Odor Detection Using an E-Nose With a Reduced Sensor Array

 ,
,  , , and
, , and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Odor Measurements by Electronic Nose
2.1. Electronic Nose
2.2. Measurement of Wine Odor
3. Classification Modeling
3.1. Extraction of Modeling Features
3.2. Model Validation
3.3. Modeling Technique
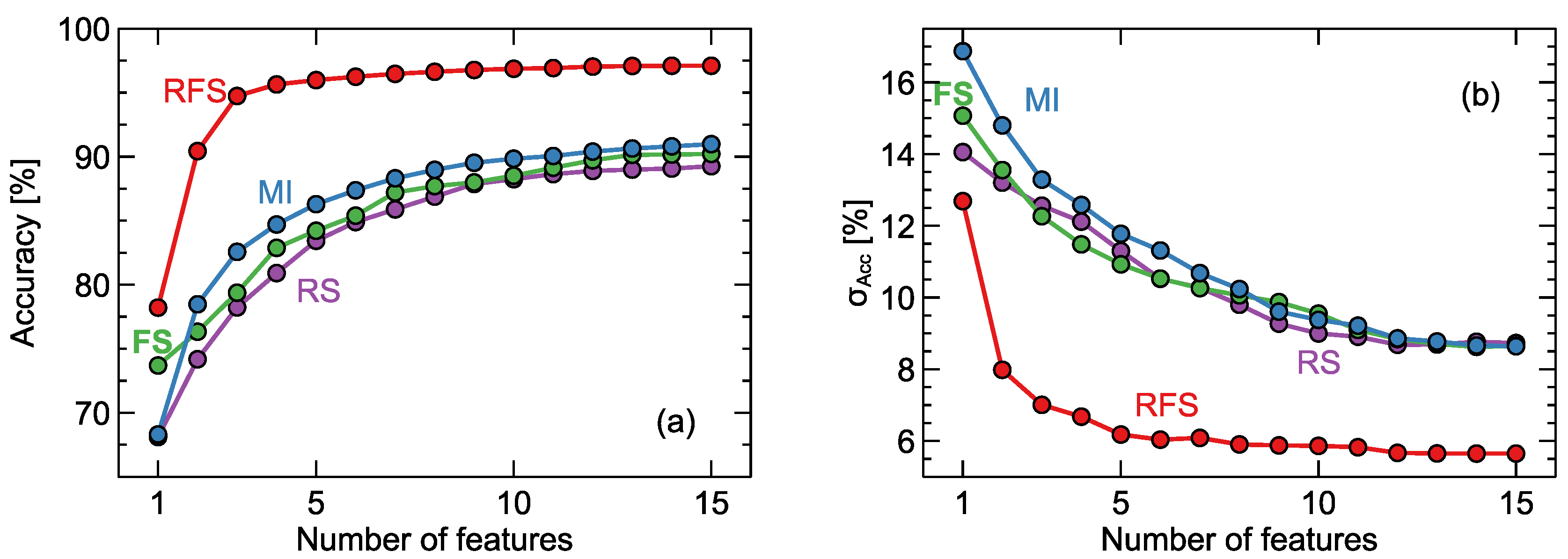
3.4. Feature Selection
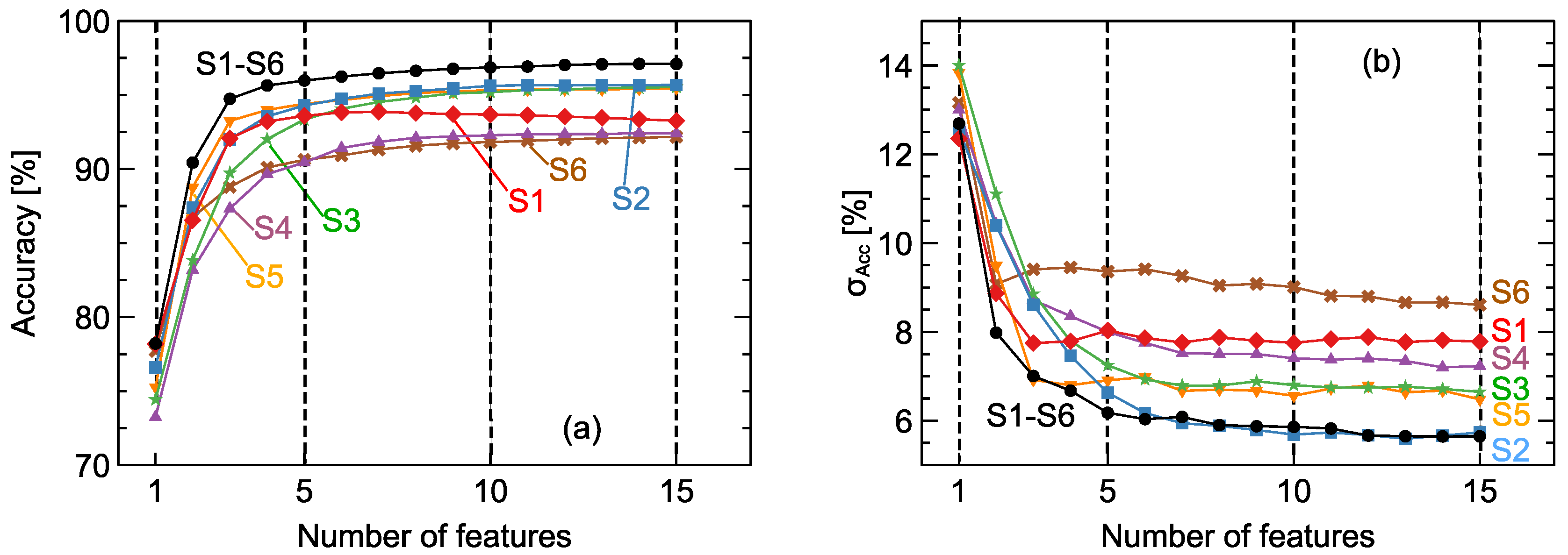
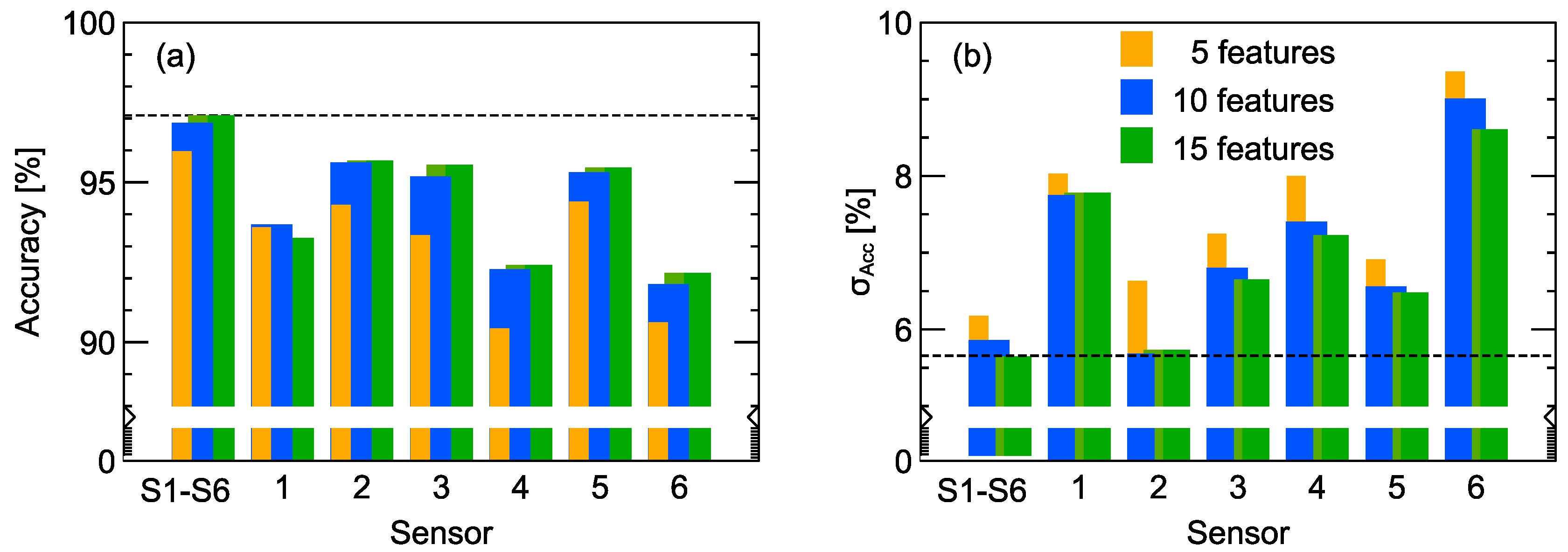
4. Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. List of aLl Features Used for Modeling
| Basic statistics calculated from the whole response curve | |
| R1.Sum/G1.Sum | Sum of sensor responses, which is equivalent to integral of the response curve. |
| R1.Median/G1.Median | Median |
| R1.Kurt/G1.Kurt | Kurtosis |
| R1.Skew/G1.Skew | Skewness |
| Basic statistics calculated from the adsorption phase of the response curve. | |
| R1.SumOn/G1.SumOn | Sum of sensor responses. |
| R1.MedOn/G1.MedOn | Median |
| R1.MinOn/G1.MaxOn | Extreme value reached by the response curve, which is equivalent to the value of the response at the end of the adsorption phase. |
| Basic statistics calculated from the desorption phase of the response curve. | |
| R1.SumOff/G1.SumOff | Sum of sensor responses. |
| R1.MedOff/G1.MedOff | Median |
| R1.MaxOff/G1.MinOff | Extreme value reached by the response curve, which is equivalent to the value of the response at the end of measurement. |
| Time needed to reach the indicated percent change of the sensor response value during the adsorption phase (from baseline to extreme). |
| R1.On10/G1.On10 10% R1.On25/G1.On25 25% R1.On50/G1.On50 50% R1.On75/G1.On75 75% |
| Time needed to reach the indicated percent change of the sensor response value during the desorption phase (from start of desorption to end of the measurement). |
| R1.Off10/G1.Off10 10% R1.Off25/G1.Off25 25% R1.Off50/G1.Off50 50% R1.Off75/G1.Off75 75% |
| Extreme value of exponential moving average filter (ema) for indicated values of the parameter. Calculated for adsorption phase. |
| R1.PMin1/G1.PMax1 R1.PMin2/G1.PMax2 R1.PMin3/G1.PMax3 |
| Time needed to reach extreme values of the exponential moving average filter (ema) of the parameter. Calculated for adsorption phase. |
| R1.PTime1/G1.PTime1 R1.PTime2/G1.PTime2 R1.PTime3/G1.PTime3 |
| Basic statistics calculated for the exponential moving average filter (ema) for indicated values of the parameter. Calculated for the adsorption phase. |
| R1.PStd1/G1.PStd1 Standard deviation, R1.PStd2/G1.PStd2 Standard deviation, R1.PStd3/G1.PSkew3 Standard deviation, R1.PSkew1/G1.PSkew1 Skewness, R1.PSkew2/G1.PSkew2 Skewness, R1.PSkew3/G1.PSkew3 Skewness, R1.PKurt1/G1.PKurt1 Kurtosis, R1.PKurt2/G1.PKurt2 Kurtosis, R1.PKurt3/G1.PKurt3 Kurtosis, |
| Extreme value of exponential moving average filter (ema) for indicated values of the parameter. Calculated for the desorption phase. |
| R1.QMax1/G1.QMin1 R1.QMax2/G1.QMin2 R1.QMax3/G1.QMin3 |
| Time needed to reach the extreme value of the exponential moving average filter (ema) for indicated values of the parameter. Calculated for the desorption phase. |
| R1.QTime1/G1.QTime1 R1.QTime2/G1.QTime2 R1.QTime3/G1.QTime3 |
| Basic statistics calculated for the exponential moving average filter (ema) for indicated values of the parameter. Calculated for the adsorption phase. |
| R1.QStd1/G1.Qtd1 Standard deviation, R1.QStd2/G1.QStd2 Standard deviation, R1.QStd3/G3.QStd3 Standard deviation, R1.QSkew1/G1.QSkew1 Skewness, R1.QSkew2/G1.QSkew2 Skewness, R1.QSkew3/G1.QSkew3 Skewness, R1.QKurt1/G1.QKurt1 Kurtosis, R1.QKurt2/G1.QKurt2 Kurtosis, R1.QKurt3/G1.QKurt3 Kurtosis, |
| Value reached by the sensor response at time when the exponential moving average filter (ema) reached its extreme. For indicated value of the parameter. |
| Calculated for the desorption phase. |
| R1.ValPMin1/G1.ValPMax1 R1.ValPMin2/G1.ValPMax2 R1.ValPMin3/G1.ValPMax3 |
| Parameters of sensor response curve fitting by polynomial function . |
| R1.Poly3/G1.Poly3 R1.Poly2/G1.Poly2 R1.Poly1/G1.Poly1 R1.Poly0/G1.Poly0 |
| Values of the response curve at the -th sampling point. To avoid measurement noise, the median of ±5 points is taken. |
| R1.v01 … R1.v15/G1.v01 .. G1.v15 |
Appendix B. Features Selected by the Modeling Algorithm
| Data Range | Sensor | Features |
| ALL | S1–S6 | G6.Poly3, G4.PSkew3, R1.Std, G3.Poly2, G2.Kurt, G4.Poly3, G6.PStd1, G5.Kurt, G4.Poly2, R3.PSkew1 |
| S1 | R1.Std, G1.QSkew1, R1.Off50, R1.QMax1, R1.PStd1, R1.ValPMin1, G1.QTime1, G1.Poly2, G1.QTime3, R1.On10 | |
| S2 | R2.PKurt1, G2.Off75, R2.PKurt3, G2.Kurt, G2.Off50, G2.QTime2, G2.Poly0, G2.Off25, R2.PSkew2, G2.On75, | |
| S3 | G3.Off50, R3.Kurt, R3.PKurt2, R3.Off10, G3.PKurt3, G3.Poly3, G3.MinOff, G3.QTime3, G3.Off75, R3.PSkew1 | |
| S4 | G4.PSkew3, G4.Poly0, G4.QKurt3, G4.On10, G4.QStd1, G4.PSkew2, G4.QMmin1, G4.On25, G4.QSkew3, G4.PTime3 | |
| S5 | G5.Kurt, G5.ValPMax3, G5.PSkew1, G5.MinOff, G5.PKurt2, G5.QStd1, G5.Skew, G5.QKurt2, R5.Kurt, G5.On50 | |
| S6 | G6.Poly3, G6.QSkew1, G6.MinOff, G6.PSkew1, G6.QTime1, G6.PStd1, R6.PKurt3, G6.QKurt1, R6.ValPMin1, G6.PMax1 |
| ALL-G | S1–S6 | G6.Poly3, G4.PSkew3, G2.PTime3, G2.Kurt, G2.PKurt3, G5.PKurt2, G5.Off75, G4.PSkew2, G4.Poly3, G6.Kurt |
| S1 | G1.Poly0, G1.QKurt2, G1.QKurt3, G1.PSkew1, G1.QKurt1, G1.MinOff, G1.Off50, G1.QSkew1, G1.v02, G1.QSkew2 | |
| S2 | G2.PTime3, G2.Kurt, G2.PKurt2, G2.Skew, G2.QTime2, G2.QStd1, G2.MinOff, G2.On75, G2.PSkew2, G2.Off75 | |
| S3 | G3.Off25, G3.MinOff, G3.PStd1, G3.QSkew1, G3.PKurt2, G3.Poly2, G3.PKurt3, G3.Poly3, G3.PKurt1, G3.QKurt1 | |
| S4 | G4.PSkew3, G4.Poly0, G4.QKurt3, G4.On10, G4.QStd1, G4.PSkew2, G4.QMmin1, G4.On25, G4.QSkew3, G4.PTime3 | |
| S5 | G5.Kurt, G5.ValPMax3, G5.PSkew1, G5.MinOff, G5.PKurt2, G5.QStd1, G5.Skew, G5.QKurt2, G5.On50, G5.PSkew2 | |
| S6 | G6.Poly3, G6.QSkew1, G6.MinOff, G6.PSkew1, G6.QTime1, G6.PStd1, G6.QKurt1, G6.v04, G6.PSkew3, G6.PMax1 |
| ALL-R | S1–S6 | R1.Std, R5.Off25, R2.Kurt, R5.On10, R3.PMin1, R6.Off50, R6.PKurt3, R2.Skew, R6.Off10, R1.SumOff |
| S1 | R1.Std, R1.QMax1, R1.PTime1, R1.ValPMin1, R1.SumOff, R1.v05, R1.QTime1, R1.PStd1, R1.Kurt, R1.MedOff | |
| S2 | R2.PKurt1, R2.Kurt, R2.PKurt3, R2.QMax3, R2.Off75, R2.QKurt3, R2.Skew, R2.PMin1, R2.On75, R2.PSkew2 | |
| S3 | R3.Kurt, R3.PKurt2, R3.Off10, R3.Std, R3.Skew, R3.QKurt2, R3.PKurt3, R3.PSkew2, R3.QKurt3, R3.QSkew2 | |
| S4 | R4.Std, R4.MinOn, R4.ValPMin3, R4.v08, R4.PStd2, R4.SumOff, R4.v02, R4.MedOn, R4.PStd1, R4.PStd3 | |
| S5 | R5.Std, R5.Skew, R5.PTime3, R5.Off10, R5.PMin1, R5.Off75, R5.Kurt, R5.On75, R5.MedOff, R5.SumOff | |
| S6 | R6.Std, R6.On10, R6.SumOff, R6.On25, R6.Off25, R6.ValPMin1, R6.v01, R6.MedOff, R6.Off75, R6.Off50 | |
| ON | S1–S6 | G6.Poly3, G4.PSkew3, G2.PTime3, G5.PKurt2, G3.PStd1, G4.v15, G2.PKurt2, R3.PMin1, G1.v01, G5.PSkew3 |
| S1 | R1.PTime1, G1.PKurt1, R1.PStd1, R1.PTime3, R1.ValPMin2, R1.PTime2, G1.v02, R1.On10, R1.On25, G1.PKurt2 | |
| S2 | R2.PKurt1, G2.PSkew1, G2.PKurt3, G2.On75, R2.PKurt3, G2.PTime3, G2.PKurt2, G2.PSkew2, R2.ValPMin2, G2.PSkew3 |
| S3 | G3.v01, G3.On50, G3.PSkew1, R3.PKurt3, G3.On75, G3.PKurt1, G3.Poly3, R3.On10, R3.PKurt1, G3.PKurt2 | |
| S4 | G4.PSkew3, G4.Poly0, G4.On75, G4.PTime3, G4.PKurt1, G4.PSkew2, G4.On25, G4.PKurt2, G4.On10, G4.On50 | |
| S5 | G5.On75, G5.ValPMax3, G5.PSkew1, G5.PSkew3, G5.ValPMax1, G5.Poly0, G5.Poly1, G5.PStd1, R5.ValPMin1, G5.v10 | |
| S6 | G6.Poly3, G6.PSkew1, G6.On25, G6.On50, G6.On75, G6.On10, G6.PTime1, G6.Poly2, G6.PTime3, R6.PTime1 | |
| ON-G | S1–S6 | G6.Poly3, G4.PSkew3, G2.PTime3, G5.PKurt2, G3.PStd1, G4.v15, G2.PKurt2, G6.PMax1, G5.PSkew3, G1.v02 |
| S1 | G1.Poly0, G1.On75, G1.PKurt1, G1.PKurt2, G1.Poly3, G1.On10, G1.ValPMax3, G1.v01, G1.PStd1, G1.On50 | |
| S2 | G2.PTime3, G2.PSkew1, G2.On75, G2.PKurt2, G2.ValPMax2, G2.On50, G2.PSkew2, G2.PTime2, G2.PKurt1, G2.PSkew3 | |
| S3 | G3.v01, G3.On50, G3.PSkew1, G3.Poly3, G3.On75, G3.PKurt1, G3.PTime1, G3.PTime3, G3.v02, G3.On25 | |
| S4 | G4.PSkew3, G4.Poly0, G4.On75, G4.PTime3, G4.PKurt1, G4.PSkew2, G4.On25, G4.PKurt2, G4.On10, G4.On50 | |
| S5 | G5.On75, G5.ValPMax3, G5.PSkew1, G5.PSkew3, G5.ValPMax1, G5.Poly0, G5.Poly1, G5.PStd1, G5.PStd2, G5.PStd3 | |
| S6 | G6.Poly3, G6.PSkew1, G6.On25, G6.On50, G6.On75, G6.On10, G6.PTime1, G6.Poly2, G6.PTime3, G6.PSkew3, G6.PStd1 | |
| ON-R | S1–S6 | R2.PKurt1, R6.PTime1, R5.ValPMin3, R1.v08, R4.MinOn, R1.PTime1, R4.v03, R1.PMin2, R4.ValPMin1, R2.PSkew2 |
| S1 | R1.PTime1, R1.PStd1, R1.ValPMin2, R1.PTime2, R1.MedOn, R1.On10, R1.PTime3, R1.PMin2, R1.v03, R1.v02 | |
| S2 | R2.PKurt1, R2.v01, R2.PKurt3, R2.PSkew3, R2.On75, R2.PSkew2, R2.PSkew1, R2.PKurt2, R2.PMin3, R2.PMin1 | |
| S3 | R3.v01, R3.PKurt3, R3.PKurt1, R3.v15, R3.On10, R3.PSkew2, R3.PTime2, R3.PMin1, R3.PSkew3, R3.PStd3 | |
| S4 | R4.PKurt1, R4.MedOn, R4.ValPMin3, R4.PSkew3, R4.v14, R4.v02, R4.PStd3, R4.PMin1, R4.PMin3, R4.v15 | |
| S5 | R5.ValPMin3, R5.On75, R5.ValPMin2, R5.v15, R5.On10, R5.MedOn, R5.PMin1, R5.v09, R5.v03, R5.v07 | |
| S6 | R6.PStd2, R6.PSkew2, R6.On10, R6.v07, R6.On75, R6.MinOn, R6.v01, R6.v06, R6.PSkew3, R6.v15 |
References
- Hurot, C.; Scaramozzino, N.; Buhot, A.; Hou, Y. Bio-Inspired Strategies for Improving the Selectivity and Sensitivity of Artificial Noses: A Review. Sensors 2020, 20, 1803. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, D.; Loo, J.; Chen, J.; Yam, Y.; Chen, S.C.; He, H.; Kong, S.; Ho, H. Recent Advances in Surface Plasmon Resonance Imaging Sensors. Sensors 2019, 19, 1266. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brenet, S.; John-Herpin, A.; Gallat, F.X.; Musnier, B.; Buhot, A.; Herrier, C.; Rousselle, T.; Livache, T.; Hou, Y. Highly-Selective Optoelectronic Nose Based on Surface Plasmon Resonance Imaging for Sensing Volatile Organic Compounds. Anal. Chem. 2018, 90, 9879–9887. [Google Scholar] [CrossRef] [PubMed]
- Capelli, L.; Sironi, S.; Del Rosso, R. Electronic Noses for Environmental Monitoring Applications. Sensors 2014, 14, 19979–20007. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Guo, D.; Yan, K. Breath Analysis for Medical Applications; Springer: Singapore, 2017. [Google Scholar]
- Berna, A. Metal Oxide Sensors for Electronic Noses and Their Application to Food Analysis. Sensors 2010, 10, 3882–3910. [Google Scholar] [CrossRef] [Green Version]
- Baldwin, E.A.; Bai, J.; Plotto, A.; Dea, S. Electronic Noses and Tongues: Applications for the Food and Pharmaceutical Industries. Sensors 2011, 11, 4744–4766. [Google Scholar] [CrossRef]
- Gliszczyńska-Świgło, A.; Chmielewski, J. Electronic Nose as a Tool for Monitoring the Authenticity of Food. A Review. Food Anal. Methods 2017, 10, 1800–1816. [Google Scholar] [CrossRef] [Green Version]
- Rodríguez-Méndez, M.L.; De Saja, J.A.; González-Antón, R.; García-Hernández, C.; Medina-Plaza, C.; García-Cabezón, C.; Martín-Pedrosa, F. Electronic Noses and Tongues in Wine Industry. Front. Bioeng. Biotechnol. 2016, 4, 81. [Google Scholar] [CrossRef] [Green Version]
- Lozano, J.; Santos, J.P.; Aleixandre, M.; Sayago, I.; Gutierrez, J.; Horrillo, M.C. Identification of typical wine aromas by means of an electronic nose. IEEE Sens. J. 2006, 6, 173–178. [Google Scholar] [CrossRef]
- Lozano, J.; Santos, J.; Arroyo, T.; Aznar, M.; Cabellos, J.; Gil, M.; Horrillo, M. Correlating e-nose responses to wine sensorial descriptors and gas chromatography–mass spectrometry profiles using partial least squares regression analysis. Sens. Actuators B Chem. 2007, 127, 267–276. [Google Scholar] [CrossRef]
- Lozano, J.; Arroyo, T.; Santos, J.P.; Cabellos, J.; Horrillo, M.C. Electronic nose for wine ageing detection. Sens. Actuators B Chem. 2008, 133, 180–186. [Google Scholar] [CrossRef]
- Lozano, J.; Santos, J.P.; Horrillo, M.C. Enrichment sampling methods for wine discrimination with gas sensors. J. Food Comp. Anal. 2008, 21, 716–723. [Google Scholar] [CrossRef]
- Aguilera, T.; Lozano, J.; Paredes, J.A.; Álvarez, F.J.; Suárez, J.I. Electronic Nose Based on Independent Component Analysis Combined with Partial Least Squares and Artificial Neural Networks for Wine Prediction. Sensors 2012, 12, 8055–8072. [Google Scholar] [CrossRef]
- Macías, M.; Manso, A.; Orellana, C.; Velasco, H.; Caballero, R.; Chamizo, J. Acetic Acid Detection Threshold in Synthetic Wine Samples of a Portable Electronic Nose. Sensors 2012, 13, 208–220. [Google Scholar] [CrossRef]
- Rodriguez-Mendez, M.L.; Apetrei, C.; Gay, M.; Medina-Plaza, C.; de Saja, J.A.; Vidal, S.; Aagaard, O.; Ugliano, M.; Wirth, J.; Cheynier, V. Evaluation of oxygen exposure levels and polyphenolic content of red wines using an electronic panel formed by an electronic nose and an electronic tongue. Food Chem. 2014, 155, 91–97. [Google Scholar] [CrossRef]
- Wei, Z.; Xiao, X.; Wang, J.; Wang, H. Identification of the Rice Wines with Different Marked Ages by Electronic Nose Coupled with Smartphone and Cloud Storage Platform. Sensors 2017, 17, 2500. [Google Scholar] [CrossRef] [Green Version]
- Liu, H.; Li, Q.; Yan, B.; Zhang, L.; Gu, Y. Bionic Electronic Nose Based on MOS Sensors Array and Machine Learning Algorithms Used for Wine Properties Detection. Sensors 2019, 19, 45. [Google Scholar] [CrossRef] [Green Version]
- Rodriguez Gamboa, J.C.; Albarracin, E.E.S.; da Silva, A.J.; de Andrade Lima, L.L.; Ferreira, T.A.E. Wine quality rapid detection using a compact electronic nose system: Application focused on spoilage thresholds by acetic acid. Lwt-Food Sci. Technol. 2019, 108, 377–384. [Google Scholar] [CrossRef] [Green Version]
- Rodriguez Gamboa, J.C.; Albarracin, E.E.S.; da Silva, A.J.; Ferreira, T.A.E. Electronic nose dataset for detection of wine spoilage thresholds. Data Brief 2019, 25, 104202. [Google Scholar] [CrossRef]
- Zhang, L.; Tian, F.; Zhang, D. Book Review and Future Work. In Electronic Nose: Algorithmic Challenges; Springer: Singapore, 2018; pp. 335–339. [Google Scholar]
- Goodner, K.L.; Dreher, J.G.; Rouseff, R.L. The dangers of creating false classifications due to noise in electronic nose and similar multivariate analyses. Sens. Actuators B Chem. 2001, 80, 261–266. [Google Scholar] [CrossRef]
- Gardner, J.W.; Boilot, P.; Hines, E.L. Enhancing electronic nose performance by sensor selection using a new integer-based genetic algorithm approach. Sens. Actuators B Chem. 2005, 106, 114–121. [Google Scholar] [CrossRef]
- Phaisangittisagul, E.; Nagle, H.T. Sensor Selection for Machine Olfaction Based on Transient Feature Extraction. IEEE Trans. Instrum. Meas. 2008, 57, 369–378. [Google Scholar] [CrossRef]
- Phaisangittisagul, E.; Nagle, H.T.; Areekul, V. Intelligent method for sensor subset selection for machine olfaction. Sens. Actuators B Chem. 2010, 145, 507–515. [Google Scholar] [CrossRef]
- Guo, D.; Zhang, D.; Zhang, L. An LDA based sensor selection approach used in breath analysis system. Sens. Actuators B Chem. 2011, 157, 265–274. [Google Scholar] [CrossRef]
- Geng, Z.; Yang, F.; Wu, N. Optimum design of sensor arrays via simulation-based multivariate calibration. Sens. Actuators B Chem. 2011, 156, 854–862. [Google Scholar] [CrossRef]
- Zhang, L.; Tian, F.; Pei, G. A novel sensor selection using pattern recognition in electronic nose. Measurement 2014, 54, 31–39. [Google Scholar] [CrossRef]
- Miao, J.; Zhang, T.; Wang, Y.; Li, G. Optimal Sensor Selection for Classifying a Set of Ginsengs Using Metal-Oxide Sensors. Sensors 2015, 15, 16027–16039. [Google Scholar] [CrossRef] [Green Version]
- Sun, H.; Tian, F.; Liang, Z.; Sun, T.; Yu, B.; Yang, S.X.; He, Q.; Zhang, L.; Liu, X. Sensor Array Optimization of Electronic Nose for Detection of Bacteria in Wound Infection. IEEE Trans. Ind. Electron. 2017, 64, 7350–7358. [Google Scholar] [CrossRef]
- Tomic, O.; Eklöv, T.; Kvaal, K.; Huaugen, J.E. Recalibration of a gas-sensor array system related to sensor replacement. Anal. Chim. Acta 2004, 512, 199–206. [Google Scholar] [CrossRef]
- Fonollosa, J.; Vergara, A.; Huerta, R. Algorithmic mitigation of sensor failure: Is sensor replacement really necessary? Sens. Actuators B Chem. 2013, 183, 211–221. [Google Scholar] [CrossRef]
- Llobet, E.; Ionescu, R.; Al-Khalifa, S.; Brezmes, J.; Vilanova, X.; Correig, X.; Barsan, N.; Gardner, J.W. Multicomponent gas mixture analysis using a single tin oxide sensor and dynamic pattern recognition. IEEE Sens. J. 2001, 1, 207–213. [Google Scholar] [CrossRef]
- Szczurek, A.; Krawczyk, B.; Maciejewska, M. VOCs classification based on the committee of classifiers coupled with single sensor signals. Chemometr Intell. Lab. Syst. 2013, 125, 1–10. [Google Scholar] [CrossRef]
- Szczurek, A.; Maciejewska, M. “Artificial sniffing” based on induced temporary disturbance of gas sensor response. Sens. Actuators B Chem. 2013, 186, 109–116. [Google Scholar] [CrossRef]
- Hossein-Babaei, F.; Amini, A. Recognition of complex odors with a single generic tin oxide gas sensor. Sens. Actuators B Chem. 2014, 194, 156–163. [Google Scholar] [CrossRef]
- Herrero-Carrón, F.; Yáñez, D.J.; de Borja Rodríguez, F.; Varona, P. An active, inverse temperature modulation strategy for single sensor odorant classification. Sens. Actuators B Chem. 2015, 206, 555–563. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn Res. 2011, 12, 2825–2830. [Google Scholar]
- Brudzewski, K.; Ulaczyk, J. An effective method for analysis of dynamic electronic nose responses. Sens. Actuators B Chem. 2009, 140, 43–50. [Google Scholar] [CrossRef]
- Kaur, R.; Kumar, R.; Gulati, A.; Ghanshyam, C.; Kapur, P.; Bhondekar, A.P. Enhancing electronic nose performance: A novel feature selection approach using dynamic social impact theory and moving window time slicing for classification of Kangra orthodox black tea (Camellia sinensis (L.) O. Kuntze). Sens. Actuators B Chem. 2012, 166-167, 309–319. [Google Scholar] [CrossRef]
- Guo, X.; Peng, C.; Zhang, S.; Yan, J.; Duan, S.; Wang, L.; Jia, P.; Tian, F. A Novel Feature Extraction Approach Using Window Function Capturing and QPSO-SVM for Enhancing Electronic Nose Performance. Sensors 2015, 15, 15198–15217. [Google Scholar] [CrossRef] [Green Version]
- Muezzinoglu, M.K.; Vergara, A.; Huerta, R.; Rulkov, N.; Rabinovich, M.I.; Selverston, A.; Abarbanel, H.D.I. Acceleration of chemo-sensory information processing using transient features. Sens. Actuators B Chem. 2009, 137, 507–512. [Google Scholar] [CrossRef]
- Vergara, A.; Vembu, S.; Ayhan, T.; Ryan, M.A.; Homer, M.L.; Huerta, R. Chemical gas sensor drift compensation using classifier ensembles. Sens. Actuators B Chem. 2012, 166–167, 320–329. [Google Scholar] [CrossRef]
- Eklöv, T.; Mårtensson, P.; Lundström, I. Enhanced selectivity of MOSFET gas sensors by systematical analysis of transient parameters. Anal. Chim. Acta 1997, 353, 291–300. [Google Scholar] [CrossRef]
- Distante, C.; Leo, M.; Siciliano, P.; Persuad, K.C. On the study of feature extraction methods for an electronic nose. Sens. Actuators B Chem. 2002, 87, 274–288. [Google Scholar] [CrossRef]
- Zhang, W.; Liu, T.; Ye, L.; Ueland, M.; Forbes, S.L.; Su, S.W. A novel data pre-processing method for odour detection and identification system. Sens. Actuators A Phys. 2019, 287, 113–120. [Google Scholar] [CrossRef]
- Yan, J.; Guo, X.; Duan, S.; Jia, P.; Wang, L.; Peng, C.; Zhang, S. Electronic Nose Feature Extraction Methods: A Review. Sensors 2015, 15, 27804–27831. [Google Scholar] [CrossRef] [PubMed]
- Marco, S.; Gutierrez-Galvez, A. Signal and Data Processing for Machine Olfaction and Chemical Sensing: A Review. IEEE Sens. J. 2012, 12, 3189–3214. [Google Scholar] [CrossRef]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature selection: A data perspective. ACM Comput Surv. 2017, 50, 94. [Google Scholar] [CrossRef] [Green Version]
- Cho, J.H.; Kurup, P.U. Decision tree approach for classification and dimensionality reduction of electronic nose data. Sens. Actuators B Chem. 2011, 160, 542–548. [Google Scholar] [CrossRef]
- Yan, K.; Zhang, D. Feature selection and analysis on correlated gas sensor data with recursive feature elimination. Sens. Actuators B Chem. 2015, 212, 353–363. [Google Scholar] [CrossRef]
- Gualdrón, O.; Brezmes, J.; Llobet, E.; Amari, A.; Vilanova, X.; Bouchikhi, B.; Correig, X. Variable selection for support vector machine based multisensor systems. Sens. Actuators B Chem. 2007, 122, 259–268. [Google Scholar] [CrossRef]
- Shi, B.; Zhao, L.; Zhi, R.; Xi, X. Optimization of electronic nose sensor array by genetic algorithms in Xihu-Longjing Tea quality analysis. Math. Comput. Model. 2013, 58, 752–758. [Google Scholar] [CrossRef]
- Wang, X.R.; Lizier, J.T.; Nowotny, T.; Berna, A.Z.; Prokopenko, M.; Trowell, S.C. Feature Selection for Chemical Sensor Arrays Using Mutual Information. PLoS ONE 2014, 9, e89840. [Google Scholar] [CrossRef]
- Wang, X.R.; Lizier, J.T.; Berna, A.Z.; Bravo, F.G.; Trowell, S.C. Human breath-print identification by E-nose, using information-theoretic feature selection prior to classification. Sens. Actuators B Chem. 2015, 217, 165–174. [Google Scholar] [CrossRef] [Green Version]
- Nowotny, T.; Berna, A.Z.; Binions, R.; Trowell, S. Optimal feature selection for classifying a large set of chemicals using metal oxide sensors. Sens. Actuators B Chem. 2013, 187, 471–480. [Google Scholar] [CrossRef] [Green Version]
- Yin, Y.; Chu, B.; Yu, H.; Xiao, Y. A selection method for feature vectors of electronic nose signal based on Wilks Λ–statistic. J. Food Meas. Charact. 2014, 8, 29–35. [Google Scholar] [CrossRef]








© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Borowik, P.; Adamowicz, L.; Tarakowski, R.; Siwek, K.; Grzywacz, T. Odor Detection Using an E-Nose With a Reduced Sensor Array. Sensors 2020, 20, 3542. https://doi.org/10.3390/s20123542
Borowik P, Adamowicz L, Tarakowski R, Siwek K, Grzywacz T. Odor Detection Using an E-Nose With a Reduced Sensor Array. Sensors. 2020; 20(12):3542. https://doi.org/10.3390/s20123542
Chicago/Turabian StyleBorowik, Piotr, Leszek Adamowicz, Rafał Tarakowski, Krzysztof Siwek, and Tomasz Grzywacz. 2020. "Odor Detection Using an E-Nose With a Reduced Sensor Array" Sensors 20, no. 12: 3542. https://doi.org/10.3390/s20123542
APA StyleBorowik, P., Adamowicz, L., Tarakowski, R., Siwek, K., & Grzywacz, T. (2020). Odor Detection Using an E-Nose With a Reduced Sensor Array. Sensors, 20(12), 3542. https://doi.org/10.3390/s20123542