Single Image De-Raining via Improved Generative Adversarial Nets †


Abstract
:1. Introduction
- In contrast to previous CNN (GAN)-based de-raining methods, the proposed model uses the divide-and-conquer strategy. The de-raining task is decomposed into rain estimating, rain removing, and detail refining sub-tasks.
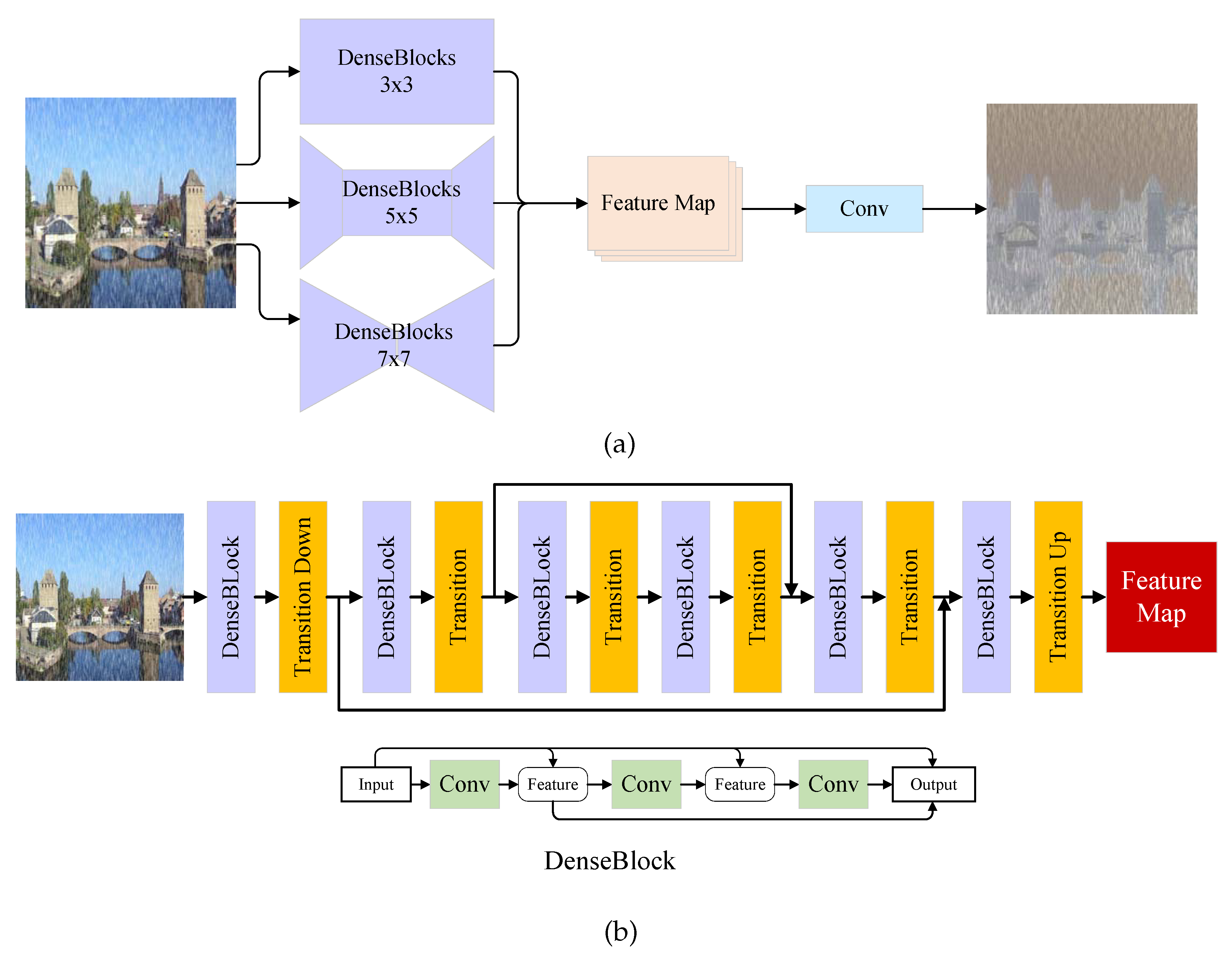
- The rain estimation network (REN) is proposed to generate a rain location map to indicate whether rain streaks exist or not at given location. The estimated rain location map can guide the followed de-raining generative network to generate better de-raining result.
- GAN is proposed to de-rain the rainy image. Squeeze-and-Exciation (SE) modules are used in generative network. Instance normalization (IN) [14] is used to normalize the features. The trainable perceptual loss function is used to guide the network to generate rain-free image which is close to real-world rain-free image semantically.
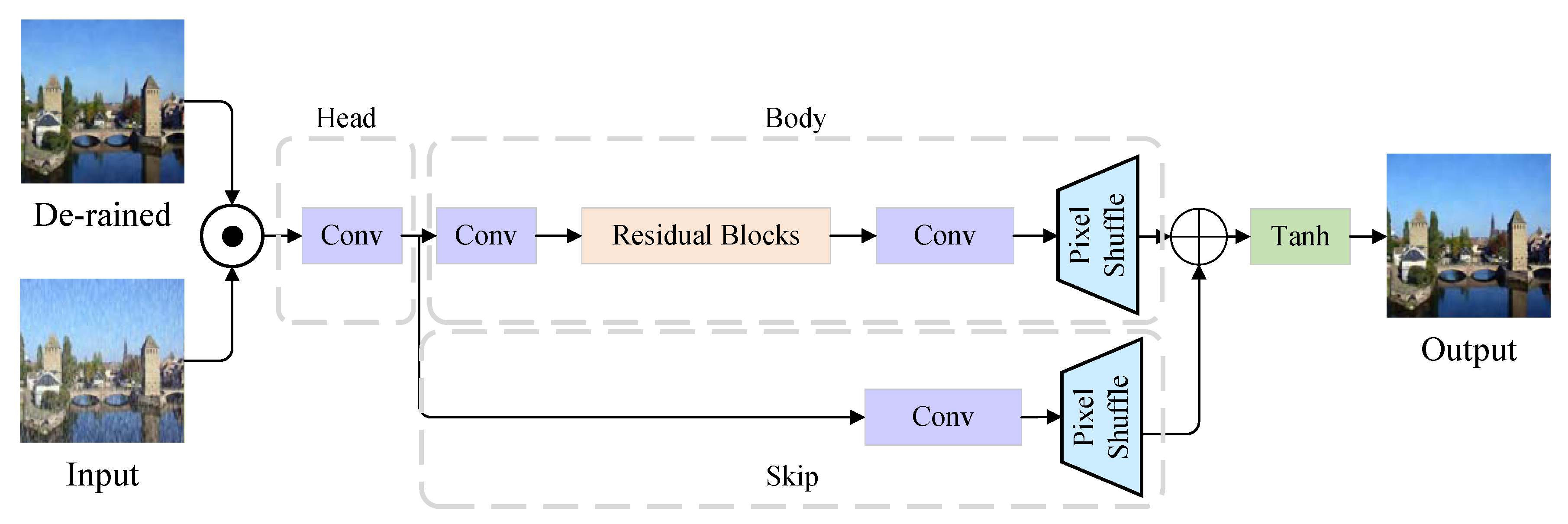
- A refinement network (RFN) to refine the de-rained image and restore more details is proposed. The input of RFN is the concatenation of the output of the generator and the original rainy image. In this way, RFN can recover the details lost in the generator.
- The ablation study demonstrates that the proposed REN and RFN greatly improves the de-raining performance with quite a few increases in parameters. The experimental results on two synthetic datasets and real-world images show that the proposed method outperforms state-of-the-art de-raining methods. Figure 1 presents an example of the de-raining result. It can be observed that compared with GAN-SID [13] (state-of-the-art work), the proposed IGAN-SID can remove the rain streaks and enhance details.
2. Related Work
2.1. Prior-Based Methods
2.2. CNN-Based Methods
2.3. GAN-Based Work
3. IGAN-SID Network
3.1. The Rain Estimation Network
3.2. The Generative Adversarial Network
3.3. The Refinement Network
3.4. The Objective Function
3.4.1. GAN Loss
3.4.2. Perceptual Loss
3.4.3. Per-pixel Loss
3.4.4. Total Loss
4. Experiments
4.1. Datasets
4.2. Implementation Details
4.3. Results in Synthetic Datasets
4.3.1. Ablation experiments
4.3.2. Comparison with state-of-the-art methods
4.4. Results on Real-world Images
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kim, J.H.; Lee, C.; Sim, J.Y.; Kim, C.S. Single-image deraining using an adaptive nonlocal means filter. In Proceedings of the Image Processing (ICIP), 2013 20th IEEE International Conference, Melbourne, Australia, 15–18 September 2013; pp. 914–917. [Google Scholar]
- Zhu, L.; Fu, C.W.; Lischinski, D.; Heng, P.A. Joint bilayer optimization for single-image rain streak removal. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2526–2534. [Google Scholar]
- Zhang, H.; Patel, V.M. Convolutional sparse and low-rank coding-based rain streak removal. In Proceedings of the Applications of Computer Vision (WACV), 2017 IEEE Winter Conference, Santa Rosa, CA, USA, 24–31 March 2017; pp. 1259–1267. [Google Scholar]
- Li, Y.; Tan, R.T.; Guo, X.; Lu, J.; Brown, M.S. Rain streak removal using layer priors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2736–2744. [Google Scholar]
- Fu, X.; Huang, J.; Ding, X.; Liao, Y.; Paisley, J. Clearing the skies: A deep network architecture for single-image rain removal. IEEE Trans. Image Process. 2017, 26, 2944–2956. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, H.; Patel, V.M. Density-aware single image de-raining using a multi-stream dense network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (CVPR), Salt Lake City, UA, USA, 18–22 June 2018. [Google Scholar]
- Fu, X.; Huang, J.; Zeng, D.; Huang, Y.; Ding, X.; Paisley, J. Removing rain from single images via a deep detail network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, GA, USA, 2017; pp. 1715–1723. [Google Scholar]
- Yang, W.; Tan, R.T.; Feng, J.; Liu, J.; Guo, Z.; Yan, S. Deep joint rain detection and removal from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1357–1366. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 2, 2672–2680. [Google Scholar]
- Zhang, H.; Sindagi, V.; Patel, V.M. Image de-raining using a conditional generative adversarial network. IEEE Trans. Circuits Syst. Video Technol. 2017. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Xu, C.; Wang, C.; Tao, D. Perceptual adversarial networks for image-to-image transformation. IEEE Trans. Image Process. 2018, 27, 4066–4079. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xiang, P.; Wang, L.; Wu, F.; Cheng, J.; Zhou, M. Single-image de-raining with feature-supervised generative adversarial network. IEEE Signal Process Lett. 2019, 26, 650–654. [Google Scholar] [CrossRef]
- Li, S.; Hou, Y.; Yue, H.; Guo, Z. Single Image De-Raining via Generative Adversarial Nets. In Proceedings of the 2019 IEEE International Conference on Multimedia and Expo (ICME), Shanghai, China, 8–12 July 2019; pp. 1192–1197. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance normalization: The missing ingredient for fast stylization. arXiv 2016, arXiv:1607.08022. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided image filtering. In European Conference on Computer Vision; Springer: Berlin, Germany, 2010; pp. 1–14. [Google Scholar]
- Ren, D.; Zuo, W.; Hu, Q.; Zhu, P.; Meng, D. Progressive image deraining networks: A better and simpler baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Wang, T.; Yang, X.; Xu, K.; Chen, S.; Zhang, Q.; Lau, R.W. Spatial Attentive Single-Image Deraining with a High Quality Real Rain Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Wang, K.; Gou, C.; Duan, Y.; Lin, Y.; Zheng, X.; Wang, F.Y. Generative adversarial networks: introduction and outlook. IEEE/CAA J. Acta Autom. Sin. 2017, 4, 588–598. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UA, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Cai, G.; Wang, Y.; He, L.; Zhou, M. Unsupervised domain adaptation with adversarial residual transform networks. IEEE Trans. Neural Netw. Learn. Syst. 2019. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. arXiv 2017, arXiv:1709.015077. [Google Scholar]
- Yu, J.; Fan, Y.; Yang, J.; Xu, N.; Wang, Z.; Wang, X.; Huang, T. Wide activation for efficient and accurate image super-resolution. arXiv 2018, arXiv:1808.08718. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal Process Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Saad, M.A.; Bovik, A.C.; Charrier, C. Blind image quality assessment: A natural scene statistics approach in the DCT domain. IEEE Trans. Image Process. 2012, 21, 3339–3352. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Liu, B.; Huang, H.; Bovik, A.C. No-reference image quality assessment based on spatial and spectral entropies. Signal Process. Image Commun. 2014, 29, 856–863. [Google Scholar] [CrossRef]
- Li, S.; Araujo, I.B.; Ren, W.; Wang, Z.; Tokuda, E.K.; Junior, R.H.; Cesar-Junior, R.; Zhang, J.; Guo, X.; Cao, X. Single image deraining: A comprehensive benchmark analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3838–3847. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Yasarla, R.; Patel, V.M. Uncertainty Guided Multi-Scale Residual Learning-using a Cycle Spinning CNN for Single Image De-Raining. arXiv 2019, arXiv:1906.11129. [Google Scholar]
- Middleton, W.E.K. Vision through the atmosphere. In Geophysik II/Geophysics II; Springer: Berlin, Germany, 1957; pp. 254–287. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| w/o IN | w/o SE | w/o PL | GAN+REN | GAN+REN+RFN | |
|---|---|---|---|---|---|
| PSNR | 27.85 | 30.69 | 30.58 | 31.06 | 32.27 |
| SSIM | 0.880 | 0.927 | 0.925 | 0.934 | 0.942 |
| GAN | GAN+REN | GAN+REN+RFN | |
|---|---|---|---|
| Parameters (M) | 8.475 | 8.666 | 9.862 |
| Time (s) | 0.029 | 0.031 | 0.037 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ren, Y.; Nie, M.; Li, S.; Li, C. Single Image De-Raining via Improved Generative Adversarial Nets. Sensors 2020, 20, 1591. https://doi.org/10.3390/s20061591
Ren Y, Nie M, Li S, Li C. Single Image De-Raining via Improved Generative Adversarial Nets. Sensors. 2020; 20(6):1591. https://doi.org/10.3390/s20061591
Chicago/Turabian StyleRen, Yi, Mengzhen Nie, Shichao Li, and Chuankun Li. 2020. "Single Image De-Raining via Improved Generative Adversarial Nets" Sensors 20, no. 6: 1591. https://doi.org/10.3390/s20061591
APA StyleRen, Y., Nie, M., Li, S., & Li, C. (2020). Single Image De-Raining via Improved Generative Adversarial Nets. Sensors, 20(6), 1591. https://doi.org/10.3390/s20061591