Indirect Recognition of Predefined Human Activities



Abstract
:
1. Introduction
2. Materials and Methods
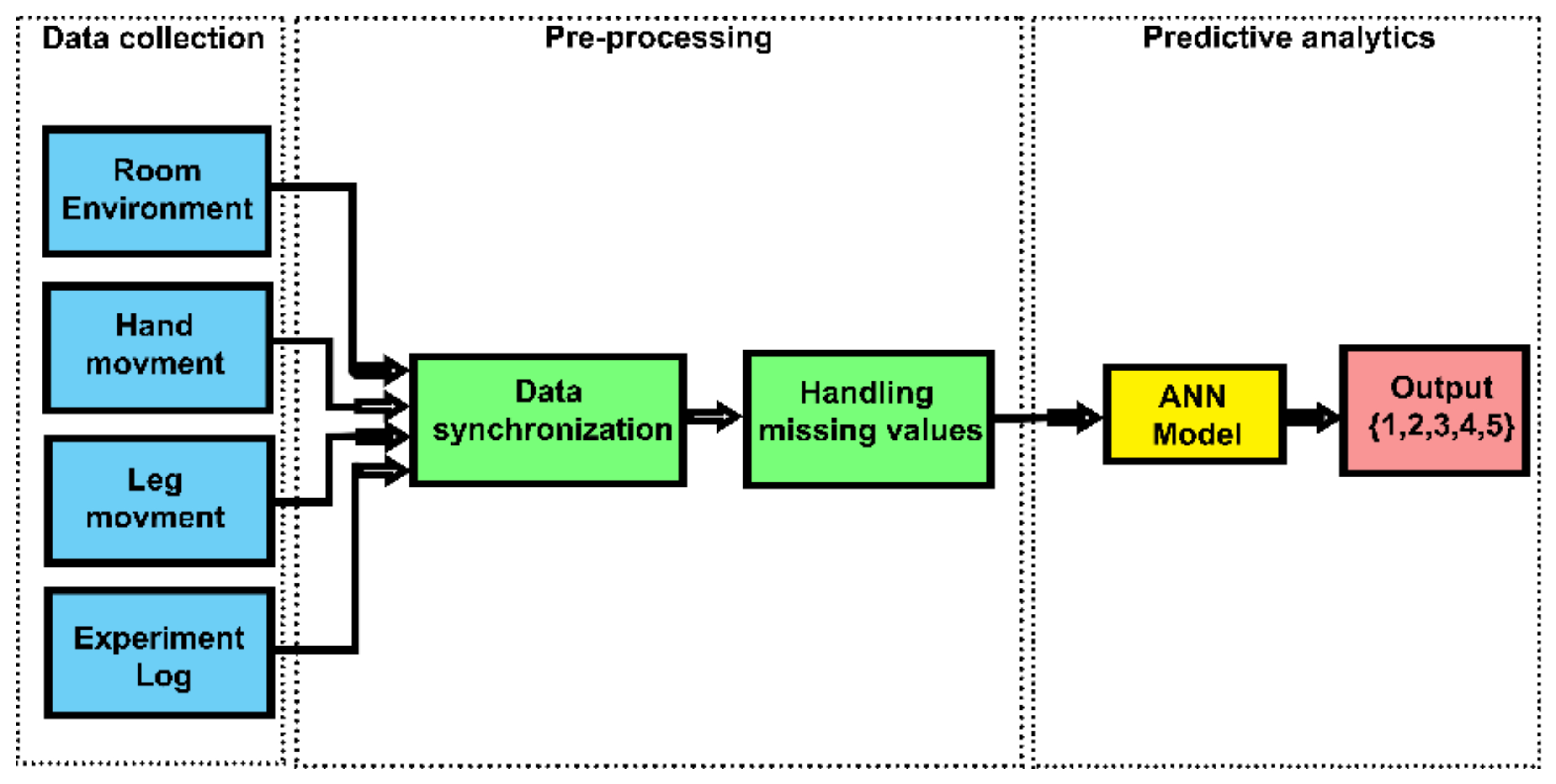
2.1. Data Collection
2.1.1. KNX Technology
2.1.2. Wearable Gadgets
2.2. Pre-Processing
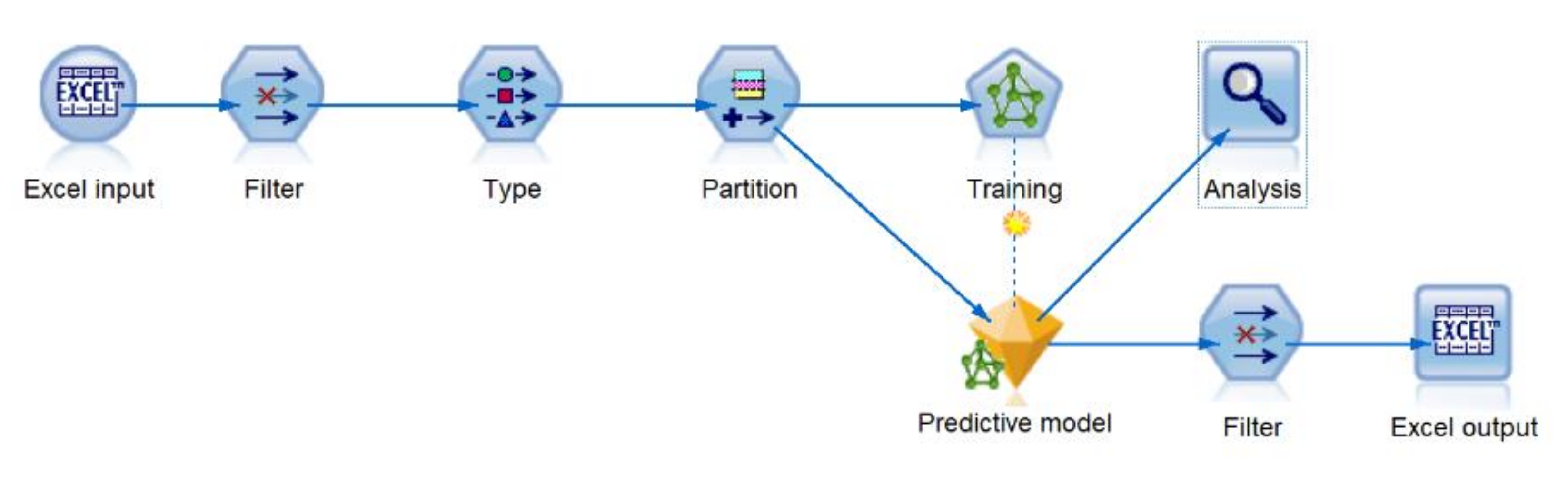
2.3. Predictive Analytics
2.3.1. Logistic Regression
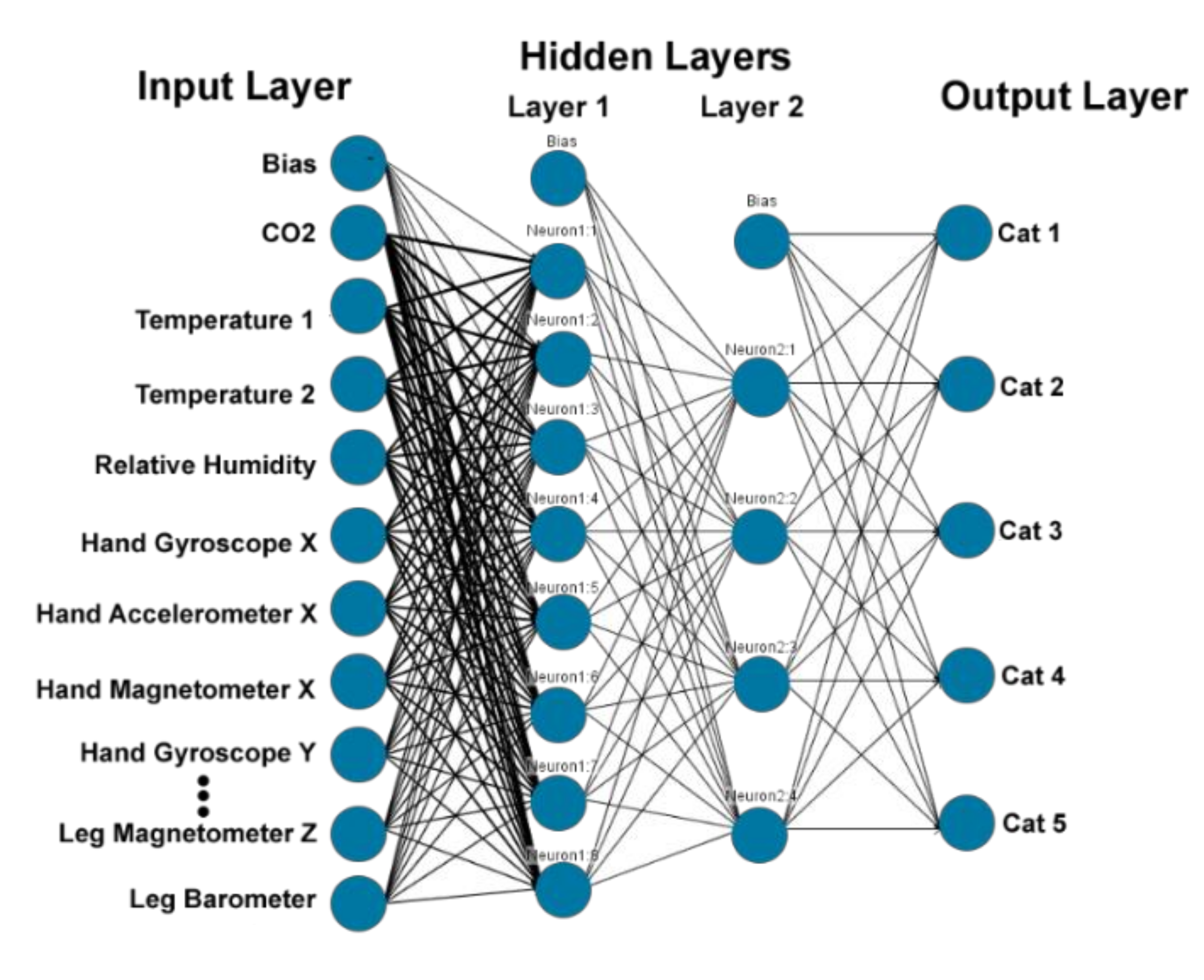
2.3.2. Artificial Neural Network
3. Implementation and Results
3.1. Linear Regression
3.2. Artificical Neural Network
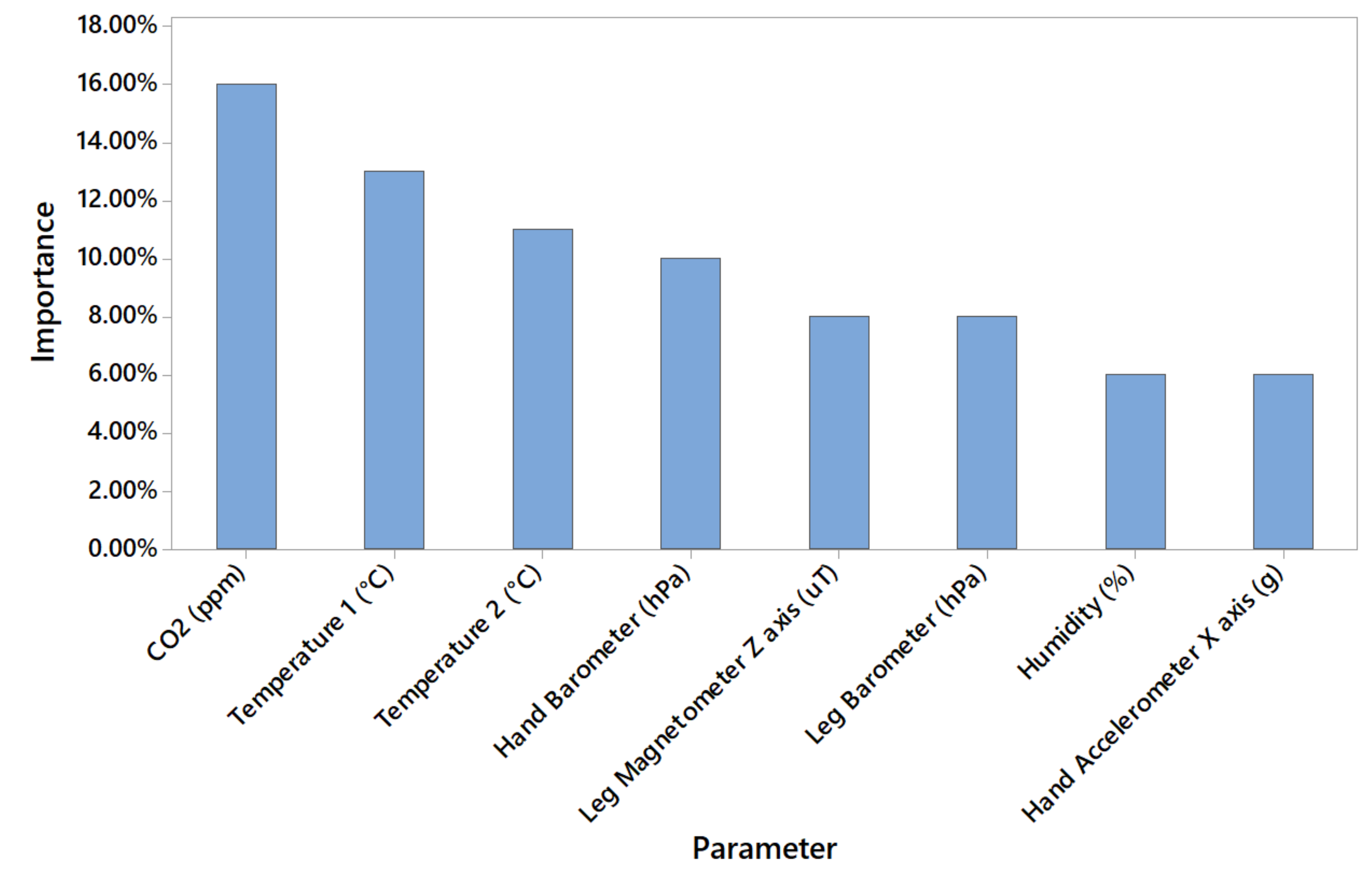
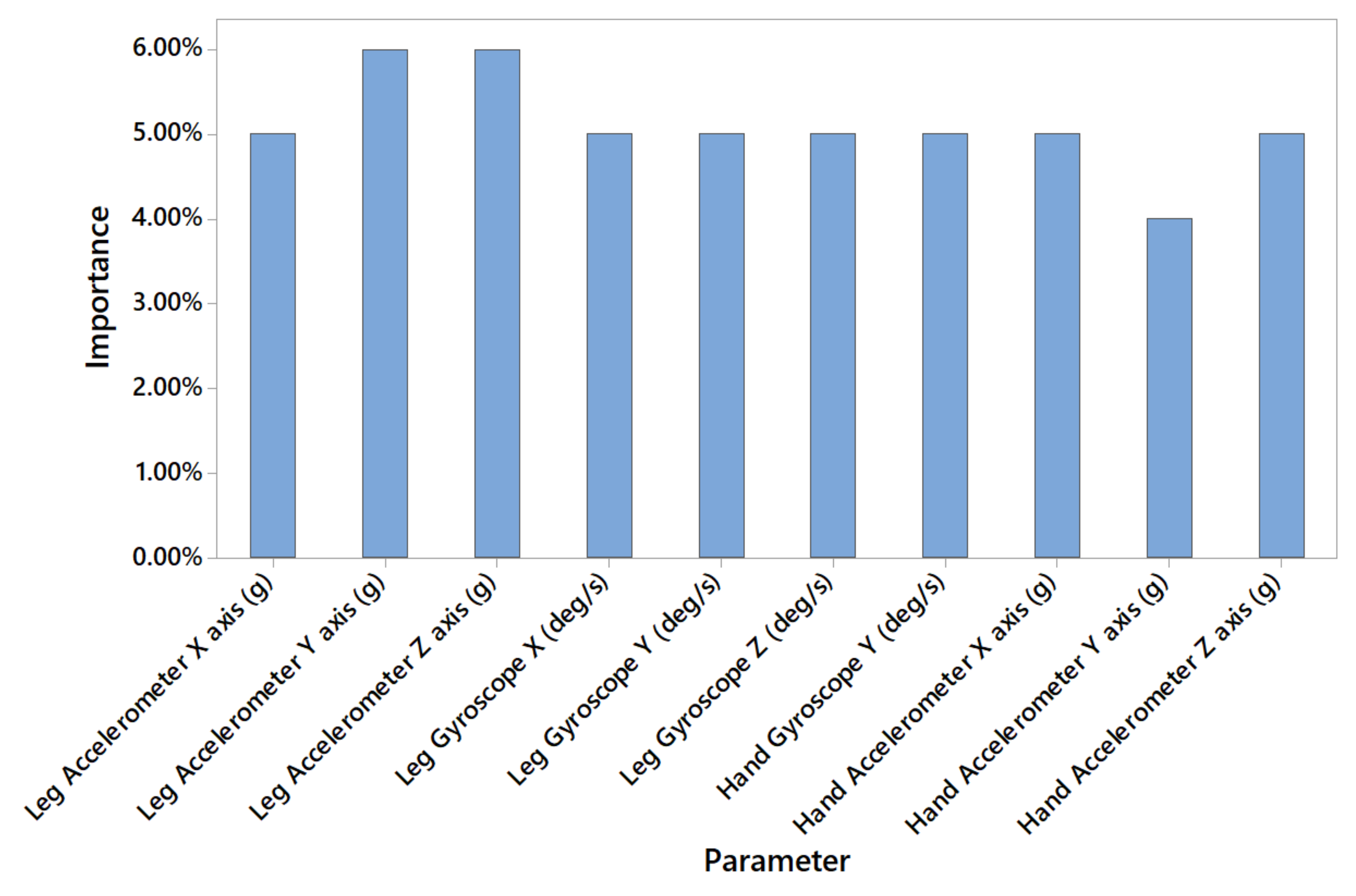
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Vanus, J.; Belesova, J.; Martinek, R.; Nedoma, J.; Fajkus, M.; Bilik, P.; Zidek, J. Monitoring of the daily living activities in smart home care. Hum. Cent. Comput. Inf. Sci. 2017, 7, 30. [Google Scholar] [CrossRef] [Green Version]
- Panagopoulos, C.; Menychtas, A.; Tsanakas, P.; Maglogiannis, I. Increasing Usability of Homecare Applications for Older Adults: A Case Study. Designs 2019, 3, 23. [Google Scholar] [CrossRef] [Green Version]
- Loukatos, D.; Arvanitis, K.G.; Armonis, N. Investigating Educationally Fruitful Speech-Based Methods to Assist People with Special Needs to Care Potted Plants. In International Conference on Human Interaction and Emerging Technologies; Springer: Cham, Switzerland, 2019; pp. 157–162. [Google Scholar]
- Wiljer, D.; Hakim, Z. Developing an artificial intelligence–enabled health care practice: Rewiring health care professions for better care. J. Med. Imaging Radiat. Sci. 2019, 50, S8–S14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sadreazami, H.; Bolic, M.; Rajan, S. Fall Detection Using Standoff Radar-Based Sensing and Deep Convolutional Neural Network. IEEE Trans. Circuits Syst. II Express Briefs 2020, 67, 197–201. [Google Scholar] [CrossRef]
- Ahamed, F.; Shahrestani, S.; Cheung, H. Intelligent Fall Detection with Wearable IoT. Adv. Intell. Syst. Comput. 2020, 993, 391–401. [Google Scholar] [CrossRef]
- Dhiraj; Manekar, R.; Saurav, S.; Maiti, S.; Singh, S.; Chaudhury, S.; Neeraj; Kumar, R.; Chaudhary, K. Activity Recognition for Indoor Fall Detection in 360-Degree Videos Using Deep Learning Techniques. Adv. Intell. Syst. Comput. 2020, 1024, 417–429. [Google Scholar] [CrossRef]
- Hsueh, Y.-L.; Lie, W.-N.; Guo, G.-Y. Human Behavior Recognition from Multiview Videos. Inf. Sci. 2020, 517, 275–296. [Google Scholar] [CrossRef]
- Szczurek, A.; Maciejewska, M.; Pietrucha, T. Occupancy determination based on time series of CO2 concentration, temperature and relative humidity. Energy Build. 2017, 147, 142–154. [Google Scholar] [CrossRef]
- Vanus, J.; Machac, J.; Martinek, R.; Bilik, P.; Zidek, J.; Nedoma, J.; Fajkus, M. The design of an indirect method for the human presence monitoring in the intelligent building. Hum. Cent. Comput. Inf. Sci. 2018, 8, 28. [Google Scholar] [CrossRef]
- Vanus, J.; Kubicek, J.; Gorjani, O.M.; Koziorek, J. Using the IBMSPSS SWTool withWavelet Transformation for CO2 Prediction within IoT in Smart Home Care. Sensors 2019, 19, 1407. [Google Scholar] [CrossRef] [Green Version]
- Vanus, J.M.; Gorjani, O.; Bilik, P. Novel Proposal for Prediction of CO2 Course and Occupancy Recognition in Intelligent Buildings within IoT. Energies 2019, 12, 4541. [Google Scholar] [CrossRef] [Green Version]
- Albert, M.V.; Toledo, S.; Shapiro, M.; Koerding, K. Using mobile phones for activity recognition in Parkinson’s patients. Front. Neurol. 2012, 3, 158. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nweke, H.F.; Teh, Y.W.; Al-Garadi, M.A.; Alo, U.R. Deep learning algorithms for human activity recognition using mobile and wearable sensor networks: State of the art and research challenges. Expert Syst. Appl. 2018, 105, 233–261. [Google Scholar] [CrossRef]
- Lara, O.D.; Labrador, M.A. A survey on human activity recognition using wearable sensors. IEEE Commun. Surv. Tutor. 2012, 15, 1192–1209. [Google Scholar] [CrossRef]
- Yousefi, S.; Narui, H.; Dayal, S.; Ermon, S.; Valaee, S. A survey on behavior recognition using wifi channel state information. IEEE Commun. Mag. 2017, 55, 98–104. [Google Scholar] [CrossRef]
- Minarno, A.E.; Kusuma, W.A.; Wibowo, H. Performance Comparisson Activity Recognition using Logistic Regression and Support Vector Machine. In Proceedings of the 2020 3rd International Conference on Intelligent Autonomous Systems (ICoIAS), Singapore, 26–29 February 2020; pp. 19–24. [Google Scholar]
- Kwapisz, J.R.; Weiss, G.M.; Moore, S.A. Activity recognition using cell phone accelerometers. ACM SIGKDD Explor. Newsl. 2011, 12, 74–82. [Google Scholar] [CrossRef]
- Bayat, A.; Pomplun, M.; Tran, D.A. A study on human activity recognition using accelerometer data from smartphones. Procedia Comput. Sci. 2014, 34, 450–457. [Google Scholar] [CrossRef] [Green Version]
- Trost, S.G.; Zheng, Y.; Wong, W.K. Machine learning for activity recognition: Hip versus wrist data. Physiol. Meas. 2014, 35, 2183. [Google Scholar] [CrossRef]
- European Committee for Standards. Home and Building Electronic System (HBES); Cenelec EN50090; European Committee for Standards: Brussels, Belgium, 2005. [Google Scholar]
- International Organization for Standardization. K.N.X. Standard ISO/IEC14543-3; International Organization for Standardization: Geneva, Switzerland, 2006. [Google Scholar]
- NGIMU X-Io Technologies. Available online: https://x-io.co.uk/ngimu/ (accessed on 13 August 2020).
- Rantalainen, T.; Karavirta, L.; Pirkola, H.; Rantanen, T.; Linnamo, V. Gait Variability UsingWaist- and Ankle-Worn Inertial Measurement Units in Healthy Older Adults. Sensors 2020, 20, 2858. [Google Scholar] [CrossRef]
- Fida, B.; Bernabucci, I.; Bibbo, D.; Conforto, S.; Schmid, M. Pre-processing effect on the accuracy of event-based activity segmentation and classification through inertial sensors. Sensors 2015, 15, 23095–23109. [Google Scholar] [CrossRef] [Green Version]
- Alankar, B.; Yousf, N.; Ahsaan, S.U. Predictive Analytics for Weather Forecasting using Back Propagation and Resilient Back Propagation Neural Networks. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2020; Volume 1030, pp. 99–115. [Google Scholar] [CrossRef]
- Poornima, S.; Pushpalatha, M. Prediction of rainfall using intensified LSTM based recurrent Neural Network with Weighted Linear Units. Atmosphere 2019, 10, 668. [Google Scholar] [CrossRef] [Green Version]
- Pooja, S.B.; Siva Balan, R.V. Linear program boosting classification with remote sensed big data for weather forecasting. Int. J. Adv. Trends Comput. Sci. Eng. 2019, 8, 1405–1415. [Google Scholar] [CrossRef]
- Yang, Y.; Hu, R.; Sun, G.; Qiu, C. Chinese Spam Data Filter Model in Mobile Internet. In Proceedings of the International Conference on Advanced Communication Technology ICACT, Xi’an, China, 17–20 February 2019; pp. 339–343. [Google Scholar] [CrossRef]
- Maguluri, L.P.; Ragupathy, R.; Buddi, S.R.K.; Ponugoti, V.; Kalimil, T.S. Adaptive Prediction of Spam Emails Using Bayesian Inference. In Proceedings of the 3rd International Conference on Computing Methodologies and Communication ICCMC, Erode, India, 27–29 March 2019; pp. 628–632. [Google Scholar] [CrossRef]
- Mansourbeigi, S.M.-H. Stochastic Methods to Find Maximum Likelihood for Spam E-mail Classification. Adv. Intell. Syst. Comput. 2019, 927, 623–632. [Google Scholar] [CrossRef] [Green Version]
- Mallik, R.; Sahoo, A.K. A novel approach to spam filtering using semantic based naive bayesian classifier in text analytics. Adv. Intell. Syst. Comput. 2019, 813, 301–309. [Google Scholar] [CrossRef]
- Van Nguyen, T.; Zhou, L.; Chong, A.Y.L.; Li, B.; Pu, X. Predicting customer demand for remanufactured products: A data-mining approach. Eur. J. Oper. Res. 2019, 281, 543–558. [Google Scholar] [CrossRef]
- Liu, C.; Lei, Z.; Morley, D.; Abourizk, S.M. Dynamic, Data-Driven Decision-Support Approach for Construction Equipment Acquisition and Disposal. J. Comput. Civ. Eng. 2020, 34, 34. [Google Scholar] [CrossRef]
- Wang, J.; Lai, X.; Zhang, S.; Wang, W.M.; Chen, J. Predicting customer absence for automobile 4S shops: A lifecycle perspective. Eng. Appl. Artif. Intell. 2020, 89. [Google Scholar] [CrossRef]
- Park, G.; Song, M. Predicting performances in business processes using deep neural networks. Decis. Support. Syst. 2020, 129, 113191. [Google Scholar] [CrossRef]
- Sarno, R.; Sinaga, F.; Sungkono, K.R. Anomaly detection in business processes using process mining and fuzzy association rule learning. J. Big Data 2020, 7, 5. [Google Scholar] [CrossRef]
- Matos, T.; Macedo, J.A.; Lettich, F.; Monteiro, J.M.; Renso, C.; Perego, R.; Nardini, F.M. Leveraging feature selection to detect potential tax fraudsters. Expert Syst. Appl. 2020, 145, 113128. [Google Scholar] [CrossRef]
- Shi, C.; Li, X.; Lv, J.; Yin, J.; Mumtaz, I. Robust geodesic based outlier detection for class imbalance problem. Pattern Recognit. Lett. 2020, 131, 428–434. [Google Scholar] [CrossRef]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Waltham, MA, USA, 2011. [Google Scholar]
- Kachalsky, I.; Zakirzyanov, I.; Ulyantsev, V. Applying Reinforcement Learning and Supervised Learning Techniques to Play Hearthstone. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 1145–1148. [Google Scholar]
- Nijhawan, R.; Srivastava, I.; Shukla, P. Land cover classification using super-vised and unsupervised learning techniques. In Proceedings of the 2017 International Conference on Computational Intelligence in Data Science (ICCIDS), Chennai, India, 2–3 June 2017; pp. 1–6. [Google Scholar]
- Liu, Q.; Liao, X.; Carin, L. Semi-Supervised Life-Long Learning with Application to Sensing. In Proceedings of the 2007 2nd IEEE International Workshop on Computational Advances in Multi-Sensor Adaptive Processing, St. Thomas, VI, USA, 12–14 December 2007; pp. 1–4. [Google Scholar]
- Yan, X. Linear Regression Analysis: Theory and Computing; World Scientific: Hackensack, NJ, USA, 2009; pp. 1–2. ISBN 9789812834119. [Google Scholar]
- Rencher, A.C.; Christensen, W.F. Chapter 10, Multivariate regression—Section 10.1 Introduction Methods of Multivariate Analysis. In Wiley Series in Probability and Statistics, 3rd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2012; Volume 709, p. 19. ISBN 9781118391679. [Google Scholar]
- Tolles, J.; Meurer, W.J. Logistic regression: Relating patient characteristics to outcomes. JAMA 2016, 316, 533–534. [Google Scholar] [CrossRef] [PubMed]
- Boyd, C.R.; Tolson, M.A.; Copes, W.S. Evaluating trauma care: The TRISS method Trauma Score and the Injury Severity Score. J. Trauma 1987, 27, 370–378. [Google Scholar] [CrossRef] [PubMed]
- Le Gall, J.R.; Lemeshow, S.; Saulnier, F. A new simplified acute physiology score (SAPS II) based on a European/North American multicenter study. JAMA 1993, 270, 2957–2963. [Google Scholar] [CrossRef] [PubMed]
- Berry, M.J.; Linoff, G.S. Data Mining Techniques: For Marketing, Sales, and Customer Relationship Management; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Truett, J.; Cornfield, J.; Kannel, W. A multivariate analysis of the risk of coronary heart disease in Framingham. J. Chronic Dis. 1967, 20, 511–524. [Google Scholar] [CrossRef]
- Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Control. Signals Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Freedman, D.A. Statistical Models: Theory and Practice; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Efroymson, M.A. Multiple Regression Analysis. Mathematical Methods for Digital Computers; Ralston, A., Wilf, H.S., Eds.; Wiley: New York, NY, USA, 1960. [Google Scholar]
- Hocking, R.R. The Analysis and Selection of Variables in Linear Regression. Biometrics 1976, 32, 1–49. [Google Scholar] [CrossRef]
- Draper, N.; Smith, H. Applied Regression Analysis, 2nd ed.; John Wiley & Sons, Inc.: New York, NY, USA, 1981. [Google Scholar]
- SAS Institute. SAS/STAT User’s Guide, 4th ed.; Version 6; SAS Institute Inc.: Cary, NC, USA, 1989; Volume 2. [Google Scholar]
- Knecht, W.R. Pilot Willingness to Take off into Marginal Weather, Part II: Antecedent Overfitting with forward Stepwise Logistic Regression. In Technical Report DOT/FAA/AM-O5/15; Federal Aviation Administration: Oklahoma City, OK, USA, 2005. [Google Scholar]
- Flom, P.L.; Cassell, D.L. Stopping Stepwise: Why Stepwise and Similar Selection Methods are Bad, and What You Should Use; NESUG: Corvallis, OR, USA, 2007. [Google Scholar]
- Myers, R.H.; Myers, R.H. Classical and Modern Regression with Applications; Duxbury Press: Belmont, CA, USA, 1990; Volume 2. [Google Scholar]
- Bendel, R.B.; Afifi, A.A. Comparison of stopping rules in forward “stepwise” regression. J. Am. Stat. Assoc. 1977, 72, 46–53. [Google Scholar]
- Kubinyi, H. Evolutionary variable selection in regression and PLS analyses. J. Chemom. 1996, 10, 119–133. [Google Scholar] [CrossRef]
- Szumilas, M. Explaining odds ratios. J. Can. Acad. Child. Adolesc. Psychiatry 2010, 19, 227. [Google Scholar]
- Moosavi, S.R.; Wood, D.A.; Ahmadi, M.A.; Choubineh, A. ANN-Based Prediction of Laboratory-Scale Performance of CO2-Foam Flooding for Improving Oil Recovery. Nat. Resour. Res. 2019, 28, 1619–1637. [Google Scholar] [CrossRef]
- Zarei, T.; Behyad, R. Predicting the water production of a solar seawater greenhouse desalination unit using multi-layer perceptron model. Sol. Energy 2019, 177, 595–603. [Google Scholar] [CrossRef]
- Yilmaz, I.; Kaynar, O. Multiple regression, ANN (RBF, MLP) and ANFIS models for prediction of swell potential of clayey soils. Expert Syst. Appl. 2011, 38, 5958–5966. [Google Scholar] [CrossRef]
- Heidari, E.; Sobati, M.A.; Movahedirad, S. Accurate prediction of nanofluid viscosity using a multilayer perceptron artificial neural network (MLP-ANN). Chemom. Intell. Lab. Syst. 2016, 155, 73–85. [Google Scholar] [CrossRef]
- Abdi-Khanghah, M.; Bemani, A.; Naserzadeh, Z.; Zhang, Z. Prediction of solubility of N-alkanes in supercritical CO2 using RBF-ANN and MLP-ANN. J. CO2 Util. 2018, 25, 108–119. [Google Scholar] [CrossRef]
- Ahmed, S.A.; Dey, S.; Sarma, K.K. Image texture classification using Artificial Neural Network (ANN). In Proceedings of the 2011 2nd National Conference on Emerging Trends and Applications in Computer Science, Shillong, India, 4–5 March 2011; pp. 1–4. [Google Scholar]
- Zarei, F.; Baghban, A. Phase behavior modelling of asphaltene precipitation utilizing MLP-ANN approach. Pet. Sci. Technol. 2017, 35, 2009–2015. [Google Scholar] [CrossRef]
- Behrang, M.; Assareh, E.; Ghanbarzadeh, A.; Noghrehabadi, A. The potential of different artificial neural network (ANN) techniques in daily global solar radiation modeling based on meteorological data. Sol. Energy 2010, 84, 1468–1480. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks: A Comprehensive Foundation, 2nd ed.; Macmillan College Publishing: New York, NY, USA, 1998. [Google Scholar]
- Ripley, B.D. Pattern Recognition and Neural Networks; Cambridge University Press (CUP): Cambridge, UK, 1996. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009. [Google Scholar]
- Rosenblatt, F. Principles of Neurodynamics. Perceptrons and the Theory of Brain Mechanisms; Defense Technical Information Center (DTIC): Baer Fort, VA, USA, 1961. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation; The MIT Press: Cambridge, MA, USA, 1985. [Google Scholar]
- IBM SPSS Modeler 18 Algorithms Guide. Available online: http://public.dhe.ibm.com/software/analytics/spss/documentation/modeler/18.0/en/AlgorithmsGuide.pdf (accessed on 1 November 2019).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Activity Class | Description |
|---|---|
| Class 1 | Relaxing with minimal movements |
| Class 2 | using the computer for checking emails and web surfing |
| Class 3 | Preparing tea and sandwich—eating breakfast |
| Class 4 | Cleaning the room by wiping the Tables and vacuum cleaning |
| Class 5 | Exercising using stationary bicycle |
| Sensor | Unit | Range |
|---|---|---|
| CO2 | ppm | 300 to 9999 |
| Temperature 1 | 0 to +40 | |
| Relative humidity sensor | % | 20 to 100 |
| Parameter | Unit |
|---|---|
| Gyroscope X, Y, Z | deg/s |
| Accelerometer X, Y, Z | g |
| Magnetometer X, Y, Z | μT |
| Barometer | hPa |
| Class | Observed | Predicted | Percentage Correct | Overall Accuracy | |
|---|---|---|---|---|---|
| 0 | 1 | ||||
| Class 1 | 0 | 273,204 | 2758 | 99.9% | 98.9% |
| 1 | 422 | 19,804 | 97.9% | ||
| Class 2 | 0 | 213,908 | 3764 | 98.3% | 97.4% |
| 1 | 3877 | 74,639 | 95.1% | ||
| Class 3 | 0 | 220,320 | 0 | 100.0% | 100.0% |
| 1 | 2 | 75,866 | 100.0% | ||
| Class 4 | 0 | 243,244 | 5327 | 97.9% | 95.4% |
| 1 | 8209 | 39,408 | 82.8% | ||
| Class 5 | 0 | 223,644 | 1096 | 99.5% | 99.3% |
| 1 | 869 | 70,579 | 98.8% | ||
| Activity | Observed | Predicted | Percentage Correct | Overall Accuracy | |
|---|---|---|---|---|---|
| 0 | 1 | ||||
| Class 1 | 0 | 270,378 | 867 | 99.7% | 99.5% |
| 1 | 640 | 18,829 | 96.7% | ||
| Class 2 | 0 | 213,182 | 3791 | 98.3% | 97.0% |
| 1 | 5068 | 68,673 | 93.1% | ||
| Class 3 | 0 | 216,883 | 95 | 100% | 99.9% |
| 1 | 51 | 73,685 | 99.9% | ||
| Class 4 | 0 | 235,594 | 9914 | 96.0% | 91.2% |
| 1 | 15,720 | 29,486 | 65.2% | ||
| Class 5 | 0 | 212,940 | 1653 | 99.2% | 98.9% |
| 1 | 1535 | 74,586 | 98.05 | ||
| Activity Class | Dataset A | Dataset B | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | |||
| KNX | Humidity | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 1.59 × 103 | 1.03 × 102 | 0.00 | 0.37 | 1.45 × 108 | |
| Temperature | 2.29 × 1062 | 1.40 × 1025 | 0.00 | 3.29 × 103 | 6.66 × 1036 | 1.55 × 1045 | 5.29 × 1028 | 0.00 | 4.45 × 103 | 1.03 × 1011 | ||
| CO2 | 0.94 | 0.89 | 0.31 | 0.86 | 0.71 | 0.12 | 0.99 | 0.00 | 0.96 | 1.05 | ||
| Leg | Gyroscope | x | 1.00 | 0.99 | 0.94 | 1.00 | 1.00 | 0.99 | 1.00 | 1.05 | 1.00 | 0.99 |
| y | 0.99 | 0.99 | 1.05 | 1.00 | 1.02 | 0.99 | 0.99 | 0.92 | 1.00 | 1.01 | ||
| z | 1.00 | 0.99 | 0.96 | 1.00 | 0.99 | 0.99 | 0.99 | 1.02 | 1.00 | 1.01 | ||
| Accelerometer | x | 4.20 | 0.55 | 7.44 | 1.57 | 0.27 | 4.98 | 0.79 | 0.00 | 1.35 | 0.34 | |
| y | 0.43 | 5.32 | 5.68 × 104 | 2.16 | 0.37 | 2.52 | 1.62 | 5.75 × 105 | 1.23 | 0.28 | ||
| z | 0.09 | 0.18 | 0.00 | 3.17 | 4.97 × 10 | 0.02 | 0.34 | 0.01 | 1.61 | 2.14 | ||
| Magnetometer | x | 0.99 | 0.99 | 1.65 | 1.01 | 0.99 | 0.99 | 0.95 | 1.17 | 1.01 | 1.04 | |
| y | 1.05 | 1.02 | 0.67 | 1.02 | 0.95 | 1.08 | 1.00 | 0.90 | 1.03 | 0.89 | ||
| z | 1.02 | 0.89 | 0.37 | 1.06 | 1.17 | 0.92 | 0.93 | 0.92 | 1.02 | 1.24 | ||
| Hand | Gyroscope | x | 1.00 | 1.00 | 1.03 | 1.00 | 1.00 | 1.00 | 1.00 | 1.02 | 1.00 | 1.00 |
| y | 1.00 | 1.00 | 1.07 | 1.00 | 1.00 | 1.01 | 1.00 | 1.03 | 1.00 | 1.00 | ||
| z | 0.99 | 0.99 | 1.09 | 1.00 | 1.00 | 0.99 | 1.00 | 1.03 | 1.00 | 1.00 | ||
| Accelerometer | x | 0.06 | 0.67 | 0.35 | 0.08 | 8.07 × 10 | 3.53 | 8.58 | 3.09 | 0.07 | 1.79 × 10 | |
| y | 3.30 | 1.50 × 10 | 1.67 × 10 | 0.14 | 0.14 | 0.01 | 0.19 | 8.01 × 102 | 0.68 | 1.85 | ||
| z | 9.42 | 0.04 | 0.00 | 2.78 × 10 | 1.13 | 0.87 | 3.99 × 10 | 0.08 | 0.05 | 4.28 | ||
| Magnetometer | x | 0.97 | 0.97 | 0.44 | 0.97 | 1.08 | 1.01 | 1.05 | 1.98 | 1.00 | 1.05 | |
| y | 1.08 | 1.067 | 0.235 | 0.967 | 0.939 | 1.024 | 0.969 | 0.662 | 0.987 | 1.01 | ||
| z | 1.00 | 0.96 | 0.86 | 1.01 | 1.08 | 1.11 | 1.07 | 1.66 | 0.99 | 0.95 | ||
| Model | Number of Neurons | Overall Accuracy | Accuracy | |||||
|---|---|---|---|---|---|---|---|---|
| Hidden Layer 1 | Hidden Layer 2 | 1 | 2 | 3 | 4 | 5 | ||
| 1 | 8 | 4 | 99.80% | 99.05% | 99.99% | 99.85% | 99.95% | 99.96% |
| 2 | 16 | 8 | 99.90% | 99.79% | 99.99% | 99.88% | 99.96% | 99.97% |
| 3 | 16 | 32 | 99.99% | 99.81% | 99.99% | 99.91% | 99.98% | 99.98% |
| 4 | 64 | 32 | 99.90% | 99.76% | 99.97% | 99.91% | 99.93% | 99.94% |
| 5 | 64 | 128 | 99.50% | 99.22% | 99.63% | 99.67% | 99.38% | 99.26% |
| 6 | 128 | 64 | 99.60% | 98.92% | 99.83% | 99.68% | 99.74% | 99.64% |
| 7 | 128 | 256 | 96.40% | 96.02% | 96.59% | 96.89% | 97.12% | 94.97% |
| 8 | 256 | 128 | 98.50% | 98.44% | 98.93% | 98.87% | 98.85% | 97.29% |
| 9 | 256 | 512 | 76.40% | 76.48% | 77.04% | 78.08% | 76.81% | 73.26% |
| 10 | 512 | 256 | 82.80% | 83.98% | 82.30% | 83.84% | 82.94% | 80.06% |
| 11 | 512 | 512 | 73.10% | 74.52% | 71.98% | 73.63% | 71.9% | 73.4% |
| Model | Number of Neurons | Overall Accuracy | Accuracy of Validation Partition | |||||
|---|---|---|---|---|---|---|---|---|
| Hidden Layer 1 | Hidden Layer 2 | 1 | 2 | 3 | 4 | 5 | ||
| 1 | 8 | 4 | 99.70 | 99.20% | 99.97% | 99.78% | 99.71% | 99.73% |
| 2 | 16 | 8 | 99.80 | 99.81% | 99.90% | 99.91% | 99.71% | 99.63% |
| 3 | 16 | 32 | 99.90 | 99.70% | 99.97% | 99.92% | 99.94% | 99.95% |
| 4 | 64 | 32 | 99.80 | 99.66% | 99.89% | 99.91% | 99.76% | 99.67% |
| 5 | 64 | 128 | 99.50 | 99.56% | 99.62% | 99.79% | 99.43% | 99.02% |
| 6 | 128 | 64 | 99.50 | 99.43% | 99.78% | 99.7% | 99.45% | 99.27% |
| 7 | 128 | 256 | 96.70 | 97.50% | 96.55% | 96.74% | 97.21% | 95.38% |
| 8 | 256 | 128 | 98.50 | 98.53% | 98.69% | 98.95% | 99.07% | 97.04% |
| 9 | 256 | 512 | 76.40 | 77.13% | 81.02% | 73.32% | 75.54% | 75.47% |
| 10 | 512 | 256 | 83.30 | 84.31% | 85.28% | 80.45% | 84.27% | 82.52% |
| 11 | 512 | 512 | 74.00 | 73.75% | 75.70% | 70.20% | 75.69% | 74.00% |
| Model | Neurons In Hidden Layers | Accuracy of Each Activity Class | |||||
|---|---|---|---|---|---|---|---|
| Layer 1 | Layer 2 | 1 | 2 | 3 | 4 | 5 | |
| 1 | 8 | 4 | 93.30% | 94.26% | 73.82% | 47.23% | 84.45% |
| 2 | 16 | 8 | 93.30% | 25.36% | 73.82% | 64.37% | 84.45% |
| 3 | 16 | 32 | 93.30% | 25.36% | 73.82% | 25.37% | 84.45% |
| 4 | 64 | 32 | 93.30% | 74.64% | 73.82% | 25.53% | 84.42% |
| 5 | 64 | 128 | 93.30% | 77.17% | 75.37% | 25.47% | 84.44% |
| 6 | 128 | 64 | 93.30% | 71.41% | 73.02% | 25.37% | 84.45% |
| 7 | 128 | 256 | 6.81% | 46.69% | 73.64% | 25.58% | 30.11% |
| 8 | 256 | 128 | 93.30% | 82.13% | 41.33% | 25.39% | 84.45% |
| 9 | 256 | 512 | 89.21% | 40.60% | 50.34% | 34.60% | 40.89% |
| 10 | 512 | 256 | 92.94% | 25.42% | 68.58% | 41.13% | 84.26% |
| 11 | 512 | 512 | 30.37% | 30.83% | 74.14% | 35.67% | 63.93% |
| Model | Neurons In Hidden Layers | Accuracy of Each Activity Class | |||||
|---|---|---|---|---|---|---|---|
| 1 | 2 | 1 | 2 | 3 | 4 | 5 | |
| 1 | 8 | 4 | 50.83% | 88.64% | 75.88% | 63.5% | 83.92% |
| 2 | 16 | 8 | 93.17% | 98.51% | 75.88% | 67.11% | 96.2% |
| 3 | 16 | 32 | 81.21% | 88.59% | 75.88% | 55.81% | 76.11% |
| 4 | 64 | 32 | 27.6% | 88.79% | 75.88% | 66.03% | 68.66% |
| 5 | 64 | 128 | 82.01% | 82.30% | 75.88% | 77.77% | 44.14% |
| 6 | 128 | 64 | 77.94% | 92.65% | 75.88% | 73.02% | 50.21% |
| 7 | 128 | 256 | 17.71% | 49.58% | 75.71% | 26.85% | 44.48% |
| 8 | 256 | 128 | 22.60% | 85.72% | 75.87% | 64.71% | 30.62% |
| 9 | 256 | 512 | 40.22% | 44.92% | 50.45% | 49.82% | 63.95% |
| 10 | 512 | 256 | 33.51% | 13.1% | 77.95% | 52.3% | 29.81% |
| 11 | 512 | 512 | 70.2% | 78.37% | 48.53% | 56.77% | 33.39% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Majidzadeh Gorjani, O.; Proto, A.; Vanus, J.; Bilik, P. Indirect Recognition of Predefined Human Activities. Sensors 2020, 20, 4829. https://doi.org/10.3390/s20174829
Majidzadeh Gorjani O, Proto A, Vanus J, Bilik P. Indirect Recognition of Predefined Human Activities. Sensors. 2020; 20(17):4829. https://doi.org/10.3390/s20174829
Chicago/Turabian StyleMajidzadeh Gorjani, Ojan, Antonino Proto, Jan Vanus, and Petr Bilik. 2020. "Indirect Recognition of Predefined Human Activities" Sensors 20, no. 17: 4829. https://doi.org/10.3390/s20174829
APA StyleMajidzadeh Gorjani, O., Proto, A., Vanus, J., & Bilik, P. (2020). Indirect Recognition of Predefined Human Activities. Sensors, 20(17), 4829. https://doi.org/10.3390/s20174829