4.2.2. Approximate Solution
The exact solution may be inefficient for large-scale tracking applications where there are hundreds of thousands or millions of passive tags deployed in the monitoring area. Under this scenario, a large number (dozens or even hundreds) of tags may be detected by a reader simultaneously. As a result, the time complexity of generation is extremely high by taking the overlap of multiple detected tags. Moreover, due to the intensive deployment, some RFID tags are close to each other, which results that the RRs of these tags are almost the same. To avoid redundant computation, we further propose an approximate solution to generate the for each reader. The approximate solution consists of two steps: (1) tag group generation and (2) determination. Next, we introduce each step in detail.
First, we divide the RFID tags into tag groups defined below.
Definition 5. Tag Group. A tag group G contains a collection of tags satisfying that
- (i)
, , where is the distance between and and is the distance threshold.
- (ii)
where is the size of the tag group, i.e., the number of tags contained in G, and is the size threshold.
Note that we use the distance threshold to control the extension ability of a tag group, i.e., more tags may be included in a tag group with a greater . On the other hand, we use the size threshold to avoid that sparse tags which have big distance are included into a tag group under the scenario of great .
Algorithm 2 shows the pseudo-code of the tag group generation, where the specific steps are as follows:
(s1) Initializing a candidate tag group G and generating a seed list (denoted by ) which is the copy of tag set (Line2-3).
(s2) Selecting a tag randomly as seed and removing it from the seed list (Lines 5 and 6).
(s3) Computing the distance between each tag and the seed (Line 9). Adding into the candidate tag group G and removing from the tag set , if the distance is smaller than the given distance threshold . Otherwise, removing from the seed list (Line 10-14).
(s4) Repeating steps (s2) and (s3) until the seed list is empty, which means the distances between the remaining tags in the tag set and any tag in the candidate tag group G are greater than .
(s5) Adding the candidate tag group into the set of tag groups (Line 15).
(s6) Repeating steps (s1)–(s5) until the tag set is empty, i.e., all tags are classified into a certain tag group.
(s7) Determining each size of the candidate tag group. If the size is greater than the give size threshold
, it is a real tag group. Otherwise, remove the candidate tag group from
(Line 16–18). Finally, returning the set of tag group
.
| Algorithm 2: TagGroupGen(, , ). |
![Sensors 20 01711 i002]() |
The time complexity of tag group generation is and in the worst case where each tag is considered as a tag group and in the best case where all RFID tags are considered as a tag group, respectively. Thus the average time complexity of tag group generation is . Moreover, since our work is proposed based on the M-RFID model where RFID tags are fixed deployed in the monitoring area, the tag group generation only needs to conduct one time. On the other hand, it is notable that an RFID tag may not belong to any tag group. For such tags, they are considered independent and used to determination with aggregated tags (to be introduced later) together.
After dividing tags into tag groups, we use the aggregated tags (generated based on the tag groups) to determine the for each reader.
Definition 6. Aggregated Tag. For a tag group G, the aggregated tag is the representation of G. Moreover, the reading of by a reader at a certain time point is computed based on the readings of tags by .
Given an RFID reader
, suppose the tag set detected by
simultaneously (i.e., at a certain time point
t), is
. We first determine each tag
belonging to which tag group. Then we generate the aggregate tags of corresponding tag groups used for
’s
generation. Since RFID tags are fixed, it is easy to locate tag
belongs to which tag group by building an inverted index. Specifically, during the tag group generation, we build an inverted index for each tag
to record the tag belongs to which tag group. The structure of the inverted index is shown in
Figure 3. Note that as mentioned earlier, an RFID tag may not belong to any tag group. Accordingly, in the inverted index, the tag points to ‘Null’ if it does not belongs to a tag group. Next, we introduce how to generate an aggregate tag for each tag group used for
’s
generation.
Suppose the tags detected by simultaneously belongs to w tag groups where ( and ) and the reading of by is . We aim to obtain the reading of the aggregated tag corresponding to the tag group , denoted by .
Since any tag
is detected by reader
at a certain time point
t, we have
,
. In addition, we assign a unique ID for
based on an independent number system. Next, we need to determine the location of the aggregated tag
and the number of detection times
. In real applications, the distance between an RFID tag
and a reader
is smaller, the reading rate of
by
is higher, and thereby the location of the
(used for determining the location of
) is more important. Therefore, we compute
and
by the weighted average of corresponding information of various tags, as shown below.
The pseudo-code of aggregated tag generation is shown in Algorithm 3.
| Algorithm 3: AggregatedTagGen(, ) |
![Sensors 20 01711 i003]() |
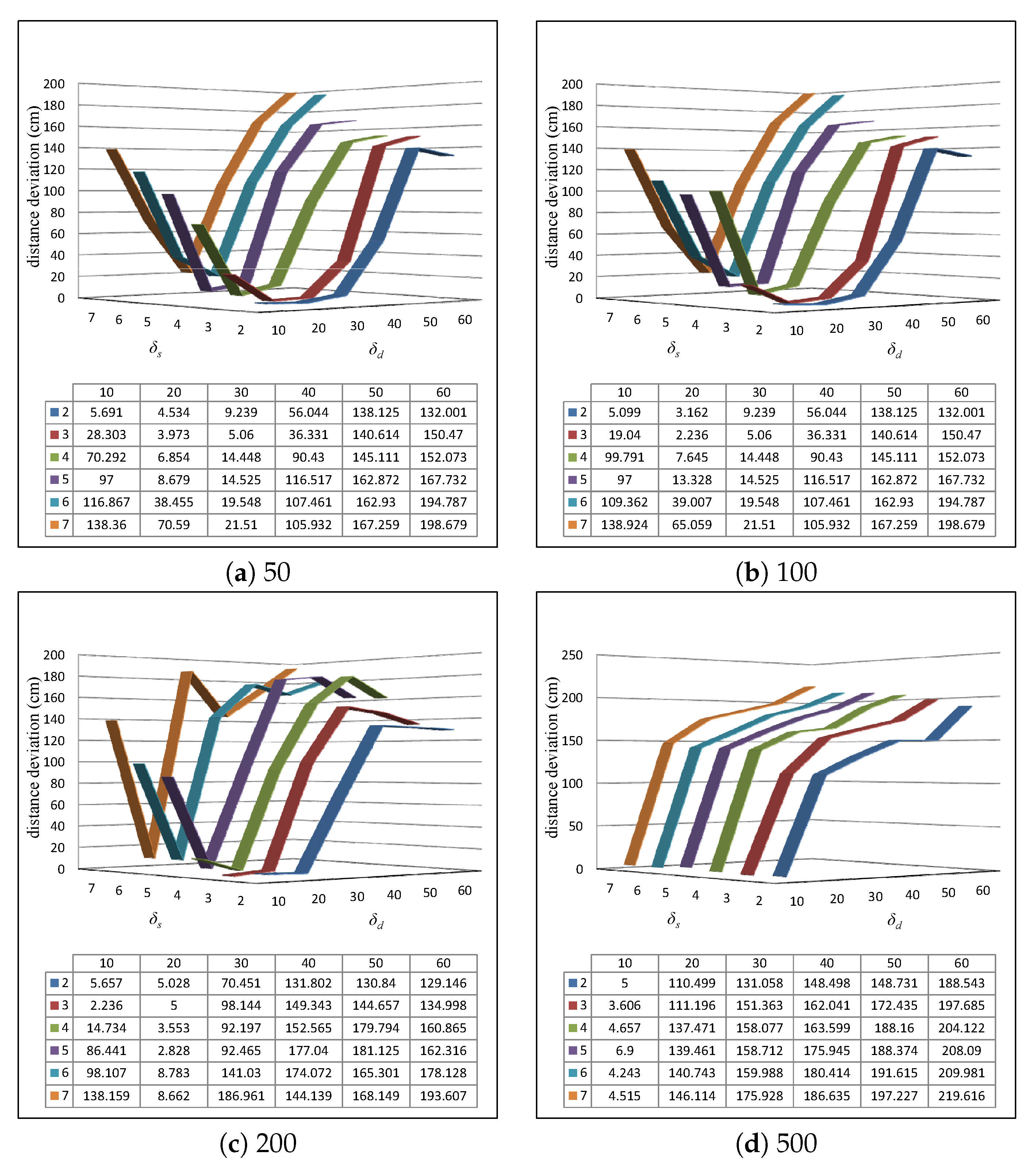
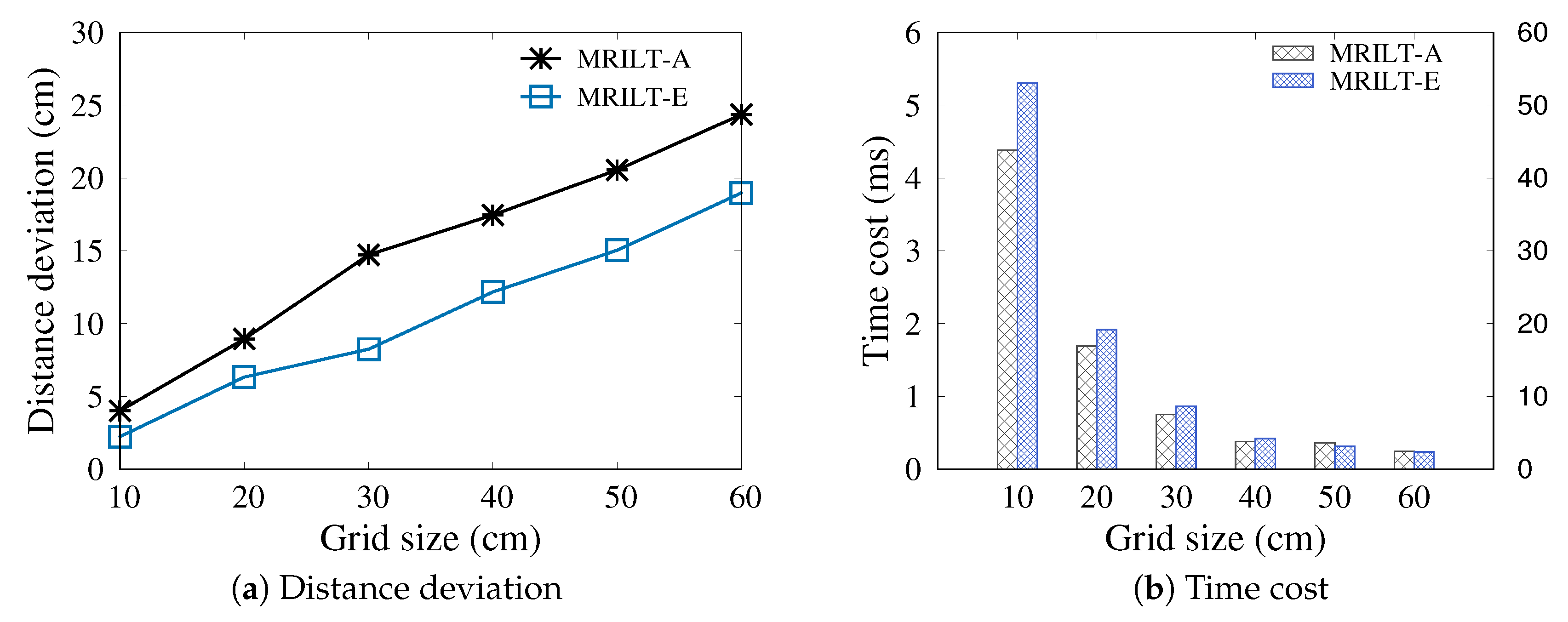
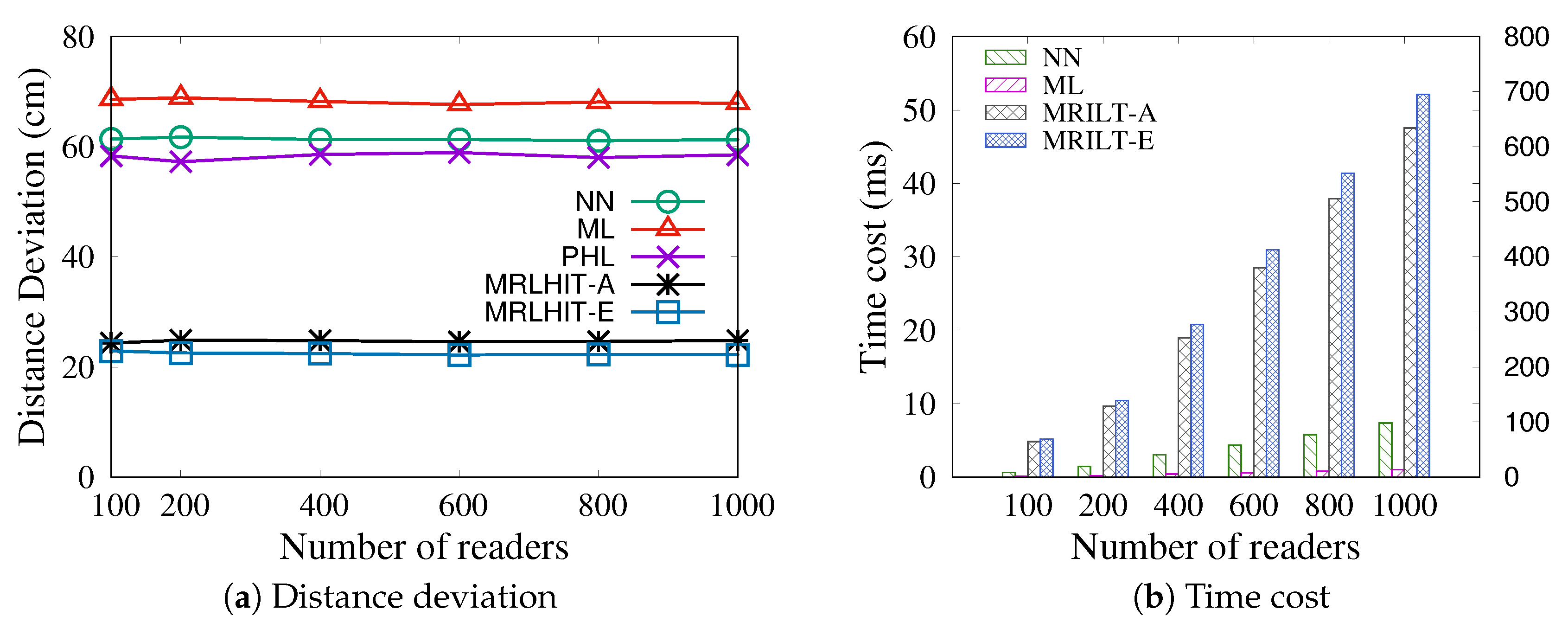
Example 4. (Example 1 Continued) We map the distribution of ten tags detected by simultaneously at time into a 2D coordinate system, as shown in Figure 4a. Additionally, the readings of tags by is shown in Table 1. The tag groups generated based on Algorithm 2 with cm and is shown in Figure 4b. Note that the candidate tag group is removed since its size is smaller than the threshold . Finally, based on Algorithm 3, the readings of corresponding aggregated tags are shown in Table 2. After aggregated tag generation, we can determine the
for each reader based on the aggregated tags. The pseudo-code is shown in Algorithm 4, where for each reader
, we first generate the readings of aggregated tags based on the readings of tags detected by
simultaneously (Line 3). Note that the tags which do not belong to any tag group are also used for PLR determination. Thus the tag list
is generated by combining such independent tags and aggregated tags together to determine the PLR of
(Line 5). Afterwards, the PLR of
is determined by intersecting the RR of each tag in the tag list
, where the procedure is the same as the exact solution (Line 7-16). Suppose
n tags are divided into
tag groups. Then the time complexity of approximate solution becomes
which is much smaller than the exact solution since
. Note that the computational cost of tag group generation is not included since it can be pre-computed once the tag deployment finished.
| Algorithm 4: PLRGenApproximate(, , , , , ) |
![Sensors 20 01711 i004]() |
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}