Face and Body-Based Human Recognition by GAN-Based Blur Restoration


Abstract
:1. Introduction
2. Related Work
2.1. Without Blur Restoration
2.2. With Blur Restoration
3. Contribution of Our Research
- -
- This is the first approach for multimodal human recognition by blur restoring the face and body images using GAN.
- -
- Different from previous work [9], the presence of a blur was determined based on a focus score method in which blur restoration was applied via GAN for image in case that input image was determined as blur existence. The error was reduced, when compared to that without proposed focus score method and GAN.
- -
- The structural complexity was reduced by separating the network for blur restoration and the CNN for human recognition. In addition, the processing speed is usually faster when one image of face and body is restored at simultaneously via GAN. However, our blur restoration proceeded separately through GAN because face images exhibit detailed information, and the generation of a blur exhibits different tendencies in face and body images.
- -
- We make Dongguk face and body database version 2 (DFB-DB2), trained VGG face net-16 and ResNet-50, and GAN model for deblurring available by other researchers through [19] for fair comparisons.
4. Proposed Method
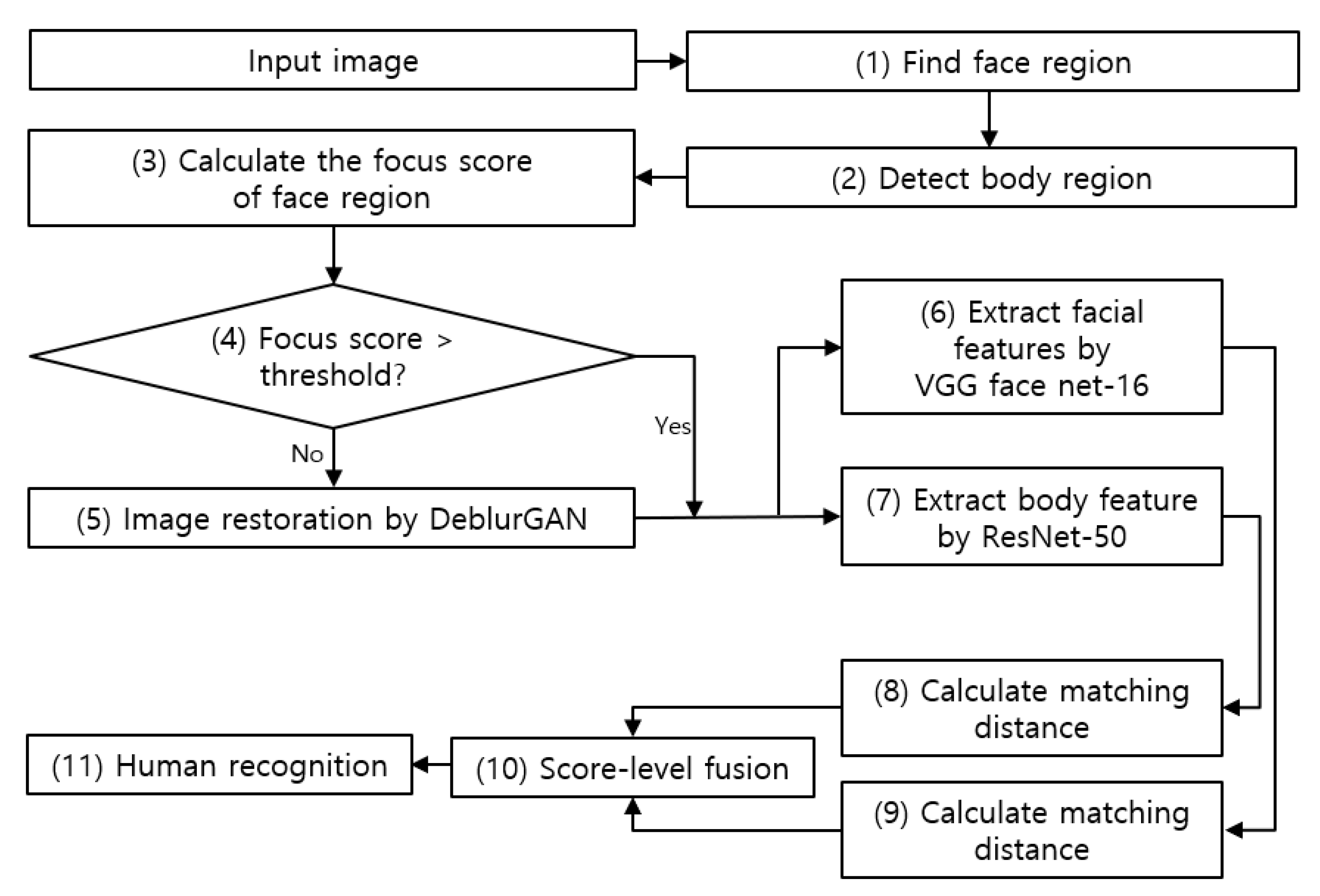
4.1. System Overview
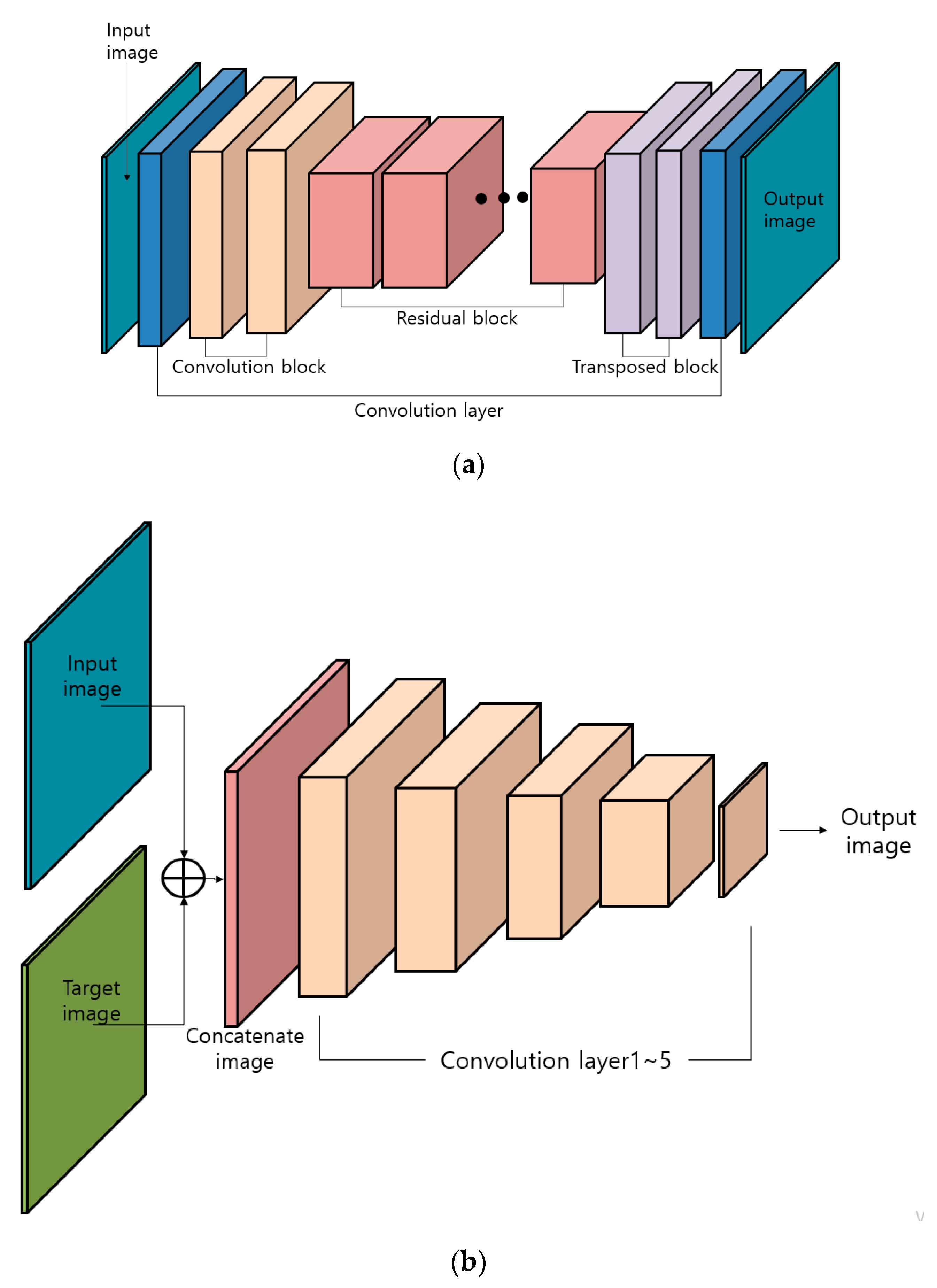
4.2. Structure of GAN
4.3. Structure of Deep Learning (VGG Face Net-16 and ResNet-50)
5. Experimental Results and Analysis
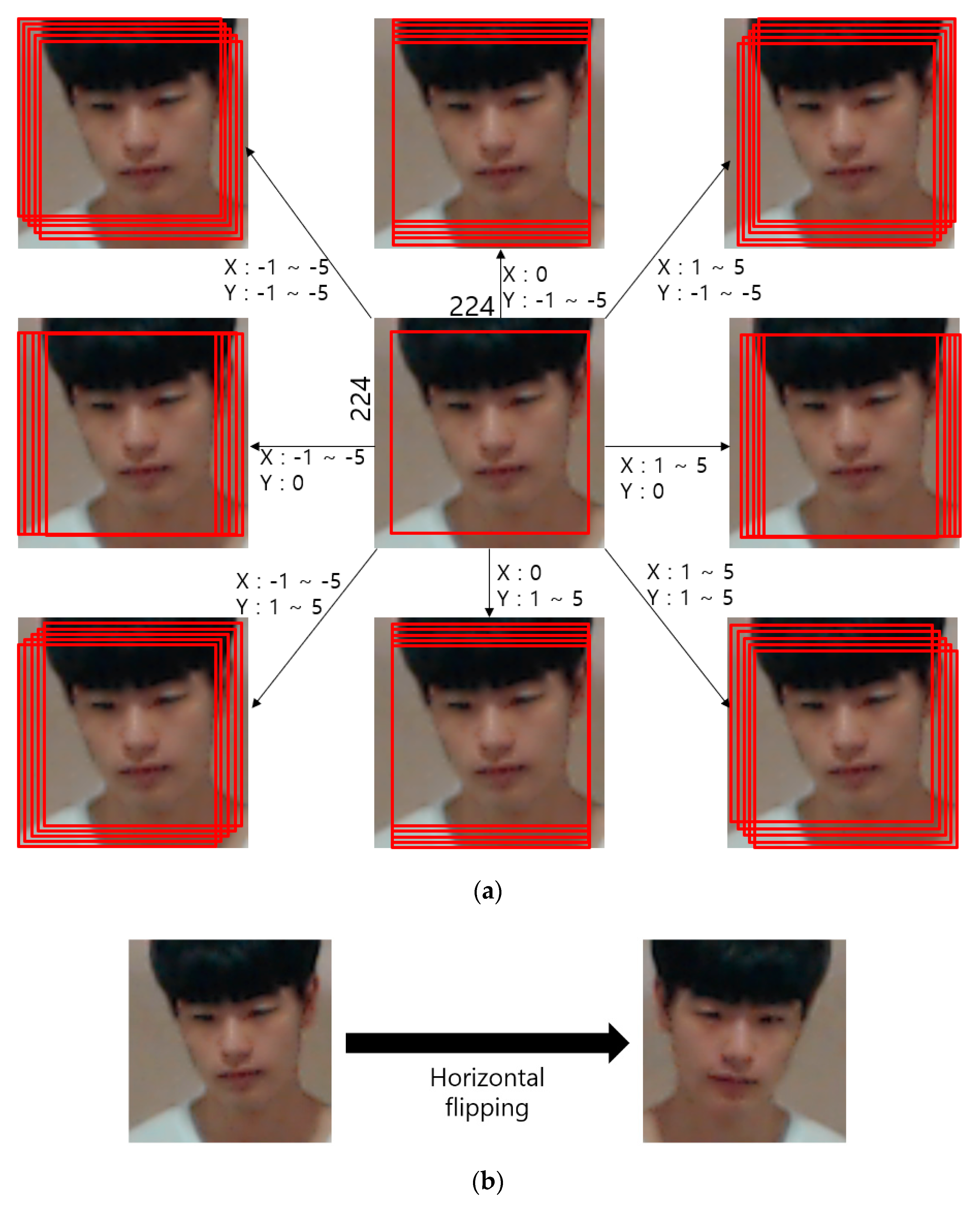
5.1. Experiments for Database and Environment
5.2. Training DeblurGAN and CNN Models
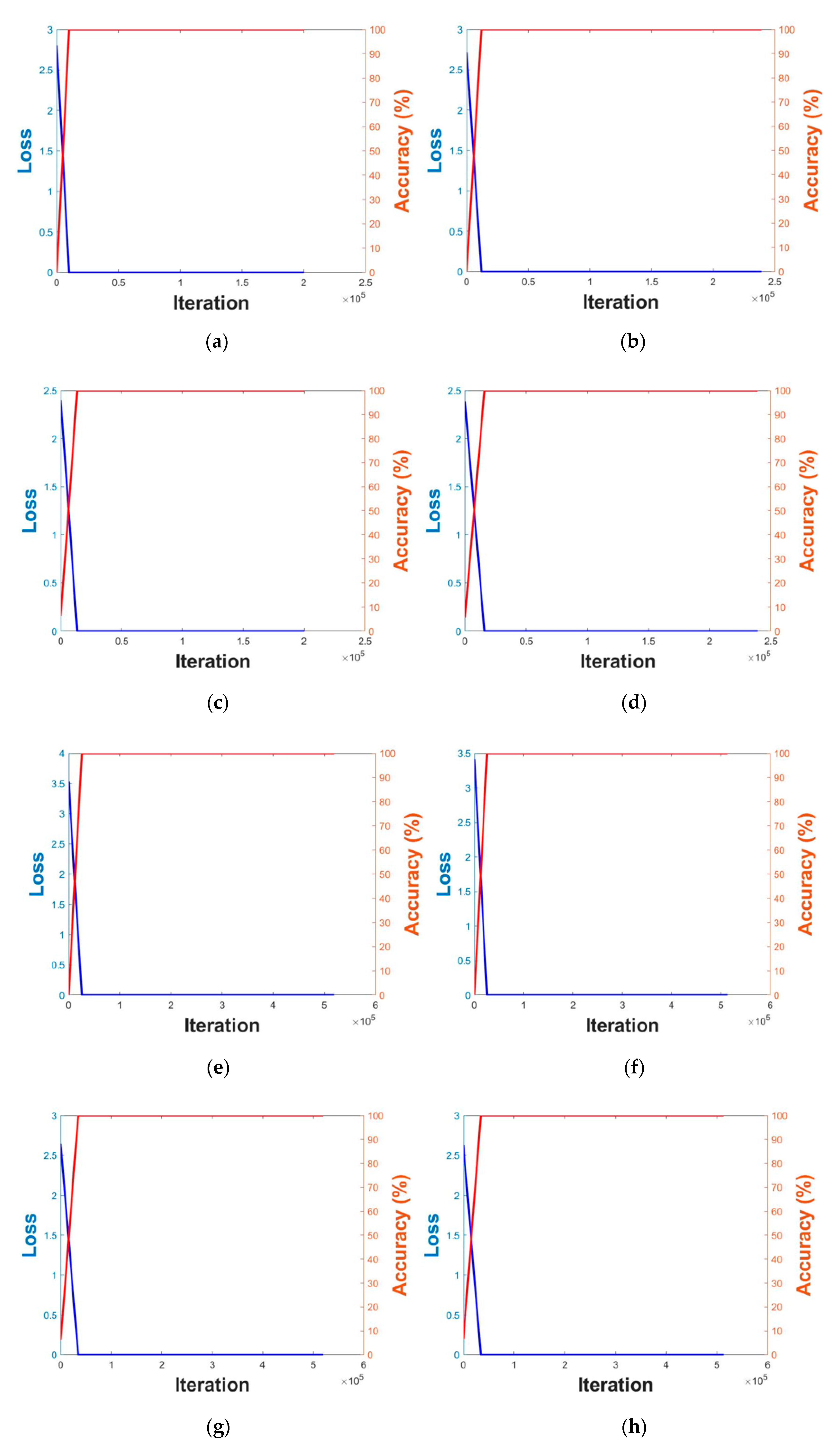
5.2.1. DeblurGAN Model Training Process and Results
5.2.2. CNN Model Training Process and Results
5.3. Testing Results from DeblurGAN and CNN Model
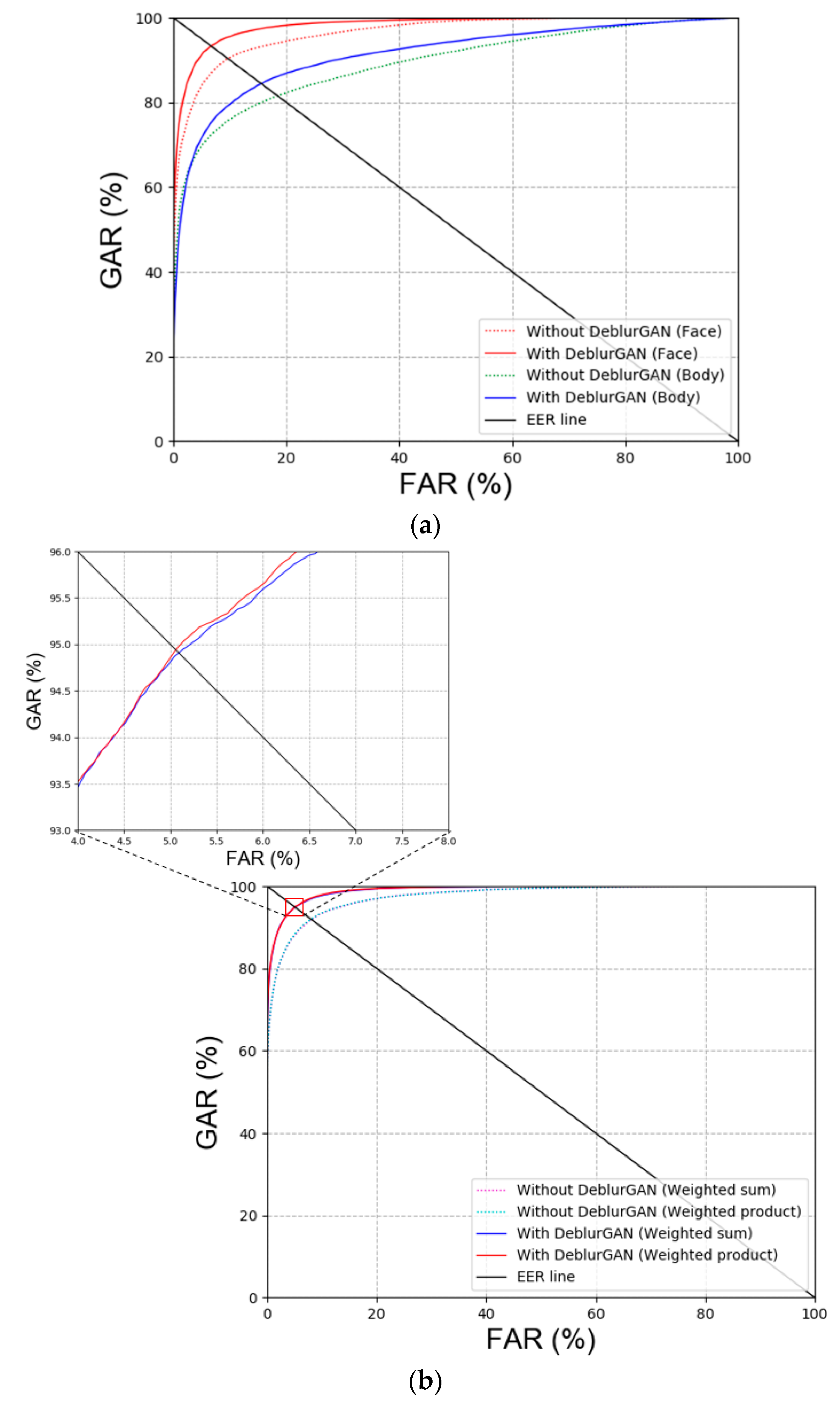
5.3.1. Testing with CNN Model for DFB-DB2
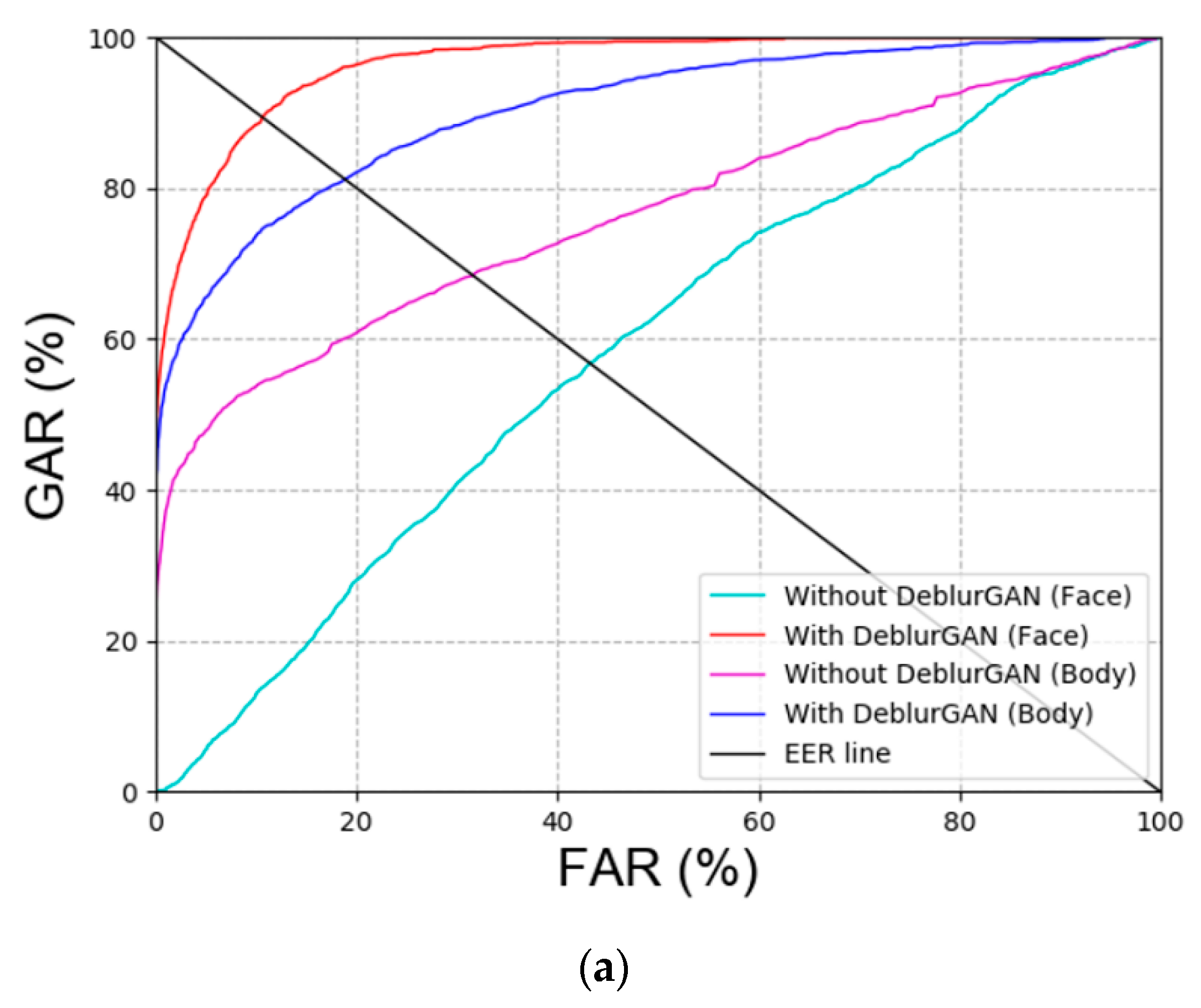
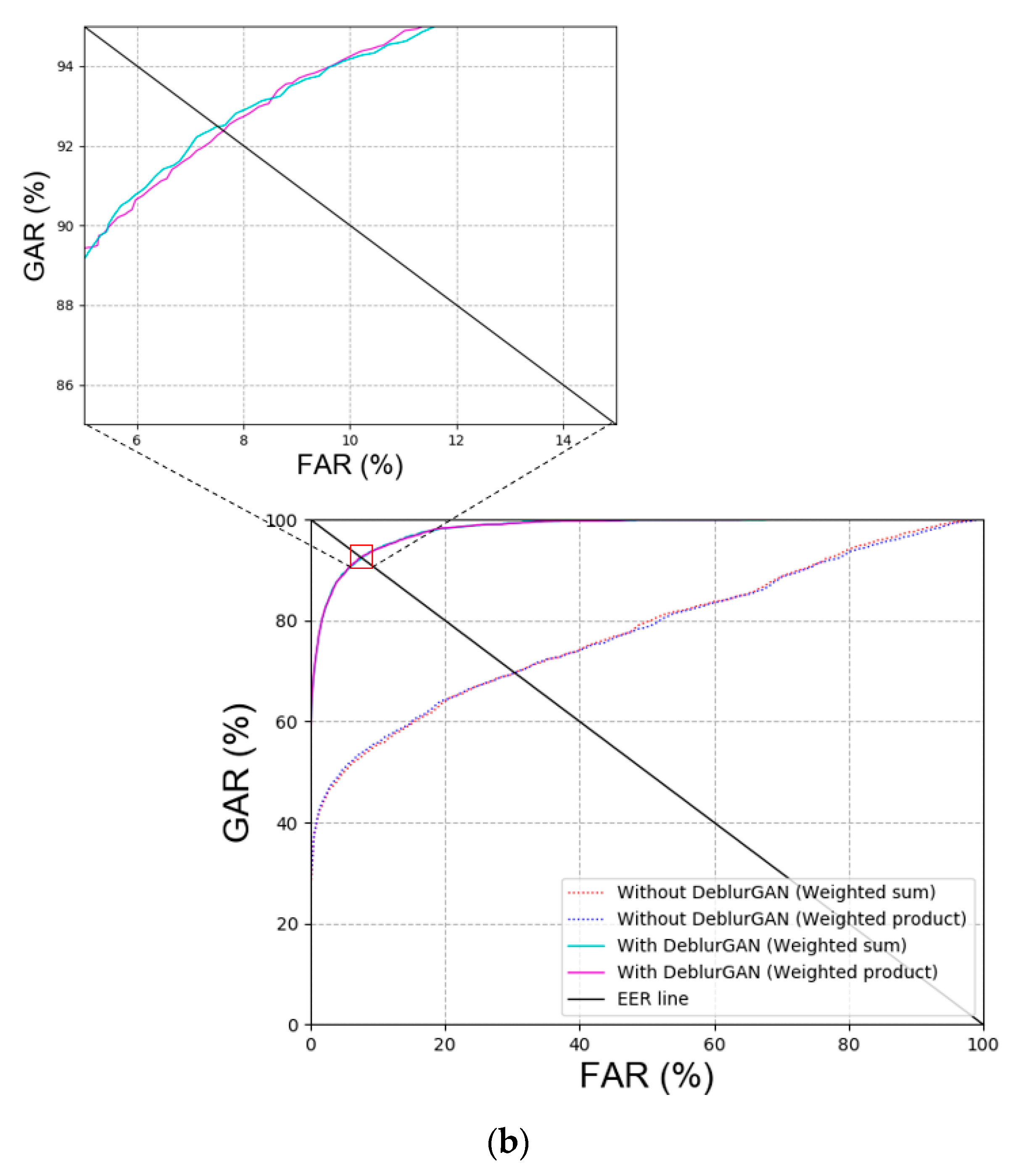
Ablation Study
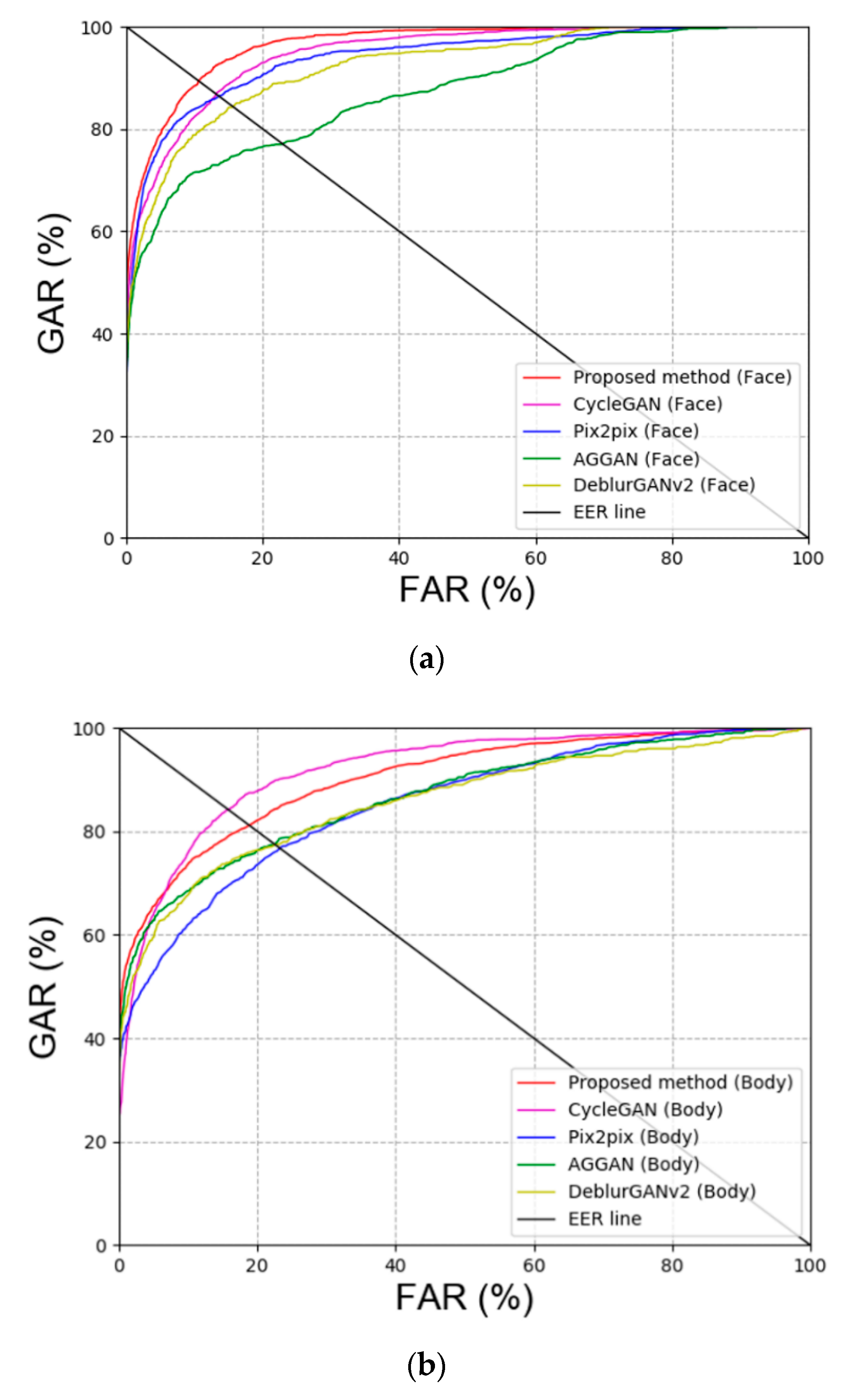
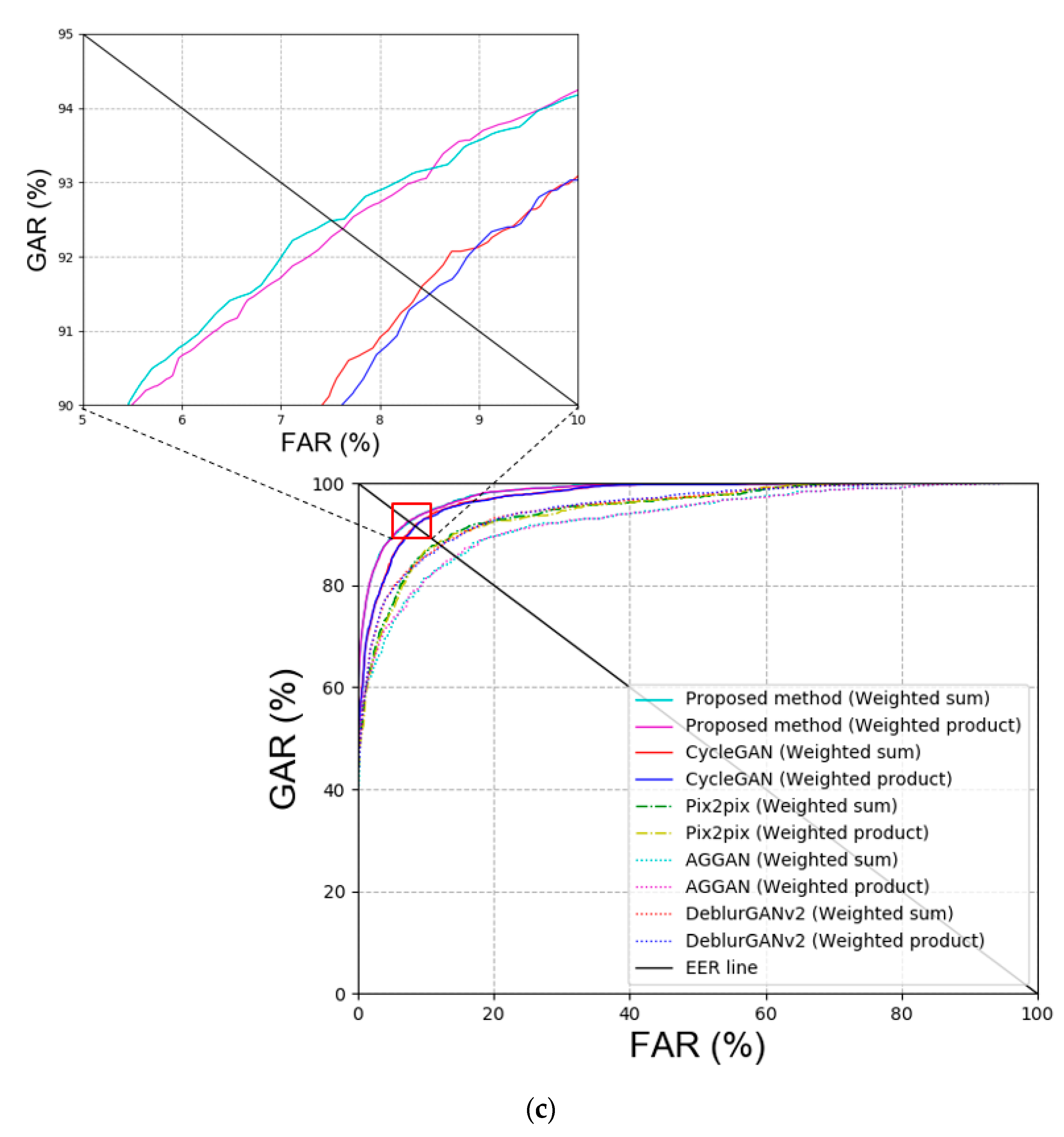
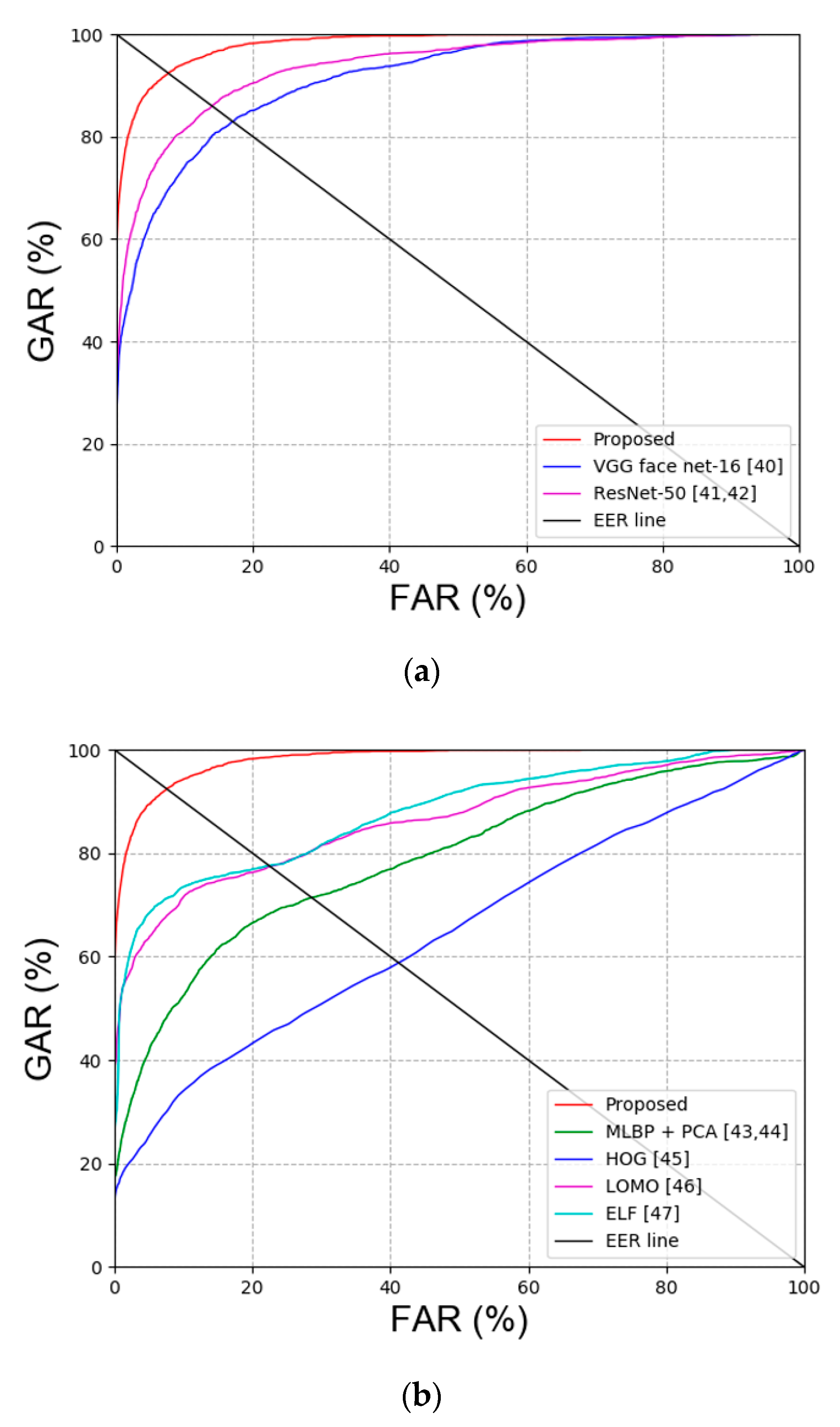
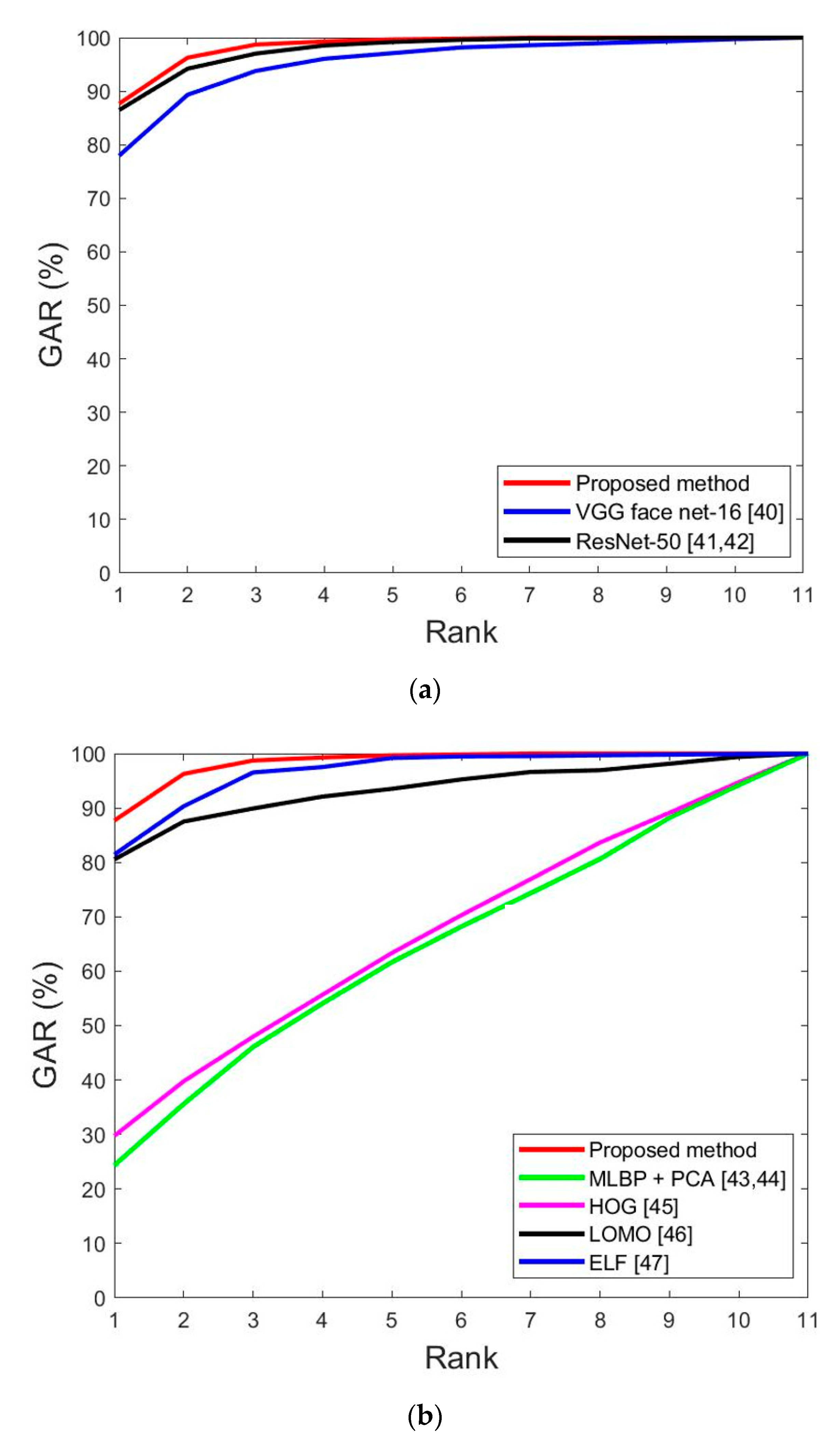
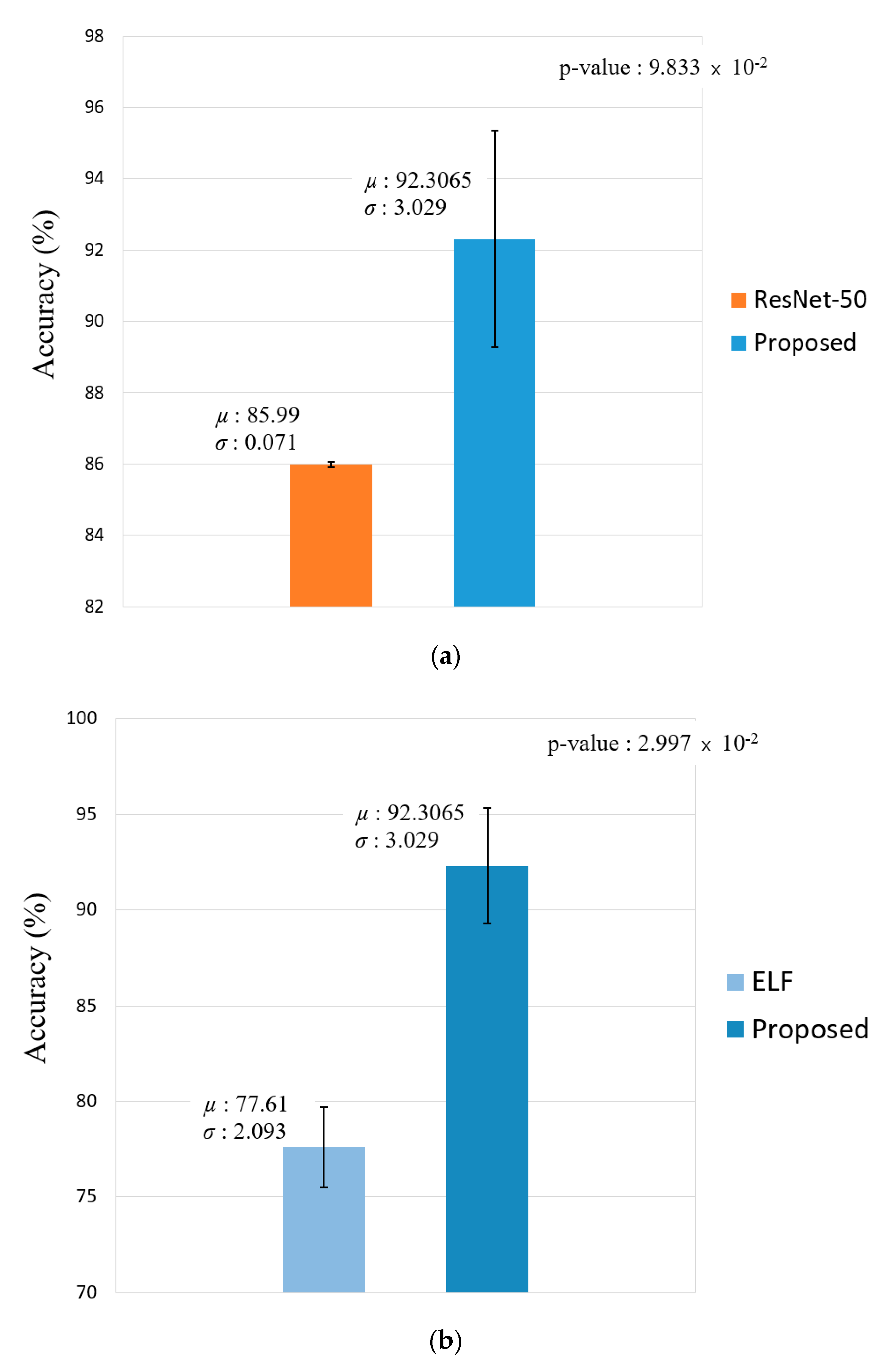
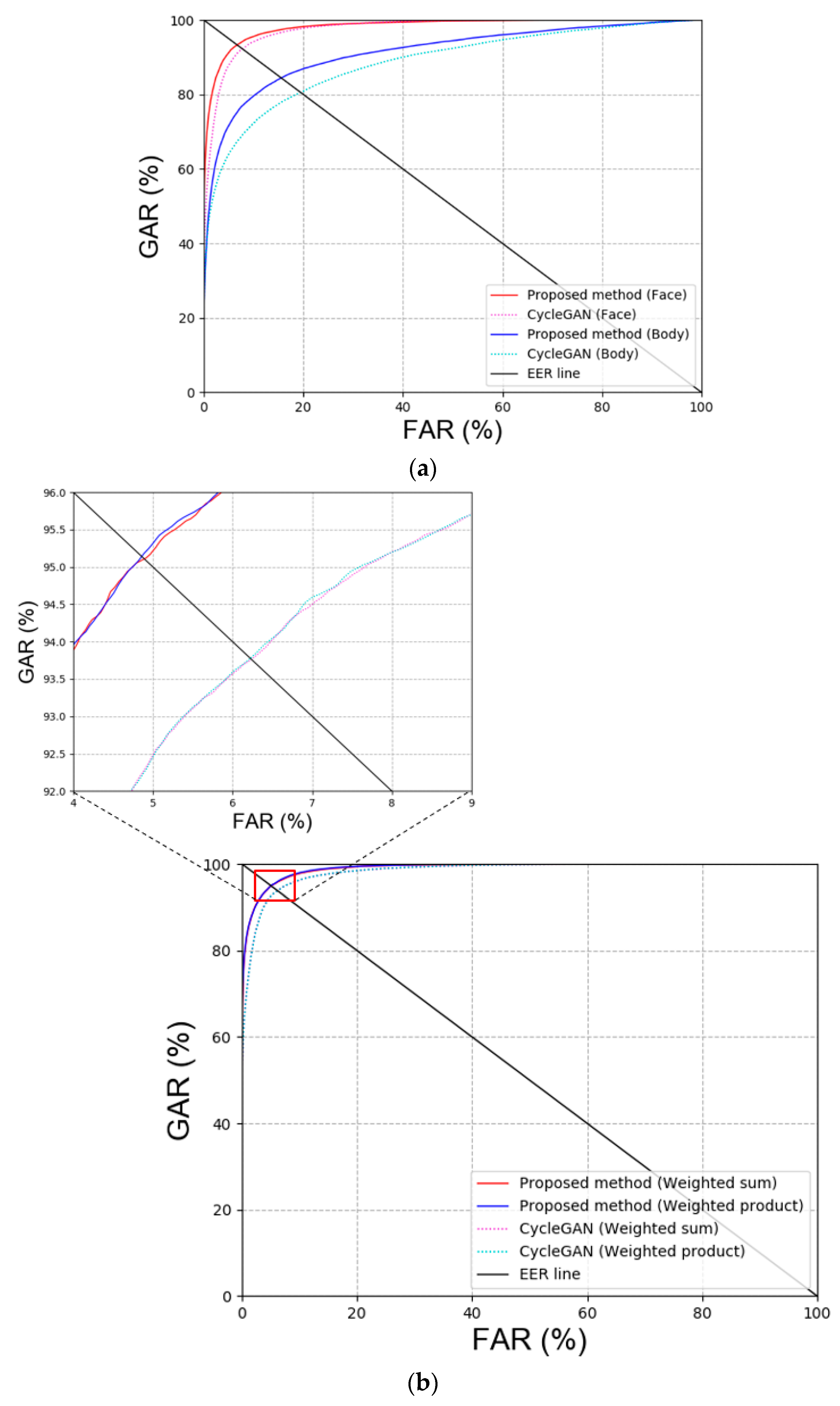
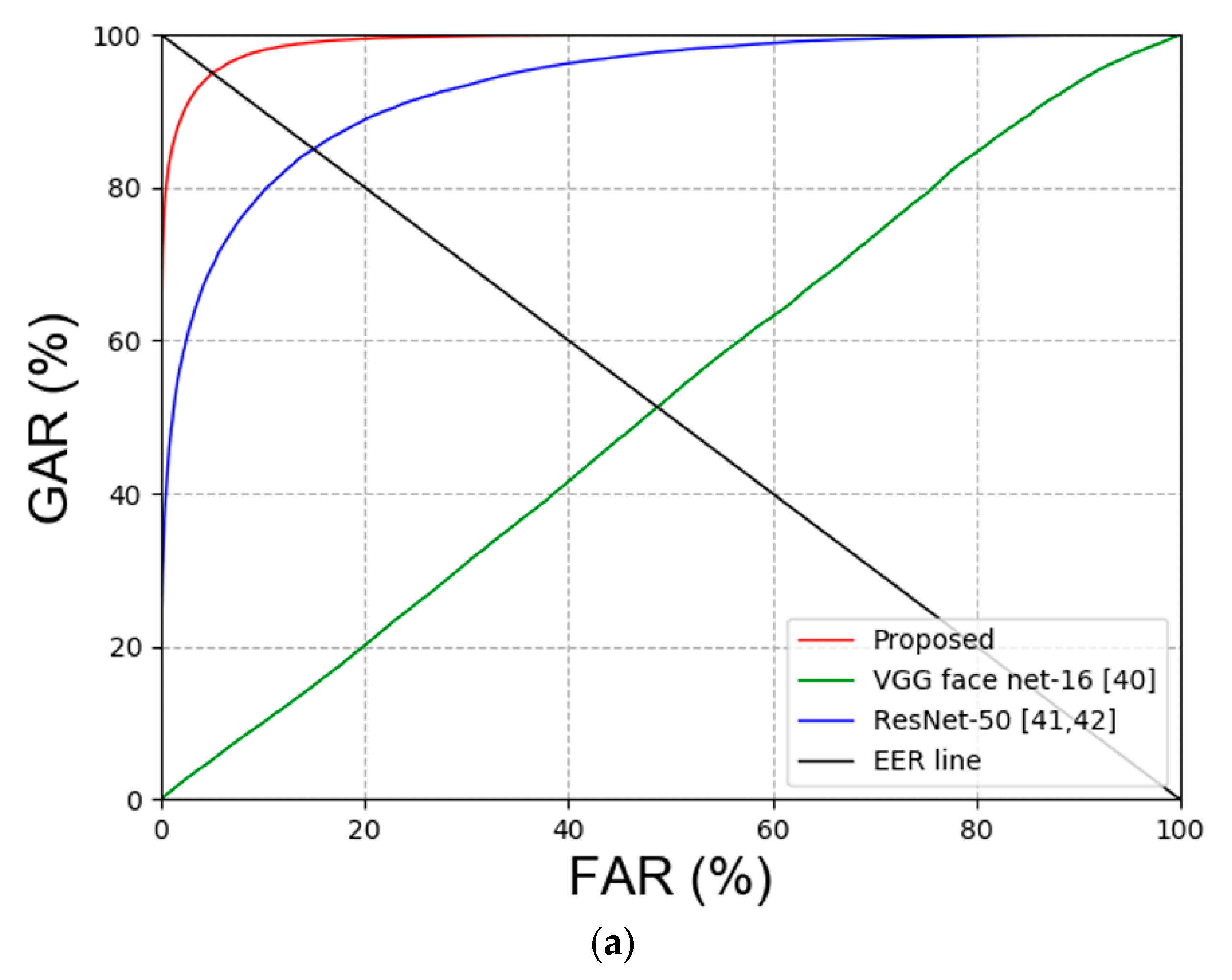
Comparison between Previous Method and Proposed Methods
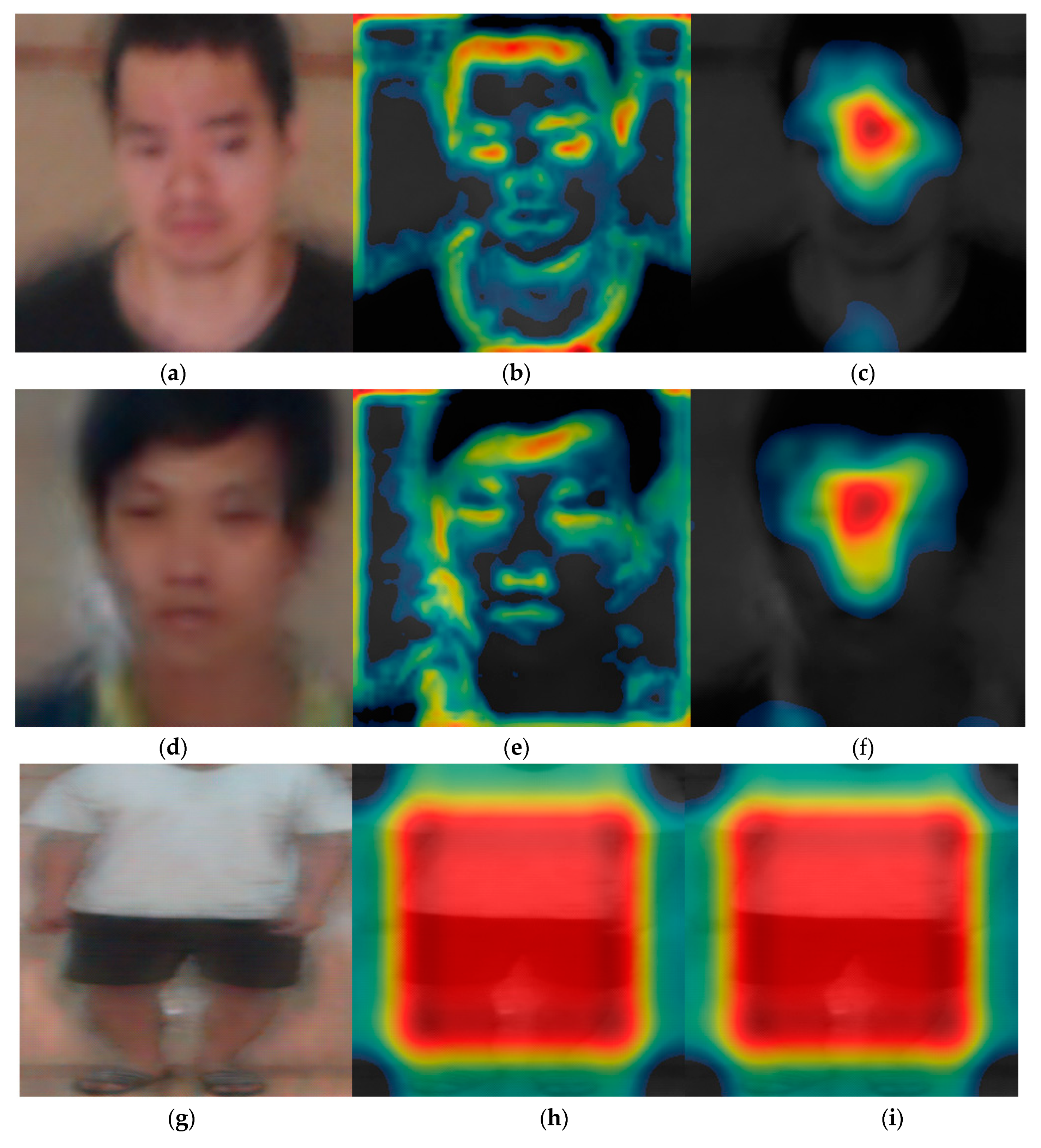
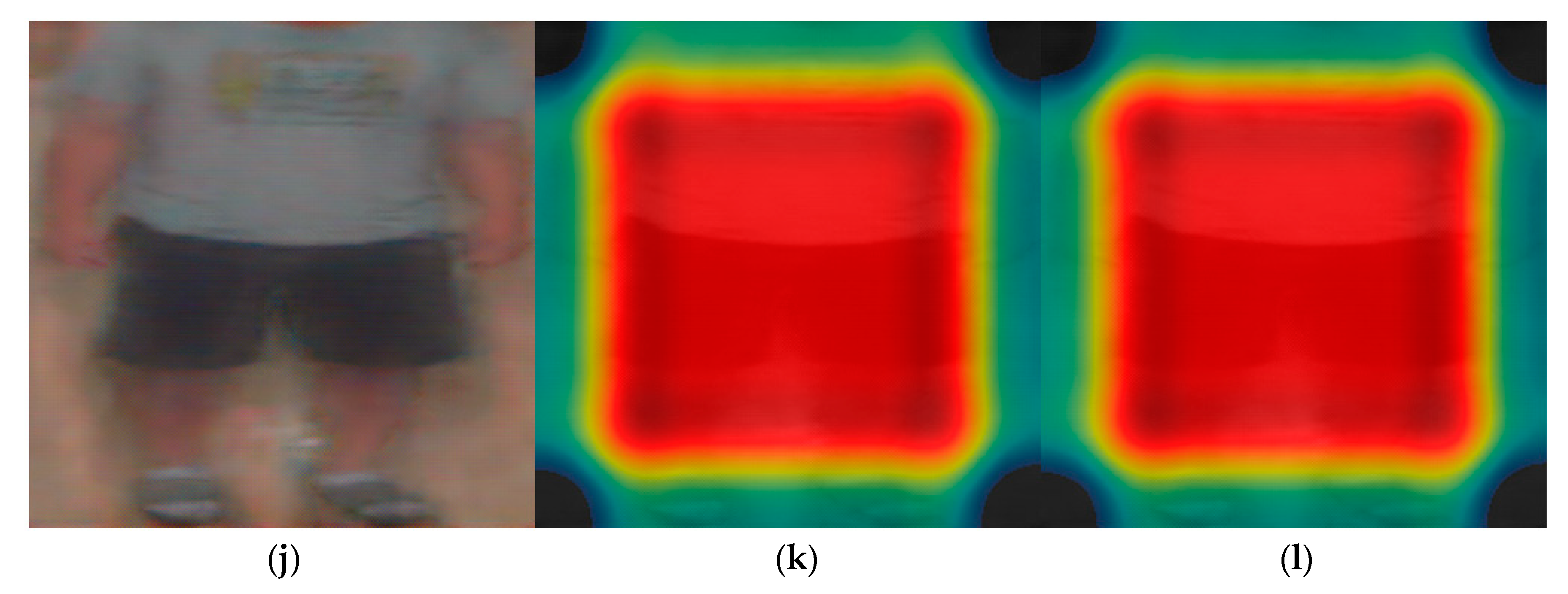
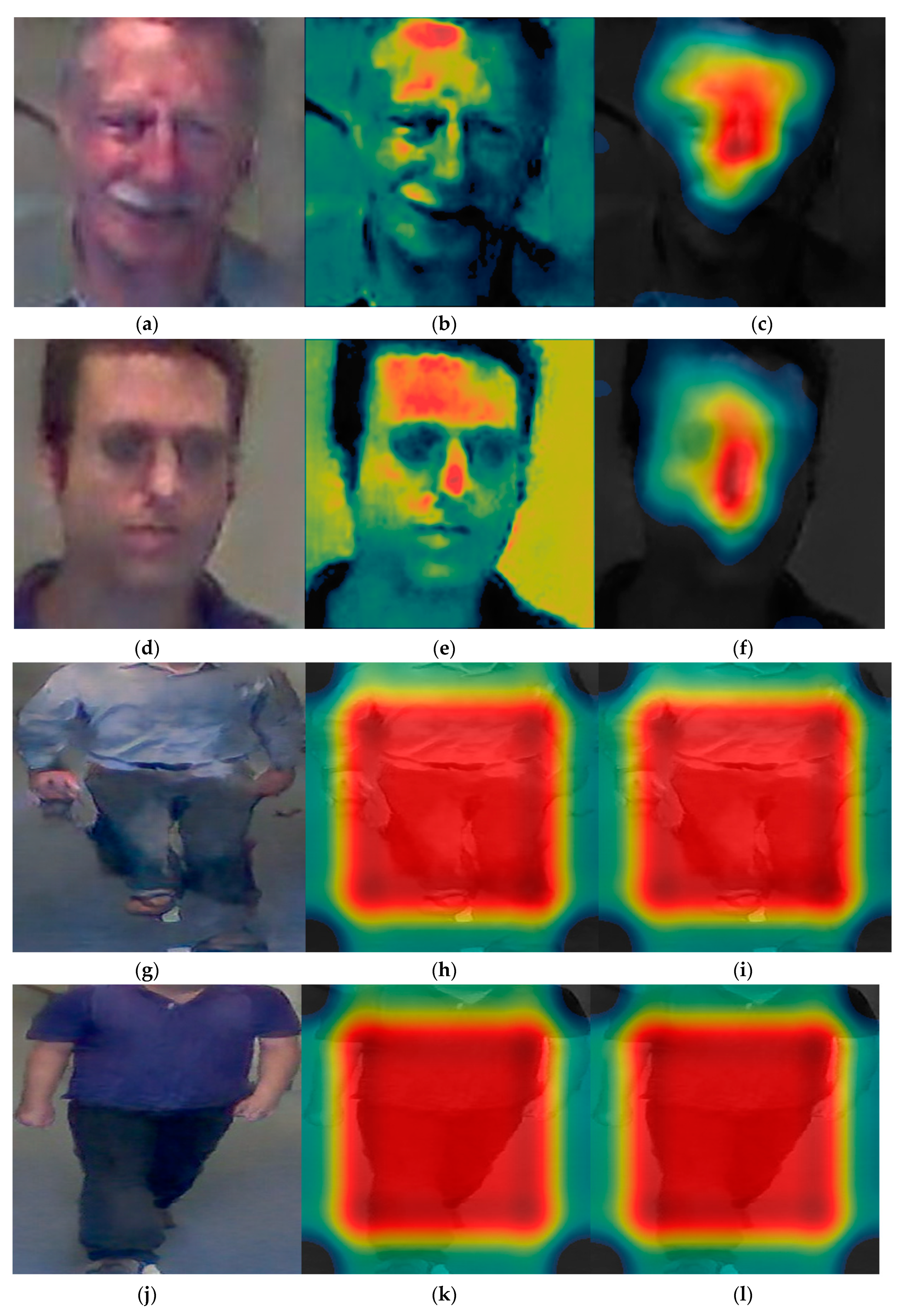
5.3.2. Class Activation Map
5.3.3. Testing with CNN Model for ChokePoint Dataset
Ablation Study
Comparison between Previous Methods and Proposed Method
5.3.4. Class Activation Map
5.3.5. Comparisons of Processing Time on Jetson TX2 and Desktop Computer
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Grgic, M.; Delac, K.; Grgic, S. SCface–surveillance cameras face database. Multimed. Tools Appl. 2011, 51, 863–879. [Google Scholar] [CrossRef]
- Banerjee, S.; Das, S. Domain adaptation with soft-Margin multiple feature-kernel learning beats deep learning for surveillance face recognition. arXiv 2016, arXiv:1610.01374v2. [Google Scholar]
- Zhou, X.; Bhanu, B. Integrating face and gait for human recognition at a distance in video. IEEE Trans. Syst. Man Cybern. Part B-Cybern. 2007, 37, 1119–1137. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Varior, R.R.; Haloi, M.; Wang, G. Gated siamese convolutional neural network architecture for human re-identification. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 791–808. [Google Scholar]
- Nguyen, D.T.; Hong, H.G.; Kim, K.W.; Park, K.R. Person recognition system based on a combination of body images from visible light and thermal cameras. Sensors 2017, 17, 605. [Google Scholar] [CrossRef] [PubMed]
- Shi, H.; Yang, Y.; Zhu, X.; Liao, S.; Lei, Z.; Zheng, W.; Li, S.Z. Embedding deep metric for individual re-identification: A study against large variations. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 732–748. [Google Scholar]
- Liu, Z.; Sarkar, S. Outdoor recognition at a distance by fusing gait and face. Image Vision. Comput. 2007, 25, 817–832. [Google Scholar] [CrossRef] [Green Version]
- Hofmann, M.; Schmidt, S.M.; Rajagopalan, A.N.; Rigoll, G. Combined face and gait recognition using Alpha Matte preprocessing. In Proceedings of the 5th IAPR International Conference on Biometrics, New Delhi, India, 29 March–1 April 2012; pp. 390–395. [Google Scholar]
- Koo, J.H.; Cho, S.W.; Baek, N.R.; Kim, M.C.; Park, K.R. CNN-based multimodal human recognition in surveillance environments. Sensors 2018, 18, 3040. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kang, B.J.; Park, K.R. A robust eyelash detection based on iris focus assessment. Pattern Recognit. Lett. 2007, 28, 1630–1639. [Google Scholar] [CrossRef]
- Alaoui, F.; Ghlaifan Abdo Saleh, A.; Dembele, V.; Nassim, A. Application of blind deblurring algorithm for face biometric. Int. J. Comput. Appl. 2014, 105, 20–24. [Google Scholar]
- Hadid, A.; Nishiyama, M.; Sato, Y. Recognition of blurred faces via facial deblurring combined with blur-tolerant descriptors. In Proceedings of the 20th IAPR International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 1160–1163. [Google Scholar]
- Nishiyama, M.; Takeshima, H.; Shotton, J.; Kozakaya, T.; Kozakaya, O. Facial deblur inference to improve recognition of blurred faces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami Beach, FL, USA, 22–24 June 2009; pp. 1115–1122. [Google Scholar]
- Mokhtari, H.; Belaidi, I.; Said, A. Performance comparison of face recognition algorithms based on face image retrieval. Res. J. Recent Sci. 2013, 2, 65–73. [Google Scholar]
- Heflin, B.; Parks, B.; Scheirer, W.; Boult, T. Single image deblurring for a real-time face recognition system. In Proceedings of the IECON 2010-36th Annual Conference on IEEE Industrial Electronic Society, Glendale, AZ, USA, 7–10 November 2010; pp. 1185–1192. [Google Scholar]
- Yasarla, R.; Perazzi, F.; Patel, V.M. Deblurring face images using uncertainty guided multi-stream semantic networks. arXiv 2020, arXiv:1907.13106v2. [Google Scholar] [CrossRef]
- Peng, X.; Huang, Z.; Lv, J.; Zhu, H.; Zhou, J.T. Comic: Multi-view clustering without parameter selection. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 5092–5101. [Google Scholar]
- Huang, Z.; Zhou, J.T.; Peng, X.; Zhang, C.; Zhu, H.; Lv, J. Multi-view spectral clustering network. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 2563–2569. [Google Scholar]
- Dongguk Face and Body Database Version 2 (DFB-DB2) and CNN Models for Deblur and Face & Body Recognition. Available online: http://dm.dgu.edu/link.html (accessed on 11 March 2020).
- Zhu, J.-Y.; Park, T.S.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. DeblurGAN: Blind motion deblurring using conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8183–8192. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance normalization: The missing ingredient for fast stylization. arXiv 2017, arXiv:1607.08022v3. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved training of wasserstein GANs. In Proceedings of the Neural Information Processing System, Long Beach, CA, USA, 4–9 December 2017; pp. 5767–5777. [Google Scholar]
- Huang, G.B.; Ramesh, M.; Berg, T.; Learned-miller, E. Labeled faces in the wild: A database for studying face recognition in unconstrained environments. In Proceedings of the Workshop on Faces in ‘Real-Life’ Images: Detection, Alignment, and Recognition, Marseille, France, 17 October 2008; pp. 1–11. [Google Scholar]
- Wolf, L.; Hassner, T.; Maoz, I. Face recognition in unconstrained videos with matched background similarity. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 529–534. [Google Scholar]
- Logitech BCC950 Camera. Available online: https://www.logitech.com/en-roeu/product/conferencecam-bcc950?crid=1689 (accessed on 20 November 2019).
- Logitech C920 Camera. Available online: https://www.logitech.com/en-us/product/hd-pro-webcam-c920?crid=34 (accessed on 23 November 2019).
- ChokePoint Dataset. Available online: http://arma.sourceforge.net/chokepoint/ (accessed on 26 September 2019).
- DeblurGAN. Available online: https://github.com/KupynOrest/DeblurGAN/ (accessed on 23 November 2019).
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Stathaki, T. Image Fusion: Algorithms and Applications; Academic Press: Cambridge, MA, USA, 2008. [Google Scholar]
- Salomon, D. Data Compression: The Complete Reference, 4th ed.; Springer: New York, NY, USA, 2006. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Mejjati, Y.A.; Richardt, C.; Tompkin, J.; Cosker, D.; Kim, K.I. Unsupervised attention-guided image-to-image translation. In Proceedings of the 32th Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 3693–3703. [Google Scholar]
- Qi, Q.; Guo, J.; Jin, W. Attention network for non-uniform deblurring. IEEE Access 2020, 8, 100044–100057. [Google Scholar] [CrossRef]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. DeblurGAN-v2: Deblurring (orders-of-magnitude) faster and better. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1–10. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep face recognition. In Proceedings of the British Machine Vision Conference, Swansea, UK, 7–10 September 2015; pp. 1–12. [Google Scholar]
- Gruber, I.; Hlaváč, M.; Železný, M.; Karpov, A. Facing face recognition with ResNet: Round one. In Proceedings of the International Conference on Interaction Collaborative Robotics, Hatfield, UK, 12–16 September 2017; pp. 67–74. [Google Scholar]
- Martínez-Díaz, Y.; Méndez-Vázquez, H.; López-Avila, L.; Chang, L.; Enrique Sucar, L.; Tistarelli, M. Toward more realistic face recognition evaluation protocols for the youtube faces database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 526–534. [Google Scholar]
- Khamis, S.; Kuo, C.-H.; Singh, V.K.; Shet, V.D.; Davis, L.S. Joint learning for attribute-consistent individual re-identification. In Proceedings of the 13th European Conference on Computer Vision Workshops, Zurich, Switzerland, 6–12 September 2014; pp. 134–146. [Google Scholar]
- Köstinger, M.; Hirzer, M.; Wohlhart, P.; Roth, P.M.; Bischof, H. Large scale metric learning from equivalence constraints. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2288–2295. [Google Scholar]
- Li, W.; Wang, X. Locally aligned feature transforms across views. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3594–3601. [Google Scholar]
- Liao, S.; Hu, Y.; Zhu, X.; Li, S.Z. Person re-identification by local maximal occurrence representation and metric learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2197–2206. [Google Scholar]
- Gray, D.; Tao, H. Viewpoint invariant pedestrian recognition with an ensemble of localized features. In Proceedings of the 10th European Conference on Computer Vision, Marseille, France, 12–18 October 2008; pp. 262–275. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Jetson TX2 Module. Available online: https://www.nvidia.com/en-us/autonomous-machines/embedded-systems-dev-kits-modules/ (accessed on 12 December 2019).
- Keras: The Python Deep Learning Library. Available online: https://keras.io/ (accessed on 11 March 2020).
- Tensorflow: The Python Deep Learning Library. Available online: https://www.tensorflow.org/ (accessed on 19 July 2019).
- CUDA. Available online: https://developer.nvidia.com/cuda-90-download-archive (accessed on 11 March 2020).
- CUDNN. Available online: https://developer.nvidia.com/cudnn (accessed on 11 March 2020).
- Lenka, M.K. Blind deblurring using GANs. arXiv 2017, arXiv:1907.11880v1. [Google Scholar]
- Zhang, S.; Zhen, A.; Stevenson, R.L. GAN based image deblurring using dark channel prior. In Proceedings of the IS&T International Symposium on Electronic Imaging, San Francisco, CA, USA, 13–17 January 2019; pp. 1–5. [Google Scholar]
- Zhang, X.; Lv, Y.; Li, Y.; Liu, Y.; Luo, P. A modified image processing method for deblurring based on GAN networks. In Proceedings of the 5th International Conference on Big Data and Information Analytics, Kunming, China, 8–10 July 2019; pp. 29–34. [Google Scholar]




























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Method | Advantage | Disadvantage | ||
|---|---|---|---|---|---|
| Without blur restoration | Single modality | Face recognition | PCA [1] | Low performance degradation due to lighting changes. | Degraded recognition performance due to distortion of image features due to a blur. |
| SML-MKFC with DA [2] | |||||
| Texture and shape-based body recognition | S-CNN [4] | Low interference of a blur for recognition. | Different individuals wearing the same clothes are recognized as the same individual. | ||
| CNN + PCA, SVM [5] | |||||
| CNN + DDML [6] | |||||
| Movement-based body recognition | PCA + MDA [3] | Less affected directly by a blur. | Requires an extensive time for acquiring data. | ||
| Multimodal | Movement-based body and face recognition | HMM/Gabor features based EBGM [7] | Less affected by a blur because it is gait-based body recognition. | Sufficient data is required for continuous images. Distortion of face image due to noise, such as lighting changes or blur. | |
| Eigenface calculation and αGEI [8] | |||||
| Texture and shape-based body and face recognition | VGG face net-16 and ResNet-50 [9] | Easy to acquire data because continuous images are not required. | Sufficient data is required for finetuning based on data characteristics. | ||
| With blur restoration | Single modality | Face recognition | Fast TV-l1 and Deconvolution+ PCA [11] | Improved recognition performance, as blurred face images are restored. | Most studies focused on comparing the deblurred facial image with the original image. |
| DeblurLPQ [12] | |||||
| Wien filters or BTV regularization [13] | |||||
| CSR + ASDS-AR [14] | |||||
| PSF + Wiener filter [15] | |||||
| UMSN [16] | |||||
| Multimodal | Texture and shape-based body and face recognition | Proposed method | Improved performance because body and face were separated for restoration. | Slow processing time due to restoration is performed twice for body and face. | |
| Layer Type | Size of Feature Map | Number of Filters | Size of Filters | Number of Strides | Number of Iterations | |
|---|---|---|---|---|---|---|
| Image input layer | 256 (height) × 256 (width) × 3 (channel) | |||||
| Convolution layer | 256 × 256 × 64 | 64 | 7 × 7 | 1 | ||
| Instance normalization layer | ||||||
| ReLU | ||||||
| Convolution block 1 | Convolution layer | 128 × 128 × 128 | 128 | 3 × 3 | 2 | |
| Instance normalization layer | ||||||
| ReLU | ||||||
| Convolution block 2 | Convolution layer | 64 × 64 × 256 | 256 | 3 × 3 | 2 | |
| Instance normalization layer | ||||||
| ReLU | ||||||
| Resblocks | Convolution layer | 64 × 64 × 256 | 256 | 3 × 3 | 1 | 9 |
| Instance normalization layer | ||||||
| ReLU | ||||||
| Convolution layer | 64 × 64 × 256 | 256 | 3 × 3 | 1 | ||
| Instance normalization layer | ||||||
| Transposed blocks 1 | Contraposed layer | 128 × 128 × 128 | 128 | 4 × 4 | 2 | 2 |
| Instance normalization layer | ||||||
| ReLU | ||||||
| Transposed blocks 2 | Contraposed layer | 256 × 256 × 64 | 64 | 4 × 4 | 2 | |
| Instance normalization layer | ||||||
| ReLU | ||||||
| Convolution layer (Output layer) | 256 × 256 × 3 | 3 | 7 × 7 | 1 | ||
| Layer Type | Size of Feature Map | Number of Filters | Size of Filters | Number of Strides |
|---|---|---|---|---|
| Input image | 256 × 256 × 3 | |||
| Target image | 256 × 256 × 3 | |||
| Concatenator | 256 × 256 × 6 | |||
| Convolution layer1 * | 129 × 129 × 64 | 64 | 4 × 4 × 6 | 2 |
| Convolution layer2 * | 65 × 65 × 128 | 128 | 4 × 4 × 64 | 2 |
| Convolution layer3 * | 33 × 33 × 256 | 256 | 4 × 4 × 128 | 2 |
| Convolution layer4 * | 34 × 34 × 512 | 512 | 4 × 4 × 256 | 1 |
| Convolution layer5 * (Output layer) | 35 × 35 × 1 | 1 | 4 × 4 × 512 | 1 |
| DFB-DB2 | Chokepoint Dataset | ||||||
|---|---|---|---|---|---|---|---|
| Number of Classes in Each Fold | Number of Augmented Images (For Training) | Number of Images (For Testing) | Number of Classes in Each Fold | Number of Augmented Images (For Training) | Number of Images (For Testing) | ||
| Face | Sub-Dataset1 | 11 | 200,134 | 827 | 14 | 519,050 | 10,381 |
| Sub-Dataset2 | 11 | 239,338 | 989 | 14 | 513,450 | 10,269 | |
| Body | Sub-Dataset1 | 11 | 200,134 | 827 | 14 | 519,050 | 10,381 |
| Sub-Dataset2 | 11 | 239,338 | 989 | 14 | 513,450 | 10,269 | |
| Method | Face | Body | |
|---|---|---|---|
| Without DeblurGAN (without focus score checking) | 1st fold | 45.29 | 33.68 |
| 2nd fold | 41.85 | 28.7 | |
| Average | 43.52 | 31.19 | |
| With DeblurGAN (with focus score checking) | 1st fold | 12.44 | 21 |
| 2nd fold | 7.94 | 16.48 | |
| Average | 10.19 | 18.74 | |
| Method | Score-Level Fusion | ||
|---|---|---|---|
| Weighted Sum | Weighted Product | ||
| Without DeblurGAN (without focus score checking) | 1st fold | 32.44 | 32.57 |
| 2nd fold | 27.94 | 27.93 | |
| Average | 30.19 | 30.25 | |
| With DeblurGAN (with focus score checking) | 1st fold | 9.835 | 9.901 |
| 2nd fold | 5.552 | 5.557 | |
| Average | 7.694 | 7.729 | |
| Method | Average | |
|---|---|---|
| Face | Proposed method | 10.19 |
| CycleGAN [20] | 13.255 | |
| Pix2pix [22] | 13.315 | |
| AGGAN [37,38] | 23.01 | |
| DeblurGANv2 [39] | 15.64 | |
| Body | Proposed method | 18.74 |
| CycleGAN [20] | 15.745 | |
| Pix2pix [22] | 23.195 | |
| AGGAN [37,38] | 22.52 | |
| DeblurGANv2 [39] | 22.71 | |
| Weighted sum | Proposed method | 7.694 |
| CycleGAN [20] | 8.29 | |
| Pix2pix [22] | 11.49 | |
| AGGAN [37,38] | 14.649 | |
| DeblurGANv2 [39] | 11.801 | |
| Weighted product | Proposed method | 7.729 |
| CycleGAN [20] | 8.41 | |
| Pix2pix [22] | 11.5605 | |
| AGGAN [37,38] | 14.342 | |
| DeblurGANv2 [39] | 11.869 | |
| Method | 1st Fold | 2nd Fold | Average |
|---|---|---|---|
| Proposed method | 9.835 | 5.552 | 7.694 |
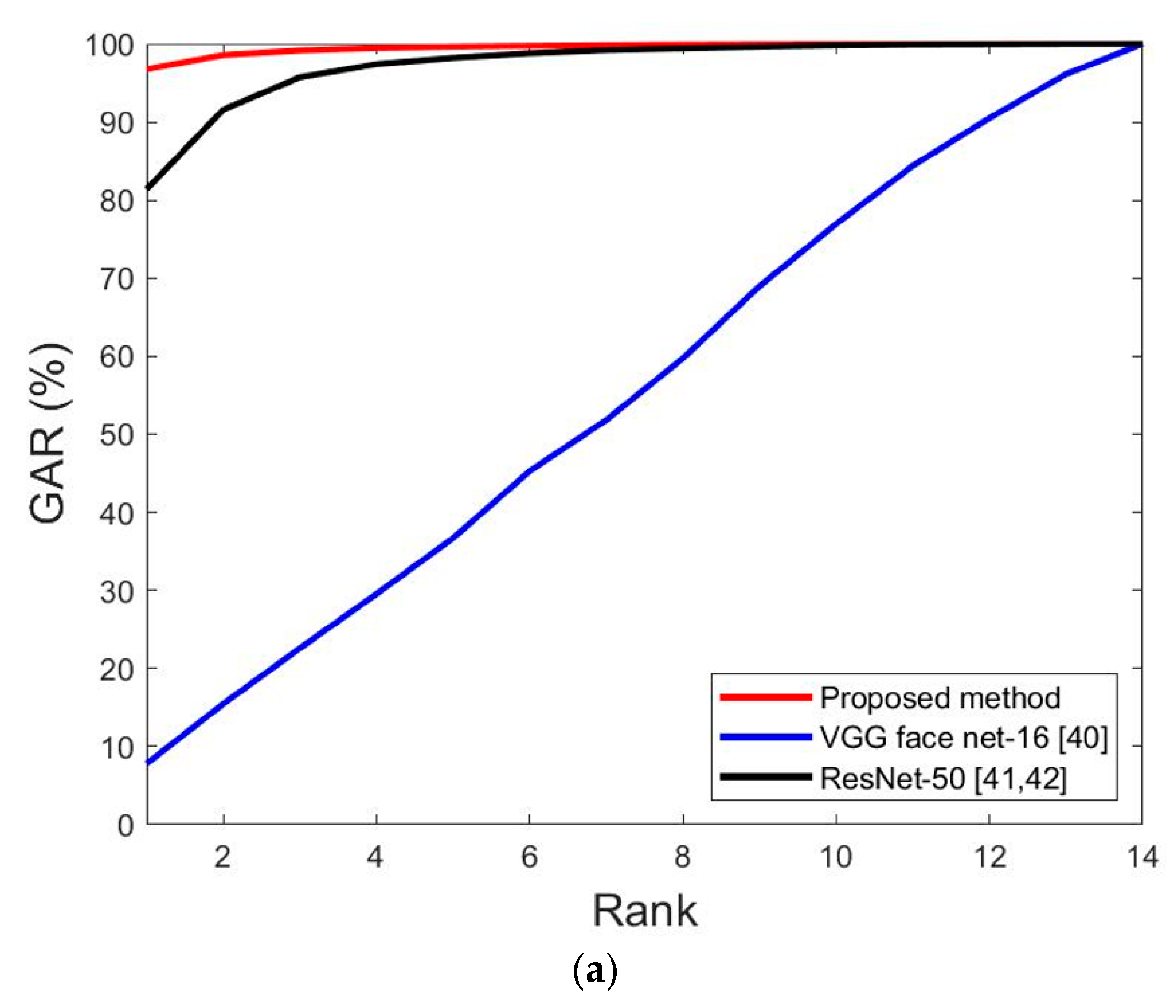
| VGG face net-16 [40] | 17.44 | 16.71 | 17.075 |
| ResNet-50 [41,42] | 13.96 | 14.06 | 14.01 |
| Method | 1st Fold | 2nd Fold | Average |
|---|---|---|---|
| Proposed method | 9.835 | 5.552 | 7.694 |
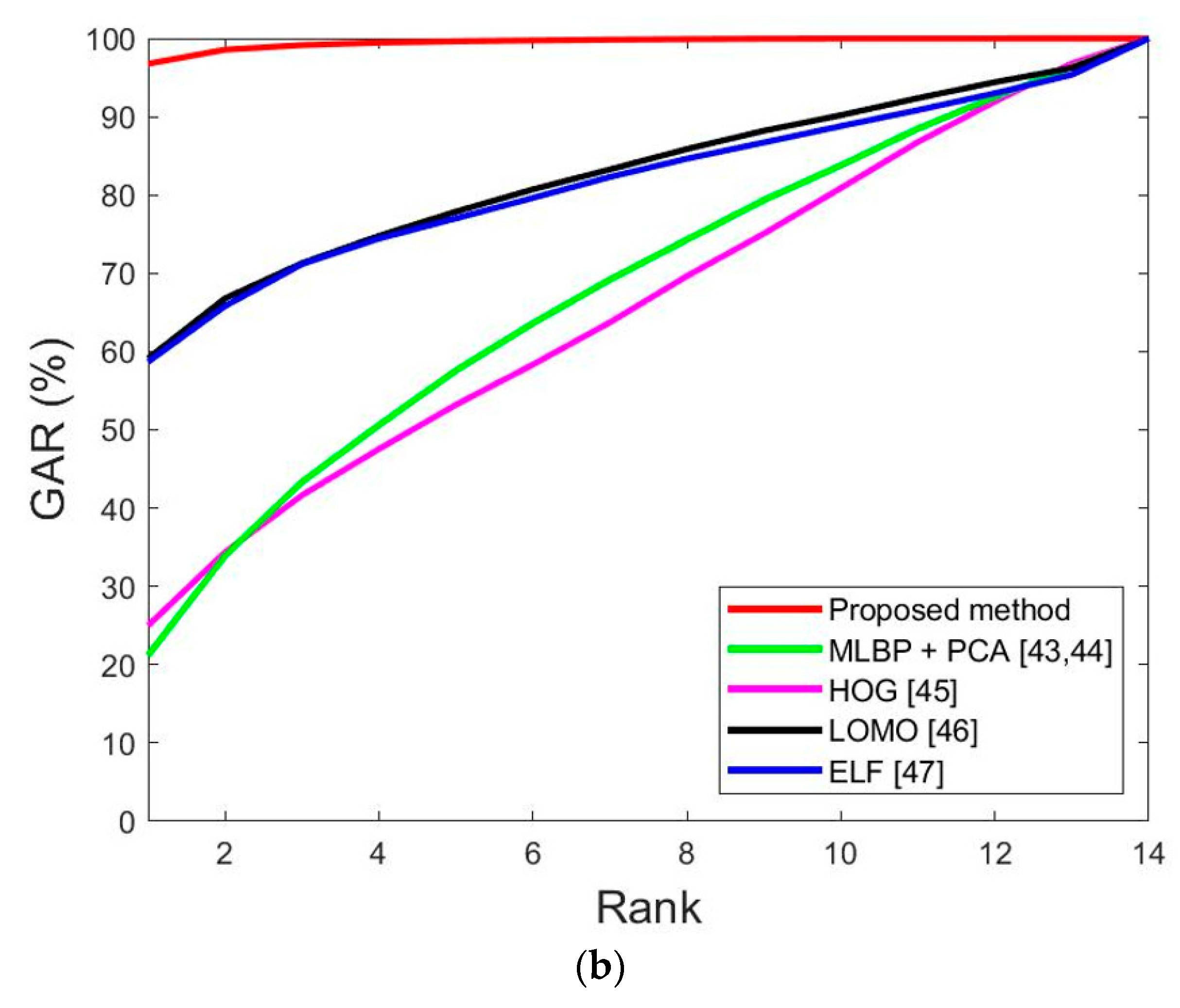
| MLBP + PCA [43,44] | 29.38 | 27.84 | 28.61 |
| HOG [45] | 38.09 | 44.14 | 41.12 |
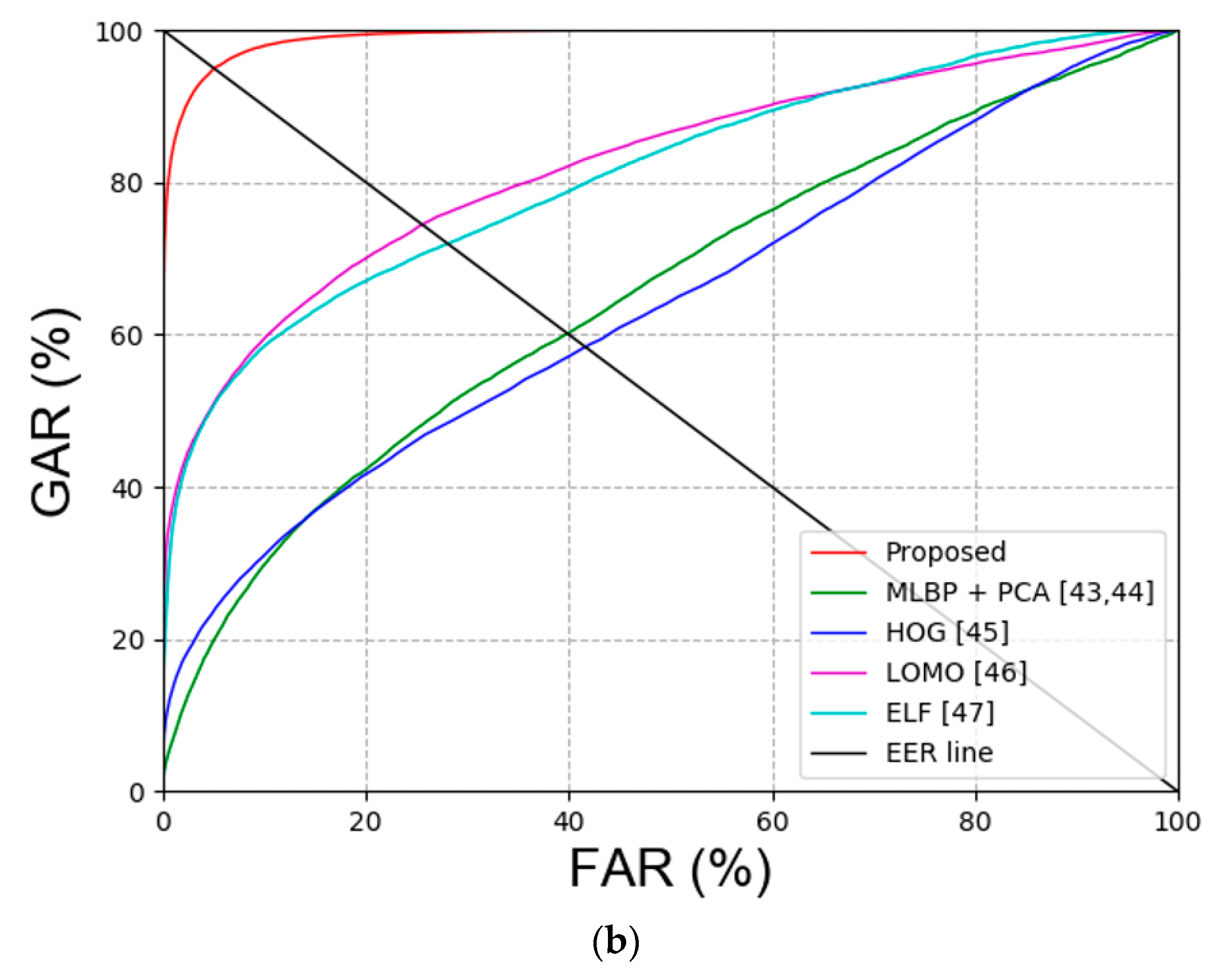
| LOMO [46] | 21.98 | 23.4 | 22.69 |
| ELF [47] | 20.91 | 23.87 | 22.39 |
| Method | Face | Body | |
|---|---|---|---|
| Without DeblurGAN (without focus score checking) | 1st fold | 11.76 | 18.50 |
| 2nd fold | 8.09 | 18.46 | |
| Average | 9.925 | 18.48 | |
| With DeblurGAN (with focus score checking) | 1st fold | 7.05 | 15.97 |
| 2nd fold | 6.39 | 15.2 | |
| Average | 6.72 | 15.585 | |
| Method | Score-Level Fusion | ||
|---|---|---|---|
| Weighted Sum | Weighted Product | ||
| Without DeblurGAN (without focus score checking) | 1st fold | 9.84 | 9.79 |
| 2nd fold | 6.55 | 6.43 | |
| Average | 8.195 | 8.11 | |
| With DeblurGAN (with focus score checking) | 1st fold | 5.162 | 5.163 |
| 2nd fold | 4.99 | 4.975 | |
| Average | 5.076 | 5.069 | |
| Method | 1st Fold | 2nd Fold | Average | |
|---|---|---|---|---|
| Face | Proposed method | 7.05 | 6.39 | 6.72 |
| CycleGAN [20] | 9.05 | 6.43 | 7.74 | |
| Body | Proposed method | 15.97 | 15.2 | 15.585 |
| CycleGAN [20] | 18.41 | 20.41 | 19.41 | |
| Weighted sum | Proposed method | 5.162 | 4.99 | 5.076 |
| CycleGAN [20] | 7.05 | 5.331 | 6.1905 | |
| Weighted product | Proposed method | 5.163 | 4.975 | 5.069 |
| CycleGAN [20] | 7.023 | 5.362 | 6.1925 | |
| Method | 1st Fold | 2nd Fold | Average |
|---|---|---|---|
| Proposed method | 5.163 | 4.975 | 5.069 |
| VGG face net-16 [40] | 49.29 | 48.25 | 48.77 |
| ResNet-50 [41,42] | 12.93 | 16.97 | 14.95 |
| Method | 1st Fold | 2nd Fold | Average |
|---|---|---|---|
| Proposed method | 5.163 | 4.975 | 5.069 |
| MLBP + PCA [43,44] | 37.75 | 42.38 | 40.07 |
| HOG [45] | 41.84 | 41.47 | 41.66 |
| LOMO [46] | 29.7 | 21.57 | 25.635 |
| ELF [47] | 31.93 | 23.94 | 27.935 |
| Platform | DeblurGAN |
|---|---|
| Desktop computer | 32 |
| Jetson TX2 | 349 |
| Platform | VGG Face Net-16 | ResNet-50 | Total |
|---|---|---|---|
| Desktop computer | 24.8 | 18.92 | 43.72 |
| Jetson TX2 | 91.9 | 40.8 | 132.7 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koo, J.H.; Cho, S.W.; Baek, N.R.; Park, K.R. Face and Body-Based Human Recognition by GAN-Based Blur Restoration. Sensors 2020, 20, 5229. https://doi.org/10.3390/s20185229
Koo JH, Cho SW, Baek NR, Park KR. Face and Body-Based Human Recognition by GAN-Based Blur Restoration. Sensors. 2020; 20(18):5229. https://doi.org/10.3390/s20185229
Chicago/Turabian StyleKoo, Ja Hyung, Se Woon Cho, Na Rae Baek, and Kang Ryoung Park. 2020. "Face and Body-Based Human Recognition by GAN-Based Blur Restoration" Sensors 20, no. 18: 5229. https://doi.org/10.3390/s20185229
APA StyleKoo, J. H., Cho, S. W., Baek, N. R., & Park, K. R. (2020). Face and Body-Based Human Recognition by GAN-Based Blur Restoration. Sensors, 20(18), 5229. https://doi.org/10.3390/s20185229