A Survey on Hand Pose Estimation with Wearable Sensors and Computer-Vision-Based Methods

Abstract
:1. Introduction
- Existing surveys focus either on glove-based devices [10,11] or vision-based [12,13,14] systems, since these works were carried out in two distinct research communities, i.e., human–computer interaction and computer vision. We covered both directions to provide a complete overview of the state-of-the-art for hand pose estimation, which can be particularly helpful for people making applications with hand pose estimation technology.
- With the boost of data-driven machine learning methods, a large number of new solutions have been proposed recently, especially in the last three years. It is now urgent to provide a comprehensive review of current progress to help researchers that are interested in this field to obtain a quick overview of existing solutions and unsolved challenges.
2. Problem Formulation
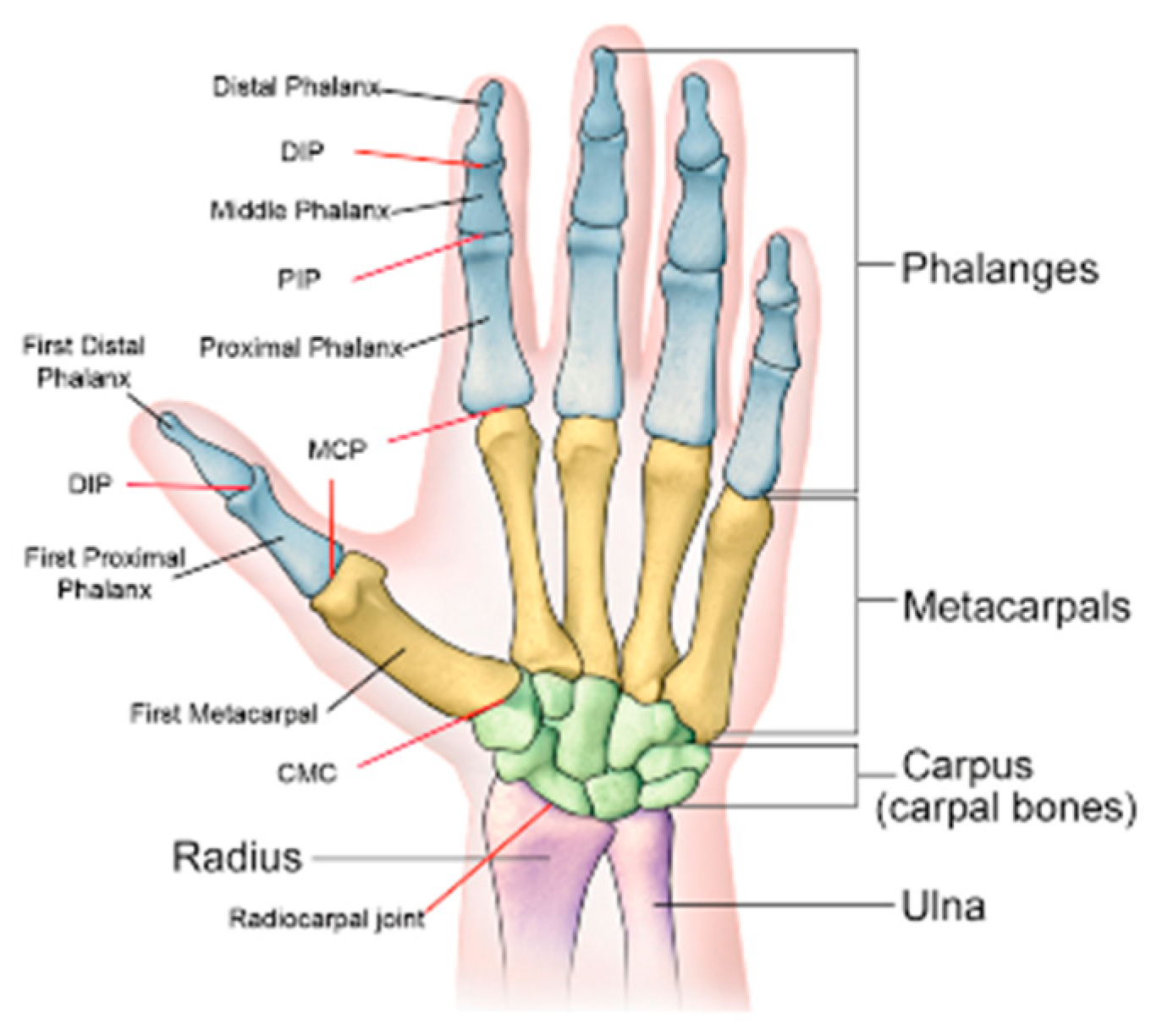
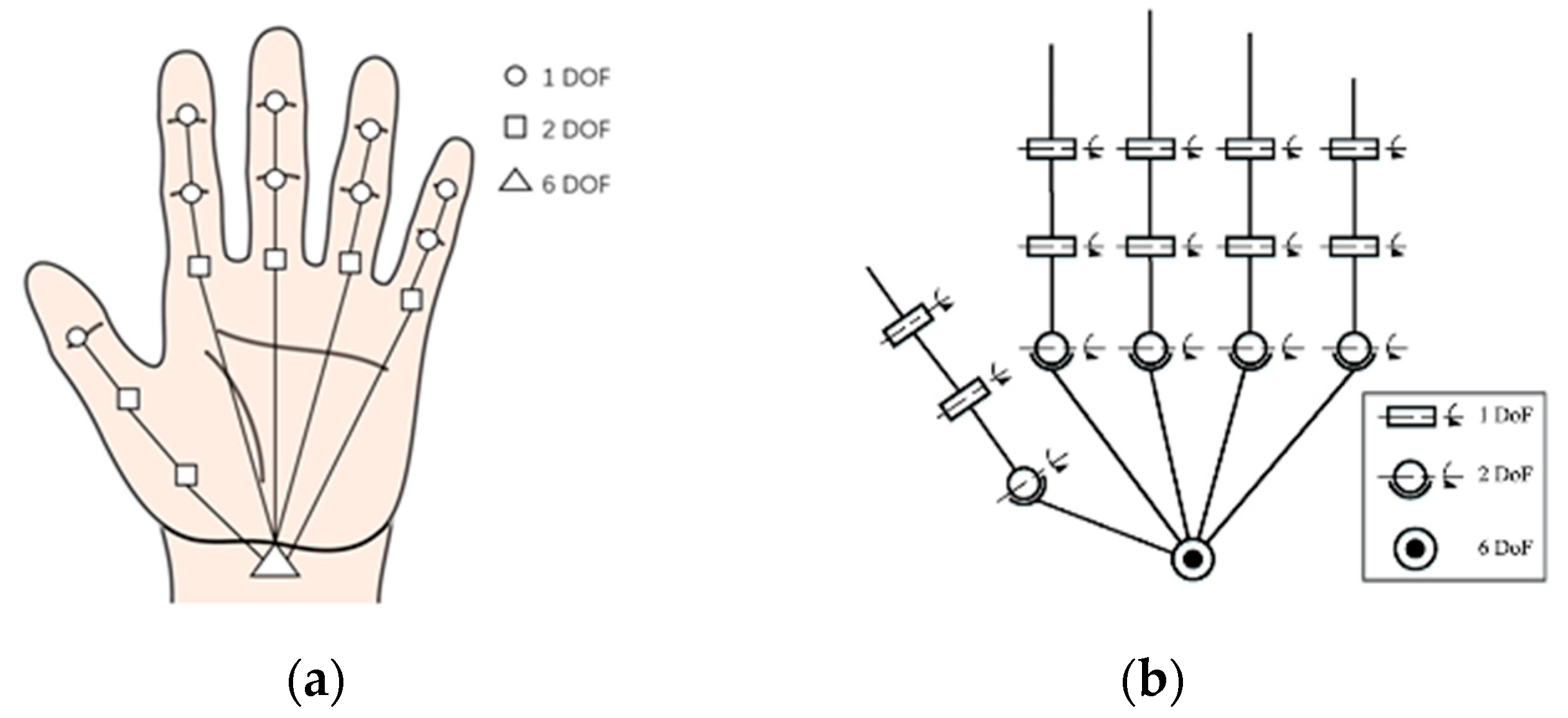
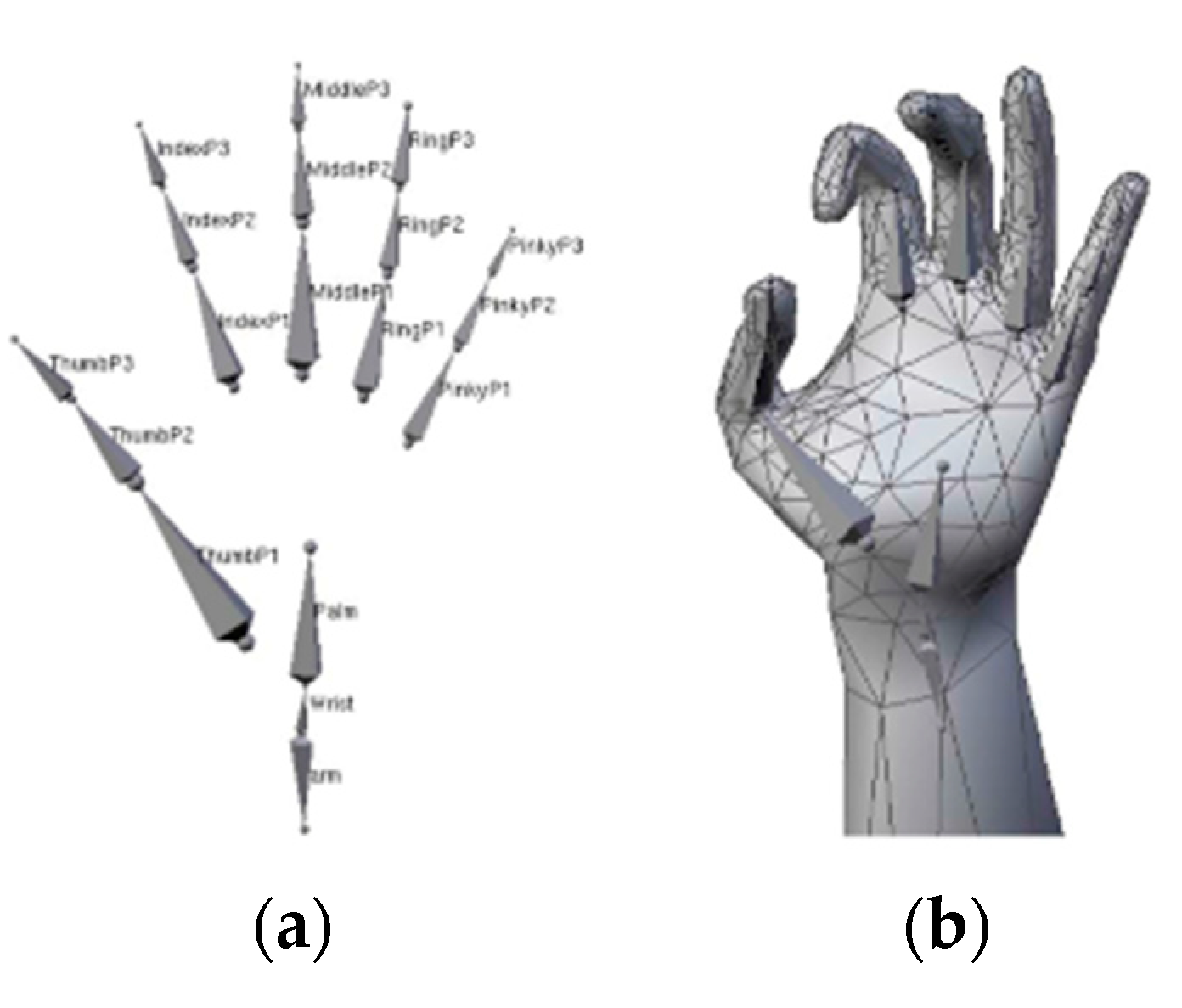
2.1. Hand Structure
- -
- Carpometacarpal (CMC): joints connecting the metacarpal bones to the wrist;
- -
- Metacarpophalangeal (MCP): joints between the fingers and the palm;
- -
- Interphalangeal (IP): joints between finger segments. They can be further distinguished as distal interphalangeal (DIP) and proximal interphalangeal (PIP);
2.2. Sensor Taxonomy
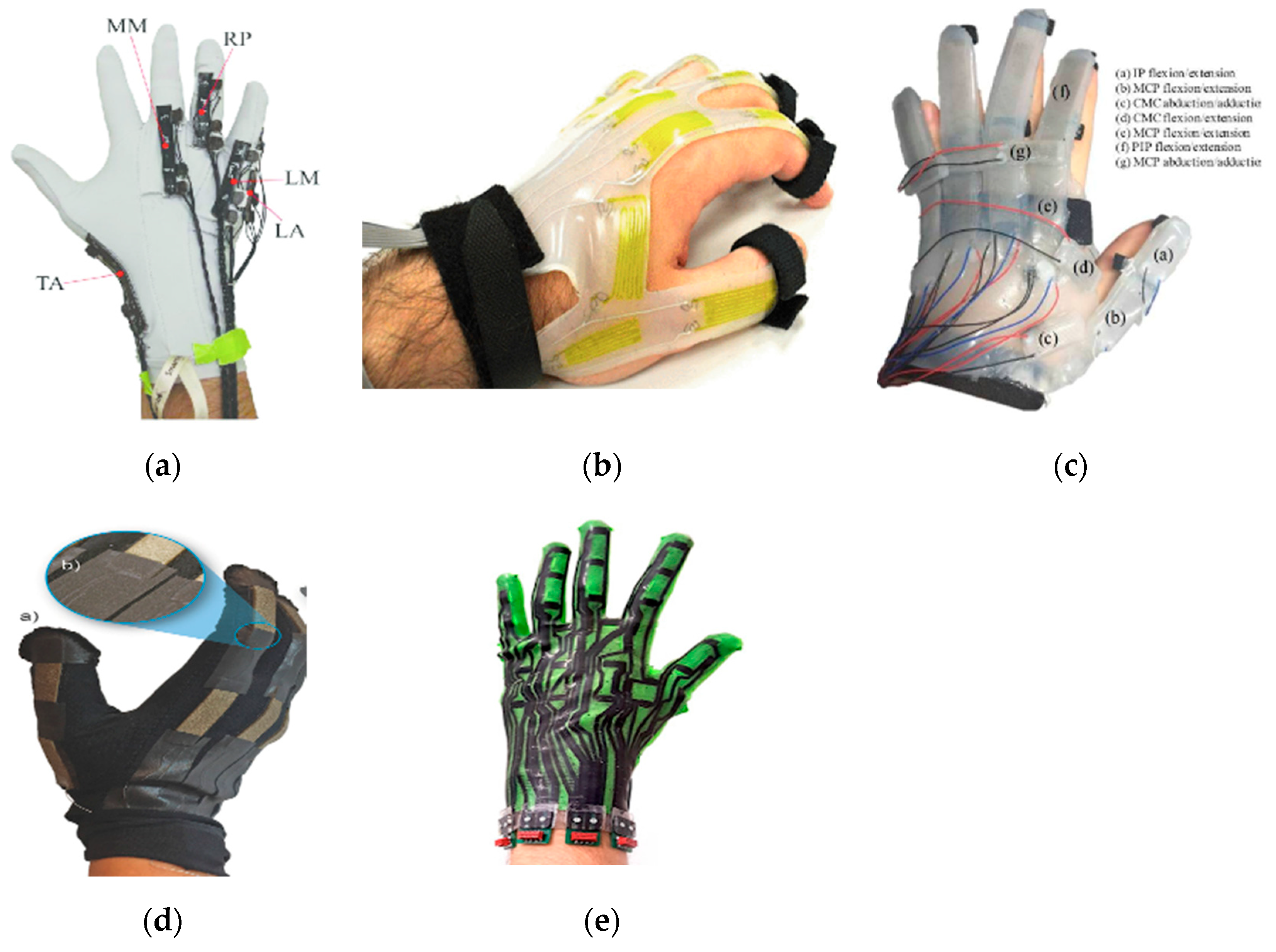
3. Wearable Devices
3.1. Bend (Flex) Sensors
3.2. Stretch (Strain) Sensors
3.3. Other Types of Sensors
3.4. Evaluations
4. Computer-Vision-Based Methods
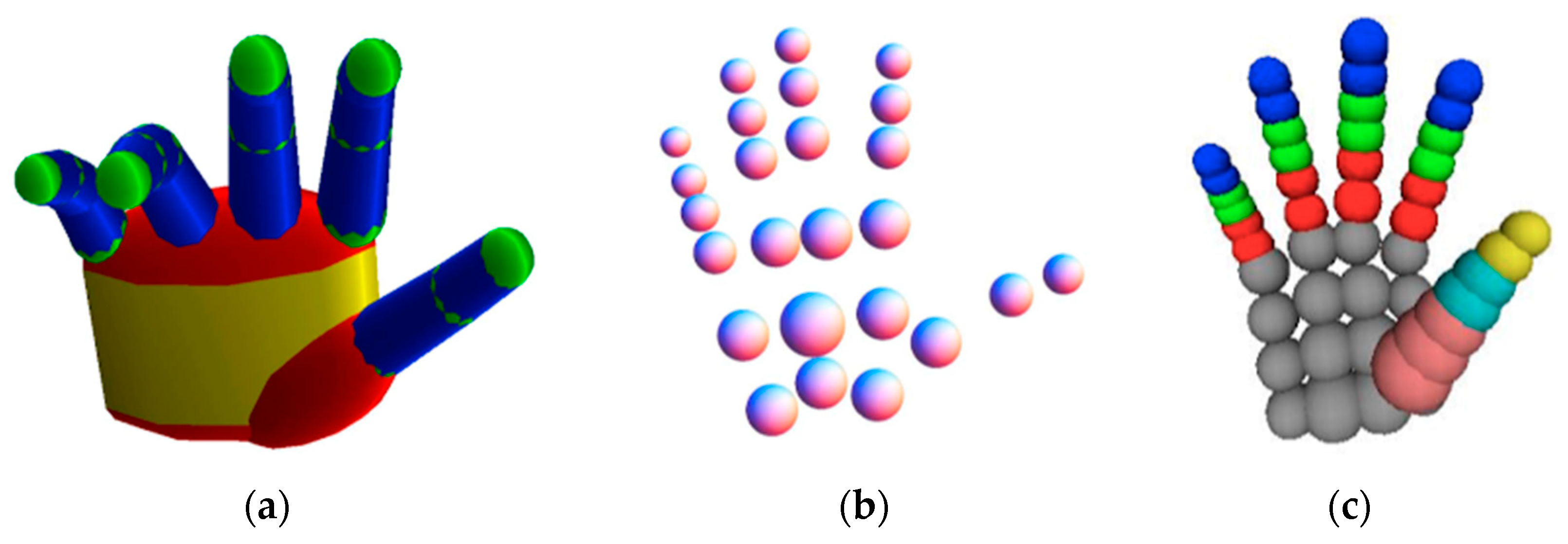
4.1. Generative Methods
4.1.1. Generalized Cylindrical Model
4.1.2. Deformable Polygonal Mesh Model
4.2. Discriminative Methods
4.2.1. Random Forest
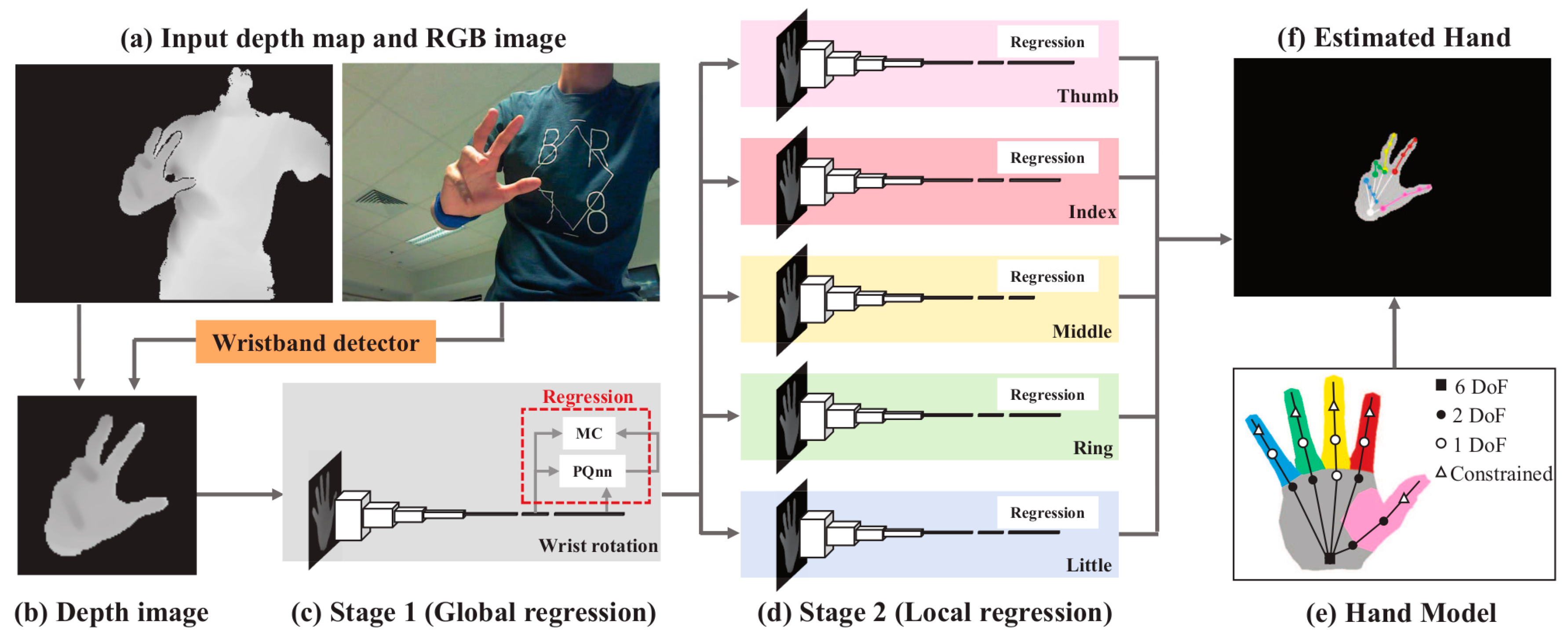
4.2.2. Convolution Neural Networks
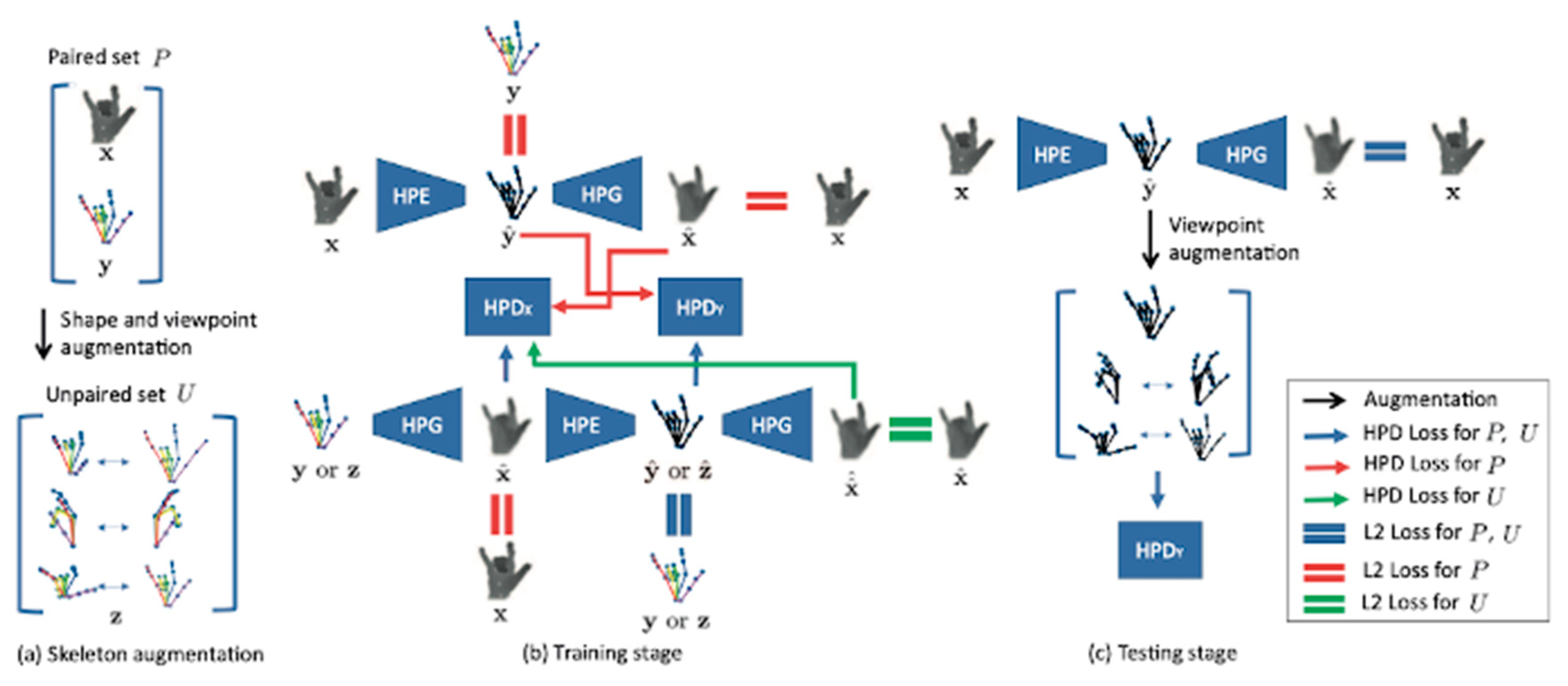
4.3. Hybrid Methods
4.4. Public Datasets
5. Challenges and Future Work
5.1. Challenges
5.2. Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Bolt, R.A. “Put-That-There”: Voice and Gesture at the Graphics Interface. SIGGRAPH Comput. Graph. 1980, 14, 262–270. [Google Scholar] [CrossRef]
- Rautaray, S.S.; Agrawal, A. Vision based hand gesture recognition for human computer interaction: A survey. Artif. Intell. Rev. 2015, 43, 1–54. [Google Scholar] [CrossRef]
- Zhao, X.; Zhao, J.; Fan, B.; Hao, L. Survey on Hand Gesture Recognition and its Application Prospect. In Proceedings of the 11th National Conference on Signal and Intelligent Information Processing and Application, Guizhou, China, 26 October 2017. [Google Scholar]
- Al-Shamayleh, A.S.; Ahmad, R.; Abushariah, M.A.; Alam, K.A.; Jomhari, N. A systematic literature review on vision based gesture recognition techniques. Multimed. Tools Appl. 2018, 77, 28121–28184. [Google Scholar] [CrossRef]
- Cheok, M.J.; Omar, Z.; Jaward, M.H. A review of hand gesture and sign language recognition techniques. Int. J. Mach. Learn. Cybern. 2019, 10, 131–153. [Google Scholar] [CrossRef]
- Park, J.; Jin, Y.; Cho, S.; Sung, Y.; Cho, K. Advanced machine learning for gesture learning and recognition based on intelligent big data of heterogeneous sensors. Symmetry 2019, 11, 929. [Google Scholar] [CrossRef] [Green Version]
- Hololens 2 From Microsoft. Available online: https://www.microsoft.com/en-us/hololens/ (accessed on 2 February 2020).
- Kinect V2, Microsoft. Available online: http://www.k4w.cn/ (accessed on 2 February 2020).
- Realsense Cameras, Intel. Available online: https://www.intel.com/content/www/us/en/architecture-and-technology/realsense-overview.html (accessed on 2 February 2020).
- Dipietro, L.; Sabatini, A.M.; Dario, P. A survey of glove-based systems and their applications. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2008, 38, 461–482. [Google Scholar] [CrossRef]
- Rashid, A.; Hasan, O. Wearable technologies for hand joints monitoring for rehabilitation: A survey. Microelectron. J. 2019, 88, 173–183. [Google Scholar] [CrossRef]
- Erol, A.; Bebis, G.; Nicolescu, M.; Boyle, R.D.; Twombly, X. Vision-based hand pose estimation: A review. Comput. Vis. Image Underst. 2007, 108, 52–73. [Google Scholar] [CrossRef]
- Supancic, J.S.; Rogez, G.; Yang, Y.; Shotton, J.; Ramanan, D. Depth-Based Hand Pose Estimation: Data, Methods, and Challenges. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015. [Google Scholar]
- Li, R.; Liu, Z.; Tan, J. A survey on 3D hand pose estimation: Cameras, methods, and datasets. Pattern Recognit. 2019, 93, 251–272. [Google Scholar] [CrossRef]
- Lee, J.; Kunii, T.L. Constraint-based hand animation. In Models and Techniques in Computer Animation; Springer: Tokyo, Japan, 1993. [Google Scholar]
- Pernkopf, E. Pernkopf Anatomy: Thorax, Abdomen, and Extremities; Urban & Schwarzenberg: München, Germany, 1989. [Google Scholar]
- Wheatland, N.; Wang, Y.; Song, H.; Neff, M.; Zordan, V.; Jörg, S. State of the art in hand and finger modeling and animation. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2015. [Google Scholar]
- Xu, C.; Cheng, L. Efficient Hand Pose Estimation from a Single Depth Image. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Qian, C.; Sun, X.; Wei, Y.; Tang, X.; Sun, J. Realtime and Robust Hand Tracking from Depth. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Sinha, A.; Choi, C.; Ramani, K. Deephand: Robust Hand Pose Estimation by Completing a Matrix Imputed with Deep Features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- McDonald, J.; Toro, J.; Alkoby, K.; Berthiaume, A.; Carter, R.; Chomwong, P.; Christopher, J.; Davidson, M.J.; Furst, J.; Konie, B. An improved articulated model of the human hand. Vis. Comput. 2001, 17, 158–166. [Google Scholar] [CrossRef] [Green Version]
- Andrews, S.; Kry, P.G. Goal directed multi-finger manipulation: Control policies and analysis. Comput. Graph. 2013, 37, 830–839. [Google Scholar] [CrossRef] [Green Version]
- Sudderth, E.B.; Mandel, M.I.; Freeman, W.T.; Willsky, A.S. Visual Hand Tracking using Nonparametric Belief Propagation. In Proceedings of the 2004 Conference on Computer Vision and Pattern Recognition Workshop, Washington, DC, USA, 27 June–2 July 2004. [Google Scholar]
- Sturman, D.J.; Zeltzer, D. A survey of glove-based input. IEEE Comput. Graph. Appl. 1994, 14, 30–39. [Google Scholar] [CrossRef]
- Saggio, G.; Riillo, F.; Sbernini, L.; Quitadamo, L.R. Resistive flex sensors: A survey. Smart Mater. Struct. 2015, 25, 013001. [Google Scholar] [CrossRef]
- Cyberglove III, CyberGlove Systems. Available online: http://www.cyberglovesystems.com/cyberglove-iii (accessed on 2 February 2020).
- 5DT Data Glove Ultra Series, 5DT Inc. Available online: http://www.5dt.com/downloads/dataglove/ultra/5DTDataGloveUltraDatasheet.pdf (accessed on 2 February 2020).
- Zheng, Y.; Peng, Y.; Wang, G.; Liu, X.; Dong, X.; Wang, J. Development and evaluation of a sensor glove for hand function assessment and preliminary attempts at assessing hand coordination. J. Meas. 2016, 93, 1–12. [Google Scholar] [CrossRef]
- Shen, Z.; Yi, J.; Li, X.; Lo, M.H.P.; Chen, M.Z.; Hu, Y.; Wang, Z. A soft stretchable bending sensor and data glove applications. Robot. Biomim. 2016, 3, 22. [Google Scholar] [CrossRef] [Green Version]
- Ciotti, S.; Battaglia, E.; Carbonaro, N.; Bicchi, A.; Tognetti, A.; Bianchi, M. A synergy-based optimally designed sensing glove for functional grasp recognition. Sensors 2016, 16, 811. [Google Scholar] [CrossRef] [Green Version]
- Saggio, G. A novel array of flex sensors for a goniometric glove. Sens. Actuators A Phys. 2014, 205, 119–125. [Google Scholar] [CrossRef]
- Lee, J.; Kim, S.; Lee, J.; Yang, D.; Park, B.C.; Ryu, S.; Park, I. A stretchable strain sensor based on a metal nanoparticle thin film for human motion detection. Nanoscale 2014, 6, 11932–11939. [Google Scholar] [CrossRef]
- Bianchi, M.; Haschke, R.; Büscher, G.; Ciotti, S.; Carbonaro, N.; Tognetti, A. A multi-modal sensing glove for human manual-interaction studies. Electronics 2016, 5, 42. [Google Scholar] [CrossRef]
- Büscher, G.; Kõiva, R.; Schürmann, C.; Haschke, R.; Ritter, H.J. Tactile Dataglove with Fabric-Based Sensors. In Proceedings of the 2012 12th IEEE-RAS International Conference on Humanoid Robots (Humanoids 2012), Osaka, Japan, 29 November–1 December 2012. [Google Scholar]
- Michaud, H.O.; Dejace, L.; De Mulatier, S.; Lacour, S.P. Design and Functional Evaluation of an Epidermal Strain Sensing System for Hand Tracking. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, South Korea, 9–14 October 2016. [Google Scholar]
- Chossat, J.-B.; Tao, Y.; Duchaine, V.; Park, Y.-L. Wearable soft Artificial Skin for Hand Motion Detection with Embedded Microfluidic Strain Sensing. In Proceedings of the 2015 IEEE international conference on robotics and automation (ICRA), Seattle, WA, USA, 26–30 May 2015. [Google Scholar]
- Park, W.; Ro, K.; Kim, S.; Bae, J. A soft sensor-based three-dimensional (3-D) finger motion measurement system. Sensors 2017, 17, 420. [Google Scholar] [CrossRef] [Green Version]
- Atalay, A.; Sanchez, V.; Atalay, O.; Vogt, D.M.; Haufe, F.; Wood, R.J.; Walsh, C.J. Batch fabrication of customizable silicone-textile composite capacitive strain sensors for human motion tracking. Adv. Mater. Technol. 2017, 2, 1700136. [Google Scholar] [CrossRef] [Green Version]
- Ryu, H.; Park, S.; Park, J.-J.; Bae, J. A knitted glove sensing system with compression strain for finger movements. Smart Mater. Struct. 2018, 27, 055016. [Google Scholar] [CrossRef]
- Glauser, O.; Panozzo, D.; Hilliges, O.; Sorkine-Hornung, O. Deformation capture via soft and stretchable sensor arrays. ACM Trans. Graph. 2019, 38, 16. [Google Scholar] [CrossRef] [Green Version]
- Glauser, O.; Wu, S.; Panozzo, D.; Hilliges, O.; Sorkine-Hornung, O. Interactive hand pose estimation using a stretch-sensing soft glove. ACM Trans. Graph. 2019, 38, 41. [Google Scholar] [CrossRef] [Green Version]
- Yang, C.-C.; Hsu, Y.-L. A review of accelerometry-based wearable motion detectors for physical activity monitoring. Sensors 2010, 10, 7772–7788. [Google Scholar] [CrossRef] [PubMed]
- Hsiao, P.-C.; Yang, S.-Y.; Lin, B.-S.; Lee, I.-J.; Chou, W. Data Glove Embedded with 9-axis IMU and Force Sensing Sensors for Evaluation of Hand Function. In Proceedings of the 2015 37th annual international conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015. [Google Scholar]
- O’Flynn, B.; Sanchez, J.T.; Connolly, J.; Condell, J.; Curran, K.; Gardiner, P.; Downes, B. Integrated Smart Glove for Hand Motion Monitoring. In Proceedings of the Sixth International Conference on Sensor Device Technologies and Applications, Venice, Italy, 23–28 August 2015. [Google Scholar]
- The Humanglove, Humanware. Available online: http://www.hmw.it/en/humanglove.html (accessed on 2 February 2020).
- Wu, J.; Huang, J.; Wang, Y.; Xing, K. RLSESN-based PID adaptive control for a novel wearable rehabilitation robotic hand driven by PM-TS actuators. Int. J. Intell. Comput. Cybern. 2012, 5, 91–110. [Google Scholar] [CrossRef]
- Chen, K.-Y.; Patel, S.N.; Keller, S. Finexus: Tracking Precise Motions of Multiple Fingertips using Magnetic Sensing. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016. [Google Scholar]
- The Keyglove. Available online: https://github.com/jrowberg/keyglove (accessed on 2 February 2020).
- The Hi5 Glove, Noitom. Available online: https://hi5vrglove.com/ (accessed on 2 February 2020).
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. CVPR 2001, 1, 3. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, Canada, 8–11 December 2014; pp. 2672–2680. [Google Scholar]
- Lu, S.; Metaxas, D.; Samaras, D.; Oliensis, J. Using Multiple Cues for Hand Tracking and Model Refinement. In Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003. [Google Scholar]
- De La Gorce, M.; Fleet, D.J.; Paragios, N. Model-based 3d hand pose estimation from monocular video. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1793–1805. [Google Scholar] [CrossRef] [Green Version]
- Delamarre, Q.; Faugeras, O. 3D articulated models and multiview tracking with physical forces. Comput. Vis. Image Underst. 2001, 81, 328–357. [Google Scholar] [CrossRef]
- Bray, M.; Koller-Meier, E.; Van Gool, L. Smart Particle filtering for high-dimensional tracking. Comput. Vis. Image Underst. 2007, 106, 116–129. [Google Scholar] [CrossRef]
- Oikonomidis, I.; Kyriazis, N.; Argyros, A.A. Efficient Model-Based 3D Tracking of Hand Articulations using Kinect. In Proceedings of the 22nd British Machine Vision Conference, Dundee, UK, 29 August–1 September 2011. [Google Scholar]
- Tkach, A.; Tagliasacchi, A.; Remelli, E.; Pauly, M.; Fitzgibbon, A. Online generative model personalization for hand tracking. ACM Trans. Graph. 2017, 36, 243. [Google Scholar] [CrossRef]
- Tagliasacchi, A.; Schröder, M.; Tkach, A.; Bouaziz, S.; Botsch, M.; Pauly, M. Robust articulated-ICP for real-time hand tracking. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2015. [Google Scholar]
- Eberhart, R.; Kennedy, J. Particle Swarm Optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, Western Australia, 27 November–1 December 1995. [Google Scholar]
- Oikonomidis, I.; Kyriazis, N.; Argyros, A.A. Markerless and Efficient 26-dof Hand Pose Recovery. In Proceedings of the Asian Conference on Computer Vision, Queenstown, New Zealand, 8–12 November 2010. [Google Scholar]
- Oikonomidis, I.; Kyriazis, N.; Argyros, A.A. Tracking the Articulated Motion of two Strongly Interacting Hands. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Oikonomidis, I.; Kyriazis, N.; Argyros, A.A. Full DOF Tracking of a Hand Interacting with an Object by Modeling Occlusions and Physical Constraints. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Magnenat-Thalmann, N.; Laperrire, R.; Thalmann, D. Joint-Dependent Local Deformations for Hand Animation and Object Grasping. In Proceedings of the Graphics interface’88, Edmonton, AB, Canada, 6–10 June 1988. [Google Scholar]
- Lewis, J.P.; Cordner, M.; Fong, N. Pose Space Deformation: A Unified Approach to Shape Interpolation and Skeleton-Driven Deformation. In Proceedings of the 27th Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 23–28 July 2000. [Google Scholar]
- Ballan, L.; Taneja, A.; Gall, J.; Van Gool, L.; Pollefeys, M. Motion Capture of Hands in Action using Discriminative Salient Points. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012. [Google Scholar]
- Sridhar, S.; Oulasvirta, A.; Theobalt, C. Interactive Markerless Articulated Hand Motion Tracking using RGB and Depth Data. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Tzionas, D.; Srikantha, A.; Aponte, P.; Gall, J. Capturing Hand Motion with an RGB-D Sensor, Fusing a Generative Model with Salient Points. In Proceedings of the 36th German Conference on Pattern Recognition, Münster, Germany, 2–5 September 2014. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Keskin, C.; Kıraç, F.; Kara, Y.E.; Akarun, L. Hand Pose Estimation and Hand Shape Classification using Multi-Layered Randomized Decision Forests. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012. [Google Scholar]
- Tang, D.; Yu, T.-H.; Kim, T.-K. Real-Time Articulated Hand Pose Estimation using Semi-Supervised Transductive Regression Forests. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013. [Google Scholar]
- Liang, H.; Yuan, J.; Thalmann, D. Parsing the hand in depth images. IEEE Trans. Multimed. 2014, 16, 1241–1253. [Google Scholar] [CrossRef]
- Tang, D.; Jin Chang, H.; Tejani, A.; Kim, T.-K. Latent Regression Forest: Structured Estimation of 3D Articulated Hand Posture. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Choi, M.J.; Tan, V.Y.; Anandkumar, A.; Willsky, A.S. Learning latent tree graphical models. J. Mach. Learn. Res. 2011, 12, 1771–1812. [Google Scholar]
- Dollár, P.; Welinder, P.; Perona, P. Cascaded Pose Regression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Sun, X.; Wei, Y.; Liang, S.; Tang, X.; Sun, J. Cascaded Hand Pose Regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Wan, C.; Yao, A.; Van Gool, L. Hand Pose Estimation from Local Surface Normals. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Tompson, J.; Stein, M.; Lecun, Y.; Perlin, K. Real-Time Continuous Pose Recovery of Human Hands using Convolutional Networks. ACM Trans. Graph. ToG 2014, 33, 169. [Google Scholar] [CrossRef]
- Oberweger, M.; Wohlhart, P.; Lepetit, V. Hands Deep in Deep Learning for Hand Pose Estimation. arXiv 2015, arXiv:1502.06807. [Google Scholar]
- Ge, L.; Ren, Z.; Li, Y.; Xue, Z.; Wang, Y.; Cai, J.; Yuan, J. 3D Hand Shape and Pose Estimation from a Single RGB Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Wan, C.; Probst, T.; Gool, L.V.; Yao, A. Self-Supervised 3D Hand Pose Estimation through Training by Fitting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Baek, S.; In Kim, K.; Kim, T.-K. Augmented Skeleton Space Transfer for Depth-Based Hand Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Oberweger, M.; Wohlhart, P.; Lepetit, V. Generalized feedback loop for joint hand-object pose estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Yao, A. Disentangling Latent Hands for Image Synthesis and Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Spurr, A.; Song, J.; Park, S.; Hilliges, O. Cross-Modal Deep Variational Hand Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Wei, S.-E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional Pose Machines. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Sapp, B.; Taskar, B. Modec: Multimodal Decomposable Models for Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Johnson, S.; Everingham, M. Learning Effective Human Pose Estimation from Inaccurate Annotation. In Proceedings of the CVPR 2011, Providence, RI, USA, 20–25 June 2011. [Google Scholar]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2D Human Pose Estimation: New Benchmark and State of the Art Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.-E.; Sheikh, Y. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Henia, O.B.; Hariti, M.; Bouakaz, S. A Two-Step Minimization Algorithm for Model-Based Hand Tracking. In Proceedings of the 18th International Conference on Computer Graphics, Visualization and Computer Vision (WSCG), Plzen, Czech Republic, 1–4 February 2010. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015. [Google Scholar]
- Misra, I.; Shrivastava, A.; Gupta, A.; Hebert, M. Cross-Stitch Networks for Multi-Task Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zhang, Z.; Luo, P.; Loy, C.C.; Tang, X. Facial Landmark Detection by Deep Multi-Task Learning. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 5–12 September 2014. [Google Scholar]
- Simon, T.; Joo, H.; Matthews, I.; Sheikh, Y. Hand Keypoint Detection in Single Images using Multiview Bootstrapping. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Joo, H.; Liu, H.; Tan, L.; Gui, L.; Nabbe, B.; Matthews, I.; Kanade, T.; Nobuhara, S.; Sheikh, Y. Panoptic Studio: A Massively Multiview System for Social Motion Capture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015. [Google Scholar]
- Zimmermann, C.; Brox, T. Learning to Estimate 3D Hand Pose from Single RGB Images. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Iqbal, U.; Molchanov, P.; Breuel Juergen Gall, T.; Kautz, J. Hand Pose Estimation via Latent 2.5 d Heatmap Regression. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Rad, M.; Oberweger, M.; Lepetit, V. Domain Transfer for 3d Pose Estimation from Color Images without Manual Annotations. In Proceedings of the 14th Asian Conference on Computer Vision, Perth, Australia, 4–6 December 2019. [Google Scholar]
- Cai, Y.; Ge, L.; Cai, J.; Yuan, J. Weakly-Supervised 3D Hand Pose Estimation from Monocular RGB Images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ge, L.; Liang, H.; Yuan, J.; Thalmann, D. Robust 3D hand pose estimation from single depth images using multi-view CNNs. IEEE Trans. Image Process. 2018, 27, 4422–4436. [Google Scholar] [CrossRef]
- Wang, P.-S.; Liu, Y.; Guo, Y.-X.; Sun, C.-Y.; Tong, X. O-CNN: Octree-based convolutional neural networks for 3d shape analysis. ACM Trans. Graph. 2017, 36, 72. [Google Scholar] [CrossRef]
- Che, Y.; Song, Y.; Qi, Y. A Novel Framework of Hand Localization and Hand Pose Estimation. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Ge, L.; Ren, Z.; Yuan, J. Point-to-Point Regression Pointnet for 3D Hand Pose Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Ge, L.; Cai, Y.; Weng, J.; Yuan, J. Hand PointNet: 3D Hand Pose Estimation using Point Sets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Dou, Y.; Wang, X.; Zhu, Y.; Deng, X.; Ma, C.; Chang, L.; Wang, H. Cascaded Point Network for 3D Hand Pose Estimation. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Li, S.; Lee, D. Point-to-Pose Voting Based Hand Pose Estimation using Residual Permutation Equivariant Layer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Deng, X.; Yang, S.; Zhang, Y.; Tan, P.; Chang, L.; Wang, H. Hand3D: Hand pose estimation using 3d neural network. arXiv 2017, arXiv:1704.02224. [Google Scholar]
- Ge, L.; Liang, H.; Yuan, J.; Thalmann, D. 3D Convolutional Neural Networks for Efficient and Robust Hand Pose Estimation from Single Depth Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Moon, G.; Chang, J.Y.; Lee, K.M. V2v-Posenet: Voxel-to-Voxel Prediction Network for Accurate 3D Hand and Human Pose Estimation from a Single Depth Map. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Ge, L.; Liang, H.; Yuan, J.; Thalmann, D. Real-time 3D hand pose estimation with 3D convolutional neural networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 956–970. [Google Scholar] [CrossRef] [PubMed]
- Yuan, S.; Ye, Q.; Garcia-Hernando, G.; Kim, T.-K. The 2017 hands in the million challenge on 3d hand pose estimation. arXiv 2017, arXiv:02237. [Google Scholar]
- Haque, A.; Peng, B.; Luo, Z.; Alahi, A.; Yeung, S.; Fei-Fei, L. Towards Viewpoint Invariant 3d Human Pose Estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Zhang, J.; Jiao, J.; Chen, M.; Qu, L.; Xu, X.; Yang, Q. 3D hand pose tracking and estimation using stereo matching. arXiv 2016, arXiv:07214. [Google Scholar]
- Sridhar, S.; Mueller, F.; Zollhöfer, M.; Casas, D.; Oulasvirta, A.; Theobalt, C. Real-Time Joint Tracking of a Hand Manipulating an Object From RGB-D Input. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Mueller, F.; Mehta, D.; Sotnychenko, O.; Sridhar, S.; Casas, D.; Theobalt, C. Real-Time Hand Tracking under Occlusion from an Egocentric RGB-D Sensor. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Hinterstoisser, S.; Lepetit, V.; Ilic, S.; Holzer, S.; Bradski, G.; Konolige, K.; Navab, N. Model Based Training, Detection and Pose Estimation of Texture-Less 3d Objects in Heavily Cluttered Scenes. In Proceedings of the Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012. [Google Scholar]
- Baek, S.; Kim, K.I.; Kim, T.-K. Pushing the Envelope for RGB-Based Dense 3D Hand Pose Estimation via Neural Rendering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Romero, J.; Tzionas, D.; Black, M. Embodied hands: Modeling and capturing hands and bodies together. ACM Trans. Graph. 2017, 36, 245. [Google Scholar] [CrossRef] [Green Version]
- Mueller, F.; Davis, M.; Bernard, F.; Sotnychenko, O.; Verschoor, M.; Otaduy, M.A.; Casas, D.; Theobalt, C. Real-time pose and shape reconstruction of two interacting hands with a single depth camera. ACM Trans. Graph. 2019, 38, 49. [Google Scholar] [CrossRef]
- Boukhayma, A.; Bem, R.D.; Torr, P.H. 3D Hand Shape and Pose from Images in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhang, H.; Bo, Z.-H.; Yong, J.-H.; Xu, F. Interaction fusion: Real-time reconstruction of hand poses and deformable objects in hand-object interactions. ACM Trans. Graph. 2019, 38, 48. [Google Scholar] [CrossRef]
- Yuan, S.; Ye, Q.; Stenger, B.; Jain, S.; Kim, T.-K. Bighand2. 2m Benchmark: Hand Pose Dataset and State of the Art Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wetzler, A.; Slossberg, R.; Kimmel, R. Rule of thumb: Deep derotation for improved fingertip detection. arXiv 2015, arXiv:1507.05726. [Google Scholar]
- Sharp, T.; Keskin, C.; Robertson, D.; Taylor, J.; Shotton, J.; Kim, D.; Rhemann, C.; Leichter, I.; Vinnikov, A.; Wei, Y. Accurate, Robust, and Flexible Real-Time Hand Tracking. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015. [Google Scholar]
- Tekin, B.; Bogo, F.; Pollefeys, M. H+ O: Unified Egocentric Recognition of 3D Hand-Object Poses and Interactions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Myanganbayar, B.; Mata, C.; Dekel, G.; Katz, B.; Ben-Yosef, G.; Barbu, A. Partially Occluded Hands: A Challenging New Dataset for Single-Image Hand Pose Estimation. In Proceedings of the 14th Asian Conference on Computer Vision (ACCV 2018), Perth, Australia, 2–6 December 2018. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Accuracy | Response time | Lifetime | Cost | Ease of Wearing |
|---|---|---|---|---|---|
| Bend (Flex) sensor | high | medium | medium | medium | medium |
| Stretch (Strain) sensor | medium | slow | short | low | easy |
| IMU | medium | fast | long | low | hard |
| Magnetic sensor | low | fast | long | medium | hard |
| Literature | Features | Hand Model | DoF | Parameters | Optimization Method | FPS |
|---|---|---|---|---|---|---|
| Oikonomidis et al. [62] | Skin and edge | GCM 1 | 26 | 27 | PSO | - |
| Oikonomidis et al. [64] | Skin and edge | GCM | 26 | 27 | PSO | - |
| Gorce et al. [55] | Surface texture and illuminant | DPMM 2 | 22 | - | Quasi-Newton method | 40 |
| Ballan et al. [67] | Skin, edges, optical flow, and collisions | DPMM | 35 | - | Levenberg–Marquard | 50 |
| Literature | Features | Hand Model | DoF | Parameters | Optimization Method | FPS |
|---|---|---|---|---|---|---|
| Oikonomidis et al. [58] | Skin and depth | GCM | 26 | 27 | PSO | 15 |
| Oikonomidis et al. [63] | Skin and depth | GCM | 26 | 27 | PSO | 4 |
| Qian et al. [19] | Depth | GCM | 26 | 26 | ICP–PSO | 25 |
| Sridhar et al. [68] | Skin and depth | DPMM | 26 | - | Gradient ascent | 10 |
| Tzionas et al. [69] | Skin and depth | DPMM | 37 | - | Self-build method | 60 |
| Literature | Datasets | Method | FPS |
|---|---|---|---|
| Keskin et al. [71] | Self-built dataset | RF: Random decision | - |
| Tang et al. [72] | Self-built dataset | RF: STR | 25 |
| Liang et al. [73] | Self-built dataset | RF: SMRF | - |
| Tang et al. [74] | Self-built dataset | RF: LRF | 62.5 |
| Sun et al. [77] | Self-built dataset | RF: Cascaded regression | 300 |
| Wan et al. [78] | - | RF: FCRF | 29.4 |
| Tompson et al. [79] | Self-built dataset | RDF + CNN | 24.9 |
| Sinha et al. [20] | Dexter1 [68], NYU | CNN: DeepHand | 32 |
| Oberweger et al. [80] | NYU, ICVL | CNN: Deep-Prior | 500 |
| Ge et al. [102] | MSRA, NYU | CNN: Multi-View CNNs | 82 |
| Che et al. [104] | NYU, ICVL | CNN: HHLN and WR-OCNN | - |
| Ge et al. [105] | NYU, ICVL, MSRA | CNN | 41.8 |
| Ge et al. [106] | NYU, ICVL, MSRA | CNN | 48 |
| Dou et al. [107] | NYU, MSRA | CNN | 70 |
| Li and Lee [108] | NYU, Hands 2017Challenge dataset [113] | CNN | - |
| Deng et al. [109] | NYU, ICVL | CNN: Hand3d | 30 |
| Ge et al. [110] | MSRA, NYU | CNN | 215 |
| Moon et al. [111] | ICVL, MSRA, NYU, HANDS2017 [113], ITOP [114] | CNN: 3D CNN | 35 |
| Ge et al. [112] | MSRA, NYU, ICVL | CNN: 3D CNN | 91 |
| Literature | Datasets | Method | FPS |
|---|---|---|---|
| Zimmermann and Brox [98] | Stereo hand pose (STB) [115], Dexter [116], Rendered hand (RHD) [98] | CNN: HandSegNet, PoseNet | - |
| Iqbal et al. [99] | Dexter [116], EgoDexter [117], STB, RHD, MPII + NZSL [96] | CNN | 150 |
| Rad et al. [100] | LINEMOD [118], STB, RHD | CNN, FCN | 116 |
| Cai et al. [101] | STB, RHD | CNN | - |
| Ge et al. [81] | STB, RHD | Graph CNN | 50 |
| Dataset | Image Type | Number of Images | Camera | Number of Annotated Joints | Description |
|---|---|---|---|---|---|
| ICVL [74] | D | 331,000 | Intel Creative Gesture Camera | 16 | Real hand and manual labeling |
| NYU [79] | RGB-D | 81,009 | Prime Sense Carmine 1.09 | 36 | Real hand and automatic labeling |
| BigHand 2.2M [124] | D | 2.2M | Intel RealSense SR300 | 21 | Real hand and automatic labeling |
| HandNet [125] | D | 12,773 | Intel RealSense Camera | Fingertip and palm coordinates | Real hand and automatic labeling |
| MSRC [126] | D | 10,2000 | - | 22 | Synthetic data |
| MSHD [126] | D | 101k | Kinect2 | - | Synthetic data |
| MSRA14 [19] | D | 2400 | - | 21 | Real hand and manual labeling |
| MSRA15 [77] | D | 76,500 | Intel’s Creative Interactive Camera | 21 | Real hand and semi-automatic labeling |
| OpenPose hand dataset [96] | RGB | 16k | - | 21 | Manual labeling from MPII [90] and automatic labeling on the Dome or Panoptic Studio [97] |
| Stereo hand pose (STB) [115] | RGB | 18,000 frame pairs | Point Grey Bumblebee2 Stereo Camera | 21 | Real-world stereo image pairs with two subsets: STB–BB and STB–SK |
| Rendered hand (RHD) [98] | RGB-D | 43,986 | - | 21 | Synthetic dataset with 20 different characters performing 39 actions in different settings |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, W.; Yu, C.; Tu, C.; Lyu, Z.; Tang, J.; Ou, S.; Fu, Y.; Xue, Z. A Survey on Hand Pose Estimation with Wearable Sensors and Computer-Vision-Based Methods. Sensors 2020, 20, 1074. https://doi.org/10.3390/s20041074
Chen W, Yu C, Tu C, Lyu Z, Tang J, Ou S, Fu Y, Xue Z. A Survey on Hand Pose Estimation with Wearable Sensors and Computer-Vision-Based Methods. Sensors. 2020; 20(4):1074. https://doi.org/10.3390/s20041074
Chicago/Turabian StyleChen, Weiya, Chenchen Yu, Chenyu Tu, Zehua Lyu, Jing Tang, Shiqi Ou, Yan Fu, and Zhidong Xue. 2020. "A Survey on Hand Pose Estimation with Wearable Sensors and Computer-Vision-Based Methods" Sensors 20, no. 4: 1074. https://doi.org/10.3390/s20041074
APA StyleChen, W., Yu, C., Tu, C., Lyu, Z., Tang, J., Ou, S., Fu, Y., & Xue, Z. (2020). A Survey on Hand Pose Estimation with Wearable Sensors and Computer-Vision-Based Methods. Sensors, 20(4), 1074. https://doi.org/10.3390/s20041074