1. Introduction
With the dynamic increase in data traffic in connected vehicles and wireless networks, satisfying cellular data traffic has become relevant. To satisfy these requirements, vehicular social networks (VSNs) have been studied [
1,
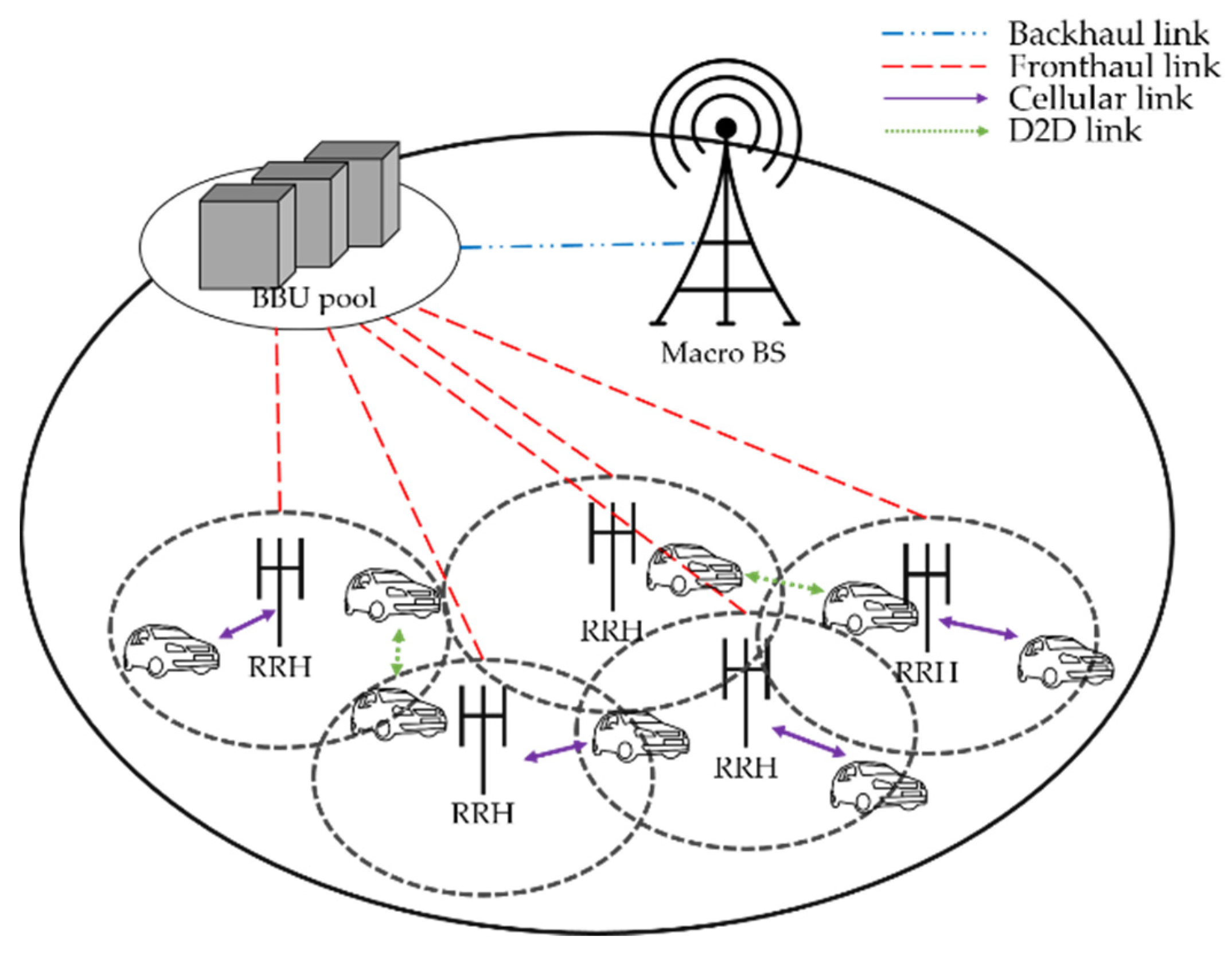
2]. VSNs consist of moving and parked vehicles on roads, and the vehicles communicate with nearby vehicles or infrastructure to report and exchange traffic information. Therefore, one of the challenges is to ensure communication quality and reduce delays in VSNs. To guarantee a high data rate in a VSN, base stations are densely deployed and overlapped. However, densely deployed base stations cause higher system energy consumption. To tackle the energy consumption problem, the traditional base station structure is changed to a centralized structure, such as a heterogeneous cloud radio access network (H-CRAN). In the H-CRAN structure, a traditional base station is divided into a signal-processing part as the baseband unit (BBU) and a signal transceiver part as the radio remote head (RRH). The BBUs are centralized as a BBU pool, and the RRHs are connected to the BBU pool through fronthaul links. The macro base station only serves voice services to users, and the RRHs are densely overlapped in macro cells.
In traditional communication in vehicular networks, vehicles communicate with other vehicles and infrastructure through RRHs. Further, vehicles have high mobility; therefore, they make frequent handovers. This causes heavy loads and energy consumption problems in the system. To solve the energy consumption problem and provide efficient communication between vehicles, device-to-device (D2D) communication has been developed. With D2D communication, nearby wireless devices can communicate directly without an RRH, which can reduce the system energy consumption from the RRH transceivers and fronthaul links. In vehicular networks, D2D communication can facilitate efficient data communication between nearby vehicles. Thus, D2D communication can decrease latency because of the relatively small distance between the transmitter and receiver vehicle. As D2D communication reuses cellular wireless resources, it helps increase the spectral capacity.
However, D2D communication is highly susceptible to interference because of the reuse of cellular resources. Specifically, for D2D communication in H-CRANs, various interference problems are caused by the dense deployment of RRHs. In addition, when traffic congestion occurs in vehicular environments, the high density of devices in D2D communication can cause a critical interference problem [
3]. To avoid the interference problem, channel extensions are conducted. However, interference problems remain because of interference from adjacent channels and shared resources [
4,
5,
6]. To solve these problems, various studies on D2D communication have been conducted. Mode selection is a technique that can solve the interference problem [
7,
8,
9]. Mode selection allows the devices to select from several communication modes: cellular mode, D2D mode, and detection mode. With mode selection, devices choose modes according to the channel state, which can ensure sufficient quality of service (QoS) for the devices and increase the system capacity. Another solution to solve the interference problem is to use the power-control method [
10,
11]. Power control is a method that manages interference by controlling the power of the D2D links. Using the power-control method increases the energy efficiency of a device by decreasing the transmission power in low-interference situations and increasing the transmission power in high-interference situations to guarantee the QoS.
In this paper, we propose a joint mode-selection and power-control algorithm using reinforcement learning in a VSN. In our algorithm, the BBU pool uses centralized Q-learning, and the vehicles use distributed Q-learning to achieve improved signal-to-interference noise ratios (SINRs). Centralized Q-learning aims to maximize the system’s energy efficiency, while distributed Q-learning aims to maximize the vehicle’s achievable data rate. As the energy efficiency of the system and the SINR of a vehicle are in a trade-off relationship, it is important to identify a point that optimizes both objectives. Our algorithm ensures vehicular capacity by considering outage probability as a QoS constraint while maximizing system energy efficiency.
The rest of this paper is organized as follows. In
Section 2, we introduce related work. In
Section 3, we formulate the system model and the problem definition. The joint mode selection and power-control algorithm using multi-Q-learning is introduced in
Section 4. A performance evaluation and discussion of our algorithm are presented in
Section 5. We present the conclusions of this study in
Section 6.
2. Materials and Methods
To reduce the load and increase the system’s energy efficiency, several optimization methods have been developed. In [
12], a mode-selection algorithm was developed to maximize the energy efficiency of the device using the transmission rate as a QoS requirement. The mode was determined adaptively, based on various factors of the device, and it could minimize the energy consumption for each successful content delivery. In [
13], a mode-selection algorithm that considered the link quality of D2D links was proposed to maximize the system throughput. It estimated the expected system throughput considering the SINR and available resources, so it could maximize the system throughput.
As D2D communication reuses cellular resources, interference management between cellular and D2D links is important. The power-control method that controls the transmission power of D2D links is one method used to manage interference. In [
14], a power-control algorithm with variable target SINRs was proposed for application in multicell scenarios. It aimed to maximize the system spectral efficiency using a soft-dropping algorithm to control the transmission power to meet the variable target SINR. A power-control algorithm using stochastic geometry was proposed in [
15]. The algorithm can be divided into two types: centralized and decentralized. The centralized type aims to guarantee the coverage probability by solving the optimization power problem. The decentralized type was an interference mitigation method to maximize the sum rates of the devices.
To take advantage of both mode selection and power control, jointly designed algorithms were proposed. In [
16], an energy-aware joint power-control and mode-selection algorithm was proposed to minimize the power consumption. It solved the power minimization problem by guaranteeing the QoS constraints and developed a joint strategy under the condition of imperfect channel state information. In [
17], a mode-selection and power-control algorithm was proposed to maximize the sum of the achievable data rate. It selected the mode to satisfy the distance and interference constraints from an operator perspective. After mode selection, it first proved that the power-control problem was quasiconvex for the D2D mode and then solved it.
Environments where cellular and D2D modes coexist involve high complexity that reflects the numerous features of network dynamics in the optimization methods. To consider network dynamics, reinforcement learning was used to adapt the optimization of the mode selection and power-control problems. In [
18], a mode-selection algorithm based on Q-learning was proposed to maximize QoS and minimize interference. It considered the delay, energy efficiency, and interference to determine the transmission mode. In [
19], a mode-selection method based on deep reinforcement learning was proposed to minimize the system power consumption in a fog radio access network. To make optimal decisions, it formulated the energy minimization problem with a Markov decision process by considering the on-off state of processors, communication mode of the device, and precoding vectors of RRH.
Reinforcement learning was implemented in [
20] to adapt the power-control algorithm for D2D communication. It consisted of centralized and distributed Q-learning and aimed to maximize the system capacity and guarantee a stable QoS level. In centralized Q-learning, called team Q-learning, the agent in each resource block (RB) managed only one Q-table. In distributed Q-learning, agents in each D2D link learned independently and managed each Q-table. Team Q-learning could reduce the complexity and avoid the overhead from managing the Q-tables in distributed Q-learning. In [
21], a joint mode-selection and power-control algorithm with multiagent learning was proposed. The agents in each device managed each Q-table and learned independently. It considered the local SINR information and device modes, such as the cellular mode, D2D mode, and detection mode. It helped D2D transmitters decide on efficient mode selection and power control to maximize the energy efficiency of the D2D links.
In a VSN, vehicles move constantly with high mobility. This high mobility results in frequent handovers in cellular communication and changes the channel states accordingly. However, none of the above studies considered vehicle mobility and changing channel states. In addition, there is a large amount of communication between adjacent vehicles in a VSN. D2D communication has distance limitations that have a significant impact on performance; thus, vehicle mobility should be considered. Therefore, any appropriate mode-selection and power-control method must consider the network dynamics that come with vehicle mobility. This mobility causes signaling overhead and data latency because of frequent changes in the channel information state.
Typical optimization methods incur high complexity if they consider the various relevant features. To make optimal decisions in a dynamic network environment, reinforcement learning can make recommendations according to the various states. In D2D communication applications, deep Q-learning has the advantage of being able to learn directly using network data and process high-dimensional data [
15]. However, deep Q-learning is more complex than Q-learning, and the available data for vehicles are limited. So, it brings high complexity and overhead problems.
In this paper, we propose a mode-selection and power-control algorithm using reinforcement learning for the H-CRAN architecture in a VSN. Our algorithm consists of two parts: centralized Q-learning and distributed Q-learning. In the centralized part, the agent in a BBU pool manages one Q-table to maximize the system’s energy efficiency and guarantee the QoS constraints. It recommends an appropriate communication mode and transmission power for the vehicles, based on the average SINR and available resources. To satisfy the outage probability as a QoS constraint, the target SINR that determines the states is adjusted. In the distributed part, the agents in each vehicle manage each table and learn to maximize the received SINR. The agents choose their actions by comparing the actions recommended by the BBU with their own actions.
3. System Model and Problem Definition
In this work, we consider the single-cell scenario in H-CRANs where cellular-mode vehicles and D2D-mode vehicles coexist. The vehicles are expressed as devices in this study. H-CRANs comprise a BBU pool and multiple RRHs, as shown in
Figure 1. The total device set can be expressed as
, and it consists of a cellular device set
and D2D device set
. The cellular devices,
, and the number of D2D devices are distributed randomly within the set
. We denote the set of RRHs as
and RBs as
. We assume that one RB can be allocated to one cellular device and shared with multiple D2D devices. Each device can select the transmission mode between the cellular mode,
, and D2D mode,
; to select the D2D mode, the distance between the D2D pairs must satisfy the D2D distance threshold.
The SINR of cellular device
at the
-th RB, as reported in [
20], is
where
is the transmission power of the RRH;
is the channel gain between the associated RRH
and cellular device
, and
is the noise power spectral density. The channel gain between cellular device
and the associated RRH
can be calculated as
, where
is the constant gain from the antenna and amplifier,
is the multipath fading gain with a log-normal distribution,
is the distance between the cellular device
and the associated RRH
, and
is the path-loss exponent. The SINR of D2D device
at the
-th RB, as reported in [
16], is
where
is the transmission power of D2D device
,
is the channel gain between another D2D pair
,
is the transmission power of cellular device
which shares the
-th RB, and
is the channel gain between cellular device
and D2D device
. The total system capacity, according to the Shannon capacity, can be expressed as
where
is the total bandwidth of the system. The power consumption of the system includes the power consumed by the RRHs and fronthaul devices. The power consumption model of the RRH can be expressed as
where
is the circuit power of the RRH,
is the slope of the load-dependent power consumption of RRH, as reported in [
22], and
is the association indicator of cellular device
, with values of 1 for an association and 0 for a nonassociation. The power consumption model for the fronthaul links was reported in [
23] and can be expressed as
where
is the circuit power from the fronthaul transceiver and switch,
is the power consumption per bit/s, and
is the traffic associated with RRH
. The macro base station provides only voice services; thus, its power consumption is not considered. Therefore, the system power consumption model can be defined as
The system energy efficiency can be defined as
Our main goal is to maximize the system’s energy efficiency, and it can be formulated as
where
is the SINR of users,
is the SINR constraint,
is the maximum transmission power,
is the outage probability, and
is the maximum outage probability constraint. The outage probability is the probability that the SINR of the devices is lower than the SINR constraint [
24].
4. Proposed Algorithm
In this section, we introduce a mode-selection and power-control algorithm based on Q-learning. When each device has Q-learning agent, the agent cannot get the information to improve system energy efficiency at system level. Even if the system sends the information to the agent, it increases that state space that agent manages and the communication load for data exchange between system and device. So, we proposed two types of Q-learning agent: centralized agent at the system level and distributed agent at each device.
In our previous research, we proposed RRH switching and power-control methods based on the Q-learning mechanism [
25]. We considered the available resources and interference levels to maximize the energy efficiency and minimize interference in the cell. However, this cannot account for the QoS of the devices, and cell coverage problems occur because of switching off the RRHs. We need to ensure the QoS of the devices while maximizing the system’s energy efficiency, which is in a trade-off relationship. Therefore, in this paper, we determine communication mode and transmission power by using Q-learning mechanism to solve the problems. The centralized agent learns to recommend optimal actions that can maximize system energy efficiency by considering the available resources and interference in the cell. The distributed agent recommends an optimal action that can maximize the SINR of the device by considering the interference of the device. Then, the agent finally selects the optimal action by comparing the expected SINRs of the recommended actions.
Existing algorithms have focused on maximizing the energy efficiency of the devices, which cannot guarantee QoS. Our proposed algorithm learns to maximize the system’s energy efficiency and the received SINRs of devices. It also adjusts the target SINR, which is the basis for the proposed Q-learning, according to the interference state. It is important to set the target SINR appropriately because as the target SINR increases, the agent increases the transmission power to increase the SINR. This increases the cellular mode and reduces the system’s energy efficiency. Conversely, when the target SINR is reduced, the agent reduces the transmission power to lower the SINR. This increases the system’s energy efficiency, but it is likely that the devices cannot guarantee the QoS. The agents of each device are in the transceiver of each device, and we assume that agents get the information of the receiver through delay-free feedback [
26].
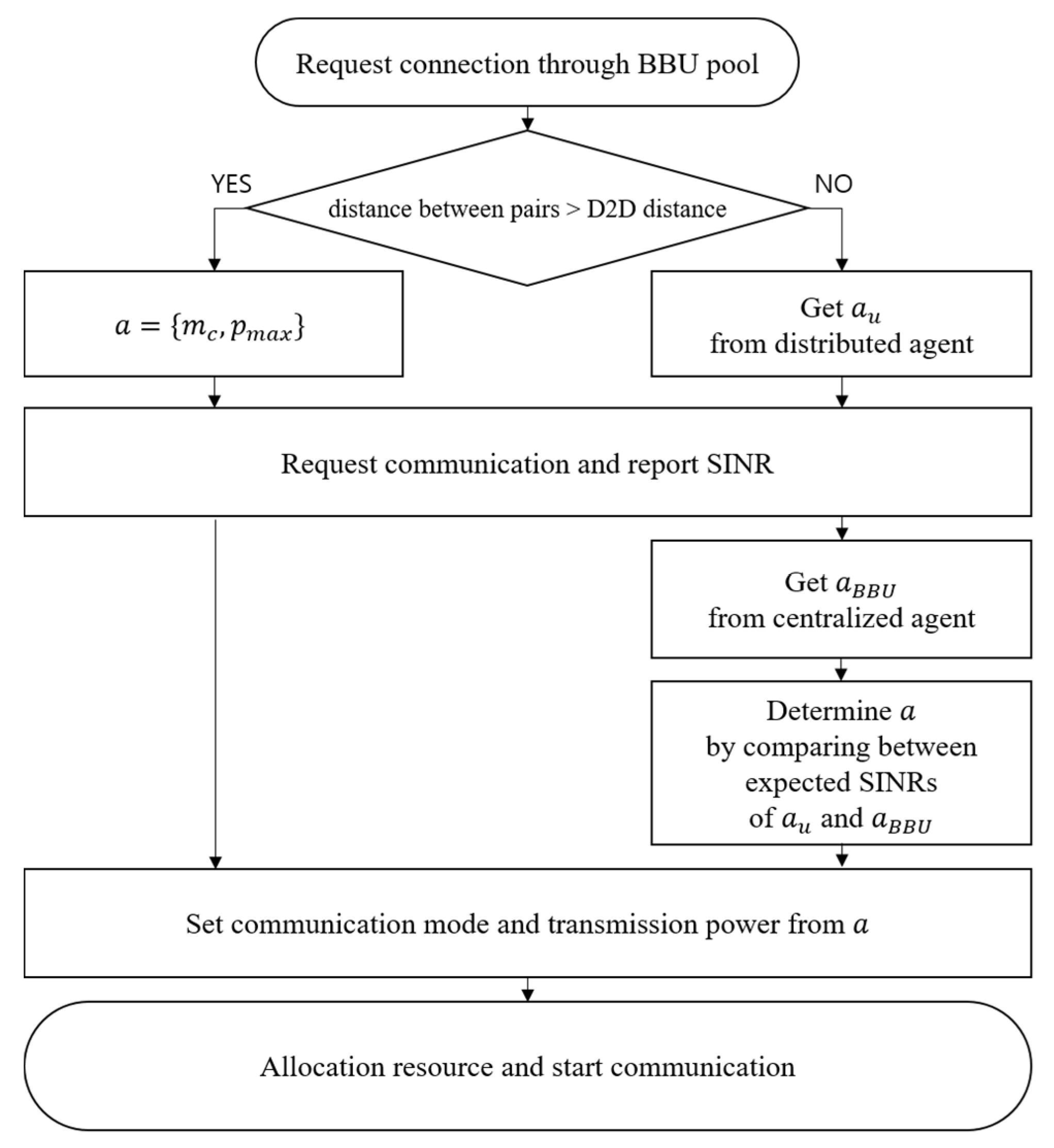
The operational procedure is described as follows. In Step 1, the device prepares to select the transmission mode. At this step, the transmitting device requests a connection through the BBU pool to communicate with the receiving device, and the BBU pool checks whether the distance between the devices is under the D2D distance threshold. If the device does not satisfy the D2D distance threshold, the device will only be able to select the cellular mode and associate with the RRH that provides the highest SINR. If the device satisfies the D2D distance threshold, it can select the D2D mode and obtain the selectable mode and transmission power from its agent. After that, the BBU pool recommends the selectable mode and transmission power to the device.
In Step 2, the agent calculates the expected SINRs of the recommended actions from its own agent and from the BBU pool. The agent chooses communication mode and transmission power as its action. The agent then informs the BBU pool of the determined action. The BBU pool allocates resources to the device, and the device starts communication based on the determined actions. This procedure is summarized in
Figure 2.
To recommend the communication mode and transmission power, Q-learning is used in the BBU pool and in each device. Q-learning is a model-free reinforcement-learning algorithm that learns to find an optimal policy that can maximize the expected reward. Q-learning involves a set of states
, a set of actions
, and a set of rewards
. The agent transits from one state to another state by performing an action
. The agent chooses an action according to the optimal policy
in its current state
. The agents manage the Q-table, and the Q-value updating rule is defined as follows:
where
is the Q-value with state
and action
at time
,
is the learning rate,
is the expected reward at time
, and
is the discount factor. The optimal policy
with state
can be expressed as
4.1. Centralized Q-Learning in the BBU Pool
To recommend the communication mode and transmission power, based on Equation (8), we use a Q-learning agent in the BBU pool. For Q-learning in the BBU pool, the state, action, and reward can be defined as follows. The state of the BBU pool at time
is defined as
where
is the binary level of the average received SINR of the devices at time
, with a value of 1 when the average SINR is greater than the target SINR,
, and 0 when the average SINR is smaller than
.
is the available RB at time
. The action of the BBU pool at time
is defined as
where
is the transmission mode at time
, and
is the transmission power at time
. The transmission power
is divided into discrete intervals,
. If the transmission mode
is the cellular mode
, the transmission power
will be set to
. The reward of the BBU pool at time
is defined as
The centralized Q-learning is summarized in Algorithm 1.
| Algorithm 1: Pseudocode for centralized Q-learning |
| Initialization: |
| for each do |
| initialize Q-table and policy |
| end for |
| Learning: |
| loop |
| estimate the state |
| generate a random real number x |
| if // for exploration |
| select the action randomly |
| else |
| select the action according to |
| recommend action to the devices in the cell |
| calculate reward |
| update Q-value and |
| end loop |
4.2. Distributed Q-Learning in the Devices
According to Equation (8), the BBU pool recommends more D2D modes for the devices. While the D2D mode has the advantage of increasing system capacity, it may not ensure an achievable data rate because of interference. To solve this problem, we use Q-learning agents in each device to maximize the received SINR.
The state of device
at time
is defined as
where
is the binary level of the received SINR of device
at time
based on current communication mode. If the mode of device is cellular mode, state of device
will be calculated based on received SINR of the cellular link. The action of device
at time
is defined as
where
is the transmission mode of device
at time
, and
is the transmission power of device
at time
. The reward of device
at time
is defined as
where
is the SINR of device
. In distributed Q-learning, the agent chooses between the action from centralized Q-learning and its own action to find the action that provides a higher expected SINR. Distributed Q-learning is summarized in Algorithm 2.
| Algorithm 2: Pseudocode for distributed Q-learning |
| Initialization: |
| for each do |
| initialize Q-table and policy |
| end for |
| Learning: |
| loop |
| estimate state |
| generate a random real number x |
| if // for exploration |
| elect action randomly |
| else |
| select action according to |
| receive action from algorithm1 |
| determine action by comparing and |
| execute action |
| calculate reward |
| update Q-value and |
| end loop |
4.3. Target SINR Updating Algorithm
In our algorithm, the state of Q-learning is determined by the target SINR. To set the target SINR to reflect the interference state, the target SINR at time interval
, denoted as
, is adjusted as follows:
where
is the weight factor,
is the largest SINR value of the devices,
is the average outage probability for the time interval
, and
is the maximum outage probability.
is the median SINR value of the devices;
is the SINR constraint, and
is the minimum outage probability.
The changed target SINR affects the learning, and therefore, the agent can make an optimal decision using the changed target SINR. However, as the optimal actions in the changed target SINR may not be optimal in the original target SINR, those actions may not be selected. To solve this problem, we must adjust the Q-table. At this time, only the Q-table of the BBU is adjusted as follows:
5. Results and Discussion
A single-cell H-CRAN environment was considered in this work, and the parameters used in the simulation are summarized in
Table 1. We set the parameters and speed requirements for mobility dataset according to the 3GPP (3rd Generation Partnership Project) specifications release 16 [
22,
27]. Four RRHs and vehicles were distributed randomly in a single macro cell with an intercell distance of
. The mobility dataset used in the simulation was a dataset in an urban area created using a simulation of urban mobility (SUMO) simulator [
28]. In the dataset, all vehicles had mobility with a random trip model at the Seoul City Hall in South Korea according to the 3GPP specification release 15 [
29]. The datasets consisted of two types of scenarios: light traffic and heavy traffic. The two types were vehicular mobility datasets for urban areas with light traffic and heavy traffic scenarios. In a light traffic scenario, vehicles can move fast and the distance between vehicles increases. This means that fewer vehicles can select the D2D mode because of the D2D distance threshold. In a heavy traffic scenario, vehicles move slowly because of the traffic jam, and the distance between vehicles becomes shorter. This allows the vehicles to select a D2D mode more often. Compared to heavy traffic scenarios, fewer vehicles move and require resources at the same system load situation in light traffic scenarios. The D2D distance threshold affects the system energy efficiency, which can also be affected by the mode selection. To consider and present the effects of the D2D distance threshold, we simulated experiments with various D2D distances, as reported in [
27]. We considered Rayleigh fading, log-normal shadowing, and the path-loss model
based on [
30]. The D2D distance threshold was varied between
and
, according to [
31,
32]. The Q-learning parameters were
,
, and
. We set the time for the D2D link establishment as
, as reported in [
33], and the size of time unit is
.
We performed simulations while changing the load of the system and the D2D distance with different traffic scenarios and compared the proposed algorithm with other existing algorithms. First, we denote our proposed algorithm as “proposed algorithm”. Second, the condition where no algorithm was applied was used to create a baseline, and we denoted the baseline as “BA”. It selects the communication mode by comparing the strength of the expected SINR between cellular and D2D modes. Third, for a comparison with a mode-selection and power-control algorithm with Q-learning, the algorithm in [
21] was used. It learned to maximize the device’s energy efficiency with a fixed target SINR. The objective that maximizes device energy efficiency can also maximize system energy efficiency by selecting more D2D modes. We denote that as “Compare1”. Fourth, we used the algorithm in [
20] to compare power control with Q-learning. It also learned to maximize device energy efficiency using a fixed target SINR. We denote that as “Compare2”.
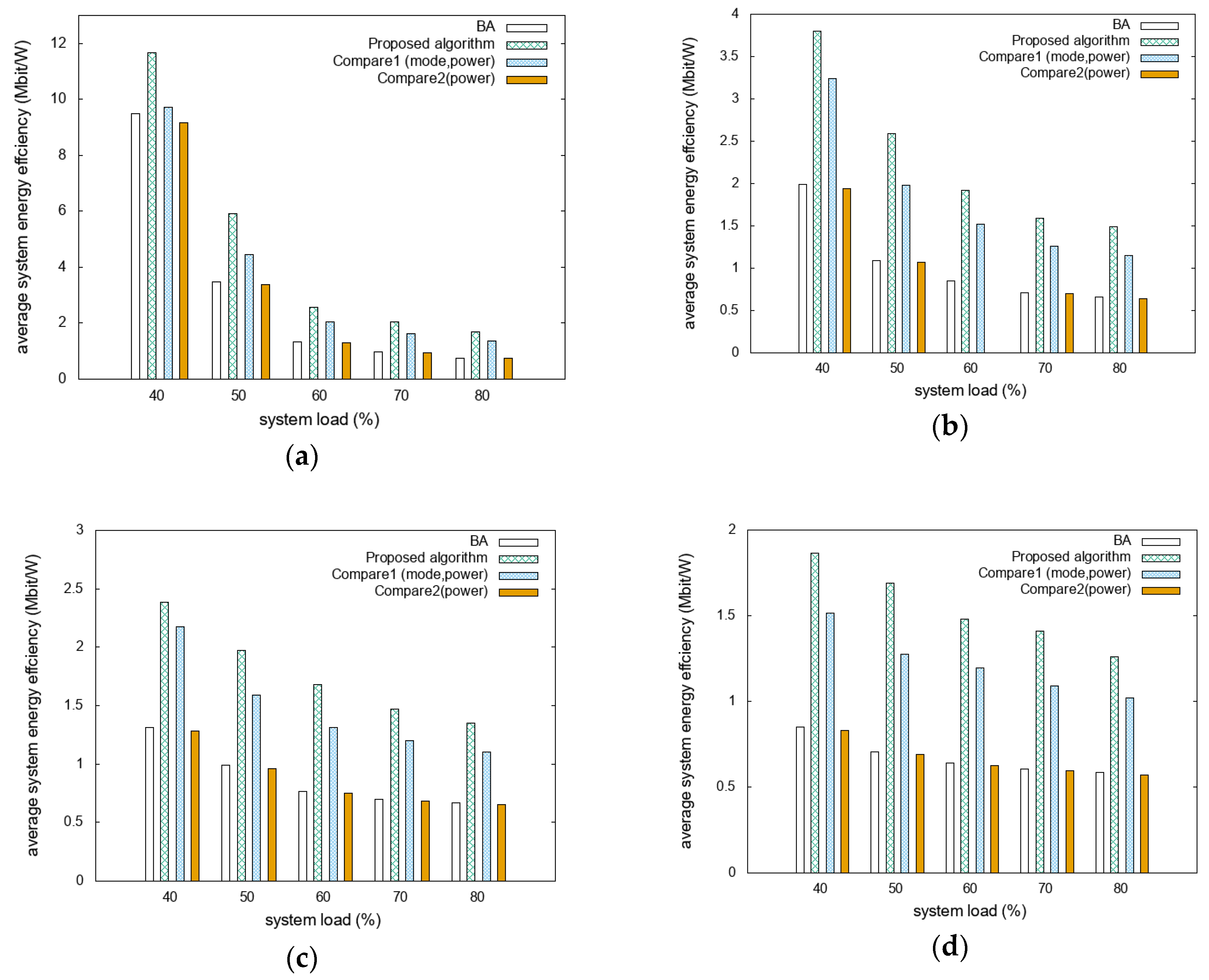
The energy efficiencies for different D2D distance scenarios are compared as functions of the system loads with different mobility scenarios, as shown in
Figure 3.
Figure 3a shows that the system energy efficiency of the proposed algorithm is 83% and 89% higher than those of BA and Compare2, respectively. Compared to Compare1, it presents high energy efficiency, with a difference of approximately 26%. In
Figure 3b it can be seen that the proposed algorithm outperformed BA, Compare1, and Compare2 by more than 121%, 26%, and 126%, respectively.
Figure 3c shows that the system energy efficiency of the proposed algorithm is 102% and 108% higher than that of BA and Compare2, respectively. Compared to Compare1, it presents higher energy efficiency, with a difference of approximately 21%.
Figure 3d shows that the proposed algorithm performed approximately 128%, 27%, and 133% better than BA, Compare1, and Compare2, respectively. As the number of devices capable of D2D communication increases as the D2D distance increases, the difference in system energy efficiency increases. This is because the devices communicate directly rather than through the RRH, which reduces the system’s energy consumption. The proposed algorithm is designed to maximize system energy efficiency; thus, it gives the best performance in scenarios with large D2D distances. Furthermore, because D2D-mode vehicles communicate with the same transmission power at different distance thresholds, the achievable data rate and system energy efficiency decrease at longer D2D distance thresholds. This reveals that the overall performance decreases as the D2D distance threshold increases, but the proposed algorithm achieves a better performance compared to other algorithms. In addition, system energy efficiencies in the light traffic scenario get higher-scale results than the heavy traffic scenario. This is because vehicles require more resources in the light traffic scenario compared to the same number of vehicles in a heavy traffic scenario. Required resources affect system capacity, so system energy efficiencies in the light traffic scenario are higher than the heavy traffic scenario in the same system load situation.
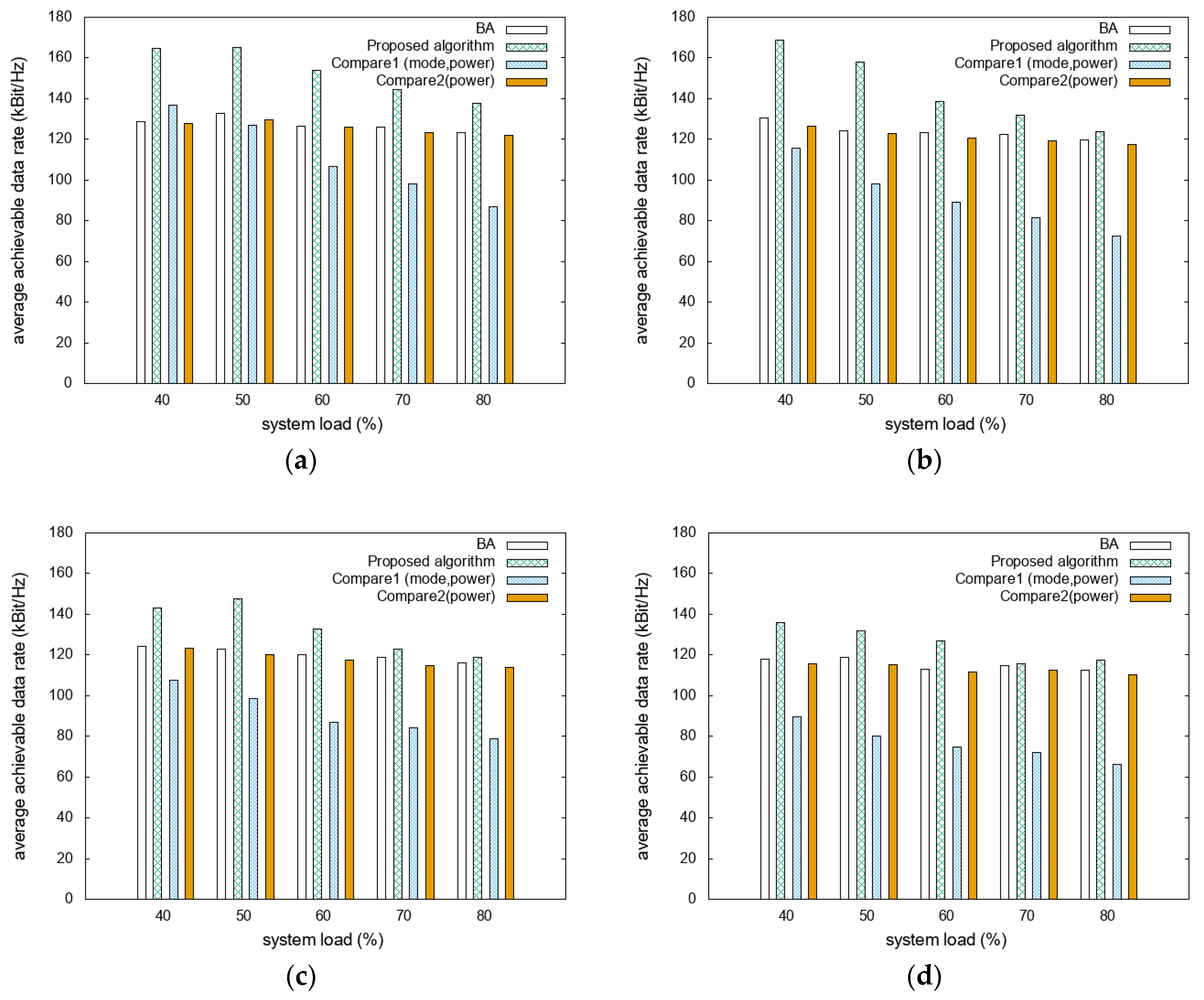
The average achievable data rates for the different D2D distance scenarios are compared as functions of system loads with different mobility scenarios, as shown in
Figure 4.
Figure 4a shows that the proposed algorithm has achievable data rates that are higher than those of BA, Compare1, and Compare2 by approximately 20%, 40%, and 22%, respectively.
Figure 4b shows that the achievable data rate of the proposed algorithm is 60% higher than that of Compare1. Compared to BA and Compare2, it presents higher energy efficiency, with differences of approximately 16% and 19%, respectively. In
Figure 4c, the proposed algorithm presents approximately 10%, 47%, and 13% higher achievable data rates compared to those of BA, Compare1, and Compare2, respectively.
Figure 4d shows that the proposed algorithm outperforms BA, Compare1, and Compare2 by approximately 9%, 65%, and 11%, respectively. As the D2D distance increases, increasing the D2D communication ratio results in reduced energy consumption. However, increasing the D2D distance decreases the achievable data rates because the D2D mode communicates with the same transmission power even in degraded interference situations. In addition, communication without mode-selection algorithms, such as BA and Compare2, can select the transmission mode by simply considering the expected SINR, so it can perform better in terms of achievable data rate than algorithms with mode selection. The proposed algorithm achieved a higher achievable data rate even in such scenarios by adjusting the target SINR.
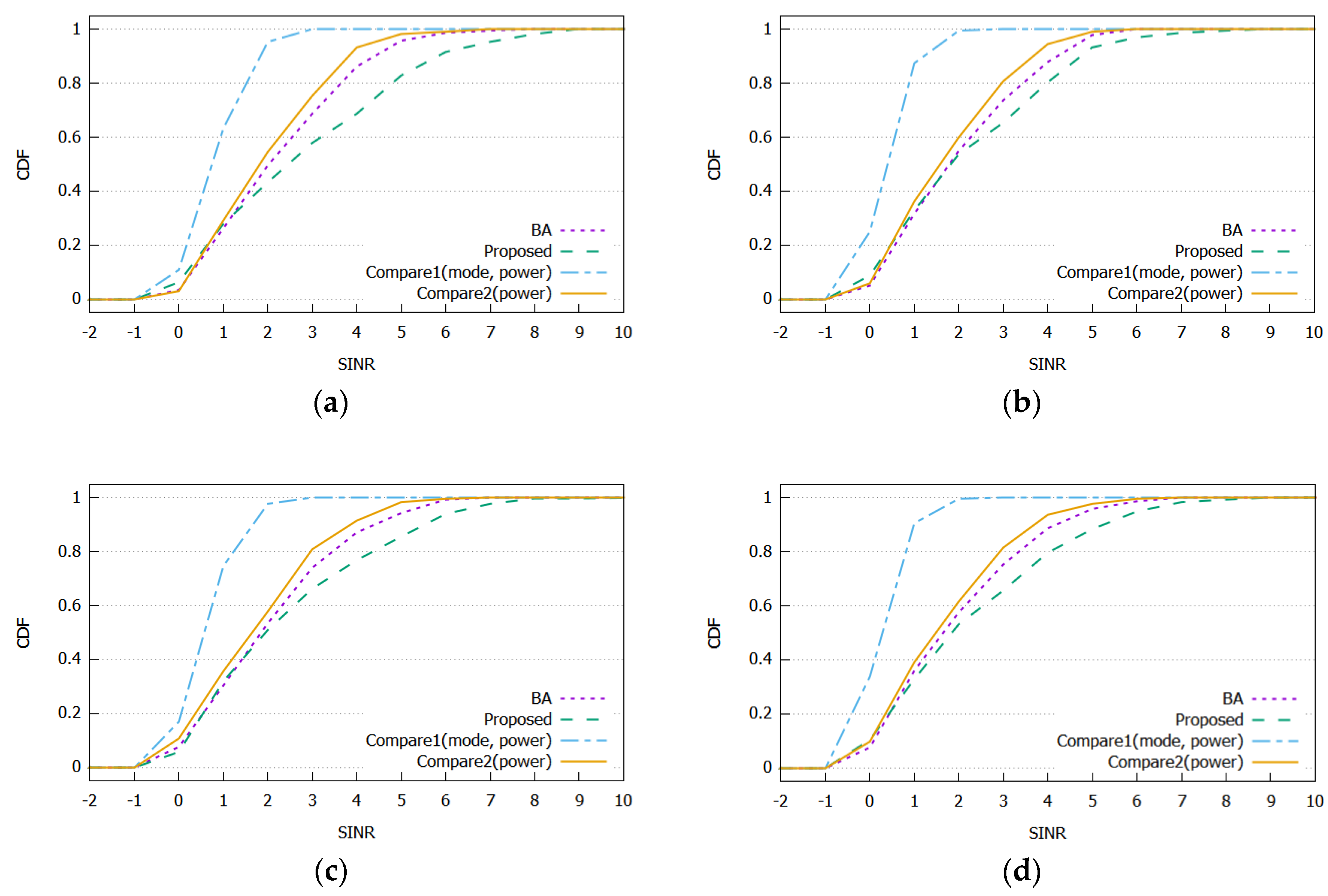
The cumulative distribution functions (CDFs) of SINR received by vehicles for different D2D distance thresholds are compared in
Figure 5.
Figure 5a–d shows the distribution of the received SINR in each algorithm. In all panels, the proposed algorithm has more vehicles that receive higher SINR compared to BA, Compare1, and Compare2. The proposed algorithm and Compare1 can select the communication mode and transmission power to maximize the system energy efficiency, allowing vehicles to select more D2D modes. It can increase spectral efficiency and reduce system energy consumption, but it can also decrease the received SINR. However, the proposed algorithm is designed to select the mode and transmission power to ensure the received SINR. Therefore, the proposed algorithm has more vehicles, receives higher SINR, and performs better with an achievable data rate compared to Compare1. The BA and Compare2 decide the communication mode based only on the expected SINR of the vehicle, so they can achieve higher performance in a longer D2D distance threshold.
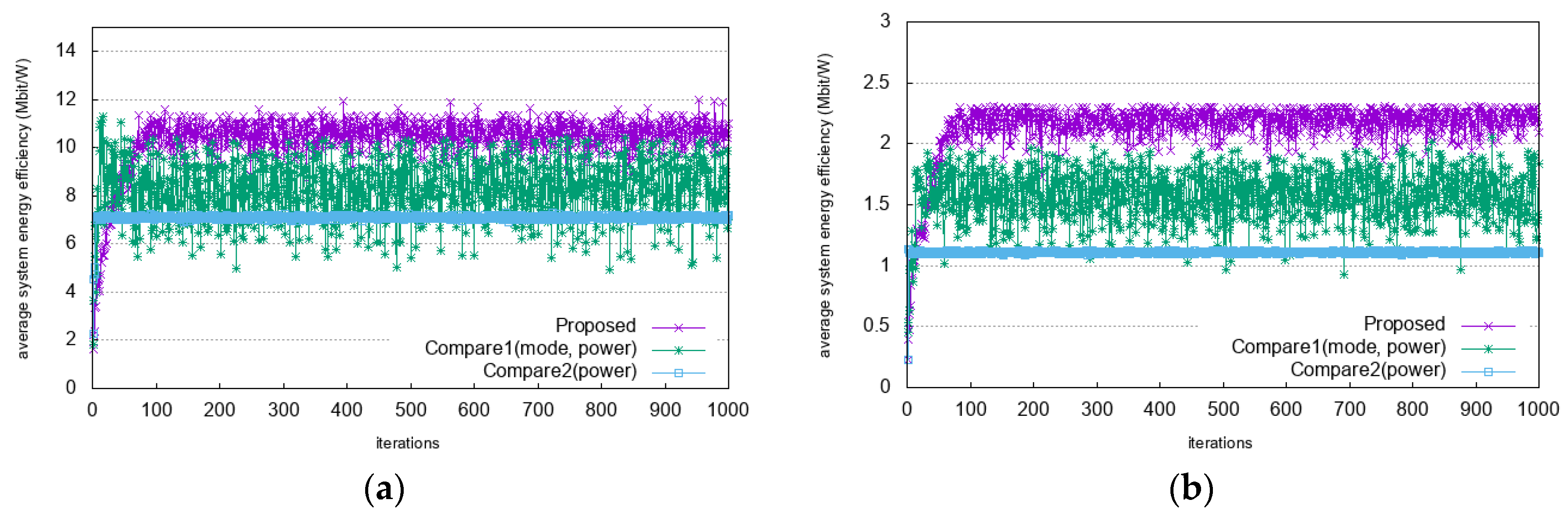
The comparisons of system energy efficiency as a reward function with an increasing number of learning iterations are shown in
Figure 6. In
Figure 6a it can be seen that as the number of learning iterations increases, the value of system energy efficiency stabilizes after 100 iterations. In heavy traffic scenario, as shown in
Figure 6b, the value of the system energy efficiency stabilizes after 100 iterations. The system energy efficiency is overserved with a low value at the beginning of the learning iterations and increases until it reaches a stable point. This means that the proposed algorithm updates its policy optimally and converges faster and in a more stable manner than the other algorithms. The convergence time of the proposed algorithm is longer than those of Compare1 and Compare2. This is because the proposed algorithm has longer decision process and considers more states in decision process. It finally decides an action by comparing two recommended actions. In addition, it considers available resources and interference level as state to make a decision. However, Compare1 and Compare2 consider only interference level as state. Although the convergence time of the proposed algorithm becomes a little bit longer, the proposed algorithm shows better performance in terms of system energy efficiency.
To show the comparison with the optimal solution, the performance values are shown in
Table 2 and
Table 3. In
Table 2, the average system energy efficiencies with system load variance are described. Based on the optimal solution, the proposed algorithm, BA, Compare1, and Compare2 obtain 44%, 20%, 35%, and 20% of the system energy efficiency, respectively. In
Table 3, the average achievable data rate with system load variance is described. Based on the optimal solution, the proposed algorithm, BA, Compare1, and Compare2 obtain 79%, 68%, 50%, and 66% of the achievable data rate, respectively. This shows that the proposed algorithm performs closest to the optimal solution among other compared algorithms because it adopts the system energy efficiency and received SINR as rewards. However, as the system load increases, the differences in performance increase. This is because the interference increases according to increasing system load environment. The proposed algorithm simply models received SINR as whether the average SINR is greater than the target SINR to take account of the interference.
To evaluate and discuss the performance of the proposed algorithm, we compared it with the BA and the two compared algorithms. The proposed algorithm exhibited the best performance in terms of system energy efficiency, achievable data rate, and SINR in cases of increasing D2D distance thresholds. The proposed algorithm learned to maximize the system energy efficiency while ensuring achievable data rates. The system energy efficiency and achievable data rate have a trade-off relationship, so the proposed algorithm used Q-learning in two ways. To maximize the system energy efficiency, the proposed algorithm sets the system energy efficiency as a reward function of centralized Q-learning. In addition, to ensure an achievable data rate, the proposed algorithm sets the received SINR as a reward function of distributed Q-learning. This implies that the proposed algorithm can achieve the highest energy efficiency when compared to other algorithms. It can also guarantee QoS while increasing the efficiency of the resource and system energy.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}