Enhancement of RGB-D Image Alignment Using Fiducial Markers




Abstract
:1. Introduction
2. Related Work
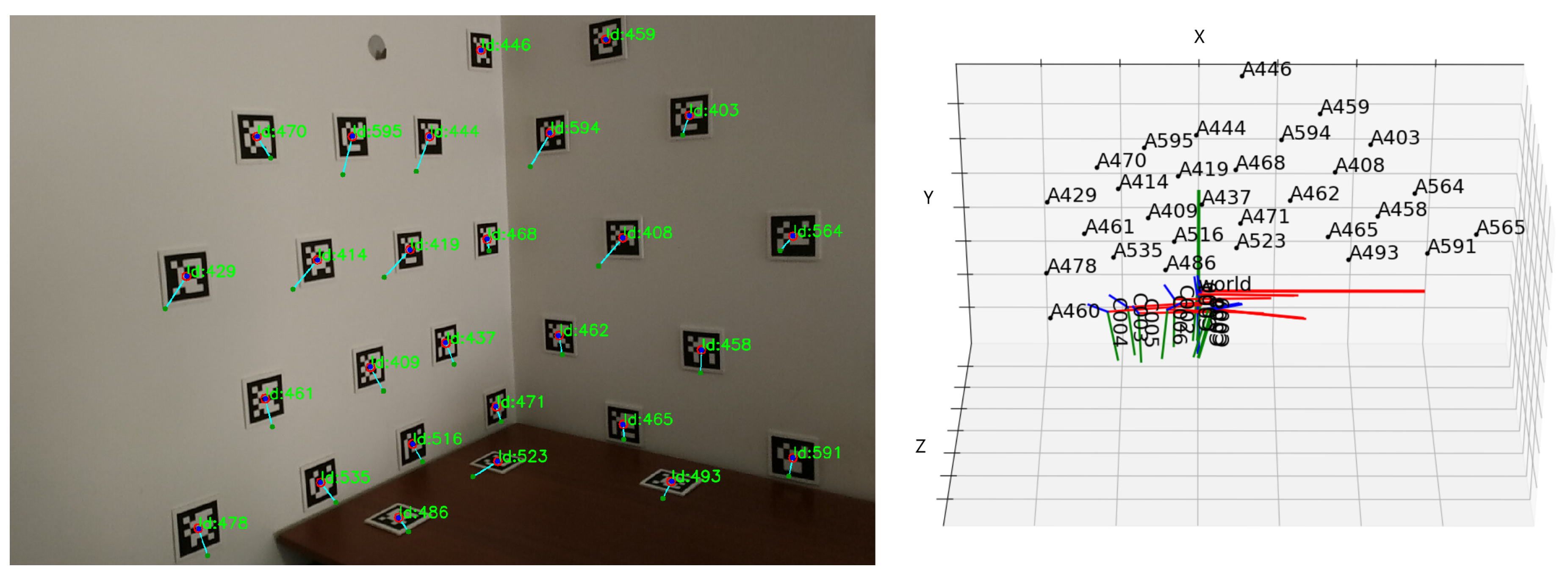
3. Optimization of Camera Pose Estimation Using Fiducial Markers
4. Texture Refinement and Marker Removal
4.1. Navier-Stokes-Based Inpainting
4.1.1. Inpaiting of Homogeneous Regions through Image Blurring
4.1.2. Inpainting Non-Detected Markers: Cross-Inpainting
4.1.3. 3D Point Cloud with RGB Visualisation
5. Results
5.1. Evaluation Methodology
5.2. Datasets
5.3. Collecting Ground Truth
5.4. Evaluation Procedure
5.5. MeetingRoom Dataset
5.6. Lobby Dataset
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Achille, C.; Adami, A.; Chiarini, S.; Cremonesi, S.; Fassi, F.; Fregonese, L.; Taffurelli, L. UAV-Based Photogrammetry and Integrated Technologies for Architectural Applications—Methodological Strategies for the After-Quake Survey of Vertical Structures in Mantua (Italy). Sensors 2015, 15, 15520–15539. [Google Scholar] [CrossRef] [Green Version]
- Pérez, L.; Rodríguez, Í.; Rodríguez, N.; Usamentiaga, R.; García, D.F. Robot Guidance Using Machine Vision Techniques in Industrial Environments: A Comparative Review. Sensors 2016, 16, 335. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Chen, H.; Waslander, S.; Yang, T.; Zhang, S.; Xiong, G.; Liu, K. Toward a More Complete, Flexible, and Safer Speed Planning for Autonomous Driving via Convex Optimization. Sensors 2018, 18, 2185. [Google Scholar] [CrossRef] [Green Version]
- Trinidad-Fernández, M.; Beckwée, D.; Cuesta-Vargas, A.; González-Sánchez, M.; Moreno, F.A.; González-Jiménez, J.; Joos, E.; Vaes, P. Validation, Reliability, and Responsiveness Outcomes Of Kinematic Assessment With An RGB-D Camera To Analyze Movement In Subacute And Chronic Low Back Pain. Sensors 2020, 20, 689. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vázquez-Arellano, M.; Griepentrog, H.; Reiser, D.; Paraforos, D. 3-D Imaging Systems for Agricultural Applications—A Review. Sensors 2016, 16, 618. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Di Angelo, L.; Di Stefano, P.; Guardiani, E.; Morabito, A.E.; Pane, C. 3D Virtual Reconstruction of the Ancient Roman Incile of the Fucino Lake. Sensors 2019, 19, 3505. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fan, H.; Yao, W.; Fu, Q. Segmentation of Sloped Roofs from Airborne LiDAR Point Clouds Using Ridge-Based Hierarchical Decomposition. Remote Sens. 2014, 6, 3284–3301. [Google Scholar] [CrossRef] [Green Version]
- Henn, A.; Gröger, G.; Stroh, V.; Plümer, L. Model driven reconstruction of roofs from sparse LIDAR point clouds. Int. J. Photogramm. Remote Sens. 2013, 76, 17–29. [Google Scholar] [CrossRef]
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohi, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A. KinectFusion: Real-time dense surface mapping and tracking. In Proceedings of the 2011 10th IEEE International Symposium on Mixed and Augmented Reality, Basel, Switzerland, 26–29 October 2011; pp. 127–136. [Google Scholar] [CrossRef] [Green Version]
- Han, J.; Shao, L.; Xu, D.; Shotton, J. Enhanced Computer Vision With Microsoft Kinect Sensor: A Review. IEEE Trans. Cybern. 2013, 43, 1318–1334. [Google Scholar] [CrossRef]
- Remondino, F.; Nocerino, E.; Toschi, I.; Menna, F. A critical review of automated photogrammetric processing of large datasets. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, XLII-2/W5, 591–599. [Google Scholar] [CrossRef] [Green Version]
- Mousavi, V.; Khosravi, M.; Ahmadi, M.; Noori, N.; Haghshenas, S.; Hosseininaveh, A.; Varshosaz, M. The performance evaluation of multi-image 3D reconstruction software with different sensors. Measurement 2018, 120, 1–10. [Google Scholar] [CrossRef]
- Westoby, M.; Brasington, J.; Glasser, N.; Hambrey, M.; Reynolds, J. ‘Structure-from-Motion’ photogrammetry: A low-cost, effective tool for geoscience applications. Geomorphology 2012, 179, 300–314. [Google Scholar] [CrossRef] [Green Version]
- Tsai, C.Y.; Huang, C.H. Indoor Scene Point Cloud Registration Algorithm Based on RGB-D Camera Calibration. Sensors 2017, 17, 1874. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, H.; Li, H.; Liu, X.; Luo, J.; Xie, S.; Sun, Y. A Novel Method for Extrinsic Calibration of Multiple RGB-D Cameras Using Descriptor-Based Patterns. arXiv 2018, arXiv:eess.IV/1807.07856. [Google Scholar] [PubMed] [Green Version]
- Chen, C.; Yang, B.; Song, S.; Tian, M.; Li, J.; Dai, W.; Fang, L. Calibrate Multiple Consumer RGB-D Cameras for Low-Cost and Efficient 3D Indoor Mapping. Remote Sens. 2018, 10, 328. [Google Scholar] [CrossRef] [Green Version]
- Diakité, A.; Zlatanova, S. First experiments with the tango tablet for indoor scanning. ISPRS Anna. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, III-4, 67–72. [Google Scholar] [CrossRef]
- Li, X.; Kesavadas, T. Surgical Robot with Environment Reconstruction and Force Feedback. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 1861–1866. [Google Scholar] [CrossRef]
- Naseer, M.; Khan, S.; Porikli, F. Indoor Scene Understanding in 2.5/3D for Autonomous Agents: A Survey. IEEE Access 2019, 7, 1859–1887. [Google Scholar] [CrossRef]
- Li, L.; Su, F.; Yang, F.; Zhu, H.; Li, D.; Xinkai, Z.; Li, F.; Liu, Y.; Ying, S. Reconstruction of Three-Dimensional (3D) Indoor Interiors with Multiple Stories via Comprehensive Segmentation. Remote Sens. 2018, 10, 1281. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Zheng, X.; Chen, R.; Hanjiang, X.; Guo, S. Image-Based Localization Aided Indoor Pedestrian Trajectory Estimation Using Smartphones. Sensors 2018, 18, 258. [Google Scholar] [CrossRef] [Green Version]
- Pan, S.; Shi, L.; Guo, S. A Kinect-Based Real-Time Compressive Tracking Prototype System for Amphibious Spherical Robots. Sensors 2015, 15, 8232–8252. [Google Scholar] [CrossRef]
- Jamali, A.; Boguslawski, P.; Abdul Rahman, A. A Hybrid 3D Indoor Space Model. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, XLII-2/W1, 75–80. [Google Scholar] [CrossRef] [Green Version]
- Zollhöfer, M.; Patrick Stotko, A.G.; Theobalt, C.; Nießner, M.; Klein, R.; Kolb, A. State of the Art on 3D Reconstruction with RGB-D Cameras. Comput. Graph. Forum 2018, 37, 625–652. [Google Scholar] [CrossRef]
- Gokturk, S.; Yalcin, H.; Bamji, C. A Time-Of-Flight Depth Sensor—System Description, Issues and Solutions. In Proceedings of the 2004 Conference on Computer Vision and Pattern Recognition Workshop, Washington, DC, USA, 27 June–2 July 2004. [Google Scholar]
- Minou, M.; Kanade, T.; Sakai, T. Method of time-coded parallel planes of light for depth measurement. IEICE Trans. 1981, 64, 521–528. [Google Scholar]
- Will, P.; Pennington, K. Grid coding: A preprocessing technique for robot and machine vision. Artif. Intell. 1971, 2, 319–329. [Google Scholar] [CrossRef]
- Curless, B.; Levoy, M. A Volumetric Method for Building Complex Models from Range Images. In Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 4–9 August 1996; pp. 303–312. [Google Scholar]
- Rusinkiewicz, S.; Hall-holt, O.; Levoy, M. Real-Time 3D Model Acquisition. ACM Trans. Graph. 2002, 21. [Google Scholar] [CrossRef]
- Minguez, J.; Montesano, L.; Lamiraux, F. Metric-based iterative closest point scan matching for sensor displacement estimation. IEEE Trans. Rob. 2006, 22, 1047–1054. [Google Scholar] [CrossRef] [Green Version]
- Manjunath, B.; Shekhar, C.; Chellappa, R. A New Approach to Image Feature Detection With Applications. Pattern Recognit. 1996, 29, 627–640. [Google Scholar] [CrossRef]
- Lowe, D. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vision 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded Up Robust Features. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Patwary, M.J.A.; Parvin, S.; Akter, S. Significant HOG-Histogram of Oriented Gradient Feature Selection for Human Detection. Int. J. Comput. Appl. 2015, 132, 20–24. [Google Scholar] [CrossRef]
- Canny, J. A Computational Approach To Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–689. [Google Scholar] [CrossRef]
- Sobel, I. An Isotropic 3x3 Image Gradient Operator. Presentation at Stanford A.I. Project 1968, 2014.
- Harris, C.; Stephens, M. A Combined Corner and Edge Detector. In Proceedings of the Fourth Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988; Volume 1988, pp. 147–151. [Google Scholar] [CrossRef]
- Smith, S.; Brady, M. SUSAN—A new approach to low level image processing. Int. J. Comput. Vis. 1997, 23, 45–78. [Google Scholar] [CrossRef]
- Kenney, C.; Zuliani, M.; Manjunath, B. An Axiomatic Approach to Corner Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Lindeberg, T.; Li, M.X. Segmentation and Classification of Edges Using Minimum Description Length Approximation and Complementary Junction Cues. Comput. Vis. Image Underst. 1997, 67, 88–98. [Google Scholar] [CrossRef] [Green Version]
- Rosten, E.; Drummond, T. Machine Learning for High-Speed Corner Detection. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Lindeberg, T. Feature Detection with Automatic Scale Selection. Int. J. Comput. Vis. 1998, 30, 77–116. [Google Scholar] [CrossRef]
- Matas, J.; Chum, O.; Urban, M.; Pajdla, T. Robust Wide Baseline Stereo from Maximally Stable Extremal Regions. Image Vis. Comput. 2004, 22, 761–767. [Google Scholar] [CrossRef]
- Deng, H.; Zhang, W.; Mortensen, E.; Dietterich, T.; Shapiro, L. Principal Curvature-Based Region Detector for Object Recognition. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar]
- Lindeberg, T. Discrete Scale-Space Theory and the Scale-Space Primal Sketch. Ph.D. Thesis, Department of Numerical Analysis and Computing Science, Royal Institute of Technology, Stockholm, Sweden, 1991. [Google Scholar]
- Jakubovic, A.; Velagic, J. Image Feature Matching and Object Detection Using Brute-Force Matchers. In Proceedings of the 2018 International Symposium ELMAR, Zadar, Croatia, 16–19 September 2018. [Google Scholar]
- Muja, M.; Lowe, D. Fast Approximate Nearest Neighbors with Automatic Algorithm Configuration. VISAPP 2009, 1, 331–340. [Google Scholar]
- Mount, D.; Netanyahu, N.; Le Moigne, J. Efficient Algorithms for Robust Feature Matching. Pattern Recognit. 2003, 32. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.S.; Hung, Y.P.; Cheng, J.B. RANSAC-Based DARCES: A new approach to fast automatic registration of partially overlapping range images. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 1229–1234. [Google Scholar] [CrossRef] [Green Version]
- Martínez, J.; González-Jiménez, J.; Morales, J.; Mandow, A.; Garcia, A. Mobile robot motion estimation by 2D scan matching with genetic and iterative closest point algorithms. J. Field Rob. 2006, 23, 21–34. [Google Scholar] [CrossRef]
- Autodesk. ReCap: Reality Capture and 3D Scanning Software for Intelligent Model Creation. Available online: https://www.autodesk.com/products/recap/overview (accessed on 5 February 2020).
- Alicevision. Meshroom: Open Source Photogrammetry Software. Available online: https://alicevision.org/#meshroom (accessed on 5 February 2020).
- Thrun, S.; Leonard, J.J. Simultaneous Localization and Mapping. Springer Handb. Rob. 2008, 871–889. [Google Scholar] [CrossRef] [Green Version]
- Jorge Nocedal, S.J.W. Numerical Optimization; Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Agarwal, S.; Snavely, N.; M. Seitz, S.; Szeliski, R. Bundle Adjustment in the Large. In Computer Vision—ECCV 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 29–42. [Google Scholar] [CrossRef]
- Harltey, A.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Romero Ramirez, F.; Muñoz-Salinas, R.; Medina-Carnicer, R. Speeded Up Detection of Squared Fiducial Markers. Image Vision Comput. 2018, 76. [Google Scholar] [CrossRef]
- Garrido-Jurado, S.; Muñoz-Salinas, R.; Madrid-Cuevas, F.; Medina-Carnicer, R. Generation of fiducial marker dictionaries using Mixed Integer Linear Programming. Pattern Recognit. 2015, 51. [Google Scholar] [CrossRef]
- Hornegger, J.; Tomasi, C. Representation issues in the ML estimation of camera motion. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999. [Google Scholar]
- Schmidt, J.; Niemann, H. Using Quaternions for Parametrizing 3-D Rotations in Unconstrained Nonlinear Optimization. In Vmv; Aka GmbH: Stuttgart, Germany, 2001. [Google Scholar]
- Oliphant, T. Python for Scientific Computing. Comput. Sci. Eng. 2007, 9, 10–20. [Google Scholar] [CrossRef] [Green Version]
- FARO. Focus Laser Scanner Series. Available online: https://www.faro.com/products/construction-bim/faro-focus (accessed on 5 February 2020).
- Klingensmith, M.; Dryanovski, I.; Srinivasa, S.; Xiao, J. Chisel: Real Time Large Scale 3D Reconstruction Onboard a Mobile Device using Spatially Hashed Signed Distance Fields. In Robotics: Science and Systems XI; RSS: Rome, Italy, 2015. [Google Scholar]
- Rote, G. Computing the minimum Hausdorff distance between two point sets on a line under translation. Inf. Process. Lett. 1991, 38, 123–127. [Google Scholar] [CrossRef]
- Oliveira, M.; Castro, A.; Madeira, T.; Dias, P.; Santos, V. A General Approach to the Extrinsic Calibration of Intelligent Vehicles Using ROS. In Iberian Robotics Conference; Springer: Cham, Switzerland, 2019. [Google Scholar]





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time (mm:ss) | |
|---|---|
| ICP | 03:02 |
| Our Approach | 03:50 |
| Mean (m) | RMS (m) | min (m) | max (m) | |
|---|---|---|---|---|
| Google Tango | 0.0337 | 0.0442 | 0.0001 | 0.1500 |
| ICP | 0.0259 | 0.0372 | 0.0001 | 0.1500 |
| Our Approach | 0.0247 | 0.0324 | 0.0001 | 0.1500 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Madeira, T.; Oliveira, M.; Dias, P. Enhancement of RGB-D Image Alignment Using Fiducial Markers. Sensors 2020, 20, 1497. https://doi.org/10.3390/s20051497
Madeira T, Oliveira M, Dias P. Enhancement of RGB-D Image Alignment Using Fiducial Markers. Sensors. 2020; 20(5):1497. https://doi.org/10.3390/s20051497
Chicago/Turabian StyleMadeira, Tiago, Miguel Oliveira, and Paulo Dias. 2020. "Enhancement of RGB-D Image Alignment Using Fiducial Markers" Sensors 20, no. 5: 1497. https://doi.org/10.3390/s20051497
APA StyleMadeira, T., Oliveira, M., & Dias, P. (2020). Enhancement of RGB-D Image Alignment Using Fiducial Markers. Sensors, 20(5), 1497. https://doi.org/10.3390/s20051497