Recurrent GANs Password Cracker For IoT Password Security Enhancement †



Abstract
:1. Introduction
2. Related Studies
2.1. Markov and Context-Free Grammar Approaches
2.2. Deep Learning Approaches
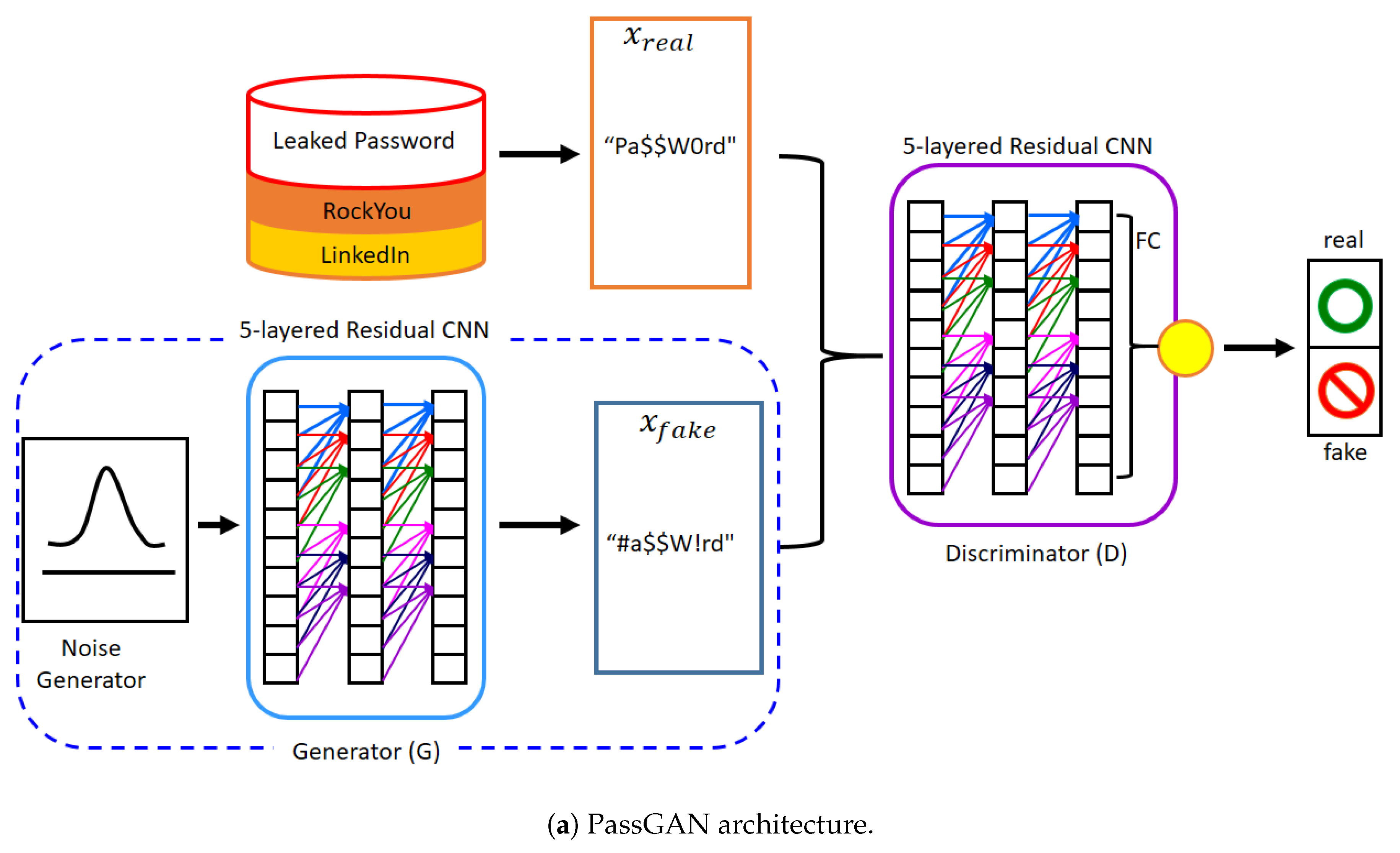
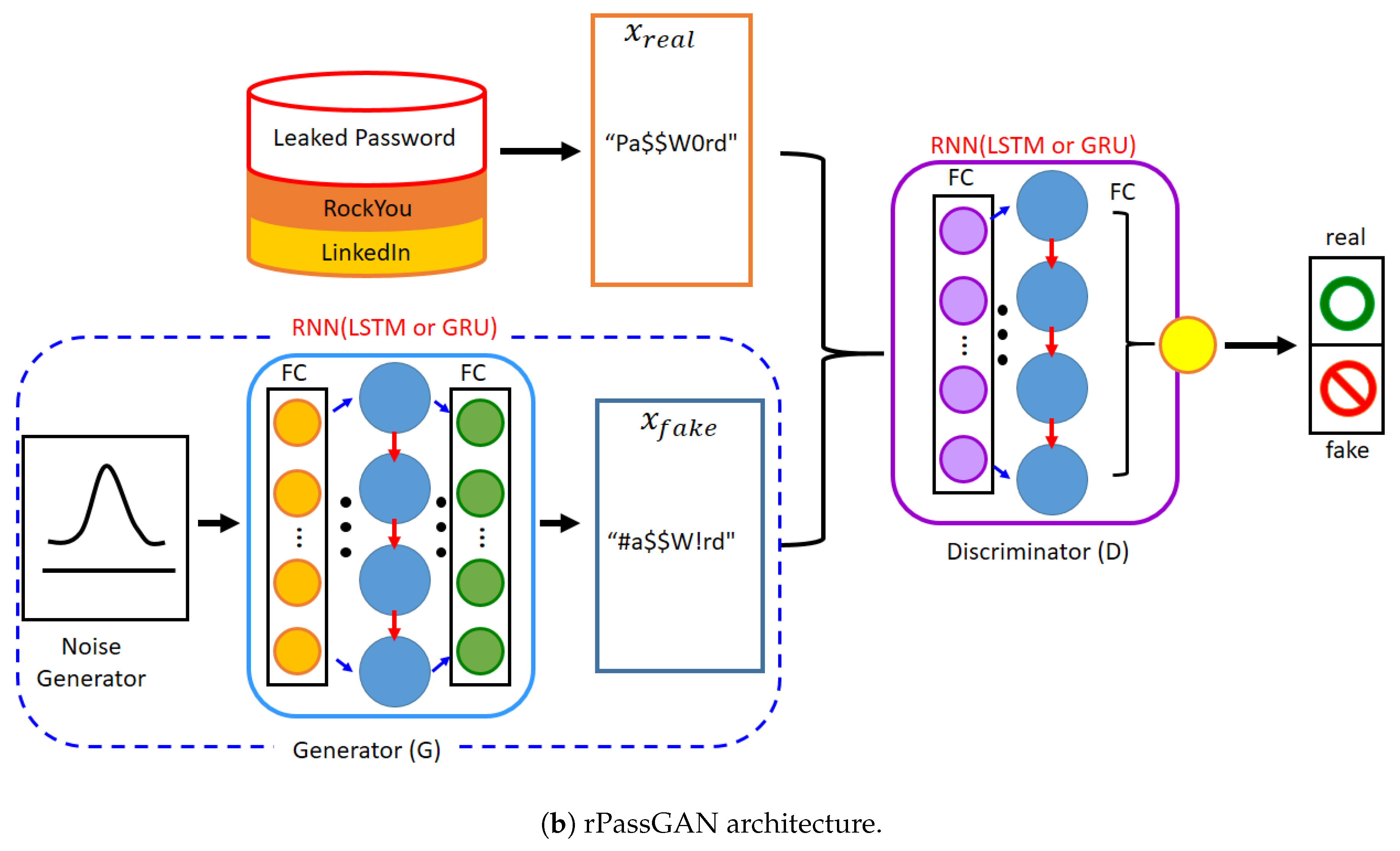
3. Proposed Model
3.1. Transformation of Neural Network Type
3.2. Transformation of Architecture
| Algorithm 1 rPassD2CGAN calculates each discriminator’s gradient penalty. We use the default values , , , , and . |
| Require: Gradient penalty coefficient , number of critic iterations per generator , number of generator iterations per discriminator , batch size m, and Adam hyper-parameters , , and . Require: Initial and critic parameters and , and initial generator parameter . while has not converged do for do for do Sample real data , latent variable , and a random number . end for end for for do Sample a batch of latent variable end for end while |
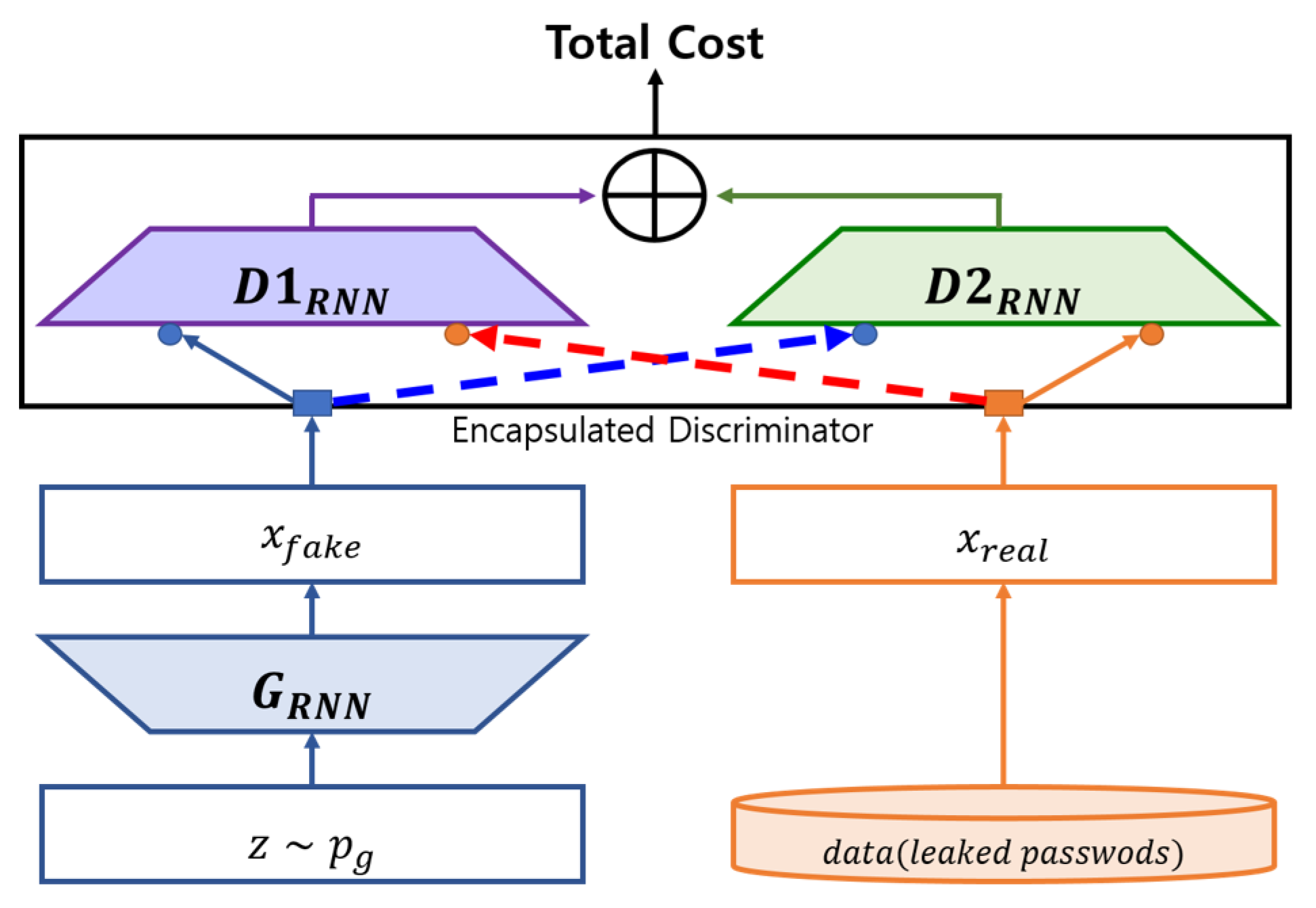
3.3. Limitation of rPassD2CGAN
3.4. New Dual-Discriminator Model
| Algorithm 2 rPassD2SGAN calculates each discriminator’s gradient penalty. We use default , , , , , . |
| Require: The gradient penalty coefficient , the number of critic iteration per generator , the number of generator iteration per discriminator , the batch size m, Adam hyper-parameters , , . Require: initial , critic parameters and , initial generator parameter while has not converged do for do for do Sample real data , latent variable , a random number . end for for do Sample real data , latent variable , a random number . end for end for for do Sample a batch of latent variable end for end while |
4. Experiments
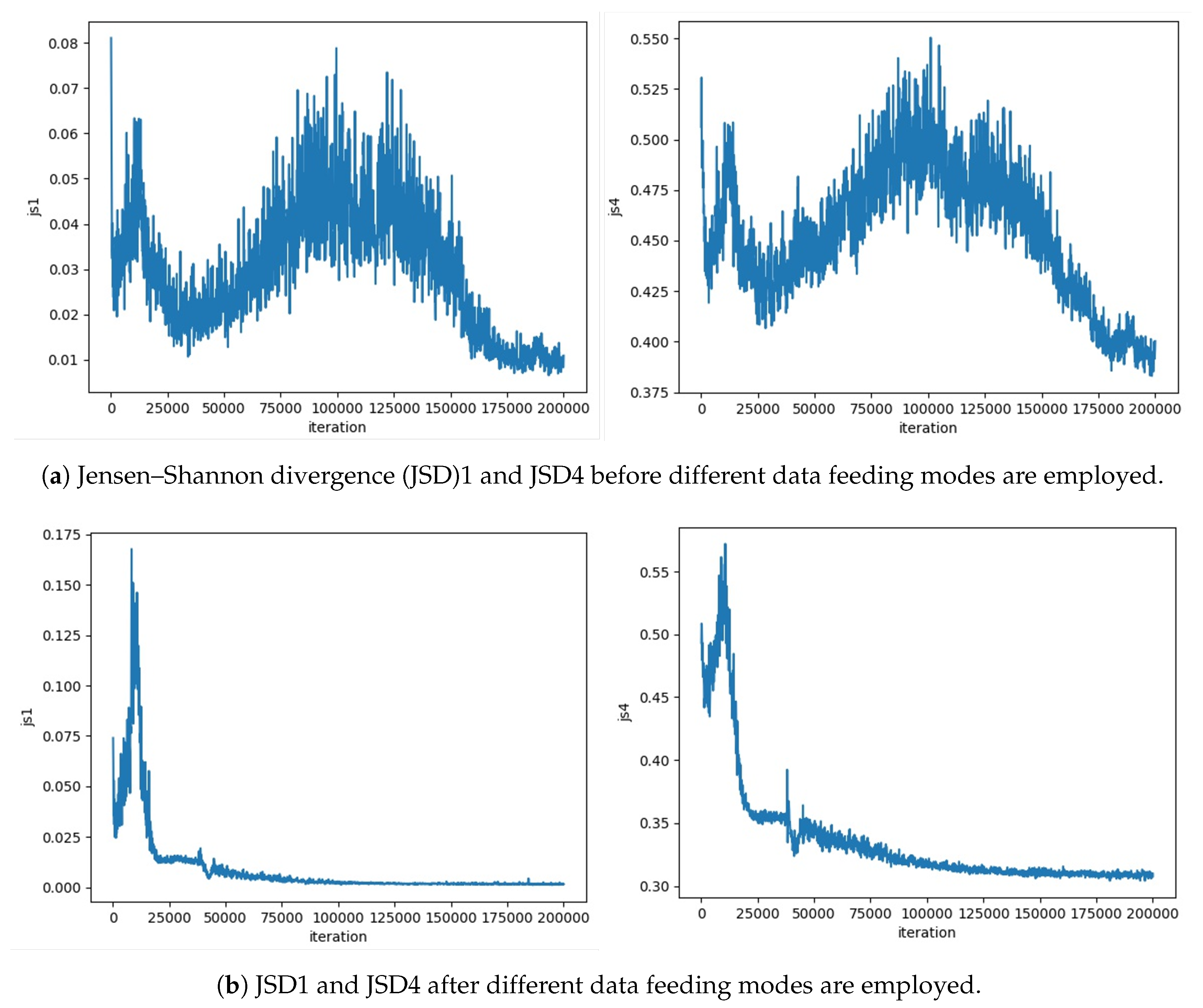
4.1. Training Configuration
4.1.1. Training Parameters
4.1.2. Training Data
4.2. Password Cracking
5. Evaluation
5.1. Dictionary Quality Perspective
5.2. Cracking Performance Perspective
5.2.1. Total Password Cracking
5.2.2. Cracking Extensibility
5.3. Password Strength Estimation
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| GAN | Generative Adversarial Network |
| PCFG | Probabilistic Context-Free Grammar |
| RNN | Recurrent Neural Network |
| CNN | Convolutional Neural Network |
| JtR | John the Ripper |
| JSD | Jensen–Shannon Divergence |
References
- Antonakakis, M.; April, T.; Bailey, M.; Bernhard, M.; Bursztein, E.; Cochran, J.; Durumeric, Z.; Halderman, J.A.; Invernizzi, L.; Kallitsis, M.; et al. Understanding the Mirai Botnet. In Proceedings of the 26th USENIX Security Symposium, Vancouver, BC, Canada, 16–18 August 2017; pp. 1093–1110. [Google Scholar]
- Herley, C.; Van Oorschot, P. A research agenda acknowledging the persistence of passwords. IEEE Secur. Priv. 2012, 10, 28–36. [Google Scholar] [CrossRef] [Green Version]
- Dell’ Amico, M.; Michiardi, P.; Roudier, Y. Password Strength: An Empirical Analysis. In Proceedings of the 2010 IEEE INFOCOM, San Diego, CA, USA, 15–19 March 2010; pp. 1–9. [Google Scholar] [CrossRef]
- Dürmuth, M.; Angelstorf, F.; Castelluccia, C.; Perito, D.; Chaabane, A. OMEN: Faster Password Guessing Using an Ordered Markov Enumerator. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2015; pp. 119–132. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Yang, W.; Luo, M.; Li, N. A study of probabilistic password models. In Proceedings of the IEEE Symposium on Security and Privacy, San Jose, CA, USA, 18–21 May 2014; pp. 689–704. [Google Scholar] [CrossRef]
- National Institute of Standards and Technology. Digital Identity Guidelines. Available online: https://pages.nist.gov/800-63-3/ (accessed on 10 June 2017).
- Wheeler, D.L. ZxCVBN: Low-budget password strength estimation. In Proceedings of the 25th USENIX Security Symposium, Austin, TX, USA, 10–12 August 2016. [Google Scholar]
- Tasevski, P. Password Attacks and Generation Strategies. Master’s Thesis, Tartu University: Faculty of Mathematics and Computer Sciences, Tartu, Estonia, 2011. [Google Scholar]
- Gosney, J.M. Hashcat Benchmarks 8x Nvidia GTX 1080 Hashcat Benchmarks. Available online: https://gist.github.com/epixoip/a83d38f412b4737e99bbef804a270c40 (accessed on 12 July 2018).
- Hashcat team. Hashcat Advanced Password Recovery. Available online: https://hashcat.net/wiki/ (accessed on 12 July 2018).
- Openwall.com. John the Ripper password cracker. Available online: http://www.openwall.com/john/ (accessed on 12 July 2018).
- Skullsecurity. RockYou Online. Available online: https://wiki.skullsecurity.org/Passwords (accessed on 12 July 2018).
- Cubrllovic, N. Rockyou Hack: From Bad To Worse. Available online: https://techcrunch.com/2009/12/14/rockyou-hack-security-myspace-facebook-passwords (accessed on 12 July 2018).
- Hashes.org. LinkedIn Online. Available online: https://hashes.org/public.php (accessed on 5 October 2018).
- Weir, M.; Aggarwal, S.; De Medeiros, B.; Glodek, B. Password cracking using probabilistic context-free grammars. In Proceedings of the 2009 30th IEEE Symposium on Security and Privacy, Oakland, CA, USA, 17–20 May 2009. [Google Scholar] [CrossRef]
- Weir, M.; Aggarwal, S.; Collins, M.; Stern, H. Testing metrics for password creation policies by attacking large sets of revealed passwords. In Proceedings of the ACM Conference on Computer and Communications Security, Chicago, IL, USA, 4–8 October 2010; pp. 162–175. [Google Scholar] [CrossRef]
- Hitaj, B.; Gasti, P.; Ateniese, G.; Perez-Cruz, F. PassGAN: A Deep Learning Approach for Password Guessing. In Applied Cryptography and Network Security; Springer: Cham, Switzerland, 2019; pp. 217–237. [Google Scholar] [CrossRef] [Green Version]
- Narayanan, A.; Shmatikov, V. Fast dictionary attacks on passwords using time-space tradeoff. In Proceedings of the ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 7–11 November 2005. [Google Scholar] [CrossRef]
- Yazdi, S.H. Probabilistic Context-Free Grammar Based Password Cracking: Attack, Defense and Applications. Ph.D. Thesis, Florida State University: Department of Computer Science, Tallahassee, FL, USA, 2015. [Google Scholar]
- Houshmand, S.; Aggarwal, S.; Flood, R. Next Gen PCFG Password Cracking. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1776–1791. [Google Scholar] [CrossRef]
- Melicher, W.; Ur, B.; Segreti, S.M.; Komanduri, S.; Bauer, L.; Christin, N.; Cranor, L.F. Fast, lean, and accurate: Modeling password guessability using neural networks. In Proceedings of the 25th USENIX Security Symposium, Austin, TX, USA, 10–12 August 2016. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved training of wasserstein GANs. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein Generative Adversarial Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 214–223. [Google Scholar]
- Liu, Y.; Xia, Z.; Yi, P.; Yao, Y.; Xie, T.; Wang, W.; Zhu, T. GENPass: A General Deep Learning Model for Password Guessing with PCFG Rules and Adversarial Generation. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Nam, S.; Jeon, S.; Moon, J. A New Password Cracking Model with Generative Adversarial Networks. In Information Security Applications; Springer: Cham, Switzerland, 2020; pp. 247–258. [Google Scholar] [CrossRef]
- Gers, F.A.; Schmidhuber, J.A.; Cummins, F.A. Learning to Forget: Continual Prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar] [CrossRef]
- Wang, H.; Qin, Z.; Wan, T. Text Generation Based on Generative Adversarial Nets with Latent Variable. In Advances in Knowledge Discovery and Data Mining; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Press, O.; Bar, A.; Bogin, B.; Berant, J.; Wolf, L. Language Generation with Recurrent Generative Adversarial Networks without Pre-training. arXiv 2017, arXiv:1706.01399. [Google Scholar]
- Subramanian, S.; Rajeswar, S.; Dutil, F.; Pal, C.; Courville, A. Adversarial Generation of Natural Language. arXiv 2017, arXiv:1705.10929. [Google Scholar] [CrossRef]
- Nguyen, T.D.; Le, T.; Vu, H.; Phung, D. Dual Discriminator Generative Adversarial Nets. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 2667–2677. [Google Scholar]
- Jolicoeur-Martineau, A. The relativistic discriminator: A key element missing from standard GAN. arXiv 2018, arXiv:1807.00734. [Google Scholar]
- Google Inc. Tensorflow Lite. Available online: https://www.tensorflow.org/lite/ (accessed on 1 December 2019).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | 1–8 | 9–15 | 16–32 | 1–32 |
|---|---|---|---|---|
| PassGAN | 7.52% | 0.55% | 0.10% | 4.08% |
| rPassGAN | 4.42% | 0.15% | 0.10% | 2.02% |
| rPassD2CGAN | 4.34% | 0.15% | 0.09% | 2.05% |
| rPassD2SGAN | 4.32% | 0.15% | 0.09% | 2.05% |
| Tr/Cr | PassGAN | rPassGAN | rPassD2CGAN | rPassD2SGAN | PCFG |
|---|---|---|---|---|---|
| rk0-rk0 | 251,592 | 287,745 | 289,753 | 292,626 | 141,278 |
| lk0-lk0 | 666,571 | 735,264 | 764,762 | 764,082 | 2,725,501 |
| rk0-lk0 | 677,542 | 765,324 | 772,956 | 777,586 | 2,186,212 |
| lk0-rk0 | 346,303 | 391,565 | 399,256 | 402,696 | 417,802 |
| rk1-rk1 | 396,851 | 440,020 | 449,401 | 448,772 | 845,539 |
| lk1-lk1 | 707,567 | 732,795 | 753,700 | 763,494 | 2,724,828 |
| rk1-lk1 | 738,499 | 803,508 | 824,561 | 823,639 | 2,505,716 |
| lk1-rk1 | 299,449 | 314,142 | 321,967 | 324,575 | 961,771 |
| Tr/Cr | JSD1 | JSD2 | JSD3 | JSD4 |
|---|---|---|---|---|
| rk0-rk0 | 0.279475 | 0.347773 | 0.433052 | 0.536094 |
| lk0-lk0 | 0.000000 | 0.000031 | 0.002026 | 0.030252 |
| rk0-lk0 | 0.010636 | 0.024597 | 0.046771 | 0.096937 |
| lk0-rk0 | 0.198082 | 0.250680 | 0.318582 | 0.415374 |
| rk1-rk1 | 0.000001 | 0.000116 | 0.004643 | 0.041829 |
| lk1-lk1 | 0.000000 | 0.000030 | 0.002032 | 0.030271 |
| rk1-lk1 | 0.002210 | 0.013319 | 0.032067 | 0.079866 |
| lk1-rk1 | 0.002188 | 0.013375 | 0.034495 | 0.095603 |
| Models | PassGAN | rPassGAN | rPassD2CGAN | rPassD2SGAN |
|---|---|---|---|---|
| PassGAN | 0 | 107,103 | 107,406 | 113,048 |
| rPassGAN | 235,937 | 0 | 143,182 | 149,495 |
| rPassD2CGAN | 235,127 | 142,069 | 0 | 148,390 |
| rPassD2SGAN | 241,456 | 149,069 | 149,077 | 0 |
| Dataset | rPassGAN | PCFG | zxcvbn | None |
|---|---|---|---|---|
| rk0-0 | 15.6% (17.91) | 2.3% (18.13) | 0.5% (18.19) | 81.6% |
| rk0-1 | 8.4% (31.84) | 12.1% (31.79) | 0.0% (32.37) | 79.5% |
| rk0-2 | 12.3% (32.59) | 12.3% (32.74) | 0.0% (33.57) | 75.4% |
| cls4(14) | 4.7% (38.43) | 5.7% (38.48) | 0.1% (39.03) | 89.5% |
| cls4(15) | 8.4% (38.68) | 4.9% (39.40) | 0.1% (39.87) | 86.6% |
| cls4(16) | 1.4% (45.18) | 4.6% (44.61) | 0.8% (45.32) | 93.2% |
| Passwords | rPassGAN | PCFG | zxcvbn |
|---|---|---|---|
| Charlotte.2010 | 18.83 | 21.852 | 23.916 |
| C0mm3m0r47!0ns | 18.83 | 41.11 | 40.11 |
| MyLinkedIn101! | 25.333 | 28.605 | 35.598 |
| Linkedin2011@@ | 17.897 | 19.167 | 27.644 |
| Profe$$1ona11$m | 18.527 | 29.824 | 29.824 |
| Concep+ua1!z!ng | 21.27 | 41.066 | 47.09 |
| C0ns4nguini+i3s | 14.997 | 47.09 | 47.09 |
| September27,1987 | 22.682 | 40.457 | 40.457 |
| JLN@linkedin2011 | 28.022 | 51.308 | 51.308 |
| @WSX$RFV1qaz3edc | 46.003 | 28.724 | 46.003 |
| !QAZ1qaz@WSX2wsx | 31.184 | 30.032 | 46.003 |
| #$ERDFCV34erdfcv | 55.142 | 24.188 | 55.142 |
| 1qaz)OKM2wsx(IJN | 46.003 | 30.741 | 46.003 |
| !QAZ#EDC%TGB7ujm | 48.253 | 28.843 | 48.325 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nam, S.; Jeon, S.; Kim, H.; Moon, J. Recurrent GANs Password Cracker For IoT Password Security Enhancement. Sensors 2020, 20, 3106. https://doi.org/10.3390/s20113106
Nam S, Jeon S, Kim H, Moon J. Recurrent GANs Password Cracker For IoT Password Security Enhancement. Sensors. 2020; 20(11):3106. https://doi.org/10.3390/s20113106
Chicago/Turabian StyleNam, Sungyup, Seungho Jeon, Hongkyo Kim, and Jongsub Moon. 2020. "Recurrent GANs Password Cracker For IoT Password Security Enhancement" Sensors 20, no. 11: 3106. https://doi.org/10.3390/s20113106
APA StyleNam, S., Jeon, S., Kim, H., & Moon, J. (2020). Recurrent GANs Password Cracker For IoT Password Security Enhancement. Sensors, 20(11), 3106. https://doi.org/10.3390/s20113106