3.1. Proposed Deep-Learning Based Method
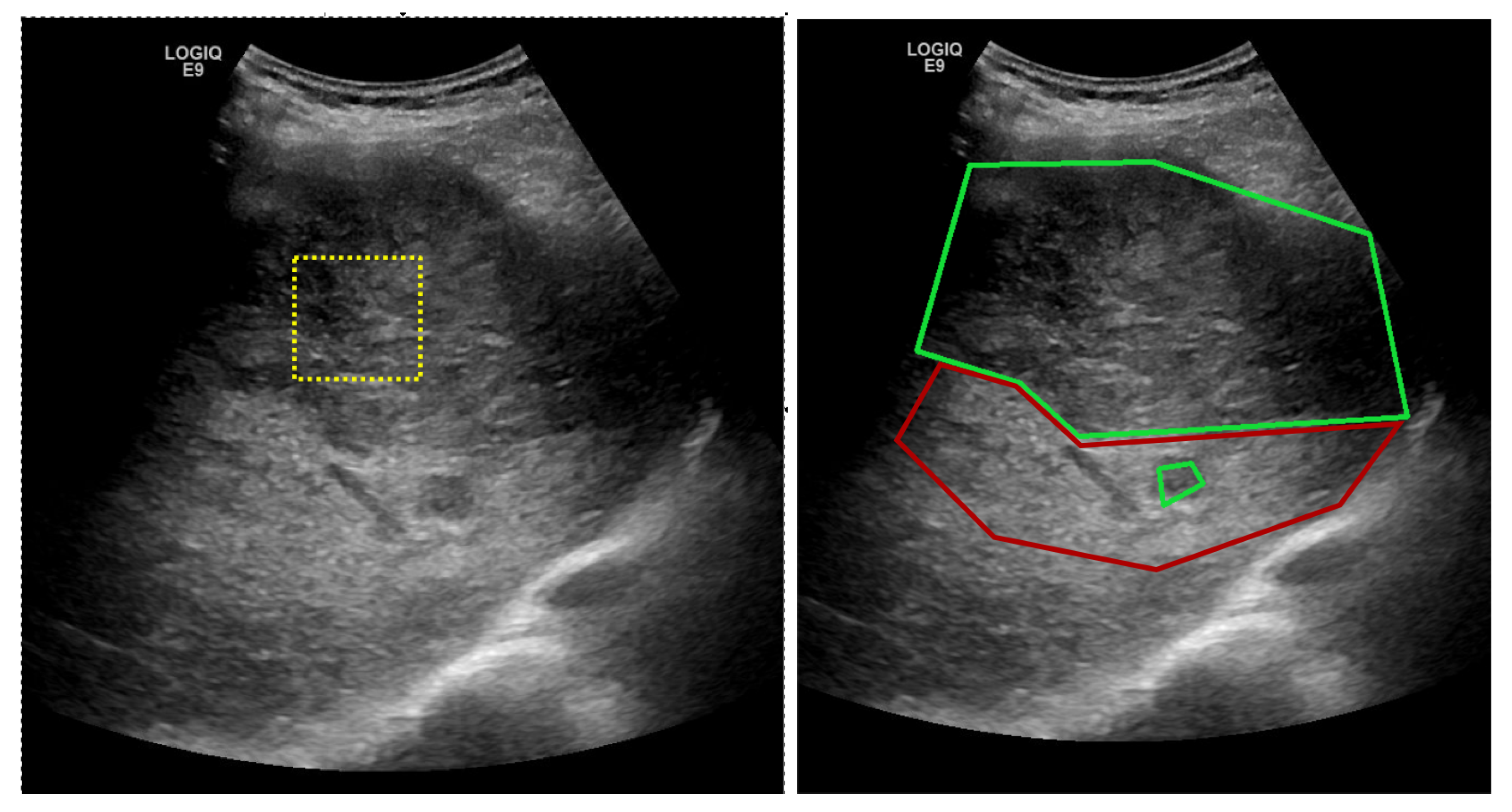
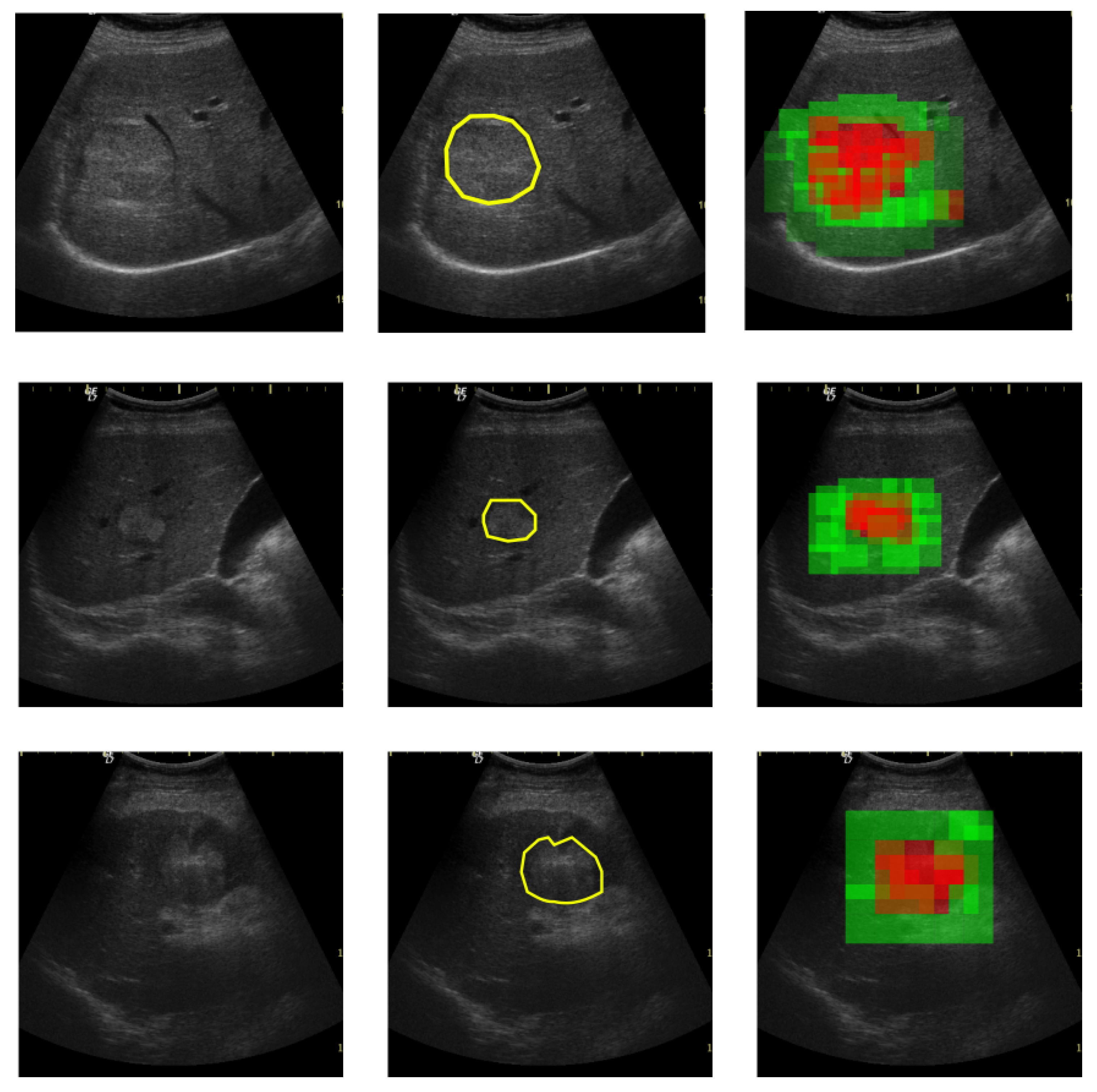
The proposed solution is envisioned for a possible computer-aided diagnosis tool, which analyzes ultrasound images and offers the likelihood that a selected region of interest is of HCC type, or it represents the cirrhotic liver tissue on which it had evolved.
The proposed network contains two modules of parallel multi-resolution convolutions, each followed by a down-sampling operation, an Atrous Spatial Pyramid Pooling (ASPP) module followed by a fully connected layer. The receptive field of the ASPP module is expended by means of multiple dilated convolutions which have as result a dense feature map. This expansion of the receptive field is done without loss of resolution or coverage. The proposed architecture is depicted in
Figure 7.
Every convolution layer is followed by a Rectified Linear Unit (RELU) and a batch normalization(BN) layer (which for convenience of the representation are not depicted in
Figure 7).
Multi-resolution features are obtained by the parallel application of convolutional filters with the kernel sizes in the set:
, where the size of
is
with
. As shown in
Figure 7 sizes of 3 × 3, 5 × 5 and 7 × 7 are included. Suppose we have a feature-map volume
x which is provided as input to the multi-resolution parallel convolution block with kernels in the set
W. The output of this block is a feature-map volume
y obtained by the concatenation of the convolution results
,
,
, where:
and the ⨁ symbol denotes the concatenation of outputs.
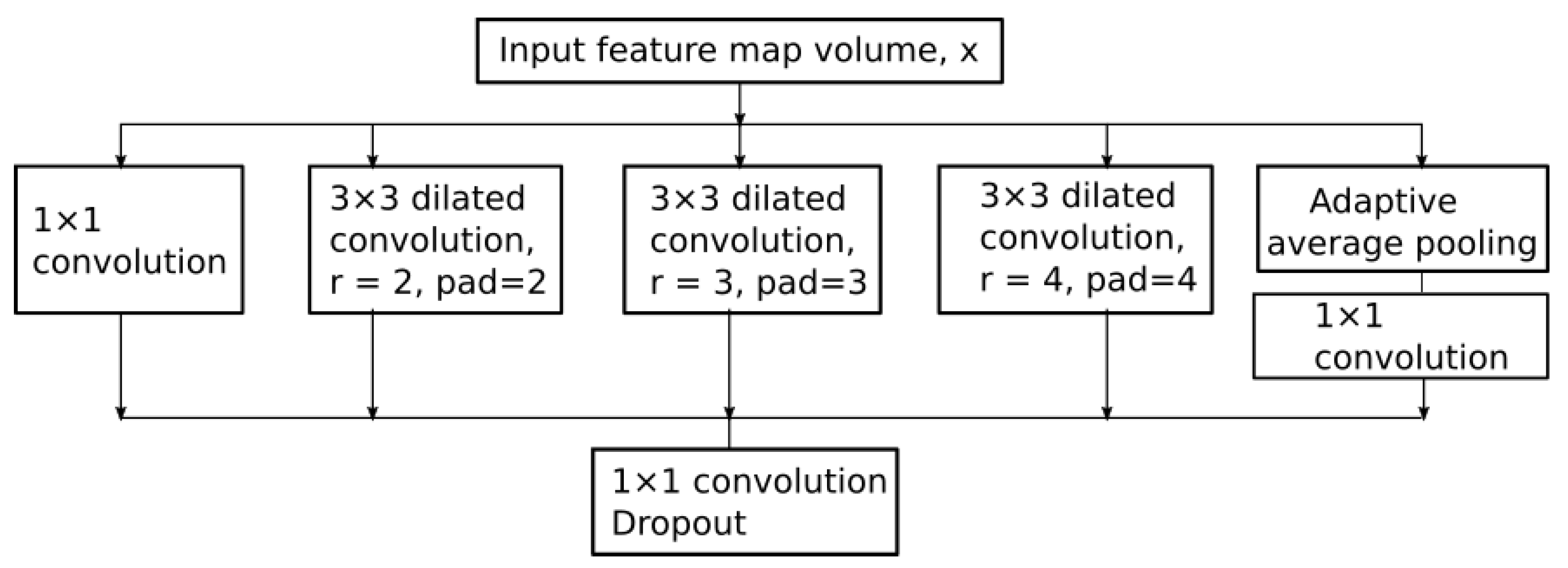
The Atrous Spatial Pyramid Pooling (ASPP) [
39] module is located at the deepest level in the network. This module is applied on top of the feature pool extracted by the parallel multi-resolution convolutions with the role of a context module tool. The ASPP structure used in the proposed network is depicted in
Figure 8.
The five branches of the ASPP module receive an input feature-map volume
x that represents the multi-resolution down-sampled spatial information computed by the previous layers in the network. The first branch of the ASPP module contains a
convolution that has the role of adapting the module’s input volume to its output feature-map volume. Dilated convolutions with atrous rates 2,3 and 4 are applied in parallel with an adaptive average pooling. The role of dilated convolutions is to expand the receptive fields of the feature maps. For example, if the atrous rates are
dilated convolutions densely sample features in the vicinity of the center pixel, as depicted in
Figure 9.
The main types of layers engaged in the network topology are as follows:
Convolutional layers that apply sliding convolutional filters with the specified stride and padding (see
Figure 9).
Dilated convolutions that perform sliding convolutional operations with the specified stride, padding and atrous sampling rate (see
Figure 9)
Batch normalization (BN) layers that have the role of normalizing the activations and gradients involved in the learning process of the neural network.
Rectified Linear Unit layers (RELU) that perform a thresholding with respect to zero on their inputs.
Max-pooling layers applied after each set of convolutional layers. Each pooling layer down-samples its input, and has the role of reducing the input volume and the parameter space for the subsequent layers.
Residual connections are used for propagating features from previous layers to the next layers in the network.
Data dropout layer is used as a regularization technique for increasing the network’s generalization capability and making it less prone to overfit the training data (see
Figure 8).
A fully connected layer combines all the features computed by the network to classify the image patches. A SoftMax function followed by a classification layer that computes the cross-entropy loss completes the model.
The proposed atrous rates (r) are tuned for the input volume that is received by the ASPP module. With the used atrous rates we accommodate the size of the filter with the size of the input feature maps. The fifth branch of the ASPP module is an adaptive average pooling used for reducing overfitting. It is followed by a convolution that adapts its result to the output depth. The resulting concatenated feature volumes are then fed to a convolution, followed by batch normalization and data dropout.
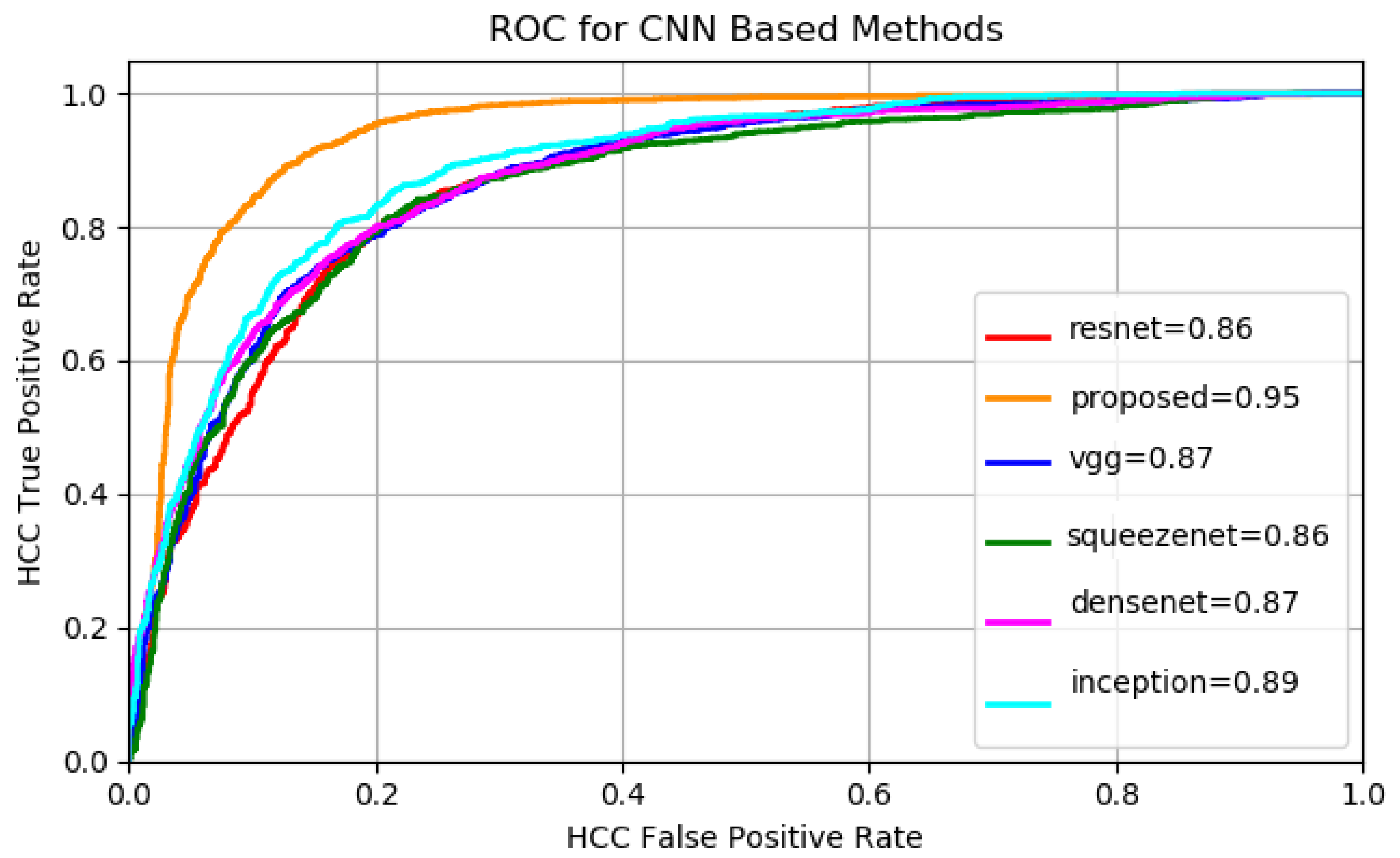
The number of filters for each multi-resolution layer helps controlling the size of the network’s parameter space. In the experimental part the relation between the size of the parameter space and the accuracy of the classification is analyzed throughout the results. The best configuration was obtained when .
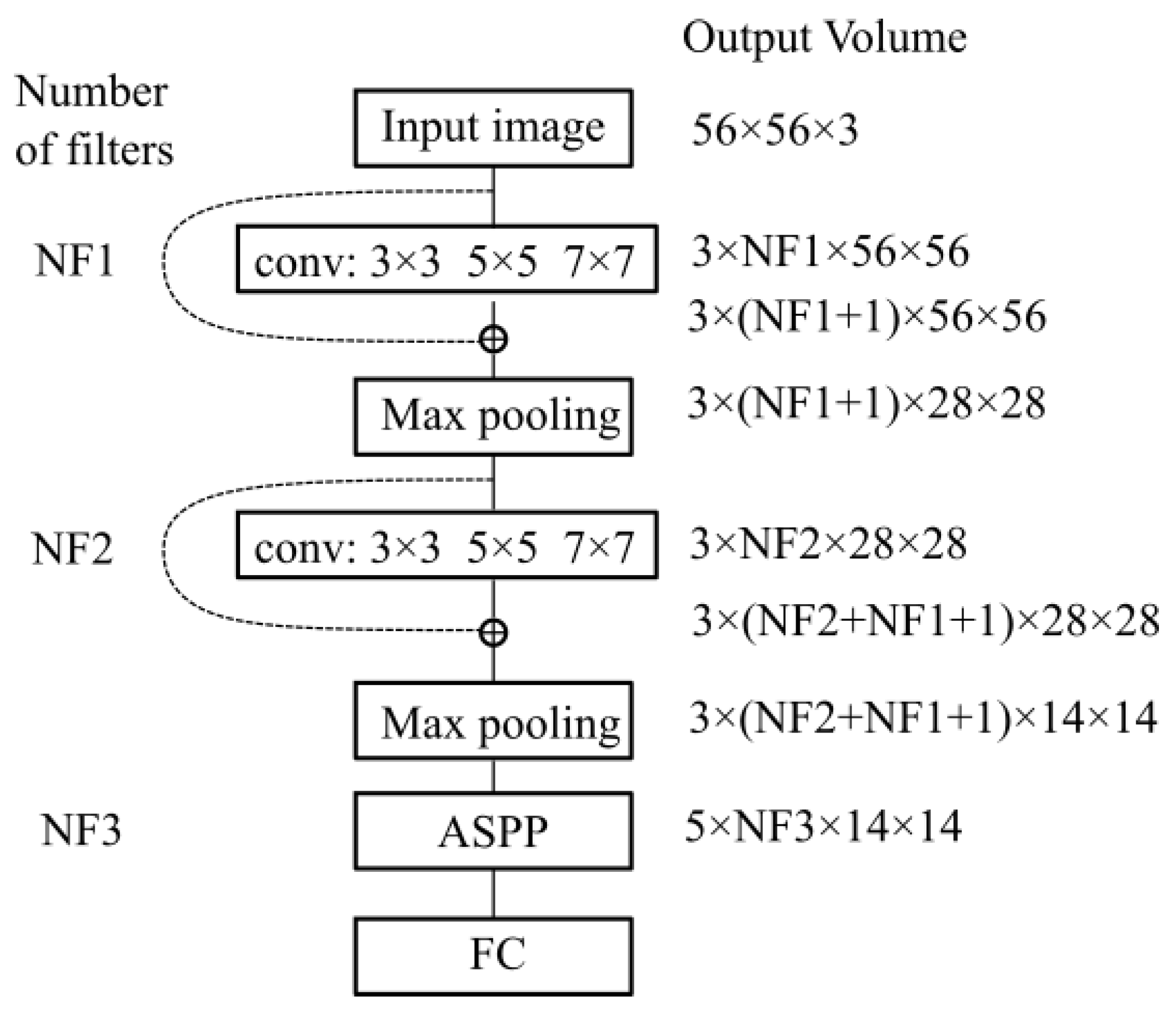
In
Figure 10 we show the variation in volume resolution all over the blocks that constitute the proposed network configuration.
Input images of size are forwarded to the first parallel multi-resolution convolution block that concatenates the results of the three convolutions with as output a volume of size 3 × NF1 × 56 × 56. The convolutions have a padding equal to half of the kernel size, hence the output is equal to the input resolution (56 × 56). The first shortcut connection of the network concatenates the input with the result of the first parallel convolution block, hence a volume of 3 × (NF1 + 1) × 56 × 56 results. This volume is input to the down-sampling layer which outputs a feature map of size 3 × NF2 × 28 × 28. Next, the second multi-resolution convolution block is applied. Its output is concatenated with the second shortcut connection leading to a volume of 3 × (NF2 + NF1 + 1) × 28 × 28. The second max-pooling outputs a size equal to 3 × (NF2 + NF1 + 1) × 14 × 14. This is provided to the ASPP module that contains 5 parallel branches whose output is concatenated in a volume of size 5 × NF3 × 14 × 14. This processing flow ensures a large and variate feature pool of the network.
In conclusion, the key design ideas taken into account in the proposal of the solution are:
Inclusion of various size convolution kernels (3 × 3, 5 × 5, 7 × 7) that ensure the extraction of different meaningful multi-resolution textural features from the input images (homogeneous areas, granular areas).
The consideration of an Atrous Spatial Pyramid Pooling module that samples relevant features with various densities, enriching the field of view of the multi-resolution textural features.
Residual connections are used to propagate the input feature maps of the current layer to its output, hence multi-resolution feature sharing throughout the network is ensured.
3.2. Conventional Machine-Learning (ML) Methods
To reveal the subtle properties of the hepatic tissue, various conventional texture analysis methods were taken into account and several features have been computed to be provided as input for conventional ML algorithms such as MLP, SVM, RF and AdaBoost combined with decision trees.
The Haralick features (homogeneity, energy, entropy, correlation, contrast and variance) were defined, based on the GLCM matrix, as described in [
34]. These features can emphasize visual and physical properties within ultrasound images, such as heterogeneity, echogenicity, gray level disorder, gray level complexity, gray level contrast. The GLCM is defined over an image and represents the distribution of co-occurring pixel values at a given offset. The definition of the GLCM of order n is provided in (
2). Thus, each element of this matrix stores the number of the n-tuples of pixels, placed at the coordinates
, with the gray level values
, being in a spatial relationship defined by the displacement vectors,
.
In Equation (
2), # stands for the cardinal number of the set, while
I stands for the image intensity function. The displacement vectors are provided in Equation (
3):
In the perfomed experiments, the second and third order GLCM were computed, (
) [
32]. For the second order GLCM, the absolute value of the corresponding displacement vector components was considered to be equal to 1, while the directions of these vectors varied between 0
and 360
, being always a multiple of 45
. In the case of the third order GLCM, specific orientations of the displacement vectors were taken into account. Thus, the corresponding three pixels involved in the computation of the third order GLCM, were either collinear, or they formed a right-angle triangle, the current pixel being situated in the central position. In the case of the collinear pixels, the direction pairs were (0
,180
), (90
, 270
), (45
, 225
), (135
, 315
), while in the case of the right-angle triangle, the direction pairs were the following: (0
,90
), (90
, 180
), (180
, 270
), (0
, 270
), (45
, 135
), (135
, 225
), (225
, 315
), and (45
, 315
). The absolute values of the corresponding displacement vector components (offsets) were either 0 or 2, in this case. Finally, the Haralick features were computed, in both cases of second and third order GLCM matrices, as the arithmetic mean of the individual values, for each of the GLCM matrices, which corresponded to each combination of parameters [
32]. The auto-correlation index [
34] was also taken into account, as a granularity measure, while the Hurst fractal index [
40] characterized the roughness of the texture. Edge-based statistics were computed as well, such as edge frequency, edge contrast and average edge orientation [
32], aiming to reveal the complexity of each class of tissue. The density (arithmetic mean) and frequency of the textural micro-structures, resulted after applying the Laws’ energy transforms [
40], were also included in the feature set. Multi-resolution textural features were considered to be well, such as the Shannon entropy computed after applying the Haar Wavelet transform recursively, twice. The low-low (ll), low-high (lh), high-low (hl) and high-high (hh) components were first determined on the original image, then the Haar Wavelet transform was applied again, on all these components. The Shannon entropy was determined on each component, at the first or second level, as expressed by Equation (
4).
In Equation (
4),
M and
N are the dimensions of the region of interest, while
I is the image intensity function [
32,
34]. All the textural features were computed on the rectangular regions of interest, with
pixels, after the application of the median filter (for speckle noise attenuation), independently on orientation, illumination and region of interest size.
Relevant feature selection was also performed, employing specific methods, such as Correlation-based Feature Selection (CFS), Consistency-based Feature Subset Evaluation, Information Gain Attribute Evaluation, respectively Gain Ratio Attribute Evaluation [
41]. Only those features with a relevance score above the selected threshold were considered to be relevant. The final set of relevant features resulted as a union of the relevant feature sets provided by each applied method. These textural features were used, before and after feature selection, in combination with the following traditional classification methods:
The approach presented in [
42] was also taken into account for comparison. Textural features extracted from LBP were combined with GLCM features. LBP features have been introduced by [
35]. To compute these features a circle of radius
R is considered around each pixel.
N neighboring pixels are selected from a circle of radius
R and center of coordinates
,
. The LBP code is obtained by a sign function
s applied to the differences between the intensity of neighbors and the intensity of the center pixel. For each neighbor if the difference is greater than 0 a code of 1 is considered otherwise a code equal to 0 is considered. The N codes form a number that represents the local binary pattern associated with that pixel.
where
is the intensity level of one of the N neighbors. Next, based on the generated codes the image is divided into non-overlapping cells and a histogram of the LBP codes is computed for each cell. The LBP histograms in combination with GLCM features were considered in the experiments, together with traditional classifiers such as SVM and AdaBoost in conjunction with decision trees.

 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}