Application-Oriented Retinal Image Models for Computer Vision


 , ,
, ,
Abstract
:
1. Introduction
- we provide a framework for designing Application-Oriented Retinal Image Models (ARIM) towards computer vision (CV) applications;
- we evaluate the use of ARIMs in a CV application of the biometry field in terms of memory storage and energy reductions;
- we discuss the trade-offs between the application’s accuracy and the reductions in the computing resources induced by the ARIMs;
- we compare our results to other common setups (original and downsized uniform-resolution images) and show that the obtained storage and energy savings are relevant; and,
- we briefly discuss the use of ARIMs in real-life application scenarios and the nuances of having an ideal hardware layer that resamples images according to ARIMs.
2. Literature Review
2.1. Hardware-Based Approaches
2.2. Software-Based Approaches
2.3. Recent Clustering Techniques
3. Proposed Approach
3.1. Definition of Application Requirements
3.2. Implicit Function Selection
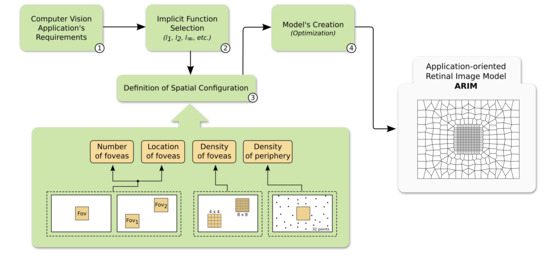
3.3. Definition of Spatial Configuration
- Number of foveas: surely a human eye has only one fovea, but it is perfectly fine for a model to comprise more than one region of uniform sampling, depending on the application on hand. In our biometric application, we took into account only one fovea.
- Location of foveas: the foveas should be spatially organized adhering to the specific requirements of the application. In ours, the fovea is centralized in the image.
- Density of foveas: the foveas can be downsampled to simulate a uniform image resolution reduction. We tested different densities (grids) for our fovea.
- Density of periphery: the periphery is an important region that encompasses few sparse data in a non-uniform sampling configuration. As discussed previously, by retaining and wisely handling sparse peripheral information (e.g., detecting motion and coarse objects in such an area), the application’s resource usage might be optimized.
3.4. Model Generation
4. Materials and Methods
4.1. Target Application: Face Detection/Recognition
4.1.1. On the Application Selection
- Step 1: We analysed the CV application’s demands and characteristics. In the biometry application considered, we observed aspects regarding:
- the use of computational resources, which should be preferably low when running in environments of large energy and storage limitations;
- the intrinsic characteristics of the application’s domain, such as the task to be executed (face authentication), the expected “behavior” of the input data (person movement and positioning in the images), camera angles, the most relevant part of the image to process, etc.;
- the possibility of balancing the pixel density of different image regions. In this sense, given the application on hand, we decided that the processed image would have different resolutions across its space. This will induce a compromise between energy, storage, and accuracy; and,
- the possibility of adopting distinct pixel representations across the image in order to save computational resources. In the current case, an additional motion analysis is performed by taking advantage of an optical flow pixel representation in some image regions.
- Step 2: subsequently, by the previous analysis, we selected an appropriate implicit function to represent the pixel distribution of the image;
- Step 3: next, we defined the spatial configuration of foveal and peripheral regions by knowing, for instance, that individuals often move to the central part of the image to allow a better authentication. In this case, we defined a single central fovea;
- Step 4: finally, we created ARIMs encompassing and consolidating the expected properties of the images defined in the previous steps.
4.1.2. On the Application Implementation
4.1.3. Simulation Details
4.1.4. Technical Information
4.2. Dataset
4.2.1. Justification for the Selected Dataset
4.2.2. Dataset Organization
- P1E and P1L: the subsets of frame sequences of people entering and leaving portal 1, respectively;
- P2E and P2L: the subsets of frame sequences of people entering and leaving portal 2, respectively.
- One (1) of the sequences of individuals entering a portal (P1E_S1_C1) was used to train the face recognizer. Such sequence comes from camera 1, which obtains near frontal-face images. That sequence is also captured by cameras 2 and 3 at different angles, hence, to avoid biased evaluations, we ignored such sequences (P1E_S1_C2 and P1E_S1_C3), as both of these contain, essentially, the same faces of the former up to slight angle variations.
- Eleven (11) sequences where no face is found in the fovea were ignored. This decision was taken because no face recognition accuracy evaluations (using our models) would apply to these sequences.
4.3. Evaluated Models
4.4. Evaluation Criteria and Hardware Setup
5. Results and Discussion
5.1. Storage Reduction
5.2. Face Recognition Accuracy
5.3. Energy Consumption Evaluation
5.4. Implications in Real-Time Applications
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bailey, D.G.; Bouganis, C.S. Vision Sensor with an Active Digital Fovea. In Recent Advances in Sensing Technology; Mukhopadhyay, S.C., Gupta, G.S., Huang, R.Y.M., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 91–111. [Google Scholar] [CrossRef]
- Bornholt, J.; Mytkowicz, T.; Mckinley, K.S. The model is not enough: Understanding energy consumption in mobile devices. In Proceedings of the 2012 IEEE Hot Chips 24 Symposium (HCS), Cupertino, CA, USA, 27–29 August 2012; pp. 1–3. [Google Scholar]
- Wandell, B.A. Foundations of Vision; Sinauer Associates, Incorporated: Sunderland, MA, USA, 1995. [Google Scholar]
- Bolduc, M.; Levine, M.D. A Review of Biologically Motivated Space-Variant Data Reduction Models for Robotic Vision. Comput. Vision Image Underst. 1998, 69, 170–184. [Google Scholar] [CrossRef] [Green Version]
- Traver, V.J.; Bernardino, A. A review of log-polar imaging for visual perception in robotics. Robot. Auton. Syst. 2010, 58, 378–398. [Google Scholar] [CrossRef]
- Berton, F.; Sandini, G.; Metta, G. Anthropomorphic visual sensors. In Encyclopedia of Sensors; Grimes, C., Dickey, E., Pishko, M.V., Eds.; American Scientific Publishers: Stevenson Ranch, CA, USA, 2006; pp. 1–16. [Google Scholar]
- González, M.; Sánchez-Pedraza, A.; Marfil, R.; Rodríguez, J.A.; Bandera, A. Data-Driven Multiresolution Camera Using the Foveal Adaptive Pyramid. Sensors 2016, 16, 2003. [Google Scholar] [CrossRef] [Green Version]
- Smeraldi, F.; Bigun, J. Retinal vision applied to facial features detection and face authentication. Pattern Recognit. Lett. 2002, 23, 463–475. [Google Scholar] [CrossRef]
- Akbas, E.; Eckstein, M.P. Object detection through search with a foveated visual system. PLOS Comput. Biol. 2017, 13, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Phillips, D.B.; Sun, M.J.; Taylor, J.M.; Edgar, M.P.; Barnett, S.M.; Gibson, G.M.; Padgett, M.J. Adaptive foveated single-pixel imaging with dynamic supersampling. Sci. Adv. 2017, 3, e1601782. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wen, W.; Kajínek, O.; Khatibi, S.; Chadzitaskos, G. A Common Assessment Space for Different Sensor Structures. Sensors 2019, 19, 568. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data Clustering: A Review. ACM Comput. Surv. 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Jain, M.; Singh, S. A survey on: Content based image retrieval systems using clustering techniques for large data sets. Int. J. Manag. Inf. Technol. 2011, 3, 23. [Google Scholar]
- Otto, C.; Klare, B.; Jain, A.K. An efficient approach for clustering face images. In Proceedings of the 2015 International Conference on Biometrics (ICB), Phuket, Thailand, 19–22 May 2015; pp. 243–250. [Google Scholar]
- Peng, X.; Feng, J.; Xiao, S.; Yau, W.; Zhou, J.T.; Yang, S. Structured AutoEncoders for Subspace Clustering. IEEE Trans. Image Process. 2018, 27, 5076–5086. [Google Scholar] [CrossRef] [PubMed]
- Peng, X.; Zhu, H.; Feng, J.; Shen, C.; Zhang, H.; Zhou, J.T. Deep Clustering With Sample-Assignment Invariance Prior. IEEE Trans. Neural Netw. Learn. Syst. 2019, 1–12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goldenstein, S.; Vogler, C.; Velho, L. Adaptive Deformable Models for Graphics and Vision. Comput. Graph. Forum 2005, 24, 729–741. [Google Scholar] [CrossRef] [Green Version]
- de Goes, F.; Goldenstein, S.; Velho, L. A Simple and Flexible Framework to Adapt Dynamic Meshes. Comput. Graph. 2008, 32, 141–148. [Google Scholar] [CrossRef]
- Wong, Y.; Chen, S.; Mau, S.; Sanderson, C.; Lovell, B.C. Patch-based Probabilistic Image Quality Assessment for Face Selection and Improved Video-based Face Recognition. In Proceedings of the IEEE Biometrics Workshop, Computer Vision and Pattern Recognition (CVPR) Workshops, Colorado Springs, CO, USA, 20–25 June 2011; pp. 81–88. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Kauai, HI, USA, 8–14 December 2001; Volume 1, pp. 511–518. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- King, D.E. Dlib-ml: A Machine Learning Toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
- Lucas, B.D.; Kanade, T. An Iterative Image Registration Technique with an Application to Stereo Vision. In Proceedings of the 7th International Joint Conference on Artificial Intelligence (IJCAI’81)—Volume 2, Vancouver, BC, Canada, 24–28 August 1981; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1981; pp. 674–679. [Google Scholar]
- Khan, K.N.; Hirki, M.; Niemi, T.; Nurminen, J.K.; Ou, Z. RAPL in Action: Experiences in Using RAPL for Power Measurements. ACM Trans. Model. Perform. Eval. Comput. Syst. 2018, 3, 1–26. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Theoretical Reference | Library | Method | Input Parameters | |
|---|---|---|---|---|
| Face Detection | Viola-Jones [20] | OpenCV 3.0.0 | detectMultiScale | scaleFactor = 1.1 |
| minNeighbors = 3 | ||||
| Face Recognition | DNN model [21] + 1-NN | Dlib 19.16 [22] | get_face_chip_details | size = 150 |
| padding = 0.25 | ||||
| winSize = (31, 31) | ||||
| maxLevel = 3 | ||||
| Optical Flow | Lukas-Kanade [23] | OpenCV 3.0.0 | cvCalcOpticalFlowPyrLK | criteria.maxCount = 20; |
| criteria.epsilon = 0.03 | ||||
| minEigThreshold = 0.001 |
| Num. of Pixels | Num. of Pixels Reduction | Bytes per Region | Total Bytes | Data Size Reduction | ||
|---|---|---|---|---|---|---|
| FOV | PER | |||||
| Original | 480,000 | - | - | - | 1440,000 | - |
| Resized (25%) | 120,000 | 75.00% | - | - | 360,000 | 75.00% |
| Model_1 | 10,384 | 97.83% | 30,000 | 768 | 30,768 | 97.86% |
| Model_2 | 22,884 | 95.23% | 67,500 | 768 | 68,268 | 95.25% |
| Model_3 | 40,384 | 91.58% | 120,000 | 768 | 120,768 | 91.61% |
| Dataset | Accuracy Loss | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Model 1 | Model 2 | Model 3 | |||||||
| Min. | Mean | Max. | Min. | Mean | Max. | Min. | Mean | Max. | |
| P1E | 0.032 | 0.123 | 0.264 | 0 | 0.050 | 0.108 | 0 | 0.006 | 0.021 |
| P1L | 0.060 | 0.248 | 0.613 | 0 | 0.094 | 0.255 | 0 | 0.023 | 0.103 |
| P2E | 0.174 | 0.353 | 0.500 | 0.032 | 0.172 | 0.318 | 0 | 0.006 | 0.037 |
| P2L | 0.143 | 0.300 | 0.529 | 0.033 | 0.086 | 0.265 | 0 | 0.063 | 0.206 |
| Dataset | Energy Reduction | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Model 1 | Model 2 | Model 3 | |||||||
| Min. | Mean | Max. | Min. | Mean | Max. | Min. | Mean | Max. | |
| P1E | 0.505 | 0.551 | 0.598 | 0.463 | 0.508 | 0.550 | 0.414 | 0.456 | 0.489 |
| P1L | 0.612 | 0.667 | 0.711 | 0.582 | 0.619 | 0.710 | 0.490 | 0.548 | 0.657 |
| P2E | 0.536 | 0.610 | 0.672 | 0.439 | 0.549 | 0.619 | 0.381 | 0.454 | 0.551 |
| P2L | 0.533 | 0.571 | 0.618 | 0.406 | 0.516 | 0.620 | 0.332 | 0.464 | 0.603 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Silva, E.; da S. Torres, R.; Pinto, A.; Tzy Li, L.; S. Vianna, J.E.; Azevedo, R.; Goldenstein, S. Application-Oriented Retinal Image Models for Computer Vision. Sensors 2020, 20, 3746. https://doi.org/10.3390/s20133746
Silva E, da S. Torres R, Pinto A, Tzy Li L, S. Vianna JE, Azevedo R, Goldenstein S. Application-Oriented Retinal Image Models for Computer Vision. Sensors. 2020; 20(13):3746. https://doi.org/10.3390/s20133746
Chicago/Turabian StyleSilva, Ewerton, Ricardo da S. Torres, Allan Pinto, Lin Tzy Li, José Eduardo S. Vianna, Rodolfo Azevedo, and Siome Goldenstein. 2020. "Application-Oriented Retinal Image Models for Computer Vision" Sensors 20, no. 13: 3746. https://doi.org/10.3390/s20133746
APA StyleSilva, E., da S. Torres, R., Pinto, A., Tzy Li, L., S. Vianna, J. E., Azevedo, R., & Goldenstein, S. (2020). Application-Oriented Retinal Image Models for Computer Vision. Sensors, 20(13), 3746. https://doi.org/10.3390/s20133746