Detecting Defects on Solid Wood Panels Based on an Improved SSD Algorithm


Abstract
:1. Introduction
2. Materials and Methods
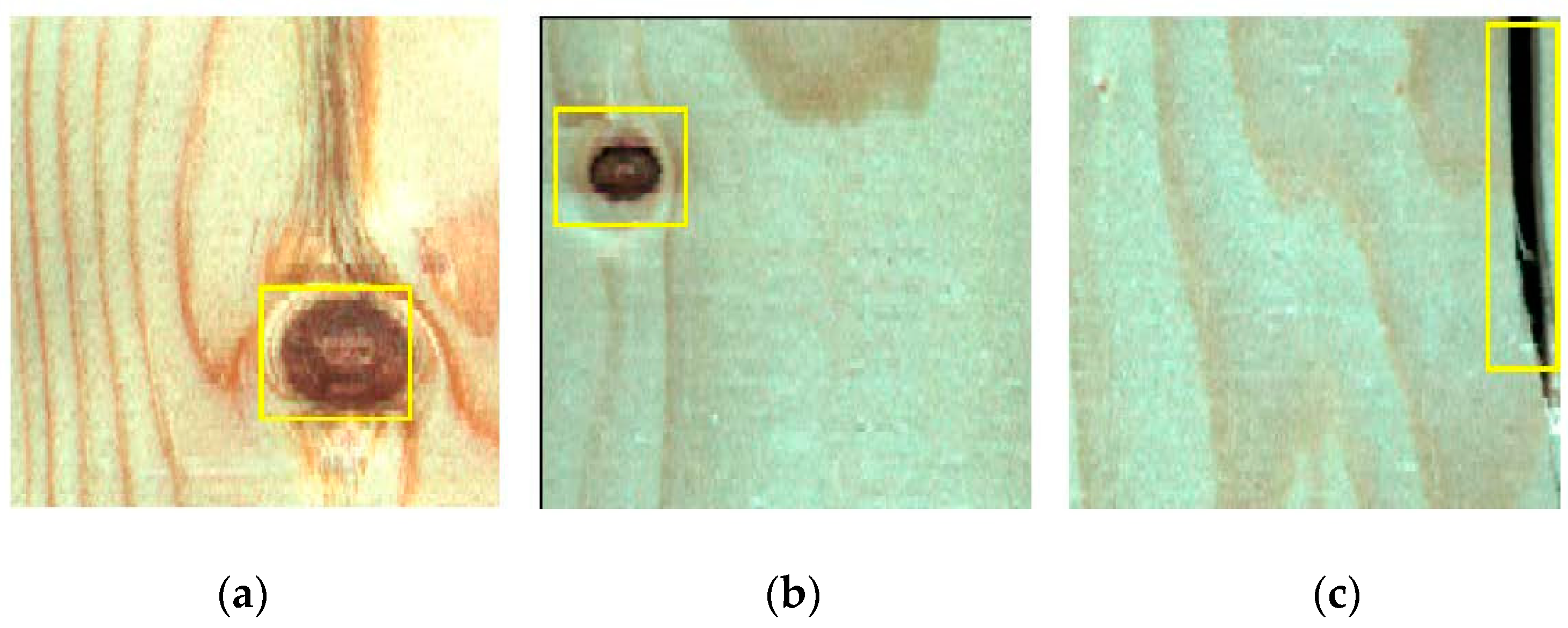
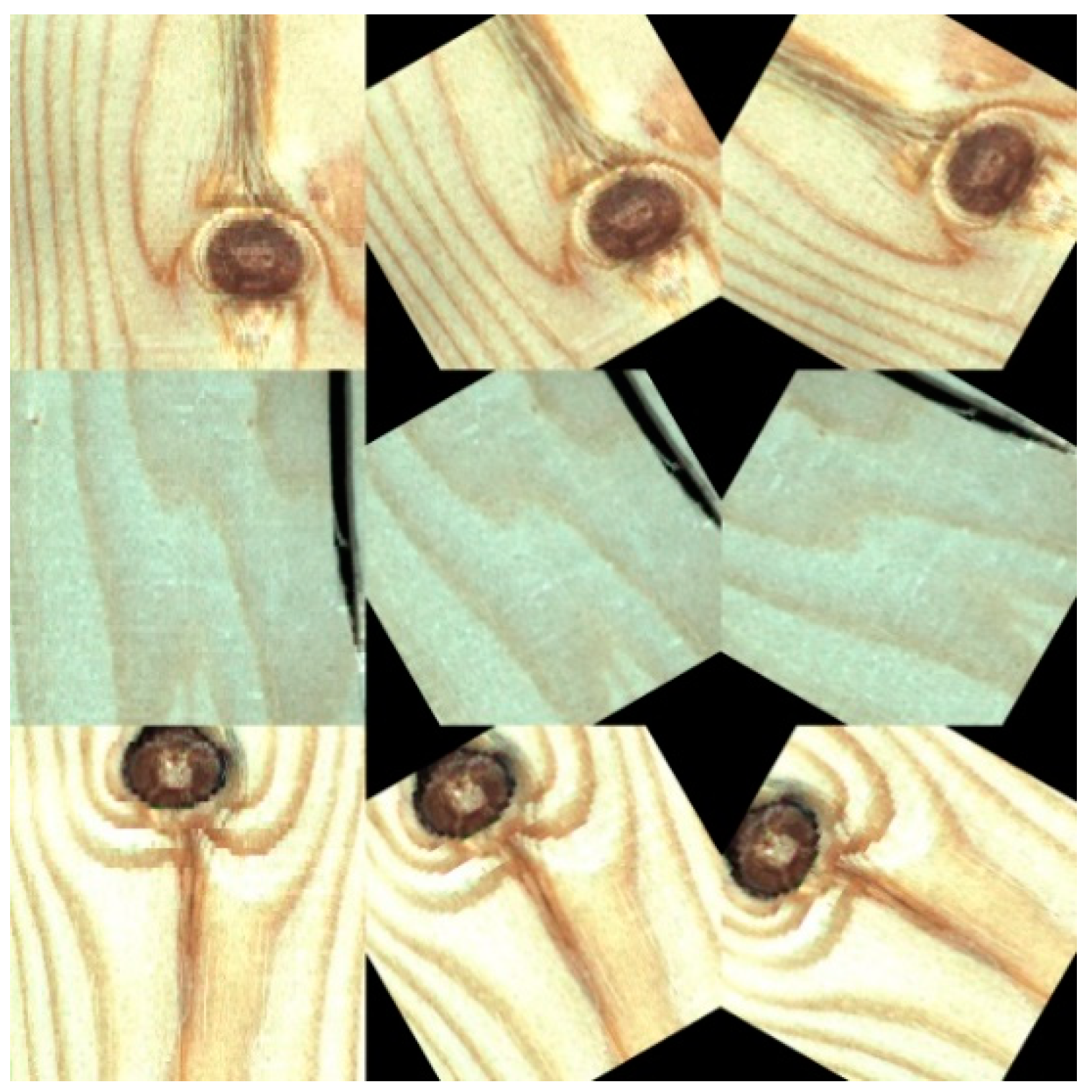
2.1. Wood Surface Defect Dataset
2.2. Original Network
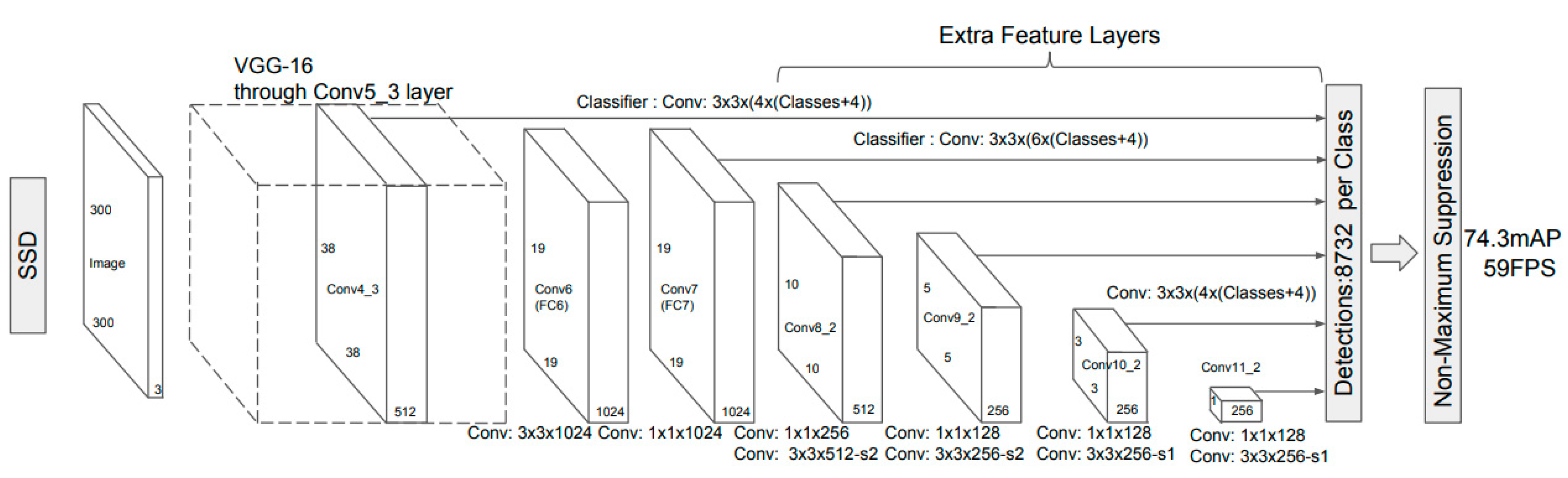
2.2.1. Network Backbone
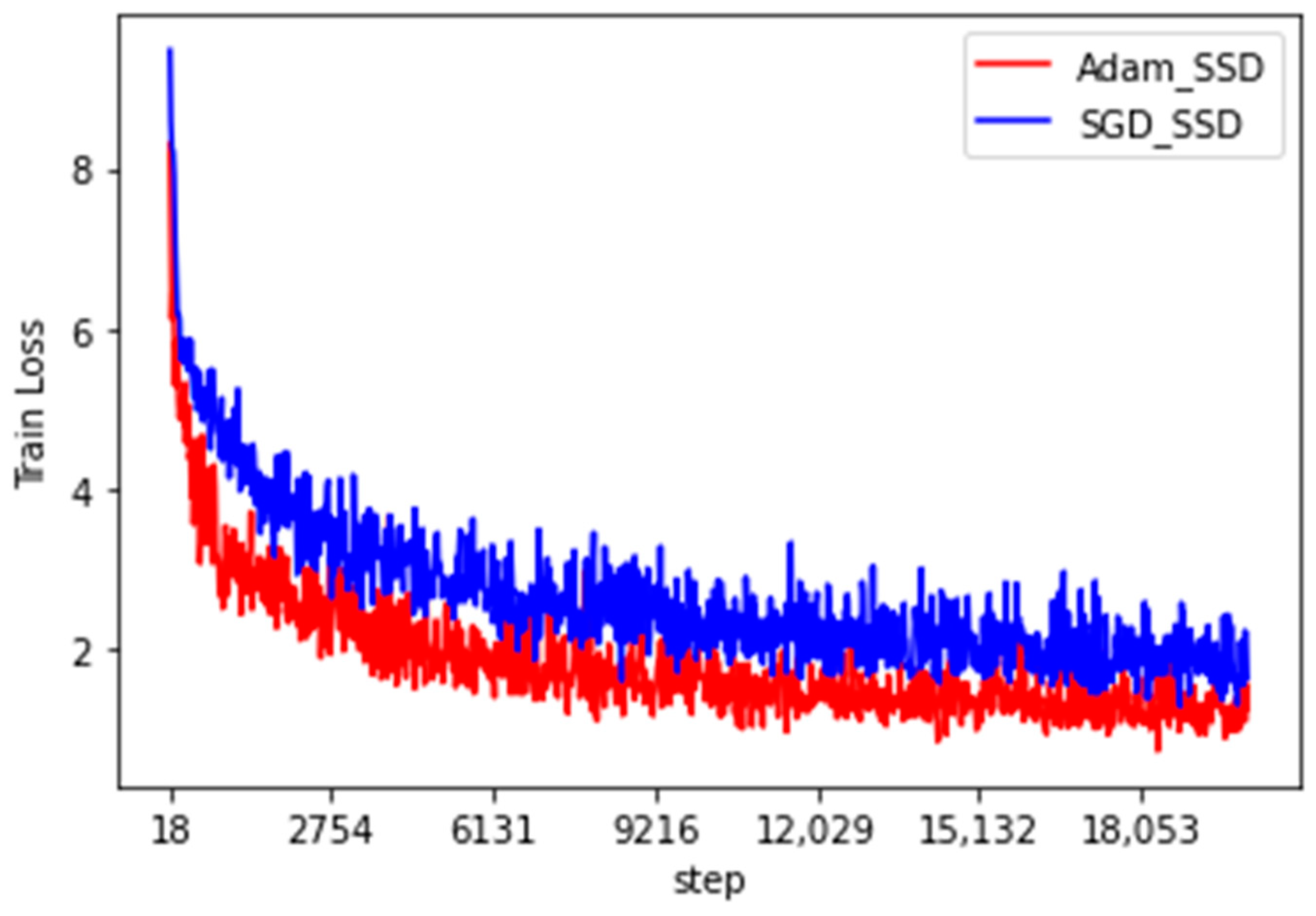
2.2.2. Verifying the Original Network
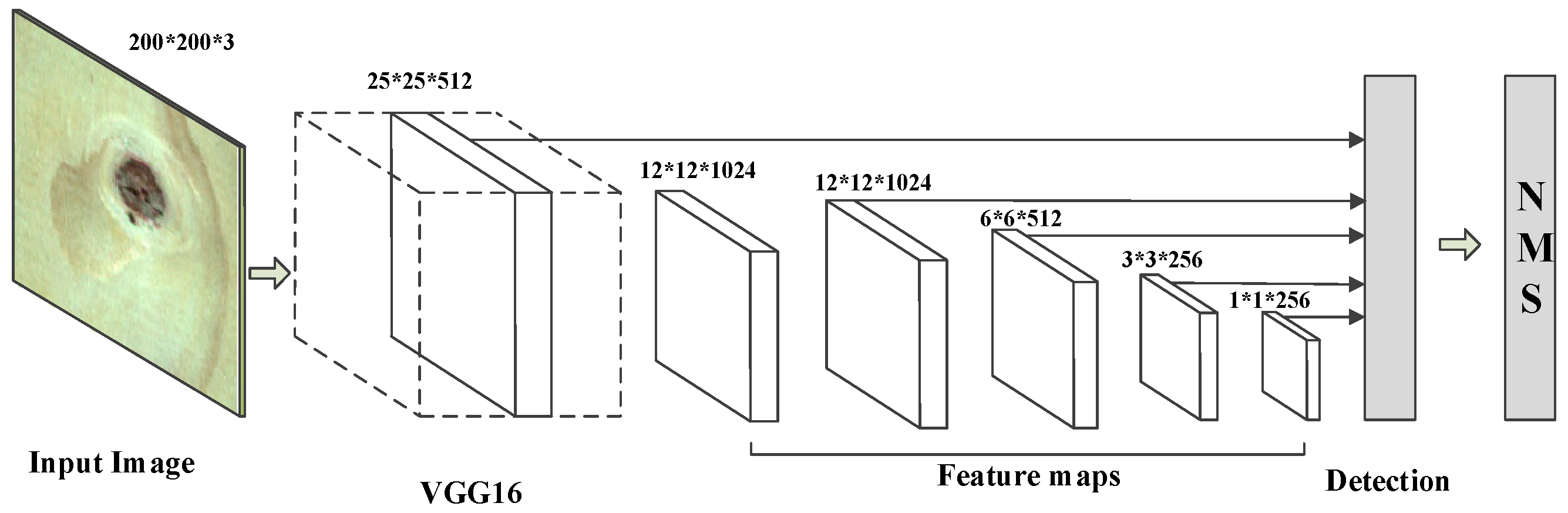
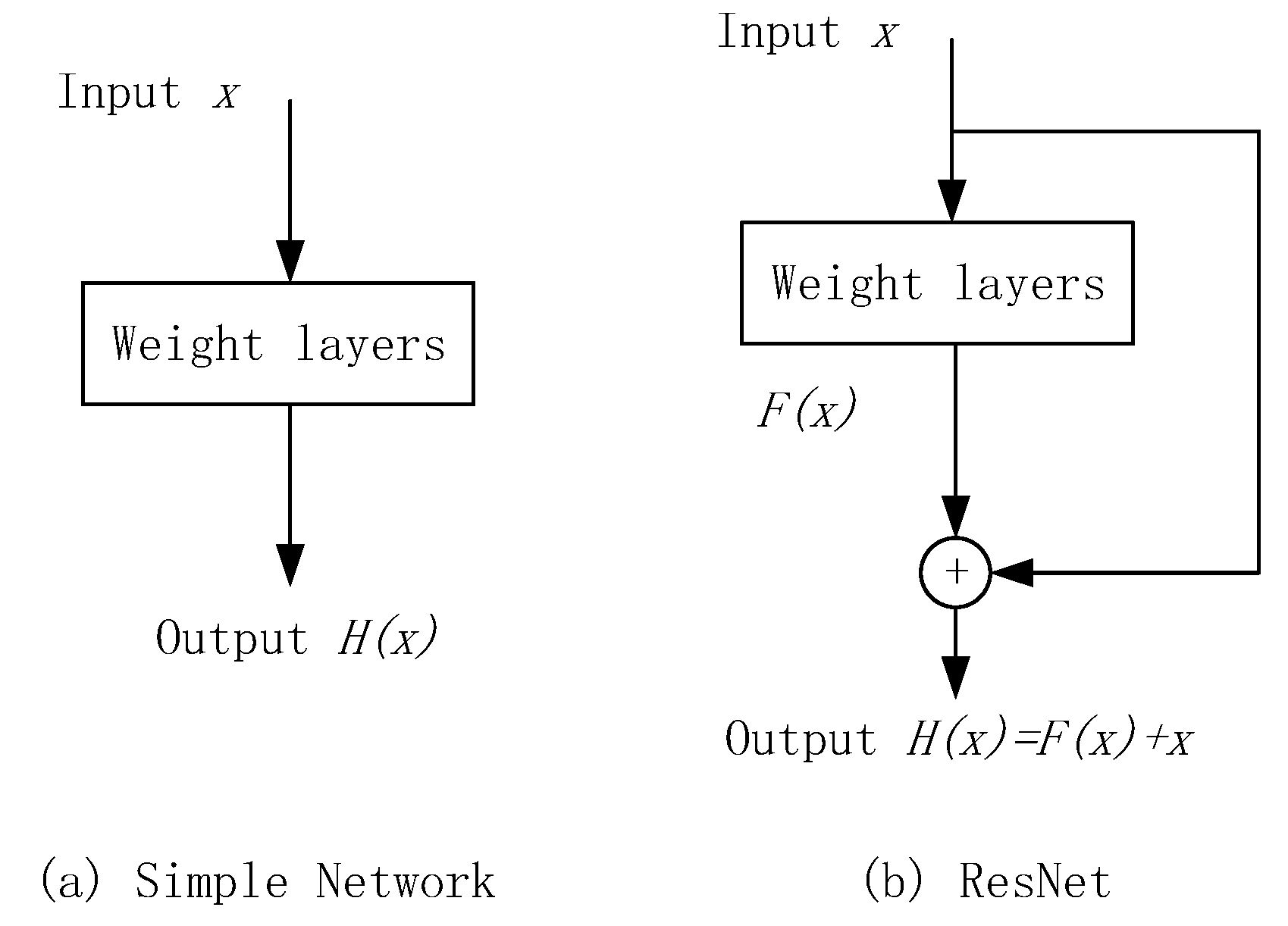
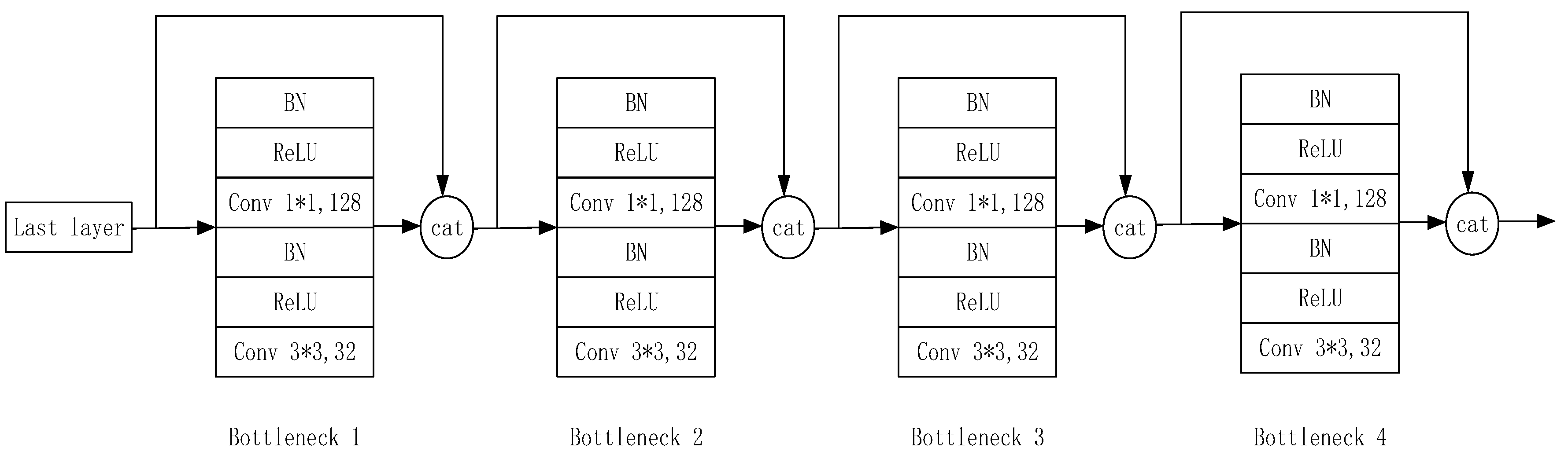
2.3. Network Improvement Method
3. Experiment and Results
3.1. Model Performance Indicators
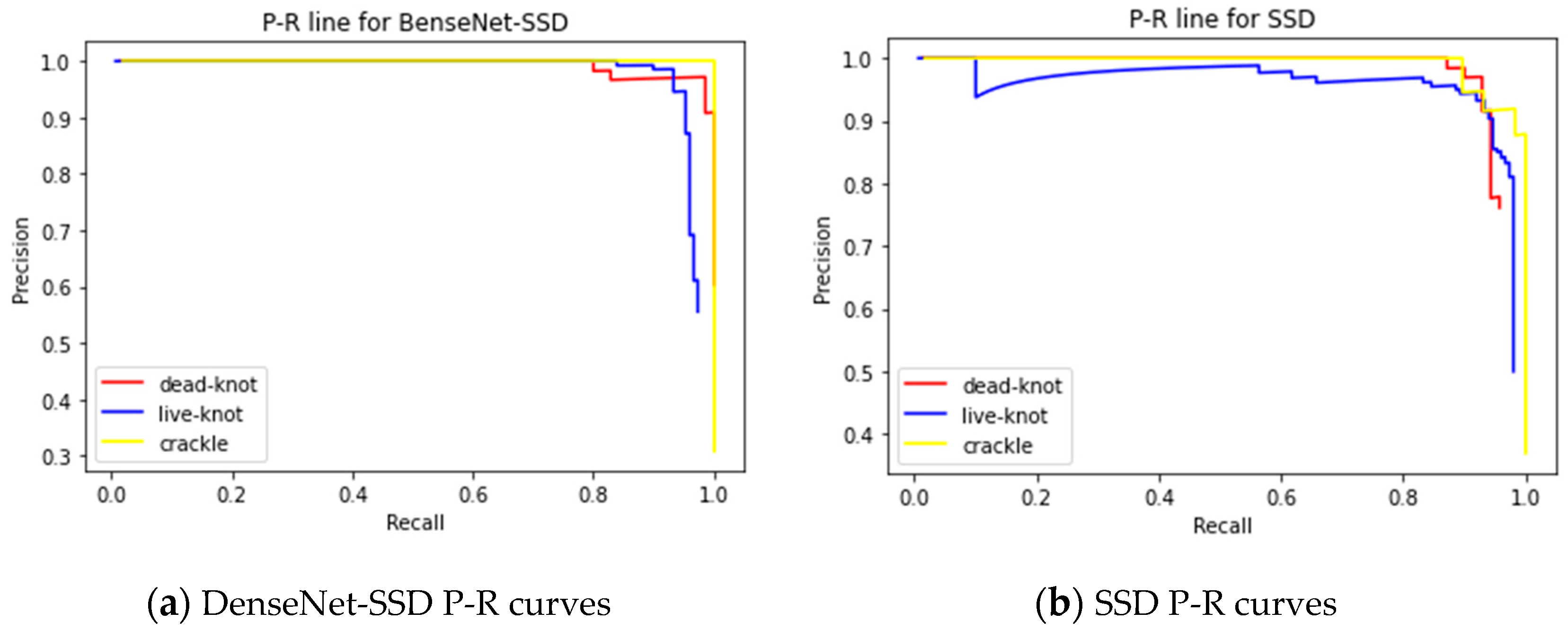
3.2. Experimental Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Fan, J.; Liu, Y.; Hu, Z.; Zhao, Q.; Shen, L.; Zhou, X. Solid wood panel defect detection and recognition system based on Faster R-CNN. J. For. Eng. 2019, 4, 112–117. [Google Scholar] [CrossRef]
- Anderson, G.C.; Owens, F.C.; Franca, F.; Ross, R.J.; Shmulsky, R. Correlations between Grain Angle Meter Readings and Bending Properties of Mill-Run Southern Pine Lumber. Forest Prod. J. 2020, 70, 275–278. [Google Scholar] [CrossRef]
- Kim, K. A note on the Hankinson formula. Wood Fiber Sci. 2007, 18, 345–348. [Google Scholar]
- Cao, J.; Liang, H.; Lin, X.; Tu, W.; Zhang, Y. Potential of Near-infrared Spectroscopy to Detect Defects on the Surface of Solid Wood Boards. Bioresources 2016, 12, 19–28. [Google Scholar] [CrossRef] [Green Version]
- Thumm, A.; Riddell, M. Resin defect detection in appearance lumber using 2D NIR spectroscopy. Eur. J. Wood Prod. 2017, 75, 995–1002. [Google Scholar] [CrossRef]
- Yu, H.; Liang, Y.; Liang, H.; Zhang, Y. Recognition of wood surface defects with near infrared spectroscopy and machine vision. J. For. Res. 2019, 30, 2379–2386. [Google Scholar] [CrossRef]
- Mousavi, M.; Taskhiri, M.S.; Holloway, D.; Olivier, J.; Turner, P. Feature extraction of wood-hole defects using empirical mode decomposition of ultrasonic signals. NDT E Int. 2020, 114, 102282. [Google Scholar] [CrossRef]
- Taskhiri, M.S.; Hafezi, M.H.; Harle, R.; Williams, D.; Kundu, T.; Turner, P. Ultrasonic and thermal testing to non-destructively identify internal defects in plantation eucalypts. Comput. Electron. Agric. 2020, 173. [Google Scholar] [CrossRef]
- Yang, H.; Yu, L. Feature extraction of wood-hole defects using wavelet-based ultrasonic testing. J. For. Res. 2016, 28, 395–402. [Google Scholar] [CrossRef]
- Wang, Q.P.; Liu, X.; Yang, S.M. Predicting Density and Moisture Content of Populus xiangchengensis and Phyllostachys edulis using the X-Ray Computed Tomography Technique. For. Prod. J. 2020, 70, 193–199. [Google Scholar] [CrossRef]
- Rummukainen, H.; Makkonen, M.; Uusitalo, J. Economic value of optical and X-ray CT scanning in bucking of Scots pine. Wood Mater. Sci. Eng. 2019, 1–10. [Google Scholar] [CrossRef]
- Qin, R.; Qiu, Q.; Lam, J.H.M.; Tang, A.M.C.; Leung, M.W.K.; Lau, D. Health assessment of tree trunk by using acoustic-laser technique and sonic tomography. Wood Sci. Technol. 2018, 52, 1113–1132. [Google Scholar] [CrossRef]
- Qiu, Q.W.; Lau, D. Grain effect on the accuracy of defect detection in wood structure by using acoustic-laser technique. Proc. SPIE 2019, 10971, 109710X. [Google Scholar] [CrossRef]
- Campbell, L.; Edwards, K.; LeMaster, R.; Velarde, G. The Use of Acoustic Emission to Detect Fines for Wood-Based Composites, Part One: Experimental Setup for Use on Particleboard. Bioresources 2018, 13, 8738–8750. [Google Scholar] [CrossRef]
- Li, X.C.; Li, M.; Ju, S. Frequency Domain Identification of Acoustic Emission Events of Wood Fracture and Variable Moisture Content. For. Prod. J. 2020, 70, 107–114. [Google Scholar] [CrossRef]
- Nasir, V.; Nourian, S.; Avramidis, S.; Cool, J. Stress wave evaluation for predicting the properties of thermally modified wood using neuro-fuzzy and neural network modeling. Holzforschung 2019, 73, 827–838. [Google Scholar] [CrossRef]
- Ni, C.; Li, Z.; Zhang, X.; Sun, X.; Huang, Y.; Zhao, L.; Zhu, T.; Wang, D. Online Sorting of the Film on Cotton Based on Deep Learning and Hyperspectral Imaging. IEEE Access 2020, 8, 93028–93038. [Google Scholar] [CrossRef]
- He, T.; Liu, Y.; Xu, C.; Zhou, X.; Hu, Z.; Fan, J. A Fully Convolutional Neural Network for Wood Defect Location and Identification. IEEE Access 2019, 7, 123453–123462. [Google Scholar] [CrossRef]
- Hu, K.; Wang, B.J.; Shen, Y.; Guan, J.R.; Cai, Y. Defect Identification Method for Poplar Veneer Based on Progressive Growing Generated Adversarial Network and MASK R-CNN Model. Bioresources 2020, 15, 3041–3052. [Google Scholar] [CrossRef]
- Shi, J.; Li, Z.; Zhu, T.; Wang, D.; Ni, C. Defect Detection of Industry Wood Veneer Based on NAS and Multi-Channel Mask R-CNN. Sensors 2020, 20, 4398. [Google Scholar] [CrossRef]
- Kurdthongmee, W.; Suwannarat, K. Locating Wood Pith in a Wood Stem Cross Sectional Image Using YOLO Object Detection. In Proceedings of the 2019 International Conference on Technologies and Applications of Artificial Intelligence (TAAI), Kaohsiung City, Taiwan, 21–23 November 2019. [Google Scholar]
- Franca, F.J.N.; Franca, T.S.F.A.; Seale, R.D.; Shmulsky, R. Nondestructive Evaluation of 2 by 8 and 2 by 10 Southern Pine Dimensional Lumber. Forest Prod. J. 2020, 70, 79–87. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE T Pattern Anal 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Neubeck, A.; Van Gool, L. Efficient Non-Maximum Suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, 20–24 August 2006; Volume 3, pp. 850–855. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Kamal, K.; Qayyum, R.; Mathavan, S.; Zafar, T. Wood defects classification using laws texture energy measures and supervised learning approach. Adv. Eng. Informatics 2017, 34, 125–135. [Google Scholar] [CrossRef]
- Xiao, J.Y.; Ma, Y.; Zhou, Z.; Fang, Y.M. Detection of Timber Surface Knots Based on Faster R-CNN. China Wood Ind. 2020, 34, 45–48. [Google Scholar] [CrossRef]
- Urbonas, A.; Raudonis, V.; Maskeliunas, R.; Damaševičius, R. Automated Identification of Wood Veneer Surface Defects Using Faster Region-Based Convolutional Neural Network with Data Augmentation and Transfer Learning. Appl. Sci. 2019, 9, 4898. [Google Scholar] [CrossRef] [Green Version]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Defect | Original Labels Data Set | Train Labels Data Set | Augmented Train Labels Data Set | Test Labels Data Set |
|---|---|---|---|---|
| Live knot | 491 | 342 | 1026 | 149 |
| Dead knot | 229 | 159 | 477 | 70 |
| Checking | 194 | 136 | 408 | 58 |
| Total | 914 | 637 | 1911 | 277 |
| Parameter | |
|---|---|
| System | Windows 10 × 64 |
| CPU | Inter Xeon [email protected] |
| GPU | Nvidia GeForce GTX 1080 Ti(11G) |
| Environment configuration | PyCharm + Pytorch1.2.0 + Python3.7.7 |
| Cuda10.0+cudnn7.6+tensorboardX2.1.0 |
| Optimizer | Defect | Average Precision | Mean Average Precision | Mean Detect Time |
|---|---|---|---|---|
| SGD (moment = 0.9) | Live knot | 89.7 ± 0.5% | 90.4 ± 0.5% | 30 ± 1 ms |
| Dead knot | 90.9 ± 0.5% | |||
| Checking | 90.7 ± 1% | |||
| Adam (betas = [0.9,0.99]) | Live knot | 90.2 ± 0.5% | 91.2 ± 0.5% | 17 ± 1 ms |
| Dead knot | 90.1 ± 0.5% | |||
| Checking | 93.4 ± 0.5% |
| ConvNet Configuration | |||||
|---|---|---|---|---|---|
| A | A-LRN | B | C | D | E |
| 11 weight layers | 11 weight layers | 13 weight layers | 16 weight layers | 16 weight layers | 19 weight layers |
| input (224 × 224 RGB image) | |||||
| conv3-64 | conv3-64 LRN | conv3-64 conv3-64 | conv3-64 conv3-64 | conv3-64 conv3-64 | conv3-64 conv3-64 |
| maxpool | |||||
| conv3-128 | conv3-128 | conv3-128 conv3-128 | conv3-128 conv3-128 | conv3-128 conv3-128 | conv3-128 conv3-128 |
| maxpool | |||||
| conv3-256 conv3-256 | conv3-256 conv3-256 | conv3-256 conv3-256 | conv3-256 conv3-256 conv1-256 | conv3-256 conv3-256 conv3-256 | conv3-256 conv3-256 conv3-256 conv3-256 |
| maxpool | |||||
| conv3-512 conv3-512 | conv3-512 conv3-512 | conv3-512 conv3-512 | conv3-512 conv3-512 conv1-512 | conv3-512 conv3-512 conv3-512 | conv3-512 conv3-512 conv3-512 conv3-512 |
| maxpool | |||||
| conv3-512 conv3-512 | conv3-512 conv3-512 | conv3-512 conv3-512 | conv3-512 conv3-512 conv1-512 | conv3-512 conv3-512 conv3-512 | conv3-512 conv3-512 conv3-512 conv3-512 |
| maxpool | |||||
| FC-4096 | |||||
| FC-4096 | |||||
| FC-1000 | |||||
| Soft-max | |||||
| Layers | DenseNet121 (k = 32) | Output Size | Channels |
|---|---|---|---|
| Input | 200 × 200 | 3 | |
| Convolution | 7 × 7 conv, stride 2 | 100 × 100 | 64 |
| Pooling | 3 × 3 max pool, stride 2 | 50 × 50 | 64 |
| Dense Block (1) | Bottleneck × 6 | 50 × 50 | 256 |
| Transition Layer (1) | 1 × 1 conv | 50 × 50 | 128 |
| 2 × 2 average pool, stride 2 | 25 × 25 | 128 | |
| Dense Block (2) | Bottleneck × 12 | 25 × 25 | 512 |
| Transition Layer (2) | 1 × 1 conv | 25 × 25 | 256 |
| 2 × 2 average pool, stride 2 | 12 × 12 | 256 | |
| Dense Block (3) | Bottleneck × 24 | 12 × 12 | 1024 |
| Transition Layer (3) | 1 × 1 conv | 12 × 12 | 512 |
| 2 × 2 average pool, stride 2 | 6 × 6 | 512 | |
| Dense Block (4) | Bottleneck × 16 | 6 × 6 | 1024 |
| Conv Layer | 1 × 1 conv | 6 × 6 | 1024 |
| Network | Defect | True Positive | False Positive | Recall | Average Precision | Mean Average Precision | Mean Detect Time |
|---|---|---|---|---|---|---|---|
| DenseNet-SSD | Live knot | 147 | 44 | 98.7% | 90.5 ± 0.3% | 96.1 ± 0.3% | 56 ± 1 ms |
| Dead knot | 70 | 8 | 100% | 98.6 ± 0.3% | |||
| Checking | 58 | 27 | 100% | 99.0 ± 0.3% |
| Algorithms | Mean Precision (%) | Time (ms) |
|---|---|---|
| mathematical morphology + ResNet152 | 83.4 | 1012 |
| Faster-RCNN | 93 | 870 |
| YOLO-tiny | 95.2 | 152 |
| SSD | 91.2 | 17 |
| DenseNet-SSD | 96.1 | 56 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, F.; Zhuang, Z.; Liu, Y.; Jiang, D.; Yan, X.; Wang, Z. Detecting Defects on Solid Wood Panels Based on an Improved SSD Algorithm. Sensors 2020, 20, 5315. https://doi.org/10.3390/s20185315
Ding F, Zhuang Z, Liu Y, Jiang D, Yan X, Wang Z. Detecting Defects on Solid Wood Panels Based on an Improved SSD Algorithm. Sensors. 2020; 20(18):5315. https://doi.org/10.3390/s20185315
Chicago/Turabian StyleDing, Fenglong, Zilong Zhuang, Ying Liu, Dong Jiang, Xiaoan Yan, and Zhengguang Wang. 2020. "Detecting Defects on Solid Wood Panels Based on an Improved SSD Algorithm" Sensors 20, no. 18: 5315. https://doi.org/10.3390/s20185315
APA StyleDing, F., Zhuang, Z., Liu, Y., Jiang, D., Yan, X., & Wang, Z. (2020). Detecting Defects on Solid Wood Panels Based on an Improved SSD Algorithm. Sensors, 20(18), 5315. https://doi.org/10.3390/s20185315