Multi-Object Tracking Algorithm for RGB-D Images Based on Asymmetric Dual Siamese Networks



Abstract
:1. Introduction
- In recent years, the accuracy of the single-object tracker in short-term tracking tasks has been greatly improved. Therefore, we transform the MOT task into the multiple short-term single-object tracking task, and we use the high quality of short trajectories to generate the high quality of the target’s trajectories.
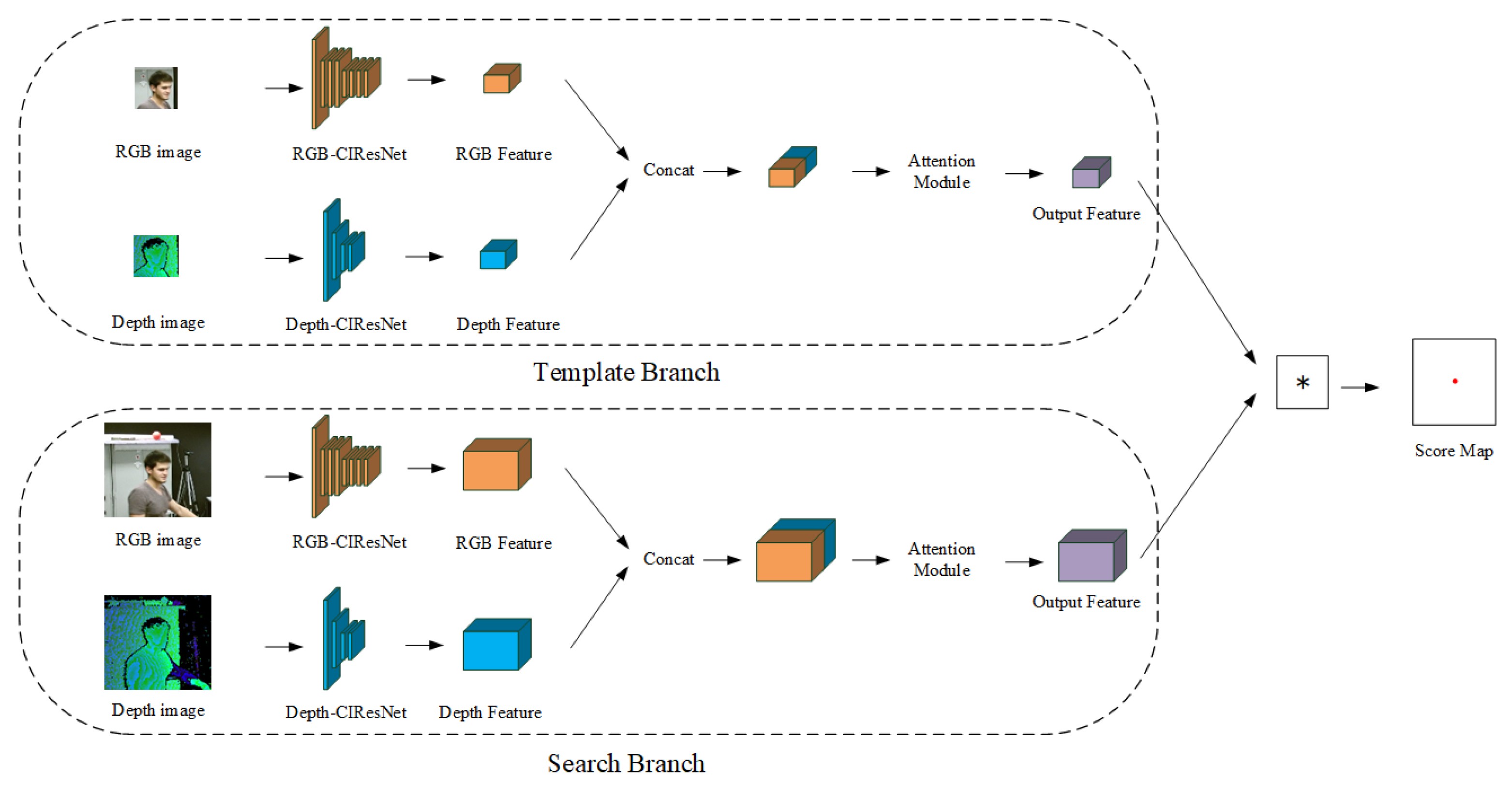
- The RGB images and the depth images contain different information. Currently, the asymmetric feature extraction networks can better consider the characteristics of the RGB image and depth images. In order to obtain a high quality of the RGB-D feature, we design the asymmetric feature extraction network.
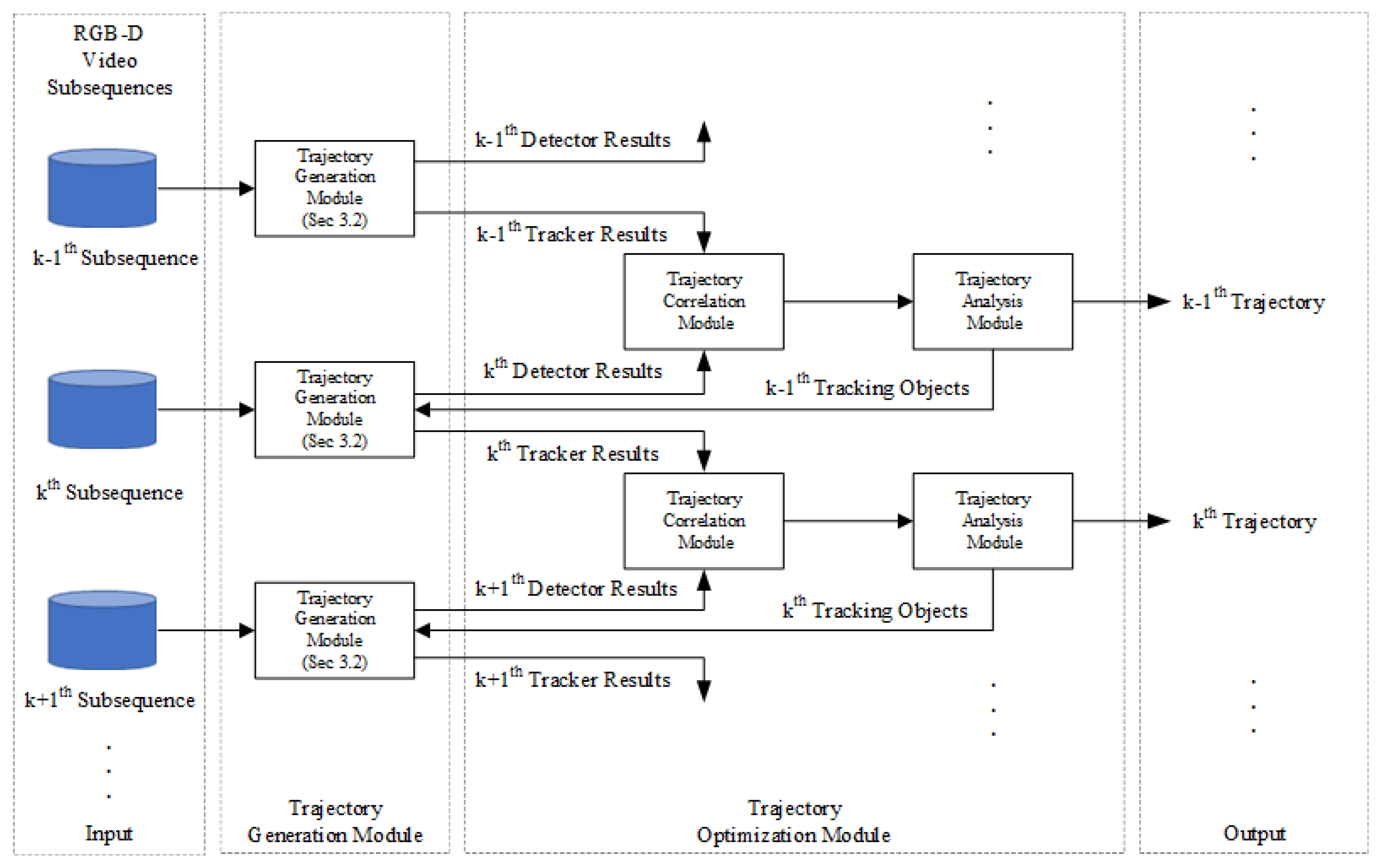
- The MOT task is a strongly time-sequential task. When the targets occlude each other or disappear from the scene, the trajectory association results of the target in the neighboring video subsequences will change accordingly. Therefore, we use the trajectory association results of the neighboring video subsequences to determine the quality of the target trajectory. We optimize the target trajectory according to different qualities to improve the target tracking quality.
- To solve the problem that the existing feature extraction networks cannot balance the differences between the RGB feature and depth feature, this paper designs the asymmetric dual Siamese network to balance the information of the RGB feature and depth feature and to extract the high-quality RGB feature and depth feature based on the characteristics of RGB images and depth images.
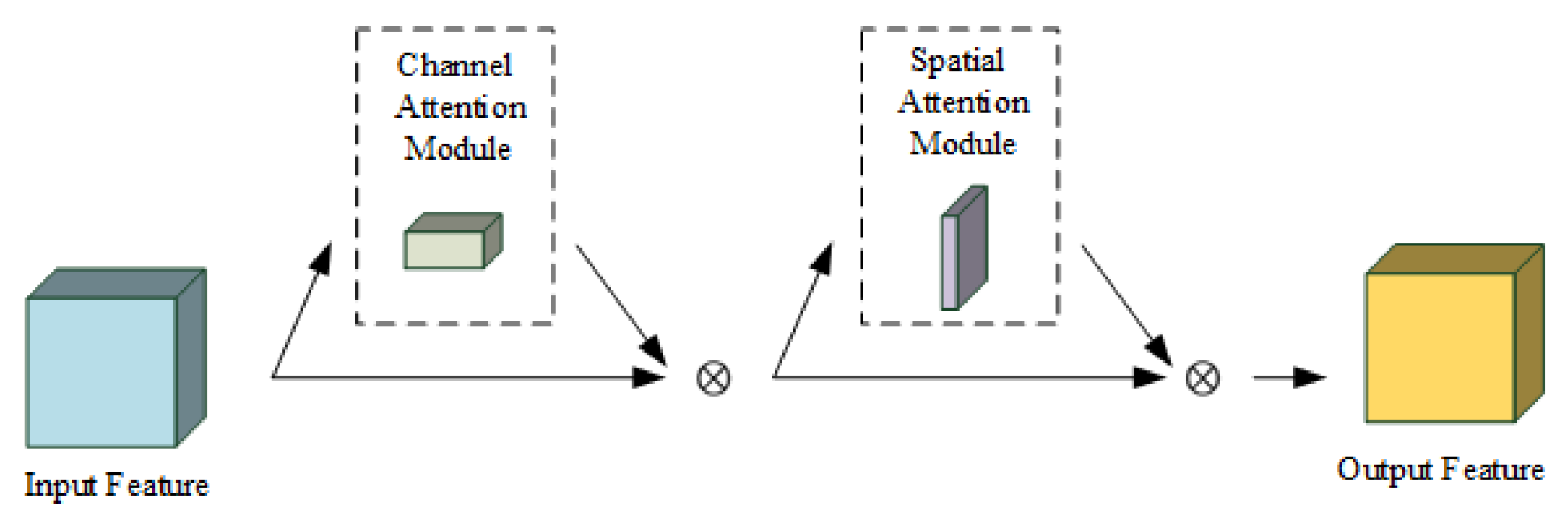
- To solve the problem that there is a large amount of redundant information in the fused RGB-D feature, this paper uses an attention mechanism to fuse the RGB feature and depth feature based on the importance of the feature’s location and channel and reduce the redundant information and holes in the RGB-D feature.
- To solve the problem that the existing MOT algorithm is easy to establish a target track on the wrong target position, this paper designs a trajectory optimization module to analyze the trajectory based on the time context information of the video sequence and suppress the error trajectories to improve the quality of the tracking algorithm.
2. Related Work
2.1. The MOT Algorithms Based on RGB Images
2.1.1. The Algorithms Based on Data Association
2.1.2. The Algorithms Based on the SOT Algorithm
2.2. The MOT Algorithms Based on the RGB-D Images
3. The Proposed Algorithm
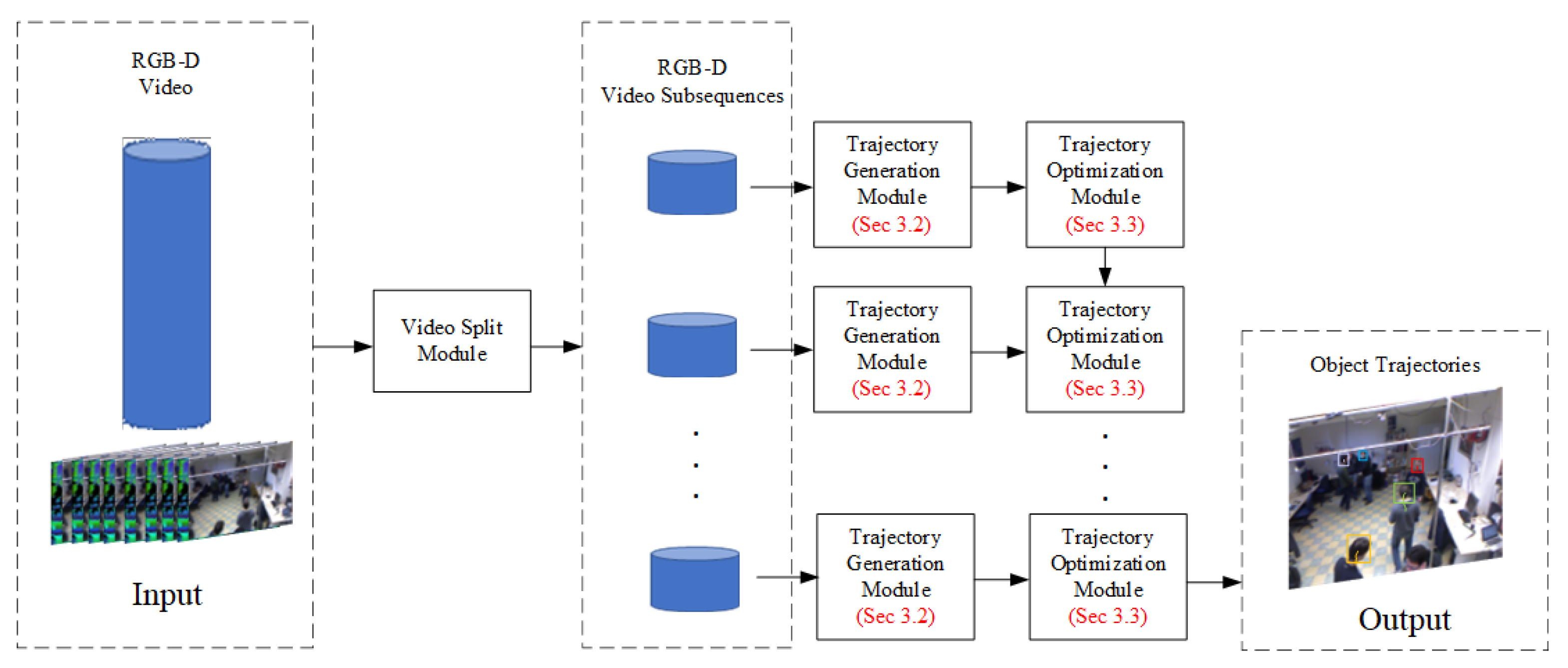
3.1. The Overall Structure of the Algorithm
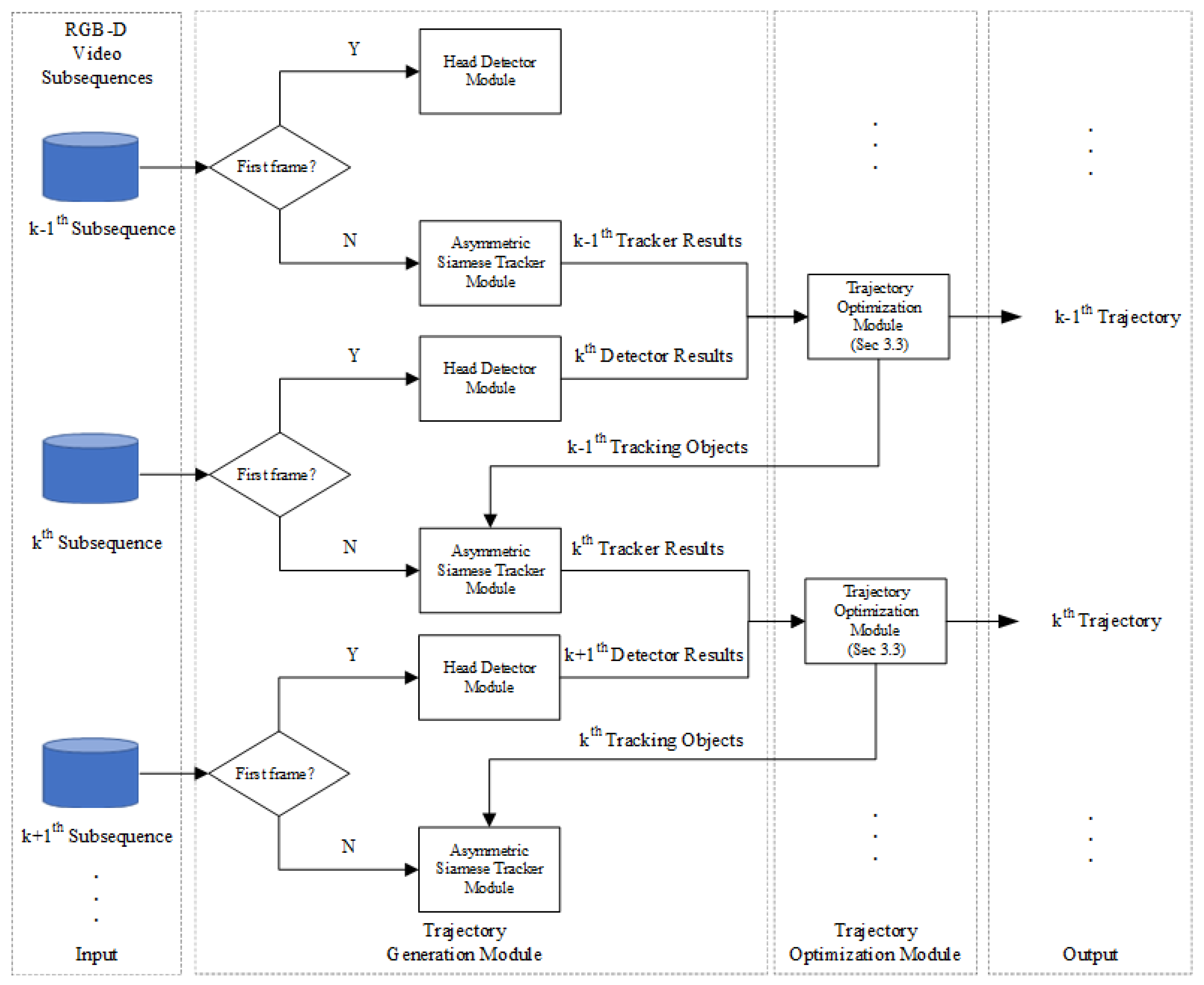
3.2. The Trajectory Generation Module
3.2.1. The Characteristics of RGB Images and Depth Images
3.2.2. The Design of the Asymmetric Siamese Tracker Module
3.3. The Trajectory Optimization Module
3.3.1. The Characteristics of the Trajectory
3.3.2. The Design of the Trajectory Optimization Module
4. Experiments
4.1. Experiment Details
4.2. Ablation Study
4.2.1. The Effectiveness of the Trajectory Generation Module
4.2.2. The Effectiveness of the Trajectory Optimization Module
4.3. State-Of-The-Art Comparison
4.4. The Discussion of the Time Consumption
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Xu, R.; Nikouei, S.Y.; Chen, Y.; Polunchenko, A.; Song, S.; Deng, C.; Faughnan, T.R. Real-time human objects tracking for smart surveillance at the edge. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]
- Yang, C.-J.; Chou, T.; Chang, F.A.; Chang, S.-Y.; Guo, J.-I. A smart surveillance system with multiple people detection, tracking, and behavior analysis. In Proceedings of the 2016 International Symposium on VLSI Design, Automation and Test (VLSI-DAT), Hsinchu, Taiwan, 25–27 April 2016; pp. 1–4. [Google Scholar]
- Ko, K.-E.; Sim, K.-B. Deep convolutional framework for abnormal behavior detection in a smart surveillance system. Eng. Appl. Artif. Intell. 2018, 67, 226–234. [Google Scholar] [CrossRef]
- Shehzed, A.; Jalal, A.; Kim, K. Multi-Person Tracking in Smart Surveillance System for Crowd Counting and Normal/Abnormal Events Detection. In Proceedings of the 2019 International Conference on Applied and Engineering Mathematics (ICAEM), Taxila, Pakistan, 27–29 August 2019; pp. 163–168. [Google Scholar]
- Milan, A.; Leal-Taixé, L.; Reid, I. Roth, Stefan and Schindler, Konrad, MOT16: A benchmark for multi-object tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Zhang, X.; Liu, X.; Yuan, S.-M.; Lin, S.-F. Eye tracking based control system for natural human-computer interaction. Comput. Intell. Neurosci. 2017, 2017, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Naiel, M.A.; Ahmad, M.O.; Swamy, M.N.S.; Lim, J.; Yang, M.-H. Online multi-object tracking via robust collaborative model and sample selection. Comput. Vis. Image Underst. 2017, 154, 94–107. [Google Scholar] [CrossRef]
- Eiselein, V.; Arp, D.; Pätzold, M.; Sikora, T. Real-time multi-human tracking using a probability hypothesis density filter and multiple detectors. In Proceedings of the 2012 IEEE Ninth International Conference on Advanced Video and Signal-Based Surveillance, Beijing, China, 18–21 September 2012; pp. 325–330. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2008; Volume 10, pp. 142–149. [Google Scholar]
- Bochinski, E.; Eiselein, V.; Sikora, T. High-speed tracking-by-detection without using image information. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Sheng, H.; Zhang, Y.; Chen, J.; Xiong, Z.; Zhang, J. Heterogeneous association graph fusion for target association in multiple object tracking. IEEE Trans. Circuits Syst. Video Technol. 2018, 11, 3269–3280. [Google Scholar] [CrossRef]
- Comaniciu, D.; Ramesh, V.; Meer, P. Real-time tracking of non-rigid objects using mean shift. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2000 (Cat. No. PR00662), Hilton Head Island, SC, USA, 13–15 June 2000; pp. 142–149. [Google Scholar]
- Avitzour, D. Stochastic simulation Bayesian approach to multitarget tracking. JIEE Proc. Radar, Sonar Navig. 1995, 2, 41–44. [Google Scholar] [CrossRef]
- Gordon, N. A hybrid bootstrap filter for target tracking in clutter. IEEE Trans. Aerosp. Electron. Syst. 1997, 1, 353–358. [Google Scholar] [CrossRef]
- Danescu, R.; Oniga, F.; Nedevschi, S.; Meinecke, M.-M. Tracking multiple objects using particle filters and digital elevation maps. In Proceedings of the 2009 IEEE Intelligent Vehicles Symposium, Xi’an, China, 3–5 June 2009; pp. 88–93. [Google Scholar]
- Yin, J.; Wang, W.; Meng, Q.; Yang, R.; Shen, J. A Unified Object Motion and Affinity Model for Online Multi-Object Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6768–6777. [Google Scholar]
- Feng, W.; Hu, Z.; Wu, W.; Yan, J.; Ouyang, W. Multi-object tracking with multiple cues and switcher-aware classification. arXiv 2019, arXiv:1901.06129. [Google Scholar]
- Chu, P.; Ling, H. Famnet: Joint learning of feature, affinity and multi-dimensional assignment for online multiple object tracking. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 6172–6181. [Google Scholar]
- Zhu, J.; Yang, H.; Liu, N.; Kim, M.; Zhang, W.; Yang, M.-H. Online multi-object tracking with dual matching attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 366–382. [Google Scholar]
- Rasoulidanesh, M.S.; Yadav, S.; Herath, S.; Vaghei, Y.; Payandeh, S. Deep Attention Models for Human Tracking Using RGBD. Sensors 2019, 19, 750. [Google Scholar] [CrossRef] [Green Version]
- Xie, Y.; Lu, Y.; Gu, S. RGB-D Object Tracking with Occlusion Detection. In Proceedings of the 2019 15th International Conference on Computational Intelligence and Security (CIS), Macao, China, 13–16 December 2019; pp. 11–15. [Google Scholar]
- Gai, W.; Qi, M.; Ma, M.; Wang, L.; Yang, C.; Liu, J.; Bian, Y.; De Melo, G.; Liu, S.; Meng, X. Employing Shadows for Multi-Person Tracking Based on a Single RGB-D Camera. Sensors 2020, 4, 1056. [Google Scholar] [CrossRef] [Green Version]
- Fu, K.; Fan, D.-P.; Ji, G.-P.; Zhao, Q.; Shen, J.; Zhu, C. Siamese Network for RGB-D Salient Object Detection and Beyond. arXiv 2020, arXiv:2008.12134. [Google Scholar]
- Liang, F.; Duan, L.-J.; Ma, W.; Qiao, Y.; Miao, J.; Ye, Q. Context-aware network for RGB-D salient object detection. Pattern Recognit. 2021, 111, 107630. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S. Anguelov, Dragomir and Erhan, Dumitru and Vanhoucke, Vincent and Rabinovich, Andrew, Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Shi, X.; Ling, H.; Pang, Y.; Hu, W.; Chu, P.; Xing, J. R Rank-1 tensor approximation for high-order association in multi-target tracking. Int. J. Comput. Vis. 2019, 127, 1063–1083. [Google Scholar] [CrossRef]
- Danelljan, M.; Bhat, G.; Shahbaz, K.F.; Felsberg, M. Eco: Efficient convolution operators for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6638–6646. [Google Scholar]
- Sadeghian, A.; Alahi, A.; Savarese, S. Tracking the untrackable: Learning to track multiple cues with long-term dependencies. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 300–311. [Google Scholar]
- Chrapek, D.; Beran, V.; Zemcik, P. Depth-based filtration for tracking boost. In Proceedings of the International Conference on Advanced Concepts for Intelligent Vision Systems, Catania, Italy, 26–29 October 2015; pp. 217–228. [Google Scholar]
- Kalal, Z.; Mikolajczyk, K.; Matas, J. Tracking-learning-detection. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 7, 1409–1422. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Q.; Fang, J.; Yuan, Y. Multi-Cue Based Tracking. Neurocomputing 2014, 131, 227–236. [Google Scholar] [CrossRef]
- Liu, J.; Liu, Y.; Cui, Y.; Chen, Y.Q. Real-time human detection and tracking in complex environments using single RGBD camera. In Proceedings of the 2013 IEEE International Conference on Image Processing, Melbourne, Australia, 15–18 September 2013; pp. 3088–3092. [Google Scholar]
- Liu, J.; Liu, Y.; Zhang, G.; Zhu, P.; Chen, Y.Q. Detecting and tracking people in real time with RGB-D camera. Pattern Recognit. Lett. 2015, 53, 16–23. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, G.; Liu, Y.; Tian, L.; Chen, Y.Q. An ultra-fast human detection method for color-depth camera. J. Vis. Commun. Image Represent. 2015, 177–185. [Google Scholar] [CrossRef]
- Ma, A.J.; Yuen, P.C.; Saria, S. Deformable distributed multiple detector fusion for multi-person tracking. arXiv 2015, arXiv:1512.05990. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [Green Version]
- Milan, A.; Schindler, K.; Roth, S. Multi-target tracking by discrete-continuous energy minimization. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 2054–2068. [Google Scholar] [CrossRef]
- Li, J.; Wei, L.; Zhang, F.; Yang, T.; Lu, Z. Joint Deep and Depth for Object-Level Segmentation and Stereo Tracking in Crowds. IEEE Trans. Multimed. 2019, 21, 2531–2544. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H.S. Fully-convolutional siamese networks for object tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 850–865. [Google Scholar]
- Zhang, Z.; Peng, H. Deeper and wider siamese networks for real-time visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 4591–4600. [Google Scholar]
- Jiang, M.; Deng, C.; Shan, J.; Wang, Y.; Jia, Y.; Sun, X. Hierarchical multi-modal fusion FCN with attention model for RGB-D tracking. Inf. Fusion 2019, 50, 1–8. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; So, K. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 1–2, 83–97. [Google Scholar] [CrossRef] [Green Version]
- He, M.; Luo, H.; Hui, B.; Chang, Z. Pedestrian flow tracking and statistics of monocular camera based on convolutional neural network and Kalman filter. Appl. Sci. 2019, 8, 1624. [Google Scholar] [CrossRef] [Green Version]
- Bagautdinov, T.; Fleuret, F.; Fua, P. Probability occupancy maps for occluded depth images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2829–2837. [Google Scholar]
- Choi, W.; Pantofaru, C.; Savarese, S. A general framework for tracking multiple people from a moving camera. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1577–1591. [Google Scholar] [CrossRef] [PubMed]
- Dendorfer, P.; Rezatofighi, H.; Milan, A.; Shi, J.; Cremers, D.; Reid, I.; Roth, S.; Schindler, K.; Leal-Taixé, L. Mot20: A benchmark for multi object tracking in crowded scenes. arXiv 2020, arXiv:2003.09003. [Google Scholar]
- Sun, S.; Akhtar, N.; Song, H.; Mian, A.S.; Shah, M. Deep affinity network for multiple object tracking. arXiv 2019, arXiv:1810.11780. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | RGB-CIResNet | Depth-CIResNet |
|---|---|---|
| Conv1 | , 64, stride 2 | |
| Conv2 | , max pooling, stride 2 | |
| 3 | 1 | |
| Conv3 | 4 | |
| Dataset | Algorithm | MOTA ↑ | MOTP ↑ | FP ↓ | FN ↓ | IDS ↓ | FM ↓ | MT ↑ | ML ↓ |
|---|---|---|---|---|---|---|---|---|---|
| MICC | ADSiamMOT-RGB | 59.9 | 69.6 | 2271 | 2775 | 34 | 225 | 11 | 0 |
| ADSiamMOT-RGBD | 62.1 | 69.9 | 2249 | 2538 | 17 | 269 | 12 | 0 | |
| EPFL | ADSiamMOT-RGB | 39.9 | 74.7 | 606 | 2114 | 28 | 61 | 6 | 1 |
| ADSiamMOT-RGBD | 42.8 | 74.8 | 581 | 2015 | 19 | 55 | 6 | 1 | |
| UM | ADSiamMOT-RGB | 66.4 | 71.7 | 1903 | 11,137 | 39 | 217 | 6 | 1 |
| ADSiamMOT-RGBD | 71.8 | 71.8 | 1985 | 9166 | 42 | 242 | 9 | 1 |
| Dataset | Interval | MOTA ↑ | MOTP ↑ | FP ↓ | FN ↓ | IDS ↓ | FM ↓ | MT ↑ | ML ↓ |
|---|---|---|---|---|---|---|---|---|---|
| MICC | 0 | 60.6 | 70.0 | 2262 | 2605 | 125 | 321 | 12 | 0 |
| 1 | 61.4 | 69.9 | 2339 | 2502 | 47 | 354 | 13 | 0 | |
| 2 | 61.8 | 69.9 | 2299 | 2505 | 33 | 318 | 12 | 0 | |
| 3 | 62.3 | 69.9 | 2230 | 2517 | 24 | 275 | 13 | 0 | |
| 4 | 63.7 | 69.8 | 2151 | 2430 | 12 | 263 | 12 | 0 | |
| 5 | 63.7 | 69.8 | 2151 | 2430 | 12 | 263 | 13 | 0 | |
| 6 | 62.6 | 69.9 | 2181 | 2528 | 22 | 259 | 12 | 0 | |
| 7 | 62.1 | 69.9 | 2249 | 2538 | 17 | 269 | 12 | 0 | |
| 8 | 62.6 | 69.6 | 2150 | 2559 | 23 | 226 | 12 | 0 | |
| 9 | 64.2 | 69.8 | 2037 | 2477 | 18 | 227 | 12 | 0 | |
| 10 | 62.8 | 69.7 | 2150 | 2541 | 17 | 250 | 12 | 0 | |
| EPFL | 0 | 46.7 | 76.2 | 546 | 1834 | 59 | 83 | 11 | 0 |
| 1 | 47.4 | 76.2 | 564 | 1805 | 38 | 87 | 11 | 0 | |
| 2 | 46.6 | 75.9 | 566 | 1846 | 30 | 82 | 10 | 1 | |
| 3 | 46.9 | 75.5 | 542 | 1866 | 21 | 77 | 12 | 1 | |
| 4 | 45.4 | 75.6 | 560 | 1913 | 23 | 74 | 8 | 1 | |
| 5 | 45.6 | 75.2 | 543 | 1921 | 23 | 69 | 7 | 1 | |
| 6 | 42.8 | 75.1 | 566 | 2019 | 30 | 69 | 7 | 1 | |
| 7 | 42.8 | 74.8 | 581 | 2015 | 19 | 55 | 6 | 1 | |
| 8 | 42.1 | 75.1 | 576 | 2053 | 18 | 58 | 6 | 1 | |
| 9 | 42.4 | 74.6 | 584 | 2035 | 16 | 60 | 7 | 1 | |
| 10 | 39.3 | 75.3 | 614 | 2147 | 15 | 53 | 4 | 1 | |
| UM | 0 | 70.2 | 72.1 | 2077 | 9397 | 343 | 507 | 9 | 1 |
| 1 | 71.4 | 72.1 | 2195 | 9019 | 124 | 650 | 9 | 1 | |
| 2 | 71.6 | 72.4 | 2133 | 9049 | 83 | 419 | 9 | 1 | |
| 3 | 71.7 | 72.6 | 2105 | 9061 | 66 | 355 | 9 | 1 | |
| 4 | 71.7 | 72.6 | 2106 | 9076 | 57 | 336 | 9 | 1 | |
| 5 | 71.4 | 72.7 | 2110 | 9184 | 48 | 296 | 9 | 1 | |
| 6 | 71.4 | 72.8 | 2135 | 9169 | 44 | 276 | 9 | 1 | |
| 7 | 71.8 | 71.8 | 1985 | 9166 | 42 | 242 | 9 | 1 | |
| 8 | 71.6 | 72.7 | 2012 | 9206 | 39 | 240 | 9 | 1 | |
| 9 | 71.4 | 72.9 | 2030 | 9292 | 37 | 249 | 9 | 1 | |
| 10 | 70.9 | 72.9 | 2102 | 9406 | 34 | 235 | 9 | 1 |
| Dataset | Algorithm | MOTA ↑ | MOTP ↑ | FP ↓ | FN ↓ | IDS ↓ | FM ↓ | MT ↑ | ML ↓ | Rank ↓ | FPS ↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| MICC | Sort | 60.8 | 70.0 | 1997 | 2877 | 84 | 282 | 11 | 0 | 3 | 20.98 |
| DeepSort | 59.6 | 69.2 | 2212 | 2874 | 25 | 340 | 11 | 0 | 4 | 13.08 | |
| IoU-tracker | 54.0 | 70.2 | 1464 | 4022 | 336 | 462 | 7 | 0 | 6 | 59.16 | |
| SST | 55.2 | 69.5 | 1633 | 3958 | 86 | 614 | 6 | 0 | 5 | 2.92 | |
| ADSiamMOT-RGB | 62.2 | 69.4 | 2006 | 2744 | 30 | 193 | 10 | 0 | 2 | 2.72 | |
| ADSiamMOT-RGBD | 64.2 | 69.8 | 2037 | 2477 | 18 | 227 | 11 | 0 | 1 | 2.64 | |
| EPFL | Sort | 40.9 | 76.1 | 407 | 2207 | 87 | 109 | 5 | 1 | 5 | 26.48 |
| DeepSort | 41.0 | 76.4 | 206 | 2468 | 22 | 112 | 2 | 1 | 4 | 19.21 | |
| IoU-tracker | 41.1 | 74.9 | 244 | 2349 | 99 | 120 | 2 | 1 | 3 | 24.12 | |
| SST | 37.9 | 72.5 | 289 | 2480 | 71 | 179 | 4 | 0 | 6 | 2.86 | |
| ADSiamMOT-RGB | 47.2 | 76.2 | 565 | 1807 | 42 | 91 | 11 | 0 | 2 | 6.65 | |
| ADSiamMOT-RGBD | 47.4 | 76.2 | 564 | 1805 | 38 | 87 | 11 | 0 | 1 | 5.93 | |
| UM | Sort | 70.5 | 7.2 | 1942 | 9731 | 41 | 366 | 9 | 1 | 2 | 21.91 |
| DeepSort | 67.4 | 71.9 | 1444 | 11,452 | 59 | 556 | 7 | 1 | 3 | 16.69 | |
| IoU-tracker | 49.1 | 75.1 | 941 | 18,700 | 558 | 658 | 4 | 4 | 5 | 64.60 | |
| SST | 51.9 | 74.4 | 1219 | 17,648 | 225 | 1446 | 4 | 3 | 4 | 3.13 | |
| ADSiamMOT-RGB | 71.8 | 72.2 | 1992 | 9173 | 39 | 235 | 9 | 1 | 1 | 7.05 | |
| ADSiamMOT-RGBD | 71.8 | 71.8 | 1985 | 9166 | 42 | 242 | 9 | 1 | 1 | 5.52 |
| Algorithm | Dataset | FPS ↑ | Average FPS ↑ | Average MOTA ↑ |
|---|---|---|---|---|
| Sort | MICC | 20.98 | 23.12 | 57.40 |
| EPFL | 26.48 | |||
| UM | 21.91 | |||
| DeepSort | MICC | 13.08 | 16.33 | 56.00 |
| EPFL | 19.21 | |||
| UM | 16.69 | |||
| IoU-tracker | MICC | 59.16 | 49.29 | 48.06 |
| EPFL | 24.12 | |||
| UM | 64.60 | |||
| SST | MICC | 2.92 | 2.97 | 48.33 |
| EPFL | 2.86 | |||
| UM | 3.13 | |||
| ADSiamMOT-RGB | MICC | 2.72 | 5.47 | 60.40 |
| EPFL | 6.65 | |||
| UM | 7.05 | |||
| ADSiamMOT-RGBD | MICC | 2.64 | 4.70 | 61.13 |
| EPFL | 5.93 | |||
| UM | 5.52 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.-L.; Yang, K.; Xin, Y.-T.; Zhao, T.-S. Multi-Object Tracking Algorithm for RGB-D Images Based on Asymmetric Dual Siamese Networks. Sensors 2020, 20, 6745. https://doi.org/10.3390/s20236745
Zhang W-L, Yang K, Xin Y-T, Zhao T-S. Multi-Object Tracking Algorithm for RGB-D Images Based on Asymmetric Dual Siamese Networks. Sensors. 2020; 20(23):6745. https://doi.org/10.3390/s20236745
Chicago/Turabian StyleZhang, Wen-Li, Kun Yang, Yi-Tao Xin, and Ting-Song Zhao. 2020. "Multi-Object Tracking Algorithm for RGB-D Images Based on Asymmetric Dual Siamese Networks" Sensors 20, no. 23: 6745. https://doi.org/10.3390/s20236745
APA StyleZhang, W. -L., Yang, K., Xin, Y. -T., & Zhao, T. -S. (2020). Multi-Object Tracking Algorithm for RGB-D Images Based on Asymmetric Dual Siamese Networks. Sensors, 20(23), 6745. https://doi.org/10.3390/s20236745