Towards a Multi-Layered Phishing Detection



Abstract
:1. Introduction
- We propose a framework to detect active phishing attacks. The framework follows a two-layered approach to identify phishing domains based on supervised machine learning. We implement and evaluate the framework on a dataset that we created based on 5995 phishing and 7053 benign domains.
- We suggest and utilise features in each layer of the framework that have been used in the literature as well as propose a new feature for layer two. We discuss their ability to resist tampering from a threat actor who is trying to circumvent the classifiers, e.g., by typosquatting.
2. Background
2.1. Detection Methods
2.2. JDL Model
3. Related Work
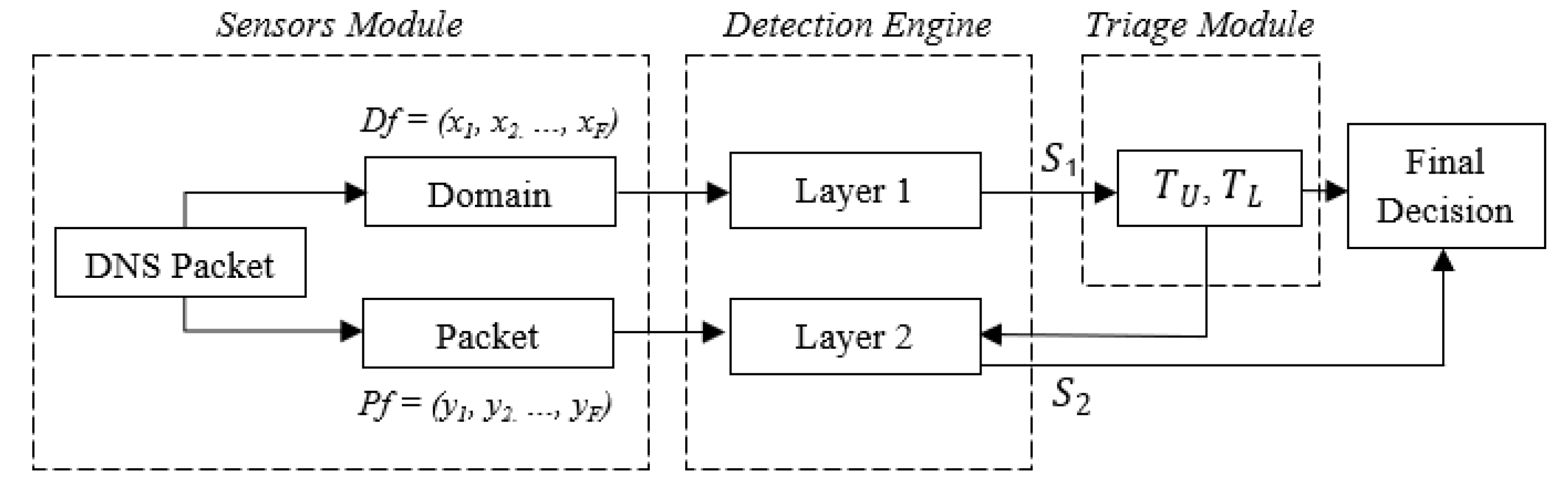
4. Two-Layered Phishing Detection Framework
4.1. Approach
4.2. Feature Selection
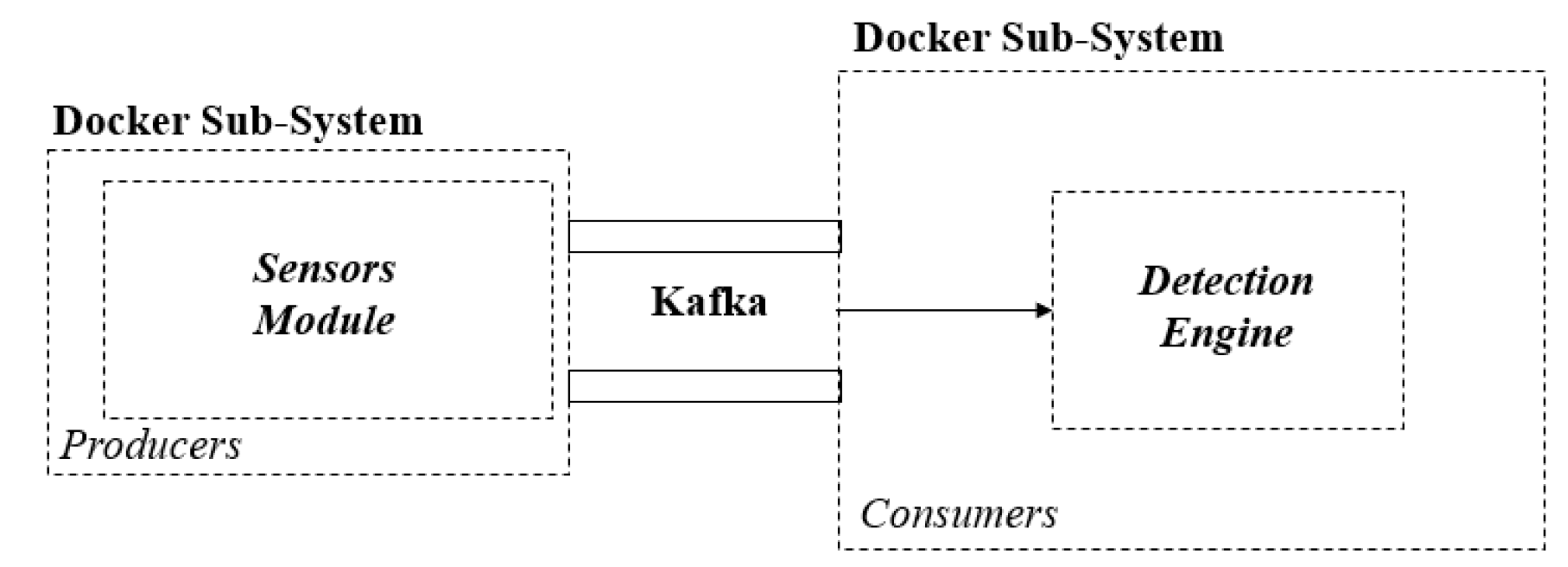
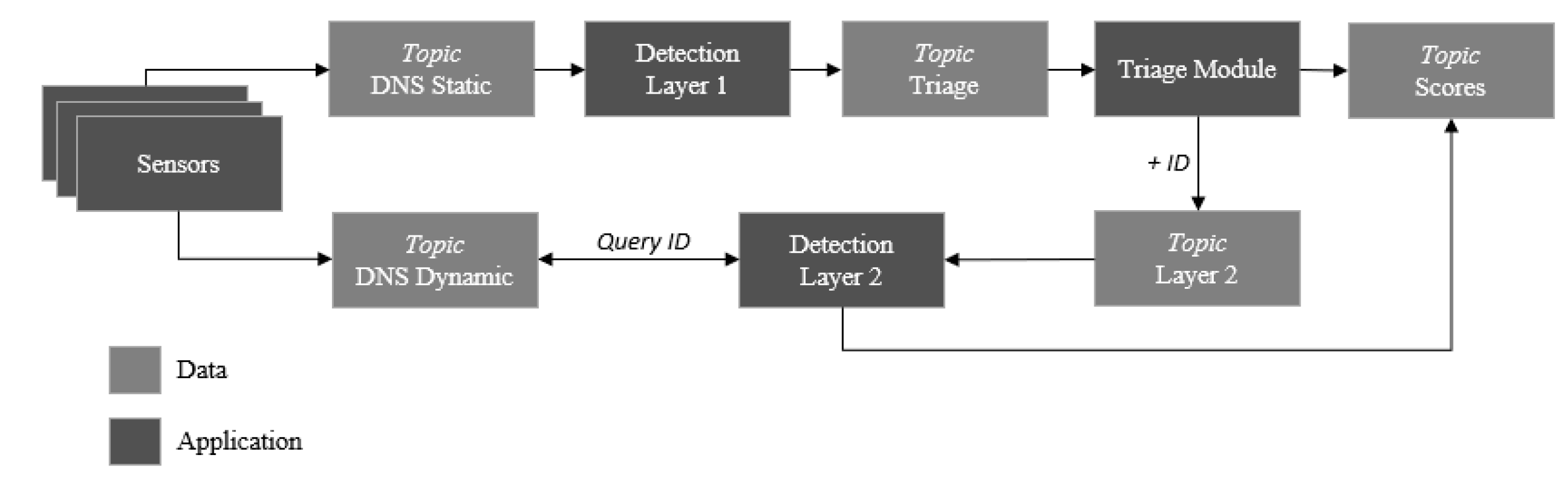
5. Implementation
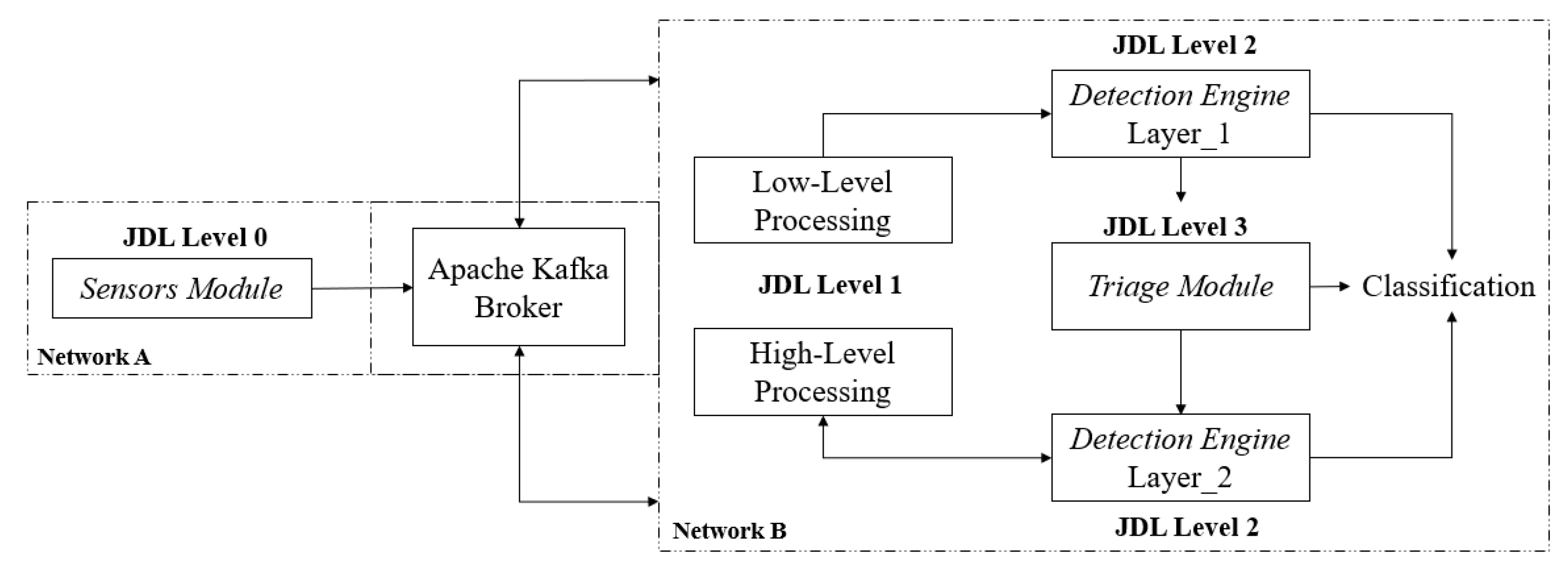
- Level 0—the collection of signal-level data for early pre-processing as part of the Sensor Module. Herein, the data is collected from a sensor that is deployed as an agent on user devices. Then, the necessary packet data aggregation is performed to enable further processing. This allows the preservation of user privacy by only forwarding the relevant data across the network via a data streaming technology.
- Level 1—Object Assessment/Refinement. In this level, which is also included in the Sensor Module, the identification and extraction of features in the data output from Level 0 take place. Our system uses a layered approach during detection, and therefore data fusion will occur as per the response of the Triage Module and might include the collection of external data sources, such as WHOIS, to refine the objects’ state, i.e., the creation of a domain date.
- Level 2—Situation Assessment/Refinement. This includes both layers of the Detection Engine and involves the detection of unusual characteristics concerning objects of interest, i.e., Domain Name System features, to achieve phishing recognition.
- Level 3—Impact Assessment. The Triage Module uses the Layer 1 classification as a feature whereby the decision boundary represents a level of reasoning. The reasoning works to capture behaviour relations to the initial object under classification as part of the fusion to create alerts.
Experimental Setup
6. Evaluation
6.1. Data Collection
6.2. Results
7. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hutchins, E.; Cloppert, M.; Amin, R. Intelligence-Driven Computer Network Defense Informed by Analysis of Adversary Campaigns and Intrusion Kill Chains. Lead. Issues Inf. Warf. Secur. Res. 2011, 1, 80. [Google Scholar]
- MITRE ATT&CK. Spearphishing Link; The MITRE Corporation, 2019. Available online: https://attack.mitre.org/wiki/Technique/T1192 (accessed on 24 February 2020).
- Singleton, C.; Carruthers, S. State of the Phish: IBM X-Force Reveals Current Phishing Attack Trends; IBM: New York, NY, USA, 2020; Available online: https://securityintelligence.com/posts/state-of-the-phish-ibm-x-force-reveals-current-phishing-attack-trends/ (accessed on 13 May 2020).
- Virvilis, N.; Tsalis, N.; Mylonas, A.; Gritzalis, D. Mobile Devices: A Phisherźs Paradise. In Proceedings of the 11th International Joint Conference on e-Business and Telecommunications, Vienna, Austria, August 2014; Science and Technology Publications: Setubal, Portugal, 2014; Volume 4, pp. 79–87. [Google Scholar]
- Virvilis, N.; Mylonas, A.; Tsalis, N.; Gritzalis, D. Security Busters: Web browser security vs. rogue sites. Comput. Secur. 2015, 52, 90–105. Available online: https://linkinghub.elsevier.com/retrieve/pii/S0167404815000590 (accessed on 12 August 2020). [CrossRef] [Green Version]
- Aonzo, S.; Merlo, A.; Tavella, G.; Fratantonio, Y. Phishing Attacks on Modern Android. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security (CCS ’18), January 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1788–1801. [Google Scholar]
- World Health Organisation. WHO Reports Fivefold Increase in Cyber Attacks, Urges Vigilance; World Health Organisation: Geneva, Switzerland, 2020; Available online: https://www.who.int/news-room/detail/23-04-2020-who-reports-fivefold-increase-in-cyber-attacks-urges-vigilance (accessed on 7 August 2020).
- Seals, T. WHO Targeted in Espionage Attempt, COVID-19 Cyberattacks Spike. Threatpost. 2020. Available online: https://threatpost.com/who-attacked-possible-apt-covid-19-cyberattacks-double/154083/ (accessed on 14 May 2020).
- Lanois, P. ICO proposes fines against British Airways and Marriott; Fieldfisher: London, UK, 2019; Available online: https://www.fieldfisher.com/en/services/privacy-security-and-information/privacy-security-and-information-law-blog/ico-proposes-fines-against-british-airways-and-marriott (accessed on 14 May 2020).
- Webroot. Webroot Quarterly Threat Update: 84% of Phishing Sites Exist for Less Than 24 Hours; Webroot: Broomfield, CO, USA, 2016; Available online: https://www.webroot.com/in/en/about/press-room/releases/quarterly-threat-update-about-phishing (accessed on 10 May 2020).
- Le Page, S.; Jourdan, G.-V.; Bochmann, G.V.; Flood, J.; Onut, I.-V. Using URL shorteners to compare phishing and malware attacks. In 2018 APWG Symposium on Electronic Crime Research (eCrime), San Diego, CA, USA, 15–17 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–13. Available online: https://ieeexplore.ieee.org/document/8376215/ (accessed on 26 April 2020).
- Das, A.; Baki, S.; El Aassal, A.; Verma, R.; Dunbar, A. SoK: A Comprehensive Reexamination of Phishing Research From the Security Perspective. IEEE Commun. Surv. Tutor. 2020, 22, 671–708. Available online: https://ieeexplore.ieee.org/document/8924660/ (accessed on 12 August 2020). [CrossRef] [Green Version]
- Tyagi, I.; Shad, J.; Sharma, S.; Gaur, S.; Kaur, G. “A Novel Machine Learning Approach to Detect Phishing Websites,”. In Proceedings of the 5th International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 22–23 February 2018; pp. 425–430. [Google Scholar]
- Jain, A.K.; Gupta, B.B. Phishing Detection: Analysis of Visual Similarity Based Approaches. Secur. Commun. Netw. 2017, 2017, 1–20. Available online: https://www.hindawi.com/journals/scn/2017/5421046/ (accessed on 12 August 2020). [CrossRef] [Green Version]
- Yan, X.; Xu, Y.; Cui, B.; Zhang, S.; Guo, T.; Li, C. Learning URL Embedding for Malicious Website Detection. IEEE Trans. Ind. Inform. 2020, 16, 6673–6681. Available online: https://ieeexplore.ieee.org/document/9022897/ (accessed on 12 August 2020). [CrossRef]
- Jeeva, S.C.; Rajsingh, E.B. Intelligent phishing url detection using association rule mining. Hum. Cent. Comput. Inf. Sci. 2016, 6, 10. Available online: http://hcis-journal.springeropen.com/articles/10.1186/s13673-016-0064-3 (accessed on 12 August 2020). [CrossRef] [Green Version]
- Hara, M.; Yamada, A.; Miyake, Y. Visual similarity-based phishing detection without victim site information. In 2009 IEEE Symposium on Computational Intelligence in Cyber Security, Nashville, TN, USA, 30 March-2 April 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 30–36. Available online: http://ieeexplore.ieee.org/document/4925087/ (accessed on 25 April 2020).
- Bridges, R.A.; Glass-Vanderlan, T.R.; Iannacone, M.D.; Vincent, M.S.; Chen, Q. (Guenevere). A Survey of Intrusion Detection Systems Leveraging Host Data. ACM Comput. Surv. 2020, 52, 1–35. [Google Scholar] [CrossRef] [Green Version]
- Monzer, M.H.; Beydoun, K.; FLAUS, J.-M. Model based rules generation for Intrusion Detection System for industrial systems. In 2019 International Conference on Control, Automation and Diagnosis (ICCAD); IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. Available online: https://ieeexplore.ieee.org/document/9037882/ (accessed on 12 August 2020).
- Casas, P.; Mazel, J.; Owezarski, P. Unsupervised Network Intrusion Detection Systems: Detecting the Unknown without Knowledge. Comput. Commun. 2012, 35, 772–783. Available online: https://linkinghub.elsevier.com/retrieve/pii/S0140366412000266 (accessed on 12 August 2020). [CrossRef] [Green Version]
- Bhuyan, M.H.; Bhattacharyya, D.K.; Kalita, J.K. A multi-step outlier-based anomaly detection approach to network-wide traffic. Inf. Sci. 2016, 348, 243–271. Available online: https://linkinghub.elsevier.com/retrieve/pii/S0020025516300779 (accessed on 12 August 2020). [CrossRef]
- Salunkhe, U.R.; Mali, S.N. Security Enrichment in Intrusion Detection System Using Classifier Ensemble. J. Electr. Comput. Eng. 2017, 2017, 1–6. Available online: https://www.hindawi.com/journals/jece/2017/1794849/ (accessed on 12 August 2020). [CrossRef]
- Stergiopoulos, G.; Talavari, A.; Bitsikas, E.; Gritzalis, D. Automatic Detection of Various Malicious Traffic Using Side Channel Features on TCP Packets. In Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; pp. 346–362. Available online: http://link.springer.com/10.1007/978-3-319-99073-6_17 (accessed on 12 August 2020).
- Aloqaily, M.; Otoum, S.; Al Ridhawi, I.; Jararweh, Y. An intrusion detection system for connected vehicles in smart cities. Ad Hoc Netw. 2019, 90, 101842. Available online: https://linkinghub.elsevier.com/retrieve/pii/S1570870519301131 (accessed on 12 August 2020). [CrossRef]
- Du, M.; Chen, Z.; Liu, C.; Oak, R.; Song, D. Lifelong Anomaly Detection Through Unlearning. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; ACM: New York, NY, USA, 2019; pp. 1283–1297. [Google Scholar] [CrossRef]
- Mudgerikar, A.; Sharma, P.; Bertino, E. E-Spion: A System-Level Intrusion Detection System for IoT Devices. In Proceedings of the 2019 ACM Asia Conference on Computer and Communications Security, Auckland, New Zealand, 7–12 July 2019; ACM: New York, NY, USA, 2019; pp. 493–500. [Google Scholar] [CrossRef]
- Sabeur, Z.; Zlatev, Z.; Melas, P.; Veres, G.; Arbab-Zavar, B.; Middleton, L.; Museux, N. Large Scale Surveillance, Detection and Alerts Information Management System for Critical Infrastructure. In IFIP Advances in Information and Communication Technology; Springer: Cham, Switzerland, 2017; pp. 237–246. Available online: http://link.springer.com/10.1007/978-3-319-89935-0_20 (accessed on 12 August 2020).
- Giacobe, N.A. Application of the JDL data fusion process model for cyber security. Proceedings of SPIE—The International Society for Optical Engineering, Orlando, FL, USA, 28 April 2010; Braun, J.J., Ed.; p. 77100R. [Google Scholar] [CrossRef]
- Li, Y.; Xiong, K.; Chin, T.; Hu, C. A Machine Learning Framework for Domain Generation Algorithm-Based Malware Detection. IEEE Access 2019, 7, 32765–32782. Available online: https://ieeexplore.ieee.org/document/8631171/ (accessed on 12 August 2020). [CrossRef]
- Chu, W.; Zhu, B.B.; Xue, F.; Guan, X.; Cai, Z. Protect sensitive sites from phishing attacks using features extractable from inaccessible phishing URLs. In 2013 IEEE International Conference on Communications (ICC); IEEE: Piscataway, NJ, USA, 2013; pp. 1990–1994. Available online: http://ieeexplore.ieee.org/document/6654816/ (accessed on 2 April 2020).
- Sonowal, G.; Kuppusamy, K.S. PhiDMA—A phishing detection model with multi-filter approach. J. King Saud Univ. Comput. Inf. Sci. 2020, 32, 99–112. Available online: https://linkinghub.elsevier.com/retrieve/pii/S1319157817301210 (accessed on 12 August 2020). [CrossRef]
- Bell, S.; Komisarczuk, P. An Analysis of Phishing Blacklists: Google Safe Browsing, OpenPhish, and PhishTank. In Proceedings of the Australasian Computer Science Week Multiconference, February 2020; ACM: New York, NY, USA, 2020; pp. 1–11. [Google Scholar] [CrossRef] [Green Version]
- Tidy, J. Google blocking 18m coronavirus scam emails every day. BBC News. 2020. Available online: https://www.bbc.co.uk/news/technology-52319093 (accessed on 23 May 2020).
- Phishlabs. 2018 PHISHING TRENDS AND INTELLIGENCE REPORT; Phishlabs: Charleston, SC, USA, 2018. [Google Scholar]
- Aburrous, M.; Hossain, M.A.; Dahal, K.; Thabtah, F. Intelligent phishing detection system for e-banking using fuzzy data mining. Expert Syst. Appl. 2010, 37, 7913–7921. Available online: https://linkinghub.elsevier.com/retrieve/pii/S0957417410003441 (accessed on 12 August 2020). [CrossRef]
- Abdelhamid, N.; Ayesh, A.; Thabtah, F. Phishing detection based Associative Classification data mining. Expert Syst. Appl. 2014, 41, 5948–5959. Available online: https://linkinghub.elsevier.com/retrieve/pii/S0957417414001481 (accessed on 12 August 2020). [CrossRef]
- Yi, P.; Guan, Y.; Zou, F.; Yao, Y.; Wang, W.; Zhu, T. Web Phishing Detection Using a Deep Learning Framework. Wirel. Commun. Mob. Comput. 2018, 2018, 1–9. Available online: https://www.hindawi.com/journals/wcmc/2018/4678746/ (accessed on 12 August 2020). [CrossRef]
- Blum, A.; Wardman, B.; Solorio, T.; Warner, G. Lexical feature based phishing URL detection using online learning. In Proceedings of the 3rd ACM Workshop on Artificial Intelligence and Security—AISec ’10, Dallas, TX, USA, November 2017; ACM Press: New York, NY, USA, 2010; p. 54. Available online: http://portal.acm.org/citation.cfm?doid=1866423.1866434 (accessed on 5 April 2020).
- Aaron, G.; Rasmussen, R. Global Phishing Survey: Trends and Domain Name Use in 2016; APWG: Lexington, MA, USA, 2017. [Google Scholar]
- Sheridan, S.; Keane, A. Detection of DNS Based Covert Channels. J. Inf. Warf. 2015, 14, 100–114. Available online: www.jstor.org/stable/26487509 (accessed on 12 August 2020).
- Bilge, L.; Sen, S.; Balzarotti, D.; Kirda, E.; Kruegel, C. Exposure: A Passive DNS Analysis Service to Detect and Report Malicious Domains. ACM Trans. Inf. Syst. Secur. 2014, 16, 1–28. [Google Scholar] [CrossRef]
- Zhauniarovich, Y.; Khalil, I.; Yu, T.; Dacier, M. A Survey on Malicious Domains Detection through DNS Data Analysis. ACM Comput. Surv. 2018, 51, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Smadi, S.; Aslam, N.; Zhang, L. Detection of online phishing email using dynamic evolving neural network based on reinforcement learning. Decis. Support Syst. 2018, 107, 88–102. Available online: https://linkinghub.elsevier.com/retrieve/pii/S0167923618300010 (accessed on 12 August 2020). [CrossRef] [Green Version]
- Islam, R.; Abawajy, J. A multi-tier phishing detection and filtering approach. J. Netw. Comput. Appl. 2013, 36, 324–335. Available online: https://linkinghub.elsevier.com/retrieve/pii/S1084804512001397 (accessed on 12 August 2020). [CrossRef]
- Sharma, J.; Giri, C.; Granmo, O.; Goodwin, M. Multi-layer intrusion detection system with ExtraTrees feature selection, extreme learning machine ensemble, and softmax aggregation. EURASIP J. Info. Secur. 2019, 2019, 15. [Google Scholar] [CrossRef] [Green Version]
- Chowdhury, M.U.; Abawajy, J.H.; Kelarev, A.V.; Hochin, T. Multilayer hybrid strategy for phishing email zero-day filtering. Concurr. Comput. Pract. Exp. 2017, 29, e3929. [Google Scholar] [CrossRef]
- Nasr, M.; Shokri, R.; Houmansadr, A. Machine Learning with Membership Privacy using Adversarial Regularization. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; ACM: New York, NY, USA, 2018; pp. 634–646. [Google Scholar] [CrossRef] [Green Version]
- Song, L.; Shokri, R.; Mittal, P. Privacy Risks of Securing Machine Learning Models against Adversarial Examples. In Proceedings of the 2019 ACM SIGSAC Conference on Computer and Communications Security, 11–15 November 2019; ACM: New York, NY, USA, 2019; pp. 241–257. [Google Scholar] [CrossRef] [Green Version]
- Nisioti, A.; Mylonas, A.; Yoo, P.D.; Katos, V. From Intrusion Detection to Attacker Attribution: A Comprehensive Survey of Unsupervised Methods. IEEE Commun. Surv. Tutor. 2018, 20, 3369–3388. Available online: https://ieeexplore.ieee.org/document/8410366/ (accessed on 12 August 2020). [CrossRef]
- Chiew, K.L.; Choo, J.S.-F.; Sze, S.N.; Yong, K.S.C. Leverage Website Favicon to Detect Phishing Websites. Secur. Commun. Netw. 2018, 2018, 1–11. Available online: https://www.hindawi.com/journals/scn/2018/7251750/ (accessed on 12 August 2020). [CrossRef]
- Tupsamudre, H.; Singh, A.K.; Lodha, S. Everything Is in the Name—A URL Based Approach for Phishing Detection. In Cyber Security Cryptography and Machine Learning; Springer: Cham, Switzerland, 2019; pp. 231–248. Available online: http://link.springer.com/10.1007/978-3-030-20951-3_21 (accessed on 12 August 2020).
- Thakur, T.; Verma, R. Catching Classical and Hijack-Based Phishing Attacks. In Information Systems Security; Springer: Cham, Switzerland, 2014; pp. 318–337. Available online: http://link.springer.com/10.1007/978-3-319-13841-1_18 (accessed on 12 August 2020).
- NCSC; CISA. Advisory: COVID-19 Exploited by Malicious Cyber Actors; NCSC: London, UK, 2020. Available online: https://www.ncsc.gov.uk/files/Joint%20Advisory%20COVID-19%20exploited%20by%20malicious%20cyber%20actors%20V1.pdf (accessed on 12 August 2020).
- Chiew, K.L.; Tan, C.L.; Wong, K.; Yong, K.S.C.; Tiong, W.K. A new hybrid ensemble feature selection framework for machine learning-based phishing detection system. Inf. Sci. 2019, 484, 153–166. [Google Scholar] [CrossRef]
- Sahingoz, O.K.; Buber, E.; Demir, O.; Diri, B. Machine learning based phishing detection from URLs. Expert Syst. Appl. 2019, 117, 345–357. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Feature | Type |
|---|---|---|
| 1 | Domain Length | Static |
| 2 | SLD Length | Static |
| 3 | TLD Length | Static |
| 4 | TLD | Static |
| 5 | Number of dots in Domain Name | Static |
| 6 | Domain number to character ratio | Static |
| 7 | Domain Creation Date | Static |
| 8 | Registrar Name | Static |
| 9 | Length of Response | Dynamic |
| 10 | Count of Resource Requests | Dynamic |
| 11 | Count of Resource Responses | Dynamic |
| 12 | Packet Delta | Dynamic |
| 13 | Time to Live (TTL) of the Resource Record | Dynamic |
| Benign | Phishing | Total | |
|---|---|---|---|
| Train | 4937 | 4937 | 9874 |
| Test | 2116 | 1058 | 3174 |
| Total | 7053 | 5995 | 13,048 |
| Algorithm | Features | Precision | Recall | F1-Score | ACC | MCC |
|---|---|---|---|---|---|---|
| Multilayer Perceptron | F1–F6 | 65% | 71% | 68% | 78% | 51% |
| F7–F13 | 69% | 78% | 74% | 81% | 59% | |
| F1–F13 | 83% | 84% | 84% | 89% | 75% | |
| Support Vector Machine | F1–F6 | 70% | 65% | 67% | 79% | 52% |
| F7–F13 | 36% | 97% | 52% | 40% | 15% | |
| F1–F13 | 84% | 82% | 83% | 89% | 75% | |
| Naïve Bayes | F1–F6 | 62% | 61% | 61% | 75% | 42% |
| F7–F13 | 35% | 98% | 52% | 39% | 13% | |
| F1–F13 | 88% | 40% | 55% | 78% | 49% | |
| Decision Trees | F1–F6 | 73% | 60% | 66% | 79% | 52% |
| F7–F13 | 72% | 60% | 66% | 79% | 51% | |
| F1–F13 | 72% | 82% | 77% | 83% | 64% |
| Algorithm | Decision Boundary | Precision | Recall | F1 | ACC | MCC |
|---|---|---|---|---|---|---|
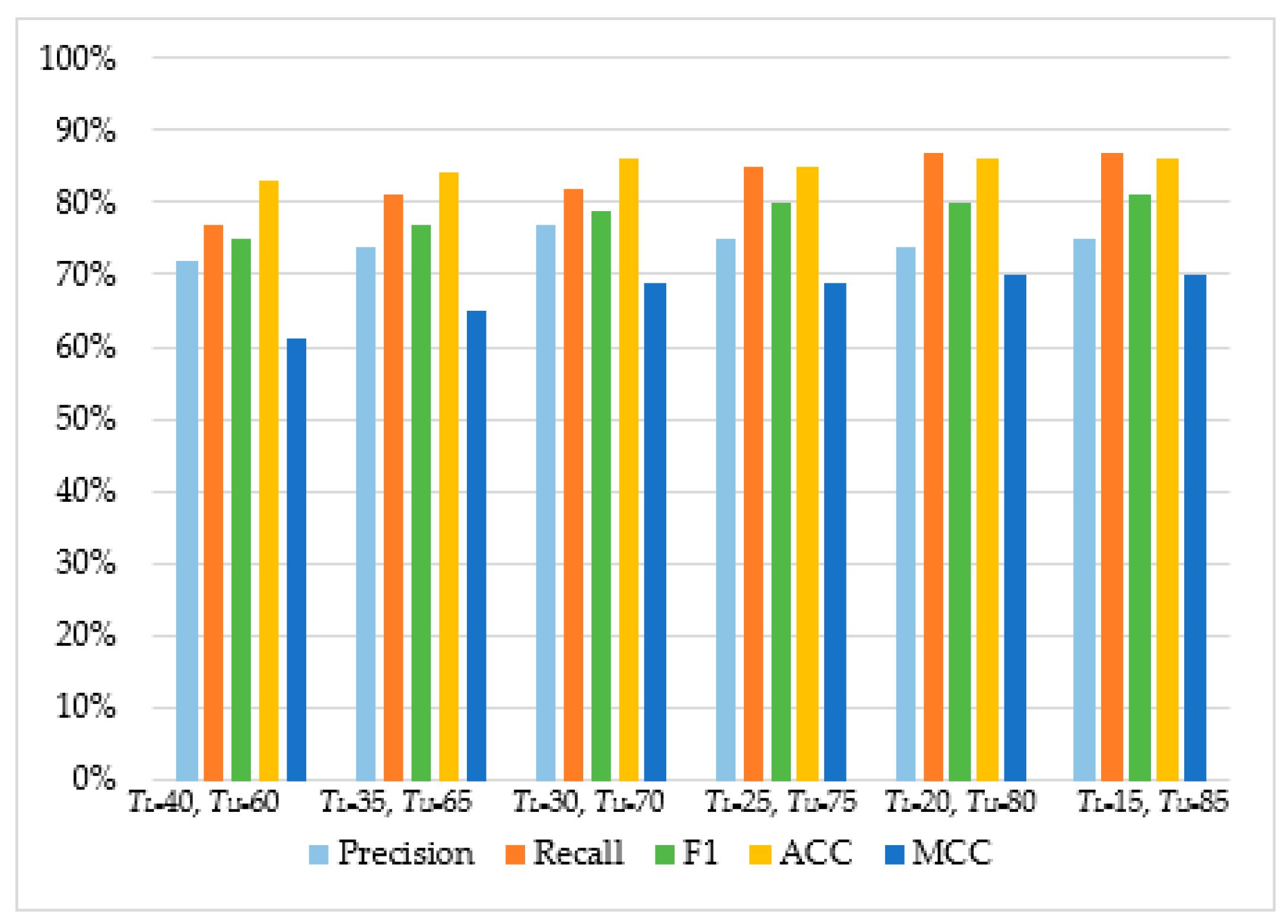
| Multilayer Perceptron | TL = 40, TU = 60 | 72% | 77% | 75% | 83% | 61% |
| TL = 35, TU = 65 | 74% | 81% | 77% | 84% | 65% | |
| TL = 30, TU = 70 | 77% | 82% | 79% | 86% | 69% | |
| TL = 25, TU = 75 | 75% | 85% | 80% | 85% | 69% | |
| TL = 20, TU = 80 | 74% | 87% | 80% | 86% | 70% | |
| TL = 15, TU = 85 | 75% | 87% | 81% | 86% | 70% | |
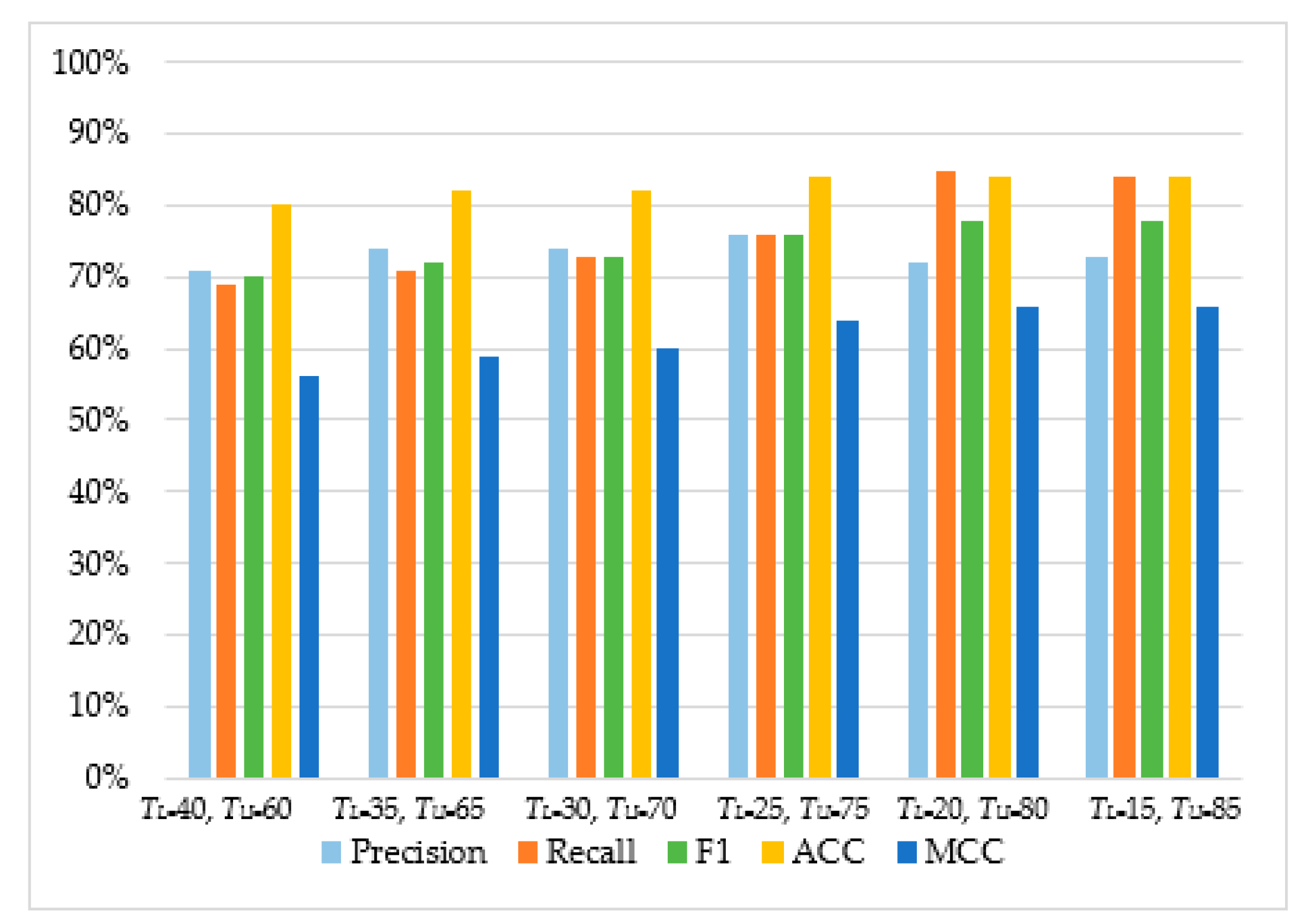
| Support Vector Machine | TL = 40, TU = 60 | 71% | 69% | 70% | 80% | 56% |
| TL = 35, TU = 65 | 74% | 71% | 72% | 82% | 59% | |
| TL = 30, TU = 70 | 74% | 73% | 73% | 82% | 60% | |
| TL = 25, TU = 75 | 76% | 76% | 76% | 84% | 64% | |
| TL = 20, TU = 80 | 72% | 85% | 78% | 84% | 66% | |
| TL = 15, TU = 85 | 73% | 84% | 78% | 84% | 66% | |
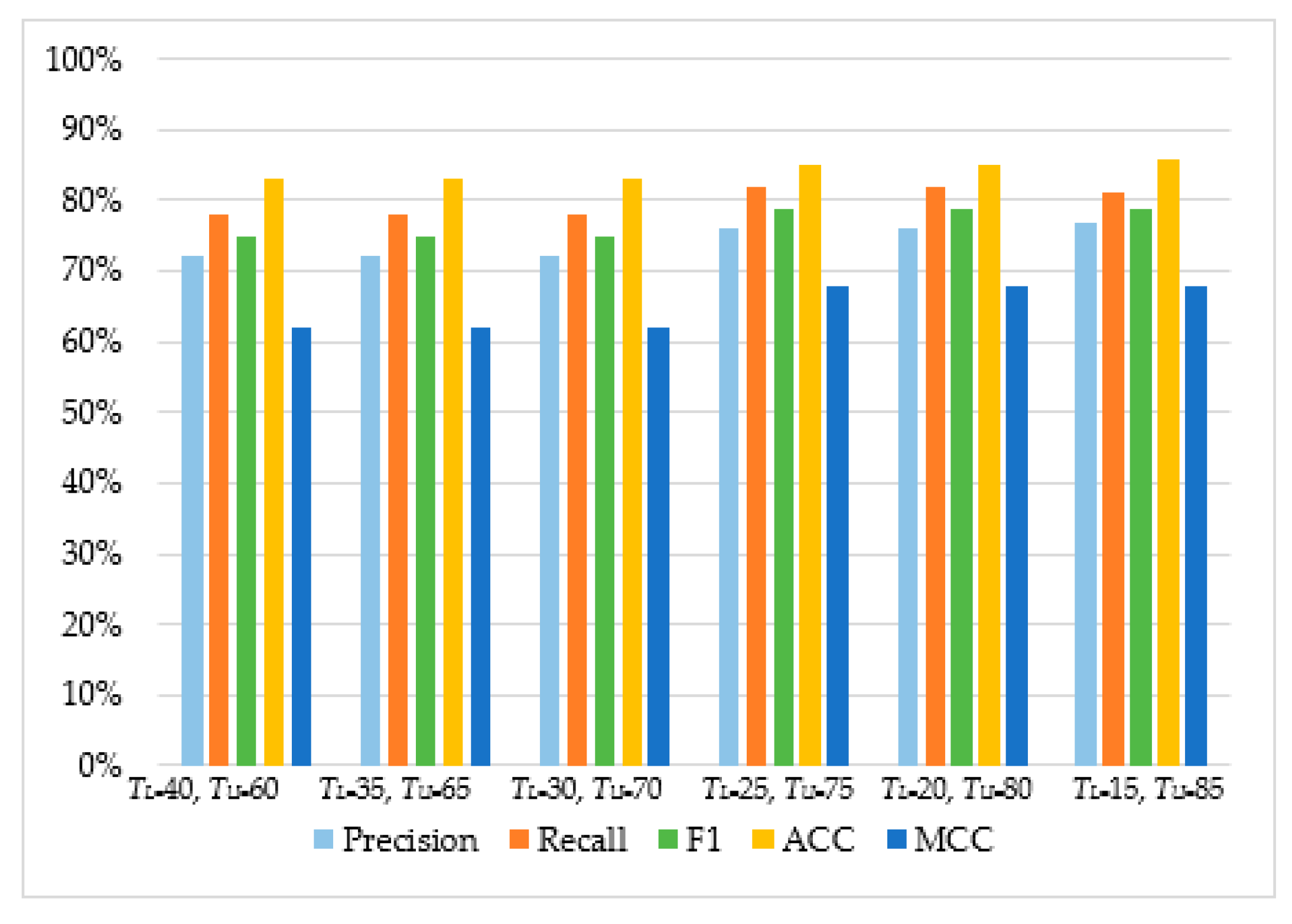
| Naïve Bayes | TL = 40, TU = 60 | 66% | 58% | 61% | 76% | 44% |
| TL = 35, TU = 65 | 70% | 56% | 62% | 77% | 47% | |
| TL = 30, TU = 70 | 73% | 56% | 64% | 79% | 50% | |
| TL = 25, TU = 75 | 74% | 55% | 63% | 79% | 49% | |
| TL = 20, TU = 80 | 78% | 52% | 62% | 79% | 51% | |
| TL = 15, TU = 85 | 79% | 51% | 62% | 79% | 51% | |
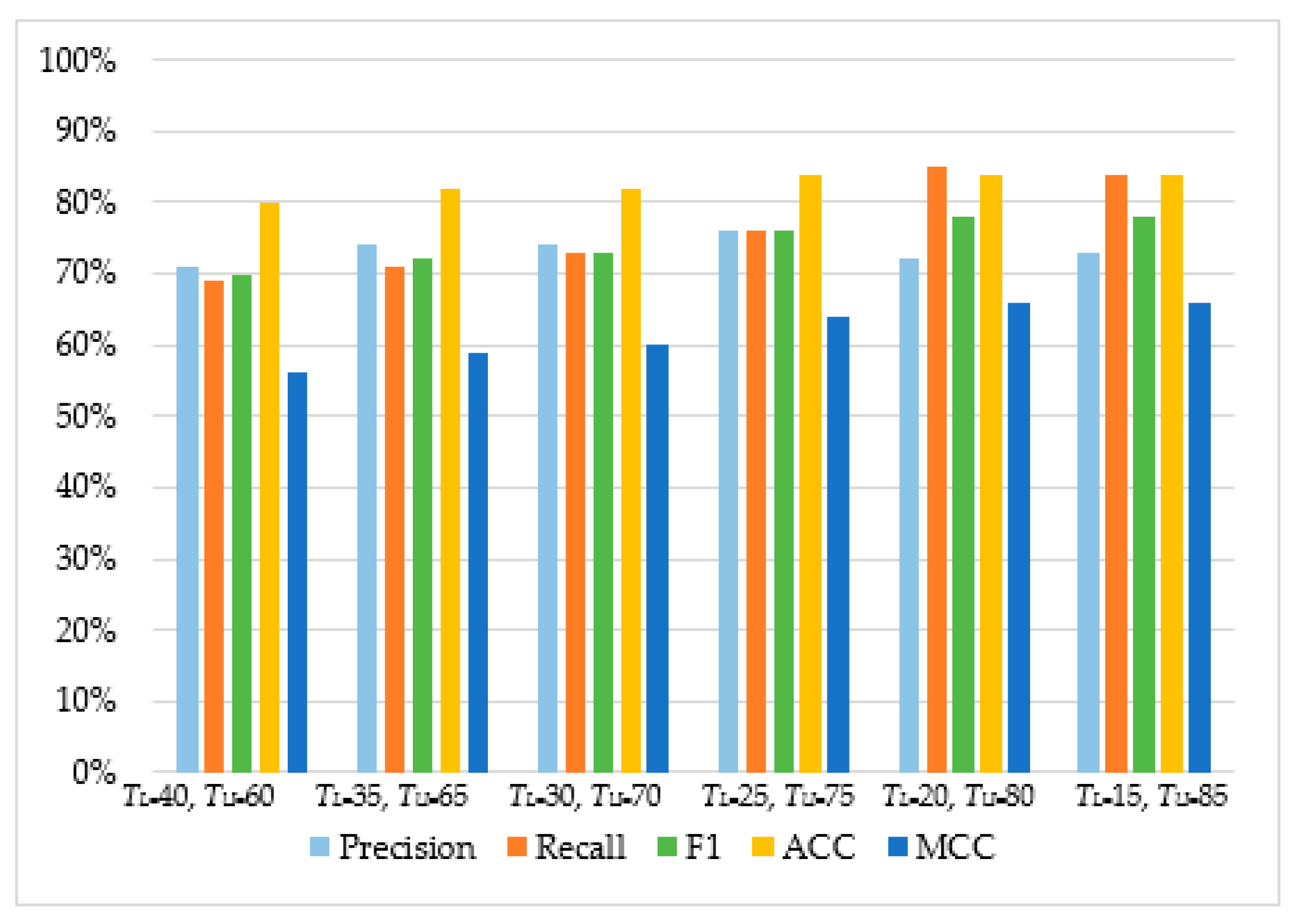
| Decision Tree | TL = 40, TU = 60 | 72% | 78% | 75% | 83% | 62% |
| TL = 35, TU = 65 | 72% | 78% | 75% | 83% | 62% | |
| TL = 30, TU = 70 | 72% | 78% | 75% | 83% | 62% | |
| TL = 25, TU = 75 | 76% | 82% | 79% | 85% | 68% | |
| TL = 20, TU = 80 | 76% | 82% | 79% | 85% | 68% | |
| TL = 15, TU = 85 | 77% | 81% | 79% | 86% | 68% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rendall, K.; Nisioti, A.; Mylonas, A. Towards a Multi-Layered Phishing Detection. Sensors 2020, 20, 4540. https://doi.org/10.3390/s20164540
Rendall K, Nisioti A, Mylonas A. Towards a Multi-Layered Phishing Detection. Sensors. 2020; 20(16):4540. https://doi.org/10.3390/s20164540
Chicago/Turabian StyleRendall, Kieran, Antonia Nisioti, and Alexios Mylonas. 2020. "Towards a Multi-Layered Phishing Detection" Sensors 20, no. 16: 4540. https://doi.org/10.3390/s20164540
APA StyleRendall, K., Nisioti, A., & Mylonas, A. (2020). Towards a Multi-Layered Phishing Detection. Sensors, 20(16), 4540. https://doi.org/10.3390/s20164540