Predictive Maintenance Scheduling with Failure Rate Described by Truncated Normal Distribution



Abstract
:1. Introduction
1.1. Complexity of Scheduling Problems
1.2. Production and Maintenance Planning Practices
1.3. Goals and Approaches
- Methods of achieving the reliability parameters of the truncated normal distribution, even in the case of the absence of complementary and reliable data on historical failure-free times;
- Methods for obtaining the best maintenance and production schedules where the goal is to maximize stability and robustness.
2. A Model of Failures
2.1. Maximum Likelihood Approach
2.2. Empirical Moments Approach
2.3. Renewal Theory Approach
2.4. Predictions of Reliability Characteristics
3. A Predictive Scheduling Model of Production and Maintenance
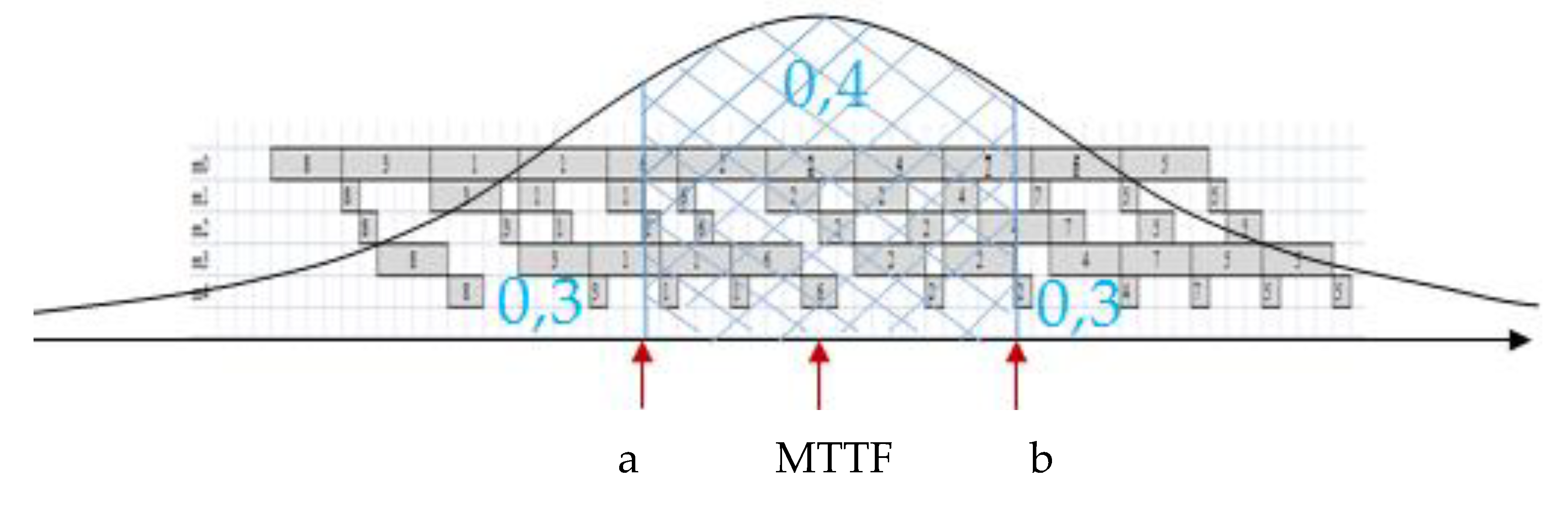
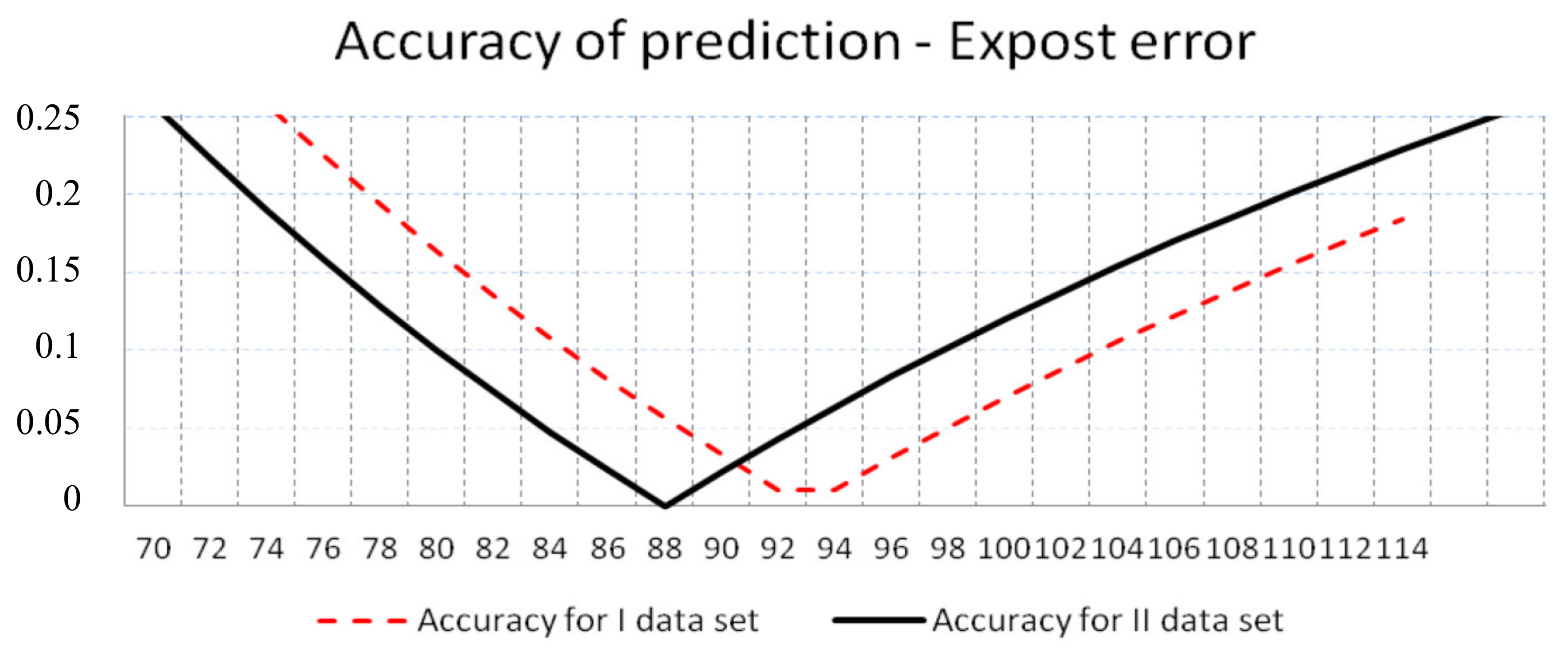
4. Mean Time to Failure MTTF Prediction
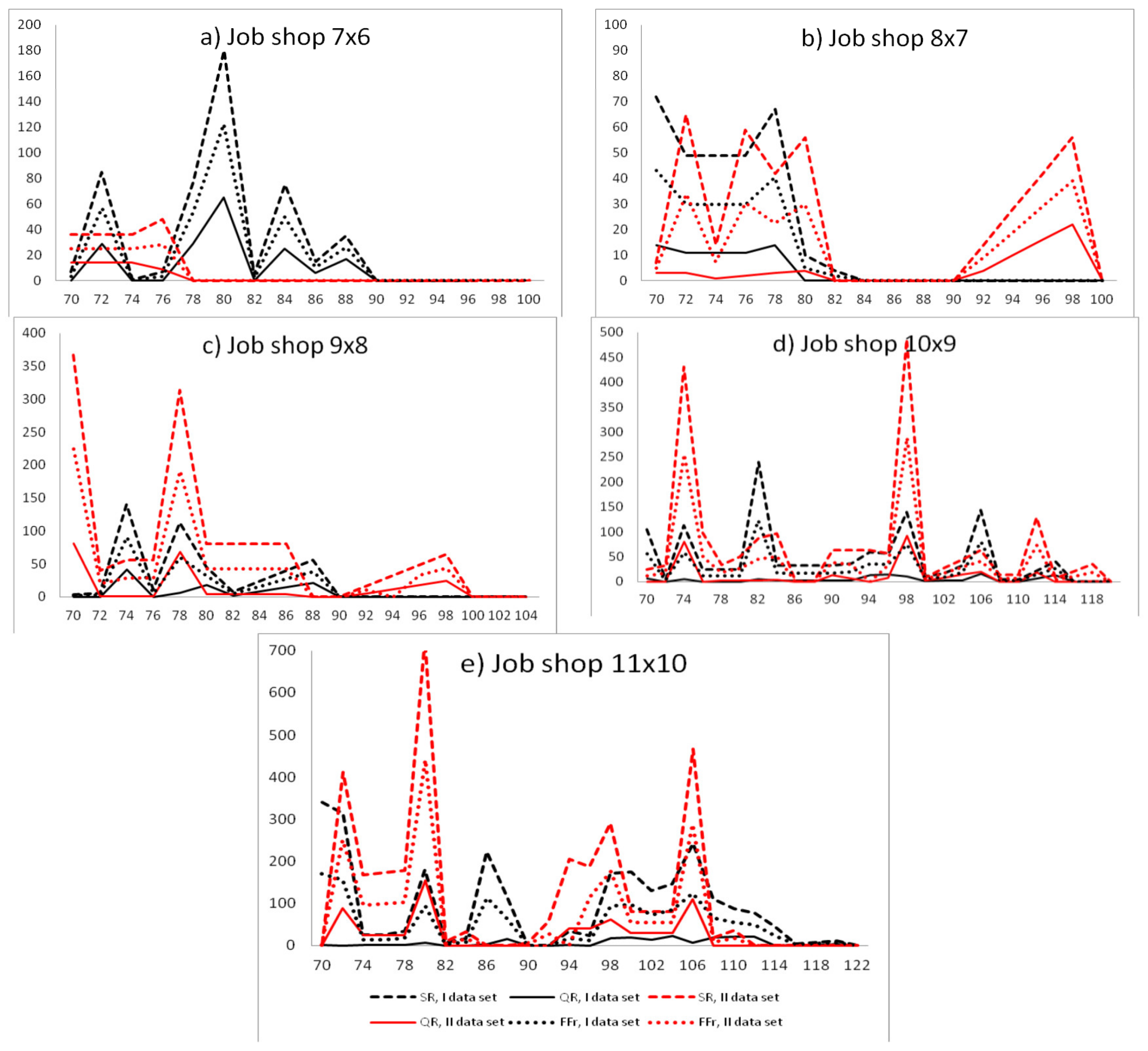
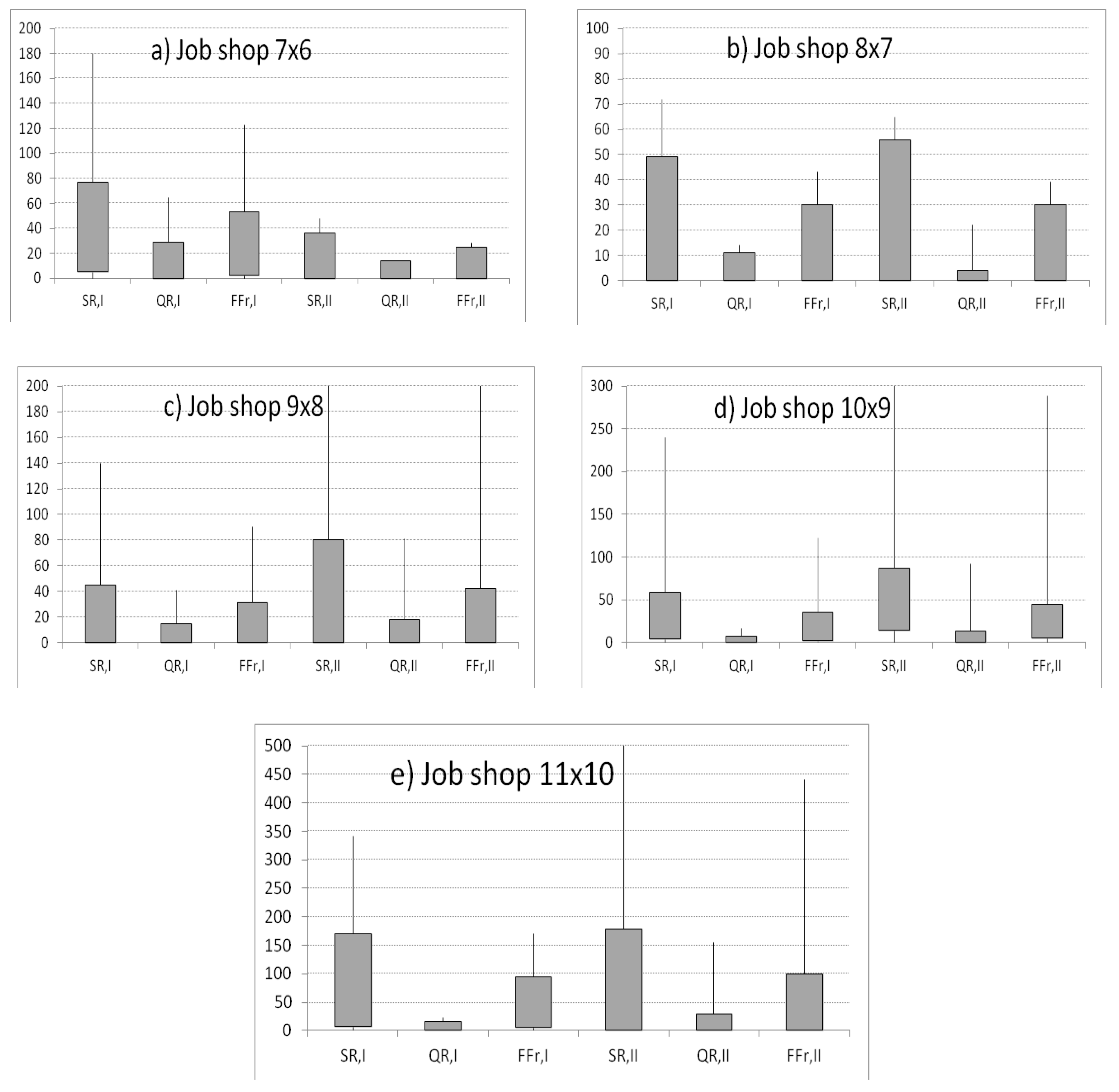
5. Computer Simulation Results and Discussion
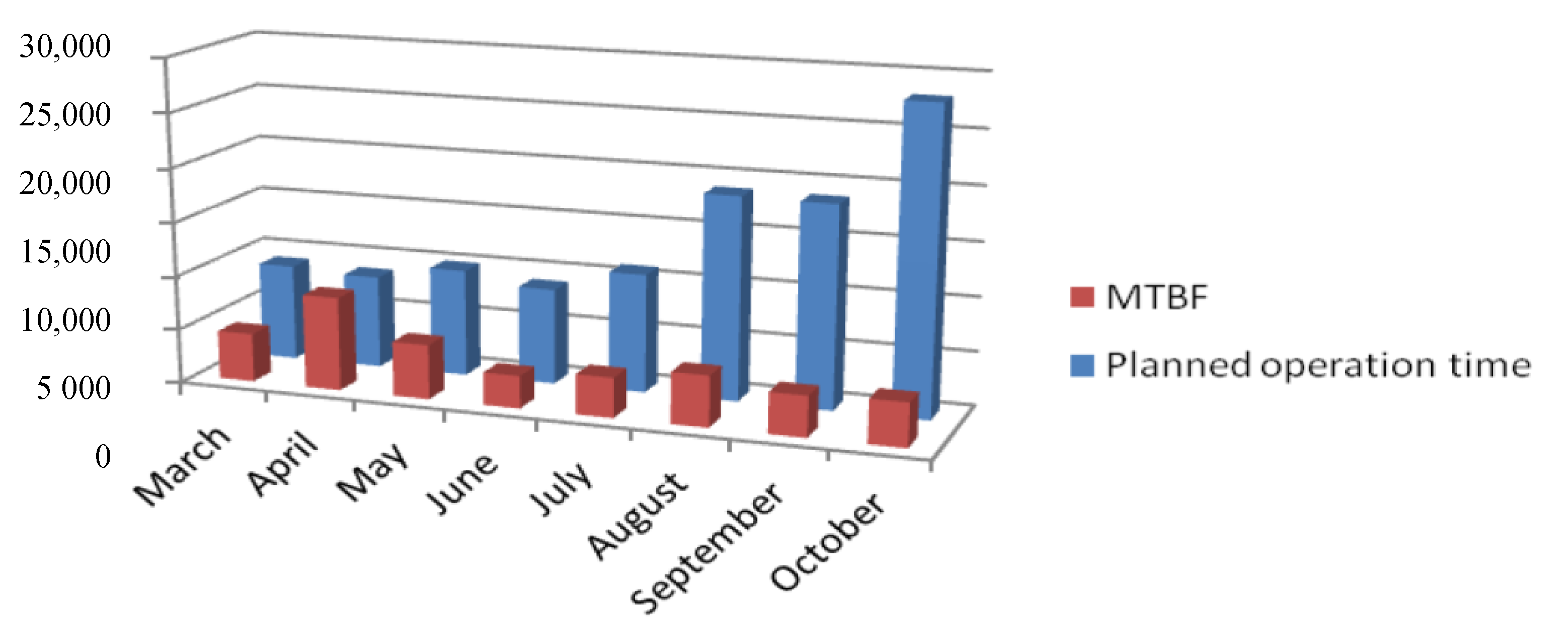
5.1. Estimation of Reliability Characteristics for the Automotive Industry
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Erginel, N.; Hasırcı, A. Reduce the Failure Rate of the Screwing Process with Six Sigma Approach. In Proceedings of the 2014 International Conference on Industrial Engineering and Operations Management, Bali, Indonesia, 7–9 January 2014; pp. 2548–2555. [Google Scholar]
- Ćwikła, G. Methods of manufacturing data acquisition for production management—A review. Adv. Mater. Res. 2014, 837, 618–623. [Google Scholar] [CrossRef]
- Ćwikła, G. The methodology of development of the Manufacturing Information Acquisition System (MIAS) for production management. Appl. Mech. Mater. 2014, 474, 27–32. [Google Scholar] [CrossRef]
- Paprocka, I.; Kempa, W.M.; Skołud, B. Predictive maintenance scheduling with reliability characteristics depending on the phase of the machine life cycle. Eng. Optim. 2020. [Google Scholar] [CrossRef]
- Ezugwu, A.E. Enhanced symbiotic organisms search algorithm for unrelated parallel machines manufacturing scheduling with setup times. Knowl. Based Syst. 2019, 172, 15–32. [Google Scholar] [CrossRef]
- Kim, T.; Kim, Y.; Cho, H. Dynamic production scheduling model under due date uncertainty in precast concrete construction. J. Clean. Prod. 2020, 257, 120527. [Google Scholar] [CrossRef]
- Durate, J.L.R.; Fan, N.; Jin, T. Multi-process production scheduling with variable renewable integration and demand response. Eur. J. Oper. Res. 2020, 281, 186–200. [Google Scholar]
- Dulebenets, M.A. Application of Evolutionary Computation for Berth Scheduling at Marine Container Terminals: Parameter Tuning Versus Parameter Control. IEEE Trans. Intell. Transp. Syst. 2018, 19, 25–37. [Google Scholar] [CrossRef]
- Mokhtari, H.; Dadgar, M. Scheduling optimization of a stochastic flexible job-shop system with time-varying machine failure rate. Comput. Oper. Res. 2015, 61, 31–45. [Google Scholar] [CrossRef]
- Liu, Q.; Dong, M.; Chen, F.F. Single-machine-based joint optimization of predictive maintenance planning and production scheduling. Robot. Comput. Integr. Manuf. 2018, 51, 238–247. [Google Scholar] [CrossRef]
- Kenne, J.P.; Nkeungoue, L.J. Simultaneous control of production, preventive and corrective maintenance rates of a failure-prone manufacturing system. Appl. Numer. Math. 2008, 58, 180–194. [Google Scholar] [CrossRef]
- Baraldi, P.; Compare, M.; Zio, E. Maintenance policy performance assessment in presence of imprecision based on Dempster-Shafer theory of evidence. Inf. Sci. 2013, 245, 180–194. [Google Scholar] [CrossRef] [Green Version]
- Baptista, M.; Sankararaman, S.; de Medeiros, I.P.; Nascimento, C., Jr.; Prendinger, H.; Henriques, E.M. Forecasting fault events for predictive maintenance using data-driven techniques and ARMA modeling. Comput. Ind. Eng. 2018, 115, 41–53. [Google Scholar] [CrossRef]
- Cui, W.W.; Lu, Z.; Pan, E. Integrated production scheduling and maintenance policy for robustness in a single machine. Comput. Oper. Res. 2014, 47, 81–91. [Google Scholar] [CrossRef]
- Pan, E.; Liao, W.; Xi, L. A joint model of production scheduling and predictive maintenance for minimizing job tardiness. Int. J. Adv. Manuf. Technol. 2012, 60, 1049–1061. [Google Scholar] [CrossRef]
- Rajkumar, M.; Asokan, P.; Vamsikrishna, V. A GRASP algorithm for flexible job-shop scheduling with maintenance constraints. Int. J. Prod. Res. 2010, 48, 6821–6836. [Google Scholar] [CrossRef]
- Lei, D. Scheduling fuzzy job shop with preventive maintenance through swarm-based neighborhood search. Int. J. Adv. Manuf. Technol. 2011, 54, 1121–1128. [Google Scholar] [CrossRef]
- Cui, W.W.; Lu, Z.; Li, C.; Han, X. A proactive approach to solve integrated production scheduling and maintenance planning problem in flow shops. Comput. Ind. Eng. 2018, 115, 342–353. [Google Scholar] [CrossRef]
- Bali, N.; Labdelaoui, H. Optimal Generator Maintenance Scheduling Using a Hybrid Metaheuristic Approach. Int. J. Comput. Intell. Appl. 2015, 14, 1550011. [Google Scholar] [CrossRef]
- Zheng, Y.; Lian, L.; Mesghouni, K. Comparative study of heuristics algorithms in solbing flexible job shop scheduling problem with condition based maintenance. J. Ind. Eng. Manag. 2014, 7, 51. [Google Scholar]
- Duenas, A.; Petrovic, D. An approach to predictive-reactive scheduling of parallel machines subject to diSRuptions. Ann. Oper. Res. 2008, 159, 65–82. [Google Scholar] [CrossRef]
- Feng, X.; Xi, L.; Xiao, L.; Xia, T.; Pan, E. Imperfect preventive maintenance optimization for flexible flowshop manufacturing cells considering sequence-dependent group scheduling. Reliab. Eng. Syst. Saf. 2018, 176, 218–229. [Google Scholar] [CrossRef]
- Blokus, A.; Kołowrocki, K. Reliability and maintenance strategy for systems with aging-dependent components. Qual. Reliab. Eng. Int. 2019, 35, 2709–2731. [Google Scholar] [CrossRef]
- Wang, Z.; Huang, H.-Z.; Li, Y.; Xiao, N.-C. An Approach to Reliability Assessment under Degradation and Shock Process. IEEE Trans. Reliab. 2011, 60, 852–863. [Google Scholar] [CrossRef]
- Kleiner, Y.; Adams, B.J.; Rogers, J.S. Long-term planning methodology for water distribution system rehabilitation. Water Resour. Res. 1998, 34, 2039–2051. [Google Scholar] [CrossRef]
- Kołowrocki, K.; Soszyńska-Budny, J. Reliability and Safety of Complex Technical Systems and Processes: Modeling–Identification–Prediction–Optimization, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Neelakantan, T.R.; Suribabu, C.R.; Lingireddy, S. Optimisation procedure for pipe-sizing with break-repair and replacement economics. Water SA 2008, 34, 217–224. [Google Scholar] [CrossRef] [Green Version]
- Romaniuk, M. Optimization of maintenance costs of a pipeline for a V-shaped hazard rate of malfunction intensities. Eksploatacja i Niezawodnosc 2018, 20, 46–54. [Google Scholar] [CrossRef]
- Song, S.; Coit, D.W.; Feng, Q.; Peng, H. Reliability analysis for multi-component systems subject to multiple dependent competing failure processes. IEEE Trans. Reliab. 2014, 63, 331–345. [Google Scholar] [CrossRef]
- Sakib, N.; Wuest, T. Challenges and opportunities of condition-based predictive maintenance: A review. Procedia CIRP 2018, 78, 267–272. [Google Scholar] [CrossRef]
- Li, J.; Meerkov, M.S.; Zhang, L. Production systems engineering: Main results and recommendations for management. Int. J. Prod. Res. 2013, 51, 7209–7234. [Google Scholar] [CrossRef]
- Larsen, R.J.; Marx, M.L. An Introduction to Mathematical Statistics and Its Applications, 5th ed.; Pearson Education Inc.: Upper Saddle River, NJ, USA, 2012. [Google Scholar]
- Dekking, F.M.; Kraaikamp, C.; Lopuhaä, H.P.; Meester, L.E. A Modern Introduction to Probability and Statistics; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Buhring, W. An asymptotic expansion for a ratio of products of gamma functions. Int. J. Math. Math. Sci. 2000, 24, 504–510. [Google Scholar] [CrossRef] [Green Version]
- Paprocka, I.; Skołud, B. A Hybrid—Multi Objective Immune Algorithm for predictive and reactive scheduling. J. Sched. 2017, 20, 165–182. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Liu, Q.; Xie, C.; Wei, F. Reliability assessment for multi-state systems with state transition dependency. Reliab. Eng. Syst. Saf. 2019, 188, 276–288. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Number of Failures of the Critical Machine (and Failure-Free Times) in Scheduling Horizon i | ||||
|---|---|---|---|---|
| 9(90,90,100,110,100, 110,110,130,130) | 7(100,105,105, 120,120,105,105) | 9(110,90,105,120, 120,100,110,130,90) | 6(105,120,140, 160,180,200) | 10(90,130,135,90, 75,80,125,90,80,100) |
| 11(100,90,95,95,90 ,90,85,85,90,90,80) | 8(100,140,150, 140,180,100,105,80) | 6(50,100,150,150, 280,270) | 8(200,100,120, 130,150,90,100,90) | 9(90,130,100,90, 130,120,130,90,100) |
| 9(80,90,100,110,120, 125,120,100,110) | 7(100,120,125,135, 140,150,160) | 10(110,90,95,90,80, 100,90,100,90,90) | 11(100,90,80,80, 85,80,90,90,85,70,70) | 10(90,95,100,100, 90,150,80,90,80,80) |
| 9(80,90,100,110,120, 125,120,120,130) | 7(100,120,125,135, 140,140,160) | 8(90,90,100,110,120, 120,140,160) | 7(100,110,120, 145,155,150,160) | 9(120,110,105,105, 110,100,100,110,120) |
| 9(80,85,100,110,115, 110,120,120,140) | 8(80,100,120,125,135, 140,140,150) | 9(75,80,85,90,110, 120,130,140,150) | 9(70,80,100,110, 115,120,135,130,140) | 7(100,110,120, 130,140,140,180) |
| 11(50,60,60,70,80,85, 100,110,115,120,125) | 10(55,60,65,65,80,90, 110,120,140,145) | 7(90,100,130,140, 150,160,170) | 10(70,75,80,85,90, 95,100,110,120,120) | 11(55,55,60,80,85,90, 90,100,120,130,130) |
| 11(45,60,60,65,80,90, 100,110,115,135,135) | 11(45,55,60,65,70,90, 90,110,120,120,150) | 10(40,55,60,90,95, 90,110,125,135,155) | 9(80,90,90,95,100, 110,125,135,155) | 10(55,60,80,90,90, 90,105,125,135,140) |
| Maximum Likelihood Approach | Empirical Moments Approach | |||
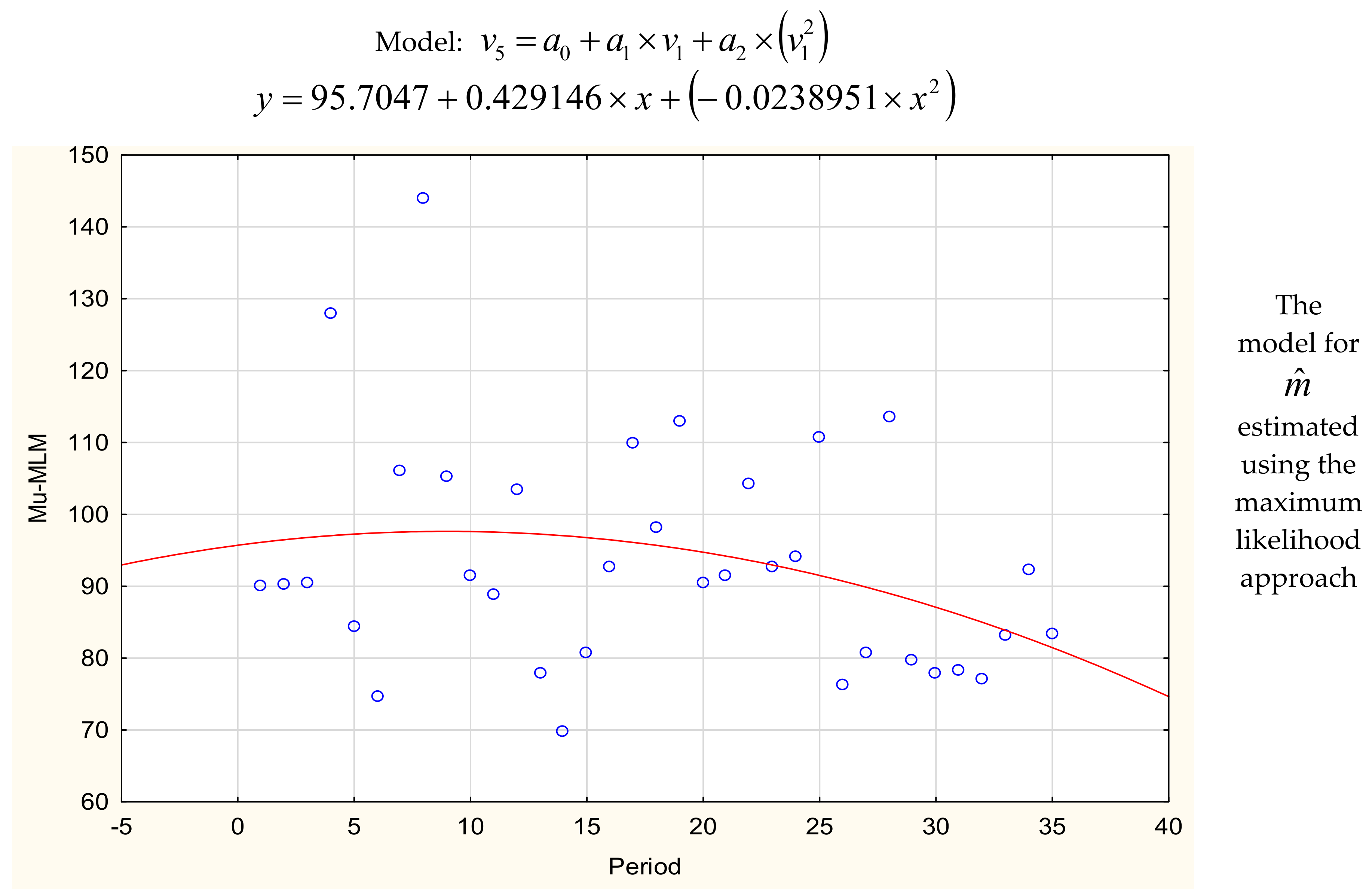
| y = 95.70 + 0.429x − 0.023x2 | 80.18 | y = 99.25 − 0.988x + 0.009x2 | 76.39 | |
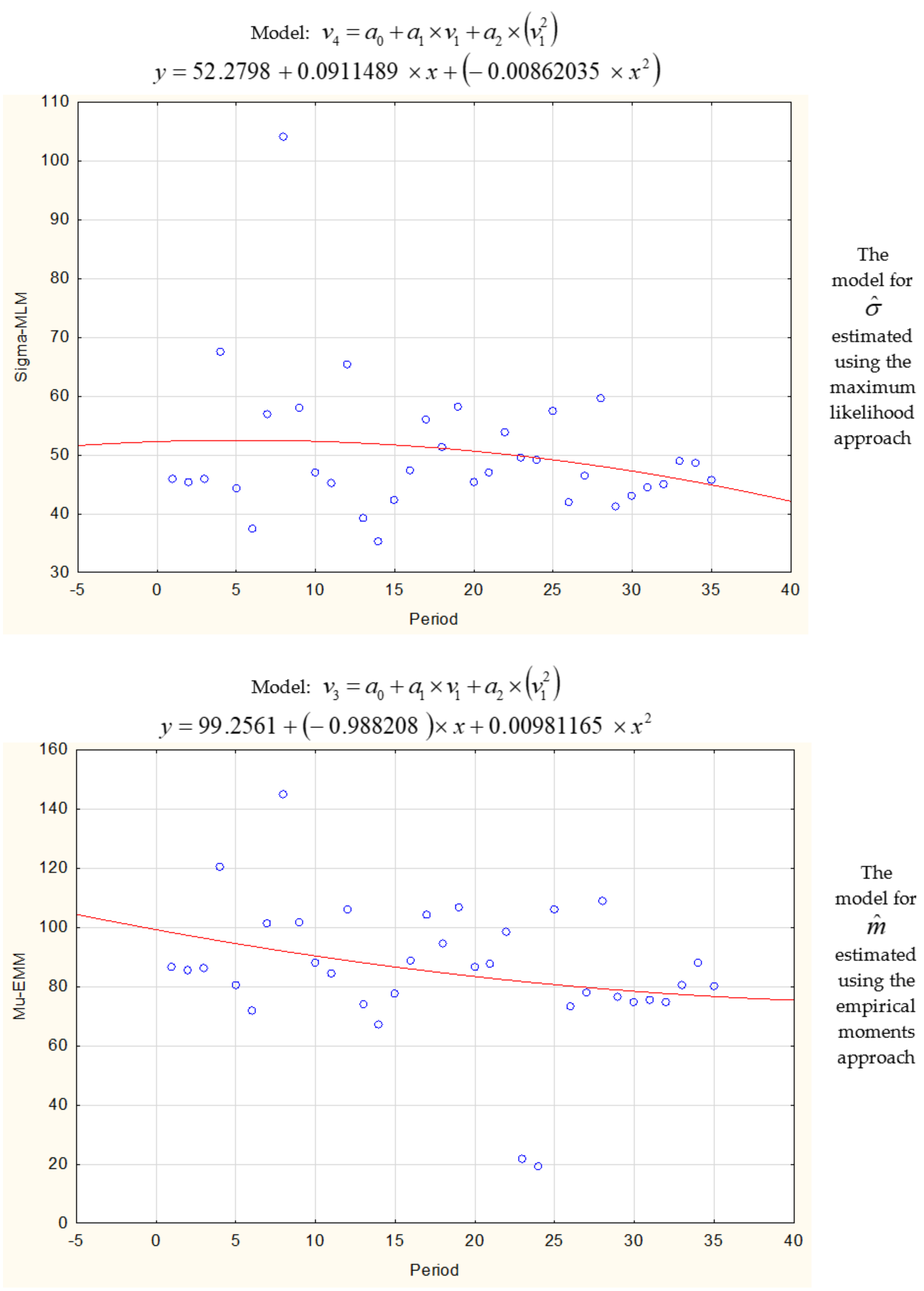
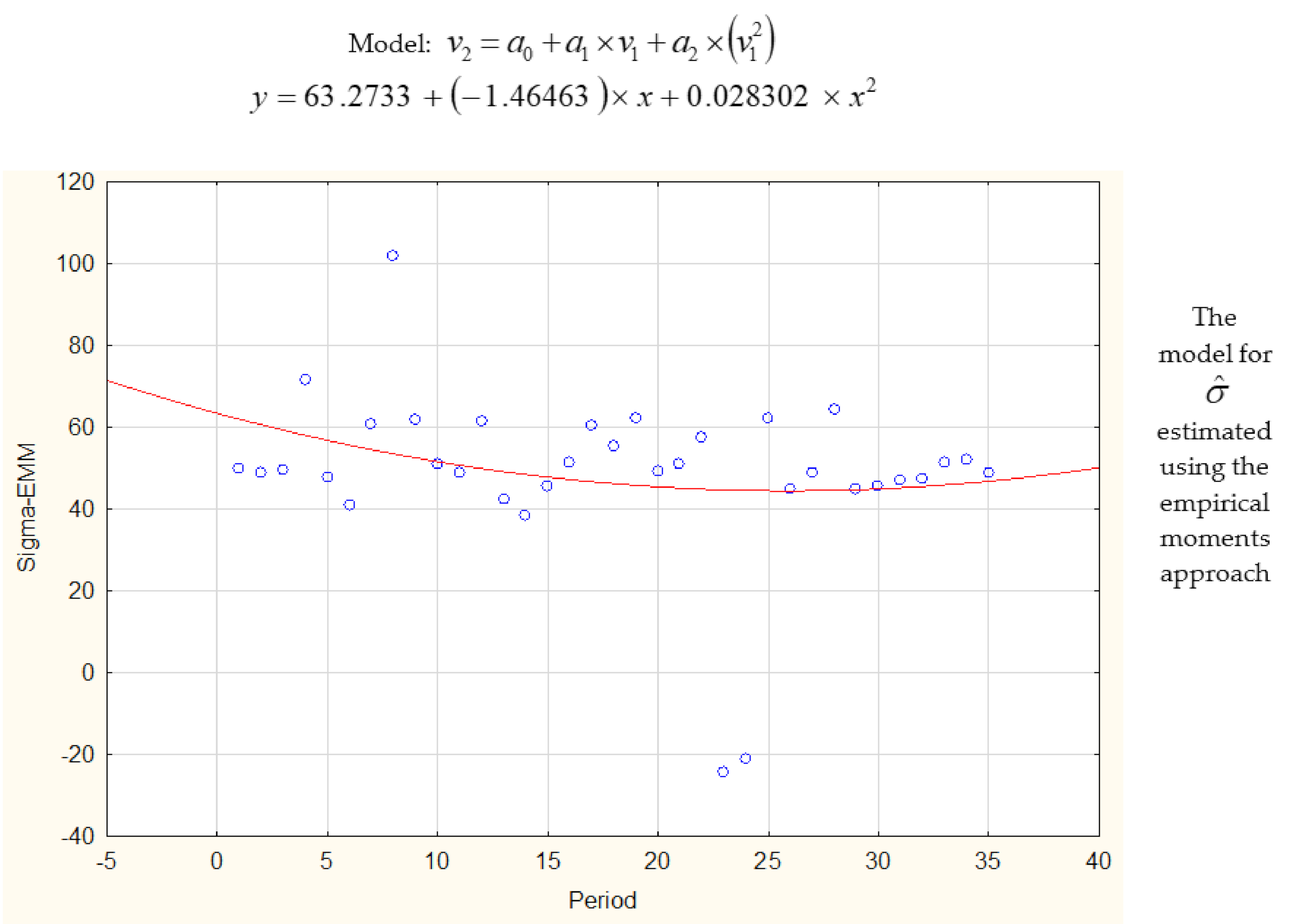
| y = 52.27 + 0.09x − 0.023x2 | 44.38 | y = 63.27 − 1.464x + 0.028x2 | 47.22 | |
| The Prediction of , , and MTTF Using the Least Squares Method | ||||
| Maximum Likelihood Approach | Empirical Moments Approach | |||
| y = −0.0239x2 + 0.4291x + 95.705 | 80.17 | y = 0.0103x2 – 1.0867x + 99.906 | 74.13 | |
| y = | 44.41 | y =0.0281x2 – 1.4997x + 63.531 | 45.95 | |
| Estimated Using the Maximum Likelihood Approach | |||||||
|---|---|---|---|---|---|---|---|
| Coefficient | SE | t Statistic | R2 | p-Value | 95% Confidence Interval (Left End) | 95% Confidence Interval (Right End) | |
| a0 | 95.70475 | 8.430837 | 11.35175 | 0.095 | 0.000000 | 78.53170 | 112.8778 |
| a1 | 0.42915 | 1.079850 | 0.39741 | 0.693702 | −1.77044 | 2.6287 | |
| a2 | −0.02390 | 0.029096 | −0.82125 | 0.417581 | −0.08316 | 0.0354 | |
| Estimated using the maximum likelihood approach | |||||||
| a0 | 52.27978 | 6.464445 | 8.087281 | 0.040 | 0.000000 | 39.11214 | 65.44743 |
| a1 | 0.09115 | 0.827988 | 0.110085 | 0.913030 | −1.59541 | 1.77771 | |
| a2 | −0.00862 | 0.022310 | −0.386394 | 0.701762 | −0.05406 | 0.03682 | |
| Estimated using the empirical moments approach | |||||||
| a0 | 99.25615 | 12.08471 | 8.213366 | 0.083 | 0.000000 | 74.64040 | 123.8719 |
| a1 | −0.98821 | 1.54785 | −0.638439 | 0.527731 | −4.14108 | 2.1647 | |
| a2 | 0.00981 | 0.04171 | 0.235257 | 0.815508 | −0.07514 | 0.0948 | |
| Estimated using the empirical moments approach | |||||||
| a0 | 63.27331 | 11.33485 | 5.58219 | 0.06209691 | 0.000004 | 40.18497 | 86.36164 |
| a1 | −1.46463 | 1.45181 | −1.00883 | 0.320622 | −4.42186 | 1.49260 | |
| a2 | 0.02830 | 0.03912 | 0.72350 | 0.474628 | −0.05138 | 0.10798 | |
| The Size of the Problem | The Job Sequence | Cmax | F | T | I | FFy |
|---|---|---|---|---|---|---|
| 7 × 6 | {5 2 3 4 6 0 1} | 117 | 273 | 330 | 0 | 1.02 |
| 8 × 7 | {5 7 2 3 4 0 6 1} | 126 | 335 | 434 | 0 | 1.02 |
| 9 × 8 | {8 5 2 3 0 4 7 6 1} | 137 | 415 | 553 | 0 | 1.01 |
| 10 × 9 | {8 5 2 3 4 6 9 0 7 1} | 164 | 530 | 756 | 0 | 0.99 |
| 11 × 10 | {3 8 2 5 4 7 6 9 0 1 10} | 169 | 623 | 863 | 0 | 1.05 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Paprocka, I.; Kempa, W.M.; Ćwikła, G. Predictive Maintenance Scheduling with Failure Rate Described by Truncated Normal Distribution. Sensors 2020, 20, 6787. https://doi.org/10.3390/s20236787
Paprocka I, Kempa WM, Ćwikła G. Predictive Maintenance Scheduling with Failure Rate Described by Truncated Normal Distribution. Sensors. 2020; 20(23):6787. https://doi.org/10.3390/s20236787
Chicago/Turabian StylePaprocka, Iwona, Wojciech M. Kempa, and Grzegorz Ćwikła. 2020. "Predictive Maintenance Scheduling with Failure Rate Described by Truncated Normal Distribution" Sensors 20, no. 23: 6787. https://doi.org/10.3390/s20236787
APA StylePaprocka, I., Kempa, W. M., & Ćwikła, G. (2020). Predictive Maintenance Scheduling with Failure Rate Described by Truncated Normal Distribution. Sensors, 20(23), 6787. https://doi.org/10.3390/s20236787