A Novel Method about the Representation and Discrimination of Traffic State



Abstract
:1. Introduction
- Since the existing research only divides the road state from the perspective of whether the road is congested, it cannot reflect the comprehensive road traffic conditions well. In this paper, we selected the indicators from the layers of road congestion, road safety, and road stability, respectively, to represent various traffic states.
- On the basis of selecting multi-layer representation indicators, we applied the K-means clustering algorithm to divide the traffic state into four classes to achieve the representation of the traffic state.
- We used the traffic states obtained by K-means as class labels and built a traffic state discriminator based on MLP to realize an accurate discrimination of the traffic state.
- Finally, we visualized the data of a certain central urban area in accordance with the proposed traffic state representation and discrimination method.
2. Materials and Methods
2.1. Datasets
2.2. The Representation of the Traffic State
2.2.1. Selection of Representation Indicators
- Road congestion layer
- Road safety layer
- Road stability layer
2.2.2. Traffic State Representation Based on K-Means
- (a)
- Input a sample set of road traffic state evaluation indicators and set the number of clusters as ;
- (b)
- Select data from the sample randomly as the mean of the initial cluster;
- (c)
- Divide all objects in the dataset into the clusters represented by the nearest average point according to the current cluster average;
- (d)
- Calculate the average central value points of the new clusters repeatedly until the average values have no changes;
- (e)
- Output the clustering results of the traffic states.
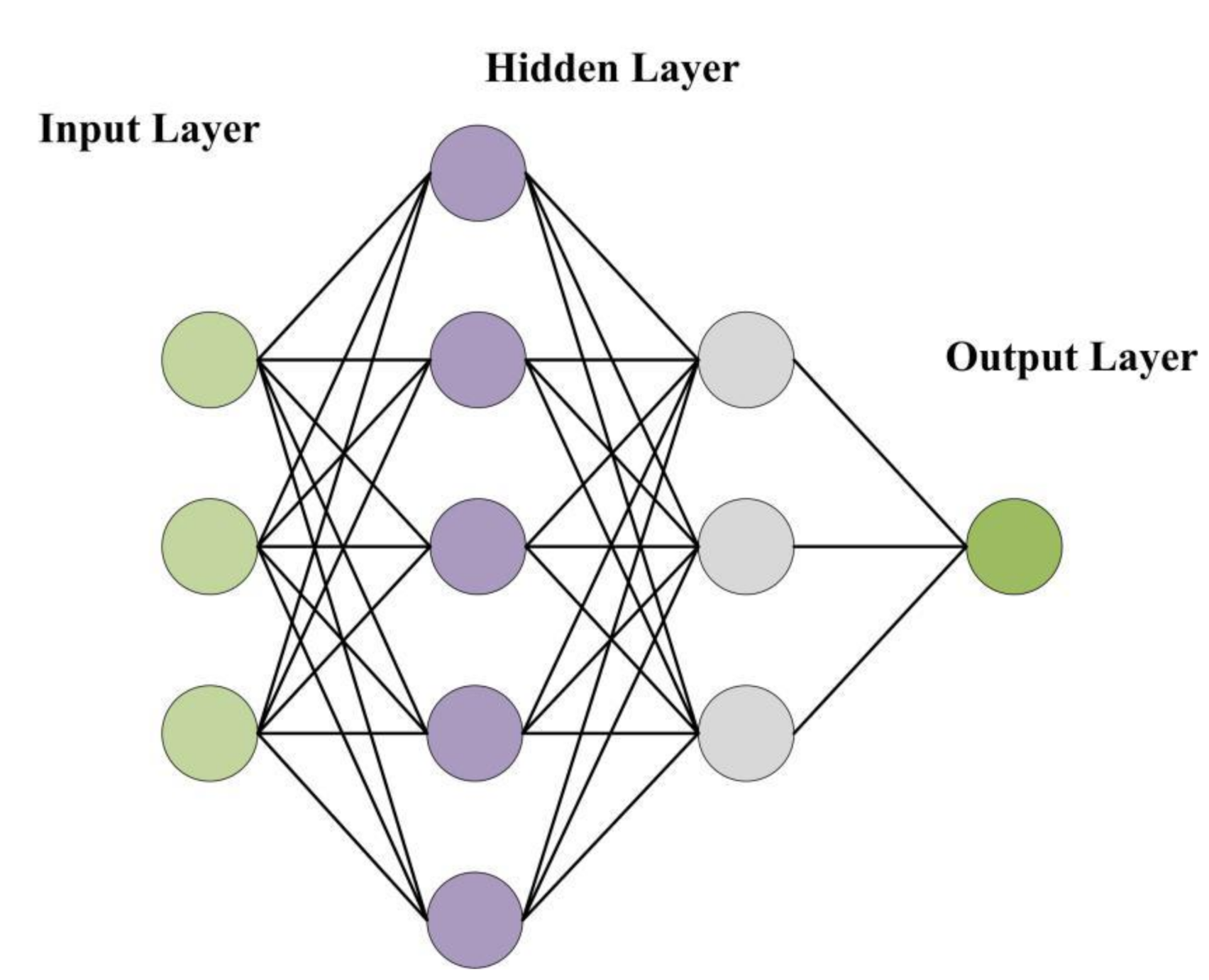
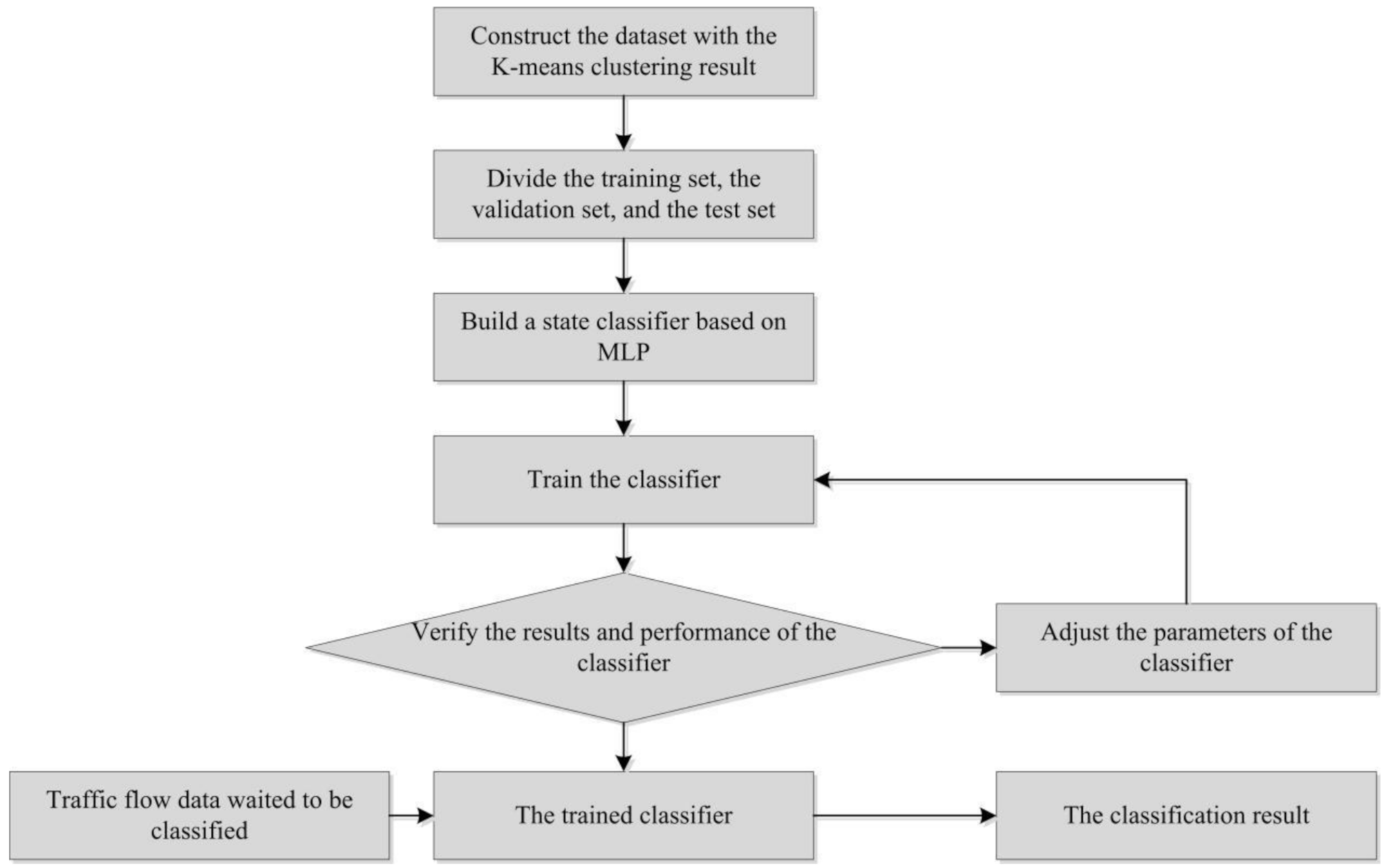
2.2.3. Traffic State Discrimination Based on MLP
- (a)
- Construct the dataset: use the arithmetic mean vehicle speed, the variance of the time–mean vehicle speed observation value, and the large ratio as the input part of the model, and the K-means clustering result as the corresponding class label;
- (b)
- Divide the training set, the test set and the validation set: the validation set and the test set each account for 10% of the total data;
- (c)
- Build a state classifier based on MLP: the classifier includes an input layer, two hidden layers, and an output layer. The number of hidden units in the two hidden layers are 64 and 16, respectively. The hidden layer applies the ReLu function as the activation function; the output layer uses the Softmax function;
- (d)
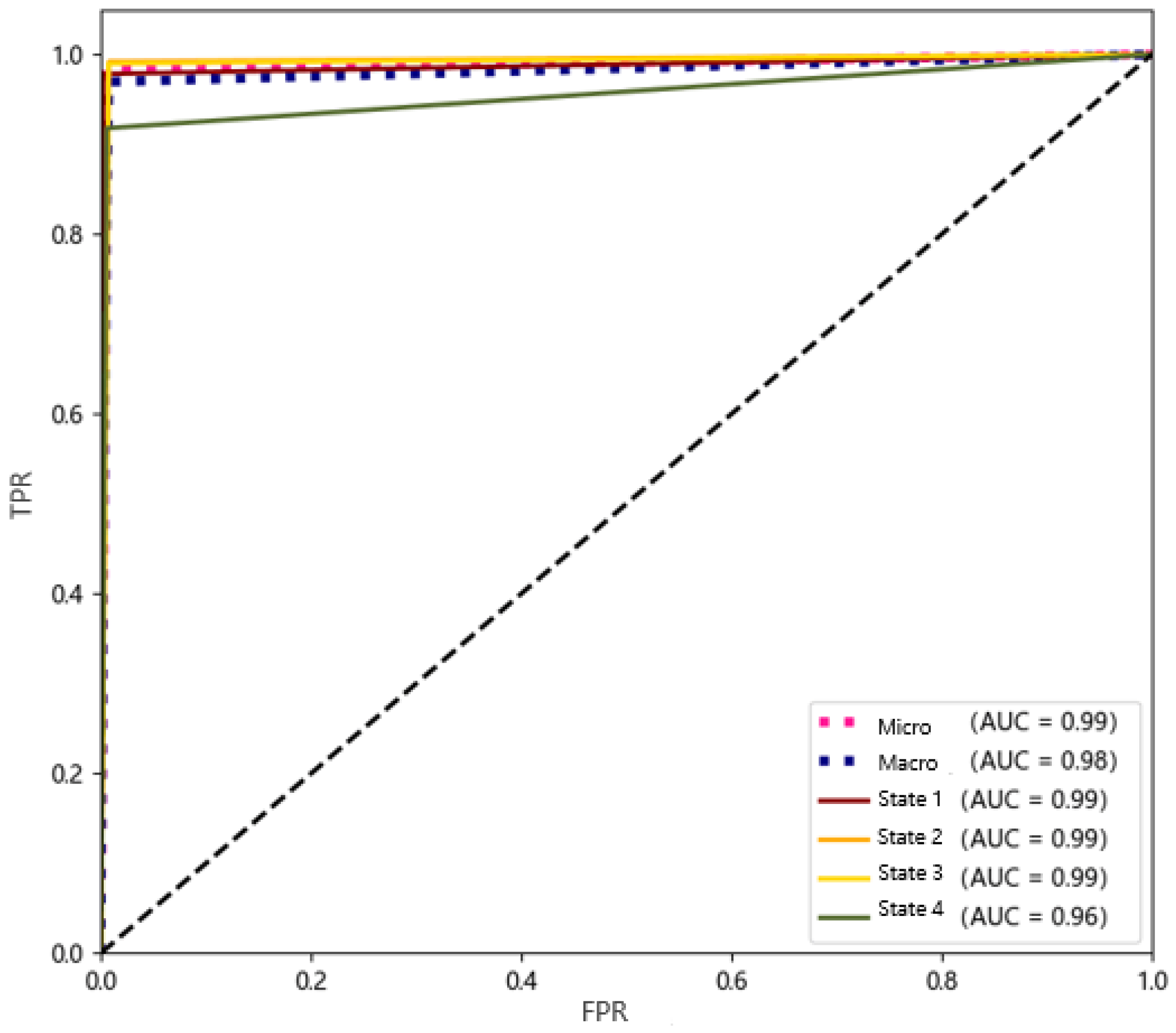
- Train the classifier and determine the hyperparameters of the model: set the initial learning rate, the number of iterations and the number of hidden layer units, and draw a graph of the loss function and the accuracy of the prediction result based on the training results. The receiver operating characteristic (ROC) curve graph of the classification result is obtained. Judge the fit degree of the model according to the graphs, and then adjust the hyperparameters.
- (e)
- Input the test set to the trained model to obtain the classification result.
3. Results.
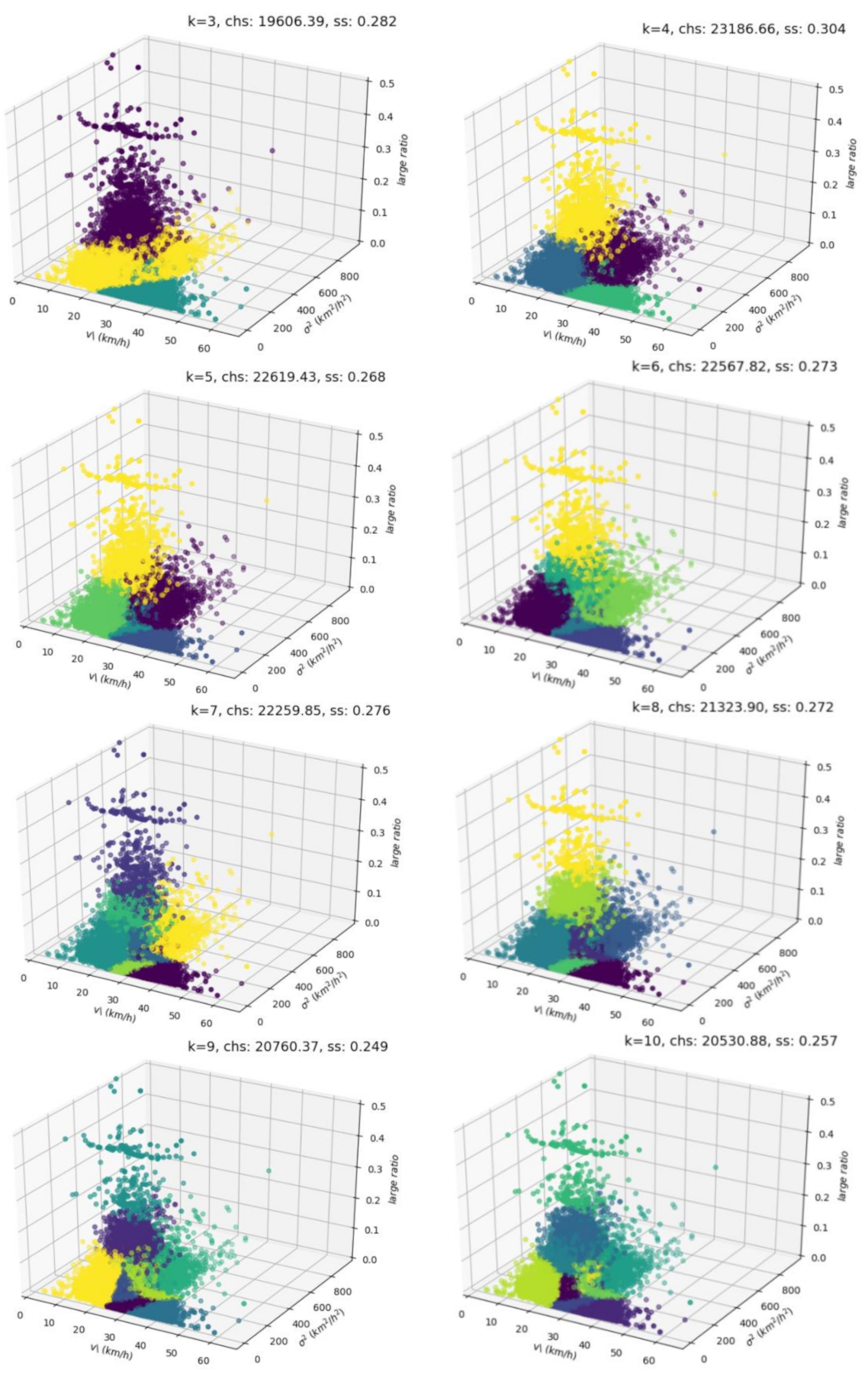
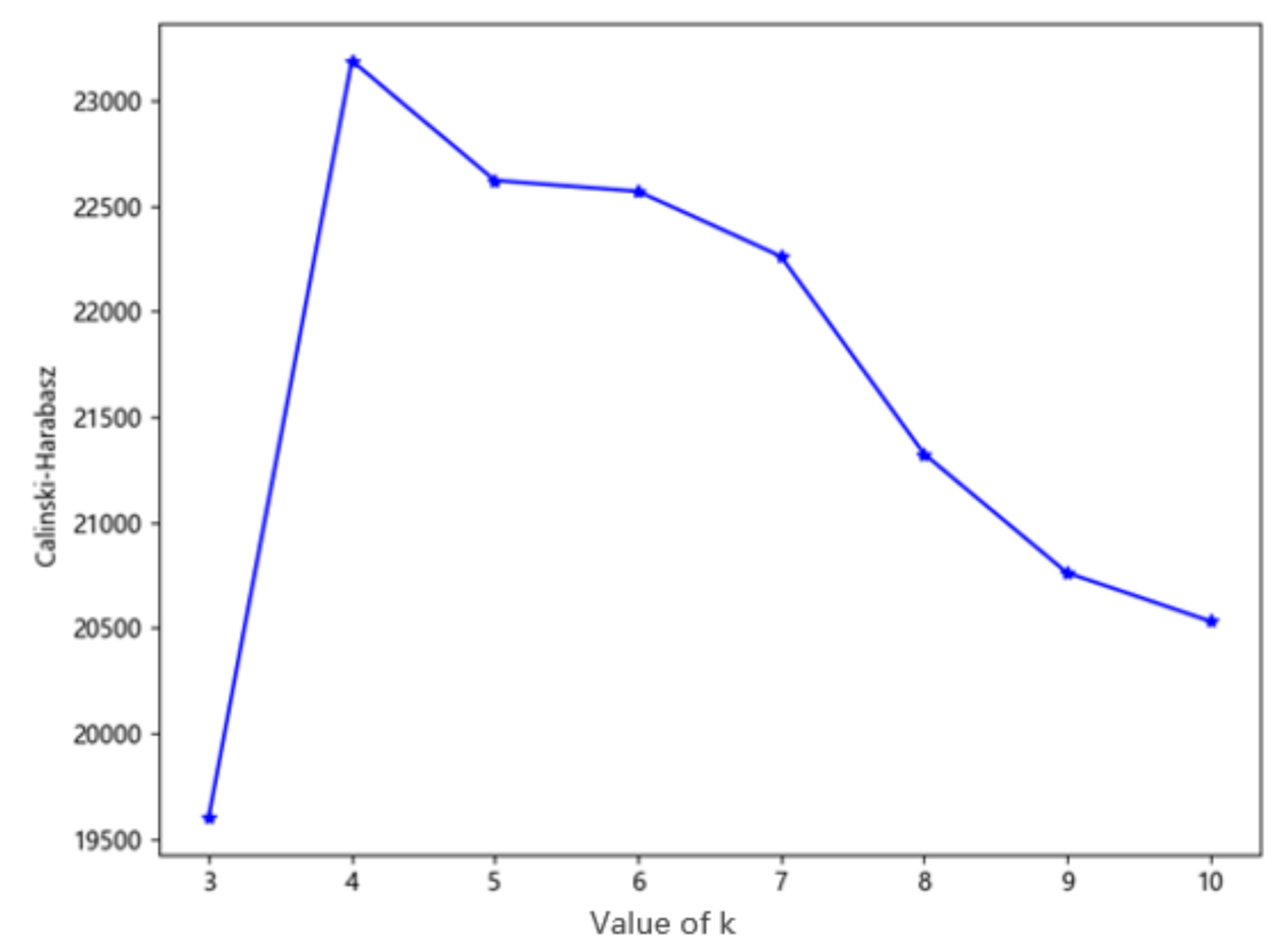
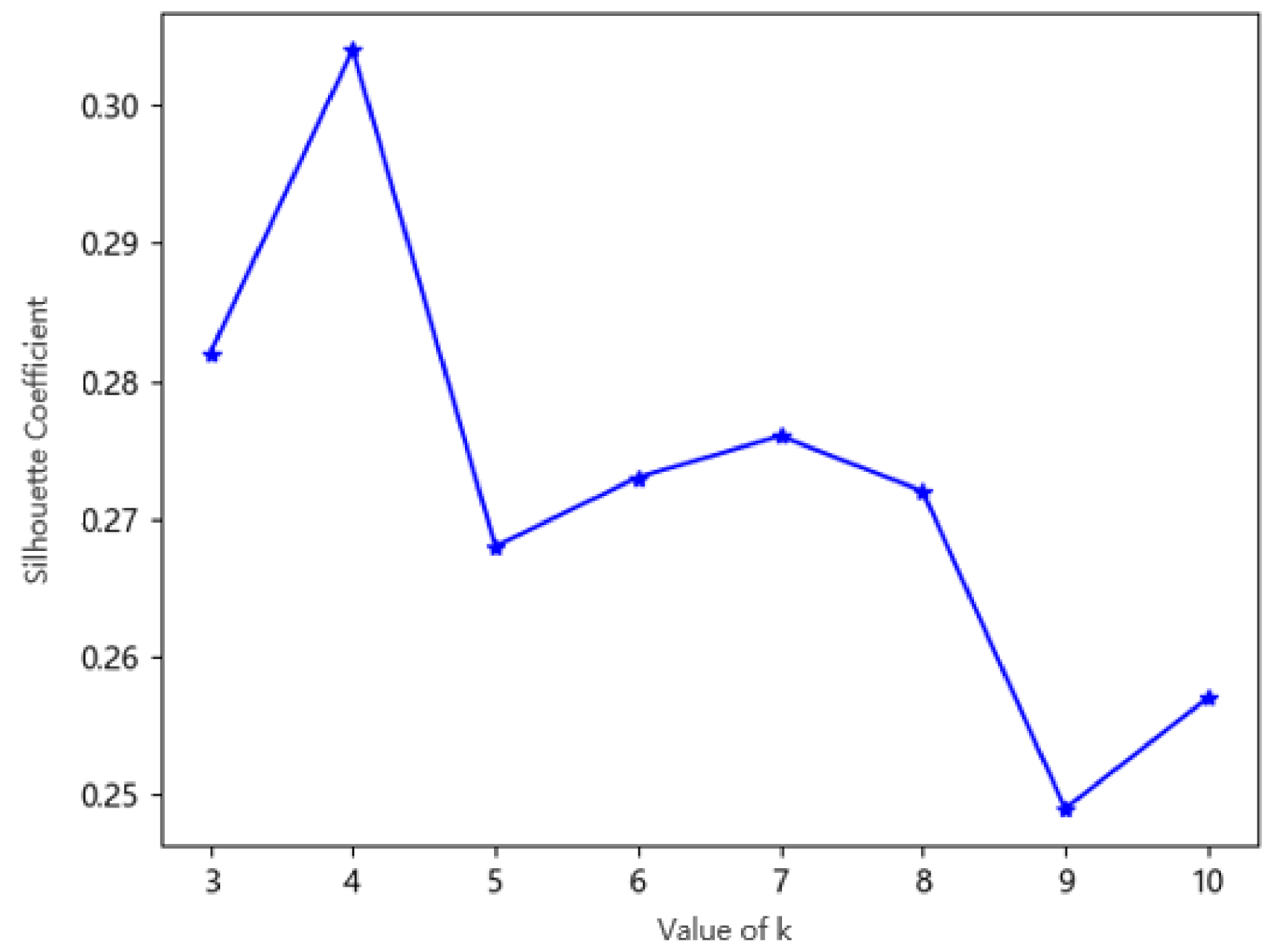
3.1. Evaluation Indicators of the Clustering Result
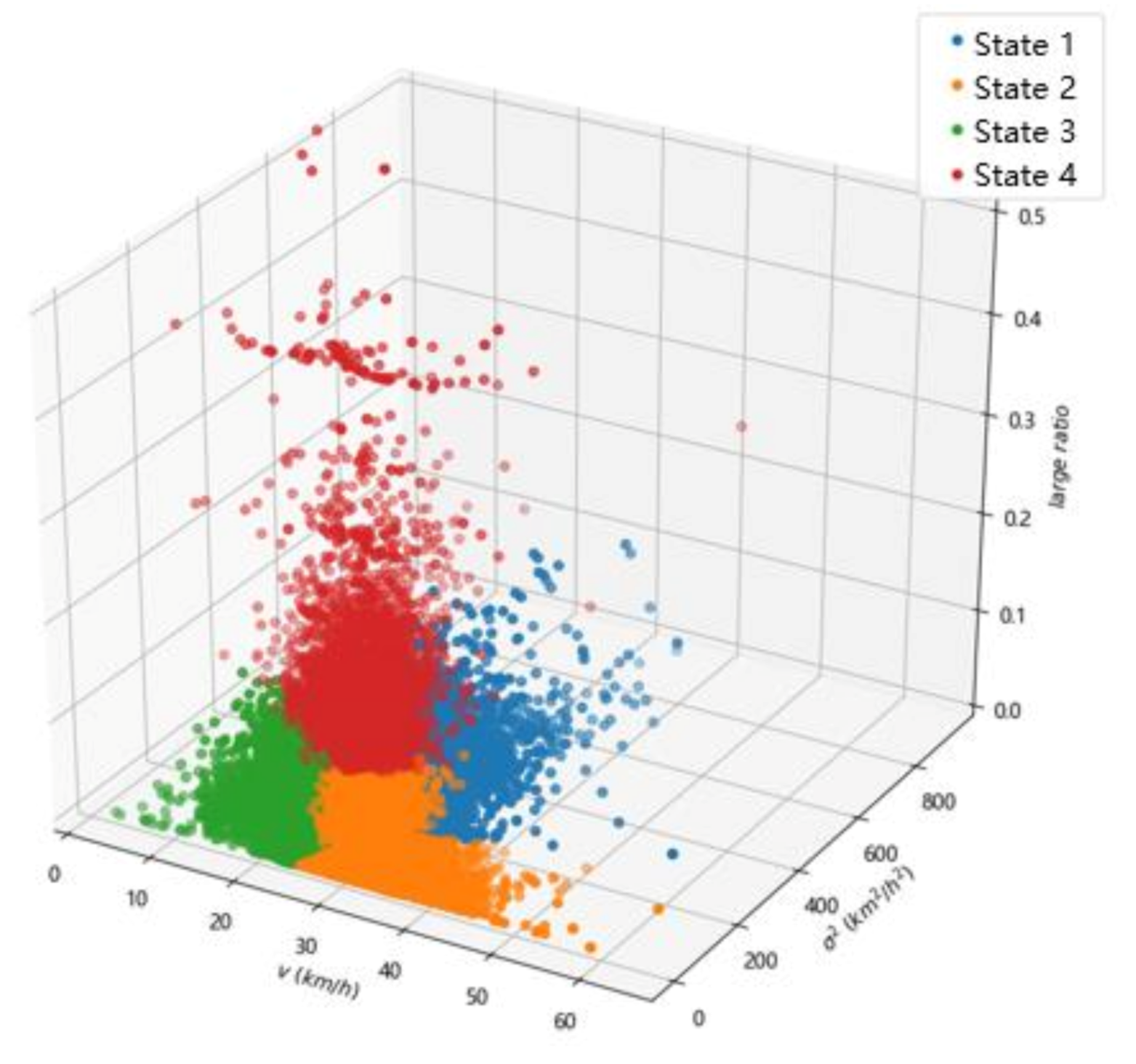
3.2. Clustering Results
- (a)
- Make a sample set: select 3,1968 traffic flow data with a sampling interval of 5 minutes in the central urban area and calculate the three traffic state evaluation indicators mentioned in Section 2.2.1 for each original sample. Three traffic state evaluation indicators constitute a clustering sample dataset;
- (b)
- Construct a traffic state clustering model based on K-means, and set multiple sets of values, cluster the clustering sample dataset and obtain multiple clustering results;
- (c)
- The CH and SC are employed as the evaluation indicators and the final clusters which is most suitable for the division of the sample set is selected according to the score of the CH and SC;
- (d)
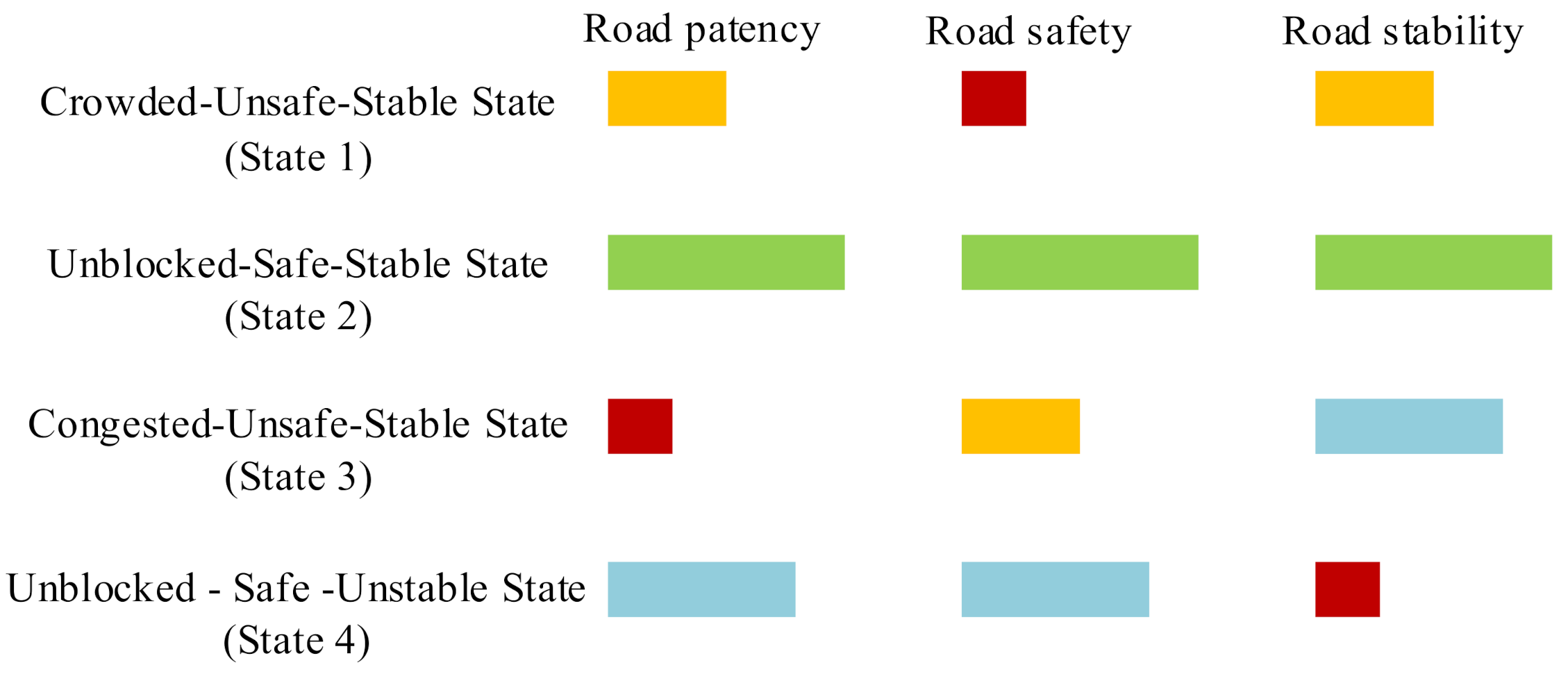
- Analyze the traffic states based on the optimal k-value clustering result.
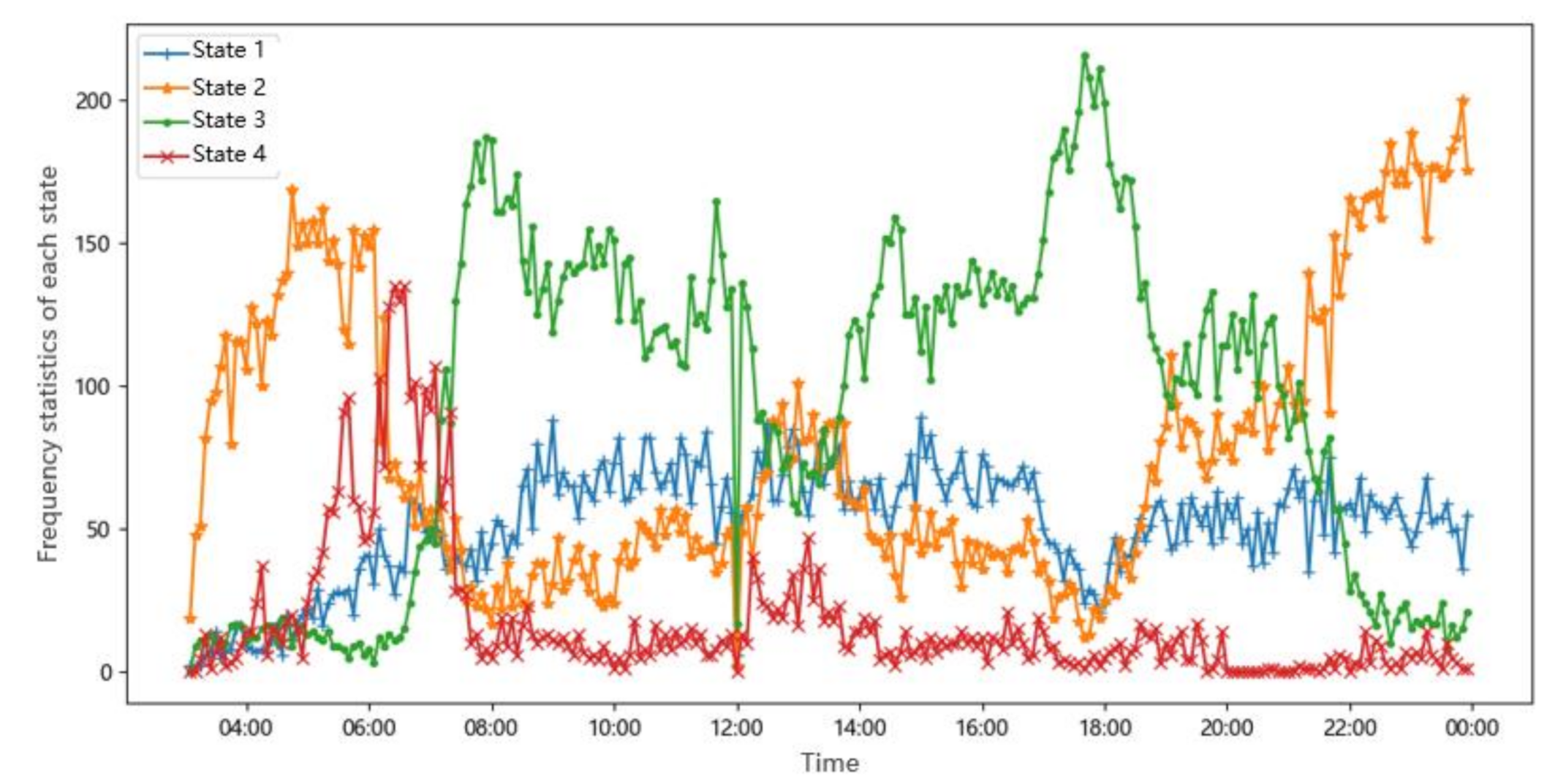
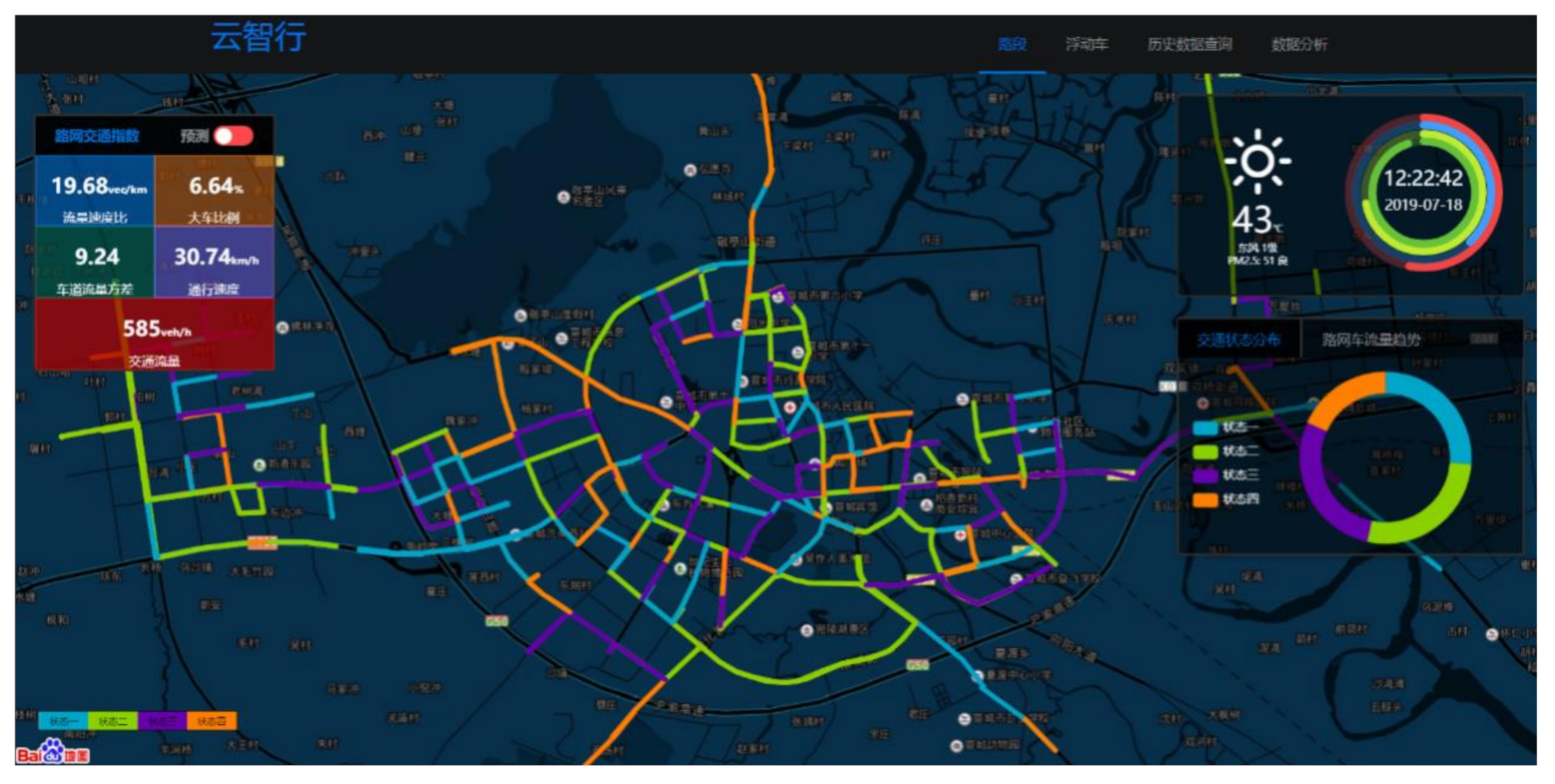
3.3. Classifying Results and Visual Display
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Barth, M.; Boriboonsomsin, K. Real-World Carbon Dioxide Impacts of Traffic Congestion. Transp. Res. Rec. 2008, 2058, 163–171. [Google Scholar] [CrossRef] [Green Version]
- Yuan, Y. Application of Intelligent Technology in Urban Traffic Congestion. In Proceedings of the 2020 International Conference on Computer Engineering and Application (ICCEA), Guangzhou, China, 18–20 March 2020. [Google Scholar]
- Zahid, M.; Chen, Y.; Jamal, A.; Memon, M.Q. Short Term Traffic State Prediction via Hyperparameter Optimization Based Classifiers. Sensors 2020, 20, 685. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Park, H.-C.; Kim, D.-K.; Kho, S.-Y. Bayesian Network for Freeway Traffic State Prediction. Transp. Res. Rec. 2018, 2672, 124–135. [Google Scholar] [CrossRef]
- Nanthawichit, C.; Nakatsuji, T.; Suzuki, H. Application of Probe-Vehicle Data for Real-Time Traffic-State Estimation and Short-Term Travel-Time Prediction on a Freeway. Transp. Res. Rec. J. 2003, 1855, 49–59. [Google Scholar] [CrossRef] [Green Version]
- Wang, B.; Sun, J.; Wang, W.; Xu, Z.; Tian, T.; Wang, Y.; Wei, J. Real Time Detection of Traffic Signal Running State and Remote Alarm for Fault Information at Road Intersection. In Proceedings of the 2018 24th International Conference on Automation and Computing (ICAC), Newcastle upon Tyne, UK, 6–7 September 2018; pp. 478–482. [Google Scholar]
- Chen, Z.; Cai, H.; Zhang, Y.; Wu, C.; Mu, M.; Li, Z.; Sotelo, M.A. A novel sparse representation model for pedestrian abnormal trajectory understanding. Expert Syst. Appl. 2019, 138, 112753. [Google Scholar] [CrossRef]
- Chen, Z.J.; Wu, C.Z.; Zhang, Y.S.; Huang, Z.; Jiang, J.F.; Lyu, N.C.; Ran, B. Vehicle Behavior Learning via Sparse Reconstruction with l2-lp Minimization and Trajectory Similarity. IEEE Trans. Intell. Transp. Syst. 2016, 18, 236–247. [Google Scholar] [CrossRef]
- Khan, S.M.; Dey, K.C.; Chowdhury, M. Real-Time Traffic State Estimation with Connected Vehicles. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1687–1699. [Google Scholar] [CrossRef]
- Shi, W.; Liu, Y. Real-time urban traffic monitoring with global positioning system-equipped vehicles. IET Intell. Transp. Syst. 2010, 4, 113–120. [Google Scholar] [CrossRef]
- Tao, S.; Manolopoulos, V.; Rodriguez, S.; Rusu, A. Real-Time Urban Traffic State Estimation with A-GPS Mobile Phones as Probes. J. Transp. Technol. 2012, 2, 22–31. [Google Scholar] [CrossRef] [Green Version]
- Hu, Q.; Deng, W.; Sun, X. The comprehensive measure model for urban traffic congestion based on value function. J. Southeast Univ. 2015, 31, 272–275. [Google Scholar] [CrossRef]
- Seo, T.; Kusakabe, T.; Asakura, Y. Estimation of Flow and Density Using Probe Vehicles with Spacing Measurement Equipment. Transp. Res. Part C Emerg. Technol. 2015, 53, 134–150. [Google Scholar] [CrossRef] [Green Version]
- Wan, Q.; Peng, G.; Li, Z.; Inomata, F.H.T. Spatiotemporal trajectory characteristic analysis for traffic state transition prediction near expressway merge bottleneck. Transp. Res. Part C Emerg. Technol. 2020, 117, 102682. [Google Scholar] [CrossRef]
- Antoniou, C.; Koutsopoulos, H.N.; Yannis, G. Dynamic data-driven local traffic state estimation and prediction. Transp. Res. Part C Emerg. Technol. 2013, 34, 89–107. [Google Scholar] [CrossRef]
- Wang, Y.; Papageorgiou, M. Real-time freeway traffic state estimation based on extended Kalman filter: A general approach. Transp. Res. Part B Methodol. 2005, 39, 141–167. [Google Scholar] [CrossRef]
- Wang, P.-W.; Yu, H.-B.; Xiao, L.; Wang, L. Online Traffic Condition Evaluation Method for Connected Vehicles Based on Multisource Data Fusion. J. Sens. 2017, 2017, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Xu, D.; Wang, Y.; Peng, P.; Beilun, S.; Deng, Z.; Guo, H. Real-time road traffic state prediction based on kernel-KNN. Transp. A Transp. Sci. 2018, 16, 104–118. [Google Scholar] [CrossRef]
- Zhan, X.; Li, R.; Ukkusuri, S.V. Link-based traffic state estimation and prediction for arterial networks using license-plate recognition data. Transp. Res. Part C Emerg. Technol. 2020, 117, 102660. [Google Scholar] [CrossRef]
- Cheng, Z.; Wang, W.; Lu, J.; Xing, X. Classifying the traffic state of urban expressways: A machine-learning approach. Transp. Res. Part A Policy Pract. 2020, 137, 411–428. [Google Scholar] [CrossRef]
- Quek, C.; Pasquier, M.; Lim, B. POP-TRAFFIC: A Novel Fuzzy Neural Approach to Road Traffic Analysis and Prediction. IEEE Trans. Intell. Transp. Syst. 2006, 7, 133–146. [Google Scholar] [CrossRef]
- Stutz, C.; Runkler, T.A. Classification and prediction of road traffic using application-specific fuzzy clustering. IEEE Trans. Fuzzy Syst. 2002, 10, 297–308. [Google Scholar] [CrossRef]
- Thomas, K.; Dia, H. A Neural Network Model for Arterial Incident Detection Using Probe Vehicle and Loop Detector Data. Available online: https://www.researchgate.net/publication/43483712_A_neural_network_model_for_arterial_incident_detection_using_probe_vehicle_and_loop_detector_data (accessed on 6 August 2020).
- Xu, D.; Wei, C.; Peng, P.; Xuan, Q.; Guo, H. GE-GAN: A novel deep learning framework for road traffic state estimation. Transp. Res. Part C Emerg. Technol. 2020, 117, 102635. [Google Scholar] [CrossRef]
- Qin, P.; Xu, Z.; Yang, W.; Liu, G. Real-Time Road Traffic State Prediction Based on SVM and Kalman Filter. In Wireless Sensor Networks; Li, J., Ed.; Springer-Verlag Singapore Pte Ltd: Singapore, 2018; pp. 262–272. [Google Scholar]
- Min, Z.; Yanlei, L.; Dihua, S.; Senlin, C. Highway Traffic Abnormal State Detection Based on PCA-GA-SVM Algorithm. In Proceedings of the 2017 29th Chinese Control and Decision Conference, Chongqing, China, 28–30 May 2017; pp. 2824–2829. [Google Scholar]
- Xue, J.; Van Gelder, P.; Reniers, G.; Papadimitriou, E.; Wu, C. Multi-attribute decision-making method for prioritizing maritime traffic safety influencing factors of autonomous ships’ maneuvering decisions using grey and fuzzy theories. Saf. Sci. 2019, 120, 323–340. [Google Scholar] [CrossRef]
- Xue, J.; Wu, C.; Chen, Z.; Van Gelder, P.; Liang, X. Modeling human-like decision-making for inbound smart ships based on fuzzy decision trees. Expert Syst. Appl. 2019, 115, 172–188. [Google Scholar] [CrossRef]
- Hawas, Y.E. A fuzzy-based system for incident detection in urban street networks. Transp. Res. Part C Emerg. Technol. 2007, 15, 69–95. [Google Scholar] [CrossRef]
- Yuan, F.; Cheu, R.L. Incident detection using support vector machines. Transp. Res. Part C Emerg. Technol. 2003, 11, 309–328. [Google Scholar] [CrossRef]
- Ritchie, S.G.; Cheu, R.L. Simulation of Freeway Incident Detection Using Artificial Neural Networks. Transp. Res. Part C Emerg. Technol. 1993, 1, 203–217. [Google Scholar] [CrossRef]
- Chen, Z.; Jiang, Y.; Sun, D.; Liu, X. Discrimination and Prediction of Traffic Congestion States of Urban Road Network Based on Spatio-Temporal Correlation. IEEE Access 2019, 8, 3330–3342. [Google Scholar] [CrossRef]
- Dong, C.; Shao, C.; Richards, S.H.; Han, L.D. Flow rate and time mean speed predictions for the urban freeway network using state space models. Transp. Res. Part C Emerg. Technol. 2014, 43, 20–32. [Google Scholar] [CrossRef]
- Raj, J.; Bahuleyan, H.; Vanajakshi, L.D. Application of data mining techniques for traffic density estimation and prediction. In Proceedings of the International Conference on Transportation Planning and Implementation Methodologies for Developing Countries, Mumbai, India, 10–12 December 2014; Patil, G.R., Mathew, T.V., Rao, K.V.K., Eds.; Elsevier: Amsterdam, The Netherlands, 2016; pp. 321–330. [Google Scholar]
- Han, E.; Ajou University; Kim, S.B.; Rho, J.H.; Yun, I. Comparison of the Methodologies for Calculating Expressway Space Mean Speed Using Vehicular Trajectory Information from a Radar Detector. J. Korea Inst. Intell. Transp. Syst. 2016, 15, 34–44. [Google Scholar] [CrossRef]
- Yu, Y.; Trouvé, A. A non-linear K-means algorithm and its application to unsupervised clustering. In Proceedings of the 6th International Conference on Signal Processing 2002 ICOSP-02, Beijing, China, 26–30 August 2002; Volume 2, pp. 1146–1149. [Google Scholar]
- Mitra, S.; Pal, S. Fuzzy multi-layer perceptron, inferencing and rule generation. IEEE Trans. Neural Netw. 1995, 6, 51–63. [Google Scholar] [CrossRef]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat. 1974, 3, 1–27. [Google Scholar]
- Stephens, C.R.; Sukumar, R. An Introduction to Data Mining; Addison-Wesley: Boston, MA, USA, 2006. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FieldName | Description |
|---|---|
| DEVICEID | Device ID |
| FROMTIME | Statistical starting time |
| TOTIME | Statistical end time |
| INTERVAL | Statistics time interval |
| LANEID | Lane ID |
| COUNT | The count of vehicles in the interval |
| REGULARCOUNT | The count of regular vehicles in the interval |
| LARGECOUNT | The count of large vehicles in the interval |
| FLOW | Section conversion hourly flow |
| ARITHMETIC_AVERAGE_SPEED | Arithmetic average of speed |
| HARMONIC_AVERAGE_SPEED | Harmonic average of speed |
| TURN | Lane direction information |
| Unblocked | Basically Unblocked | Lightly Congested | Moderately Congested | Severely Congested | |
|---|---|---|---|---|---|
| Express Way | |||||
| Trunk Road | |||||
| Secondary Road and Branch Road |
| State | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| Indicator | |||||
| Mean flow (vec/5min) | 43.16 | 26.74 | 47.30 | 24.25 | |
| Mean speed (km/) | 28.16 | 30.99 | 23.94 | 28.68 | |
| Maximum speed (km/h) | 48.51 | 55.38 | 29.03 | 51.59 | |
| Minimum speed (km/h) | 18.89 | 25.12 | 3.60 | 11.82 | |
| Mean speed variance | 221.87 | 73.94 | 115.86 | 109.51 | |
| Mean large ratio | 3.56% | 1.78% | 3.51% | 16.62% | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, J.; Chen, Q.; Xue, J.; Wang, H.; Chen, Z. A Novel Method about the Representation and Discrimination of Traffic State. Sensors 2020, 20, 5039. https://doi.org/10.3390/s20185039
Jiang J, Chen Q, Xue J, Wang H, Chen Z. A Novel Method about the Representation and Discrimination of Traffic State. Sensors. 2020; 20(18):5039. https://doi.org/10.3390/s20185039
Chicago/Turabian StyleJiang, Junfeng, Qiushi Chen, Jie Xue, Haobo Wang, and Zhijun Chen. 2020. "A Novel Method about the Representation and Discrimination of Traffic State" Sensors 20, no. 18: 5039. https://doi.org/10.3390/s20185039
APA StyleJiang, J., Chen, Q., Xue, J., Wang, H., & Chen, Z. (2020). A Novel Method about the Representation and Discrimination of Traffic State. Sensors, 20(18), 5039. https://doi.org/10.3390/s20185039