Deep Joint Spatiotemporal Network (DJSTN) for Efficient Facial Expression Recognition




Abstract
:1. Introduction
2. Related Works
2.1. Facial Expression Recognition Approaches
2.1.1. Classical Approaches
2.1.2. Deep Learning-Based Approaches
- We design a new hybrid network structure based on appearance feature (3D CNN) and geometric feature (2D CNN).
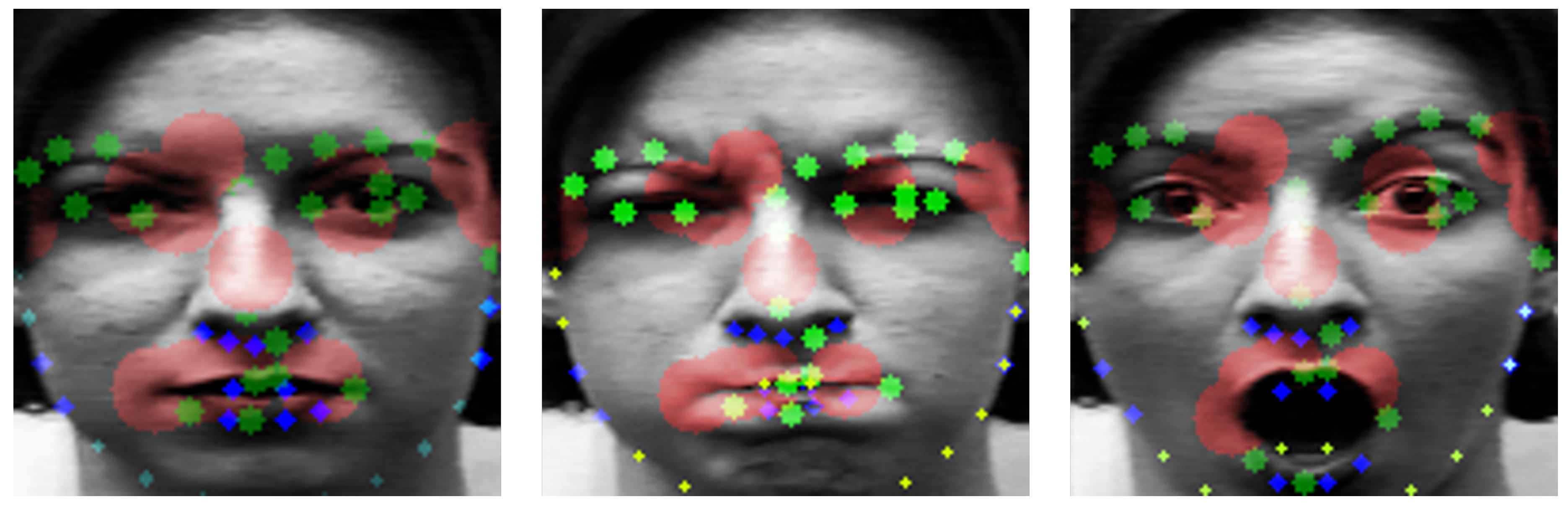
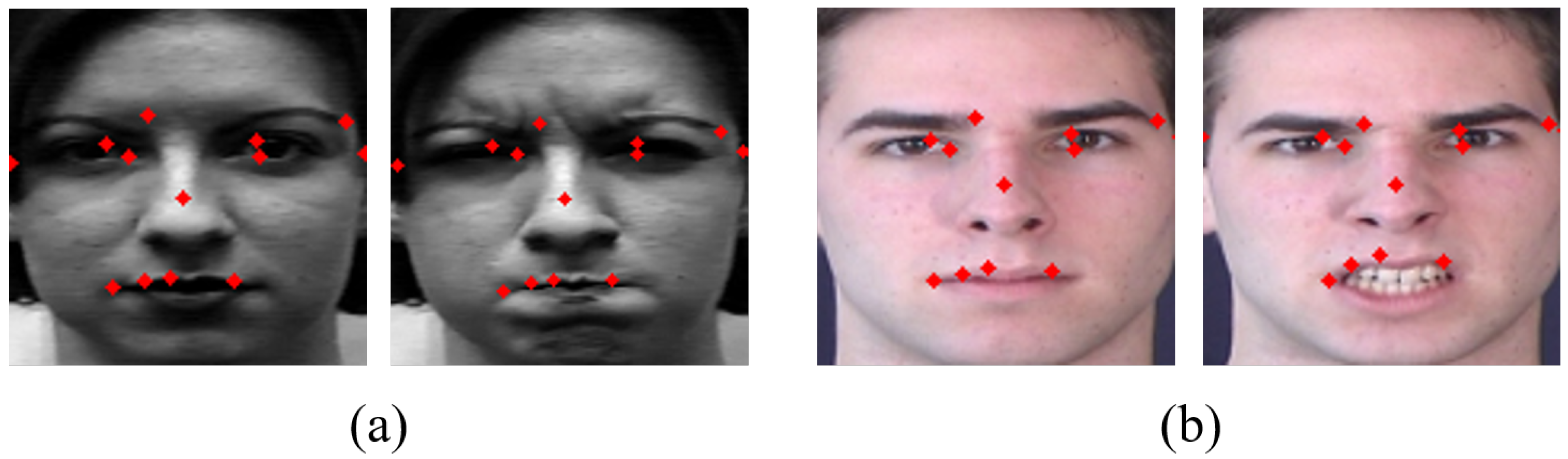
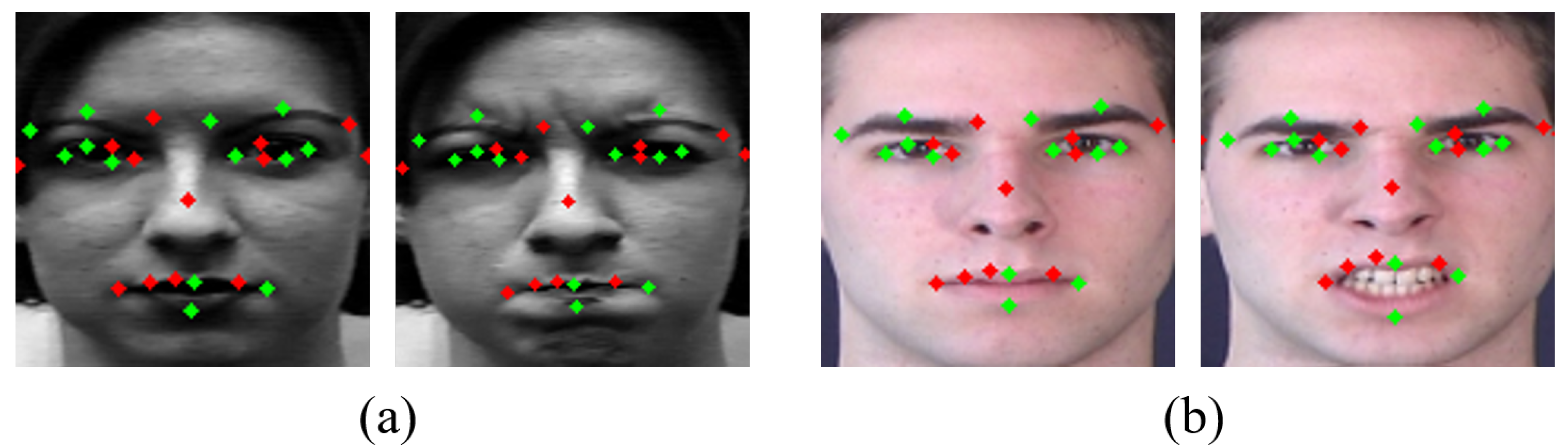
- We experimentally identify dominant facial landmarks with large variation (motion energy) when facial expression changes, to design the geometric feature-based network. We obtain similar effects as when using all landmarks by using only 21 landmarks.
- We design the joint fusion classifier combining two networks from the appearance feature-based network and geometric feature-based network.
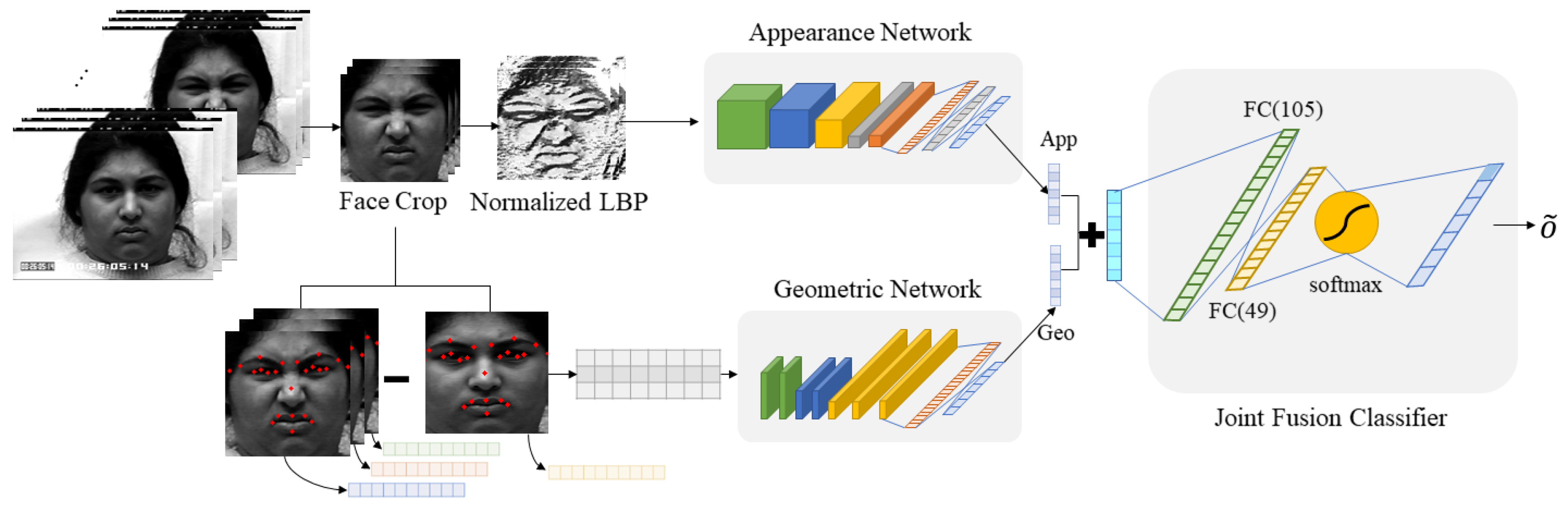
3. Proposed Scheme
3.1. Datasets and Data Augmentation
3.2. Appearance Feature-based Spatiotemporal Network
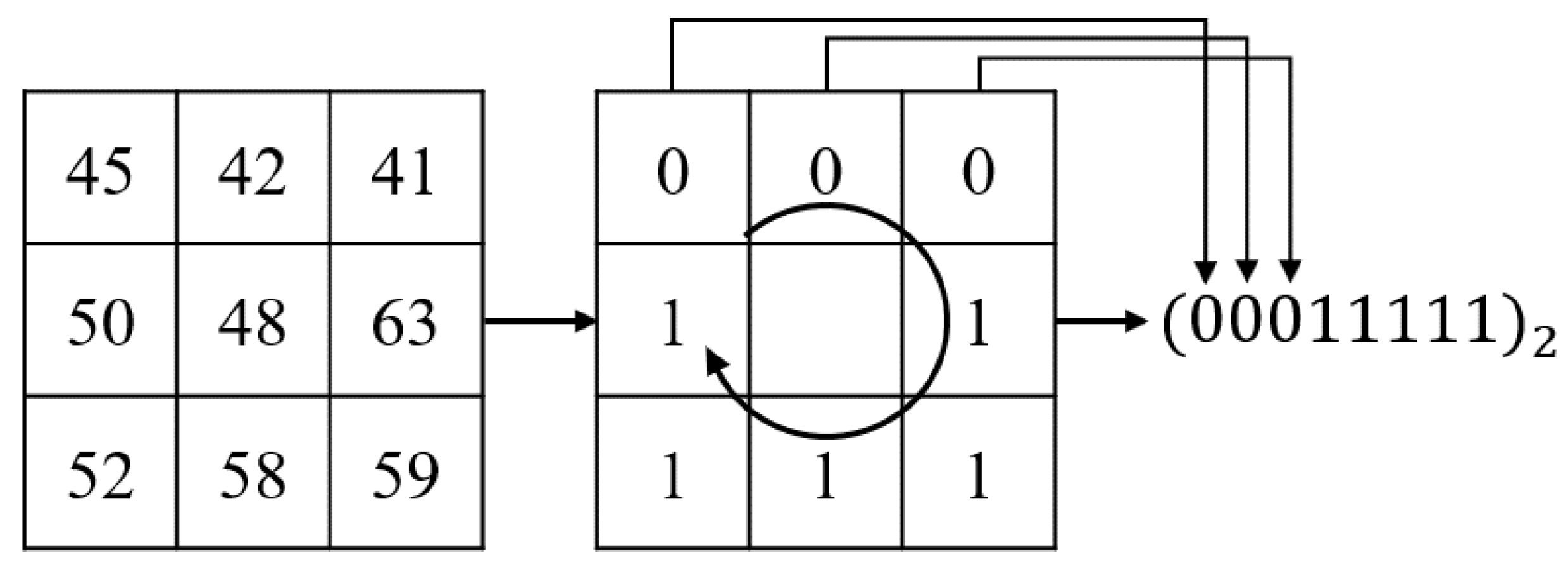
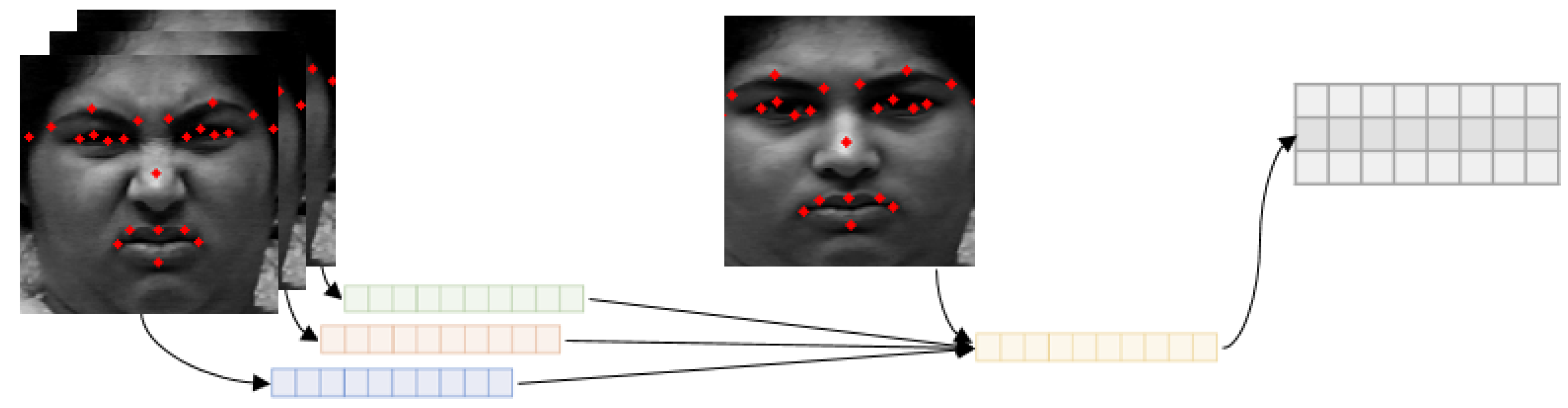
3.2.1. Feature Extraction
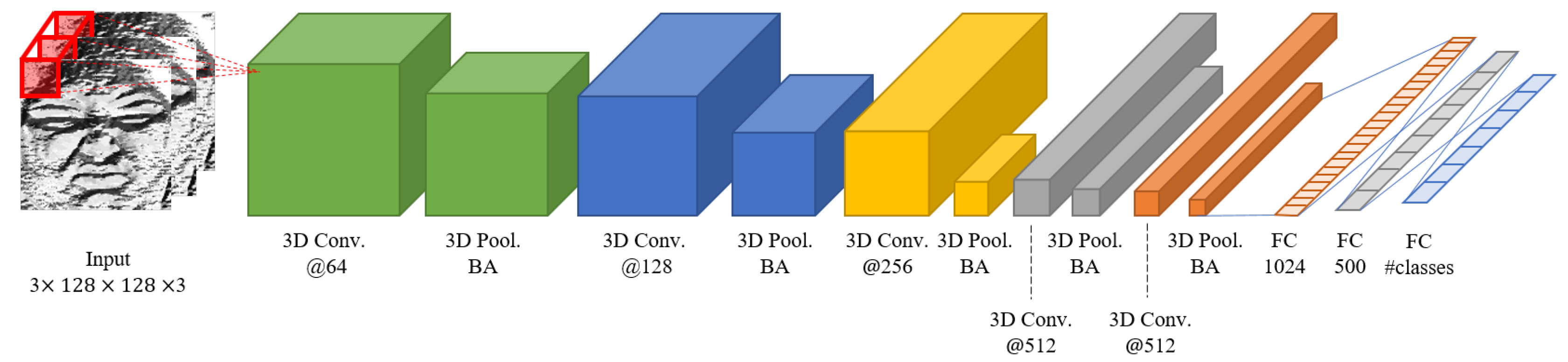
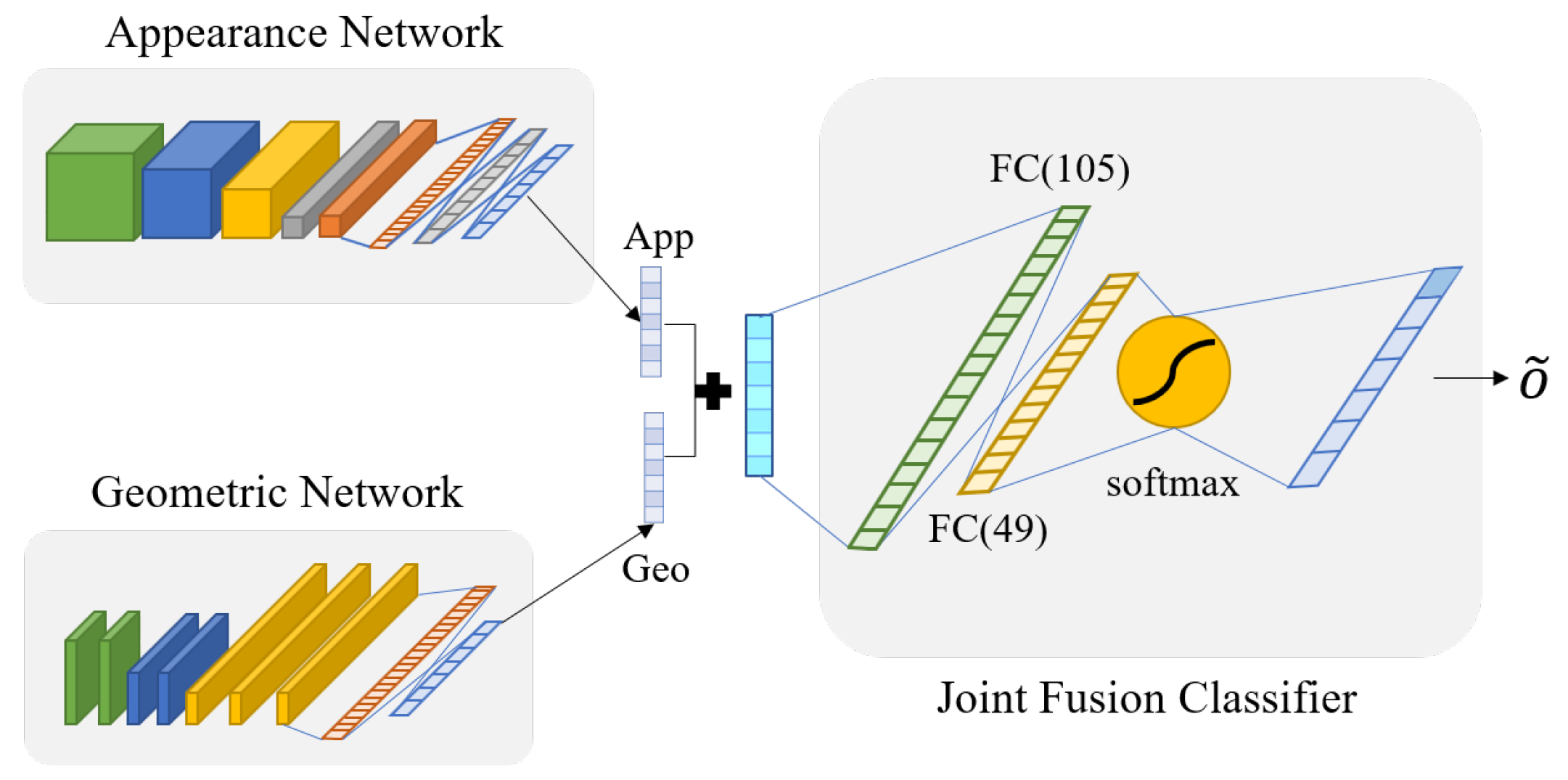
3.2.2. Appearance Feature-Based Network Structure
3.3. Geometric Feature-Based Network
3.3.1. Landmark Detection
3.3.2. Geometric Feature-Based Network Structure
3.4. Joint Fusion Classifier
4. Experimental Results and Discussion
4.1. Performance as the Number of Input Frames
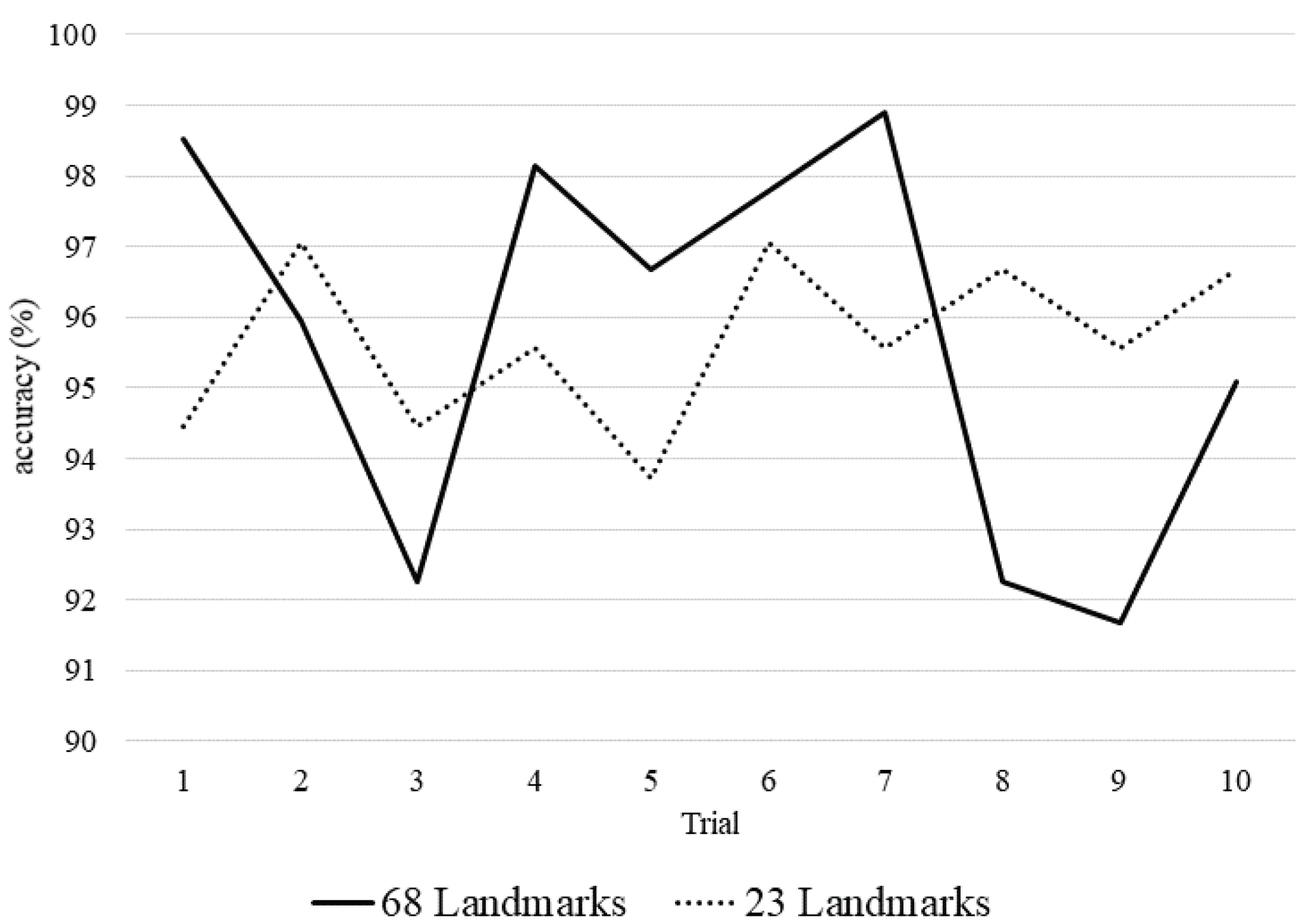
4.2. Performance as the Number of Landmarks
4.3. Optimal Weight Analysis for Joint Fusion Classifier
4.4. Performance of the Accuracy
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Tao, J.; Tan, T. Affective Computing: A Review. Int. Conf. Affect. Comput. Intell. Interact. 2005, 3784, 981–995. [Google Scholar]
- Zeng, Z.; Pantic, M.; Roisman, G.; Huang, T.S. A survey of affect recognition methods: Audio, visual, and spontaneous expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 39–58. [Google Scholar] [CrossRef] [PubMed]
- Ekman, P.; Friesen, W. Facial Action Coding System: A Technique for the Measurement of Facial Movement; Consulting Psychologists Press: Berkeley, CA, USA, 1978. [Google Scholar]
- McDuff, D.; El Kaliouby, R.; Senechal, T.; Amr, M.; Cohn, J.F.; Picard, R. AMFED facial expression dataset: Naturalistic and spontaneous facial expressions collected in–the–wild. In Proceedings of the IEEE Conference on Computer Vision Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 881–888. [Google Scholar]
- Dhall, A.; Goecke, R.; Lucey, S.; Gedeon, T. Collecting large, richly annotated facial–expression databases from movies. IEEE Multimed. 2012, 19, 34–41. [Google Scholar] [CrossRef] [Green Version]
- Lucey, P.; Cohn, J.F.; Prkachin, K.M.; Solomon, P.E.; Matthews, I. Painful data: The UNBC–McMaster shoulder pain expression archive database. In Proceedings of the IEEE International Conference on Automatic Face and Gesture Recognition and Workshops, Santa Barbara, CA, USA, 21–25 March 2011; pp. 57–64. [Google Scholar]
- Yu, Z.; Zhang, C. Image based Static Facial Expression Recognition with Multiple Deep Network Learning. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 435–442. [Google Scholar]
- Martinez, B.; Valstar, M.F. Advances, Challenges, and Opportunities in Automatic Facial Expression Recognition. In Advances in Face Detection and Facial Image Analysis; Kawulok, M., Celebi, M., Smolka, B., Eds.; Springer: Cham, Switerland, 2016. [Google Scholar]
- Li, S.; Deng, W. Deep Emotion Transfer Network for Cross–database Facial Expression Recognition. Int. Conf. Pattern Recognit. 2018, 1, 3092–3099. [Google Scholar]
- Mayer, C.; Egger, M.; Radig, B. Cross–database evaluation for facial expression recognition. Pattern Recognit Image Anal. 2014, 24, 124–132. [Google Scholar] [CrossRef]
- Hasani, B.; Mahoor, M.H. Facial Expression Recognition Using Enhanced Deep 3D Convolutional Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 2278–2288. [Google Scholar]
- Zhu, Q.; Yeh, M.; Cheng, K.; Avidan, S. Fast Human Detection Using a Cascade of Histograms of Oriented Gradients. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. 2006, 2, 1491–1498. [Google Scholar]
- Ojala, T.; Pietikäinen, M.; Harwood, D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar] [CrossRef]
- Lowe, D.G. Object recognition from local scale–invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; pp. 1150–1157. [Google Scholar]
- Lee, T.S. Image Representation Using 2D Gabor Wavelets. IEEE Trans. Pattern Anal. Mach. Intell. 1996, 18, 959–971. [Google Scholar]
- Suykens, J.A.K.; Vandewalle, J. Least Squares Support Vector Machine Classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Vasanth, P.C.; Nataraj, K.R. Facial Expression Recognition Using SVM Classifier. Indones. J. Electr. Eng. Inf. 2015, 3, 16–20. [Google Scholar]
- Abdulrahman, M.; Eleyan, A. Facial Expression Recognition Using Support Vector Machines. In Proceedings of the 2015 23rd Signal Processing and Communications Applications Conference (SIU), Malatya, Turkey, 16–19 May 2015. [Google Scholar]
- Xu, X.; Quan, C.; Ren, F. Facial Expression Recognition based on Gabor Wavelet Transform and Histogram of Oriented Gradients. In Proceedings of the 2015 IEEE International Conference on Mechatronics and Automation (ICMA), Beijing, China, 2–5 August 2015. [Google Scholar]
- Klaser, A.; Marszalek, M. A spatio-temporal descriptor based on 3d-gradients. In Proceedings of the BMVC 2008—19th British Machine Vision Conference, Leeds, UK, 1–4 September 2008. [Google Scholar]
- Zhao, G.; Pietikainen, M. Dynamic texture recognition using local binary patterns with an application to facial expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 915–928. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Scovanner, P.; Ali, S.; Shah, M. A 3-dimensional sift descriptor and its application to action recognition. In Proceedings of the 15th International Conference on Multimedia, Augsburg, Germany, 24–29 September 2007; pp. 357–360. [Google Scholar]
- Berretti, S.; Bimbo, A.D.; Pala, P.; Amor, B.B.; Daoudi, M. A Set of Selected SIFT Features for 3D Facial Expression Recognition. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010. [Google Scholar]
- Tawari, A.; Trivedi, M.M. Face Expression Recognition by Cross Modal Data Association. IEEE Trans. Multimed. 2013, 15, 1543–1552. [Google Scholar] [CrossRef]
- Kirana, K.C.; Wibawanto, S.; Herwanto, H.W. Facial Emotion Recognition Based on Viola-Jones Algorithm in the Learning Environment. In Proceedings of the 2018 International Seminar on Application for Technology of Information and Communication, Semarang, Indonesia, 21–22 September 2018; pp. 406–410. [Google Scholar]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.H.; et al. Challenges in Representation Learning: A Report on Three Machine Learning Vontests. In International Conference on Neural Information Processing; Springer: Berlin/Heidelberg, Germany, 2013; pp. 117–124. [Google Scholar]
- Dhall, A.; Goecke, R.; Lucey, S.; Gedeon, T. Acted Facial Expressions in the Wild Databas; Technical Report TR–CS–11; Australian National University: Canberra, Australia, 2011. [Google Scholar]
- Zhao, X.; Liang, X.; Liu, L.; Li, T.; Han, Y.; Vasconcelos, N.; Yan, S. Peak-Piloted Deep Network for Facial Expression Recognition. In European Conference on Computer Vision; Springer: Cham, Switerland, 2016. [Google Scholar]
- Kim, J.; Kim, B.; Roy, P.; Jeong, D. Efficient Facial Expression Recognition Algorithm Based on Hierarchical Deep Neural Network Structure. IEEE Access 2019, 7, 41273–41285. [Google Scholar] [CrossRef]
- Liu, M.; Li, S.; Shan, S.; Wang, R.; Chen, X. Deeply learning deformable facial action parts model for dynamic expression analysis. In Asian Conference on Computer Vision; Springer: Cham, Switerland, 2014; pp. 143–157. [Google Scholar]
- Liu, M.; Shan, S.; Wang, R.; Chen, X. Learning expressionlets on spatio-temporal manifold for dynamic facial expression recognition. In Proceedings of the CVPR 2014: 27th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014. [Google Scholar]
- Hasani, B.; Mahoor, M.H. Spatio-temporal facial expression recognition using convolutional neural networks and conditional random fields. arXiv 2017, arXiv:1703.06995v2. [Google Scholar]
- Yim, J.; Park, S.; Kim, J. Joint Fine-Tuning in Deep Neural Networks for Facial Expression Recognition. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Dhall, A.; Goecke, R.; Joshi, J.; Wagner, M.; Gedeon, T. Emotion recognition in the wild challenge. Int. Conf. Multimodal Interact. 2013, 10, 95–97. [Google Scholar]
- Fan, Y.; Lu, X.; Li, D.; Liu, Y. Video–based emotion recognition using CNN-RNN and C3D hybrid networks. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 445–450. [Google Scholar]
- Tian, Y.; Cheng, J.; Li, Y.; Wang, S. Secondary Information Aware Facial Expression Recognition. IEEE Signal Process Lett. 2019, 26, 1753–1757. [Google Scholar] [CrossRef]
- Raheel, A.; Majid, M.; Anwar, S.M. Facial Expression Recognition based on Electroencephalography. In Proceedings of the 2019 2nd International Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Sukkur, Pakistan, 30–31 January 2019; pp. 1–5. [Google Scholar]
- Xie, S.; Hu, H. Facial Expression Recognition Using Hierarchical Features With Deep Comprehensive Multipatches Aggregation Convolutional Neural Networks. IEEE Trans. Multimed. 2019, 21, 211–220. [Google Scholar] [CrossRef]
- Wang, X.; Chen, X.; Cao, C. Human emotion recognition by optimally fusing facial expression and speech feature. Signal Process. Image Commun. 2020, 84, 115831. [Google Scholar] [CrossRef]
- Yu, M.; Zheng, H.; Peng, Z.; Dong, J.; Du, H. Facial expression recognition based on a multi-task global-local network. Pattern Recognit. Lett. 2020, 131, 166–171. [Google Scholar] [CrossRef]
- Project Oxford. Available online: https://blogs.microsoft.com/ai/microsofts-project-oxford-helps-developers-build-more-intelligent-apps/ (accessed on 24 March 2020).
- FaceReader. Available online: https://www.noldus.com/facereader (accessed on 24 March 2020).
- Emotient. Available online: https://www.crunchbase.com/organization/emotient (accessed on 24 March 2020).
- Affectiva. Available online: https://www.affectiva.com/ (accessed on 24 March 2020).
- Eyeris & EmoVu. Available online: https://www.eyeris.ai/ (accessed on 24 March 2020).
- Kairos. Available online: https://www.kairos.com/ (accessed on 24 March 2020).
- Nviso. Available online: https://www.nviso.ai/en (accessed on 24 March 2020).
- Sightcorp. Available online: https://sightcorp.com/ (accessed on 24 March 2020).
- SkyBiometry. Available online: https://skybiometry.com/ (accessed on 24 March 2020).
- Face++. Available online: https://www.faceplusplus.com/ (accessed on 24 March 2020).
- Imotions. Available online: https://imotions.com/ (accessed on 24 March 2020).
- CrowdEmotion (ElementHuman). Available online: https://www.crowdemotion.co.uk/ (accessed on 24 March 2020).
- FacioMetrics. Available online: http://www.faciometrics.com (accessed on 24 March 2020).
- Findface. Available online: https://findface.pro/en/ (accessed on 24 March 2020).
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion–specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition—Workshops, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Valstar, M.; Pantic, M. Induced disgust, happiness and surprise: An addition to the mmi facial expression database. In Proceedings of the 3rd International Workshop on EMOTION (satellite of LREC): Corpora for Research on Emotion and Affect, Marrakech, Morocco, 28–30 May 2010. [Google Scholar]
- Banziger, T.; Scherer, K.R. Introducing the geneva multimodal emotion portrayal (gemep) corpus. In Blueprint for Affective Computing: A Sourcebook; Université de Genève: Genève, Switerland, 2010. [Google Scholar]
- Valstar, M.F.; Jiang, B.; Mehu, M.; Pantic, M.; Scherer, K. The first facial expression recognition and analysis challenge. In Proceedings of the Face and Gesture 2011, Santa Barbara, CA, USA, 21–25 March 2011. [Google Scholar]
- Li, S.; Deng, W. Deep facial expression recognition: A survey. arXiv 2018, arXiv:1804.08348. [Google Scholar] [CrossRef] [Green Version]
- Huang, D.; Shan, C.; Ardabilian, M.; Wang, Y.; Chen, L. Local binary patterns and its application to facial image analysis: A survey. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2011, 41, 765–781. [Google Scholar] [CrossRef] [Green Version]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary Robust invariant scalable keypoints. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2548–2555. [Google Scholar]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. BRIEF: Binary Robust Independent Elementary Features. In Computer Vision—ECCV 2010, Lecture Notes in Computer Science; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Kumar, S.; Bhuyan, M.K.; Chakraborty, B.K. Extraction of informative regions of a face for facial expression recognition. IET Comput. Vis. 2016, 10, 567–576. [Google Scholar] [CrossRef]
- Chan, C.; Kittler, J.; Messer, K. Multi–scale local binary pattern histograms for face recognition. In Proceedings of the International Conference on Biometrics, Seoul, Korea, 27–29 August 2007; pp. 809–818. [Google Scholar] [CrossRef] [Green Version]
- Zhang, G.; Huang, X.; Li, S.Z.; Wang, Y.; Wu, X. Boosting local binary pattern-based face recognition. In Proceedings of the Advances in Biometric Person Authentication, Guangzhou, China, 13–14 December 2004; pp. 179–186. [Google Scholar]
- Yang, Z.; Ai, H. Demographic classification with local binary pattern. In Proceedings of the International Conference on Biometrics, Seoul, Korea, 27–29 August 2007; pp. 464–473. [Google Scholar]
- Ahonen, T.; Hadid, A.; Pietikainen, M. Face Description with Local Binary Patterns: Application to Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 2037–2041. [Google Scholar] [CrossRef] [PubMed]
- Heusch, G.; Rodriguez, Y.; Marcel, S. Local binary patterns as an image preprocessing for face authentication. In Proceedings of the International Conference on Automatic Face and Gesture Recognition, Southampton, UK, 10–12 April 2006. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the The IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [Green Version]
- Yu, Z.; Liu, G.; Liu, Q.; Deng, J. Spatio–tmpeoral convolutional features with nested LSTM for facial expression recognition. Neurocomputing 2018, 317, 50–57. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Cheng, S.; Man, P.C. 3D multi-resolution wavelet convolutional neural networks for hyperspectral image classification. Inf. Sci. 2017, 420, 49–65. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1867–1874. [Google Scholar]
- Sagonas, C.; Antonakos, E.; Tzimiropoulos, G.; Zafeiriou, S.; Pantic, M. 300 faces in-the-wild challenge: Database and results. Image Vis. Comput. 2016, 47, 3–18. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Huang, Y.; Du, Y.; Wang, L. Facial expression recognition based on deep evolutional spatial-temporal networks. IEEE Trans. Image Process. 2017, 26, 4193–4203. [Google Scholar] [CrossRef] [PubMed]
- Kim, D.H.; Baddar, W.J.; Jang, J.; Ro, Y.M. Multi-Objective Based Spatio-Temporal Feature Representation Learning Robust to Expression Intensity Variations for Facial Expression Recognition. IEEE Trans. Affect. Comput. 2019, 10, 223–236. [Google Scholar] [CrossRef]
- Ruiz, G.; Michell, J.A. Design and Architectures for Digital Signal Processing; IntechOpen: London, UK, 2013. [Google Scholar]
- Varbanescu, A.L.; Molnos, A.; van Nieuwpoor, R. Computer Architecture, Lecture Note on Computer Sciences 6161; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Items | Description | Developers |
|---|---|---|
| Project Oxford [41] | As part of the Machine Learning (Machine Learning) project, it provides API including Face API for machine learning technology, which is being promoted to four major categories. | Oxford Univ. and Microsoft |
| Face Reader [42] | The Project Analysis Module includes the Stimulus Presentation Tool. By designing a test, this tool automatically shows the test participants the stimuli while FaceReader accurately analyzes the participant’s face. | Noldus |
| Emotient [43] | Emotient is spearheading the use of machine learning for facial expression analysis, a new category of natural user interface that is rapidly expanding as more companies seek to improve technology responsiveness and increase customer engagement. | crunchbase |
| Affectiva [44] | The first multi-modal in-cabin sensing AI that identifies, from face and voice, complex and nuanced emotional and cognitive states of drivers and passengers. This helps improve road safety and the transportation experience. | Affectiva |
| EmoVu [45] | EmoVu specializes in creating emotionally intelligent tools that can perceive the emotions of people by analyzing microexpressions using webcams. | Eyeris |
| Kairos [46] | Kairos provides featured platforms such as face detection/recognition, age, gender detection, etc. | Kairos |
| Nviso [47] | Nviso develops face detection, face verification, demographic detection, emotion classification, action unit detection, and pose detection. | Nviso |
| Sightcorp [48] | Sightcorp provides technologies for face recognition, emotion detection, attention analysis, and mood detection. | Sightcorp |
| SkyBiometry [49] | SkyBiometry is state-of-the-art face recognition and face detection cloud biometrics API allowing developers and marketers. | SkyBiometry |
| Face++ [50] | It ensures that operator behind a transaction is a live human by facial landmarks localization, face tracking technique, etc. | Face++ |
| Imotions [51] | Motions helps you quantify engagement and emotional responses. The iMotions Platform is an emotion recognition software that seamlessly integrates multiple sensors. | Imotions |
| CrowdEmotion [52] | An emotion inspired artificial intelligence company that enables technology to see, hear, and feel the way humans do. | CrowdEmotion |
| FacioMetrics [53] | FacioMetrics develops facial analysis software for mobile applications including facial image analysis—with all kinds of applications including augmented/virtual reality, animation, and audience reaction measurement. | Facebook Research |
| Findface [54] | A face recognition technology developed by the Russian company NtechLab that specializes in neural network tools. It compares photos to profile pictures on social network Vkontakte and works out identities with 70% reliability | Findface |
| Neu | Ang | Dis | Fea | Hap | Sad | Sur | Total | |
|---|---|---|---|---|---|---|---|---|
| CK+ | 316 | 360 | 448 | 192 | 552 | 224 | 624 | 2716 |
| MMI | 366 | 288 | 492 | 258 | 204 | 366 | 366 | 2340 |
| FERA | 603 | 529 | - | 479 | 606 | 695 | - | 2915 |
| 3 Frames | 5 Frames | 7 Frames | |
|---|---|---|---|
| CK+ | 99.27 | 94.45 | 95.57 |
| MMI | 87.23 | 83.76 | 81.88 |
| FERA | 90.67 | 87.85 | 87.15 |
| Average | 92.39 | 88.68 | 88.20 |
| CK+ | MMI | FERA | |
|---|---|---|---|
| 0.60 | 98.87 | 87.28 | 91.31 |
| 0.57 | 99.20 | 86.64 | 91.78 |
| 0.54 | 99.21 | 87.88 | 91.83 |
| 0.50 | 99.36 | 87.49 | 91.79 |
| 0.47 | 99.09 | 87.51 | 90.77 |
| 0.44 | 99.02 | 87.23 | 90.60 |
| 0.40 | 99.07 | 86.79 | 89.13 |
| Method | Database | Input Construction | Model |
|---|---|---|---|
| DTAGN [33] | CK+ | DTAN, DTGN | Hybrid network |
| 3DIR [11] | CK+, MMI, FERA | Multiple frames, Facial landmarks | 3D CNN, LSTM, Inception-ResNet |
| DESTN [82] | CK+ | Single image frame, Multiple landmarks | Hybrid network |
| nestedLSTM [72] | CK+, MMI | Multiple frames | 3D CNN, LSTM |
| STCNN-CRF [32] | CK+, MMI, FERA | Multiple frames | 2D CNN, CRF, Inception-ResNet |
| STFR [83] | MMI | Multiple frames | LSTM |
| Methods | Accuracy (%) |
|---|---|
| DTAGN [33] | 97.25 |
| STCNN-CRF [32] | 93.04 |
| 3DIR (S/I) [11] | 93.21 |
| DESTN [82] | 98.50 |
| nestedLSTM [72] | 99.80 |
| Proposed (App.) | 97.50 |
| Proposed (Geo,) | 95.68 |
| Proposed (Joint) | 99.21 |
| Methods | Accuracy (%) |
|---|---|
| STCNN-CRF [32] | 68.51 |
| 3DIR [11] | 77.50 |
| STFR [83] | 78.61 |
| nestedLSTM [72] | 84.53 |
| Proposed (App.) | 84.84 |
| Proposed (Geo.) | 75.24 |
| Proposed (Joint) | 87.88 |
| Methods | Accuracy |
|---|---|
| STCNN-CRF [32] | 66.66 |
| 3DIR (S/I) [11] | 77.42 |
| Proposed (App.) | 87.80 |
| Proposed (Geo.) | 85.48 |
| Proposed (Joint) | 91.83 |
| Actual values | NE | AN | DI | FE | HA | SA | SU | |
| NE | 0.97 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.00 | |
| AN | 0.00 | 0.99 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | |
| DI | 0.00 | 0.01 | 0.99 | 0.00 | 0.00 | 0.00 | 0.00 | |
| FE | 0.00 | 0.00 | 0.00 | 0.98 | 0.02 | 0.00 | 0.00 | |
| HA | 0.00 | 0.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | |
| SA | 0.00 | 0.00 | 0.00 | 0.02 | 0.00 | 0.98 | 0.00 | |
| SU | 0.01 | 0.00 | 0.00 | 0.00 | 0.01 | 0.00 | 0.98 | |
| Predicted values | ||||||||
| Actual values | NE | AN | DI | FE | HA | SA | SU | |
| NE | 0.89 | 0.00 | 0.03 | 0.02 | 0.01 | 0.03 | 0.03 | |
| AN | 0.16 | 0.62 | 0.10 | 0.01 | 0.01 | 0.08 | 0.01 | |
| DI | 0.09 | 0.09 | 0.79 | 0.01 | 0.02 | 0.01 | 0.00 | |
| FE | 0.07 | 0.00 | 0.10 | 0.78 | 0.00 | 0.05 | 0.10 | |
| HA | 0.15 | 0.00 | 0.00 | 0.00 | 0.85 | 0.00 | 0.00 | |
| SA | 0.10 | 0.06 | 0.00 | 0.06 | 0.02 | 0.76 | 0.00 | |
| SU | 0.05 | 0.00 | 0.00 | 0.02 | 0.02 | 0.00 | 0.91 | |
| Predicted values | ||||||||
| Actual values | RE | AN | FE | JO | SA | |
| RE | 0.90 | 0.03 | 0.01 | 0.06 | 0.00 | |
| AN | 0.15 | 0.83 | 0.00 | 0.02 | 0.00 | |
| FE | 0.04 | 0.01 | 0.96 | 0.03 | 0.00 | |
| JO | 0.05 | 0.02 | 0.01 | 0.92 | 0.00 | |
| SA | 0.01 | 0.00 | 0.01 | 0.00 | 0.98 | |
| Predicted values | ||||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jeong, D.; Kim, B.-G.; Dong, S.-Y. Deep Joint Spatiotemporal Network (DJSTN) for Efficient Facial Expression Recognition. Sensors 2020, 20, 1936. https://doi.org/10.3390/s20071936
Jeong D, Kim B-G, Dong S-Y. Deep Joint Spatiotemporal Network (DJSTN) for Efficient Facial Expression Recognition. Sensors. 2020; 20(7):1936. https://doi.org/10.3390/s20071936
Chicago/Turabian StyleJeong, Dami, Byung-Gyu Kim, and Suh-Yeon Dong. 2020. "Deep Joint Spatiotemporal Network (DJSTN) for Efficient Facial Expression Recognition" Sensors 20, no. 7: 1936. https://doi.org/10.3390/s20071936
APA StyleJeong, D., Kim, B. -G., & Dong, S. -Y. (2020). Deep Joint Spatiotemporal Network (DJSTN) for Efficient Facial Expression Recognition. Sensors, 20(7), 1936. https://doi.org/10.3390/s20071936