Towards Breathing as a Sensing Modality in Depth-Based Activity Recognition



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- A novel method is proposed that is able to perform respiration signal and rate estimation under several challenging conditions including user motion and partial occlusions of the user’s chest. This method works under the assumptions that the observed users are indoors and generally facing a depth camera, and relies on a model of the user’s torso that detects and corrects for occlusions, time domain noise filtering, and an estimation of breathing by observing differences in an adaptive, maximally relevant window of depth pixels.
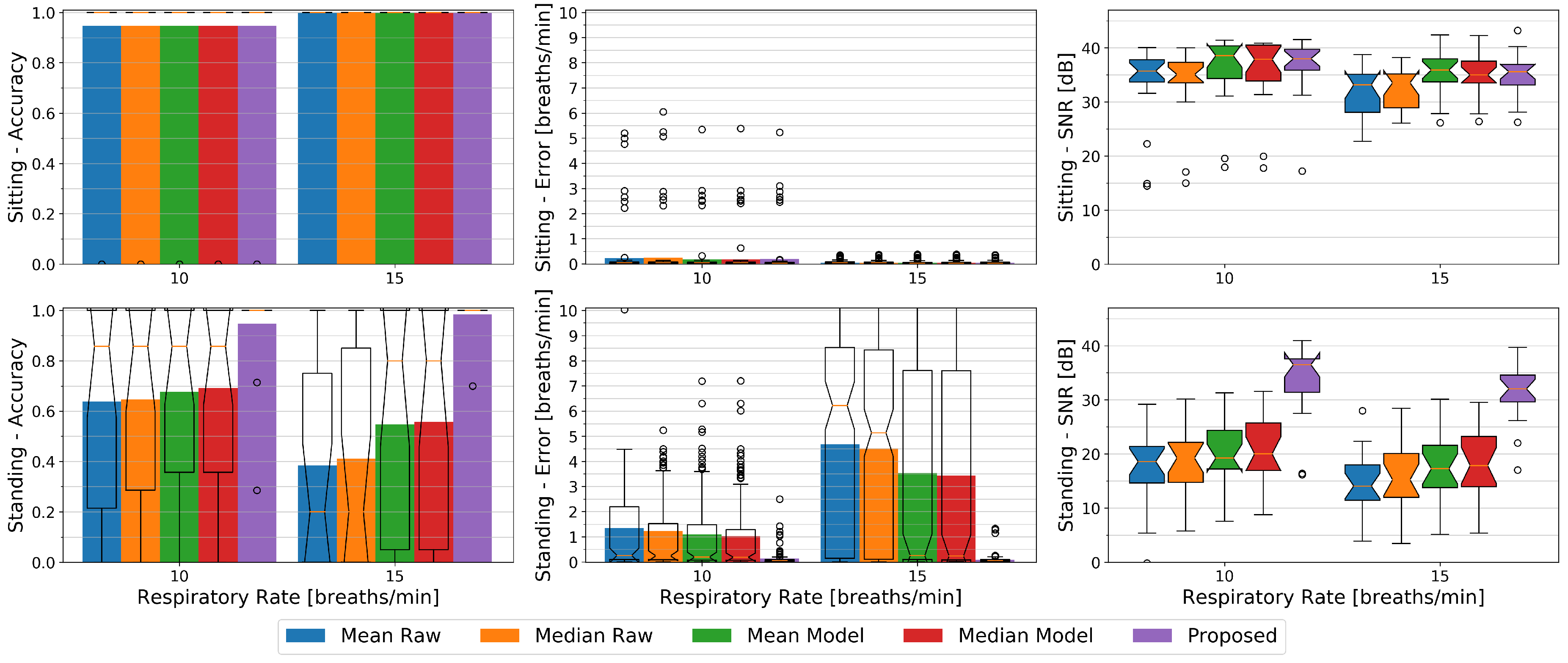
- A series of experiments on this dataset is presented, in which we validate our method against ground truth from a respiration belt, compare it to related approaches, and highlight the used parameters and design choices for our approach which deliver the best results. Results show that especially for the standing upright and occlusion situations, our method shows a more robust and accurate estimation of breathing rate, compared to previous methods.
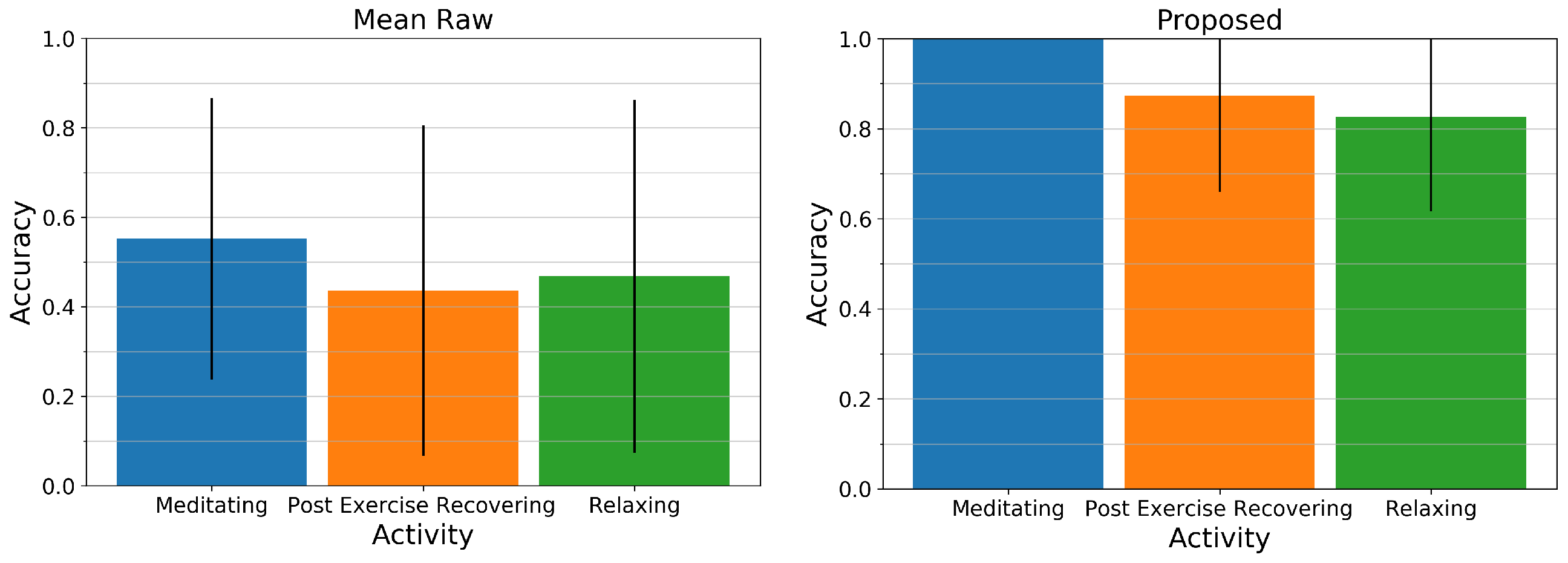
- On this dataset, we show that the obtained respiration signal from our method can be used to generate breathing-related features that characterize and separate several breathing-specific activities that would otherwise, for instance by observing the user’s body pose, be hard to detect.
2. Related Work
2.1. Breathing as a Modality for Activity Recognition
2.2. Remote Respiration Estimation
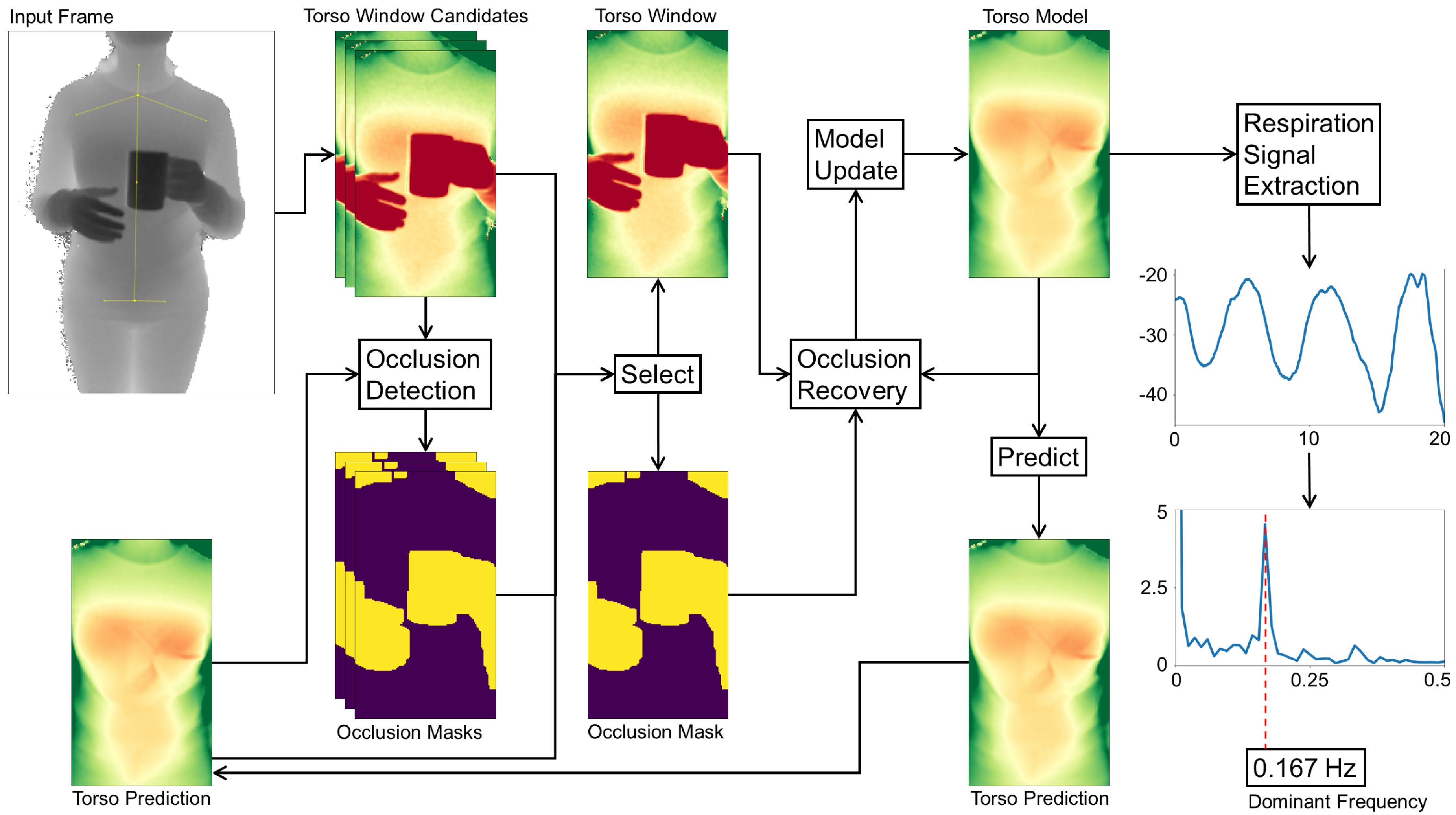
3. Method Description
3.1. Locating Users and Torso Windows
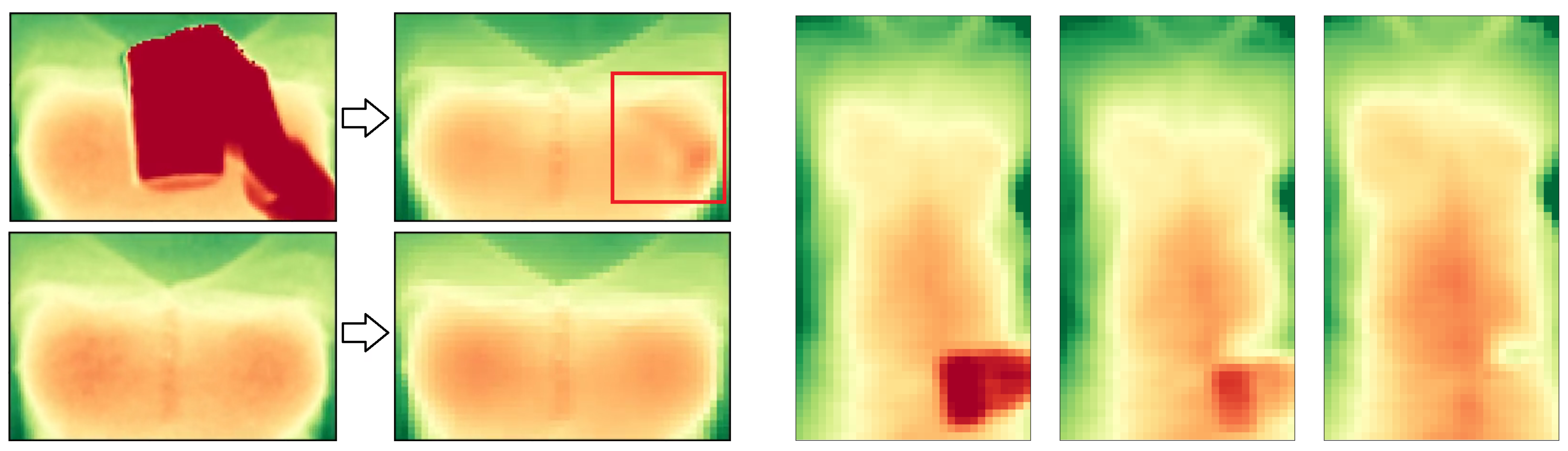
3.2. Occlusion Mask
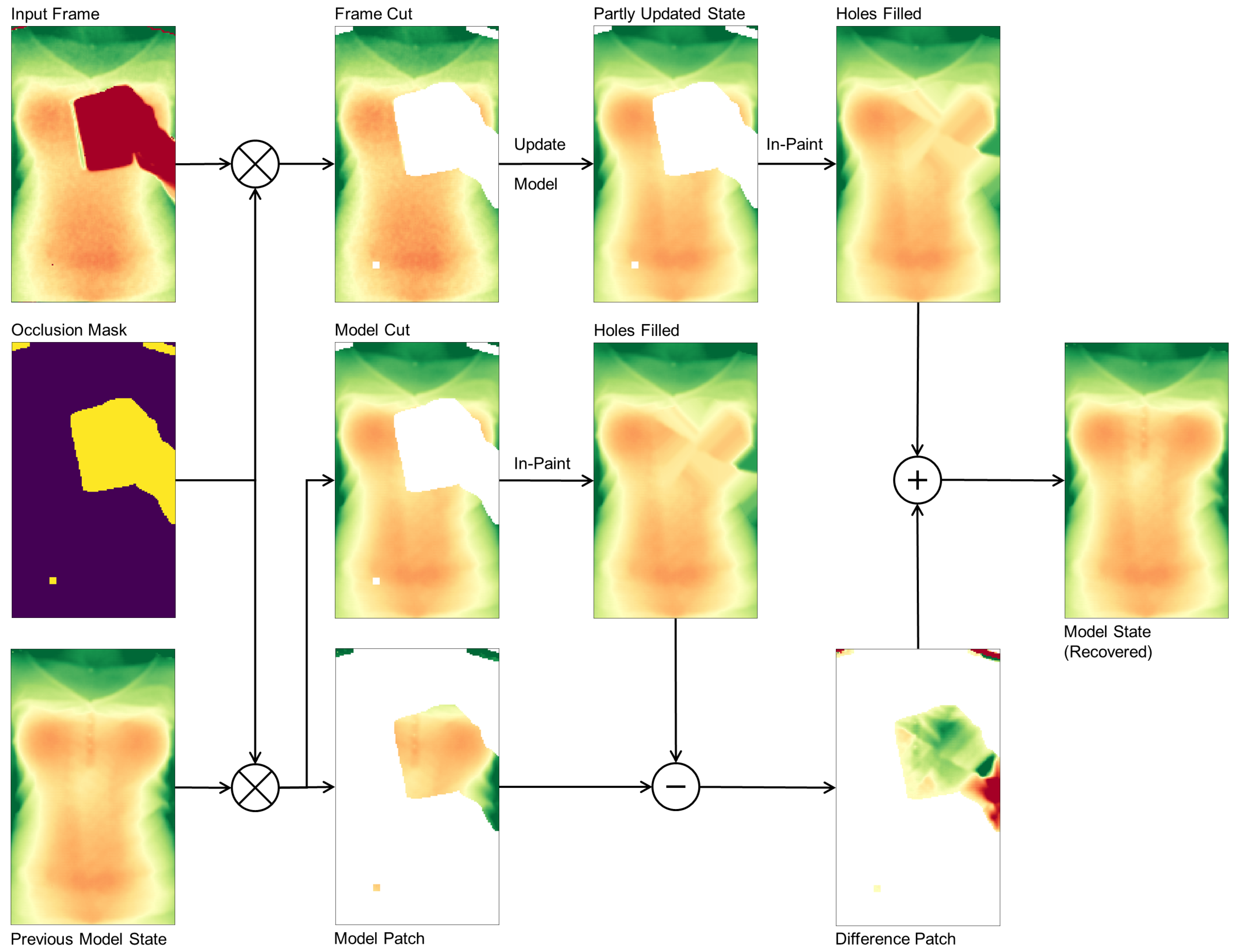
3.3. Occlusion Recovery
3.4. Adaptive Torso Model
3.4.1. Initialization of the Torso Model
3.4.2. Model Update with Time Domain Filtering
3.5. Extraction of Respiration Signal
4. Study Design and Overview
4.1. Setup and Environment
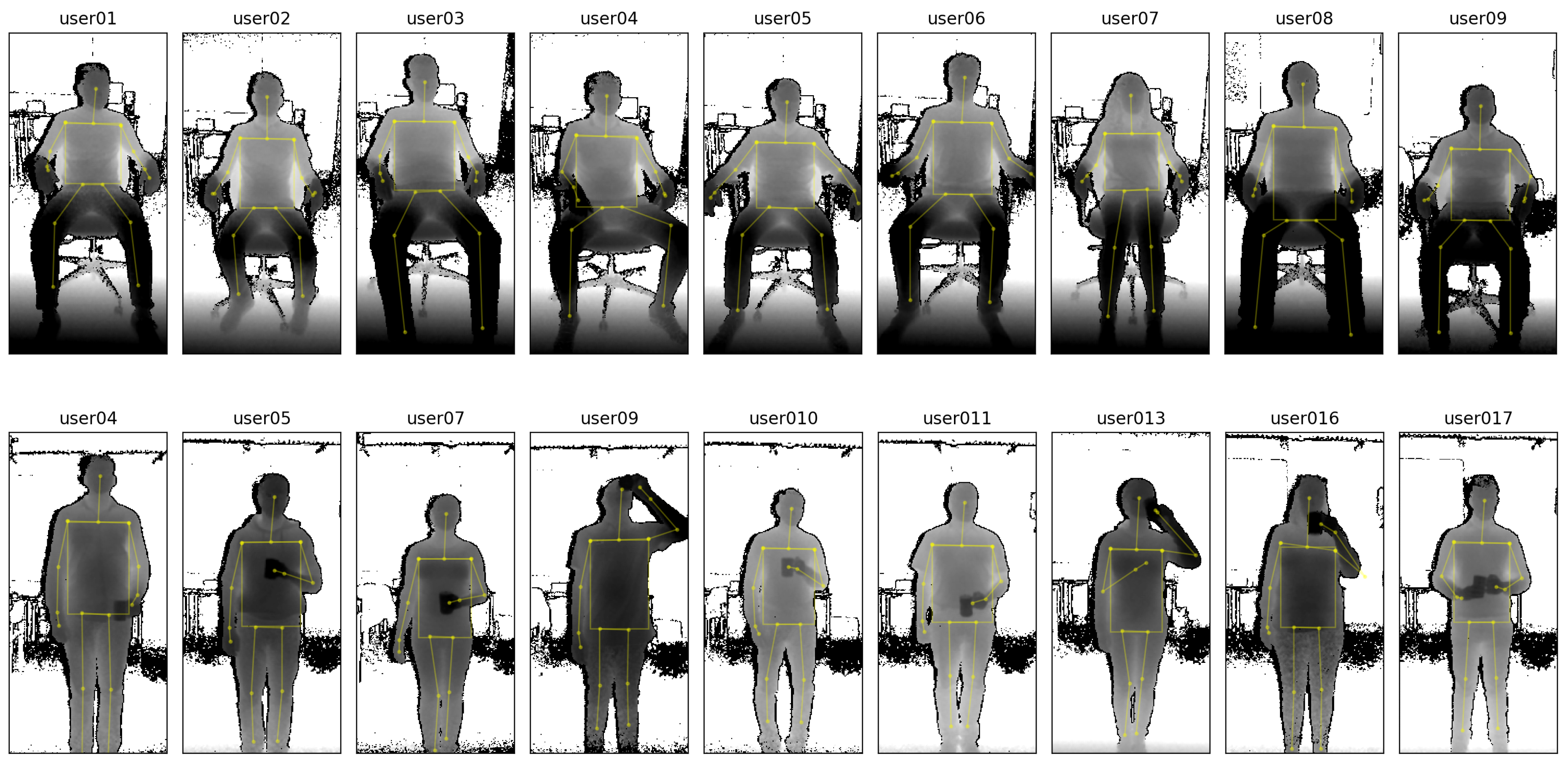
4.2. Study Participants and Protocol
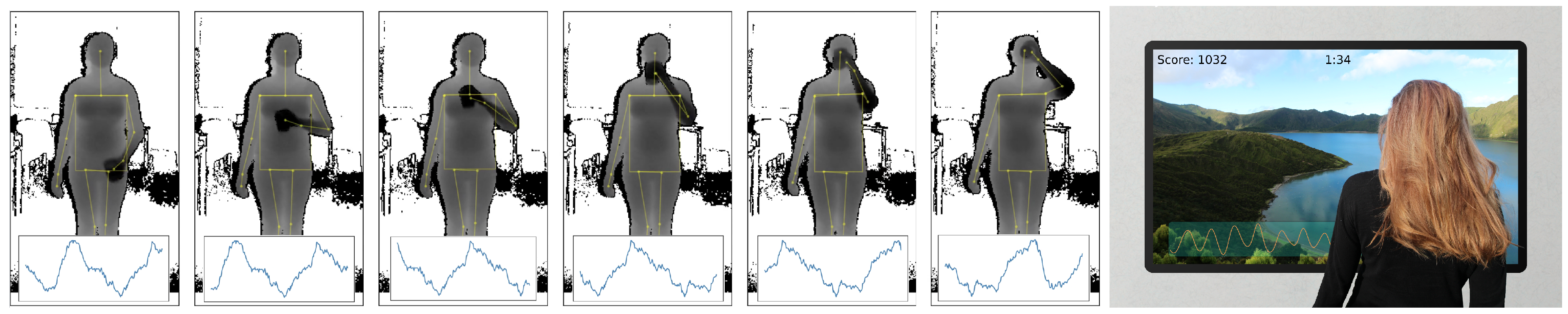
- A paced-breathing meditating recording, where participants were shown a paced breathing display of a growing and shrinking circle with instructions to breathe in and out at the relatively fast frequency of 0.25 Hz (or 15 breaths per minute). This is a common target breathing rate for meditation, whereas a higher-paced breathing experiment would come with its own risks for the study participants.
- A relaxing recording, while the display showing a video of landscapes with relaxing background music, to entice a person-dependent slow breathing rate during a relaxing activity.
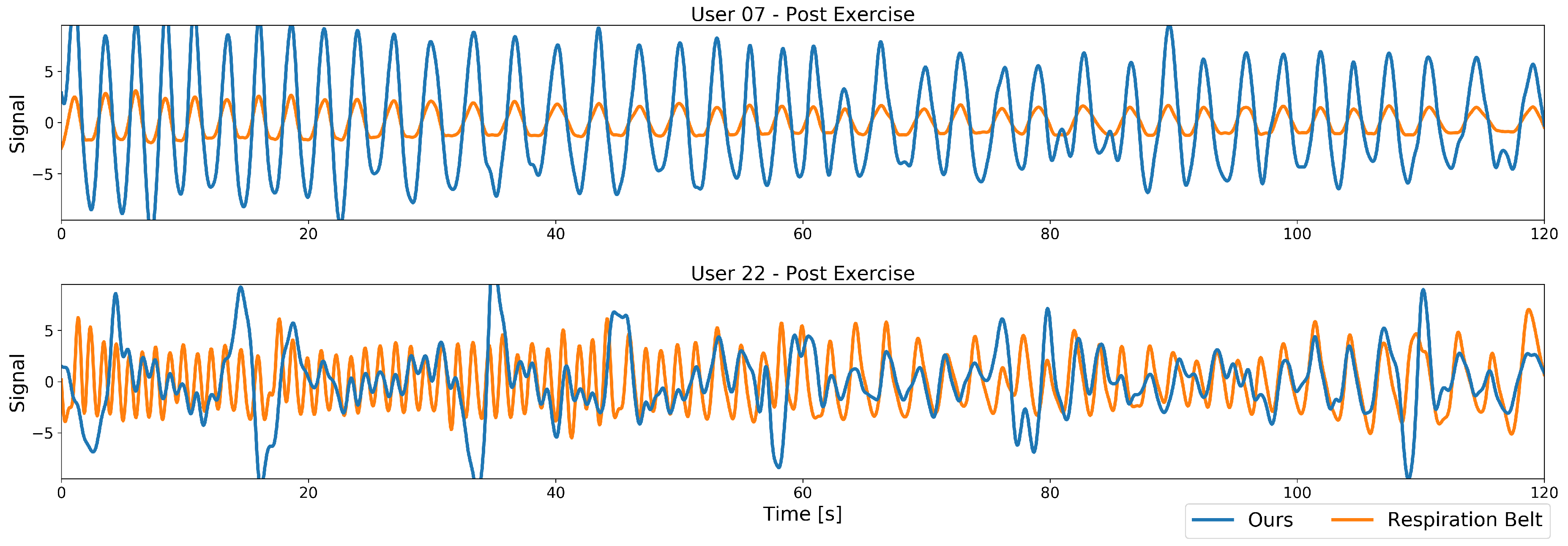
- A post-exercise recovering recording, where participants were monitored after strenuous exercise comprising running down and up 12 flights of stairs, and the display showing the aforementioned relaxation videos. This exercise was chosen to heighten the respiration rate of the study participants, for the safety of the study participants. This recording comprises a high variance of the respiratory rate and, especially in the beginning, many random movements from the user breathing heavily, and is considered even more challenging to our method.
- In a first condition, participants were asked to sit in an adjustable office chair in front of the depth sensor. The height of the chair was fixed to 0.5 m, but its back support could be reclined and did not need to be used (i.e., participants could lean back or not, as they preferred). To fix the distances between chair and depth camera, markers were taped to the floor to define the exact positions where the chair had to be placed. Participant were asked to face the depth camera and to keep the arms away from the chest area (e.g., on the chair’s armrests) such that the participant’s upper body was fully visible to the depth sensor.
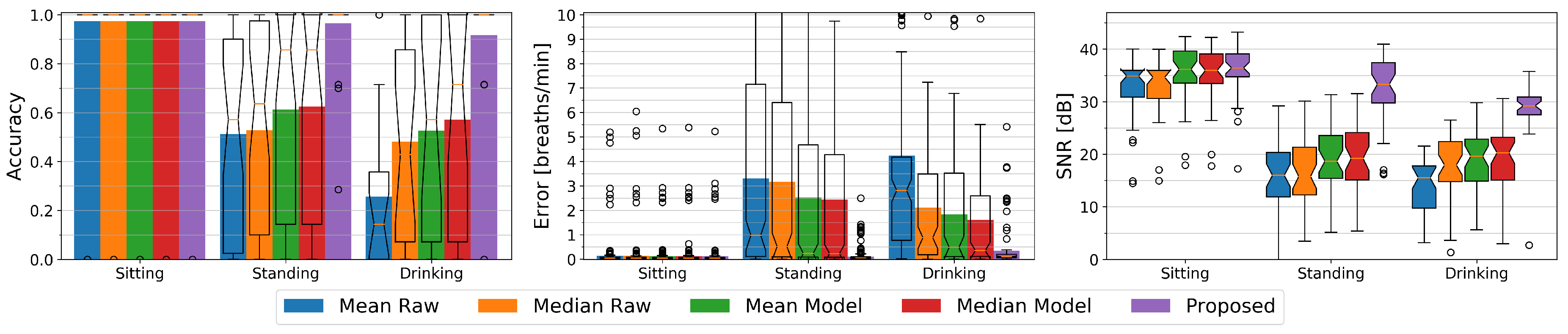
- In a second condition, the participants were instructed to stand in an upright position following the same rule as in the first session, i.e., to keep their arms away from the torso region. The goal of this session is to observe the torso’s motion while the observed person is standing relatively still, but does not have the support of a chair’s seating and back surfaces. Having to stand upright for several minutes tends to introduce a range of motions that are unrelated to the breathing movements of the torso region; Some participants did move their arms in different positions during the recordings (for instance, switching between hands on the back and hands in the pockets) or repositioned themselves to a more comfortable posture, making it potentially challenging to extract a respiration signal from these data.
- A third condition introduced frequent occlusions by instructing the participants to hold a cup of tea in front of their torso while standing upright. At the start of the session, participants were recorded for 20 s while holding their cup away from the torso. For the remainder of the session, participants were instructed to occlude their stomach and chest regions with the cup. Such self-occlusions also occur when gesticulating, but the drinking gestures were found to be particularly challenging due to their relatively slower speeds of execution and the larger, additional occlusion of an in-hand object.
4.3. Performance Measures
5. Comparison Study with a Wearable Respiration Belt
5.1. Visual Inspection
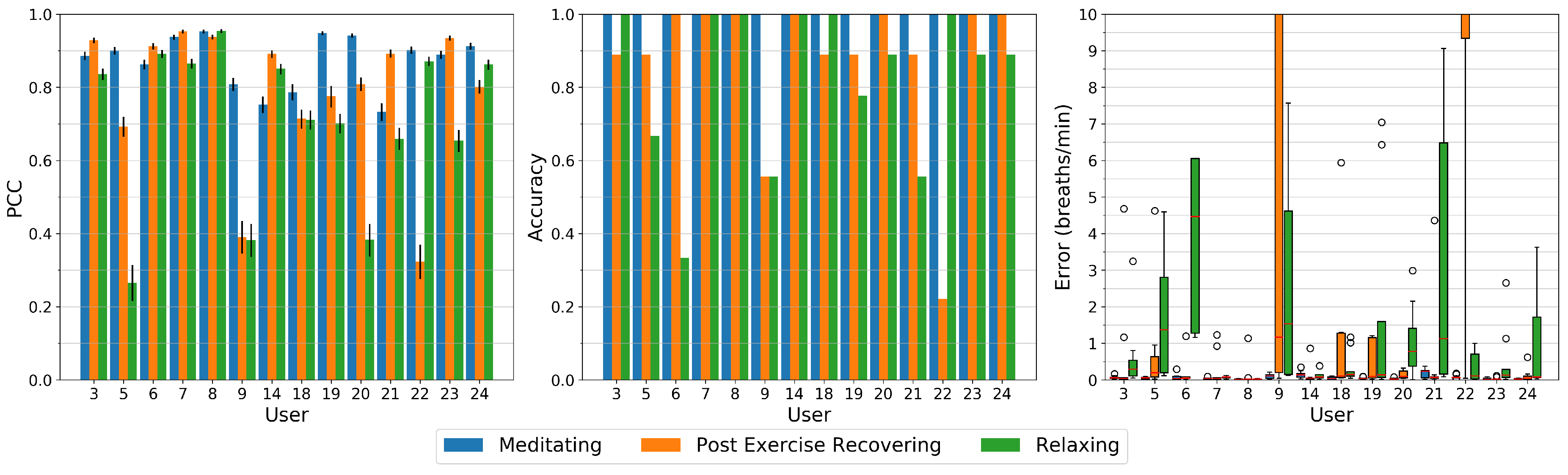
5.2. Overall Evaluation Results
6. Study on the Influence of User Activity
The Influence of Respiratory Rate
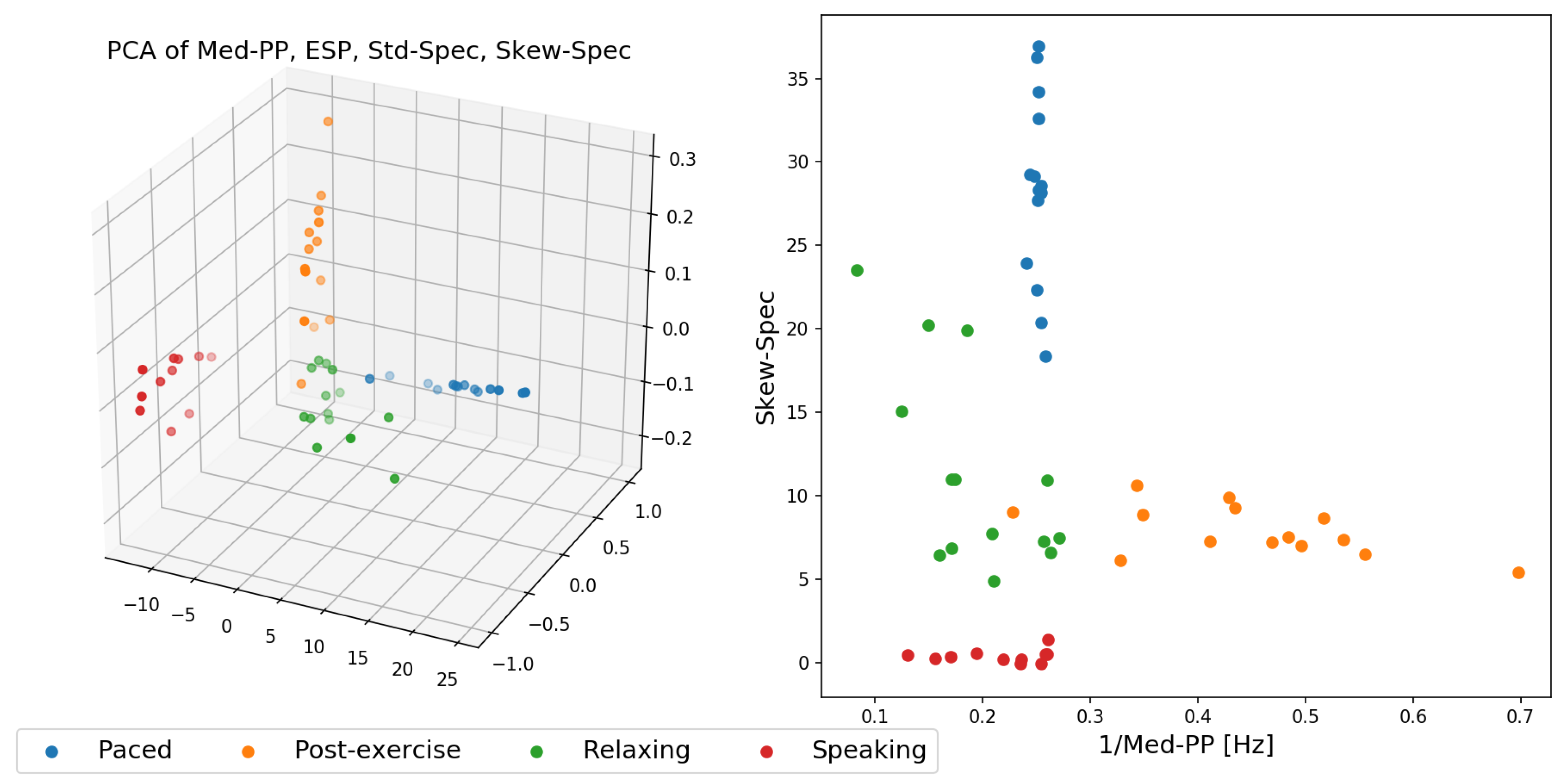
7. Feature Extraction
- Standard deviation Std-Spec, skew Skew-Spec, and kurtosis Kurt-Spec of frequency spectrum amplitudes.
- Signal to noise ratio SNR.
- Median of the time deltas between peaks in the signal Med-PP.
- Spectral entropy of the signal obtained in frequency domain ESP.
- Standard deviation of the first order time derivative of the signal Std-Deriv.
8. Discussion
8.1. Comparison of Our Method to State-of-the-Art (Wearable or from a Distance)
8.2. Limitations of Our Dataset and Method
9. Conclusions and Future Work
- Estimation of respiration rate from depth data becomes significantly harder when the observed person is standing freely. When, as in prior work, persons are lying down in a supine position or sitting in a chair, body movement is restricted significantly. Our studies showed that even when persons are standing in front of a depth camera, traditional optical respiration estimation approaches tend to fail when (1) the body sways through motion from hips and legs, as well as (2) occlusions, in particular those coming from the persons gesturing themselves. Previous methods show here significant drops (to around 26%) in accuracy.
- The observed torso region plays a crucial role in the reliability of the respiratory rate detection. Especially in the standing or occlusion scenarios, our results confirm that the chest region is highly recommended for capturing the respiration signal, whereas observing the stomach area performs less well. If user movements and occlusions are not too large, our method’s torso tracking and filtering performs well and reaches a comparable performance to commercial respiration monitors.
- The respiration signal that our approach provides as an estimate of users’ breathing can be used to distinguish between particular activities. In an analysis of several possible descriptors for the breathing signal, especially the features Med-PP, ESP, STD-Spec, and Skew-Spec were found to be promising to be used in activity recognition.
- Person-dependent features, such as clothing, have been found to greatly influence what regions are primarily important to derive the respiration signal. The method can therefore be improved by not resorting to predefined areas on chest or abdomen, but instead using an adaptive method considering multiple regions. Performance results between participants under the same conditions were surprisingly variable.
Author Contributions
Funding
Conflicts of Interest
References
- Cretikos, M.A.; Bellomo, R.; Hillman, K.; Chen, J.; Finfer, S.; Flabouris, A. Respiratory rate: The neglected vital sign. Med. J. Aust. 2008, 188, 657–659. [Google Scholar] [CrossRef] [PubMed]
- Parkes, R. Rate of respiration: The forgotten vital sign. Emerg. Nurse 2011, 19, 12–17. [Google Scholar] [CrossRef] [PubMed]
- Massaroni, C.; Nicolò, A.; Lo Presti, D.; Sacchetti, M.; Silvestri, S.; Schena, E. Contact-Based Methods for Measuring Respiratory Rate. Sensors 2019, 19, 908. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lara, O.D.; Labrador, M.A. A survey on human activity recognition using wearable sensors. IEEE Commun. Surv. Tutor. 2012, 15, 1192–1209. [Google Scholar] [CrossRef]
- Castro, D.; Coral, W.; Rodriguez, C.; Cabra, J.; Colorado, J. Wearable-based human activity recognition using an iot approach. J. Sens. Actuator Netw. 2017, 6, 28. [Google Scholar] [CrossRef] [Green Version]
- Haescher, M.; Matthies, D.J.; Trimpop, J.; Urban, B. A study on measuring heart-and respiration-rate via wrist-worn accelerometer-based seismocardiography (SCG) in comparison to commonly applied technologies. In Proceedings of the 2nd International Workshop on Sensor-Based Activity Recognition and Interaction, Rostock, Germany, 25–26 June 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1–6. [Google Scholar]
- Lara, O.D.; Pérez, A.J.; Labrador, M.A.; Posada, J.D. Centinela: A human activity recognition system based on acceleration and vital sign data. Pervasive Mob. Comput. 2012, 8, 717–729. [Google Scholar] [CrossRef]
- Luštrek, M.; Cvetković, B.; Mirchevska, V.; Kafalı, Ö.; Romero, A.E.; Stathis, K. Recognising lifestyle activities of diabetic patients with a smartphone. In Proceedings of the 2015 9th International Conference on Pervasive Computing Technologies for Healthcare (PervasiveHealth), Istanbul, Turkey, 20–23 May 2015; pp. 317–324. [Google Scholar]
- Singh, A.; Piana, S.; Pollarolo, D.; Volpe, G.; Varni, G.; Tajadura-Jiménez, A.; Williams, A.C.; Camurri, A.; Bianchi-Berthouze, N. Go-with-the-flow: Tracking, analysis and sonification of movement and breathing to build confidence in activity despite chronic pain. Hum. Comput. Interact. 2016, 31, 335–383. [Google Scholar] [CrossRef]
- Guede-Fernández, F.; Fernández-Chimeno, M.; Ramos-Castro, J.; García-González, M.A. Driver drowsiness detection based on respiratory signal analysis. IEEE Access 2019, 7, 81826–81838. [Google Scholar] [CrossRef]
- Igasaki, T.; Nagasawa, K.; Akbar, I.A.; Kubo, N. Sleepiness classification by thoracic respiration using support vector machine. In Proceedings of the 2016 9th Biomedical Engineering International Conference (BMEiCON), Laung Prabang, Laos, 7–9 December 2016; pp. 1–5. [Google Scholar]
- Hameed, R.A.; Sabir, M.K.; Fadhel, M.A.; Al-Shamma, O.; Alzubaidi, L. Human emotion classification based on respiration signal. In Proceedings of the International Conference on Information and Communication Technology, Kuala Lumpur, Malaysia, 24–26 July 2019; pp. 239–245. [Google Scholar]
- Guendil, Z.; Lachiri, Z.; Maaoui, C.; Pruski, A. Multiresolution framework for emotion sensing in physiological signals. In Proceedings of the 2016 2nd International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), Monastir, Tunisia, 21–23 March 2016; pp. 793–797. [Google Scholar]
- Bernardino, A.; Vismara, C.; i Badia, S.B.; Gouveia, É.; Baptista, F.; Carnide, F.; Oom, S.; Gamboa, H. A dataset for the automatic assessment of functional senior fitness tests using kinect and physiological sensors. In Proceedings of the 2016 1st International Conference on Technology and Innovation in Sports, Health and Wellbeing (TISHW), Vila Real, Portugal, 1–3 December 2016; pp. 1–6. [Google Scholar]
- Tan, K.S.; Saatchi, R.; Elphick, H.; Burke, D. Real-time vision based respiration monitoring system. In Proceedings of the 2010 7th International Symposium on Communication Systems Networks and Digital Signal Processing (CSNDSP), Newcastle upon Tyne, UK, 21–23 July 2010; pp. 770–774. [Google Scholar]
- Nakajima, K.; Matsumoto, Y.; Tamura, T. Development of real-time image sequence analysis for evaluating posture change and respiratory rate of a subject in bed. Physiol. Meas. 2001, 22, N21. [Google Scholar] [CrossRef] [PubMed]
- Kuo, Y.M.; Lee, J.S.; Chung, P.C. A visual context-awareness-based sleeping-respiration measurement system. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 255–265. [Google Scholar] [PubMed]
- Bauer, S.; Wasza, J.; Hornegger, J. Photometric estimation of 3D surface motion fields for respiration management. In Bildverarbeitung für die Medizin 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 105–110. [Google Scholar]
- Abdelnasser, H.; Harras, K.A.; Youssef, M. UbiBreathe: A Ubiquitous non-Invasive WiFi-based Breathing Estimator. In Proceedings of the 16th ACM International Symposium on Mobile Ad Hoc Networking and Computing, Hangzhou, China, 22–25 June 2015; ACM: New York, NY, USA, 2015; pp. 277–286. [Google Scholar] [CrossRef]
- Wang, X.; Yang, C.; Mao, S. TensorBeat: Tensor Decomposition for Monitoring Multiperson Breathing Beats with Commodity WiFi. ACM Trans. Intell. Syst. Technol. 2017, 9, 1–27. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, D.; Ma, J.; Wang, Y.; Wang, Y.; Wu, D.; Gu, T.; Xie, B. Human Respiration Detection with Commodity Wifi Devices: Do User Location and Body Orientation Matter? In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 25–36. [Google Scholar] [CrossRef]
- Zeng, Y.; Wu, D.; Gao, R.; Gu, T.; Zhang, D. FullBreathe: Full Human Respiration Detection Exploiting Complementarity of CSI Phase and Amplitude of WiFi Signals. Mob. Wearable Ubiquitous Technol. 2018, 2. [Google Scholar] [CrossRef]
- Xia, J.; Siochi, R.A. A real-time respiratory motion monitoring system using KINECT: Proof of concept. Med. Phys. 2012, 39, 2682–2685. [Google Scholar] [CrossRef] [PubMed]
- Benetazzo, F.; Freddi, A.; Monteriù, A.; Longhi, S. Respiratory rate detection algorithm based on RGB-D camera: Theoretical background and experimental results. Healthc. Technol. Lett. 2014, 1, 81–86. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kempfle, J.; Laerhoven, K.V. Respiration Rate Estimation with Depth Cameras. In Proceedings of the 5th International Workshop on Sensor-Based Activity Recognition and Interaction—iWOAR’18, Berlin, Germany, 20–21 September 2018; ACM Press: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Centonze, F.; Schätz, M.; Procházka, A.; Kuchyňka, J.; Vyšata, O.; Cejnar, P.; Vališ, M. Feature extraction using MS Kinect and data fusion in analysis of sleep disorders. In Proceedings of the 2015 International Workshop on Computational Intelligence for Multimedia Understanding (IWCIM), Prague, Czech Republic, 29–30 October 2015; pp. 1–5. [Google Scholar]
- Schätz, M.; Centonze, F.; Kuchyňka, J.; Ťupa, O.; Vyšata, O.; Geman, O.; Procházka, A. Statistical recognition of breathing by MS Kinect depth sensor. In Proceedings of the 2015 International Workshop on Computational Intelligence for Multimedia Understanding (IWCIM), Prague, Czech Republic, 29–30 October 2015; pp. 1–4. [Google Scholar]
- Procházka, A.; Schätz, M.; Vyšata, O.; Vališ, M. Microsoft kinect visual and depth sensors for breathing and heart rate analysis. Sensors 2016, 16, 996. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aoki, H.; Nakamura, H. Non-Contact Respiration Measurement during Exercise Tolerance Test by Using Kinect Sensor. Sports 2018, 6, 23. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Soleimani, V.; Mirmehdi, M.; Damen, D.; Dodd, J.; Hannuna, S.; Sharp, C.; Camplani, M.; Viner, J. Remote, Depth-Based Lung Function Assessment. IEEE Trans. Biomed. Eng. 2017, 64, 1943–1958. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wasza, J.; Bauer, S.; Haase, S.; Hornegger, J. Sparse principal axes statistical surface deformation models for respiration analysis and classification. In Bildverarbeitung für die Medizin 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 316–321. [Google Scholar]
- Martinez, M.; Stiefelhagen, R. Breath rate monitoring during sleep using near-IR imagery and PCA. In Proceedings of the 2012 21st International Conference on Pattern Recognition (ICPR), Tsukuba, Japan, 11–15 November 2012; pp. 3472–3475. [Google Scholar]
- Wijenayake, U.; Park, S.Y. Real-Time External Respiratory Motion Measuring Technique Using an RGB-D Camera and Principal Component Analysis. Sensors 2017, 17, 1840. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shotton, J.; Sharp, T.; Kipman, A.; Fitzgibbon, A.; Finocchio, M.; Blake, A.; Cook, M.; Moore, R. Real-time Human Pose Recognition in Parts from Single Depth Images. Commun. ACM 2013, 56, 116–124. [Google Scholar] [CrossRef] [Green Version]
- Knutsson, H.; Westin, C. Normalized and differential convolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 15–17 June 1993; pp. 515–523. [Google Scholar] [CrossRef]













© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kempfle, J.; Van Laerhoven, K. Towards Breathing as a Sensing Modality in Depth-Based Activity Recognition. Sensors 2020, 20, 3884. https://doi.org/10.3390/s20143884
Kempfle J, Van Laerhoven K. Towards Breathing as a Sensing Modality in Depth-Based Activity Recognition. Sensors. 2020; 20(14):3884. https://doi.org/10.3390/s20143884
Chicago/Turabian StyleKempfle, Jochen, and Kristof Van Laerhoven. 2020. "Towards Breathing as a Sensing Modality in Depth-Based Activity Recognition" Sensors 20, no. 14: 3884. https://doi.org/10.3390/s20143884
APA StyleKempfle, J., & Van Laerhoven, K. (2020). Towards Breathing as a Sensing Modality in Depth-Based Activity Recognition. Sensors, 20(14), 3884. https://doi.org/10.3390/s20143884