Signal Status Recognition Based on 1DCNN and Its Feature Extraction Mechanism Analysis

Abstract
:1. Introduction
- (1)
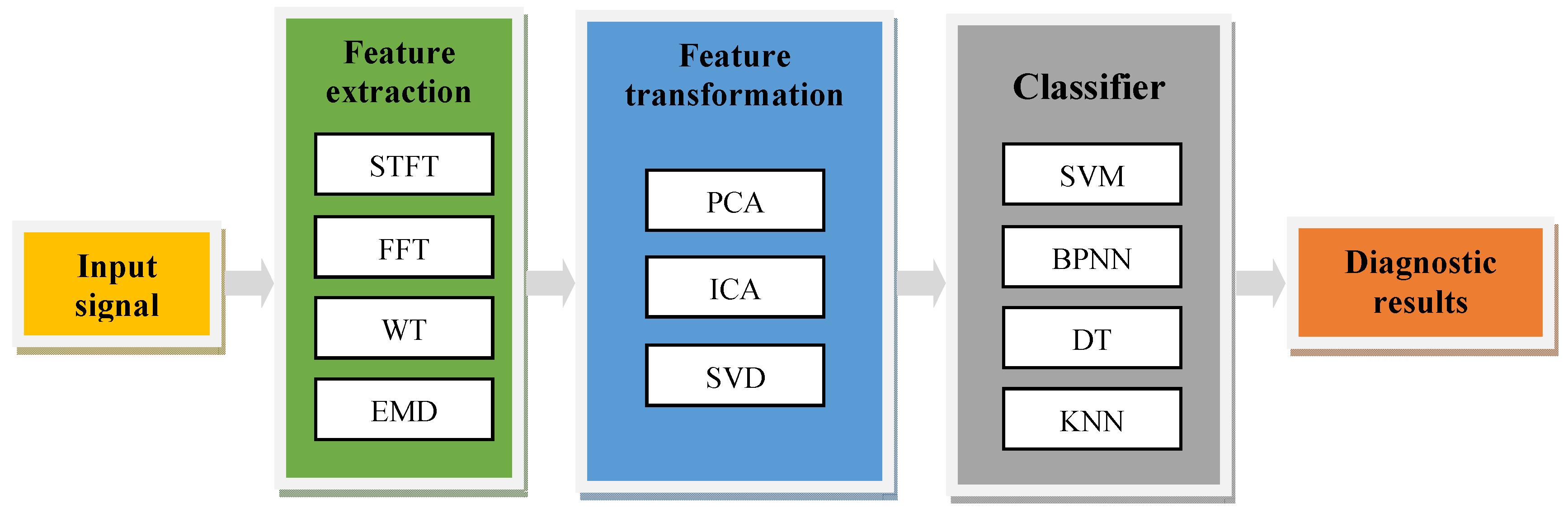
- The first kind is to transform the signals into the frequency domain. To complete the classification, the frequency features are extracted by CNN. For example Janssen et al. [26] from Ghent University in Belgium used CNN to diagnose bearing and gear faults in the gearbox. They applied a Discrete Fourier Transform (DFT) to transform vibration signals into the frequency domain, and trained the CNN with labeled samples to complete the diagnosis. The accuracy of fault diagnosis was increased by 6%. Obviously, in this kind of researches, CNN just worked as the classifier, its excellent multi-layer feature extraction and abstraction ability were underutilized.
- (2)
- The second kind is to use the images of time-series signals as the input of 2DCNN. Wen et al. [27] used images of bearing vibration signals as the input of CNN, and the diagnosis accuracy was above 95%. Hoang et al. [28] adopted a deep CNN structure in the fault diagnosis of rolling bearings, which had higher accuracy and robustness, even in noisy environments. Actually, this kind of method treats the fault diagnosis problem as an image recognition problem. However, complex machines often work in large noisy environments. Their state signals often contain various frequency components. If the fault diagnosis is only based on the shape of the time-series signal, instead of digging out the deeper features, whether it can maintain a good identification ability when faced with the complex signal of complex machine is questionable.
- (3)
- The third kind is to convert time-series signals into two-dimensional time-frequency diagrams, and use them as the input of 2DCNN for diagnosis. For example, Guo et al. [29] used the transform result after continuous WT as the input matrix of CNN to diagnose the fault of rotating machinery, and achieved a good diagnosis result. Wang et al. [30] preprocessed the original signal with STFT to obtain the time-frequency diagram, and then used CNN to adaptively extract the time-frequency features to complete diagnosis. This kind of methods adds a time-frequency step before CNN, but as mentioned earlier, the current commonly used time-frequency transformation methods may cause some degree of distortion of the original signal, such as the loss of useful features, the appearance of false features, signal distortion and so on.
2. The One Dimensional Convolutional Neural Network Model
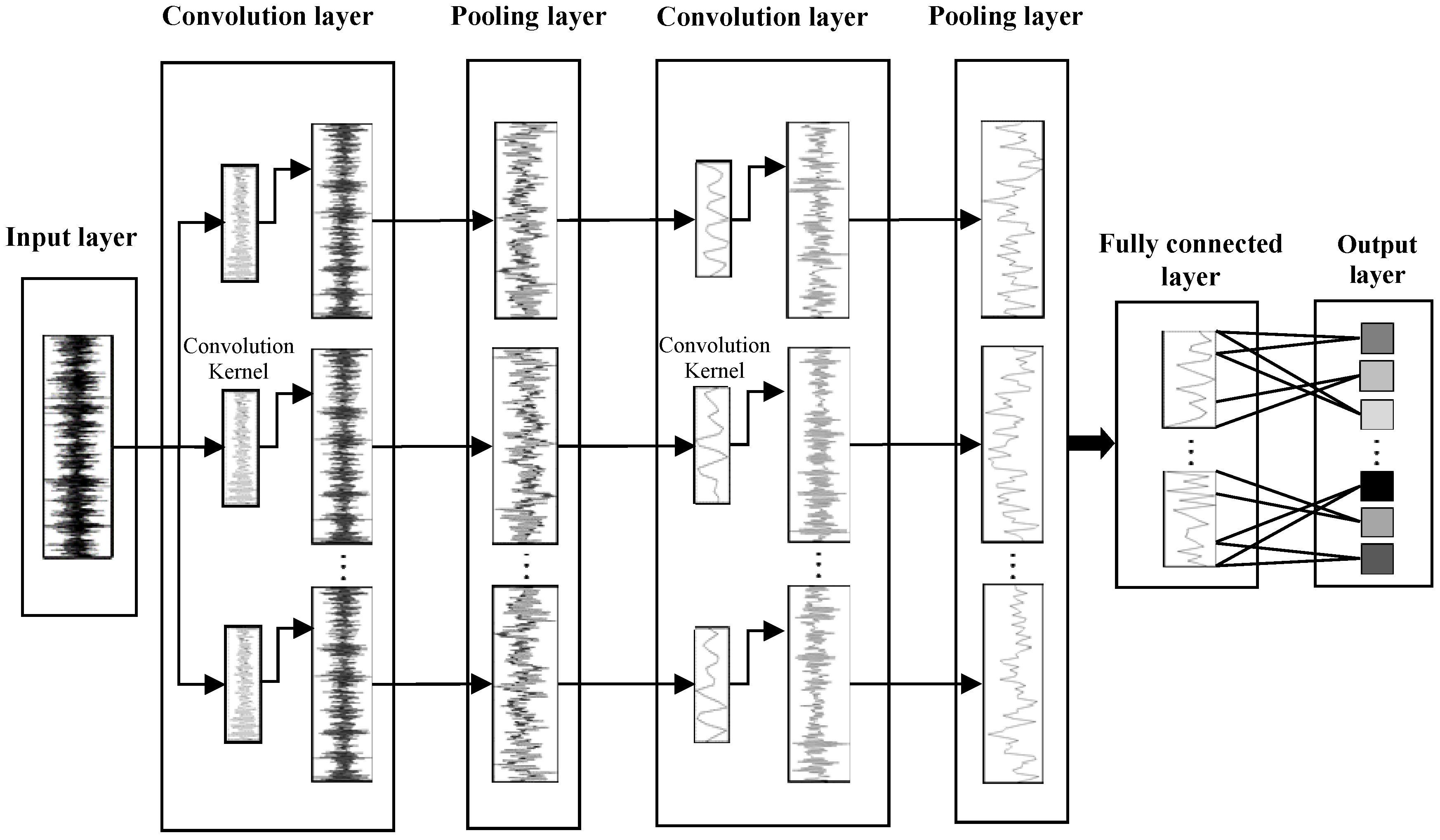
2.1. The Structure of 1DCNN
2.1.1. Convolution Layer
2.1.2. Pooling Layer
2.1.3. Fully Connected Layer
2.2. Network Training
3. Feature Extraction Mechanism Analysis
3.1. The Pattern Recognition of Simulation Signal
3.1.1. Creation of Experimental Samples
3.1.2. Parameter Setting of the 1DCNN
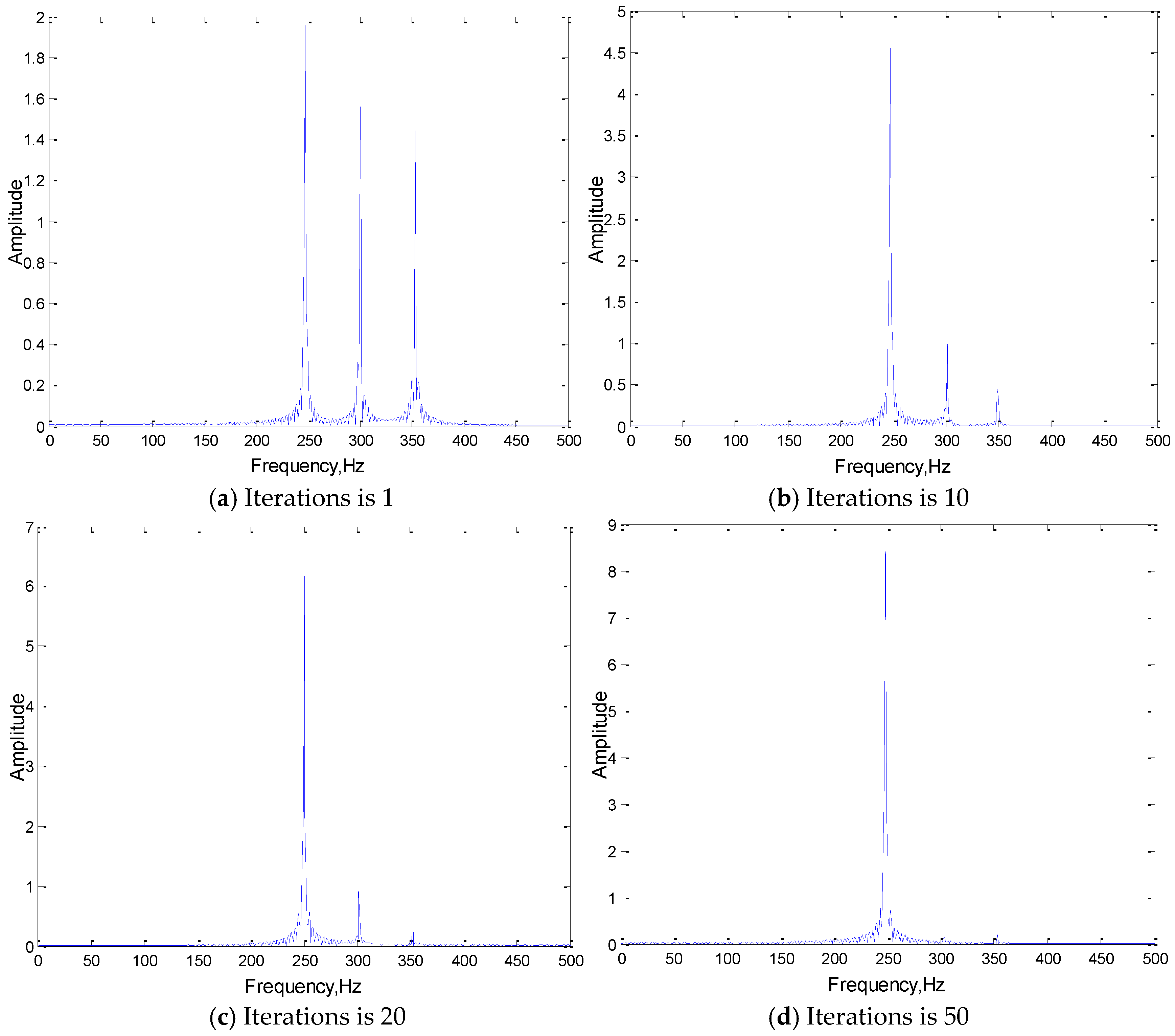
3.1.3. Training Results and Preliminary Conclusions
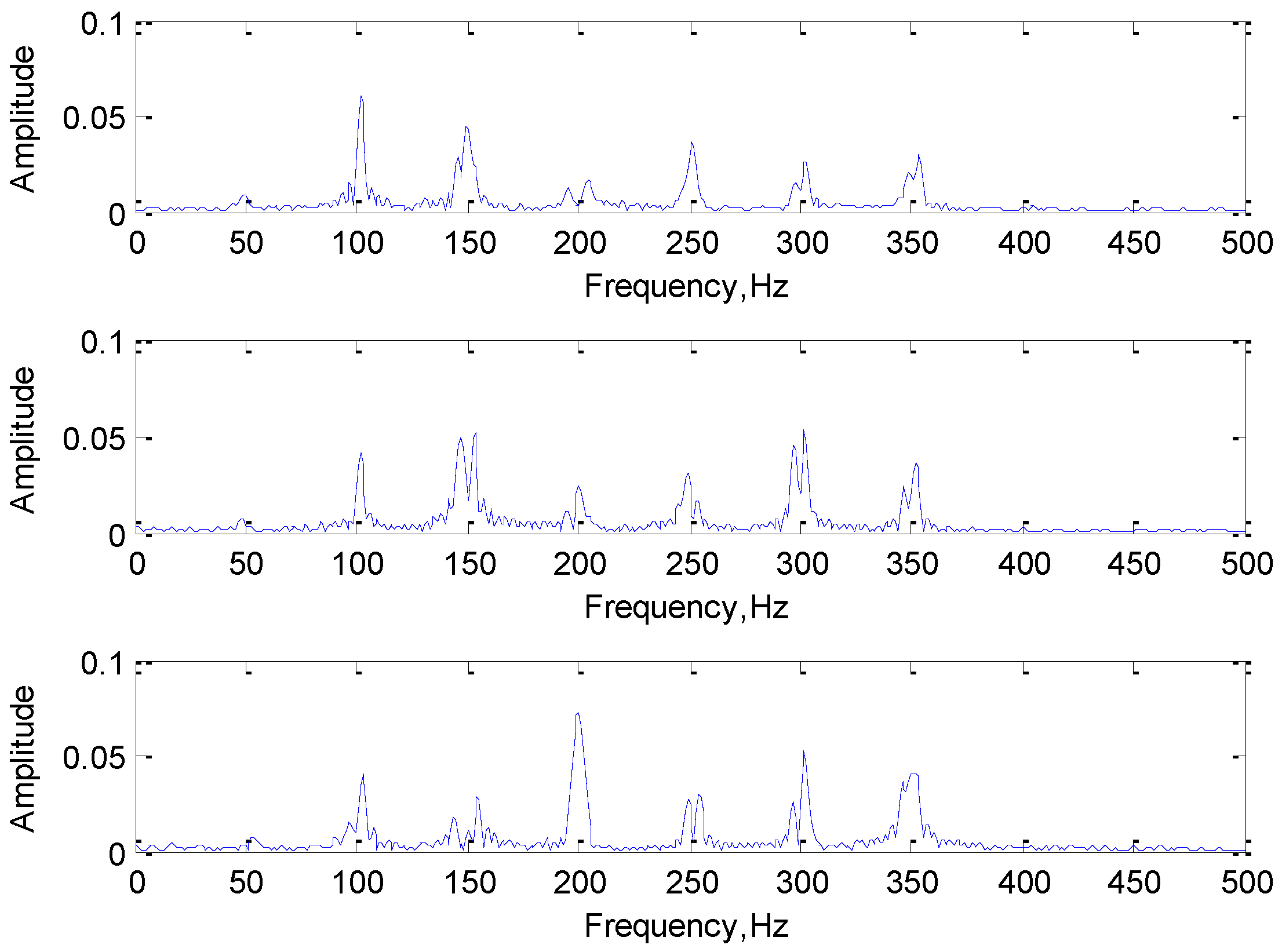
3.2. The Role of Convolutional Kernel
3.2.1. The Evolution of the Convolution Kernel
3.2.2. Convolution Results Analysis
3.3. Collaborative Optimization for Classification Problems
3.3.1. The Qualitative Analysis
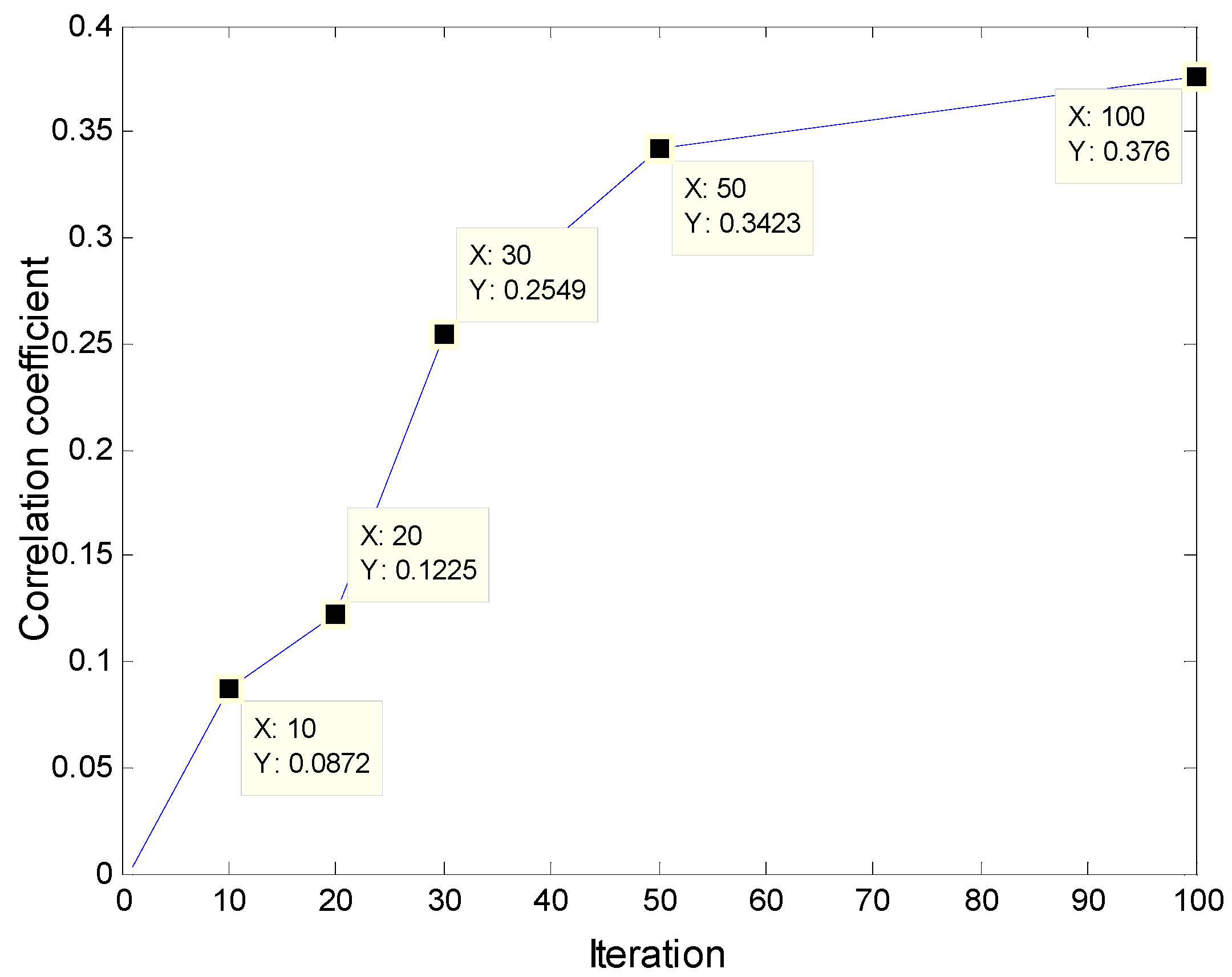
3.3.2. The Quantitative Analysis
4. Fault Diagnosis of Bearing Vibration Signals
4.1. Data Preparation
4.1.1. Data Description
4.1.2. Data Augmentation
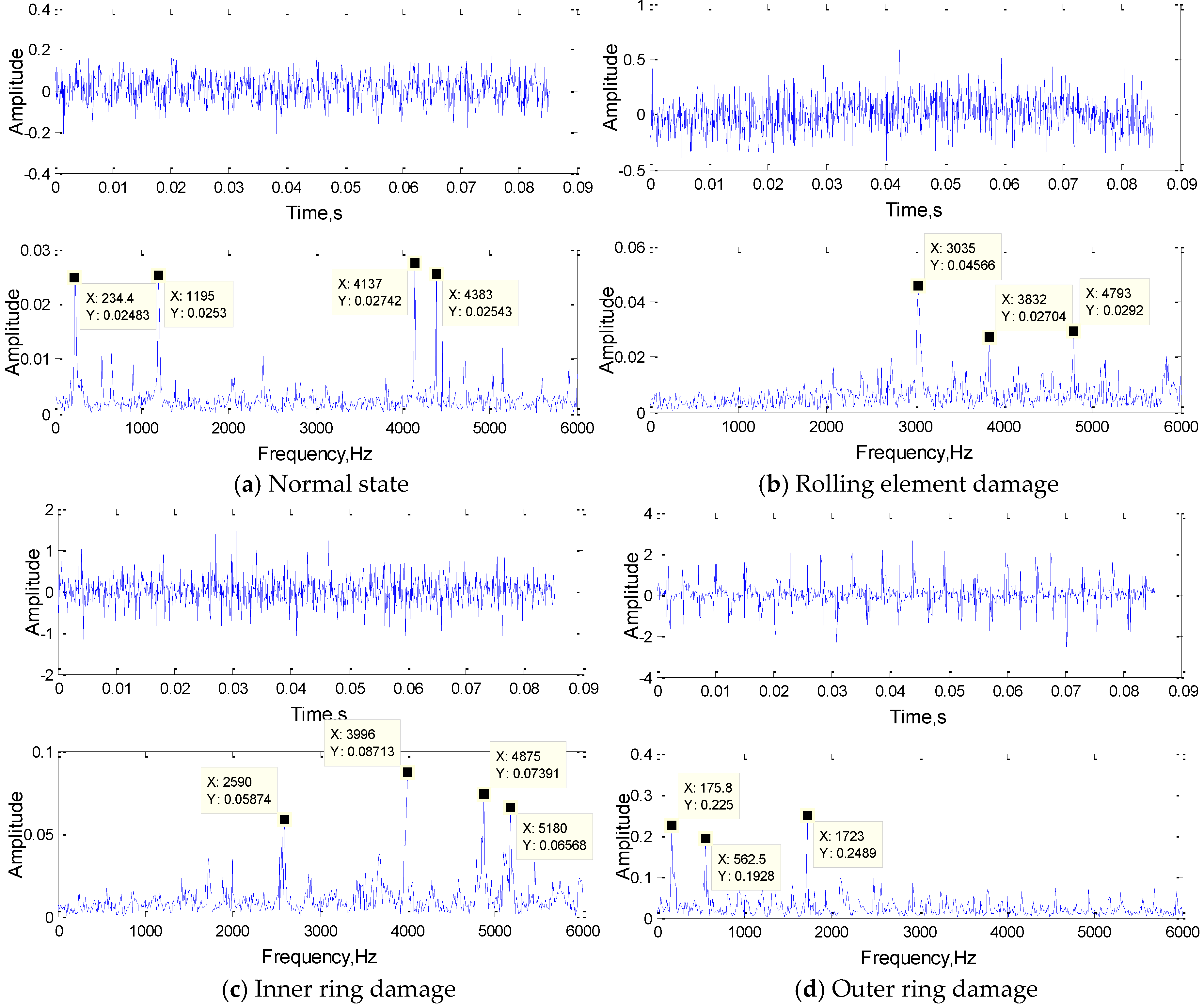
4.1.3. Data Analysis
4.2. Feature Extraction Mechanism Analysis
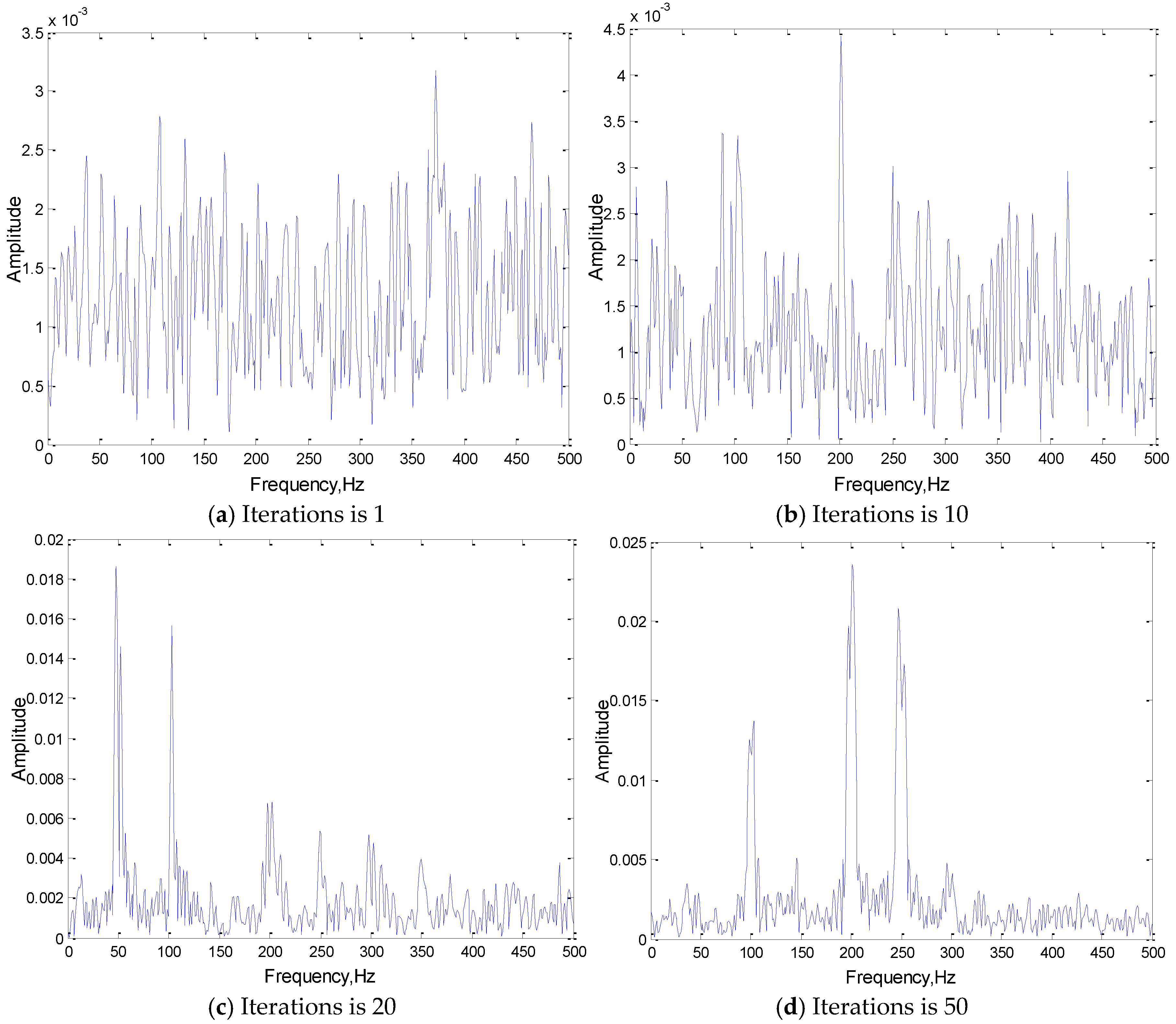
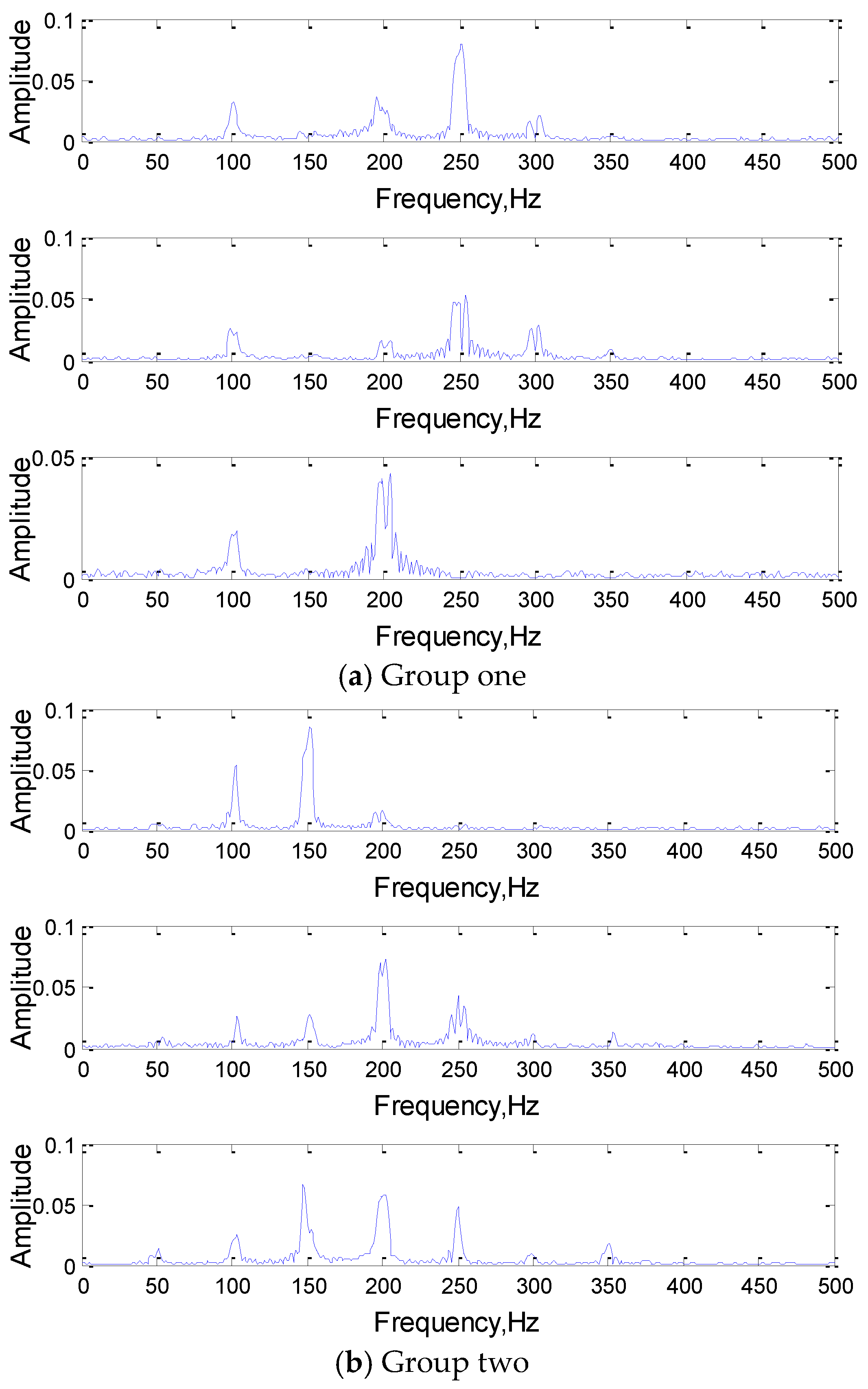
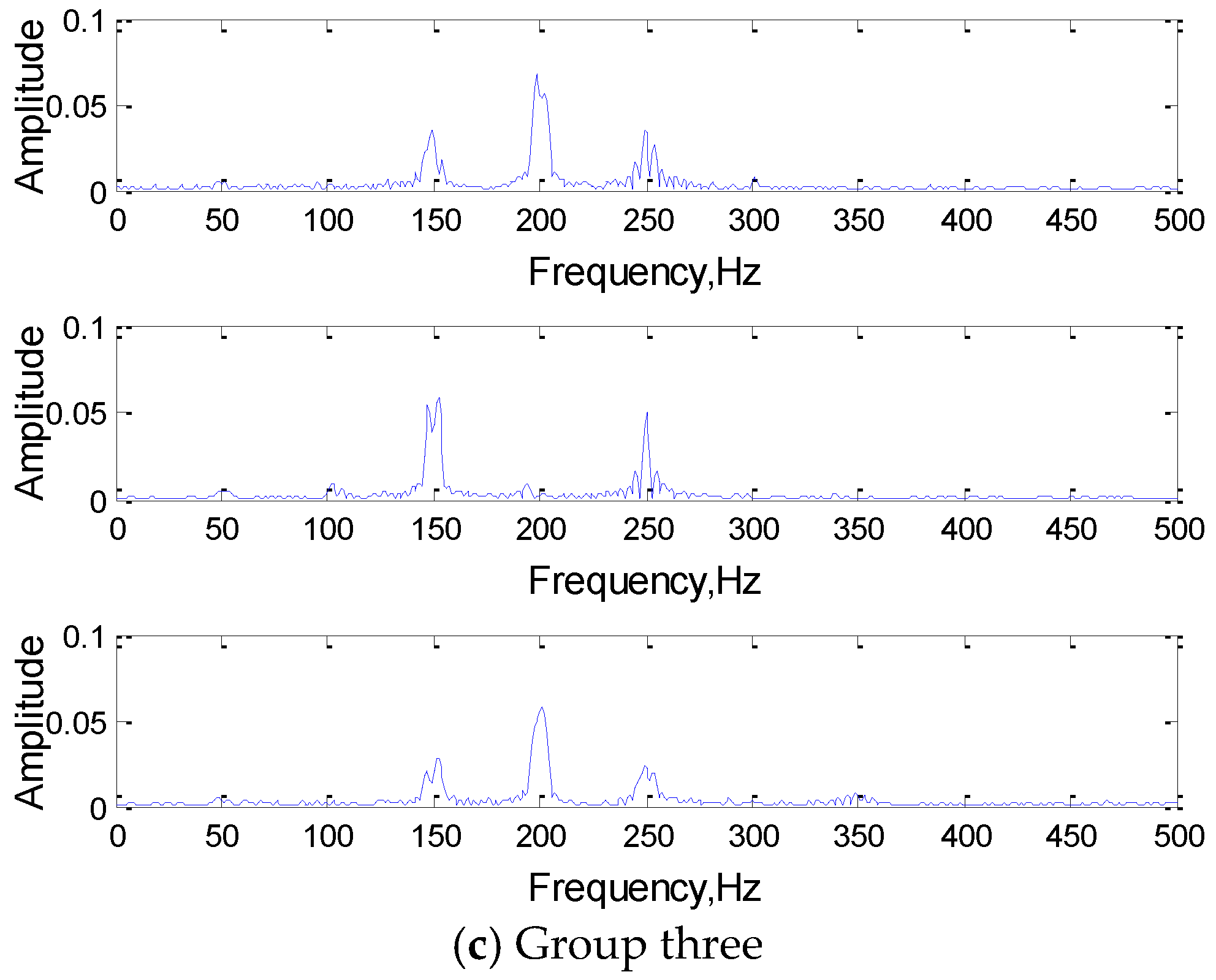
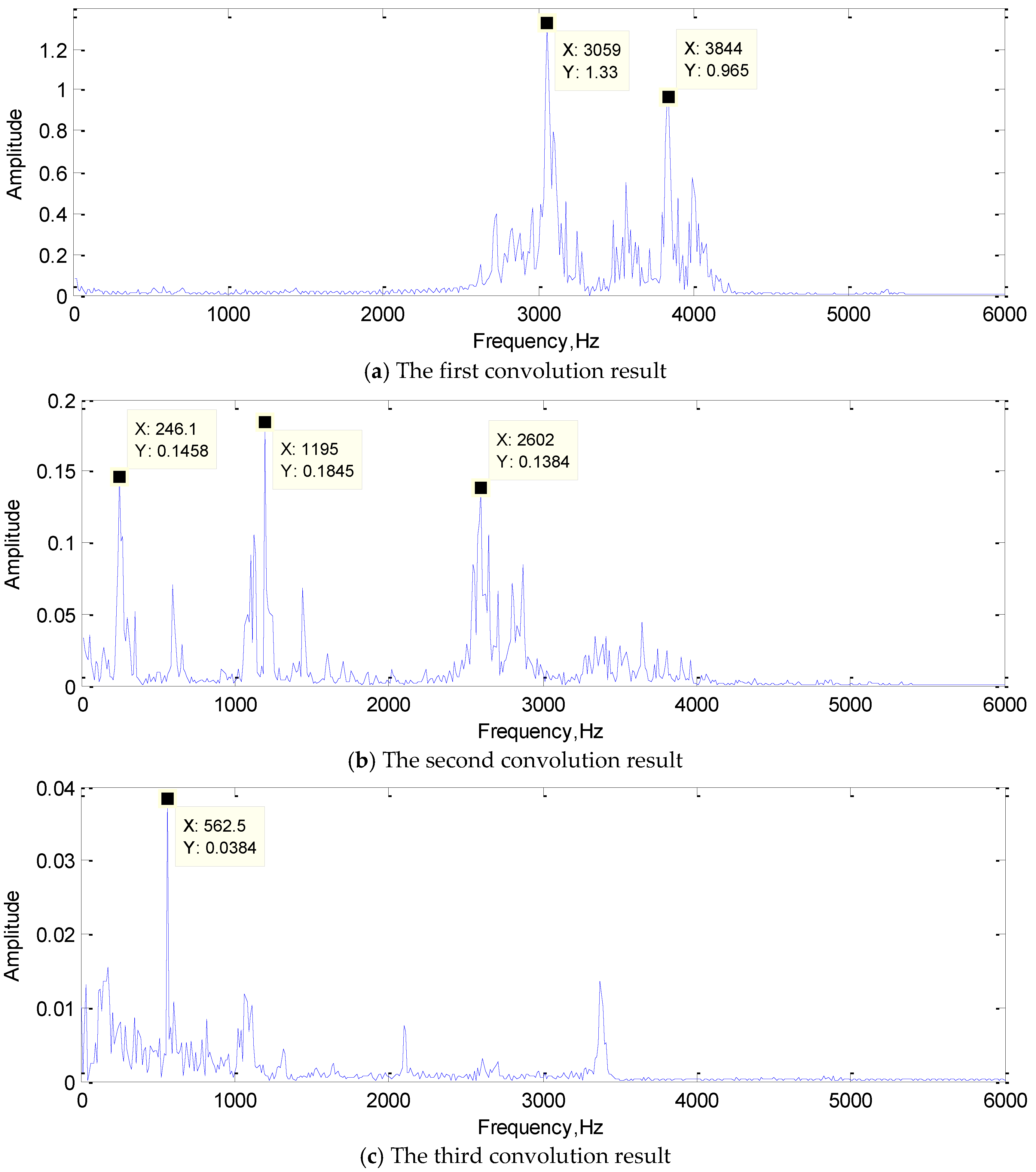
4.2.1. Convolution Result Analysis
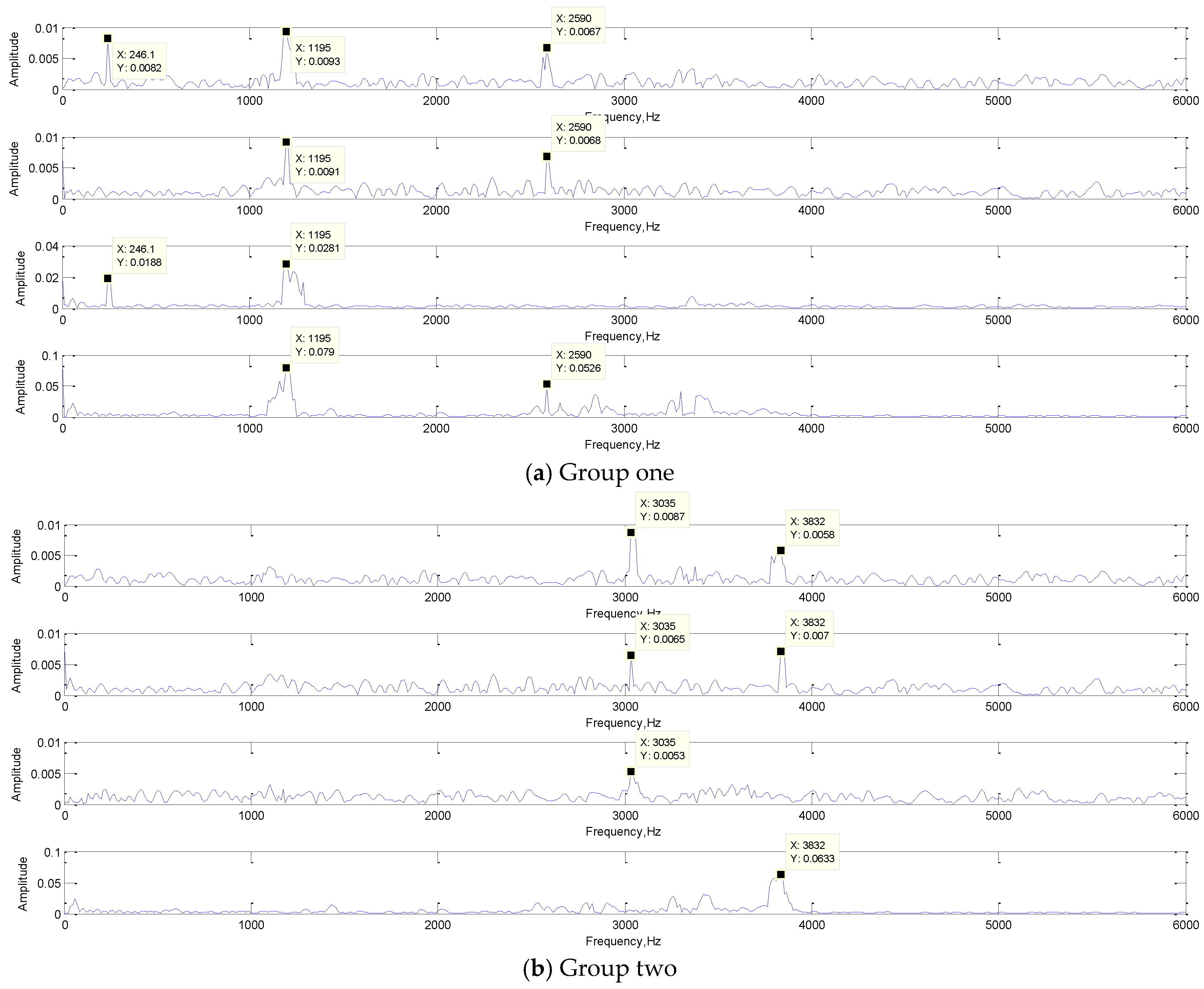
4.2.2. Convolution Kernel Analysis
4.3. Network Optimization
4.3.1. Optimization Method
4.3.2. Contrast Experiment
5. Conclusions
- In the 1DCNN, the convolution kernel acts as the frequency domain filter. Its signal feature form will be similar to the input signals after convolution with the input signals, and the main frequency components of input signals will be extracted. Moreover, the same set of convolution kernels extract the features of input signals from different perspectives, and the extraction results act on the classification together, and the collaborative optimization of signal classification is achieved. Through the study of its convolutional mechanism, it explains why 1DCNN has such a good feature extraction ability.
- The network parameters (the number of convolution kernels) can be optimized by analyzing the frequency domain characteristics of the input signals. The optimization method consists of two steps: firstly, preliminary analysis the original signal by signal processing methods (FFT, STFT), and counting the number of the typical frequency components. Secondly, to express the characteristics of the input signals and improve the network efficiency greatly, and save computing resources, the number of convolution kernels should correspond to the number of typical frequency components of the input signal as far as possible.
Author Contributions
Funding
Conflicts of Interest
References
- Gao, Z.; Cecati, C. A Survey of Fault Diagnosis and Fault-Tolerant Techniques—Part II: Fault Diagnosis With Knowledge-Based and Hybrid/Active Approaches. IEEE Trans. Ind. Electron. 2015, 62, 3768–3774. [Google Scholar] [CrossRef]
- Gao, Z.; Cecati, C. A Survey of Fault Diagnosis and Fault-Tolerant Techniques—Part I: Fault Diagnosis With Model-Based and Signal-Based Approaches. IEEE Trans. Ind. Electron. 2015, 62, 3757–3767. [Google Scholar] [CrossRef] [Green Version]
- Dai, X.; Gao, Z. From model, signal to knowledge: A data-driven perspective of fault detection and diagnosis. IEEE Trans. Ind. Inform. 2013, 9, 2226–2238. [Google Scholar] [CrossRef]
- Lei, Y.; Jia, F. An intelligent fault diagnosis method using unsupervised feature learning towards mechanical big data. IEEE Trans. Ind. Electron. 2016, 63, 3137–3147. [Google Scholar] [CrossRef]
- Jia, F.; Lei, Y. Deep neural networks: A promising tool for fault characteristic mining and intelligent diagnosis of rotating machinery with massive data. Mech. Syst. Signal Proc. 2016, 72, 303–315. [Google Scholar] [CrossRef]
- Hoou, H.; Meng, H. Time-frequency Signal Analysis in Machinery Fault Diagnosis: Review. Adv. Mater. Res. 2014, 845, 41–45. [Google Scholar]
- Mogal, S.P.; Lalwani, D.I. A Brief Review on Fault Diagnosis of Rotating Machineries. Appl. Mech. Mate. 2014, 541, 635–640. [Google Scholar] [CrossRef]
- Li, S.; Lv, F. Wavelet Selection in Fault Diagnosis of Wavelet Transform. Adv. Mater. Res. 2012, 591, 2127–2130. [Google Scholar] [CrossRef]
- Yu, H.; Zhao, X. Rotating Machinery Fault Diagnosis Using Frequency Auxiliary Signal and EMD. Semicond. Opto-Electron. 2017, 38, 271–277. [Google Scholar]
- Yu, D.; Cheng, J. Application of EMD method and Hilbert spectrum to the fault diagnosis of roller bearings. Mech. Syst. Signal Proc. 2005, 19, 259–270. [Google Scholar] [CrossRef]
- Widodo, A.; Yang, B. Combination of independent compoent analysis and support vector machines for intelligent faults diagnosis of induction motors. Expert Syst. Appl. 2007, 32, 299–312. [Google Scholar] [CrossRef]
- Song, H.; Zhong, L. Structural damage detection by integrating independent component analysis and support vector machine. In Proceedings of the Advanced Data Mining and Applications, Wuhan, China, 22–24 July 2005; pp. 670–677. [Google Scholar]
- Fan, D.; Wen, G. Fault feature extraction for roller bearings based on DTCWPT and SVD. In Proceedings of the 2016 13th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI), Xi’an, China, 19–22 August 2016; pp. 19–22. [Google Scholar]
- Li, K.; Zhang, Y. Application Research of Kalman Filter and SVM Applied to Condition Monitoring and Fault Diagnosis. Appl. Mech. Mate. 2011, 121, 268–272. [Google Scholar] [CrossRef] [Green Version]
- Cheng, J.; Shi, M. A Roller Bearing Fault Diagnosis Method Based on Improved LMD and SVM. J. Meas. Sci. Instr. 2011, 2, 1–5. [Google Scholar]
- Yuan, K.; Guo, X. Fault Diagnosis of Diesel Engine based on BP Neural Network. Inf. Eng. Appl. 2012, 154, 890–897. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G.E. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [Green Version]
- Dong, Y.; Li, D. Deep learning and its applications to signal and information processing. IEEE Signal Process. Mag. 2011, 28, 145–154. [Google Scholar]
- Li, S.; Liu, G. An Ensemble Deep Convolutional Neural Network Model with Improved D-S Evidence Fusion for Bearing Fault Diagnosis. Sensors 2017, 17, 1729. [Google Scholar] [CrossRef]
- Yoo, H.J. Deep convolution neural networks in computer vision: A rewiew. IEIE Trans. Process. Comput. 2015, 4, 35–43. [Google Scholar] [CrossRef]
- Ákos, Z.; Csaba, R. Overview of CNN research: 25 years history and the current trends. In Proceedings of the 2015 IEEE International Symposium on Circuits and Systems (ISCAS), Lisbon, Portugal, 24–27 May 2015; pp. 401–404. [Google Scholar]
- Tivive, F.H.C.; Bouzerdoum, A. An eye feature detector based on convolutional neural network. In Proceedings of the Signal Processing and Its Applications, Sydney, Australia, 28–31 August 2005; pp. 90–93. [Google Scholar]
- LeCun, Y.; Bottou, L. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural. Inform. Process. Syst. 2012, 25, 1097–1208. [Google Scholar] [CrossRef]
- Olivier, J.; Viktor, S. Convolutional neural network based fault detection for rotating machinery. J. Sound Vibr. 2016, 377, 331–345. [Google Scholar]
- Wen, L.; Li, X. A New Convolutional Neural Network Based Data-Driven Fault Diagnosis Method. IEEE Trans. Ind. Electron. 2018, 65, 5990–5998. [Google Scholar] [CrossRef]
- Hoang, D.T.; Kang, H.J. Rolling Element Bearing Fault Diagnosis using Convolutional Neural Network and Vibration Image. Cogn. Syst. Res. 2019, 53, 42–50. [Google Scholar] [CrossRef]
- Guo, S.; Yang, T. A Novel Fault Diagnosis Method for Rotating Machinery Based on a Convolutional Neural Network. Sensors 2018, 18, 1429. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Zhao, X. Motor Fault Diagnosis Based on Short-time Fourier Transform and Convolutional Neural Network. Chin. J. Mech. Eng. 2017, 30, 1357–1368. [Google Scholar] [CrossRef]
- Turker, I.; Serkan, K. Real-Time Motor Fault Detection by 1D Convolutional Neural Networks. IEEE Trans. Ind. Electron. 2016, 63, 7067–7075. [Google Scholar]
- Peng, D.; Liu, Z. A Novel Deeper One-Dimensional CNN with Residual Learning for Fault Diagnosis of Wheelset Bearings in High-Speed Trains. IEEE Access 2018, 99, 10278–10293. [Google Scholar] [CrossRef]
- Levent, E.; Turker, I. A Generic Intelligent Bearing Fault Diagnosis System Using Compact Adaptive 1D CNN Classifier. J. Signal. Process. Syst. 2018, 91, 179–189. [Google Scholar]
- Li, K.; Shi, H. Complex Convolution Kernel for Deep Networks. In Proceedings of the International Conference on Wireless Communications & Signal Processing, Yangzhou, China, 13–15 October 2016; pp. 1–5. [Google Scholar]
- He, K.; Sun, J. Convolutional Neural Networks at Constrained Time Cost. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5353–5360. [Google Scholar]
- Wu, H.; Zhao, J. Deep convolutional neural network model based chemical process fault diagnosis. Comput. Chem. Eng. 2018, 115, 185–197. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type/i | |||
|---|---|---|---|
| 1 | = 6, B1 = 4, C1 = 2 | ~u(197,203) ~u(247,253) ~u(297,303) | = rand[1,100] |
| 2 | = 6, B2 = 2, C2 = 4 | ~u(247,253) ~u(297,303) ~u(347,353) | = rand[1,100] |
| 3 | = 4, B3 = 6, C3 = 2 | ~u(147,153) ~u(197,203) ~u(247,253) | = rand[1,100] |
| 4 | = 2, B4 = 4, C4 = 6 | ~u(47,53) ~u(97,103) ~u(147,153) | = rand[1,100] |
| Convolution Kernel Parameter | Average Accuracy/% | Number of Iterations | Training Time per Iterations/s | Total Time/s |
|---|---|---|---|---|
| 1(301)-1(301) | Failure | Failure | 0.92 | \ |
| 3(301)-3(301) | 100 | 63 | 3.4 | 214.2 |
| 4(301)-4(301) | 100 | 82 | 5.1 | 418.2 |
| 8(301)-8(301) | 95 | 92 | 13.7 | 1260.4 |
| 16(301)-16(301) | 85 | 124 | 46.7 | 5790.8 |
| 1 | 0.0201 | 0.0948 | |
| 0.0201 | 1 | 0.1059 | |
| 0.0948 | 0.1059 | 1 |
| 1 | 0.0548 | 0.0930 | |
| 0.0548 | 1 | 0.0852 | |
| 0.0930 | 0.0852 | 1 |
| 1 | 0.0337 | 0.0745 | |
| 0.0337 | 1 | 0.1570 | |
| 0.0745 | 0.1570 | 1 |
| 1 | 0.0373 | 0.0641 | |
| 0.0473 | 1 | 0.0138 | |
| 0.0641 | 0.0138 | 1 |
| Convolution Kernel Parameter | The Accuracy of Training Data/% | The Accuracy of Test Data/% | Training Time per Iterations/s | Total Time/s |
|---|---|---|---|---|
| 2(301)-4(301) | Failure | Failure | 0.8 | \ |
| 3(301)-6(301) | 75 | 75 | 1.7 | 1854.3 |
| 4(301)-8(301) | 90 | 87.5 | 3.0 | 1742.6 |
| 5(301)-10(301) | 77.5 | 77.5 | 3.2 | 2667.0 |
| 2(301)-4(163)-8(80) | 72.5 | 72.5 | 2.0 | 2137.8 |
| 3(301)-6(163)-12(80) | 90 | 87.5 | 4.2 | 5548.7 |
| 4(301)-8(163)-16(80) | 100 | 100 | 6.6 | 5537.4 |
| 5(301)-10(163)-20(80) | 95 | 95 | 9.2 | 9583.4 |
| 6(301)-12(163)-24(80) | 100 | 100 | 14.2 | 10,432.7 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, S.; Tang, J.; Dai, J.; Wang, Y. Signal Status Recognition Based on 1DCNN and Its Feature Extraction Mechanism Analysis. Sensors 2019, 19, 2018. https://doi.org/10.3390/s19092018
Huang S, Tang J, Dai J, Wang Y. Signal Status Recognition Based on 1DCNN and Its Feature Extraction Mechanism Analysis. Sensors. 2019; 19(9):2018. https://doi.org/10.3390/s19092018
Chicago/Turabian StyleHuang, Shuzhan, Jian Tang, Juying Dai, and Yangyang Wang. 2019. "Signal Status Recognition Based on 1DCNN and Its Feature Extraction Mechanism Analysis" Sensors 19, no. 9: 2018. https://doi.org/10.3390/s19092018
APA StyleHuang, S., Tang, J., Dai, J., & Wang, Y. (2019). Signal Status Recognition Based on 1DCNN and Its Feature Extraction Mechanism Analysis. Sensors, 19(9), 2018. https://doi.org/10.3390/s19092018