2.1. Environment Variables
Natal is a city located in northeastern Brazil, and has a population of about 900,000 and an area of 167 km, considered the second smallest capital of Brazil. Natal has a typical tropical climate, with warm temperatures and high humidity throughout the year. The average low and high annual temperatures are 23 C (F) and 29.7 C (F), respectively, and the average annual precipitation in the year is mm ( inches). The measurements were carried out in June and July, the coolest months with an average low temperature of 22 C (F) and an average high temperature of 29 C (F).
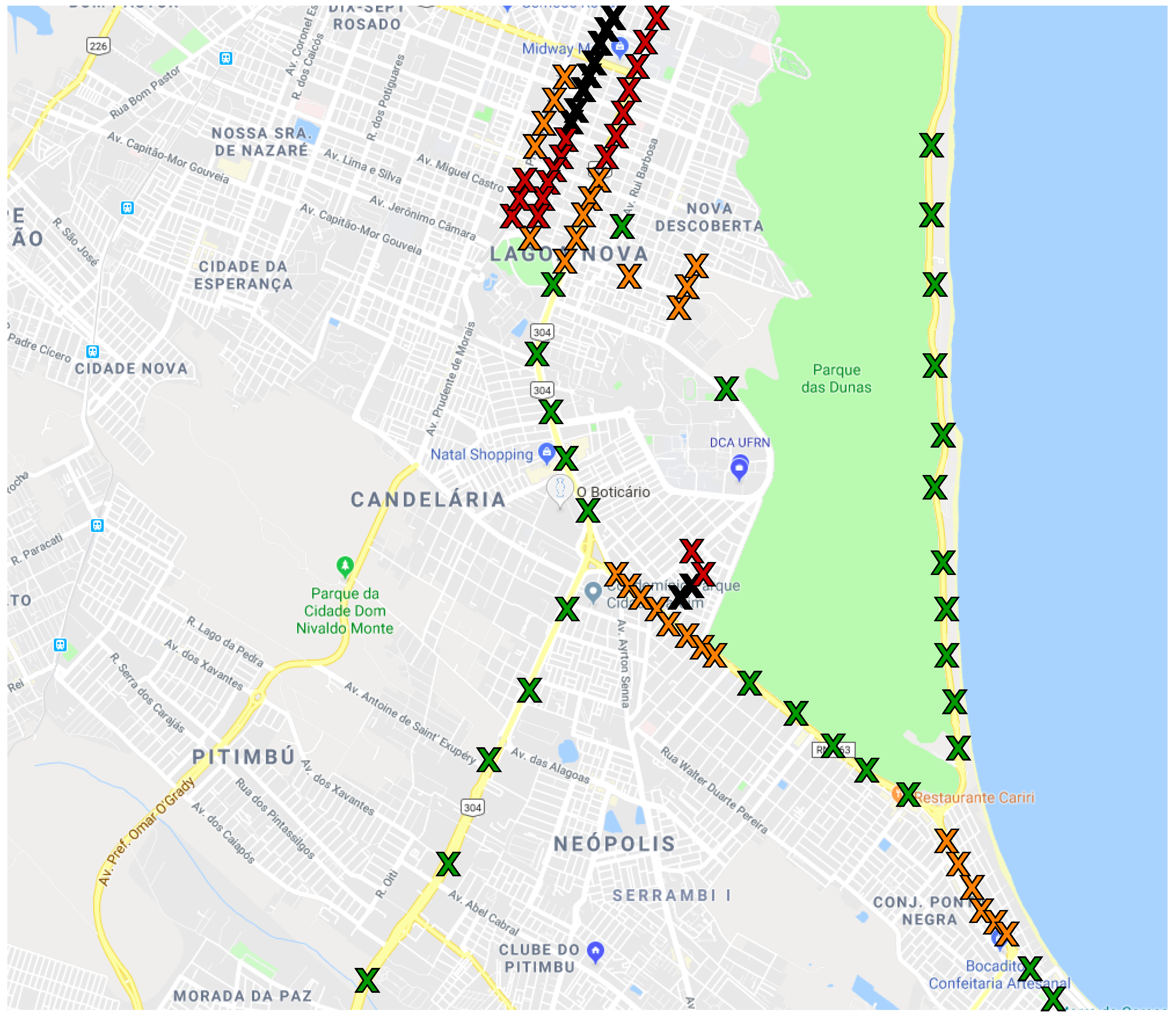
The sampling points were located in different streets and avenues spreading the uncontrolled conditions such as crowd and traffic, as illustrated in
Figure 1. The traffic conditions were defined following the Google Maps traffic conditions policy [
45]. Each sampling point was assigned to one of four possible traffic conditions in a specific location. Those locations may have different features, which is why the sampling point was spread for different regions of the city. For example, while the highway near the coast (with 6.2 m) has strong winds blowing from the ocean that may cause higher noise levels, the quiet streets usually present lower noise levels. All measurements were obtained on asphalt with smooth road surface conditions with no presence of potholes or unevenness.
Table 1 presents all the possible conditions of the four environmental variables that were controlled during the measurements. Those are the position of the car windows, the presence of rain, the traffic condition, and the maximum speed of the car.
We acquired a large number of measurements. Care was taken to obtain data for the combination of all possible conditions of the controlled variables. During a measurement, the participants did not speak or make any noise. To identify outliers in the data, we reviewed the audio signals to check for highly impulsive events (such as sounds due to potholes in the road or a person’s sudden shouting near the vehicle).
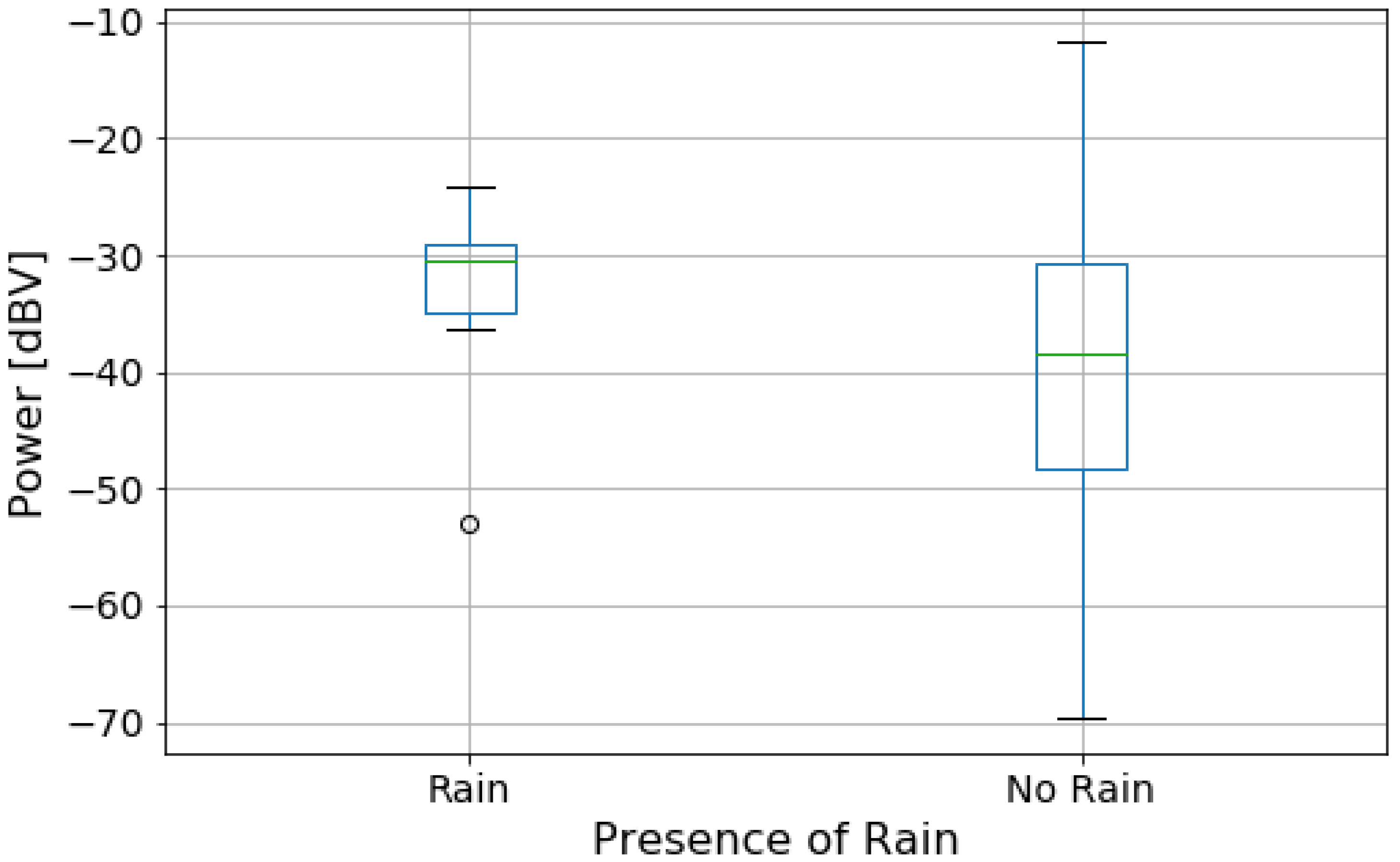
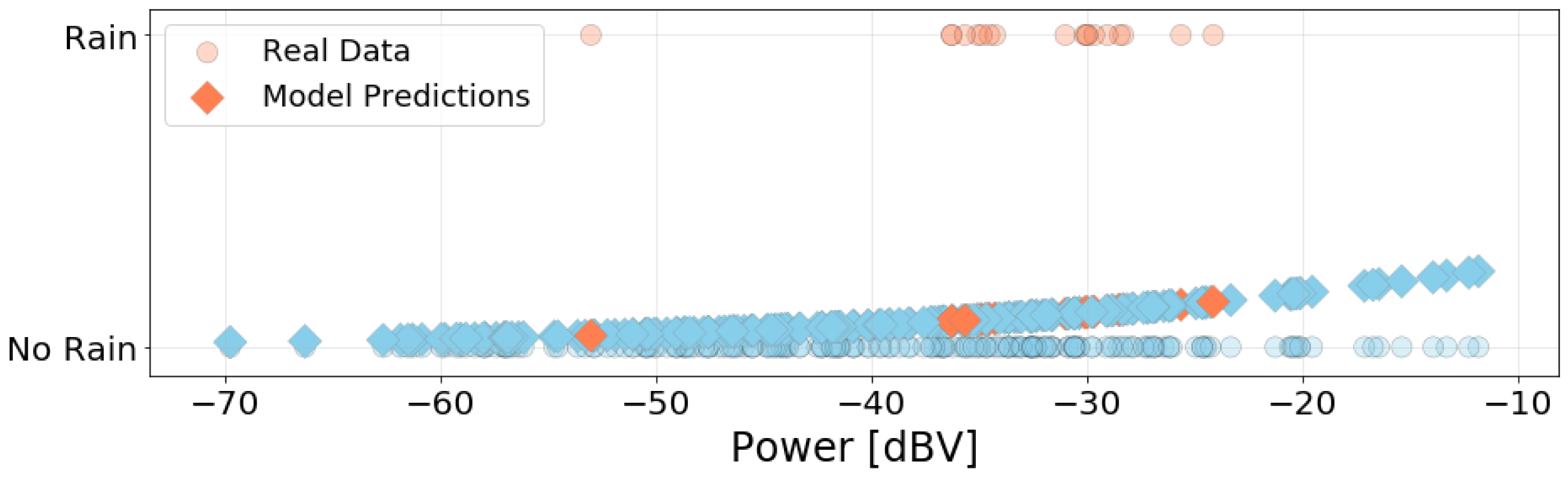
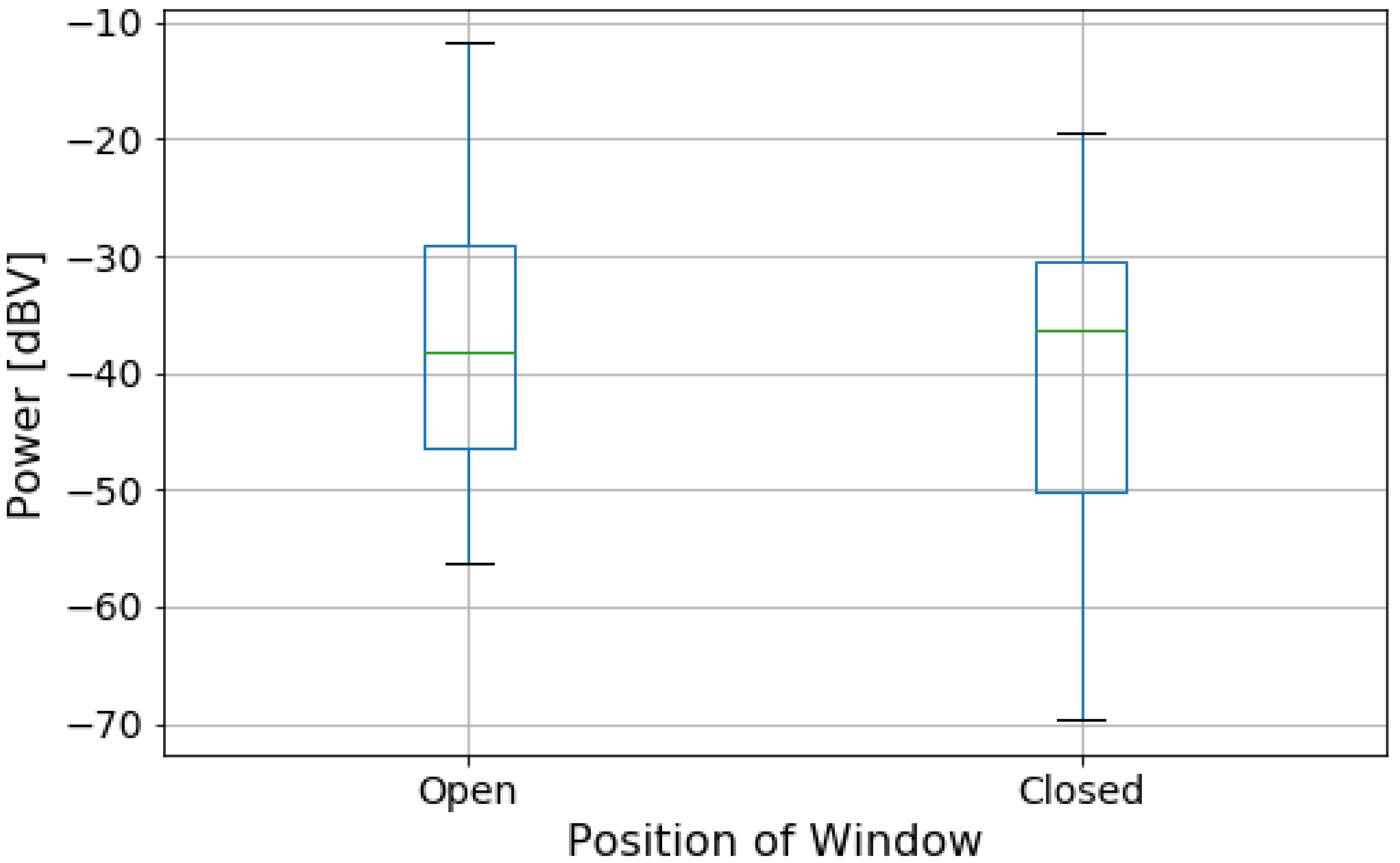
For measurements with no rain, all four windows were either fully open or closed. In the case of measuring during rainfall, the windows were kept closed.
We also measured noise levels in different traffic conditions, as shown in
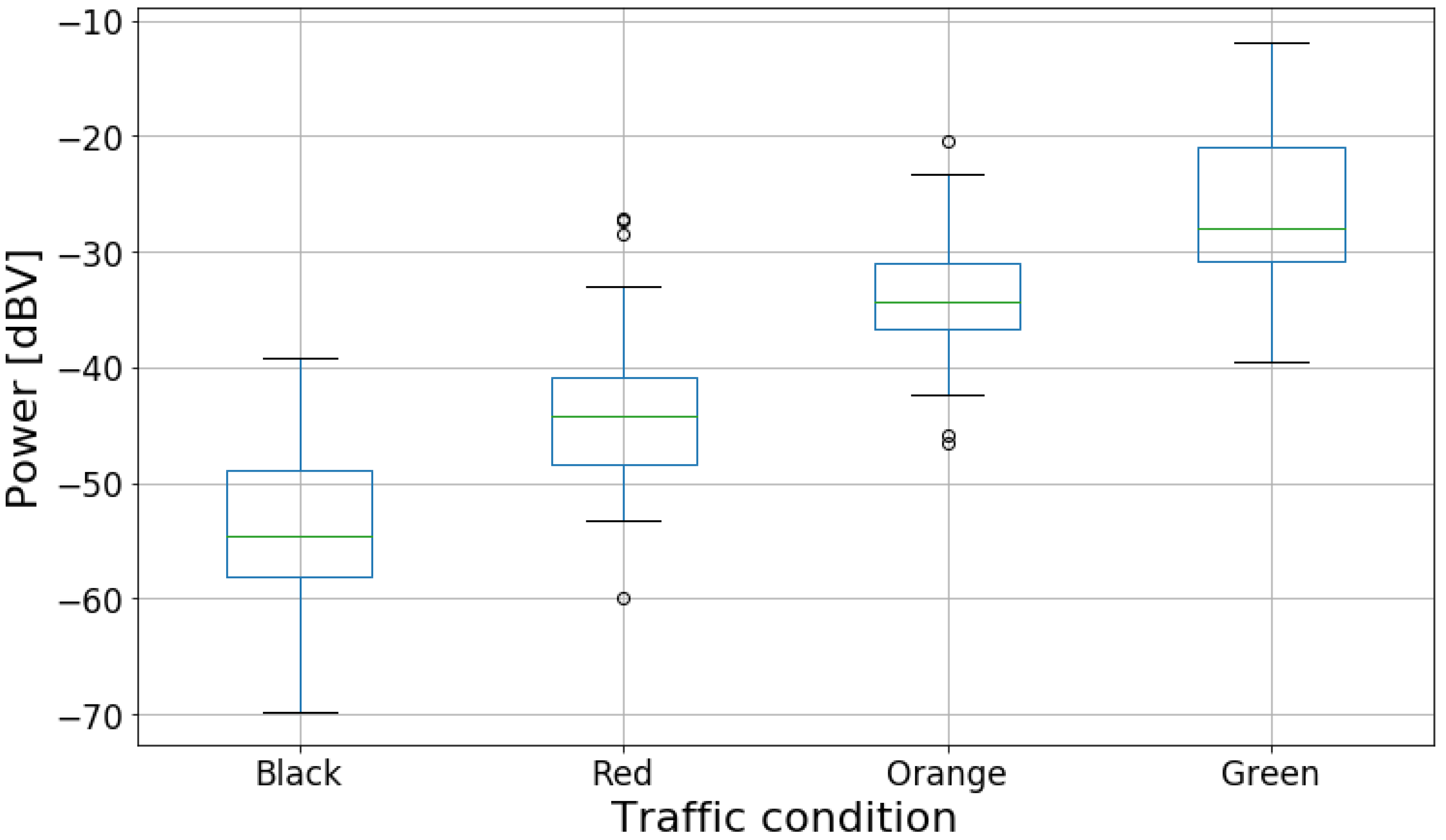
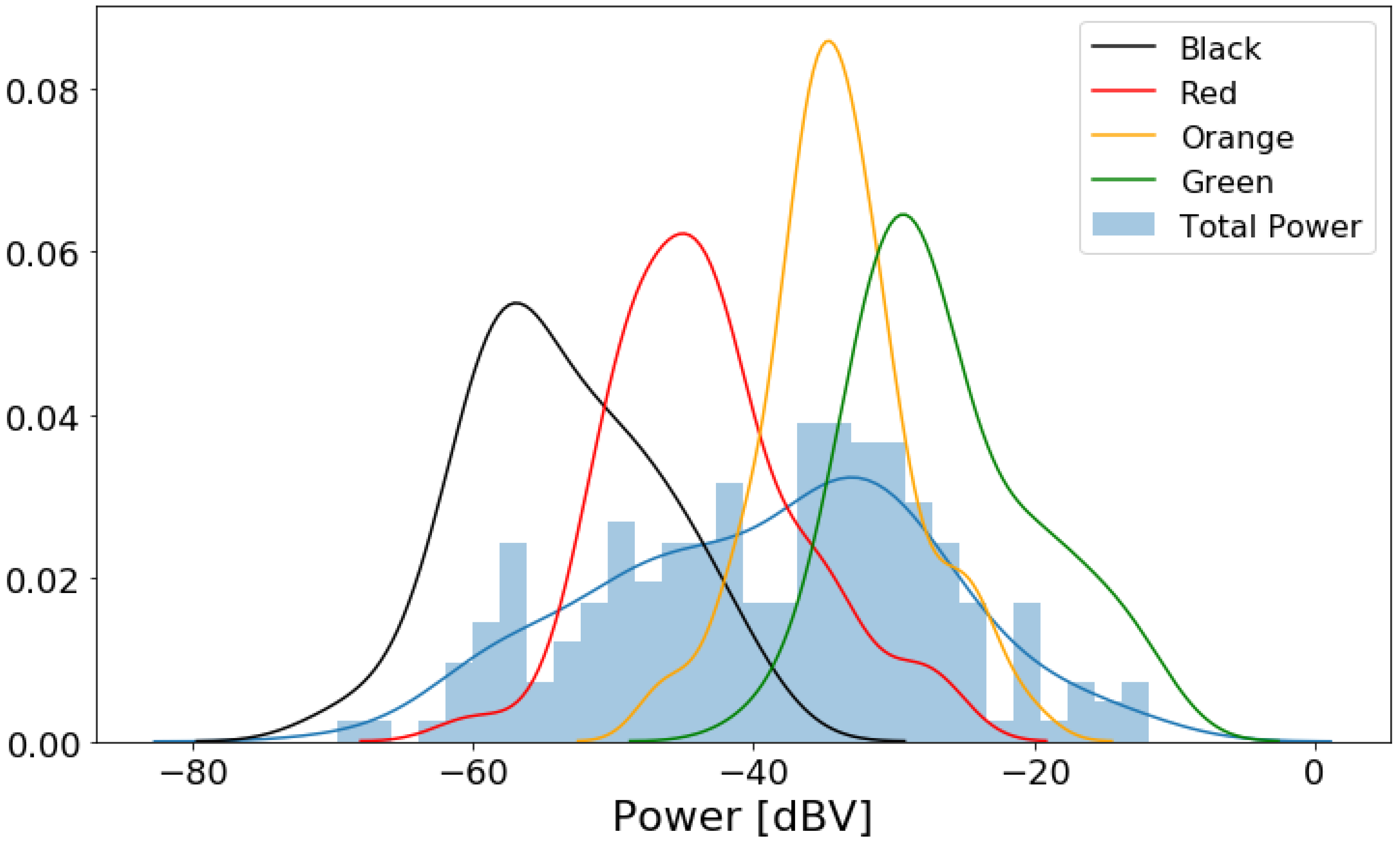
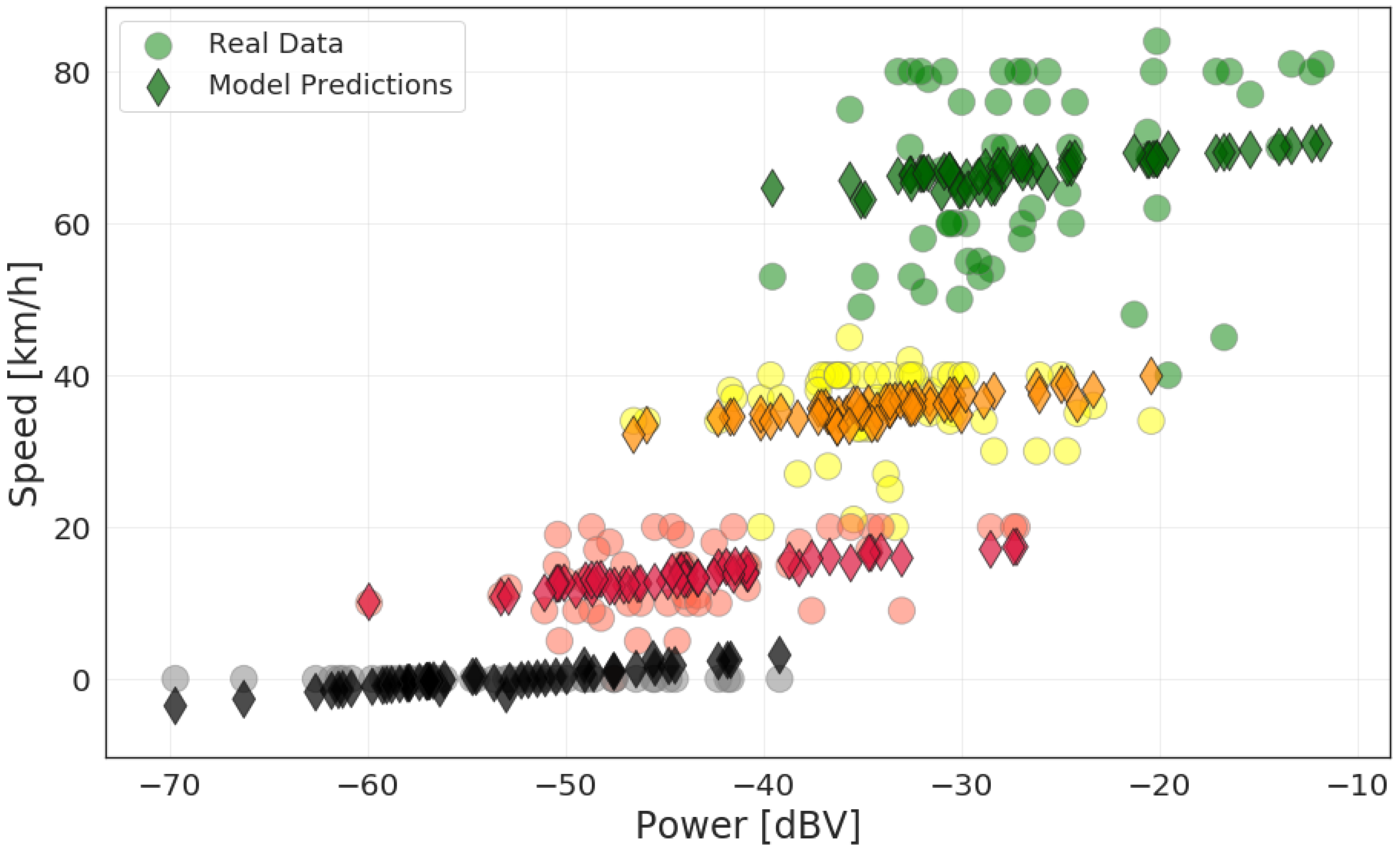
Table 2. To record this information, we utilized Google Maps’ color codes for traffic and noted the color of the road displayed on the application during measurement. For example, when measuring in a high-speed highway with no traffic delays, the condition was recorded as Green.
Finally, we also recorded the maximum speed of the car during the interval of each measurement. The speed of the car was always compatible with the traffic condition displayed in Google Maps.
Table 2 shows the speed intervals for each traffic category.
2.2. Statistical Methods
Our goal was to understand how each environmental factor affects the noise level inside a vehicle. To achieve this, we utilized visualization tools such as histograms and box plots to analyze the data. We also employed statistical modeling to highlight the relationship between the studied variables.
Initially, we quantified the signal power for each measurement. There are many different ways to calculate signal energy or power. One approach is to compute the energy from the cepstral coefficients [
46]. The cepstral coefficients are a set of features obtained by first taking the natural logarithm of the magnitude of the Fourier transform of a signal, and then obtaining the inverse Fourier transform of the result. They are often applied in speech recognition and transcription tasks. Another approach is to use the Teager–Kaiser (TK) operator. The TK operator is a measure of energy that takes into account both the signal’s amplitude and frequency. Despite their low complexity, the operators and their derivations are capable of estimating useful features of a signal such as instantaneous frequency and spatial envelope and phase [
47]. They can be used, for example, in the instantaneous estimation of AM-FM signals and images. For our objective in this work, however, it was sufficient to compute the average power of the measurements in the following way:
where
N is the length of sampling and
is the voltage signal from the microphone.
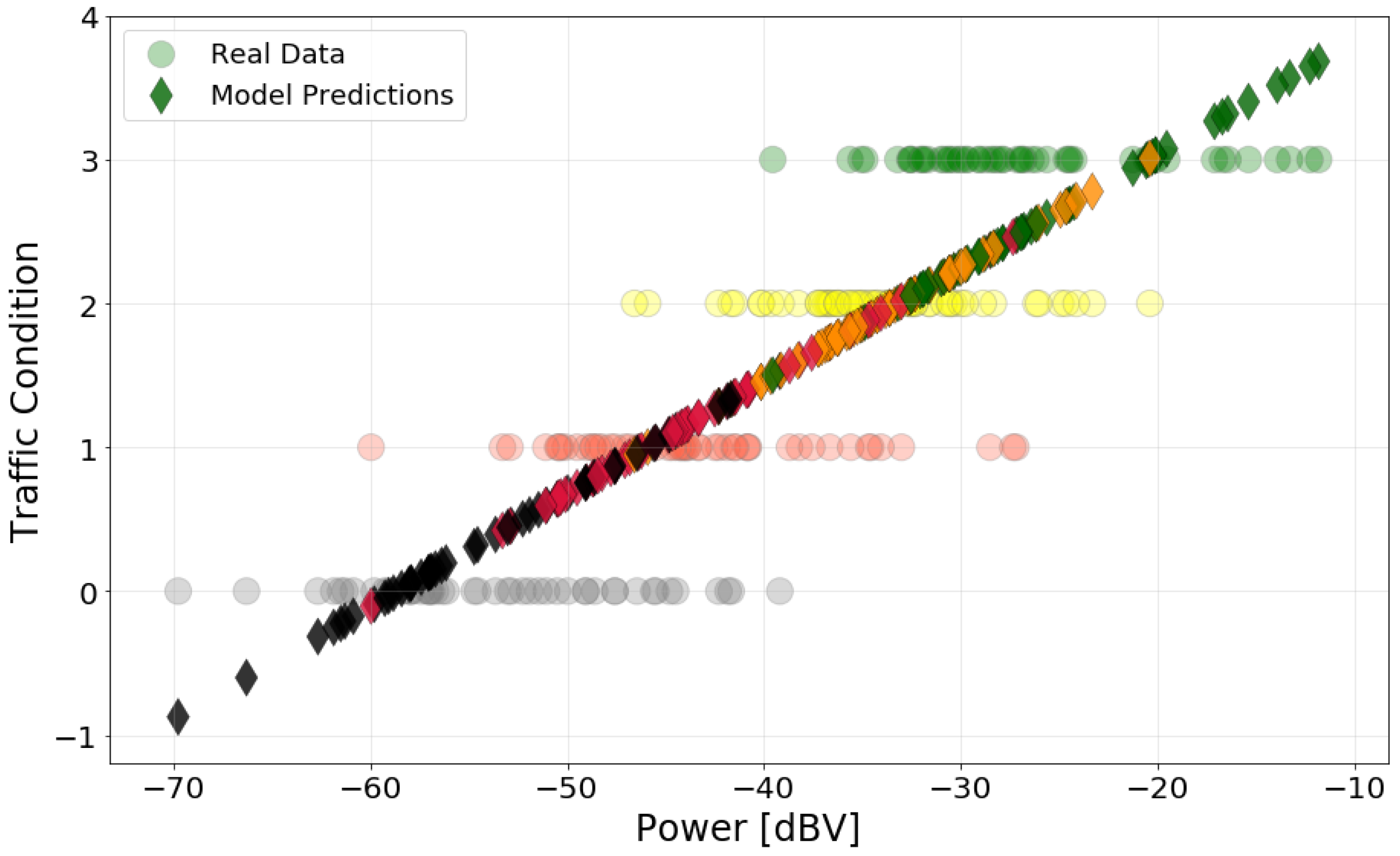
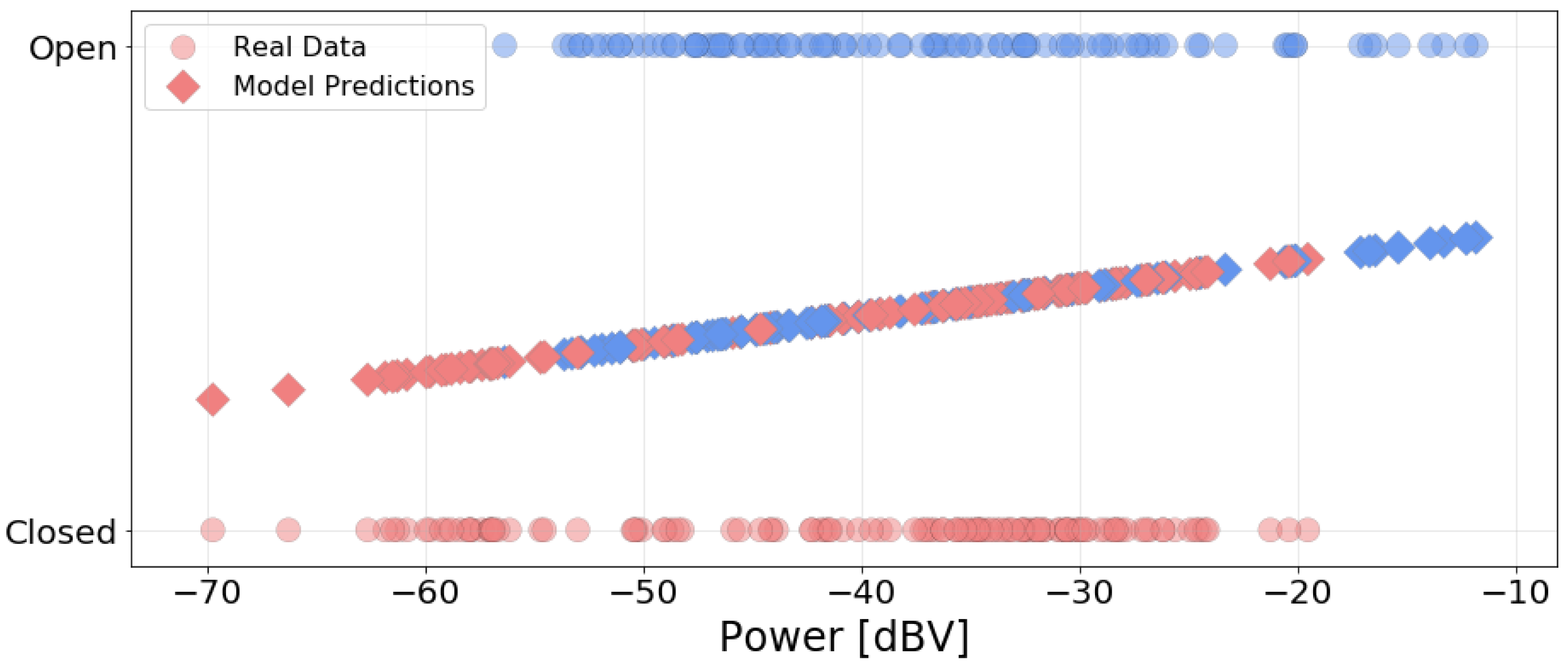
The dataset contains 212 samples, with five features for each measurement: noise power, presence of rain, window position, traffic condition, and maximum speed. Power and speed are numeric, while the three other are categorical. We encoded the latter using natural numbers. The binary variables (window position and rain) were encoded with 0s and 1s. Traffic condition was encoded in descending order of severeness, i.e., “Green” corresponds to 3, and “Black” corresponds to 0.
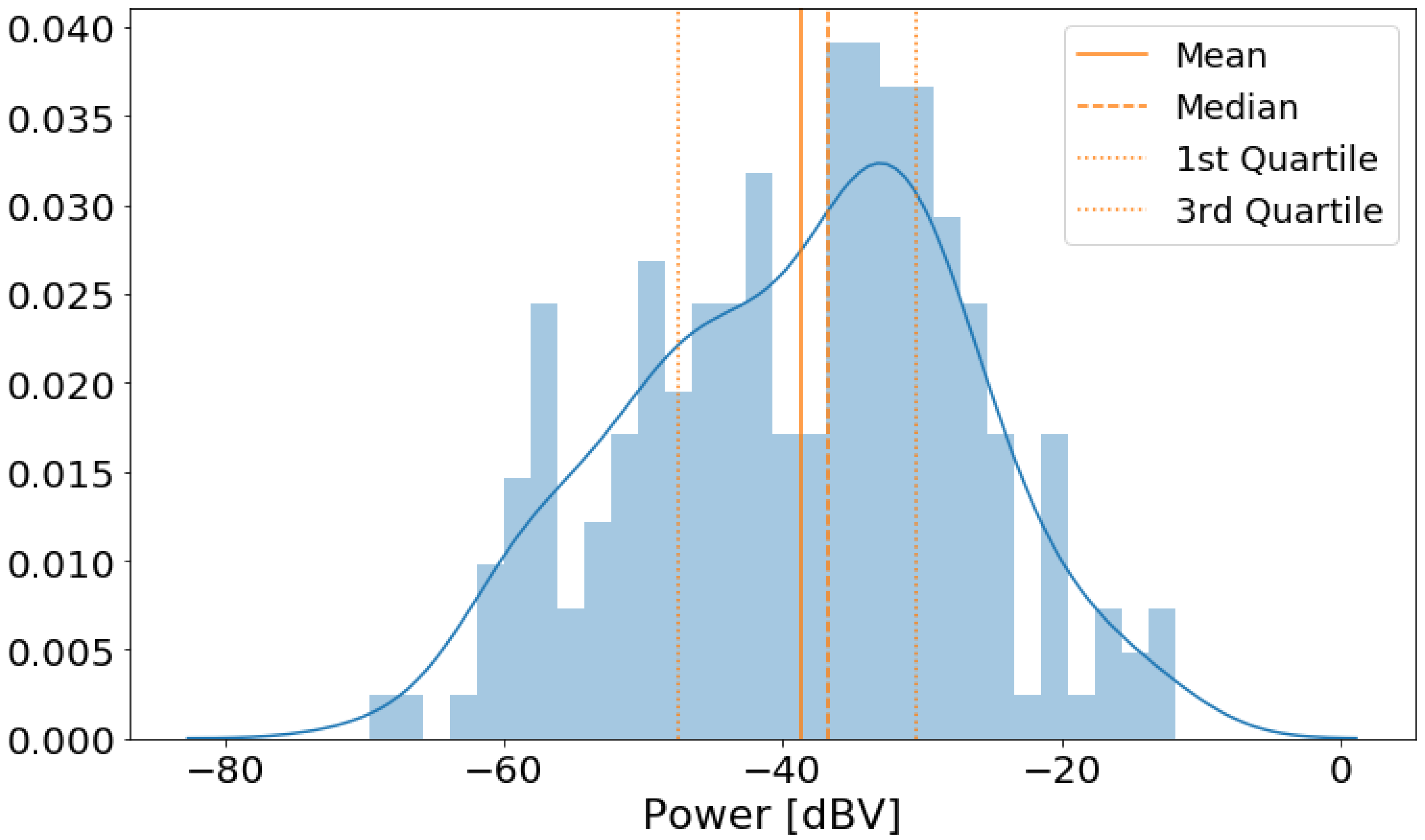
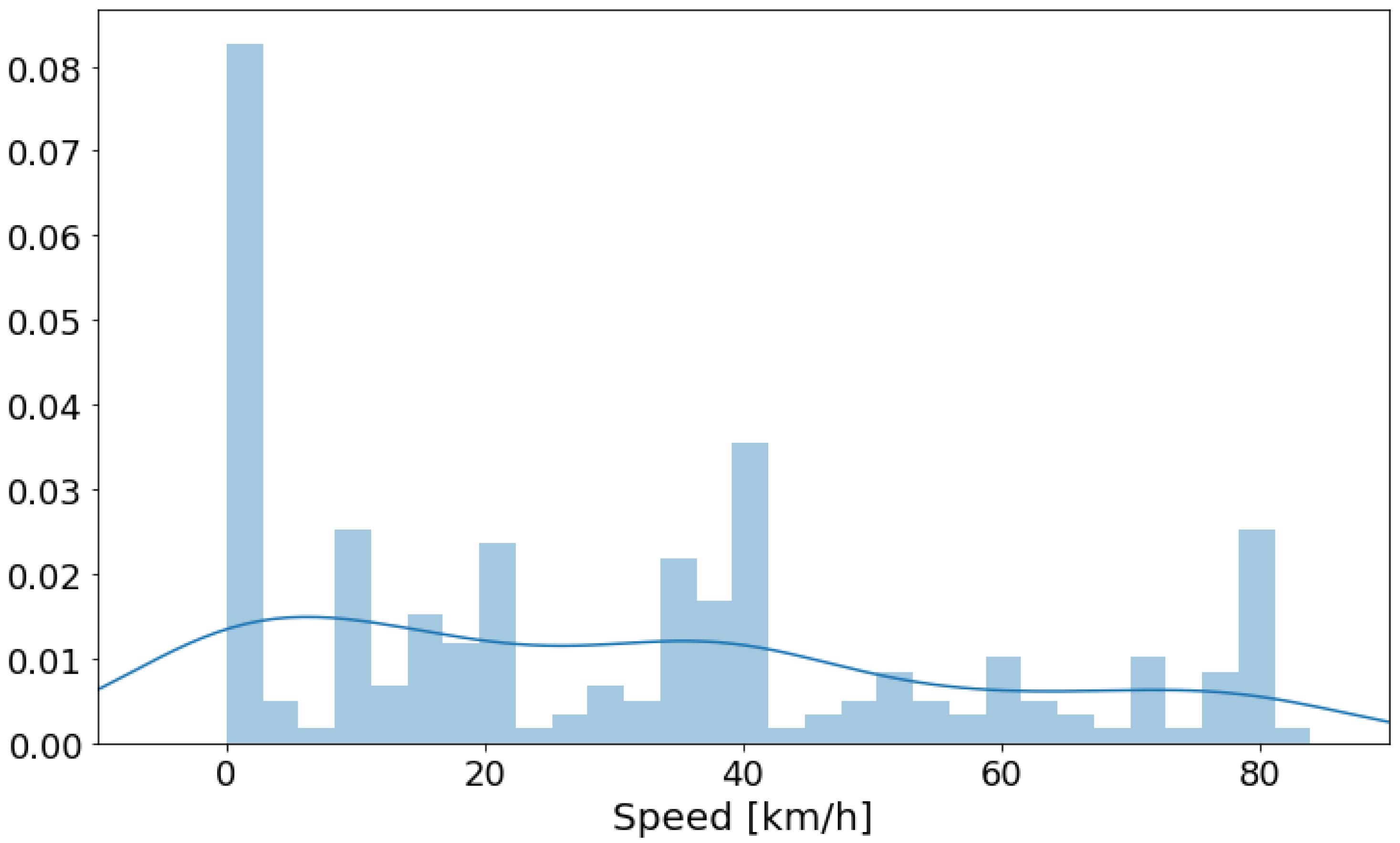
We then performed an initial exploratory analysis. For the numeric features, we obtained a histogram plot to understand the distribution of power and speed data. We also obtained a histogram for noise power level by traffic condition to compare the distribution of noise level for each condition. For categorical data, we obtained the box plot of power levels for each category separately to highlight the difference of noise levels in them.
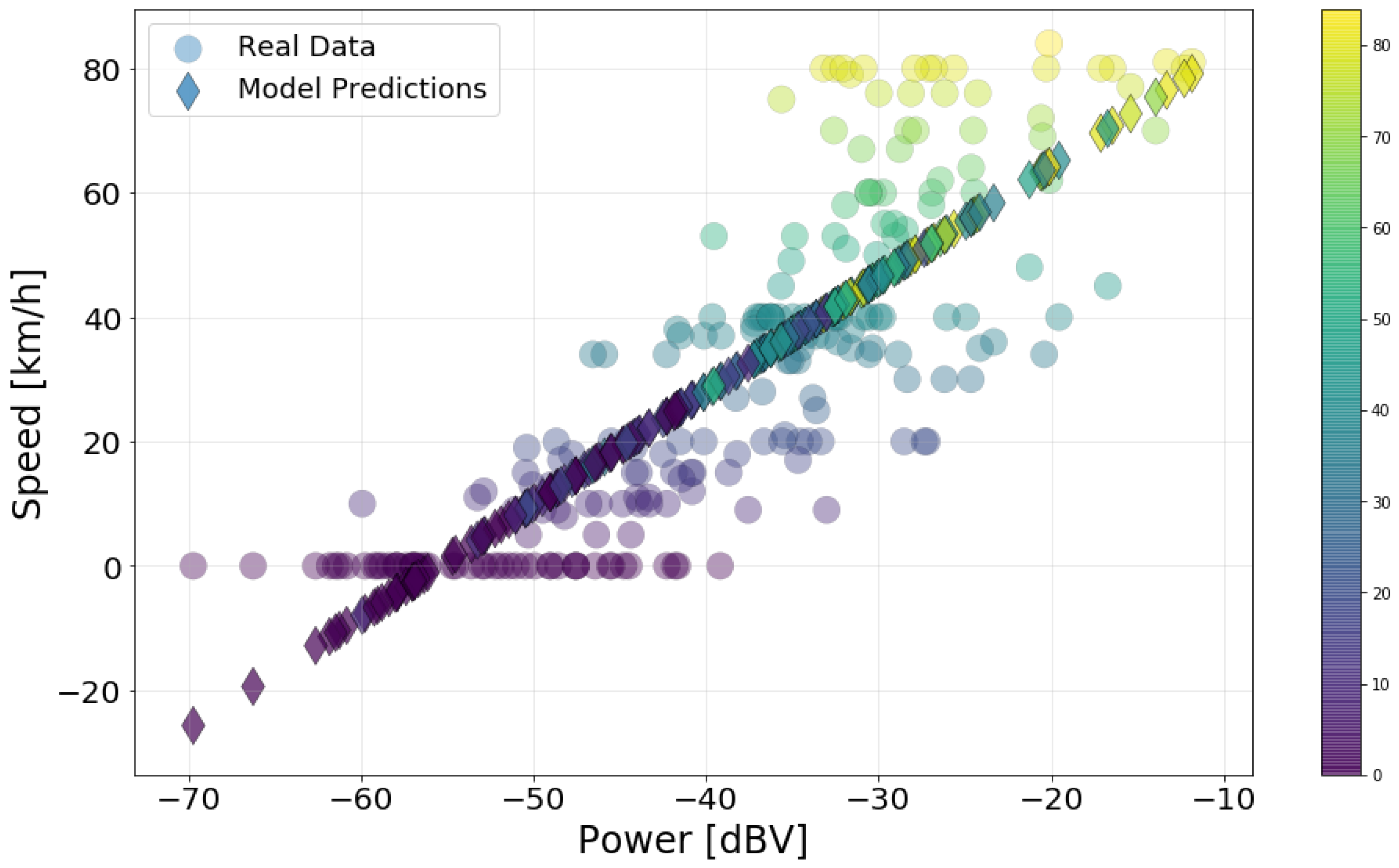
Next, we created a linear regression model for each feature. In the models, power is always the explanatory (dependent) variable and the other features are the response (independent) variable. The linear regression model, based on second-order, is the simplest feature extractor. It can be used to measure to what extent two or more variables have a linear relationship. Even if this relationship is only approximately linear, the model is a simple way to identify the influence of the inputs in the model output. To compute the models (estimate the coefficients of a linear regression model), we used the Ordinary Least Square (OLS) method [
48]. It does so by minimizing the sum of the squared differences (residuals) between the observed dependent variable and the prediction line.
We computed three metrics of the goodness of fit to compare the influence of the environment features in the average noise power. First, we obtained the mean squared error (MSE) [
49]. The MSE is the average of the square of the errors between the model and the actual values. A smaller MSE indicates a better fit, although the actual values of MSE depend on the scale of the data. It is mostly used to compare different models for the same response variable in the same scale. We also computed the coefficient of determination, R
2 [
49]. This value is the ratio of the sum of squared residuals to the variance of the actual data values. It is always between 0 and 1 and represents the variation in the response variable that is accounted or explained by the model. In the context of acoustic noise, the R
2 is also related to the noise power, that is, how much of the noise power can be attributed to the explanatory variables.
The R
2 can highlight the correlation between variables. However, it is not a complete description of the goodness of fit of a model. The R
2 assumes that all independent variables in the model explain the variation in the response variable. It always increases when more variables are added to a model, even if they in reality do not affect the independent variable. Thus, it does not evaluate the significance of the relationships shown by the model [
49].
A way to verify this significance is by computing the F-statistic [
49]. Similar to the R
2, the F-statistic (or F-value) compares the explained and unexplained variation in the model, but weighted by the degrees of freedom of the model, that is, how many model coefficients are used in relation to the number of observations. Thus, it takes into account the complexity of the model.
The F-statistic is used in the F-test. In this test, the null hypothesis is that the model coefficients are zero, and the alternative hypothesis is that at least one coefficient is not zero. The F-test shows if the relationship between the variables is a result of chance or not. The higher is the F-value, the more significant are the results drawn from the model.
For categorical data, the linear regression model can be used to describe the relationship between two of more variables. However, it is not always adequate to represent this relationship as a linear function, as there is a limited, discrete range of values for the response variable. Thus, we also obtained a logistic regression model for the binary variables [
49]. The logistic model was obtained by transforming the predicted values of the linear model to another scale that is bounded by 0 and 1. Thus, the output of the model can be interpreted as a probability that a data point belongs to a certain category, and the coefficients of the model are adjusted to find the best match of these probabilities to the data. For logistic models, the goodness of fit metrics described above are not used. To compare the models, we computed McFadden’s Pseudo-R
2 [
50]. While its calculation is different from the regular R
2, it has a similar interpretation.
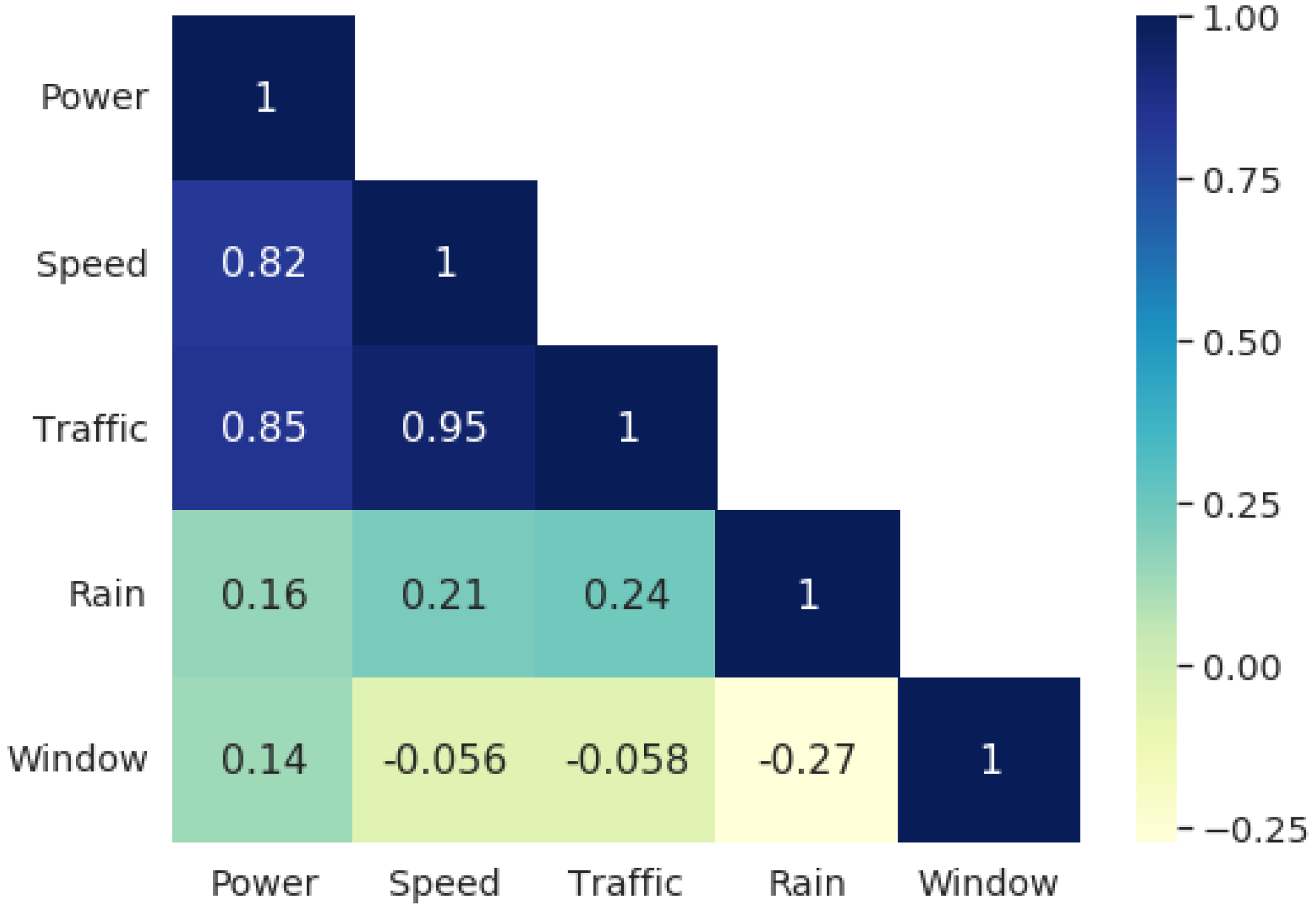
We concluded our analysis by measuring the relationship between the environmental variables, highlighting how much correlation they present with each other. We also built a multiple variable regression model, using speed as the dependent variable and the reminder as explanatory variables. We compared the contribution of each variable, and how much better a model with multiple predictors is than the previous one variable model.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}