Electronic Tongue Recognition with Feature Specificity Enhancement



Abstract
:1. Introduction
- (1)
- A specificity metric scheme is presented to enhance the useful features in electrode responses in Hilbert space by exploiting a kernel function.
- (2)
- We present the scheme with both the proposed feature extraction method and KELM to obtain remarkable effects in speed and accuracy compared with other methodologies.
2. Methods
2.1. Notations
2.2. Machine Learning Model
- (1)
- Recognition results should be quickly obtained from a large number of digital pulse-like signals.
- (2)
- Feature specificity should be enhanced by eliminating the common-mode components.
- (3)
- The nonlinear relationships exhibited in sensor responses should be well exploited.
2.2.1. Feature Specificity Enhancement
| Algorithm 1. The FSE Method |
| Input: |
| The sample data matrix |
| The kernel function form , kernel parameters |
| Output: |
| The feature matrix |
| Procedure: |
| for |
| for |
| end |
| end |
| output the feature matrix |
2.2.2. Kernel Extreme Learning Machine
3. Experiments and Discussions
3.1. Datasets
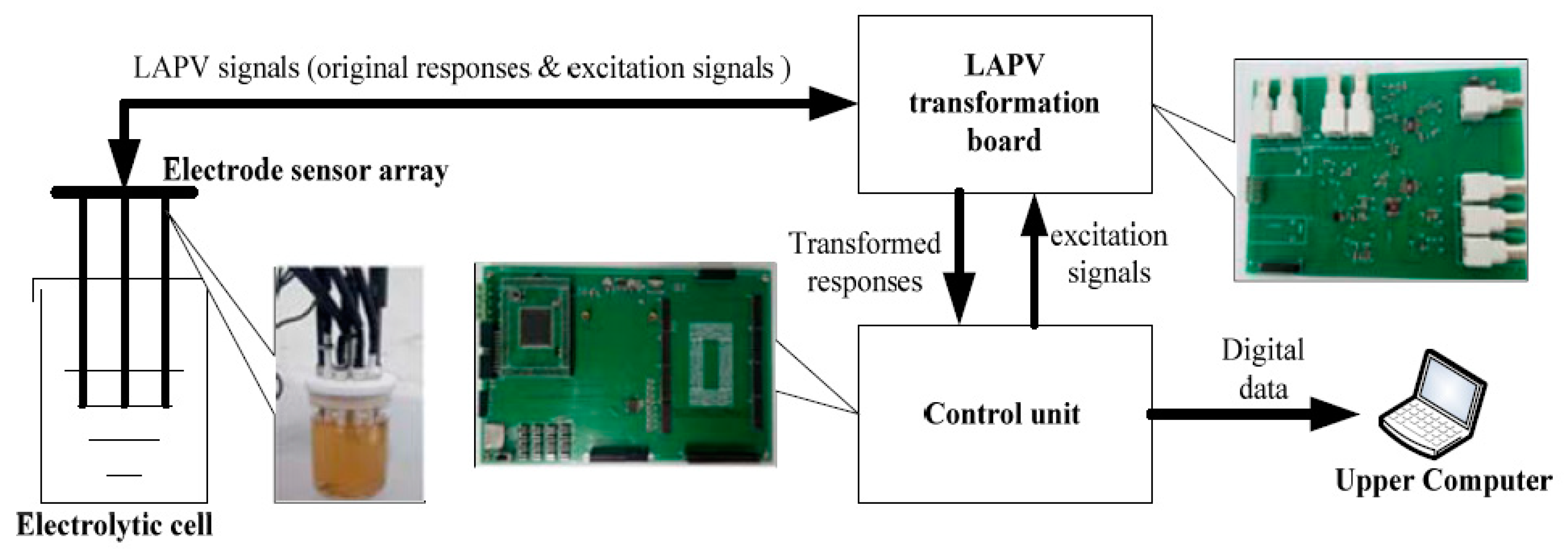
3.1.1. Our Own Dataset
3.1.2. Public Benchmark
3.2. Method Settings
3.3. Model Performance Evaluation
- (1)
- The proposed FSE method is an effective feature extraction method in E-tongue identifications. FSE based models are the winners on accuracy in all scenarios with the same classifiers.
- (2)
- The recognition rates of the KBM-based models seriously fall for the public benchmark, which indicates the importance of common-mode signal reduction. We believe FSE method enhances the feature specificity via common-mode signal counteraction.
- (3)
- As for classifiers, KELM-based machine-learning models reached the highest accuracy six times in 10 scenarios (2 datasets × 5 feature extraction methods). This means that KELM has sufficient approximation and generalization ability for E-tongue recognition.
3.4. Time and Memory Cost Comparisons
3.5. Parameter Sensitivity Analysis
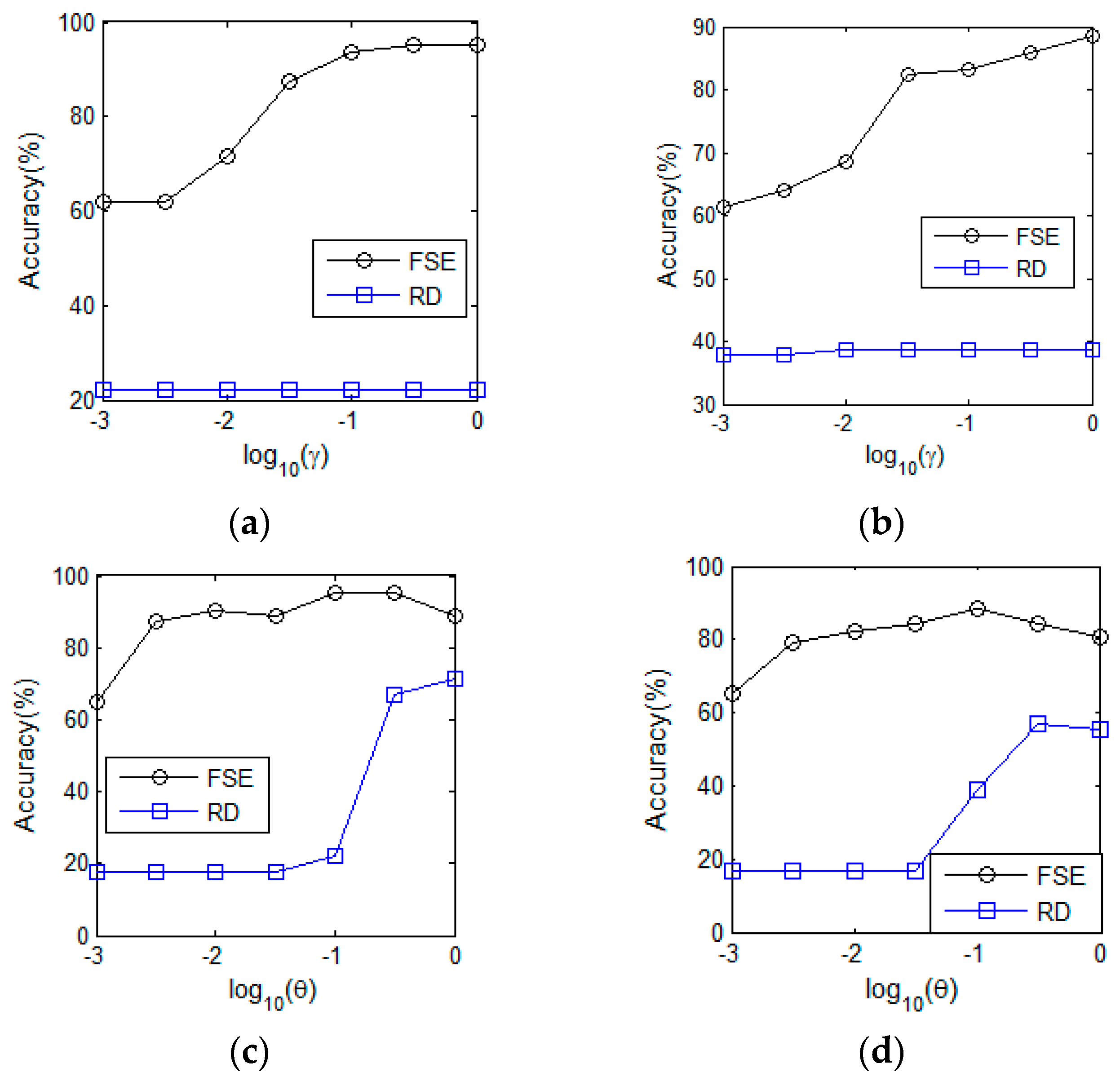
3.5.1. Analysis of FSE Parameters
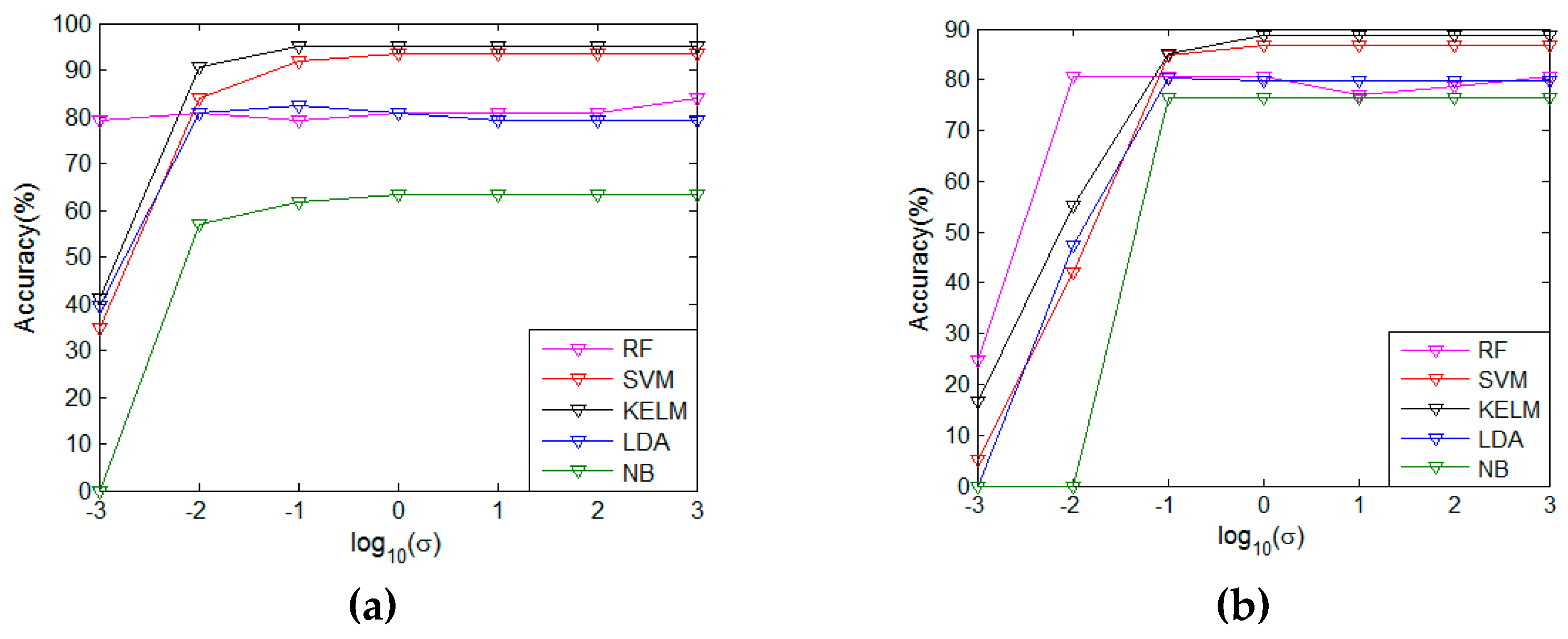
3.5.2. Analysis of KELM Parameters
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Legin, A.; Rudnitskaya, A.; Lvova, L.; Vlasov, Y.; Di Natale, C.; D’amico, A. Evaluation of Italian wine by the electronic tongue: Recognition, quantitative analysis and correlation with human sensory perception. Analytica Chimica Acta 2003, 484, 33–44. [Google Scholar] [CrossRef]
- Ghosh, A.; Bag, A.K.; Sharma, P.; Tudu, B.; Sabhapondit, S.; Baruah, B.D.; Tamuly, P.; Bhattacharyya, N.; Bandyopadhyay, R. Monitoring the Fermentation Process and Detection of Optimum Fermentation Time of Black Tea Using an Electronic Tongue. IEEE Sensors J. 2015, 15, 6255–6262. [Google Scholar] [CrossRef]
- Verrelli, G.; Lvova, L.; Paolesse, R.; Di Natale, C.; D’Amico, A. Metalloporphyrin—Based Electronic Tongue: An Application for the Analysis of Italian White Wines. Sensors 2007, 7, 2750–2762. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tahara, Y.; Toko, K. Electronic Tongues—A Review. IEEE Sensors J. 2013, 13, 3001–3011. [Google Scholar] [CrossRef]
- Krantz-Rülcker, C.; Stenberg, M.; Winquist, F.; Lundström, I. Electronic tongues for environmental monitoring based on sensor arrays and pattern recognition: a review. Anal. Chim. Acta 2001, 426, 217–226. [Google Scholar] [CrossRef]
- Kirsanov, D.; Legin, E.; Zagrebin, A.; Ignatieva, N.; Rybakin, V.; Legin, A. Mimicking Daphnia magna bioassay performance by an electronic tongue for urban water quality control. Anal. Chim. Acta 2014, 824, 64–70. [Google Scholar] [CrossRef]
- Wei, Z.; Wang, J. Tracing floral and geographical origins of honeys by potentiometric and voltammetric electronic tongue. Comput. Electron. Agric. 2014, 108, 112–122. [Google Scholar] [CrossRef]
- Wang, L.; Niu, Q.; Hui, Y.; Jin, H. Discrimination of Rice with Different Pretreatment Methods by Using a Voltammetric Electronic Tongue. Sensors 2015, 15, 17767–17785. [Google Scholar] [CrossRef] [Green Version]
- Apetrei, I.; Apetrei, C. Application of voltammetric e-tongue for the detection of ammonia and putrescine in beef products. Sensors Actuators B Chem. 2016, 234, 371–379. [Google Scholar] [CrossRef]
- Ciosek, P.; Brzozka, Z.; Wróblewski, W. Classification of beverages using a reduced sensor array. Sensors Actuators B Chem. 2004, 103, 76–83. [Google Scholar] [CrossRef]
- Domínguez, R.B.; Moreno-Barón, L.; Muñoz, R.; Gutiérrez, J.M. Voltammetric Electronic Tongue and Support Vector Machines for Identification of Selected Features in Mexican Coffee. Sensors 2014, 14, 17770–17785. [Google Scholar] [CrossRef] [PubMed]
- Rodrigues, D.R.; De Oliveira, D.S.M.; Pontes, M.J.C.; Lemos, S.G. Voltammetric e-Tongue Based on a Single Sensor and Variable Selection for the Classification of Teas. Food Anal. Methods 2018, 11, 1958–1968. [Google Scholar] [CrossRef]
- Palit, M.; Tudu, B.; Bhattacharyya, N.; Dutta, A.; Dutta, P.K.; Jana, A.; Bandyopadhyay, R.; Chatterjee, A. Comparison of multivariate preprocessing techniques as applied to electronic tongue based pattern classification for black tea. Anal. Chim. Acta 2010, 675, 8–15. [Google Scholar] [CrossRef] [PubMed]
- Cetó, X.; Apetrei, C.; Del Valle, M.; Rodríguez-Méndez, M.L.; Cetó, X. Evaluation of red wines antioxidant capacity by means of a voltammetric e-tongue with an optimized sensor array. Electrochim. Acta 2014, 120, 180–186. [Google Scholar] [CrossRef]
- Gutiérrez, M.; Llobera, A.; Ipatov, A.; Vila-Planas, J.; Mínguez, S.; Demming, S.; Büttgenbach, S.; Capdevila, F.; Domingo, C.; Jiménez-Jorquera, C. Application of an E-Tongue to the analysis of monovarietal and blends of white wines. Sensors 2011, 11, 4840–4857. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dias, L.; Peres, A.; Veloso, A.; Reis, F.S.; Vilas-Boas, M.; Machado, A. An electronic tongue taste evaluation: Identification of goat milk adulteration with bovine milk. Sensors Actuators B Chem. 2009, 136, 209–217. [Google Scholar] [CrossRef]
- Ciosek, P.; Maminska, R.; Dybko, A.; Wróblewski, W. Potentiometric electronic tongue based on integrated array of microelectrodes. Sensors Actuators B Chem. 2007, 127, 8–14. [Google Scholar] [CrossRef]
- Legin, A.; Bychkov, E.; Seleznev, B.; Vlasov, Y. Development and analytical evaluation of a multisensor system for water quality monitoring. Sensors Actuators B Chem. 1995, 27, 377–379. [Google Scholar] [CrossRef]
- Erenas, M.M.; Pegalajar, M.; Cuéllar, M.; De Orbe-Payá, I.; Capitán-Vallvey, L. Disposable optical tongue for alkaline ion analysis. Sensors Actuators B Chem. 2011, 156, 976–982. [Google Scholar] [CrossRef]
- Ariza-Avidad, M.; Cuéllar, M.; Salinas-Castillo, A.; Pegalajar, M.; Vuković, J.; Capitán-Vallvey, L. Feasibility of the use of disposable optical tongue based on neural networks for heavy metal identification and determination. Anal. Chim. Acta 2013, 783, 56–64. [Google Scholar] [CrossRef]
- Ivarsson, P.; Holmin, S.; Höjer, N.-E.; Krantz-Rülcker, C.; Winquist, F. Discrimination of tea by means of a voltammetric electronic tongue and different applied waveforms. Sensors Actuators B Chem. 2001, 76, 449–454. [Google Scholar] [CrossRef]
- Gutés, A.; Ibanez, A.B.; Del Valle, M.; Cespedes, F. Automated SIA E-tongue Employing a Voltammetric Biosensor Array for the Simultaneous Determination of Glucose and Ascorbic Acid. Electroanalysis 2010, 18, 82–88. [Google Scholar] [CrossRef]
- Lvova, L.; Martinelli, E.; Dini, F.; Bergamini, A.; Paolesse, R.; Di Natale, C.; Damico, A. Clinical analysis of human urine by means of potentiometric Electronic tongue. Talanta 2009, 77, 1097–1104. [Google Scholar] [CrossRef] [PubMed]
- Erenas, M.M.; Piñeiro, O.; Pegalajar, M.; Cuellar, M.; De Orbe-Payá, I.; Capitán-Vallvey, L. A surface fit approach with a disposable optical tongue for alkaline ion analysis. Anal. Chim. Acta 2011, 694, 128–135. [Google Scholar] [CrossRef] [PubMed]
- Ciosek, P.; Wróblewski, W. Sensor arrays for liquid sensing—Electronic tongue systems. Analyst 2007, 132, 963. [Google Scholar] [CrossRef] [PubMed]
- Winquist, F.; Wide, P.; Lundström, I. An electronic tongue based on voltammetry. Anal. Chim. Acta 1997, 357, 21–31. [Google Scholar] [CrossRef]
- Lu, L.; Hu, X.; Tian, S.; Deng, S.; Zhu, Z. Visualized attribute analysis approach for characterization and quantification of rice taste flavor using electronic tongue. Anal. Chim. Acta 2016, 919, 11–19. [Google Scholar] [CrossRef]
- Tian, S.-Y.; Deng, S.-P.; Chen, Z.-X. Multifrequency large amplitude pulse voltammetry: A novel electrochemical method for electronic tongue. Sensors Actuators B Chem. 2007, 123, 1049–1056. [Google Scholar] [CrossRef]
- Ghosh, A.; Sharma, P.; Tudu, B.; Sabhapondit, S.; Baruah, B.D.; Tamuly, P.; Bhattacharyya, N.; Bandyopadhyay, R. Detection of Optimum Fermentation Time of Black CTC Tea Using a Voltammetric Electronic Tongue. IEEE Trans. Instrum. Meas. 2015, 64, 2720–2729. [Google Scholar] [CrossRef]
- Palit, M.; Tudu, B.; Dutta, P.K.; Dutta, A.; Jana, A.; Roy, J.K.; Bhattacharyya, N.; Bandyopadhyay, R.; Chatterjee, A. Classification of black tea taste and correlation with tea taster’s mark using voltammetric electronic tongue. IEEE Trans. Instrum. Meas. 2010, 59, 2230–2239. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Machine Learning 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Huang, G.-B.; Zhu, Q.-Y.; Siew, C.-K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, X.; Huang, G.-B.; Liu, T.; Tan, X. Taste Recognition in E-Tongue Using Local Discriminant Preservation Projection. IEEE Trans. Cybern. 2018, 49, 947–960. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2012, 42, 513–529. [Google Scholar] [CrossRef] [Green Version]
- Liu, T.; Chen, Y.; Li, D.; Wu, M. An Active Feature Selection Strategy for DWT in Artificial Taste. J. Sensors 2018, 2018, 9709505. [Google Scholar] [CrossRef] [Green Version]
- Tian, S.; Xiao, X.; Deng, S. Sinusoidal envelope voltammetry as a new readout technique for electronic tongues. Microchim. Acta 2012, 178, 315–321. [Google Scholar] [CrossRef]
- Adhikari, B.; Mahato, M.; Sinha, T.; Halder, A.; Bhattacharya, N.; Sinha, T.; Halder, A. Development of novel polymeric sensors for taste sensing: Electronic tongue. In Proceedings of the SENSORS, 2013 IEEE, Baltimore, MD, USA, 3–6 November 2013; pp. 1–4. [Google Scholar] [CrossRef]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Machine Learning 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Li, T.; Zhu, S.; Ogihara, M. Using discriminant analysis for multi-class classification: an experimental investigation. Knowl. Inf. Syst. 2006, 10, 453–472. [Google Scholar] [CrossRef]
- Friedman, N.; Geiger, D.; Goldszmidt, M. Bayesian Network Classifiers. Mach. Learn. 1997, 29, 131–163. [Google Scholar] [CrossRef] [Green Version]
- Kearns, M.; Ron, D. Algorithmic Stability and Sanity-Check Bounds for Leave-One-Out Cross-Validation. Neural Comput. 1999, 11, 1427–1453. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | Feature Extraction Methods | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| RD | PCA | DWT | KBM | FSE | |||||||
| Acc. | STD | Acc. | STD | Acc. | STD | Acc. | STD | Acc. | STD | ||
| Our own dataset | RF | 74.60 | 17.82 | 61.90 | 17.53 | 77.78 | 7.10 | 71.43 | 15.06 | 80.95 | 13.47 |
| LDA | - | - | 46.03 | 16.19 | 53.97 | 16.19 | 60.32 | 17.53 | 79.37 | 7.10 | |
| NB | - | - | 46.03 | 17.53 | 55.56 | 14.20 | 68.25 | 16.19 | 63.49 | 15.22 | |
| SVM | 34.92 | 11.88 | 80.95 | 15.06 | 66.67 | 16.50 | 71.43 | 17.82 | 93.65 | 7.10 | |
| KELM | 22.22 | 9.78 | 69.84 | 21.76 | 93.65 | 9.78 | 68.25 | 22.11 | 95.24 | 6.73 | |
| Public benchmark | RF | 71.59 | 6.85 | 70.32 | 7.91 | 75.38 | 5.28 | 18.27 | 6.07 | 79.63 | 6.07 |
| LDA | - | - | 61.63 | 10.26 | 63.89 | 5.61 | 24.53 | 3.89 | 79.80 | 11.90 | |
| NB | 59.28 | 12.11 | 63.38 | 9.19 | 66.70 | 3.17 | 24.38 | 8.25 | 76.34 | 8.04 | |
| SVM | 16.76 | 2.14 | 60.66 | 5.62 | 69.36 | 3.85 | 24.53 | 3.89 | 86.73 | 4.00 | |
| KELM | 50.93 | 3.61 | 72.67 | 11.31 | 78.76 | 4.40 | 29.88 | 3.06 | 88.65 | 4.36 | |
| Classifier | Feature Extraction Methods | |||||
|---|---|---|---|---|---|---|
| RD | PCA | DWT | KBM | FSE | ||
| Our Own Dataset | RF | 164.74 s | 37.80 s | 52.01 s | 4.32 s | 4.18s |
| LDA | - | 39.61 s | 53.71 s | 1.03 s | 1.65 s | |
| NB | - | 38.31 s | 50.84 s | 0.45 s | 0.53 s | |
| SVM | 10.64 s | 33.31 s | 47.92 s | 0.30 s | 0.45 s | |
| KELM | 6.40 s | 37.50 s | 53.77 s | 0.27 s | 0.31 s | |
| Public Benchmark | RF | 25.08 s | 11.19 s | 97.98 s | 2.26 s | 2.62 s |
| LDA | - | 9.16 s | 91.28 s | 0.78 s | 1.67 s | |
| NB | 3.34 s | 8.77 s | 90.62 s | 0.25 s | 0.33 s | |
| SVM | 2.56 s | 8.33 s | 89.45 s | 0.11 s | 0.17 s | |
| KELM | 0.95 s | 7.89 s | 90.32 s | 0.09 s | 0.16 s | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, T.; Chen, Y.; Li, D.; Yang, T.; Cao, J. Electronic Tongue Recognition with Feature Specificity Enhancement. Sensors 2020, 20, 772. https://doi.org/10.3390/s20030772
Liu T, Chen Y, Li D, Yang T, Cao J. Electronic Tongue Recognition with Feature Specificity Enhancement. Sensors. 2020; 20(3):772. https://doi.org/10.3390/s20030772
Chicago/Turabian StyleLiu, Tao, Yanbing Chen, Dongqi Li, Tao Yang, and Jianhua Cao. 2020. "Electronic Tongue Recognition with Feature Specificity Enhancement" Sensors 20, no. 3: 772. https://doi.org/10.3390/s20030772
APA StyleLiu, T., Chen, Y., Li, D., Yang, T., & Cao, J. (2020). Electronic Tongue Recognition with Feature Specificity Enhancement. Sensors, 20(3), 772. https://doi.org/10.3390/s20030772