Deep Neural Networks for the Classification of Pure and Impure Strawberry Purees



Abstract
:1. Introduction
2. Materials and Methods
2.1. The Strawberry Dataset
2.2. Training Criterions and Evaluation Metrics
2.3. Training Descriptions
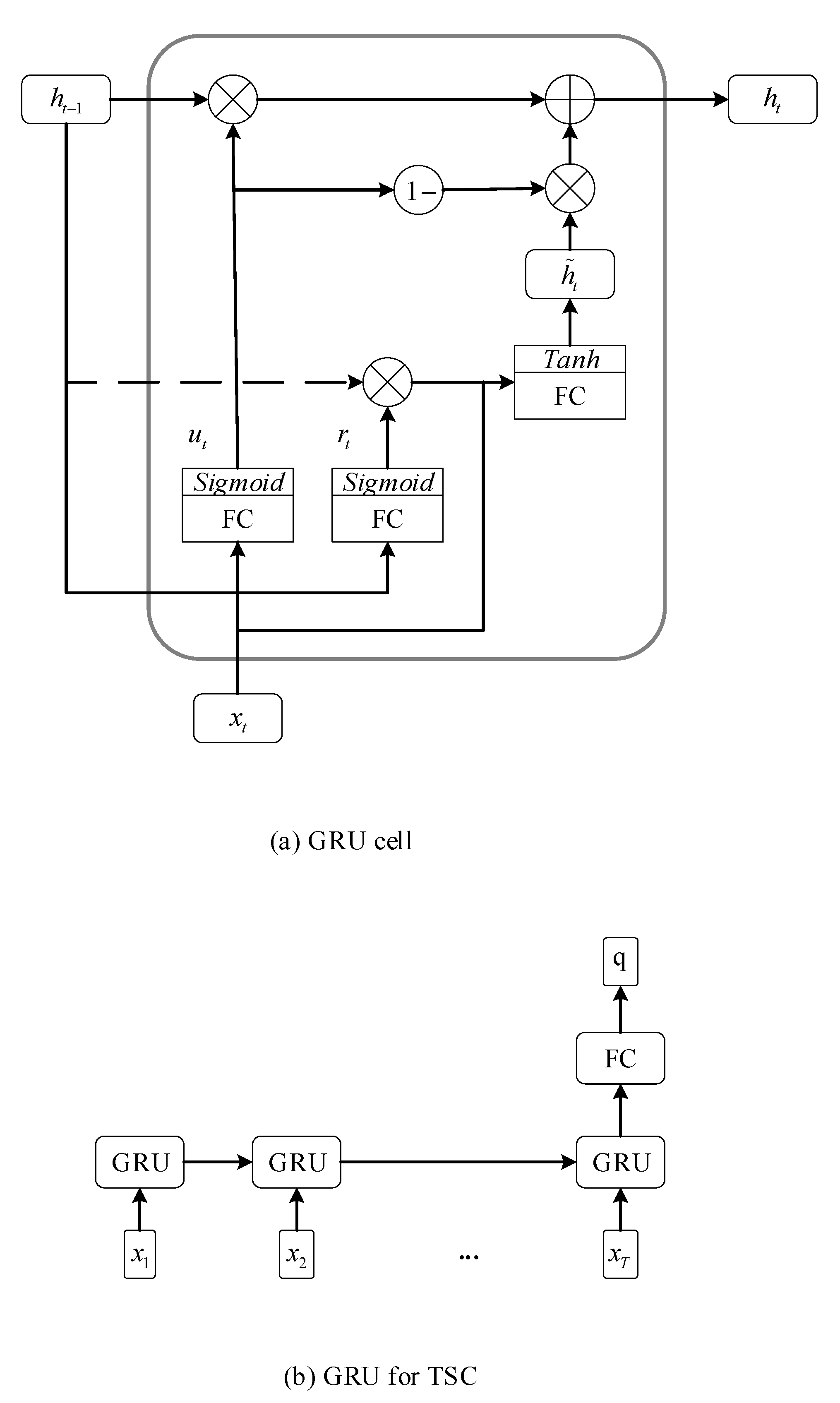
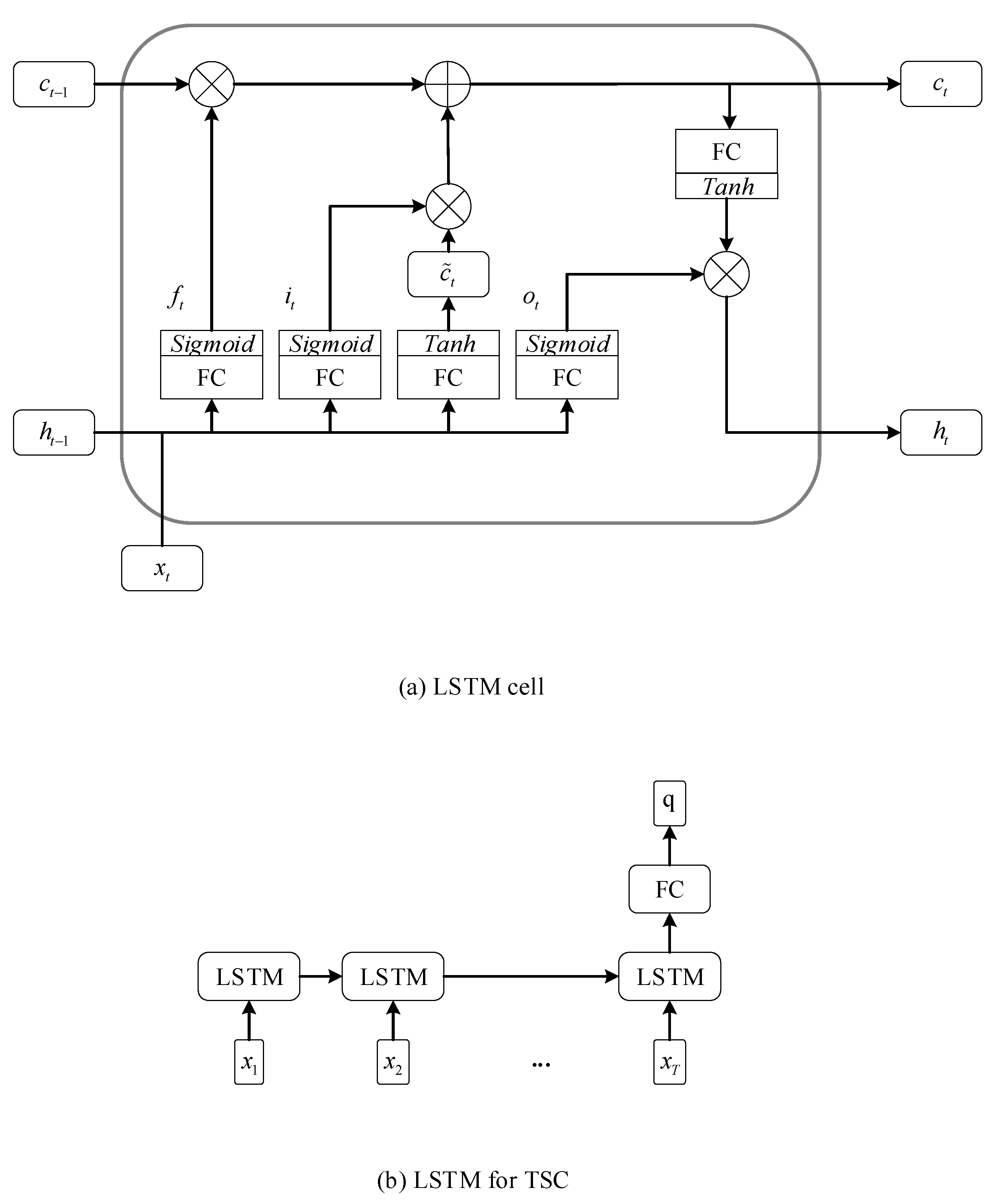
2.4. GRU and LSTM for TSC
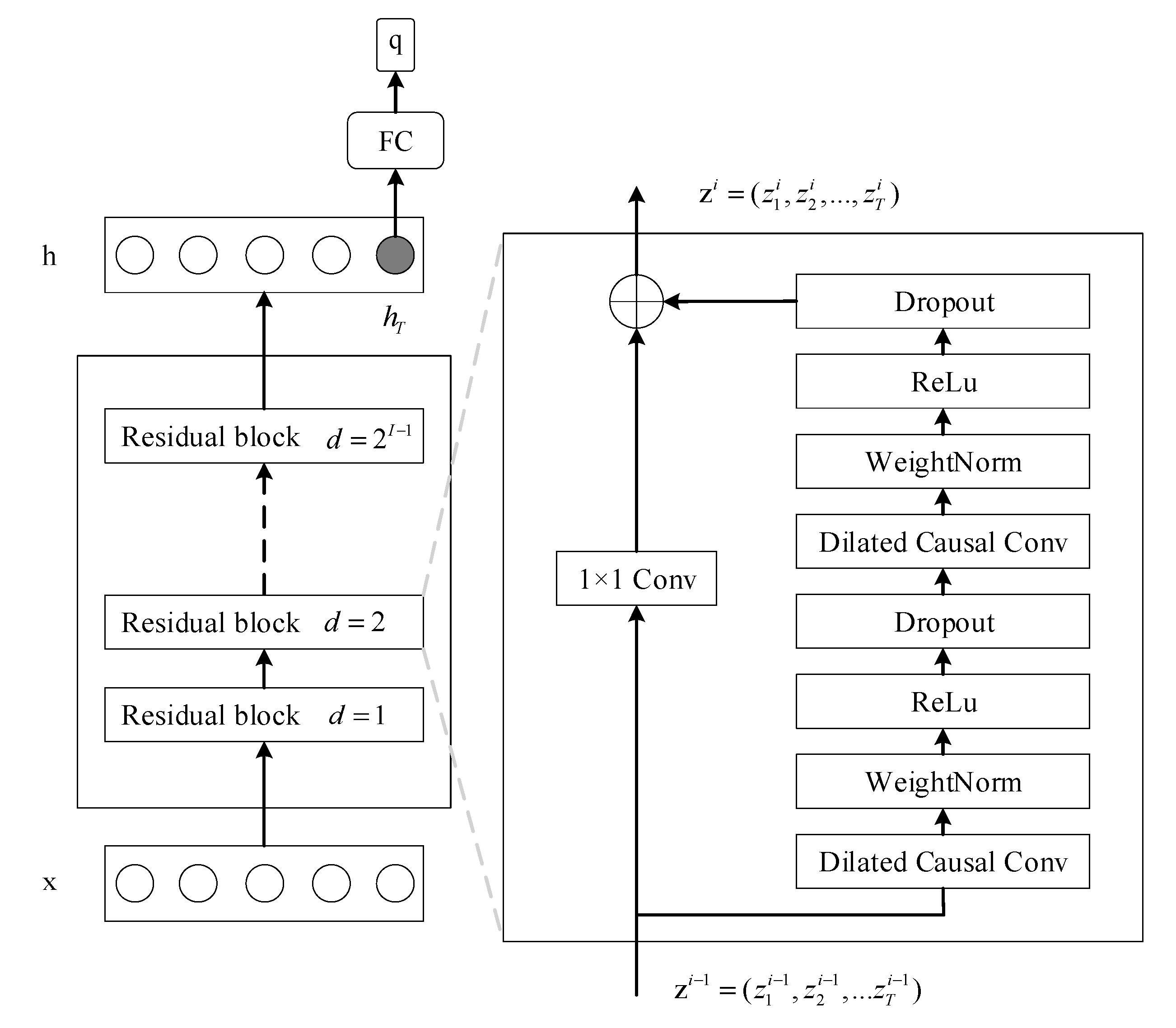
2.5. TCN for TSC
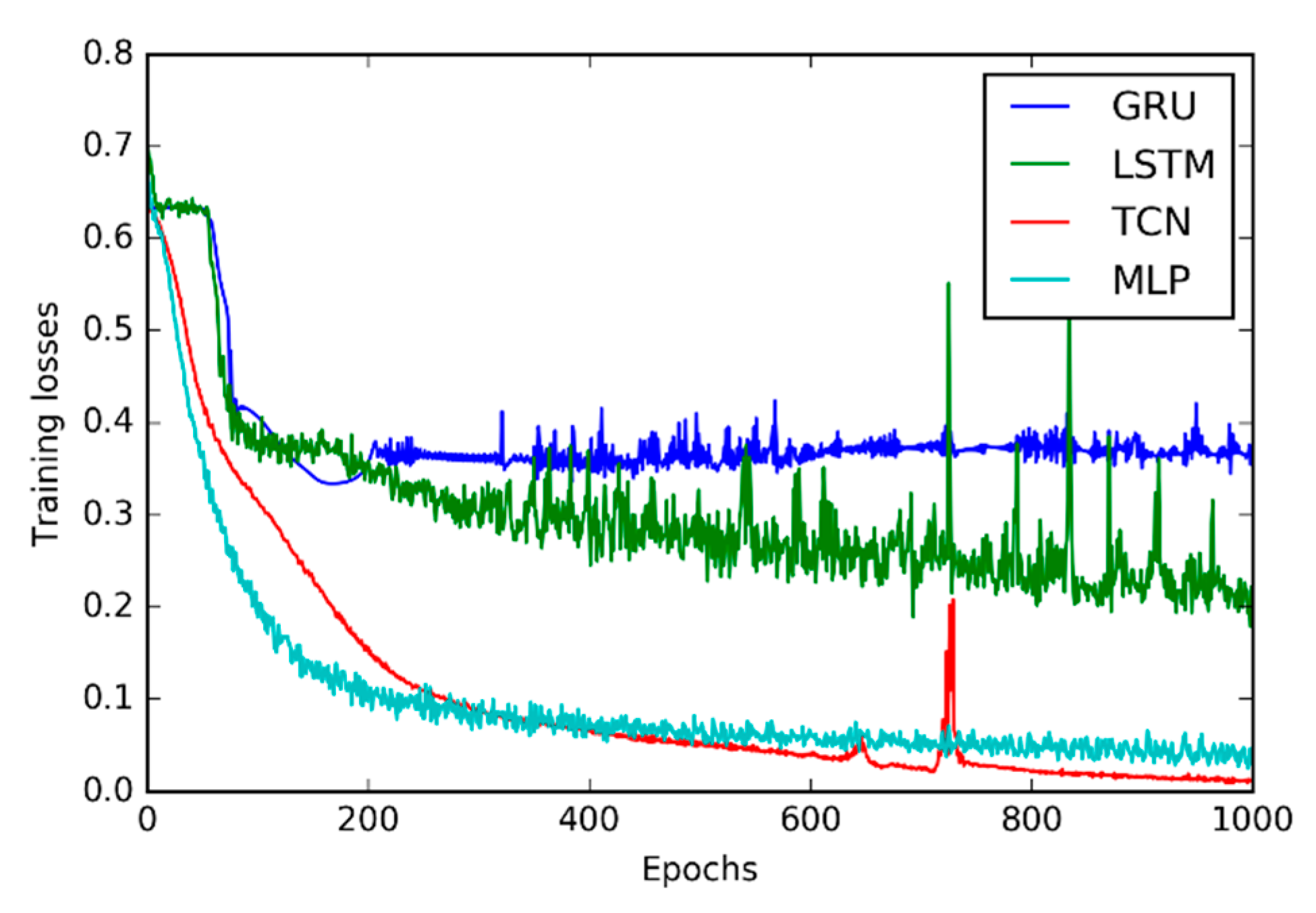
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Holland, J.; Kemsley, E.; Wilson, R. Use of Fourier Transform Infrared Spectroscopy and Partial Least Squares Regression for the Detection of Adulteration of Strawberry Purees. J. Sci. Food Agric. 1998, 76, 263–269. [Google Scholar] [CrossRef]
- Robards, K.; Antolovich, M. Methods for Assessing the Authenticity of Orange Juice. A Review. Analyst 1995, 120, 1–28. [Google Scholar] [CrossRef]
- Lai, Y.W.; Kemsley, E.K.; Wilson, R.H. Potential of Fourier Transform Infrared Spectroscopy for the Authentication of Vegetable Oils. J. Agric. Food Chem. 1994, 42, 1154–1159. [Google Scholar] [CrossRef]
- Briandet, R.; Kemsley, E.K.; Wilson, R.H. Discrimination of Arabica and Robusta in Instant Coffee by Fourier Transform Infrared Spectroscopy and Chemometrics. J. Agric. Food Chem. 1996, 44, 170–174. [Google Scholar] [CrossRef]
- Petrakis, E.A.; Polissiou, M.G. Assessing Saffron (Crocus Sativus L.) Adulteration with Plant-Derived Adulterants by Diffuse Reflectance Infrared Fourier Transform Spectroscopy Coupled with Chemometrics. Talanta 2017, 162, 558–566. [Google Scholar] [CrossRef] [PubMed]
- Defernez, M.; Kemsley, E.K.; Wilson, R.H. Use of Infrared Spectroscopy and Chemometrics for the Authentication of Fruit Purees. J. Agric. Food Chem. 1995, 43, 109–113. [Google Scholar] [CrossRef]
- Rakthanmanon, T.; Campana, B.; Mueen, A.; Batista, G.; Westover, B.; Zhu, Q.; Zakaria, J.; Keogh, E. Addressing Big Data Time Series: Mining Trillions of Time Series Subsequences under Dynamic Time Warping. ACM Trans. Knowl. Discov. Data TKDD 2013, 7, 10. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Rodriguez, J.J.; Kuncheva, L.I.; Alonso, C.J. Rotation Forest: A New Classifier Ensemble Method. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1619–1630. [Google Scholar] [CrossRef] [PubMed]
- Bagnall, A.; Lines, J.; Bostrom, A.; Large, J.; Keogh, E. The Great Time Series Classification Bake off: A Review and Experimental Evaluation of Recent Algorithmic Advances. Data Min. Knowl. Discov. 2017, 31, 606–660. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.-A. Deep Learning for Time Series Classification: A Review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef] [Green Version]
- Huang, C.; Wang, L.; Lai, L.L. Data-Driven Short-Term Solar Irradiance Forecasting Based on Information of Neighboring Sites. IEEE Trans. Ind. Electron. 2018, 66, 9918–9927. [Google Scholar] [CrossRef]
- Long, H.; Sang, L.; Wu, Z.; Gu, W. Image-Based Abnormal Data Detection and Cleaning Algorithm via Wind Power Curve. IEEE Trans. Sustain. Energy 2019. [CrossRef]
- Zhang, S.; Wu, Y.; Che, T.; Lin, Z.; Memisevic, R.; Salakhutdinov, R.R.; Bengio, Y. Architectural Complexity Measures of Recurrent Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 29, NIPS2016, Barcelona, Spain, 5–10 December 2016; pp. 1822–1830. [Google Scholar]
- Wang, Z.; Yan, W.; Oates, T. Time Series Classification from Scratch with Deep Neural Networks: A Strong Baseline. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1578–1585. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder-Decoder Approaches. arXiv 2014, arXiv:14091259. [Google Scholar]
- Aksan, E.; Hilliges, O. STCN: Stochastic Temporal Convolutional Networks. arXiv 2019, arXiv:190206568. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:180301271. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. Trellis Networks for Sequence Modeling. arXiv 2018, arXiv:181006682. [Google Scholar]
- Van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A Generative Model for Raw Audio. arXiv 2016, arXiv:160903499. [Google Scholar]
- Dau, H.A.; Keogh, E.; Kamgar, K.; Yeh, C.-C.M.; Zhu, Y.; Gharghabi, S.; Ratanamahatana, C.A.; Chen, Y.; Hu, B.; Begum, N.; et al. The UCR Time Series Classification Archive. 2018. Available online: https://www.cs.ucr.edu/~eamonn/time_series_data_2018/ (accessed on 22 February 2020).
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Samples |
|---|---|
| Training dataset | 613 |
| Test dataset | 370 |
| Model | Classification Accuracy |
|---|---|
| RotF [2] | 97.30 |
| MLP | 96.76 |
| GRU | 90.54 |
| LSTM | 87.84 |
| TCN | 98.65 |
| Model | Training Time |
|---|---|
| MLP | 41.44 |
| GRU | 253.03 |
| LSTM | 250.81 |
| TCN | 131.58 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Z.; Zhang, X.; Yu, J.; Guo, R.; Zhangzhong, L. Deep Neural Networks for the Classification of Pure and Impure Strawberry Purees. Sensors 2020, 20, 1223. https://doi.org/10.3390/s20041223
Zheng Z, Zhang X, Yu J, Guo R, Zhangzhong L. Deep Neural Networks for the Classification of Pure and Impure Strawberry Purees. Sensors. 2020; 20(4):1223. https://doi.org/10.3390/s20041223
Chicago/Turabian StyleZheng, Zhong, Xin Zhang, Jinxing Yu, Rui Guo, and Lili Zhangzhong. 2020. "Deep Neural Networks for the Classification of Pure and Impure Strawberry Purees" Sensors 20, no. 4: 1223. https://doi.org/10.3390/s20041223
APA StyleZheng, Z., Zhang, X., Yu, J., Guo, R., & Zhangzhong, L. (2020). Deep Neural Networks for the Classification of Pure and Impure Strawberry Purees. Sensors, 20(4), 1223. https://doi.org/10.3390/s20041223