City Data Hub: Implementation of Standard-Based Smart City Data Platform for Interoperability


Abstract
:1. Introduction
2. Related Works
2.1. Interoperability Levels
2.2. Standard IoT APIs and Data Models
2.3. NGSI-LD
2.4. Data Marketplaces
3. City Data Hub Architecture
3.1. Introduction
- Interoperability with standards
- Maintainability with openness
- Extensibility with ecosystem
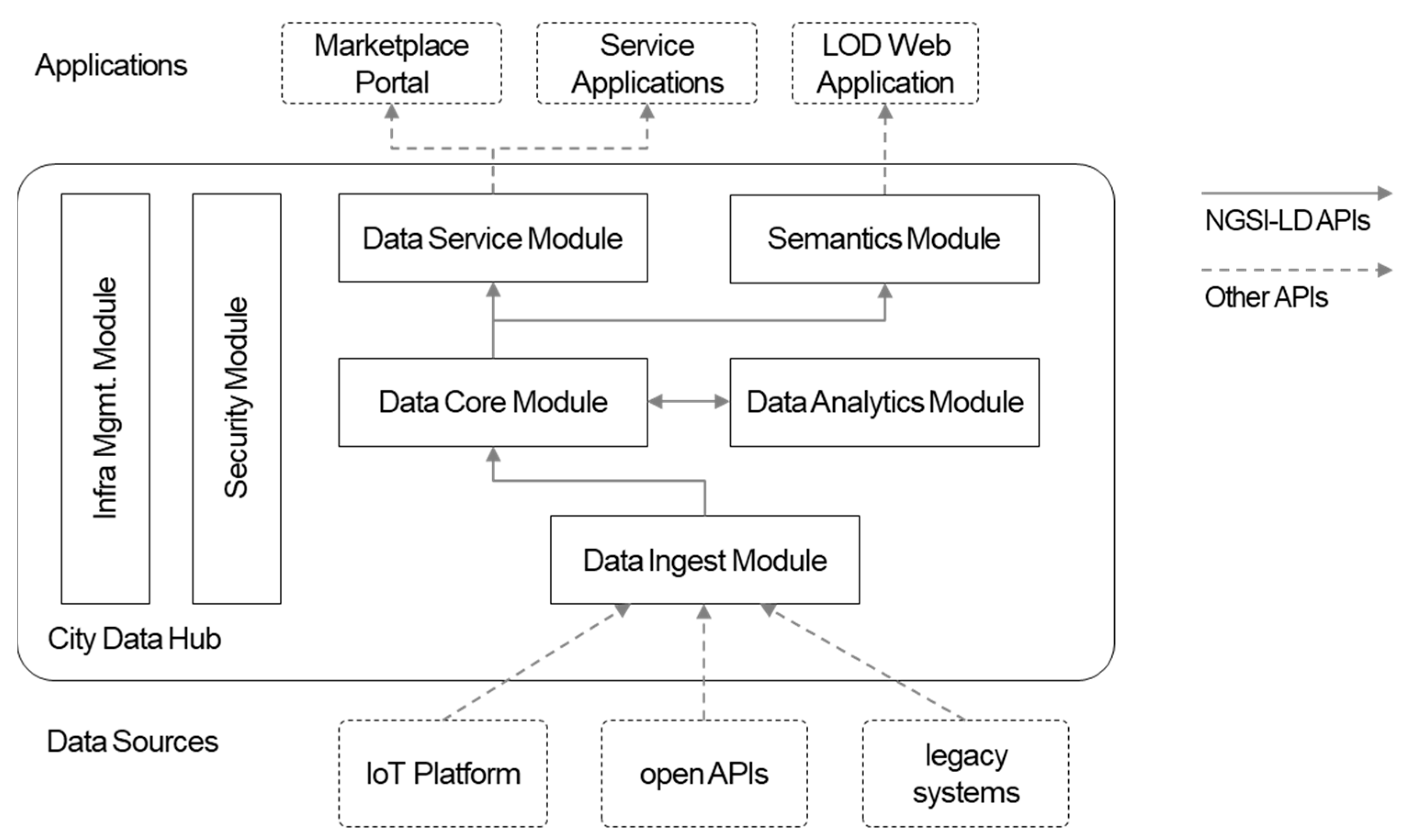
3.2. Architecture Overview
4. City Data Hub Modules
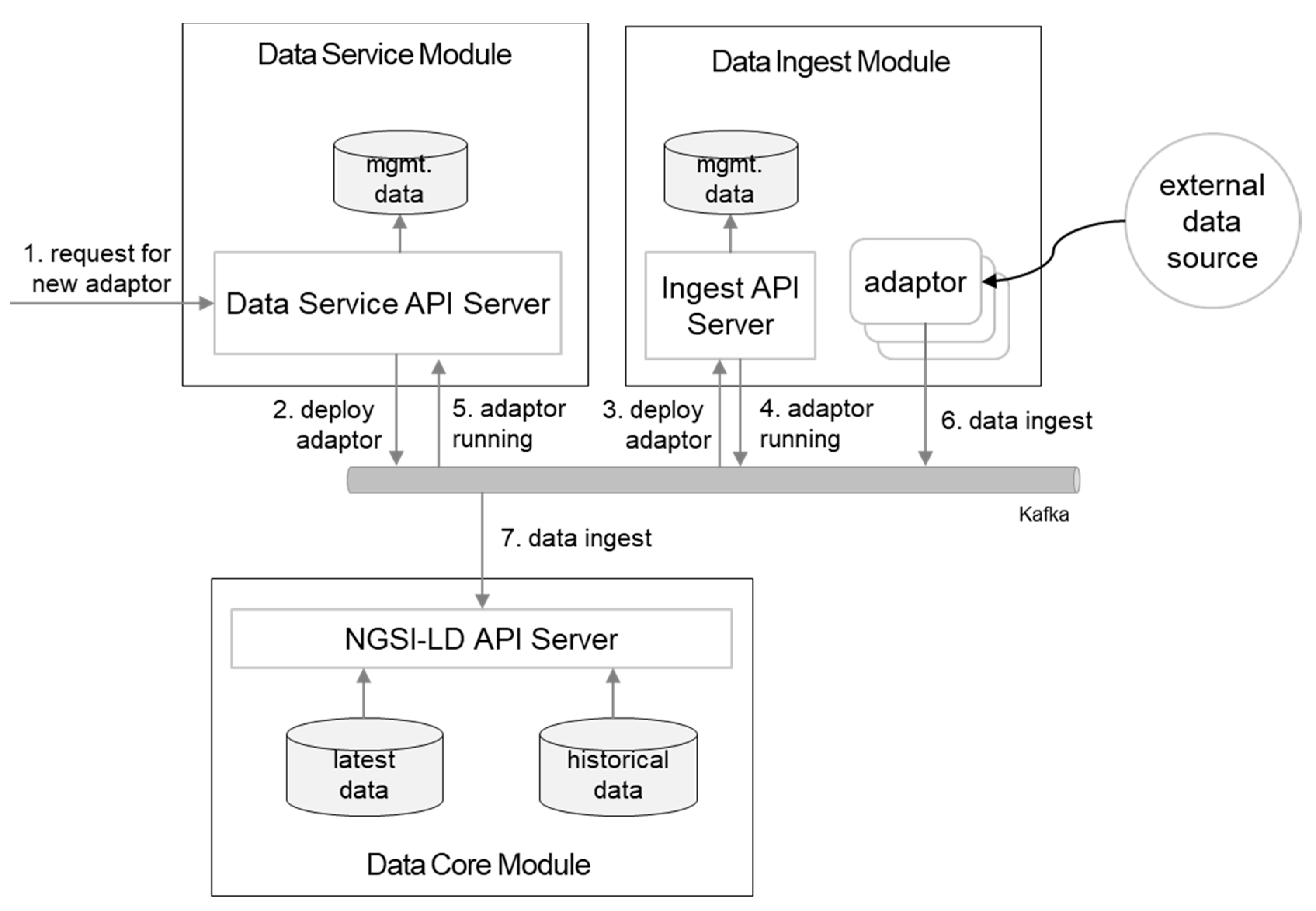
4.1. Data Ingest
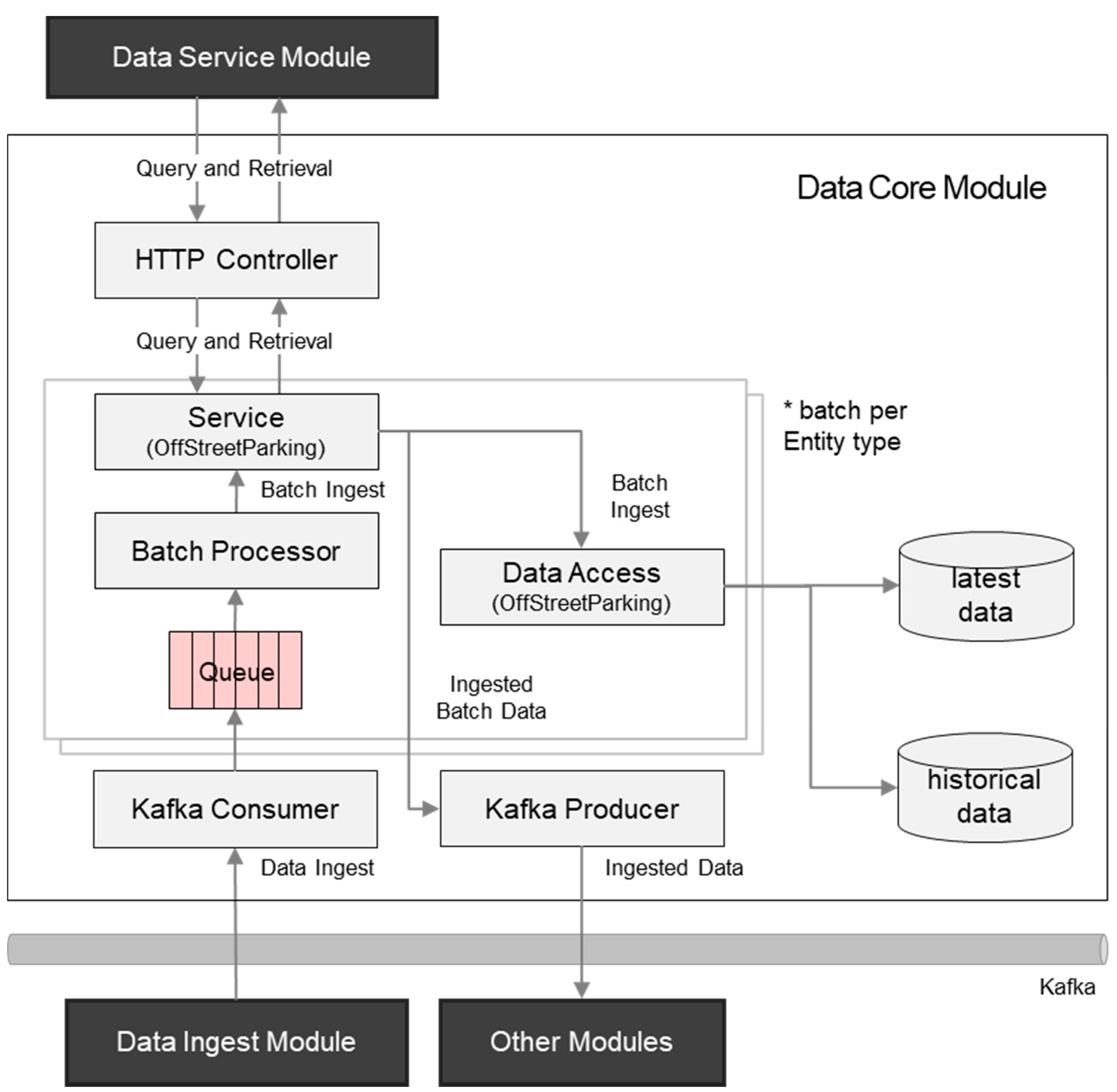
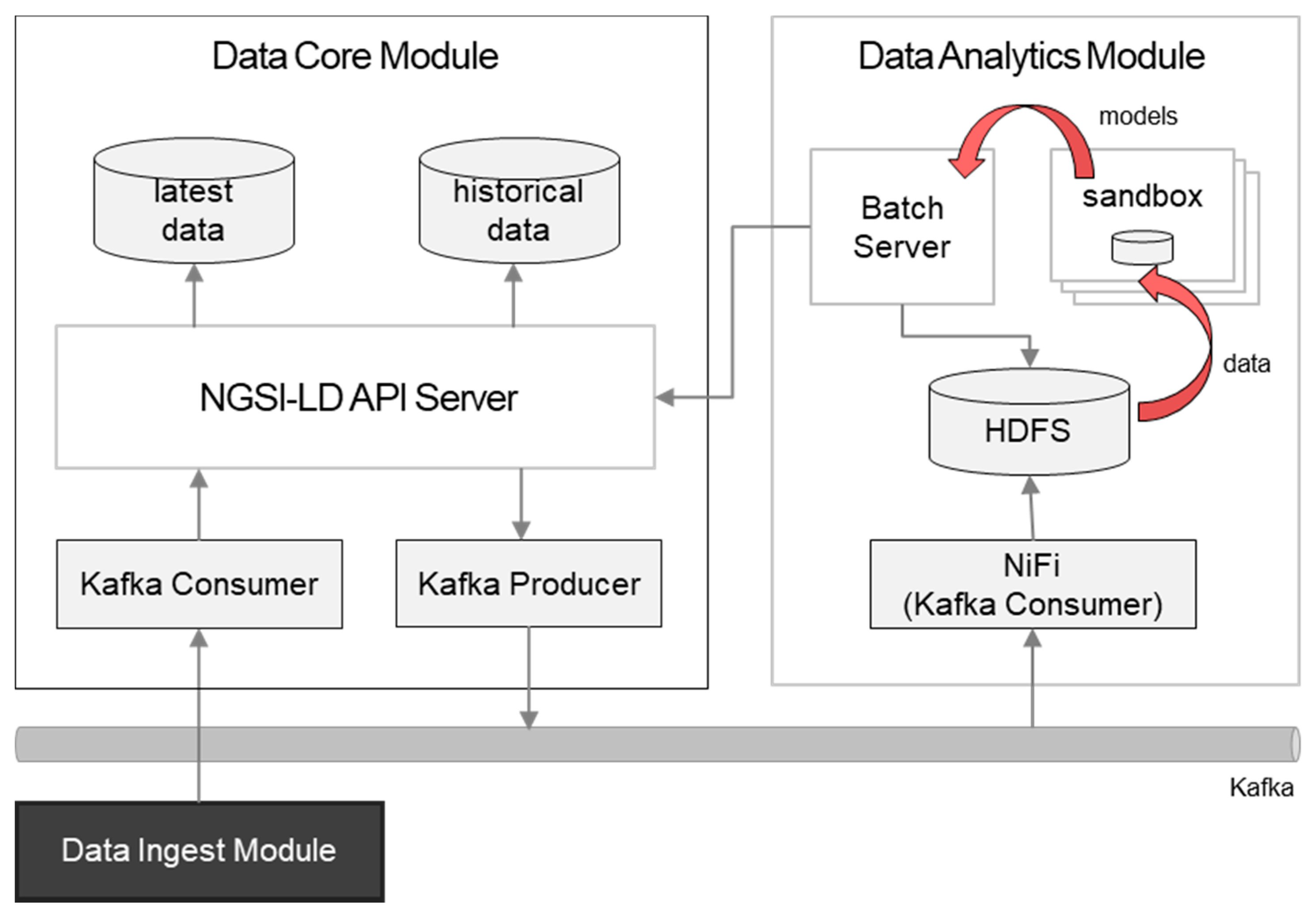
4.2. Data Core Module
4.2.1. Standard API Implementations
4.2.2. Access Control
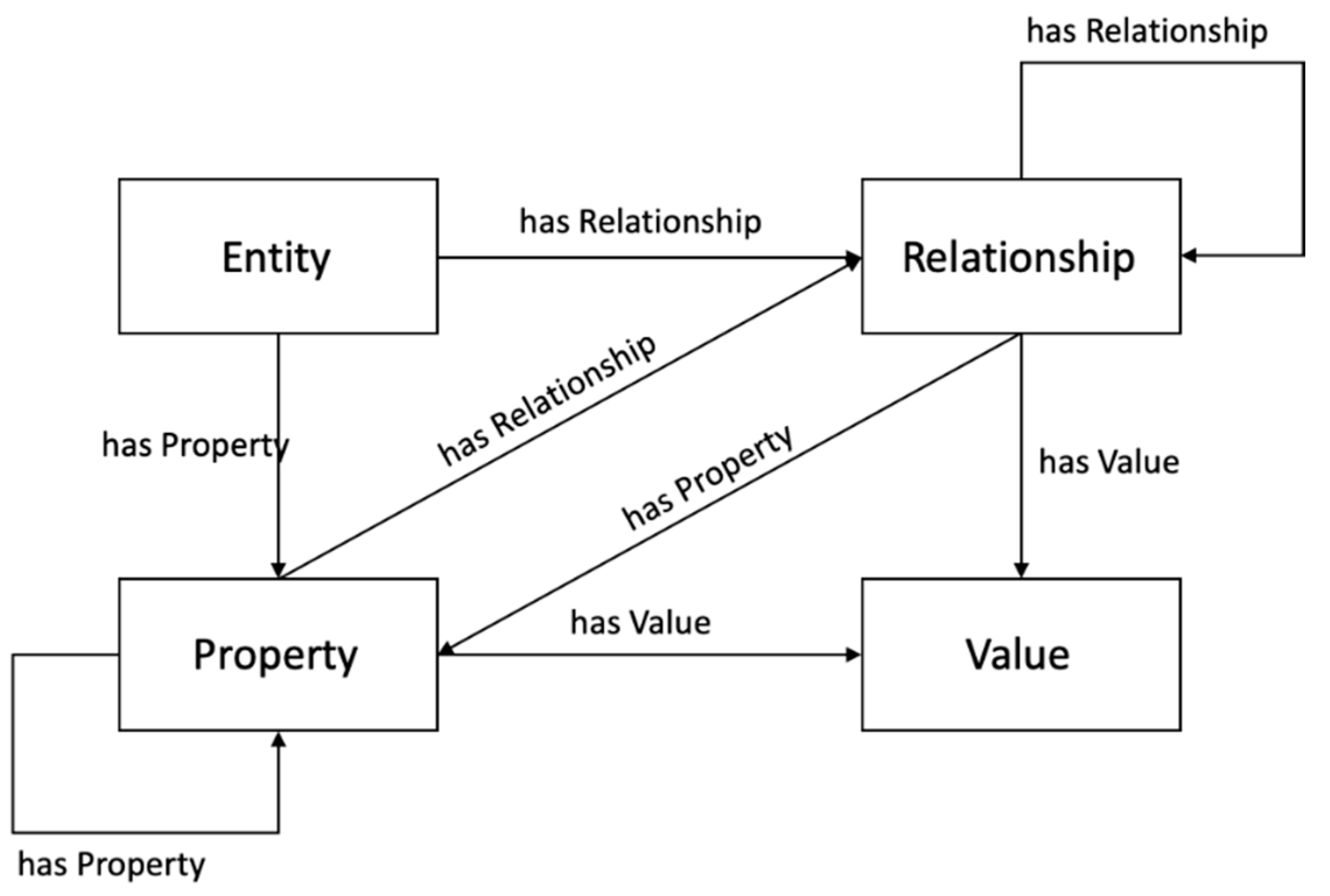
4.2.3. NGSI-LD Data Modeling
NGSI-LD Entity Modeling Principles
- A model per entity
- Raw data vs. processed data
- Linkage between processed data and raw data
4.2.4. Dynamic Schema for New Data Models
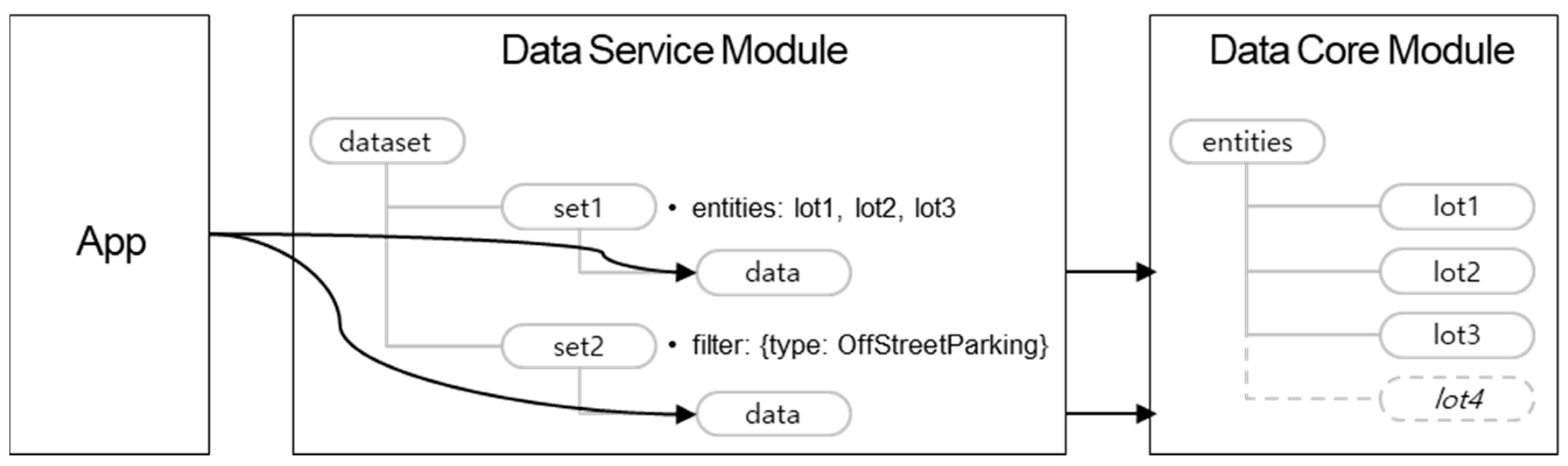
4.3. Data Service Module
- A data owner yields access management to the data service;
- A data consumer makes a purchase on the marketplace portal, and it is recorded as a resource on the data service module;
- Based on a dataset purchase records, the data service module grants access to the consumer who made the purchase.
4.4. Data Analytics
5. Proof-of-Concept (PoC)
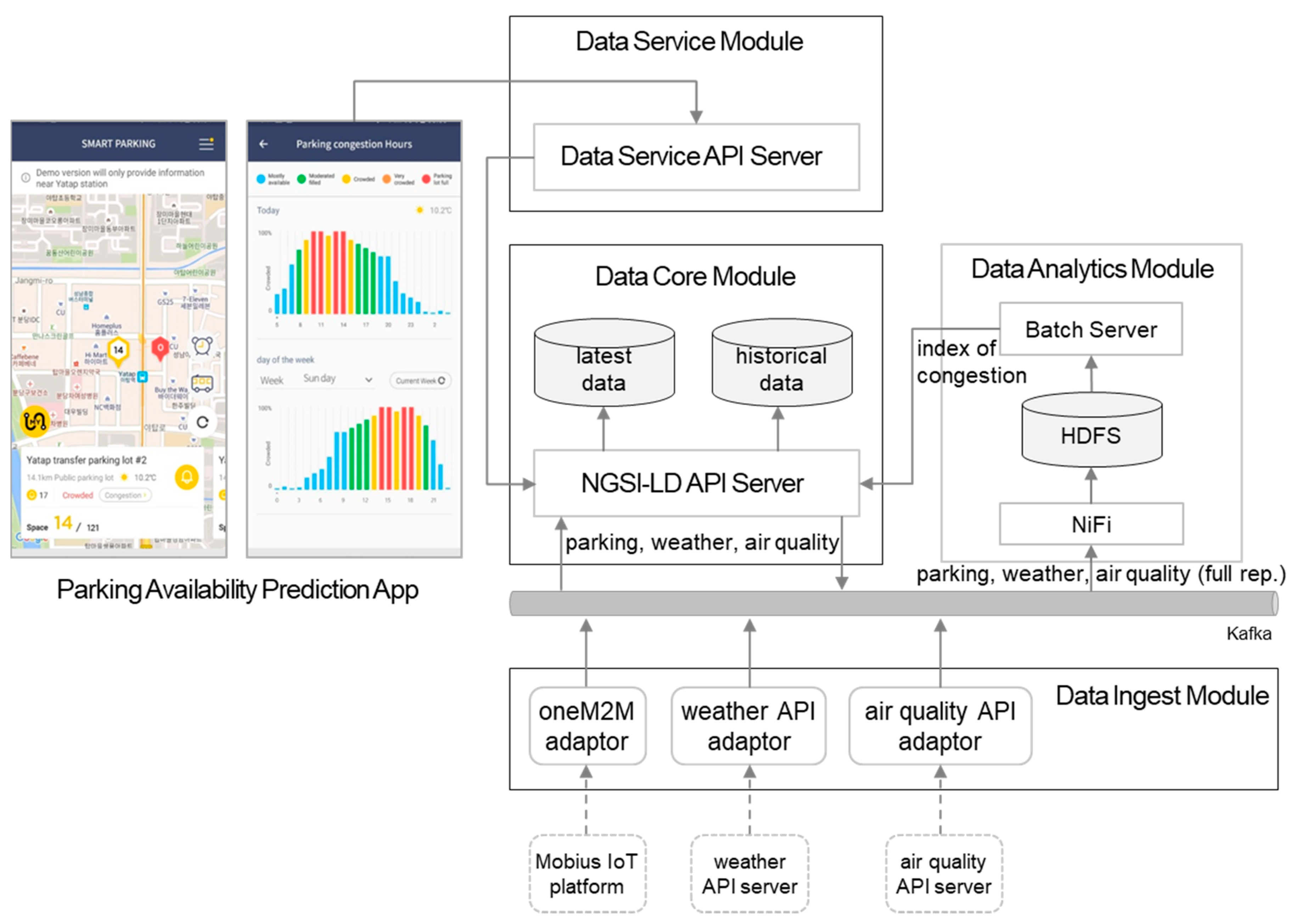
5.1. Parking Availability Prediction Service
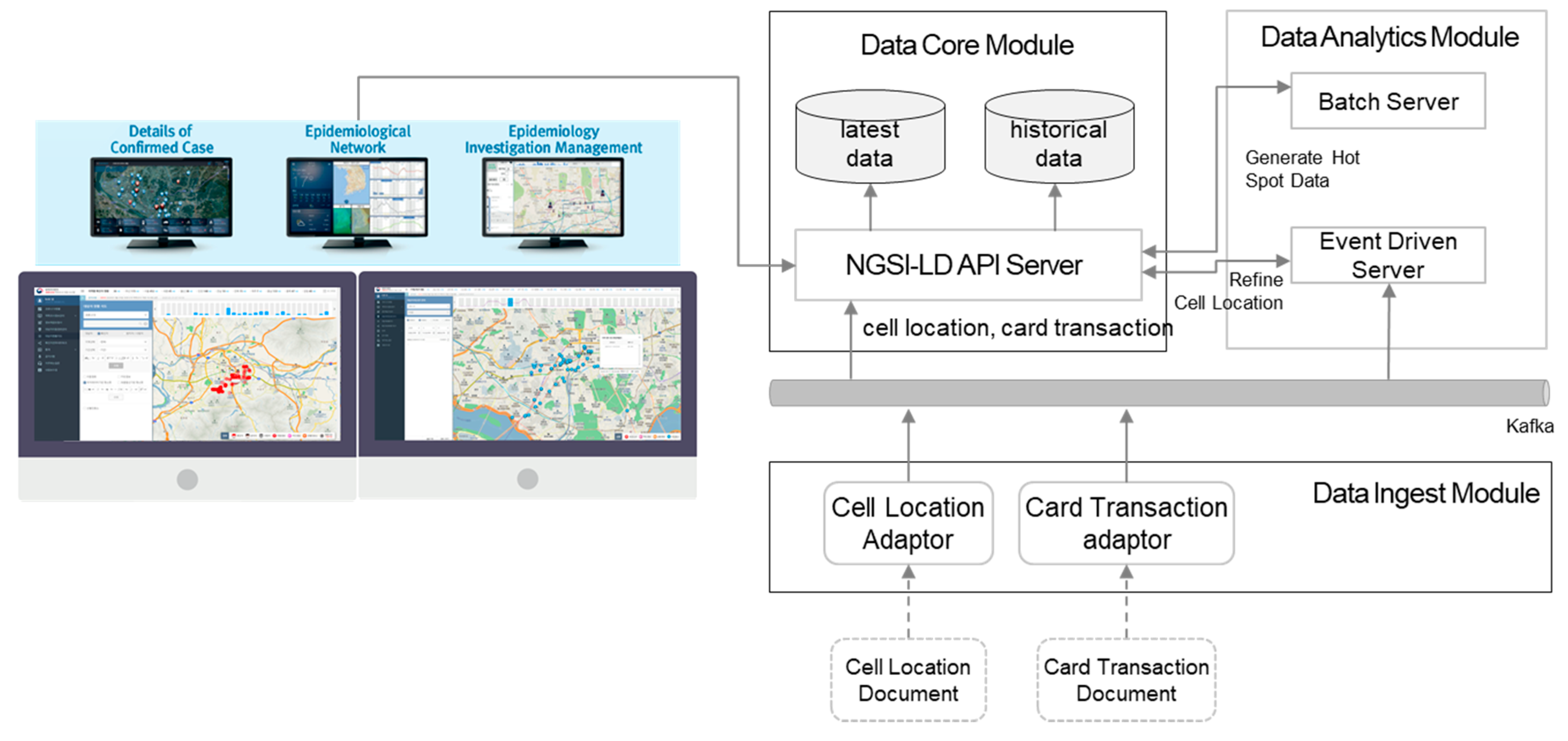
5.2. COVID-19 EISS
6. Remaining Works
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Albino, V.; Berardi, U.; Dangelico, R.M. Smart Cities: Definitions, Dimensions, Performance, and Initiatives. J. Urban Technol. 2015, 22, 3–21. [Google Scholar] [CrossRef]
- Osman, A.M.S. A novel big data analytics framework for smart cities. Future Gener. Comput. Syst. 2019, 91, 620–633. [Google Scholar] [CrossRef]
- IES-City Framework. Available online: https://pages.nist.gov/smartcitiesarchitecture/ (accessed on 30 June 2020).
- OASC. A Guide to SynchroniCity. Available online: https://synchronicity-iot.eu/wp-content/uploads/2020/01/SynchroniCity-guidebook.pdf (accessed on 30 June 2020).
- National Smart City Strategic Program. Available online: http://www.smartcities.kr/about/about.do (accessed on 30 June 2020).
- Karpenko, A.; Kinnunen, T.; Madhikermi, M.; Robert, J.; Främling, K.; Dave, B.; Nurminen, A. Data Exchange Interoperability in IoT Ecosystem for Smart Parking and EV Charging. Sensors 2018, 18, 4404. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- oneM2M. Functional Architecture. Available online: http://member.onem2m.org/Application/documentapp/downloadLatestRevision/default.aspx?docID=32876 (accessed on 30 June 2020).
- ETSI. Korean Smart Cities Based on oneM2M Standards. Available online: https://www.etsi.org/images/files/Magazine/Enjoy-ETSI-MAG-October-2019.pdf (accessed on 30 June 2020).
- oneM2M. SDT Based Information Model and Mapping for Vertical Industries. Available online: http://member.onem2m.org/Application/documentapp/downloadLatestRevision/default.aspx?docID=28733 (accessed on 30 June 2020).
- OCF. OCF Resource Type Specification. Available online: https://openconnectivity.org/specs/OCF_Resource_Type_Specification_v2.1.2.pdf (accessed on 30 June 2020).
- OCF. OCF Core Specification. Available online: https://openconnectivity.org/specs/OCF_Core_Specification_v2.1.2.pdf (accessed on 30 June 2020).
- OCF. OCF Resource to oneM2M Module Class Mapping Specification. Available online: https://openconnectivity.org/specs/OCF_Resource_to_OneM2M_Module_Class_Mapping_Specification_v2.1.2.pdf (accessed on 30 June 2020).
- FIWARE. Data Models. Available online: https://fiware-datamodels.readthedocs.io/en/latest/Parking/doc/introduction/index.html (accessed on 30 June 2020).
- SynchroniCity. Catalogue of OASC Shared Data Models for Smart City Domains. Available online: https://synchronicity-iot.eu/wp-content/uploads/2020/02/SynchroniCity_D2.3.pdf (accessed on 30 June 2020).
- OMA. Next Generation Service Interfaces Architecture. Available online: http://www.openmobilealliance.org/release/NGSI/V1_0-20120529-A/OMA-AD-NGSI-V1_0-20120529-A.pdf (accessed on 30 June 2020).
- ETSI. GS CIM 009-NGSI-LD API. Available online: https://www.etsi.org/deliver/etsi_gs/CIM/001_099/009/01.02.02_60/gs_CIM009v010202p.pdf (accessed on 30 June 2020).
- ETSI. GS CIM 006-Information Model. Available online: https://www.etsi.org/deliver/etsi_gs/CIM/001_099/006/01.01.01_60/gs_CIM006v010101p.pdf (accessed on 30 June 2020).
- López, M.; Antonio, J.; Martínez, J.A.; Skarmeta, A.F. Digital Transfomation of Agriculture through the Use of an Interoperable Platform. Sensors 2020, 20, 1153. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abid, A.; Dupont, C.; Le Gall, F.; Third, A.; Kane, F. Modelling Data for A Sustainable Aquaculture. In Proceedings of the 2019 Global IoT Summit (GIoTS), Aarhus, Denmark, 17–21 June 2019. [Google Scholar]
- Rocha, B.; Cavalcante, E.; Batista, T.; Silva, J. A Linked Data-Based Semantic Information Model for Smart Cities. In Proceedings of the 2019 IX Brazilian Symposium on Computing Systems Engineering (SBESC), Natal, Brazil, 19–22 November 2019; pp. 1–8. [Google Scholar]
- Kamienski, C.; Soininen, J.-P.; Taumberger, M.; Dantas, R.; Toscano, A.; Salmon Cinotti, T.; Filev Maia, R.; Torre Neto, A. Smart water management platform: Iot-based precision irrigation for agriculture. Sensors 2019, 19, 276. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cirillo, F.; Gómez, D.; Diez, L.; Maestro, I.E. Smart City IoT Services Creation through Large Scale Collaboration. IEEE Internet Things J. 2020, 7, 5267–5275. [Google Scholar] [CrossRef] [Green Version]
- Busan Smart City Data Portal. Available online: http://data.k-smartcity.kr/ (accessed on 30 June 2020).
- Goyang Smart City Data Portal. Available online: https://data.smartcitygoyang.kr/ (accessed on 30 June 2020).
- Synchronicity. Advanced Data Market Place Enablers. Available online: https://synchronicity-iot.eu/wp-content/uploads/2020/02/SynchroniCity_D2.5.pdf (accessed on 30 June 2020).
- Apache Flume. Available online: https://flume.apache.org/ (accessed on 30 June 2020).
- oneM2M. Core Protocol. Available online: http://member.onem2m.org/Application/documentapp/downloadLatestRevision/default.aspx?docID=32898 (accessed on 30 June 2020).
- Apache Kafka. Available online: https://kafka.apache.org/ (accessed on 30 June 2020).
- oneM2M. Security Solutions. Available online: http://member.onem2m.org/Application/documentapp/downloadLatestRevision/default.aspx?docID=32564 (accessed on 30 June 2020).
- FIWARE Identity Manager—Keyrock. Available online: https://fiware-idm.readthedocs.io/en/latest/ (accessed on 30 June 2020).
- FIWARE PEP Proxy—Wilma. Available online: https://fiware-pep-proxy.readthedocs.io/en/latest/ (accessed on 30 June 2020).
- FIWARE AuthzForce. Available online: https://authzforce-ce-fiware.readthedocs.io/en/latest/ (accessed on 30 June 2020).
- Seongyun, K.; SeungMyeong, J. Guidelines of Data Modeling on Open Data Platform for Smart City. In Proceedings of the International Conference on Internet (ICONI), Jeju Island, Korea, 13–16 December 2020. [Google Scholar]
- JSON Schema. Available online: https://json-schema.org/specification.html (accessed on 30 June 2020).
- JSON-LD 1.0-A JSON-Based Serialization for Linked Data. Available online: http://www.w3.org/TR/2014/REC-json-ld-20140116/ (accessed on 30 June 2020).
- JSON Web Token (JWT). Available online: https://tools.ietf.org/html/rfc7519 (accessed on 30 June 2020).
- Apache NiFi. Available online: https://nifi.apache.org/ (accessed on 30 June 2020).
- Hue. Available online: https://gethue.com/ (accessed on 30 June 2020).
- Apache Hive. Available online: https://hive.apache.org/ (accessed on 30 June 2020).
- Scikit-Learn. Available online: https://scikit-learn.org/ (accessed on 30 June 2020).
- Syed, R.; Susan, Z.; Stephan, O. ASPIRE an Agent-Oriented Smart Parking Recommendation System for Smart Cities. IEEE Intell. Transp. Syst. Mag. 2019, 11, 48–61. [Google Scholar]
- City Data Hub PoC Data Models. Available online: https://github.com/IoTKETI/datahub_data_modeling (accessed on 30 June 2020).
- Postal Address. Available online: https://schema.org/PostalAddress (accessed on 30 June 2020).
- Korea Meteorological Administration Open API. Available online: https://www.data.go.kr/data/15059093/openapi.do (accessed on 30 June 2020).
- Air Korea Open API. Available online: https://www.data.go.kr/data/15000581/openapi.do (accessed on 30 June 2020).
- OCEAN, Mobius. Available online: https://developers.iotocean.org/archives/module/mobius (accessed on 30 June 2020).
- Young, P.; Cho, S.Y.; Lee, J.; ParK, W.-H.; Jeomg, S.; Kim, S.; Lee, S.; Kim, J.; Park, O. Development and Utilization of a Rapid and Accurate Epidemic Investigation Support System for COVID-19. Osong Public Health Res. Perspect. 2020, 11, 112–117. [Google Scholar]
- An, J.; Kumar, S.; Lee, J.; Jeong, S.; Song, J. Synapse: Towards Linked Data for Smart Cities using a Semantic Annotation Framework. In Proceedings of the IEEE 6th World Forum on Internet of Things, New Orleans, LA, USA, 2–16 June 2020. [Google Scholar]
- Stellio. Available online: https://www.stellio.io/en/your-smart-solution-engine (accessed on 30 June 2020).
- Cirillo, F.; Solmaz, G.; Berz, E.L.; Bauer, M.; Cheng, B.; Kovacs, E. A standard-based open source IoT platform: FIWARE. IEEE Internet Things Mag. 2019, 2, 12–18. [Google Scholar] [CrossRef]
- Esposte, A.D.M.D.; Santana, E.F.; Kanashiro, L.; Costa, F.M.; Braghetto, K.R.; Lago, N.; Kon, F. Design and evaluation of a scalable smart city software platform with large-scale simulations. Future Gener. Comput. Syst. 2019, 93, 427–441. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Property | Multiplicity | Data Type | Description |
|---|---|---|---|
| entityType | 1 | String | ‘type’ value of NGSI-LD entity |
| version | 1 | String | scheme version |
| description | 1 | String | scheme description |
| indexAttributeIds | 0..N | String | attribute IDs for indexing |
| rootAttributes | 0..N | Attribute 1 | ‘Property’ or ‘Relationship’ of NGSI-LD entity |
| Child Property | Multiplicity | Data Type | Description |
|---|---|---|---|
| id | 1 | String | attribute ID |
| required | 0..1 | Boolean | attribute cardinality |
| type | 1 | String | ‘Property’, ‘GeoProperty’, or ‘Relationship’ |
| maxLength | 0..1 | String | max length of digits or max number of characters |
| valueType | 1 | String | E.g. ‘GeoJSON’, ‘String’, ‘ArrayString’, ‘Object’ |
| valueEnum | 0..N | String | list of allowed enumeration values |
| observedAt | 0..1 | Boolean | this is true when a property includes ‘observedAt’ timestamp |
| objectKeys | 0..N | ObjectKey 1 | when valueType is ‘object’, its key IDs and value types are defined |
| childAttributes | 0..N | Attribute | child ‘Property’ or ‘Relationship’ of NGSI-LD entity |
| Child Property | Multiplicity | Data Type | Description |
|---|---|---|---|
| id | 1 | String | attribute ID |
| required | 1 | Boolean | attribute cardinality |
| maxLength | 0..1 | String | max length of digits or max number of characters |
| valueType | 1 | String | ‘String’, ‘ArrayString’, ‘Integer’, ‘ArrayInteger’, ‘Double’, or ‘ArrayDouble’ |
| Entity Type | Entity Specific Property | Reference |
|---|---|---|
| OffStreetParking | availableSpotNumber, congestionIndexPrediction | [13,43] |
| ParkingSpot | occupancy | [13,43] |
| AirQualityObserved | airQualityIndexObservation, indexRef | [44] |
| AirQualityForecast | airQualityIndexPrediction, indexRef | [44] |
| WeatherObserved | weatherObservation | [45] |
| WeatherForecast | weatherPrediction | [45] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, S.; Kim, S.; Kim, J. City Data Hub: Implementation of Standard-Based Smart City Data Platform for Interoperability. Sensors 2020, 20, 7000. https://doi.org/10.3390/s20237000
Jeong S, Kim S, Kim J. City Data Hub: Implementation of Standard-Based Smart City Data Platform for Interoperability. Sensors. 2020; 20(23):7000. https://doi.org/10.3390/s20237000
Chicago/Turabian StyleJeong, Seungmyeong, Seongyun Kim, and Jaeho Kim. 2020. "City Data Hub: Implementation of Standard-Based Smart City Data Platform for Interoperability" Sensors 20, no. 23: 7000. https://doi.org/10.3390/s20237000
APA StyleJeong, S., Kim, S., & Kim, J. (2020). City Data Hub: Implementation of Standard-Based Smart City Data Platform for Interoperability. Sensors, 20(23), 7000. https://doi.org/10.3390/s20237000