1. Introduction
Pycnocline has always been one of the focuses of physical oceanography. The characteristics of pycnocline relate to water masses, circulation, and internal waves in the ocean [
1]. At the same time, the characteristics of pycnocline have an effect on underwater acoustic communication, detection, monitoring, submarine warfare and so on in the military field [
2]. Therefore, the study of marine pycnocline is of great value in the field of marine hydrology and military affairs.
The formation of pycnocline is mainly affected by seawater temperature and salinity. Usually, when the wind is calm, the water temperature decreases as the depth increases. When there is a large wind wave, the sea water is mixed up and down, the upper water temperature is gradually uniform, and the temperature of the lower ocean current, which can not be affected by the wind wave, is still decreasing. As a result, the sea water temperature between the upper and lower layers changes dramatically, resulting in the formation of pycnocline. Besides temperature, salinity also plays an important role in the formation of marine pycnocline [
3]. For example, where a warm current flows through, the solubility of salt is higher and the salinity is higher, the density of the area will increase [
4]. As a general rule, in the vicinity of rivers entering the sea, fresh water desalinating the sea water, which reduces the salinity of the sea water, it also leads to the sudden change of sea water density, thus it is easy to form pycnocline at the boundary between fresh water and sea water [
5].
In order to study ocean pycnocline, we need to get a lot of accurate ocean data. However, due to the breadth of the ocean area and the unpredictable nature of the deep sea, it is very difficult for human beings to detect in the sea water [
6]. The data obtained by traditional underwater sensors only involve scalar data such as temperature, pressure, depth and so on. For practical applications, the types of observation data fall far short of the requirements [
7]. So it’s becoming more and more necessary to analyze existing hydrological data and get new unknown data [
8,
9]. Through the prediction and analysis of ocean data, we can also improve the existing model and improve the accuracy of data analysis [
10,
11,
12].
On the other hand, with the increasing scale and complexity of ocean hydrological data, the traditional physical statistical model is not robust. Jiang’s article on “A Machine Learning Approach to Argo Data Analysis in a Thermocline” gives a good example of combining the statistical model with the prediction model, which analyses the historical data of the thermocline [
13]. The machine learning algorithm is used to find out the most important factors affecting thermocline. This suggests that we can maximize the relationship between ocean hydrological elements (water speed, temperature, salinity, depth, density) under a limited sample training set using the machine learning correlation algorithm [
14]. This is of great significance for predicting the distribution characteristics of ocean pycnocline.
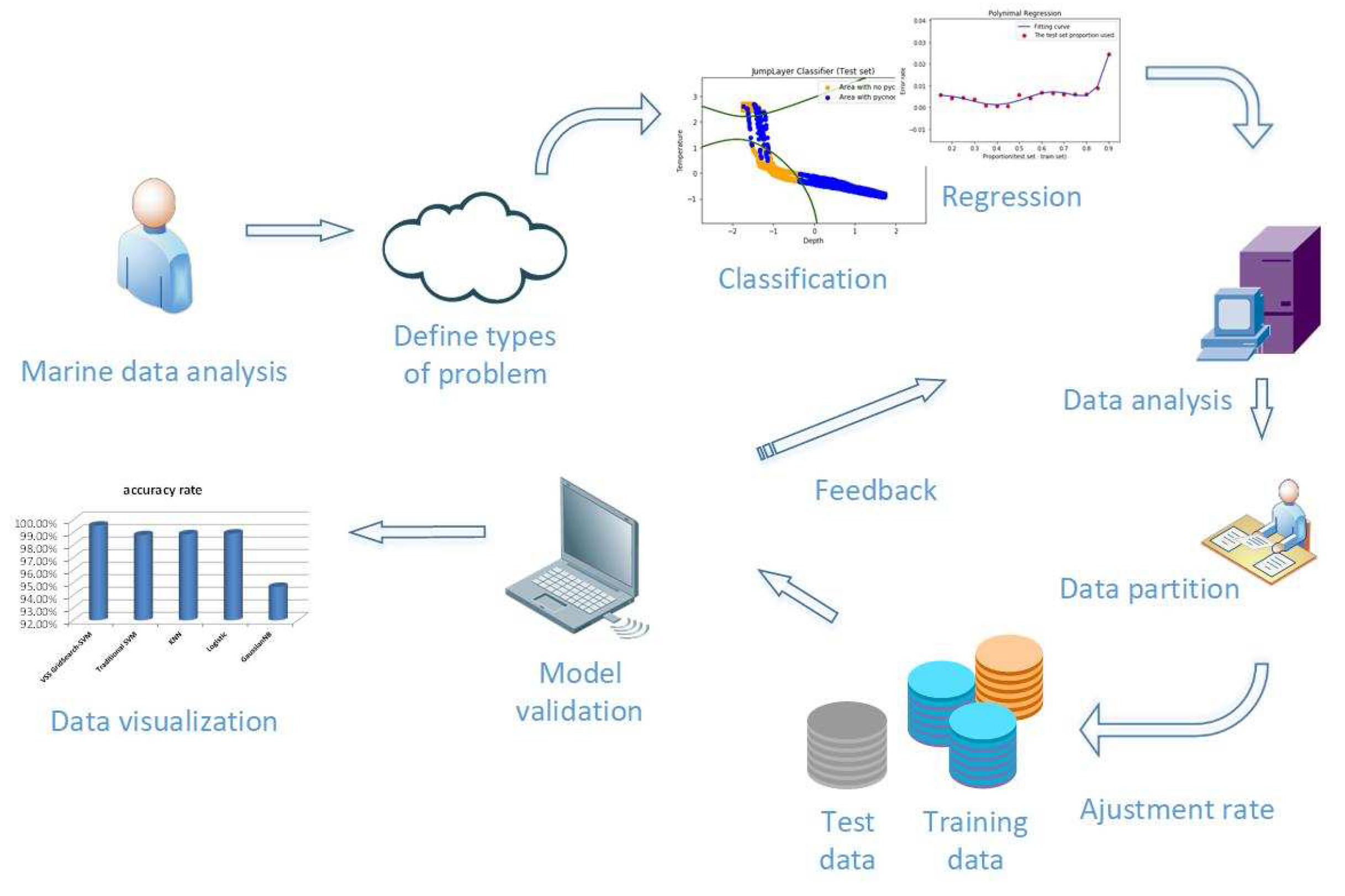
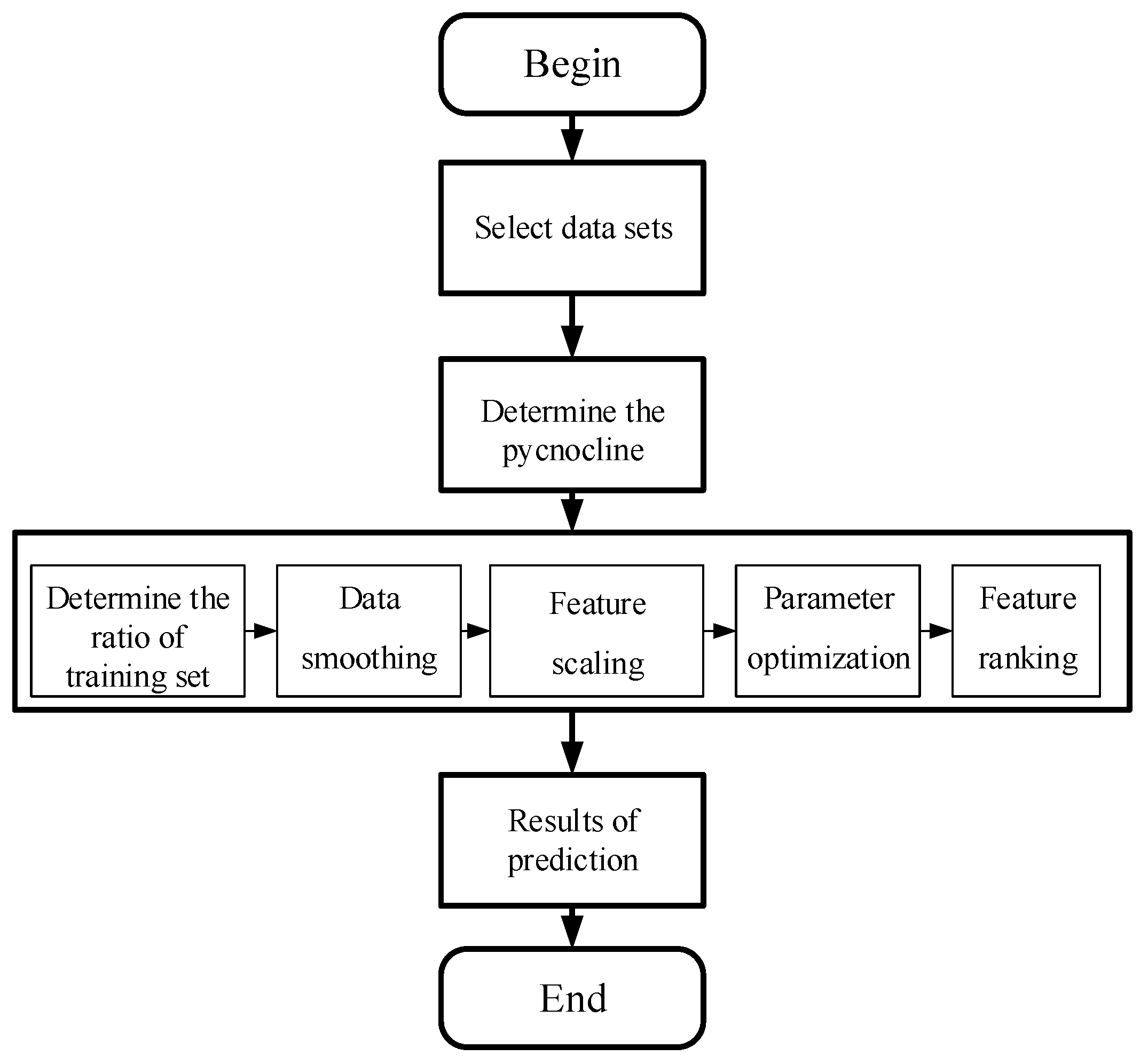
The prediction of ocean hydrological data based on machine learning algorithm is different from the general physical statistical model. The following
Figure 1 shows the ocean hydrological data process based on machine learning:
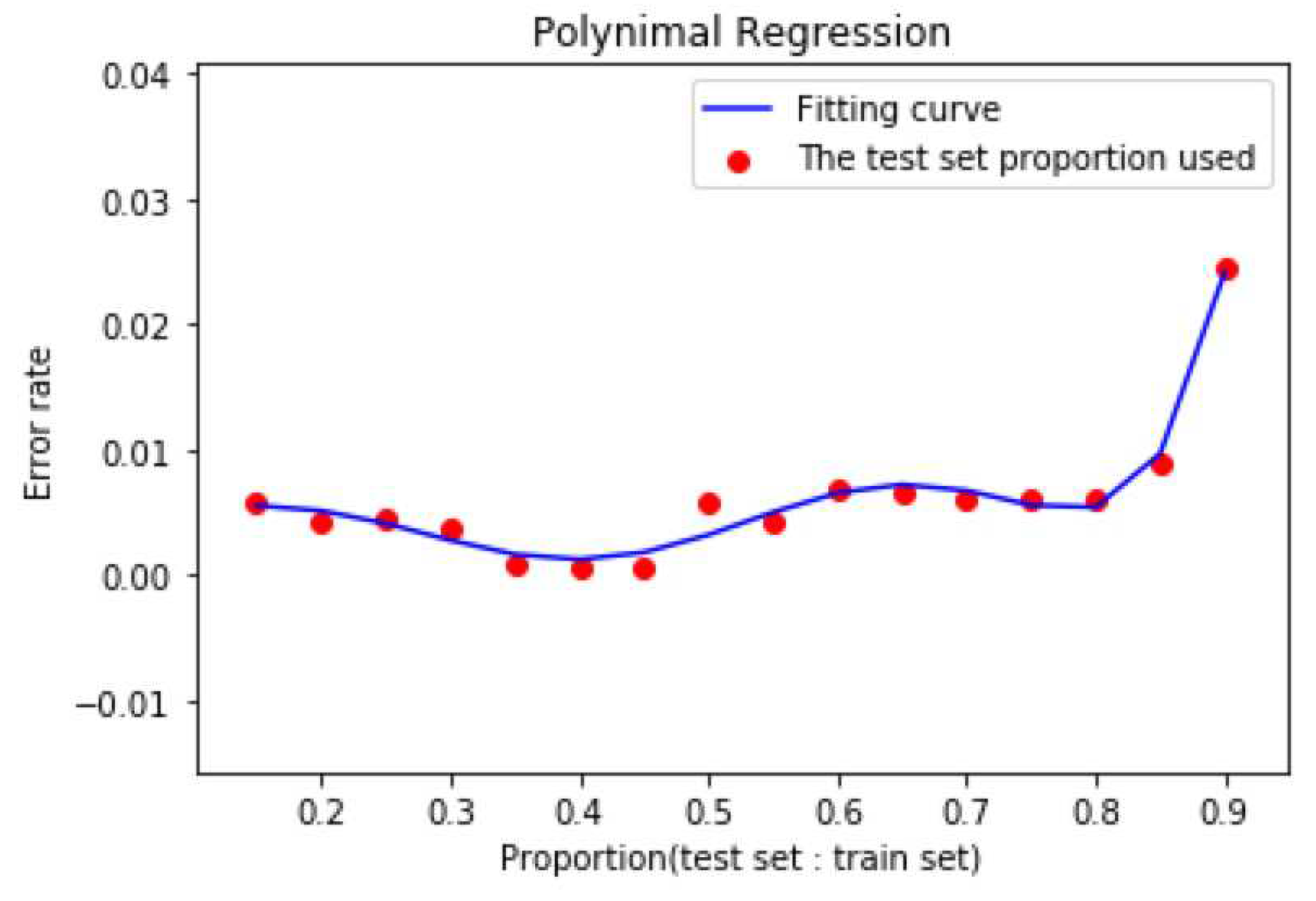
The innovations of this article are as follows: 1, We use the ocean density algorithm to calculate the density of the original temperature and salt data, and extract the features of the original open source Argo data structure. Feature extraction is to reduce the dimension, thus reducing the computational complexity. Then we structured the data set after feature extraction and stored it. 2, On the basis of traditional statistical analysis, this paper also analyzes the pycnocline distribution characteristics after calculation, and verifies the characteristics of pycnocline under the influence of time, space, pressure, temperature, salinity and so on. 3, In the experimental part of machine learning, the proportion of the training set is selected by polynomial regression, so as to ensure that the prediction model will not be overfitted to the maximum extent. 4, Subsequently, the feature scaling of the input data accelerated the gradient convergence, and a grid search algorithm with variable step size was proposed to determine the super parameter c and gamma of the SVM model. 5, The prediction results not only used the confusion matrix to analyze the accuracy of GridSearch-SVM with variable step size, but also compared the traditional SVM and the similar algorithm. 6, At the end of the experiment, two features which have the greatest influence on the Marine density thermocline are found out by the feature ranking algorithm based on learning.
The next part is divided into the following parts: in the second part, the related knowledge and characteristics of pycnocline are briefly described. What’s more, the distribution characteristics of pycnocline are analyzed by using the data collected by the open Argo buoy, and the ocean density algorithm is introduced. At the same time, the paper explains why it is necessary to use kernel support vector machine algorithm to predict marine pycnocline. In the third part, the existing ocean data is used to model, and the prediction model of pycnocline is obtained.
2. Related Work
In this part, we will enumerate the ocean density algorithm and analyze its calculation process. In addition, we will also expound and explain the causes of formation for the Marine pycnocline and the classification of the pycnocline. At the same time, we will give the ocean data analysis structure based on machine learning kernel-SVM.
2.1. A Formula for Calculating Ocean Density
Studies of the density of oceans have yielded preliminary achievement for decades. According to the “Background papers and supporting data on the International Equation of State of Seawater 1980” published by UNESCO in marine science and technology, the functional relationship between density and pressure, temperature and salinity is presented in detail [
15].
Density on the spot of the ocean
can be represented as:
In the formula, S,t,P respectively represent the salinity,temperature,pressure. indicates the density of seawater at a standard atmospheric pressure P = 0. , are the coefficients of salinity in this equation which are varying with time. C is a constant.
The
is standard average seawater density, which is given by the following formula:
is called the secant volume modulus, which can be expressed as:
Secant volume modulus formula: As, Bs, Aw, Bw is a function of time and salinity. denotes the cut volume modulus at standard atmospheric pressure P = 0.
In the equation for , ,, are just equations that change over time.
2.2. Ocean Data Formatting
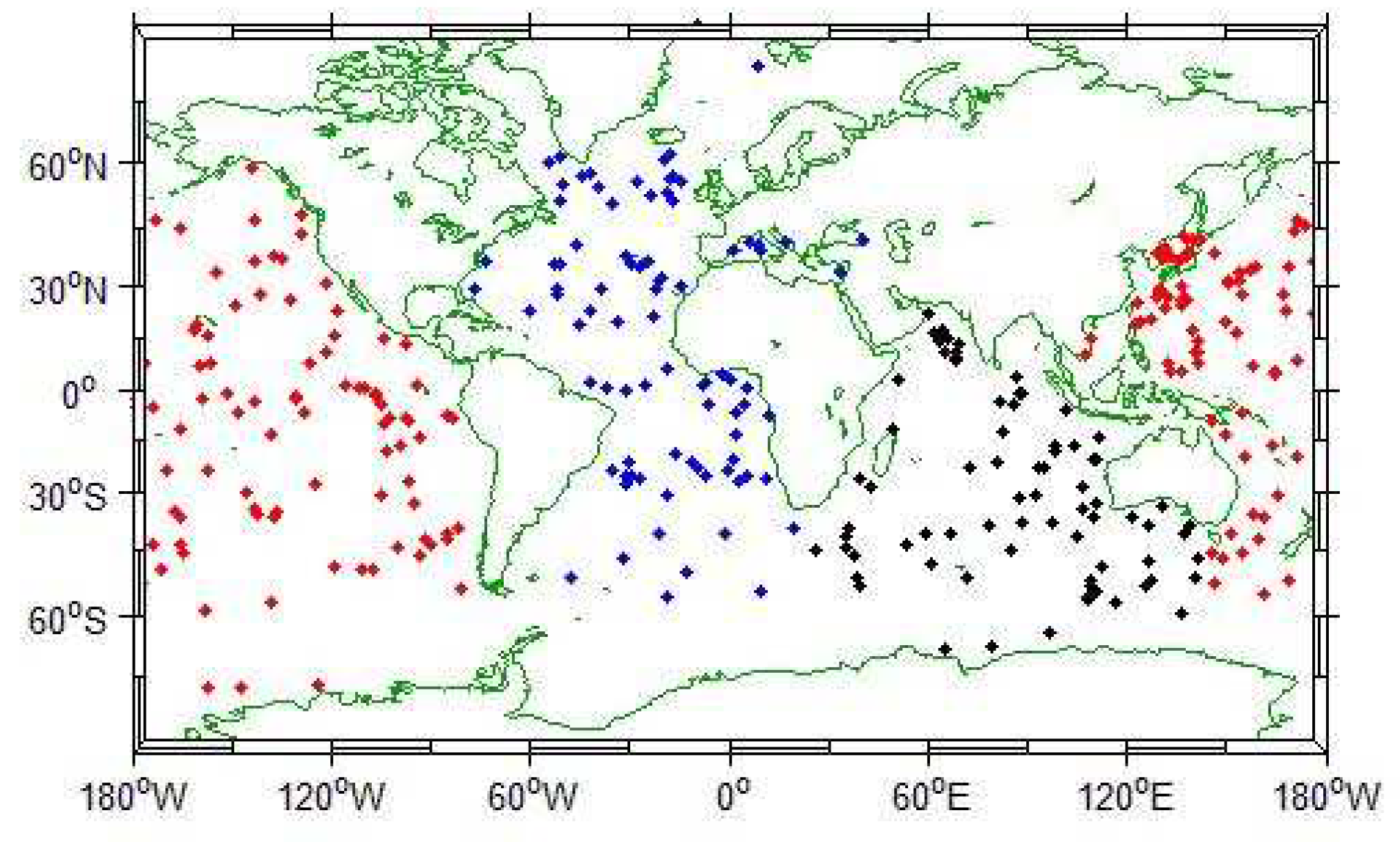
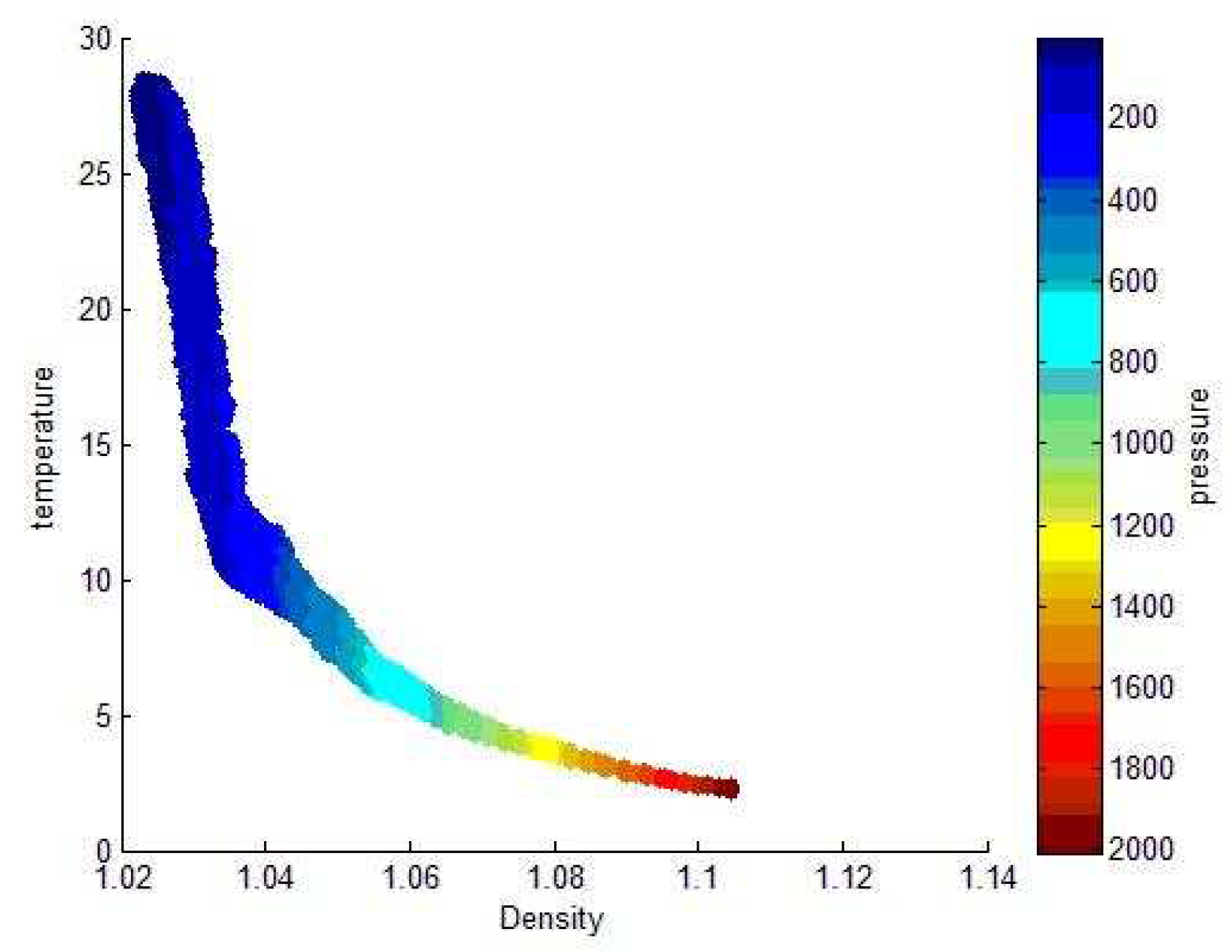
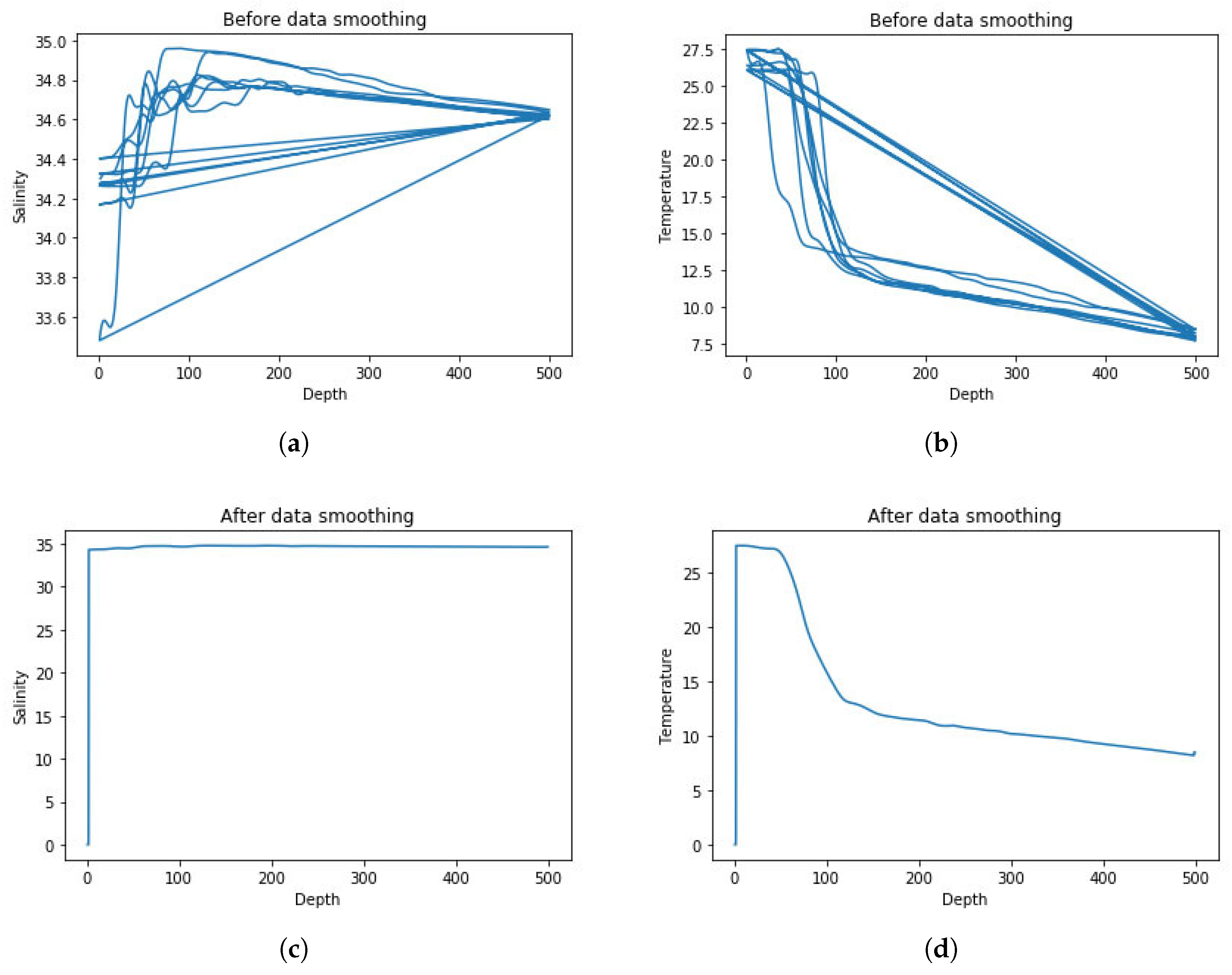
Using the Argo data set published by China Argo Real time data Center, we use matlab to study the distribution characteristics of pycnocline. The monthly mean temperature and salt standard layer data from 2004 to 2010 are used. The Argo data set is a three-dimensional grid data set, covering a longitude and latitude range of , . It has a horizontal resolution of and a depth range of 0–2000 m.
We selected the data from 2004 to 2010 at
and
longitude. Temperature and salt data with depth interval of about 1 m were obtained by interpolation method published by Reiniger et al. Finally, the density of seawater between 102
and 105
, that is, 1.02
to 1.05
, is obtained by the conversion of density to pressure, temperature and salinity [
16,
17].
We format the above 10 columns (
Table 1) of data. Then, according to the density calculation method mentioned above, the data in 12 columns of data format are stored in combination with time and latitude and longitude.
Table 1 below contains the raw Argo data type and the collated data type, respectively:
2.3. Determination of Pycnocline
For the study of pycnocline, one of the most important steps is to determine the pycnocline. There are many methods used to determine the cline structure in history, including vertical gradient method, maximum curvature point method and pycnocline determination method (S-T method) proposed by Srintall and Tomczak [
18,
19].
In this paper, according to the vertical gradient method used in “China Marine Survey Code”, the pycnocline is determined. When the water depth is greater than 200 m, the density gradient is greater than or equal to, and when the water depth is less than 200 m, the density gradient is defined as pycnocline [
20]. The depth of the upper and lower end of the cline is the depth of the upper and lower boundary of the cline, and the difference between the upper and lower boundary is the depth of the cline [
21,
22,
23].
According to the traditional definition of pycnocline, a layer of water that suddenly changes in vertical density is called pycnocline. We define the density gradient as G, and by definition we can write the relationship between the density gradient G and the density
D, depth d (or pressure), and the number of layers
n:
For the upper formula, G may be positive or negative. For pycnocline, to simplify the formula here:
For a special case, when the computational depth is the first layer (n = 1), we will define the density gradient G = 0.
2.4. Kernel-SVM Algorithm
Support vector machine (SVM) is an optimal design criterion for linear classifiers proposed by Vapnik et al on the basis of statistical learning theory. It can effectively solve the problem of linear separability [
24]. Support vector machine (SVM) is a supervised learning model, which aims to find a hyperplane in the feature space and separate positive and negative samples with minimum error rate [
25]. Support vector machines are usually used in pattern recognition, classification and regression analysis [
26,
27,
28].
For the linear inseparability problem, SVM can also use nonlinear mapping algorithm to map the sample space to a high dimensional or even infinite dimensional feature space (Albert space). So that the problem of nonlinear separability in the original sample space is transformed into a problem of high dimensional linear separability [
29]. To put it simply, it is to increase and linearize the original problem. However, the dimension elevation can greatly increase the computational complexity, the display expression of nonlinear mapping can not be determined in some situations. How to find the most suitable dimension is the direction of the optimization of SVM algorithm by relevant researchers in the past decade or so [
30].
In order to solve the complexity of ascending dimension, kernel support vector machine came into being. By the expansion theorem of kernel function, we can skillfully avoid the kernel function of high dimensional display expression. Kernel support vector machine which must be obtained in three forms: 1, Poly nomial Kernel; 2, Sigmoid Kernel; 3, Gaussian RBF Kernel.
The purpose of this paper is to find the best prediction model to predict the location of pycnocline with the least amount of data. So how to find the kernel function suitable for ocean pycnocline prediction is very important.
Polynomial kernel function is a common kernel function, which is very suitable for the prediction of orthogonal normalized data. However, polynomial kernel functions often increase the complexity of functions because of the number of determined parameters.
When Sigmoid function is used as kernel function, support vector machine(SVM) implements a multilayer perceptron neural network. Because it finally obtains the global optimal value rather than the local minimum value, it also ensures its good generalization ability to unknown samples without ever learning phenomenon. However, the use of Sigmoid kernel function will also make the calculation of the activation function large, and the gradient will disappear easily when it is propagated back.
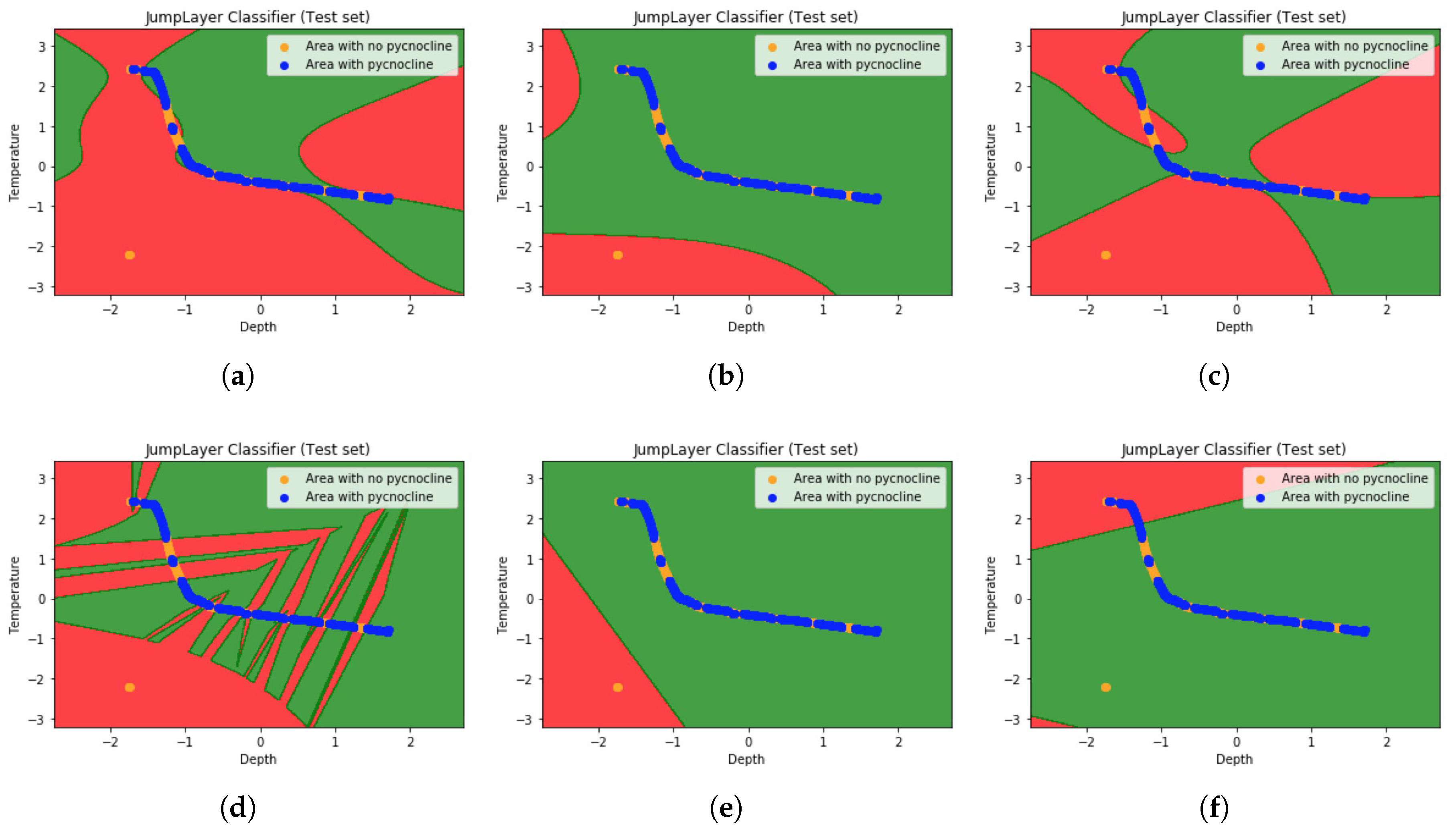
In this paper, Gaussian RBF function is used as kernel function. Not only does it have fewer parameters than polynomial kernel function and faster caculation speed than Sigmoid kernel function, but RBF can achieve similar performance to sigmoid [
31,
32] by setting some parameters At the same time, it also has good anti-interference ability to the noise in the data.
4. Conclusions and Future Work
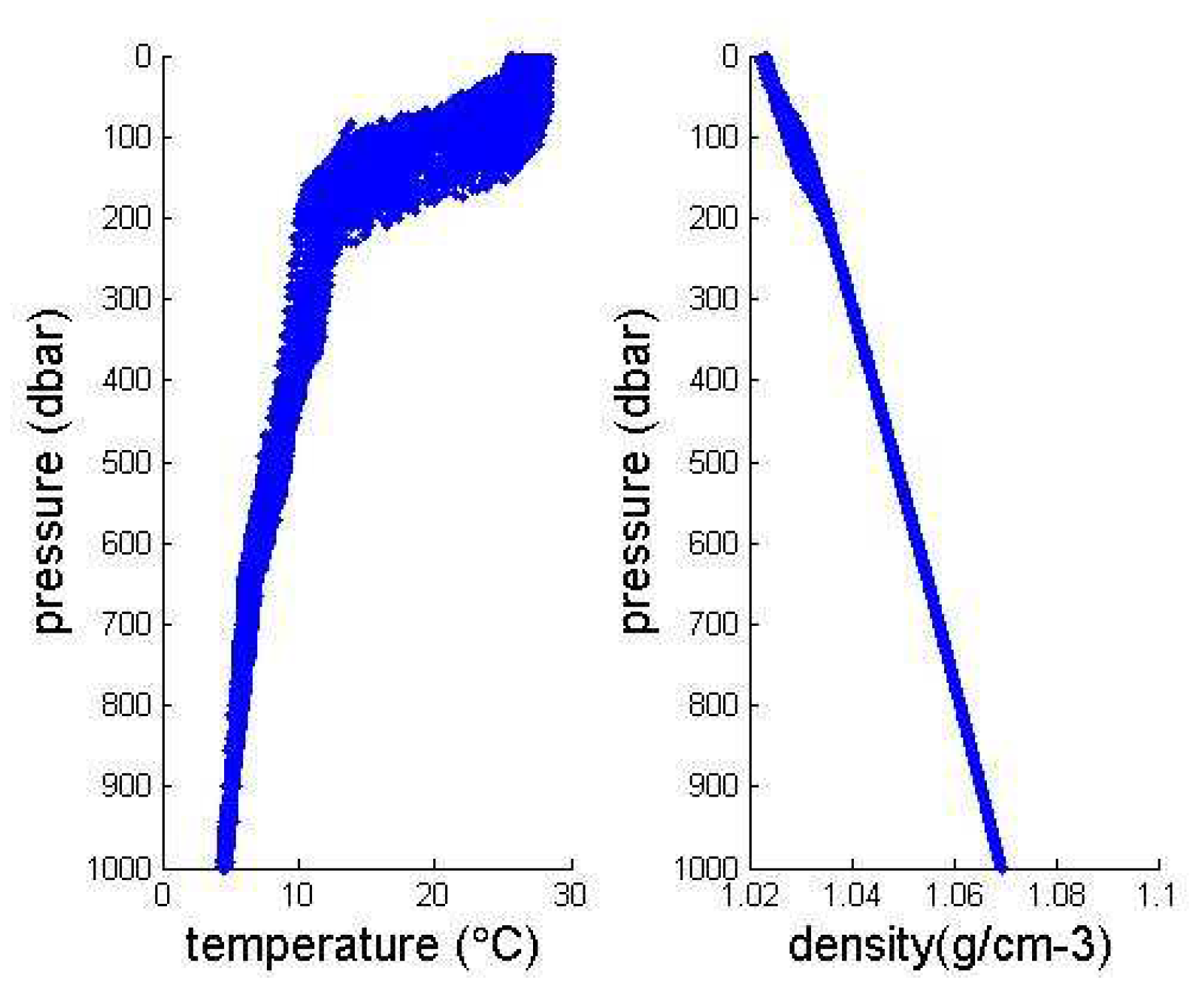
In this paper, the characteristics of ocean density varying with longitude and latitude, depth, temperature, salinity, season and so on are summarized, and the distribution characteristics of ocean density are verified from images by matlab. Secondly, combined with the polynomial regression model of machine learning and Kernel-SVM algorithm, the ocean hydrological data is trained and predicted, and good accuracy is obtained. Compared with the traditional choice of pycnocline, using machine learning method can use less known data (such as only known depth and density gradient) to predict pycnocline. We know that in many cases, ocean hydrological data measurements are not easy and some polar regions or regions with bad weather are more difficult to detect oceanic hydrological data. If we can get the classified data with very high prediction rate, we can reduce the dependence on unknown data when we judge the existence of pycnocline. To some extent, it is convenient for marine underwater research and marine military activities.
In the future, with the explosive growth of marine big data, making efficient use of oceanic big data is still an important research direction. We will continue to explore faster, more accurate and more complex prediction models for ocean hydrological data with a combination of in-depth learning and integrated learning.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}