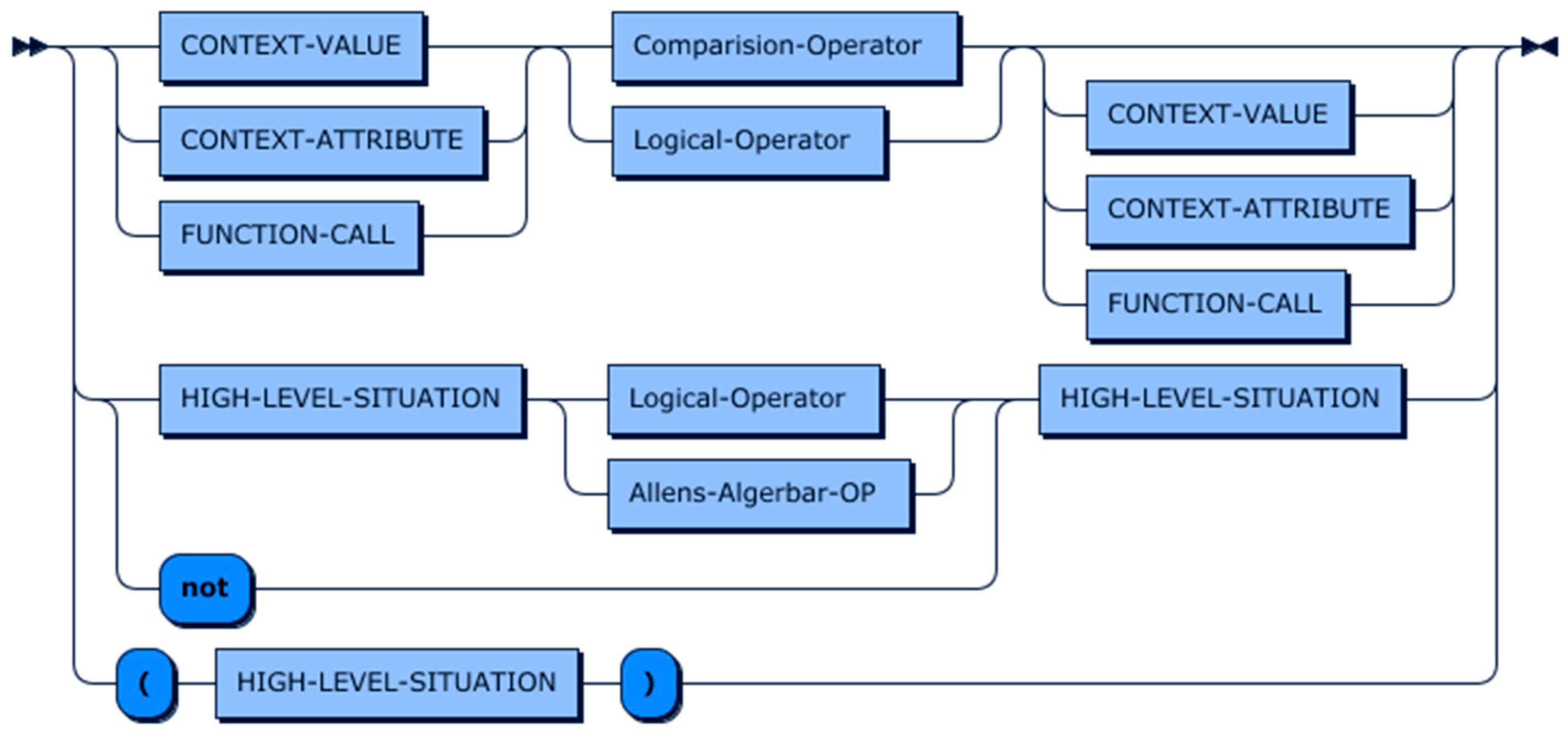
6. Context Definition and Query Language (CDQL)
6.1. CQL
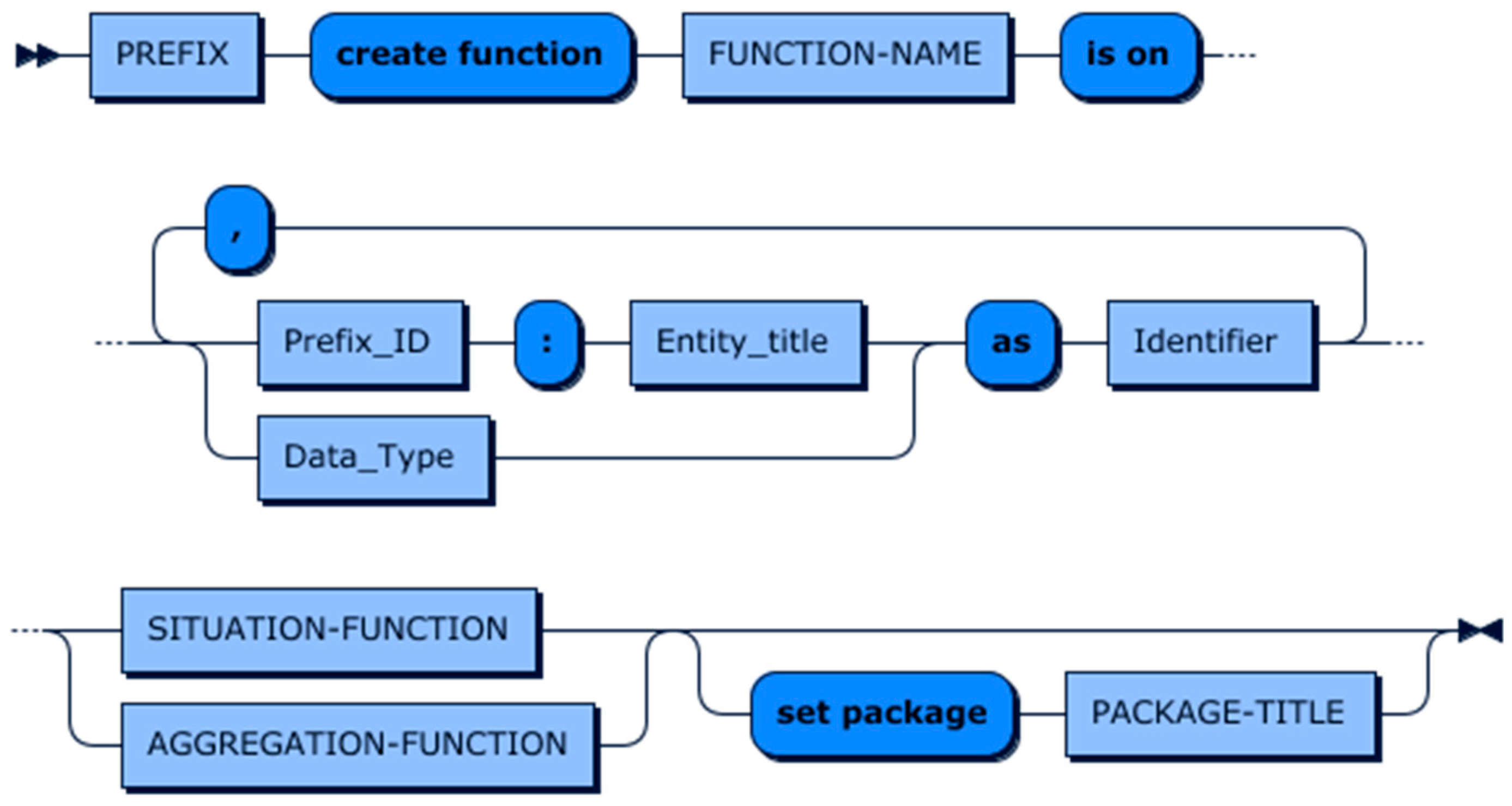
6.2. CDL
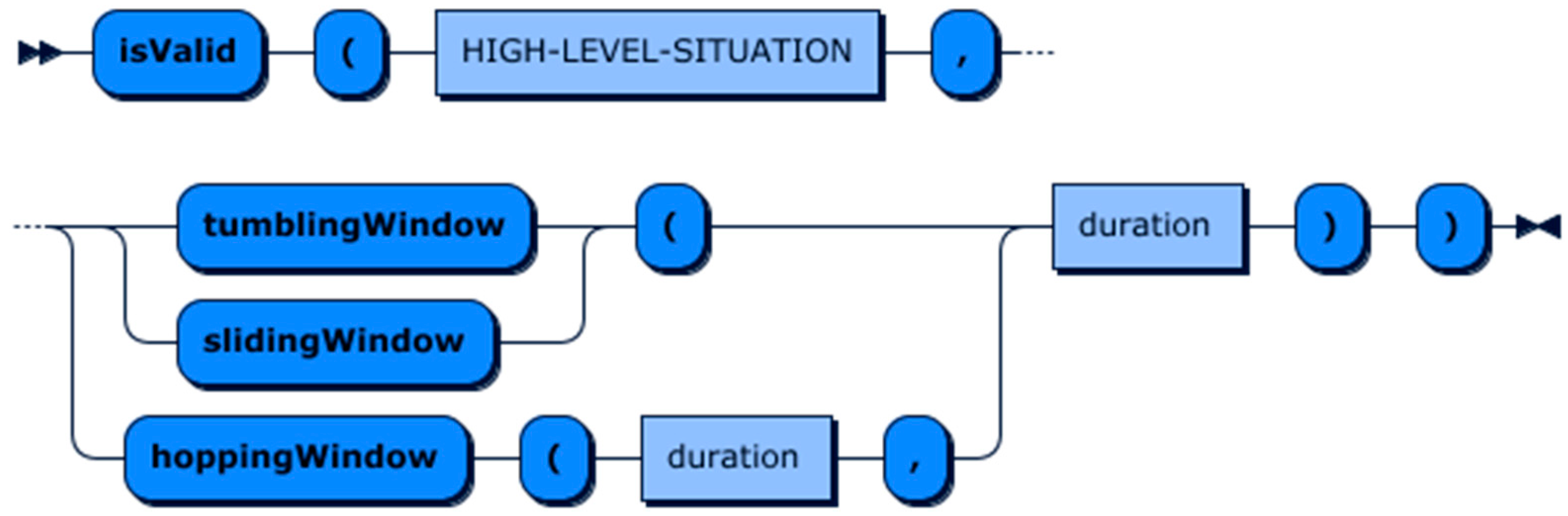
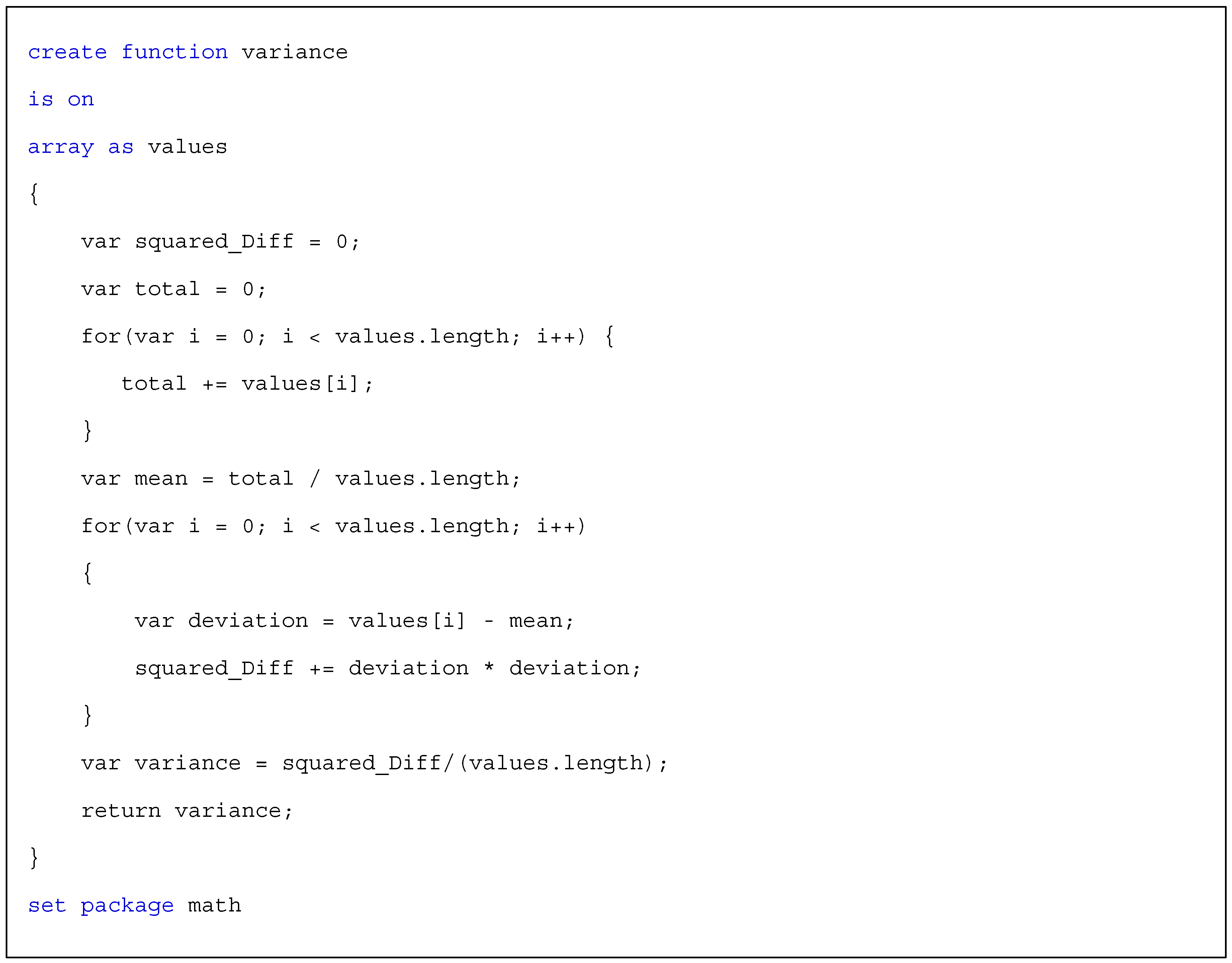
6.2.1. Aggregation Function
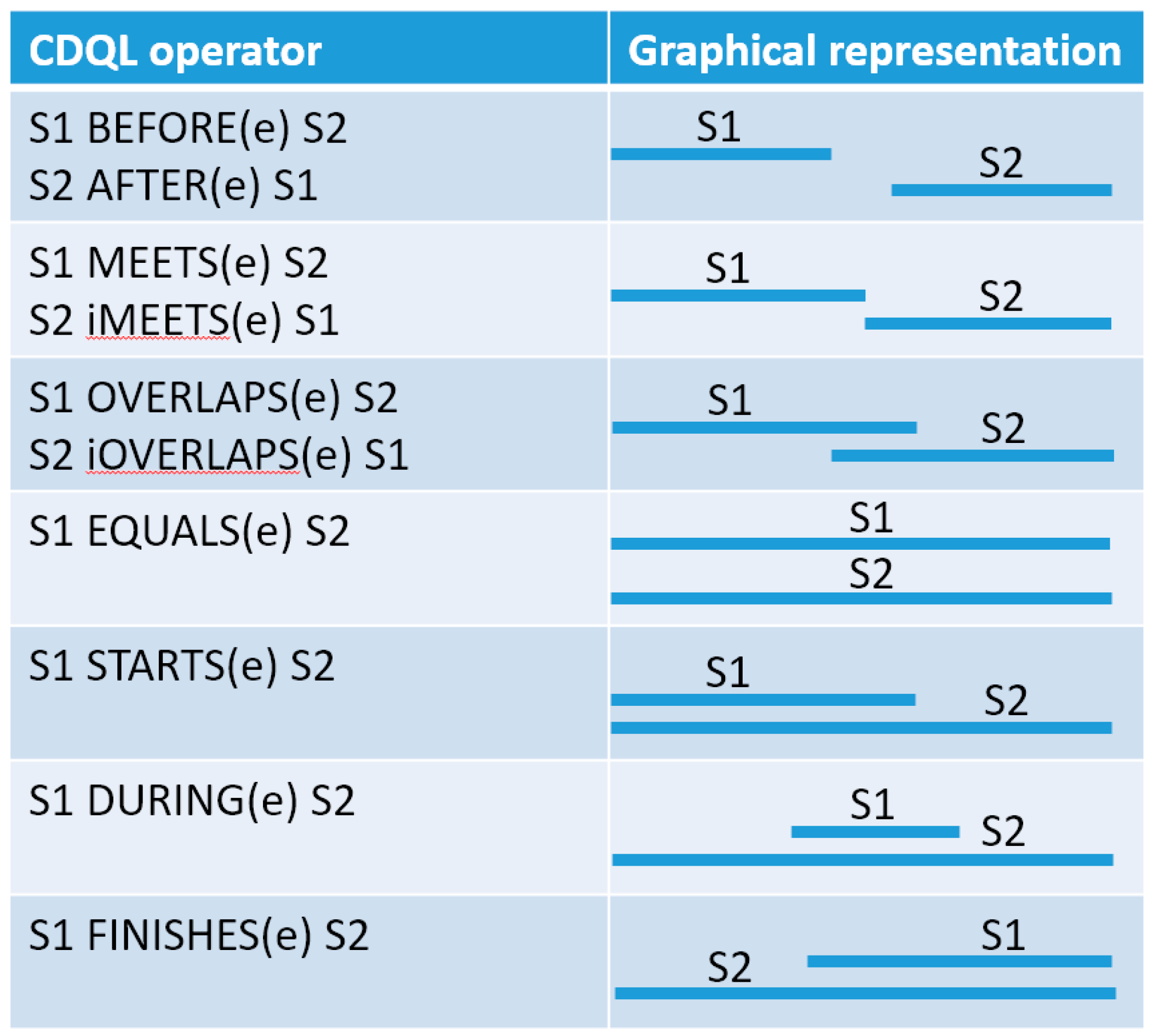
6.2.2. Situation Function
7. Evaluation
7.1. Feasibility Demonstration
7.1.1. Use Case 1: School Safety
7.1.2. Use Case 2: Smart Parking Recommender
7.1.3. Use Case 3: Vehicle Preconditioning
- Is there an upcoming meeting where the driver is likely to use the vehicle?
- Is the driver in walking distance from the car? Is the driver walking towards the car?
- Is the distance between the driver and the car less than the distance between the driver and the meeting location?
- Is the distance between the driver and the meeting location out of walking distance?
- Is the temperature lower or higher than a certain threshold, so is the pre-conditioning necessary?
- Is the vehicle connected to a charging point? Is the battery level high enough for both pre-conditioning and driving to the next destination?
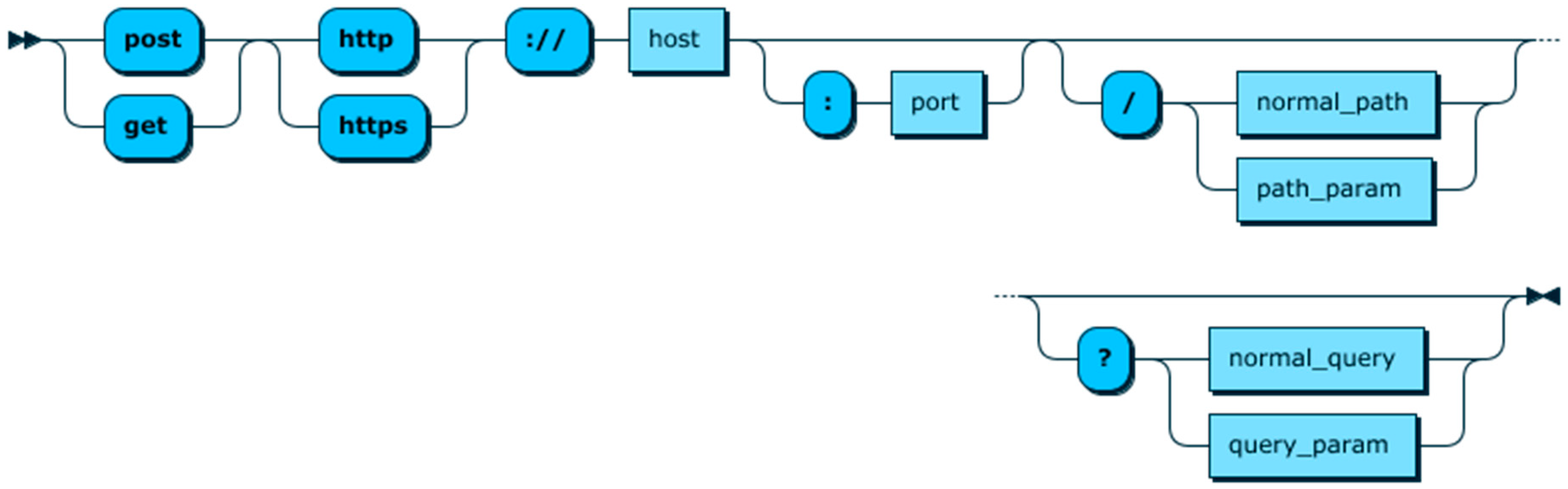
7.2. Comparison of CDQL with NGSI
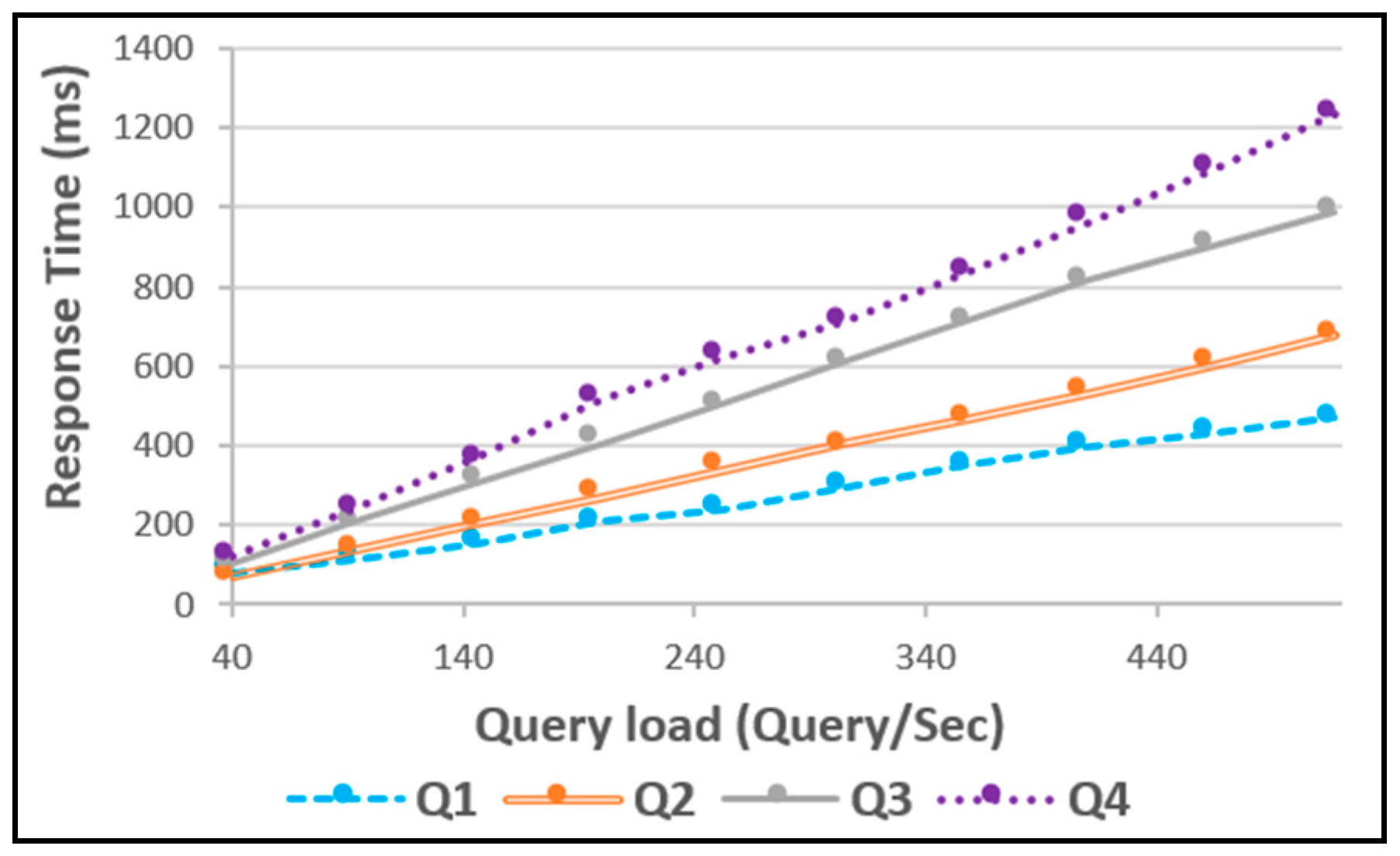
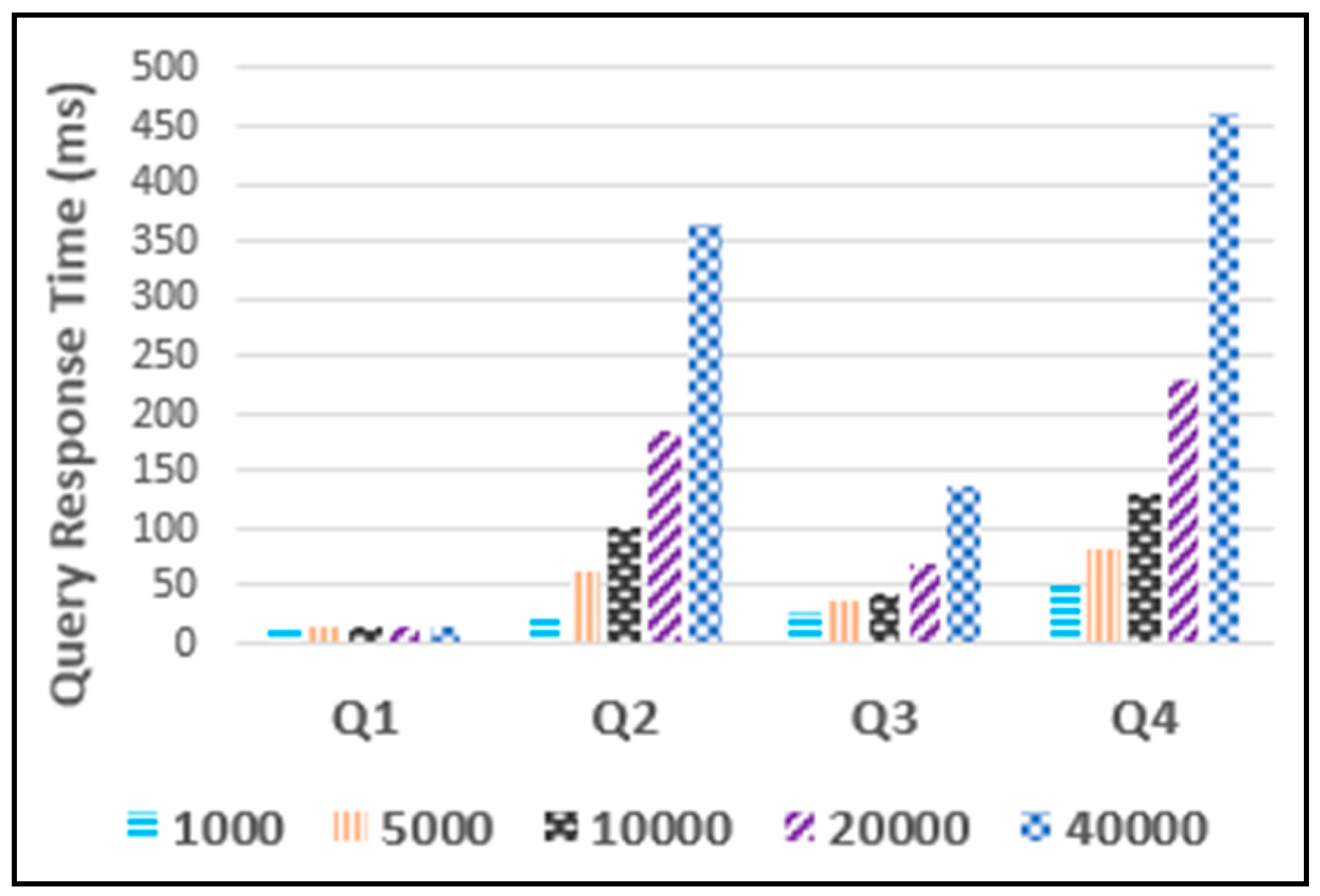
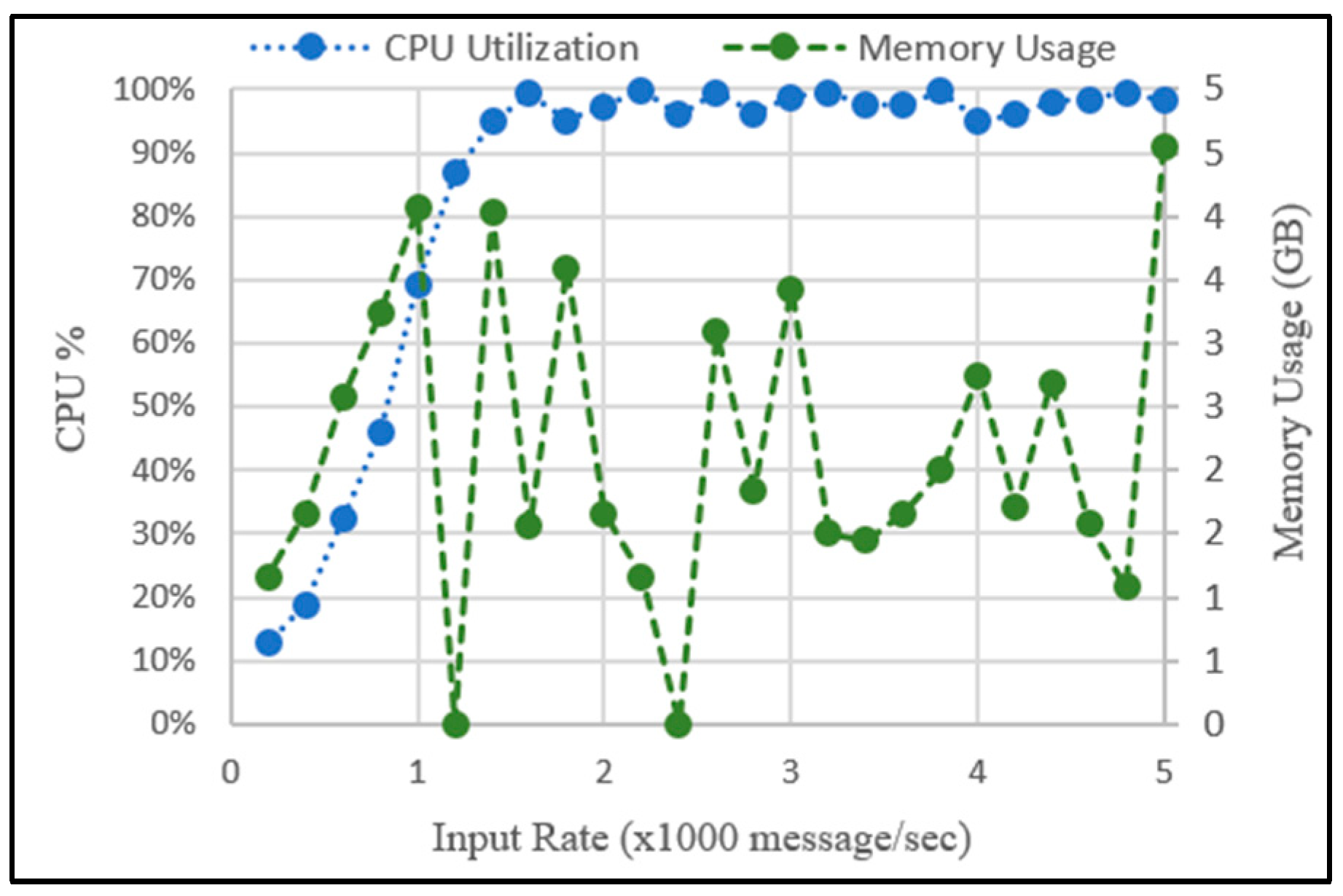
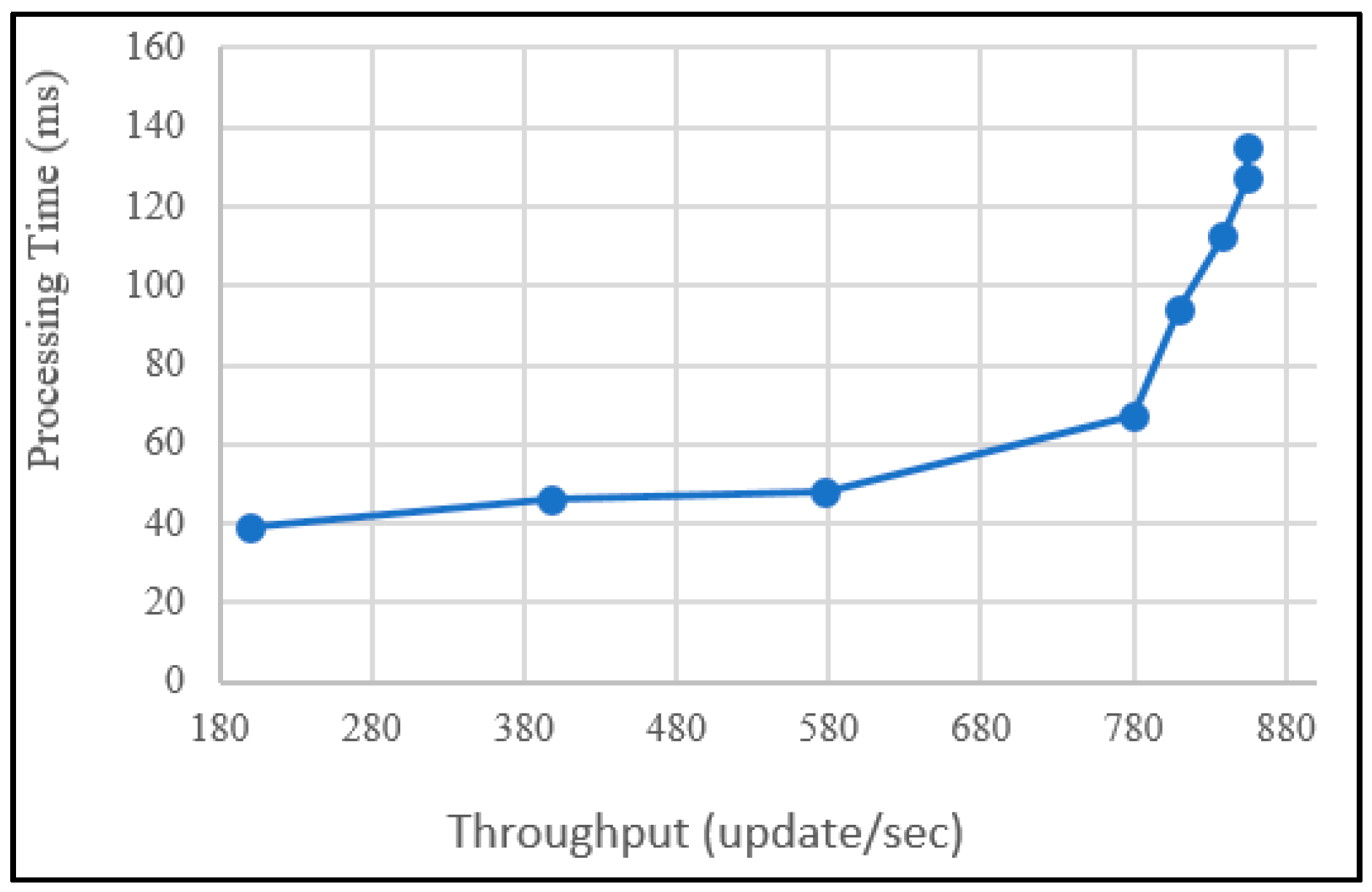
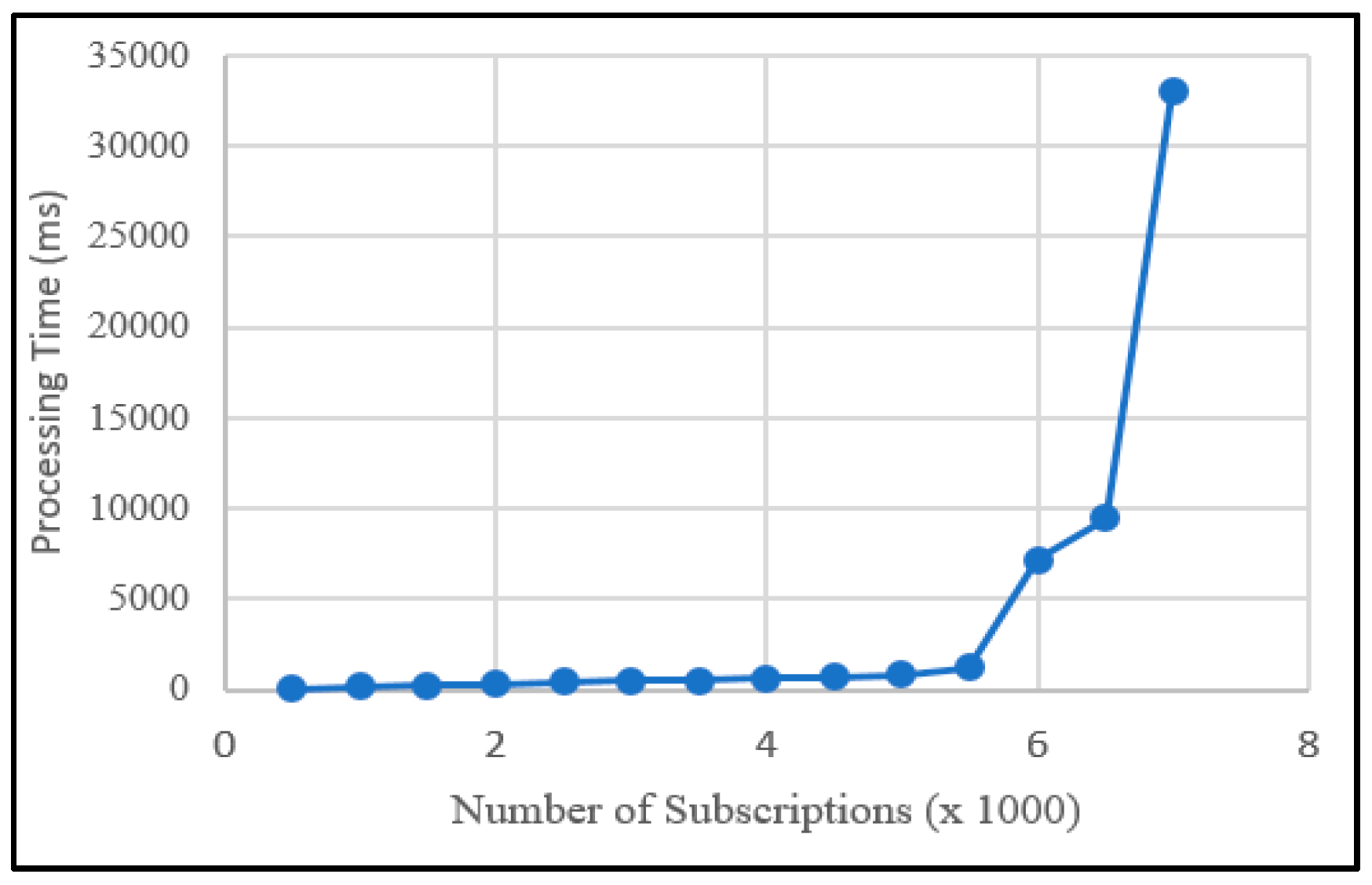
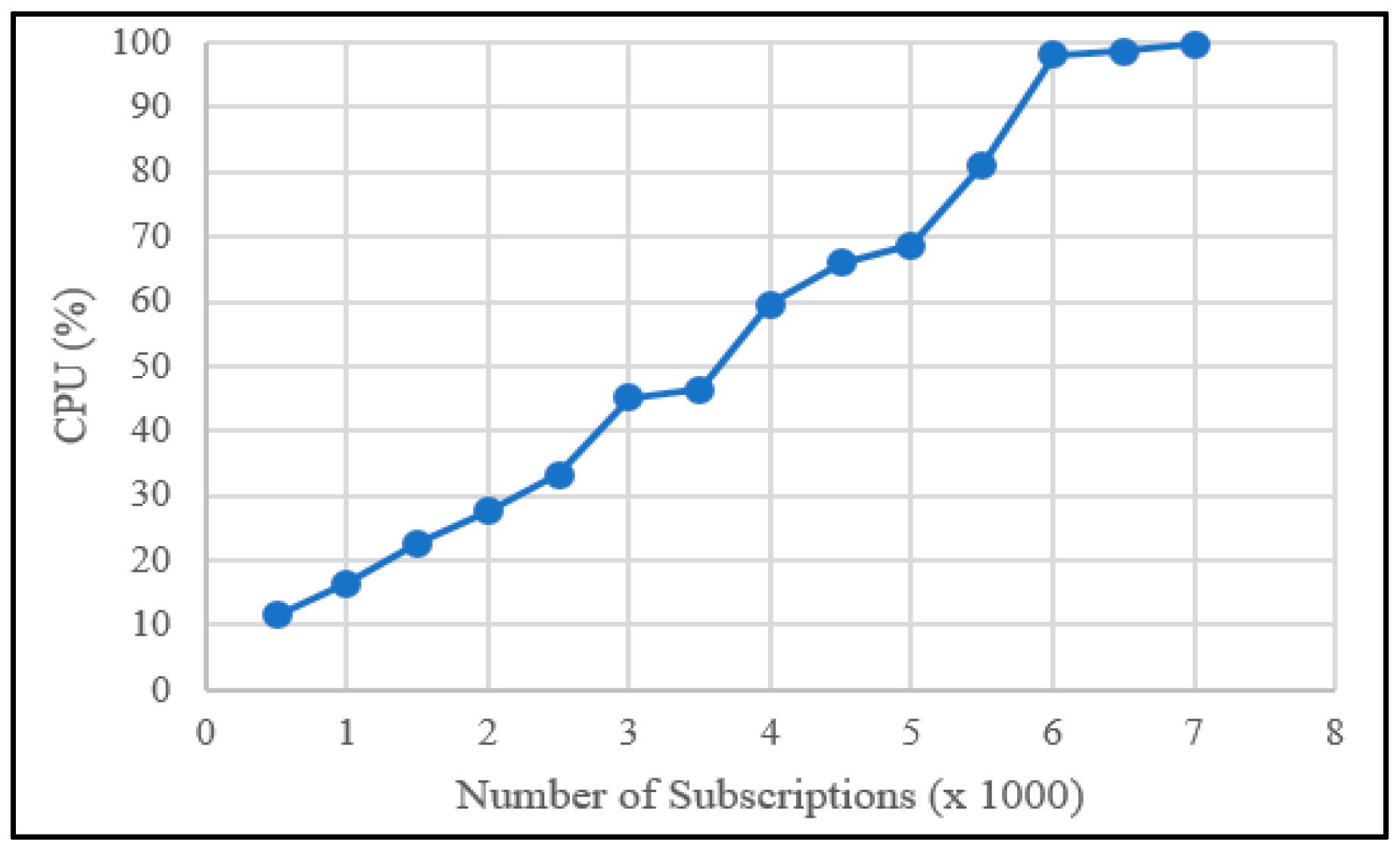
7.3. Performance Evaluation
Experiment 1
Experiment 2
8. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Dey, A.K. Understanding and using context. Pers. Ubiquitous Comput. 2001, 5, 4–7. [Google Scholar] [CrossRef]
- Perera, C.; Zaslavsky, A.; Christen, P.; Georgakopoulos, D. Context aware computing for the internet of things: A survey. IEEE Commun. Surv. Tutor. 2014, 16, 414–454. [Google Scholar] [CrossRef]
- Baldauf, M.; Dustdar, S.; Rosenberg, F. A survey on context-aware systems. Int. J. Ad Hoc Ubiquitous Comput. 2007, 2, 263–277. [Google Scholar] [CrossRef]
- Truong, H.-L.; Dustdar, S. A survey on context-aware web service systems. Int. J. Web Inf. Syst. 2009, 5, 5–31. [Google Scholar] [CrossRef]
- Hong, J.Y.; Suh, E.H.; Kim, S.J. Context-aware systems: A literature review and classification. Expert Syst. Appl. 2009, 36, 8509–8522. [Google Scholar] [CrossRef] [Green Version]
- Knappmeyer, M.; Kiani, S.L.; Reetz, E.S.; Baker, N.; Tonjes, R. Survey of context provisioning middleware. IEEE Commun. Surv. Tutor. 2013, 15, 1492–1519. [Google Scholar] [CrossRef]
- Want, R.; Hopper, A.; Falcão, V.; Gibbons, J. The active badge location system. ACM Trans. Inf. Syst. 1992, 10, 91–102. [Google Scholar] [CrossRef] [Green Version]
- Gu, T.; Pung, H.K.; Zhang, D.Q. A service-oriented middleware for building context-aware services. J. Netw. Comput. Appl. 2005, 28, 1–18. [Google Scholar] [CrossRef]
- Chen, H.L. COBRA: An Intelligent Broker Architecture for Pervasive Context-Aware Systems. Interfaces 2004, 54, 129. [Google Scholar]
- Perera, C.; Zaslavsky, A.; Christen, P.; Georgakopoulos, D. CA4IOT: Context awareness for Internet of Things. In GreenCom 2012, Conference on Internet of Things, iThings 2012 and Conference on Cyber, Physical and Social Computing, Proceedings of the 2012 IEEE International Conference on Green Computing and Communications, Besancon, France, 20–23 November 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 775–782. [Google Scholar]
- Wei, E.J.Y.; Chan, A.T.S. CAMPUS: A middleware for automated context-aware adaptation decision making at run time. Pervasive Mob. Comput. 2013, 9, 35–56. [Google Scholar] [CrossRef]
- Hassani, A.; Haghighi, P.D.; Jayaraman, P.P.; Zaslavsky, A.; Ling, S.; Medvedev, A. CDQL: A Generic Context Representation and Querying Approach for Internet of Things Applications. In Proceedings of the 14th International Conference on Advances in Mobile Computing and Multi Media—MoMM ’16, Singapore, 28–30 November 2016; pp. 79–88. [Google Scholar]
- Hassani, A.; Medvedev, A.; Zaslavsky, A.; Haghighi, P.D.; Ling, S.; Jayaraman, P.P. Context-as-a-Service Platform: Exchange and Share Context in an IoT Ecosystem. In Proceedings of the 2018 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Athens, Greece, 19–23 March 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Kofod-petersen, A.; Mikalsen, M. Context: Representation and Reasoning Environment. Communication 2005, 19, 479–498. [Google Scholar]
- Theimer, M.M.; Schilit, B.N. Disseminating Active Map Information to Mobile Hosts. IEEE Netw. 1994, 8, 22–32. [Google Scholar]
- Abowd, G.D.; Mynatt, E.D. Charting past, present, and future research in ubiquitous computing. ACM Trans. Comput. Interact. 2000, 7, 29–58. [Google Scholar] [CrossRef] [Green Version]
- Ward, A.; Jones, A.; Hopper, A. A new location technique for the active office. IEEE Pers. Commun. 1997, 4, 42–47. [Google Scholar] [CrossRef] [Green Version]
- Hull, R.; Neaves, P.; Bedford-Roberts, J. Towards situated computing. In Proceedings of the First International Symposium on Wearable Computers (ISWC ’97), Cambridge, MA, USA, 3–14 October 1997; pp. 146–153. [Google Scholar]
- Rodden, T.; Cheverst, K.; Davies, N.; Dix, A. Exploiting context in HCI design for mobile systems. In Proceedings of the Workshop on Human Computer Interaction with Mobile Devices, Glasgow, UK, 21–23 May 1998; pp. 21–22. [Google Scholar]
- Franklin, D.; Flachsbart, J. All Gadget and No Representation Makes Jack a Dull Environment Sensing. In Proceedings of the AAAI 1998 Spring Symposium on Intelligent Environments (SprSym’98), Palo Alto, CA, USA, 23–25 March 1998; pp. 155–160. [Google Scholar]
- Brown, P.J.; Bovey, J.D.; Chen, X. Context-aware applications: From the laboratory to the marketplace. IEEE Pers. Commun. 1997, 4, 58–64. [Google Scholar] [CrossRef]
- Ryan, N.; Pascoe, J.; Morse, D. Enhanced Reality Fieldwork: The Context Aware Archaeological Assistant. In Archaeology in the Age of the Internet. CAA97. Computer Applications and Quantitative Methods in Archaeology, Proceedings of the 25th Anniversary Conference, University of Birmingham, April 1997 (BAR International Series 750), Birmingham, UK, April 1997; Archaeopress: Oxford, UK, 1999; pp. 269–274. [Google Scholar]
- Schmidt, A.; Aidoo, K.A.; Takaluoma, A.; Tuomela, U.; van Laerhoven, K.; van de Velde, W. Advanced interaction in context. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 1999; Volume 1707, pp. 89–101. [Google Scholar]
- Chen, G.; Kotz, D. A Survey of Context-Aware Mobile Computing Research; Technical Report TR2000-381; Dartmouth College: Hanover, NH, USA, 2000. [Google Scholar]
- Abowd, G.D.; Dey, A.K.; Brown, P.J.; Davies, N.; Smith, M.; Steggles, P. Towards a better understanding of context and context-awareness. In Proceedings of the First International Symposium on Handheld and Ubiquitous Computing (HUC ’99), Karlsruhe, Germany, 27–29 September 1999; pp. 304–307. [Google Scholar]
- Chen, H.; Finin, T.; Joshi, A. A context broker for building smart meeting rooms. In Proceedings of the AAAI Symposium on Knowledge Representation and Ontology for Autonomous Systems Symposium, Palo Alto, CA, USA, 22–24 March 2004; pp. 53–60. [Google Scholar]
- Razzaque, M.; Dobson, S.; Nixon, P. Categorisation and Modelling of Quality in Context Information; University of Limerick: Limerick, Ireland, 2005. [Google Scholar]
- Becker, C.; Nicklas, D. Where do spatial context-models end and where do ontologies start? A proposal of a combined approach. In Proceedings of the First International Workshop on Advanced Context Modelling, Reasoning and Management, in Conjunction with UbiComp, Nottingham, UK, 7 September 2004; pp. 48–53. [Google Scholar]
- Huebscher, M.C.; McCann, J.A. Adaptive middleware for context-aware applications in smart-homes. In Proceedings of the 2nd Workshop on Middleware for Pervasive and ad-hoc Computing, Toronto, ON, Canada, 18–22 October 2004; pp. 111–116. [Google Scholar]
- McIlraith, S.A.; San, T.C.; Zeng, H. Semantic Web services. IEEE Intell. Syst. 2011, 16, 46–53. [Google Scholar] [CrossRef]
- W3C. OWL-S: Semantic markup for web services. W3C Memb. Submiss. 2004, 22, 1–29. [Google Scholar]
- Domingue, J.; Roman, D.; Stollberg, M. Web Service Modeling Ontology (WSMO): An ontology for Semantic Web Services. In Proceedings of the W3C Workshop on Frameworks for Semantics in Web Services, Innsbruck, Austria, 9–10 June 2005; pp. 776–784. [Google Scholar]
- Kopecký, J.; Vitvar, T.; Bournez, C.; Farrell, J. SAWSDL: Semantic annotations for WSDL and XML schema. IEEE Internet Comput. 2007, 11, 60–67. [Google Scholar] [CrossRef]
- Fujii, K.; Suda, T. Semantics-based context-aware dynamic service composition. ACM Trans. Auton. Adapt. Syst. 2009, 4, 12. [Google Scholar] [CrossRef]
- Guinard, D.; Trifa, V.; Karnouskos, S.; Spiess, P.; Savio, D. Interacting with the SOA-based internet of things: Discovery, query, selection, and on-demand provisioning of web services. IEEE Trans. Serv. Comput. 2010, 3, 223–235. [Google Scholar] [CrossRef]
- Hossain, M.A.; Parra, J.; Atrey, P.K.; El Saddik, A. A framework for human-centered provisioning of ambient media services. Multimed. Tools Appl. 2009, 44, 407–431. [Google Scholar] [CrossRef]
- Haghighi, P.D.; Zaslavsky, A.; Krishnaswamy, S. An Evaluation of Query Languages for Context-Aware Computing. In Proceedings of the 17th International Workshop on Database and Expert Systems Applications (DEXA’06), Krakow, Poland, 4–8 September 2006; pp. 455–462. [Google Scholar]
- Riva, O.; di Flora, C. Contory: A smart phone middleware supporting multiple context provisioning strategies. In Proceedings of the 26th IEEE International Conference on Distributed Computing Systems Workshops (ICDCSW’06), Lisboa, Portugal, 4–7 July 2006. [Google Scholar]
- Henricksen, K.; Indulska, J. A software engineering framework for context-aware pervasive computing. In Proceedings of the Second IEEE Annual Conference on Pervasive Computing and Communications, (PerCom 2004), Orlando, FL, USA, 17 March 2004; pp. 77–86. [Google Scholar]
- McFadden, T.; Henricksen, K.; Indulska, J. Automating Context-aware Application Development. In Proceedings of the biComp 1st International Workshop on Advanced Context Modelling, Reasoning and Management, Nottingham, UK, 7 September 2004; pp. 90–95. [Google Scholar]
- Feng, L. Supporting context-aware database querying in an Ambient Intelligent environment. In Proceedings of the 2010 3rd IEEE International Conference on Ubi-Media Computing, Jinhua, China, 5–6 July 2010; pp. 161–166. [Google Scholar]
- Schreiber, F.; Camplani, R. Perla: A language and middleware architecture for data management and integration in pervasive information systems. IEEE Trans. Softw. Eng. 2012, 38, 478–496. [Google Scholar] [CrossRef]
- Chen, P.; Sen, S.; Pung, H.K.; Wong, W.C. A SQL-based Context Query Language for Context-aware Systems. In Proceedings of the IMMM 2014: The Fourth International Conference on Advances in Information Mining and Management, Paris, France, 20–24 July 2014; pp. 96–102. [Google Scholar]
- Prud’hommeaux, E.; Seaborne, A. SPARQL Query Language for RDF. W3C Recomm. 2008, 2009, 1–106. [Google Scholar]
- Reichle, R.; Wagner, M.; Khan, M.U.; Geihs, K.; Valla, M.; Fra, C.; Paspallis, N.; Papadopoulos, G.A. A Context Query Language for Pervasive Computing Environments. In Proceedings of the 2008 Sixth Annual IEEE International Conference on Pervasive Computing and Communications (PerCom), Hong Kong, China, 17–21 March 2008; pp. 434–440. [Google Scholar]
- Floreen, P.; Przybilski, M.; Nurmi, P.; Koolwaaij, J.; Tarlano, A.; Wagner, M.; Luther, M.; Bataille, F.; Boussard, M.; Mrohs, B.; et al. Towards a Context Management Framework for MobiLife. In Proceedings of the 14th IST Mobile & Wireless Summit, Dresden, Germany, 19–23 June 2005; pp. 120–131. [Google Scholar]
- Bauer, M.; Becker, C.; Rothermel, K. Location Models from the Perspective of Context-Aware Applications and Mobile Ad Hoc Networks. Pers. Ubiquitous Comput. 2002, 6, 322–328. [Google Scholar] [CrossRef]
- Hönle, N.; Käppeler, U.-P.; Nicklas, D.; Schwarz, T.; Grossmann, M. Benefits of Integrating Meta Data into a Context Model. In Proceedings of the Third IEEE International Conference on Pervasive Computing and Communications Workshops, Kauai Island, HI, USA, 8–12 March 2005; pp. 25–29. [Google Scholar]
- Grossmann, M.; Bauer, M.; Hönle, N.; Käppeler, U.P.; Nicklas, D.; Schwarz, T. Efficiently managing context information for large-scale scenarios. In Proceedings of the Third IEEE International Conference on Pervasive Computing and Communications, PerCom 2005, Kauai Island, HI, USA, 8–12 March 2005; Volume 2005, pp. 331–340. [Google Scholar]
- Open Mobile Alliance. NGSI Context Management. 2012. Available online: http://www.openmobilealliance.org/release/NGSI/V1_0-20120529-A/OMA-TS-NGSI_Context_Management-V1_0-20120529-A.pdf (accessed on 25 March 2019).
- Fiware-Orion. Available online: https://fiware-orion.readthedocs.io/en/develop/ (accessed on 18 February 2019).
- Sophia Antipolis. ETSI Launches New Group on Context Information Management for Smart City Interoperability. 2017. Available online: https://www.etsi.org/news-events/news/1152-2017-01-news-etsi-launches-new-group-on-context-information-management-for-smart-city-interoperability (accessed on 2 December 2018).
- ETSI—ETSI ISG CIM Group Releases First Specification for Context Exchange in Smart Cities. Available online: https://www.etsi.org/newsroom/news/1300-2018-04-news-etsi-isg-cim-group-releases-first-specification-for-context-exchange-in-smart-cities (accessed on 18 February 2019).
- Esper—EsperTech. Available online: http://www.espertech.com/esper/ (accessed on 18 February 2019).
- EPL Reference: Clauses. Available online: http://esper.espertech.com/release-5.2.0/esper-reference/html/epl_clauses.html (accessed on 18 February 2019).
- Knappmeyer, M.; Kiani, S.L.; Frà, C.; Moltchanov, B.; Baker, N. ContextML: A light-weight context representation and context management schema. In Proceedings of the ISWPC 2010 IEEE 5th International Symposium on Wireless Pervasive Computing 2010, Modena, Italy, 5–7 May 2010; pp. 367–372. [Google Scholar]
- Medvedev, A.; Indrawan-Santiago, M.; Haghighi, P.D.; Hassani, A.; Zaslavsky, A.; Jayaraman, P.P. Architecting IoT context storage management for context-as-a-service platform. In Proceedings of the 2017 Global Internet of Things Summit (GIoTS), Geneva, Switzerland, 6–9 June 2017. [Google Scholar]
- Haghighi, P.D.; Krishnaswamy, S.; Zaslavsky, A.; Gaber, M.M. Reasoning about context in uncertain pervasive computing environments. In Lecture Notes in Computer Science (including Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinformatics), Proceedings of the European Conference on Smart Sensing and Context 2008, Zurich, Switzerland, 29–31 October 2008; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5279, pp. 112–125. [Google Scholar]
- Hassani, A.; Haghighi, P.D.; Jayaraman, P.P.; Zaslavsky, A.; Ling, S. Querying IoT Services: A Smart Carpark Recommender Use Case. In Proceedings of the 2018 IEEE 4th World Forum on Internet of Things (WF-IoT), Singapore, 5–8 February 2018. [Google Scholar]
- Wirth, N. Extended Backus-Naur Form (EBNF); ISO/IEC: Geneva, Switzerland, 1996; 14977:1996. [Google Scholar]
- Padovitz, A.; Loke, S.W.; Zaslavsky, A. Towards a theory of context spaces. In Proceedings of the Second IEEE Annual Conference on Pervasive Computing and Communications, Workshops, PerCom, Orlando, FL, USA, 14–17 March 2004; pp. 38–42. [Google Scholar]
- Padovitz, A.; Loke, S.W.; Zaslavsky, A.; Burg, B.; Bartolini, C. An approach to data fusion for context awareness. In Proceedings of the International and Interdisciplinary Conference on Modeling and Using Context, Paris, France, 5–8 July 2005; pp. 353–367. [Google Scholar]
- Allen, J.F. Maintaining Knowledge about Temporal Intervals. In Readings in Qualitative Reasoning About Physical Systems; Morgan Kaufmann: Burlington, MA, USA, 2013. [Google Scholar]
- Mavrommatis, A.; Artikis, A.; Skarlatidis, A.; Paliouras, G. A distributed event calculus for event recognition. In Proceedings of the 2nd Workshop on Artificial Intelligence and Internet of Things (AI-IoT 2016), volume 1724 of CEUR Workshop Proceedings, The Hague, The Netherlands, 30 August 2016. [Google Scholar]
- Patroumpas, K.; Sellis, T. Window specification over data streams. In Proceedings of the International Conference on Extending Database Technology, Munich, Germany, 26–31 March 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 445–464. [Google Scholar]
- On-Street Parking Data—City of Melbourne. Available online: https://www.melbourne.vic.gov.au/about-council/governance-transparency/open-data/Pages/on-street-parking-data.aspx (accessed on 2 December 2018).



















































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Title | CQL Type | Requirements | |||||
|---|---|---|---|---|---|---|---|
| #1 | #2 | #3 | #4 | #5 | #6 | ||
| Contory [38] | SQL-based | ✖ | ✖ | ✔ | ✖ | ✖ | ✔ |
| CML [39] | SQL-based | ↘ | ✖ | ✖ | ↘ | ↘ | ✔ |
| PerLa [42] | SQL-based | ↗ | ✖ | ✔ | ↘ | ↗ | ↘ |
| NGSI-9/10 [43] | API-based | ✖ | ↗ | ✔ | ↘ | ✔ | ↗ |
| SPARQL [44] | RDF-based | ✔ | ↗ | ✖ | ✖ | ✖ | ✖ |
| MUSIC-CQL [45] | RDF-based | ✖ | ✔ | ✔ | ↗ | ↗ | ↗ |
| SOCAM [8] | RDF-based | ✖ | ✔ | ✔ | ↘ | ↗ | ↘ |
| Nexus [47] | XML-based | ↗ | ↘ | ✔ | ✖ | ✔ | ✔ |
| MobiLife [46] | XML-based | ↘ | ✔ | ✔ | ↘ | ✖ | ↗ |
| ContextML [56] | XML-based | ↗ | ✔ | ✔ | ↘ | ✖ | ↗ |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassani, A.; Medvedev, A.; Delir Haghighi, P.; Ling, S.; Zaslavsky, A.; Prakash Jayaraman, P. Context Definition and Query Language: Conceptual Specification, Implementation, and Evaluation. Sensors 2019, 19, 1478. https://doi.org/10.3390/s19061478
Hassani A, Medvedev A, Delir Haghighi P, Ling S, Zaslavsky A, Prakash Jayaraman P. Context Definition and Query Language: Conceptual Specification, Implementation, and Evaluation. Sensors. 2019; 19(6):1478. https://doi.org/10.3390/s19061478
Chicago/Turabian StyleHassani, Alireza, Alexey Medvedev, Pari Delir Haghighi, Sea Ling, Arkady Zaslavsky, and Prem Prakash Jayaraman. 2019. "Context Definition and Query Language: Conceptual Specification, Implementation, and Evaluation" Sensors 19, no. 6: 1478. https://doi.org/10.3390/s19061478
APA StyleHassani, A., Medvedev, A., Delir Haghighi, P., Ling, S., Zaslavsky, A., & Prakash Jayaraman, P. (2019). Context Definition and Query Language: Conceptual Specification, Implementation, and Evaluation. Sensors, 19(6), 1478. https://doi.org/10.3390/s19061478