3.1.1. Model Training Result Analysis
As shown in
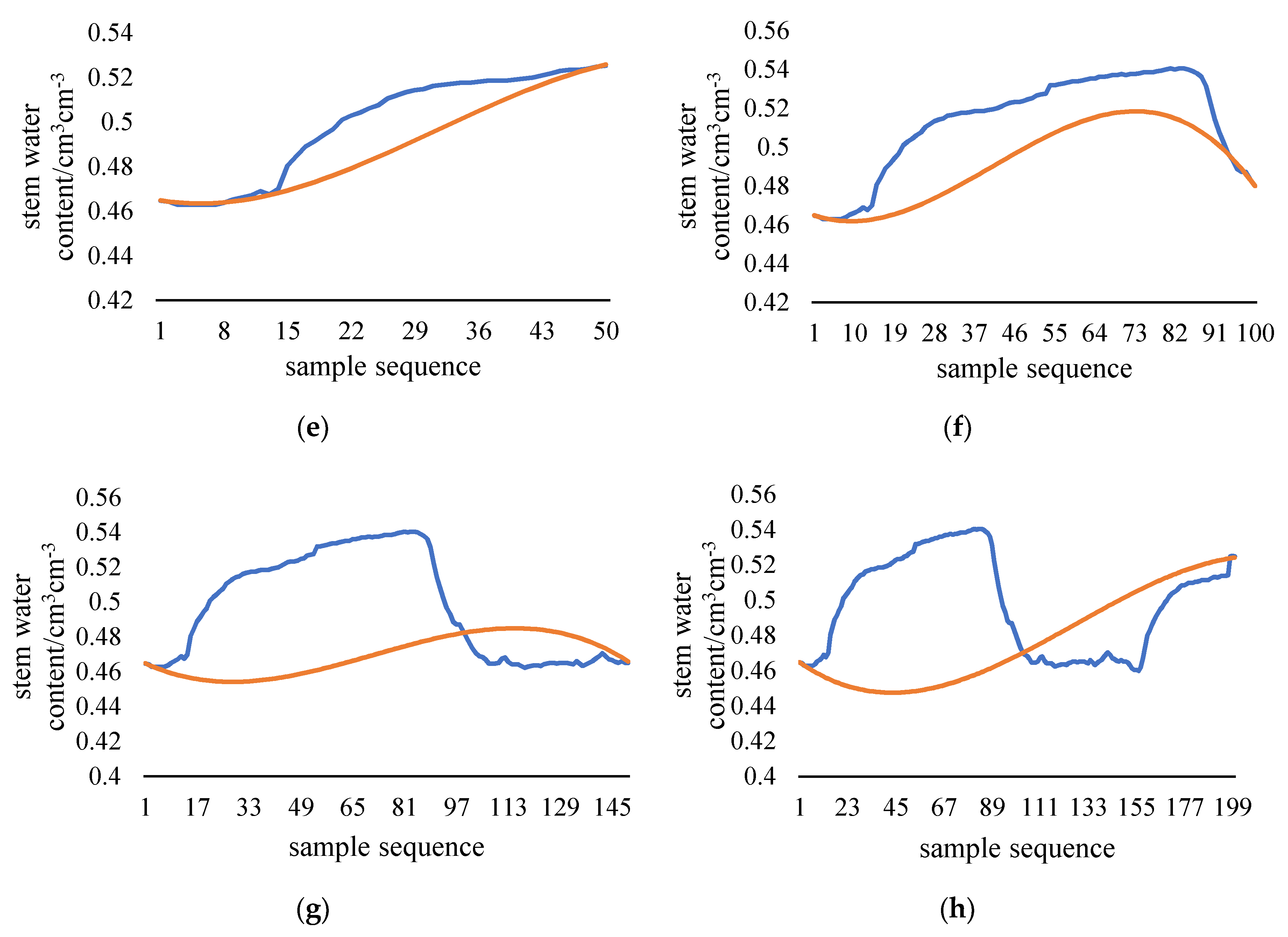
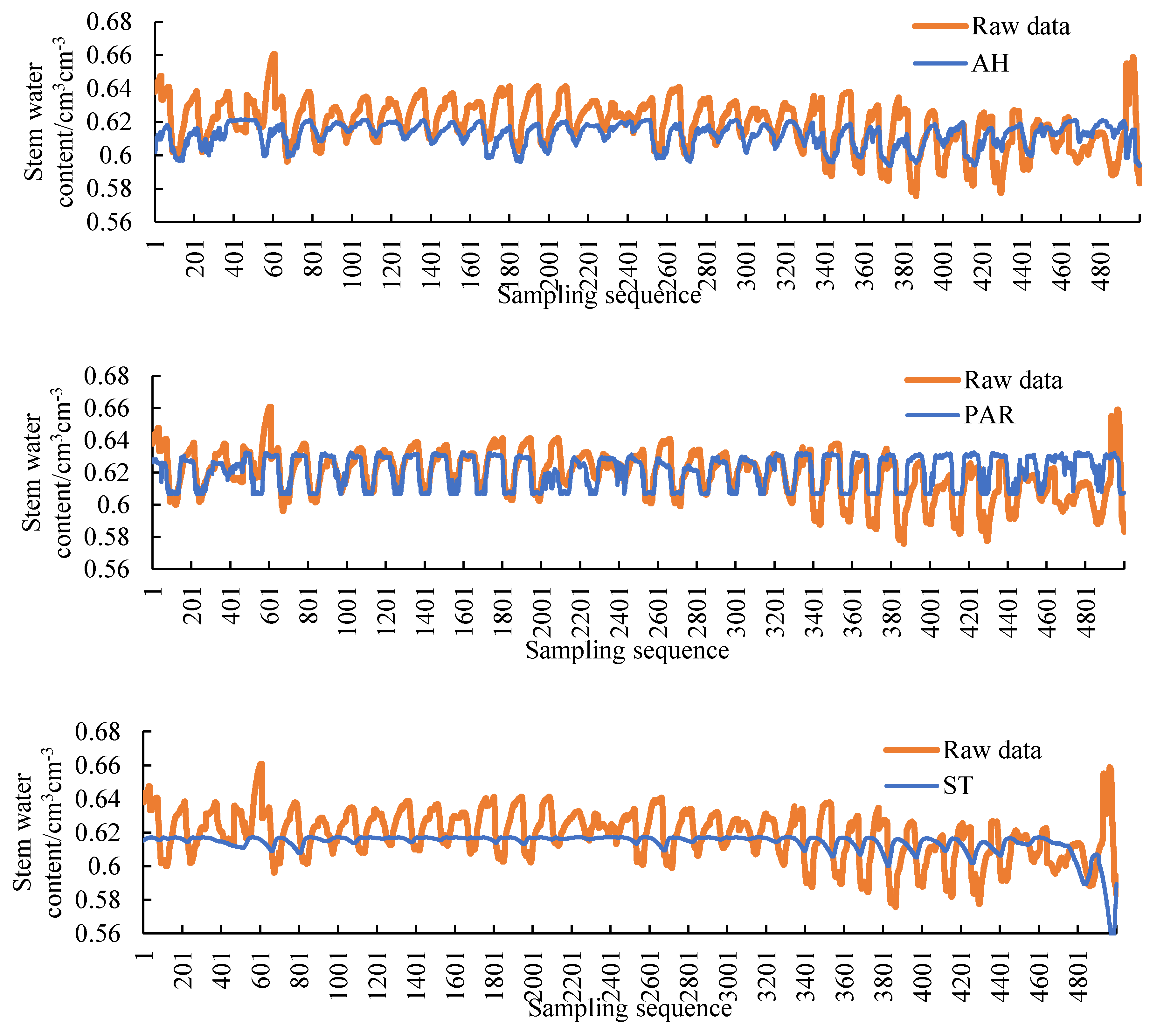
Figure 4, spline interpolation method can’t fit the plant stem moisture when the data length exceeds 100. The longer the filling sequence is, the worse the fitting will be. Since there is no obvious fluctuation of stem moisture when the sequence length is less than 100, interpolation filling method can meet the requirement of data filling when the sequence length is short. This paper discusses the filling method of long-term series data that cannot be filled by interpolation method. Therefore, the length of the filling data should include at least a complete diurnal variation of plant stem moisture. Sensor data collection quantity is 144 data per day, 1008 data per week. The training data length is taken as 1000 adhering to the principle of taking integers as much as possible. The test data length is 200 which is larger than 144 and is an integer multiple of 100. The ratio of training data to test data is 5:1. The batch size of model is set to 100. It can be considered that one day of data is filled with one week of data.
In order to ensure the uniformity of data characteristics, the data selected in the article are all data from May to October. At this stage, the trees have entered a stable growth period, and the stem moisture presents regular fluctuations. The original data will be artificially divided into training and test sets. The training set is used for model training. The test set is used to compare with the model output to verify the performance of the model. A total of 2200 pieces of data are randomly taken from the database, as shown in
Figure 5. The abscissa is the data order; the ordinate is the moisture content of the stem of the plant returned by the sensor, and the water content of the stem is from 43% to 57%. The data in the range of 1201 to 1200 is selected as the test data, the data length is 200, and the yellow dotted line is marked. The test data is in the middle of the 2200 pieces of data, ensuring that there are 1000 pieces of training data in both forward and backward filling. Suppose that the yellow dotted line represents a time period when there is a problem with the sensor or collector and other equipment, resulting in communication interruption and the data cannot be collected. The problem to be solved in this paper is to fill this missing data as accurately as possible. Through the data trend of
Figure 5, it can be seen that the stem moisture of the plant is affected by the external environment, and fluctuates regularly with the sunrise and sunset cycles. The specific conditions of stem moisture at a certain moment will be affected by the specific external environment, but the overall fluctuation trend remains unchanged. Regularly varying data in time series is suitable for training and filling of LSTM networks, which is consistent with the original idea.
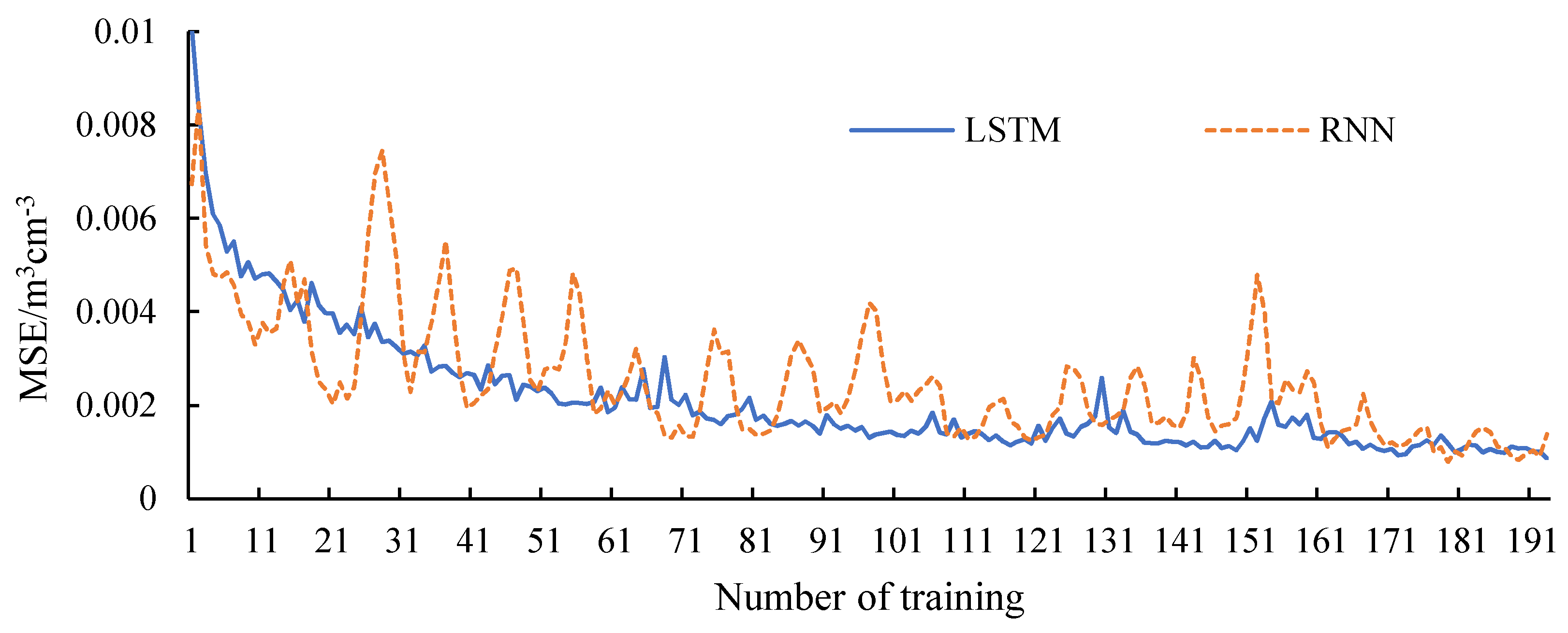
Figure 6 shows the change of loss during the training of LSTM and RNN. It can be seen that the loss value of the LSTM model decreases steadily throughout the whole process. The loss value of the RNN model has a general trend of decline, but it fluctuates sharply in the process of decline. The loss function is the mean-square error (MSE), indicating the deviation between the filling value and the real value during training. Since LSTM model has better memory ability than RNN, it can store long-term memories of the training data, and LSTM can approach the optimal value more stably.
In this paper, the filling method of LSTM neural network is to make up a window with 200 original values to fill the unknown value for the next step. The window move forward one step the filling value was added at the end, and delete the original value at the beginning to form a new window with 200 values. Continuously push the window forward in this way, until all the fillings you get. Since there are 144 pieces of data in just one day, single-step predictions is of little significance in this paper. The filling results in the article are all multi-step predictions.
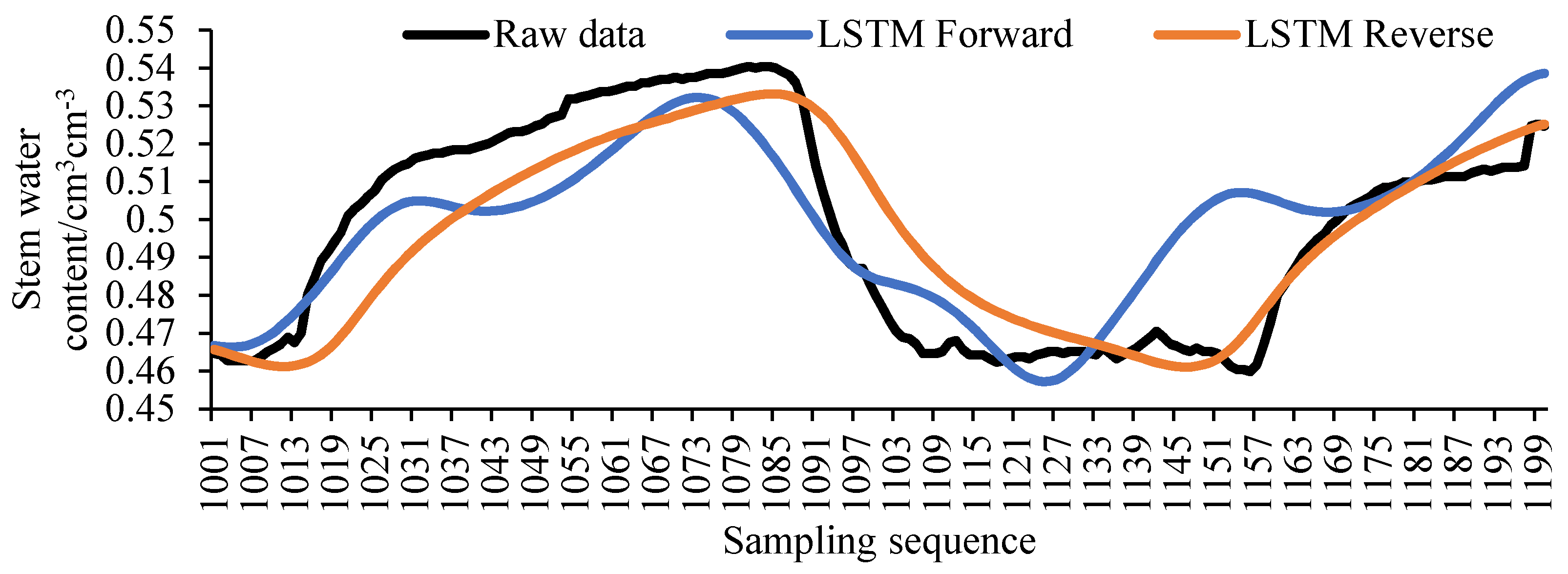
However, with the decrease of the original value and the increase of the filling value, such a filling method will lead to the accumulation of errors, making the filling error gradually increase with the translation of the window and the trend of the filling value deviates from the original value. The filling error of the LSTM one-way model is calculated, and its error distribution is shown in
Figure 7. It can be clearly seen from the figure that the filling error of the forward model in the sequence of 1001 to 1100 is slightly smaller than that of the reverse model, and the filling error of the reverse model in the sequence of 1200 to 1101 is significantly smaller than that of the forward model. Based on the distribution law of the filling error of the LSTM one-way model, the two-way LSTM model can be considered.
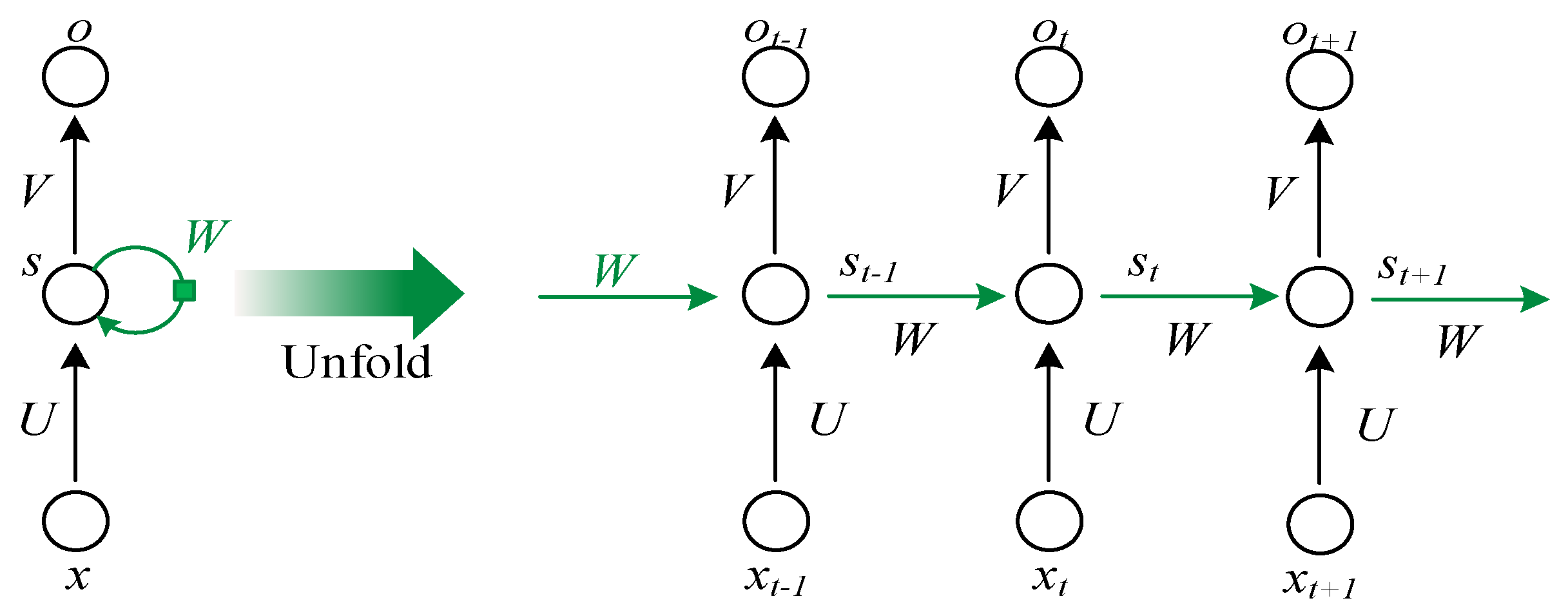
NLP (Natural Language Processing) is an important research direction in the field of computer science and artificial intelligence. In this paper, the idea of using LSTM to fill plant stem water data was inspired by NLP training. In the field of NLP, LSTM makes up for the shortcoming that RNN cannot recognize long-distance sentences. But NLP training is different from the situation in this article: the amount of data required in NLP training is much larger than the existing data in this article, and the language information is more complicated than the stem water time series data. To a large extent, this article needs a method that is as light and fast as possible while solving the accumulation of errors. Inspired by bidirectional semantic recognition, this paper innovatively adopts bidirectional filling. Two groups of filling results are weighted to generate new and more accurate filling values to make up for the cumulative errors in the filling process.
According to the different weights of the LSTM unidirectional model, two bidirectional LSTM models were proposed in this experiment, namely the LSTM bidirectional equal weight model and the LSTM bidirectional decreasing weight model. Let the sequence number of the missing sample be
i, the predictive value of the LSTM forward model is
xi, the predictive value of the LSTM reverse model is
yi, the predictive value of the LSTM bidirectional model is
zi, and
ai,
bi are the weights of
xi and
yi, respectively. Therefore, for the LSTM two-way equal-weight model:
where
i∈(1001:1:1200).
For the LSTM bidirectional decreasing weight model:
where
i∈(1001:1:1200),
ai∈(1:0.05:0.05),
bi∈(0:0.05:0.95), 0.05 is the gradient value.
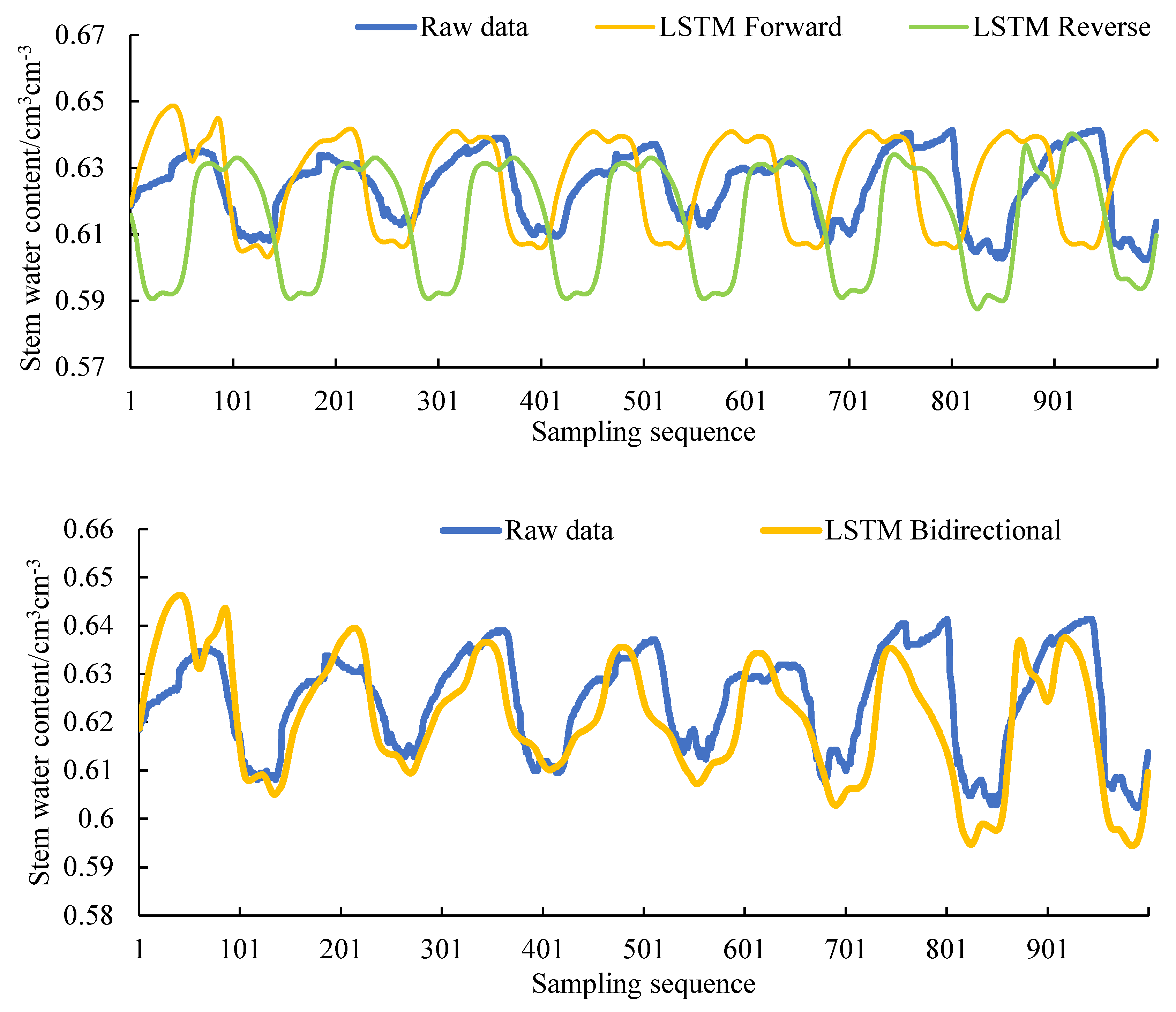
The filling result of the unidirectional LSTM model is shown in
Figure 8. The filling result of the bidirectional LSTM model is shown in
Figure 9. Comparing
Figure 8 and
Figure 9, it can be found that the filling result of the bidirectional LSTM model is superior to the unidirectional LSTM model in the entire sequence. And the filling result of LSTM bidirectional decreasing weight model is also better than LSTM bidirectional equal weight model in the whole sequence.
Based on the unidirectional LSTM model, this experiment also proposed a LSTM bidirectional segmented model. That is, the first half of the missing sequence (1001 to 1100) is filled with the LSTM forward model, and the second half of the missing sequence (1101 to 1200) is filled with the LSTM reverse model. The filling result of the LSTM bidirectional segmented model is shown in
Figure 10. It can be seen from the figure that the fill value of the LSTM bidirectional segmented model has a large fluctuation at the intersection, which is not conducive to later data analysis.
In order to quantitatively evaluate the filling performance of the above five different LSTM models, based on the original values, the five model error parameters were calculated, and the results are shown in
Table 4. It can be clearly seen from the table that the filling value of the LSTM bidirectional decreasing weight model has the smallest error. In the calibration test of the plant stem moisture sensor, the average measurement error of the sensor is 0.008 cm
3 cm
−3, and the average error of the LSTM bidirectional decreasing weight model is 0.009 cm
3 cm
−3, the two are very close, and the filling accuracy can basically meet the subsequent tests analysis. Therefore, the LSTM bidirectional decreasing weight model can be used to fill the missing sampling sequence.
Figure 11 compares the filling results of several models with the original data. As can be seen from
Figure 11, the fitting degree between the filling value of LSTM and the original data is better than that of RNN, interpolation, ARMA, and ARIMA. The specific error values of each model are shown in
Table 5.
Table 5 shows the error parameters of several models. In order to remove the influence of the variable amplitude on the error parameters, the error calculation results are as follows:
e is the error value.
is the filling result.
x is the true value. In
Table 5, the error values of the bidirectional LSTM model are the smallest among several models, and the MAPE is 1.813%, less than the filling error of the one-way LSTM model, 1/3 of the filling error of the RNN model, and 1/4 of the interpolation filling error. The performance of ARIMA is better than that of ARMA, but the error is still larger than that of the LSTM model.
In order to show the error distribution, the number of filling errors less than the fixed value of each model was counted, and the results were shown in
Table 6.
Table 6 shows the proportion of the filling error of each model less than the set value, and the conditions are not more than 0.01, 0.02, 0.03, 0.04, and 0.05, respectively. It can be seen from
Table 6 that the accuracy of LSTM unidirectional and LSTM bidirectional filling results is much better than other models, and the bidirectional filling accuracy after adding weight processing is the highest. Of the points, 100% in the bidirectional filling result satisfy the error within 5%. Even if the required error is within 2%, more than half of the points still meet the requirements. The LSTM unidirectional filling performance is also excellent, but the small part of the point deviation is large. LSTM unidirectional filling is 9.5% less than the number of bidirectional LSTM in less than 5%, but still more than 90%. The error of RNN and interpolation method is very large, and accuracy 60% cannot be achieved under the requirement of error less than 5%, which makes it difficult to meet the requirement of data filling. The performance of ARIMA is the best in the traditional method, and the total error is less than 5%.
Combining the data in
Table 6 with
Table 5, for the data of the longer sequence to be filled, the traditional data filling method has difficulty meeting the demand, and neither the degree of fitting nor the specific error-index can be compared with the filling method added to the neural network. The advantage of LSTM is more obvious than that of RNN. The ARIMA method is the best among several traditional methods, but it cannot fit data fluctuations well. The accuracy performance is not as good as LSTM.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}