Distributed Compressed Hyperspectral Sensing Imaging Based on Spectral Unmixing

Abstract
:1. Introduction
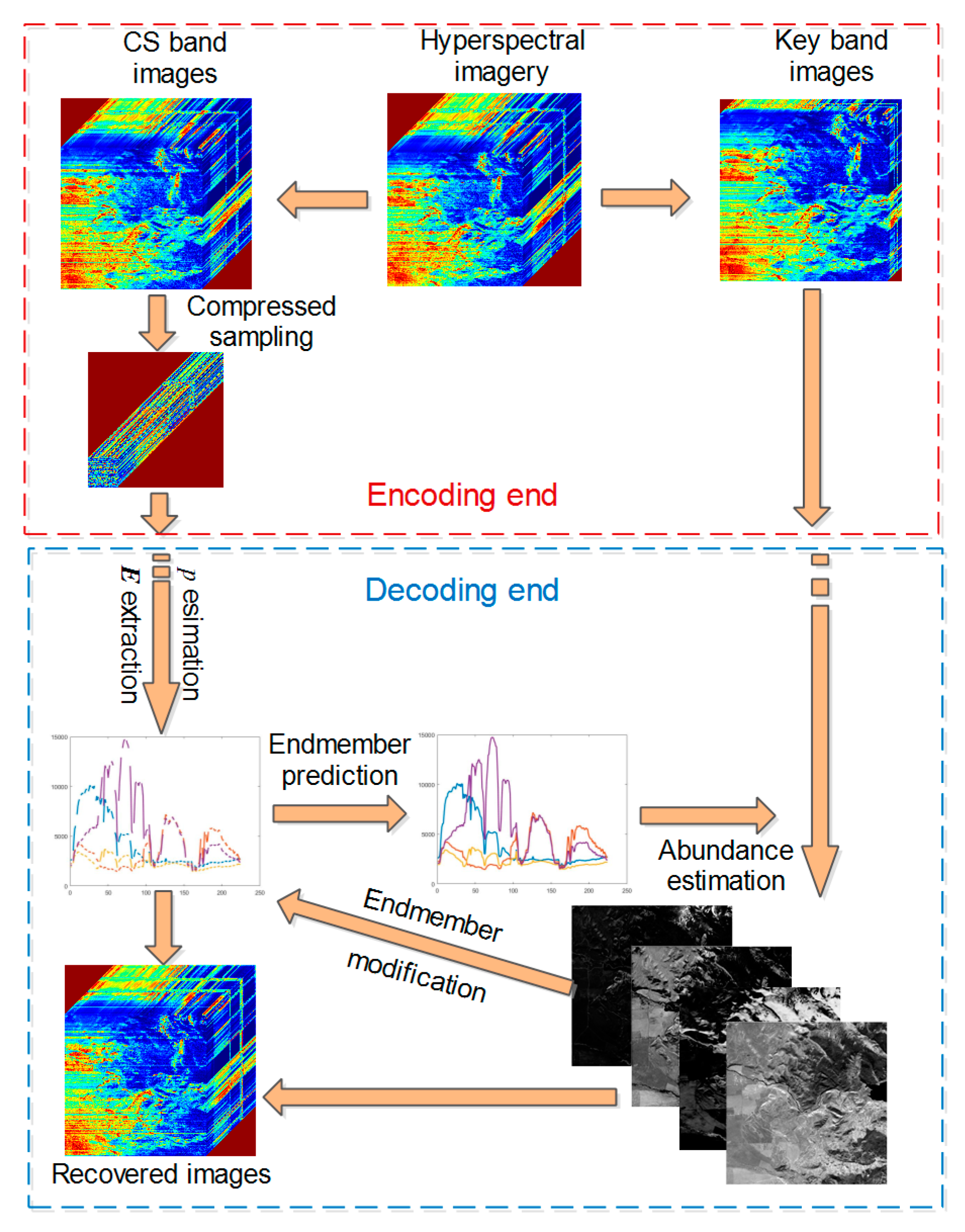
2. Distributed Compressed Sampling Framework
3. Reconstruction Algorithm of CS Band
3.1. Endmember Extraction
3.2. Abundant Estimation
3.3. Recovery of CS Band
| Algorithm 1: DCHS reconstruction algorithm |
| Inputs:, , and Output: 1. Estimate by HySime algorithm from 2. Extract from by VCA algorithm 3. Predict by using interpolation algorithm 4. Set parameters: , , and 5. Initialize: , , , , , , , , , , 6. While and 7. Compute by soft-threshold function according to (12) 8. Compute by (15) 9. Compute by (16) 10. Compute by (17) 11. Update Lagrange multipliers , , and by (18) 12. Compute and by (19) 13. , End while 14. Modify by (20) 15. Recover CS band according to LMM by (21) |
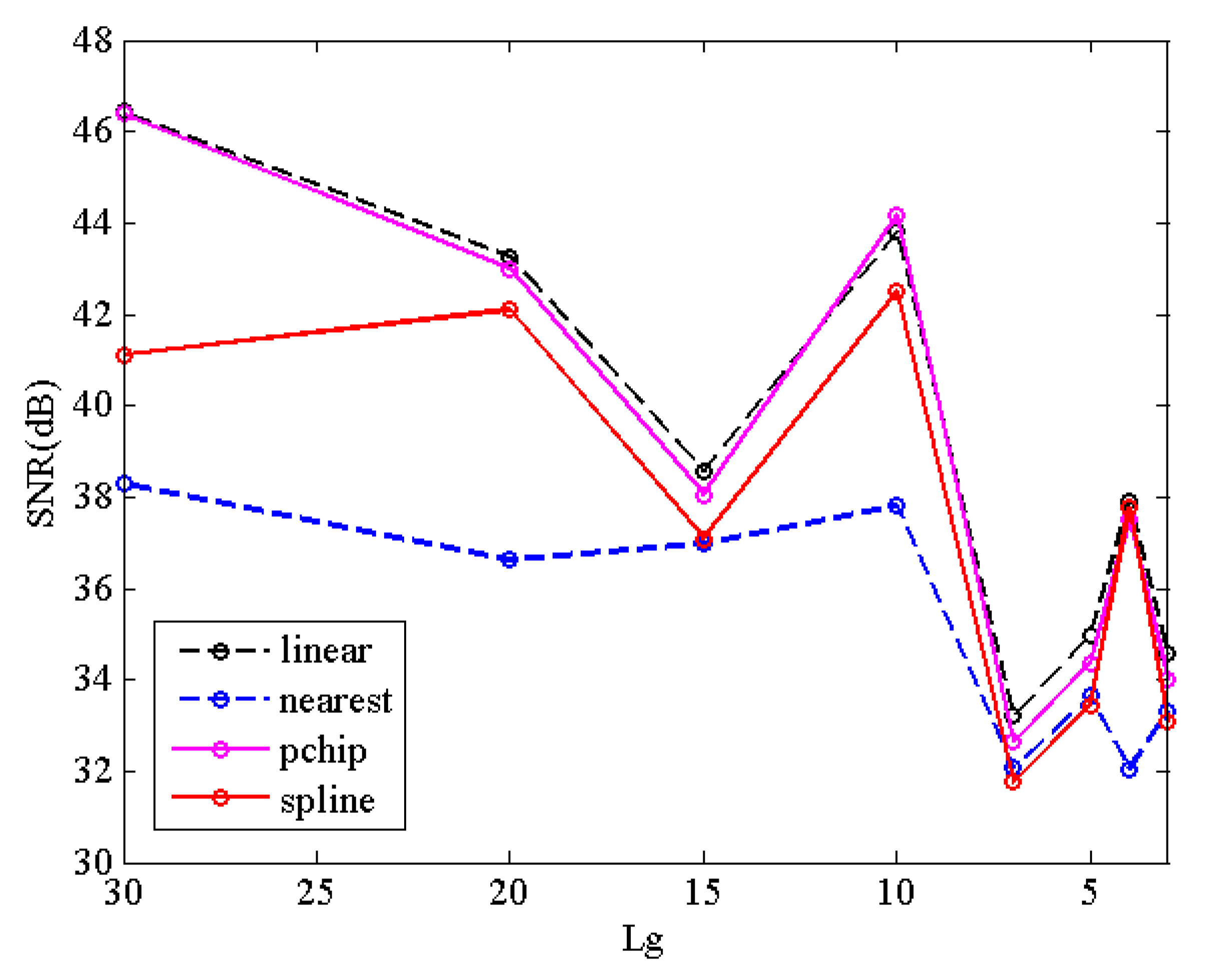
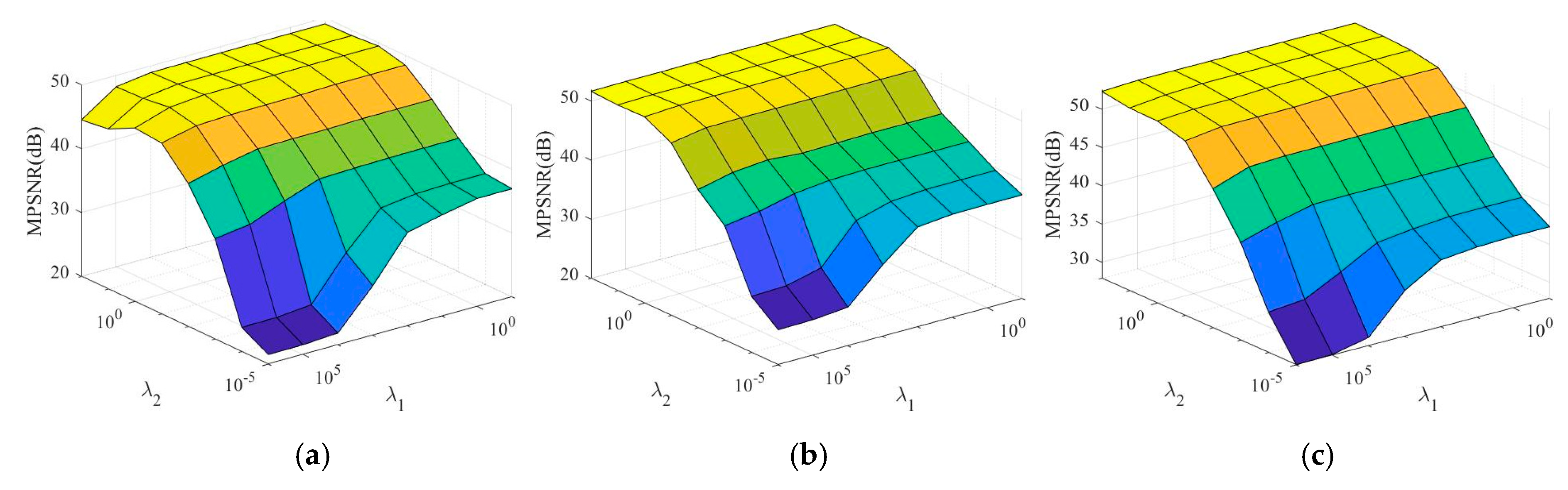
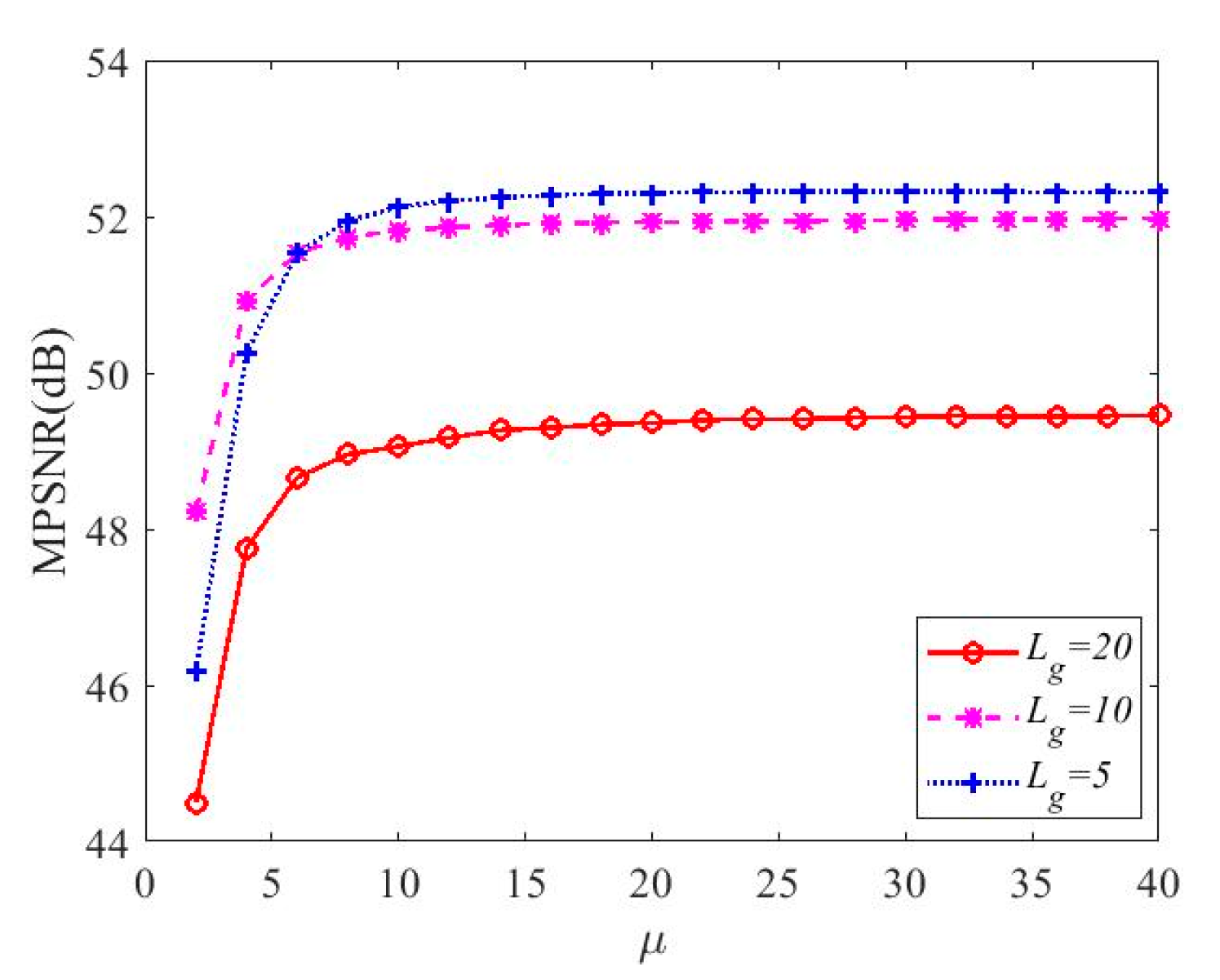
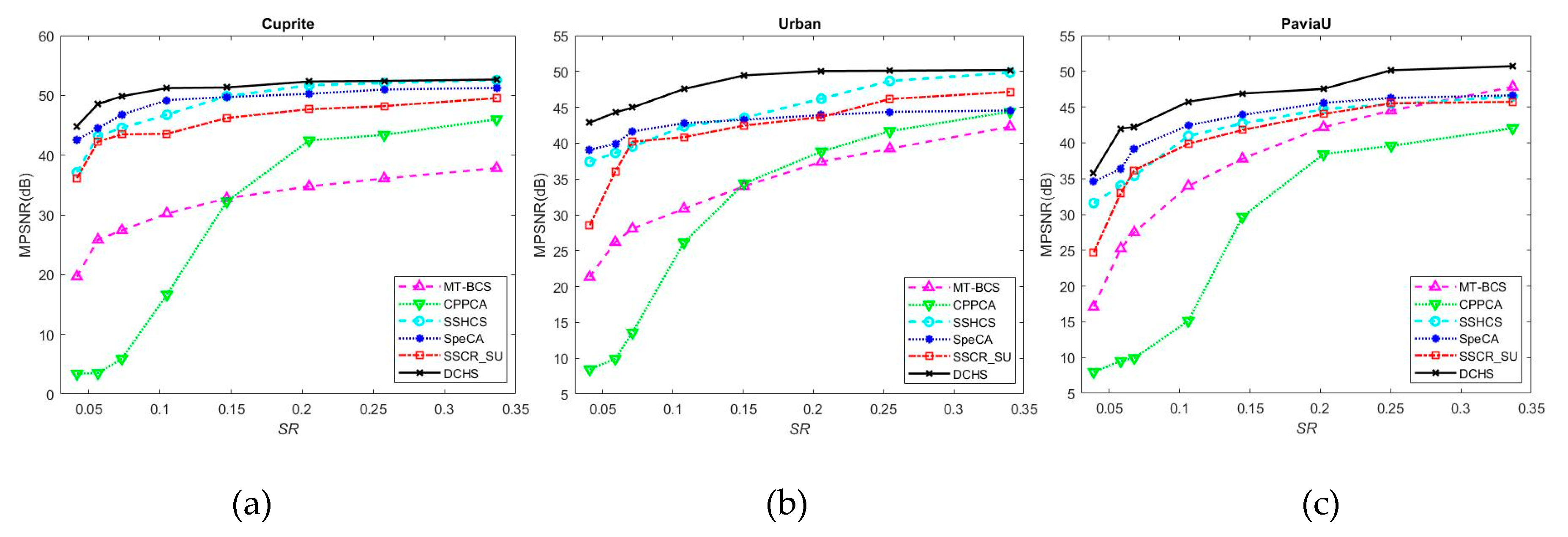
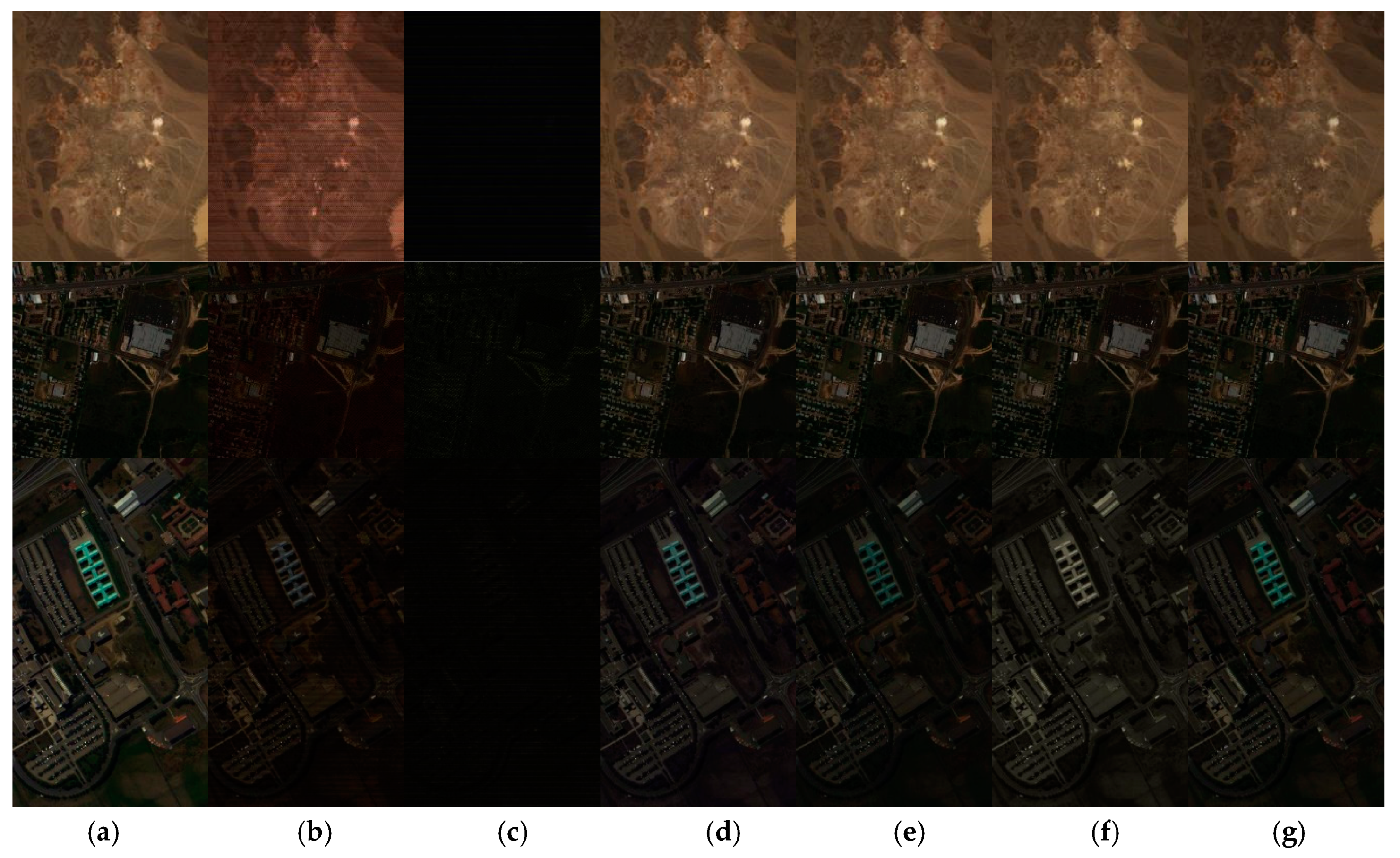
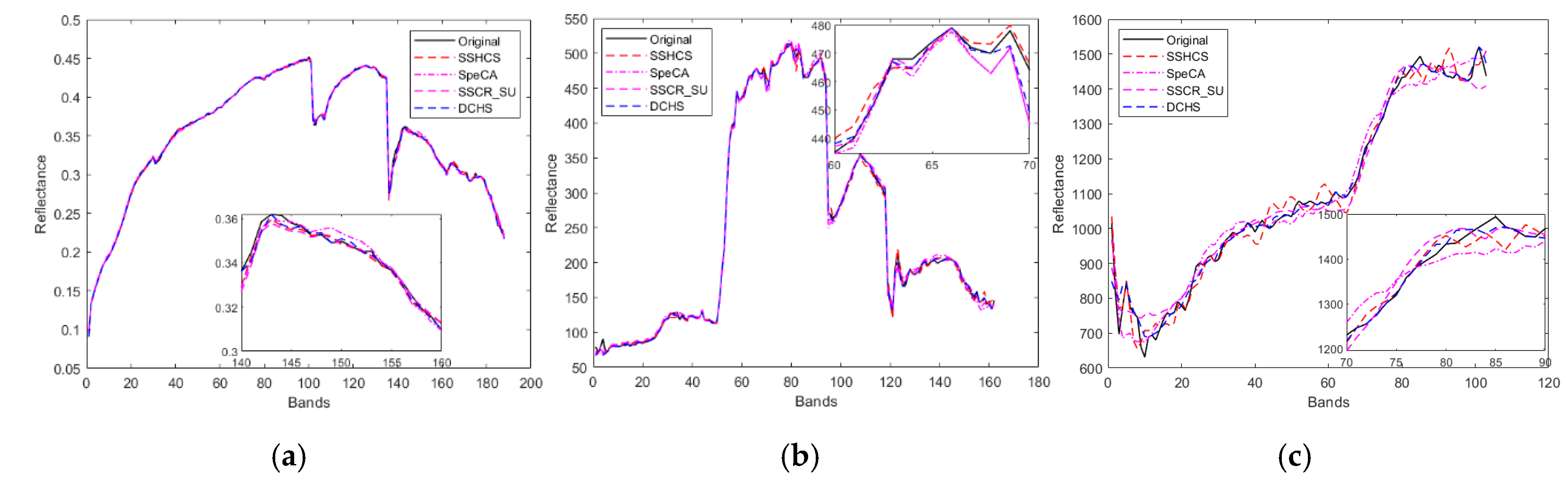
4. Experiments and Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lin, X.; Liu, Y.B.; Wu, J.M.; Dai, Q.H. Spatial-spectral encoded compressive hyperspectral imaging. ACM Trans. Graph. 2014, 33. [Google Scholar] [CrossRef]
- Bioucas-Dias, J.M.; Plaza, A.; Dobigeon, N.; Parente, M.; Qian, D.; Gader, P.; Chanussot, J. Hyperspectral unmixing overview: Geometrical, statistical, and sparse regression-based approaches. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 354–379. [Google Scholar] [CrossRef] [Green Version]
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Candes, E.J.; Wakin, M.B. An introduction to compressive sampling. IEEE Signal Process. Mag. 2008, 25, 21–30. [Google Scholar] [CrossRef]
- Rauhut, H.; Schnass, K.; Vandergheynst, P. Compressed sensing and redundant dictionaries. IEEE Trans. Inf. Theory 2008, 54, 2210–2219. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Wei, W.; Zhang, Y.; Yan, H.; Li, F.; Tian, C. Locally similar sparsity-based hyperspectral compressive sensing using unmixing. IEEE Trans. Comput. Imaging 2016, 2, 86–100. [Google Scholar] [CrossRef]
- Zhang, L.; Wei, W.; Tian, C.; Li, F.; Zhang, Y. Exploring structured sparsity by a reweighted laplace prior for hyperspectral compressive sensing. IEEE Trans. Image Process. 2016, 25, 4974–4988. [Google Scholar] [CrossRef]
- Duarte, M.F.; Sarvotham, S.; Baron, D.; Wakin, M.B.; Baraniuk, R.G. Distributed compressed sensing of jointly sparse signals. In Proceedings of the Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 28 October–1 November 2005; pp. 1537–1541. [Google Scholar]
- Duarte, M.F.; Baraniuk, R.G. Kronecker compressive sensing. IEEE Trans. Image Process. 2012, 21, 494–504. [Google Scholar] [CrossRef]
- Fowler, J.E. Compressive-projection principal component analysis. IEEE Trans. Image Process. 2009, 18, 2230–2242. [Google Scholar] [CrossRef] [PubMed]
- Fowler, J.E.; Qian, D. Reconstructions from compressive random projections of hyperspectral imagery. In Optical Remote Sensing: Advances in Signal Processing and Exploitation Techniques; Prasad, S.B.L.M., Chanussot, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 31–48. [Google Scholar]
- Li, W.; Prasad, S.; Fowler, J.E. Integration of spectral-spatial information for hyperspectral image reconstruction from compressive random projections. IEEE Geosci. Remote Sens. Lett. 2013, 10, 1379–1383. [Google Scholar] [CrossRef]
- Ly, N.H.; Du, Q.; Fowler, J.E. Reconstruction from random projections of hyperspectral imagery with spectral and spatial partitioning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 466–472. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Wei, L.; Tramel, E.W.; Fowler, J.E. Reconstruction of hyperspectral imagery from random projections using multihypothesis prediction. IEEE Trans. Geosci. Remote Sens. 2014, 52, 365–374. [Google Scholar] [CrossRef] [Green Version]
- Martín, G.; Bioucas-Dias, J.M. Hyperspectral blind reconstruction from random spectral projections. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 2390–2399. [Google Scholar] [CrossRef]
- Shu, X.; Ahuja, N. Imaging via three-dimensional compressive sampling (3DCS). In Proceedings of the IEEE International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 439–446. [Google Scholar]
- Zhang, B.; Tong, X.; Wang, W.; Xie, J. The research of Kronecker product-based measurement matrix of compressive sensing. Eurasip J. Wirel. Commun. Netw. 2013, 2013, 1–5. [Google Scholar] [CrossRef] [Green Version]
- Slepian, D.; Wolf, J. Noiseless coding of correlated information sources. IEEE Trans. Inf. Theory 1973, 19, 471–480. [Google Scholar] [CrossRef]
- Kang, L.-W.; Lu, C.-S. Distributed compressive video sensing. In Proceedings of the Acoustics, Speech and Signal Processing, 2009. ICASSP 2009. IEEE International Conference, Taipei, Taiwan, 19–24 April 2009; pp. 1169–1172. [Google Scholar]
- Do, T.T.; Yi, C.; Nguyen, D.T.; Nguyen, N.; Lu, G.; Tran, T.D. Distributed compressed video sensing. In Proceedings of the IEEE International Conference on Image Processing, Cairo, Egypt, 7–10 November 2009; pp. 1393–1396. [Google Scholar]
- Liu, H.; Li, Y.; Wu, C.; Lv, P. Compressed hyperspectral image sensing based on interband prediction. J. Xidian Univ. 2011, 38, 37–41. (In Chinese) [Google Scholar] [CrossRef]
- Jia, Y.B.; Feng, Y.; Wang, Z.L. Reconstructing hyperspectral images from compressive sensors via exploiting multiple priors. Spectr. Lett. 2015, 48, 22–26. [Google Scholar] [CrossRef]
- Wang, Y.; Lin, L.; Zhao, Q.; Yue, T.; Meng, D.; Leung, Y. Compressive sensing of hyperspectral images via joint tensor tucker decomposition and weighted total variation regularization. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2457–2461. [Google Scholar] [CrossRef]
- Xue, J.; Zhao, Y.; Liao, W.; Chan, J. Nonlocal tensor sparse representation and low-rank regularization for hyperspectral image compressive sensing reconstruction. Remote Sens. 2019, 11, 193. [Google Scholar] [CrossRef] [Green Version]
- Hong, D.; Yokoya, N.; Chanussot, J.; Zhu, X.X. An augmented linear mixing model to address spectral variability for hyperspectral unmixing. IEEE Trans. Image Process. 2019, 28, 1923–1938. [Google Scholar] [CrossRef] [Green Version]
- Halimi, A.; Honeine, P.; Bioucasdias, J. Hyperspectral unmixing in presence of endmember variability, nonlinearity or mismodelling effects. IEEE Trans. Image Process. 2016, 25, 4565–4579. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Z.; Feng, Y.; Jia, Y. Spatio-spectral hybrid compressive sensing of hyperspectral imagery. Remote Sens. Lett. 2015, 6, 199–208. [Google Scholar] [CrossRef]
- Wang, L.; Feng, Y.; Gao, Y.; Wang, Z.; He, M. Compressed sensing reconstruction of hyperspectral images based on spectral unmixing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1266–1284. [Google Scholar] [CrossRef]
- Sun, W.; Du, Q. Hyperspectral band selection: A review. IEEE Geosci. Remote Sens. Mag. 2019, 7, 118–139. [Google Scholar] [CrossRef]
- Hsu, P.-H. Feature extraction of hyperspectral images using wavelet and matching pursuit. ISPRS J. Photogramm. Remote Sens. 2007, 62, 78–92. [Google Scholar] [CrossRef]
- Uddin, M.P.; Mamun, M.A.; Hossain, M.A. Feature extraction for hyperspectral image classification. In Proceedings of the 2017 IEEE Region 10 Humanitarian Technology Conference (R10-HTC), Dhaka, Bangladesh, 21–23 December 2017; pp. 379–382. [Google Scholar]
- Setiyoko, A.; Dharma, I.G.W.S.; Haryanto, T. Recent development of feature extraction and classification multispectral/hyperspectral images: A systematic literature review. J. Phys. Conf. Ser. 2017. [Google Scholar] [CrossRef]
- Marcinkiewicz, M.; Kawulok, M.; Nalepa, J. Segmentation of multispectral data simulated from hyperspectral imagery. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3336–3339. [Google Scholar]
- Lorenzo, P.R.; Tulczyjew, L.; Marcinkiewicz, M.; Nalepa, J. Hyperspectral band selection using attention-based convolutional neural networks. IEEE Access 2020, 8, 42384–42403. [Google Scholar] [CrossRef]
- Nascimento, J.M.P.; Dias, J.M.B. Vertex component analysis: A fast algorithm to unmix hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 898–910. [Google Scholar] [CrossRef] [Green Version]
- Bengio, Y.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Peng, X.; Lu, C.; Yi, Z.; Tang, H. Connections between nuclear-norm and frobenius-norm-based representations. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 218–224. [Google Scholar] [CrossRef] [Green Version]
- Peng, X.; Feng, J.; Xiao, S.; Yau, W.; Zhou, J.T.; Yang, S. Structured autoencoders for subspace clustering. IEEE Trans. Image Process. 2018, 27, 5076–5086. [Google Scholar] [CrossRef] [PubMed]
- Peng, X.; Zhu, H.; Feng, J.; Shen, C.; Zhang, H.; Zhou, J.T. Deep clustering with sample-assignment invariance prior. IEEE Trans. Neural Netw. Learn. Syst. 2019, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Peng, X.; Feng, J.; Zhou, J.T.; Lei, Y.; Yan, S. Deep subspace clustering. IEEE Trans. Neural Netw. Learn. Syst. 2020, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Bioucas-Dias, J.M.; Nascimento, J.M.P. Hyperspectral subspace identification. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2435–2445. [Google Scholar] [CrossRef] [Green Version]
- Kokaly, R.F.; Clark, R.N.; Swayze, G.A.; Livo, K.E.; Hoefen, T.M.; Pearson, N.C.; Wise, R.A.; Benzel, W.M.; Lowers, H.A.; Driscoll, R.L.; et al. USGS Spectral Library Version 7. 2017. Available online: https://www.researchgate.net/publication/323486055_USGS_Spectral_Library_Version_7 (accessed on 10 February 2020).
- Eckstein, J.; Bertsekas, D.P. On the douglas—Rachford splitting method and the proximal point algorithm for maximal monotone operators. Math. Program. 1992, 55, 293–318. [Google Scholar] [CrossRef] [Green Version]
- Lin, Y.; Wohlberg, B.; Vesselinov, V. ADMM penalty parameter selection with krylov subspace recycling technique for sparse coding. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 1945–1949. [Google Scholar]
- Combettes, P.; Wajs, R.V. Signal Recovery by Proximal Forward-Backward Splitting. Multiscale Model. Simul. 2005, 4, 1164–1200. [Google Scholar] [CrossRef] [Green Version]
- Shihao, J.; Dunson, D.; Carin, L. Multitask compressive sensing. IEEE Trans. Signal Process. 2009, 57, 92–106. [Google Scholar]
- Zhu, F.; Wang, Y.; Xiang, S.; Fan, B.; Pan, C. Structured sparse method for hyperspectral unmixing. ISPRS J. Photogramm. Remote Sens. 2014, 88, 101–118. [Google Scholar] [CrossRef] [Green Version]
- Gamba, P. A collection of data for urban area characterization. In Proceedings of the IGARSS 2004, 2004 IEEE International Geoscience and Remote Sensing Symposium, Anchorage, AK, USA, 20–24 September 2004; pp. 1–72. [Google Scholar]
- Zhou, W.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 30 | 20 | 15 | 10 | 7 | 5 | 4 | 3 | |
|---|---|---|---|---|---|---|---|---|
| Results on the Cuprite Dataset | ||||||||
| 0.0416 | 0.0564 | 0.0732 | 0.1048 | 0.1469 | 0.2048 | 0.2575 | 0.3365 | |
| MT-BCS | 13.135 | 6.5641 | 5.6391 | 4.4379 | 3.5327 | 3.0821 | 2.8048 | 2.529 |
| CPPCA | 87.408 | 82.683 | 63.714 | 21.502 | 3.5086 | 0.9931 | 0.9064 | 0.6554 |
| SSHCS | 1.8222 | 0.9963 | 0.8775 | 1.1346 | 0.6602 | 0.4074 | 0.387 | 0.3658 |
| SpeCA | 0.8355 | 0.8227 | 0.6226 | 0.5005 | 0.4706 | 0.4523 | 0.4222 | 0.4079 |
| SSCR_SU | 1.7216 | 1.0615 | 0.983 | 0.9051 | 0.7575 | 0.6331 | 0.5846 | 0.5059 |
| DCHS | 0.9694 | 0.7088 | 0.6528 | 0.5735 | 0.5083 | 0.4901 | 0.4537 | 0.4352 |
| Results on the Urban Dataset | ||||||||
| 0.0406 | 0.0589 | 0.0711 | 0.1078 | 0.1506 | 0.2056 | 0.2544 | 0.34 | |
| MT-BCS | 20.949 | 12.691 | 10.356 | 7.7535 | 5.5784 | 3.9322 | 3.1864 | 2.241 |
| CPPCA | 87.626 | 73.818 | 50.011 | 13.114 | 4.9118 | 3.1499 | 2.3014 | 1.7288 |
| SSHCS | 3.8007 | 3.5748 | 3.1717 | 2.2219 | 2.0846 | 1.4805 | 1.1498 | 1.0011 |
| SpeCA | 3.2096 | 2.8107 | 2.5085 | 2.1831 | 2.0845 | 2.0381 | 1.9604 | 1.9545 |
| SSCR_SU | 8.9135 | 4.6612 | 2.94 | 2.6452 | 2.3153 | 2.1638 | 1.6217 | 1.3918 |
| DCHS | 2.671 | 2.2361 | 2.0754 | 1.533 | 1.2448 | 1.1214 | 1.0631 | 0.9546 |
| Results on the PaviaU Dataset | ||||||||
| 0.0388 | 0.0581 | 0.0677 | 0.1061 | 0.1446 | 0.2022 | 0.2503 | 0.3368 | |
| MT-BCS | 41.148 | 15.13 | 11.286 | 5.7488 | 3.6916 | 2.3748 | 1.8101 | 1.2232 |
| CPPCA | 88.814 | 87.689 | 82.943 | 59.258 | 8.9603 | 3.4445 | 3.1112 | 2.357 |
| SSHCS | 8.2997 | 6.0203 | 4.7841 | 2.8518 | 2.3971 | 1.8155 | 1.6073 | 1.4682 |
| SpeCA | 4.9424 | 4.1384 | 3.3207 | 2.3286 | 2.0295 | 1.809 | 1.6015 | 1.5467 |
| SSCR_SU | 15.2691 | 5.7259 | 5.0558 | 3.477 | 2.6279 | 2.144 | 1.7809 | 1.7833 |
| DCHS | 5.5415 | 3.211 | 3.0072 | 2.4134 | 2.2623 | 2.1816 | 1.3542 | 1.1391 |
| 30 | 20 | 15 | 10 | 7 | 5 | 4 | 3 | |
|---|---|---|---|---|---|---|---|---|
| Results on the Cuprite Dataset | ||||||||
| 0.0416 | 0.0564 | 0.0732 | 0.1048 | 0.1469 | 0.2048 | 0.2575 | 0.3365 | |
| MT-BCS | 0.2987 | 0.6297 | 0.7213 | 0.8332 | 0.91 | 0.9461 | 0.9604 | 0.9729 |
| CPPCA | 0.0001 | 0.0026 | 0.0191 | 0.3278 | 0.9535 | 0.9862 | 0.9876 | 0.9926 |
| SSHCS | 0.9624 | 0.987 | 0.9855 | 0.9916 | 0.9940 | 0.9962 | 0.9965 | 0.997 |
| SpeCA | 0.9863 | 0.9875 | 0.9912 | 0.9946 | 0.9953 | 0.9956 | 0.9961 | 0.9964 |
| SSCR_SU | 0.9737 | 0.988 | 0.9874 | 0.9876 | 0.9896 | 0.9925 | 0.9933 | 0.9949 |
| DCHS | 0.9857 | 0.9888 | 0.9902 | 0.9922 | 0.9938 | 0.994 | 0.9949 | 0.9953 |
| Results on the Urban Dataset | ||||||||
| 0.0406 | 0.0589 | 0.0711 | 0.1078 | 0.1506 | 0.2056 | 0.2544 | 0.34 | |
| MT-BCS | 0.4105 | 0.614 | 0.6823 | 0.7563 | 0.828 | 0.8924 | 0.9158 | 0.9487 |
| CPPCA | 0.0051 | 0.0332 | 0.2008 | 0.6924 | 0.8842 | 0.9393 | 0.9609 | 0.9734 |
| SSHCS | 0.9443 | 0.9424 | 0.9314 | 0.959 | 0.9558 | 0.973 | 0.9832 | 0.9863 |
| SpeCA | 0.9467 | 0.9474 | 0.9675 | 0.9741 | 0.9754 | 0.9793 | 0.9795 | 0.9804 |
| SSCR_SU | 0.8762 | 0.9344 | 0.9648 | 0.9711 | 0.9742 | 0.9771 | 0.9822 | 0.9839 |
| DCHS | 0.9667 | 0.9722 | 0.9749 | 0.9825 | 0.9857 | 0.9871 | 0.9883 | 0.9901 |
| Results on the PaviaU Dataset | ||||||||
| 0.0388 | 0.0581 | 0.0677 | 0.1061 | 0.1446 | 0.2022 | 0.2503 | 0.3368 | |
| MT-BCS | 0.124 | 0.4773 | 0.5716 | 0.7687 | 0.8617 | 0.9239 | 0.9492 | 0.9742 |
| CPPCA | 0.0068 | 0.0072 | 0.0173 | 0.1254 | 0.7075 | 0.9013 | 0.9154 | 0.9351 |
| SSHCS | 0.803 | 0.8714 | 0.8928 | 0.9445 | 0.9585 | 0.9717 | 0.9755 | 0.9814 |
| SpeCA | 0.8149 | 0.863 | 0.8841 | 0.9341 | 0.9471 | 0.958 | 0.9641 | 0.9655 |
| SSCR_SU | 0.6054 | 0.8653 | 0.8354 | 0.9105 | 0.9383 | 0.945 | 0.9566 | 0.9565 |
| DCHS | 0.861 | 0.9187 | 0.92 | 0.9413 | 0.9505 | 0.9572 | 0.9755 | 0.9834 |
| 30 | 20 | 15 | 10 | 7 | 5 | 4 | 3 | |
|---|---|---|---|---|---|---|---|---|
| 0.0416 | 0.0564 | 0.0732 | 0.1048 | 0.1469 | 0.2048 | 0.2575 | 0.3365 | |
| MT-BCS | 19.0391 | 22.1187 | 17.7807 | 25.6069 | 29.3980 | 34.6212 | 43.4569 | 52.9737 |
| CPPCA | 0.1005 | 0.0627 | 0.0585 | 0.1006 | 0.1066 | 0.1727 | 0.2139 | 0.5978 |
| SSHCS | 0.2831 | 0.1351 | 0.1269 | 0.0917 | 0.1132 | 0.1012 | 0.0919 | 0.0932 |
| SpeCA | 15.5695 | 30.4764 | 49.2695 | 58.9999 | 58.9444 | 59.8885 | 57.1876 | 56.5255 |
| SSCR_SU | 4.2837 | 3.3935 | 1.2450 | 3.4530 | 1.3813 | 1.2545 | 1.3005 | 1.3809 |
| DCHS | 33.0788 | 34.6071 | 36.2856 | 34.2655 | 33.2441 | 30.8957 | 29.1711 | 26.9435 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Xiao, H. Distributed Compressed Hyperspectral Sensing Imaging Based on Spectral Unmixing. Sensors 2020, 20, 2305. https://doi.org/10.3390/s20082305
Wang Z, Xiao H. Distributed Compressed Hyperspectral Sensing Imaging Based on Spectral Unmixing. Sensors. 2020; 20(8):2305. https://doi.org/10.3390/s20082305
Chicago/Turabian StyleWang, Zhongliang, and Hua Xiao. 2020. "Distributed Compressed Hyperspectral Sensing Imaging Based on Spectral Unmixing" Sensors 20, no. 8: 2305. https://doi.org/10.3390/s20082305
APA StyleWang, Z., & Xiao, H. (2020). Distributed Compressed Hyperspectral Sensing Imaging Based on Spectral Unmixing. Sensors, 20(8), 2305. https://doi.org/10.3390/s20082305