1. Introduction
Writing in the air is a process to write something in a 3D space by using gestures or trajectory information. It allows users to write in a touchless system. Especially, it is useful when traditional writing is difficult such as gesture-based interaction, augmented reality (AR), virtual reality (VR), etc. Air-writing solves such issues. In pen-and-paper-based systems, characters are written in a multi-stroke manner. However, air-writing has no such option [
1], which represents its principal drawback. The gesture-based writing is a helpful way to avoid this problem; nevertheless, it is not an optimum solution [
2] due to the limitations of gesture varieties. Normally, the number of gestures is limited by human posture, but it is possible to increase the number of gestures by combining them [
3]. However, remembering all of these is a little difficult for new users. On the other hand, users can write in the same order as traditional methods in the air-writing system.
Trajectory-based writing is performed in an imaginary box in front of a 2D [
4,
5] or 3D [
6,
7,
8] camera. The principal problems when imposing a virtual boundary are spatiotemporal variability and segmentation ambiguity. It is difficult for even the same user to repeat the same trajectory again in the same position and pattern. Recently, Leap Motion and Kinect cameras have greatly advanced the emerging field of 3D vision-based trajectory tracking; it is now possible to write in the air without the need for any extra device or sensor. Some Kinect-based online handwriting recognition system has been developed [
6,
7,
9,
10]; this includes long-range body posture and finger tracking system. Leap Motion provides a precise finger location in the 3D space [
11]. They used a heuristic approach to analyze the stroke length between two successive sequences. We prioritized usability when choosing a device. Kinect is a long-range tracking device and better for human pose or skeleton detection. Besides, Leap Motion is a small device that has a short-range but affords millimeter-level accuracy. This device is useful in a tabletop and VR environment. On the other hand, the Intel RealSense SR300 camera is an intermediate-level device that minimizes this tradeoff and provides an optimal solution for our purpose.
The trajectory-based writing system unveils new horizons of possibilities [
6,
7,
12,
13,
14,
15,
16]. Trajectory estimation is more complicated than evaluation of pen-up/pen-down activity; users employ different writing styles and speeds, which in turn yield different trajectories. However, some state-of-the-art motion sensors and devices give us redemption from this problem. Gloves, wearable devices [
12,
14] and Wi-fi based [
16] sensors yield accurate trajectory information, but for the general users they are hard to write with and to adapt to. The Leap Motion [
11,
17], Microsoft Kinect [
6,
7] and Intel RealSense cameras [
18] provide effortless trajectory data. In this research, we used the Intel RealSense 3D depth camera to collect trajectory information.
It is essential to remove erroneous temporal and spatial trajectory data by applying some filters and normalization techniques. However, zigzag effects persist due to the special writing style. Users write digits in the 3D space inside an imaginary box, which is not fixed; no delimiter identifies the boundary of the region of interest. Hence, the trajectory is shaky whereas unwanted sequences are drawn that make the system more challenging. In that case, it needs to be normalized. Normalization is imperative to prune weak features. Machine learning-based approaches require subjective feature selection, which is a challenging task. Better features yield better results. However, the deep learning-based approach obviates the need for manual feature generation. Therefore, we implemented two efficient deep learning-based algorithms, named the long short-term memory recurrent neural network (LSTM) and the convolutional neural network (CNN). The LSTM network outperforms for all cases.
The main contributions of this paper are as follows.
- (1)
We design two efficient deep learning models allowing accurate air-writing digit recognition. The proposed LSTM and CNN networks are robust under different experimental conditions such as normalized/non-normalized situations. However, the 3D normalized trajectory provides a better result, especially for a distorted case.
- (2)
We create a large publicly available dataset that will play a vital role in deep learning and machine learning. The dataset contains 21,000 trajectories, which is sufficient for any deep learning algorithm. Among those, 1000 test trajectories are also included to measure the model’s performance in the unknown data.
- (3)
We verify the accuracy and feasibility of the model using our own dataset and publicly available dataset (6DMG). The quantitative performance comparison shows that the proposed model outperforms with the prior work.
The rest of the paper is organized as follows. In
Section 2, we discuss the related prior work. The methodology is described in
Section 3 including trajectory collection and network design.
Section 4 and
Section 5 are an experiment and result section, respectively. In the results section, we compare the model performance with a publicly available dataset.
Section 6 contains conclusion and future work.
2. Related Work
Standalone devices [
12,
13,
14,
19,
20,
21,
22] have been used for air-writing and gesture-based digit recognition. Some cost as little as
$1 [
19], are readily applicable and serve as a prototype for user interface (UI) designers who lack knowledge of pattern recognition. Performance has been compared among various algorithms and devices. The MEMS gyroscope [
20], accelerometer [
14,
23,
24], motion sensor [
12], Wiimote [
13], HP slate 2 [
21], Wi-fi [
16], and analog inertial measurement unit [
22,
25] are the leading devices and sensors for trajectory estimation in a 3D spatiotemporal domain. Wi-fi based writing system is new in this field, authors named it Wri-Fi and utilized the channel state information which derived from wireless signals to experience the device-free air writing system. Recently, inertial sensor-based portable devices have been used to collect human motion trajectory information from accelerations [
14,
20,
22]. All current devices are handheld or attached to the body. Importantly, the sensors operate without external control. Researchers have focused on reducing the error from trajectory by manipulating the velocities and signals of inertial sensors [
25,
26]. Many of them have been focused on designing efficient and effective algorithms to minimize the tradeoff between complexity and accuracy. Motion sensing technologies ascribe some behavioral issues. For example, wearing a sensing device is often considered burdensome. The gyroscope-based method uses the extended Kalman filter to detect the motion appropriately. The main purpose of that method was to use the system on a digital pen, and the accelerometer-based devices are used for the same purpose [
14]. This pen features a triaxial accelerometer with a wireless transmitter. It is applicable for both writing and hand gesture detection. The IMU pen [
25] and Magic Wand [
27] are inertia sensor-based input devices. The Wiimote and HP Slate are commercial sensor-based motion detection devices. Recent studies used a six-degree-of-freedom (6DMG) dataset [
13,
15] collected by the Wiimote device. The word-based recognition error rate was reasonably low. Moreover, an extensive comparison has been done between air-writing and virtual keyboard. In terms of accuracy and ease, air-writing was more accurate and simpler than the virtual keyboard. However, these sensors are handheld, which makes them difficult and complicated to use. Therefore, we developed a 3D vision-based approach and used a depth sensor-based camera known as the time of flight (TOF) camera whose main working principle is the IR sensor. Since the TOF camera measures the distance between the objects and camera, which is calculated using the reflection principle, it can work in a low-light environment.
There are different algorithms that have been used for air-writing recognition. The most prominent algorithms are hidden Markov model (HMM) [
8,
11,
13,
16,
22], dynamic time warping (DTW) [
6,
7,
28], support vector machine (SVM) [
7,
22], and bi-directional LSTM (BLSTM) [
29]. The HMM is a Markov model containing hidden states that play an important role. DTW is the time series analysis algorithm measuring the similarities between pairs of temporal sequences. HMM, DTW, and SVM based recognizers assume that the observation is conditionally exclusive. Therefore, overlapping or long-range observable feature processing is complex and sometimes erroneous [
6]. Discriminative methods avoid this problem because they accommodate nonlocal dependencies. However, HMM is the widely used algorithm in the field of gesture recognition and air-writing. Nowadays, LSTM has become popular for time series prediction, speech recognition, handwriting recognition, etc.; hence, we used the LSTM algorithm for this research. Nowadays CNN is also becoming popular for different applications for its different variants and robustness. For this research, we also used a depth-wise CNN network.
Recently, researchers have been following different strategies for air-writing recognition. Nguyen and C. Bartha introduced shape writing and compared it with the Swype on a smartphone [
21]. It is shown that shape writing performs better as a virtual keyboard. Amma et al. proposed an air-writing system using the inertial measurement unit, which required attaching with the hand [
22]. The HMM recognizer and SVM classifier were used to detect the character in the air. The main drawback of this work is that it is handheld; always attaching this device with the hand is very difficult and tedious. To overcome this situation, Qu et al. proposed a Kinect based online digit recognition system using DTW and SVM [
7]. Lately, Mohammadi and Maleki proposed a Kinect based Persian number recognition system. However, those are not full writing systems. Chen et al. [
17] and Kumar et al. [
11] proposed a full writing system in the air including character and word. Both used Leap Motion as a trajectory detection device and HMM as a recognizer, but the accuracies were not significant. However, Kumar et al. used the BLSTM algorithm and showed that the accuracy was higher than HMM. Most of the research has been done by using the trajectory information directly, i.e., using the temporal information. On the other hand, Setiawan and Pulungan [
30] proposed a 2D mapping approach, in which trajectories were collected by the Leap Motion device and converted to the 2D image matrix like the popular MNIST dataset. Nowadays, WiFi and Radar-based technology have become popular. Fu et al. [
16] proposed a Wi-Fi device-based (named as Wri-Fi) method using principal component analysis (PCA) and HMM algorithm. The main drawback of this work is that accuracy is not reasonable. However, Arsalan and Santra [
29] solved the accuracy issues using millimeter-wave radar technology. They used three radars calibrated with trilateration techniques to detect and localize the hand marker, which is troublesome to implement for real-life applications. Therefore, we were motivated to develop a vision-based and hassle-free system for all users. At the same time, we achieved very good recognition accuracy.
3. Methodology
The whole process is divided into four principal parts: fingertip detection, data collection, normalization, and network design. A complete block diagram is shown in
Figure 1 to describe the details of the proposed method. The following subsections provide an in-depth explanation for each part.
3.1. Fingertip Detection
Fingertip detection was performed by an Intel RealSense SR300 camera. It is a widely used TOF camera for gesture detection, finger joint tracking, and depth-sensing research area. Firstly, hand segmentation and detection were done. Normally, there are 22 finger joints in our hands. Amongst them, the index fingertip was tracked for trajectory writing for user convenience. However, the trajectory was drawn through a virtual window. To fit and display in the physical window (such as a computer screen), scaling was required. We calculated the physical distance by multiplying the window size and the adaptive value for both x (horizontal) and y (vertical) directions. The adaptive value is the normalized value between 0 and 1 collected through the RealSense camera. In the User Interface (UI), the window sizes were 640 and 480 for x and y, respectively. The original pixel value was calculated by multiplying the window size and adaptive value.
3.2. Data Collection
A simple interactive UI was designed requiring minimal instructions. 10 participants (8 males and 2 females) aged 23 to 30 years were recruited; all were graduate students. The writing order is shown in
Figure 2, which is similar to the traditional writing order. We did not apply graffiti or uni-stroke writing constraints [
31]. The stroke orders for each letter were defined in the usual manner, i.e., the box-writing process [
13]. There are two types of approaches to recognize the air-writing system, online and offline. Herein, we followed an offline method which is also known as the ‘push-to-write’ approach to collect the data [
11,
13,
28,
32]. In this process, users were requested to write digits in front of the depth camera, and that was collected as a spatial trajectory sequence.
The collected RealSense trajectory digits (RTD) dataset parameters are listed in
Table 1. The digits 4, 5, and 8 are relatively longer than the other trajectories. Digit 1 had the shortest and 4 had the longest trajectory. Depending on personal preference, each user could employ a very small or very large writing area. However, the differences between the maximum and minimum length of the same trajectory are large, showing that the dataset contains a variety of data points. The mean Equation (1) and standard deviation (STD) indicate that most data points are distributed within a reasonable range. The variance Equation (2) indicates the spread of the dataset; this is helpful to design the input layer of the deep learning algorithm. The STD Equation (3) represents the deviation from the mean value. Although the minimum and the maximum ranges are numerous, the minimal STD difference indicates that most of the data points reside within the normal range.
where
is the mean value,
is the ith datum,
is the variance, and
is the STD. Some data were collected for testing purposes to verify the accuracy of unknown data.
3.3. Normalization
The main challenge for air-writing is that the trajectory is zigzag, i.e., not smooth, thus requiring normalization before feeding the network. We employed two normalization techniques—the nearest neighbor and root point. The details are as follows:
3.3.1. Nearest Neighbor Point Normalization
The nearest neighbor point normalization technique is simple and heuristic. As it is not a pen-up/pen-down system, some displaced points are captured, which may change the trajectory shape. To deal with this situation, averaging the nearest-point transformation is used to change the deviated line to a smooth and straight line. The Equations (4) to (6) are applied to calculate the nearest point.
Here
i is the individual position in a trajectory and
n is the number of points considered during normalization. It is observed from the experiment that considering six points are optimal. More points smoothened the trajectory, but it shrank the corner(s) that produce distorted shape. On the other hand, lower points could not properly normalize the trajectory.
3.3.2. Root Point Normalization
During air-writing, users write in an imaginary (“virtual”) box in the air. All digits are written in the first quadrant in a cartesian plane but in a different position. The virtual box does not have fix boundaries or margins; thus, the same digit may be written in different positions, even by the same user. This causes a random initial position. We used root point translation to generalize the starting point. By doing this, all the starting points commenced from the root coordinate. The Equations (7) to (9) calculate the root point.
where [
,
,
] is the starting point of a sequence and [
,
,
] is the instantaneous point derived from the entire trajectory. The non-normalized digit 0 is shown in
Figure 3a; it is noisy and has a zigzag effect, while the fully normalized trajectory (
Figure 3b) is smooth. In this figure, the
x and
y are the distance value in the virtual window; i.e., the passing distance between the start and end position. The
z is the distance between the hand fingertip and the camera. All are in centimeters (cm). The negative value in
Figure 3b indicates the relative distance. It is due to using the Equations (7) to (9) in the normalization process. The geometric root point is considered as the starting point; for example, −5 in the
x-direction, −30 in the
y-direction, and −6 in the
z-direction indicate that the point is 5 cm left, 30 cm below, and 6 cm closer to the camera from the start position, respectively. Here, the negative sign indicates the direction, not the mathematical operator.
3.4. The Dataset
In our work, two datasets are employed, one is self-collected (RTD) and another is the 6DMG [
33]. The details are described below.
3.4.1. RTD Dataset
RTD is our self-collected trajectory dataset which contains 20,000 trajectories, i.e., 2000 data points for each digit. The writing order and parameters are shown in
Figure 2 and
Table 1, respectively. To the best of our knowledge, this is the largest digit dataset currently available based on the number of trajectories per digit. The RTD dataset is freely available on the internet as are detailed instructions for use. The RTD dataset:
https://www.shahinur.com/en/RTD/.
3.4.2. 6DMG
6DMG is a motion gesture dataset containing gestures and alphanumeric air-writing data [
33]. The dataset was collected through the Wiimote device, performed by 28 participants. Wiimote is a handheld device that works based on acceleration and angular speed. The orientation of this device was computed using the inertial measurement. In this study, we employed this 6DMG air-writing dataset. Some sample characters are shown in
Figure 4. All characters are written in a uni-stroke manner.
3.5. Network Design
In this research, we employed two state-of-the-art neural network algorithms, CNN and LSTM. CNN and LSTM work based on convolution and recurrent units, respectively. Both are widely applicable for time series prediction.
3.5.1. LSTM Network
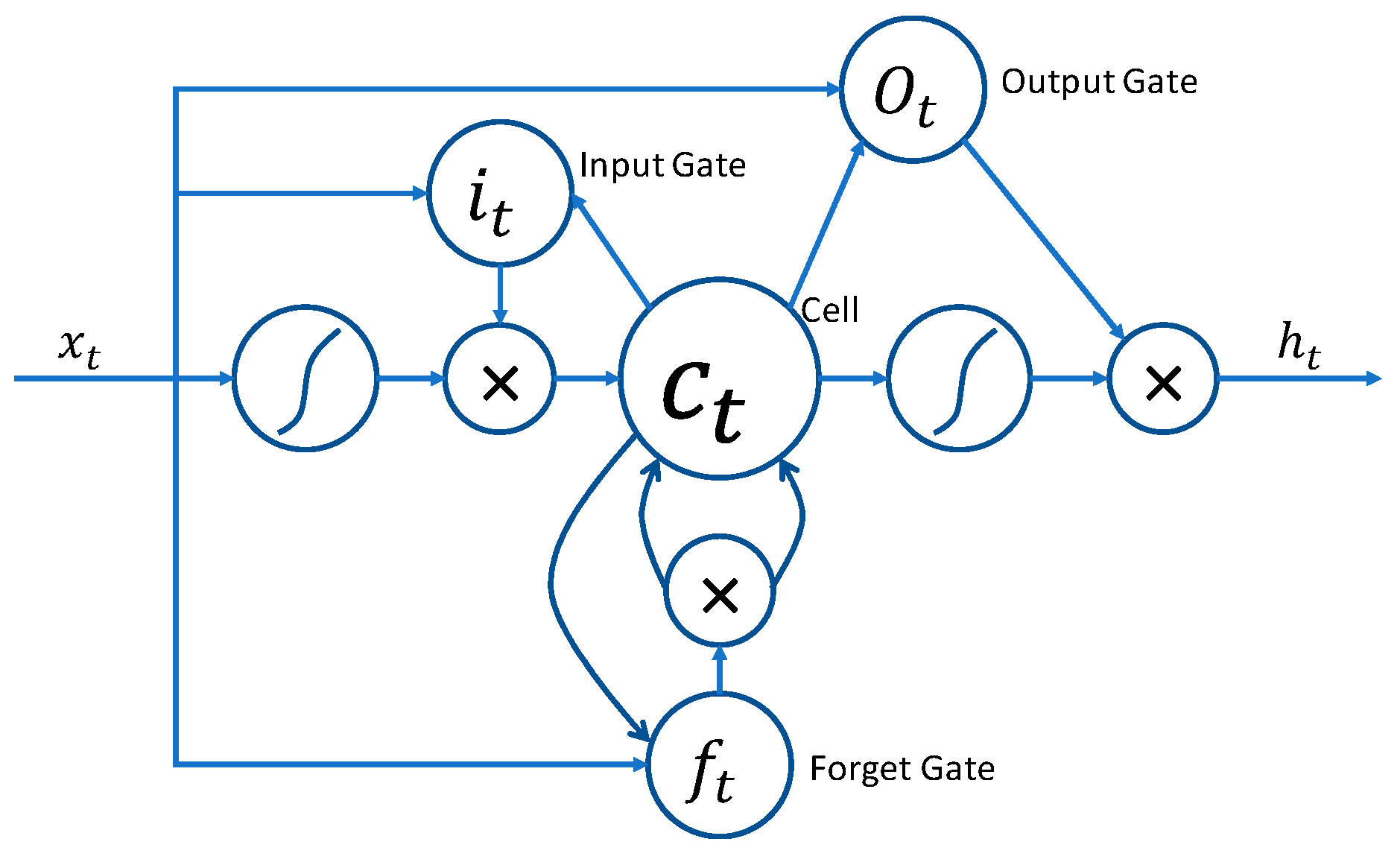
LSTM [
34] is a variant of a recurrent neural network (RNN). Unlike the standard feed-forward network, LSTM has feedback connections that make it significant. The architecture of an LSTM cell is shown in
Figure 5.
The LSTM layer is composed of a cell containing an input Equation (10), forget Equation (11), and output Equation (12) gates. It is also known as a cell state Equation (13). This state is modified by the forget gate. It helps to decide what to be removed from the previous state, and thus, the cell keeps only the expected information. The output gate in a cell passes the information to the next state.
where
i,
f, and
o are the input, forget, and output gate, respectively. The weight matrices
W and bias
b is the parameter which is required to learn during the training. The symbol
is the Hadamard product [
35] which produces the same dimensional matrix as the input.
The proposed network contains two LSTM and two dense layers. The input layer is the very first layer in the network, and it does not compute anything; instead, it transfers inputs to the next LSTM layer. The trajectory length is not fixed. Each trajectory has a different 3D spatial points, and even the same digit may vary in length depending on the writing speed and direction. However, fixed-length sequences are required to feed the LSTM-RNN. Therefore, the input layer is set to the maximum trajectory length.
The proposed LSTM model has been shown in
Figure 6;
,
are inputs containing the
x,
y, and
z values from the trajectory. LSTM 1 and LSTM 2 contain 64 and 128 cells, respectively. The cell is used to compute the output activation of the LSTM unit. To employ the cross-validation, we used a mini-batch size of 256. DENSE 1 and DENSE 2 contain 64 and 256 neurons, respectively. DENSE 1 and 2 employ the Rectified Linear Unit (ReLU) activation function Equation (14), which is simple and easy to use. The most important property of ReLU is that the output is straightforward, and it does not saturate. The ReLU function eliminates the negative part of the output by transmitting only the positive part to the next layer.
where
x is the input to the neuron. However, the softmax activation function Equation (15) is used in the output layer. This yields an integral output whereas the output of a SoftMax function is a probability between 0 and 1.
Dropout is a regularization technique patented by Google for reducing overfitting in neural networks by preventing complex co-adaptations in training data. It helps to prevent overfitting [
36] by randomly subsampling the data and is used in the dense layer. The dropout rate is 0.5. Moreover, an extension of the stochastic gradient descent algorithm Adam [
37] is employed to optimize the model at a learning rate of 0.0005. Its implementation is straightforward and computationally efficient requiring a little memory.
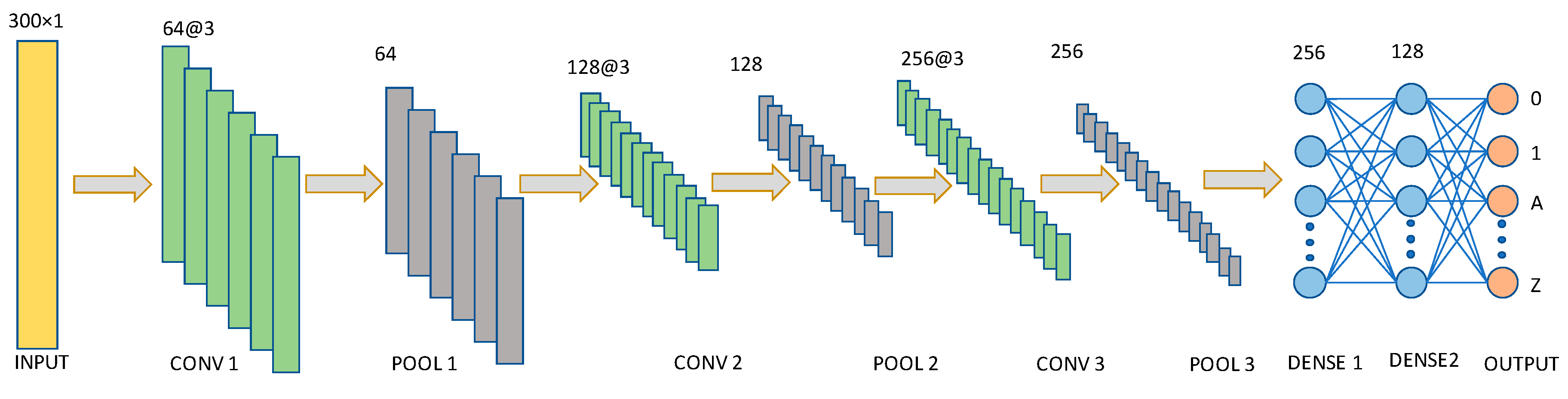
3.5.2. CNN Network
A CNN network consists of an input and output layers composed of multiple hidden layers. Hidden layers include convolution, pooling, and activation layers. CNN has different variants based on the application and dataset. The normal CNN network contains lots of calculations due to the convolution and pooling layer. Hence, we applied the separable convolution layer which is faster than the general CNN layer. It is widely known as a depth wise convolution.
The proposed CNN network is shown in
Figure 7. Like the LSTM network, the input layer is also set to the maximum length of the trajectories. The input layer is a 300 × 1-dimensional vector that transfers the input value to the 1st separable convolution layer. Convolution layers 1, 2, and 3 contain 64, 128, and 256 channels, respectively. In all the cases the filter size is 3. Each convolution layer is associated with the 1D max-pooling layer. There are two dense layers containing 256 and 128 neurons, respectively. Dropout rate 0.5 is used in the DENSE1 and DENSE2 layers. The ReLU Equation (14) activation function is used for all the cases except the output layer. The softmax Equation (15) regularization is used in the output layer. Adam is used as an optimizer with a learning rate of 0.0001 and categorical cross-entropy as a loss function.
4. Experimental Setup
The experiment was done by connecting an Intel RealSense SR300 camera with a computer. A graphical user interface (GUI) was designed to collect the appropriate trajectory data. The C# and Python programming languages were used for interfacing and training, respectively. The proposed networks were implemented in Keras high-level API over the TensorFlow backend.
The trajectory was captured in real-time (50 fps). We used the NVIDIA GeForce GTX 1050 Ti graphics processing (GPU) unit with 32 GB memory to speed up the training process. The experimental environment is shown in
Figure 8. The digit 0 was written in the air and tracked by the RealSense camera. It is not normalized; hence, the trajectory is a little bit distorted. Some of the complex digits and corresponding sample frames are shown in
Figure 9. The frame by frame representation helps to understand the motion for the digit writing order. The trajectory capturing process started from the first frame (F#1). However, the ending frame is different for each individual character due to the different motion and writing patterns.
4.1. User Interface
In the user interface, there were three basic buttons to start, stop, and save trajectory. The GUI displays both depth information and the trajectory. The depth and the trajectory part were used to display the full hand indicating the tracked fingertip point and the captured trajectory, respectively. The GUI was very simple, so minimal instruction was needed. It was also highly interactive, featuring real-time trajectory capture and display. For simplicity, each digit was shown in 2D cartesian coordinates, but it is three dimensional. In
Figure 8, digit 0 is shown on the left side; the depth maps of the finger and body appear on the right. As soon as the ‘start’ button clicked, the camera became active and started to detect the fingertip position. If the drawn trajectory is the expected trajectory, the user clicks the ‘stop’ button. If the trajectory is not expected or the user cannot draw properly, then they can click the ‘Refresh’ button to clear the window. Finally, the trajectory can be saved by pressing the ‘Save’ button. Users do not need to write down the label, the system itself incrementally generates one by one. Basically, the ‘start’ and ‘stop’ buttons in the UI control the initial and end points, respectively. To trim the unwanted starting or ending points, we used the ‘cut’ button to eliminate the terminal point according to the instructions.
4.2. Usability
A user study was conducted to verify usability. Users were directed to write in the air in front of the camera. Initially, they needed training, but that is for a short time. The average training time was less than 3 min. In the first 5–10 attempts, they were experiencing a few problems such as shaky effect, stiff and numb hand, etc., but later it was fixed. Most users gave positive feedback and appreciated this work.
6. Conclusions
In this paper, we proposed a trajectory-based air writing recognition system using an Intel RealSense SR300 camera and developed two deep learning-based algorithms to recognize the trajectory. This is a paperless writing system. Researchers previously used different motion sensors and handheld devices; instead, we used a vision-based approach for better user experience. To verify the method and assess its accuracy, we proposed two neural network models—LSTM and CNN.
We thoroughly assessed the method using different normalization conditions and found that the normalized 3D data were optimal. We also employed the 6DMG dataset and achieved the highest accuracy. The main contribution of this paper is to design a network for higher recognition accuracy and solve the dataset issues in the current research. The highest recognition accuracies for RTD and 6DMG datasets for CNN are 99.06% and 99.26%, respectively. However, the highest recognition accuracy was found for LSTM, which is 99.17% and 99.32% for RTD and 6DMG datasets, respectively. This can be achieved within a reasonable iteration, which proves that the model is very efficient and learns very fast. We performed a comparative analysis of our work with prior research and observed that the accuracy is relatively higher. In the future, we will try to design and develop a model for continuous writing systems to apply to AR/VR or gesture alternatives.

 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}