Visual Browse and Exploration in Motion Capture Data with Phylogenetic Tree of Context-Aware Poses


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
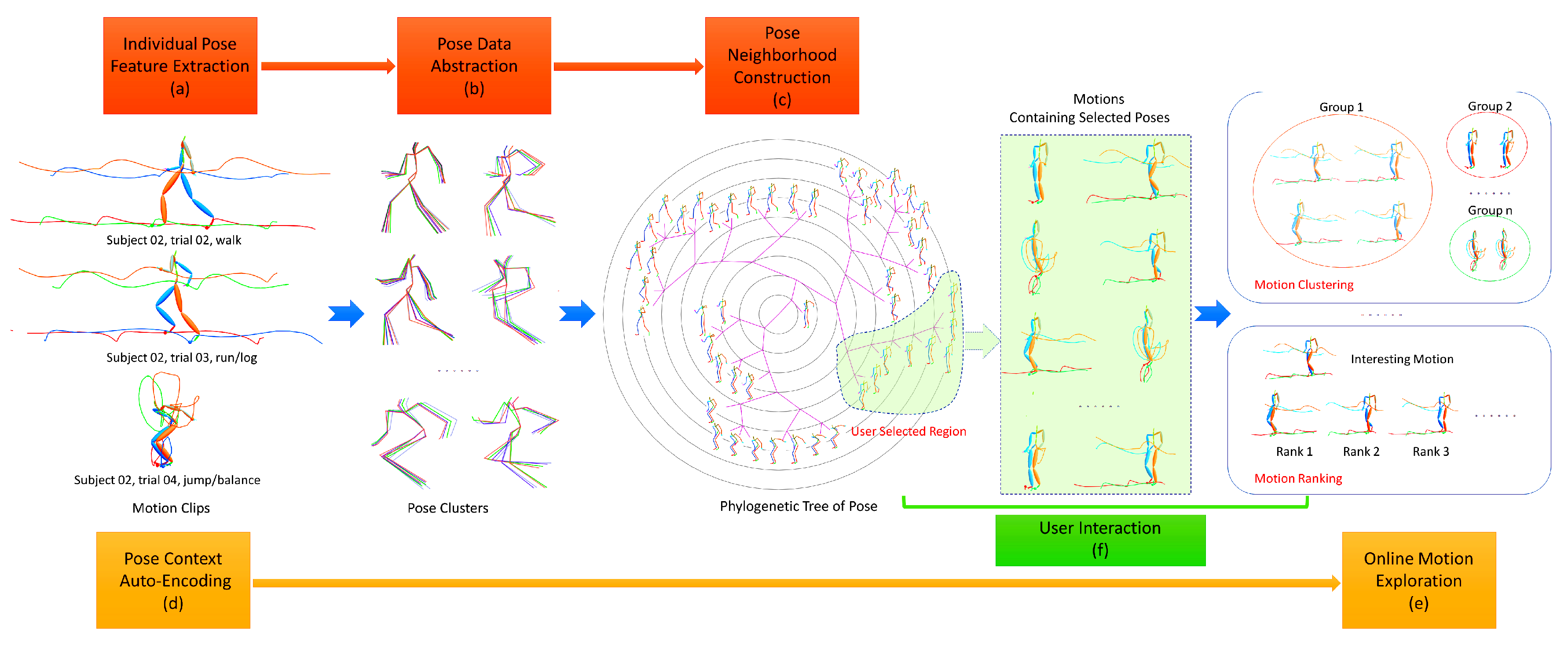
:1. Introduction
- (1)
- We present a progressive schema for visual motion search which starts from pose browse, then locates the interesting region and then switches to relevant motion exploration including online motion ranking, clustering.
- (2)
- For data abstraction, it applies affinity propagation to the numerical similarity measure of pose to generate data clusters, the abstracted level of which can easily be consist with human perception by controlling the unique parameter of preference.
- (3)
- For neighborhood construction, it further merges logical similarity measures with weight quartets to represent topological constrains of poses and their reliability, which can produce more reliable neighbors for each pose with global analysis.
- (4)
- For online motion exploration, the high-dimensional pose context is encoded into the compact latent space based on biLSTM, the performance of which matches the classical distance algorithms for time series but with high computation efficiency.
2. Related Work
3. Our Method
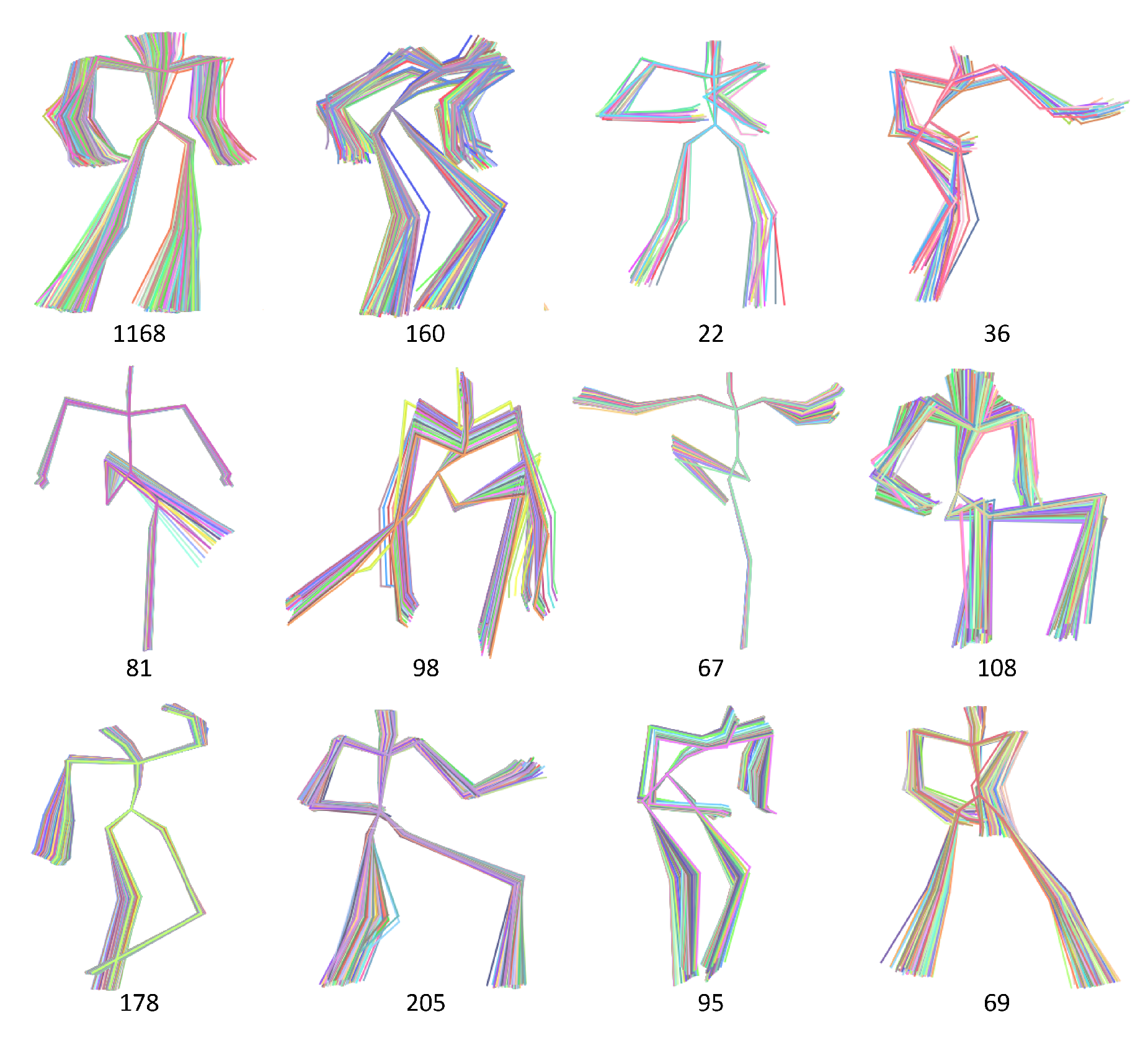
3.1. Data Abstraction
- (1)
- Calculate the matrix S of pose similarity, , where is joint index.
- (2)
- Set the preference p for exemplars, , is the regulatory factor. Run following iterations.
- (3)
- Calculate the responsibility between pose i and pose k, .
- (4)
- Calculate the availability between pose i and pose k, and .
- (5)
- Update the responsibility, , where is the damping factor.
- (6)
- Update the availability, .
- (7)
- Terminate the loop if the exemplar poses are unchanged for several loops. Otherwise, go to step (3).
- (8)
- Output the exemplar k for pose i as .
3.2. Neighborhood Construction
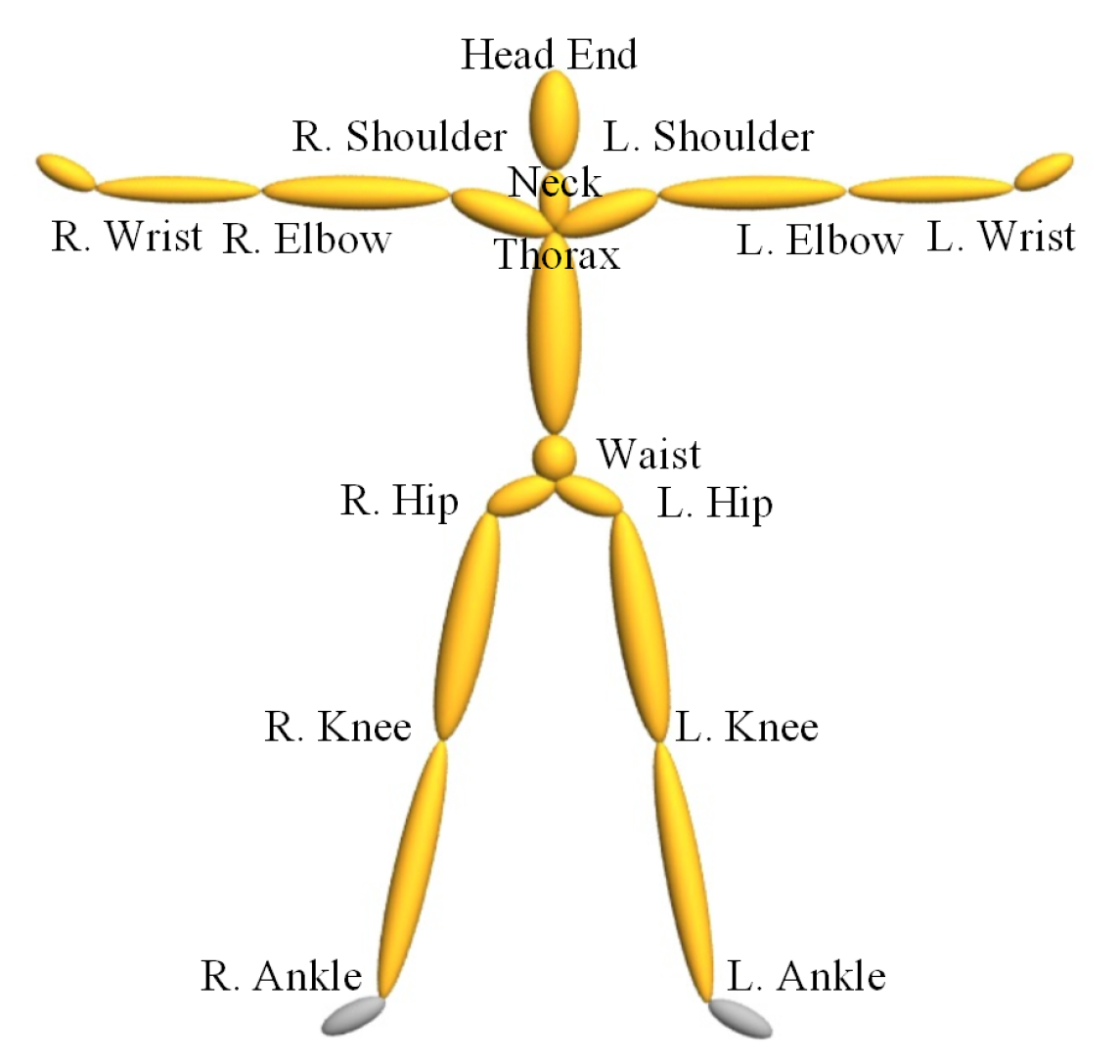
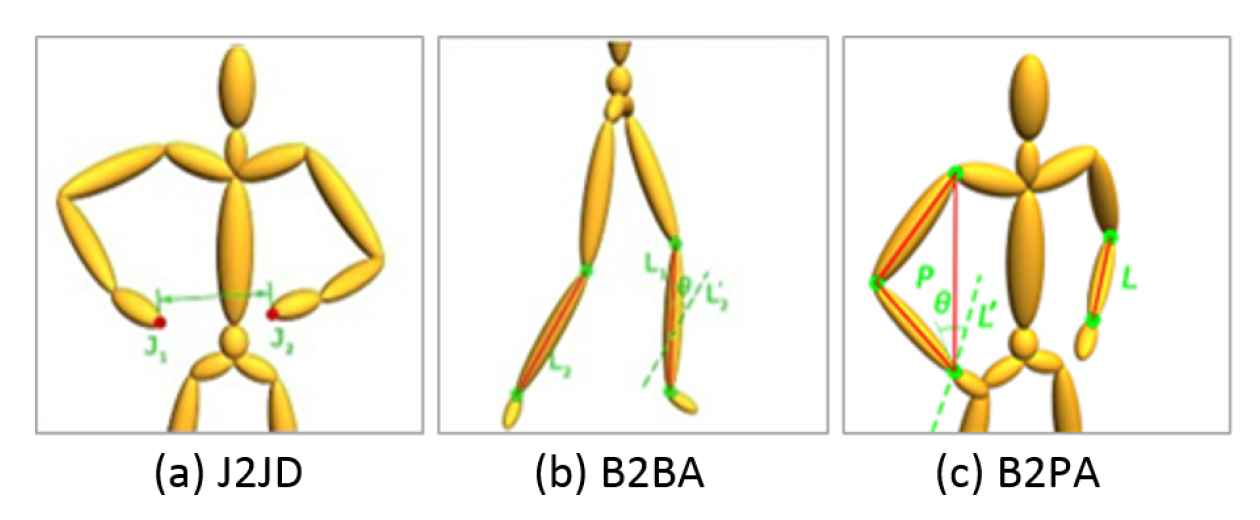
3.2.1. Feature Extraction
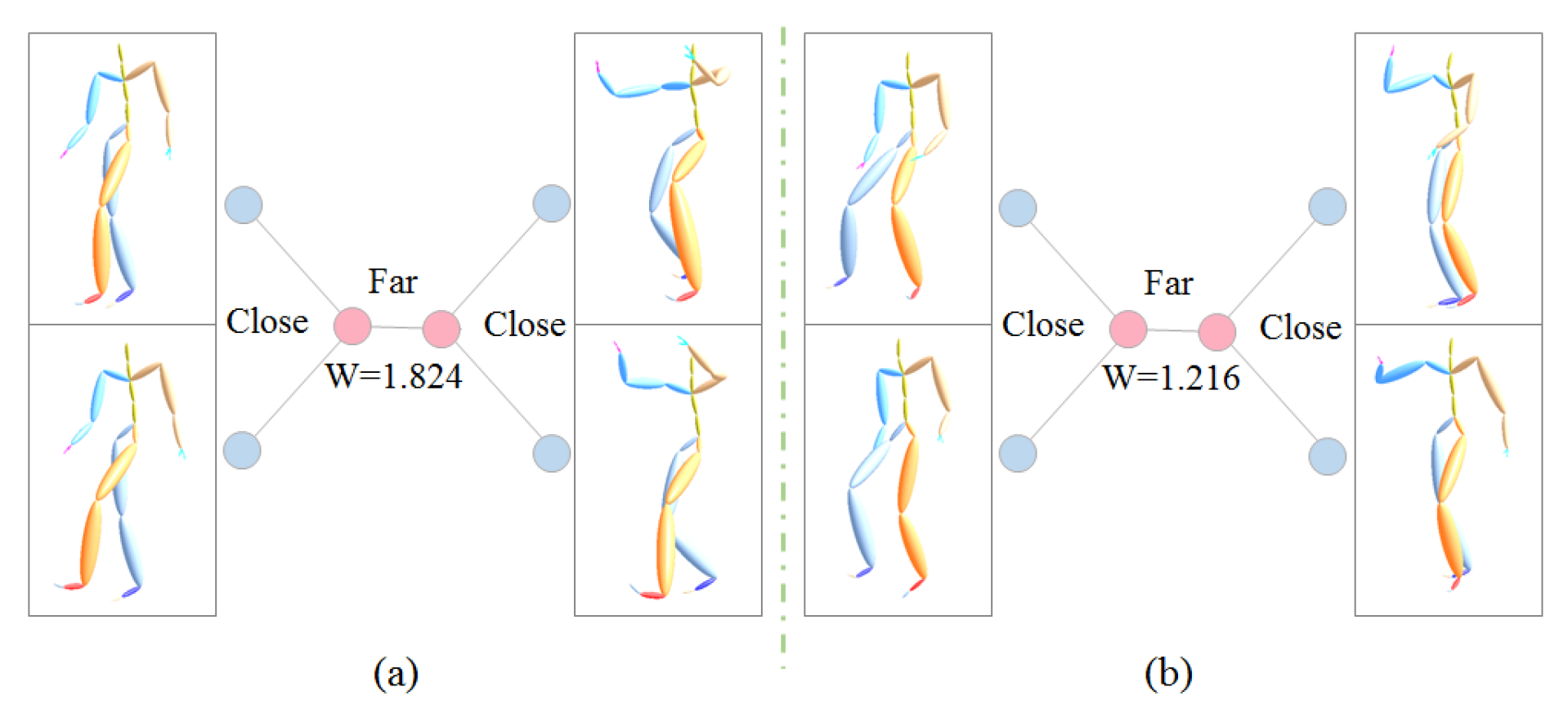
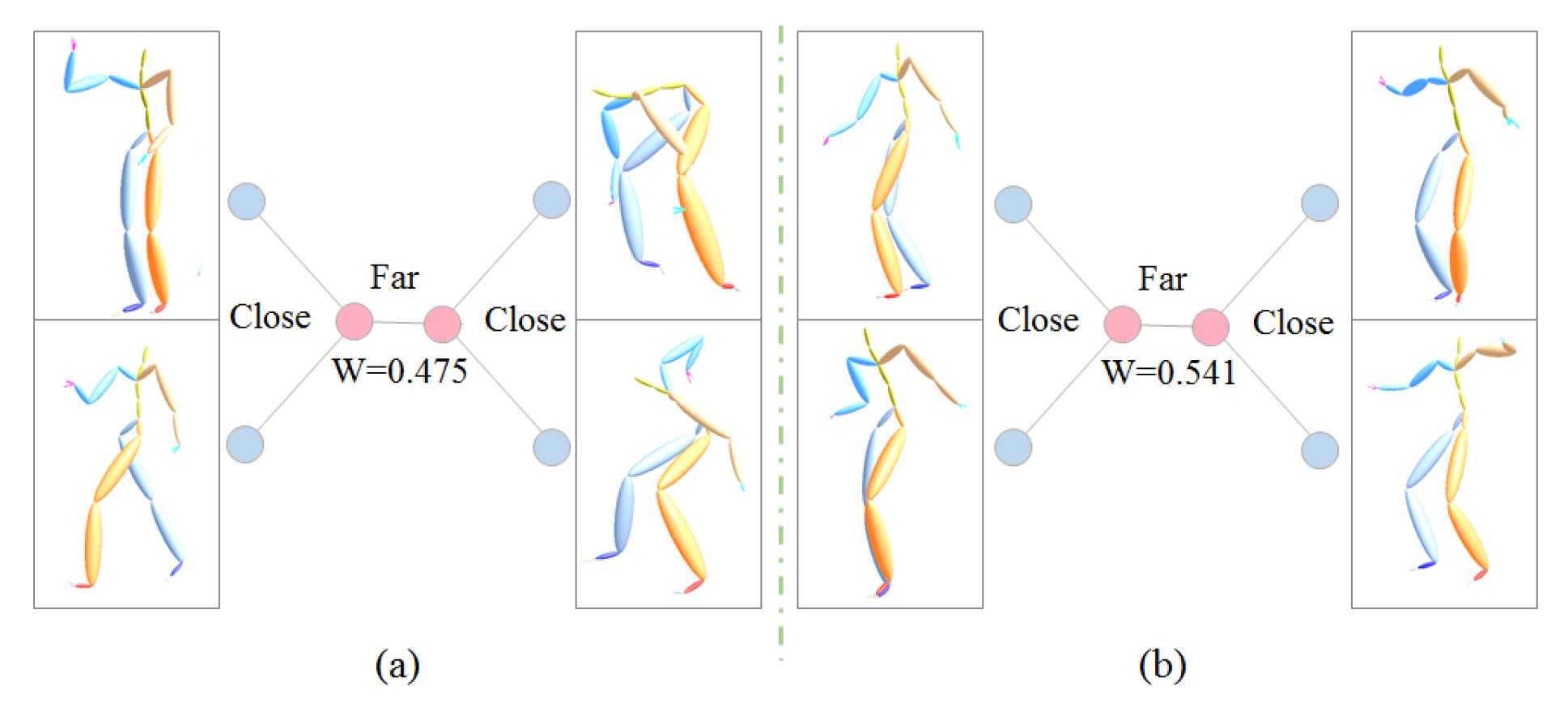
3.2.2. Weight Quartet Generation
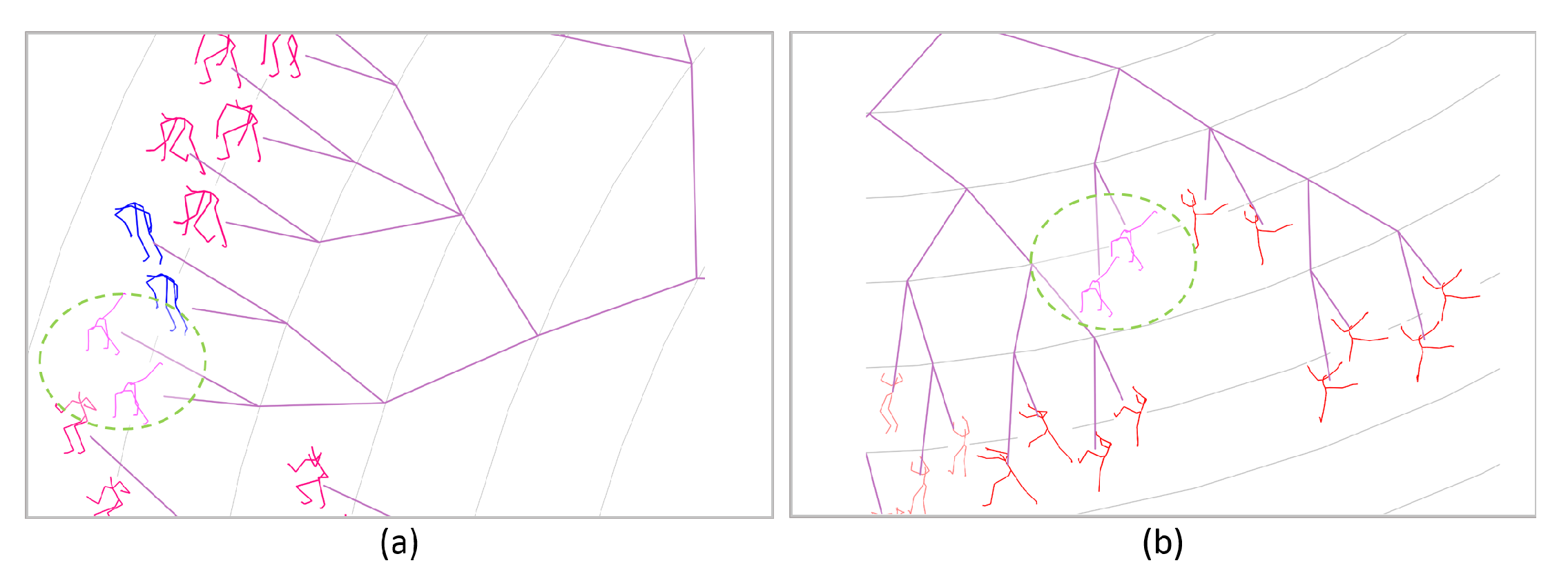
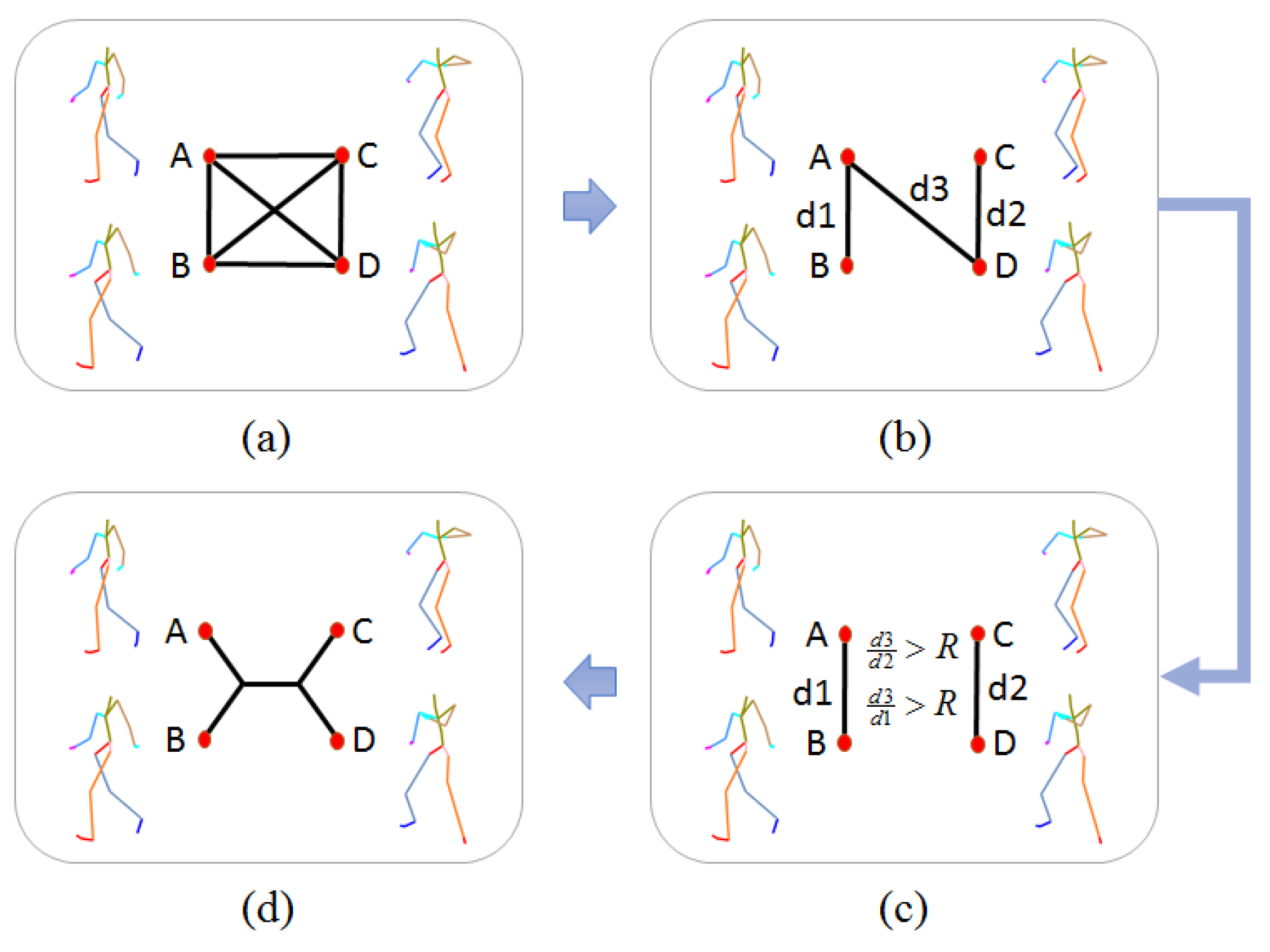
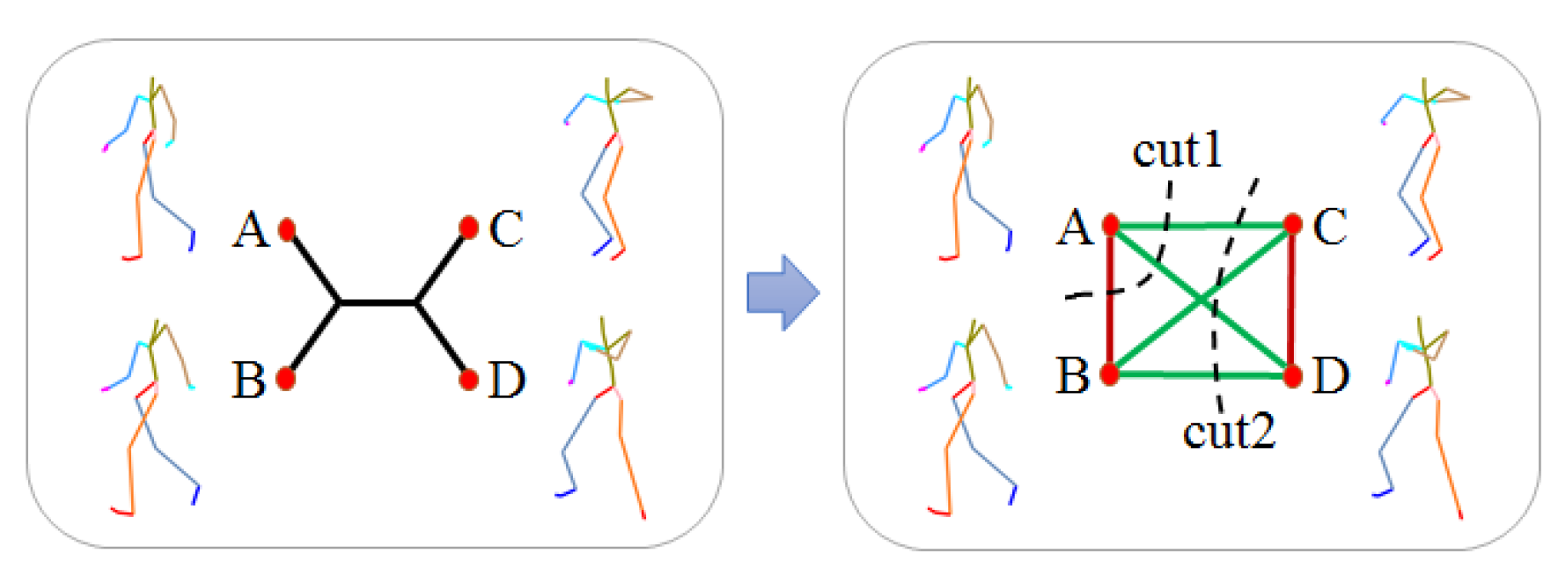
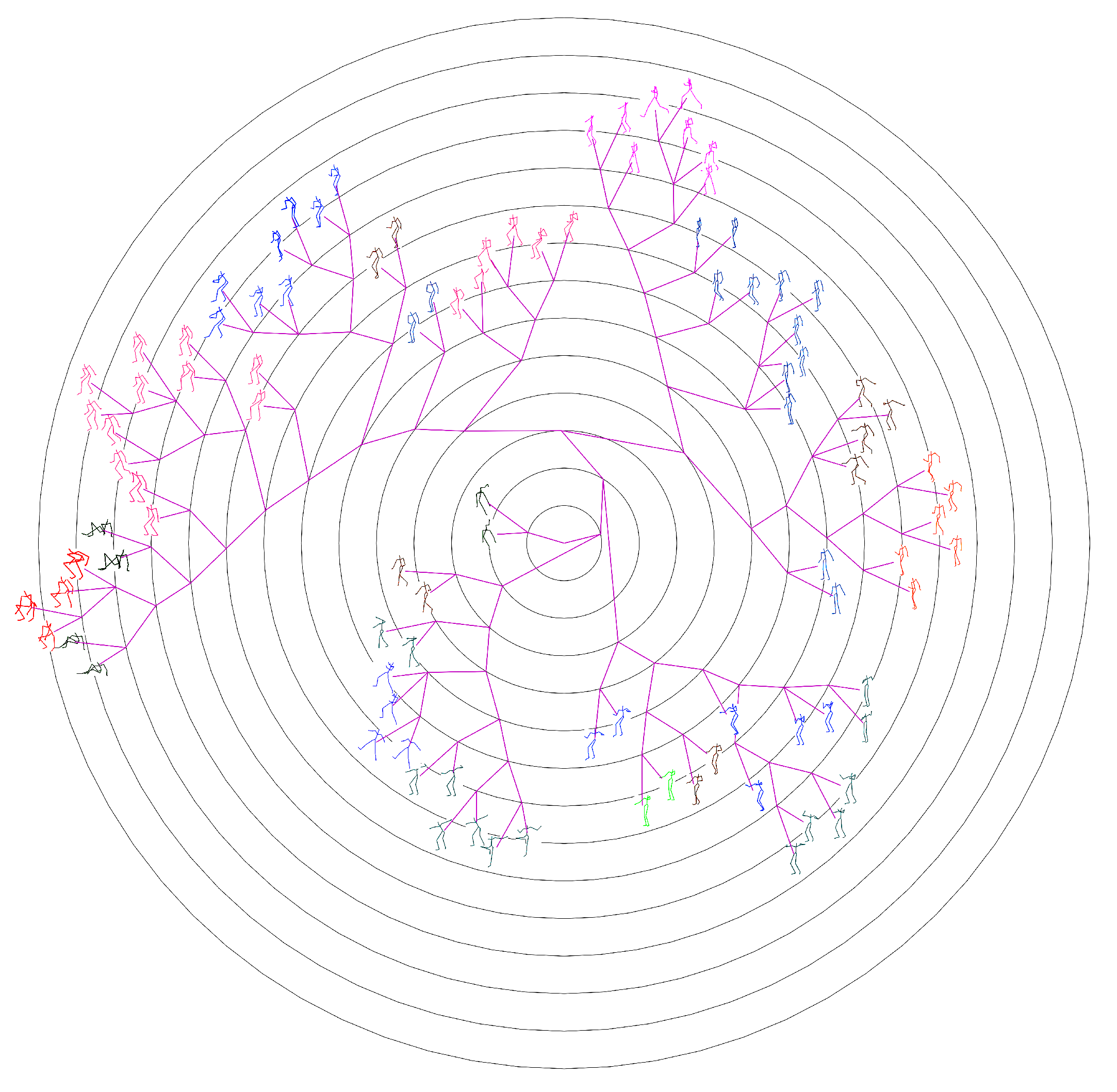
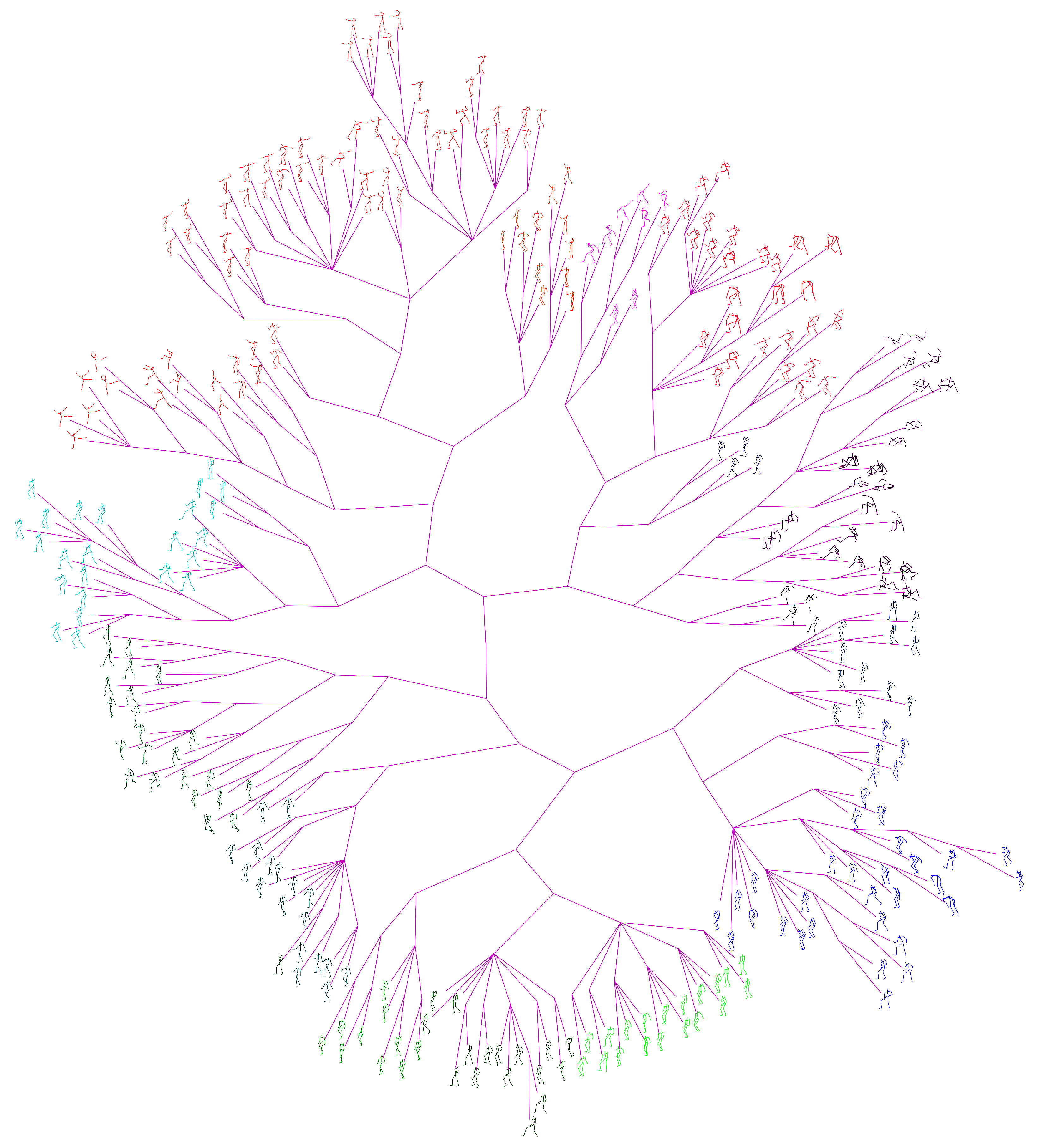
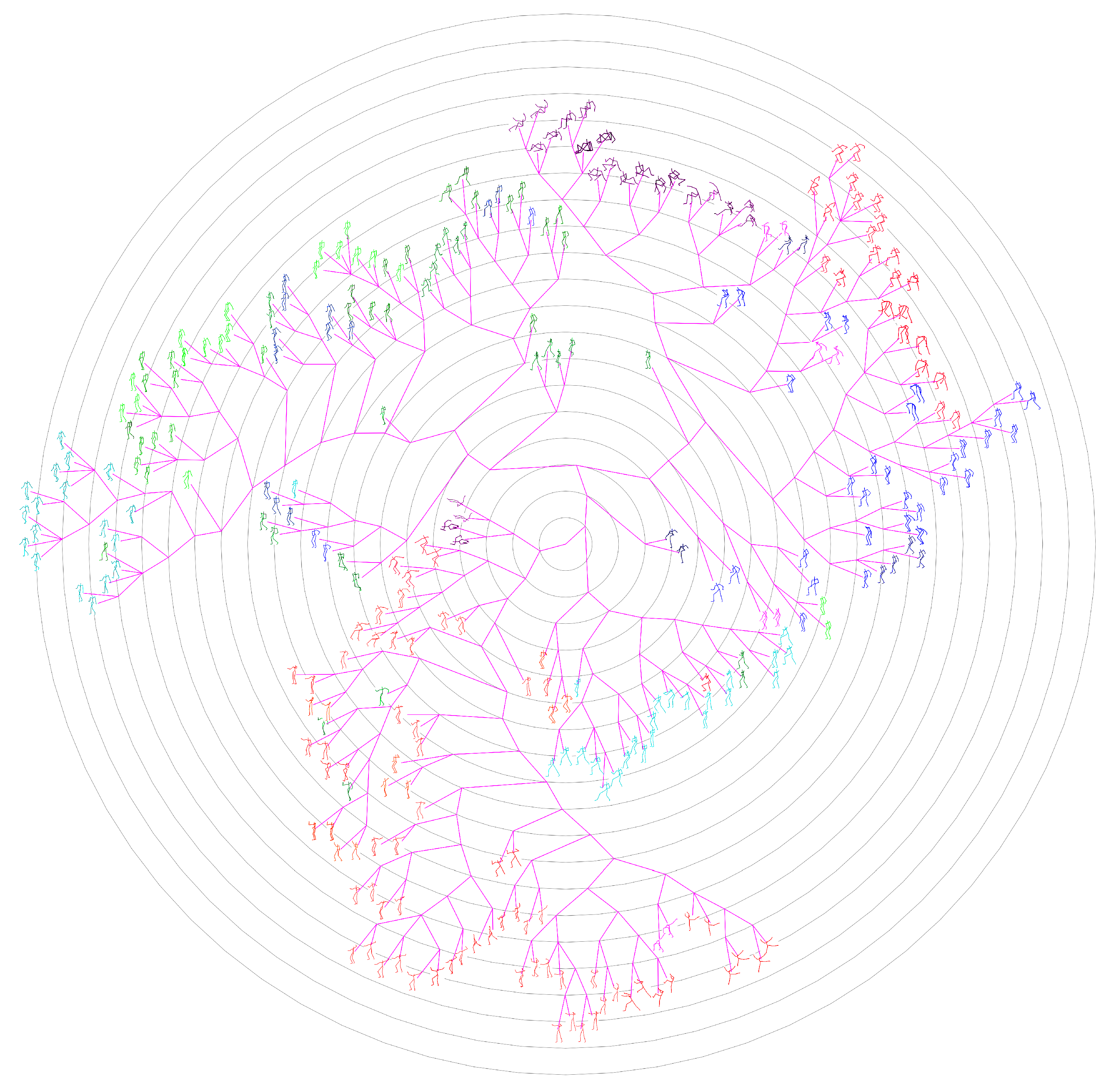
3.2.3. Phylogenetic Tree Construction
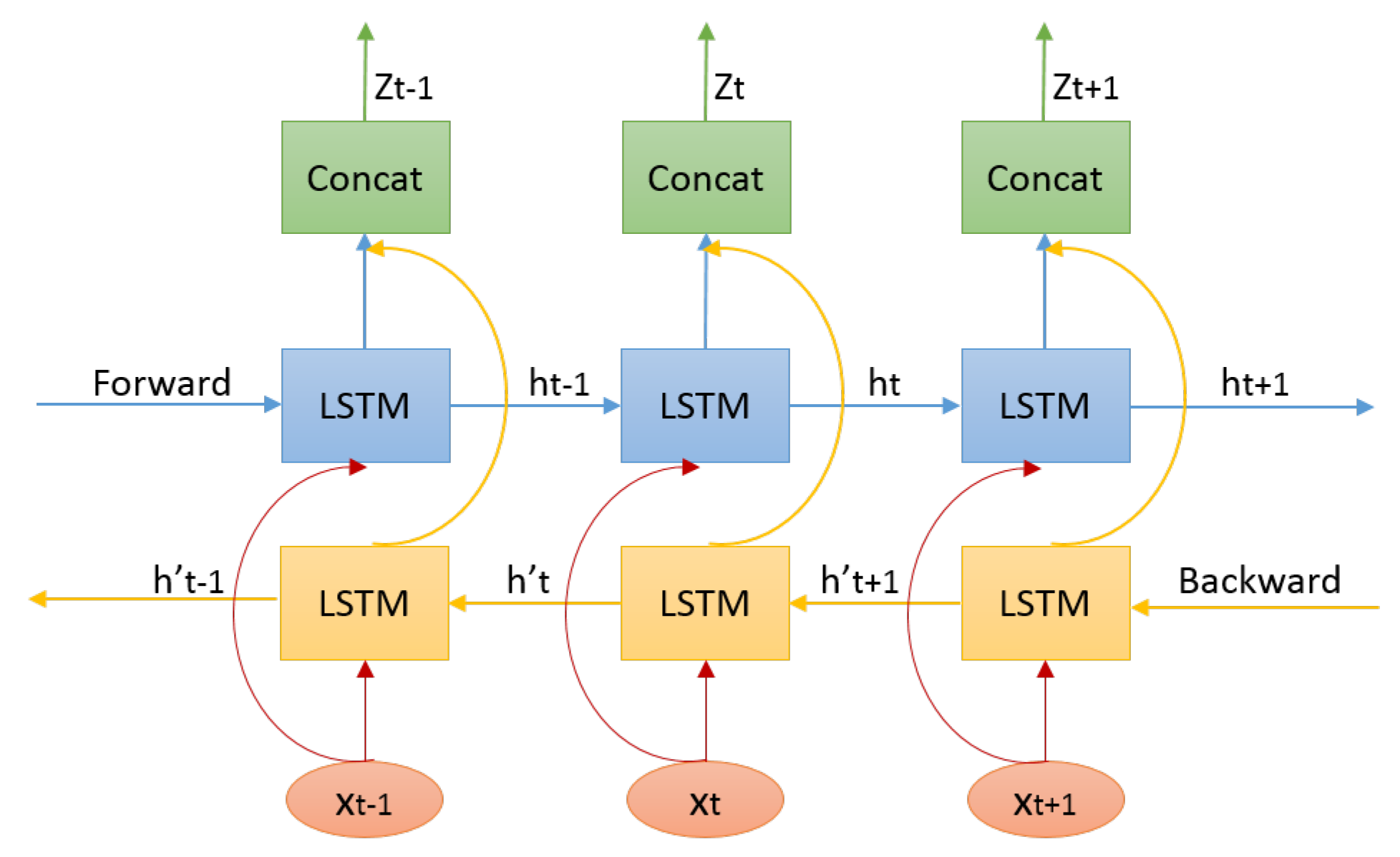
3.3. Pose Context Auto-Encoding
4. Experiments and Evaluations
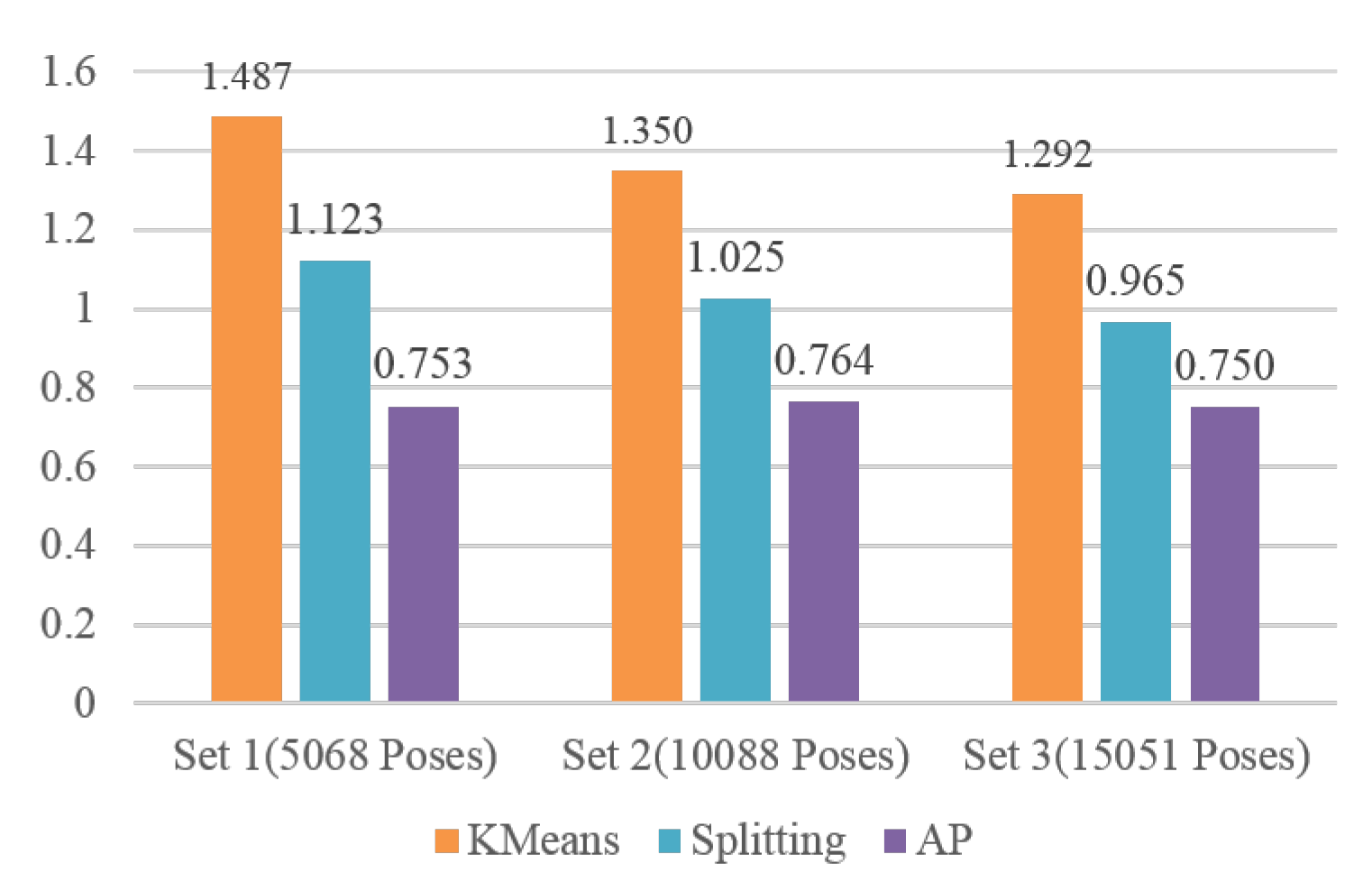
4.1. Evaluation of Data Abstraction
4.2. Evaluation of Neighborhood Construction
4.2.1. Criteria
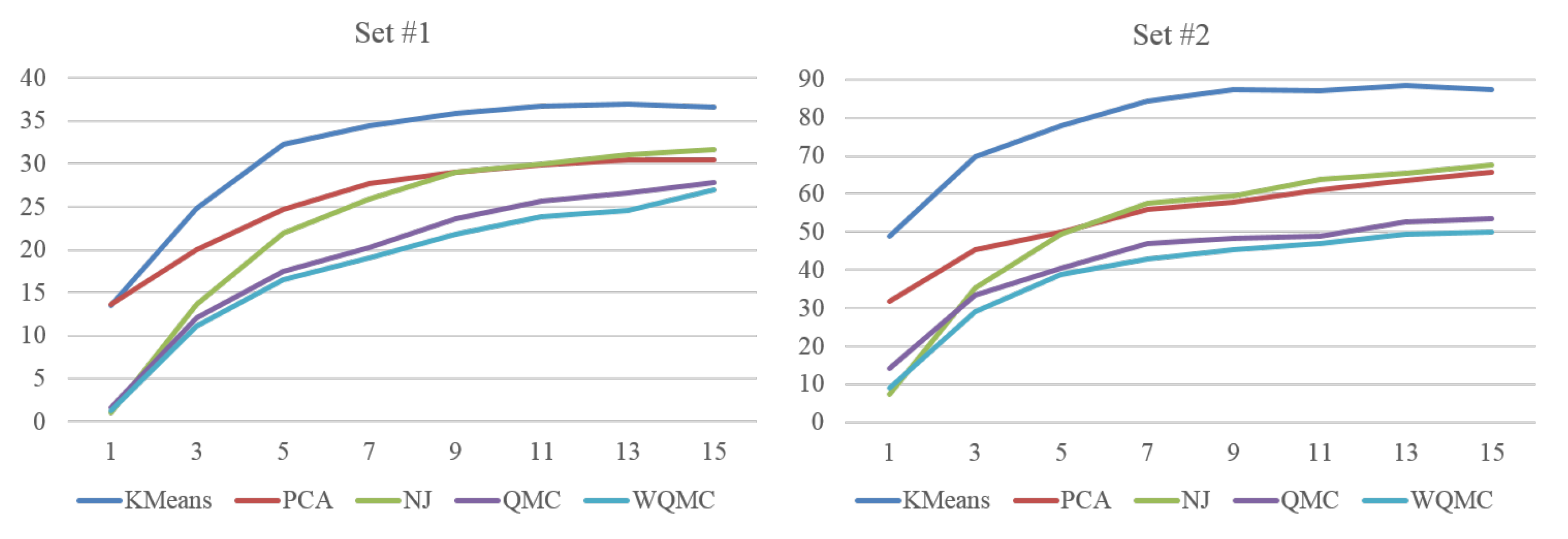
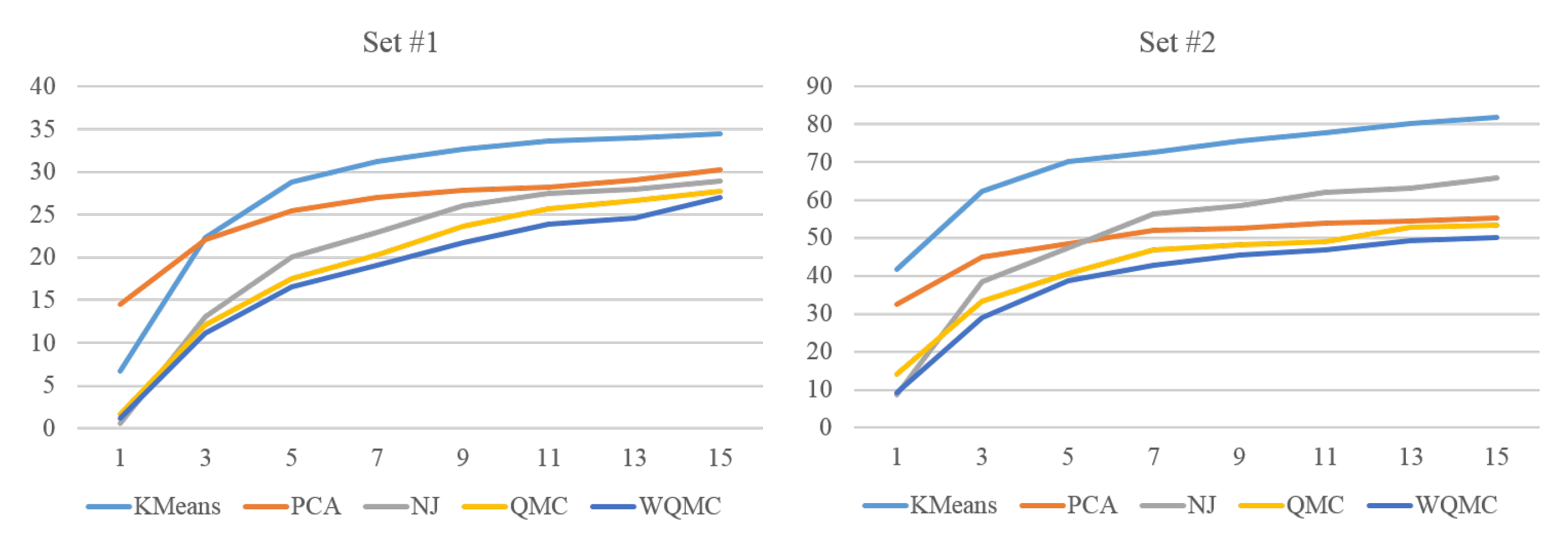
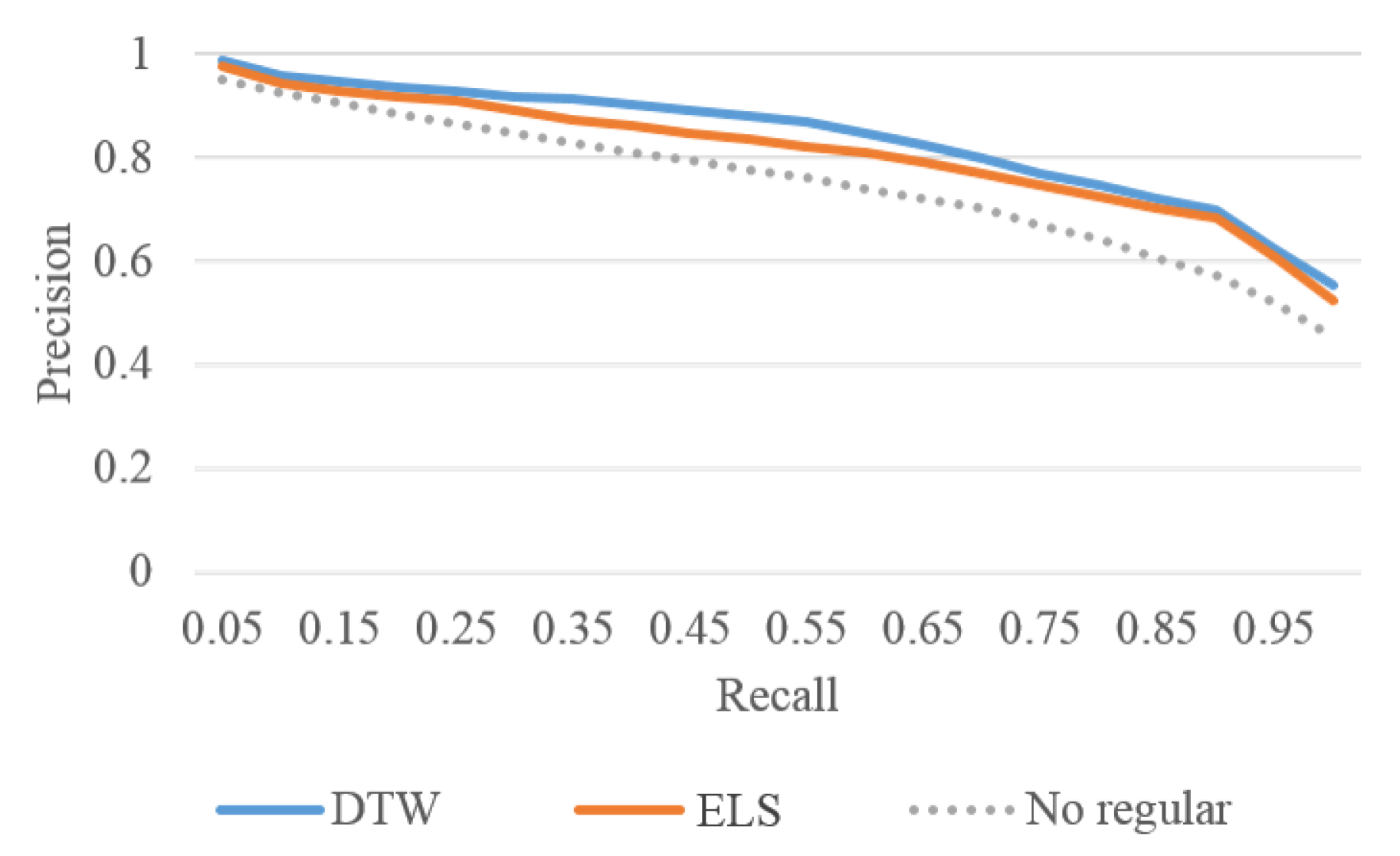
4.2.2. Comparison with the State-Of-Arts
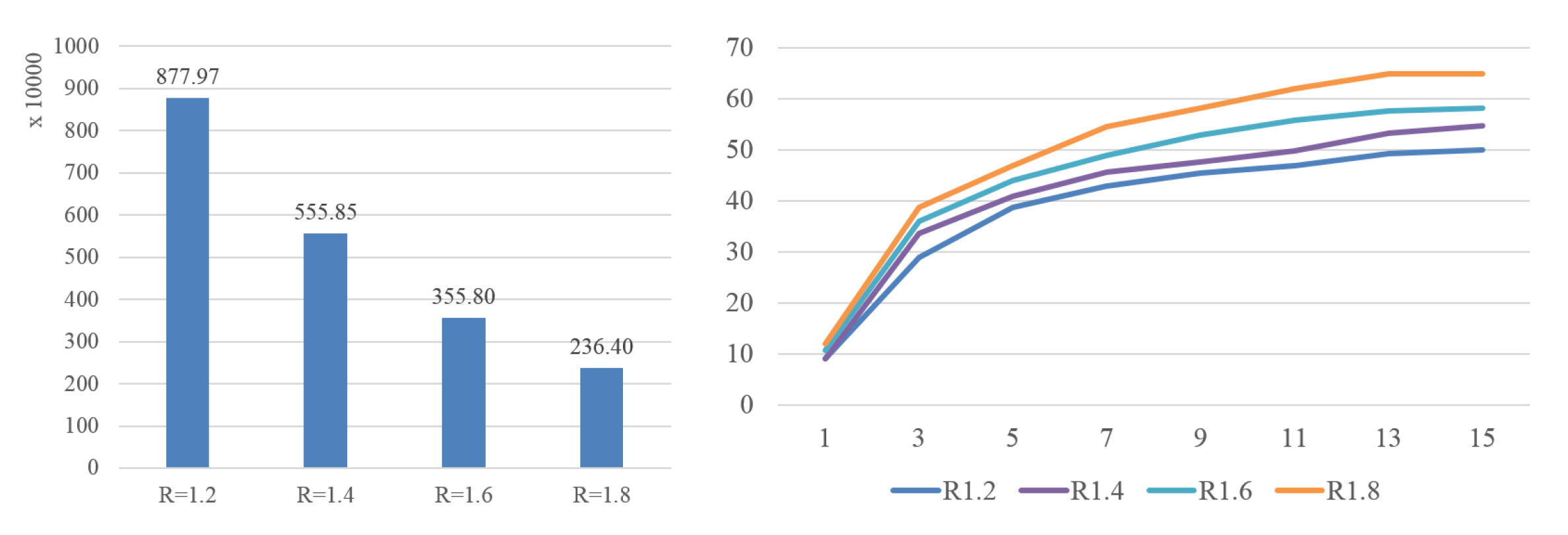
4.2.3. Self Comparisons
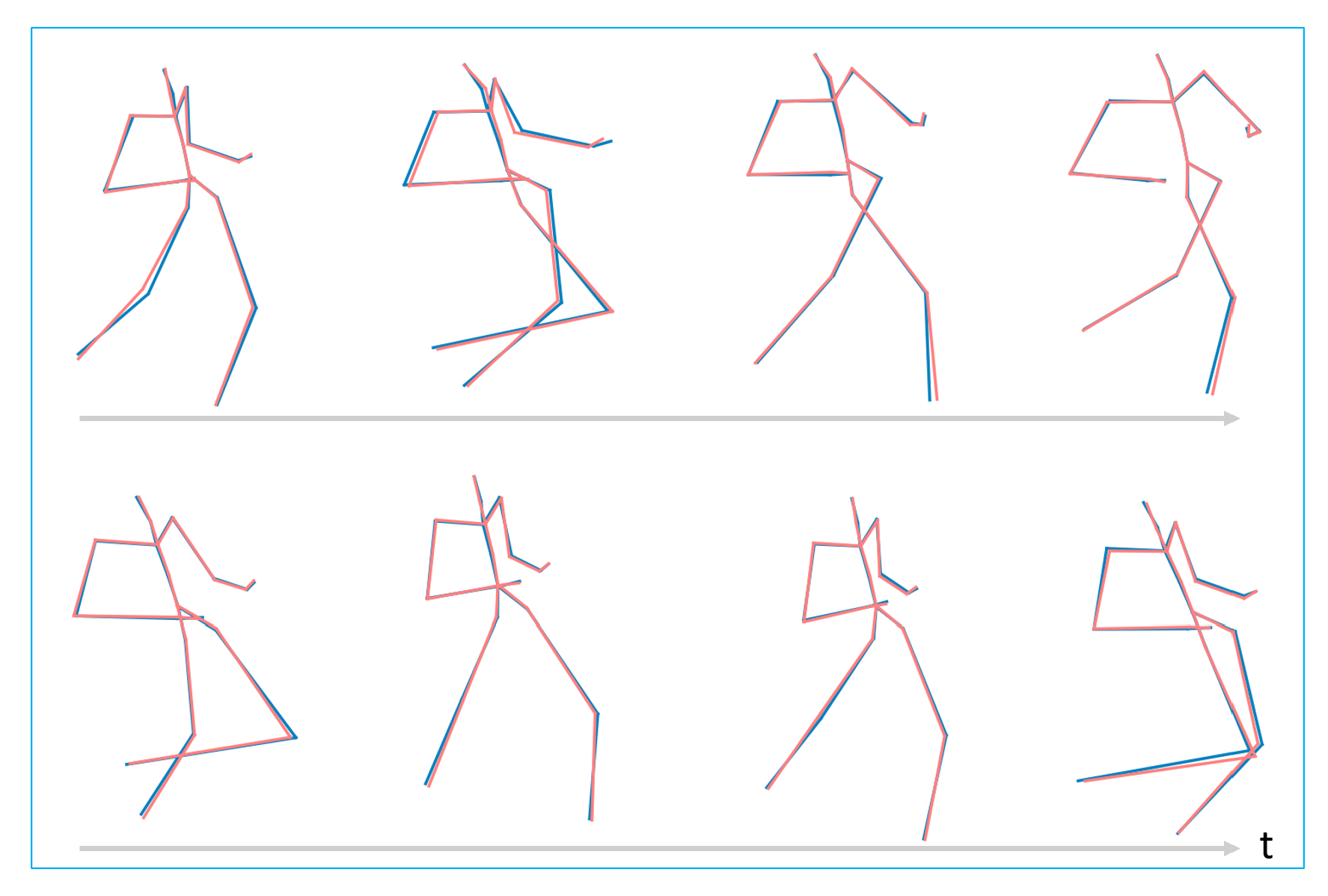
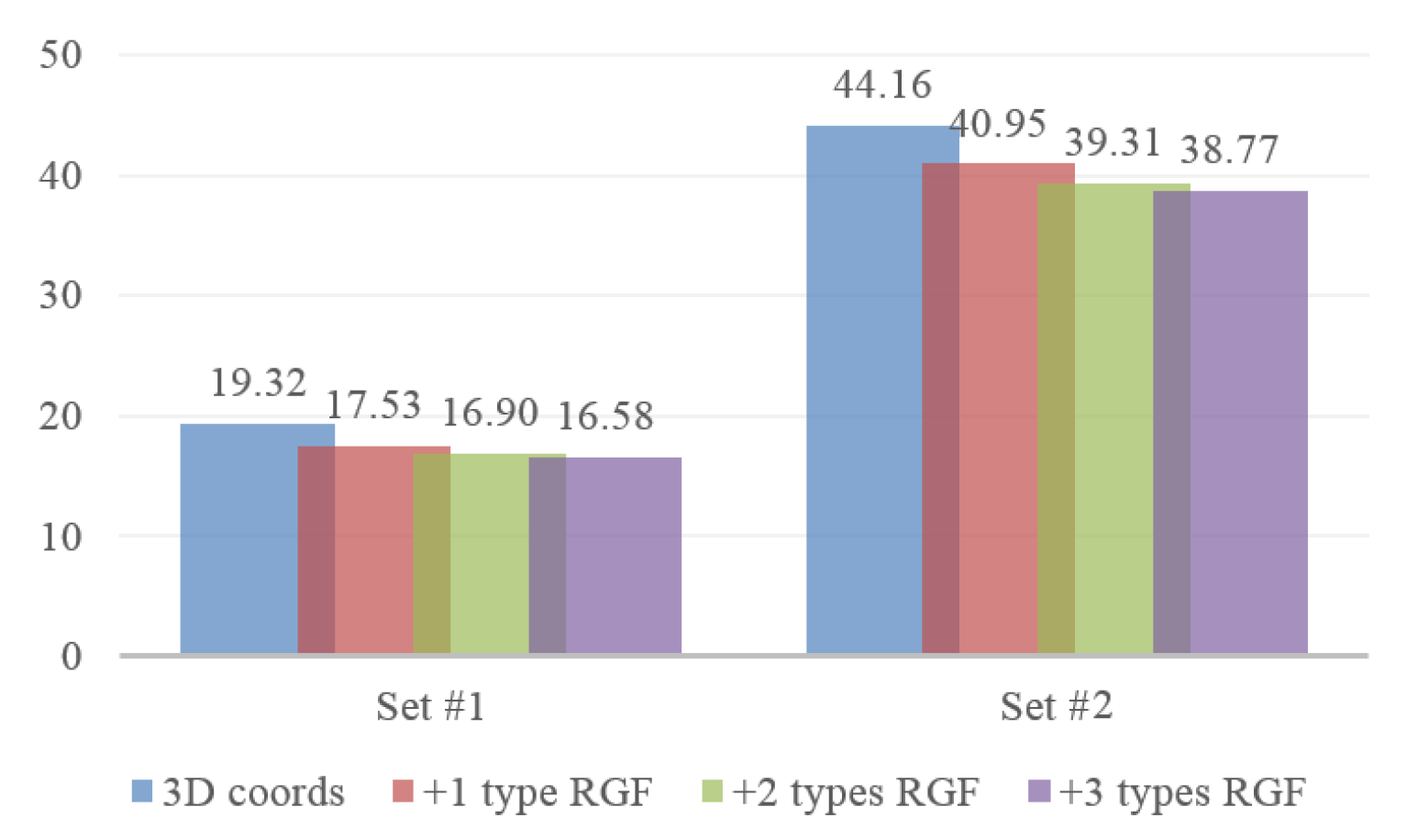
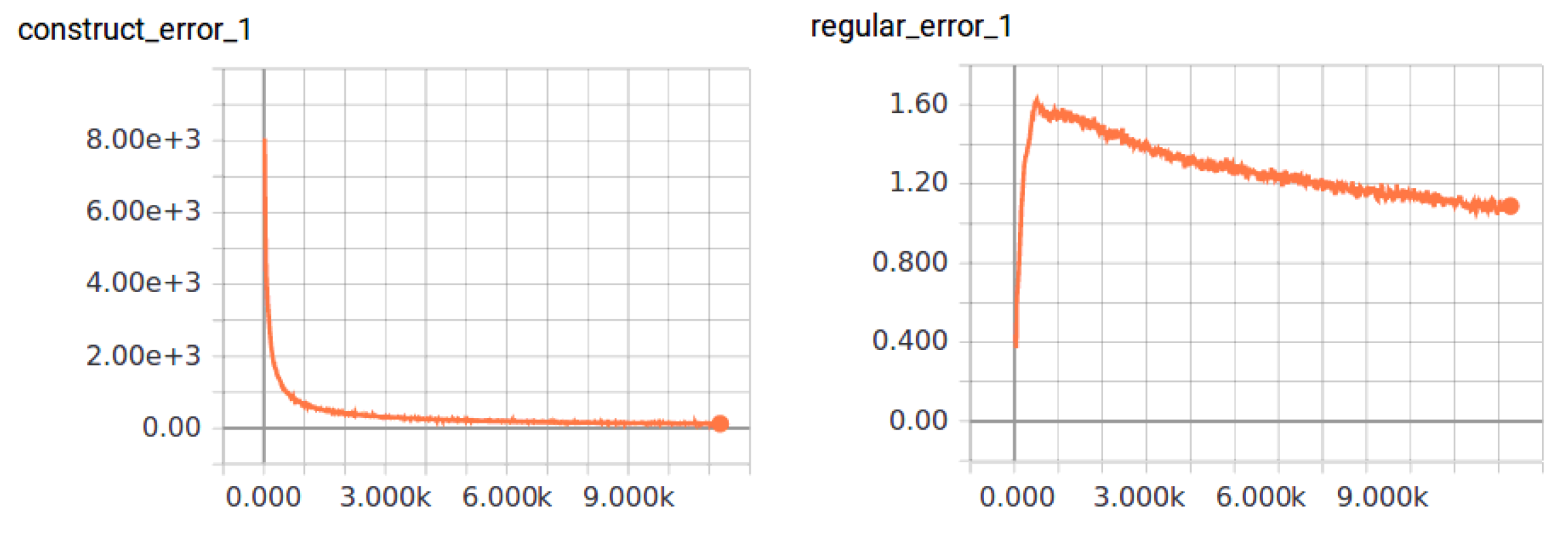
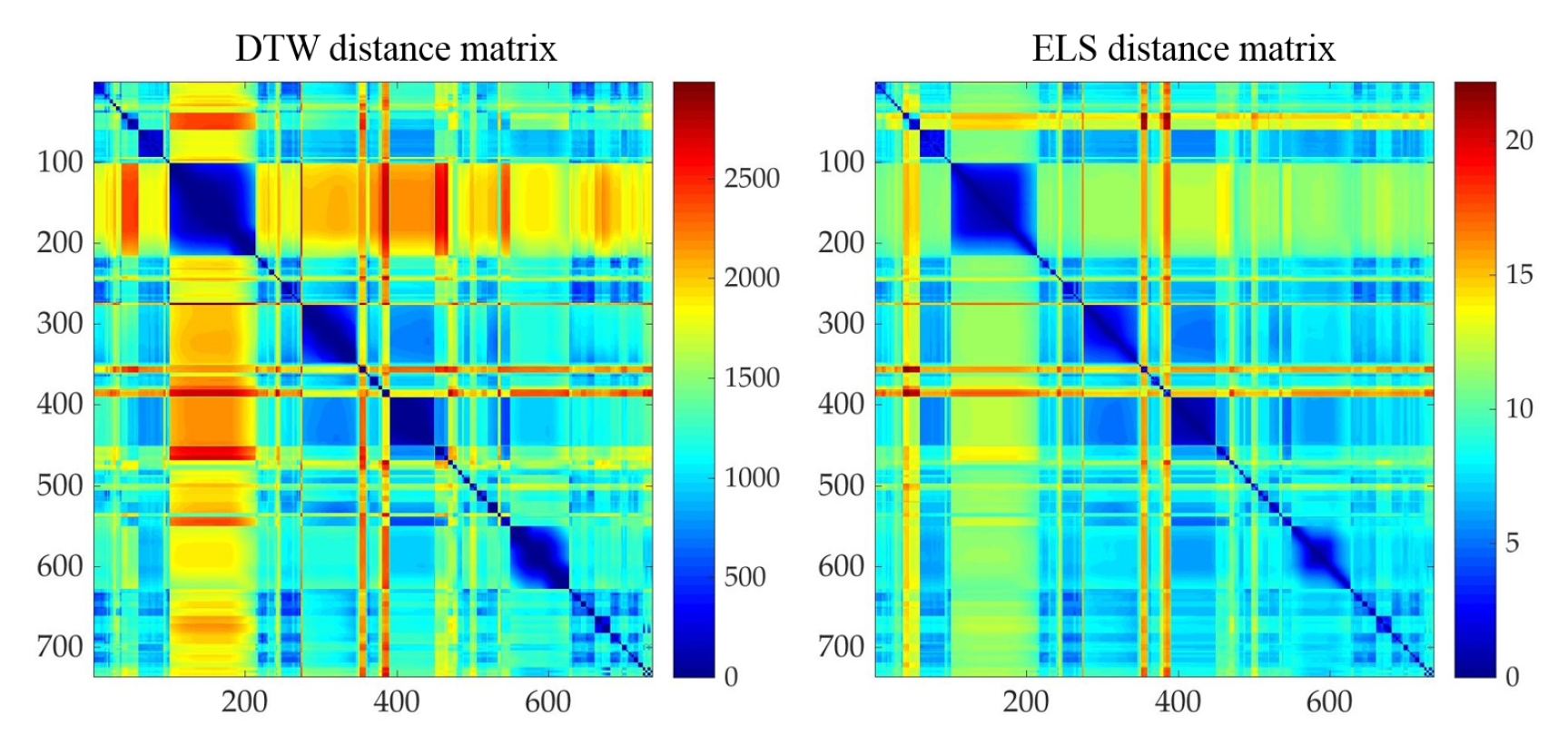
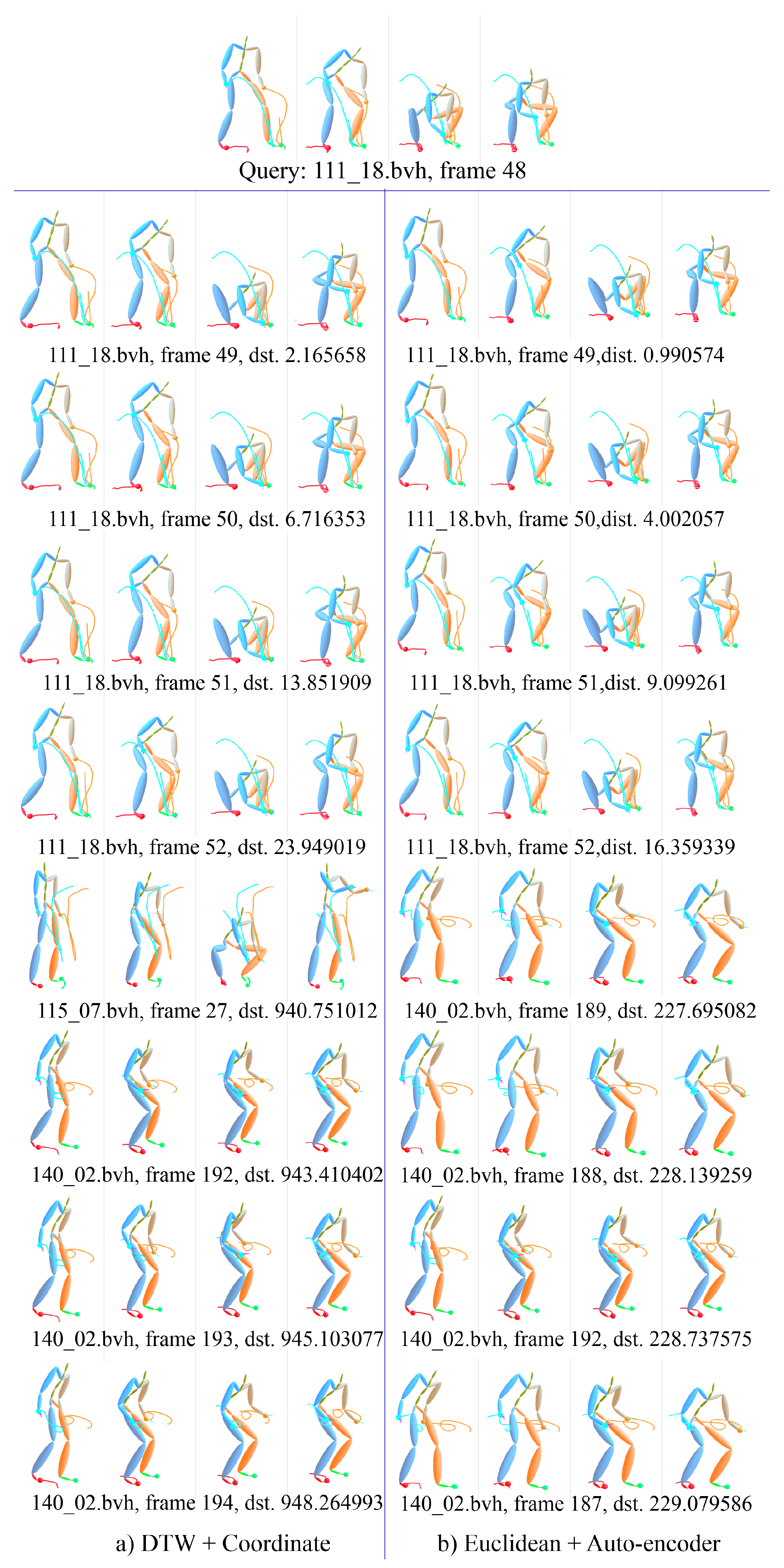
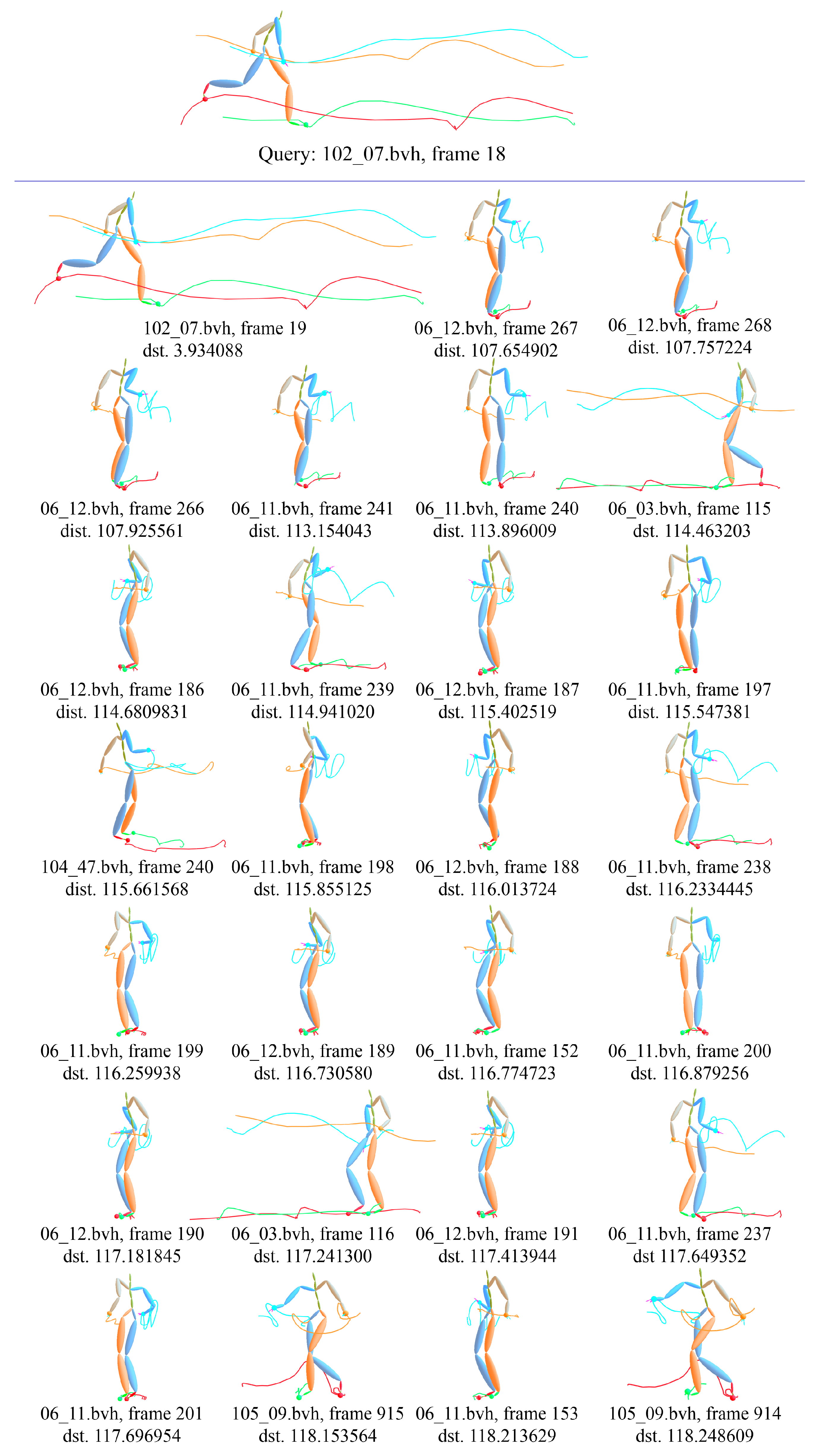
4.3. Evaluation of Pose Context Auto-Encoding
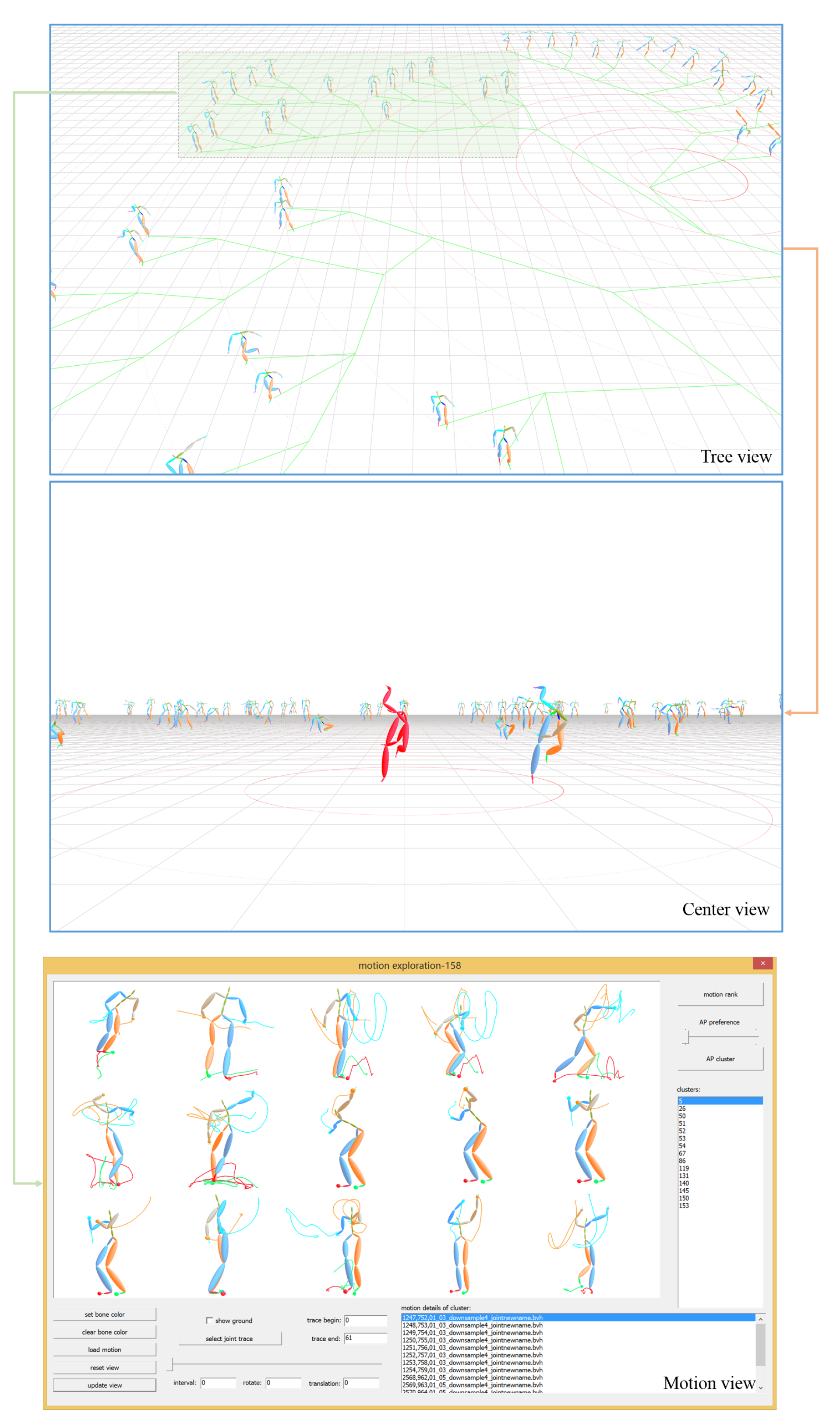
5. Prototype of Our System
6. Conclusions and Future Work
- (1)
- Our approach uses several common distance measures of pose, but fuses them in an effective manner. However, the final phylogenetic tree relies ultimately on the effectiveness of the measure of pose, and more measures which consist with the similarity of human conception are needed to enhance the performance for neighborhood construction.
- (2)
- The traditional hierarchical clustering algorithms used for motion capture data [10] are greedy while our method performs global analysis. However, the generation of weight quartets is independent of the construction of phylogenetic tree, which leads to large number of quartets are generated but many of them may not be necessary. Move effective method is needed to fuse these two processes to enhance the efficiency.
- (3)
- The confliction of quartets generated by different features is solved by WQMC and can be regarded as a form of voting. In fact, this confliction also can be settled by active learning. We can first find violated quartets and rank the triples contained in the violated quartets according to the inconsistence degree. Then, the user labels the recommended triples and the system generates a new phylogenetic tree with the refined quartets. The above gives an outline of one possible solution, but further in-depth study need to be conducted.
- (4)
- We provide KNN-based motion ranking and AP-based motion clustering with the proposed Euclidean distance on latent space for motion exploration. These two analysis tools are necessary for fast motion location on the coarse level. More methods with their visualization techniques are needed for quantitative detail motion analysis.
Author Contributions
Funding
Conflicts of Interest
References
- Carnegie Mellon University Motion Capture Database. 2003. Available online: http://mocap.cs.cmu.edu/ (accessed on 12 September 2020).
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1325–1339. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Zhuang, Y.; Nie, F.; Yang, Y.; Wu, F.; Xiao, J. Learning a 3D human pose distance metric from geometric pose descriptor. IEEE Trans. Vis. Comput. Graph. 2010, 17, 1676–1689. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Müller, M.; Röder, T.; Clausen, M. Efficient content-based retrieval of motion capture data. ACM Trans. Graph. TOG 2005, 24, 677–685. [Google Scholar] [CrossRef]
- Chao, M.; Lin, C.; Assa, J.; Lee, T. Human motion retrieval from hand-drawn sketch. IEEE Trans. Vis. Comput. Graph. 2011, 18, 729–740. [Google Scholar] [CrossRef] [Green Version]
- Tang, J.K.; Leung, H. Retrieval of logically relevant 3D human motions by adaptive feature selection with graded relevance feedback. Pattern Recognit. Lett. 2012, 33, 420–430. [Google Scholar] [CrossRef]
- Chen, S.; Sun, Z.; Zhang, Y.; Li, Q. Relevance feedback for human motion retrieval using a boosting approach. Multimed. Tools Appl. 2016, 75, 787–817. [Google Scholar] [CrossRef]
- Lv, N.; Jiang, Z.; Huang, Y.; Meng, X.; Meenakshisundaram, G.; Peng, J. Generic content-based retrieval of marker-based motion capture data. IEEE Trans. Vis. Comput. Graph. 2017, 24, 1969–1982. [Google Scholar] [CrossRef]
- Tang, Z.; Xiao, J.; Feng, Y.; Yang, X.; Zhang, J. Human motion retrieval based on freehand sketch. Comput. Animat. Virtual Worlds 2014, 25, 271–279. [Google Scholar] [CrossRef] [Green Version]
- Bernard, J.; Wilhelm, N.; Krüger, B.; May, T.; Schreck, T.; Kohlhammer, J. Motionexplorer: Exploratory search in human motion capture data based on hierarchical aggregation. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2257–2266. [Google Scholar] [CrossRef] [Green Version]
- White, R.W.; Roth, R.A. Exploratory search: Beyond the query-response paradigm. Synth. Lect. Inf. Concept. Retr. Serv. 2009, 1, 1–98. [Google Scholar] [CrossRef]
- Heesch, D. A survey of browsing models for content based image retrieval. Multimed. Tools Appl. 2008, 40, 261–284. [Google Scholar] [CrossRef]
- Gan, Y.; Zhang, Y.; Sun, Z.; Zhang, H. Qualitative photo collage by quartet analysis and active learning. Comput. Graph. 2020, 88, 35–44. [Google Scholar] [CrossRef]
- Schoeffmann, K.; Ahlström, D.; Bailer, W.; Cobârzan, C.; Hopfgartner, F.; McGuinness, K.; Gurrin, C.; Frisson, C.; Le, D.D.; Del Fabro, M.; et al. The video browser showdown: A live evaluation of interactive video search tools. Int. J. Multimed. Inf. Retr. 2014, 3, 113–127. [Google Scholar] [CrossRef] [Green Version]
- Huang, S.; Shamir, A.; Shen, C.; Zhang, H.; Sheffer, A.; Hu, S.; Cohen-Or, D. Qualitative organization of collections of shapes via quartet analysis. ACM Trans. Graph. TOG 2013, 32, 1–10. [Google Scholar] [CrossRef]
- Sakoe, H.; Chiba, S. Dynamic programming algorithm optimization for spoken word recognition. IEEE Trans. Acoust. Speech Signal Process. 1978, 26, 43–49. [Google Scholar] [CrossRef] [Green Version]
- Ismail, M.M.B. A Survey on Content-based Image Retrieval. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 159–170. [Google Scholar]
- Sedmidubsky, J.; Elias, P.; Zezula, P. Searching for variable-speed motions in long sequences of motion capture data. Inf. Syst. 2019, 80, 148–158. [Google Scholar] [CrossRef]
- Chattopadhyay, S.; Bhandarkar, S.M.; Li, K. Human motion capture data compression by model-based indexing: A power aware approach. IEEE Trans. Vis. Comput. Graph. 2006, 13, 5–14. [Google Scholar] [CrossRef]
- Liu, G.; Zhang, J.; Wang, W.; McMillan, L. A System for Analyzing and Indexing Human-Motion Databases. In Proceedings of the 2005 ACM SIGMOD International Conference on Management of Data, Baltimore, MD, USA, 14–16 June 2005; pp. 924–926. [Google Scholar]
- Keogh, E.; Palpanas, T.; Zordan, V.B.; Gunopulos, D.; Cardle, M. Indexing Large Human-Motion Databases. In Proceedings of the Thirtieth International Conference on Very Large Data Bases, Toronto, ON, Canada, 29 August–3 September 2004; pp. 780–791. [Google Scholar]
- Pradhan, G.N.; Prabhakaran, B. Indexing 3-D human motion repositories for content-based retrieval. IEEE Trans. Inf. Technol. Biomed. 2009, 13, 802–809. [Google Scholar] [CrossRef]
- Kovar, L.; Gleicher, M.; Pighin, F. Motion Graphs. ACM Trans. Graph. TOG 2002, 21, 473–482. [Google Scholar] [CrossRef]
- Min, J.; Chai, J. Motion graphs++: A compact generative model for semantic motion analysis and synthesis. ACM Trans. Graph. TOG 2012, 31, 153. [Google Scholar] [CrossRef]
- Bernard, J.; Dobermann, E.; Vögele, A.; Krüger, B.; Kohlhammer, J.; Fellner, D. Visual-interactive semi-supervised labeling of human motion capture data. Electron. Imaging 2017, 2017, 34–45. [Google Scholar] [CrossRef]
- Wagner, M.; Slijepcevic, D.; Horsak, B.; Rind, A.; Zeppelzauer, M.; Aigner, W. KAVAGait: Knowledge-assisted visual analytics for clinical gait analysis. IEEE Trans. Vis. Comput. Graph. 2018, 25, 1528–1542. [Google Scholar] [CrossRef] [Green Version]
- Jang, S.; Elmqvist, N.; Ramani, K. Motionflow: Visual abstraction and aggregation of sequential patterns in human motion tracking data. IEEE Trans. Vis. Comput. Graph. 2015, 22, 21–30. [Google Scholar] [CrossRef] [PubMed]
- Schroeder, D.; Korsakov, F.; Knipe, C.M.P.; Thorson, L.; Ellingson, A.M.; Nuckley, D.; Carlis, J.; Keefe, D.F. Trend-centric motion visualization: Designing and applying a new strategy for analyzing scientific motion collections. IEEE Trans. Vis. Comput. Graph. 2014, 20, 2644–2653. [Google Scholar] [CrossRef] [Green Version]
- Jang, S.; Elmqvist, N.; Ramani, K. GestureAnalyzer: Visual analytics for pattern analysis of mid-air hand gestures. In Proceedings of the 2nd ACM Symposium on Spatial User Interaction, Honolulu, HI, USA, 4–5 October 2014; pp. 30–39. [Google Scholar]
- Chen, S.; Sun, Z.; Zhang, Y. Scalable organization of collections of motion capture data via quantitative and qualitative analysis. In Proceedings of the 5th ACM on International Conference on Multimedia Retrieval, Shanghai, China, 23–26 June 2015; pp. 411–418. [Google Scholar]
- Holden, D.; Saito, J.; Komura, T.; Joyce, T. Learning motion manifolds with convolutional autoencoders. In Proceedings of the SIGGRAPH Asia 2015 Technical Briefs, Kobe, Japan, 2–5 November 2015; pp. 1–4. [Google Scholar]
- Wang, Y.; Neff, M. Deep signatures for indexing and retrieval in large motion databases. In Proceedings of the 8th ACM SIGGRAPH Conference on Motion in Games, Lisbon, Portugal, 7–8 May 2016; pp. 37–45. [Google Scholar]
- Sedmidubsky, J.; Elias, P.; Zezula, P. Effective and efficient similarity searching in motion capture data. Multimed. Tools Appl. 2018, 77, 12073–12094. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Frey, B.J.; Dueck, D. Clustering by passing messages between data points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef] [Green Version]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Soc. Ser. C Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Weiming, L.; Du Chenyang, W.B.; Chunhui, S.; Zhenchao, Y. Distributed affinity propagation clustering based on map reduce. J. Comput. Res. Dev. 2012, 49, 1762–1772. [Google Scholar]
- Tang, J.K.; Leung, H.; Komura, T.; Shum, H.P. Emulating human perception of motion similarity. Comput. Animat. Virtual Worlds 2008, 19, 211–221. [Google Scholar] [CrossRef] [Green Version]
- Avni, E.; Cohen, R.; Snir, S. Weighted quartets phylogenetics. Syst. Biol. 2015, 64, 233–242. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhuang, Y.; Rui, Y.; Huang, T.S.; Mehrotra, S. Adaptive key frame extraction using unsupervised clustering. In Proceedings of the International Conference on Image Processing, Chicago, IL, USA, 4–7 October 1998; pp. 866–870. [Google Scholar]
- Xia, D.; Wu, F.; Zhang, X.; Zhuang, Y. Local and global approaches of affinity propagation clustering for large scale data. J. Zhejiang Univ. Sci. A 2008, 9, 1373–1381. [Google Scholar] [CrossRef] [Green Version]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Saitou, N.; Nei, M. The neighbor-joining method: A new method for reconstructing phylogenetic trees. Mol. Biol. Evol. 1987, 4, 406–425. [Google Scholar] [PubMed]
- Pečenovió, Z.; Do, M.N.; Vetterli, M.; Pu, P. Integrated browsing and searching of large image collections. In Proceedings of the International Conference on Advances in Visual Information Systems, Lyon, France, 2–4 November 2000; pp. 279–289. [Google Scholar]




























© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Zhao, X.; Luo, B.; Sun, Z. Visual Browse and Exploration in Motion Capture Data with Phylogenetic Tree of Context-Aware Poses. Sensors 2020, 20, 5224. https://doi.org/10.3390/s20185224
Chen S, Zhao X, Luo B, Sun Z. Visual Browse and Exploration in Motion Capture Data with Phylogenetic Tree of Context-Aware Poses. Sensors. 2020; 20(18):5224. https://doi.org/10.3390/s20185224
Chicago/Turabian StyleChen, Songle, Xuejian Zhao, Bingqing Luo, and Zhixin Sun. 2020. "Visual Browse and Exploration in Motion Capture Data with Phylogenetic Tree of Context-Aware Poses" Sensors 20, no. 18: 5224. https://doi.org/10.3390/s20185224
APA StyleChen, S., Zhao, X., Luo, B., & Sun, Z. (2020). Visual Browse and Exploration in Motion Capture Data with Phylogenetic Tree of Context-Aware Poses. Sensors, 20(18), 5224. https://doi.org/10.3390/s20185224