Vision Measurement of Gear Pitting Under Different Scenes by Deep Mask R-CNN



Abstract
:1. Introduction
2. The proposed Method
2.1. Overview
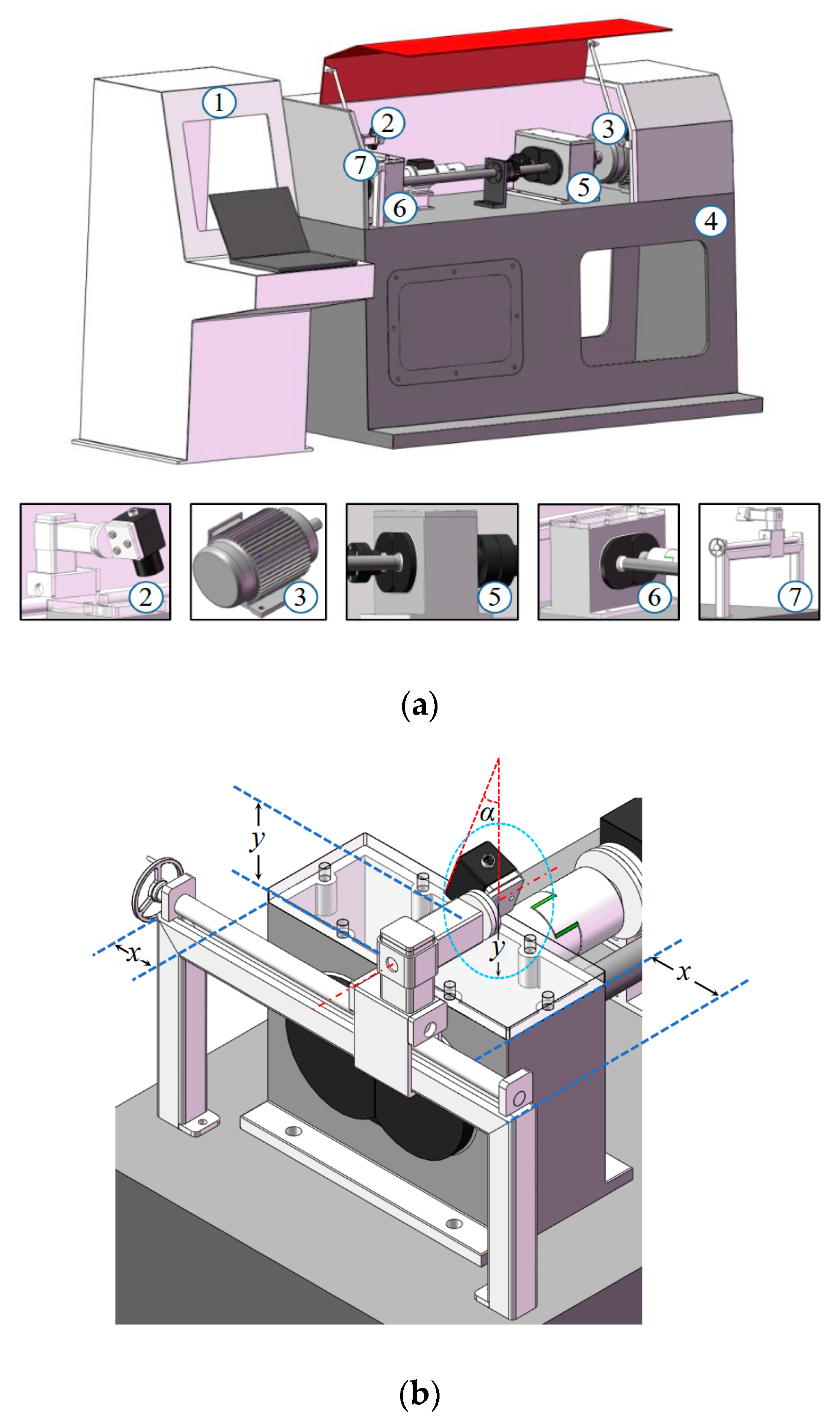
2.2. Tunable Visual Detection Platform (TVDP)
2.3. Image Acquisition
2.3.1. Multi-Level Pitting
2.3.2. Multi-Illumination
2.3.3. Multi-Angle
2.4. Dataset Description
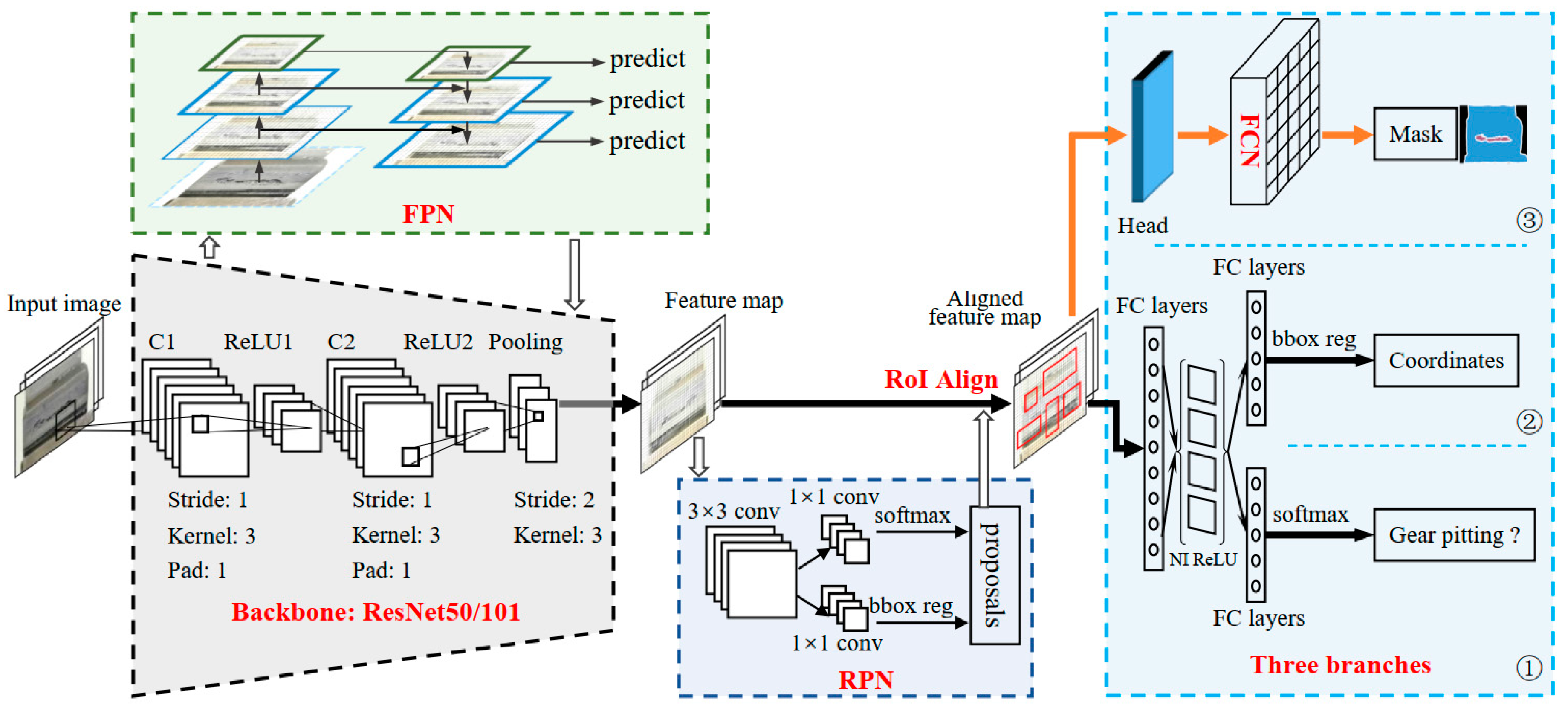
2.5. Gear Pitting Detection by Deep Mask R-CNN
2.5.1. Structure of the Deep Mask R-CNN
2.5.2. Gear Pitting Feature Exaction
2.5.3. Region Generation and RoIAlign Operation
2.5.4. Loss Function
3. Training and Evaluation
4. Results and Discussion
4.1. Traditional Segmentation Result
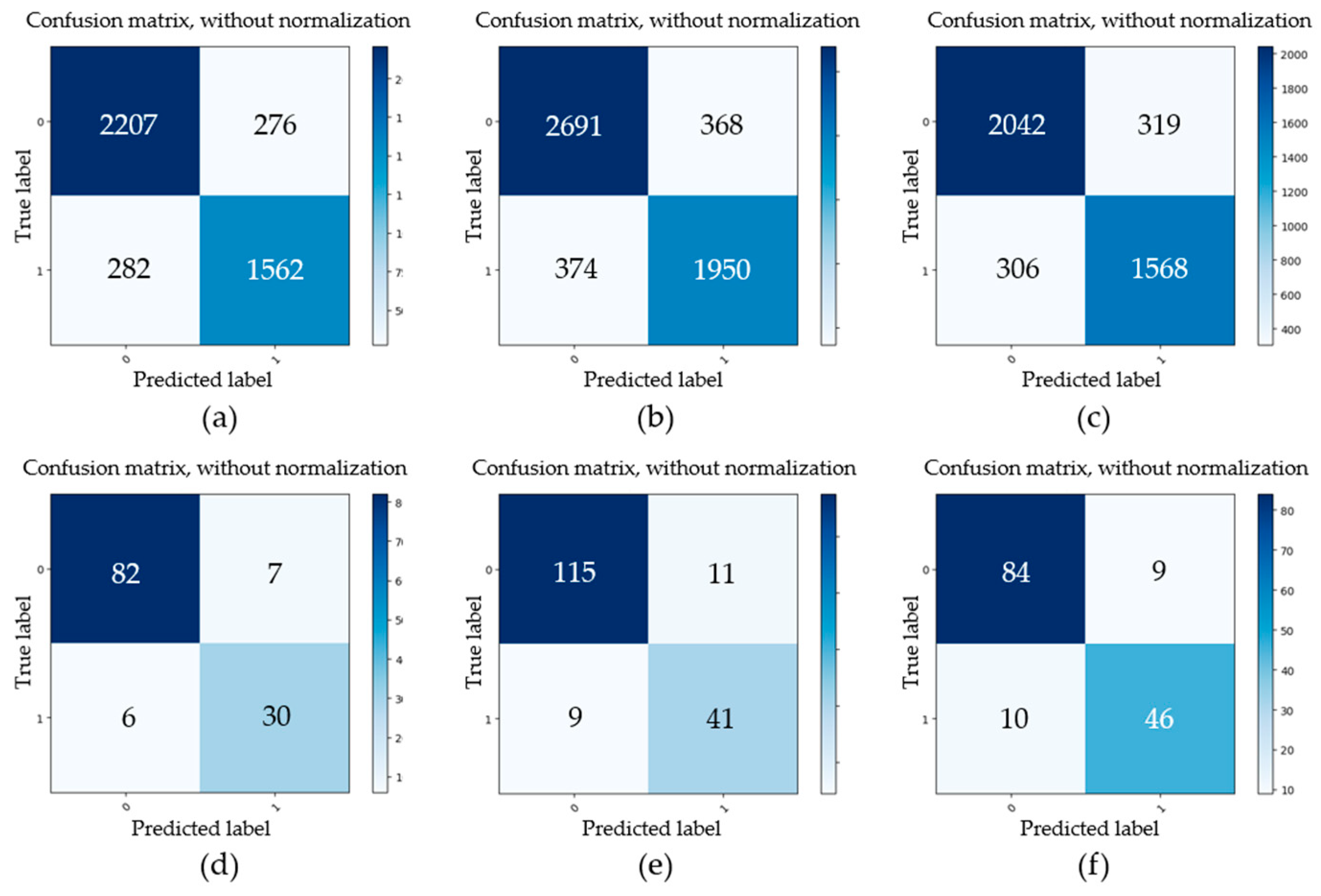
4.2. Results of Object Detection
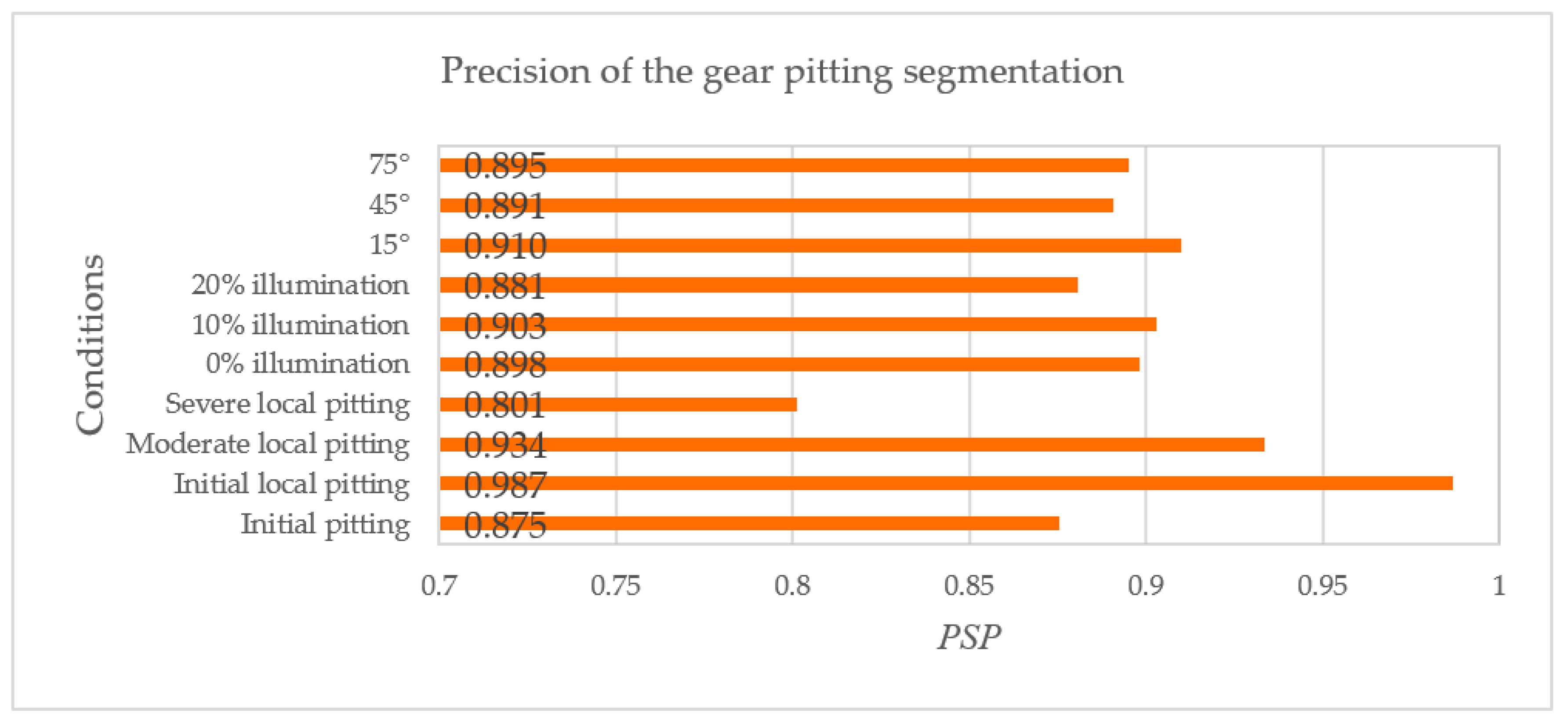
4.3. Results of Image Segmentation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Liu, S.; Song, C.; Zhu, C.; Liang, C.; Yang, X. Investigation on the influence of work holding equipment errors on contact characteristics of face-hobbed hypoid gear. Mech. Mach. Theory 2019, 38, 95–111. [Google Scholar] [CrossRef]
- Qin, Y.; Mao, Y.; Tang, B.; Wang, Y.; Chen, H. M-band flexible wavelet transform and its application into planetary gear transmission fault diagnosis. Mech. Syst. Signal Proc. 2019, 134. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, Z.; Long, H.; Xu, J.; Liu, R. Wind Turbine Gearbox Failure Identification with Deep Neural Networks. IEEE Trans. Ind. Inform. 2017, 13, 1360–1368. [Google Scholar] [CrossRef]
- Wang, Y.; Wei, Z.; Yang, J. Feature trend extraction and adaptive density peaks search for intelligent fault diagnosis of machines. IEEE Trans. Ind. Inform. 2018, 15, 105–115. [Google Scholar] [CrossRef]
- Zhao, M.; Kang, M.; Tang, B.; Pecht, M. Multiple Wavelet Coefficients Fusion in Deep Residual Networks for Fault Diagnosis. IEEE Trans. Ind. Electron. 2019, 66, 4696–4706. [Google Scholar] [CrossRef]
- Feng, Z.; Liang, M.; Zhang, Y.; Hou, S. Fault diagnosis for wind turbine planetary gearboxes via demodulation analysis based on ensemble empirical mode decomposition and energy separation. Renew. Energy. 2012, 47, 112–126. [Google Scholar] [CrossRef]
- Qin, Y.; Zou, J.; Tang, B.; Wang, Y.; Chen, H. Transient feature extraction by the improved orthogonal matching pursuit and K-SVD algorithm with adaptive transient dictionary. IEEE Trans. Ind. Inform. 2020, 16, 215–227. [Google Scholar] [CrossRef]
- Ha, J.M.; Youn, B.D.; Oh, H.; Han, B.; Jung, Y.; Park, J. Autocorrelation-based time synchronous averaging for condition monitoring of planetary gearboxes in wind turbines. Mech. Syst. Signal Proc. 2016, 70, 161–175. [Google Scholar] [CrossRef]
- Chen, R.; Huang, X.; Yang, L.; Xu, X.; Zhang, X.; Yong, Z. Intelligent fault diagnosis method of planetary gearboxes based on convolution neural network and discrete wavelet transform. Comput. Ind. 2019, 48–59. [Google Scholar] [CrossRef]
- Yin, A.; Yan, Y.; Zhang, Z.; Li, C.; Sánchez, R. Fault Diagnosis of Wind Turbine Gearbox Based on the Optimized LSTM Neural Network with Cosine Loss. Sensors 2020, 20, 2339. [Google Scholar] [CrossRef] [Green Version]
- Xiang, S.; Qin, Y.; Zhu, C.; Wang, Y.; Chen, H. Long short-term memory neural network with weight amplification and its application into gear remaining useful life prediction. Eng. Appl. Artif. Intell. 2020, 91. [Google Scholar] [CrossRef]
- Wang, X.; Qin, Y.; Wang, Y.; Xiang, S.; Chen, H. ReLTanh: An activation function with vanishing gradient resistance for SAE-based DNNs and its application to rotating machinery fault diagnosis. Neurocomputing 2019, 363, 88–98. [Google Scholar] [CrossRef]
- Li, X.; Li, J.; Qu, Y.; He, D. Gear pitting fault diagnosis using integrated CNN and GRU network with both vibration and acoustic emission signal. Appl. Sci. 2019, 9, 768. [Google Scholar] [CrossRef] [Green Version]
- Li, D.; Zhao, D.; Chen, Y.; Zang, Q. Deepsign: Deep learning based traffic sign recognition. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar]
- Topol, E. High-performance medicine: The convergence of human and artificial intelligence. Nat. Med. 2019, 25, 44–56. [Google Scholar] [CrossRef]
- Ren, L.; Cui, J.; Sun, Y.; Cheng, X. Multi-bearing remaining useful life collaborative prediction: A deep learning approach. J. Manuf. Syst. 2017, 43, 248–256. [Google Scholar] [CrossRef]
- Menotti, D.; Chiachia, G.; Pinto, A.; Schwartz, W.; Pedrini, H.; Falcao, A.; Rocha, A. Deep representations for iris, face, and fingerprint spoofing detection. IEEE Trans. Inf. Forensic Secur. 2015, 10, 864–879. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.; Chen, Y.; Wang, X. Recognition of handwritten characters in chinese legal amounts by stacked autoencoders. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014. [Google Scholar]
- Zhan, C.; Duan, X.; Xu, S.; Zheng, S.; Min, L. An improved moving object detection algorithm based on frame difference and edge detection. In Proceedings of the Fourth International conference on image and graphics, Sichuan, China, 22–24 August 2007. [Google Scholar]
- Zitnick, C.; Jojic, N.; Kang, S. Consistent segmentation for optical flow estimation. In Proceedings of the Tenth IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2005. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Qiao, Y.; Cappelle, C.; Ruichek, Y.; Yang, T. Convnet and LSH-based visual localization using localized sequence matching. Sensors 2019, 19, 2439. [Google Scholar] [CrossRef] [Green Version]
- Kumar, S.; Pandey, A.; Satwik, K.; Kumar, S.; Singh, S.; Singh, A.; Mohan, A. Deep learning framework for recognition of cattle using muzzle point image pattern. Measurement 2018, 116, 1–17. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Li, K.; Hariharan, B.; Malik, J. Iterative instance segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Las Vegas, NE, USA, 27–30 June 2016. [Google Scholar]
- Pinheiro, P.; Collobert, R.; Dollár, P. Learning to segment object candidates. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Pinheiro, P.; Lin, T.; Collobert, R.; Dollar, P. Learning to refine object segments. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 75–91. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International conference on computer vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems. Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y. YOLACT: Real-time instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, South Korea, 27 October–2 November 2019. [Google Scholar]
- Hariharan, B.; Arbelaez, P.; Girshick, R.; Malik, J. Simultaneous detection and segmentation. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 297–312. [Google Scholar]
- Lee, Y.; Park, J. CenterMask: Real-Time Anchor-Free Instance Segmentation. Comput. Vis. Pattern Recognit. 2019. [Google Scholar]
- Qiao, Y.; Truman, M.; Sukkarieh, S. Cattle segmentation and contour extraction based on Mask R-CNN for precision live-stock farming. Comput. Electron. Agric. 2019, 165. [Google Scholar] [CrossRef]
- Everingham, M.; Eslami, S.; Van Gool, L.; Williams, C.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comp. Vis. 2015, 111, 98–136. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Super Parameter Category | Super Parameter Name | Super Parameter Value |
|---|---|---|
| RPN training parameters | Positive threshold | 0.7 |
| Negative threshold | 0.3 | |
| Ratio between positive and negative samples | 1:2 | |
| Non maximum suppression (NMS) | 0.5 | |
| Number of NMS output window | 2000 | |
| Number of training samples | 300 | |
| RPN test parameters | NMS threshold | 0.7 |
| Number of output windows after NMS | 1000 | |
| Candidate window parameters | Coincidence degree of positive sample | 0.5 |
| Coincidence degree of negative sample | 0.5 | |
| Number of training batches | 200 | |
| NMS threshold | 0.5 | |
| Learning parameters | Learning rate | 0.001 |
| Step of learning rate change | 20,000 | |
| Multiple of learning rate change | 0.1 | |
| Optimization algorithm | SGD |
| True Objects | False Objects | |
|---|---|---|
| Detected | TP (True Positives) | FP (False Positives) |
| Undetected | FN (False Negatives) | TN (True Negatives) |
| Pitting Levels | Initial Minor Pitting | Initial Local Pitting | Moderate Local Pitting | Severe Local Pitting | |
|---|---|---|---|---|---|
| Pitting | P | 0.851 | 0.983 | 0.919 | 0.730 |
| R | 0.846 | 0.963 | 0.925 | 0.778 | |
| F1 | 0.849 | 0.973 | 0.922 | 0.753 | |
| A | 0.823 | 0.956 | 0.878 | 0.747 | |
| FDR | 0.149 | 0.017 | 0.081 | 0.270 | |
| FOR | 0.217 | 0.159 | 0.269 | 0.235 | |
| TS | P | 0.908 | 0.939 | 0.927 | 0.898 |
| R | 0.922 | 0.930 | 0.918 | 0.914 | |
| F1 | 0.915 | 0.935 | 0.922 | 0.906 | |
| A | 0.887 | 0.893 | 0.890 | 0.884 | |
| FDR | 0.092 | 0.061 | 0.073 | 0.102 | |
| FOR | 0.156 | 0.304 | 0.200 | 0.139 | |
| Illumination | I (94 cd/m2) | II (125 cd/m2) | III (151 cd/m2) | |
|---|---|---|---|---|
| Pitting | P | 0.869 | 0.899 | 0.884 |
| R | 0.868 | 0.897 | 0.868 | |
| F1 | 0.869 | 0.898 | 0.876 | |
| A | 0.856 | 0.862 | 0.847 | |
| FDR | 0.131 | 0.101 | 0.116 | |
| FOR | 0.159 | 0.215 | 0.212 | |
| TS | P | 0.917 | 0.938 | 0.927 |
| R | 0.904 | 0.931 | 0.912 | |
| F1 | 0.910 | 0.934 | 0.919 | |
| A | 0.875 | 0.906 | 0.879 | |
| FDR | 0.083 | 0.062 | 0.073 | |
| FOR | 0.219 | 0.173 | 0.262 | |
| α | 75° | 45° | 15° | |
|---|---|---|---|---|
| Pitting | P | 0.865 | 0.870 | 0.889 |
| R | 0.870 | 0.878 | 0.887 | |
| F1 | 0.867 | 0.879 | 0.888 | |
| A | 0.871 | 0.862 | 0.852 | |
| FDR | 0.111 | 0.120 | 0.135 | |
| FOR | 0.153 | 0.161 | 0.163 | |
| P | 0.903 | 0.913 | 0.921 | |
| TS | R | 0.894 | 0.927 | 0.932 |
| F1 | 0.898 | 0.9200 | 0.927 | |
| A | 0.896 | 0.886 | 0.873 | |
| FDR | 0.079 | 0.087 | 0.097 | |
| FOR | 0.167 | 0.180 | 0.179 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xi, D.; Qin, Y.; Wang, Y. Vision Measurement of Gear Pitting Under Different Scenes by Deep Mask R-CNN. Sensors 2020, 20, 4298. https://doi.org/10.3390/s20154298
Xi D, Qin Y, Wang Y. Vision Measurement of Gear Pitting Under Different Scenes by Deep Mask R-CNN. Sensors. 2020; 20(15):4298. https://doi.org/10.3390/s20154298
Chicago/Turabian StyleXi, Dejun, Yi Qin, and Yangyang Wang. 2020. "Vision Measurement of Gear Pitting Under Different Scenes by Deep Mask R-CNN" Sensors 20, no. 15: 4298. https://doi.org/10.3390/s20154298
APA StyleXi, D., Qin, Y., & Wang, Y. (2020). Vision Measurement of Gear Pitting Under Different Scenes by Deep Mask R-CNN. Sensors, 20(15), 4298. https://doi.org/10.3390/s20154298