1. Introduction
An ad-hoc network, as a group of wireless mobile nodes, can be implemented in various forms, including wireless mesh networks, wireless sensor networks, mobile ad-hoc networks, and vehicle ad-hoc networks [
1,
2]. Ad-hoc networks can provide flexible communication even when it is not possible to install new infrastructure or use existing infrastructure due to geographical and cost restrictions [
3]. Ad-hoc networks have the advantage of node communication with other nodes without a base station. Moreover, they also have the features of self-forming and self-healing. Accordingly, they are adopted in various applications, such as battlefield situations, where topology changes frequently, disaster relief, environmental monitoring, smart space, medical systems, and robot exploration [
4,
5,
6,
7,
8].
Unlike mobile communication networks, which allow centralized resource scheduling, an ad-hoc network requires distributed scheduling based on the information exchanged among nodes. A major problem with distributed node scheduling is packet collisions among nodes if resources are not efficiently distributed, which can lead to significant throughput degradation [
9]. Considering these characteristics, supporting quality of service (QoS) through distributed scheduling is a very challenging task. QoS support for high- and low-priority data is essential in various applications. For instance, on a battlefield, a commander’s orders must be delivered as soon as possible. In addition, for environmental monitoring, it is necessary to send emergency disaster information, such as an earthquake alert, to a destination node with very high priority [
10].
The nodes of an ad-hoc network consume a lot of energy in sensing data and processing high-priority packet. However, in many situations, it is difficult to replace or recharge the battery of the nodes. Accordingly, it is important to increase energy efficiency and to enhance overall network lifetime through clustering, transmission power control, and efficient network information exchange [
11,
12,
13,
14,
15,
16]. Fairness and load balancing among nodes also have a great influence on the battery lifetime and the connectivity of the entire network. However, low fairness among nodes due to inefficient resource allocation causes increased packet collisions and packet retransmission to some nodes, and these detrimental effects reduce the battery lifetime. Meanwhile, some other nodes will be allocated an unnecessarily much amount of resources, resulting in severe inefficiency for the entire network. Hence, resource allocation for an ad-hoc network is a very important and challenging issue.
Fairness measurements can be categorized into qualitative and quantitative methods, depending on whether the fairness can be quantified. Qualitative methods cannot quantify fairness to an actual value, but they can judge whether a resource allocation algorithm achieves a fair allocation. Maximum-minimum fairness [
17,
18] and proportional fairness [
19] are qualitative methods. Maximum-minimum fairness aims to achieve a max-min state, where the resources allocated to a node can no longer be increased without reducing the resources allocated to neighboring nodes. Proportional fair scheduling maximizes the log utility of the whole network by preferentially scheduling nodes with the highest ratios of currently achievable rates to long-term throughput. Measuring the fairness of an entire network is also an important issue. Jain’s fairness index [
20] is a quantitative fairness measurement method, however, it cannot measure the fairness of nodes to which a weight factor is assigned.
In this paper, a distributed scheduling algorithm, which takes weight factors and traffic load into account, is proposed. In the proposed algorithm, self-fairness [
21] is adopted for resource reallocation. Increment of self-fairness means that resources are fairly allocated to nodes proportionally to the weight of each node. Therefore, even in the distributed scheduling which supports packets with different importance, if the slot allocation for each node is adjusted to the direction of increasing self-fairness, the overall performance of the network can be significantly increased. Moreover, the proposed algorithm adjusts throughput and delay based on the assigned weight factor rather than an absolute distinction between high-priority packets and low-priority packets.
The contribution of this work is summarized as follows:
A novel distributed scheduling scheme for an ad-hoc network is proposed, where both the load-balancing among neighboring nodes and the preferential processing for high importance packets are considered.
An intra-node slot reallocation algorithm is proposed. Each node is equipped with multiple queues, and this algorithm re-arranges the slot allocation between the queues inside a node. Moreover, this algorithm enables a flexible adjustment of throughput and delay, reflecting assigned weight factors.
Self-fairness for packets with unequal importance is introduced. This metric incorporates both the weight factor and traffic load. The metric plays an important role in achieving a fairness among the packets with the same weight factor and in supporting service differentiation among packets with different weight factors. It is validated that the proposed scheduling scheme substantially increases the performance of the network.
It is confirmed that the proposed node scheduling outperforms the absolute priority-based scheduling scheme in terms of delay and throughput. This result is supported by thorough simulation studies accommodating various operation scenarios.
The remainder of this paper is organized as follows:
Section 2 describes the various distributed resource allocation medium access control (MAC) protocols proposed in the literature.
Section 3 describes the proposed algorithm. In
Section 4, the performance of the proposed algorithm is analyzed based on an extensive simulation study, and, finally,
Section 5 presents some observational conclusions.
2. Related Works
In [
22], the authors proposed a distributed randomized (DRAND) time division multiple access (TDMA) scheduling algorithm, which is a distributed version of the randomized (RAND) time slot scheduling algorithm [
23]. DRAND operates in a round-by-round manner and it does not require time synchronizations on the round boundaries, resulting in energy consumption reduction. In this scheme, there are four states for each node: IDLE, REQUEST, GRANT, and RELEASE. Each node is assigned a slot that does not cause a collision within the 2-hop neighboring nodes by sending a state message to the neighboring nodes. The basic idea of the deterministic distributed TDMA (DD-TDMA) [
24] is that each node collects information from its neighboring nodes to determine slot allocations. DD-TDMA is superior to DRAND in terms of running time and message complexity. This feature increases energy efficiency because DD-TDMA does not need to wait for a GRANT message, which is transmitted as a response of REQUEST message and it contains a slot allocation permission for unused slots. However, DRAND and DD-TDMA do not consider load balancing and fairness among the nodes.
Algorithms for allocating resources based on the states of networks and nodes were proposed in [
25,
26,
27,
28]. In [
25], a load balancing algorithm for TDMA-based node scheduling was proposed. This scheme makes the traffic load semi-equal and improves fairness in terms of delay. In adaptive topology and load-aware scheduling (ATLAS) [
26], nodes determine the amount of resources to be allocated through resource allocation (REACT) algorithms, where each node auctions and bids on time slots. Each node acts as both an auctioneer and a bidder at the same time. During each auction, an auctioneer updates an offer (maximum available capacity) and a bidder updates a claim (capacity to bid in an auction). Through this procedure, resources are allocated to the nodes in a maximum-minimum manner [
17]. In [
27], an algorithm consisting of two sub-algorithms was proposed. The first is a fair flow vector scheduling algorithm (FFVSA) aiming to improve fairness and optimize slot allocation by considering the active flow requirements of a network. FFVSA uses a greedy collision vector method that has less complexity than the genetic algorithm. The second is a load balanced fair flow vector scheduling algorithm (LB-FFVSA), which increases the fairness of the amount of allocated resources among nodes. In [
28], the fairness among nodes was improved in terms of energy consumption through an upgraded version of DRAND. Energy-Topology (E-T) factor was adopted as a criterion for allocating time slots, and E-T-DRAND algorithm was proposed to request time slots. Instead of the randomized approach of DRAND, E-T-DRAND algorithm provides high priority to the nodes with high energy consumption and low residual energy due to the large number of neighboring nodes. E-T-DRAND balances the energy consumption among nodes and enhances scheduling efficiency. Each node determines the number of slots to be reallocated using the number of packets accumulated in the queue of its 1-hop neighboring nodes and the number of allocated slots for these nodes. The slot reallocation procedure must check whether a slot is shared by nodes within 2-hop distance. As a result, the load between nodes becomes semi-equal, and the nodal delay is reduced.
In [
29,
30,
31,
32,
33], scheduling schemes considering priority were proposed. In [
29], for the purpose of reducing delay of emergency data, energy and load balanced priority queue algorithm (ELBPQA) was proposed. In this scheme, four different priority levels are defined according to the position of a node in a network. In [
30], the highest priority is given to real-time traffic, and the other priority levels are given to non-real time traffics. In order to reduce the end-to-end delay, the packets with the highest priority are processed in a preemptive manner. In [
31], priority- and activity-based QoS MAC (PAQMAC) was proposed. In this scheme, the active time of traffic is dynamically allocated according to priority. Specifically, by adopting a distributed channel access scheme, the packet with high priority have reduced back-off and wait times. In [
32], I-MAC protocol, which combines carrier sense multiple access (CSMA) and TDMA schemes, was proposed to increase the slot allocation for nodes with high priority. I-MAC consists of a set-up phase and a transmission phase. The set-up phase consists of neighbor discovery, TDMA time-slot allocation using a distributed neighborhood information-based (DNIB) algorithm, local framing for reuse of time slots, and global synchronization for transmission. Nodes with high priority reduce back-off time to increase the opportunity of winning slot allocation, and nodes with the same priority compete for slot allocation. This scheme reduces the energy consumption of nodes with high priority.
In [
33], a QoS-aware media access control (Q-MAC) protocol composed of both intra-node and inter-node scheduling was proposed. Intra-node scheduling determines the priority of packets arriving at the queue of a node. Priority is determined according to the importance of packets and the number of hops to a destination node. Q-MAC consists of five queues, where a queue called an instant queue transmits packets as soon as they arrive. The remaining queues transmit packets following the maximum-minimum fairness principle. Inter-node scheduling is a scheme of data transmission among nodes sharing the same channel. A power conservation MACAW (PC-MACAW) protocol based on the multiple access with collision avoidance protocol for Wireless LANs (MACAW) is applied to schedule data transmission. Q-MAC guarantees QoS through dynamic priority assignment; however, latency can be increased due to heavy computational complexity [
34].
A comparative analysis of the protocols mentioned in this section is summarized in
Table 1. It is largely classified into with and without prioritizations. In the load-balancing classification, “High” means the clear load-balancing by adopting max-min fairness criterion; “Medium” is an indirect load-balancing method by adjusting idle time and access time; and “Low” is the case where the load-balancing method and its effects are not clearly addressed. In the weight factor classification, “No” is strict priority without quantitative values, and PAQMAC and Q-MAC assign quantitative weight values to packets.
One of the representative fairness measurement methods is Jain’s fairness index, which is a value range (0, 1), and the closer it is to 1 the fairer it is [
20]. Jain’s fairness index can measure the fairness of an entire system in a relatively simple way, but it cannot measure the fairness of nodes to which a weight factor is assigned. In [
21], the authors proposed a quantitative fairness measurement method applicable to scheduling algorithms with unequal weight factors.
3. Proposed Node Scheduling with Weight Factor
Instead of conventional absolute priority-based scheduling, an adjustable and flexible scheduling scheme is proposed. This scheme reallocates slots by taking the weights assigned to the queues of nodes into account. Specifically, intra-node scheduling, which reallocates slots between the queues for high- and low-importance packets, is introduced. Then, it is followed by inter-node scheduling adopted from [
25], which reallocates slots among neighboring nodes to increase the fairness measured in terms of traffic load.
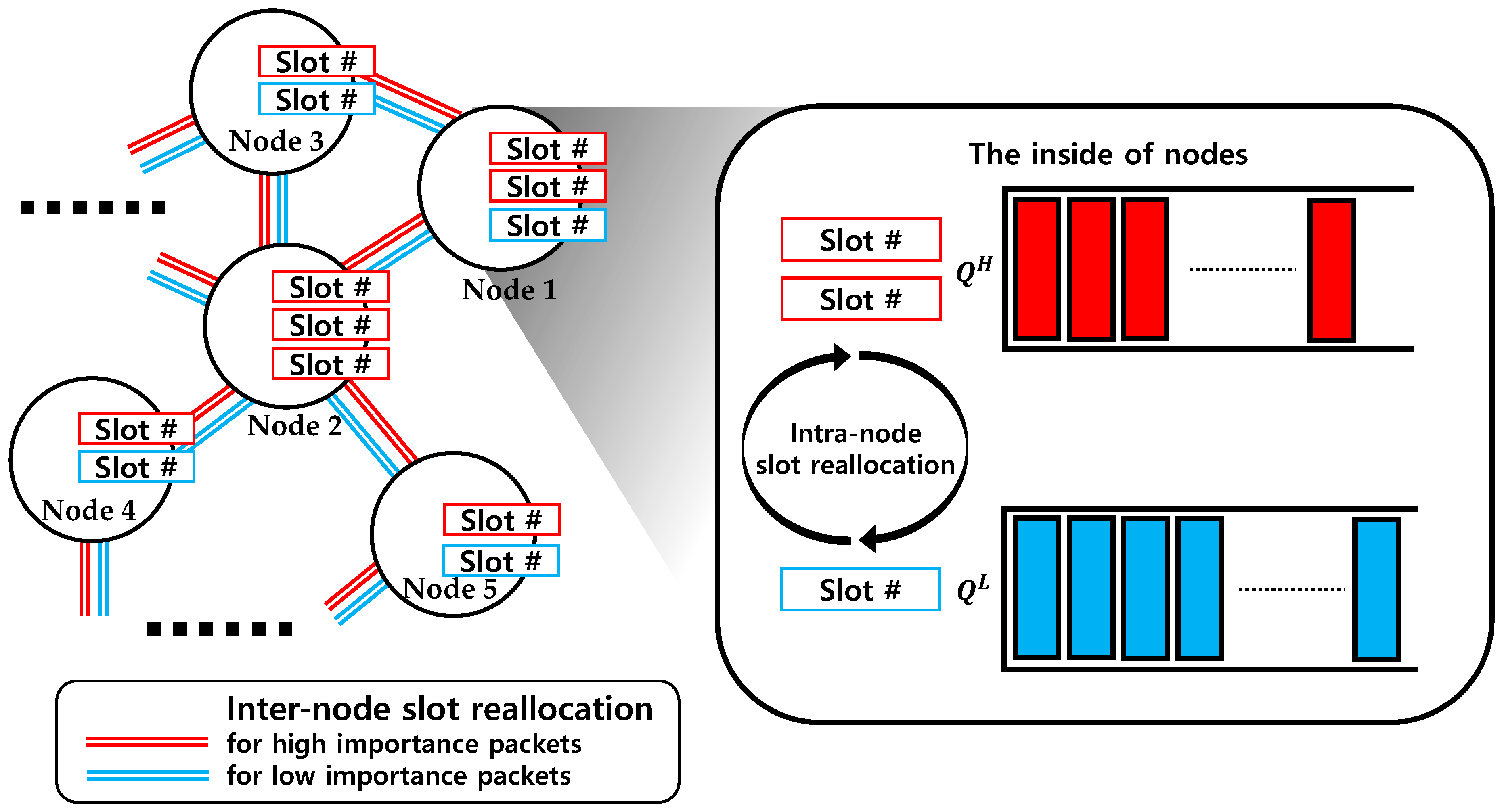
The proposed algorithm consists of three steps: (1) free time slot allocation, which is a process of allocating the initialized slots (unallocated empty slots) to packets; (2) the intra-node slot reallocation algorithm, which exchanges slots between the queues of a node with different importance values using self-fairness; and (3) the inter-node slot reallocation among 1-hop neighbors using a load balancing algorithm (slot exchange between queues with the same importance). The procedure of this algorithm is depicted in
Figure 1.
All the nodes have two types of queues for storing packets of different importance. and are queues for high- and low-importance packets, respectively. represent or according to the indicator , respectively. In the following, is used as an indicator representing importance. The number of slots required to transmit all the packets at of node at frame time is represented by , and the number of slots assigned to of node at frame time for packet transmission is represented by . Assuming that the packet and the slot sizes are the same, is equal to the number of packets in . is the inverse load of and expressed as .
Free time slot allocation requires REQUEST and RELEASE messages exchanges, as in DRAND. The number of packets to be transmitted by node is + , and node with can be allocated slots that are not reserved by the nodes within 2-hop distance. Note that the nodes within 2-hop distance cannot reuse time slot to avoid packet collisions and this reuse can be prevented by slot reallocation between 1-hop nodes. Node allocates as many as slots to and increases by the number of allocated slots. If , does not need to be allocated more slots; accordingly, the slots are allocated to , and is increased. Afterwards, and are reallocated through the intra-node slot reallocation algorithm. If both and are allocated as many as and , no more slots are assigned.
In the intra-node slot reallocation, a self-fairness index is used to reallocate packets between and of each node. Self-fairness is a measure of how fairly an amount of "resources" is assigned to a particular node by considering the weight assigned to that node. In this measurement, the resource can be bandwidth, time slots, etc. The proposed algorithm uses inverse load as a resource for self-fairness measurement.
In the proposed algorithm, self-fairness applies to two different queues of each node. Hence, each node has two self-fairness values for its two queues (
and
). The self-fairness value for
of node
is denoted by
and defined as it is presented in Equations (1)–(3) [
21]:
where
is the ratio of resources allocated to
at node
to the sum of resource allocated to
and
at 1-hop neighboring nodes,
is a set of 1-hop neighbor nodes of node
,
is the weight assigned to
of node
, and
is the sum of the weights of 1-hop neighboring nodes. When the weight is high, more slots are allocated to increase the inverse-load, resulting in a fairer resource allocation. By setting
, more important packets are allocated more slots than less important packets. Accordingly,
is a quantitative value for
of node
, indicating whether the load of
is high or low considering the weight assigned. Therefore, it is used as an index to compare the fairness of slot allocation with unequal weight factor.
When , the allocation is in the fairest state. When the amount of slots allocated is small compared to the assigned weight factor, can be satisfied because . In this case, it is necessary to gain more slots from the other queue. In the opposite case, if too many slots are allocated, can be satisfied, and must release its own slots. When a slot is gained, and will increase, resulting in a decrement of . In contrast, when a slot is released, increases. The intra-node slots reallocation algorithm adjusts and to be as close to 1 as possible, which improves the self-fairness. Specifically, when , the slots allocated to are released to , and vice versa when . The algorithm for is detailed in Algorithm 1.
| Algorithm 1. Increasing slot allocation |
| 1: for all node i do |
| 2: if !=0 |
| 3: Calculate
|
| 4: end if |
| 5: if !=0 |
| 6: Calculate
|
| 7: end if |
| 8: if |
| 9: if |
| 10: |
| 11: |
| 12: |
| 13: |
| 14: end if |
| 15: while do |
| 16: |
| 17: |
| 18: |
| 19: |
| 20: |
| 21: else break; |
| 22: end if |
| 23: end while |
| 24: end if |
| 25: end if |
In Algorithm 1, and are the expected self-fairness values calculated assuming that slots are reallocated. It is assume that gains a slot from , hence, is calculated by increasing by 1, and is calculated by decreasing by 1. The updated and are transmitted to its 1-hop neighboring nodes at the end of each frame. Accordingly, during slot exchange at frame time , is calculated using only the locally updated and by intra-node slot exchange. In the next frame, the self-fairness is updated through information exchanges among neighboring nodes. When and releases a slot, will be 0. This makes , and becomes infinity. To prevent this, a minimum default value above 0 is assigned to under this situation.
At every frame, slots are reallocated until self-fairness can no longer be improved. Note that the fairness index 1 is the fairest state. Consequently, the Euclidean distance between the fairest status
and a current
combination is introduced as a metric representing a target fairness, as it is presented in Equation (4):
Now, the expected Euclidean distance from the expected fairness is compared with the current Euclidean distance from . If , gains a slot from , and and are updated. Because slot reallocation is an intra-node process, collisions with 2-hop neighboring nodes need not be considered.
When , the slot reallocation algorithm is very similar to Algorithm 1, and and are calculated with and , respectively. However, instead of in lines 9 and 18 of Algorithm 1, is used as a slot release condition. This prevents from being zero by releasing all slots to to improve the fairness when . That is, is guaranteed in any situation.
After the intra-node slot reallocation algorithm, the inter-node slots reallocation [
25] follows. At this time, the slot exchange does not consider the weights of
and
any more because these exchanges take place among the queues with the same importance. Node
’s
computes
to determine how many slots to reallocate with a 1-hop neighboring node as it is presented in Equation (5) [
25]:
If , slots are gained from the 1-hop neighboring node. If , slots are released to the 1-hop neighboring node. The number of reallocated slots is determined by . This increases the equality of the inverse-load of the same importance among node and its 1-hop neighboring nodes. These processes are performed for all nodes in a node-by-node manner. The same intra-node and inter-node slot reallocations are repeated in the next frame.
4. Performance Evaluation
A network simulator [
35] implemented in Java was used for performance analysis of the proposed algorithm. No isolated nodes are assumed, i.e., all the nodes have at least a single 1-hop neighbor node. Accordingly, in establishing a connection, any two nodes can be connected with each other through multi-hop links. The connections are established using arbitrarily chosen pairs of a source node and a destination node, and high- and low-importance connections generate high- and low-importance packets, respectively. In the following, high- and low-importance packets are denoted by
and
, respectively.
For the performance analysis, the throughput, delay, and fairness are measured by changing the connection creation ratio (between and ) and the weight factor setting. Then, the proposed algorithm is compared with the absolute priority-based algorithm in which preempts time slots when allocating free time slots. Note that the absolute priority algorithm adopts only the inter-node slot reallocation algorithm, not the intra-node slot one.
The generation ratios of high- and low-importance connections are denoted by . The weight factor setting in is denoted by . Assuming that and of all nodes have the same weight settings as and , respectively, the node index can be dropped from the weight factors. The weight factors are set as: and .
The performance of the proposed scheme was measured in two scenarios.
Table 2 lists the parameters setting for each scenario. In the first scenario, a fixed number of connections are created at the starting epoch of the simulation, the packets of the connections are generated at fixed time intervals, and the number of packets generated for each connection is the same. In the second scenario, connections are created based on Poisson processes. Unlike the first scenario, the number of packets generated per connection follows a Poisson distribution. The arrival rate
determines the connection creation interval. The duration of each connection follows an exponential distribution of parameter
, which determines the number of packets generated in each connection. The packets are generated at a fixed interval, as in the first scenario. Each connection is closed if all the packets arrive at its destination node. Because the connections are continually generated, in the second scenario, the simulation duration is specified at the beginning of the simulation. For both scenarios, the final measurement is the average over 1000 independent simulations.
In the first scenario, the performance of the proposed algorithm was analyzed with the increasing total number of connections and the various settings of the weight factor and The total number of created connections is the sum of the high- and low-importance connections. Throughput, packet delivery ratio, 1-hop delay, and fairness are measured and compared with those of absolute priority-based scheduling. Throughput refers to the number of all packets arriving at a destination node during the simulation. However, in the first scenario, since the number of generated connections is determined at the beginning of the simulation, the throughput measured when all packets arrive at a destination node will be simply the product of (number of connections) and (number of generated packets per connection). Therefore, throughput is measured not at the end of the simulation but at a predefined time , which is large enough for the transmission of packets in the network to be in a steady state. The packet delivery ratio means the proportion of received packets to the packets sent. The 1-hop delay is measured as the average of ((the time when a packet is dequeued) minus (the time when a packet is enqueued)). The results of the absolute priority-based algorithm are marked as and .
Figure 2,
Figure 3,
Figure 4,
Figure 5 and
Figure 6 show the results of the first scenario.
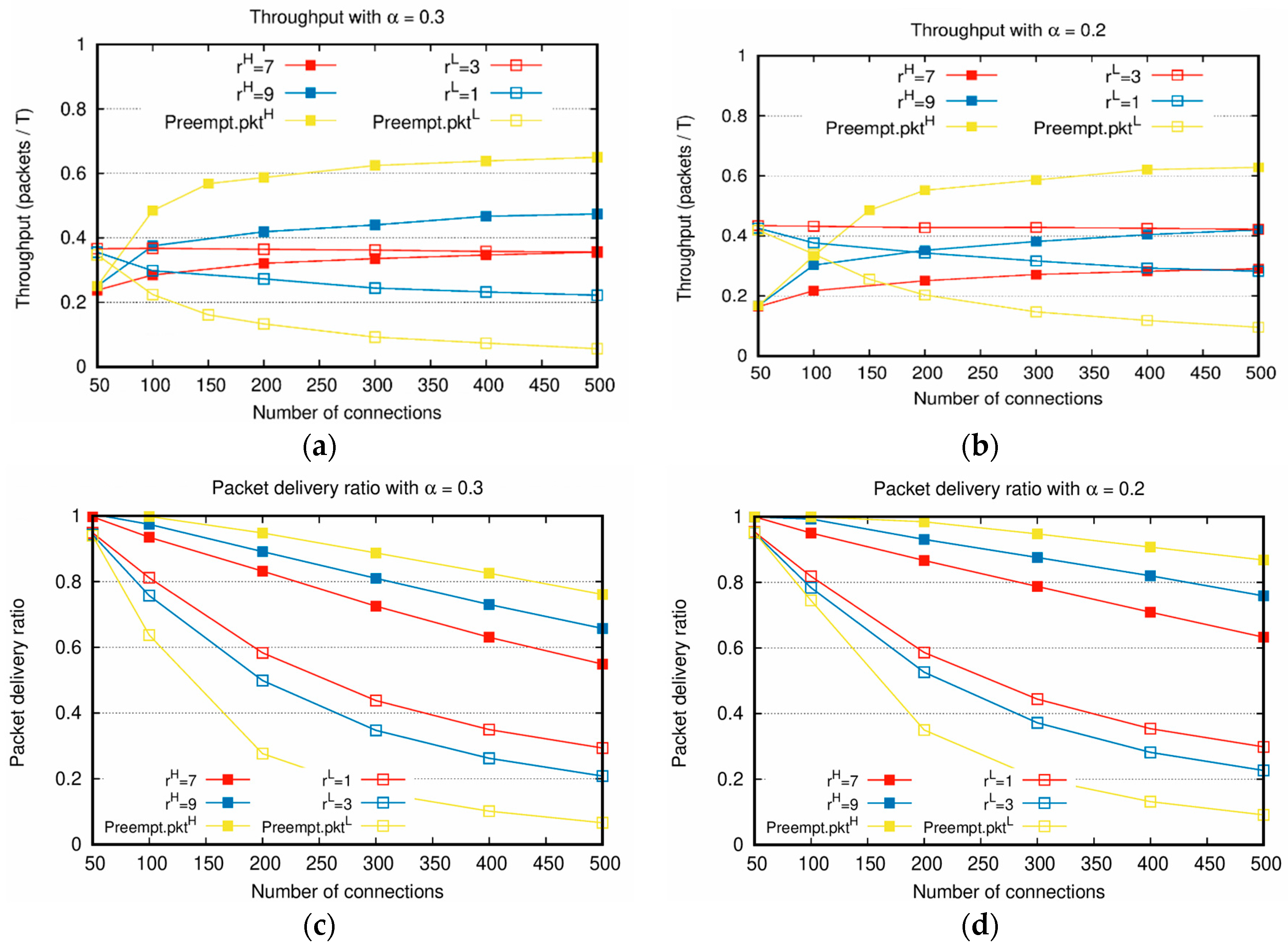
Figure 2 depicts the throughputs with the increasing total number of connections, various weight factors, and
. When the number of connections is small, most packets are delivered to the destination nodes until the predefined time
because the network is not heavily loaded. For this reason, in
Figure 2a,b, when the number of connections is 50, the throughput of
is lower than that of
because the number of
is lower than
. In most cases, if the number of connections increases, the throughput of
is higher than that of
. However, in
Figure 2b, when the weight factors are
and
, the throughput of
is higher than that of
, even when the number of connections increases. Note that the proposed algorithm considers not only the weight factors but the traffic load as well; hence, even when
the throughput of
is higher than that of
in the entire range of
. The service differentiation between
and
is more evidently shown in
Figure 2c,d. As shown in these figures, over all the range of the number of connections, the packet delivery ratio of
is higher than
. Specifically,
Figure 2b with
,
can be compared with
Figure 2d with
,
. In this case,
Figure 2b shows that the throughput of
is higher than
. However,
Figure 2d shows that the packet delivery ratio of
is still twice as high as that of
. This result clearly shows that the proposed scheme preferentially processes packets reflecting the weight factors. When the absolute priority-based algorithm is applied, as the number of
to be transmitted increases owing to the increment of the number of connections, the opportunity for
slot allocation decreases, resulting in a further decrease in the throughput of
.
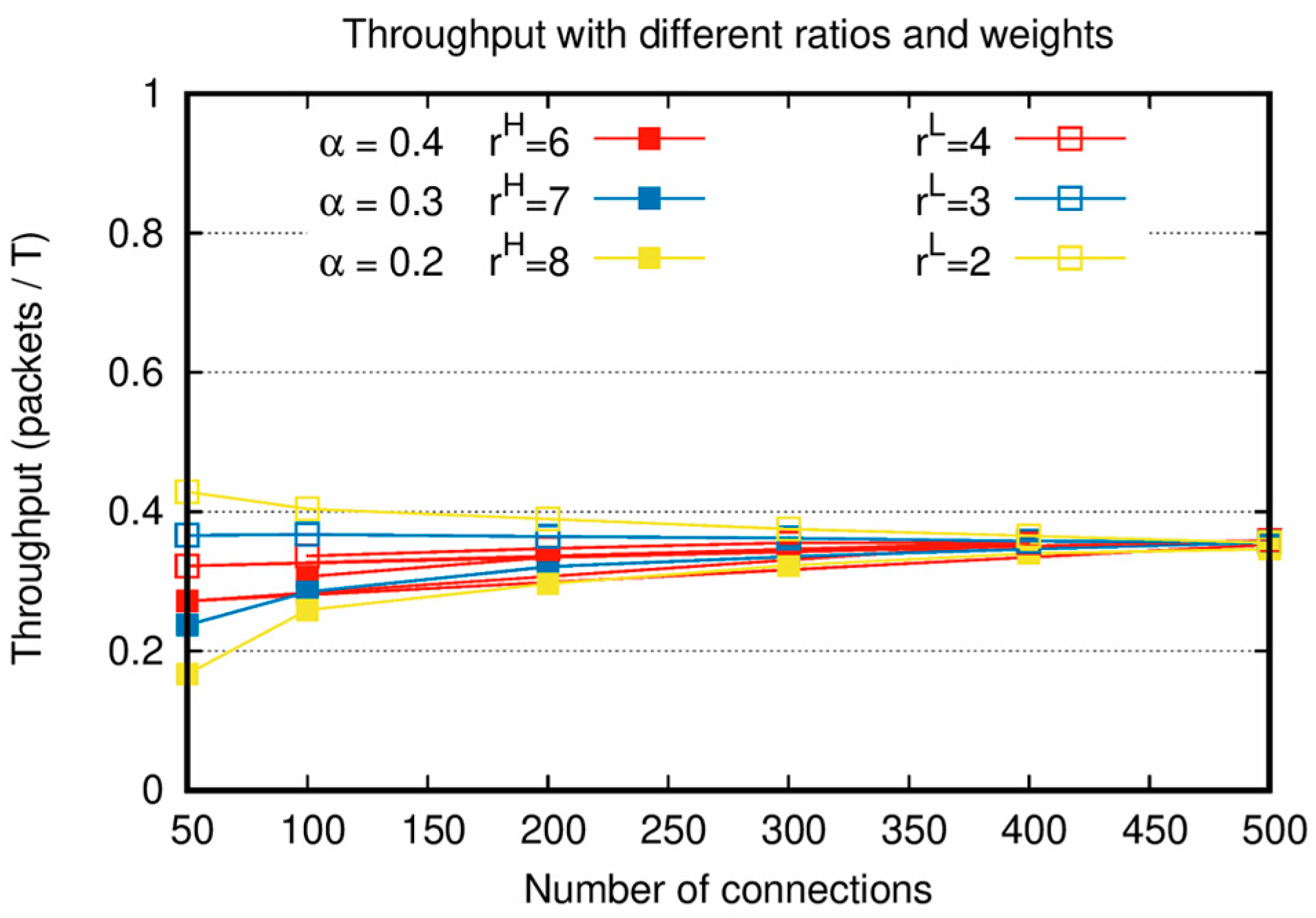
In
Figure 3, throughputs are measured when
is satisfied under the condition of increasing number of connections.
Figure 3 shows the characteristics of the proposed algorithm by considering both the weight factor and traffic load. When
is satisfied, it is confirmed that the throughputs of
and
have similar values and converge to a single value, as shown in
Figure 3.
As shown in
Figure 2 and
Figure 3, the sums of the throughputs of
and
are similar when
is the same, even though
and the weight factors are different. This is because even when the number of allocated slots of
and
are changed by
and the weight factors during the process of reallocation, the number of allocated slots in the entire network does not change. Therefore, there is a tradeoff between the throughputs of
and
depending on the weight factors. From
Figure 2 and
Figure 3, it is confirmed that an appropriate weight factor setting is necessary to adjust the throughputs of
and
for various network situations with different
.
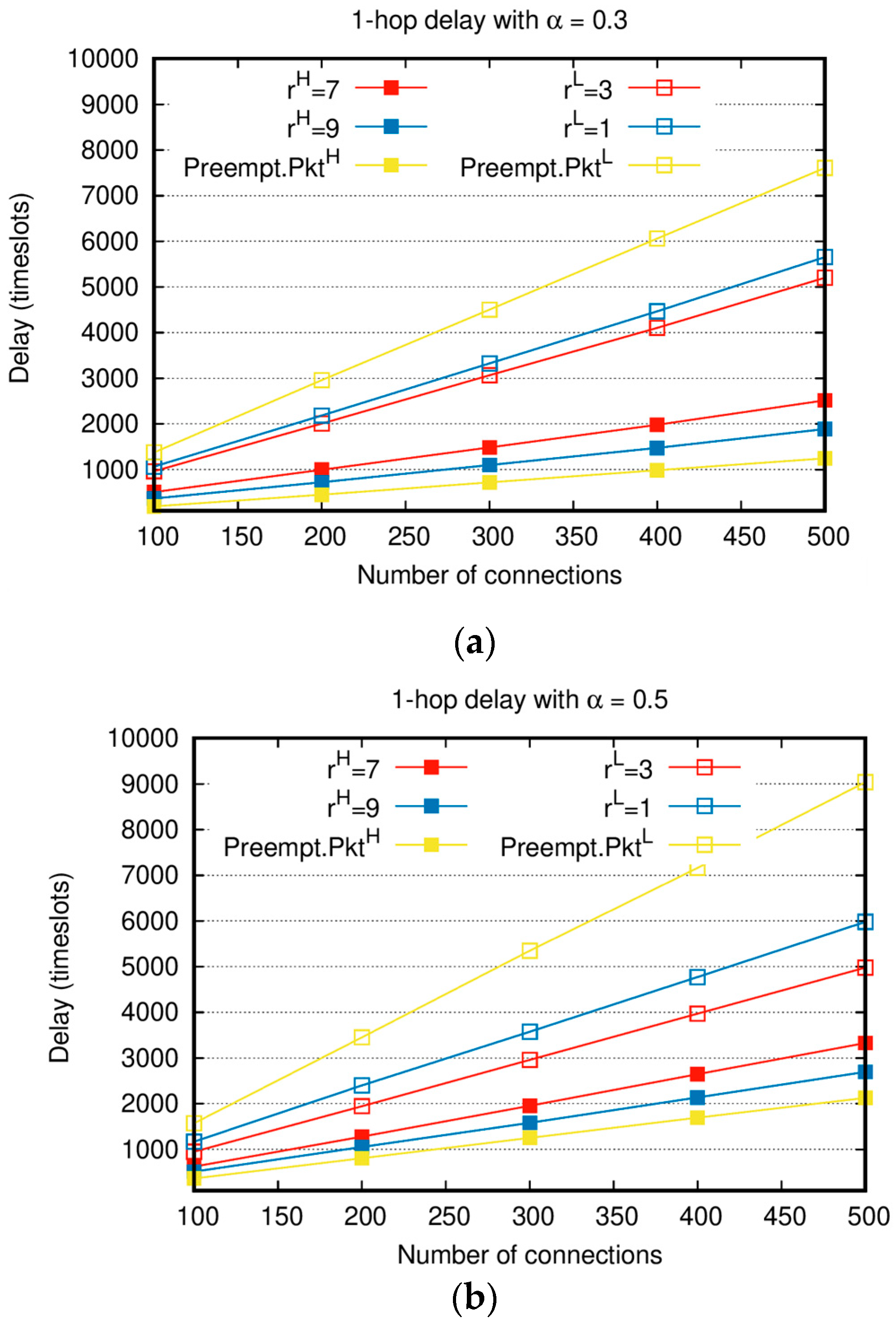
Figure 4 shows 1-hop delay with various weight factors and
with the increasing total number of connections. Similar to in
Figure 2 and
Figure 3, when the number of connections is small, all the generated packets can be delivered to destination nodes, resulting in nearly no difference in the delay between
and
. However, as the number of connections increases, the delays of both
and
increase, and the delay difference between
and
becomes conspicuous. Compared to the absolute priority-based algorithm, the delay gap between
and
of the proposed algorithm is relatively small. In the case of
and
shown in
Figure 4a, when
is 500, the delay of
is twice that of
. On the other hand, the delay of Preempt.
is more than 6 times the delay of
. The delay of
increases compared to Preempt.
, but the delay of
decreases much more than Preempt.
. In particular, when
, and
in
Figure 4b, the delay of
increases by approximately 500 time slots compared to
, but the delay of
decreases by approximately 3000 time slots compared to
, and it is a noticeable improvement. The average sum delay of
and
is reduced by 20% compared to that of
and
. This means that, compared to the absolute priority-based algorithm, the proposed algorithm achieves the higher performance. Moreover, the proposed algorithm can achieve the same delay performance with
by throttling
, i.e., with
and
. When
, the number of
to be transmitted increases and the delay of
, at the same
, increases compared to the case of
. In the whole range of
, the delay of
in
Figure 4b is higher than that of
in
Figure 4a. In addition,
‘s delay when
in
Figure 4a and that when
in
Figure 4b are similar.
In
Figure 2 and
Figure 4, for
, the higher
is, the better the performances of throughput and delay are. The decrement in
due to the increased
leads to the worse performance of throughput and delay of
. The larger the difference between the values of
and
, the larger the performance gap between the throughput and delay of
and
. This confirms that
and
are flexibly adjusted based on the values of the weight factor in various network situations.
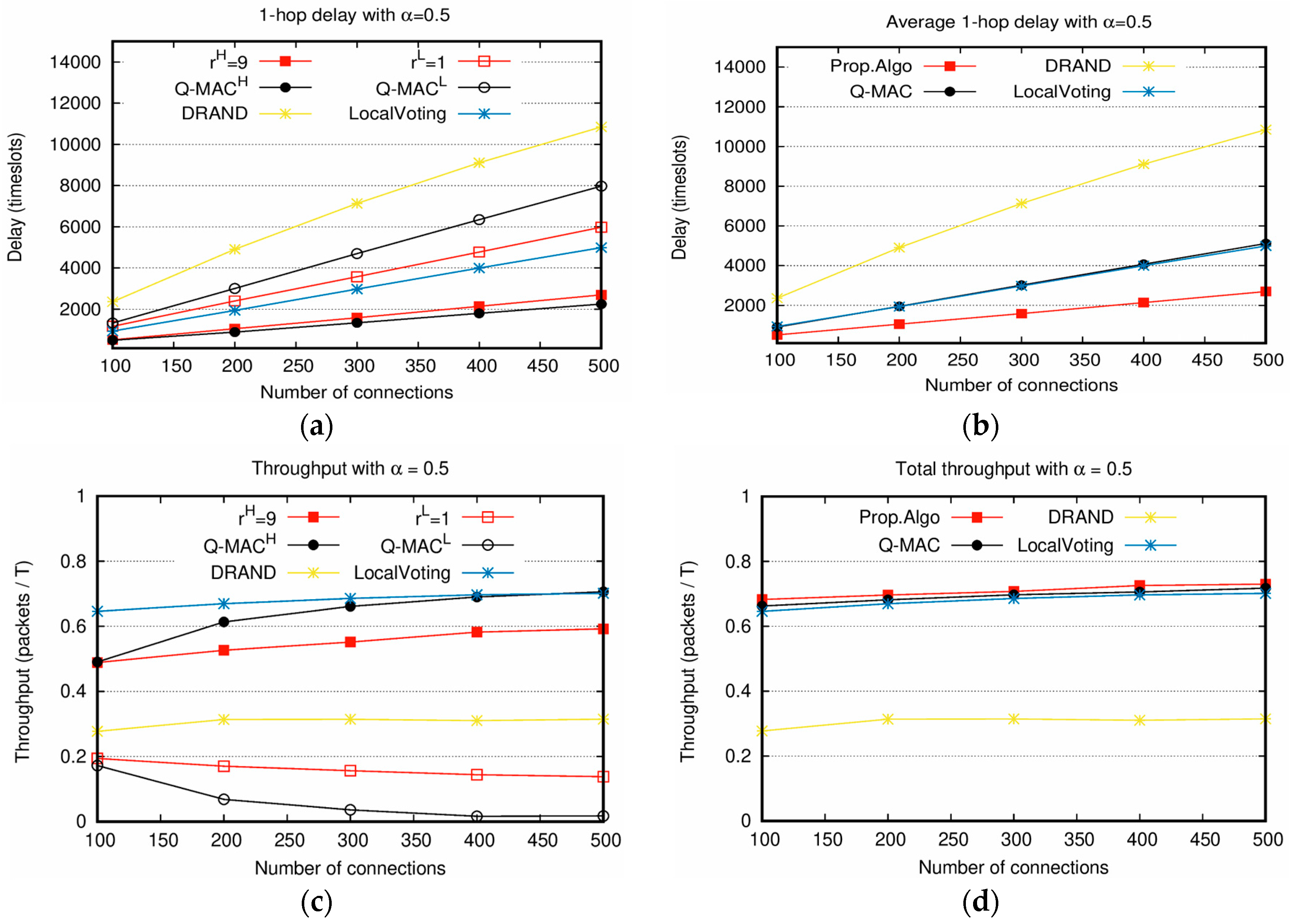
In
Figure 5, the proposed scheduling scheme is compared with DRAND, LocalVoting, and Q-MAC. Q-MAC was developed for CSMA/CA and the packets with high weight value had a relatively high probability of accessing channel. For comparison, Q-MAC was modified to be applicable to TDMA. Specifically, the slots of Q-MAC are initialized according to the weight values, and the inter-node reallocation of LocalVoting is followed. As shown in
Figure 5a, the delay of
is better than both DRAND and LocalVoting, and slightly worse than Q-MAC with
. Even
shows the better performance than DRAND and slightly worse than LocalVoting. Specifically, the delay of DRAND is twice longer than
and four times longer than
. LocalVoting shows the performance better than DRAND through the neighbor-aware load balancing. However, the proposed scheme of
still outperforms LocalVoting. The delay of
is 1.8 times smaller than LocalVoting. In
Figure 5b, the average delay of the proposed scheme shows the best performance. Q-MAC and LocalVoting show the similar performance with each other. In
Figure 5c, the throughput of the proposed scheme with
lower than Q-MAC with
. However, the throughput of the proposed scheme with
is higher than Q-MAC with
. Note that the throughput of LocalVoting in
Figure 5c is the sum of its
and
. In
Figure 5d, the proposed scheme achieves the highest throughput. In
Figure 5b,d, it is ensured that the proposed scheme possesses the excellent performance in slot allocation because it achieves the highest throughput and the lowest delay.
Moreover,
Figure 5a,c show that the service differentiation of the proposed scheme is enabled compared with other schemes. These are the major contributions of the proposed scheme.
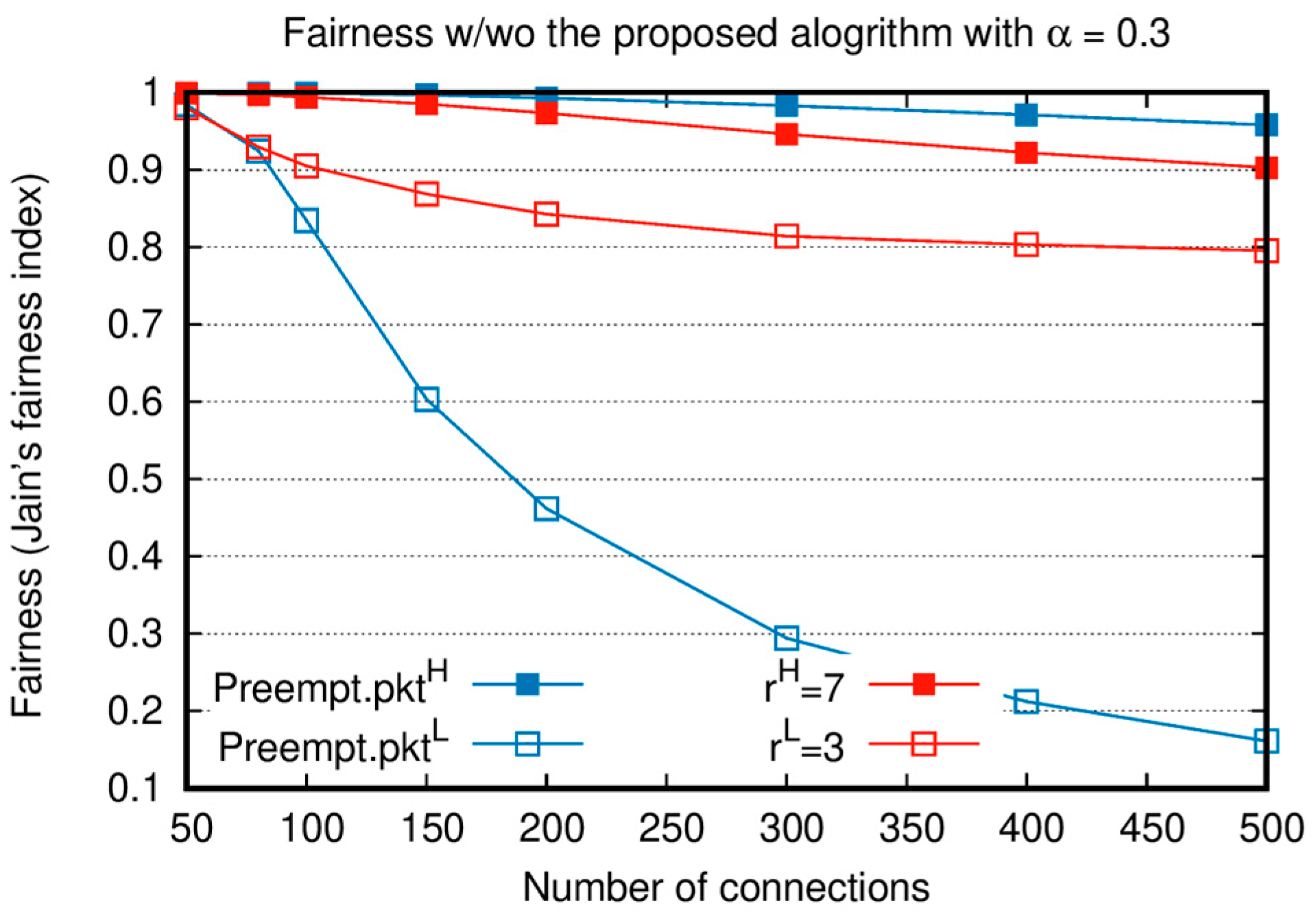
Figure 6 compares Jain’s fairness [
20] of
and
with and without the proposed algorithm. In this figure, in terms of
, Jain’s fairness index shows how fairly resources are allocated among the queues of the same importance.
is the ratio of the accumulative number of packets transmitted from a queue to the number of accumulated packets in a queue until
, which can be expressed as Equation (6). Similar to the throughput measurement, at the end of the simulation, all packet delivery is completed; accordingly, Jain’s fairness is calculated at time
.
In this analysis, and , are considered. When the number of connections is small, the fairness index is high regardless of the adoption of the proposed algorithm because the of most nodes becomes close to 1. For the absolute priority-based algorithm, as the number of connections increases, only a few nodes are allocated slots for Preempt.. Since most nodes cannot transmit Preempt., the fairness of Preempt. is very low. In contrast, when the intra-node slot reallocation of the proposed algorithm is adopted, time slots proportional to are allocated to , and this results in an increase in the fairness index. As a result, the fairness performance of is significantly increased compared to that of when the intra-node slot exchange algorithm is applied.
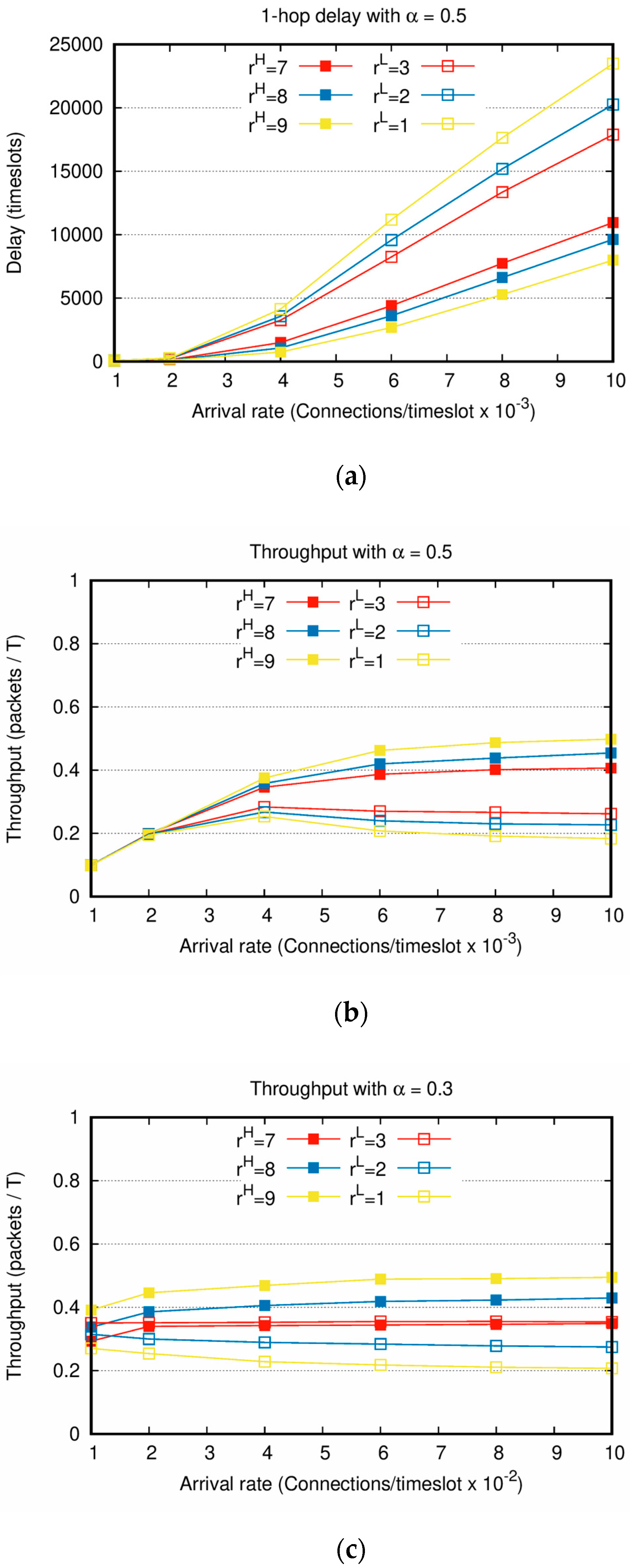
Figure 7 shows the delay and throughput performance of the second scenario with the increasing Poisson arrival rate
. In
Figure 7a,b, because
is applied, the numbers of
and
are similar. Although the connection creation interval and the number of packets generated for each connection are varied,
Figure 7 shows similar performances to those of the first scenario. The larger the difference between
and
, the greater the performance gap between
and
. For instance, in
Figure 7a, when the arrival rate is 0.01
and the weight factors are
and
, the
delay is approximately 1.5 times longer than the
delay. However, when the weight factors are
and
,
delay is over two times
delay. When the arrival rate is low, the connection creation interval is long, and the number of connections created during the entire simulation is small. As shown in
Figure 7a,b, when the arrival rates are as low as 0.001 and 0.002
, there is only a slight difference in delay and throughput between
and
regardless of the weight factor setting.
Figure 7c shows the throughput when the number of
is larger than that of
, by setting
. The result of
Figure 7c is very similar to that of
Figure 2a when
ranges between 100 and 500. In particular, if
is satisfied by setting
, the throughputs of
and
converge to a constant value. However, note that
is set as 0.3, i.e., 70% of the generated packets are
and the remaining 30% is
. Even in this asymmetric packet generation scenario,
achieves the higher throughput than
. Accordingly, this clearly shows that the service differentiation between
and
is attained.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}