1. Introduction
Mobile robots are widely used in industrial production, the service industry, and other fields. Mobile robots need to realize autonomous navigation instead of being manipulated by human beings. To achieve this purpose, positioning is one of the key technologies. The global positioning system (GPS) can be used accurately in an outdoor environment; however, in an indoor environment, the global navigation satellite system (GNSS) signal is weak; thus, it cannot complete the positioning function [
1]. At present, the commonly used indoor positioning technologies are laser, inertial navigation system, infrared, and wireless local area network (WLAN), but these indoor navigation technologies cannot be widely used because of problems such as allele accuracy and cost. With the rapid development of machine vision and computer technology, the performance of small industrial cameras and the microelectromechanical system (MEMS) inertial devices was continuously improved [
2,
3,
4]. The technology of a visual–inertial odometer (VIO) was gradually realized in engineering applications at the theoretical verification stage.
A monocular visual–inertial navigation algorithm was developed rapidly in recent years. In 2016, Usenko, from the Munich University of Technology, proposed a binocular visual–inertial positioning method based on tight coupling and direct methods. Using the photometric errors and residuals of images, an objective function was established, and a semi-dense map was constructed to achieve a positional accuracy of less than 0.1% of the motion distance [
5]. Mur-Artal, author of ORB-SLAM, and others also proposed the addition of an inertial measurement unit (IMU) error model to the cost function of tracking and the local bundle adjustment (BA) module to improve the positioning accuracy in 2016 [
6]. The VINS-MONO system proposed by Shaojie’s research group from the Hong Kong University of Science and Technology in 2017 is a VIO system based on sliding window optimization. It only optimizes the information in the sliding window and does not optimize the previous state or measurement value. Its translation error based on loop detection is less than 0.3% of the accuracy of the motion distance [
7]. On one hand, all of these algorithms need rich features in the scene. On the other hand, they do not optimize the previous state or measurement value. In an indoor environment, corridors, white walls, and other weak-texture scenarios, as well as the influence of the illumination intensity, make the existing fusion algorithms less robust, sharply decline the precision, or even cause location failure.
The indoor environment has spatial constraints and can be used to eliminate some incorrect positioning results. It is an additional data source to improve the accuracy and reliability of an indoor positioning system. The process of utilizing map information in the positioning process is called map matching. This method can establish a matching model through the corresponding relationship between the attitude sequence obtained by the visual–inertial positioning system and the sequence of the state points in the map; therefore, the positioning accuracy of the system can be improved without adding any hardware [
8].
In an indoor map matching algorithm, points (doors), lines (grids), and surfaces (rooms) need to be constrained. In Reference [
9], the indoor structure model was constructed by using the indoor basic vector information, and the wireless location results were constrained by fusing the sensor information and the map information. However, the final location results were constrained by the map in this document. The smoothing filtering problem of the location results was not considered in the constraints process. At present, the common methods are based on a hidden Markov model (HMM) and a particle filter (PF) [
10,
11,
12], because of its non-parameterized characteristics. Here, the stochastic variables must satisfy the Gaussian distribution when solving the problem of nonlinear filtering, which provides an effective solution for the analysis of nonlinear dynamic systems. One of the major issues of the PF is the computation time, as a large number of particles are typically required to ensure a good estimation of the continuous probability distribution, particularly when dealing with noisy inertial data and large maps. The MapCraft system proposed by Xiao is the first in which a map matching algorithm based on a conditional random field is tightly coupled with the positioning system [
13]. The system obtains the original measurement value directly from the sensor as the input of the algorithm and fuses it with the map information. When this system is used for real-time tracking, the delay caused by the backward phase of the conditional random field will affect the efficiency of the algorithm and reduce the positioning accuracy. Therefore, in this study, we developed a map matching algorithm based on a conditional random field model, which used only the output of the position information from a visual–inertial system as the input of the conditional random field model and constrained it with the map information. The error in the position updating process was reduced by the feedback correction method, and the positioning result of the visual–inertial system was continuously corrected to make it more accurate. Finally, the algorithm was validated experimentally. The experimental results showed that the algorithm yielded good results with respect to improving the positioning error of the visual–inertial system.
3. Design of Map Matching Algorithms
3.1. Preprocessing of Indoor Maps
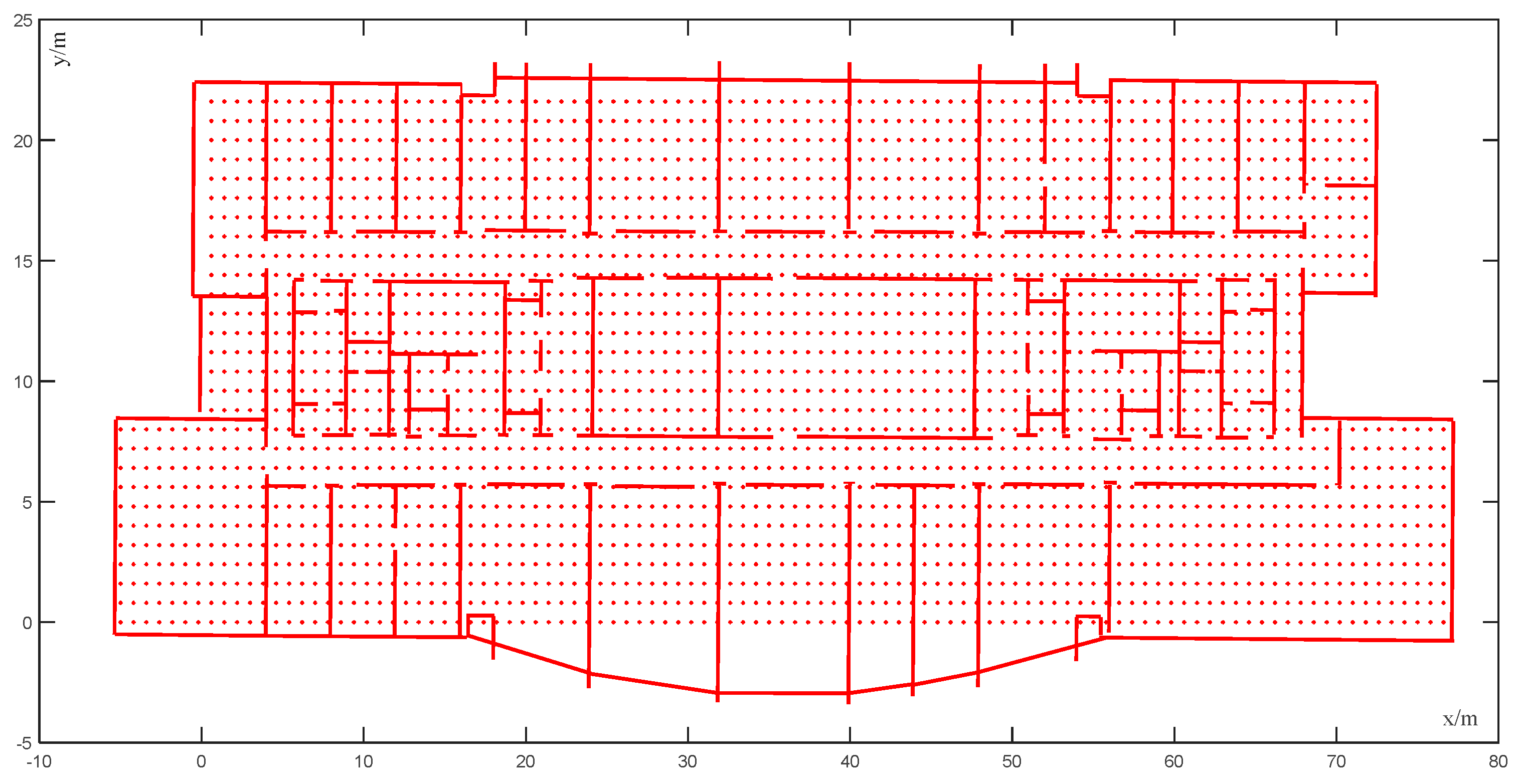
Indoor maps come in a variety of formats, such as image file formats, PDF files, or CAD files. These formats cannot be directly used for map matching algorithms, and the map needs to be digitized to create mathematical models. The map in this article is in the label image file format (TIFF). We used the mapinfo software to digitize the electronic version of the indoor map, using only the wall information of the map. The digital information format features the coordinates of the end point of each line segment.
Map matching can be divided into two types: point-to-point matching and trajectory matching. The point-to-point matching method matches the position point with the position of the indoor space according to the floor plan. This method is simple and computationally efficient. Trajectory matching is the matching of the motion trajectory obtained by the initial positioning system with the geometric topology information of corners, corridors, and rooms. This method is highly accurate but computationally intensive. In this study, the map matching of the conditional random field model was adopted, and the point-to-point matching method was more suitable for the visual–inertial positioning system. The method covered the entire indoor area with equally spaced points and stored the coordinates of each state point [
9]. At the same time, we removed the state point of the unreachable area. In
Figure 3, the red points indicate a state point, while the red lines indicate an indoor structure.
3.2. Conditional Random Field Model
The conditional random field model was proposed by Lafferty et al. in 2001 [
14]. Conditional random fields (CRFs) are a type of discriminative undirected probabilistic graphical model. They are used to encode known relationships between observations and construct consistent interpretations, and they are often used for the labeling or parsing of sequential data, such as natural language processing or biological sequences, and in computer vision [
15,
16,
17,
18,
19].
A conditional random field can be viewed as an undirected graphical model or a Markov random field. Ideally, if the description of the sequence of states has conditional independence, the structure of the graph can be arbitrary. However, when building the model, we usually choose the linear-chain undirected graph structure, which is the most commonly used, as shown in
Figure 4.
In this study, we defined
for a given sequence of observations (a sequence of
observation points).
is the output state point sequence, which is the predicted robot motion trajectory. Then, the output sequence conditional probability can be defined as shown in Equation (1).
Equation (1) denotes that, under the condition, the joint distribution form of sequences can be evaluated. is a normalizing factor, which can be calculated using Equation (2). and are the feature weights that can be determined by training the model. In this study, we set both weights to one. In general, the value of the feature function is zero or one; that is, the dissatisfaction feature condition is zero; otherwise, it is one. As summarized in the review, the value of the linear-chain condition random field depends mainly on the characteristic coefficient and the feature function.
In Equation (1), both
and
are feature functions; further details follow in
Section 3.3 and
Section 3.4, but the meanings are different. A function corresponds to the corresponding meaning at each position. The same function can be added at different positions to convert the original local features functions into global feature functions. The conditional random field expression can then be rewritten as a vector form, also known as a conditional random field simplification. The previous local feature function can be uniformly written as a global feature function. Assuming that the conditional random field contains
transfer functions and
observation functions, then the conditional random field contains
global eigenfunctions.
Then, the sum of the global feature functions at various locations
can be calculated as follows:
Similarly, the weight of the local function can be replaced with the global weight as follows:
Then, Equations (1) and (2) can be expressed as follows:
We can denote weight
in the vector form
; thus, the global feature function can be composed into a vector; then,
. Therefore, Equations (6) and (7) can be rewritten in vector form as follows:
3.3. Observation Probability
A motion trajectory
can be defined as a set of interconnected trajectory segments between two position points. The VINS-MONO system outputs a position point coordinate at every
time point. In order to reduce the number of candidate state points in
Section 3.4 we used the method of the robot’s fixed length distance to extract the observation points. When the distance between the current time and the previous time is equal to a certain threshold, the visual–inertial system output is used as the observation point
in the mathematical model, and the time of the sampling point is recorded simultaneously. As shown in
Table 1, the record of one observation point
includes the position coordinate
at time
.
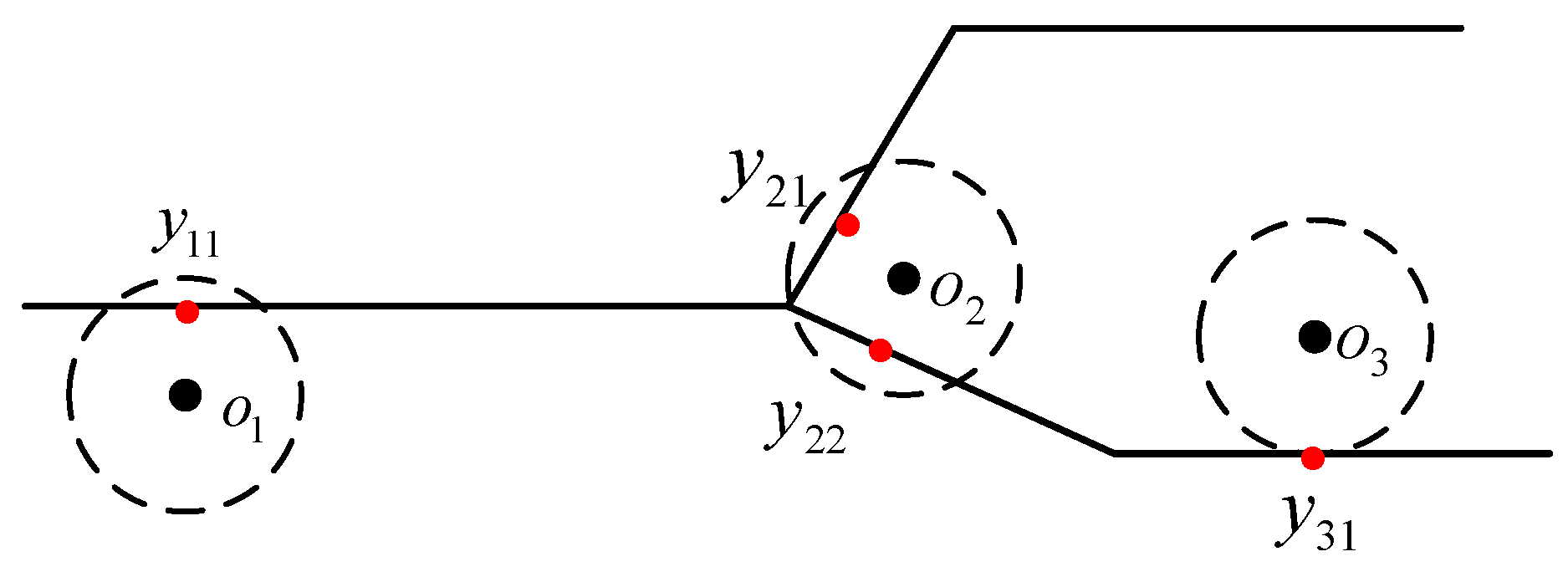
Newson and Krumm proposed a map matching algorithm to find the optimal moving trajectory sequence based on the location of the anchor point and the error radius [
17]. In general, map matching associates each anchor point with all the candidate road segments located within a preset error radius, as shown in
Figure 5. In the method based on the conditional random field model, the position coordinate point is regarded as an observation state. Each candidate path represents a hidden state; that is, a hidden state represents a candidate state point. In this study, each candidate path represented the point closest to the observation point on the candidate path. The probability of observation depends on the distance between itself and the anchor point. It is intuitively assumed that candidate state points closer to the anchor point have higher observation probability. In the real state, there is a measurement error in the distance between the anchor point and the candidate state point, generally assuming a zero-mean Gaussian distribution. For a given observation point
and candidate state point
, the observation probability is
and can be expressed as follows:
where
is the Euclidean distance between the observation point and the candidate status point,
is the standard deviation of the measured data, and
is only obtained when
is connected to
. Furthermore, the state can be transferred, and the potential energy is one and blocked by the obstacle. Alternatively, if the map is far away, the state transition is not performed, and all of the transfer potentials are zero.
3.4. State Transition Probability
In the map, the status point may be a free space or may be occupied by a wall or an obstacle. To perform a state transition, it is necessary to know the state points adjacent to each state point, and those adjacent to the other state points [
20]. In this study, the area that defined the search from the current location to the next location was called the buffer [
9]. The maximum conversion distance allowed in each direction was called the buffer size. Furthermore, we set the buffer size to the distance
between two state points. In the absence of any obstacles, the state transitioned between adjacent state points. In the case of obstacles, there was a conversion in the position of two buffers.
Figure 6a shows the state transition when an obstacle is not present, and
Figure 6b shows the state transition when an obstacle exists. The next state is shown by pink-shaded diamonds.
The transition probability refers to the transition probability between the candidate state point from time
to the candidate state point at time
. The robot at the candidate state point
at time
is transferred to the candidate state point
through
, and the shortest path passed via the Dijkstra algorithm or the Floyd algorithm is obtained, which is taken as the candidate path. The set of candidate paths between the marked observation point
and the next observation point
is
, where
denotes a candidate path of one candidate state point
of the observation point
to another candidate state point
of the observation point
. For two adjacent candidate state points, the transition probability can be defined as follows:
where
is the Euclidean distance between two observation points,
is the length of the shortest path of the two candidate state points
and
, and
has the same meaning as above. Considering the shortest path between candidate state points, it is possible to avoid the occurrence of detours and trajectories in the matching result.
3.5. Best Path Matching
The Viterbi algorithm was proposed by Viterbi in 1976 as one of the basic algorithms of the hidden Markov model [
21,
22]. The main problem solved by the Viterbi algorithm is to find the optimal state sequence in the sequence of state values corresponding to the sequence of observations in the case of a given model; thus, it is an optimal dynamic programming algorithm and can trace back the entire path. Suppose that
time needs to pass from S to E, there are
states
at each moment; then, we only need to record the shortest path corresponding to each state. At any time, it is only necessary to consider a very limited number of the shortest paths (depending on the number of states corresponding to the moment), and there is no need to consider the previous moments upward; thus, so there is no multidimensional condition problem. As shown in
Figure 7, we set
and
as an example to illustrate the algorithm, and the red path in the figure is the shortest path finally obtained.
In this study, it was applied to solve indoor positioning and used to find the optimal path. In the above, we used Equation (10) to get the observation probability and Equation (11) to get the state transition probability. We combined these two formulas into Equation (12) to find the most likely hidden sequence (the most likely trajectory). Finally, we used the Viterbi algorithm to solve the problem. Thus, the hidden sequence looking for the maximum probability was transformed into the path selection problem with the highest normalized probability as follows:
Here, in order to considerably reduce the computational complexity and solve the problem more conveniently, there was no need to normalize the probability, and the problem could be converted into the following formula:
where
is the local feature vector.
Equation (13) was solved using the Viterbi algorithm. Initialization was performed to find the non-normalized state at the most beginning position in the conditional random field as follows:
Then, we recursively computed the other nodes in the conditional random field, sought the maximum conditional probability at each node, and saved the maximum path.
When we recursively computed the end node, the maximum conditional probability was , the optimal path was , and the Viterbi algorithm obtained the optimal path as .
5. Conclusions
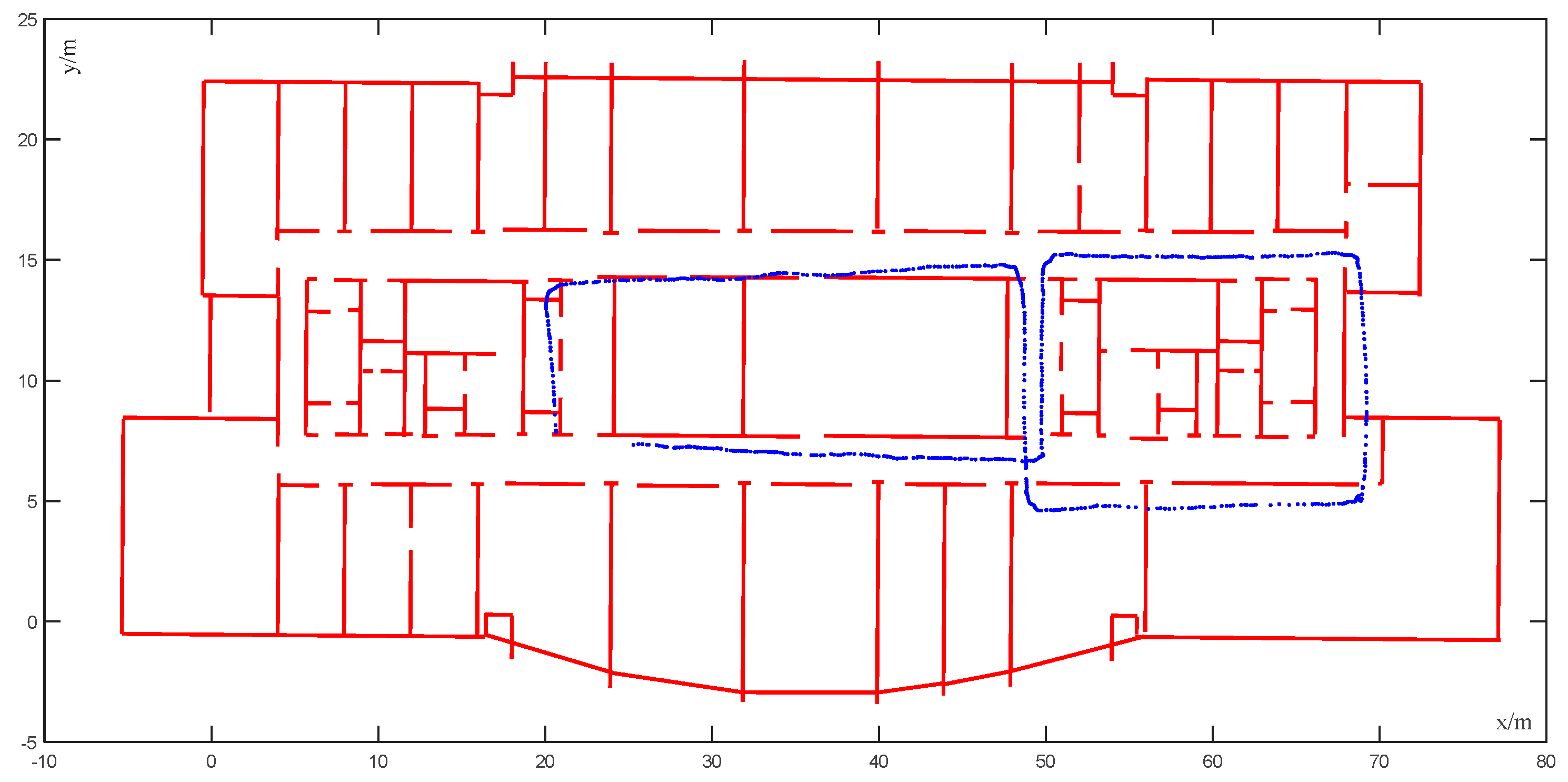
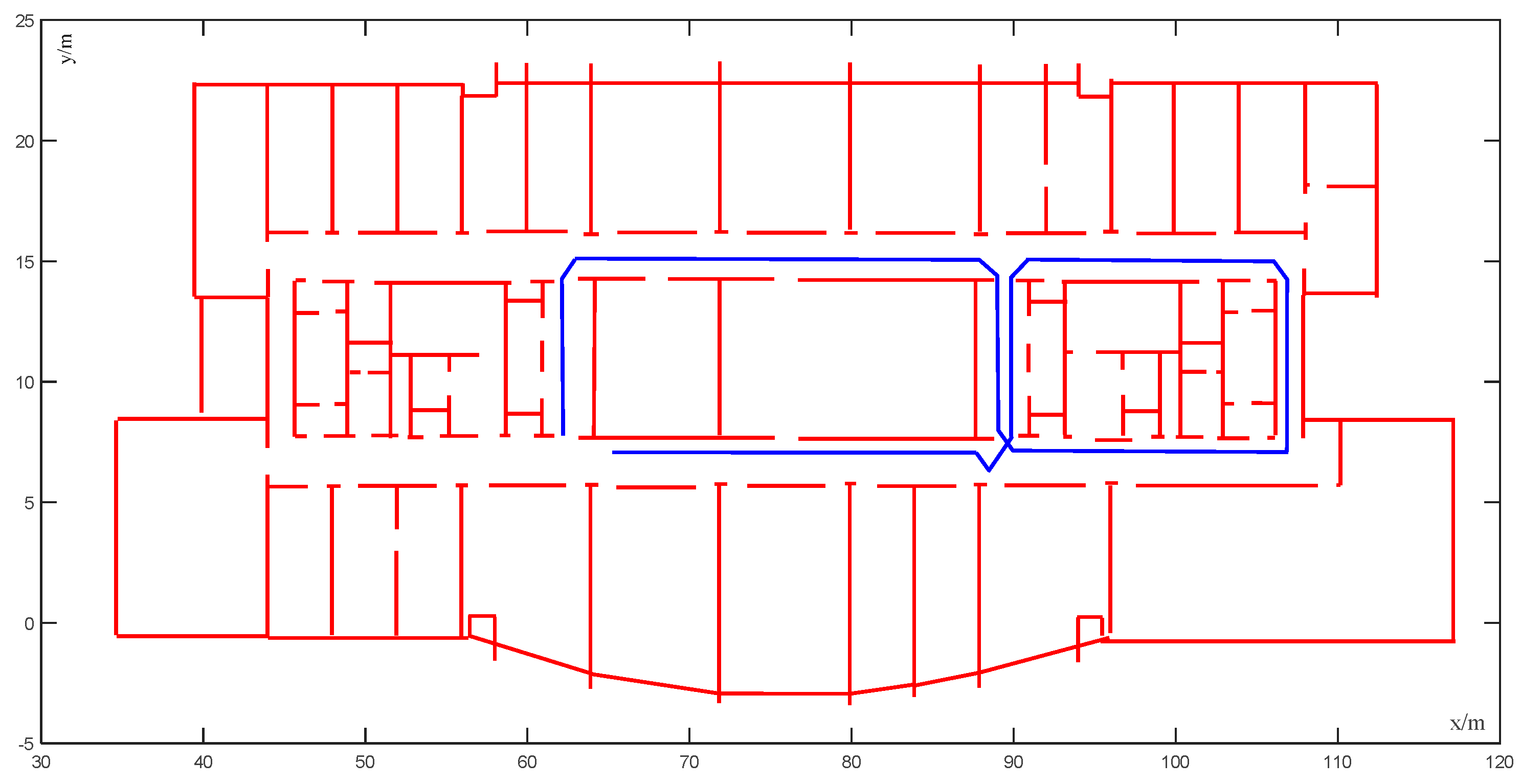
Aimed at solving the problem of the positioning accuracy of a visual–inertial system (VIS) decreasing in some indoor areas, in this study, we applied the output position of VIS to the conditional random field model by extracting the observation points and the corresponding possible state points at a fixed distance. Moreover, we made full use of the indoor structure information. In the proposed model, the Viterbi algorithm was used to find the best matching state points of the observation points in the window, finally finding the maximum probability trajectory. It fully embodied the advantages of the map matching algorithm and the probability algorithm. This algorithm was not only applicable to the VINS-MONO system; it might also be equally applicable to other visual–inertial systems. In this paper, the positioning accuracy was required to be high, but the positioning time was a little insufficient, which will be improved in the future research. For the actual scenarios, many experiments were carried out to obtain relatively good map matching results.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}