Anonymous Real-Time Analytics Monitoring Solution for Decision Making Supported by Sentiment Analysis

 , ,
, ,  ,
,  ,
, 
Abstract
:1. Introduction
2. Basic Concepts
2.1. Data Visualization
2.2. Social Media Data Analysis
2.3. Social Bots
2.4. Anonymity Systems
3. State-of-the-Art Review and Related Work
3.1. Sentiment Analysis in Text Classification
3.2. Visualization Review
3.3. Main Contribution of This Work
4. Problem Statement and Proposed Solution
4.1. Problem Definition
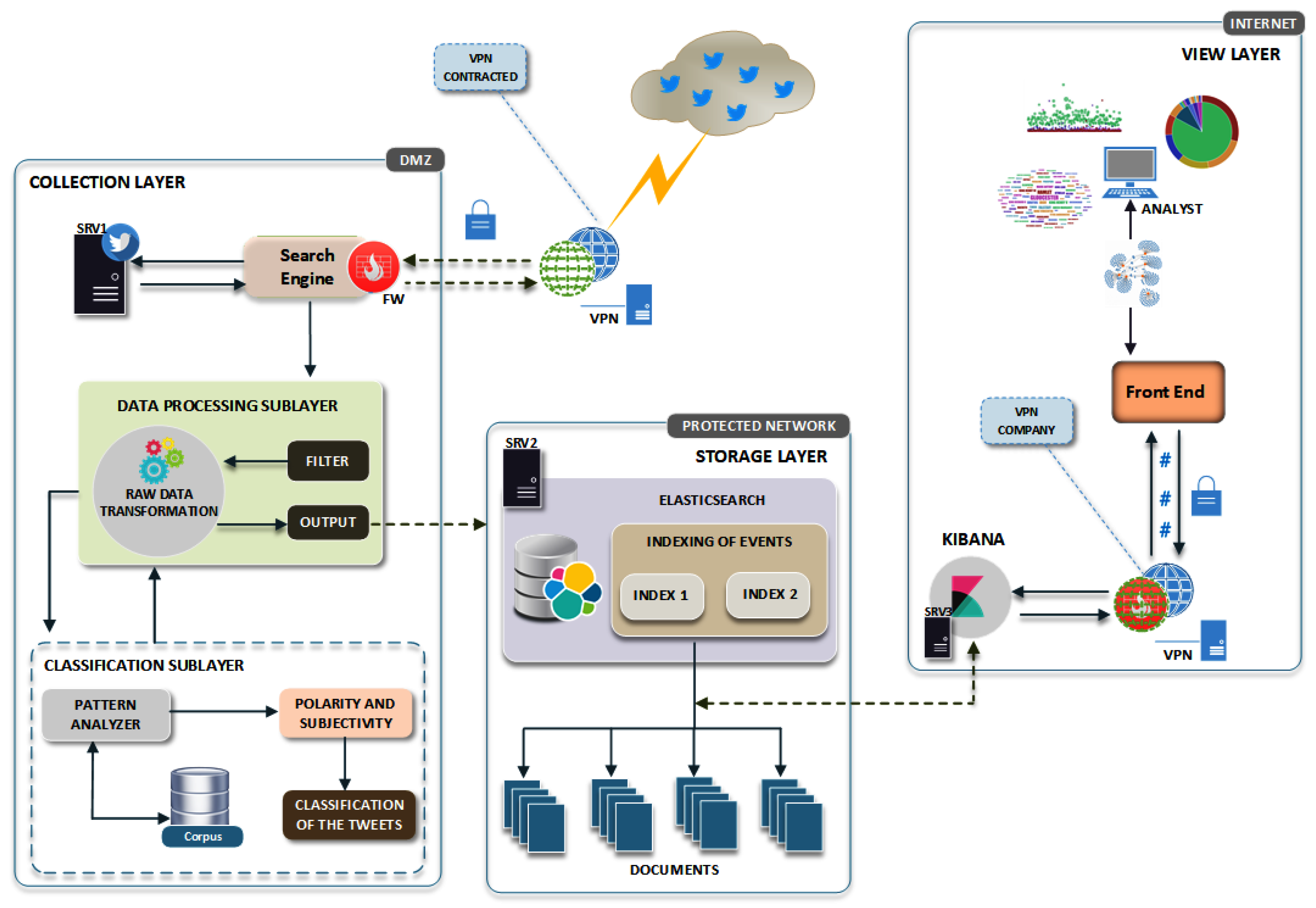
4.2. Proposed Environment Architecture
5. Description of the Implementation Phases
5.1. Phase 1: Data Collection Layer
5.2. Phase 2: Data Processing Sublayer
5.2.1. Translation and Correction of Textual Data
5.2.2. Stop Words and Special Characters
5.2.3. Tokenization
5.3. Phase 3: Classification Sublayer
5.3.1. Sentiment Analysis
5.3.2. Lexical Dataset
- Document XML that includes four entries: polarity, subjectivity, intensity, and confidence;
- Adjectives have polarity (negative or positive −1.0 to +1.0) and subjectivity (objective or subjective, +0.0 to +1.0);
- The score of each word is defined according to the meaning of the sentence, for example ridiculous (regrettable) = negative and ridiculous (humorous) = positive;
- Uses the Penn Treebank [49] tag set to determine the grammatical class (POS tagger) of the words: NN = noun, JJ = adjective, VB = verb, RB= adverb, CC = conjunction, IN = preposition, and UH = interjection.
5.4. Phase 4: Distributed Storage Layer
5.5. Phase 5: Visualization Layer
6. Case Study: 2018 FIFA World Brazilian National Soccer Team Theme
6.1. Data Collection
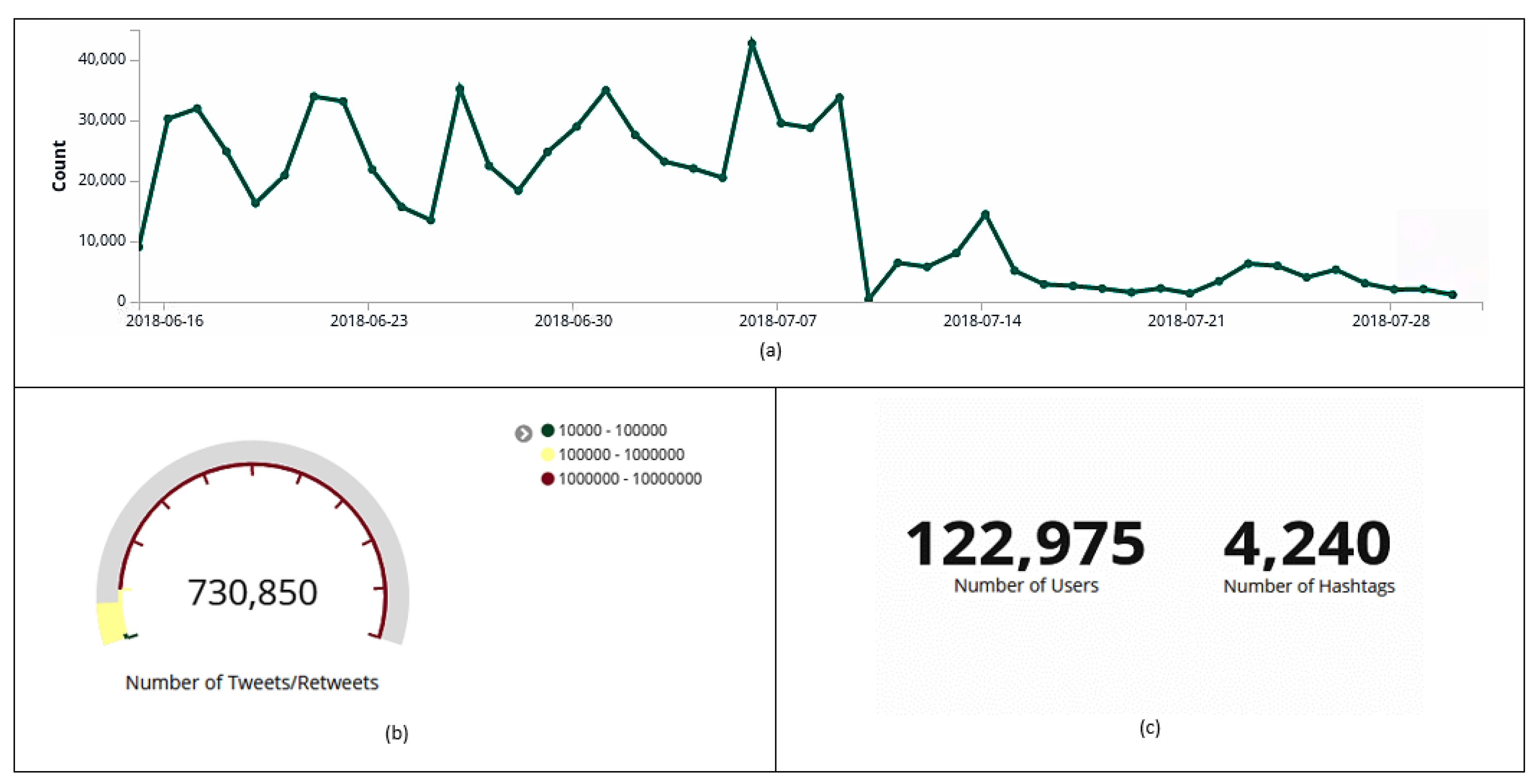
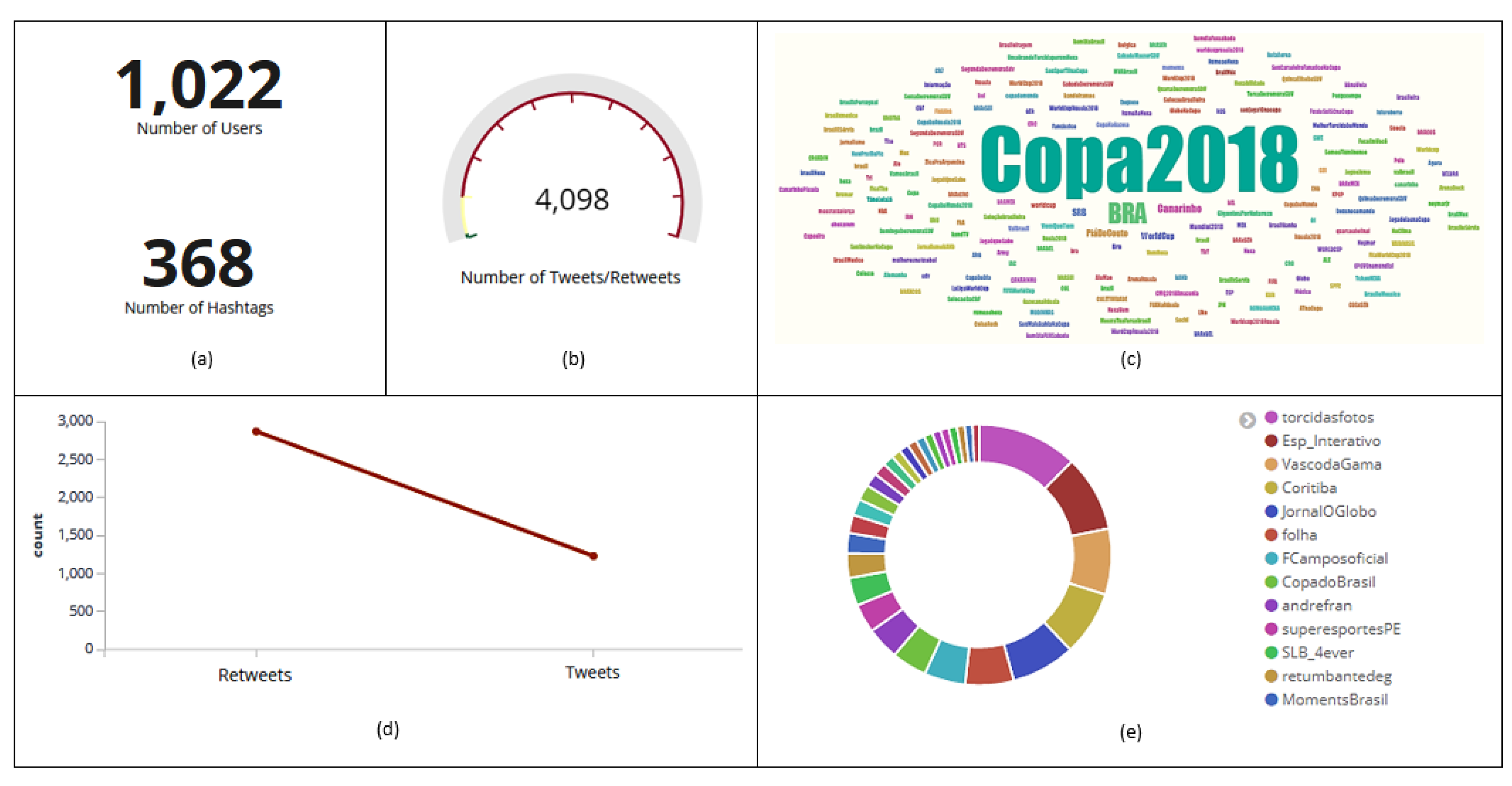
6.2. General Collection Summary Presentation
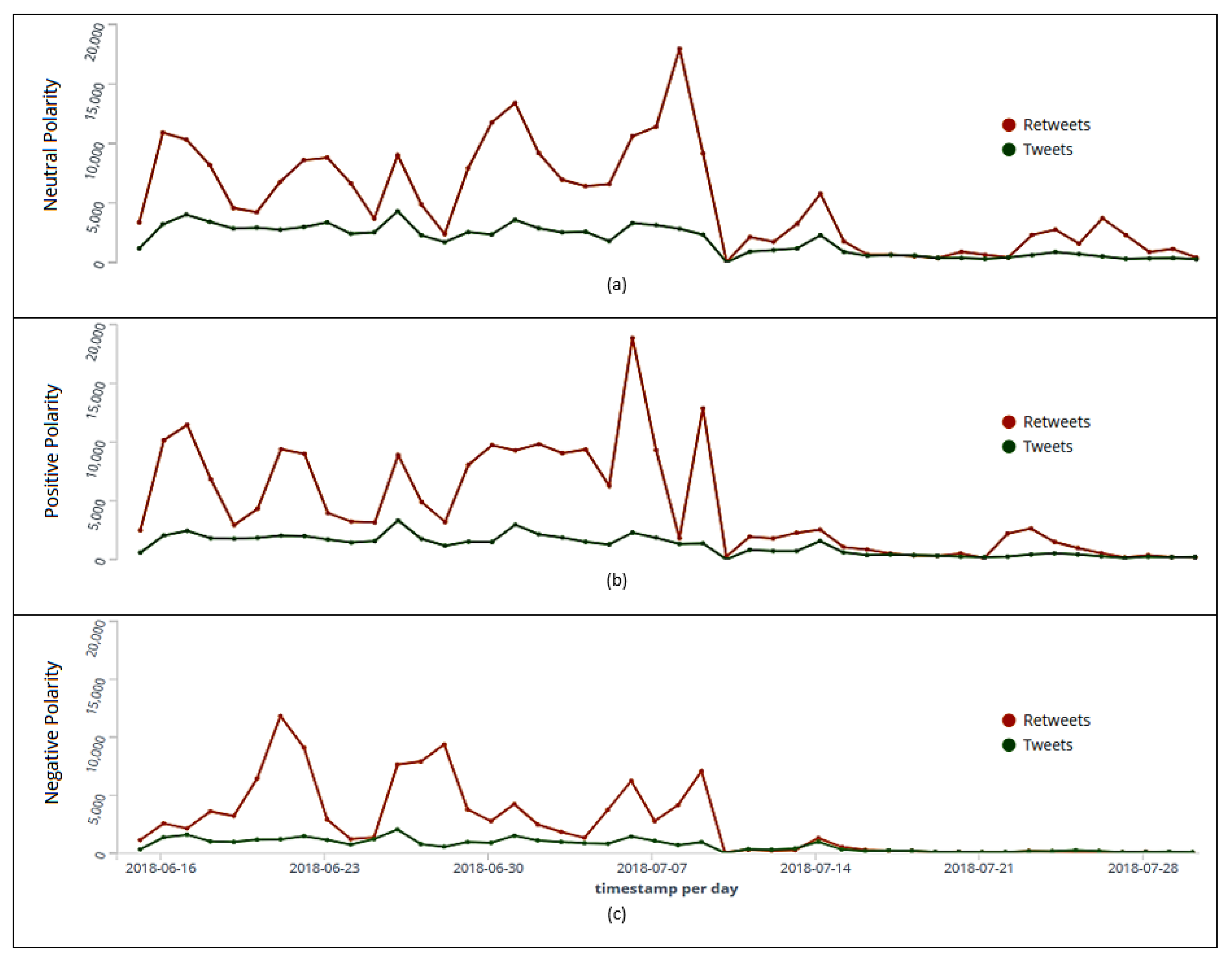
6.3. Tweets’ and Retweets’ Analysis
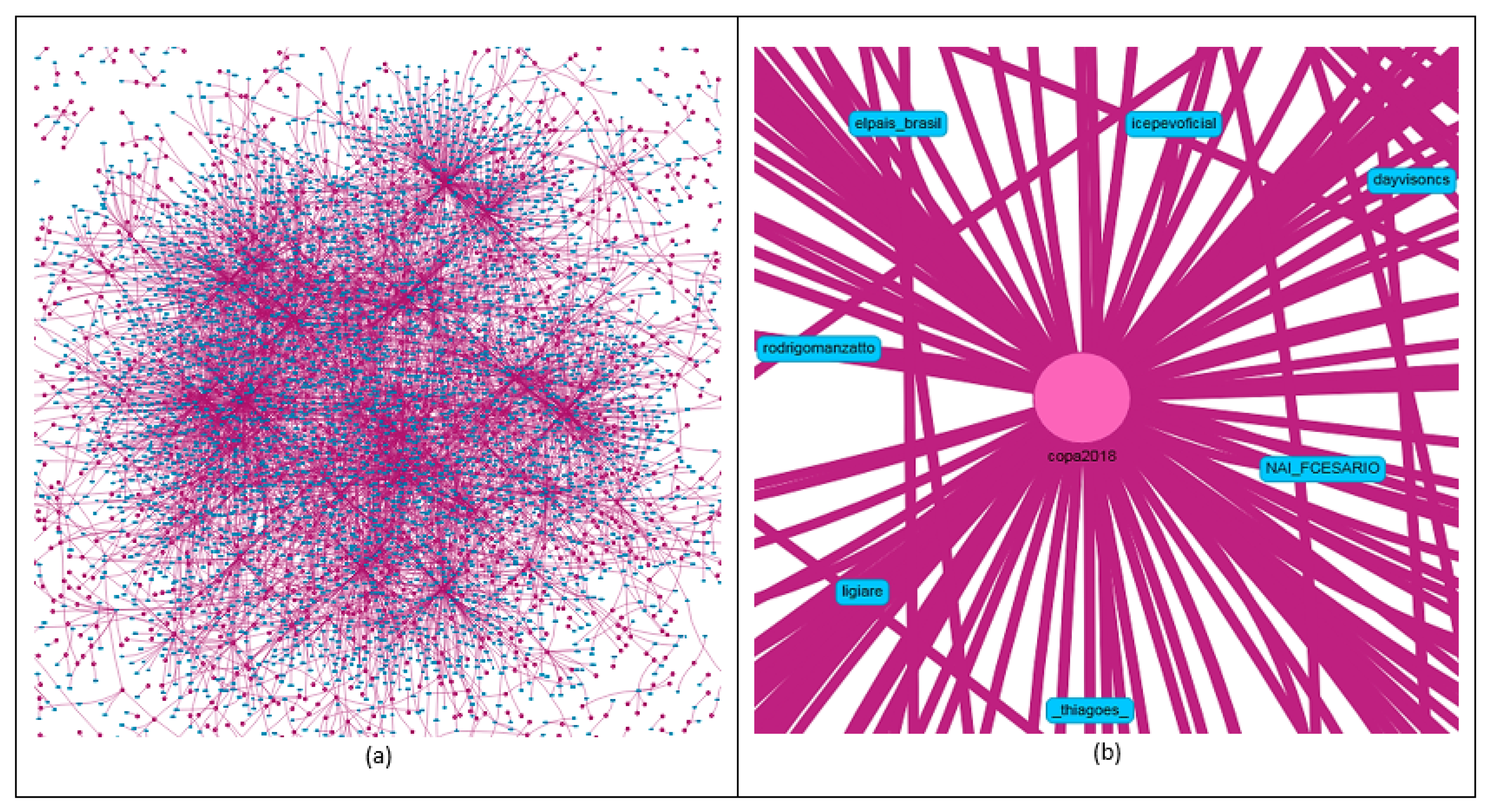
6.4. Hashtag Analysis
Filter Application
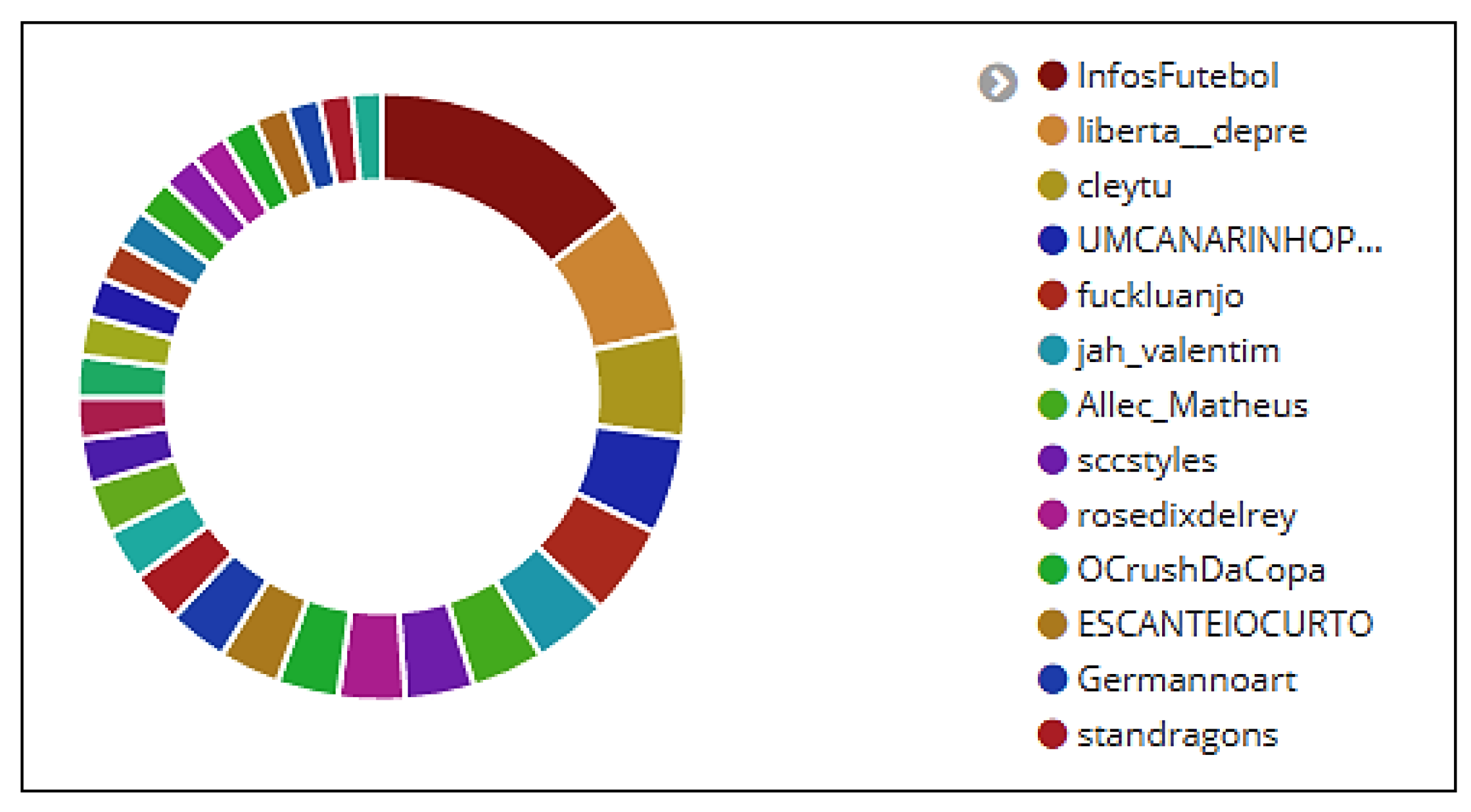
6.5. User Analysis
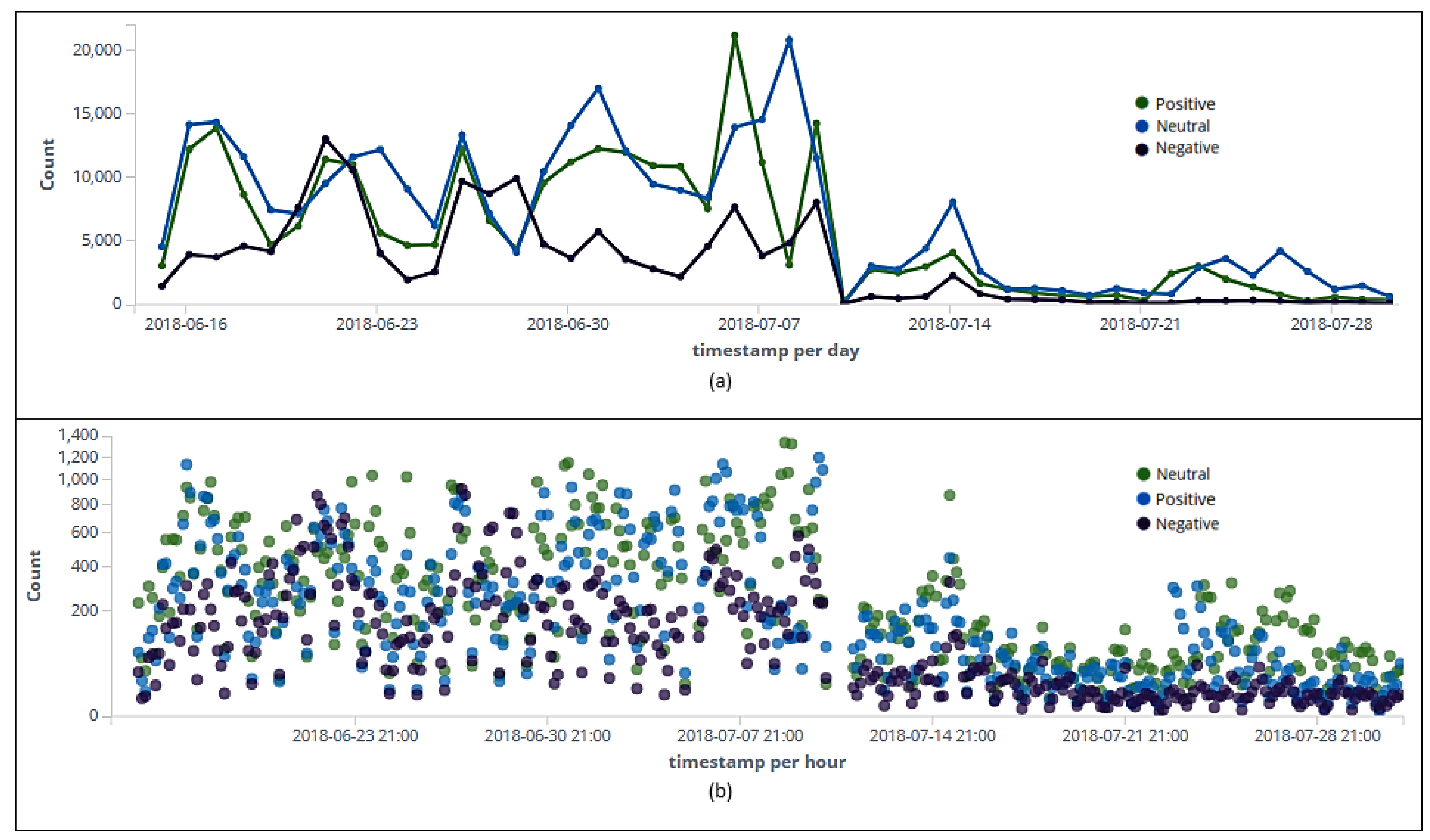
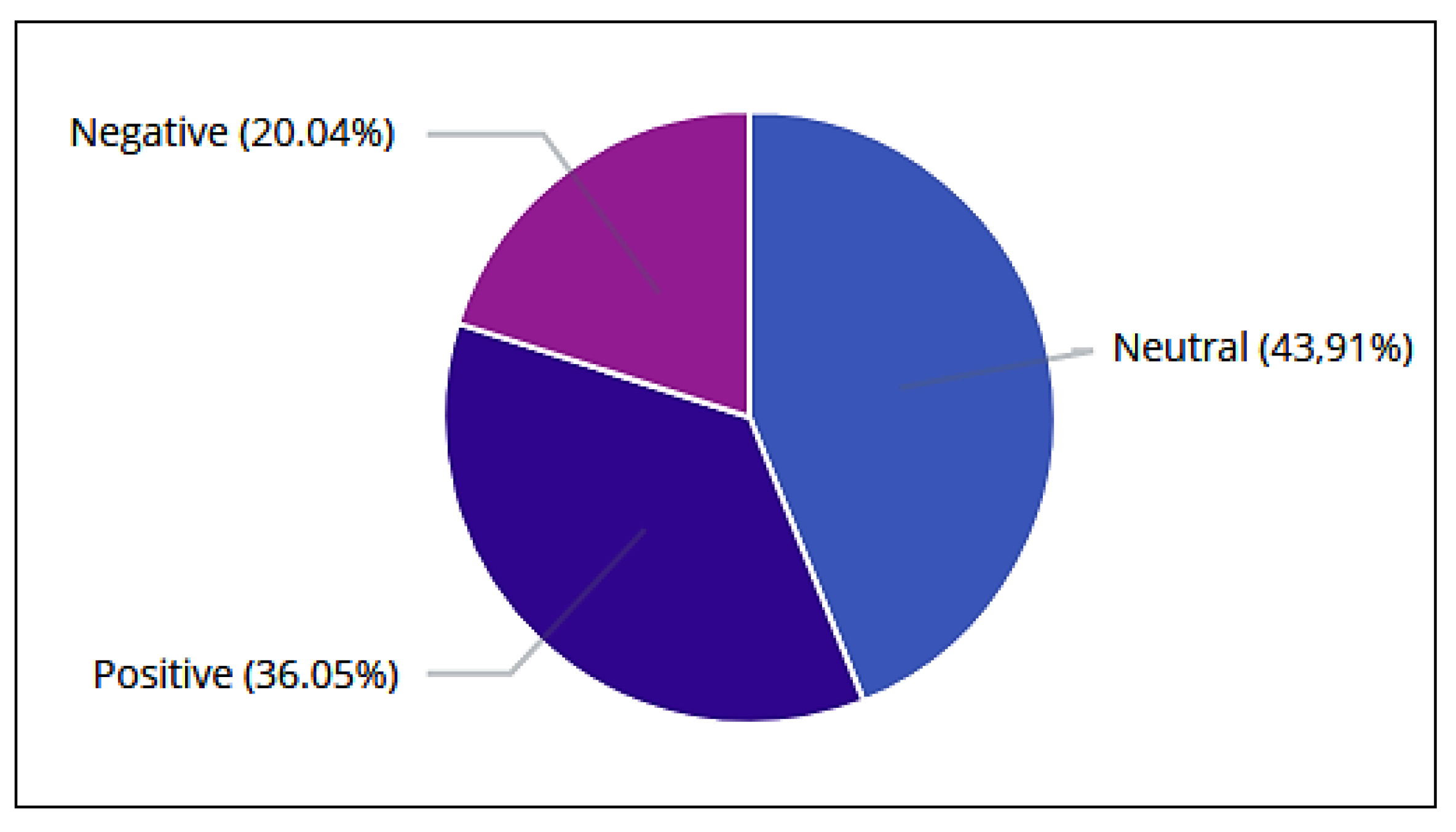
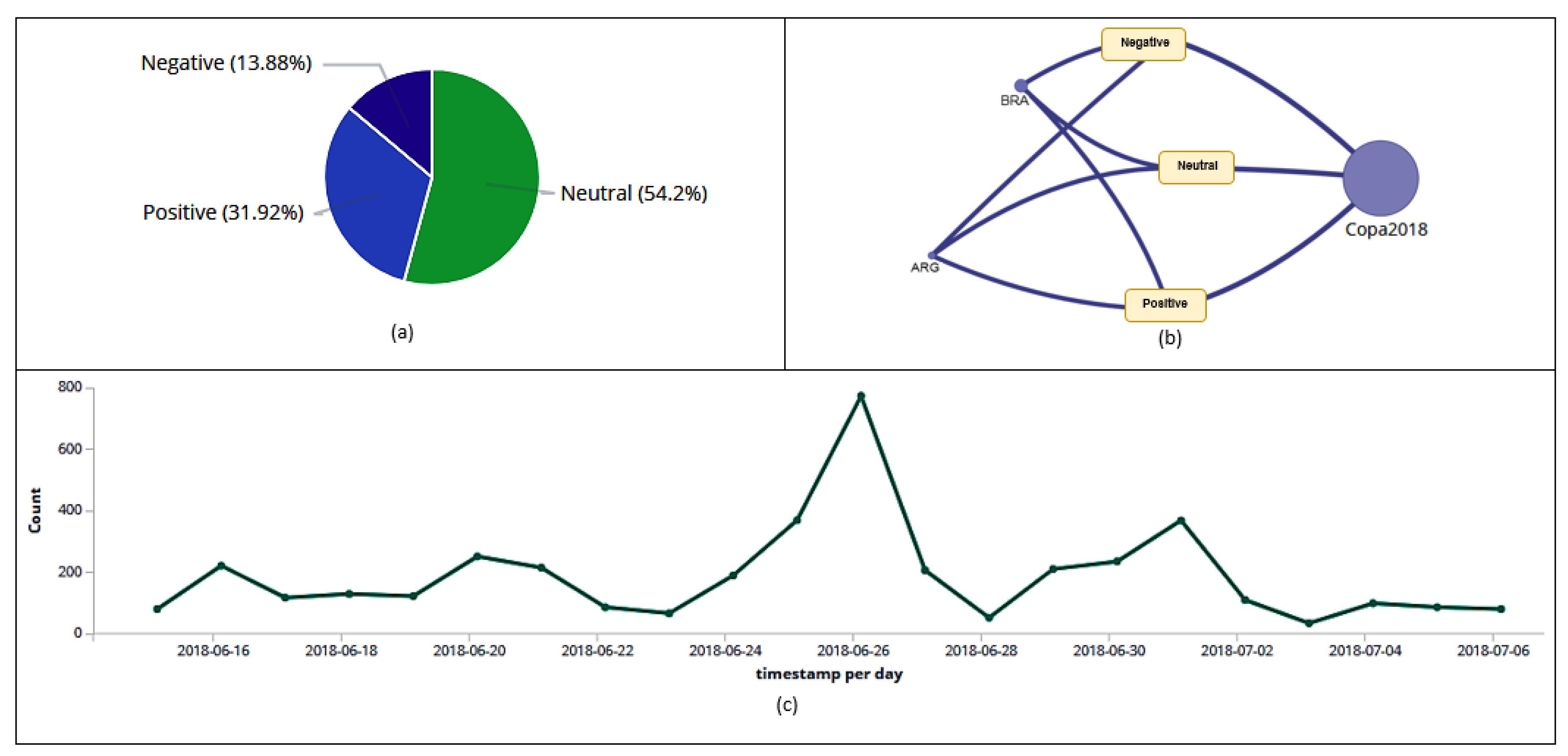
6.6. Sentiment Analysis
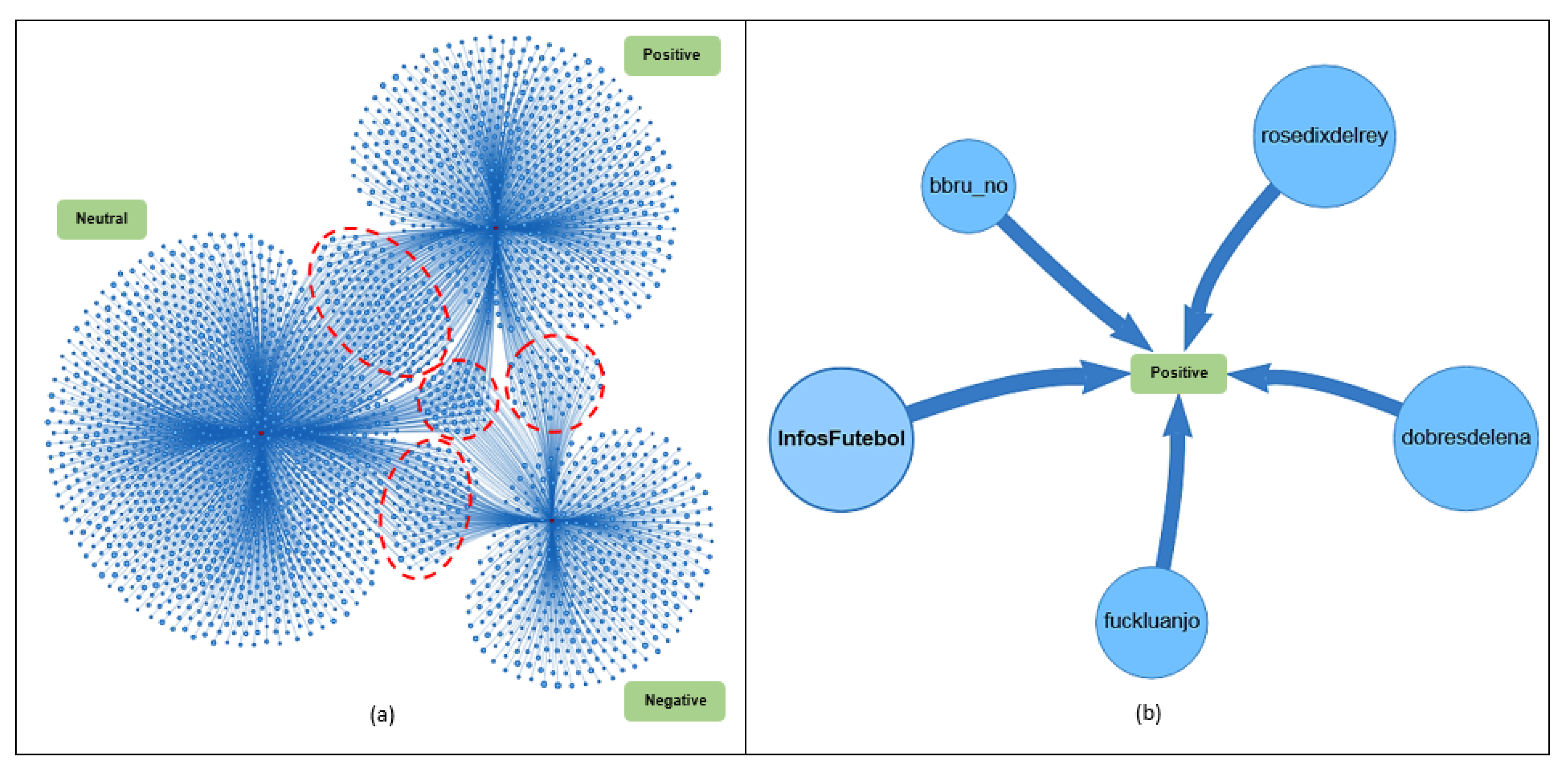
6.7. Link Analysis
6.8. Analysis of the Most Commented on Hashtag in the Quarterfinals
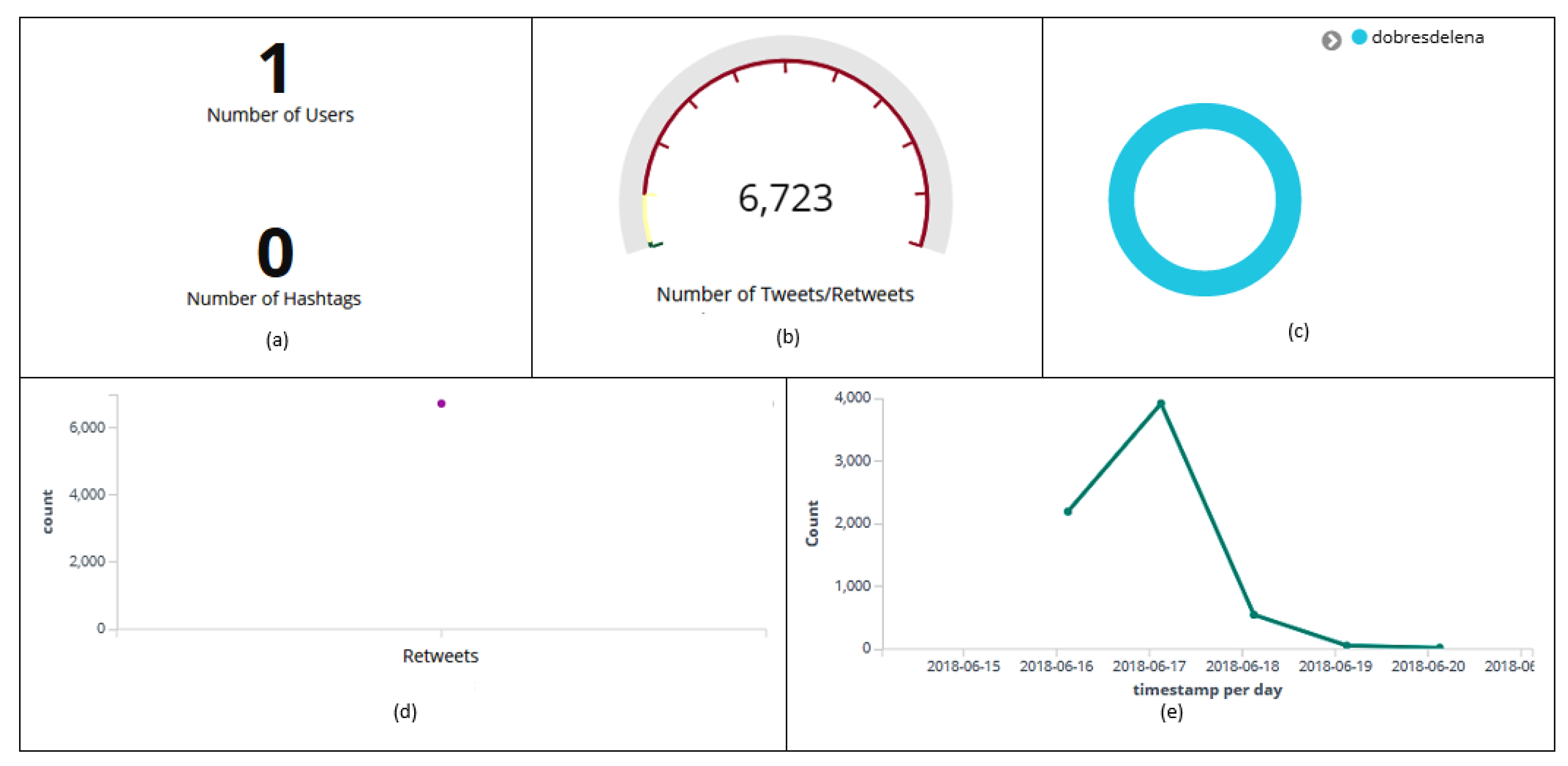
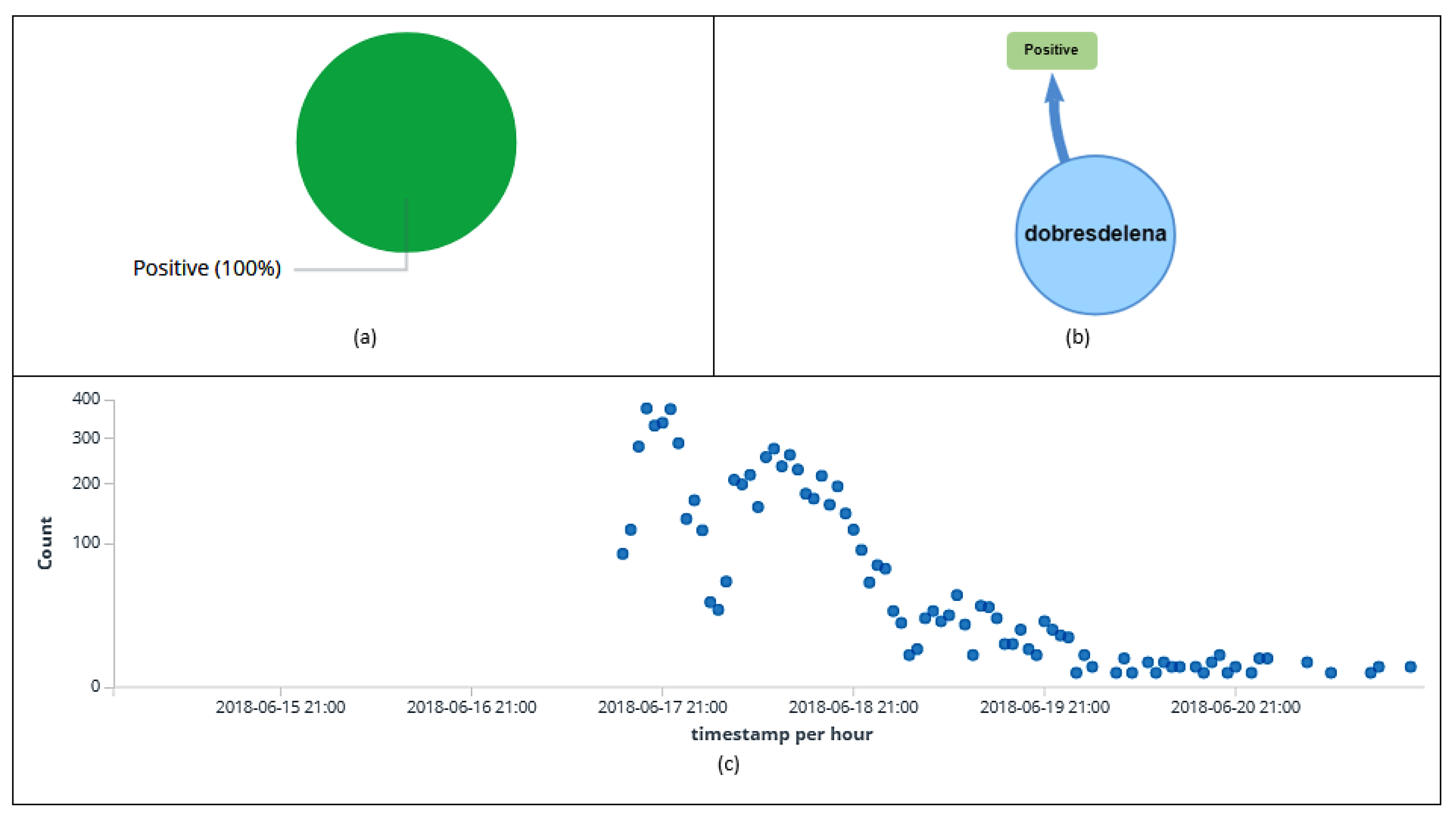
6.9. Outliers Analysis
6.10. Botnet Analysis
7. Implications of Attacks on Sentiment Analysis
8. Conclusions
Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| API | Application Programming Interface |
| CNN | Convolutional Neural Network |
| DLTU | Deep Learning-based Text Understanding |
| DMZ | Demilitarized Zone |
| DPI | Deep Packet Inspection |
| ELK | Elasticsearch, Logstash, and Kibana |
| ISP | Internet Service Provider |
| NLP | Natural Language Processing |
| NLTK | Natural Language Toolkit |
| POS | Parts-Of-Speech |
| RSS | Rich Site Summary |
| SVM | Support Vector Machines |
| TOR | The Onion Router |
| URL | Uniform Resource Locator |
| VPN | Virtual Private Network |
| WSD | Word Sense Disambiguation |
| XML | Extensible Markup Language |
References
- Marques, L.K.d.S.; Vidigal, F. Prosumers and social networks as marketing information sources. An analysis from the perspective of competitive intelligence in Brazilian companies. Transinformação 2018, 30, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Pereira-Kohatsu, J.C.; Quijano-Sánchez, L.; Liberatore, F.; Camacho-Collados, M. Detecting and monitoring hate speech in Twitter. Sensors 2019, 19, 4654. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Anjaria, M.; Guddeti, R.M.R. Influence factor based opinion mining of Twitter data using supervised learning. In Proceedings of the 2014 Sixth International Conference on Communication Systems and Networks (COMSNETS), Bangalore, India, 6–10 January 2014; pp. 1–8. [Google Scholar]
- Russell, M.A. Mining the Social Web: Data Mining Facebook, Twitter, LinkedIn, Google+, GitHub, and More, 2nd ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2013. [Google Scholar]
- Hernandez-Suarez, A.; Sanchez-Perez, G.; Toscano-Medina, K.; Martinez-Hernandez, V.; Perez-Meana, H.; Olivares-Mercado, J.; Sanchez, V. Social sentiment sensor in twitter for predicting cyber-attacks using 1 regularization. Sensors 2018, 18, 1380. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Murray, S. Interactive Data Visualization for the Web: An Introduction to Designing with D3; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2017. [Google Scholar]
- Gershon, N.; Page, W. What storytelling can do for information visualization. Assoc. Comput. Mach. Commun. ACM 2001, 44, 31–37. [Google Scholar] [CrossRef]
- Heer, J.; Bostock, M.; Ogievetsky, V. A Tour Through the Visualization Zoo. Commun. ACM 2010, 53, 59–67. [Google Scholar] [CrossRef]
- Gray, J.; Chambers, L.; Bounegru, L. The Data Journalism Handbook: How Journalists Can Use Data to Improve the News; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2012. [Google Scholar]
- Brooks, M. Human Centered Tools for Analyzing Online Social Data. Ph.D. Thesis, University of Washington Libraries, Seattle, WA, USA, 2015. [Google Scholar]
- Chin, G., Jr.; Kuchar, O.A.; Wolf, K.E. Exploring the Analytical Processes of Intelligence Analysts. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Boston, MA, USA, 11 April 2009; pp. 11–20. [Google Scholar] [CrossRef]
- Diakopoulos, N.; Naaman, M.; Kivran-Swaine, F. Diamonds in the Rough: Social Media Visual Analytics for Journalistic Inquiry. In Proceedings of the 2010 IEEE Symposium on Visual Analytics Science and Technology, Salt Lake City, UT, USA, 25–26 October 2010; pp. 115–122. [Google Scholar] [CrossRef]
- Diakopoulos, N.; De Choudhury, M.; Naaman, M. Finding and Assessing Social Media Information Sources in the Context of Journalism. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Austin, TX, USA, 12 May 2012; pp. 2451–2460. [Google Scholar] [CrossRef] [Green Version]
- Karine, N.; Kevin, C. Introduction to the Digital and Social Media Track. In Proceedings of the 2016 49th Hawaii International Conference on System Sciences (HICSS), Koloa, HI, USA, 5–8 January 2016; p. 1808. [Google Scholar]
- Ferrara, E.; Varol, O.; Davis, C.; Menczer, F.; Flammini, A. The rise of social bots. Commun. ACM 2016, 59, 96–104. [Google Scholar] [CrossRef] [Green Version]
- Kitzie, V.L.; Mohammadi, E.; Karami, A. “Life never matters in the DEMOCRATS MIND”: Examining strategies of retweeted social bots during a mass shooting event. Proc. Assoc. Inf. Sci. Technol. 2018, 55, 254–263. [Google Scholar] [CrossRef]
- Boshmaf, Y.; Muslukhov, I.; Beznosov, K.; Ripeanu, M. Design and analysis of a social botnet. Comput. Netw. 2013, 57, 556–578. [Google Scholar] [CrossRef] [Green Version]
- Hwang, T.; Pearce, I.; Nanis, M. Socialbots: Voices from the fronts. Interactions 2012, 19, 38–45. [Google Scholar] [CrossRef]
- Conover, M.D.; Ratkiewicz, J.; Francisco, M.; Gonçalves, B.; Menczer, F.; Flammini, A. Political polarization on twitter. In Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, Barcelona, Spain, 17–21 July 2011. [Google Scholar]
- Edwards, C.; Edwards, A.; Spence, P.R.; Shelton, A.K. Is that a bot running the social media feed? Testing the differences in perceptions of communication quality for a human agent and a bot agent on Twitter. Comput. Hum. Behav. 2014, 33, 372–376. [Google Scholar] [CrossRef]
- Messias, J.; Schmidt, L.; Oliveira, R.A.R.d.; Souza, F.B.d. You followed my bot! Transforming robots into influential users in Twitter. First Monday 2013, 18, 7. [Google Scholar] [CrossRef]
- Kramer, A.D.; Guillory, J.E.; Hancock, J.T. Experimental evidence of massive-scale emotional contagion through social networks. Proc. Natl. Acad. Sci. USA 2014, 111, 8788–8790. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Edman, M.; Yener, B. On Anonymity in an Electronic Society: A Survey of Anonymous Communication Systems. ACM Comput. Surv. 2009, 42, 5:1–5:35. [Google Scholar] [CrossRef]
- Schanzenbach, M. Hiding from Big Brother. In Proceedings of the Seminars Future Internet (FI) and Innovative Internet Technologies and Mobile Communications (IITM); Carle, G., Raumer, D., Schwaighofer, L., Eds.; Chair for Network Architectures and Services, Department of Computer Science, Technische Universität München: Munich, Germany, 2014; Volume NET-2014-03-1, pp. 67–73. [Google Scholar]
- Çalışkan, E.; Minárik, T.; Osula, A.M. Technical and Legal Overview of the Tor Anonymity Network; NATO Cooperative Cyber Defence Centre of Excellence: Tallinn, Estonia, 2015. [Google Scholar]
- IVPN. Privacy Guides. Including VPN’s and Threat Models Guide. Available online: https://www.ivpn.net/privacy-guides (accessed on 18 March 2020).
- Mladenović, M.; Krstev, C.; Mitrović, J.; Stanković, R. Using lexical resources for irony and sarcasm classification. In Proceedings of the 8th Balkan Conference in Informatics, Skopje, Macedonia, 20–23 September 2017; pp. 1–8. [Google Scholar]
- Gomes, H.; de Castro Neto, M.; Henriques, R. Text Mining: Sentiment analysis on news classification. In Proceedings of the 2013 8th Iberian Conference on Information Systems and Technologies (CISTI), Lisboa, Portugal, 19–22 June 2013; pp. 1–6. [Google Scholar]
- Rodrigues Barbosa, G.A.; Silva, I.S.; Zaki, M.; Meira, W., Jr.; Prates, R.O.; Veloso, A. Characterizing the Effectiveness of Twitter Hashtags to Detect and Track Online Population Sentiment. In Proceedings of the CHI ’12 Extended Abstracts on Human Factors in Computing Systems, Austin, TX, USA, 7–12 May 2012; pp. 2621–2626. [Google Scholar] [CrossRef] [Green Version]
- Hasan, A.; Moin, S.; Karim, A.; Shamshirband, S. Machine Learning-Based Sentiment Analysis for Twitter Accounts. Math. Comput. Appl. 2018, 23, 11. [Google Scholar] [CrossRef] [Green Version]
- Kunal, S.; Saha, A.; Varma, A.; Tiwari, V. Textual Dissection of Live Twitter Reviews using Naive Bayes. Procedia Comput. Sci. 2018, 132, 307–313. [Google Scholar] [CrossRef]
- Cerón-Guzmán, J.A.; León-Guzmán, E. A sentiment analysis system of Spanish tweets and its application in Colombia 2014 presidential election. In Proceedings of the 2016 IEEE International Conferences on Big Data and Cloud Computing (BDCloud), Social Computing and Networking (Socialcom), Sustainable Computing and Communications (Sustaincom) (BDCloud-Socialcom-Sustaincom), Atlanta, GA, USA, 8–10 October 2016; pp. 250–257. [Google Scholar]
- Tumitan, D.; Becker, K. Sentiment-Based Features for Predicting Election Polls: A Case Study on the Brazilian Scenario. In Proceedings of the 2014 IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT), Warsaw, Poland, 11–14 August 2014; pp. 126–133. [Google Scholar] [CrossRef]
- Praciano, B.J.G.; da Costa, J.P.C.L.; Maranhao, J.P.A.; de Mendonca, F.L.L.; de Sousa, R.T., Jr.; Prettz, J.B. Spatio-Temporal Trend Analysis of the Brazilian Elections Based on Twitter Data. In Proceedings of the 2018 IEEE International Conference on Data Mining Workshops (ICDMW), Singapore, 17–20 November 2018; pp. 1355–1360. [Google Scholar] [CrossRef]
- Marcus, A.; Bernstein, M.S.; Badar, O.; Karger, D.R.; Madden, S.; Miller, R.C. Twitinfo: Aggregating and Visualizing Microblogs for Event Exploration. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011; pp. 227–236. [Google Scholar] [CrossRef] [Green Version]
- Sijtsma, B.; Qvarfordt, P.; Chen, F. Tweetviz: Visualizing Tweets for Business Intelligence. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, 16 July 2016; pp. 1153–1156. [Google Scholar] [CrossRef]
- Oliveira Júnior, G.A.; de Sousa, R.T., Jr.; de Albuquerque, R.O.; Canedo, E.D.; Grégio, A. HoneySELK: Um Ambiente para Pesquisa e Visualização de Ataques Cibernéticos em Tempo Real. In Proceedings of the XVI Simpósio Brasileiro em Segurança da Informação e de Sistemas Computacionais, Niteroi, Rio de Janeiro, Brazil, 7–10 November 2016; pp. 697–706. [Google Scholar]
- Rodrigues, G.A.P.; Albuquerque, R.d.O.; de Deus, F.E.G.; de Sousa, R.T., Jr.; de Oliveira Júnior, G.A. Cybersecurity and Network Forensics: Analysis of Malicious Traffic towards a Honeynet with Deep Packet Inspection. Appl. Sci. 2017, 7, 1082. [Google Scholar] [CrossRef] [Green Version]
- Citrix. XenServer Current Release. Available online: https://docs.citrix.com/en-us/xenserver/current-release.html (accessed on 30 March 2020).
- Elastic. Elastic Stack Product Documentation. Available online: https://www.elastic.co/guide/index.html (accessed on 18 March 2020).
- KBN Network. Network Plugin for Kibana. Available online: https://github.com/dlumbrer/kbn_network (accessed on 26 January 2020).
- Tweepy. An Easy-To-Use Python Library for Accessing the Twitter API. Available online: https://www.tweepy.org/ (accessed on 20 January 2020).
- Python. Python: A Programming Language That Lets You Work Quickly and Integrate Systems More Effectively. Available online: https://www.python.org/ (accessed on 20 January 2020).
- NLTK. Natural Language Toolkit. Available online: https://www.nltk.org/ (accessed on 22 January 2020).
- TextBlob. TextBlob: Simplified Text Processing Online. Available online: https://textblob.readthedocs.io/en/dev/index.html (accessed on 22 January 2020).
- Google. Google Translate Online. Available online: https://https://translate.google.com/ (accessed on 22 January 2020).
- CLiPS. Computational Linguistics & Psycholinguistics. Available online: https://www.clips.uantwerpen.be/pages/pattern-en (accessed on 22 January 2020).
- Pang, B.; Lee, L. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts. In Proceedings of the 42nd annual meeting on Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004; p. 271. [Google Scholar]
- Taylor, A.; Marcus, M.; Santorini, B. The Penn treebank: An overview. In Treebanks; Springer: Berlin/Heidelberg, Germany, 2003; pp. 5–22. [Google Scholar]
- Google. Google Images. Available online: https://images.google.com/imghp?hl=en&gl=ar&gws_rd=ssl (accessed on 30 March 2020).
- TinEye. TinEye Image Recognition. Available online: https://www.tineye.com/ (accessed on 30 March 2020).
- Kearney, M.W. TweetBotOrNot: An R Package for Classifying Twitter Accounts as Bot or not. Available online: https://github.com/mkearney/tweetbotornot (accessed on 30 March 2020).
- Hosseini, H.; Kannan, S.; Zhang, B.; Poovendran, R. Deceiving google’s perspective api built for detecting toxic comments. arXiv 2017, arXiv:1702.08138. [Google Scholar]
- Perspective. API That Makes It Easier to Host Better Conversations. Available online: https://www.perspectiveapi.com (accessed on 20 January 2020).
- Tsai, Y.T.; Yang, M.C.; Chen, H.Y. Adversarial Attack on Sentiment Classification. In Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Florence, Italy, 1 August 2019; pp. 233–240. [Google Scholar]
- Li, J.; Ji, S.; Du, T.; Li, B.; Wang, T. Textbugger: Generating adversarial text against real-world applications. arXiv 2018, arXiv:1812.05271. [Google Scholar]
- Samanta, S.; Mehta, S. Generating adversarial text samples. In Proceedings of the European Conference on Information Retrieval, Grenoble, France, 26–29 March 2018; pp. 744–749. [Google Scholar]
- Alzantot, M.; Sharma, Y.; Elgohary, A.; Ho, B.; Srivastava, M.B.; Chang, K. Generating Natural Language Adversarial Examples. arXiv 2018, arXiv:1804.07998. [Google Scholar]
- Sohangir, S.; Petty, N.; Wang, D. Financial sentiment lexicon analysis. In Proceedings of the 2018 IEEE 12th International Conference on Semantic Computing (ICSC), Laguna Hills, CA, USA, 31 Janurary–2 February 2018; pp. 286–289. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
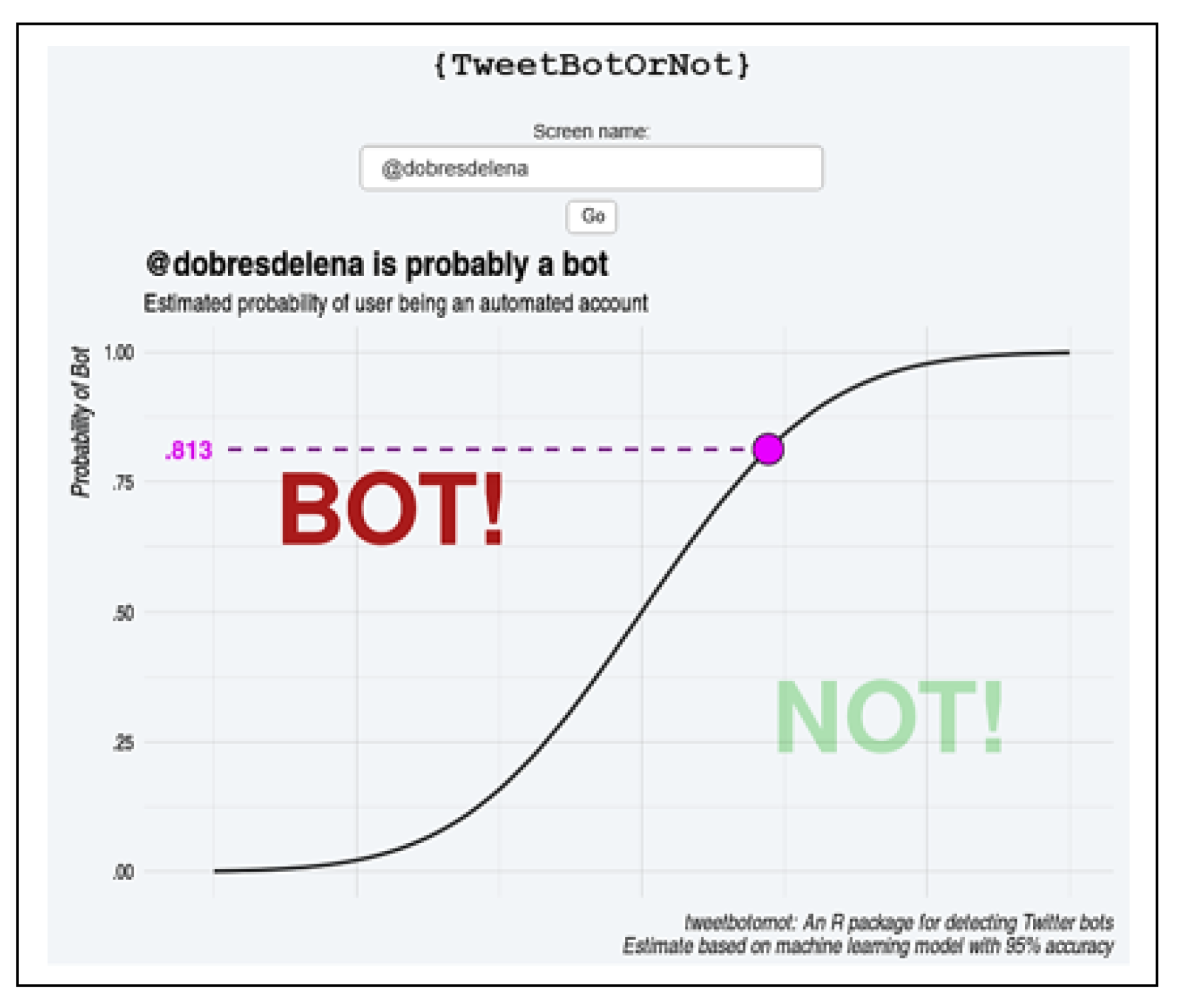{kind=link}
| Anonymization | Sentiment | Real Time | Distributed | Visualization | |
|---|---|---|---|---|---|
| Analysis | Operation | Storage | |||
| OctopusViz | x | x | x | x | x |
| [12] | – | x | x | – | – |
| [29] | – | x | – | – | – |
| [30] | – | x | – | – | – |
| [31] | – | x | x | – | – |
| [32] | – | x | – | – | – |
| [33] | – | x | – | – | – |
| [34] | – | x | – | – | – |
| [35] | – | x | x | x | x |
| [36] | – | x | – | – | x |
| [37] | – | – | x | x | x |
| [38] | – | – | – | x | x |
| Server | Configuration |
|---|---|
| Dell PowerEdge R730 | Intel Xeon processor E5-2690 v3 @ X5560 2.6 GHz, 48 cores with Intel VT technology, 128 GB RAM, 6 disks with 1TB configured with RAID 5, and 6 network cards 10/100/1000. |
| Hypervisor | XenServer 7.4, DBV 2018.0223. |
| Guest Systems | Configuration |
|---|---|
| Fw (Firewall) | 2 core processor, 4 GB RAM, one 50 GB virtual disk, and 3 virtual network interfaces. pfSense-2.4.3-RELEASE version based on the FreeBSD Operating System. |
| Srv1 (Collection) | 12 core processor, 16 GB RAM, one 50 GB virtual disk, and one virtual network interface. Operating system: Linux Debian Stretch 9.0 with the Python 3 programming language and libraries tweepy, json, time, elasticsearch, datatime, os, re, and textblob. |
| Srv2 (Storage) | 12 core processor, 32 GB RAM, one 400 GB virtual disk, and one virtual network interface. Operating system: Linux Debian Stretch 9.0 with thee elasticsearch-6.2.4 service. |
| Srv3 (Visualization) | 8 core processor, 8 GB RAM, one 50 GB virtual disk, and one virtual network interface. Operating system: Linux Debian Stretch 9.0 with kibana-6.2.4 service. |
| Example of Data Input in Portuguese | O Brasil jogou muito bem contra a Costa Rica |
| tweet = TextBlob(“O Brasil jogou muito bem contra a Costa Rica") | |
| if tweet.detect_language() != ’en’: | |
| translate_to_english = TextBlob(str(tweet.translate(to=’en’))) | |
| Data Preprocessing | correct_tweet = translate_to_english.correct() |
| (Translation and Correction) | print (correct_tweet) |
| else: | |
| tweet.correct() | |
| print (tweet.correct()) | |
| Data Output | Brazil played very well against Costa Rich |
| Methods | Method Description | Data Output |
|---|---|---|
| stopWords = set(stopwords.words(’english’)) print(stopWords) | Corpus words stop words | [’i’, ’me’, ’my’, ’we’, ’our’, ’ours’, ’his’, ’y’, ’your’, ’it’] |
| string.punctuation | Scores and special characters | ’!"#$%&’()*+,-./:; <=>?@[]‘{|} ’ |
| Example of Data Input | Brazil is an excellent soccer team:) !!! |
| tweet = TextBlob(“Brazil is an excellent soccer team:) !!!") | |
| translation_correction(tweet) | |
| stopwords_english = stopwords.words(’english’) | |
| words = tweet.words | |
| Data Preprocessing | words_clean = [] |
| (Stop Words and Special Characters) | for word in words: |
| if word not in stop words_english: | |
| if word not in string.punctuation: | |
| words_clean.append(word) | |
| print (words_clean) | |
| Data Output | [’Brazil’, ’excellent’, ’soccer’, ’team’] |
| Example of Data Input | Brazil played very well against Costa Rica |
| tweet = TextBlob(“Brazil played very well against Costa Rica") | |
| Data Preprocessing | translation_correction(tweet) |
| (Tokenization) | tweet_clean_stop words(tweet) |
| print (tweet.words) | |
| Data Output | [’Brazil’, ’played’, ’very’, ’well’, ’against’, ’Costa’, ’Rica’] |
| Example of Data Input | Brazil is an excellent soccer team:) !!! |
| tweet = TextBlob(“Brazil is an excellent soccer team:) !!!") | |
| translation_correction(tweet) | |
| tweet_clean_stop words(tweet) | |
| tokenization(tweet) | |
| if tweet.sentiment.polarity > 0: | |
| print (tweet.sentiment) | |
| Data Classification | print (’Polarity: Positive’) |
| (Polarity and Subjectivity) | elif tweet.sentiment.polarity == 0: |
| print (tweet.sentiment) | |
| print (’Polarity: Neutral’) | |
| else: | |
| print (tweet.sentiment) | |
| print (’Polarity: Negative’) | |
| Data Output | Sentiment(polarity = 0.98828125, subjectivity = 1.0) |
| Polarity: Positive |
| Hashtags | Tweets | Retweets | Total |
|---|---|---|---|
| #Copa2018 | 1356 | 3193 | 4549 |
| #BRA | 575 | 2701 | 3276 |
| #VaiBrasil | 100 | 1062 | 1162 |
| #BrasilGanha | 95 | 960 | 1055 |
| #BRAMEX | 123 | 821 | 944 |
| Hashtags | Tweets | Hashtags | Retweets |
|---|---|---|---|
| #Copa2018 | 1356 | #Copa2018 | 3193 |
| #BRA | 575 | #BRA | 2701 |
| #WorldCup | 277 | #VaiBrasil | 1062 |
| #expedientefutebol | 273 | #BrasilGanha | 960 |
| #Brasil | 238 | #soujoga10nacopa | 923 |
| Users | Tweets | Retweets | Total |
|---|---|---|---|
| InfosFuteboI | 34 | 35,504 | 35,538 |
| liberta_depre | 16 | 17,575 | 17,591 |
| cleytu | 2 | 13,856 | 13,858 |
| UMCANARINHOPUTO | 7 | 12,799 | 12,806 |
| fuckluanjo | 1 | 11,997 | 11,998 |
| jah_valentim | 2 | 9899 | 9901 |
| Allec_Matheus | 0 | 9529 | 9529 |
| sccstyles | 4 | 9046 | 9050 |
| rosedixdelrey | 0 | 8776 | 8776 |
| OCrushDaCopa | 1 | 8073 | 8074 |
| ESCANTEIOCUTO | 3 | 7986 | 7989 |
| Germannoart | 1 | 7901 | 7902 |
| standragons | 14 | 6971 | 6985 |
| Polarity | Day | Tweets | Retweets | Total |
|---|---|---|---|---|
| Neutral | July 9th | 2824 | 17,946 | 20,770 |
| Positive | July 7th | 2291 | 18,855 | 21,146 |
| Negative | June 22nd | 1196 | 11,811 | 13,007 |
| Polarity | Tweets | Retweets | Total |
|---|---|---|---|
| Positive | 53,993 | 209,492 | 263,485 |
| Negative | 31,230 | 115,215 | 146,445 |
| Neutral | 83,286 | 237,634 | 320,920 |
| Users | Tweets | Retweets | Total |
|---|---|---|---|
| dobresdelena | 0 | 6723 | 6723 |
| lorenzopaag | 0 | 4877 | 4877 |
| whindersson | 0 | 4526 | 4526 |
| cleytu | 0 | 4003 | 4003 |
| PAPAIDIDICOLIFE | 2 | 3481 | 3483 |
| frasesdebebada | 1 | 3170 | 3171 |
| moniqueppaes | 1 | 2299 | 2300 |
| QuebrandoOTabu | 1 | 2279 | 2280 |
| liberta_depre | 5 | 1686 | 1691 |
| adrianowilkson | 0 | 1388 | 1388 |
| petermaxiff | 1 | 1385 | 1386 |
| lacaxarruda | 0 | 1296 | 1296 |
| InfosFutebol | 5 | 1287 | 1292 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Oliveira Júnior, G.A.; de Oliveira Albuquerque, R.; Borges de Andrade, C.A.; de Sousa, R.T., Jr.; Sandoval Orozco, A.L.; García Villalba, L.J. Anonymous Real-Time Analytics Monitoring Solution for Decision Making Supported by Sentiment Analysis. Sensors 2020, 20, 4557. https://doi.org/10.3390/s20164557
de Oliveira Júnior GA, de Oliveira Albuquerque R, Borges de Andrade CA, de Sousa RT Jr., Sandoval Orozco AL, García Villalba LJ. Anonymous Real-Time Analytics Monitoring Solution for Decision Making Supported by Sentiment Analysis. Sensors. 2020; 20(16):4557. https://doi.org/10.3390/s20164557
Chicago/Turabian Stylede Oliveira Júnior, Gildásio Antonio, Robson de Oliveira Albuquerque, César Augusto Borges de Andrade, Rafael Timóteo de Sousa, Jr., Ana Lucila Sandoval Orozco, and Luis Javier García Villalba. 2020. "Anonymous Real-Time Analytics Monitoring Solution for Decision Making Supported by Sentiment Analysis" Sensors 20, no. 16: 4557. https://doi.org/10.3390/s20164557
APA Stylede Oliveira Júnior, G. A., de Oliveira Albuquerque, R., Borges de Andrade, C. A., de Sousa, R. T., Jr., Sandoval Orozco, A. L., & García Villalba, L. J. (2020). Anonymous Real-Time Analytics Monitoring Solution for Decision Making Supported by Sentiment Analysis. Sensors, 20(16), 4557. https://doi.org/10.3390/s20164557