1. Introduction
Internet of Things (IoT) [
1,
2] has provided the possibility of easily deploying tiny, cheap, available, and durable devices, which are able to collect various data in real time, with continuous supply [
3,
4,
5,
6,
7]. IoT devices are vulnerable and usually deployed in harsh and extreme natural environments, thus solutions that can improve monitoring services and the security of IoT devices are needed [
8,
9,
10]. Most smart objects can accumulate log data obtained through sensors during operation. The logs record the states and events of the devices and systems, thus providing a valuable source of information which can be exploited both for research and industrial purposes. The reason is that a large amount of log data stored in such devices can be analyzed to observe user behavior patterns or detect errors in the system. Based on log analysis, better IoT solutions can be developed or updated and presented to the user [
11]. Therefore, logs are one of the most valuable data sources for device management, root cause analysis, and IoT solutions updating. Log analysis plays an important role in IoT system management to ensure the reliability of IoT services [
12]. Log anomaly detection is a part of log analysis that analyzes the log messages to detect the anomalous state caused by sensor hardware failure, energy exhaustion, or the environment [
13].
Logs are semi-structured textual data. An important task is that of anomaly detection in log [
14], which is different from the classification and detection in computer vision [
15,
16,
17,
18], digital time serial [
19,
20,
21,
22,
23], and graph data [
24]. In fact, the traditional ways of dealing with anomalies in logs are very inefficient. Operators manually check the system log with regular expression matching or keyword searching (for example, “failure”, “kill”) to detect anomaly, which is based on their domain knowledge. However, this kind of anomaly detection is not applicable to large-scale systems.
Many existing works propose schemes to process the logs automatically. Log messages are free-form texts and semi-structured data which should turn into structured data for further analysis. Log parsing [
25,
26,
27] extracts the structured or constant part from log messages. The constant part is named by the
log template or
log event. For example, a log message is “
CE sym 2, at 0x0b85eee0, mask 0x05”. The log event of the log message is
“CE sym , at , mask ”.
Although log events are structured, they are still text data. Most machine learning models for anomaly detection are not able to handle text data directly. Therefore, to extract features of the log event or derive a digital representation of it is a core step. According to the feature extraction results, several machine learning models are used for anomaly detection, such as Regression, Random Forest, Clustering, Principal Component Analysis (PCA), and Independent Component Analysis (ICA) [
28]. At first, many statistical features of log event [
29,
30] are extracted, such as sequence, frequency, surge, seasonality, event ratio, mean inter-arrival time, mean inter-arrival distance, severity spread, and time-interval spread.
More and more works start to apply natural language processing (NLP) methods for the log event vectorization, such as bag-of-words [
31], term frequency-inverse document frequency (tf-idf) [
32,
33] and word2vec [
34,
35]. Most of the above works are based on the word. Anomalies in logs mostly depend on the log message sequence. Meng et al. [
32] form the log event vector by the frequency and weights of words. The log event vector is transformed into the log sequence vector as the input of the anomaly detection model. The transformation from word vector to log event vector or log sequence vector is called
coordinate transformation. The frequency and weight of words ignore the relevance between words. Bertero et al. [
34] detect the anomaly based on the word vector from word2vec [
36], which is an efficient method to extract the relevance between words. The word vector is converted to the log event vector, and then the log event vector is converted to the log sequence vector before anomaly detection. However, the computing cost of training word2vec is high and it needs to transform the word vector twice.
As the systems become increasingly complex, there is a large amount of log data. The number of words in each log message is in the range from 10 to 102. Processing words directly is not suitable for large-scale log anomaly detection. Therefore, He et al. [
31] propose to count the occurrence number of log events to obtain log sequence vectors directly. The coordinate transformation is unnecessary. In addition, the number of log events is far less than the number of words. The length of the vector is based on the number of words or log events. The dimension of the vector is shortened, which further reduces the computational cost. However, the frequency of log events ignores the relevance of log events.
Therefore, to extract the relevance between log events, reduce the computational cost, and avoid multiple transformations, we investigate the log anomaly detection problem by word2vec with log events as input. The main contributions can be summarized as follows:
We propose an offline low-cost feature extraction model, named LogEvent2vec, which first takes log events as input of the word2vec model to vectorize the log event vector directly. The relevance between log events can be extracted by word2vec. Only one coordinate transformation is necessary to get the log sequence vector from the log event vector, which decreases the number of coordinate transformations. Training log events is more efficient because the number of log events is less than that of words, which reduces the computational cost.
LogEvent2vec can work with any coordinate transformation methods and anomaly detection models. After getting the log event vector, the log event vector is transformed into the log sequence vector by bary or tf-idf. Three kinds of supervised models (Random Forests, Naive Bayes, and Neural Networks) are trained to detect the anomaly.
We have conducted extensive experiments on a real public log dataset from BlueGene/L (BGL). The experimental results demonstrate that our proposed LogEvent2vec can significantly reduce computational time by 30 times and improve the accuracy of anomaly detection, comparing with word2vec.
Among different coordinate transformation methods and anomaly detection models, LogEvent2vec with bary and Random Forest can achieve the best F1-score and LogEvent2vec with tf-idf and Naive Bayes needs the least computational time. Tf-idf is weaker than bary in aspect of accuracy, but it can significantly reduce the computational time.
The rest of the paper is organized as follows. We introduce the related work in
Section 2, and present the general framework of log anomaly detection and the formulation of our work in
Section 3. We further provide an overview of our scheme, the log parsing, feature extraction, and anomaly detection model in
Section 4. Finally, we evaluate the performance of the proposed algorithms through extensive experiments in
Section 5 and conclude the work in
Section 6.
3. General Framework and System Model
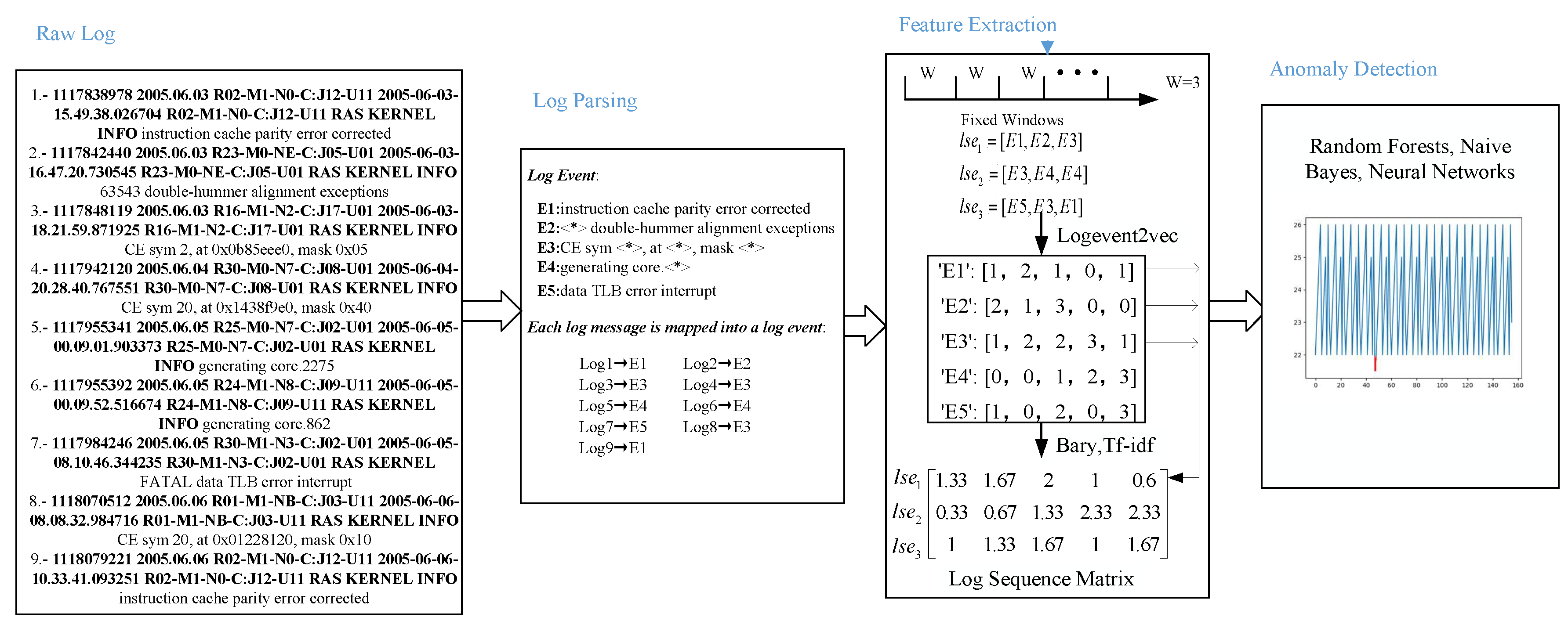
In this section, we introduce the general framework of log anomaly detection and the formulation of our work. The general framework of log anomaly detection consists of three steps: log parsing, feature extraction, and anomaly detection, as shown in
Figure 1.
Table 2 summarizes the notations and definitions used in this paper.
3.1. Log Parsing
Logs are semi-structured. A log message can be divided into two parts: a constant part and a variable part (some specific parameters). A log event is the template (constant part) of a log message. To turn semi-structured raw logs into structured data, log parsing extracts a set of templates to record events that occur during the execution of a system. In this paper, we do not distinguish between the log template and the log event.
The log data from a system are denoted by L. The log data contain N lines of log messages. The ith log message is denoted by . Every log message is generated by an application of the system to report an event. Every log message consists of a list of words, similar to a sentence.
The log parsing [
27] is used to remove all specific parameters from log messages and extract all the log events. The set of log events is denoted by
E, in which the number of log events is
M. In this way, each log message is mapped into a log event. Log parsing can be represented by the mapping function
p. The log event of the log message
can be described as
:
Then, log data are divided into various chunks. A chunk is a log sequence. We assume that the fixed window is used and the window size decides the length of log sequences, denoted by
W. There are
log sequences, where the set of log sequences is denoted by
. The
ith sequence consists of
W log messages from
, to
. Each log message in a log sequence can be mapped into a log event [
47]. As a result, the log sequence can be treated as a list of log events. The log sequence
is denoted by
3.2. Feature Extraction
Although log events are structured, they still consist of text. Therefore, the log event should be numerically encoded for further anomaly detection. Text of log events can be encoded by NLP models. The list of logs are divided into various chunks, which are log sequences. A feature vector is generated to represent a log sequence.
Word2vec [
36] is used to extract features of log events. Generally speaking, word2vec maps words of a text corpus into a Euclidean space. In the Euclidean space, relevant words are close, while irrelevant words are far away.
In our case, we use word2vec to map log events of log sequence into a Euclidean space. The input of word2vec is a list of log events instead of a list of words. Thus, every log event gets a coordinate, denoted by
in a vector space
T. After mapping each log event, a log sequence can be represented by a function of its all log events’ coordinates. It means that each log sequence is also mapped into the vector space. The mapping of log event and log sequence can be represented as two functions:
According to the definition of log sequence in Equation (
2), the log events of log sequence
are
. The coordinate of the log event related to the log message
can be denoted by
. Therefore, the coordinates of these log events are
. By the above-described procedure, the coordinate of the log sequence depends on all its log events’ coordinates. The log sequence
can be assigned to a coordinate by
.
3.3. Anomaly Detection
All feature vectors of log sequence are the samples, which are trained for machine learning or deep learning models to detect anomaly. Then, the trained model predicts whether a new log sequence is anomalous or not.
A binary classifier c is trained on . This kind of classifier c can be treated as an ideal separation function: The classifier determines whether a log sequence is anomalous (label denotes an anomalous log sequence and denotes a normal log sequence) or not. When the anomalous event occurs, the log message at that time is labeled anomalous. If an anomalous log message belongs to a log sequence, this log sequence is labeled as an anomaly. Otherwise, the log sequence is normal when all log messages in it are normal. In the case log sequence contains log events which do not occur, those are simply ignored.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}