Spatio-Temporal Scale Coded Bag-of-Words


Abstract
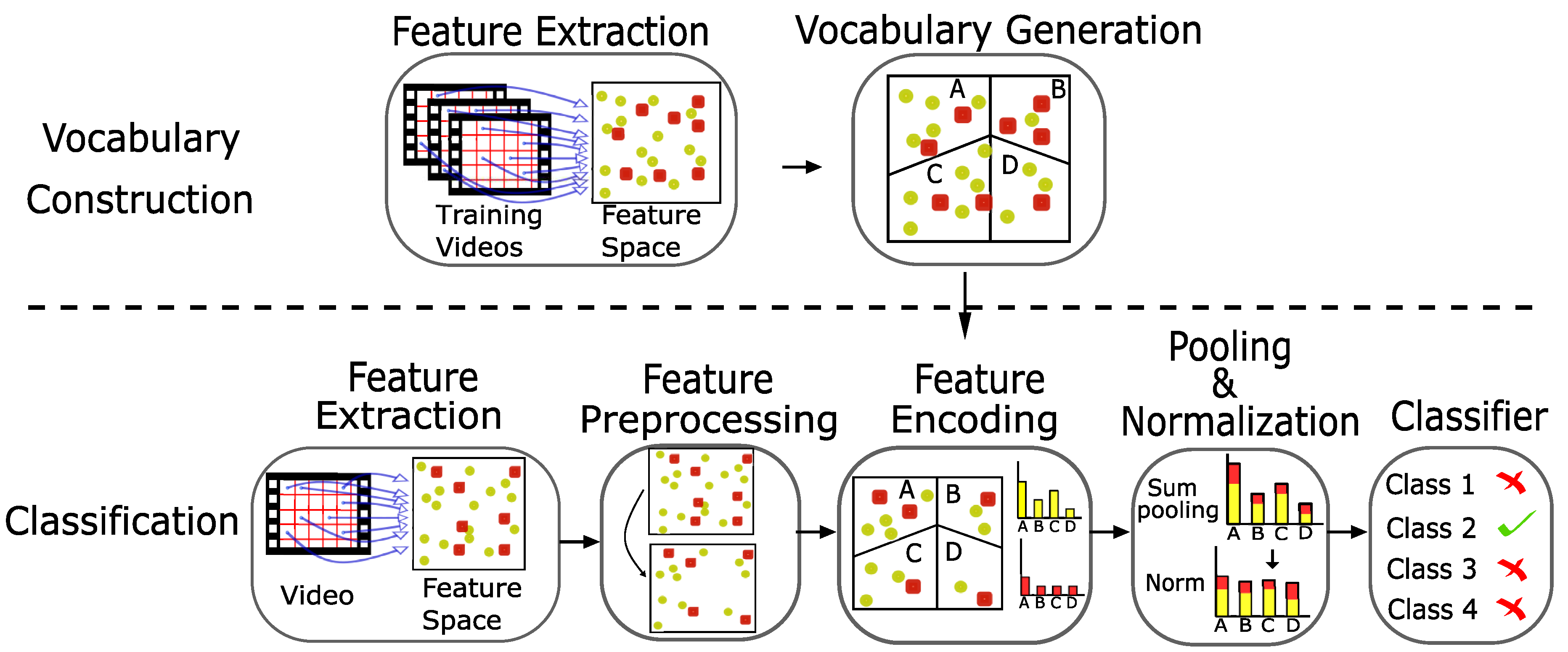
:1. Introduction
2. Related Work
3. Preliminary Knowledge
3.1. Criteria for Real-Time Action Recognition
3.2. Scale Invariant Bag of Words
4. Spatio-Temporal Scale Coded Bag-of-Words (SC-BoW)
- Size variations of the bounding box, , over each frame, t;
- Capturing temporal information.
4.1. Absolute Scale Coding
4.2. Relative Scale Coding
4.3. Scale Partitioning Strategies
| Algorithm 1: Dynamic Scaling Parameter Definition |
 |
4.4. Scaled Spatio-Temporal Pyramids
5. Pipeline for Action Recognition with SC-BoW
5.1. Real-Time Pipeline Design
5.1.1. Object Detection
5.1.2. Visual Tracker
| Algorithm 2: DCF-DSST Tracker: Iteration at Frame t |
| Inputs: : Image patch : previous frame target position : previous frame target scale : regression target for translation model (Gaussian shaped) : regression target for scale model (Gaussian shaped) Outputs: : detected target position : detected target scale Training: 1 Compute the Gaussian kernel correlation between x and itself, , using (A2) 2 Compute the DFT of the solution coefficients in the dual space, , using (A1) Translation Detection: 3 Construct the test sample, , from at and 4 Compute the correlation response, , using (A3) 5 Maximize the response, , to find target position, Scale Detection: 6 Construct the test sample, , from at and 7 Compute the correlation response, , using (A10) 8 Maximize the response, , to find target scale, Update: 9 Extract training samples and from at and 10 Update the translation model using (A4) and (A5) 11 Update the scale model using (A7) and (A8) |
5.1.3. Multi-Scale Sampling
| Algorithm 3: Definition of the Spatial Scales |
 |
5.1.4. PCA-HOG Feature Computation
5.1.5. Spatio-Temporal Scale Coded BoW (SC-BoW)
5.2. Experimental Setup
5.2.1. PC Specifications
5.2.2. Datasets
5.2.3. Object Detection
5.2.4. Visual Tracker
5.2.5. Bag of Words
5.2.6. Classification
5.3. Results and Discussion
5.3.1. Scale Partitioning Strategies
5.3.2. Scale Coding Schemes
5.3.3. Computational Cost
5.3.4. Comparison to Existing Methods
5.3.5. Setbacks
- Removing the need for a visual tracker by using alternative methods to define the target object through subsequent frames;
- Removing dependence of the relative coding scheme on the definition of a bounding box by using alternative cues to compute relative scale (e.g., depth information).
6. Scale Coding Dense Trajectories
6.1. Experimental Setup
6.1.1. PC Specifications and Datasets
6.1.2. Dense Trajectories
6.1.3. SC-BoW Representation
6.2. Results and Discussion
6.2.1. Performance Analysis
6.2.2. Number of Scale Partitions
6.2.3. Comparison To Existing Methods
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. DCF-DSST Visual Tracker
Appendix A.1. Translation Model
Appendix A.2. Scale Model
References
- Piergiovanni, A.; Angelova, A.; Toshev, A.; Ryoo, M.S. Evolving space-time neural architectures for videos. In Proceedings of the 2018 IEEE International Conference on Computer Vision, Instanbul, Turkey, 30–31 January 2018; pp. 1793–1802. [Google Scholar]
- Peng, X.; Wang, L.; Wang, X.; Qiao, Y. Bag of Visual Words and Fusion Methods for Action Recognition: Comprehensive Study and Good Practice. Comput. Vis. Image Understanding 2016, 150, 109–125. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Kläser, A.; Schmid, C.; Liu, C.L. Dense trajectories and motion boundary descriptors for action recognition. Int. J. Comput. Vis. 2013, 103, 60–79. [Google Scholar] [CrossRef] [Green Version]
- Passalis, N.; Tefas, A. Learning Bag-of-Features Pooling for Deep Convolutional Neural Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5755–5763. [Google Scholar]
- Nazir, S.; Yousaf, M.H.; Nebel, J.C.; Velastin, S.A. A Bag of Expression Framework for Improved Human Action Recognition. Pattern Recognit. Lett. 2018, 103, 39–45. [Google Scholar] [CrossRef] [Green Version]
- Shi, F.; Petriu, E.; Laganiere, R. Sampling Strategies for Real-Time Action Recognition. In Proceedings of the 26th IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2595–2602. [Google Scholar]
- Shi, F.; Petriu, E.M.; Cordeiro, A. Human action recognition from Local Part Model. In Proceedings of the 2011 IEEE International Workshop on Haptic Audio Visual Environments and Games, Qinhuangdao, China, 14–17 November 2011; pp. 35–38. [Google Scholar]
- Van Opdenbosch, D.; Oelsch, M.; Garcea, A.; Steinbach, E. A joint compression scheme for local binary feature descriptors and their corresponding bag-of-words representation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Zhang, B.; Wang, L.; Wang, Z.; Qiao, Y.; Wang, H. Real-time Action Recognition with Deeply Transferred Motion Vector CNNs. IEEE Trans. Image Process. 2018, 27, 2326–2339. [Google Scholar] [CrossRef]
- Chen, X.; Zhou, W.; Jiang, X.; Liu, Y. Real-time Human Action Recognition Based on Person Detection. In Proceedings of the 2019 IEEE International Conference on Real-time Computing and Robotics (RCAR), Irkutsk, Russia, 4–9 August 2019; pp. 225–230. [Google Scholar]
- Sanchez, J.; Perronnin, F.; Mensink, T.; Verbeek, J. Image Classification with the Fisher Vector: Theory and Practice. Int. J. Comput. Vis. 2013, 105, 222–245. [Google Scholar] [CrossRef]
- Li, L.; Dai, S. Action Recognition with deep network features and dimension reduction. KSII Trans. Internet Inf. Syst. 2019, 13, 832–854. [Google Scholar]
- Khan, F.S.; Weijer, J.v.d.; Anwer, R.M.; Bagdanov, A.D.; Felsberg, M.; Laaksonen, J. Scale coding bag of deep features for human attribute and action recognition. Mach. Vis. Appl. 2018, 29, 55–71. [Google Scholar] [CrossRef]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE 2013 International Conference on Computer Vision, Sydney, Australia, 3–6 December 2013; pp. 3551–3558. [Google Scholar]
- Xu, Z.; Hu, R.; Chen, J.; Chen, C.; Chen, H.; Li, H.; Sun, Q. Action recognition by saliency-based dense sampling. Neurocomputing 2017, 236, 82–92. [Google Scholar] [CrossRef]
- Khan, F.S.; Weijer, J.v.d.; Bagdanov, A.D.; Felsber, M. Scale Coding Bag-of-Words for Action Recognition. In Proceedings of the 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014. [Google Scholar]
- Scovanner, P.; Ali, S.; Shah, M. A 3-dimensional SIFT Descriptor and its Application to Action Recognition. Proccedings of the 15th ACM Conference on Multimedia, Augsburg, Germany, 24–29 September 2007. [Google Scholar]
- Hu, J.; Xia, G.S.; Hu, F.; Sun, H.; Zhang, L. A Comparative Study of Sampling Analysis in Scene Classification of High-resolution Remote Sensing Imagery. In Proceedings of the 2015 IEEE International geoscience and remote sensing symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 2389–2392. [Google Scholar]
- Nowak, E.; Jurie, F.; Triggs, B. Sampling strategies for bag-of-features image classification. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 490–503. [Google Scholar]
- Willems, G.; Tuytelaars, T.; Van Gool, L. An Efficient Dense and Scale-invariant Spatio-temporal Interest Point Detector. In Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 650–663. [Google Scholar]
- Yeffet, L.; Wolf, L. Local trinary patterns for human action recognition. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; pp. 492–497. [Google Scholar]
- Klaser, A.; Marszałek, M.; Schmid, C. A Spatio-temporal Descriptor Based on 3D-gradients. In Proceedings of the 19th British Machine Vision Conference, Leeds, UK, 1–4 September 2008; p. 275. [Google Scholar]
- Schüldt, C.; Laptev, I.; Caputo, B. Recognizing Human Actions: A Local SVM Approach. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 26 August 2004. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the 13th International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2556–2563. [Google Scholar]
- Li, T.; Mei, T.; Kweon, I.S.; Hua, X.S. Contextual Bag-of-Words for Visual Categorization. IEEE Trans. Circuits Syst. Video Technol. 2011, 21, 381–392. [Google Scholar] [CrossRef]
- Filliat, D. A Visual Bag of Words Method for Interactive Qualitative Localization and Mapping. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation, Roma, Italy, 10–17 April 2007; pp. 3921–3926. [Google Scholar]
- Zeng, F.; Ji, Y.; Levine, M.D. Contextual Bag-of-Words for Robust Visual Tracking. IEEE Trans. Image Process. 2018, 27, 1433–1447. [Google Scholar] [CrossRef]
- O’Hara, S.; Draper, B.A. Introduction to the bag of features paradigm for image classification and retrieval. arXiv 2011, arXiv:1101.3354. [Google Scholar]
- Loussaief, S.; Abdelkrim, A. Deep learning vs. bag of features in machine learning for image classification. In Proceedings of the 2nd International Conference on Advanced Systems and Electric Technologies, Hammamet, Tunisia, 22–25 March 2018; pp. 6–10. [Google Scholar]
- Wang, H.; Kläser, A.; Schmid, C.; Liu, C.L. Action Recognition by Dense Trajectories. In Proceedings of the IEEE 2011 Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 21–23 June 2011. [Google Scholar]
- Laptev, I. On Space-Time Interest Points. Int. J. Comput. Vis. 2005, 64, 107–123. [Google Scholar] [CrossRef]
- Laptev, I.; Marszałek, M.; Schmid, C.; Rozenfeld, B. Learning realistic human actions from movies. In Proceedings of the CVPR 2008-IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; Volume 2, pp. 2169–2178. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Montreal, QC, Canada, 2014; pp. 568–576. [Google Scholar]
- Sehgal, S. Human Activity Recognition Using BPNN Classifier on HOG Features. In Proceedings of the 2018 International Conference on Intelligent Circuits and Systems, Phagwara, India, 20–21 April 2018; pp. 286–289. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with Convolutional Neural Networks. In Proceedings of the 2014 IEEE conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1725–1732. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional Two-stream Network Fusion for Video Action Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Aslan, M.F.; Durdu, A.; Sabanci, K. Human action recognition with bag of visual words using different machine learning methods and hyperparameter optimization. Neural Comput. Appl. 2020, 32, 8585–8597. [Google Scholar] [CrossRef]
- Baccouche, M.; Mamalet, F.; Wolf, C.; Garcia, C.; Baskurt, A. Sequential deep learning for Human Action Recognition. In Proceedings of the 2nd International Workshop on Human Behavior Understanding, Amsterdam, The Netherlands, 16 November 2011; pp. 29–39. [Google Scholar]
- Kuo, S.M.; Lee, B.H.; Tian, W. Introduction to Real-time Digital Signal Processing. In Real-Time Digital Signal Processing: Fundamentals, Implementations and Applications, 3rd ed.; John Wiley and Sons, Ltd.: Chichester, West Sussex, UK, 2013; Volume 1, pp. 1–43. [Google Scholar]
- Shin, K.G.; Ramanathan, P. Real-time computing: A new discipline of computer science and engineering. Proc. IEEE 1994, 82, 6–24. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.; Felsberg, M. Accurate scale estimation for robust visual tracking. In Proceedings of the 2014 British Machine Vision Conference, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, J.; Marszałek, M.; Lazebnik, S.; Schmid, C. Local features and kernels for classification of texture and object categories: A comprehensive study. Int. J. Comput. Vis. 2007, 73, 213–238. [Google Scholar] [CrossRef] [Green Version]
- Vert, J.P.; Tsuda, K.; Schölkopf, B. A primer on kernel methods. Kernel Methods Comput. Biology 2004, 47, 35–70. [Google Scholar]
- Singh, D.; Bhure, A.; Mamtani, S.; Mohan, C.K.; Kandi, S. Fast-BoW: Scaling Bag-of-Visual-Words Generation. In Proceedings of the 2018 British Machine Vision Conference, Newcastle, UK, 2–6 September 2018. [Google Scholar]
- Shi, J.; Tomasi, C. Good Features to Track. In Proceedings of the 1994 IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 593–600. [Google Scholar]
- Govender, D.; Tapamo, J.R. Factors Affecting the Cost to Accuracy Balance for Real-Time Video-Based Action Recognition. In Proceedings of the 20th International Conference on Computational Science and Applications, University of Calgari, Calgari, Italy (held online), 1–4 July 2020. [Google Scholar]
- Farnebäck, G. Two-frame motion estimation based on polynomial expansion. In Proceedings of the Scandinavian Conference on Image analysis, Berlin, Heidelberg, 29 June–2 July 2003; pp. 363–370. [Google Scholar]
- Arandjelović, R.; Zisserman, A. Three things everyone should know to improve object retrieval. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2911–2918. [Google Scholar] [CrossRef]
- Basha, S.; Pulabaigari, V.; Mukherjee, S. An Information-rich Sampling Technique over Spatio-Temporal CNN for Classification of Human Actions in Videos. arXiv 2020, arXiv:2002.02100. [Google Scholar]
- Bolme, D.S.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual object tracking using adaptive correlation filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description | Value |
|---|---|---|
| Parameters for Translation Model (DCF) as per [46] | ||
| Regularization parameter for translation model | 0.0001 | |
| Learning rate for translation model | 0.02 | |
| Parameters for Scale Model as per [45] | ||
| Regularization parameter for scale model | 0.01 | |
| Learning rate for translation model | 0.025 | |
| S | Number of scales | 33 |
| Scale Factor | 1.02 | |
| Scale Coding | Parameter Definition | Hyper-Parameters | Accuracy (%) |
|---|---|---|---|
| Absolute | Static | kernel = ‘linear’ | 63.42 |
| Dynamic | kernel = ‘linear’ | 63.89 | |
| Relative | Static | kernel = ‘linear’ | 61.57 |
| Dynamic | kernel = ‘linear’ | 64.81 |
| Scale Coding Scheme | Hyper-Parameters | Accuracy (%) |
|---|---|---|
| Absolute | kernel = ‘rbf’, | 27.78 |
| Relative | kernel = ‘rbf’, | 21.24 |
| Task | KTH | HMDB51 |
|---|---|---|
| Object Detection | 1.01 s | 1.81 s |
| Feature Extraction | 7.15 s | 7.73 s |
| Scale Coding | 5.44 s | 4.35 s |
| Total Processing Time | 13.60 s | 13.89 s |
| Average Number of frames per video | 335.95 | 417.95 |
| Processing Frequency | 24.70 fps | 30.09 fps |
| Capturing Frequency | 25 fps [23] | 30 fps [24] |
| Method | Accuracy (%) |
|---|---|
| HMDB51 [24] (Combined) | 23.18 |
| HOGHOF | 20.44 |
| HOG | 15.47 |
| HOF | 22.48 |
| Local Part Model [6] (Combined) | 47.6 * |
| HOG | 21.0 |
| HOF | 33.5 |
| HOG3D | 34.7 |
| MBH | 43.0 |
| Motion Vector CNNs [9] | 55.3 * |
| Scale Coded BoW | 27.78 |
| Task | Computation Time (s) | Computation Frequency (fps) |
|---|---|---|
| BoW Formation with Scale Coding | 192.24 | 5.22 |
| BoW Formation without Scale Coding | 186.65 | 6.10 |
| Added Cost | 5.59 | 0.88 |
| Description | KTH | HMDB51 (Reduced) |
|---|---|---|
| DT (%) | 94.0 | 81.21 |
| DT + SC-BoW (%) | 96.76 | 84.85 |
| Net Performance Change (%) | +2.76 | +3.64 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Govender, D.; Tapamo, J.-R. Spatio-Temporal Scale Coded Bag-of-Words. Sensors 2020, 20, 6380. https://doi.org/10.3390/s20216380
Govender D, Tapamo J-R. Spatio-Temporal Scale Coded Bag-of-Words. Sensors. 2020; 20(21):6380. https://doi.org/10.3390/s20216380
Chicago/Turabian StyleGovender, Divina, and Jules-Raymond Tapamo. 2020. "Spatio-Temporal Scale Coded Bag-of-Words" Sensors 20, no. 21: 6380. https://doi.org/10.3390/s20216380
APA StyleGovender, D., & Tapamo, J. -R. (2020). Spatio-Temporal Scale Coded Bag-of-Words. Sensors, 20(21), 6380. https://doi.org/10.3390/s20216380