Breast Tumor Classification in Ultrasound Images Using Combined Deep and Handcrafted Features

 ,
,  , , ,
, , ,  and
and
Abstract
:1. Introduction
- Employ a two-phase optimization procedure to select the best deep feature combination that maximizes the BUS image classification performance as well as identify the components of the pre-trained VGG19 model that correspond to the optimized deep feature combination. In the first phase, we extracted deep features from the pre-trained VGG19 model at six different extraction levels. In the second phase, the deep features extracted at each extraction level are processed using a features selection algorithm and classified using a SVM classifier to identify the feature combinations that maximize the BUS image classification performance at that level. Furthermore, the deep feature combinations that are identified at all extraction levels are analyzed to find the best deep feature combination that enables the highest classification performance across all levels.
- Investigate the possibility of improving the BUS image classification performance by combining the deep features extracted from the pre-trained VGG19 model with the handcrafted features that were introduced in previous studies. In fact, the handcrafted features considered in the current study are the texture and morphological features. The features selection algorithm is used to select the best combination of deep and handcrafted features that maximizes the classification performance.
- Perform cross-validation analysis using a dataset that includes 380 BUS images to evaluate the classification performance obtained using the optimized combinations of deep features and combined deep and handcrafted features. Moreover, the classification performance obtained using the optimized combinations of deep features and combined deep and handcrafted features was compared with the results achieved using the optimized combinations of handcrafted features as well as the fine-tuned VGG19 model. Furthermore, the cross-validation analysis investigates the effect of classifying the deep features without applying the features selection algorithm.
- Evaluate the generalization performance of the optimized combination of deep features and the optimized combination of combined deep and handcrafted features. In particular, the 380 breast ultrasound images were used to train two SVM classifiers that employ the optimized combination of deep features and the optimized combination of combined deep and handcrafted features. The performance of the trained classifiers were evaluated using another dataset that includes 163 BUS images.
2. Materials and Methods
2.1. BUS Image Datasets
2.2. BUS Image Classification Using the Deep Features
2.2.1. Deep Features Extraction
2.2.2. Deep Features Selection and Classification
2.3. BUS Image Classification by Combining the Deep Features with Handcrafted Features
2.4. Performance Comparison
2.5. Generalization Performance
2.6. Performance Metrics
3. Results and Discussions
3.1. BUS Image Classification Results Obtained Using the Deep Features
3.2. BUS Image Classification Results Obtained by Combining the Deep Features with Handcrafted Features
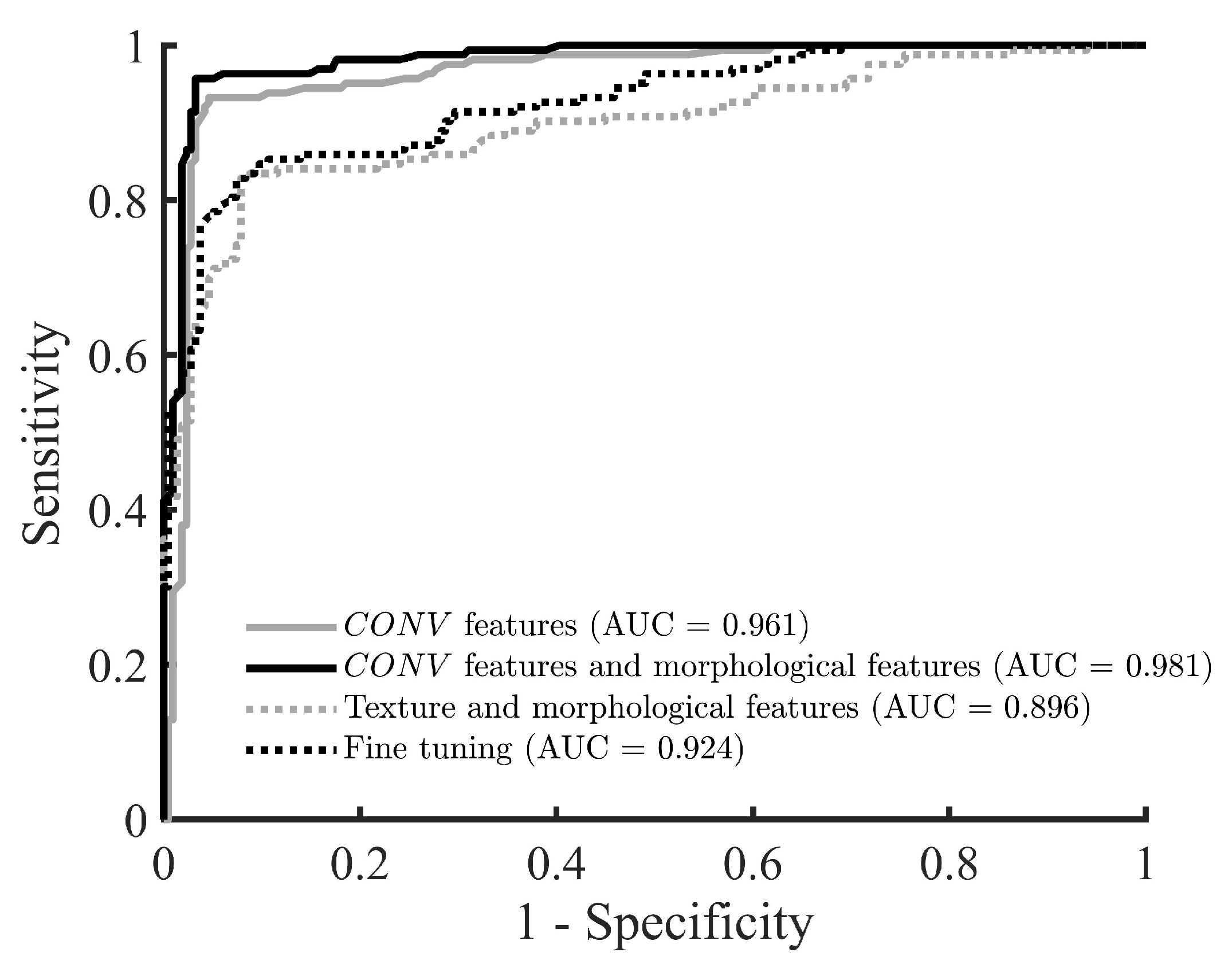
3.3. Performance Comparison Results
3.4. Generalization Performance Results
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bray, F.; Ferlay, J.; Soerjomataram, I.; Siegel, R.L.; Torre, L.A.; Jemal, A. Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA A Cancer J. Clin. 2018, 68, 394–424. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nothacker, M.; Duda, V.; Hahn, M.; Warm, M.; Degenhardt, F.; Madjar, H.; Weinbrenner, S.; Albert, U. Early detection of breast cancer: Benefits and risks of supplemental breast ultrasound in asymptomatic women with mammographically dense breast tissue. A systematic review. BMC Cancer 2009, 9, 335. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chotai, N.; Kulkarni, S. Breast Ultrasound. In Breast Imaging Essentials; Springer: Singapore, 2020. [Google Scholar]
- Ding, J.; Cheng, H.D.; Huang, J.; Liu, J.; Zhang, Y. Breast ultrasound image classification based on multiple-instance learning. J. Digit. Imaging 2012, 25, 620–627. [Google Scholar] [CrossRef] [PubMed]
- Rouhi, R.; Jafari, M.; Kasaei, S.; Keshavarzian, P. Benign and malignant breast tumors classification based on region growing and CNN segmentation. Expert Syst. Appl. 2015, 42, 990–1002. [Google Scholar] [CrossRef]
- Prabusankarlal, K.M.; Thirumoorthy, P.; Manavalan, R. Assessment of combined textural and morphological features for diagnosis of breast masses in ultrasound. Human-Centric Comput. Inf. Sci. 2015, 5, 12. [Google Scholar] [CrossRef] [Green Version]
- Daoud, M.I.; Bdair, T.M.; Al-Najar, M.; Alazrai, R. A fusion-based approach for breast ultrasound image classification using multiple-ROI texture and morphological analyses. Comput. Math. Methods Med. 2016, 2016, 6740956. [Google Scholar] [CrossRef]
- Daoud, M.I.; Saleh, A.; Hababeh, I.; Alazrai, R. Content-based image retrieval for breast ultrasound images using convolutional autoencoders: A Feasibility study. In Proceedings of the 3rd International Conference on Bio-Engineering for Smart Technologies (BioSMART), Paris, France, 24–26 April 2019; pp. 1–4. [Google Scholar]
- Han, S.; Kang, H.; Jeong, J.; Park, M.; Kim, W.; Bang, W.; Seong, Y. A deep learning framework for supporting the classification of breast lesions in ultrasound images. Phys. Med. Biol. 2017, 62, 7714–7728. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.J.; Lin, S.W.; Moon, W.K. Combining support vector machine with genetic algorithm to classify ultrasound breast tumor images. Comput. Med. Imaging Graph. 2012, 36, 627–633. [Google Scholar] [CrossRef]
- Nemat, H.; Fehri, H.; Ahmadinejad, N.; Frangi, A.F.; Gooya, A. Classification of breast lesions in ultrasonography using sparse logistic regression and morphology-based texture features. Med. Phys. 2018, 45, 4112–4124. [Google Scholar] [CrossRef] [PubMed]
- Moon, W.K.; Lo, C.M.; Cho, N.; Chang, J.M.; Huang, C.S.; Chend, J.H.; Chang, R.F. Computer-aided diagnosis of breast masses using quantified BI-RADS findings. Comput. Methods Programs Biomed. 2013, 111, 84–92. [Google Scholar] [CrossRef] [PubMed]
- Chang, R.F.; Wu, W.J.; Moon, W.K.; Chen, D.R. Automatic ultrasound segmentation and morphology based diagnosis of solid breast tumors. Breast Cancer Res. Treat. 2005, 89, 179–185. [Google Scholar] [CrossRef] [PubMed]
- Gomez, W.; Pereira, W.C.A.; Infantosi, A.F.C. Analysis of co-occurrence texture statistics as a function of gray-level quantization for classifying breast ultrasound. IEEE Trans. Med. Imaging 2012, 31, 1889–1899. [Google Scholar] [CrossRef]
- Lin, C.; Hou, Y.; Chen, T.; Chen, K. Breast nodules computer-aided diagnostic system design using fuzzy cerebellar model neural networks. IEEE Trans. Fuzzy Syst. 2014, 22, 693–699. [Google Scholar] [CrossRef]
- Daoud, M.I.; Abdel-Rahman, S.; Alazrai, R. Breast ultrasound image classification using a pre-trained convolutional neural network. In Proceedings of the 15th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Sorrento, Italy, 26–29 November 2019; pp. 167–171. [Google Scholar]
- Liu, S.; Wang, Y.; Yang, X.; Lei, B.; Liu, L.; Li, S.X.; Ni, D.; Wang, T. Deep learning in medical ultrasound analysis: A review. Engineering 2019, 5, 261–275. [Google Scholar] [CrossRef]
- Huang, Q.; Zhang, F.; Li, X. Machine learning in ultrasound computer-aided diagnostic systems: A survey. BioMed Res. Int. 2018, 2018, 5137904. [Google Scholar] [CrossRef] [PubMed]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.W.M.; van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fujioka, T.; Kubota, K.; Mori, M.; Kikuchi, Y.; Katsuta, L.; Kasahara, M.; Oda, G.; Ishiba, T.; Nakagawa, T.; Tateishi, U. Distinction between benign and malignant breast masses at breast ultrasound using deep learning method with convolutional neural network. Jpn. J. Radiol. 2019, 37, 466–472. [Google Scholar] [CrossRef]
- Byra, M. Discriminant analysis of neural style representations for breast lesion classification in ultrasound. Biocybern. Biomed. Eng. 2018, 38, 684–690. [Google Scholar] [CrossRef]
- Byra, M.; Galperin, M.; Ojeda-Fournier, H.; Olson, L.; O’Boyle, M.; Comstock, C.; Andre, M. Breast mass classification in sonography with transfer learning using a deep convolutional neural network and color conversion. Med. Phys. 2019, 46, 746–755. [Google Scholar] [CrossRef]
- Xiao, T.; Liu, L.; Li, K.; Qin, W.; Yu, S.; Li, Z. Comparison of transferred deep neural networks in ultrasonic breast masses discrimination. BioMed Res. Int. 2018, 2018, 4605191. [Google Scholar] [CrossRef]
- Tanaka, H.; Chiu, S.W.; Watanabe, T.; Kaoku, S.; Yamaguchi, T. Computer-aided diagnosis system for breast ultrasound images using deep learning. Phys. Med. Biol. 2019, 64, 235013. [Google Scholar] [CrossRef] [PubMed]
- Antropova, N.; Huynh, B.; Giger, M. A deep feature fusion methodology for breast cancer diagnosis demonstrated on three imaging modality datasets. Phys. Med. Biol. 2017, 44, 5162–5171. [Google Scholar] [CrossRef] [PubMed]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Duda, R.; Hart, P. Pattern Classification and Scene Analysis, 1st ed.; Wiley: New York, NY, USA, 1973. [Google Scholar]
- Vapnik, V.N. The Nature of Statistical Learning Theory, 2nd ed.; Springer: New York, NY, USA, 2000. [Google Scholar]
- Yap, M.H.; Pons, G.; Marti, J.; Ganau, S.; Sentis, M.; Zwiggelaar, R.; Davison, A.K.; Marti, R. Automated breast ultrasound lesions detection using convolutional neural networks. IEEE J. Biomed. Health Inform. 2018, 22, 1218–1226. [Google Scholar] [CrossRef] [Green Version]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. Vol. 2015, 115, 159–252. [Google Scholar] [CrossRef] [Green Version]
- Zheng, L.; Zhao, Y.; Wang, S.; Wang, J.; Tian, Q. Good practice in CNN feature transfer. arXiv 2016, arXiv:1604.00133. [Google Scholar]
- Arandjelović, R.; Zisserman, A. Three things everyone should know to improve object retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2012), Providence, RI, USA, 16–21 June 2012; pp. 2911–2918. [Google Scholar]
- Urbanowicz, R.J.; Meeker, M.; La Cava, W.; Olson, R.S.; Moore, J.H. Relief-based feature selection: Introduction and review. J. Biomed. Inform. 2018, 85, 189–203. [Google Scholar] [CrossRef]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef]
- Matthews, B.W. Comparison of the predicted and observed secondary structure of T4 phage lysozyme. Biochim. Biophys. Acta (BBA) Protein Struct. 1975, 405, 442–451. [Google Scholar] [CrossRef]
- Chicco, D. Ten quick tips for machine learning in computational biology. BioData Min. 2017, 10, 1–17. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- Hawkins, D.M. The problem of overfitting. J. Chem. Inf. Comput. Sci. 2004, 44, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Hsu, C.W.; Chang, C.C.; Lin, C.J. A Practical Guide to Support Vector Classification; Technical Report; Department of Computer Science and Information Engineering, National Taiwan University: Taipei, Taiwan, 2008. [Google Scholar]
- Daoud, M.I.; Atallah, A.A.; Awwad, F.; Al-Najjar, M.; Alazrai, R. Automatic superpixel-based segmentation method for breast ultrasound images. Expert Syst. Appl. 2019, 121, 78–96. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef] [Green Version]
- Moon, W.K.; Huang, Y.; Lo, C.; Huang, C.; Bae, M.S.; Kim, W.H.; Chen, J.; Chang, R. Computer-aided diagnosis for distinguishing between triple-negative breast cancer and fibroadenomas based on ultrasound texture features. Med. Phys. 2015, 42, 3024–3035. [Google Scholar] [CrossRef]
- Shen, W.C.; Chang, R.F.; Moon, W.K.; Chou, Y.H.; Huang, C.S. Breast ultrasound computer-aided diagnosis using BI-RADS features. Acad. Radiol. 2007, 14, 928–939. [Google Scholar] [CrossRef]
- Rangayyan, R.M.; Mudigonda, N.R.; Desautels, J.E.L. Boundary modelling and shape analysis methods for classification of mammographic masses. Med. Biol. Eng. Comput. 2000, 38, 487–496. [Google Scholar] [CrossRef]
- Nie, K.; Chen, J.H.; Yu, H.J.; Chu, Y.; Nalcioglu, O.; Su, M.Y. Quantitative analysis of lesion morphology and texture features for diagnostic prediction in breast MRI. Acad. Radiol. 2008, 15, 1513–1525. [Google Scholar] [CrossRef] [Green Version]
- Soh, L.K.; Tsatsoulis, C. Texture analysis of SAR sea ice imagery using gray level co-occurrence matrices. IEEE Trans. Geosci. Remote Sens. 1999, 37, 780–795. [Google Scholar] [CrossRef] [Green Version]
- Clausi, D.A. An analysis of co-occurrence texture statistics as a function of grey level quantization. Can. J. Remote Sens. 2002, 28, 45–62. [Google Scholar] [CrossRef]
- Cheng, H.D.; Shan, J.; Ju, W.; Guo, Y.; Zhang, L. Automated breast cancer detection and classification using ultrasound images: A survey. Pattern Recognit. 2010, 43, 299–317. [Google Scholar] [CrossRef] [Green Version]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
| Deep Features Extraction Level | Feature Sets | Description |
|---|---|---|
| CF Extraction Level 1 | , , , , , , , , , , , , , , , | A total of 11,008 convolution features organized into 16 feature sets are extracted from the ROI that includes the tumor, where each feature set corresponds to one of the convolution layers of the VGG19 model. To generate a given feature set, the convolution features and extracted from the convolution layer that corresponds to the feature set are concatenated and normalized. |
| CF Extraction Level 2 | , , , , | A total of 11,008 convolution features organized into 5 feature sets are extracted from the ROI that includes the tumor, where each feature set corresponds to one of the convolution blocks of the VGG19 model. To generate a given feature set, the feature sets extracted from the layers of the convolution block that corresponds to the feature set are concatenated and normalized. |
| CF Extraction Level 3 | A total of 11,008 convolution features organized into 1 feature set are extracted from the ROI that includes the tumor. To generate the feature set, the feature sets extracted from all convolution blocks of the VGG19 model are concatenated and normalized. | |
| FCF Extraction Level 1 | and | Two feature sets, where each set includes 4096 fully connected features, are extracted from the ROI that includes the tumor. The computation of the two feature sets is achieved by extracting and normalizing the activations of first and second fully connected layers of the VGG19 model. |
| FCF Extraction Level 2 | A feature set that includes 8192 fully connected features is extracted from the ROI that includes the tumor. The computation of the feature set is achieved by concatenating and normalizing the two feature sets extracted from the first and second fully connected layers of the VGG19 model. | |
| Combined CF FCF Extraction | A feature set that includes 19,200 convolution and fully connected features is extracted from the ROI that includes the tumor. The computation of the feature set is performed by extracting deep features from all convolution blocks and all fully connected layers of the VGG19 model and then concatenating and normalizing the extracted features. |
| Type | Features | Description |
|---|---|---|
| Texture features | Autocorrelation [50], contrast [14], correlation [50], cluster prominence [50], cluster shade [50], dissimilarity [50], energy [50], entropy [50], homogeneity [50], maximum probability [50], sum of squares [45], sum average [45], sum entropy [45], sum variance [45], difference variance [45], difference entropy [45], information measure of correlation I [45], information measure of correlation II [45], inverse difference normalized [51], inverse difference moment normalized [51] | A total of 800 texture features are extracted from the ROI that includes the tumor. In particular, 40 GLCMs are generated using 10 distances and 4 orientations . Moreover, each GLCM is analyzed to extract 20 texture features. |
| Morphological features | Tumor area [12], tumor perimeter [12], tumor form factor [10,13], tumor roundness [10,13], tumor aspect ratio [10,13], tumor convexity [10,13], tumor solidity [10,13], tumor extent [10,13], tumor undulation characteristics [47], tumor compactness [12,48], NRL entropy [12,49], NRL variance [12,49], length of the ellipse major axis [12], length of the ellipse minor axis [12], ratio between the ellipse major and minor axes [12], ratio of the ellipse perimeter and the tumor perimeter [12], angle of the ellipse major axis [12], overlap between the ellipse and the tumor [12] | A total of 18 morphological features are extracted from the tumor outline. In particular, 10 morphological features are computed directly based on the tumor outline. Moreover, 2 morphological features are computed based on the NRL of the tumor. In addition, 6 morphological features are computed by fitting an ellipse to the tumor outline. |
| Deep Features Extraction Level | Feature Set | Total No. of Features | No. of Selected Features | Selected Features | Accuracy | Sensitivity | Specificity | PPV | NPV | MCC |
|---|---|---|---|---|---|---|---|---|---|---|
| CF Extraction Level 1 | 128 | 34 | (34) | |||||||
| 128 | 21 | (21) | ||||||||
| 256 | 25 | (25) | ||||||||
| 256 | 38 | (38) | ||||||||
| 512 | 33 | (33) | ||||||||
| 512 | 47 | (47) | ||||||||
| 512 | 29 | (29) | ||||||||
| 512 | 86 | (86) | ||||||||
| 1024 | 20 | (20) | ||||||||
| 1024 | 61 | (61) | ||||||||
| 1024 | 31 | (31) | ||||||||
| 1024 | 32 | (32) | ||||||||
| 1024 | 58 | (58) | ||||||||
| 1024 | 41 | (41) | ||||||||
| 1024 | 23 | (23) | ||||||||
| 1024 | 31 | (31) | ||||||||
| CF Extraction Level 2 | 256 | 34 | (17), (17) | |||||||
| 512 | 23 | (5), (18) | ||||||||
| 2048 | 15 | (7), (8) | ||||||||
| 4096 | 34 | (8), (4), CONV4_3 (8), CONV4_4 (14) | ||||||||
| 4096 | 27 | (7), (8), (12) | ||||||||
| CF Extraction Level 3 | 11,008 | 25 | (1), (3), (1), (1), (5), (14) | 94.2 ± 2.7 | 93.3 ± 5.1 | 94.9 ± 4.1 | 93.3 ± 5.6 | 94.9 ± 4.4 | 88.2 ± 5.5 | |
| FCF Extraction Level 1 | 4096 | 36 | (36) | |||||||
| 4096 | 98 | (98) | ||||||||
| FCF Extraction Level 2 | 8192 | 36 | (36) | |||||||
| Combined CF FCF Extraction | 19,200 | 25 | (1), (3), (1), (1), (5), (14) | 94.2 ± 2.7 | 93.3 ± 5.1 | 94.9 ± 4.1 | 93.3 ± 5.6 | 94.9 ± 4.4 | 88.2 ± 5.5 |
| Features | Total No. of Features | No. of Selected Features | Selected Features | Accuracy | Sensitivity | Specificity | PPV | NPV | MCC |
|---|---|---|---|---|---|---|---|---|---|
| feature set | 11,008 | 25 | (1), (3), (1), (1), (5), (14) | 94.2 ± 2.7 | 93.3 ± 5.1 | 94.9 ± 4.1 | 93.3 ± 5.6 | 94.9 ± 4.4 | 88.2 ± 5.5 |
| feature set and texture features | 11,808 | 25 | (1), (3), (1), (1), (5), (14) | 94.2 ± 2.7 | 93.3 ± 5.1 | 94.9 ± 4.1 | 93.3 ± 5.6 | 94.9 ± 4.4 | 88.2 ± 5.5 |
| feature set and morphological features | 11,026 | 21 | (4), (14), morphological (3) | 96.1 ± 2.2 | 95.7 ± 4.2 | 96.3 ± 3.6 | 95.1 ± 5.4 | 96.8 ± 3.1 | 92.0 ± 5.0 |
| feature set, texture features, and morphological features | 11,826 | 21 | (4), (14), morphological (3) | 96.1 ± 2.2 | 95.7 ± 4.2 | 96.3 ± 3.6 | 95.1 ± 5.4 | 96.8 ± 3.1 | 92.0 ± 5.0 |
| Features | Total No. of Features | No. of Selected Features | Accuracy | Sensitivity | Specificity | PPV | NPV | MCC |
|---|---|---|---|---|---|---|---|---|
| feature set (with features selection) | 11,008 | 25 | 94.2± 2.7 | 93.3 ± 5.1 | 94.9± 4.1 | 93.3 ± 5.6 | 94.9 ± 4.4 | 88.2 ± 5.5 |
| feature set and morphological features (with features selection) | 11,026 | 21 | 96.1 ± 2.2 | 95.7 ± 4.2 | 96.3 ± 3.6 | 95.1 ± 5.4 | 96.8 ± 3.1 | 92.0 ± 5.0 |
| feature set (without features selection) | 11,008 | - | 80.5 ± 4.5 | 82.2 ± 9.0 | 79.3 ± 8.0 | 74.9 ± 7.1 | 85.6 ± 7.4 | 60.9 ± 8.6 |
| Texture features (with features selection) | 800 | 38 | 84.2 ± 4.3 | 81.0 ± 9.6 | 86.6 ± 6.6 | 82.0 ± 10.6 | 85.8 ± 5.5 | 67.7 ± 9.2 |
| Morphological features (with features selection) | 18 | 8 | 87.1 ± 4.7 | 82.2 ± 8.9 | 90.8 ± 7.9 | 87.0 ± 11.9 | 87.2 ± 6.2 | 73.6 ± 9.7 |
| Texture and morphological features (with features selection) | 818 | 29 | 87.9 ± 6.1 | 82.8 ± 12.3 | 91.7 ± 3.9 | 88.2 ± 6.1 | 87.7 ± 7.7 | 75.2 ± 12.7 |
| Fine-tuning | - | - | 88.2 ± 4.5 | 83.4 ± 8.0 | 91.7 ± 5.5 | 88.3 ± 8.1 | 88.1 ± 6.9 | 75.8 ± 9.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Daoud, M.I.; Abdel-Rahman, S.; Bdair, T.M.; Al-Najar, M.S.; Al-Hawari, F.H.; Alazrai, R. Breast Tumor Classification in Ultrasound Images Using Combined Deep and Handcrafted Features. Sensors 2020, 20, 6838. https://doi.org/10.3390/s20236838
Daoud MI, Abdel-Rahman S, Bdair TM, Al-Najar MS, Al-Hawari FH, Alazrai R. Breast Tumor Classification in Ultrasound Images Using Combined Deep and Handcrafted Features. Sensors. 2020; 20(23):6838. https://doi.org/10.3390/s20236838
Chicago/Turabian StyleDaoud, Mohammad I., Samir Abdel-Rahman, Tariq M. Bdair, Mahasen S. Al-Najar, Feras H. Al-Hawari, and Rami Alazrai. 2020. "Breast Tumor Classification in Ultrasound Images Using Combined Deep and Handcrafted Features" Sensors 20, no. 23: 6838. https://doi.org/10.3390/s20236838
APA StyleDaoud, M. I., Abdel-Rahman, S., Bdair, T. M., Al-Najar, M. S., Al-Hawari, F. H., & Alazrai, R. (2020). Breast Tumor Classification in Ultrasound Images Using Combined Deep and Handcrafted Features. Sensors, 20(23), 6838. https://doi.org/10.3390/s20236838