1. Introduction
Growing energy demands globally have raised concerns leading stakeholders towards renewable energy [
1,
2]. Industrial development in developing countries has called upon the need to increase the installed capacity. In the past decade, it has been found that wind farms can serve both purposes of increasing installed capacity and minimising environmental concerns. However, with increased installation, more turbine failures occur, thereby driving the need for investment and research in condition monitoring (CM) systems [
3,
4]. Wind turbines observe highly irregular loads due to stochastic and turbulent wind conditions, which makes components undergo high stress throughout their lifetime [
5]. With increasing offshore wind farm installations, the operation and maintenance (O+M) cost is identified as an area with cost-saving potential [
6]. Literature suggests that O+M costs for offshore wind turbines can be up to 30% of the overall cost of energy [
7]. A major part of CM involves identifying patterns in wind turbine variables like rotor speed, power output, gearbox temperature, gear bearing temperature and generator faults. A commonly used CM system in modern-day wind turbines consists of sensor-based networks that create and record data streams from which the failure is identifiable. Often, the prognosis of wind turbine components is carried out by segmenting the same into different subsystems, such as mechanical and electrical components. Basic CM techniques include vibration analysis (wheels and bearings of the gearbox, generator bearings), oil analysis, thermography and acoustic monitoring (sensors mounted on the turbine equipment) [
8]. Nondestructive testing (NDT) is a common way to evaluate the structural integrity of several underground structures [
9,
10] and aerospace applications [
11]. Furthermore, integration of sensors and data mining based technologies has enabled a reliable monitoring process [
12].
Gill et al. studied condition monitoring based on a modeling wind turbine power curve where an anomalous behavior in a wind turbine is identified from the deviation-caused turbine power [
13]. Butler et al. discussed a similar approach based on Gaussian process models to model the wind turbine power curve [
14]. Results revealed a performance degradation three months before a failure in the turbine main bearing. Studies have shown that gearbox bearing causes approximately 70% and 50% of turbine downtime for small and medium-scale generators and large-scale generators, respectively. Availability of gearbox bearing, oil, nacelle temperature through supervisory control and data acquisition (SCADA) has emerged as a popular candidate among the research community to facilitate data-based preventive maintenance for wind turbines. SCADA data are transmitted and stored at an averages of 10 min, which makes the processing speed and storage much easier for the operator. As far as fault identification and diagnosis are concerned, machine learning techniques are often classified in two ways, that is, classification and regression-based approaches. Since machine learning classification problems are based on the prediction of a discrete variable, the turbine condition is classifiable into “healthy” or “abnormal” states, and algorithms used for classification are assessed based on metrics such as accuracy, precision, recall and F1-score, while regression-based approaches are based on the prediction of a continuous variable. The predicted variable is compared against the measured one and error metrics such as mean squared error and mean absolute error are used to compare model effectiveness.
The literature on the classification and regression-based condition monitoring of wind turbines is discussed. Leahy et al. presented a support vector machine (SVM)-based fault diagnosis and fault classification using SCADA data for a 3 MW turbine located in Ireland [
15]. A total of 29 features are used to train the SVM algorithm. Results reveal an accuracy of 80% with a recall value in the range of 78–95%. Ibrahim et al. presented a neural network-based model for the detection of mechanical faults in a wind turbine [
16]. The model is based on a current signal acquired at different ranges of speed, used as an input with classification accuracy in the range of 93–98%. In [
17], authors implement Shannon wavelet-based SVM technique for the fault classification of wind turbine gearbox faults. A non-linear feature selection technique is used with SVM resulting in an accuracy of 92% compared to 72% with standard SVM with radial basis function as a kernel. Jiang et al. studied a multi-scale convolutional neural network (CNN) for fault diagnosis of a wind turbine [
18]. In this method, the feature extraction for classification task is carried out from the vibration signals. The performance of multi-scale CNN is compared with the conventional CNN method which results in an accuracy of 98.53%. Jiminez et al. studied linear and non-linear feature selection techniques for ice detection in wind turbines [
19]. Among linear feature selection techniques, auto-regressive and principle component analysis (PCA) is used, and in case of non-linear feature selection techniques, neighborhood component analysis (NCA) and hierarchical non-linear PCA is used. Ice detection and diagnosis are carried out based on SVM, decision tree, k-nearest neighbors (kNN) and discriminant analysis. In [
20], a deep neural network-based technique is applied for anomaly and fault detection in wind turbine components. Based on SCADA data, a deep auto-encoder based deep neural network is established. Carroll et al. discussed logistic regression, two-class neural networks and SVM for classifying gear tooth and gear bearing scenarios from SCADA data [
21]. In [
22], authors use signal processing techniques such as sideband analysis, time-synchronous analysis, amplitude modulation to extract features for classifying the healthy and abnormal state of a wind turbine. Algorithms like kNN, SVM and decision tree are utilized to achieve the same with an accuracy of 90.2%, 91.3% and 91% respectively.
Anomaly detection can be seen as a problem of both, supervised and unsupervised machine learning [
23]. While a majority of anomaly detection problems have been addressed using unsupervised learning such as K-means clustering and local outlier factor (LOF), that estimates the distance between all the samples using K-nearest neighbor concept and deviation in density function [
24]. Japkowicz et al. [
25] presented novelty detection using a classification approach. In the classification-based approach, each sample in the training set has a labelled output for which the anomalies are obtained. However, with a classification-based approach, the problem of imbalanced instances may arise which deteriorates the quality of the classification model for unseen testing samples. On the other hand, semi-supervised learning assumes that labelled instances are available for normal or healthy classes. In the wind industry, the concept of anomaly detection is utilized to identify vulnerable equipment in the machine using a data mining approach [
26,
27].
The motivation behind this work arises from the ability of a class of SVR models to yield excellent results in the case of a wind speed forecasting scenario [
28]. SVR models with a particular choice of loss function result in an optimal estimate for a given noise model. For example, a quadratic loss function in the least square support vector regression (LSSVR) model enables it to perform optimally for a normally distributed noise. While a majority of the work on wind turbine condition monitoring is reported as a classification task to the best of our knowledge, we are the first group to use a class of SVR models and discuss residual analysis for gearbox condition monitoring. The main contributions of this work are as follows:
Predictive analytics for wind turbine gearbox are studied based on a class of support vector regression (SVR) models in the form of twin support vector regression combined with neighborhood component analysis. The impact of feature selection is studied on the prediction metrics of gearbox oil and bearing temperature.
The SCADA data procured consist of a list of variables that are scanned under the banner of feature selection for the accurate prediction of gearbox oil and bearing temperature. The performance of SVR based models as compared to the multi-layer perceptron neural network, decision tree and logistic regression, is presented.
Statistical analysis is carried out for SVR based models to analyze residuals and their correlation. Specifically, Diebold–Mariano and Durbin–Watson tests help analyze the residuals for establishing the robustness among tested models.
The organization of this manuscript is as follows:
Section 2 gives an idea about the machine learning-based regression methods considered in this analysis. Methods like SVR and its variants, neural network, decision tree and logistic regression are presented with their mathematical formulation and parameters involved. Furthermore, in
Section 2, the feature selection technique based on neighborhood component analysis is discussed with a graphical illustration.
Section 3 consists of the description of SCADA data where various feature variables are highlighted; the experimental results concerning the prediction analysis are discussed followed by Conclusions in
Section 4.
3. Results and Discussion
According to the National Renewable Energy Laboratory’s (NREL) Gearbox Reliability Database (GRD), 76% of gearboxes failures happen due to bearings, and 17% from gear failures [
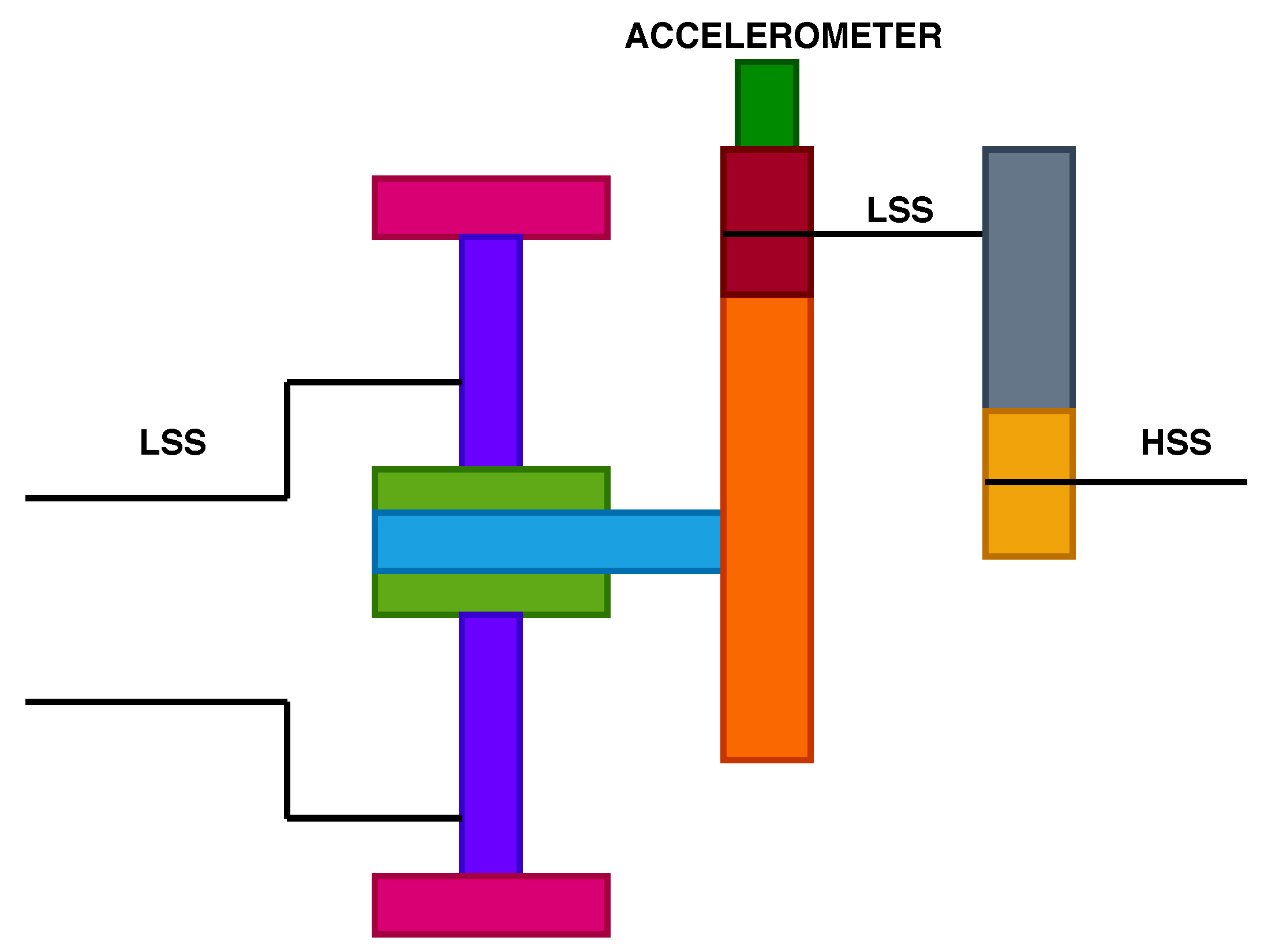
33]. The gearbox models include a low-speed planetary stage (LSS), an intermediate stage and a high-speed parallel stage (HSS) as illustrated in
Figure 2 and
Figure 3. The two gearbox models come from a different turbine type. The gearbox configurations are used extensively for turbines rated 2 MW and 4MW, with rotor diameter ranging between 80 to 120 m. Both turbine types use high-speed gearboxes with induction generators. Gearbox “A” consists of two planetary stages and one parallel stage, while gearbox type “B” consists of one planetary stage and two parallel stages.
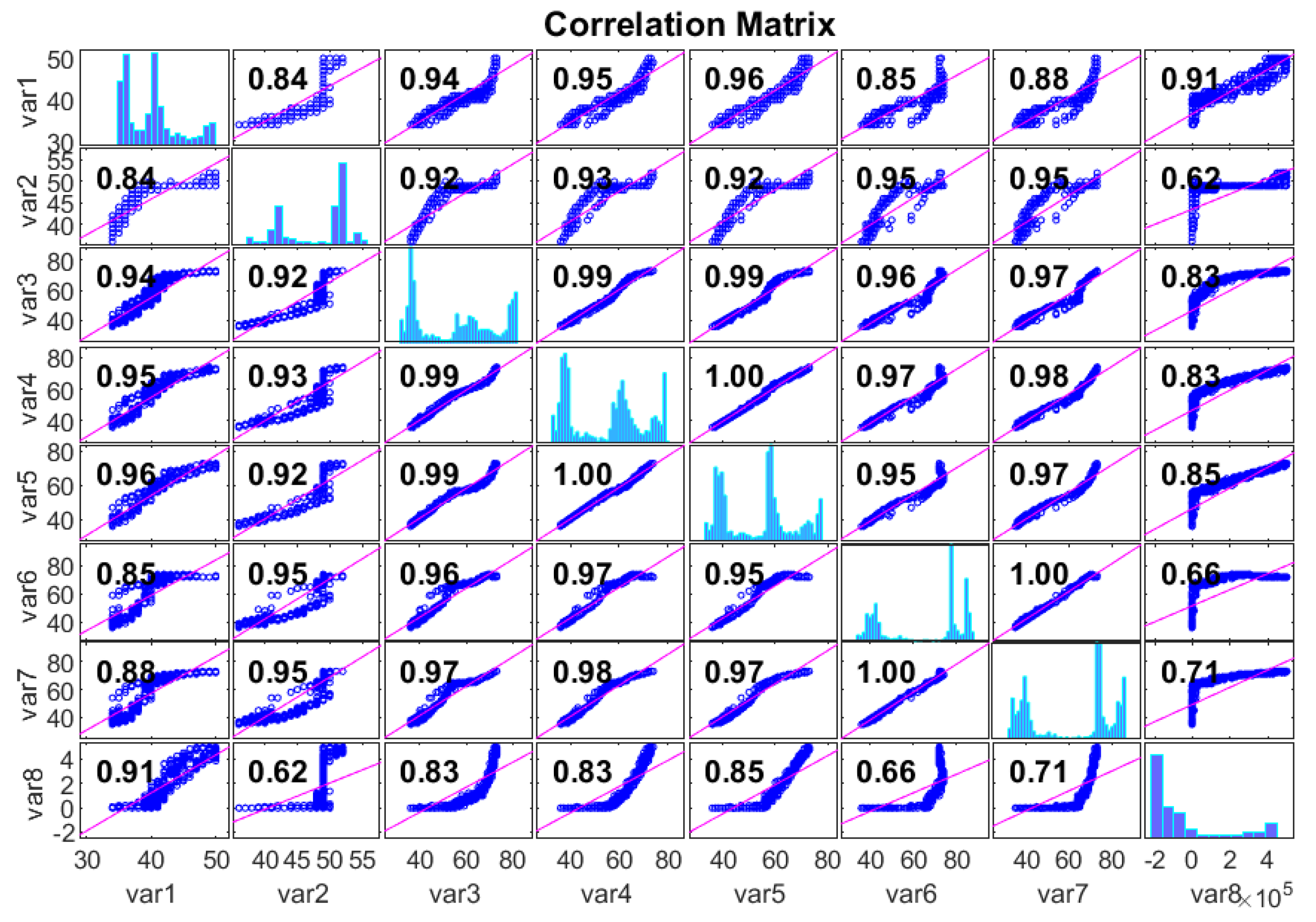
Figure 4 describes the correlation coefficient between gearbox oil and the bearing temperature.
Table 1 depicts the computations of the Pearson correlation coefficient for these variables in this analysis. The sampling interval of these variables is 10 min, which is appropriate from an industrial standpoint, as the majority of the market-clearing operations are taking place in this interval. The data acquired are checked for missing values. After corroboration of the SCADA data quality, the sensor temperature readings are subtracted from each other to obtain differences in temperature (
) to train the supervised learning algorithms. For example, as acquired from SCADA data, a gear oil temperature reading (
) and an ambient temperature reading (
) are used to determine the difference in temperatures as
. The
provide extra variables for training and testing.
The experimental setup is as follows; all experiments have been performed on Intel Core i3 6th generation processor with 4 GB of RAM in MATLAB 18.0 environment (
http://in.mathworks.com/). In this section, we discuss the experimental results for the predictive analytics performed on a wind turbine. SCADA data available for 1 year and 1 month prior to failure consist of several variables, as discussed in the previous section. Gearbox oil and bearing temperature are analyzed through a regression-based approach. Since the temperature of oil and bearing is a continuous variable, a regression-based approach helps one to identify abnormal trends in its time-series. Since the available SCADA consists of 54 feature variables (27 from 1 year prior and rest from 1 month before failure), it is important to identify important features and remove redundant ones. One such feature selection technique is the neighborhood component analysis as described in
Section 2. We choose the best-suited features as input to the machine learning-based regression model. In this manuscript, the prediction of the gearbox oil (sensor 1) and bearing temperatures takes place, using a set of ML techniques. In
Table 2, variable index 1 is treated as target variable, and the rest of the 53 (26 + 27) variables are considered inputs to the model. It is important to note that machine learning algorithms work well with a significant amount of data, and hence getting the right amount of data from SCADA systems is essential for identifying faulty situations. SCADA data for this analysis consist of 1009 samples, out of which 800 samples are used in the training phase and rest for testing.
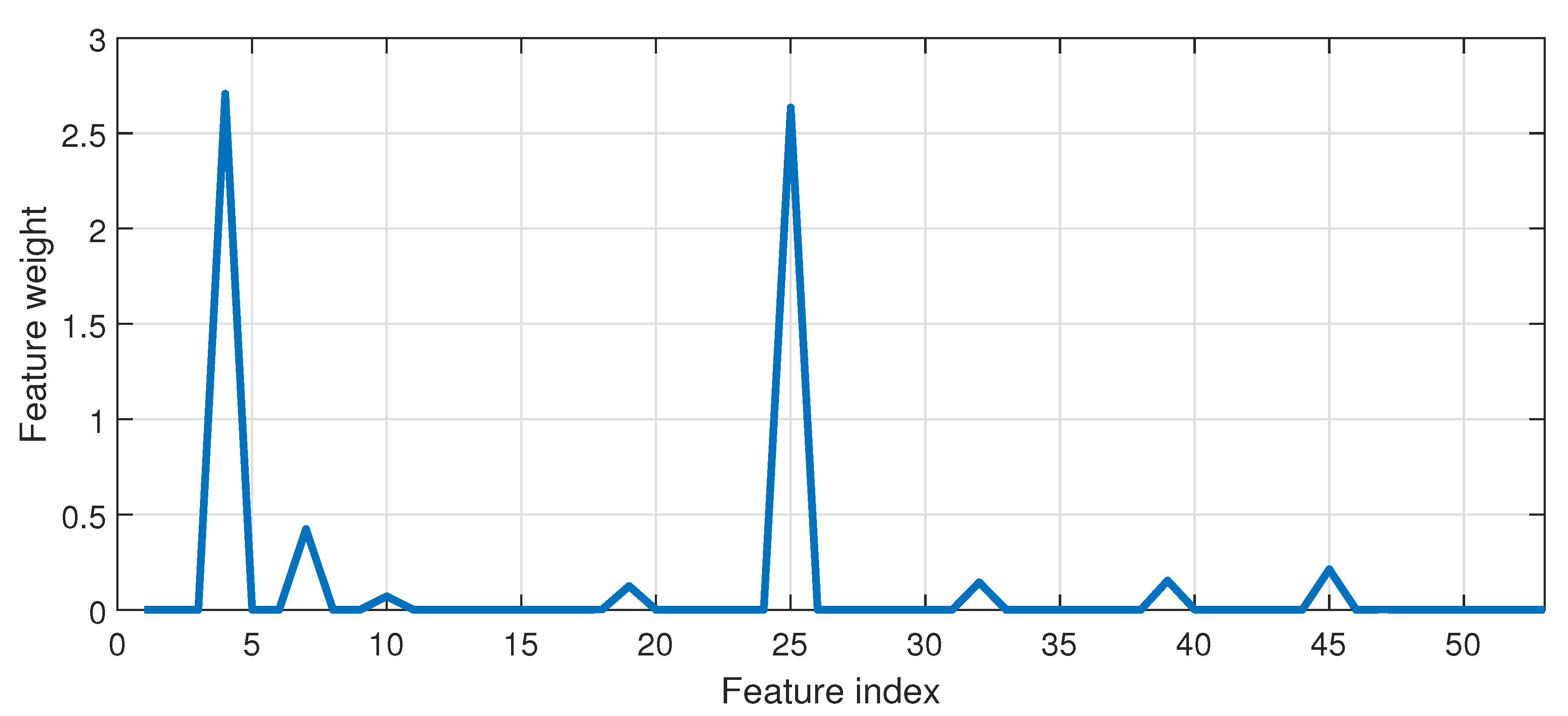
Figure 5 illustrates the weights corresponding to the feature variables.
A detailed description of SCADA variables can be found in
Table 2. It is observed that feature variables such as
oil sensor 1 and ambient, gear bearing 1 temperature, ambient temperature and nacelle temperature have significant weightage compared to others. Hence, in order to predict gearbox oil temperature, these variables are treated as features or inputs to the prediction model.
The detailed flowchart of the proposed methodology is illustrated in
Figure 6. Since machine learning models are stochastic, to validate the importance of training data, we perform 10-fold cross-validation for all models and compute the accuracy results with a standard deviation error, as depicted in
Table 3 and
Table 4. The bold values indicate the prediction results when NCA is used as a feature selection technique.
Among the tested regression techniques, decision trees give minimum RMSE values. This behavior of decision trees can be understood with its simplicity while predicting unseen data once trained with an optimal number of features. Out of the tested models, for condition monitoring of wind turbine, it is observed that for diagnosing a failure associated with gearbox oil temperature, TSVR gives accurate prediction. However, for raising alarms regarding failures in gearbox bearing, a decision tree-based model yields highest accuracy. This analysis is carried out with SCADA data 1 month and 1 year prior to failure. Reducing the dimension of feature space using NCA reduces computational effort and increases reliability of an intelligent condition monitoring system for wind turbines.
4. Residual Analysis
In this section, the residuals from gearbox oil temperature prediction are analyzed from a statistical point of view. Methods like TSVR, LSSVR and Huber-SVR are tested against standard-SVR using a Diebold–Mariano (DM) test that compares the accuracy of two forecasting models. According to a DM test, when two prediction models have similar accuracy, a null hypothesis is adopted [
34]. With respect to the current objective, the DM test is conducted with TSVR (Test 1), LSSVR (Test 2) and Huber-SVR (Test 3) to test its accuracy against standard the SVR model. The results are depicted in
Table 5 with 1% significance level, and it is observed that, TSVR, LSSVR and Huber-SVR models have substantial prediction edge over a standard SVR (
-SVR) model, thereby establishing the robustness of the tested models.
Furthermore, in order to examine the nature of residuals and potential auto-correlation among them, the Durbin–Watson (DW) statistic is computed for the class of SVR models. The test is based on the fact that for a statistical regression model, the errors are independent. The DW statistic can be given as
where
denotes the
ith error term of a
error column vector. The error vector for class of SVR models is tested for potential autocorrelation which can be modeled in the form of a hypothesis as follows
where
and
are the lower and upper critical limits which can be found from the DW table for any
-level of significance [
35]. In this manuscript, the DW statistic is calculated at 1% significance level and is tabulated in
Table 6.
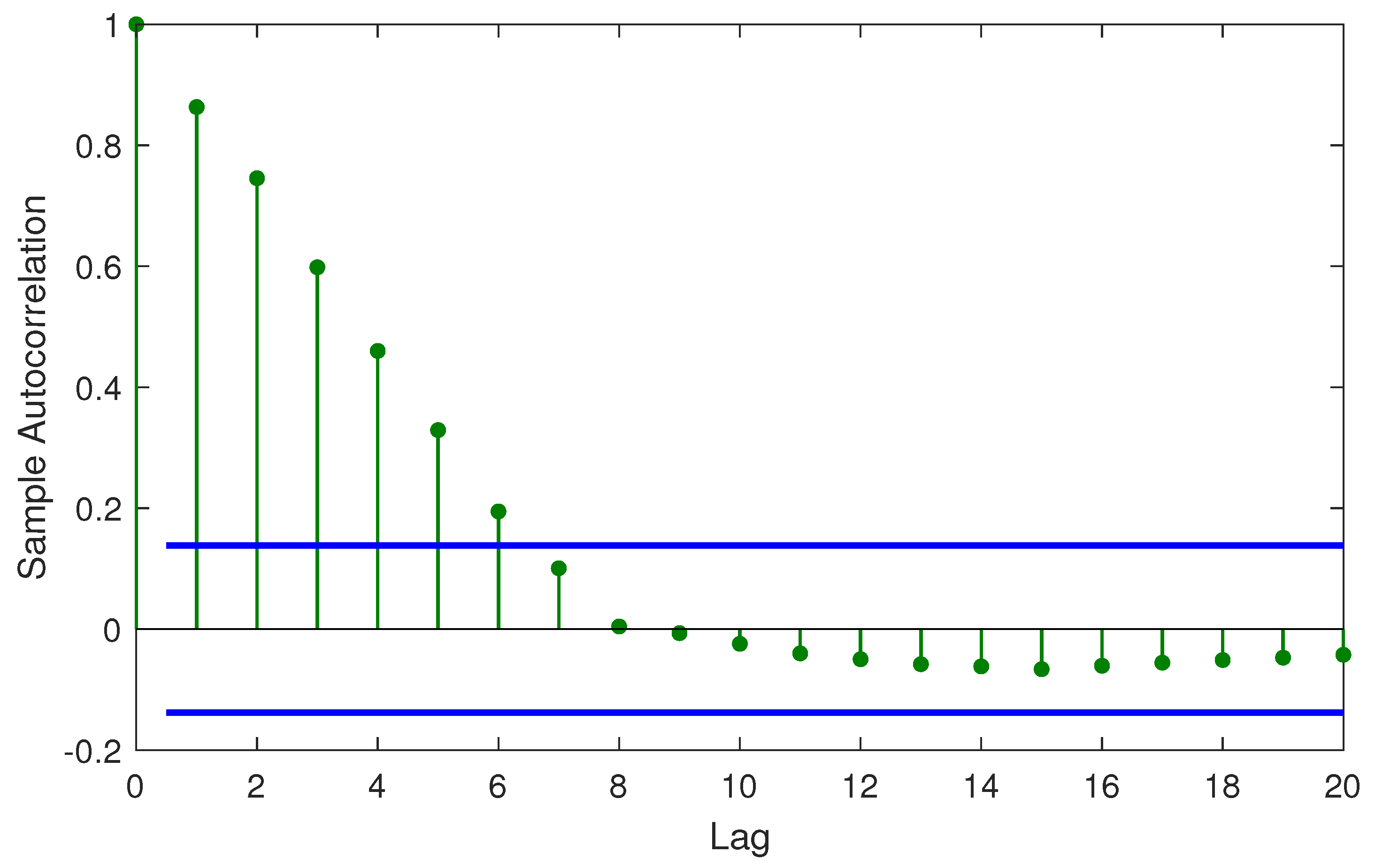
The results of the DW test indicate that for the class of SVR models, the errors are auto-correlated and can be represented by an auto-regressive (AR) process of suitable lag. For example,
Figure 7 illustrates the autocorrelation at various lag instants. It is observed that till lag instant 6, the errors indicate a high level of autocorrelation. A typical
p-order AR process with lag coefficients
and noise
can be expressed as follows
The main idea behind carrying out residual analysis is to identify the time-series relationship for a class of SVR models. The residuals obtained from
-SVR, LSSVR, TSVR and Huber-SVR are tested for the identification of the orders of ARIMA models.
Table 7 depicts statistical parameters of ARIMA models, and we observe that LSSVR and TSVR follow ARIMA order (4,1,1) and (3,1,1) respectively. We find that the Akaike information criteria (AIC) and Bayesian information criteria (BIC) values for LSSVR and TSVR are lower as compared to SVR and Huber-SVR, indicating that the fitted ARIMA orders reflect the true model. AIC and BIC of the ARIMA models for residuals are computed in R studio.
Figure 8 represents the fitting of residuals obtained from a class of SVR methods. The residuals obey a certain distribution. The majority of the time for wind speed and power forecast errors, the distribution that fits well is Gaussian distribution. It is observed that for residuals of TSVR, the distribution closely follows normal distribution, hence making it feasible to forecast the gearbox oil and bearing temperature with higher accuracy. Regression-based approach for condition monitoring may be further extended to minimize the false positive rate that is a pertinent issue with most of the classification algorithms. Since the gearbox oil and bearing temperature is essentially a time-series, statistical modeling of residuals can help in increasing the turbine reliability in terms of the generation of trip signals. It would also help the operator to schedule the timely maintenance of an unhealthy wind turbine(s). In future, a time-series can be analyzed adaptively to identify instances of anomalous behavior and reduce the false-positive rate which is an issue with classification-based approaches [
21].
5. Conclusions
This manuscript highlights the importance of feature selection for condition monitoring of wind turbine. Modern day SCADA data contain a lot of variables from which redundant data need to be removed. Neighborhood component analysis for regression aids this process by calculating feature weights. Features with higher importance are considered for regression analysis with methods like SVR, neural network, decision tree and logistic regression under evaluation. Based on the experimental results, we observe that with an accuracy of 99.91 ± 0.007%, a TSVR-based model outperforms all other models for gearbox oil temperature prediction followed by MLPNN. However, for gearbox bearing temperature, decision tree outperforms TVSR, MLPNN and logistic regression with an accuracy of 98.74 ± 0.91%. Quantitatively, with NCA, the prediction accuracy is found superior to without NCA. This is indicative of the fast computation aided by relevant features. From statistical point of view, the residuals are evaluated using the Diebold–Mariano and Durbin–Watson statistics, where the robustness of the tested models is ascertained. For the Durbin–Watson test, -SVR, LSSVR, Huber-SVR and TSVR obtain statistic values of 0, 0.284, 0.0234 and 0.0302 respectively, which rejects null hypothesis and indicates the presence of autocorrelation among residuals for tested models. The residuals are also analyzed for their ARIMA orders and it is observed that LSSVR and TSVR depict close relationship in their AIC values of 691.53 and 696.62 respectively. Furthermore, it must be noted that in this study Bayesian analysis is not considered because of the dependency among feature variables.

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}