JsrNet: A Joint Sampling–Reconstruction Framework for Distributed Compressive Video Sensing


Abstract
:1. Introduction
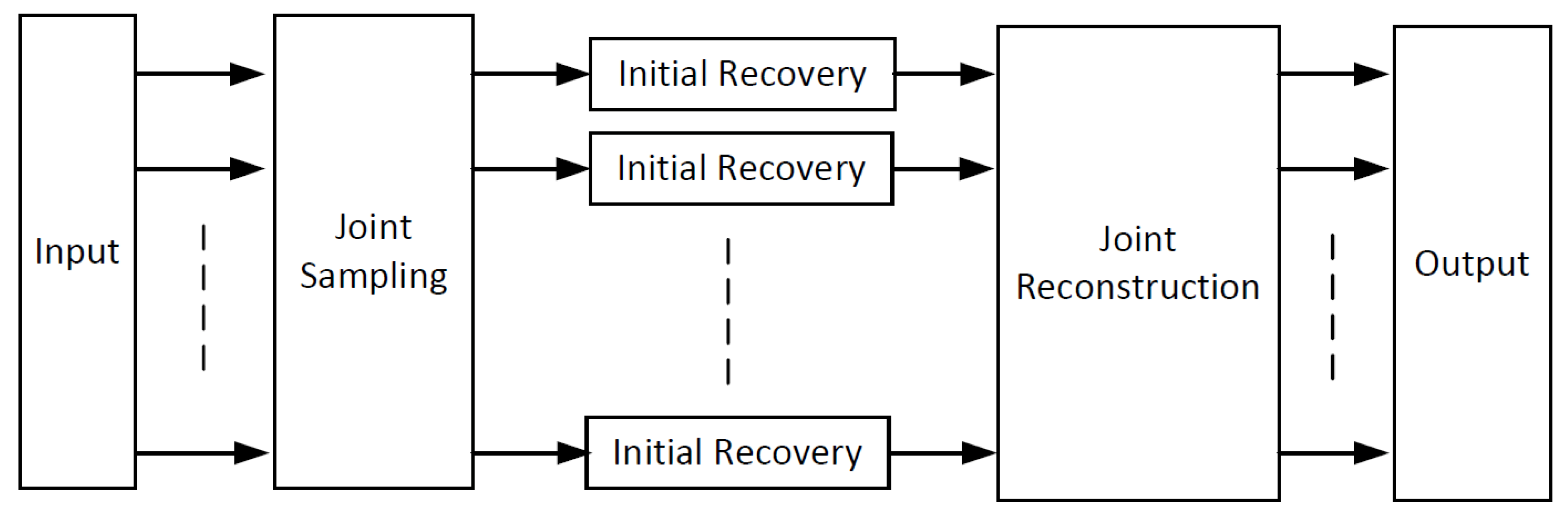
- JsrNet utilizes the whole group of frames as the reference to reconstruct each frame, regardless of key frames and non-key frames.
- JsrNet not only applies the conception of exploiting complementary information between frames in joint reconstruction, but also in joint sampling by adopting learnable convolutions to sample multiple frames jointly and simultaneously in an encoder.
- JsrNet exploits spatial–temporal correlation in both sampling and reconstruction, and achieves a competitive performance on both the quality of reconstruction and computational complexity, making it a promising candidate in source-limited, real-time scenarios.
2. Backgrounds
2.1. Preliminary of CS Theory
2.2. Unsupervised Learning
3. The Proposed JsrNet
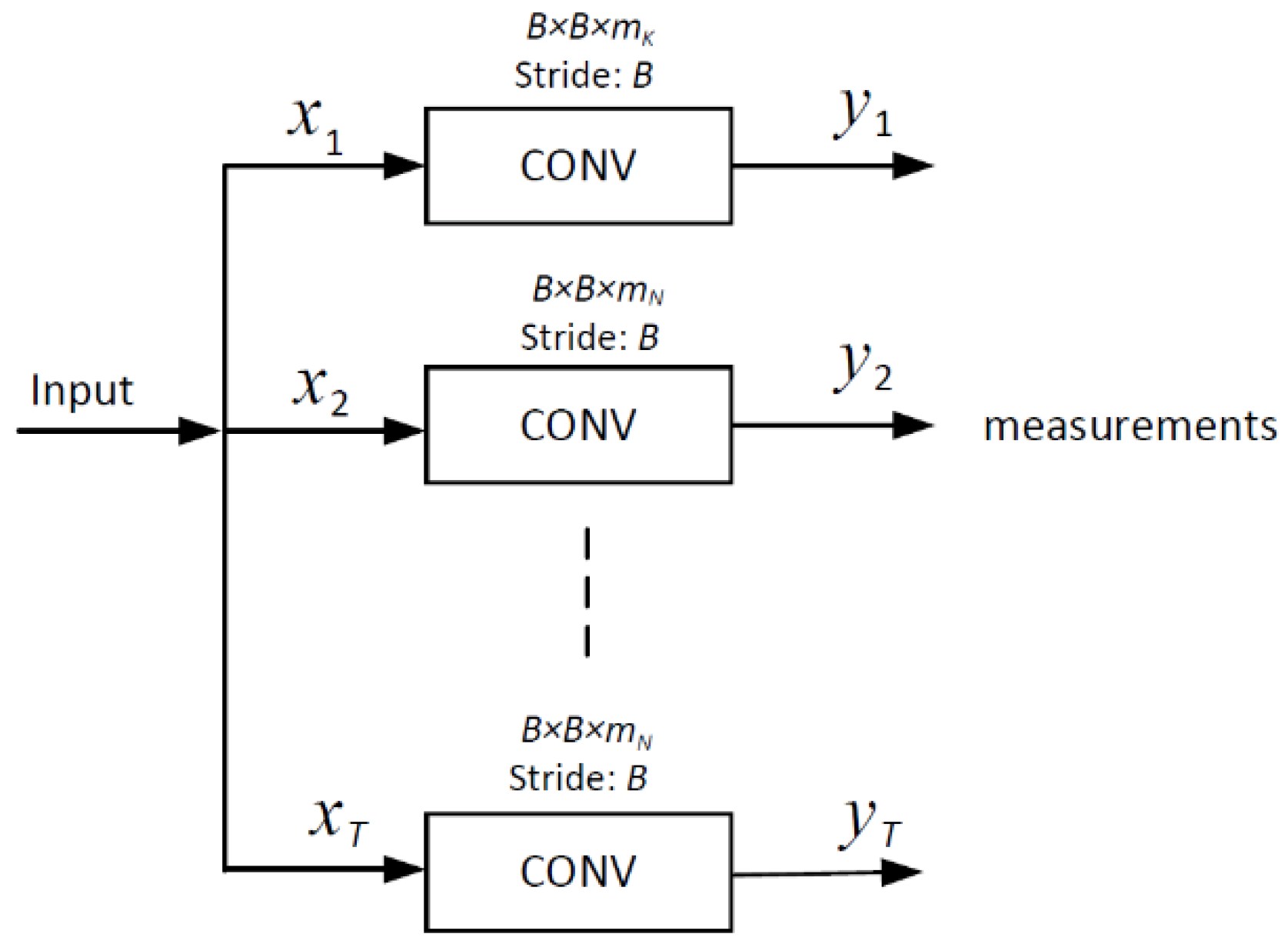
3.1. CNN for Joint Sampling
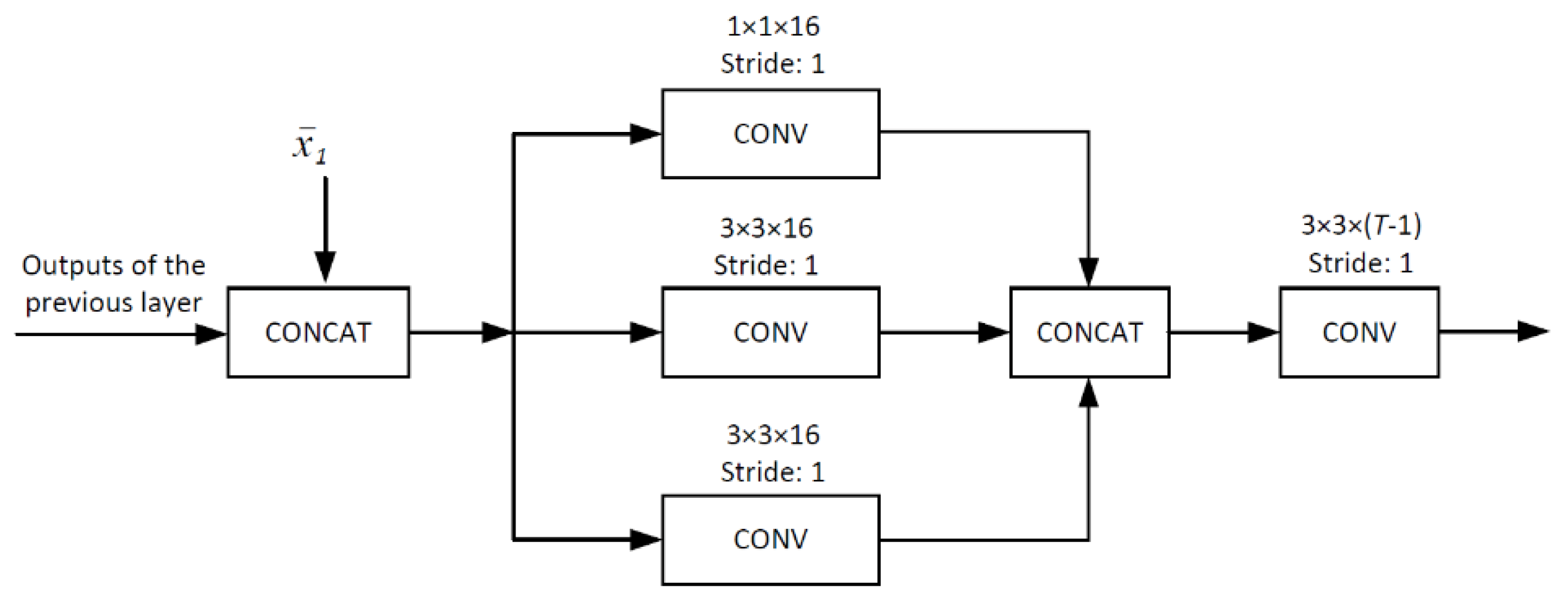
3.2. Spatial DCNN for Initial Recovery
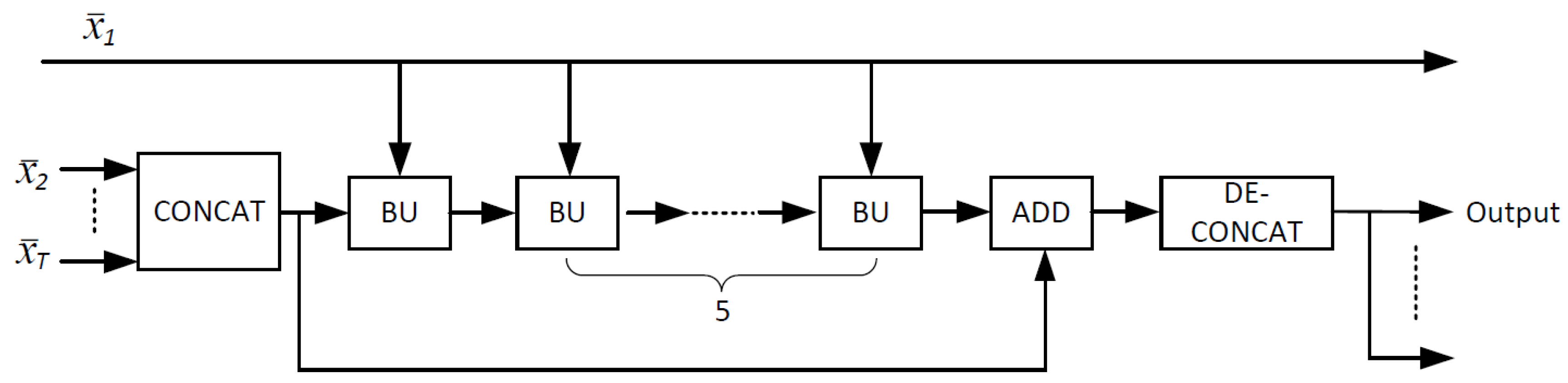
3.3. Temporal DCNN for Joint Reconstruction
4. Experiments
4.1. Training Settings
4.2. Performance Comparisons
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Candès, E.J.; Romberg, J.; Tao, T. Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information. IEEE Trans. Inf. Theory 2006, 52, 489–509. [Google Scholar] [CrossRef] [Green Version]
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Cheng, J.Y.; Chen, F.; Sandino, C.; Mardani, M.; Pauly, J.M.; Vasanawala, S.S. Compressed Sensing: From Research to Clinical Practice with Data-Driven Learning. arXiv 2019, arXiv:1903.07824. [Google Scholar]
- Sharma, S.K.; Lagunas, E.; Chatzinotas, S.; Ottersten, B. Application of compressive sensing in cognitive radio communications: A survey. IEEE Commun. Surv. Tutor. 2016, 18, 1838–1860. [Google Scholar] [CrossRef] [Green Version]
- Landau, H.J. Sampling, data transmission, and the Nyquist rate. Proc. IEEE 1967, 55, 1701–1706. [Google Scholar] [CrossRef]
- Figueiredo, M.A.T.; Nowak, R.D.; Wright, S.J. Gradient projection for sparse reconstruction: Application to compressed sensing and other inverse problems. IEEE J. Sel. Top. Signal Process. 2007, 1, 586–597. [Google Scholar] [CrossRef] [Green Version]
- Metzler, C.A.; Maleki, A.; Baraniuk, R.G. From denoising to compressed sensing. IEEE Trans. Inf. Theory 2016, 62, 5117–5144. [Google Scholar] [CrossRef]
- Gan, L. Block compressed sensing of natural images. In Proceedings of the 2007 IEEE 15th International Conference on Digital Signal Processing, Cardiff, UK, 1–4 July 2007. [Google Scholar]
- Do, T.T.; Chen, Y.; Nguyen, D.T.; Nguyen, N.; Gan, L.; Tran, T.D. Distributed compressed video sensing. In Proceedings of the 2009 IEEE 16th International Conference on Image Processing, Cairo, Egypt, 7–10 November 2009. [Google Scholar]
- Mun, S.; Fowler, J.E. Residual reconstruction for block-based compressed sensing of video. In Proceedings of the 2011 IEEE Data Compression Conference, Snowbird, UT, USA, 29–31 March 2011. [Google Scholar]
- Fowler, J.E.; Mun, S.; Tramel, E.W. Block-based compressed sensing of images and video. Found. Trends® Signal Process. 2012, 4, 297–416. [Google Scholar] [CrossRef]
- Azghani, M.; Karimi, M.; Marvasti, F. Multihypothesis compressed video sensing technique. IEEE Trans. Circuits Syst. Video Technol. 2015, 26, 627–635. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Chen, Y.; Qin, D.; Kuo, Y. An elastic net-based hybrid hypothesis method for compressed video sensing. Multimed. Tools Appl. 2015, 74, 2085–2108. [Google Scholar] [CrossRef]
- Zhao, C.; Ma, S.; Zhang, J.; Xiong, R.; Gao, W. Video compressive sensing reconstruction via reweighted residual sparsity. IEEE Trans. Circuits Syst. Video Technol. 2016, 27, 1182–1195. [Google Scholar] [CrossRef]
- Chen, C.; Zhou, C.; Liu, P.; Zhang, D. Iterative Reweighted Tikhonov-regularized Multihypothesis Prediction Scheme for Distributed Compressive Video Sensing. IEEE Trans. Circuits Syst. Video Technol. 2018. [Google Scholar] [CrossRef]
- Chen, C.; Zhang, D.; Liu, J. Resample-based hybrid multi-hypothesis scheme for distributed compressive video sensing. IEICE Trans. Inf. Syst. 2017, 100, 3073–3076. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Wang, N.; Xue, F.; Gao, Y. Distributed compressed video sensing based on the optimization of hypothesis set update technique. Multimed. Tools Appl. 2017, 76, 15735–15754. [Google Scholar] [CrossRef]
- Kuo, Y.; Wu, K.; Chen, J. A scheme for distributed compressed video sensing based on hypothesis set optimization techniques. Multimed. Tools Appl. 2017, 28, 129–148. [Google Scholar] [CrossRef]
- Mousavi, A.; Patel, A.B.; Baraniuk, R.G. A deep learning approach to structured signal recovery. In Proceedings of the 2015 IEEE 53rd Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 29 September–2 October 2015. [Google Scholar]
- Mousavi, A.; Baraniuk, R.G. Learning to invert: Signal recovery via deep convolutional networks. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing, New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Metzler, C.; Mousavi, A.; Baraniuk, R. Learned D-AMP: Principled neural network based compressive image recovery. Adv. Neural Inf. Process. Syst. 2017, 2017, 1773–1784. [Google Scholar]
- Kulkarni, K.; Lohit, S.; Turaga, P.; Kerviche, R.; Ashok, A. Reconnet: Non-iterative reconstruction of images from compressively sensed measurements. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Mousavi, A.; Dasarathy, G.; Baraniuk, R.G. Deepcodec: Adaptive sensing and recovery via deep convolutional neural networks. arXiv 2017, arXiv:1707.03386. [Google Scholar]
- Xu, K.; Ren, F. Csvideonet: A real-time end-to-end learning framework for high-frame-rate video compressive sensing. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018. [Google Scholar]
- Xie, X.; Wang, C.; Du, J.; Shi, G. Full image recover for block-based compressive sensing. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo, San Diego, CA, USA, 23–27 July 2018. [Google Scholar]
- Guan, Z.; Xing, Q.; Xu, M.; Yang, R.; Liu, T.; Wang, Z. MFQE 2.0: A New Approach for Multi-frame Quality Enhancement on Compressed Video. arXiv 2019, arXiv:1902.09707. [Google Scholar] [CrossRef] [Green Version]
- Beck, A.; Teboulle, M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Dai, W.; Zou, J.; Xiong, H.; Zheng, Y.F. Structured sparse representation with union of data-driven linear and multilinear subspaces model for compressive video sampling. IEEE Trans. Signal Process. 2017, 65, 5062–5077. [Google Scholar] [CrossRef]
- Van Chien, T.; Dinh, K.Q.; Jeon, B.; Burger, M. Block compressive sensing of image and video with nonlocal Lagrangian multiplier and patch-based sparse representation. Signal Process. Image Commun. 2017, 54, 93–106. [Google Scholar] [CrossRef] [Green Version]
- Chang, K.; Ding, P.L.K.; Li, B. Compressive sensing reconstruction of correlated images using joint regularization. IEEE Signal Process. Lett. 2016, 23, 449–453. [Google Scholar] [CrossRef]
- Wen, Z.; Hou, B.; Jiao, L. Joint sparse recovery with semisupervised MUSIC. IEEE Signal Process. Lett. 2017, 24, 629–633. [Google Scholar] [CrossRef] [Green Version]
- Yao, H.; Dai, F.; Zhang, S.; Zhang, Y.; Tian, Q.; Xu, C. Dr2-net: Deep residual reconstruction network for image compressive sensing. Neurocomputing 2019. [Google Scholar] [CrossRef] [Green Version]
- Du, J.; Xie, X.; Wang, C.; Shi, G.; Xu, X.; Wang, Y. Fully convolutional measurement network for compressive sensing image reconstruction. Neurocomputing 2019, 328, 105–112. [Google Scholar] [CrossRef] [Green Version]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 2010 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| JsrNet | Reconnet | MH-BCS-SPL | FIR | D-AMP | |
|---|---|---|---|---|---|
| 0.01 | 29.81 dB/0.8604 | 21.44 dB/0.5766 | 26.90 dB/0.7837 | 25.78 dB/0.7419 | 13.12 dB/0.2283 |
| 0.04 | 31.99 dB/0.9018 | 23.58 dB/0.6554 | 29.02 dB/0.8372 | 29.27 dB/0.8499 | 20.36 dB/0.6284 |
| 0.1 | 34.15 dB/0.9390 | 25.44 dB/0.7371 | 30.21 dB/0.8604 | 32.71 dB/0.9107 | 26.56 dB/0.7625 |
| JsrNet | Reconnet | MH-BCS-SPL | FIR | D-AMP | |
|---|---|---|---|---|---|
| 0.01 | 0.003 | 0.008 | 4.631 | 0.034 | 14.935 |
| 0.04 | 0.003 | 0.008 | 3.805 | 0.033 | 14.822 |
| 0.1 | 0.003 | 0.008 | 1.932 | 0.034 | 13.097 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.; Wu, Y.; Zhou, C.; Zhang, D. JsrNet: A Joint Sampling–Reconstruction Framework for Distributed Compressive Video Sensing. Sensors 2020, 20, 206. https://doi.org/10.3390/s20010206
Chen C, Wu Y, Zhou C, Zhang D. JsrNet: A Joint Sampling–Reconstruction Framework for Distributed Compressive Video Sensing. Sensors. 2020; 20(1):206. https://doi.org/10.3390/s20010206
Chicago/Turabian StyleChen, Can, Yutong Wu, Chao Zhou, and Dengyin Zhang. 2020. "JsrNet: A Joint Sampling–Reconstruction Framework for Distributed Compressive Video Sensing" Sensors 20, no. 1: 206. https://doi.org/10.3390/s20010206
APA StyleChen, C., Wu, Y., Zhou, C., & Zhang, D. (2020). JsrNet: A Joint Sampling–Reconstruction Framework for Distributed Compressive Video Sensing. Sensors, 20(1), 206. https://doi.org/10.3390/s20010206