3DMGNet: 3D Model Generation Network Based on Multi-Modal Data Constraints and Multi-Level Feature Fusion



Abstract
:1. Introduction
- (1)
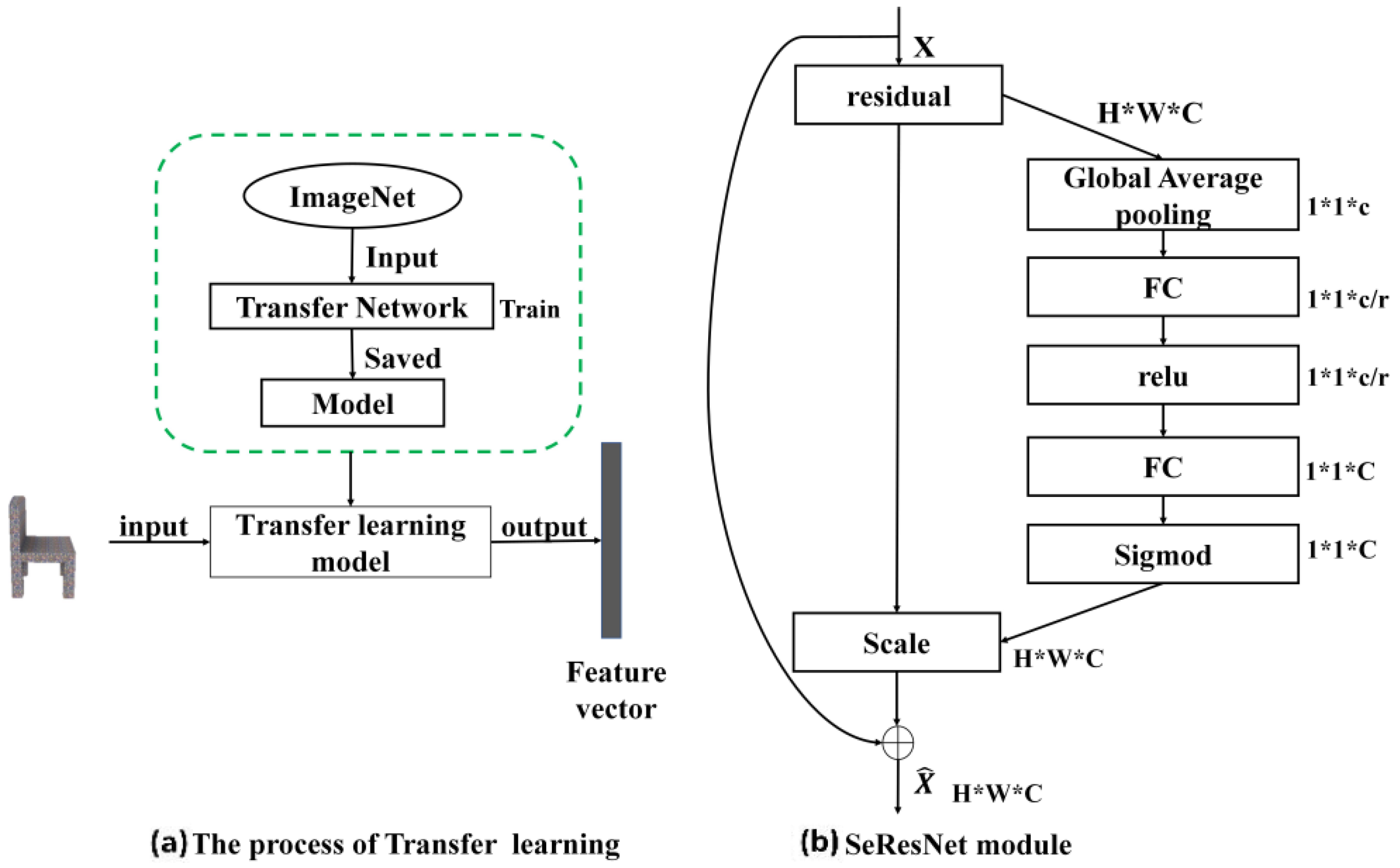
- An image feature extraction network is introduced in the 2DNet for the 3D model generation. As shown in Figure 1a, Se-ResNet-101 is implemented to extract image features based on transfer learning method. As shown in Figure 1b, SeNet [15] is embedded into the residual module of the ResNet [11], to construct the basic architecture of the Se-ResNet-101.
- (2)
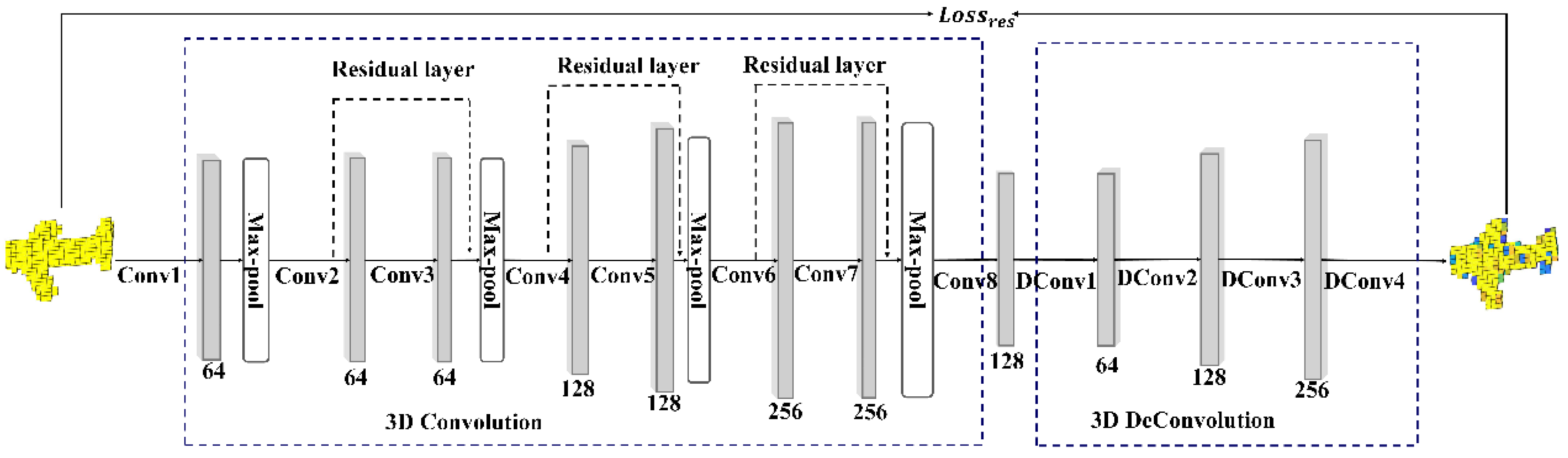
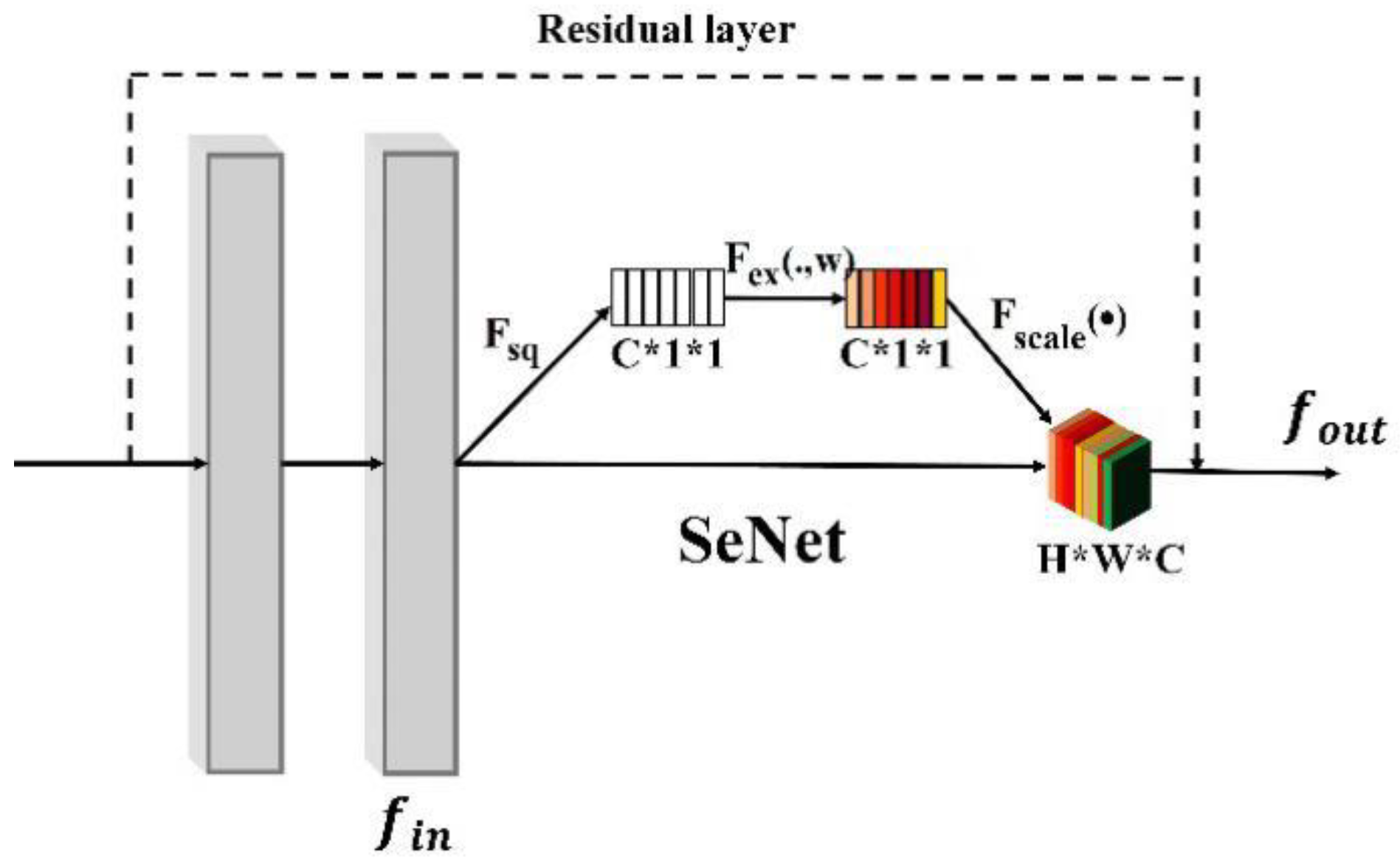
- A new 3D voxel model feature extraction network is proposed. For this network, the features of the high-level feature map and the low-level feature map are merged to enhance the quality and robustness of the 3D voxel features, by adding skip connections to the 3D Autoencoder structure. Besides, an attention mechanism is introduced to learn the weights of fusion features in each channel, and enhance the quality of the feature by feature redirection.
- (3)
- We propose a novel 3D model generation network based on multi-modal data constraints and multi-level feature fusion, i.e., 3DMGNet. Notably, 3DMGNet combines a multi-view contour constraint into the construction of loss function, which improves the effect of the 3D models generation network.
2. Related Works
2.1. Volumetric 3D Modeling
2.2. Point Cloud Modeling
2.3. Mesh Modeling
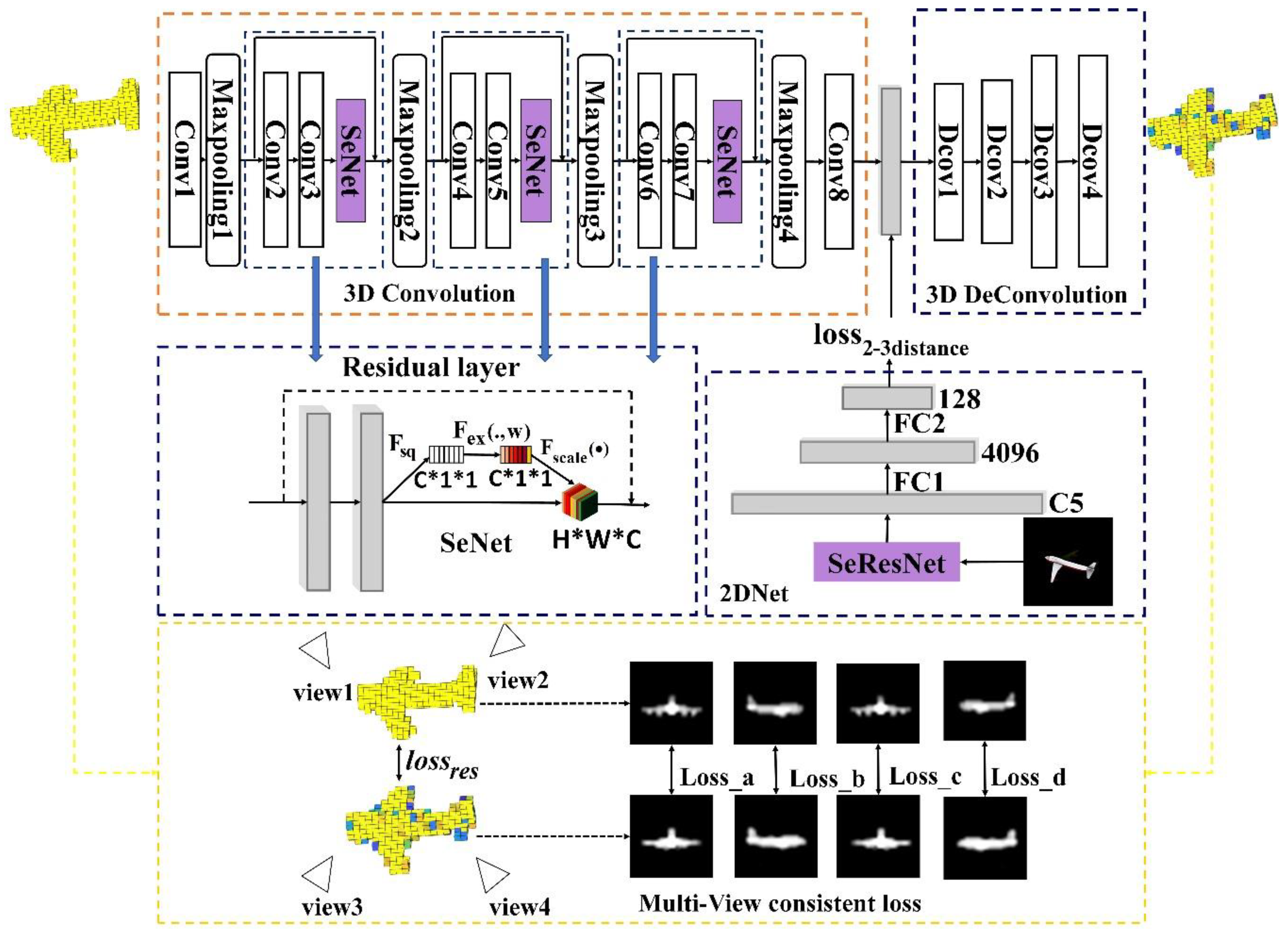
3. The Proposed Method
3.1. Image Feature Extraction
3.2. Self-Supervised Learning and Multi-Level Feature Fusion Network for 3D Reconstruction
3.3. The Attention Mechanism
3.4. Multi-View Contour Constraints
3.5. Loss Function
3.6. The Training and Test of the Model
4. Results
4.1. Dataset
4.2. Metrics and Implementation
4.2.1. Metrics
4.2.2. Implementation
4.3. Experiment and Comparison
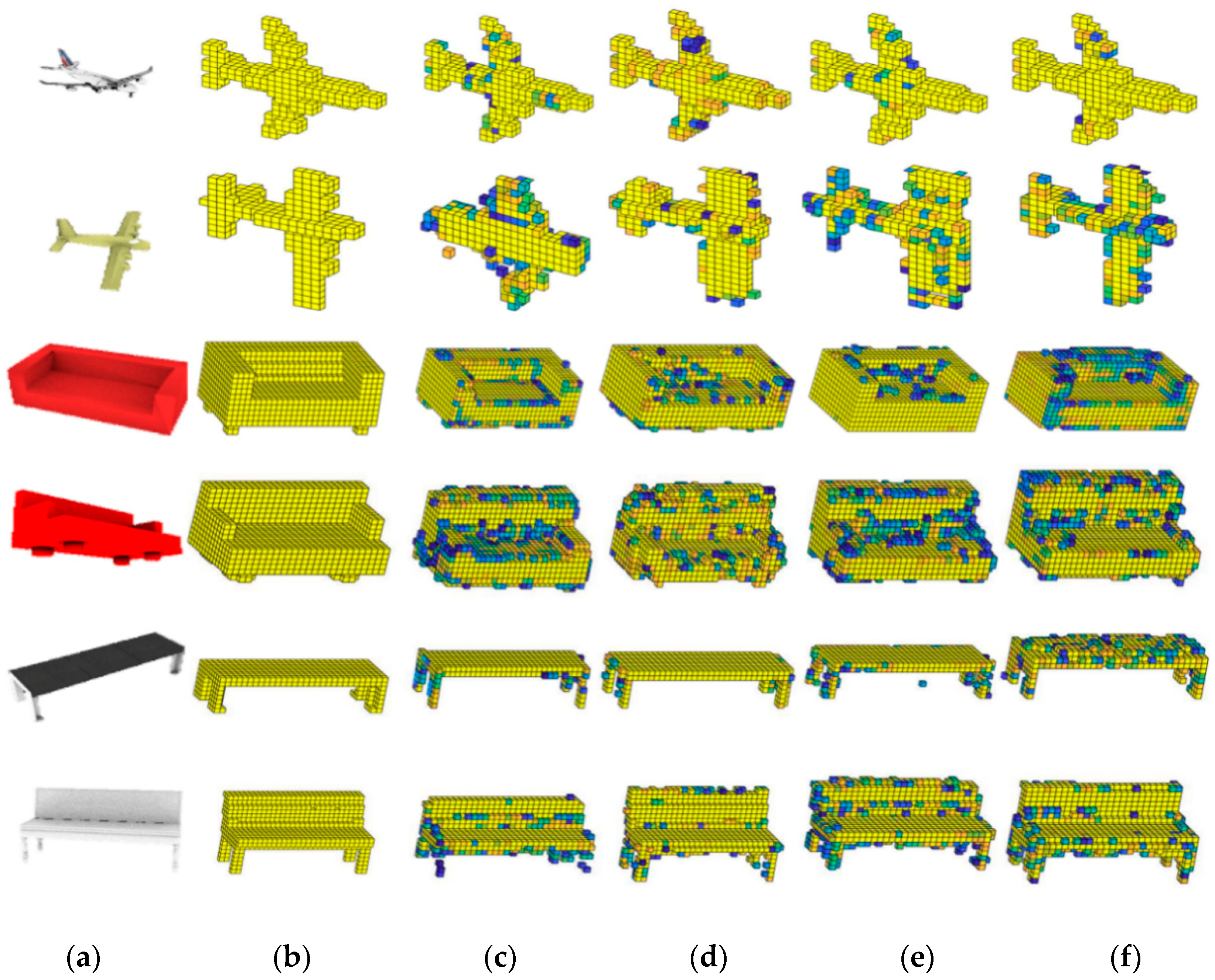
4.3.1. Ablation Studies and Comparisons
- (a)
- TL-Net: The TL-Net [9] method is a single-view 3D model generation method based on voxel data. We directly use the original network as the baseline in the experiment.
- (b)
- Voxel-Se-ResNet: This network combines the Se-ResNet-based transfer learning method with our baseline to evaluate the effectiveness of Se-ResNet-based transfer learning in the proposed 3D model generation.
- (c)
- Voxel-ResidualNet: This network combines the multiple feature fusion and attention mechanism with the feature extraction of 3D voxel model in our baseline to evaluate the effectiveness of multi-level feature fusion and attention mechanism in our 3D model generation.
- (d)
- 3DMGNet: The loss of multi-view contours is added to the Voxel-SeNet network, to verify the overall performance of the designed 3DMGNet.
- (a)
- The Voxel-Se-ResNet usually outperforms the baseline network TL-Net [9]. For plane, sofa, and bench, the IoU of Voxel-Se-ResNet-101 is at least 0.026 higher than TL-Net, as the improved 2DNet can extract better 2D image features through Se-ResNet-101, to promote the accuracy of the generated model.
- (b)
- The Voxel-ResidualNet outperforms the baseline network (TL-Net [9]) and Voxel-Se-ResNet in most cases, as the more robust 3D model features are obtained through multi-level feature fusion and attention mechanism. The 3D model generation ability of 3D auxiliary network is improved, and the overall network performance is promoted to further constraint the image feature. Thus, the accuracy of the 3D model generation base on image is improved.
- (c)
- The 3DMGNet outperforms TL-Net [9], Voxel-Se-ResNet, and Voxel-ResidualNet. The main reason is that the multi-view contour constraint is added to the 3DMGNet, which proves that the reconstruction accuracy of the 3D auxiliary network is improved.
- (d)
- When the threshold is 0.1, 0.3, 0.5, and 0.7, the IOU value of 3DMGNet does not change much. For example, the difference in IOU values of plane, sofa, and bench at different thresholds is less than 0.011. When the threshold is set to 0.3, our method usually achieves the best performance.
4.3.2. Comparison with Other Methods
- (1)
- (2)
- The 3DMGNet can achieve better generation accuracy than PixVox-F [38] and PixVox++/F [39] in most categories, i.e., Airplane, Bench, Chair, Display, Lamp, Rifle, Sofa and Telephone. Pix2Vox-F and PixVox++/F solves the single-view-based 3D model generation problem by spatial mapping, while the 3DMGNet solves this problem from the perspective of multi-modal feature fusion. Although PixVox++/F can achieve the best average IOU, which is mainly caused by the fact that the IOU value of Speaker is obviously higher than 3DMGNet; the 3DMGNet performs its best performance in most categories of objects (at least nine categories).
4.3.3. Multi-Category Joint Training
- (1)
- The Joint-3DMGNet outperforms the baseline network TL-Net [9], which proves that the combination of multi-modal feature fusion of 3D auxiliary network, multi-view contour constraint, and the improved image feature extraction network are effective for higher reconstruction performance.
- (2)
- The IOU of Joint-3DMGNet is at least 0.023 higher than Direct-2D-3D, mainly because the image lacks spatial information, and it is not easy to generate a 3D model with higher accuracy without an auxiliary network part.
- (3)
- For the multi-category joint training results, the best IOU results are achieved by Joint-3DMGNet in most cases, which illustrates that the Joint-3DMGNet can achieve better generalization performance than the compared methods.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lai, Z.; Hu, Y.; Cui, Y.; Sun, L.; Dai, N.; Lee, H. Furion: Engineering High-Quality Immersive Virtual Reality on Today’s Mobile Devices. IEEE Trans. Mob. Comput. 2020, 19, 1586–1602. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H. ShapeNet: An Information-Rich 3D Model Repository. arXiv 2015, arXiv:1512.03012. Available online: https://arxiv.org/abs/1512.03012 (accessed on 9 December 2015).
- Matheus, G.; Aartika, R.; Subhransu, M.J.; Rui, W. Inferring 3D Shapes from Image Collections using Adversarial. Netw. Int. J. Comput. Vison 2020, 128, 1–14. [Google Scholar]
- Wang, N.; Zhang, Y.; Li, Z.; Fu, Y.; Liu, W.; Jiang, Y.G. Pixel2Mesh: Generating 3D Mesh Models from Single RGB Images. In Proceedings of the European Conference on Computer Vision (ECCV 2018), Munich, Germany, 8–14 September 2018; pp. 55–71. [Google Scholar]
- Brilakis, L.; Haas, C. Infrastructure Computer Vision; Butterworch-Heinemann: Boston, MA, USA, 2020; pp. 65–167. [Google Scholar]
- Zhang, Y.; Huo, K.; Liu, Z.; Zang, Y.; Liu, Y.; Li, X.; Zhang, Q.; Wang, C. PGNet: A Part-based Generative Network for 3D object reconstruction. Knowl. -Based Syst. 2020, 194, 105574. [Google Scholar] [CrossRef]
- Wu, J.; Zhang, C.; Xue, T.; Freeman, W.T.; Tenenbaum, J.B. Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling. In Advances in Neural Information Processing Systems 29 (NIPS 2016), Proceedings of the Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; MIT Press: Cambridge, MA, USA, 2016; pp. 82–90. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 221–231. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girdhar, R.; Fouhey, D.F.; Rodriguez, M.; Gupta, A. Learning a Predictable and Generative Vector Representation for Objects. arXiv 2016, arXiv:1603.08637. Available online: https://arxiv.org/abs/1603.08637 (accessed on 31 August 2016).
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. Available online: https://arxiv.org/abs/1409.1556 (accessed on 23 December 2014).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Tchapmi, L.; Choy, C.; Armeni, I.; Gwak, J.; Savarese, S. SEGCloud: Semantic Segmentation of 3D Point Clouds. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 537–547. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Ahmed, E.; Saint, A.; Shabayek, A.E.R.; Cherenkova, K.; Das, R.; Gusev, G.; Aouada, D.; Ottersten, B. A survey on deep learning advances on different 3D data representations. arXiv 2018, arXiv:1808.01462. Available online: https://arxiv.org/abs/1808.01462 (accessed on 4 August 2018).
- Maturana, D.; Scherer, S. VoxNet: A 3D Convolutional Neural Network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Abhishek, S.; Oliver, G.; Mario, F. VConv-DAE: Deep Volumetric Shape Learning Without Object Labels. In Proceedings of the Geometry Meets Deep Learning Workshop at European Conference on Computer Vision (ECCV-W), Amsterdam, The Netherlands, 8–10 October 2016; pp. 236–250. [Google Scholar]
- Zhi, S.; Liu, Y.; Li, X.; Guo, Y. Toward real-time 3D object recognition: A lightweight volumetric CNN framework using multitask learning. Comput. Graph. 2018, 71, 199–207. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 1. [Google Scholar] [CrossRef] [PubMed]
- Xu, B.; Zhang, X.; Li, Z.; Leotta, M.; Chang, S.; Shan, J. Deep Learning Guided Building Reconstruction from Satellite Imagery-derived Point Clouds. arXiv 2020, arXiv:2005.09223. Available online: https://arxiv.org/abs/2005.09223 (accessed on 19 May 2020).
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J.; Fisher, Y. 3D ShapeNets: A deep representation for volumetric shapes. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Choy, C.B.; Xu, D.; Gwak, J.; Chen, K.; Savarese, S. 3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction. arXiv 2016, arXiv:1604.00449. Available online: https://arxiv.org/abs/1604.00449 (accessed on 2 April 2016).
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. Available online: https://arxiv.org/abs/1411.1784 (accessed on 6 November 2014).
- Wu, Z.; Wang, X.; Lin, D.; Lischinski, D.; Cohen-Or, D.; Huang, H. Sagnet: Structure-aware generative network for 3d-shape modeling. ACM Trans. Graphic. 2019, 38, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Mandikal, P.; Navaneet, K.L.; Agarwal, M.; Babu, R.V. 3D-LMNet: Latent embedding matching for accurate and diverse 3D point cloud reconstruction from a single image. In Proceedings of the British Machine Vision Conference 2018 (BVLC), Newcastle, UK, 3–6 September 2018; pp. 55–56. [Google Scholar]
- Gadelha, M.; Wang, R.; Maji, S. Multiresolution tree networks for 3d point cloud processing. In Proceedings of the 15th European Conference on Computer Vision (ECCV 2018), Munich, Germany, 8–14 September 2018; pp. 103–118. [Google Scholar]
- Jiang, L.; Shi, S.; Qi, X.; Jia, J. Gal: Geometric adversarial loss for single-view 3d-object reconstruction. In Proceedings of the 15th European Conference on Computer Vision (ECCV 2018), Munich, Germany, 8–14 September 2018; pp. 802–816. [Google Scholar]
- Li, C.L.; Zaheer, M.; Zhang, Y.; Poczos, B.; Salakhutdinov, R. Point cloud Gan. arXiv 2018, arXiv:1810.05795. Available online: https://arxiv.org/abs/1810.05795 (accessed on 13 October 2018).
- Mandikal, P.; Radhakrishnan, V.B. Dense 3d point cloud reconstruction using a deep pyramid network. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1052–1060. [Google Scholar]
- Sinha, A.; Unmesh, A.; Huang, Q.; Ramani, K. Surfnet: Generating 3d shape surfaces using deep residual networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6040–6049. [Google Scholar]
- Pumarola, A.; Agudo, A.; Porzi, L.; Sanfeliu, A.; Lepetit, V.; Moreno-Noguer, F. Geometry-aware network for non-rigid shape prediction from a single view. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4681–4690. [Google Scholar]
- Groueix, T.; Fisher, M.; Kim, V.G.; Russell, B.C.; Aubry, M. A papier-mâché approach to learning 3d surface generation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 216–224. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Zeiler, M.D.; Krishnan, D.; Taylor, G.W.; Fergus, R. Deconvolutional networks. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPRW), San Francisco, CA, USA, 13–18 June 2010; pp. 2528–2535. [Google Scholar]
- Tatarchenko, M.; Dosovitskiy, A.; Brox, T. Octree generating networks: Efficient convolutional architectures forhigh-resolution 3D outputs. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2107–2115. [Google Scholar]
- Tulsiani, S.; Zhou, T.; Efros, A.A.; Malik., J. Multi-view supervision for single-view reconstruction via differentiable ray consistency. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2626–2634. [Google Scholar]
- Xie, H.; Yao, H.; Sun, X.; Zhou, S.; Zhang, S. Pix2vox: Context-aware 3d reconstruction from single and multi-view images. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 2690–2698. [Google Scholar]
- Xie, H.; Yao, H.; Zhang, S.; Zhou, S.; Sun, W. Pix2Vox++: Multi-scale Context-aware 3D Object Reconstruction from Single and Multiple Images. Int. J. Comput. Vis. 2020, 1, 1–17. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Total Number | Training Data | Test Data |
|---|---|---|---|
| Plane | 3641 | 2831 | 810 |
| Bench | 1635 | 1271 | 364 |
| Cabinet | 1415 | 1100 | 315 |
| Car | 6748 | 5247 | 1501 |
| Chair | 6101 | 4744 | 1357 |
| Monitor | 986 | 766 | 220 |
| Lamp | 2087 | 1622 | 465 |
| Speaker | 1457 | 1132 | 325 |
| Rifle | 2135 | 1660 | 475 |
| Sofa | 2857 | 2222 | 635 |
| Table | 7659 | 5956 | 1703 |
| Telephone | 947 | 736 | 211 |
| Watercraft | 1746 | 1357 | 389 |
| Name | 3D Encoder | 3D Decoder | 2D Encoder |
|---|---|---|---|
| TL-Net | 3DConv | Deconvolution | AlexNet |
| Voxel-SeResNe | 3DConv | Deconvolution | Se-ResNet |
| Voxel-ResidualNet | 3DConv+Residual+SeNet | Deconvolution | Se-ResNet |
| 3DMGNet(Ours) | 3DConv+Residual+SeNet+Mvcontour | Deconvolution | Se-ResNet |
| Threshold | ||||||
|---|---|---|---|---|---|---|
| 0.1 | 0.3 | 0.5 | 0.7 | 0.9 | ||
| Plane | TL-Net | 0.6565 | 0.6579 | 0.6545 | 0.6481 | 0.6315 |
| Voxel-Se-ResNet | 0.7041 | 0.7062 | 0.7005 | 0.7022 | 0.6942 | |
| Voxel-ResidualNet | 0.6713 | 0.6839 | 0.6860 | 0.6837 | 0.6709 | |
| 3DMGNet(Ours) | 0.6975 | 0.7039 | 0.7047 | 0.7031 | 0.6948 | |
| Sofa | TL-Net | 0.6378 | 0.6405 | 0.6380 | 0.6319 | 0.6143 |
| Voxel-Se-ResNet | 0.6683 | 0.6665 | 0.6639 | 0.6605 | 0.6523 | |
| Voxel-ResidualNet | 0.6800 | 0.6854 | 0.6830 | 0.6764 | 0.6560 | |
| 3DMGNet(Ours) | 0.6939 | 0.6973 | 0.6941 | 0.6867 | 0.6659 | |
| Bench | TL-Net | 0.4683 | 0.4589 | 0.4460 | 0.4277 | 0.3908 |
| Voxel-Se-ResNet | 0.5364 | 0.5310 | 0.5253 | 0.5183 | 0.5035 | |
| Voxel-ResidualNet | 0.5503 | 0.5567 | 0.5492 | 0.5342 | 0.4937 | |
| 3DMGNet(Ours) | 0.5761 | 0.5803 | 0.5778 | 0.5711 | 0.5524 | |
| Monitor | TL-Net | 0.5052 | 0.4996 | 0.4935 | 0.4836 | 0.4625 |
| Voxel-Se-ResNet | 0.5223 | 0.5131 | 0.5004 | 0.4829 | 0.4462 | |
| Voxel-ResidualNet | 0.5111 | 0.5103 | 0.5031 | 0.4835 | 0.4380 | |
| 3DMGNet(Ours) | 0.5335 | 0.5335 | 0.5189 | 0.4912 | 0.4250 | |
| Speaker | TL-Net | 0.6157 | 0.6105 | 0.6030 | 0.5911 | 0.5621 |
| Voxel-Se-ResNet | 0.6150 | 0.6095 | 0.6039 | 0.5969 | 0.5811 | |
| Voxel-ResidualNet | 0.6164 | 0.6111 | 0.6028 | 0.5896 | 0.5579 | |
| 3DMGNet(Ours) | 0.6197 | 0.6175 | 0.6065 | 0.5861 | 0.5367 | |
| Telephone | TL-Net | 0.7649 | 0.7689 | 0.7697 | 0.7694 | 0.7654 |
| Voxel-Se-ResNet | 0.7724 | 0.7748 | 0.7754 | 0.7754 | 0.7736 | |
| Voxel-ResidualNet | 0.7863 | 0.7907 | 0.7900 | 0.7868 | 0.7744 | |
| 3DMGNet(Ours) | 0.7875 | 0.7920 | 0.7896 | 0.7828 | 0.7633 | |
| Average | TL-Net | 0.6081 | 0.6061 | 0.6008 | 0.5920 | 0.5711 |
| Voxel-Se-ResNet | 0.6364 | 0.6335 | 0.6282 | 0.6227 | 0.6085 | |
| Voxel-ResidualNet | 0.6359 | 0.6367 | 0.6357 | 0.6257 | 0.5985 | |
| 3DMGNet(Ours) | 0.6514 | 0.6541 | 0.6486 | 0.6368 | 0.6064 | |
| Class | 3D-R2-N2 [23] | OGN [36] | DRC [37] | Pix2Vox-F [38] | Pix2Vox++/F [39] | 3DMGNet |
|---|---|---|---|---|---|---|
| Airplane | 0.513 | 0.587 | 0.571 | 0.600 | 0.607 | 0.704 |
| Bench | 0.421 | 0.481 | 0.453 | 0.538 | 0.544 | 0.580 |
| Cabinet | 0.716 | 0.729 | 0.635 | 0.765 | 0.782 | 0.741 |
| Car | 0.798 | 0.828 | 0.755 | 0.837 | 0.841 | 0.806 |
| Chair | 0.466 | 0.483 | 0.469 | 0.535 | 0.548 | 0.566 |
| Display | 0.468 | 0.502 | 0.419 | 0.511 | 0.529 | 0.534 |
| Lamp | 0.381 | 0.398 | 0.415 | 0.435 | 0.448 | 0.455 |
| Speaker | 0.662 | 0.637 | 0.609 | 0.707 | 0.721 | 0.618 |
| Rifle | 0.544 | 0.593 | 0.608 | 0.598 | 0.594 | 0.628 |
| Sofa | 0.628 | 0.646 | 0.606 | 0.687 | 0.696 | 0.697 |
| Table | 0.513 | 0.536 | 0.424 | 0.587 | 0.609 | 0.586 |
| Telephone | 0.661 | 0.702 | 0.413 | 0.770 | 0.782 | 0.792 |
| Watercraft | 0.513 | 0.632 | 0.556 | 0.582 | 0.583 | 0.600 |
| Average | 0.560 | 0.596 | 0.545 | 0.634 | 0.645 | 0.639 |
| Method | Threshold | |||
|---|---|---|---|---|
| 0.3 | 0.5 | 0.7 | ||
| Plane | TL-Net | 0.6579 | 0.6545 | 0.6481 |
| Diect-2D-3D | 0.6212 | 0.5914 | 0.5044 | |
| Joint-3DMGNet | 0.6628 | 0.6642 | 0.6599 | |
| Sofa | TL-Net | 0.6405 | 0.6380 | 0.6319 |
| Diect-2D-3D | 0.4228 | 0.3527 | 0.1699 | |
| Joint-3DMGNet | 0.6576 | 0.6460 | 0.6306 | |
| Bench | TL-Net | 0.4589 | 0.4460 | 0.4277 |
| Diect-2D-3D | 0.5429 | 0.5038 | 0.3559 | |
| Joint-3DMGNet | 0.5452 | 0.5413 | 0.5281 | |
| Average | TL-Net | 0.5858 | 0.5795 | 0.5692 |
| Diect-2D-3D | 0.5290 | 0.4826 | 0.3434 | |
| Joint-3DMGNet | 0.6219 | 0.6172 | 0.6062 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, E.; Xue, L.; Li, Y.; Zhang, Z.; Hou, X. 3DMGNet: 3D Model Generation Network Based on Multi-Modal Data Constraints and Multi-Level Feature Fusion. Sensors 2020, 20, 4875. https://doi.org/10.3390/s20174875
Wang E, Xue L, Li Y, Zhang Z, Hou X. 3DMGNet: 3D Model Generation Network Based on Multi-Modal Data Constraints and Multi-Level Feature Fusion. Sensors. 2020; 20(17):4875. https://doi.org/10.3390/s20174875
Chicago/Turabian StyleWang, Ende, Lei Xue, Yong Li, Zhenxin Zhang, and Xukui Hou. 2020. "3DMGNet: 3D Model Generation Network Based on Multi-Modal Data Constraints and Multi-Level Feature Fusion" Sensors 20, no. 17: 4875. https://doi.org/10.3390/s20174875
APA StyleWang, E., Xue, L., Li, Y., Zhang, Z., & Hou, X. (2020). 3DMGNet: 3D Model Generation Network Based on Multi-Modal Data Constraints and Multi-Level Feature Fusion. Sensors, 20(17), 4875. https://doi.org/10.3390/s20174875