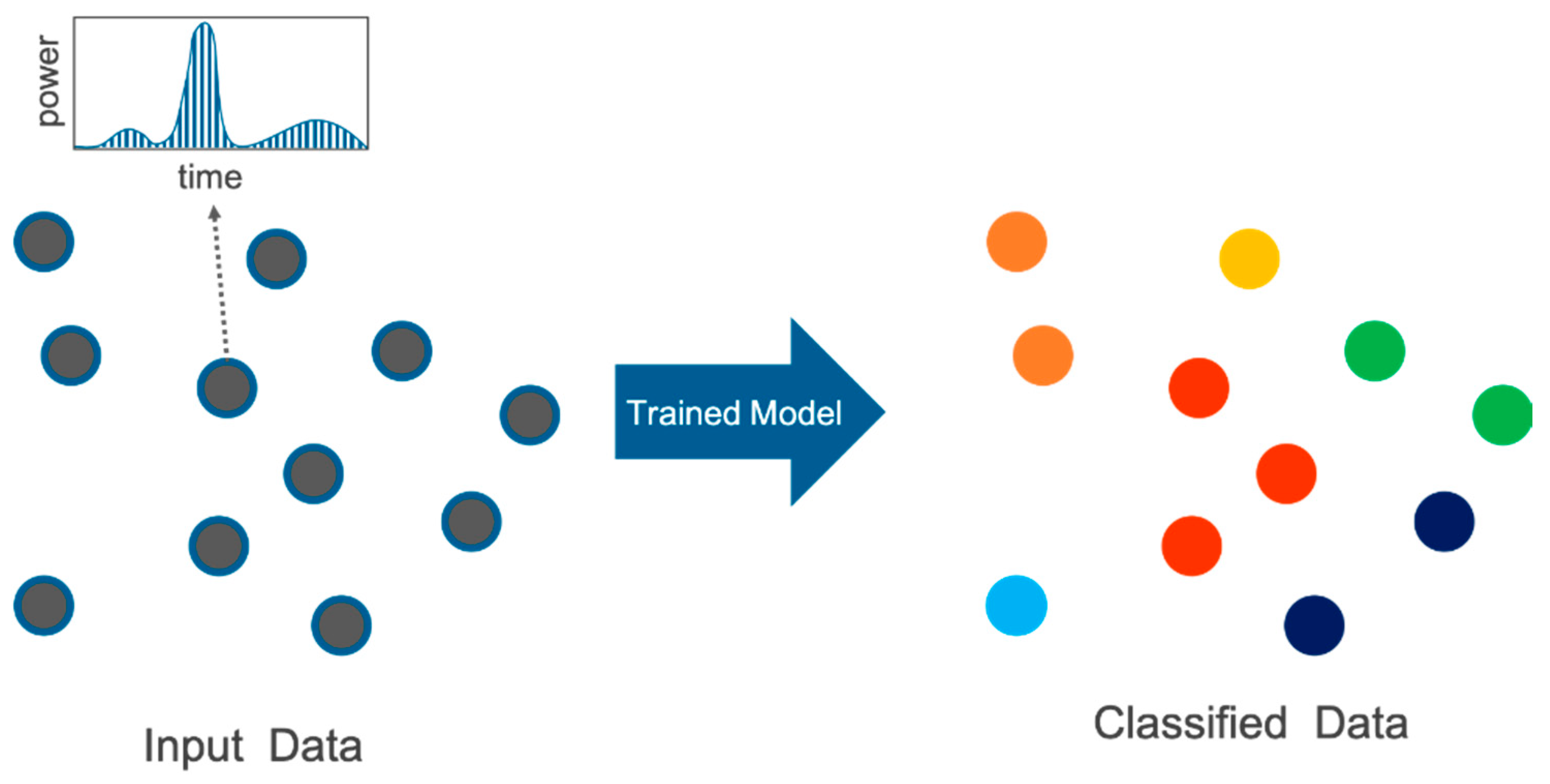
FWNet: Semantic Segmentation for Full-Waveform LiDAR Data Using Deep Learning


Abstract
:1. Introduction
- (1)
- Extending FWNetAE, which have only shown the effectiveness of unsupervised spatial representational learning on waveforms, we propose FWNet for supervised semantic segmentation and empirically showed that it outperformed previously proposed methods.
- (2)
- Our FWNet can discriminate six ground objects (ground, vegetation, buildings, power lines, transmission towers, and street path) with high performance, merely using waveform and its coordinates without explicitly converting them into images or voxels in the semantic segmentation task.
- (3)
- We experimentally demonstrated the effectiveness of the waveforms via an ablation study, which is an experiment to investigate whether or not each element contributes to the accuracy improvement when multiple elements related to the accuracy improvement are included in the proposed method, and the spatial learning method by visualizing the features extracted by the trained model.
2. Related Studies
2.1. Deep Learinig
2.2. Full-Waveform Data Analysis
3. Proposed Method
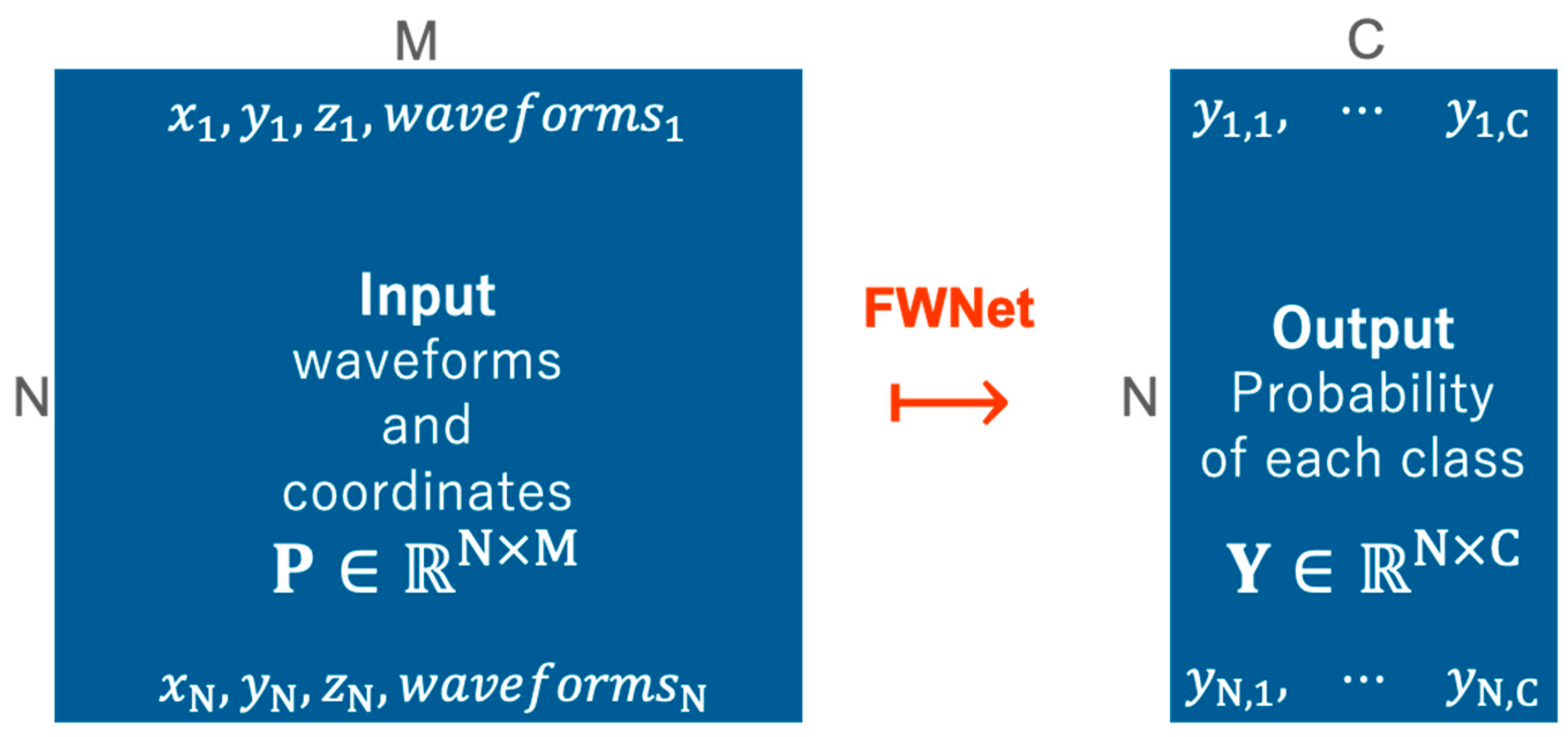
3.1. Problem Statement and Notation
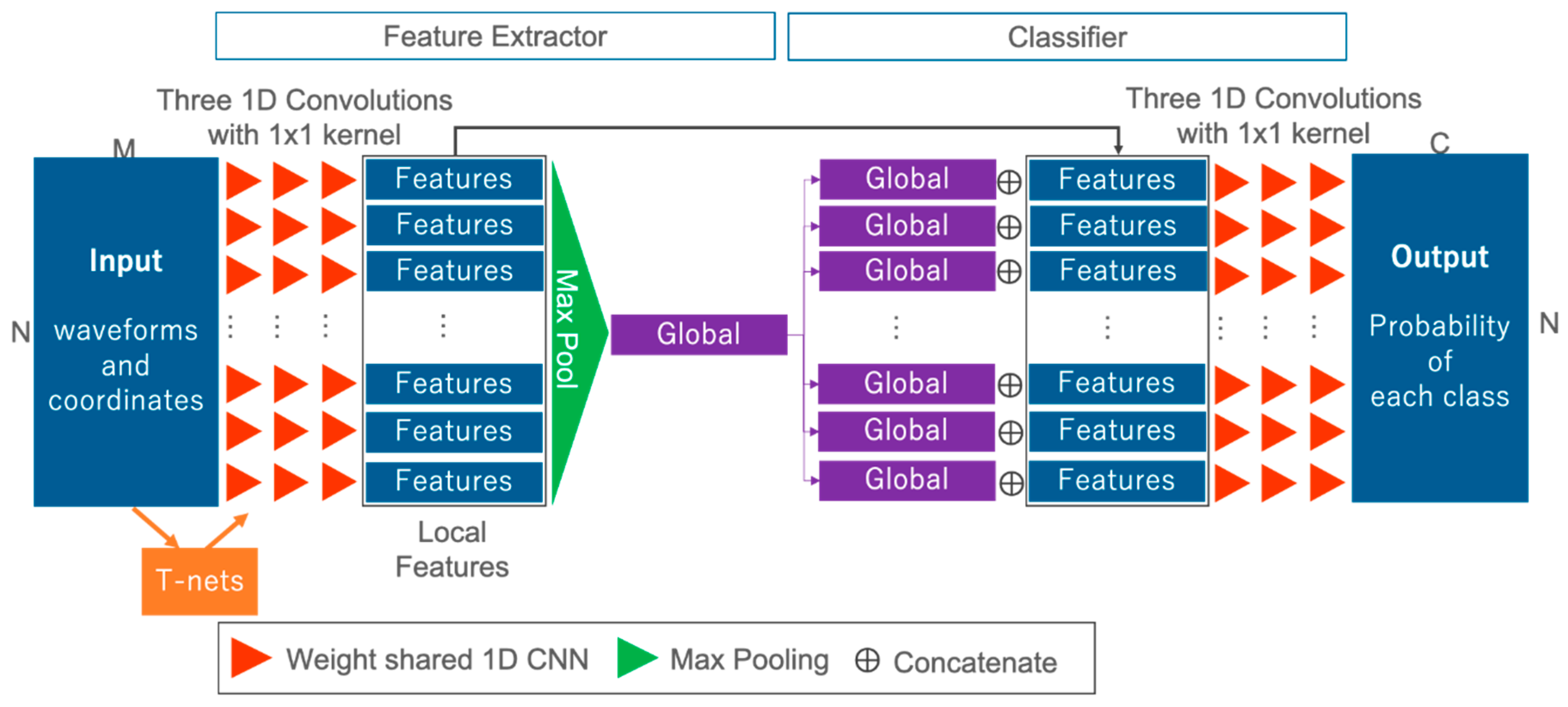
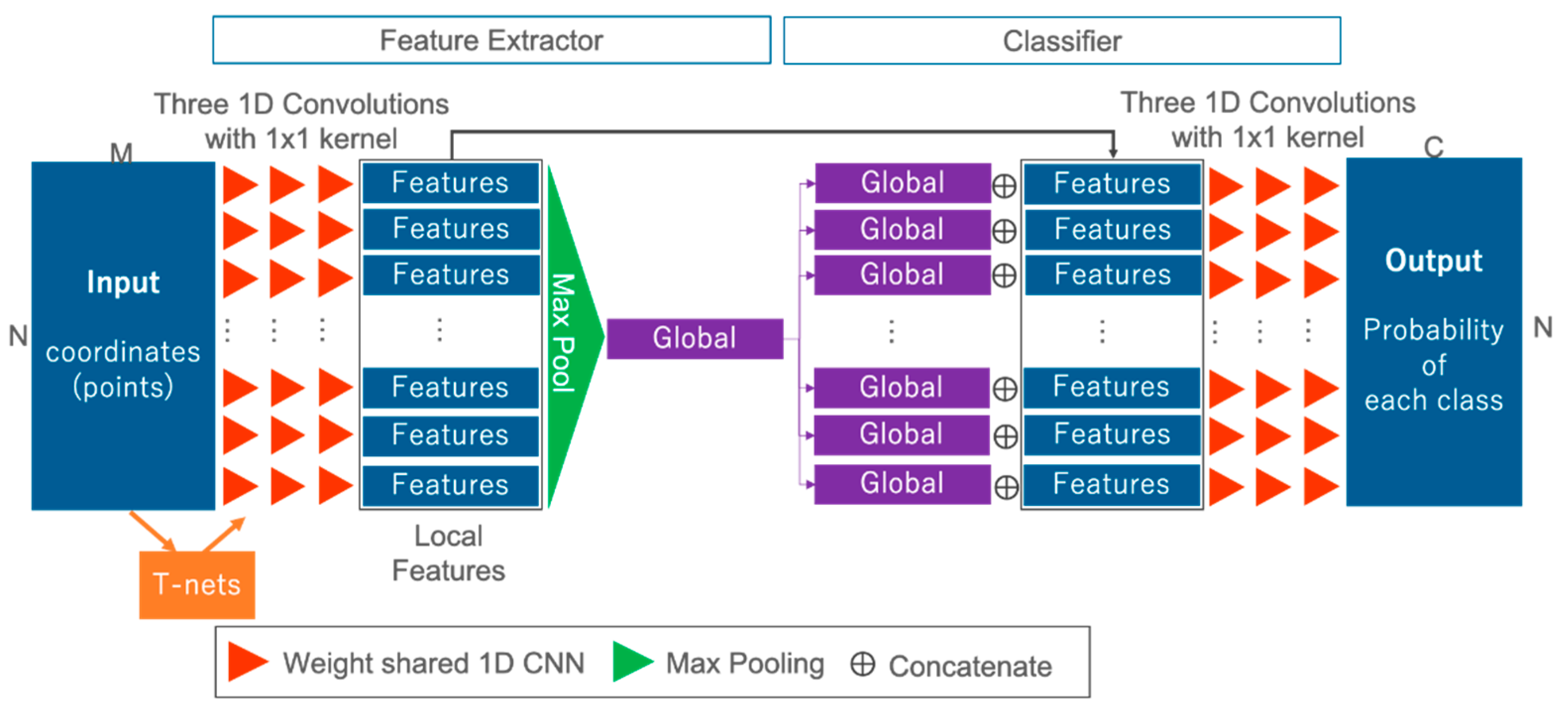
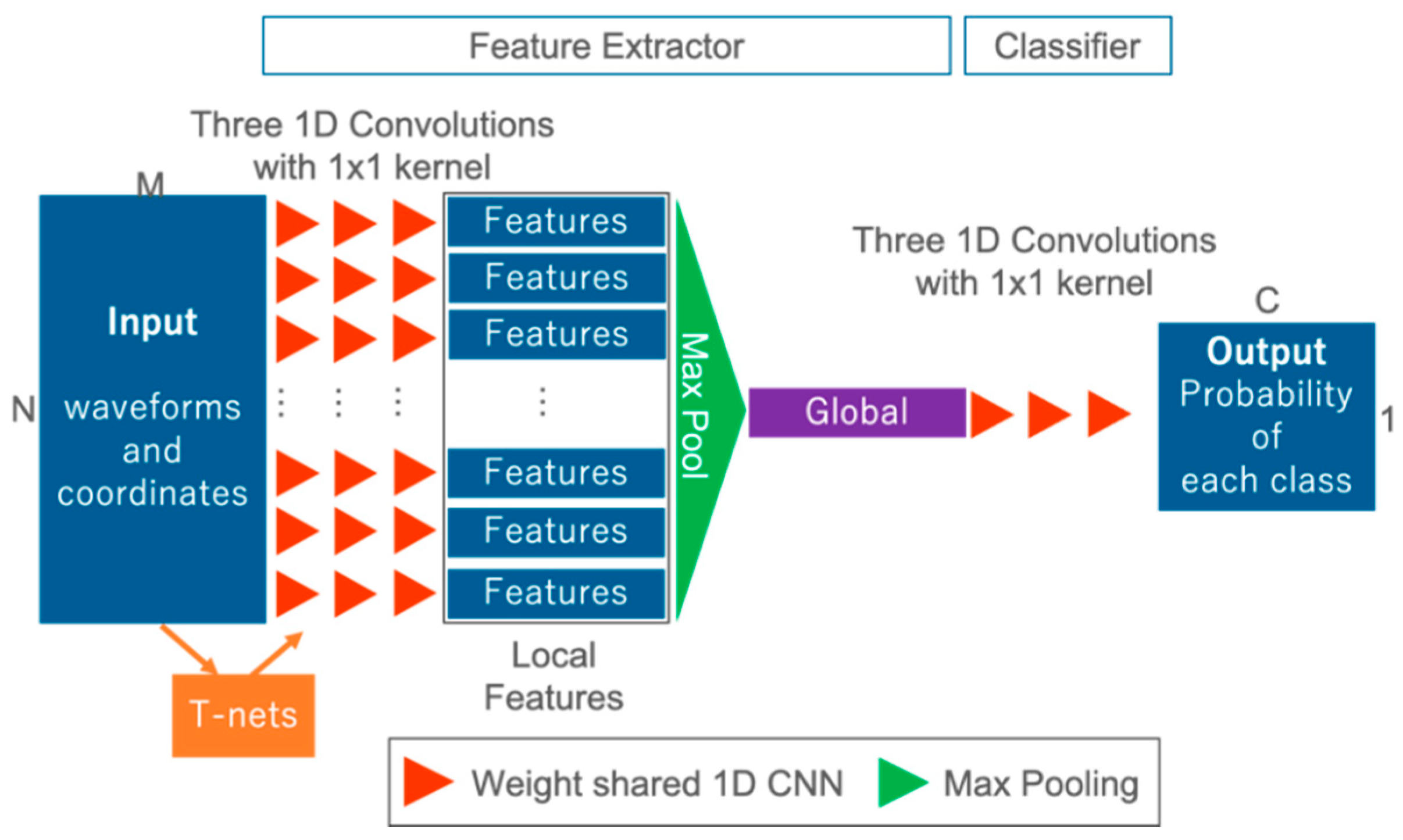
3.2. Proposed FWNet Architecture
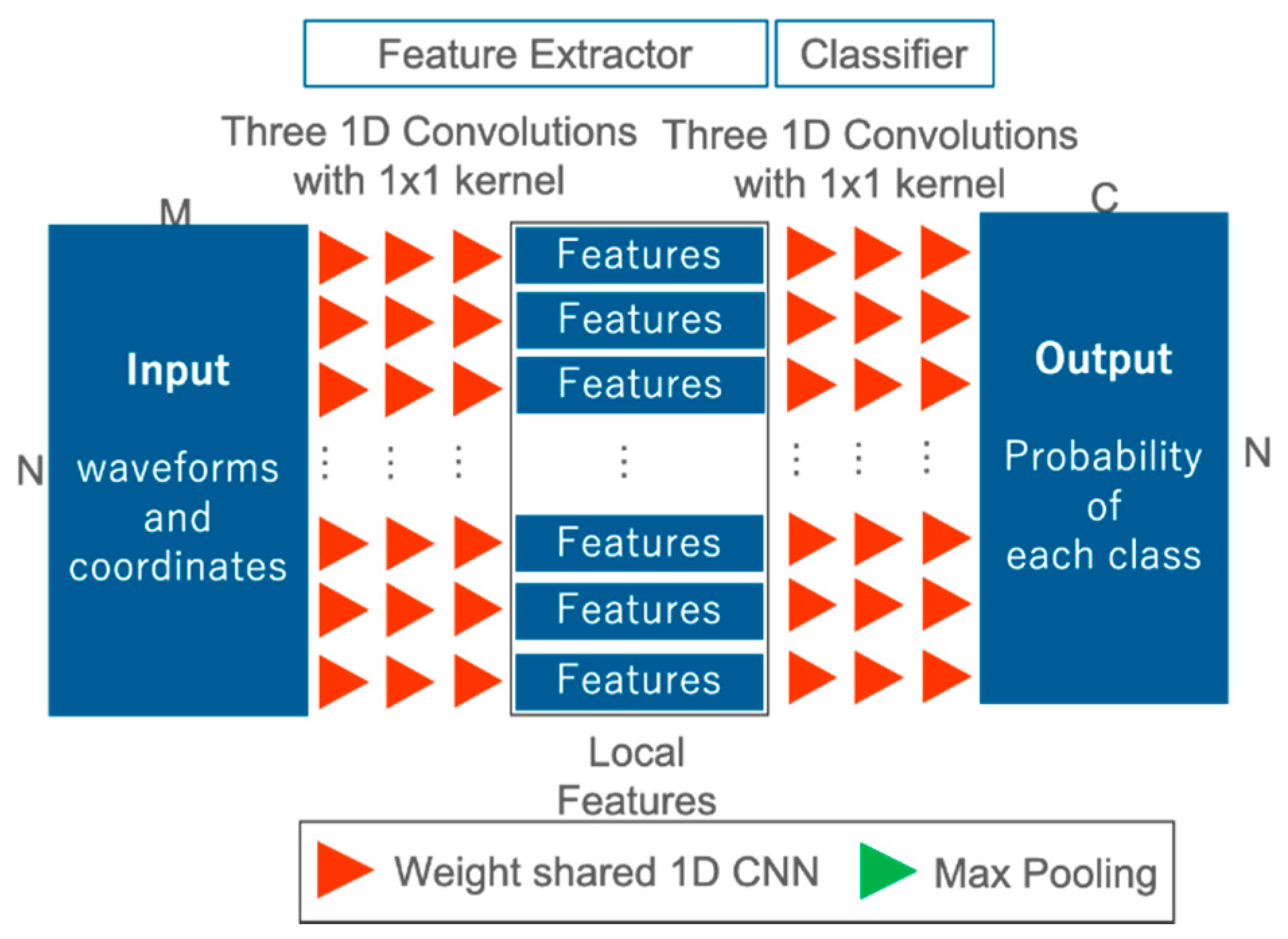
3.3. Model for Comparative Experiments
3.4. Model for Ablation Study
3.5. Training Detail
3.6. Evaluation Metrics
3.7. Predictions
| Algorithm 1 Prediction method for test data |
| Input:test_data |
| Output:predicted_classes |
| predict_Testdata(test_data) |
| define predicted_classes = test_data |
| central_points = get_Centralpoint(test_data) |
| for i in len(central_points) |
|
| return predicted_classes |
4. Experimental Results and Discussion
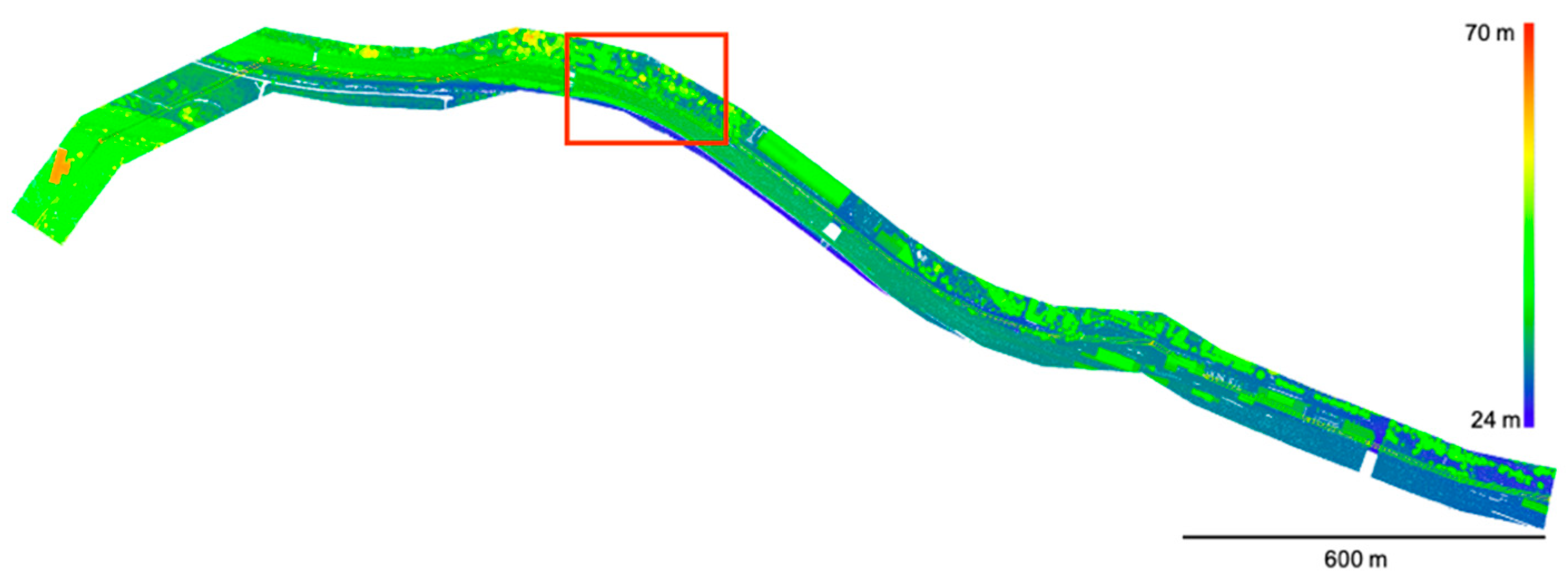
4.1. Dataset
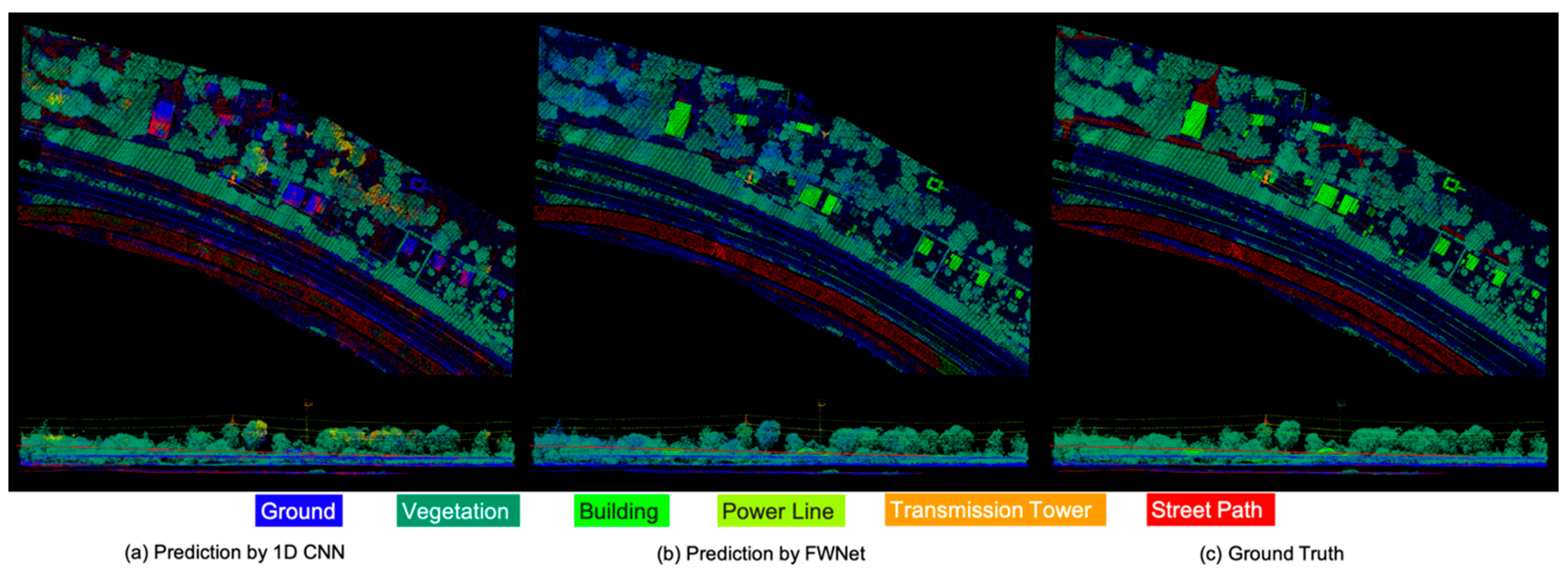
4.2. Classification Result
4.3. Ablation Study
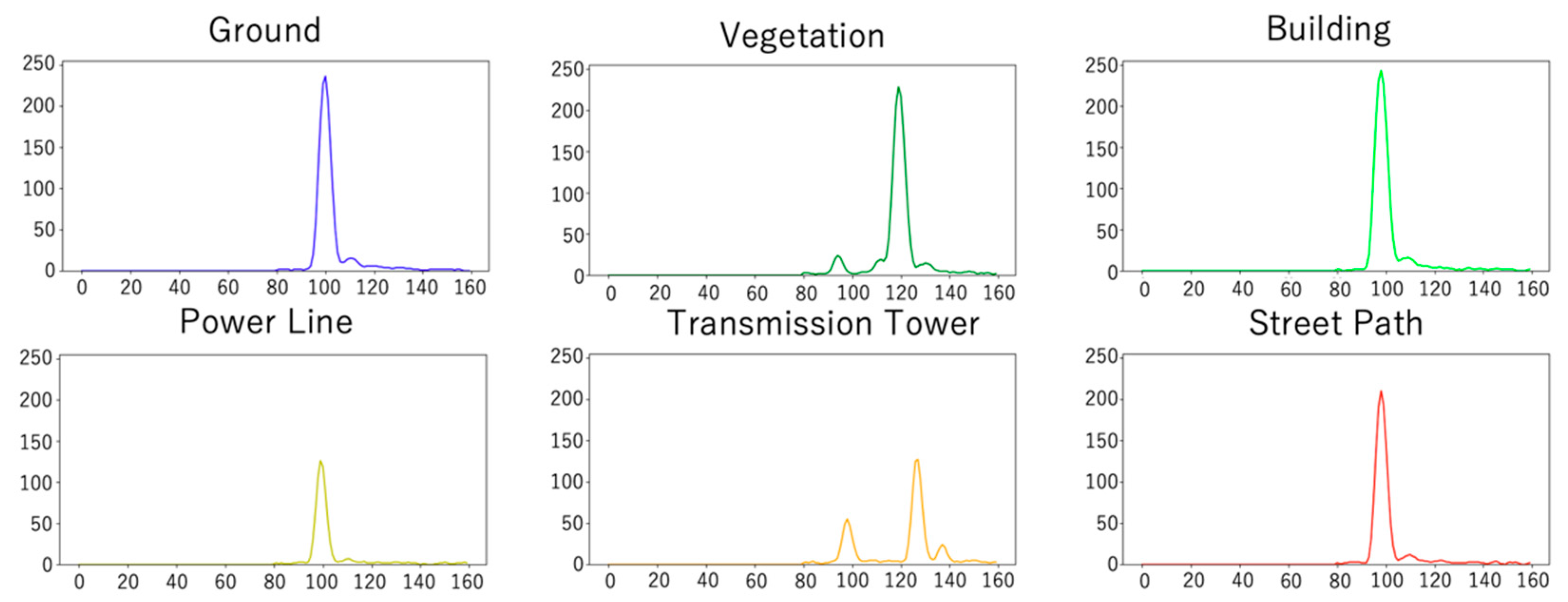
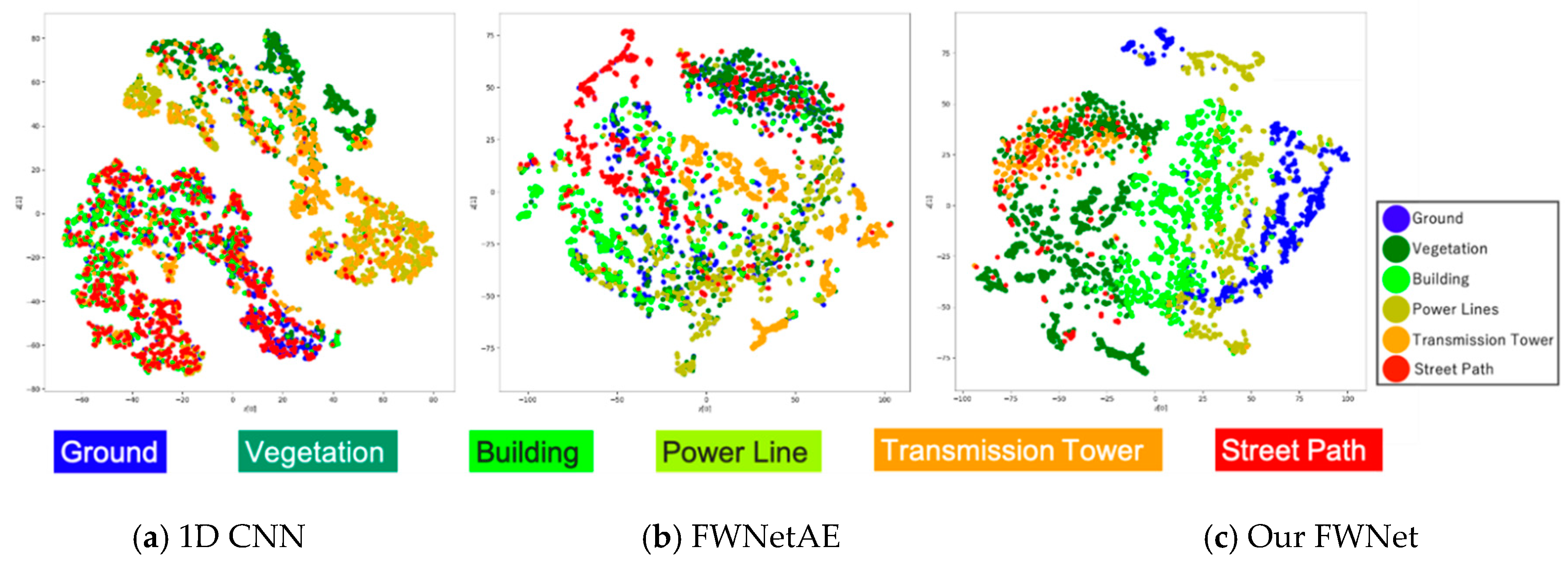
4.4. Effects of Spatial Feature Extraction
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Xie, Y.; Tian, J.; Zhu, X.X. A Review of Point Cloud Semantic Segmentation. Available online: https://arxiv.org/abs/1908.08854 (accessed on 30 December 2019).
- Antonarakis, A.S.; Richards, K.S.; Brasington, J. Objectbased land cover classification using airborne LiDAR. Remote Sens. 2008, 29, 1433–1452. [Google Scholar]
- Tran, T.; Ressl, C.; Pfeifer, N. Integrated change detection and classification in urban areas based on airborne laser scanning point clouds. Sensors 2018, 18, 448. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ahmed, E.; Saint, A.; Shabayek, A.E.R.; Cherenkova, K.; Das, R.; Gusev, G.; Aouada, D.; Ottersten, B. Deep Learning Advances on Different 3d Data Representations: A Survey. arXiv 2018, arXiv:1808.01462. [Google Scholar]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep Learning for 3D Point Clouds: A Survey. Available online: https://arxiv.org/abs/1912.12033 (accessed on 30 December 2019).
- Liu, W.; Sun, J.; Li, W.; Hu, T.; Wang, P. Deep learning on point clouds and its application: A survey. Sensors 2019, 19, 4188. [Google Scholar] [CrossRef] [Green Version]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep Learning on Point Sets for 3d Classification and Segmentation. In CoRR; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Axelsson, P. DEM generation from laser scanner data using adaptive TIN models. Int. Arch. Photogramm. Remote Sens. 2000, 33, 110–117. [Google Scholar]
- Mongus, D.; Žalik, B. Computationally efficient method for the generation of a digital terrain model from airborne LiDAR data using connected operators. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 7, 340–351. [Google Scholar] [CrossRef]
- Andersen, H.E.; McGaughey, R.J.; Reutebuch, S.E. Estimating forest canopy fuel parameters using LIDAR data. Remote Sens. Environ. 2005, 94, 441–449. [Google Scholar] [CrossRef]
- Solberg, S.; Brunner, A.; Hanssen, K.H.; Lange, H.; Næsset, E.; Rautiainen, M.; Stenberg, P. Mapping LAI in a Norway spruce forest using airborne laser scanning. Remote Sens. Environ. 2009, 113, 2317–2327. [Google Scholar] [CrossRef]
- Zhao, K.; Popescu, S. Lidar-based mapping of leaf area index and its use for validating GLOBCARBON satellite LAI product in a temperate forest of the southern USA. Remote Sens. Environ. 2009, 349113, 1628–1645. [Google Scholar] [CrossRef]
- Ene, L.T.; Næsset, E.; Gobakken, T.; Bollandsås, O.M.; Mauya, E.W.; Zahabu, E. Large-scale estimation of change in aboveground biomass in miombo woodlands using airborne laser scanning and national forest352inventory data. Remote Sens. Environ. 2017, 188, 106–117. [Google Scholar] [CrossRef]
- Kada, M.; McKinley, L. 3D building reconstruction from LiDAR based on a cell decomposition approach.354International Archives of Photogrammetry. Remote Sens. Spat. Inf. Sci. 2009, 38, W4. [Google Scholar]
- Yang, B.; Huang, R.; Li, J.; Tian, M.; Dai, W.; Zhong, R. Automated reconstruction of building lods from airborne lidar point clouds using an improved morphological scale space. Remote Sens. 2017, 9, 14. [Google Scholar] [CrossRef] [Green Version]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. Scannet: Richly-annotated 3d Reconstructions of Indoor Scenes. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5828–5839. [Google Scholar]
- Pham, Q.H.; Nguyen, T.; Hua, B.S.; Roig, G.; Yeung, S.K. JSIS3D: Joint Semantic-Instance Segmentation of 3d Point Clouds with Multi-Task Pointwise Networks and Multi-Value Conditional Random Fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 8827–8836. [Google Scholar]
- Mallet, C.; Bretar, F. Full-waveform topographic LiDAR: State-of- the-art. ISPRS J. Photogramm. Remote Sens. 2009, 64, 1–16. [Google Scholar] [CrossRef]
- Wolfgang, W.; Melzer Dr, T.; Briese, C.; Kraus, K.H. From Single-Pulse to Full-Waveform Airborne Laser Scanners: Potential and Practical Challenges; International Archives of Photogrammetry and Remote Sensing: Freiburg, Germany, 3–6 October 2004; Volume 35, pp. 201–206. [Google Scholar]
- Mostafa, K.; Ebadi, H.; Ahmadi, S. An improved snake model for automatic extraction of buildings from urban aerial images and LiDAR data. Comput. Environ. Urban Syst. 2010, 34, 435–444. [Google Scholar]
- Friedrich, A. Airborne laser scanning—Present status and future expectations. ISPRS J. Photogramm. Remote Sens. 1999, 54, 64–67. [Google Scholar]
- Mallet, C.; Bretar, F.; Roux, M.; Soergel, U.; Heipke, C. Relevance assessment of full-waveform lidar data for urban area classification. ISPRS J. Photogramm. Remote Sens. 2011, 66, 71–84. [Google Scholar] [CrossRef]
- Hu, B.; Gumerov, D.; Wang, J.; Zhang, W. An integrated approach to generating accurate DTM from airborne full-waveform LiDAR data. Remote Sens. 2017, 9, 871. [Google Scholar] [CrossRef] [Green Version]
- Nanni, L.; Ghidoni, S.; Brahnam, S. Handcrafted vs Non-Handcrafted Features for computer vision classification. Pattern Recognition 2017, 71. [Google Scholar] [CrossRef]
- Maset, E.; Carniel, R.; Crosilla, F. Unsupervised classification of raw full-waveform airborne lidar data by self organizing maps. In Proceedings of the International Conference on Image Analysis Process, Genoa, Italy, 7–11 September 2015; pp. 62–72. [Google Scholar]
- Zorzi, S.; Maset, E.; Fusiello, A.; Crosilla, F. Full-Waveform Airborne LiDAR Data Classification Using Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8255–8261. [Google Scholar] [CrossRef]
- Shinohara, T.; Xiu, H.; Matsuoka, M. FWNetAE: Spatial Representation Learning for Full Waveform Data Using Deep Learning. In Proceedings of the 2019 IEEE International Symposium on Multimedia (ISM), San Diego, CA, USA, 9–11 December 2019; pp. 259–2597. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 6088. [Google Scholar] [CrossRef]
- Zeiler, D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Lee, H.; Ekanadham, C.; Ng, A. Sparse deep belief net model for visual area V2. Adv. Neural Inf. Process. Syst. 2008, 20, 873–880. [Google Scholar]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Yang, Z.; Jiang, W.; Xu, B.; Zhu, Q.; Jiang, S.; Huang, W. A convolutional neural network-based 3D semantic labeling method for ALS point clouds. Remote Sens. 2017, 9, 936. [Google Scholar] [CrossRef] [Green Version]
- Zhao, R.; Pang, M.; Wang, J. Classifying airborne LiDAR point clouds via deep features learned by a multi-scale convolutional neural network. Int. J. Geogr. Inf. Sci. 2018, 32332, 960–979. [Google Scholar] [CrossRef]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. SEMANTIC3D.NET: A new large-scale point cloud classification benchmark. ISPRS Annals of the Photogrammetry. Remote Sens. Spat. Inf. Sci. 2017, IV-1-W1, 91–98. [Google Scholar]
- Maturana, D.; Scherer, S.A. VoxNet: A 3D Convolutional Neural Network for Real-Time Object Recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS, Hamburg, German, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Yousefhussien, M.; Kelbe, D.J.; Ientilucci, E.J.; Salvaggio, C. A multi-scale fully convolutional network for semantic labeling of 3D point clouds. ISPRS J. Photogramm. Remote Sens. 2018, 143, 191–204. [Google Scholar] [CrossRef]
- Wang, S.; Suo, S.; Ma, W.C.; Pokrovsky, A.; Urtasun, R. Deep Parametric Continuous Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2589–2597. [Google Scholar]
- Wen, C.; Yang, L.; Peng, L.; Li, X.; Chi, T. Directionally Constrained Fully Convolutional Neural Network for Airborne Lidar Point Cloud Classification. ISPRS J. Photogramm. Remote Sens. 2020, 162, 50–62. [Google Scholar] [CrossRef] [Green Version]
- Xiu, H.; Shinohara, T.; Matsuoka, M. Dynamic-Scale Graph Convolutional Network for Semantic Segmentation of 3D Point Cloud. In Proceedings of the IEEE Int. Symp. Multimed. (ISM), San Diego, CA, USA, 9–11 December 2019; pp. 271–2717. [Google Scholar] [CrossRef]
- Jia, M.; Li, A.; Wu, Z. A Global Point-Sift Attention Network for 3d Point Cloud Semantic Segmentation. In Proceedings of the International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 5065–5068. [Google Scholar]
- Lian, Y.; Feng, T.; Zhou, J. A Dense Pointnet++ Architecture for 3d Point Cloud Semantic Segmentation. In Proceedings of the International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 5061–5064. [Google Scholar]
- Winiwarter, L.; Mandlburger, G.; Schmohl, S.; Pfeifer, N. Classification of ALS Point Clouds Using End-to-End Deep Learning. PFG J. Photogramm. Remote Sens. Geoinf. Sci. 2019, 87, 75–90. [Google Scholar] [CrossRef]
- Zhang, J.; Hu, X.; Dai, H.; Qu, S. DEM Extraction from ALS Point Clouds in Forest Areas via Graph Convolution Network. Remote Sens. 2020, 12, 178. [Google Scholar] [CrossRef] [Green Version]
- Janssens-coron, E.; Guilbert, E. Ground point filtering from airborne lidar point clouds using deep learning: A preliminary study. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. ISPRS Arch. XLII-2/W13 2019, 4213, 1559–1565. [Google Scholar] [CrossRef] [Green Version]
- Briechle, S.; Krzystek, P.; Vosselman, G. Semantic labeling of als point clouds for tree species mapping using the deep neural network pointnet++. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. ISPRS Arch. 2019, 42, 951–955. [Google Scholar] [CrossRef] [Green Version]
- Zhou, T.; Popescu, S.; Malambo, L.; Zhao, K.; Krause, K. From LiDAR Waveforms to Hyper Point Clouds: A Novel Data Product to Characterize Vegetation Structure. Remote Sens. 2018, 10, 1949. [Google Scholar] [CrossRef] [Green Version]
- Ducic, V.; Hollaus, M.; Ullrich, A.; Wagner, W.; Melzer, T. 3D Vegetation Mapping and Classification Using Full-Waveform Laser Scanning. In Proceedings of the Workshop 3D Remote Sensing, Vienna, Austria, 14–15 February 2006; International Workshop: Vienna, Austria, 2006; pp. 211–217. [Google Scholar]
- Mallet, C.; Bretar, F.; Soergel, U. Analysis of full-waveform LiDAR data for classification of urban areas. Photogramm. Fernerkund. Geoinf. 2008, 5, 337–349. [Google Scholar]
- Neuenschwander, A.L.; Magruder, L.A.; Tyler, M. Landcover classification of small-footprint, full-waveform lidar data. J. Appl. Remote Sens. 2009, 3, 033544. [Google Scholar] [CrossRef]
- Reitberger, J.; Krzystek, P.; Stilla, U. Benefit of Airborne Full Waveform LiDAR for 3D Segmentation and Classification of Single Trees. In Proceedings of the ASPRS 2009 Annual Conference, Baltimore, MD, USA, 9–13 March 2009. [Google Scholar]
- Fieber, K.D.; Davenport, I.J.; Ferryman, J.M.; Gurney, R.J.; Walker, J.P.; Hacker, J.M. Analysis of full-waveform LiDAR data for classification of an orange orchard scene. ISPRS J. Photogramm. Remote Sens. 2013, 82, 63–82. [Google Scholar] [CrossRef] [Green Version]
- Wagner, W.; Hollaus, M.; Briese, C.; Ducic, V. 3D vegetation mapping using small-footprint full-waveform airborne laser scanners. Int. J. Remote Sens. 2008, 29, 1433–1452. [Google Scholar] [CrossRef] [Green Version]
- Alexander, C.; Tansey, K.; Kaduk, J.; Holland, D.; Tate, N.J. Backscatter coefficient as an attribute for the classification of full-waveform airborne laser scanning data in urban areas. ISPRS J. Photogramm. Remote Sens. 2010, 65, 423–432. [Google Scholar] [CrossRef] [Green Version]
- Höfle, B.; Hollaus, M.; Hagenauer, J. Urban vegetation detec- tion using radiometrically calibrated small-footprint full-waveform air-borne LiDAR data. ISPRS J. Photogramm. Remote Sens. 2012, 67, 134–147. [Google Scholar] [CrossRef]
- Azadbakht, M.; Fraser, C.; Khoshelham, K. The Role of Full-Waveform Lidar Features in Improving Urban Scene Classification. In Proceedings of the 9th International Symposium on Mobile Mapping Technology (MMT 2015), Sydney, Australia, 9–11 December 2015. [Google Scholar]
- Zhou, M.; Li, C.R.; Ma, L.; Guan, H.C. Land cover classification from full-waveform Lidar data based on support vector machines. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. ISPRS Arch. 2016, 41, 447–452. [Google Scholar] [CrossRef]
- Ma, L.; Zhou, M.; Li, C. Land covers classification based on Random Forest method using features from full-waveform LiDAR data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. ISPRS Arch. 2017, 42, 263–268. [Google Scholar] [CrossRef] [Green Version]
- Azadbakht, M.; Fraser, C.S.; Khoshelham, K. Synergy of sampling techniques and ensemble classifiers for classification of urban environments using full-waveform LiDAR data. Int. J. Appl. Earth Obs. Geoinf. 2018, 73, 277–291. [Google Scholar] [CrossRef]
- Wang, C.; Shu, Q.; Wang, X.; Guo, B.; Liu, P.; Li, Q. A random forest classifier based on pixel comparison features for urban LiDAR data. ISPRS J. Photogramm. Remote Sens. 2019, 148, 75–86. [Google Scholar] [CrossRef]
- Lai, X.; Yuan, Y.; Li, Y.; Wang, M. Full-Waveform LiDAR Point Clouds Classification Based on Wavelet Support Vector Machine and Ensemble Learning. Sensors 2019, 19, 3191. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, H.; Glennie, C. Fusion of waveform LiDAR data and hyper-spectral imagery for land cover classification. ISPRS J. Photogramm. Remote Sens. 2015, 108, 1–11. [Google Scholar] [CrossRef]
- Luo, S.; Wang, C.; Xi, X.; Zeng, H.; Li, D.; Xia, S.; Wang, P. Fusion of Airborne Discrete-Return LiDAR and Hyperspectral Data for Land Cover Classification. Remote Sens. 2016, 8, 3. [Google Scholar] [CrossRef] [Green Version]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Pytorch Official Document. Available online: https://pytorch.org/docs/master/generated/torch.nn.CrossEntropyLoss.html (accessed on 25 May 2020).
- Kingma, D.P.; Adam, J.B. A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the Difficulty of Training Deep Feedforward Neural Networks. In Proceedings of the 13th International conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems 32, Vancouver, Canada, 8–14 December 2019; pp. 8026–8037. [Google Scholar]
- TSUBAME 3.0. Available online: https://www.gsic.titech.ac.jp/en/tsubame (accessed on 10 June 2020).
- RIEGL LMS-Q780. Available online: http://www.riegl.com/uploads/tx_pxpriegldownloads/DataSheet_LMS-Q780_2015-03-24.pdf (accessed on 25 May 2020).
- Maaten, L.V.D.; Hinton, G. Visualizing data using t-sne. J. Mach. Learn. Res. 2008, 5, 2579–2605. [Google Scholar]
- Michael, M.; Bronstein, J.B.; Lecun, Y.; Szlam, A.; Vandergheynst, P. Geometric deep learning: Going beyond euclidean data. IEEE Signal Process. Mag. 2017, 34, 18–42. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the 2017 Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Yi, L.; Su, H.; Guo, X.; Guibas, L.J. SyncSpecCNN: Synchronized Spectral CNN for 3D Shape Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6584–6592. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Trans. Graph. (TOG) 2019, 38, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Gong, J.; Zhou, J.; Tan, X.; Xie, Y.; Ma, L. SceneEncoder: Scene-Aware Semantic Segmentation of Point Clouds with A Learnable Scene Descriptor. arXiv 2020, arXiv:2001.09087. [Google Scholar]
- Zhao, H.; Jiang, L.; Fu, C.W.; Jia, J. Pointweb: Enhancing Local Neighborhood Features for Point Cloud Processing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 5565–5573. [Google Scholar]
- Wu, W.; Qi, Z.; Li, F. Pointconv: Deep Convolutional Networks on 3d Point Clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–21 June 2019; pp. 9621–9630. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Train | Test | ||
|---|---|---|---|---|
| Number of Data | % | Number of Data | % | |
| Ground | 1,787,352 | 20.4 | 193,070 | 18.1 |
| Vegetation | 4,719,634 | 53.9 | 765,327 | 71.7 |
| Building | 1,514,486 | 17.3 | 49,138 | 4.6 |
| Power Line | 71,978 | 0.8 | 8151 | 0.8 |
| Trans. Tower | 32,008 | 0.4 | 1829 | 0.2 |
| Street Path | 633,606 | 7.2 | 49,580 | 4.6 |
| Method | Metrics | Ground | Veg. | Build. | Power Line | Trans. Tower | Street Path | Mean |
|---|---|---|---|---|---|---|---|---|
| 1D CNN [26] | Recall | 0.07 | 0.79 | 0.13 | 0.91 | 0.42 | 0.56 | 0.48 |
| Precision | - | - | - | - | - | - | - | |
| F1 score | - | - | - | - | - | - | - | |
| 1D CNN Reproduce | Recall | 0.68 | 0.83 | 0.02 | 0.80 | 0.36 | 0.58 | 0.55 |
| Precision | 0.51 | 0.96 | 0.14 | 0.26 | 0.05 | 0.29 | 0.37 | |
| F1 score | 0.59 | 0.89 | 0.04 | 0.40 | 0.08 | 0.38 | 0.40 | |
| FWNet | Recall | 0.91 | 0.85 | 0.83 | 0.84 | 0.48 | 0.62 | 0.73 |
| Precision | 0.56 | 0.97 | 0.95 | 0.92 | 0.61 | 0.94 | 0.81 | |
| F1 score | 0.69 | 0.91 | 0.88 | 0.88 | 0.53 | 0.75 | 0.76 |
| Method | FW | All Points | Weight | mRecall | mPrec. | mF1 | Time(h) |
|---|---|---|---|---|---|---|---|
| Geometry Model | - | ✔ | ✔ | 0.68 | 0.71 | 0.65 | 1 |
| One Output Model | ✔ | - | ✔ | 0.63 | 0.77 | 0.62 | 13 |
| No Weight Model | ✔ | ✔ | - | 0.28 | 0.28 | 0.27 | 1 |
| FWNet | ✔ | ✔ | ✔ | 0.73 | 0.73 | 0.73 | 1 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shinohara, T.; Xiu, H.; Matsuoka, M. FWNet: Semantic Segmentation for Full-Waveform LiDAR Data Using Deep Learning. Sensors 2020, 20, 3568. https://doi.org/10.3390/s20123568
Shinohara T, Xiu H, Matsuoka M. FWNet: Semantic Segmentation for Full-Waveform LiDAR Data Using Deep Learning. Sensors. 2020; 20(12):3568. https://doi.org/10.3390/s20123568
Chicago/Turabian StyleShinohara, Takayuki, Haoyi Xiu, and Masashi Matsuoka. 2020. "FWNet: Semantic Segmentation for Full-Waveform LiDAR Data Using Deep Learning" Sensors 20, no. 12: 3568. https://doi.org/10.3390/s20123568
APA StyleShinohara, T., Xiu, H., & Matsuoka, M. (2020). FWNet: Semantic Segmentation for Full-Waveform LiDAR Data Using Deep Learning. Sensors, 20(12), 3568. https://doi.org/10.3390/s20123568