1. Introduction
As a spontaneous, low-intensity facial expression, micro-expression (ME) is a non-verbal way of expressing emotions, and it reveals the inner emotional state of human beings [
1]. Lasting for only 1/3 to 1/25s, ME is usually an unconscious appearance of an emotional state, and can be detected even when a person tries to hide or suppress emotions. These involuntary expressions provide insight into the true feelings of a person. Due to these facts, MEs can provide valuable clues for emotional intelligence research, polygraph detection, political psychoanalysis, and clinical diagnosis of depression [
2]. Thus, the study of MEs has recently attracted widespread attention at the forefront of psychology [
3,
4,
5].
Since MEs are almost imperceptible to human beings, their subtlety and brevity impose significant challenges for observation with the naked eye. In this field, Ekman developed the first ME training tool (METT) [
6]. After METT training, the performance of human subjects improved greatly. Even so, it was reported that the performance of human subjects in identifying MEs was only 47% on the post-test phase of METT [
7]. It can be clearly seen that, although the study of MEs is an active and well-established research field in psychology, the research on ME recognition, especially in combination with computer vision, is still in its infancy and needs to be further developed. Furthermore, the automatic recognition of MEs has great significance in the mechanisms of computer vision, psychological research, and other practical applications. In consequence, exploring machine vision techniques for ME recognition has important research value and urgency.
The ME recognition research based on computer vision includes three steps: pre-processing, feature representation, and classification [
8]. The development of powerful feature representations plays a crucial role in ME recognition, which is similar to other image classification tasks. Therefore, feature representation has been developed into one of the main focus points of recent research on ME recognition [
9]. Currently, advances in computer vision-based image classification, such as machine learning and deep learning algorithms, provide unprecedented opportunities for automated ME recognition. In this context, many handcrafted techniques and deep learning methods have been proposed to predict MEs using different feature extraction methods, yielding valuable insights into the progression patterns of ME recognition [
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28]. The mainstream feature representation methods for ME recognition are mainly based on the optical flow [
13,
14,
15,
16,
17], local binary patterns (LBP) [
18,
19,
20,
21,
22,
23], and deep learning techniques [
24,
25,
26,
27,
28]. With their robustness to subtle facial changes, early studies of LBP and optical-flow-based handcrafted techniques have gradually become the benchmark methods for ME recognition tasks. LBP-based descriptors can obtain high-quality facial texture, which helps improve the representation ability of facial movements. The optical-flow-based studies also follow the idea of capturing facial details to describe motion information between adjacent frames, and many studies demonstrated their effectiveness for ME recognition tasks. Constrained by the sensitivity to the illumination, most of the optical-flow-based studies suffer from the interference of background noise, which limits their applicability. In recent years, the deep learning technology, with a rapid revival, has made it possible to avoid complicated handcrafted features design [
28]. However, the expected performance is achieved by requiring a large number of training samples. Since it is difficult to induce spontaneous MEs and label them, the lack of large-scale benchmark datasets has considerably limited the performance of deep models. Therefore, due to the lack of large-scale datasets for the deep learning methods, mainstream ME recognition methods are still dominated by the traditional handcrafted techniques.
Based on reports, LBP, a typical handcrafted technique, is widely used in various pattern recognition tasks due to its outstanding advantages, such as computational efficiency, robustness to gray-scale changes, and rotation invariance. Similarly, as a three-dimensional (3D) extension of LBP, local binary patterns from three orthogonal planes (LBP-TOP) was first applied for the ME recognition task [
18], which compensates for the shortcomings of LBP in time-domain features encoding. Although the spatiotemporal features show improvements in ME recognition performance compared with the traditional LBP features, the indirect acquisition of LBP-TOP features may introduce noise, which cannot be ignored. Moreover, different variant studies based on LBP-TOP only reveal information related to the three orthogonal planes, which leads to the loss of some hidden clues [
21]. Due to these facts, the representational capabilities in the time-domain is weakened to some extent by adopting the coding patterns of three orthogonal planes. Besides, the handcrafted techniques can be designed to identify discriminative information in specific tasks, which allows different variants of LBP to have different coding concerns. As a result of using only one type of binary feature, the representation ability and robustness are inefficient or insufficient. On such occasions, the integration of multiple complementary descriptors (e.g., the complementary spatial and temporal descriptors), while bringing a high redundancy of data and thus compromising the quality of the representation, can compensate for the limitations of the spatiotemporal representation in a single descriptor. In fact, the high-dimensional problems with redundant information pose a severe challenge in various fields. Further, as the LBP-based technique introduces division grids to capture local information, this leads to a difference in the contribution of different local regions to the recognition task. In response to this issue, the adoption of a group sparse regularizer provides cues and references for conducting feature selection and calculating the contribution of different regions. Moreover, the impact of different sparse strategies on recognition performance is particularly important. In such a context, choosing the appropriate sparse strategy and combining it with different types of binary encoding patterns would be a better choice for ME recognition tasks. Moreover, due to the lack of flexibility, a single kernel function may limit the performance of the task. Therefore, the representations mapped by the Multi-kernel Support Vector Machine (SVM) can be more accurately and reasonably expressed in the new combination kernel space for final classification, which makes the results of the ME recognition method more convincing.
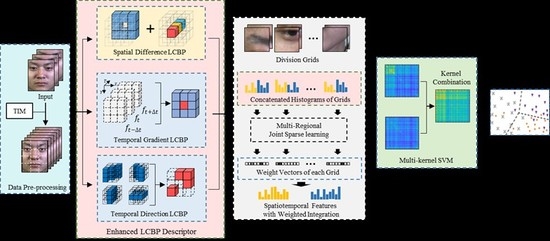
In this paper, a sparse spatiotemporal descriptor for ME recognition using Enhanced Local Cube Binary Pattern (Enhanced LCBP) is developed to classify MEs. The framework of the proposed method is shown in
Figure 1. Our method emphasizes the integration of three complementary descriptors in the spatial and temporal domains, so as to improve the high distinctiveness and good robustness of the spatiotemporal representation. In response to the importance of spatiotemporal information for the ME recognition, the proposed complementary binary feature descriptors include Spatial Difference Local Cube Binary Pattern (Spatial Difference LCBP), Temporal Direction Local Cube Binary Pattern (Temporal Direction LCBP), and Temporal Gradient Local Cube Binary Pattern (Temporal Gradient LCBP). These descriptors are designed to capture spatial differences, temporal direction, and temporal intensity changes, respectively. The Enhanced LCBP not only takes full advantage of the LBP algorithm but also integrates more complementary feature extraction capability in the spatiotemporal domain. In addition, to direct the model to focus more on important local regions, Multi-Regional Joint Sparse Learning is designed to measure the contribution of different regions to distinguish micro-expressions, which captures the intrinsic connections among local regions. It not only reduces redundant information by using the sparse penalty term, but also employs an extra penalty term for constraining the distance between different classes in the feature space, thus further improving the discriminability of sparse representations. Furthermore, by mapping the sparse representations through a Multi-kernel SVM, it can be combined with the mapping capabilities of each kernel space, ultimately allowing for a more accurate and reasonable expression of the data in the synthetic kernel space. Finally, we performed comparative and quantitative experiments on the four benchmark datasets to study the effectiveness of our method.
The structure of this paper is as follows:
Section 2 reviews the related work of mainstream ME recognition methods and presents the contribution of this paper. The proposed method is presented in
Section 3. The experimental results and comparative analysis is discussed in
Section 4.
Section 5 provides the conclusion.
2. Related Work
State-of-the-art ME recognition methods can be broadly classified into three categories: optical flow, LBP descriptors, and deep learning algorithms. The related work of these three methods is briefly reviewed in this section.
The purpose of optical-flow estimation is to observe the facial motion information between adjacent frames. The optical-flow-based techniques calculate the pixel changes in the time domain and the correlation between adjacent frames to find the correspondence of facial action between the previous frame and the current frame. To answer the challenges of short duration and low intensity of MEs, Liu et al. [
13] proposed a simple yet effective Main Directional Mean Optical-flow (MDMO) feature for ME recognition. MDMO is a normalized statistical function based on regions of interest (ROIs), which is divided based on the definition of action units. It divides the main optical flow into amplitude and direction according to the characteristics of the main optical flow in each region of interest. To extract subtle face displacements, Xu et al. [
14] proposed a method to describe the movement of MEs at different granularities, called Facial Dynamics Map (FDM). They used optical flow estimation to pixel-align the ME sequences. They also developed an optimal iterative strategy to calculate the main optical flow direction of each cuboid, which is obtained by dividing each expression sequence according to the selected granularity. This is done in a purposeful way to characterize facial movements containing time-domain information to predict MEs. Further, in response to the problem that MDMO lost the underlying manifold structure inherent in the feature space, Liu et al. [
15] proposed a Sparse MDMO feature that uses a new distance metric method to reveal the underlying manifold structure effectively. This improvement makes full use of the sparseness of the sample points in the MDMO feature space, which is obtained by adding new metrics to the classic Graph Regularized Sparse Coding scheme. Due to optical flow estimation that can capture dense temporal information, some researchers advocated using the key frames, or fuzzy histograms, to reduce the impact of redundant information on ME recognition. Specifically, Liong et al. [
16] proposed a Bi-Weighted Oriented Optical Flow (Bi-WOOF) to encode essential expressiveness of the apex frame. Happy and Routray [
17] proposed a Fuzzy Histogram of Optical Flow Orientations (FHOFO) method, which constructs an angle histogram from the direction of the optical flow vector using histogram fuzzification.
Taken together, the optical-flow field can effectively convey temporal micro-level variations in MEs. Since OP-based features can describe the location and geometry of refined facial landmarks, they require a more precise facial alignment process. This brings some complexity to the ME recognition process and the current models. Meanwhile, its sensitivity to illumination changes makes it highly susceptible to background noise, which causes the OP-based method to amplify local facial details while also amplifying redundant information.
Since the spatiotemporal features play an important role in identifying ME, these LBP-based studies on ME recognition have gradually developed towards improvement in encoding time-domain representations. Earlier work explored extending different coding patterns to three orthogonal planes to develop descriptors that are robust to time-domain changes, including LBP-TOP [
18], Centralized Binary Pattern from three orthogonal planes (CBP-TOP) [
19], etc. In particular, Pfister et al. [
18] extended LBP to three orthogonal planes (LBP-TOP) to identify MEs. The LBP-TOP inherited the excellent computing efficiency of the LBP, which can effectively extract texture features in the spatiotemporal domain. Since then, the LBP-TOP has been used as a classic algorithm to provide the basis and verification benchmark for follow-up studies. Wang et al. [
20] proposed a Local Binary Pattern with Six Intersection Points (LBP-SIP), which contains four points in the airspace and the center points of two adjacent frames. Guo et al. [
19] proposed to extend the Centralized Binary Pattern (CBP) features in three orthogonal planes to CBP-TOP descriptors, thereby obtaining lower-dimensional and more enriched representations. Meanwhile, due to the problem of losing information by encoding only in the three orthogonal planes, we extended the LBP encoding to the cube space and proposed Local Cube Binary Patterns (LCBP) for ME recognition [
21]. LCBP concatenated the feature histograms of direction, amplitude, and central difference to obtain spatiotemporal features, which reduces the feature dimension while preserving the spatiotemporal information. In addition to calculating the sign of pixel differences, Huang et al. [
22] proposed a Spatiotemporal Local Binary Pattern with an Integral Projection (STLBP-IP), which is an integral projection method based on differential images. It obtains the horizontal and vertical projections while retaining the shape attributes of the face image, which enriches the time domain representation but loses some spatial details. To address this issue, they further proposed a Discriminative Spatiotemporal Local Binary Pattern with Revisited Integral Projection (DISTLBP-RIP) by incorporating the shape attribute into the spatiotemporal representations [
23].
The LBP technique is more effective than the optical flow technique and therefore has a broader application. The coding patterns of existing methods are based on capturing time-domain information in three orthogonal planes. For these reasons, the motion cues in other directions, and the temporal correlation between adjacent frames are ignored to some extent. Although the LBP-based approach provides a refined description of the local texture, the relationship between different local regions and the relationship between the same local locations in different temporal sequences can still not be disregarded. Additionally, the higher feature dimensions and the redundancy of representations also constrain the model’s recognition performance. Based on the above discussion, it is not surprising to see that research on ME recognition based on LBP technology still has great promise. In particular, an effective combination of multiple coding patterns and correlation modeling between descriptors will make the results of the ME recognition approach more compelling.
In recent years, with its advantages of avoiding manual function design, the success of deep learning in a wide range of applications has been witnessed. Many researchers have tried to apply deep learning techniques to the field of ME recognition. Khor et al. [
24] proposed an Enriched Long-term Recurrent Convolutional Network to predicted MEs. The network contains two variants of an Enriched LRCN model, including the channel-wise stacking of input data for spatial enrichment and the feature-wise stacking of features for temporal enrichment. However, due to the limited training data of the ME dataset, early attempts based on deep learning are difficult to achieve competitive performance. In order to leverage the limited data, Wang et al. [
25] proposed a Transferring Long-term Convolutional Neural Network (TLCNN) to identify MEs. TLCNN used two-step transfer learning to solve the issue: (1) transfer from expression data, and (2) transfer from a single frame of ME video clips. Li et al. [
26] developed a 3D-CNN model to extract high-level features, which uses optical flow images and gray-scale images as input data, thereby alleviating the issue of limited training samples. In addition, some studies mainly focus on the improvement of deep learning models to achieve better performance. Yang et al. [
27] proposed a cascade structure of three VGG-NETs and a Long Short-Term Memory (LSTM) network LSTM, and integrated three different attention models in the spatial-domain. Song et al. [
28] developed a Three-stream Convolutional Neural Network (TSCNN) by encoding the discriminative representations in three key frames. TSCNN consisted of a dynamic-temporal stream, static-spatial stream, and local-spatial stream module, which are used to capture the characteristics of temporal, entire facial region, and local facial region, respectively.
Indeed, the application of deep learning has provided an important boost to the study of ME recognition. Although deep learning models have been applied in studies of ME recognition with good results in some studies, the limited sample size still constrains the maximization of its potential. According to some reports, the main problem for researchers with deep learning models is in dealing with limited training data. Moreover, due to the trigger mechanism and spontaneity of MEs, it is extremely complex to construct large datasets for ME recognition tasks by deliberately controlling the subtle movements of facial muscles.
In accordance with the above discussion, the main idea of our solution is adequately extending the advantages of binary patterns to the time-domain for capturing rich facial movements, which is the key to ME recognition algorithms. For this purpose, three important issues need to be considered. To begin with, a suitable binary feature descriptor needs to be developed for the ME recognition task. Maintaining this binary encoding pattern with its theoretical simplicity, high computational efficiency, and excellent spatial texture representation capabilities is important. Unlike the traditional LBP-TOP, simply extending to the three orthogonal planes cannot capture the expected spatiotemporal variation. Due to the demand for spatiotemporal information for the ME recognition, we developed spatial and temporal descriptors emphasizing the complementary properties of the temporal and spatial domains. The proposed Enhanced LCBP integrates spatial differences, temporal directions, and temporal intensity changes in local regions, which aims to provide more evidence of facial action to predict MEs.
Second, Enhanced LCBP requires capturing local representations by division grids. Within this context, it is necessary to consider not only the relationships between the local regions triggered by MEs, but also the redundancy of information caused by the fusion of multiple descriptors. For this purpose, to enhance the sparsity and discriminability of the representation, the Multi-Regional Joint Sparse Learning is proposed to implement feature selection between different grids. Specifically, to prevent over-fitting caused by the high-dimensional vector, the -norm penalty term is fused in the group sparse regularizer so that the different groups have similar sparse patterns. At the same time, interclass distance constraint is introduced to enhance the discriminative power of the sparse representations in feature space.
Third, the existing literature [
29] reports that the kernel method is an effective way to solve the problem of nonlinear model analysis. However, for ME data, the classifier consisting of a single kernel function does not meet the practical needs of the sample data with uneven distribution of emotion categories and inflexible feature mapping capabilities. Therefore, it is a better choice to combine the different sparse representations separately through a multi-kernel SVM to obtain an optimal result.
To summarize, the contribution of this paper is presented as follows:
- (1)
In order to achieve our goal of fully exploiting the implied spatiotemporal information, an Enhanced LCBP binary descriptor is proposed that encodes subtle changes from different aspects, including spatial differences, temporal directions, and temporal intensity changes. Our research focuses on extracting the complementary features by integrating the spatial and temporal descriptors, thereby obtaining richer temporal variations that are robust to subtle facial action. With the help of descriptors, it is possible to provide binary representations containing more detail changes in the spatiotemporal domain, thus the discriminatory information implicit in the image sequence could be revealed;
- (2)
Second, to alleviate the interference of high-dimensional vectors on the learning algorithm, the Multi-Regional Joint Sparse Learning is designed to conduct feature selection, and thereby the discriminatory power of the representation is enhanced. Moreover, the proposed feature selection model can effectively model the intrinsic correlation among local regions, which can be utilized to focus the attention on important local regions, thus clearly describing the local spatial changes triggered by facial MEs;
- (3)
Sparse representations of spatial and temporal domains are mapped to different kernel spaces, aiming to exploit the different mapping capabilities of the individual kernel, which are further integrated into the synthetic kernel space. This takes full advantage of the more accurate and powerful classification capabilities of the multi-kernel SVM, especially for the fusion of multiple descriptors in our model, whose benefits are clear.
4. Experiments and Analysis
4.1. Datasets
To verify the effectiveness of the proposed method, the proposed algorithm will be evaluated in four spontaneous ME databases, including Spontaneous Micro-Expression Database (SMIC) [
35], Chinese Academy of Sciences Micro-expression (CASME-I) [
36], Chinese Academy of Sciences Micro-expression2 (CASME-II) [
37], and Spontaneous Micro-facial Movement Dataset (SAMM) [
38].
Table 1 shows the detailed properties of the four databases.
SMIC contains 164 ME videos across 16 subjects. All samples are classified into three categories, i.e., Positive (51 samples), Negative (70 samples), and Surprising (43 samples). SMIC data are available in three versions: high-speed camera (HS) version at 100 fps, normal vision camera (VIS) version at 25 fps, and near-infrared camera (NIR) version at 25 fps. In this paper, the HS samples are used for experiments.
CASME-I contains 195 ME video clips from 19 subjects. All samples are coded with the onset frames, apex frames and offset frames, and marked with action units (AUs) and expression states. There are eight classes of MEs in this database, i.e., Tense, Disgust, Repression, Surprise, Happiness, Fear, Sadness, and Contempt. Due to the limited sample size in the categories of Happiness, Fear, Contempt, and Sadness, we chose the remaining four categories: Tension (69 samples), Disgust (44 samples), Repression (38 samples), and Surprise (20 samples) for the experiment.
CASME-II is an updated version of CASME-I and contains 247 ME videos from 26 subjects. All samples were classified into seven classes, i.e., Disgust, Repression, Surprise, Happiness, Others, Fear, and Sadness, and all samples were also marked with onset frame, apex frame, offset frame, and action units (AUs). The temporal resolution of CASME-II was improved from 60 fps in CASME-I to 200 fps. The spatial resolution has also improved, with a partial face resolution of 280 × 340. Because of the limited sample size in the Fear and Sadness groups, the remaining five classes were selected for the experiment, i.e., Disgust (64 samples), Repression (27 samples), Surprise (25 samples), Happiness (32 samples), and Others (99 samples).
SAMM database contains 159 ME video clips from 29 subjects. All samples were recorded at a time resolution of 200 frames per second. These samples were divided into seven AU based objective classes. For the convenience of the comparison with our previous research, the samples used for the experiment were divided into five classes based on the emotional link of AUs in FACS, which consisted of Happiness (24 samples), Surprise (13 samples), Anger (20 samples), Disgust (8 samples), and Sadness (3 samples).
4.2. Implementation Details
For the convenience in the analysis of the results, our implementation follows the same data pre-processing and evaluation protocol as in the previous work:
- (1)
pre-cropped video frames provided in SMIC, CASME, and CASME-II were used as experimental data. For images in SAMM, facial images are extracted using the Dlib face detection [
39] and resized to a uniform image resolution of 128 × 128;
- (2)
due to the different time lengths of these four datasets, the temporal interpolation model (TIM) [
40] is used to fix the time length of the image sequence to 20;
- (3)
leave-one-subject-out (LOSO) cross-validation [
41] is used to evaluate the performance of the model. Specifically, all samples from a subject are used as a test set, and the rest are used for training. LOSO cross-validation ensures that the same subject samples are not duplicated in the training and test sets, improving sample-efficiency while ensuring the reliability of results;
- (4)
overall recognition accuracy and F1 scores are used to evaluate the performance of the model. Recognition accuracy can be calculated by the following equation:
where
indicates the number of correct predictions of each subject,
represents the total number of samples for each subject, and
denotes the number of subjects. In addition, the F1 score is used to reveal the classifier’s recognition performance for each category due to the imbalance of sample distribution in the MEs dataset. The F1 score can be calculated as:
where
and
are the precision and recall of the
ME class, respectively, and c is the number of MEs classes.
4.3. Parameter Evaluation
The binary feature histogram of Enhanced LCBP consists of three complementary spatial and temporal descriptors, i.e., Spatial Difference LCBP, Temporal Direction LCBP, Temporal Gradient LCBP.
Table 2 presents the experimental results of different combinations of the spatial and temporal descriptors on CASME-II. The results are obtained using 8 × 8 grid division parameters. The experimental model of combining different descriptors do not contain the Multi-Regional Joint Sparse Learning and are implemented using the SVM classifier. Spatial Difference LCBP is mainly responsible for capturing the spatial features in the cube space, while describing the spatial difference between different frames. In the single descriptor experiment, the recognition rate of using Spatial Difference LCBP is only 56.09%, which is due to the fact that the key to the ME recognition task is to extract temporal variation. The Spatial Difference LCBP is employed as an auxiliary binary descriptor to help Enhanced LCBP enrich the spatial representation. As the time-domain feature descriptor, Temporal Direction LCBP shows better recognition results in the single descriptor experiment. The accuracy is 5.7% higher than using Spatial Difference LCBP alone. Besides, the results reveal that the combination of Temporal Direction LCBP and Temporal Gradient LCBP can effectively integrate the motion direction with the motion tendency, with an improvement of 4.88% compared with a single Temporal Direction LCBP descriptor. This improvement evidences that the combined result of Temporal Direction LCBP and Temporal Gradient LCBP are enhanced for time-domain feature extraction. Moreover, the recognition rate obtained by the combination of Temporal Direction LCBP and Spatial Difference LCBP is not significant compared with that obtained by a single Temporal Direction LCBP descriptor. However, the combined results of the Temporal Direction LCBP and Spatial Difference LCBP are not significantly improved. It shows that the ability to capture time-domain features has a significant impact on the performance of the model. The recognition rate reaches 69.10% with the combination of three descriptors fusion and an SVM classifier. Such a result is consistent with our assumption that fusing spatiotemporal features provides a more detailed representation of subtle changes. The results for all three descriptor combinations are significantly improved compared with a single descriptor or any combination of the two.
In addition, there are three parameters that need to be adjusted in the objective function of our proposed Multi-Regional Joint Sparse Learning, i.e.,
,
and
. This is because these three parameters balance the relative contributions of the group sparse regular term and the constraint term of interclass distance. Therefore, the effect of different parameter settings on classification performance needs to be studied in terms of parameter selection. Specifically,
and
vary in the range of
and
in the range of
. The parameter setting strategy is to adjust the remaining two parameters by first fixing the value to one parameter. First, the value of
is fixed to 0.1, and we change
and
within their respective adjustable ranges. Then we fix
to 0.1 and change
and
within their respective adjustable ranges. Finally, we fix the value of
to 0.1 and change the remaining two parameters in the corresponding adjustable ranges. The experiments are implemented based on CASME-II, and the grid division parameter is set to 8 × 8. The classifier employs the multi-kernel SVM. The histogram of the recognition accuracy with the variation of parameters is shown in
Figure 7. The results show slight fluctuations when the proposed method fixes one parameter and adjusts the remaining two parameters, indicating that our method is not sensitive to the variation in parameter values.
Furthermore, since grid division parameters affect model performance, fewer grids result in insufficient location information and detailed changes, while excessive grids may bring the noise. Therefore, we discuss the impact of different grid division parameters on recognition performance. The experimental result is shown in
Table 3. The optimal results in CASME-I and CASME-II are obtained using the 8 × 8 grid division parameters. The best results in SMIC and SAMM databases are obtained using 6 × 6 grid division parameters. It can be seen that the differences in the results among different grid delineation parameters are within acceptable ranges.
4.4. Comparison with Other State-of-the-Art Methods
To assess the performance of the proposed method, we compared the results with other mainstream approaches based on four published datasets.
Figure 8 illustrates the LOSO recognition results obtained by our method in four datasets. The horizontal coordinates in the figure represent the different subjects, and the vertical coordinates represent the recognition rate obtained by each subject. The results show that half of the subjects in CASME-I, SAMM, and SMIC achieved 100% recognition rate. Although the number of subjects that achieved 100% accuracy rate in CASME-II is less than half the total, the prediction accuracy rate for all subjects exceeded 60%. Meanwhile, due to the small sample size of some testing sets in SAMM, this resulted in subject 7 recognizing one correct sample and thus achieving the 50% accuracy rate. By further calculating the average accuracy of the LOSO results obtained for each dataset, it can be concluded that CASME-I: 88.70%, CASME-II: 82.90%, SMIC: 87.72%, and SAMM: 88.12%. It can be seen that the average LOSO recognition rate of the four datasets exceeded 80%, indicating the good reliability and accuracy of our method.
Based on the LOSO results obtained by the proposed method, the confusion matrix is calculated to assess the model’s recognition performance for each category. As shown in
Figure 9, the proposed method has a higher prediction accuracy for the Negative in SMIC compared with the others. The same situation occurs with the Tense in CASME-I and Others in CASME-II. This is owing to the fact that ME recognition datasets all suffer from unbalanced class distribution, and these expression categories with larger sample sizes are more likely to receive attention from classification algorithms. It can be seen that SMIC has the smallest accuracy difference among categories, which is attributed to the fact that the unbalanced class distribution is more severe in all three remaining databases. The unbalanced class distribution poses significant challenges to the classification algorithm. However, the results show that the performance gaps of different categories are mitigated compared with our previous study [
21]. The discriminability of weighted features is enhanced by the term of interclass distance constraint in the objective function, which helps to reduce the interclass accuracy gap. Our model guarantees a recognition rate of more than half for different categories. The difference in accuracy among the categories is within an acceptable range.
Finally, we compare the best results obtained by our method with the baseline method and the other representative algorithms. Since the performance of different protocols varies substantially, we only compare methods that use the same LOSO strategy. The baseline methods include LBP-TOP [
18] and LBP-SIP [
20], which use the same grid division parameters as our method. The time-domain radius of LBP-TOP is set to 2, and the number of sampling points is set to 8. The asterisk (*) indicates that we are using the experimental results reported from corresponding literature. The results of the comparison are shown in
Table 4. The proposed method achieves better recognition rates in four datasets than the other algorithms. Our method achieved 78.23% and 78.45% recognition accuracy in the CASME-I and CASME-II, and 79.26% and 79.41% recognition rates in the SMIC and SAMM, respectively. Compared with the baseline approach, the proposed method shows superior performance. Compared with the optical-flow-based methods Sparse MDMO [
15] and Bi-WOOF+Phase [
42], our method exhibits an accuracy improvement of 11.5% and 15.9% in CASME-II, respectively. The proposed method improved the accuracy of CASME-II by 4.51% and 8.35%, respectively, compared with the results reported by the recent handcrafted methods ELBPTOP [
43] and LCBP [
21]. This advantage is facilitated by the fact that the Enhanced LCBP consisted of spatial and temporal descriptors focused on capturing spatiotemporal information. Moreover, the combination of Multi-Regional Joint Sparse Learning allows the use of relevant information between different regions, which helps select more discriminating features.
Table 5 compares the F1-scores of our method, LBP-TOP, and LCBP in all four datasets. The results show that our method is better than the other two methods in four aspects. Compared with LCBP, the proposed method improved F1 scores in SMIC and CASME-II by 0.1162 and 0.0547, respectively, proving that the improvement of the proposed method is effective compared with our previous study.
Table 6 summarizes our approach in comparison to the deep learning approach in the CASME-II and SMIC. In contrast to the deep learning approach, our method still shows an advantage in terms of recognition rate and F1 score. It can be demonstrated through the above comparative experiments that our method is valid for the ME recognition task.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}