Radiomics for Gleason Score Detection through Deep Learning



Abstract
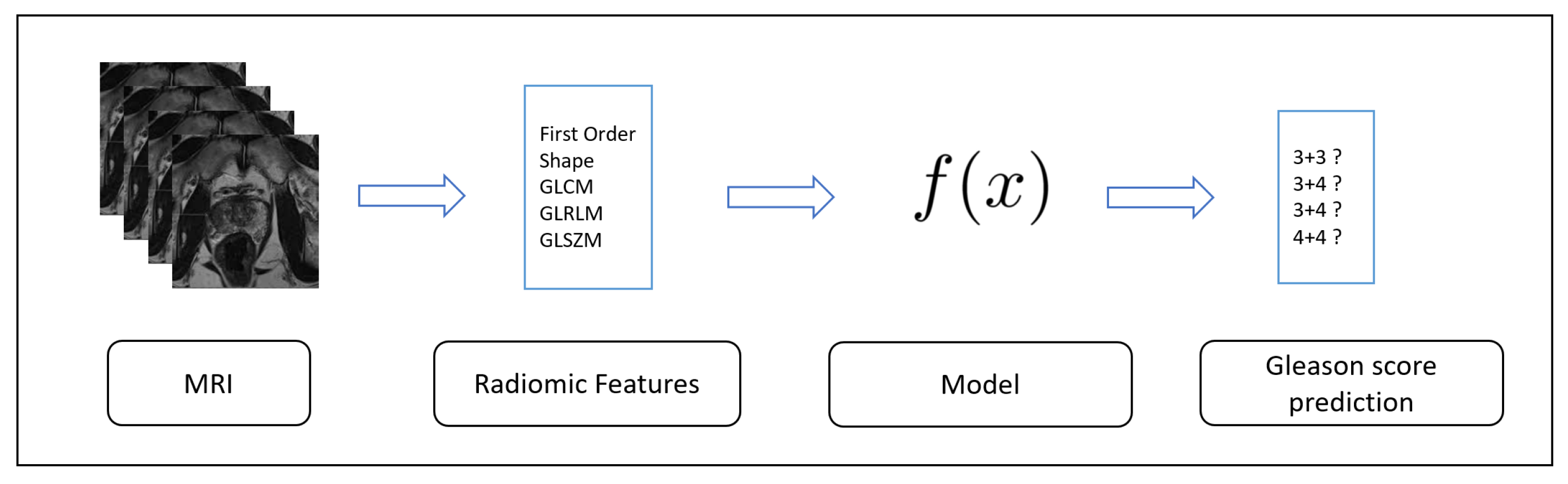
:1. Introduction
- 3 + 3 = 6: the attribution to this category is symptomatic of there being individual discrete well-formed glands (this category is representing the less aggressive one);
- 3 + 4 = 7: the cancer is mainly composed of well-formed glands, but a small component of poorly formed, fused and or cribriform glands appears;
- 4 + 3 = 7: the cancer is mainly composed of poorly formed, fused and/or cribriform glands with fewer well-formed glands;
- 4 + 4 = 8: when a cancer is labeled as belonging to this category, it is usually composed only of poorly formed, fused and/or cribriform glands.
- we propose a method aimed to automatically discriminate between different prostate cancers and healthy cases;
- we consider a set of 71 radiomic features obtainable directly from MRIs;
- we designed and implemented a deep architecture based on convolutional layers aimed to demonstrate the effectiveness of the proposed feature set in Gleason score detection;
- we cross-evaluated the proposed method using real-world MRIs for research purposes obtained from three datasets freely available for research purposes. We consider freely available datasets for easy result replication;
- we compare the proposed method with supervised machine learning algorithms and with the Embedded Localisation Features technique with the aim to demonstrate the effectiveness of the designed deep learning network;
- to provide a diagnostic tool useful for radiologists, we present the obtained results also at a patient-grain.
2. Method
2.1. The Radiomic Feature Set
2.2. The Classification Approach
2.3. The Deep Neural Network
- Input Layer: from each MRI we extract the 71 considered radiomic features. Each analyzed MRI is represented as a vector of 71 elements i.e., 71 neurons. This is the “height” of the dataset i.e., the length of one instance (i.e., an MRI) which is fed into the network (localized by the yellow point n. 1 in Figure 3). The yellow point n. 2 identifies the “width” of the instance which is fed into the network. In our case, this parameter is equal to 1 (the instance related to the MRI is modeled as a vector), the width is also referred to as the depth;
- 1D Convolution Layer: the first 1D convolutional layer. The yellow point n. 3 identifies the kernel size i.e., the size/height of the sliding windows that convolves across the data. It is also referred to as kernel size or filter length. We set this parameter equal to 10. With a height of 71 and a kernel size of 10, the window will slide through the data for 62 steps (). The yellow point n. 4 identifies the filters i.e., how many sliding windows will run through the data. We set this parameter as 20, and in this way, 20 different features can be detected in this layer (also called feature detectors). This is the reason why this operation is results in a 62 × 20 output matrix: this initial layer will learn the basic features. The considered activation function is relu (also for the others considered convolutional layers of the network), because usually models with the relu activation function neurons converge much faster than neurons with other activation functions. Basically, the relu function gives an output x if x is positive and 0 otherwise (the choice of the activation function is a parameter chosen by the network designer);
- 1D Convolution Layer: the second 1D convolutional layer. We set the kernel size as 10 and the filters as 20: considering that the input matrix belonging to the first convolutional layer is 62 × 20, the output of this layer is a 53 × 20 matrix ().
- 1D Convolution Layer: the third 1D convolutional layer. In this layer, we set the kernel size as 10 and the filters as 20. The input from the previous convolution layer is a 53 × 20 matrix, for this reason the output is resulting of a 44 × 20 matrix ();
- 1D Convolution Layer: the last 1D convolutional layer. It considers as the input from the third convolution layer a 44 × 20 matrix and, considering that, as in the previous layers, we set the kernel size as 10 and the filters as 20, it outputs a 35 × 20 matrix ();
- Pooling Layer: this kind of layer is usually considered after CNN layers with the aim to reduce the complexity. It is aimed to decrease the spatial dimensions. This step will prevent the overfitting of learned features by gathering the maximum value of multiple features using a sliding windows approach (yellow point n. 6 in Figure 3). In detail we consider a max-pooling layer, which slides a window in the same way as a normal convolution, and obtains the biggest value as the output (for instance from the matrix the result will be applying the max pooling with a size equal to 2). In the designed network, we consider a size equal to 3: the input 35 × 20 input matrix from the fourth convolutional layer is transformed in an 11 × 20 matrix. The output matrix size of this layer is a third of the input matrix;
- Flatten Layer: this layer is aimed to flat the layer input. As an example, a rows × columns matrix is flattened to a simple vector output of rows * columns shape. In this case the Flatten layer input is the 11 × 20 matrix, for this reason the output is a vector of 220 elements;
- Dropout Layer: we introduce another layer considered to prevent overfitting. This layer is aimed at randomly selecting neurons that are excluded in the training. In this way, their contribution is temporally avoided on the forward pass and, for this reason, any weight updates are not applied to the neuron on the backward pass. This improves generalization because we are forcing to learn, with different neurons, the same “concept”. We set the dropout parameter as 0.5:50% of neurons will be deactivated. Usually using the dropout layer, worse performances are obtained, but the aim is to trade training performance to obtain more generalization and the network will become less sensitive to smaller variations in the data;
- Dense Layer: this layer reduces the vector of height 220 to a vector of 5 elements (since we have to predict four different classes Gleason score based: 3 + 3, 3 + 3, 4 + 3 and 4 + 4 and the normal class i.e., the class related to healthy patients). This reduction is performed by matrix multiplication. We choose softmax as an activation function: it takes an un-normalized vector, and normalizes it into a probability distribution, it is usually considered for multiclass classification problems (yellow point n. 7 in Figure 3). The output will represent the probability for each of the four classes.
- Output Layer: the final output layer consists of five neurons (one for each class we have to represent) with included probability for each class. The neuron with the higher probability will be selected as a result of the prediction (yellow point n. 8 in Figure 3).
3. Results
3.1. Descriptive Statistics
3.2. Hypothesis Testing
3.3. Classification Analysis
- J48: bathSize equal to 100, confidence factor of :
- RF: bathSize 100, bagSizePercent 100, numIterations 100;
- BN: bathSize 100, maxParents 1.
- NN: epoch 10, batchsize of 100,
- SVM: kernel function degree equal to 3, batchsize of 100,
- kNN nearest neighbours equal to 1, batchsize of 100.
4. Discussion
4.1. Prostate Cancer Prediction
4.2. Prostate Cancer Prediction Using Radiomic Features
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gillies, R.J.; Kinahan, P.E.; Hricak, H. Radiomics: Images are more than pictures, they are data. Radiology 2016, 278, 563–577. [Google Scholar] [CrossRef] [Green Version]
- Aerts, H.J.; Velazquez, E.R.; Leijenaar, R.T.; Parmar, C.; Grossmann, P.; Carvalho, S.; Bussink, J.; Monshouwer, R.; Haibe-Kains, B.; Rietveld, D.; et al. Decoding tumour phenotype by noninvasive imaging using a quantitative radiomics approach. Nat. Commun. 2014, 5, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Shakir, H.; Deng, Y.; Rasheed, H.; Khan, T.M.R. Radiomics based likelihood functions for cancer diagnosis. Sci. Rep. 2019, 9, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Brunese, L.; Mercaldo, F.; Reginelli, A.; Santone, A. Explainable Deep Learning for Pulmonary Disease and Coronavirus COVID-19 Detection from X-rays. Comput. Methods Programs Biomed. 2020, 196, 105608. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef]
- Eren, L.; Ince, T.; Kiranyaz, S. A generic intelligent bearing fault diagnosis system using compact adaptive 1D CNN classifier. J. Signal Process. Syst. 2019, 91, 179–189. [Google Scholar] [CrossRef]
- Abo-Tabik, M.; Costen, N.; Darby, J.; Benn, Y. Towards a smart smoking cessation app: A 1D-CNN model predicting smoking events. Sensors 2020, 20, 1099. [Google Scholar] [CrossRef] [Green Version]
- Jana, G.C.; Sharma, R.; Agrawal, A. A 1D-CNN-Spectrogram Based Approach for Seizure Detection from EEG Signal. Procedia Comput. Sci. 2020, 167, 403–412. [Google Scholar] [CrossRef]
- Hectors, S.J.; Cherny, M.; Yadav, K.K.; Beksaç, A.T.; Thulasidass, H.; Lewis, S.; Davicioni, E.; Wang, P.; Tewari, A.K.; Taouli, B. Radiomics Features Measured with Multiparametric Magnetic Resonance Imaging Predict Prostate Cancer Aggressiveness. J. Urol. 2019, 202, 498–505. [Google Scholar] [CrossRef]
- Brunese, L.; Mercaldo, F.; Reginelli, A.; Santone, A. An ensemble learning approach for brain cancer detection exploiting radiomic features. Comput. Methods Programs Biomed. 2020, 185, 105134. [Google Scholar] [CrossRef] [PubMed]
- Van Griethuysen, J.J.; Fedorov, A.; Parmar, C.; Hosny, A.; Aucoin, N.; Narayan, V.; Beets-Tan, R.G.; Fillion-Robin, J.C.; Pieper, S.; Aerts, H.J. Computational radiomics system to decode the radiographic phenotype. Cancer Res. 2017, 77, e104–e107. [Google Scholar] [CrossRef] [Green Version]
- Brunese, L.; Mercaldo, F.; Reginelli, A.; Santone, A. Formal methods for prostate cancer Gleason score and treatment prediction using radiomic biomarkers. Magn. Reson. Imaging 2019, 66, 165–175. [Google Scholar] [CrossRef] [PubMed]
- Brunese, L.; Mercaldo, F.; Reginelli, A.; Santone, A. Prostate gleason score detection and cancer treatment through real-time formal verification. IEEE Access 2019, 7, 186236–186246. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Jais, I.K.M.; Ismail, A.R.; Nisa, S.Q. Adam optimization algorithm for wide and deep neural network. Knowl. Eng. Data Sci. 2019, 2, 41–46. [Google Scholar] [CrossRef]
- Massich, J.; Rastgoo, M.; Lemaître, G.; Cheung, C.Y.; Wong, T.Y.; Sidibé, D.; Mériaudeau, F. Classifying DME vs normal SD-OCT volumes: A review. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 1297–1302. [Google Scholar]
- Lemaître, G.; Martí, R.; Freixenet, J.; Vilanova, J.C.; Walker, P.M.; Meriaudeau, F. Computer-aided detection and diagnosis for prostate cancer based on mono and multi-parametric MRI: A review. Comput. Biol. Med. 2015, 60, 8–31. [Google Scholar] [CrossRef] [Green Version]
- Benbihi, A.; Geist, M.; Pradalier, C. ELF: Embedded Localisation of Features in pre-trained CNN. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–3 November 2019; pp. 7940–7949. [Google Scholar]
- Tabesh, A.; Teverovskiy, M.; Pang, H.Y.; Kumar, V.P.; Verbel, D.; Kotsianti, A.; Saidi, O. Multifeature prostate cancer diagnosis and Gleason grading of histological images. IEEE Trans. Med. Imaging 2007, 26, 1366–1378. [Google Scholar] [CrossRef]
- Arvaniti, E.; Fricker, K.S.; Moret, M.; Rupp, N.J.; Hermanns, T.; Fankhauser, C.; Wey, N.; Wild, P.J.; Rueschoff, J.H.; Claassen, M. Automated Gleason grading of prostate cancer tissue microarrays via deep learning. bioRxiv 2018, 8, 12056. [Google Scholar] [CrossRef]
- Kumar, N.; Verma, R.; Arora, A.; Kumar, A.; Gupta, S.; Sethi, A.; Gann, P.H. Convolutional neural networks for prostate cancer recurrence prediction. In Proceedings of the Medical Imaging 2017: Digital Pathology, Orlando, FL, USA, 11–16 February 2017. [Google Scholar]
- Nagpal, K.; Foote, D.; Liu, Y.; Chen, P.; Wulczyn, E.; Tan, F.; Olson, N.; Smith, J.L.; Mohtashamian, A.; Wren, J.H.; et al. Development and Validation of a Deep Learning Algorithm for Improving Gleason Scoring of Prostate Cancer. CoRR 2018. Available online: http://xxx.lanl.gov/abs/1811.06497 (accessed on 20 August 2020). [CrossRef] [PubMed] [Green Version]
- Tan, A.C.; Gilbert, D. Ensemble Machine Learning on Gene Expression Data for Cancer Classification. Ph.D. Thesis, Brunel University, Wellington, New Zealand, 13–14 February 2003. [Google Scholar]
- Hussain, L.; Ahmed, A.; Saeed, S.; Rathore, S.; Awan, I.A.; Shah, S.A.; Majid, A.; Idris, A.; Awan, A.A. Prostate cancer detection using machine learning techniques by employing combination of features extracting strategies. Cancer Biomark. 2018, 21, 393–413. [Google Scholar] [CrossRef] [PubMed]
- Chaddad, A.; Kucharczyk, M.; Niazi, T. Multimodal Radiomic Features for the Predicting Gleason Score of Prostate Cancer. Cancers 2018, 10, 249. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khalvati, F.; Wong, A.; Haider, M.A. Automated prostate cancer detection via comprehensive multi-parametric magnetic resonance imaging texture feature models. BMC Med Imaging 2015, 15, 27. [Google Scholar] [CrossRef] [Green Version]
- Vos, P.C.; Hambrock, T.; Barenstz, J.O.; Huisman, H.J. Computer-assisted analysis of peripheral zone prostate lesions using T2-weighted and dynamic contrast enhanced T1-weighted MRI. Phys. Med. Biol. 2010, 55, 1719. [Google Scholar] [CrossRef]
- Doyle, S.; Madabhushi, A.; Feldman, M.; Tomaszeweski, J. A boosting cascade for automated detection of prostate cancer from digitized histology. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Copenhagen, Denmark, 2006; pp. 504–511. [Google Scholar]
- Zhang, Y.; Li, Q.; Xin, Y.; Lv, W. Differentiating prostate cancer from benign prostatic hyperplasia using PSAD based on machine learning: Single-center retrospective study in China. IEEE/ACM Trans. Comput. Biol. Bioinform. 2018, 16, 936–941. [Google Scholar] [CrossRef]
- Huang, F.; Ing, N.; Eric, M.; Salemi, H.; Lewis, M.; Garraway, I.; Gertych, A.; Knudsen, B. Abstract B094: Quantitative Digital Image Analysis and Machine Learning for Staging of Prostate Cancer at Diagnosis. 2018. Available online: https://cancerres.aacrjournals.org/content/78/16_Supplement/B094 (accessed on 20 September 2020).
- Nguyen, T.H.; Sridharan, S.; Marcias, V.; Balla, A.K.; Do, M.N.; Popescu, G. Automatic Gleason grading of prostate cancer using SLIM and machine learning. In Quantitative Phase Imaging II; International Society for Optics and Photonics: San Diego, CA, USA, 2016; Volume 9718, p. 97180Y. [Google Scholar]
- Cao, H.; Bernard, S.; Sabourin, R.; Heutte, L. Random forest dissimilarity based multi-view learning for Radiomics application. Pattern Recognit. 2019, 88, 185–197. [Google Scholar] [CrossRef]
- Junior, J.R.F.; Koenigkam-Santos, M.; Cipriano, F.E.G.; Fabro, A.T.; de Azevedo-Marques, P.M. Radiomics- based features for pattern recognition of lung cancer histopathology and metastases. Comput. Methods Programs Biomed. 2018, 159, 23–30. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # Feature | Wald–Wolfowitz | Mann–Whitney | Test Result |
|---|---|---|---|
| [1–8] | p < 0.001 | p < 0.001 | passed |
| 9 | p < 0.001 | p < 0.001 | passed |
| [10–14] | p < 0.001 | p < 0.001 | passed |
| 15 | p > 0.10 | p < 0.001 | not passed |
| 16 | p > 0.10 | p > 0.10 | not passed |
| [17–19] | p < 0.001 | p < 0.001 | passed |
| 20 | p < 0.001 | p < 0.001 | passed |
| 21 | p > 0.10 | p > 0.10 | not passed |
| 22 | p < 0.001 | p < 0.001 | passed |
| 23 | p < 0.001 | p < 0.001 | passed |
| 24 | p < 0.001 | p < 0.001 | passed |
| 25 | p < 0.001 | p < 0.001 | passed |
| 26 | p < 0.001 | p < 0.001 | passed |
| [27–28] | p > 0.10 | p > 0.10 | not passed |
| 29 | p < 0.001 | p < 0.001 | passed |
| 30 | p < 0.001 | p < 0.001 | passed |
| 31 | p < 0.001 | p < 0.001 | passed |
| 32 | p < 0.001 | p < 0.001 | passed |
| [33–36] | p < 0.001 | p < 0.001 | passed |
| 37 | p < 0.001 | p < 0.001 | passed |
| 38 | p < 0.001 | p < 0.001 | passed |
| 39 | p < 0.001 | p < 0.001 | passed |
| 40 | p < 0.001 | p < 0.001 | passed |
| [41–42] | p < 0.001 | p < 0.001 | passed |
| 43 | p > 0.10 | p > 0.10 | not passed |
| 44 | p > 0.10 | p > 0.10 | not passed |
| 45 | p < 0.001 | p < 0.001 | passed |
| 46 | p < 0.001 | p < 0.001 | passed |
| 47 | p < 0.001 | p < 0.001 | passed |
| 48 | p < 0.001 | p < 0.001 | passed |
| 49 | p < 0.001 | p < 0.001 | passed |
| 50 | p < 0.001 | p < 0.001 | passed |
| 51 | p < 0.001 | p < 0.001 | passed |
| 52 | p < 0.001 | p < 0.001 | passed |
| 53 | p < 0.001 | p < 0.001 | passed |
| 54 | p < 0.001 | p < 0.001 | passed |
| 55 | p < 0.001 | p < 0.001 | passed |
| 56 | p > 0.10 | p < 0.001 | not passed |
| 57 | p < 0.001 | p < 0.001 | passed |
| [58–62] | p < 0.001 | p < 0.001 | passed |
| 63 | p < 0.001 | p < 0.001 | passed |
| 64 | p < 0.001 | p < 0.001 | passed |
| 65 | p < 0.001 | p < 0.001 | passed |
| 66 | p > 0.10 | p > 0.10 | not passed |
| 67 | p < 0.001 | p < 0.001 | passed |
| 68 | p < 0.001 | p < 0.001 | passed |
| 69 | p < 0.001 | p < 0.001 | passed |
| 70 | p < 0.001 | p < 0.001 | passed |
| 71 | p < 0.001 | p < 0.001 | passed |
| Label | TD#1 | ED#1 | ED#2 | Tot |
|---|---|---|---|---|
| 123 | 31 | 78 | 232 | |
| 270 | 68 | 234 | 572 | |
| 138 | 35 | 182 | 355 | |
| 127 | 32 | 182 | 341 | |
| normal | 200 | 50 | 50 | 300 |
| Label | Sens. | Spec. | Acc. |
|---|---|---|---|
| 0.98 | 0.98 | 0.98 | |
| 0.96 | 0.97 | 0.96 | |
| 0.98 | 0.99 | 0.98 | |
| 0.97 | 0.98 | 0.97 | |
| normal | 0.96 | 0.97 | 0.96 |
| Algorithm | Sensitivity | Specificity | Accuracy | Label |
|---|---|---|---|---|
| 0.76 | 0.77 | 0.76 | 3 + 3 | |
| 0.77 | 0.77 | 0.76 | 3 + 4 | |
| J48 | 0.76 | 0.75 | 0.76 | 4 + 3 |
| 0.74 | 0.73 | 0.74 | 4 + 4 | |
| 0.72 | 0.72 | 0.73 | normal | |
| 0.78 | 0.079 | 0.79 | 3 + 3 | |
| 0.77 | 0.77 | 0.77 | 3 + 4 | |
| RF | 0.76 | 0.77 | 0.76 | 4 + 3 |
| 0.78 | 0.78 | 0.78 | 4 + 4 | |
| 0.75 | 0.76 | 0.75 | normal | |
| 0.76 | 0.77 | 0.76 | 3 + 3 | |
| 0.75 | 0.75 | 0.75 | 3 + 4 | |
| BN | 0.75 | 0.76 | 0.75 | 4 + 3 |
| 0.76 | 0.76 | 0.76 | 4 + 4 | |
| 0.77 | 0.76 | 0.77 | normal | |
| 0.80 | 0.79 | 0.80 | 3 + 3 | |
| 0.79 | 0.79 | 0.79 | 3 + 4 | |
| NN | 0.80 | 0.81 | 0.80 | 4 + 3 |
| 0.81 | 0.80 | 0.80 | 4 + 4 | |
| 0.82 | 0.80 | 0.81 | normal | |
| 0.85 | 0.84 | 0.86 | 3 + 3 | |
| 0.84 | 0.85 | 0.85 | 3 + 4 | |
| SVM | 0.86 | 0.87 | 0.87 | 4 + 3 |
| 0.87 | 0.86 | 0.87 | 4 + 4 | |
| 0.88 | 0.89 | 0.88 | normal | |
| 0.77 | 0.77 | 0.77 | 3 + 3 | |
| 0.75 | 0.74 | 0.74 | 3 + 4 | |
| kNN | 0.79 | 0.77 | 0.78 | 4 + 3 |
| 0.79 | 0.77 | 0.79 | 4 + 4 | |
| 0.77 | 0.77 | 0.78 | normal |
| Sensitivity | Specificity | Accuracy | Label |
|---|---|---|---|
| 0.96 | 0.96 | 0.97 | 3 + 3 |
| 0.96 | 0.95 | 0.95 | 3 + 4 |
| 0.96 | 0.98 | 0.97 | 4 + 3 |
| 0.94 | 0.95 | 0.96 | 4 + 4 |
| 0.94 | 0.95 | 0.94 | normal |
| Sensitivity | Specificity | Accuracy | Label |
|---|---|---|---|
| 0.96 | 0.98 | 0.97 | 3 + 3 |
| 0.95 | 0.96 | 0.96 | 3 + 4 |
| 0.97 | 0.98 | 0.98 | 4 + 3 |
| 0.96 | 0.96 | 0.96 | 4 + 4 |
| 0.96 | 0.97 | 0.96 | normal |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Brunese, L.; Mercaldo, F.; Reginelli, A.; Santone, A. Radiomics for Gleason Score Detection through Deep Learning. Sensors 2020, 20, 5411. https://doi.org/10.3390/s20185411
Brunese L, Mercaldo F, Reginelli A, Santone A. Radiomics for Gleason Score Detection through Deep Learning. Sensors. 2020; 20(18):5411. https://doi.org/10.3390/s20185411
Chicago/Turabian StyleBrunese, Luca, Francesco Mercaldo, Alfonso Reginelli, and Antonella Santone. 2020. "Radiomics for Gleason Score Detection through Deep Learning" Sensors 20, no. 18: 5411. https://doi.org/10.3390/s20185411
APA StyleBrunese, L., Mercaldo, F., Reginelli, A., & Santone, A. (2020). Radiomics for Gleason Score Detection through Deep Learning. Sensors, 20(18), 5411. https://doi.org/10.3390/s20185411