3.1. Multi-View Sequence Acquisition
We used multiple optical sensors attached to a road vehicle for data acquisition, as shown in
Figure 2. Two types of optical sensors (cameras) were used, where one served for localization and the other for crack detection purposes. For image-based localization, two large field-of-view cameras were used to cover a wide surface area (the entire bridge deck) and to compensate the relative pose changes through performing stereo reconstruction of 3D points on the bridge deck in real-scale. The other two cameras were used for crack detection and have a longer focal length to capture the surface of a bridge deck with high resolution images (provides two-times finer resolution than the other pair of cameras).
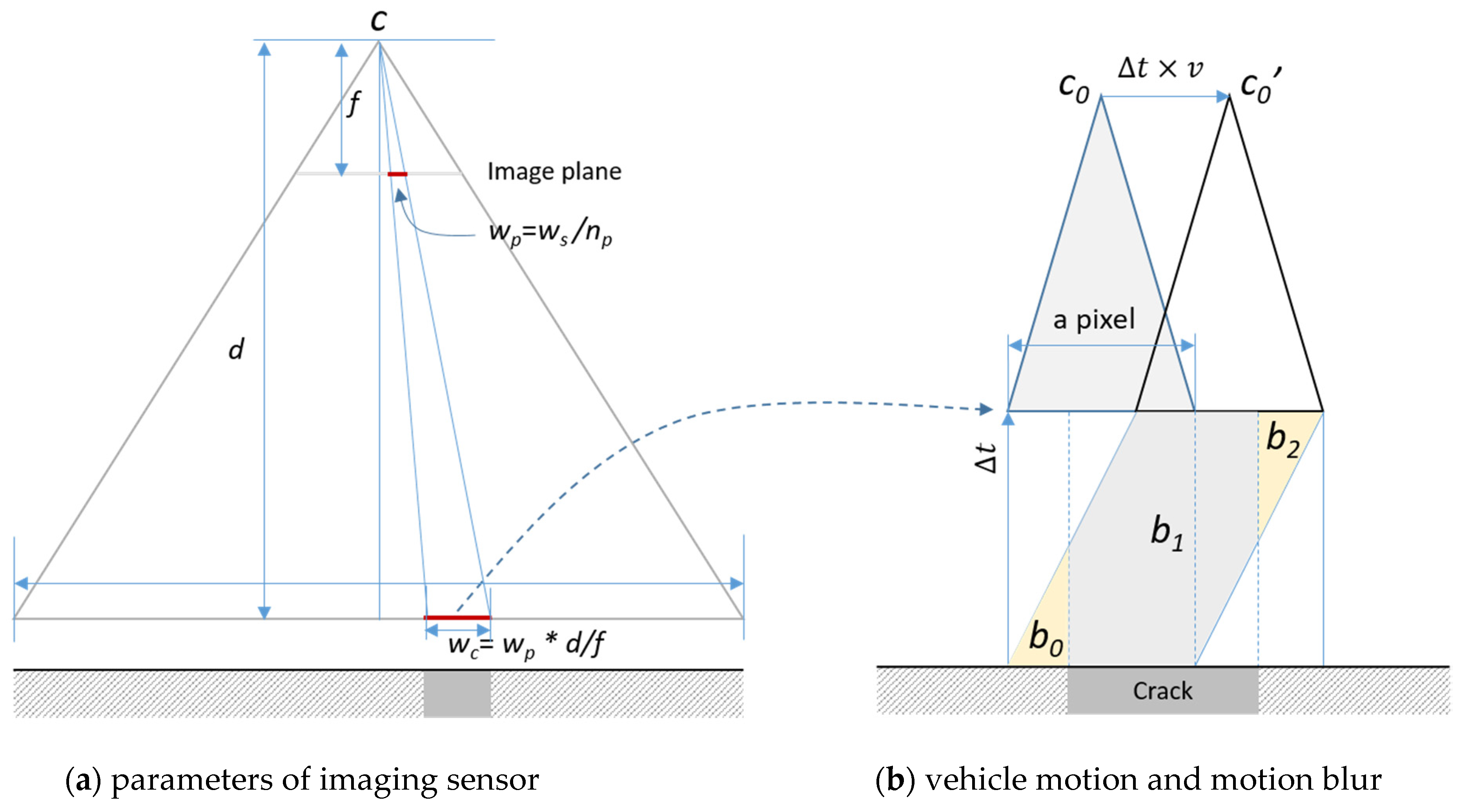
The typical width of a crack pixel projected on the ground,
wc, should be smaller than the (desired) minimum measurable width of cracks to increase the accuracy of crack measurements, as shown in
Figure 3a, where
ws is width of the sensor,
np is the number of pixels,
f is the focal length, and
d is the distance between the focal point and the target surface. Another important factor that affects the accuracy of the measurement is motion blur, caused when the vehicle is moving at high speed. In
Figure 3b,
Δt represents the exposure time and
v is the speed of the vehicle. During
Δt, the proportion (
b0+
b2)/(
Δt×wc) of the value of one pixel is obtained and accumulated from the adjacent area, and this creates blur around the boundary of a crack pixel. The smaller
Δt is, the blur will decrease. However, noise will increase under low illumination conditions and the results depend on the changes in ambient lighting. If needed, an additional light source is required to decrease this noise level.
The four imaging sensors capture multi-view sequences along the direction of traffic. The sensors are synchronized by a trigger signal. The ith sequence si consists of multi-view frames fi,j, (0 ≤ j < ni). Each frame has four images I0, I1, I0h, and I1h. The images are undistorted using the distortion parameters. The frames have an order in their sequences, but they do not have information about adjacency to other sequences in transverse direction of the bridge.
We extracted image features for each frame of all sequences before the localization step. The main purpose of extracting features is to find pixel-level correspondences between frames and image-level correspondences among sequences. We have selected ORB (
Oriented FAST [
11] and
Rotated
BRIEF—Binary Robust Independent Elementary Features [
12]) which detects FAST (Features from Accelerated Segment Test) corners and produces a binary descriptor of 256 bits for each feature point [
13]. It is fast and simple but invariant to orientation changes. The features and descriptors are extracted after warping each image using a homography matrix, which represents a mapping from the image to the ground plane and is obtained by sparse stereo matching [
14]. This process decreases the scale differences within a frame or among frames generated by perspective projection or by the motion of the vehicle. This will adjust and minimize the error that can accumulate based on vehicle dynamics.
3.2. Image-Based Localization and Mapping
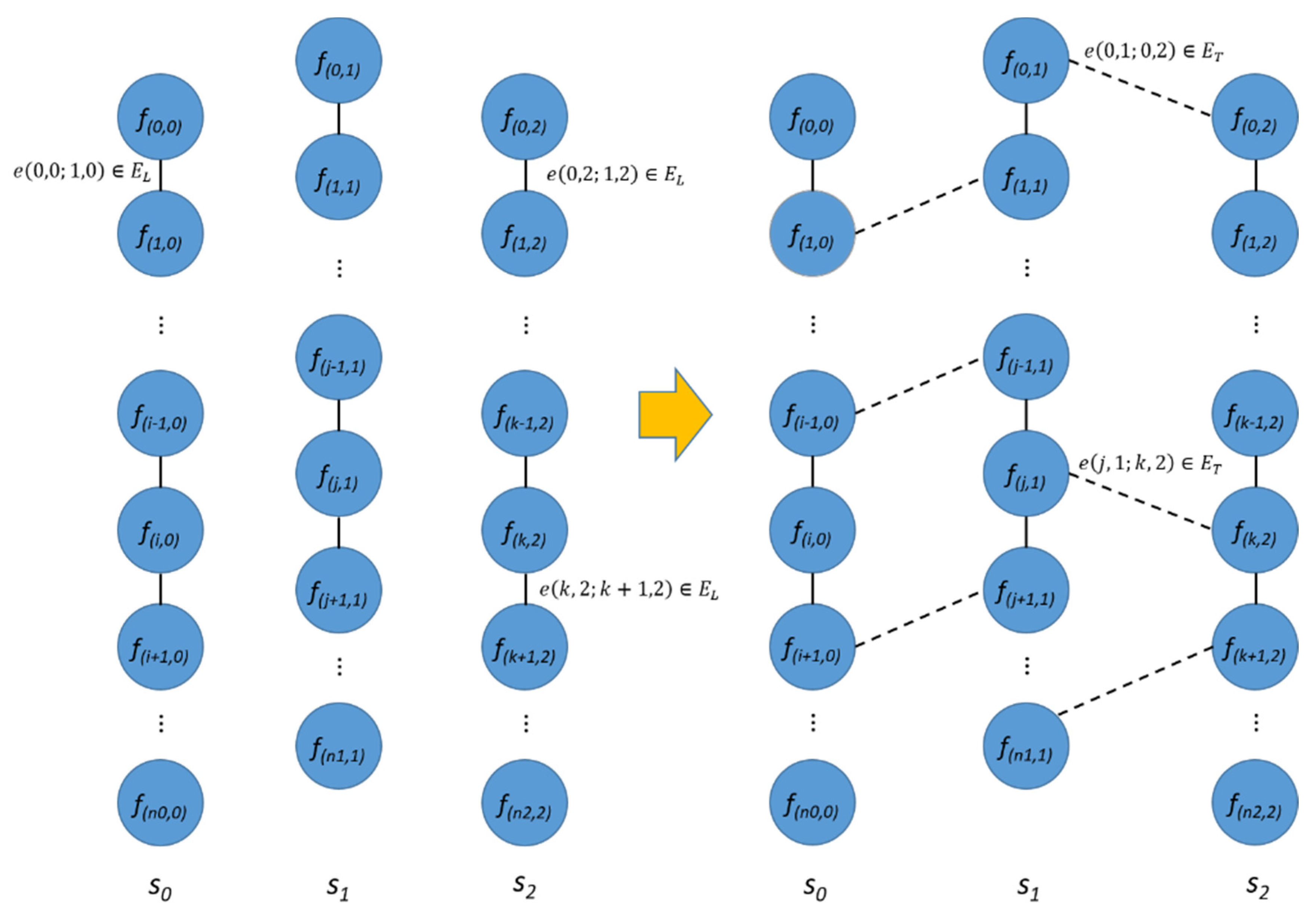
We performed two levels of image-based localization. First, we aligned the sequences in transverse direction and defined an adjacency graph,
G = (V, E), including frames of all sequences. The vertex,
V, is a set of all frames and a set of all edges,
E which, consists of edges within a longitudinal sequence,
EL, and edges across transverse sequences,
ET can be expressed as Equation (1).
ET can be obtained by comparing features of a frame to those of all frames of other sequences.
The time complexity is O(n2m2) where n is the number of total frames and m is an average number of features in a frame.
Instead of using the brute-force approach, we used image to image comparison with the Bag-of-Words (BoW) representation of images. This method represents each image using a vector which records the presence of certain features within an image as words in a dictionary [
15]. By comparing these vectors, we can get a similarity score between the two different images. In addition, we can assume that the two sequences should be matched monotonically in an increasing or decreasing (if sequences are matched in a reverse direction) order, if two sequences are adjacent to each other. We computed the similarity scores within a specified size of window and found the best matches by aggregating the scores through the dynamic programming strategy. The computation was completed for every
kth frame (these frames are defined as key frames),
fi’,
i′ =
ki of a source sequence to the corresponding
w frames
fj, j = (
ki −
w/2, …,
ki +
w/2) of the target sequence, as shown in
Figure 4. The aggregated score is defined as follows:
where,
S(I, j) contains BoW-based similarity score,
wa is the size of the aggregation window (
Figure 4).
The best score between the two sequences was defined as:
where,
nk is the index of the last key frame of the source sequence. The matches can be backtracked from the last match (
n,
jbest).
For each sequence, the sequences of the
k-highest scores were considered as the adjacent sequences, and the corresponding matches were included in the set of transverse edges,
ET. These image-level correspondences were further verified on the next step of the localization process. The transverse edges were removed if there was not a sufficient number of matched features, or if the correspondences did not meet the geometric requirements (e.g., a plane homography matrix).
Figure 5 shows the sequences and adjacency graph
G with longitudinal and transverse edges
EL and
ET.
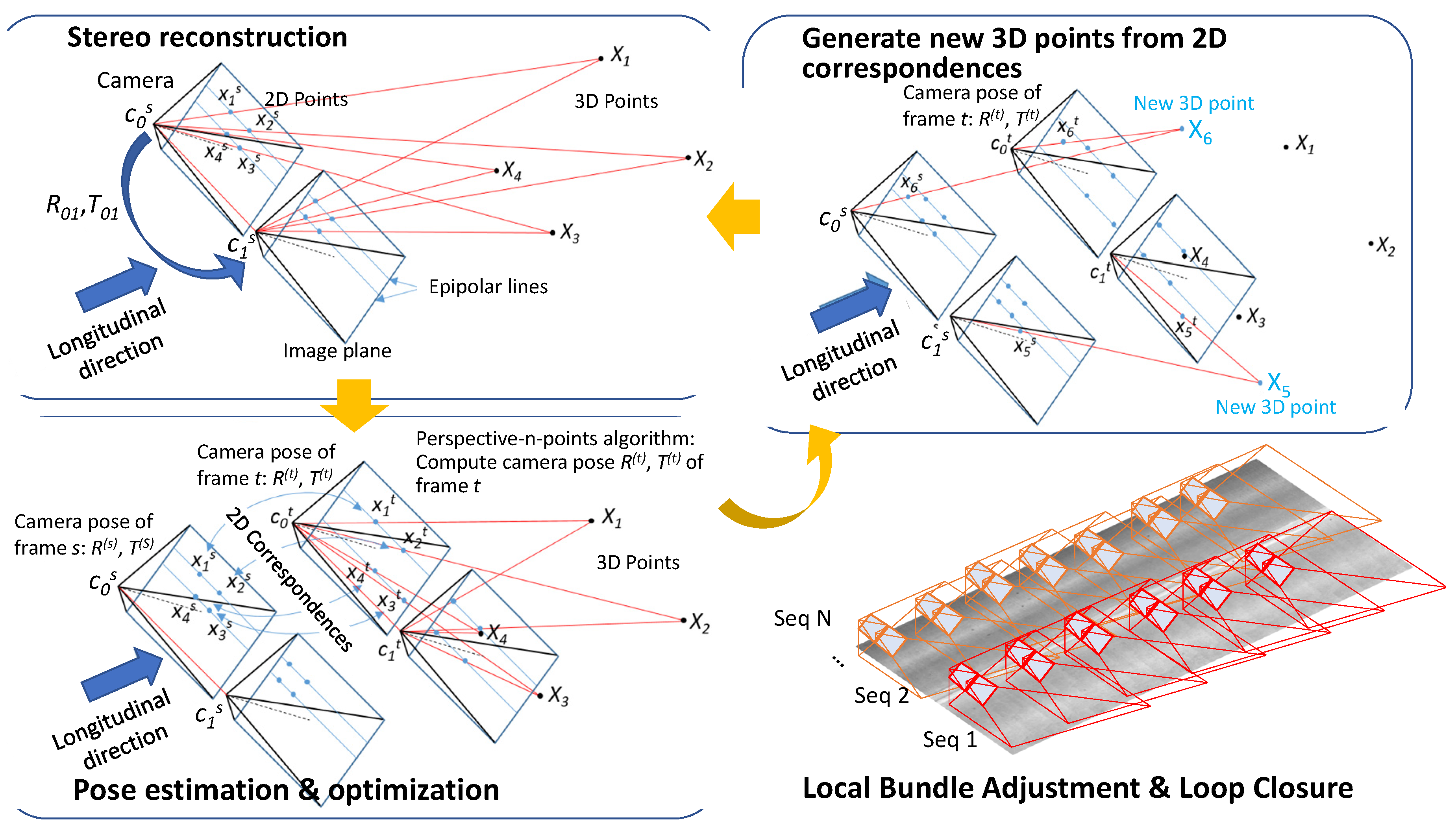
The second step for image-based localization and mapping was conducted to obtain the 3D translation and rotation of each frame, by traversing each node of the adjacency graph, G in breath-first order.
As illustrated in
Figure 6, we reconstructed 3D points using 2D correspondences among views within a frame since our multi-view camera sensors were calibrated. After, a frame has 3D information for enough number of 2D feature points, we can compute the rotation and translation of an adjacent frame by searching for the 2D feature correspondences and solving a perspective-n-point problem.
The projection of a 3D point is represented as the following equation [
14]:
where,
K is the intrinsic parameter and obtained by calibration,
(x, y) and
X are the 2D feature point and the corresponding 3D point.
R and
T are the rotation matrix and translation vector, respectively. We computed the
R and
T using the ePnP algorithm [
14,
16] with 2D to 3D correspondences. Then, we optimized both
R and
T, by minimizing the following objective function, which is defined using the stereo re-projection error.
where,
D(·,·) is the distance function defined between the projected point and the observed point.
R01 and
T01 is the rotation and translation from the first to the second cameras.
Xi is the 3D point and
xi0 and
xi1 are the observed points in the first and second camera, respectively.
We generated more 3D points using the direct linear triangulation method with 2D correspondences between these two frames that have external camera parameters. This frame by frame estimation may have errors and the reconstructed 3D point should be consistent (by having the similar reprojection errors) for all frames which can observe those points. So, the iteration process requires a bundle adjustment for each key frame to minimize the errors in the estimation of camera poses and 3D points at the same time. The objective function is as follows:
where,
R and
T are the rotations and translations of target frames,
D(·,·) is the distance function,
P(
Ki(
Ri,
Ti),
Xj) projects a 3D point
Xj using a projection matrix defined by the intrinsic matrix
Ki, and rotation and translation,
Ri and
Ti. A visibility function,
vij represents the visibility of
jth 3D point,
Xj, to the
ith camera defined by
Ki,
Ri, and
Ti. The set of participating frames,
Fb, are selected by building a breadth-first search tree and taking the nodes of the first
l-levels starting from the root node. The set of 3D points,
Pb, consists of all observable 3D points from any frames in
Fb. A set of frames,
Ff, which can observe any 3D points in
Pb, but not in
Fb, will also participate in the process, but their values will not be changed (fixed) and they will only contribute to the evaluation of the objective function. In Equation (6),
n is |
Fb U
Ff| and
m is |
Pb|, where |·| represents a cardinality of a set.
Because the key frames have both longitudinal and transverse edges in the adjacency graph, there are cycles in the graph. So, the breath-first traversal may visit the same node multiple times if there is a loop. In this case, the pose difference (error) between the estimated pose of the frame before revisiting and the estimated pose along the loop needs to be corrected to minimize the accumulated error. This accumulated loop closing errors can be distributed by the pose graph optimization [
17,
18]. This iterative process localizes each frame as well as generates the 3D points of the bridge deck.
3.3. Crack Detection
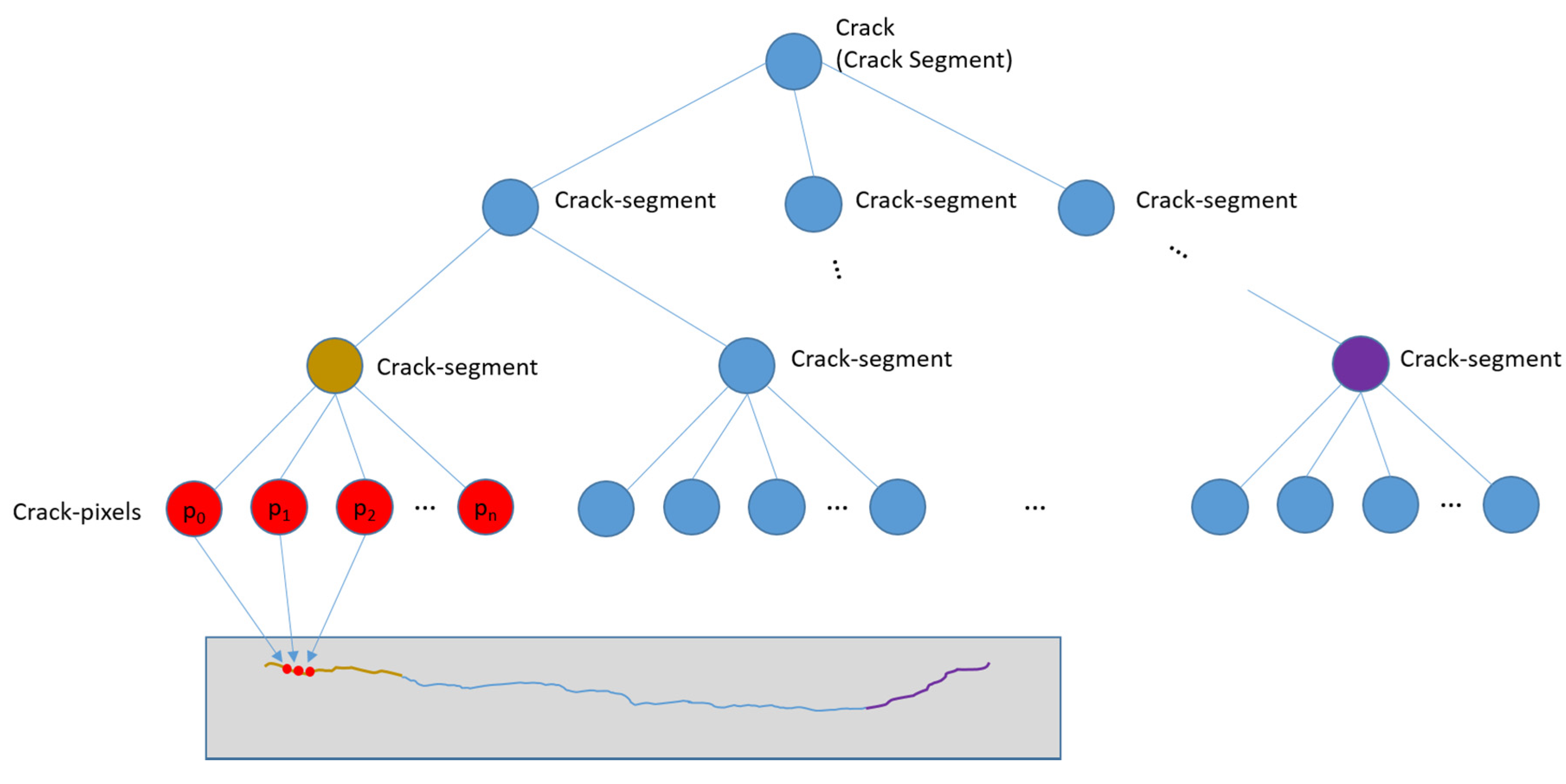
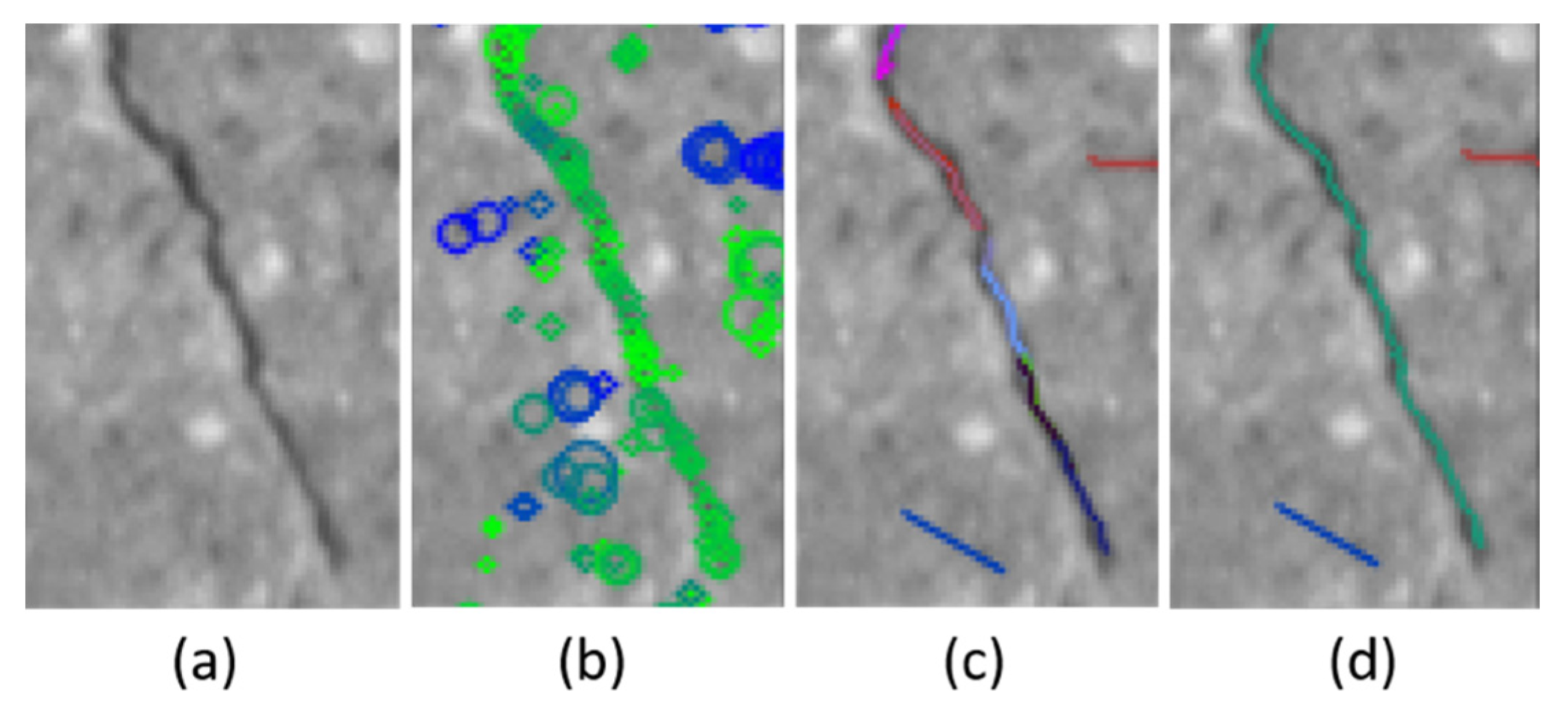
In order to detect cracks from images, we have defined a crack hierarchy using crack pixels and crack segments, as shown in
Figure 7. The crack pixel is the basic unit of the crack within an image. A crack pixel has low-intensity values and has a dominant orientation. A crack segment is an ordered set of crack pixels or it is recursively defined by a set of crack segments. Each crack pixel of a crack segment should have similar orientation with those of the neighboring crack pixels. The relative position to the neighboring crack pixels should be consistent with the orientations of them as well.
where,
p(u, v) is the position of the crack pixel in the coordinates of the stitched image,
u and
v indicate the position in transverse and longitudinal direction, respectively.
s is the scale of the crack pixel.
I(p) is the intensity value of the pixel,
θ is the orientation,
g(p) is the gradient of pixel values in the perpendicular direction of
θ, and
w is the width of the crack.
Many of the previous research studies assumed that a crack has low intensity and the local shape can be approximated by a line segment. Our definition of a crack element is stricter considering the dominating characteristics of the pixels (low-intensity and a dominant local orientation), but more flexible (less strict) for the shape of the crack. By the definitions of a crack pixel and a crack segment, each crack is represented by a tree structure, as shown in
Figure 7. The nodes of the tree are crack segments and the leaf nodes have crack pixels, as shown in the
Figure 7.
The detection of cracks is completed in two steps. In the first step, we detected crack pixels by examining the local image patch centered at each pixel. We prepared a scale-space to take into account different scales of cracks to detect the cracks greater than a single pixel. Then, for each pixel
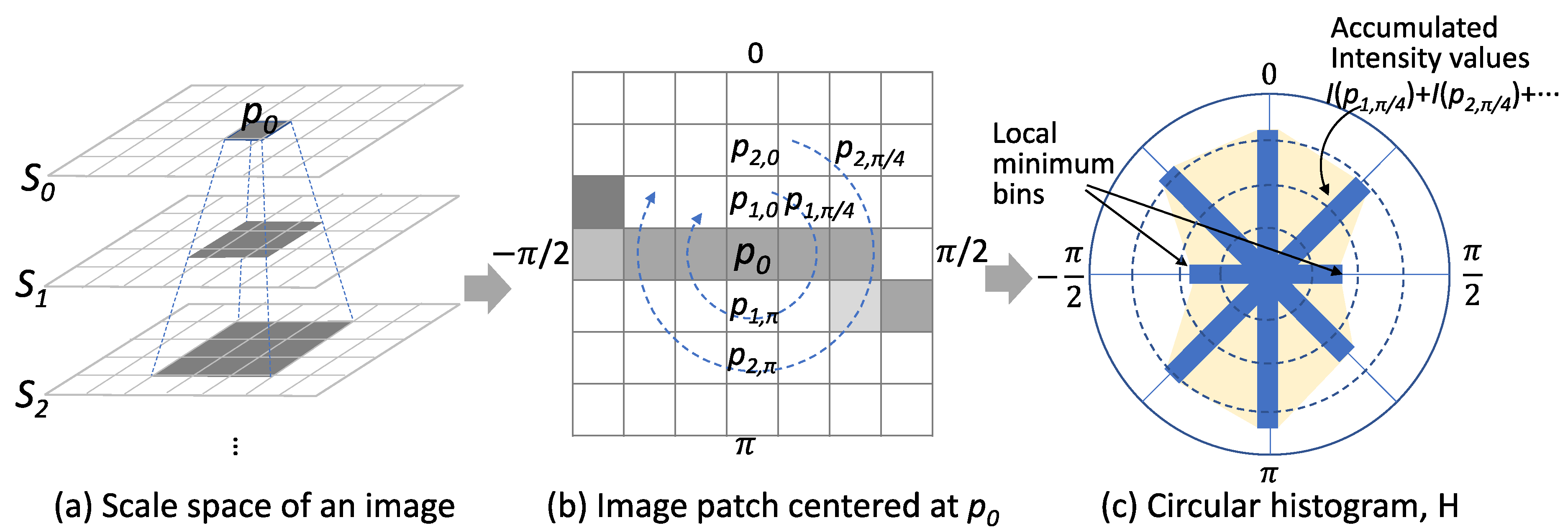
p0, we built a circular histogram from the image patches of all scales to check whether the pixel has a dominant orientation of low-intensity pixels or not. Each bin of the histogram represents the relative orientation of pixels within the patch. Each histogram accumulates pixel values along the relative direction of the pixels in the patch as illustrated in
Figure 8. In the figure,
I(
p1,
π/4) represents a pixel value of the pixel that is located at the direction of π/4 and has distance of 1 from the pixel
p0. We determined a dominant orientation by detecting two bins that have local minimums and averaging the corresponding orientations, as shown in
Figure 8. Once the orientation was determined, the gradient of pixel values to the perpendicular direction of the orientation was computed. In the figure, the average of |
I(
p0) −
I(
p1,0)| and |
I(
p0) −
I(
p1,π)| is the value of
g(
p0). The scale selection was done by comparing
g(
p0) values of the crack pixels of all scales. The crack pixel that had the maximum
g(
p0) and the corresponding scale was selected as the value of
s for the location
p0. This weak classifier inherently produced false-positives because the properties we used for crack pixel detection were not sufficient for describing a crack element.
In the second step, we formed crack segments and classified them into cracks and non-cracks. For each detected crack pixel, we counted the number of supporting crack pixels that satisfies the following conditions: (1) the supporting crack pixels should be within a local window defined by a radius
r, (2) they should have the similar orientation with that of the crack pixel, (3) the relative direction of the crack pixels with respect to the crack pixel should be consistent with the orientations of themselves and the crack pixel. These three conditions are represented in the following equations:
where,
,
,
is the orientation of the crack pixel
p(u,v) and
θi is the orientation of the
i-th crack pixel
p(ui,vi).
θs represents the maximum angle difference.
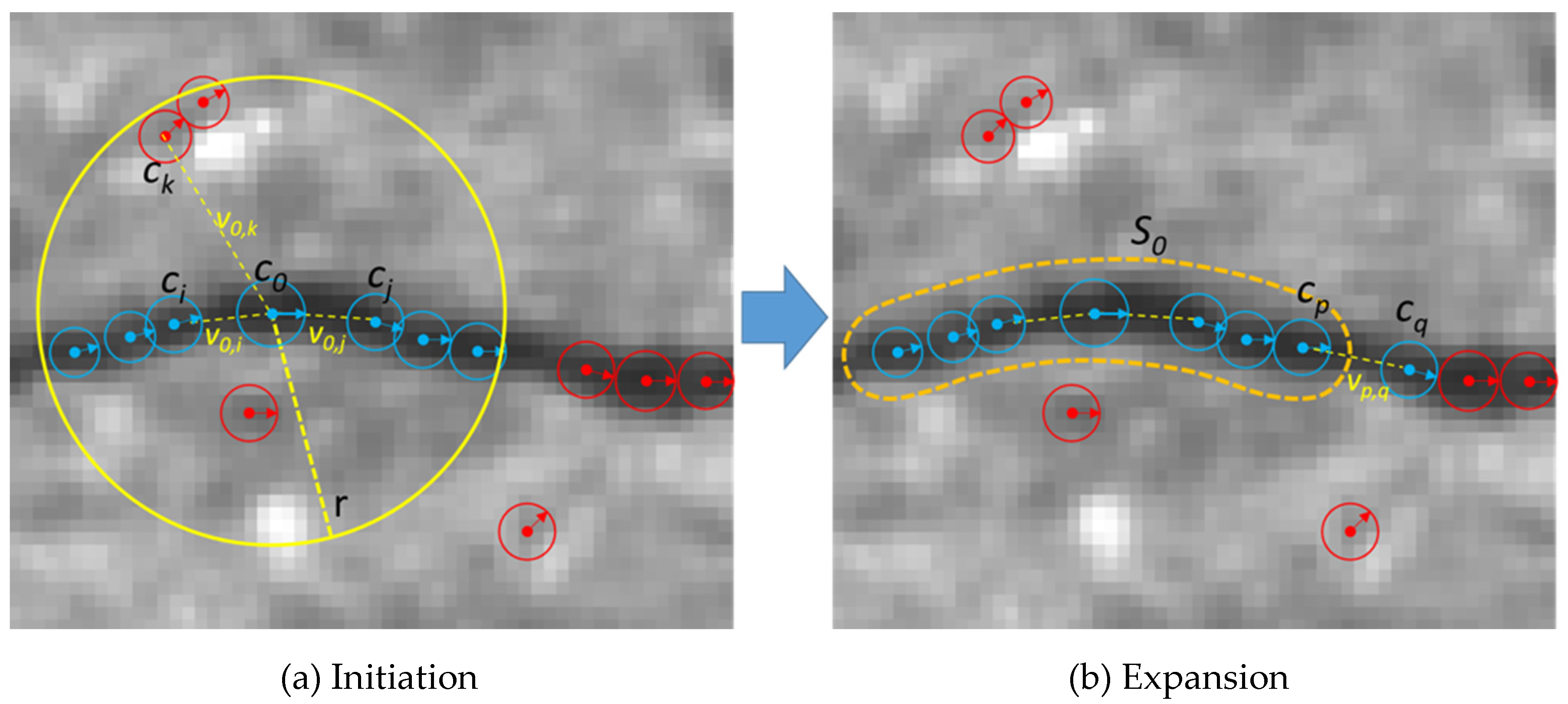
We initialized a crack segment using a crack pixel that has the maximum number of supporting pixels within a local window. This process is illustrated in
Figure 9. For a crack pixel
c0, the pixels
ci and
cj (blue-colored pixels) are the supporting pixels, but
ck is not a supporting pixel of
c0 because the vector
v0,k and the orientation of
c0 are different. Crack segments will have a sorted list of crack pixels, location, average orientation, length, and an average width. A sorted list of crack pixels is obtained by projecting the pixels onto the principle axis of the crack pixels (the direction that the crack pixels are aligned with). We expanded the initial segments in two directions by adding crack pixels that were not assigned to any crack segments. Two end-points are the first and last elements of the sorted list of crack pixels. In
Figure 9,
cp is one of the end-points of an initial crack segment
s0, and
cq is a candidate crack pixel which can be included into
s0. The crack pixels that are not assigned to any crack segments will be discarded. In the next step, crack segments are compared and linked if end-points of two crack segments are close enough and the average orientations of two crack segments are similar (when it is less than
θs). The existing approaches also connect locally detected cracks which are mostly consisted of line segments, but the crack segment defined in our study is an ordered set of crack pixels detected through the clustering and linking process.
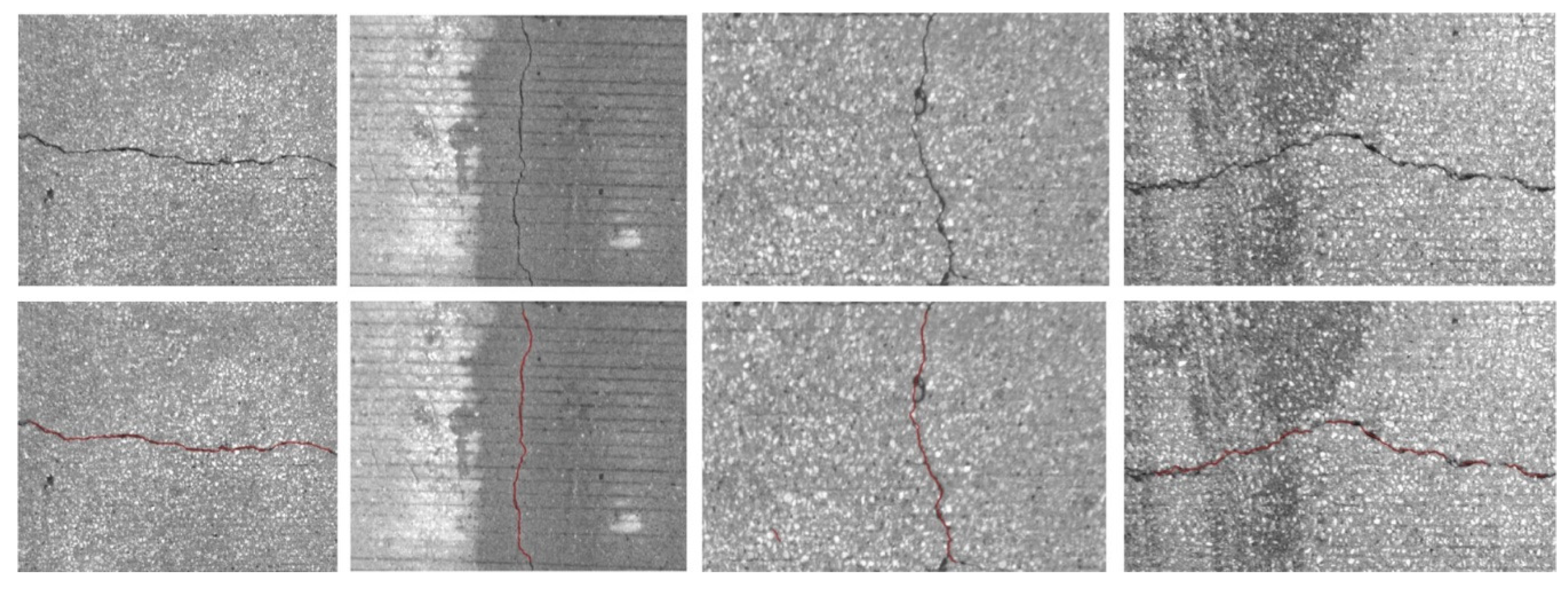
3.4. Crack Measurements
We measured the width of a crack for each crack pixel. Each crack pixel has an orientation and the width is measured in the perpendicular direction of the orientation of the crack-pixel. We assumed that two step-edges can be observed in the perpendicular direction. If those edges are aligned with the pixel boundaries, we are able to detect the edges by observing two neighboring pixels, but in most cases, the edges were not aligned to the pixel boundaries. Therefore, we observed more consecutive pixels along the perpendicular direction to the orientation of the crack segment and detected the edges. We used the following compositing equation, which explains the color composition at the boundary between the foreground and background [
19]. In our case, the foreground color is the intensity of the crack (crack pixel), the background color is the intensity of non-crack pixels.
where,
.
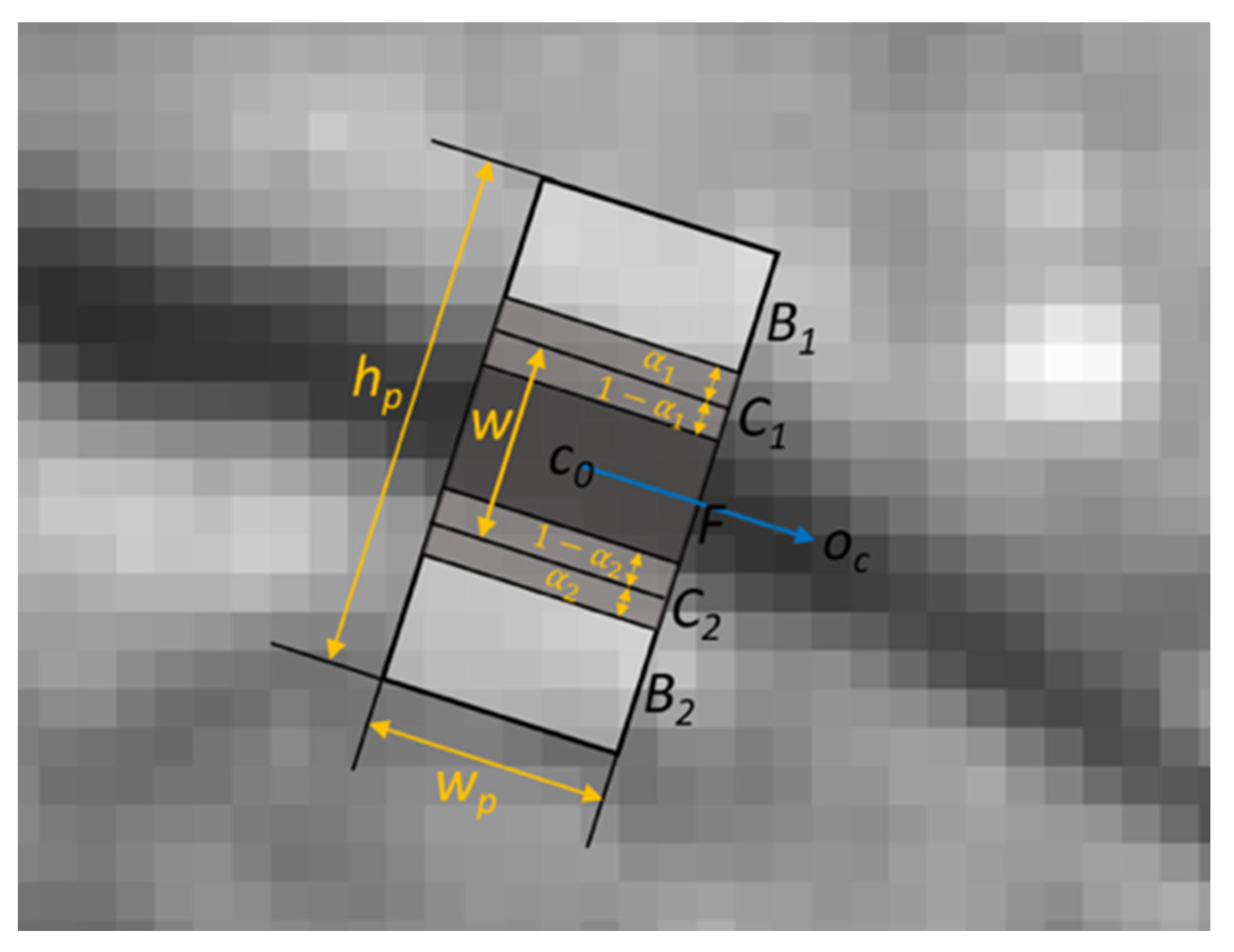
The blending factor
α can be computed by observing
F,
B and
C, and this factor can provide us the information of whether how much portion of the composite pixel is from a crack or non-crack area (the physical area where the image is captured), as illustrated in
Figure 10.
Oc is the orientation of a crack pixel,
C0. In the figure, a rectangular patch centered at
C0 is rotated and aligned to
Oc. The location of composite pixels can be found by comparing
I(
p), the value of pixel
p, and
I(
p + 2), the value of the second neighboring pixel of a pixel p. In the coordinates of the patch (left-bottom corner is the origin), if
I(
p) −
I(
p + 2) is the positive maximum and
I(
p) >
I(
p + 1) >
I(
p + 2), then the pixel, (
p + 1) corresponds to the area
C2 in the Figure. If
I(
p) −
I(
p + 2) is the largest negative value and
I(
p) <
I(
p + 1) <
I(
p + 2), then the pixel, (
p + 1) is
C1. The blending factor
α1 and
α2 can be calculated by the image compositing Equation (11). The width of the crack pixel,
w is the sum of the width of the area
F and (1 −
α1 + 1 −
α2), as illustrated in
Figure 10.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
















