1. Introduction
A satellite navigation system with global coverage is called a global navigation satellite system (GNSS). It allows small electronic receivers to find its position in longitude and latitude coordinates. Current international GNSS standards for International Civil Aviation address only two core constellations: the U.S. Global Positioning System (GPS) and the Global Navigation Satellite System (GLONASS) [
1,
2]. These systems allow small electronic receivers to determine their location with the values of longitude and latitude to high precision using time signals transmitted along a line of sight by radio from satellites. Moreover, GPS receivers released in 2018 that use the L5 band [
3] can have much higher accuracy. Many studies, that have used different techniques to improve observation precisions of GNSS positioning [
4,
5,
6], can support this study. In this study, the corresponding locations of the latitude and longitude coordinates provided by a GNSS are evaluated. We also assume there is a large number of targets. Each target has a GNSS receiver that can acquire its current latitude and longitude coordinates and delivers its coordinates to a server. The coordinates of targets can be acquired by a computer manner. Our proposition is to assume that, when spaces of specific areas are large, such as New York City, Wuhan City China, and Taipei City, the number of targets to evaluate their locations, such as the population of a city, is also large.
During the spread of an epidemic, such as COVID-19 [
7,
8,
9], it is an effective option to limit the movement range of people in order to control the epidemic. Determining the locations of targets can help determine whether people are in quarantine. There are two topics in this research. The first item is whether the target is within a certain range, which can be used to determine whether the quarantined person is in the isolation zone. The second item is the number of targets is in a specific area, thereby, it can be used to determine whether too many people are likely to cause infectious diseases. For example, in Taiwan, the four days from 2 April to 5 April 2020, are a consecutive holiday. During this period, there were a large number of tourists. The National Health Command Center (NHCC) in Taiwan [
9] estimates that there were 1.5 million visits in 11 scenic spots through the telecommunications operator signal. Since the average stay time of these visits exceeded 15 min, the command center was worried about triggering a cluster infection of COVID-19 and urgently issued a national police call to the 11 scenic spots to call for evacuation, as well as the health management of tourists.
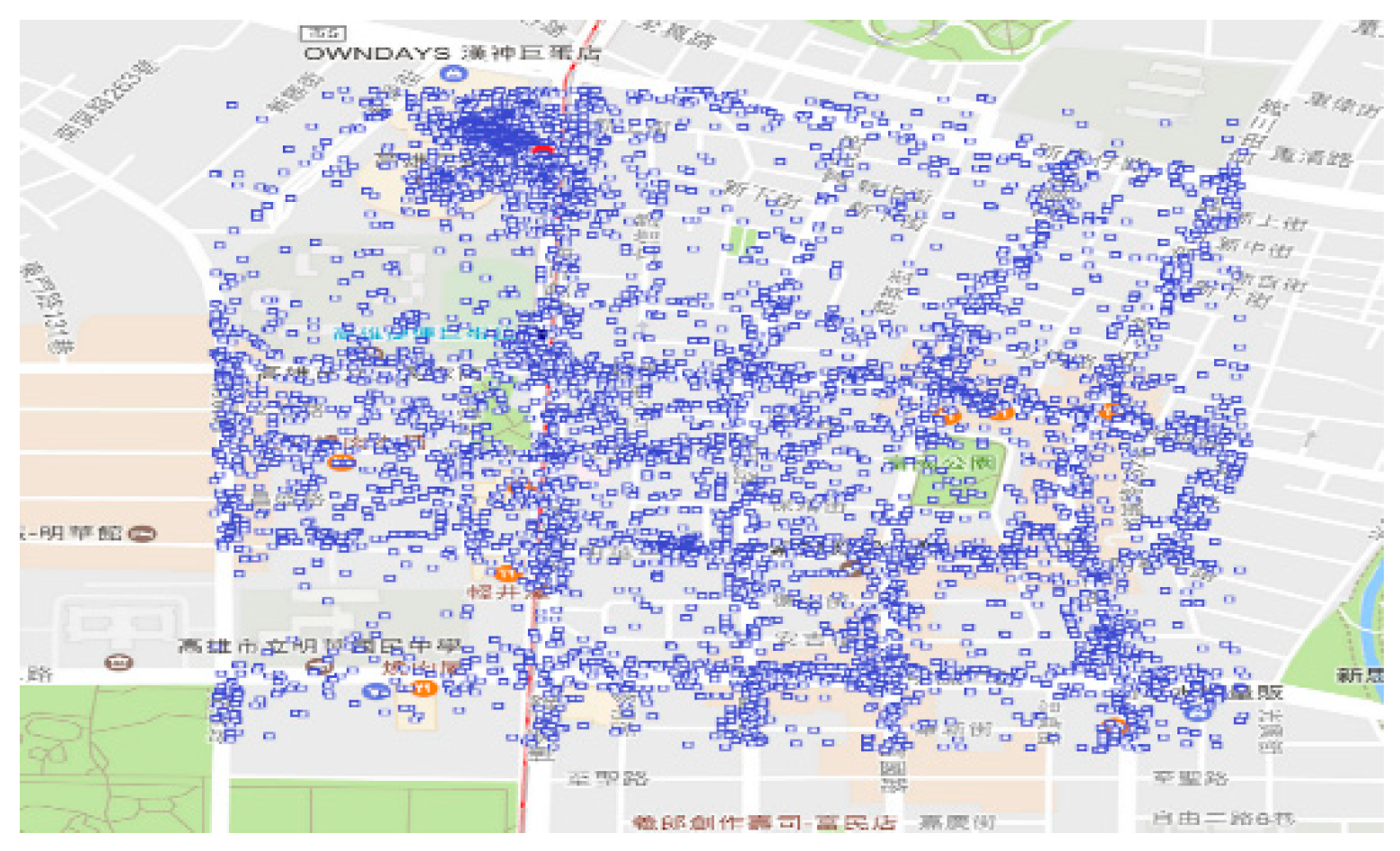
In general, a location with latitude and longitude is termed as a geographical point. There are very many geographical points generated by various social network services (SNSs) of the platforms, such as Facebook, Twitter, Google, and Foursquare. Check-in for some targets is a location-based service. It provides a mechanism to record users who have visited these geographical points. Among these platforms, Facebook is the largest one with regard to the number of users. In Facebook, these points are termed as “places”. In other words, the check-in places are the locations that people actually visited. So, using these points as experimental samples to explore the crowd distribution is reasonable and credible. The Facebook penetration rate in Taiwan is the highest in the world. Here, the number of daily users reached 13 million of approximately 23 million. Accordingly, Taiwan is an appropriate selection as the experimental area, where the main island has an area of 35,808 square kilometers.
In light of above discussions, this study proposes solutions to the following:
For real-time coordinates of targets, this strategy can be used to determine the number of targets in the specified area in time and can also be used to determine whether the target is in the specified area.
For historical coordinates of targets, this strategy can be used to determine areas in which the targets can easily gather or which locations are the hot spots.
The rest of the paper is organized as follows. In
Section 2, the research related to our study is introduced. In
Section 3, the system architecture and the problems are described, in which the proposition is formalized. In
Section 4, the crowd-sensing strategy is proposed. In
Section 5, a demonstration is given by taking the area of Taiwan Island as the experimental area and the Facebook check-in places as the targets and examples. In
Section 6, a discussion about the performance is described. Finally, a conclusion is given in
Section 7.
2. Related Work
Accurate latitude and longitude positioning supports our research to evaluate the corresponding social locations. In [
4,
5,
6], there are different techniques to improve observation precisions of GNSS positioning. In [
10], the authors focused on the integrated methodology of GNSS and device-to-device measurements. The simulation and experimental results demonstrated that the integrated methodology outperforms the nonintegrated one. In [
11], a two-step approach is studied, namely, computing first the Fisher Information Matrix (FIM) for the channel parameters, and then transforming it into the FIM of the position, rotation, and clock-bias. The analysis demonstrated the advantages of the hybrid positioning in terms of (1) localization accuracy, (2) coverage, (3) precise rotation estimation, and (4) clock-error estimation. In [
12], this study presented a wideband/multiband quad-antenna system for 4G/5G/GPS metal-frame mobile phones. The merit of the proposed antenna system is that a quad-antenna system is achieved under the condition of a metal frame and, without using any decoupling structure, the desired bands for 4G/5G/GPS are covered.
The Internet environment has generated a large number of geographical points, such as Facebook check-in places [
13,
14,
15], Google Maps places, Foursquare check-in places, etc. These places in Social Networking Services (SNS) are special kinds of geographical points. However, each SNS point contains not only a geographical coordinate and some contents to introduce this point. Accordingly, there are many studies focused on these points with their contents. In [
16], the paper aimed to assess the role that interactive technology can play in enhancing urban governance to meet social needs. In [
17], a real-time Google Maps-based arterial traffic information system for urban streets is presented. In [
18], the authors proposed the reuse of up-to-date and low-cost place data from social media applications for land use mapping purposes by Foursquare place data. In [
19], the study aimed to explore Foursquare mobility networks and investigate the phenomena of clustering venues across the cities. In [
20], the study aimed to inform on how scientific researchers could utilize data generated in location-based social networks to attain a deeper understanding of human mobility. In [
21], the authors proposed to find the geographical points related to a special folk belief. In [
22], the author utilized the Markov Chain model with their proposed activity detection method to predict the activity category of the user’s next check-in location. In [
23], an urban tourism check algorithm is proposed. It can find those who are tourists and find out where the people come from and the route of their visit. In [
24], the structure analysis of place networks is explored, in which vertices of geographic places, while the links between places are formed, are based on the user’s check-in history. In [
25], a new feature fusion-based prediction approach is proposed, based on carefully designed feature extraction methods. If these points can be mapped to social locations, not only coordinates, these applications could have further enhancements. To acquire the social locations of geographical points is also a promising topic, such as in epidemic management. In computational geometry, this is the point-in-polygon (PIP) problem [
26,
27,
28,
29,
30]. These studies provide methods to evaluate that a point is inside an area or is not-inside an area without error. In [
29], a computer-friendly method was proposed for the PIP problem.
In [
30], the authors developed a PIP algorithm that can evaluate that a point is inside or is not-inside an area. Based on this PIP algorithm, the method to find all points within a specific geographical area was developed. It first plans a range that can cover the entire specific area. Then, it finds all the points in the planned range. For each point, the PIP algorithm is used to calculate whether this point is in the specified area. Because the PIP method is verified, this method can be applied to evaluate all the points in the specified area without error. However, this method is inefficient when the area is large with a large number of points. The planned range is often much larger than the specific area. This method selects a large number of points that are not in this specific area and confirms their locations by PIP. If the planned range can be smaller, the points that need to be confirmed by PIP will be reduced a lot. In addition, if certain points are known in the area or known outside the area, there is no need to confirm through PIP. In this way, the performance will be improved a lot.
3. System Architecture and Problem Description
The architecture of the system assumes that the target has a GNSS receiver. It can convert the received signal into coordinate data and send it to storage, such as databases, according to the transmission mechanism of the wired or wireless network. The target will be represented by a geographic point, referring to a point that has its latitude and longitude coordinate. In geometry, a point with coordinate is termed as a geographical point. Moreover, a geographical area (a specific area) is a polygon. A polygon is composed of edges with geographical points. These edges enclose a measurable interior [
21]. Moreover, for a geographical point
p,
x(
p) and
y(
p) are used to represent the coordinate of
p. For a geographical area
A with
n points,
a0,
a1, …, and
an are used to represent these
n points, where
a0 =
an.The architecture of this system can be simplified into a geographic area
A and a set
P of geographical points. Because the area of area
A is large and the size of set
P is also very large, it is impossible in the field of computers to load all the points of
P into the variables in the programming language and then calculate whether each point is in the range of
A. It must be planned to only take points in part of the area in
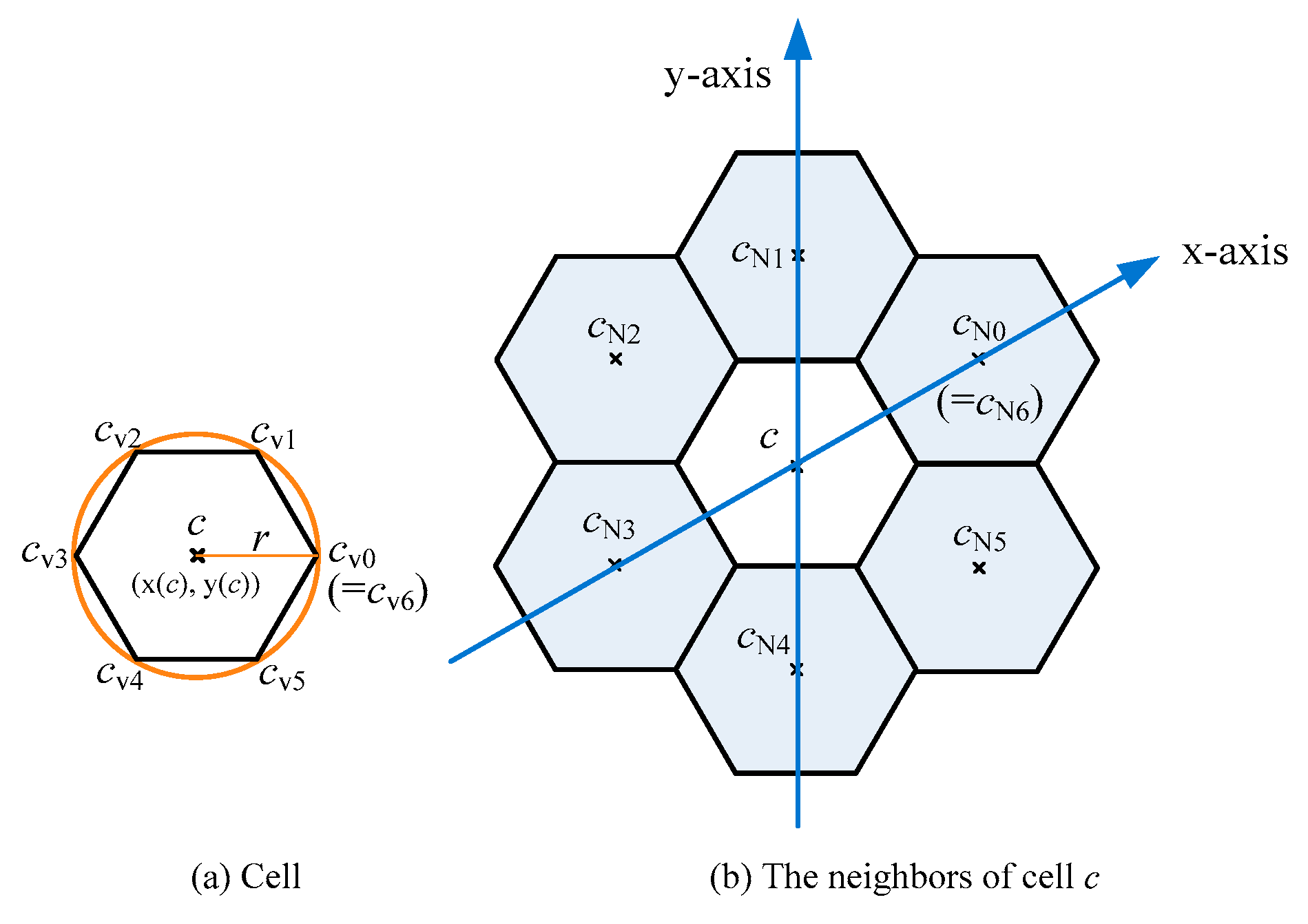
A at a time and these points are affordable by computers. The type of this area is chosen as a circle. There are two reasons. The first reason is that some well-known platforms (servers), such as Facebook, also provide geographical points in a circle manner. The other reason is to follow the access method of storages. The storage in general is a database system. To retrieve some records from the storage, it must be obtained through the access mechanism of the database system, such as structured query language (SQL). The circle-area manner can be mapped to the corresponding SQL commands. However, the configuration of the circle manner is not easy to fully cover a geographical area. Here the cellular architecture using a regular hexagonal configuration, instead of the circular configuration, can be applied. The cell architecture is shown in
Figure 1, in which
Figure 1a provides the layout of a cell and
Figure 1b provides the relative positions of cell
c and its six neighbors. If the radius of the circle is
r, then the length of the regular hexagonal side is
r. For convenience, a cell is used to represent a regular hexagon. There are six cells around a cell, termed as the neighbors of this cell. For a cell
c, cells
cN0,
cN1, …, and
cN5 are used to represent the six neighbors of cell
c. The relative positions of cell
c and its six neighbors can be expressed by an oblique coordinate architecture with 60 degrees (i.e., the angle between the
x-axis and the
y-axis is 60 degrees). Moreover, for cell
c with radius
r,
Table 1 provides the coordinates of each vertex.
Table 2 provides the coordinates of each neighbor.
Moreover, if expressed by the geographic coordinate system (i.e., use latitude and longitude values to describe a coordinate with cell
c), the offset coordinates of the six neighbors are shown in
Table 2. Notably, the distance
r is transformed by the Cartesian coordinate. Every point that is expressed in ellipsoidal coordinates can be expressed as rectilinear
x y z (Cartesian) coordinates. Cartesian coordinates simplify many mathematical calculations. The Cartesian systems of different data are not equivalent. The distance between the points of longitude 121 and latitude 21 to the point of longitude 122 and latitude 21 is about 103 km. The distance between the points of longitude 122 and latitude 21 to the point of longitude 122 and latitude 22 is about 111 km. If it is configured with a radius of 1 km,
r can be set to about 0.009 (=1/111) near this area.
A cell
c is a regular hexagon area, defined as (
c,
r), where (
x(
c),
y(
c)) is the geographical coordinate, and
r is the length of the regular hexagonal side. Moreover, V(
c) = {
cV0,
cV1,
cV2,
cV3,
cV4,
cV5} is defined as the set of six vertices and NB(
c) = {
cN0,
cN1,
cN2,
cN3,
cN4,
cN5} is defined as the set of six neighboring cells.
Table 1 provides the coordinates of each vertex in
V(
c) and
Table 2 provides the coordinates of each neighbor in
NB(
c).
Hereafter, the word “geographical point” is simply termed as a “point” and the word “geographical area” is simply termed as an “area”. Evaluating whether a point is inside or is not-inside is the PIP problem. It can count the intersections of the polygon with the ray of this point. A ray of a point is starting from this point to any fixed direction. That the number of intersections between the polygon and the ray is odd indicates this point is inside this polygon. Otherwise, it indicates this point is not-inside this polygon. This method can evaluate the locations of points with respect to an area without error. To implement this method, it must first be able to determine whether two lines are intersected. In [
29], a computer-friendly method was proposed to do it. Suppose there are two lines. The first line crosses over both point
o1 and point
o2. The other line crosses over both point
o3 and point
o4. First,
ρ, as shown in (1), can be evaluated. If the value of
ρ equal 0, these two lines are parallel. Next,
κ1 and
κ2, as, respectively, shown in (2) and (3), can be evaluated. If the value of
κ1 is between 0 and 1, the intersection is between
o1 and
o2. If the value of
κ2 is between 0 and 1, the intersection is between
o3 and
o4. In other words, if edge (
o1,
o2) and edge (
o3,
o4) are intersected, the value of
κ1 is between 0 and 1 and the value of
κ2 is also between 0 and 1.
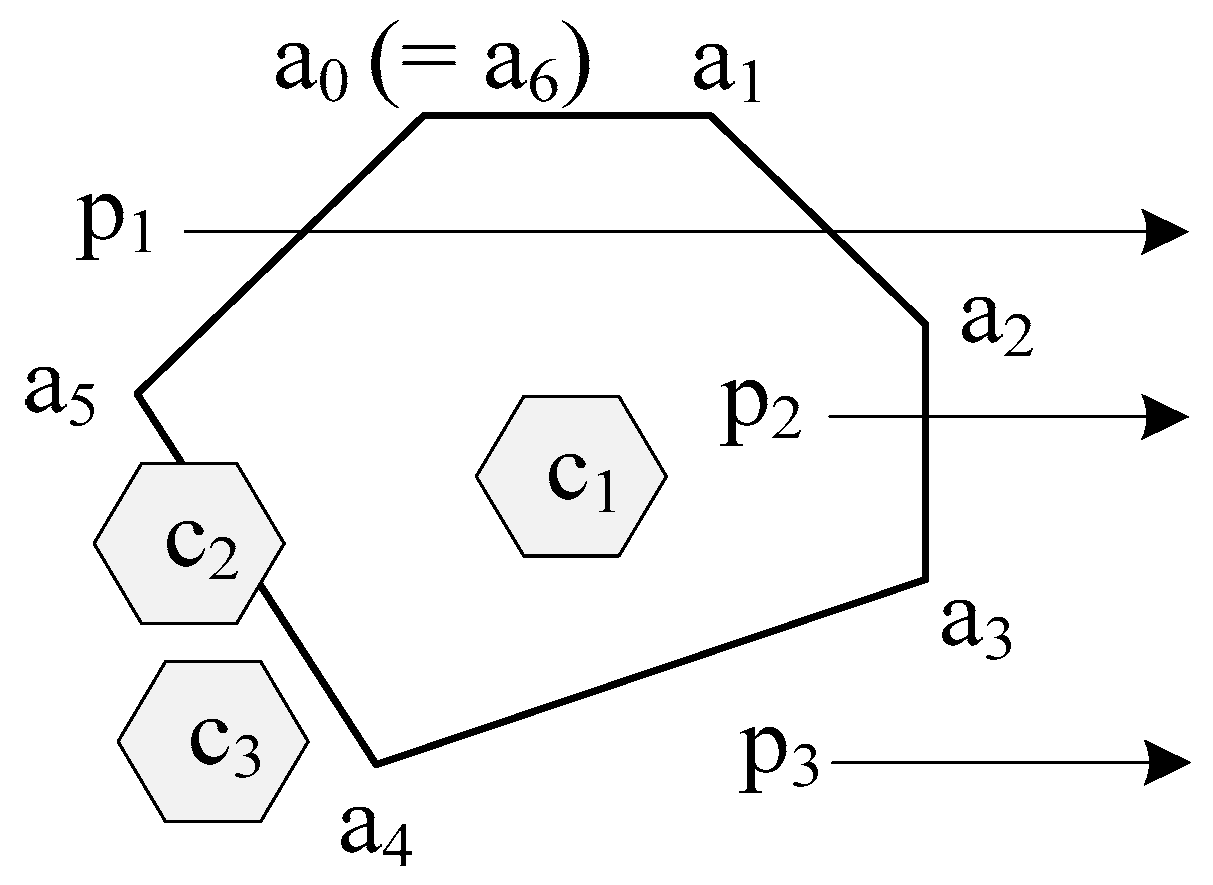
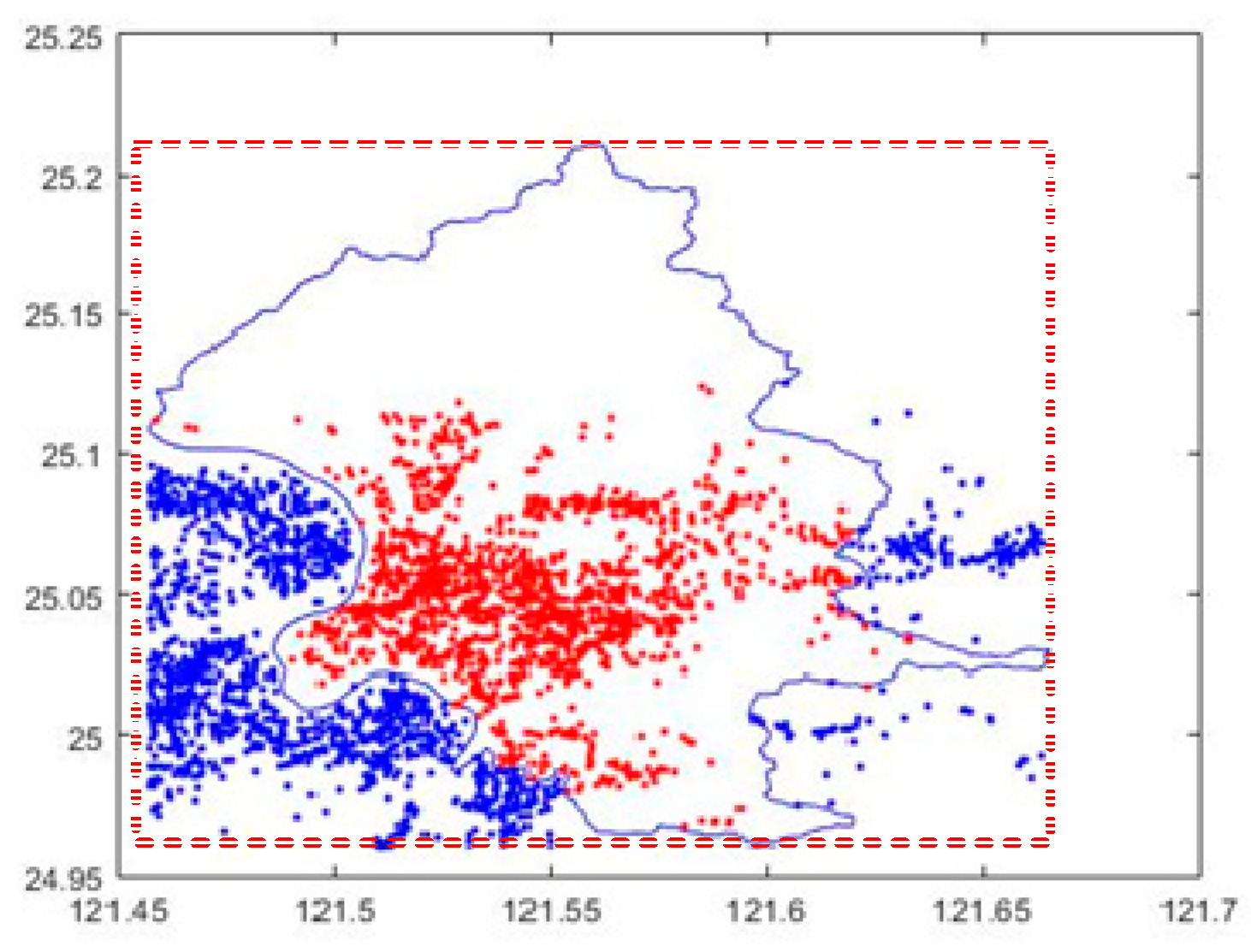
The overlap of an area A with a cell c, where the space of A is far greater than the space of c, is also considered. There are two overlapping cases between A and c. The first case is the space of A is overlapped with the space of c. Non-first relationship is the second relationship. The first case can be evaluated when all six points are inside A and there are no intersection points among the edges of c and the edges of A.
As shown in
Figure 2, an area is composed of a convex polygon with six points, a
0, a
1, …, and a
5. The rays of p
1, p
2, and p
3 within this area, respectively, have 2, 1, and 0 intersection(s). Since the ray of a point has odd intersections within the area, it means that the point is inside the area; otherwise, the point is not-inside the area. Then, both point p
1 and point p
3 are not-inside the area and point p
2 is inside the area. Continually, there are three cells, c
1, c
2, and c
3. Since all vertices of c
1 are in this area, two vertices of c
2 are in this area, and no vertices of c
3 are in this area, both c
1 and c
2 overlap with this area and c
3 does not overlap with this area.
6. Discussion
Let
A be a specific area and
P be the set of points. Our proposed strategy provided a solution to acquire all points in
P inside
A. The PIA algorithm can be used to evaluate whether point
p is inside or not-inside area
A. The time complexity is O(
nA), where
nA is the number of vertices (or edges) of area
A. The reason is that it needs to count the number of intersections among the ray of
p and the
nA edges. The simple method to acquire all of points inside area
A is to evaluate each point of
P by PIP. The candidate points, which are points needing the evaluation of PIA, are all of the
nP points. The time complexity is O(
nA ×
nP), where
nP is the number of points in set
P. When
nP is a very large number, it is greatly time-consuming to acquire these points. In [
30], an enhanced strategy was proposed. It first evaluates the boundary (i.e., a space of rectangle). This rectangle is fully covered by the space of area
A. The points within the rectangle are evaluated. In our strategy, we allocate a set of cells to fully cover area
A. The total space of these cells is slightly larger than the space of area
A. Then, the cells are divided into inside cells and not-inside cells. Only points within not-inside cells must be evaluated. The not-inside cells are the cells that have intersections with area
A. In fact, only points near the edges of area
A are evaluated. The number of candidate points is reduced to a very small number. Therefore, our strategy is efficient to acquire the targets in an area.
7. Conclusions
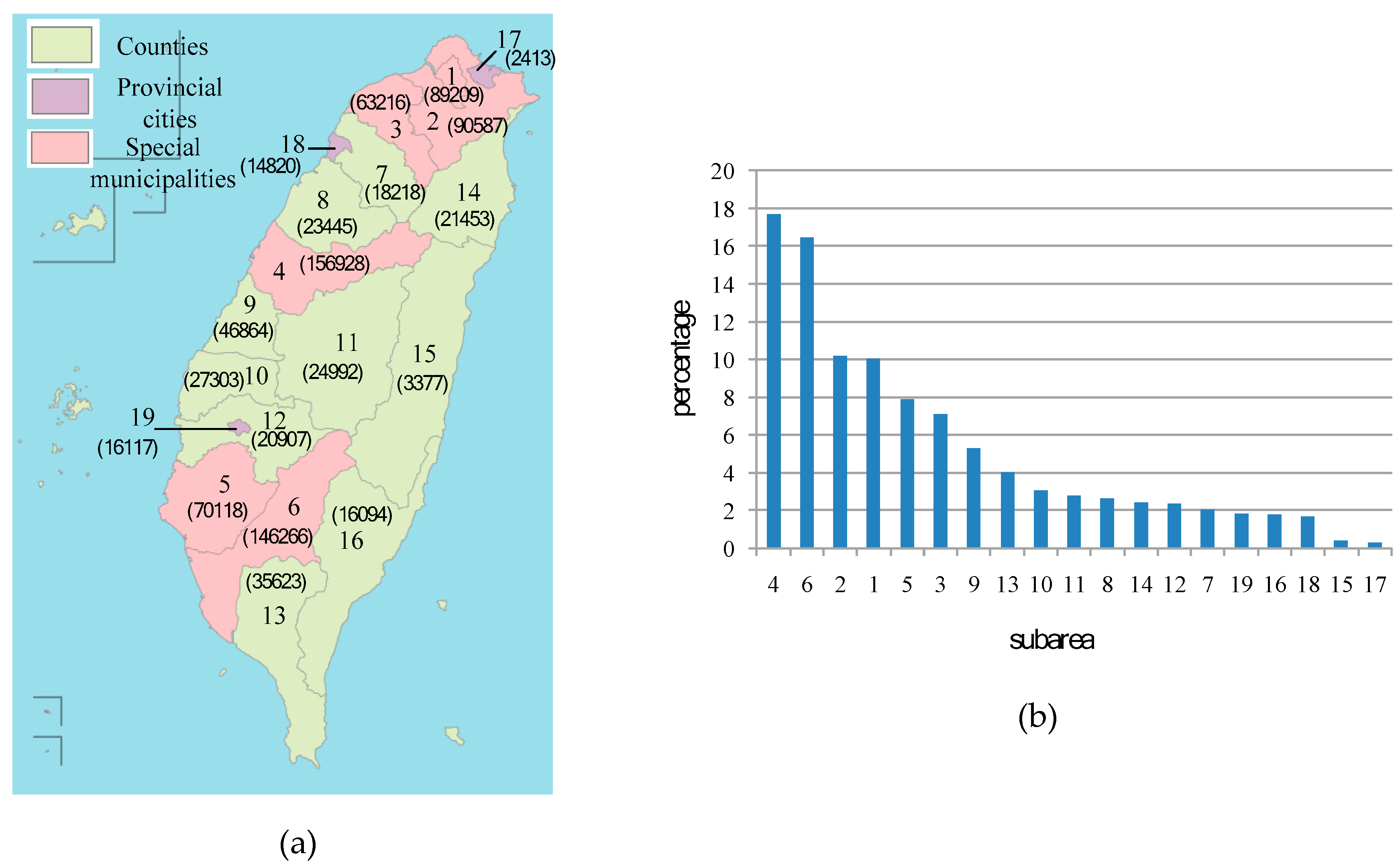
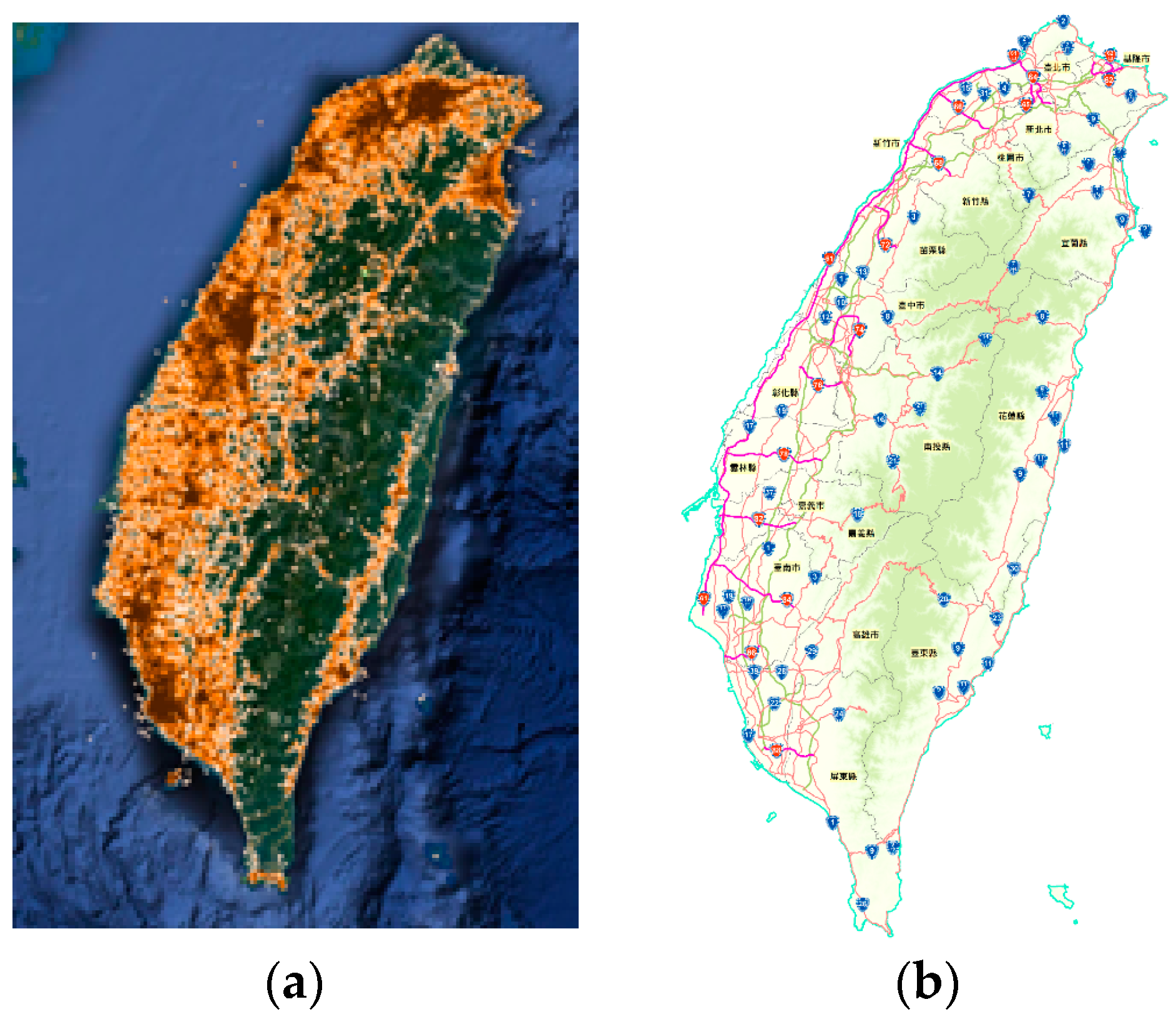
In this study, Taiwan Island and the administrative areas are used as geographic areas, and check-in places on Facebook are used as geographic points to verify the proposed strategy. These are the actual data. Due to the fact that the spot height map, respectively, matches the distribution of administrative areas and matches the distribution of highways, it verifies the practicability of our strategy. This strategy mainly provides two techniques. The first technique is used to calculate whether the geographic points are in a specific area. The second technique is used to calculate the number of points in a specific area. In our demonstration, we first, respectively, analyzed the numbers of points of the 16 administrative areas. Then the populations of the administrative areas and the spaces of the administrative areas were included in the discussion. This provided these results: the number of geographic points per unit area and the ratio of geographic points to the population. This is the category of hot areas.
Because the numbers of geographic points in geographic areas are not enough to represent the distribution of geographic points, we planned a space of about 1 square kilometer as a unit, termed as a spot, and calculated the number of geographic points in each spot. This is a hotspot category. Of course, the size of a spot depends on the actual situation. Based on the above discussion, our strategy is a GNSS-based crowd-sensing strategy for specific areas. This research is very useful in many fields. We used non-real-time and real-time GNSS coordinates for the applications. Non-real-time coordinates (i.e., historical records), can be used to know where hot areas hot spots can develop. It can be deployed in advance for this area to avoid or mitigate future events. For real-time coordinates, it can be used to know where it is becoming a hot area or where it is becoming a hot spot. It can be deployed ahead of schedule to avoid or mitigate ongoing events. The acquisition of coordinates may have privacy constraints. To acquire current location information with user consent may be available. Observing privacy constraints to do more epidemic prevention management is the goal of our future work.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}