Mobility-Aware Service Caching in Mobile Edge Computing for Internet of Things


Abstract
:1. Introduction
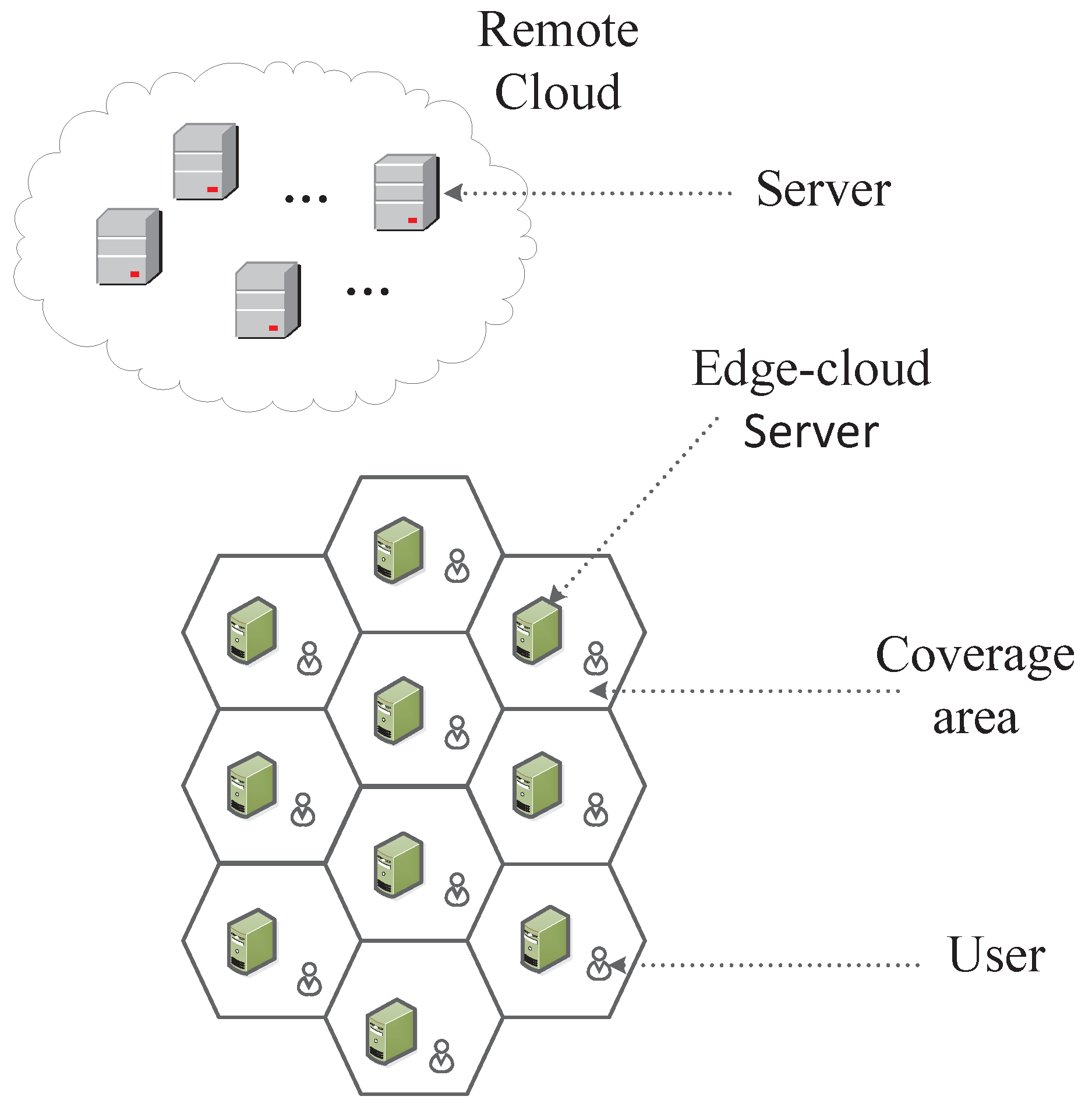
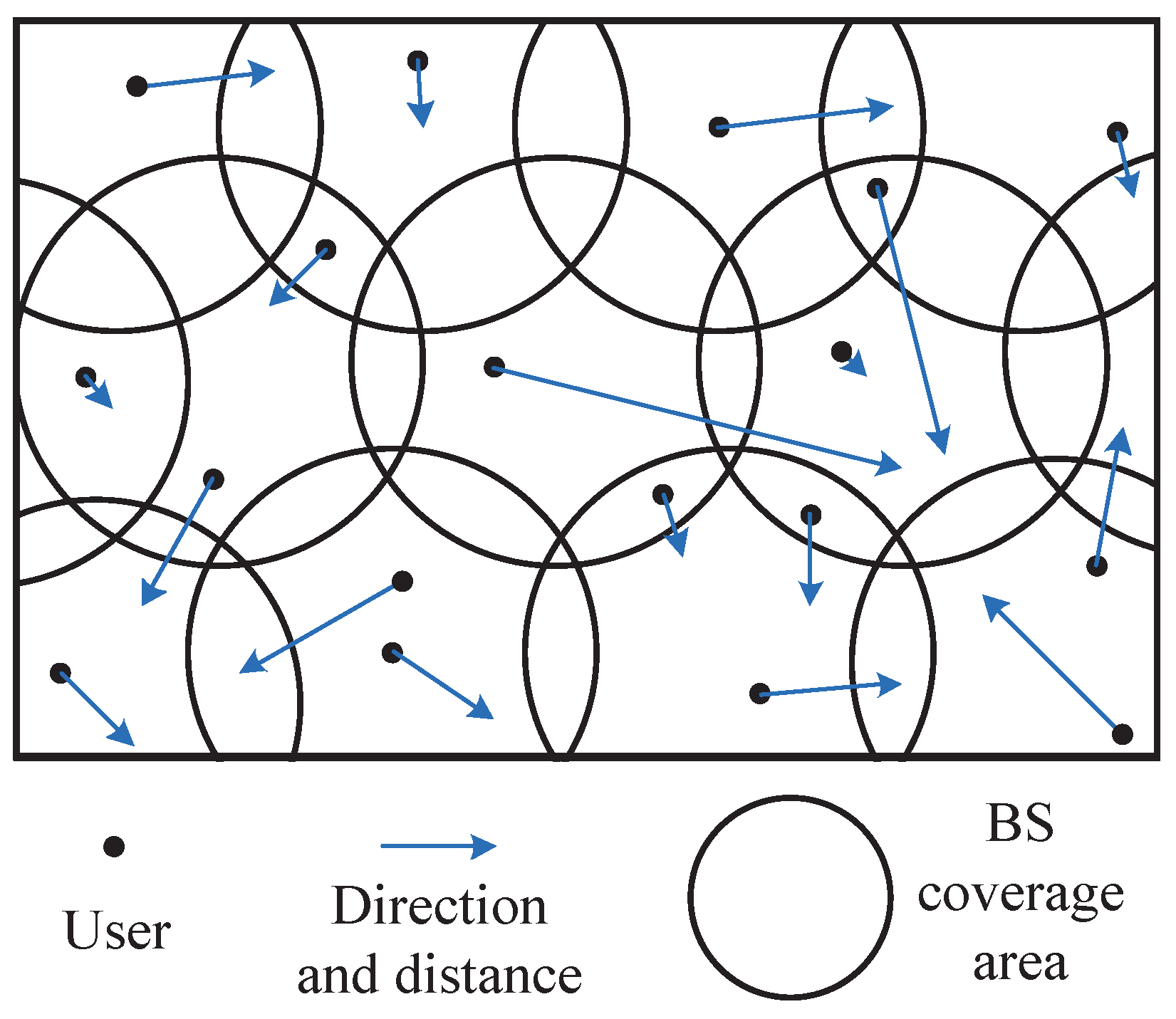
- We propose a new edge-cloud computing model, considering the BS coverage overlap and user mobility, to ensure that user requests are executed as much as possible in local edge server.
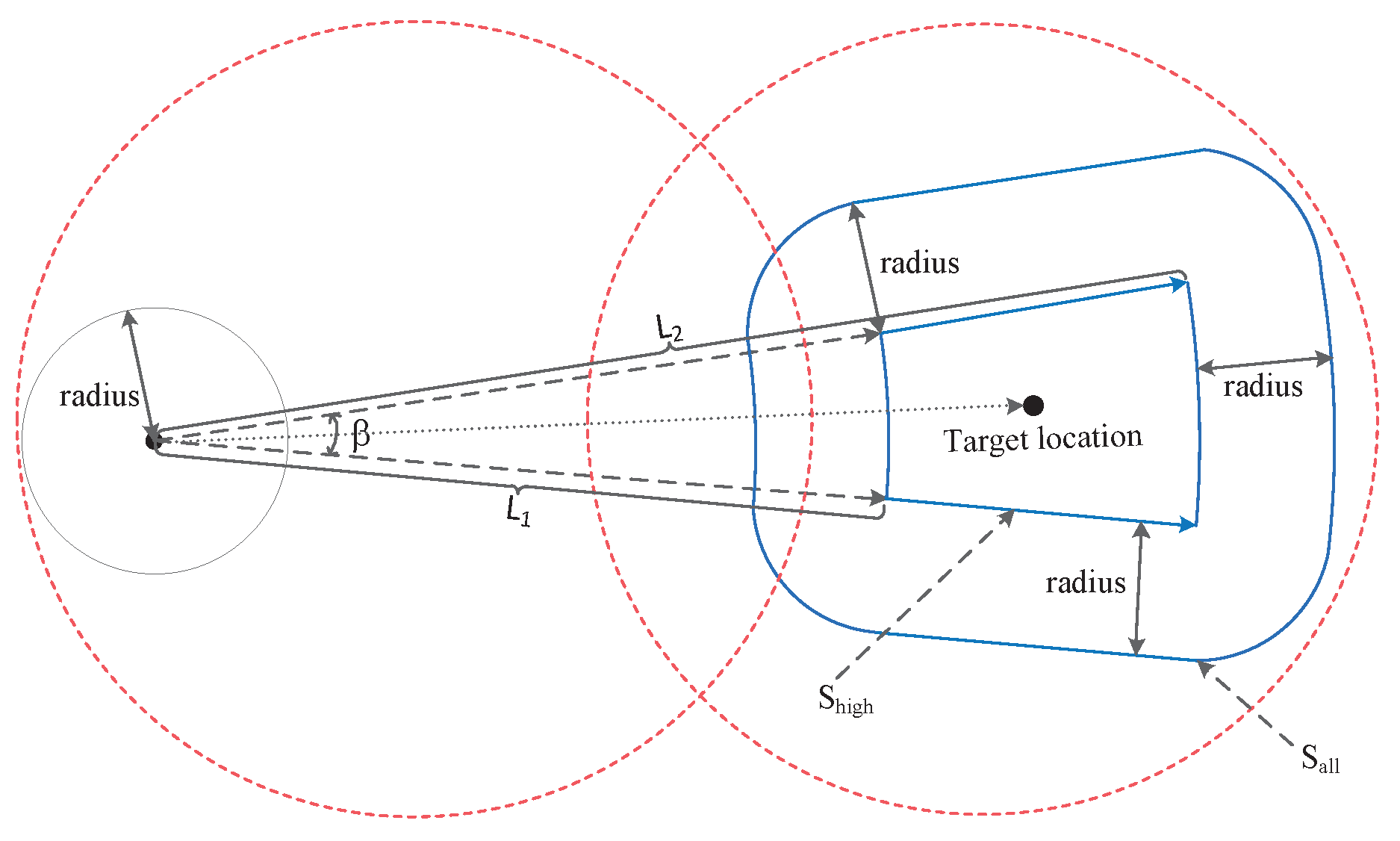
- We design a user location prediction model. It uses the existing information to determine the BS where the user is located when the service is completed. Since it is difficult to obtain all the information needed by the model in practical applications, we use frequent patterns to mine local moving track information.
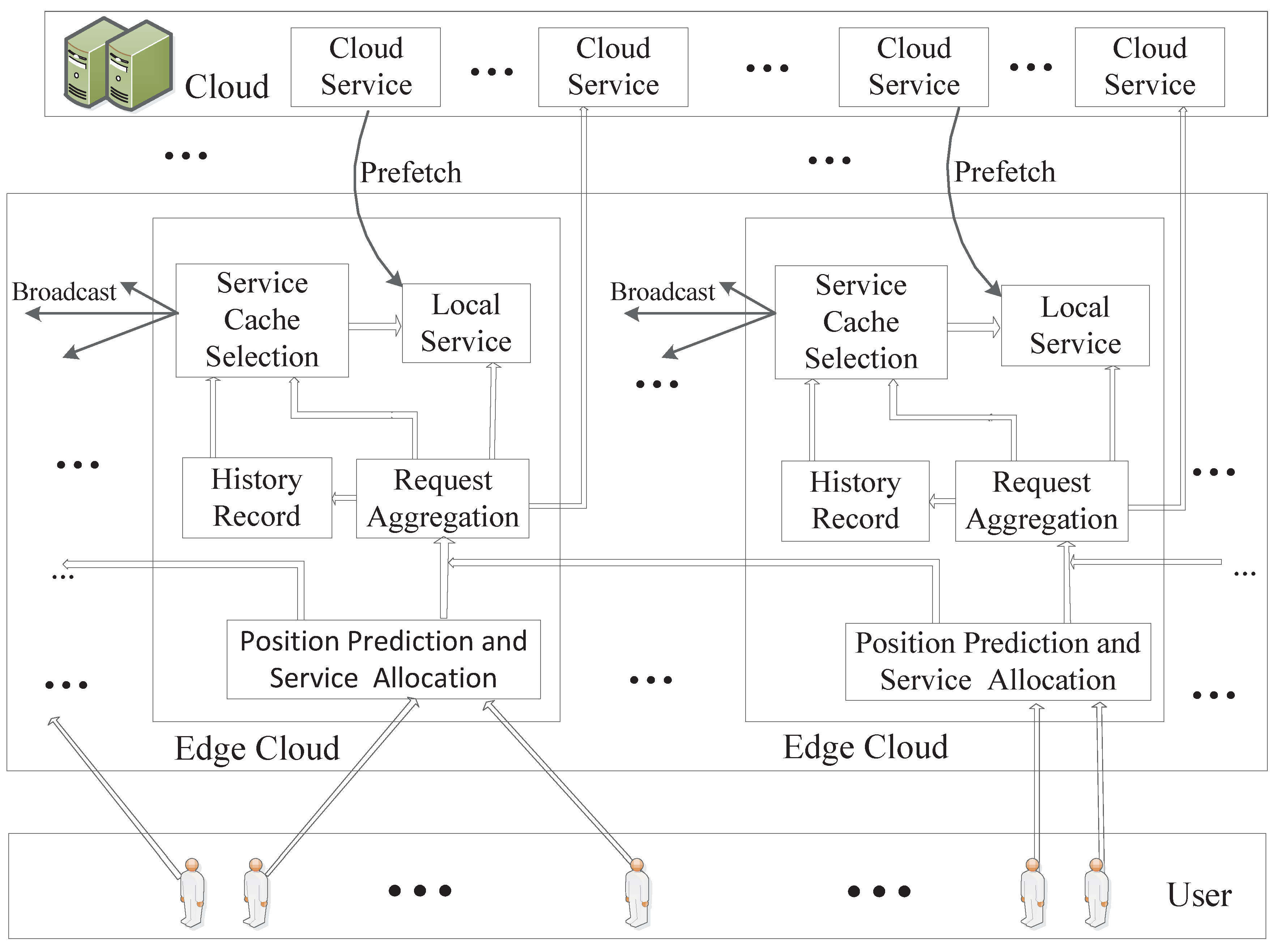
- We propose a service cache selection algorithm based on BP neural network for the edge-cloud server. It uses the historical information and existing service requests to predict the most popular services online.
2. Related Work
3. System Model
4. User Location Prediction and Service Allocation
4.1. Idealized Geometric Model
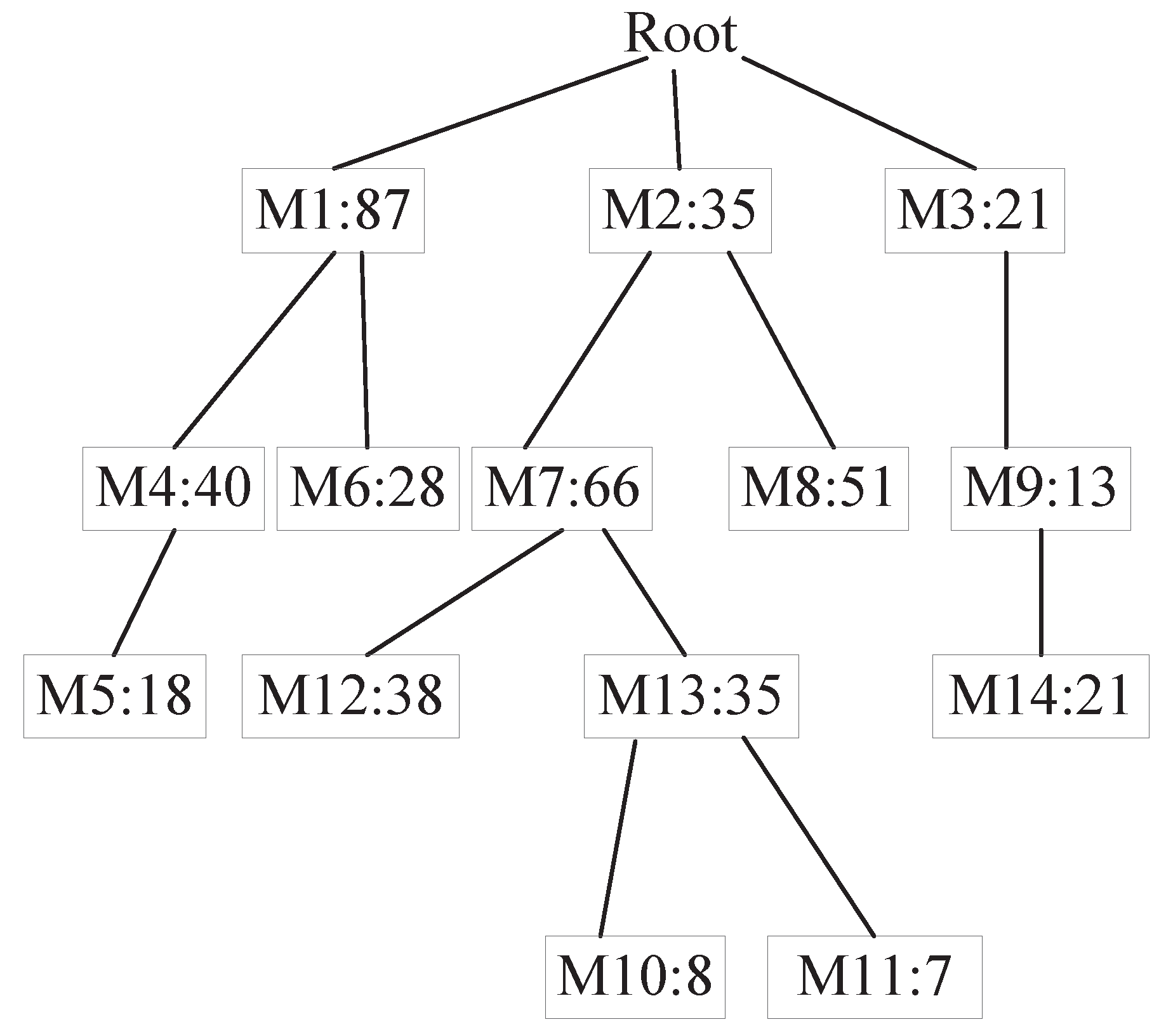
4.2. Mining Frequent Patterns
4.3. Service Allocation Algorithm
| Algorithm 1 Service Allocation Algorithm |
|
5. Service Cache Selection Algorithm
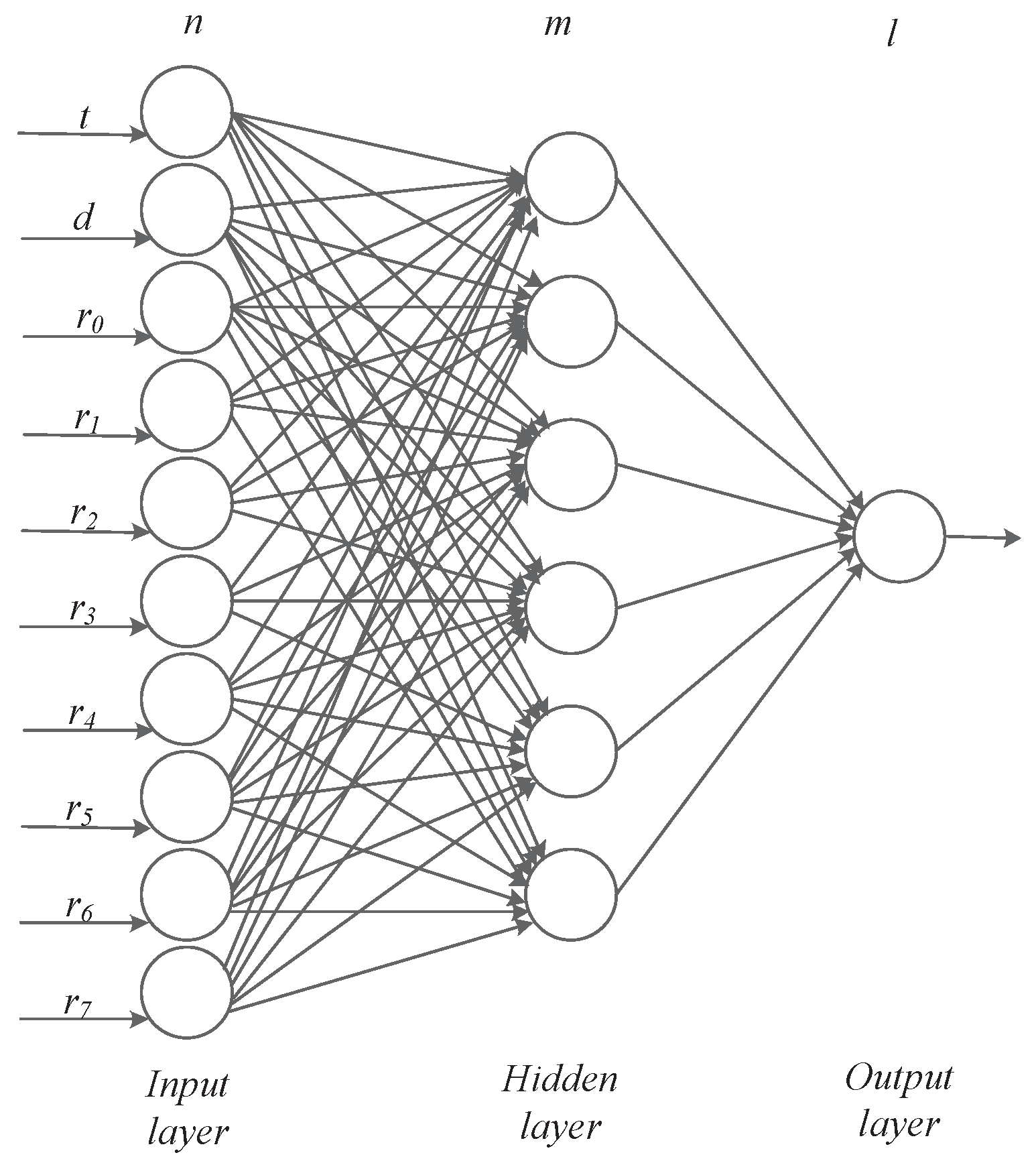
5.1. BP Neural Network Model
| Algorithm 2 BP Neural Network Training Model |
|
5.2. Service Cache Selection Algorithm
| Algorithm 3 Service Cache Selection Algorithm |
Require:, local historical data.
|
5.3. Model Performance Analysis
6. Experiment and Performance Evaluation
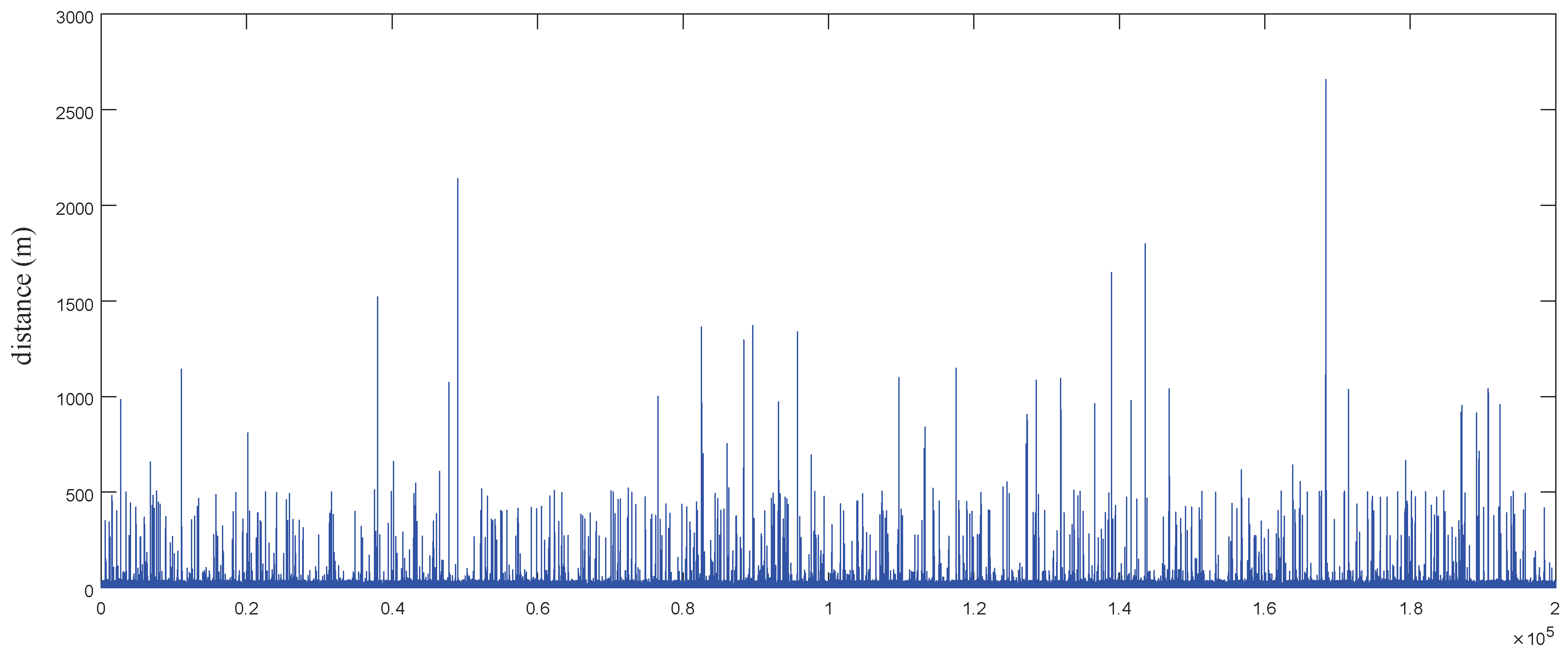
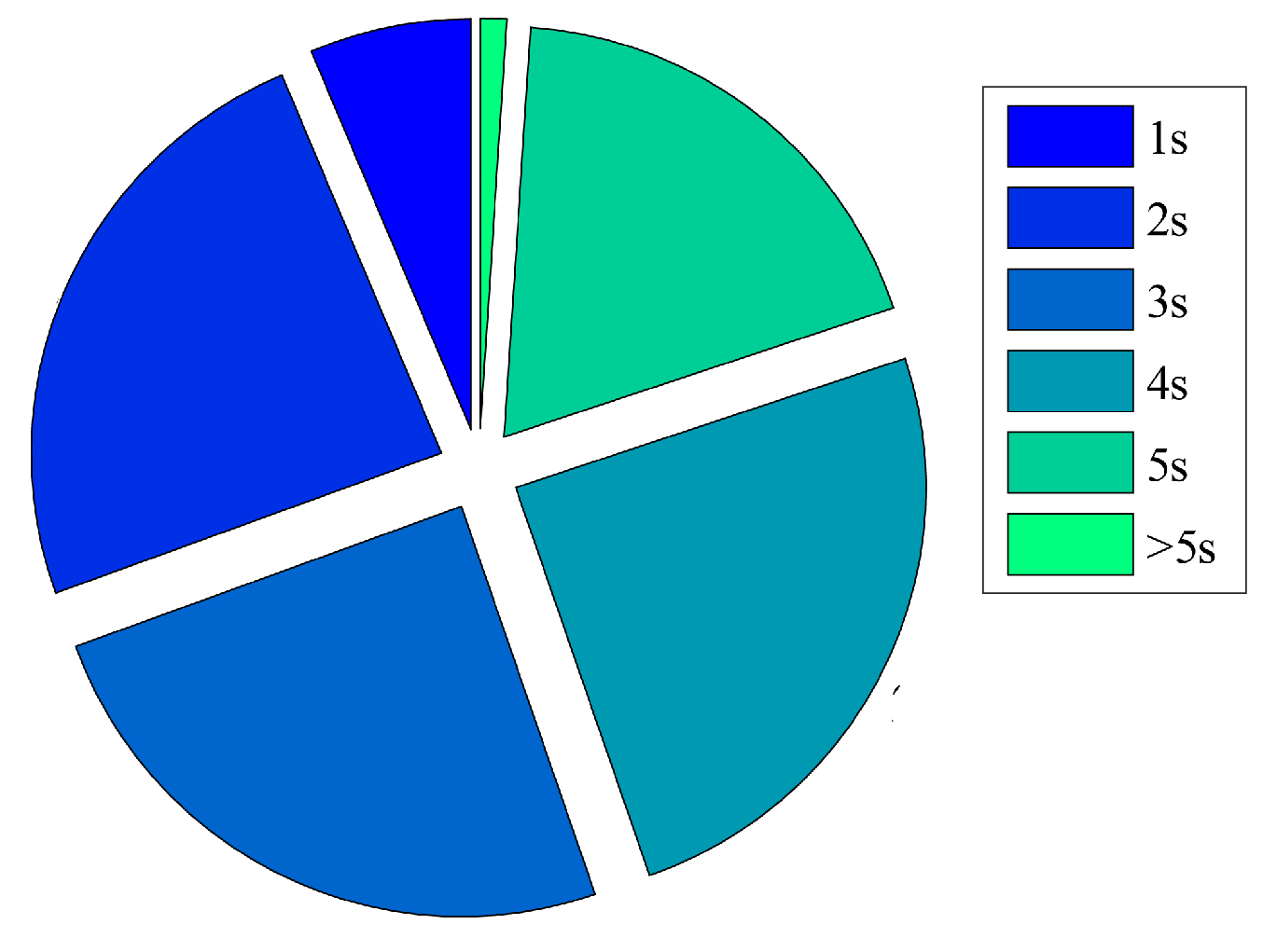
6.1. Experimental Environment
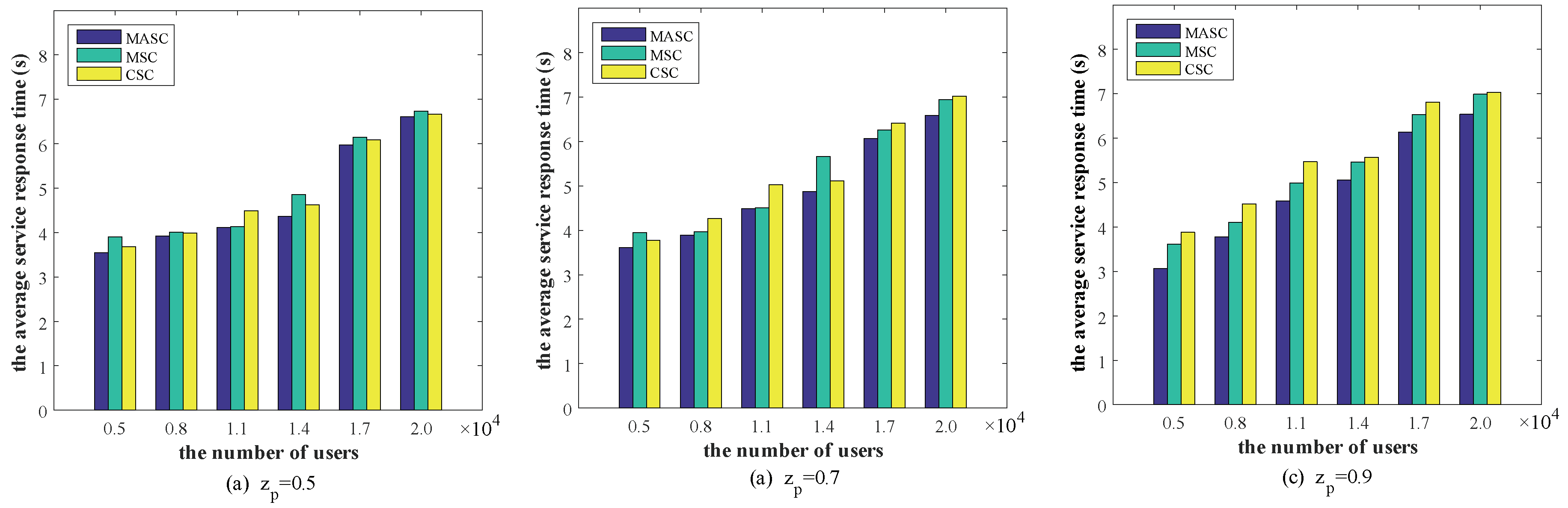
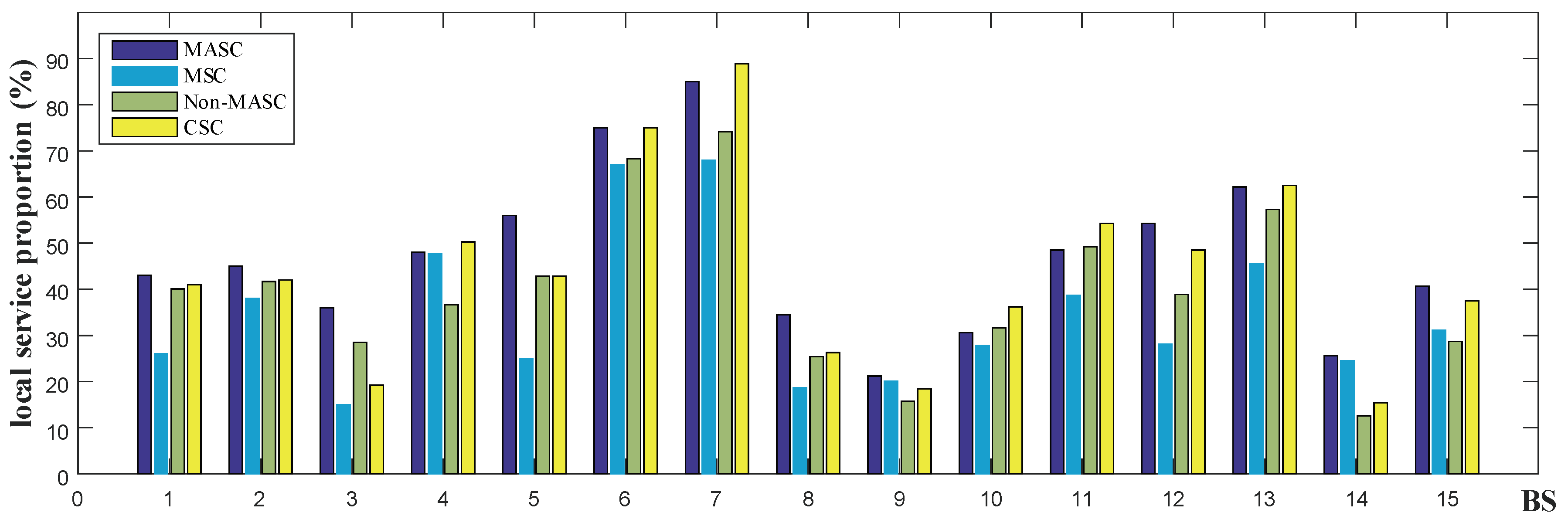
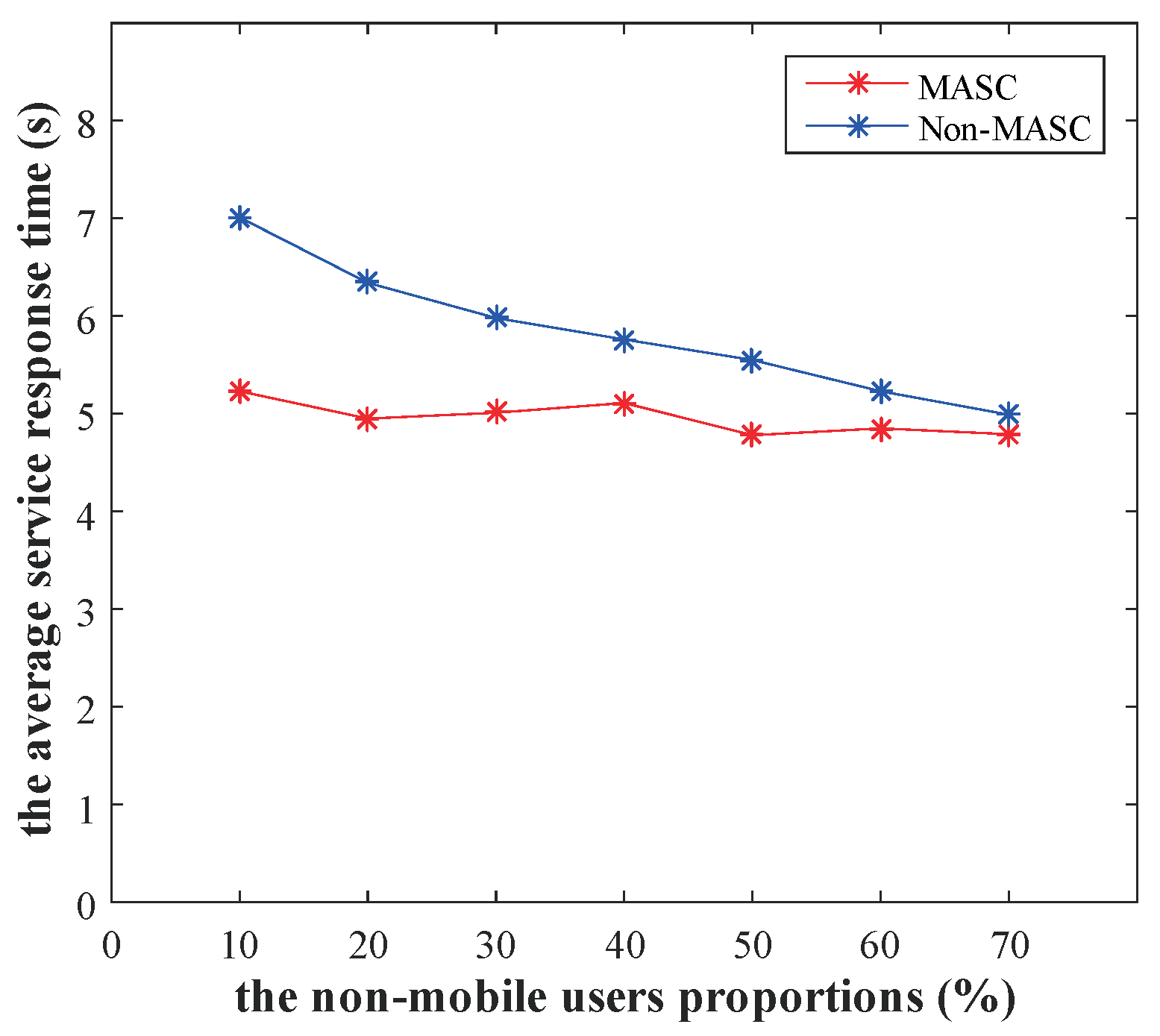
6.2. Performance Comparison
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Li, S.; Da Xu, L.; Zhao, S. 5G Internet of Things: A survey. J. Ind. Inf. Integr. 2018, 10, 1–9. [Google Scholar] [CrossRef]
- Wang, T.; Mei, Y.; Jia, W.; Zheng, X.; Wang, G.; Xie, M. Edge-based differential privacy computing for sensor–cloud systems. J. Parallel Distrib. Comput. 2020, 136, 75–85. [Google Scholar] [CrossRef]
- Xu, J.; Chen, L.; Zhou, P. Joint service caching and task offloading for mobile edge computing in dense networks. In Proceedings of the 2018 IEEE Conference on Computer Communications (INFOCOM), Honolulu, HI, USA, 16–19 April 2018; pp. 207–215. [Google Scholar]
- Patel, M.; Naughton, B.; Chan, C.; Sprecher, N.; Abeta, S.; Neal, A. Mobile-Edge Computing Introductory Technical White Paper. White Paper, Mobile-Edge Computing (MEC) Industry Initiative. 2014. Available online: https://www.scirp.org/reference/ReferencesPapers.aspx?ReferenceID=2453997 (accessed on 1 January 2020).
- Abbas, N.; Zhang, Y.; Taherkordi, A.; Skeie, T. Mobile edge computing: A survey. IEEE Internet Things J. 2017, 5, 450–465. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Bhuiyan, M.Z.A.; Wang, G.; Qi, L.; Wu, J.; Hayajneh, T. Preserving Balance between Privacy and Data Integrity in Edge-Assisted Internet of Things. IEEE Internet Things J. 2019. [Google Scholar] [CrossRef]
- Wang, T.; Luo, H.; Zheng, X.; Xie, M. Crowdsourcing mechanism for trust evaluation in cpcs based on intelligent mobile edge computing. ACM Trans. Intell. Syst. Technol. 2019, 10, 62. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Huang, H.; Wu, N.; Wang, Y.; Bhuiyan, M.Z.A.; Wang, T. An incentive-based protection and recovery strategy for secure big data in social networks. Inf. Sci. 2020, 508, 79–91. [Google Scholar] [CrossRef]
- Chen, L.; Xu, J. Collaborative service caching for edge computing in dense small cell networks. arXiv 2017, arXiv:1709.08662. [Google Scholar]
- Machen, A.; Wang, S.; Leung, K.K.; Ko, B.J.; Salonidis, T. Live service migration in mobile edge clouds. IEEE Wirel Commun. 2017, 25, 140–147. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Zhu, Q.; Zhani, M.F.; Boutaba, R.; Hellerstein, J.L. Dynamic service placement in geographically distributed clouds. IEEE J. Sel. Areas Commun. 2013, 31, 762–772. [Google Scholar] [CrossRef]
- Nan, Y.; Li, W.; Bao, W.; Delicato, F.C.; Pires, P.F.; Dou, Y.; Zomaya, A.Y. Adaptive energy-aware computation offloading for cloud of things systems. IEEE Access 2017, 5, 23947–23957. [Google Scholar] [CrossRef]
- Satyanarayanan, M.; Schuster, R.; Ebling, M.; Fettweis, G.; Flinck, H.; Joshi, K.; Sabnani, K. An open ecosystem for mobile-cloud convergence. IEEE Commun. Mag. 2015, 53, 63–70. [Google Scholar] [CrossRef]
- Taleb, T.; Ksentini, A. Follow me cloud: Interworking federated clouds and distributed mobile networks. IEEE Netw. 2013, 27, 12–19. [Google Scholar] [CrossRef]
- Hou, X.; Li, Y.; Chen, M.; Wu, D.; Jin, D.; Chen, S. Vehicular fog computing: A viewpoint of vehicles as the infrastructures. IEEE Trans. Veh. Technol. 2016, 65, 3860–3873. [Google Scholar] [CrossRef]
- Becvar, Z.; Plachy, J.; Mach, P. Path selection using handover in mobile networks with cloud-enabled small cells. In Proceedings of the 2014 IEEE 25th Annual International Symposium on Personal, Indoor, and Mobile Radio Communication (PIMRC), Washington, DC, USA, 2–5 September 2014; pp. 1480–1485. [Google Scholar]
- Wang, S. Dynamic Service Placement in Mobile Micro-Clouds. Ph.D. Thesis, Imperial College, London, UK, 2015. [Google Scholar]
- Wu, H.; Knottenbelt, W.; Wolter, K. An Efficient Application Partitioning Algorithm in Mobile Environments. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 1464–1480. [Google Scholar] [CrossRef]
- Wu, H.; Wolter, K. Stochastic analysis of delayed mobile offloading in heterogeneous networks. IEEE Trans. Mob. Comput. 2017, 17, 461–474. [Google Scholar] [CrossRef]
- Yang, L.; Cao, J.; Liang, G.; Han, X. Cost aware service placement and load dispatching in mobile cloud systems. IEEE Trans. Comput. 2015, 65, 1440–1452. [Google Scholar] [CrossRef]
- Tan, H.; Han, Z.; Li, X.Y.; Lau, F.C. Online job dispatching and scheduling in edge-clouds. In Proceedings of the 2017 IEEE Conference on Computer Communications (INFOCOM), Atlanta, GA, USA, 1–4 May 2017; pp. 1–9. [Google Scholar]
- Wu, H. Performance Modeling of Delayed Offloading in Mobile Wireless Environments With Failures. IEEE Commun. Lett. 2018, 22, 2334–2337. [Google Scholar] [CrossRef]
- Wu, H.; Sun, Y.; Wolter, K. Energy-efficient decision making for mobile cloud offloading. IEEE Trans. Cloud Comput. 2018. [Google Scholar] [CrossRef]
- Varadharajulu, P.; Saqiq, M.; Yu, F.; McMeekin, D.; West, G.; Arnold, L.; Moncrieff, S. Spatial data supply chains. Int. Arch. Photogramm. Remote Sens. Spatial Inf. Sci. 2015, 40, 41–45. [Google Scholar] [CrossRef] [Green Version]
- Corner, M.D.; Levine, B.N.; Ismail, O.; Upreti, A. Advertising-based Measurement: A Platform of 7 Billion Mobile Devices. In Proceedings of the 23rd Annual International Conference on Mobile Computing and Networking (MobiCom), Snowbird, UT, USA, 16–20 October 2017; pp. 435–447. [Google Scholar]
- Hu, P.; Dhelim, S.; Ning, H.; Qiu, T. Survey on fog computing: Architecture, key technologies, applications and open issues. J. Netw. Comput. Appl. 2017, 98, 27–42. [Google Scholar] [CrossRef]
- Rao, B.; Minakakis, L. Evolution of mobile location-based services. Commun. ACM 2003, 46, 61–65. [Google Scholar] [CrossRef]
- Beresford, A.R.; Stajano, F. Location privacy in pervasive computing. IEEE Pervasive Comput. 2003, 1, 46–55. [Google Scholar] [CrossRef] [Green Version]
- Cai, C.; Gao, Y.; Pan, L.; Zhu, J. Precise point positioning with quad-constellations: GPS, BeiDou, GLONASS and Galileo. Adv. Space Res. 2015, 56, 133–143. [Google Scholar] [CrossRef]
- Monreale, A.; Pinelli, F.; Trasarti, R.; Giannotti, F. Wherenext: A location predictor on trajectory pattern mining. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), Paris, France, 28 June–1 July 2009; pp. 637–646. [Google Scholar]
- Han, J.; Pei, J.; Yin, Y. Mining frequent patterns without candidate generation. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data (SIGMOD), Dallas, TX, USA, 15–18 May 2000; pp. 1–12. [Google Scholar]
- Li, H.; Wang, Y.; Zhang, D.; Zhang, M.; Chang, E.Y. Pfp: Parallel fp-growth for query recommendation. In Proceedings of the 2008 ACM conference on Recommender systems (RecSys), Lausanne, Switzerland, 23–25 October 2008; pp. 107–114. [Google Scholar]
- Jin, W.; Li, Z.J.; Wei, L.S.; Zhen, H. The improvements of BP neural network learning algorithm. In Proceedings of the 2000 5th International Conference on Signal Processing Proceedings (ICSP), Beijing, China, 21–25 August 2000; pp. 1647–1649. [Google Scholar]
- Wang, L.; Zeng, Y.; Chen, T. Back propagation neural network with adaptive differential evolution algorithm for time series forecasting. Expert Syst. Appl. 2015, 42, 855–863. [Google Scholar] [CrossRef]
- Zeng, M.; Lin, T.H.; Chen, M.; Yan, H.; Huang, J.; Wu, J.; Li, Y. Temporal-spatial mobile application usage understanding and popularity prediction for edge caching. IEEE Wirel Commun. 2018, 25, 36–42. [Google Scholar] [CrossRef]
- Hussain, A.; Aleem, M. GoCJ: Google cloud jobs dataset for distributed and cloud computing infrastructures. Data 2018, 3, 38. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Y.; Li, Q.; Chen, Y.; Xie, X.; Ma, W.Y. Understanding mobility based on GPS data. In Proceedings of the 10th International Conference on Ubiquitous Computing (UbiComp), Seoul, Korea, 21–24 September 2008; pp. 312–321. [Google Scholar]
- Zheng, Y.; Liu, L.; Wang, L.; Xie, X. Learning transportation mode from raw gps data for geographic applications on the web. In Proceedings of the 17th International Conference on World Wide Web (WWW), Beijing, China, 21–25 April 2008; pp. 247–256. [Google Scholar]
- Zheng, Y.; Chen, Y.; Li, Q.; Xie, X.; Ma, W.Y. Understanding transportation modes based on GPS data for web applications. ACM Trans. Web 2010, 4, 1. [Google Scholar] [CrossRef]
- Gramaglia, M.; Fiore, M.; Tarable, A.; Banchs, A. Preserving mobile subscriber privacy in open datasets of spatiotemporal trajectories. In Proceedings of the IEEE Conference on Computer Communications (INFOCOM), Atlanta, GA, USA, 1–4 May 2017; pp. 1–9. [Google Scholar]
- Zhang, D.; Huang, J.; Li, Y.; Zhang, F.; Xu, C.; He, T. Exploring human mobility with multi-source data at extremely large metropolitan scales. In Proceedings of the 20th Annual International Conference on Mobile Computing and Networking (MobiCom), Maui, HI, USA, 7–11 September 2014; pp. 201–212. [Google Scholar]
- Xu, F.; Li, Y.; Wang, H.; Zhang, P.; Jin, D. Understanding mobile traffic patterns of large scale cellular towers in urban environment. IEEE ACM Trans. Netw. 2017, 25, 1147–1161. [Google Scholar] [CrossRef] [Green Version]
- Che, H.; Tung, Y.; Wang, Z. Hierarchical web caching systems: Modeling, design and experimental results. IEEE J. Sel. Areas Commun. 2002, 20, 1305–1314. [Google Scholar] [CrossRef] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Position Accuracy | Timing Accuracy | Speed Accuracy |
|---|---|---|---|
| GPS | 2–10 m | 20 ns | 0.1 m/s |
| Galileo | 1–5 m | 20 ns | 0.1 m/s |
| Glonas | 10–20 m | 25 ns | 0.1 m/s |
| Beidou | 5–15 m | 50 ns | 0.2 m/s |
| Kind | Group | Iterations | MAE | RMSE |
|---|---|---|---|---|
| 3-layer BP | ||||
| 1 | 2000 | 26.51 | 29.17 | |
| 2 | 895 | 15.17 | 17.56 | |
| 3 | 1118 | 26.82 | 29.25 | |
| 4 | 1690 | 7.53 | 8.86 | |
| 5 | 2000 | 13.86 | 15.43 | |
| average | 1540.6 | 18.178 | 20.054 | |
| DNN | ||||
| 1 | 2000 | 18.92 | 24.35 | |
| 2 | 1083 | 26.57 | 34.58 | |
| 3 | 1601 | 32.1 | 43.57 | |
| 4 | 2000 | 8.98 | 11.13 | |
| 5 | 1920 | 6.52 | 8.52 | |
| average | 1720.8 | 18.618 | 24.43 | |
| RNN | ||||
| 1 | 1575 | 13.74 | 19.04 | |
| 2 | 1119 | 18.98 | 25.36 | |
| 3 | 2000 | 22.45 | 29.81 | |
| 4 | 2000 | 14.83 | 18.18 | |
| 5 | 2000 | 21.17 | 23.56 | |
| average | 1738.4 | 18.234 | 23.19 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, H.; Luo, H.; Sun, Y. Mobility-Aware Service Caching in Mobile Edge Computing for Internet of Things. Sensors 2020, 20, 610. https://doi.org/10.3390/s20030610
Wei H, Luo H, Sun Y. Mobility-Aware Service Caching in Mobile Edge Computing for Internet of Things. Sensors. 2020; 20(3):610. https://doi.org/10.3390/s20030610
Chicago/Turabian StyleWei, Hua, Hong Luo, and Yan Sun. 2020. "Mobility-Aware Service Caching in Mobile Edge Computing for Internet of Things" Sensors 20, no. 3: 610. https://doi.org/10.3390/s20030610
APA StyleWei, H., Luo, H., & Sun, Y. (2020). Mobility-Aware Service Caching in Mobile Edge Computing for Internet of Things. Sensors, 20(3), 610. https://doi.org/10.3390/s20030610