A Novel Point Cloud Encoding Method Based on Local Information for 3D Classification and Segmentation




Abstract
:1. Introduction
2. Related Work
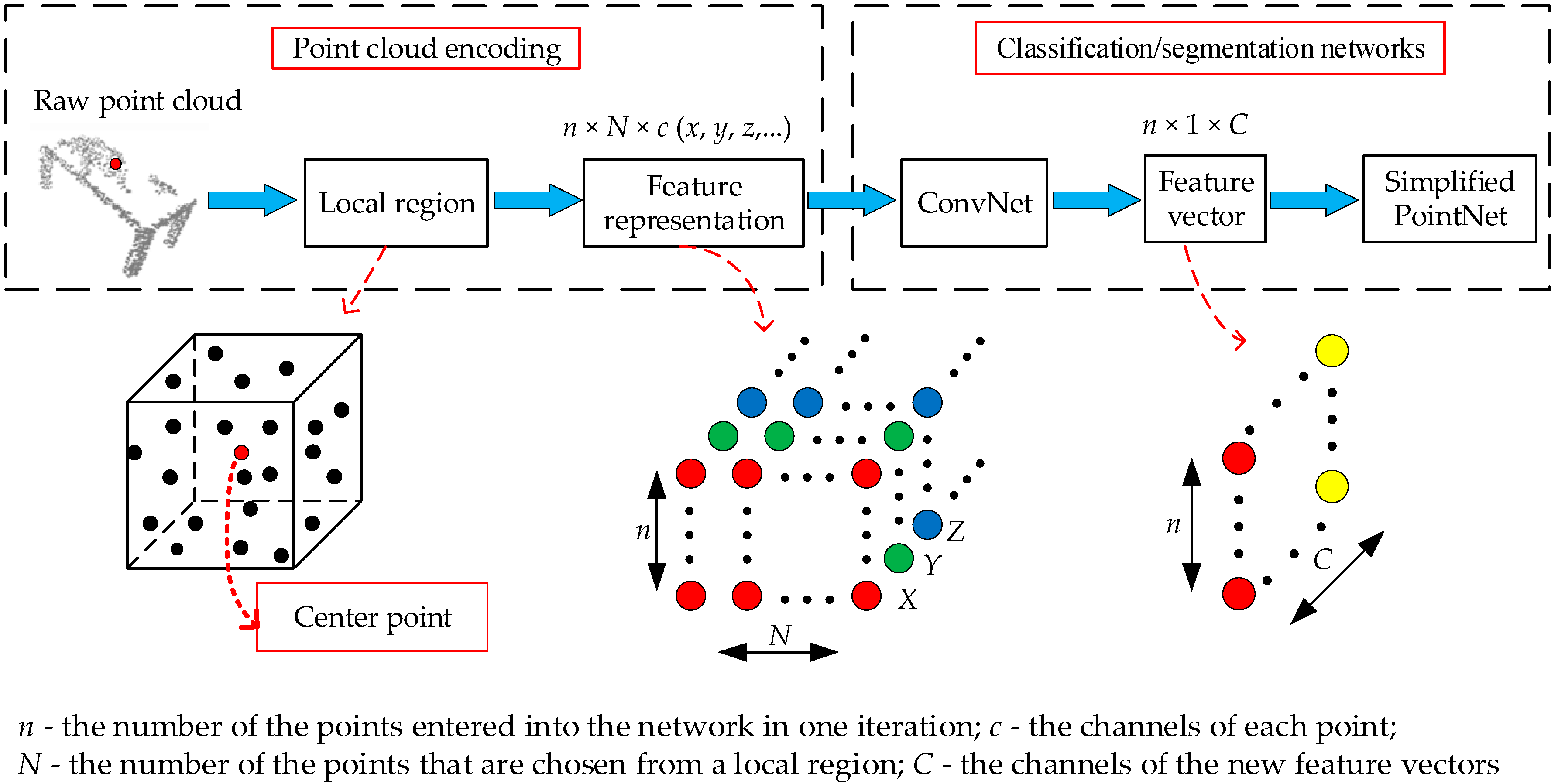
3. Proposed Method for 3D Classification and Segmentation
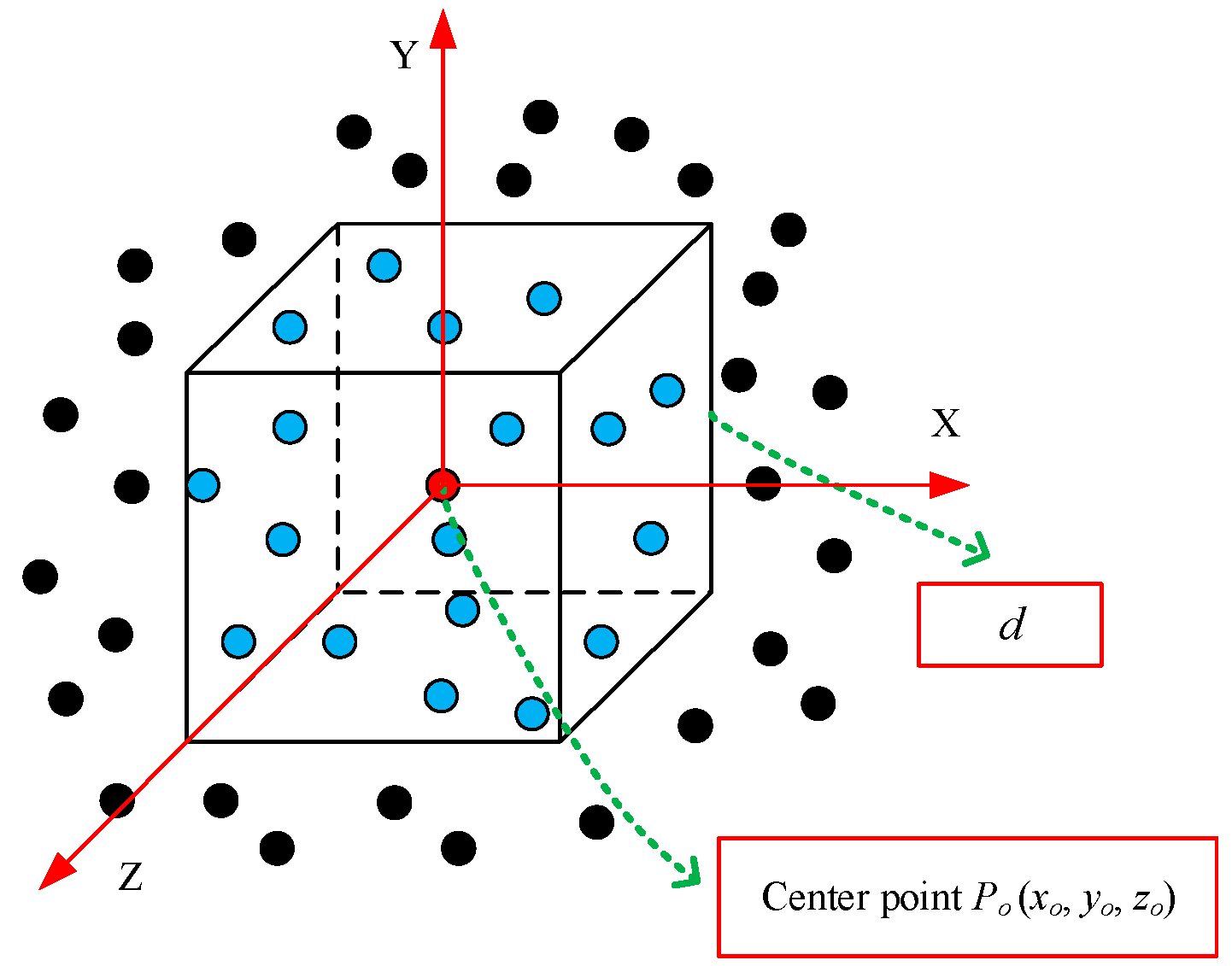
3.1. Search for Local Region
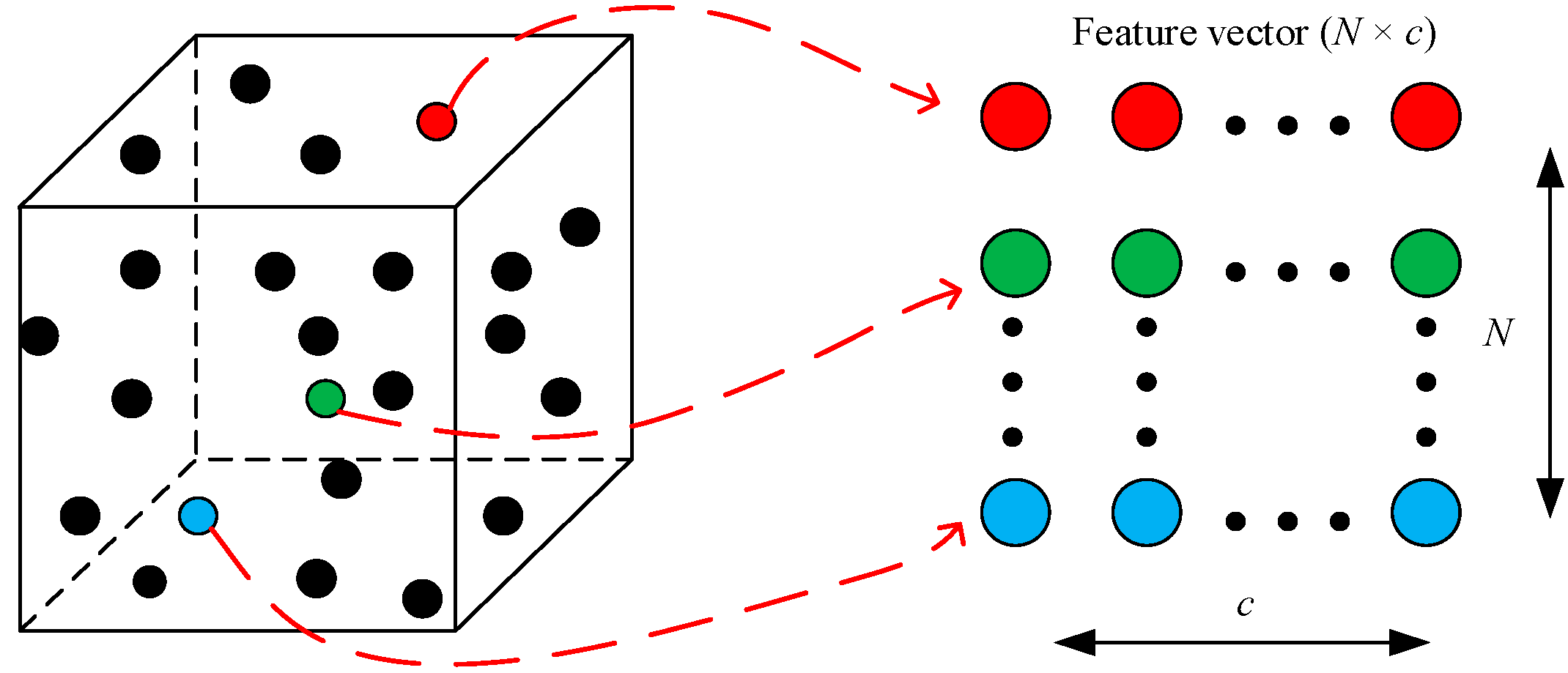
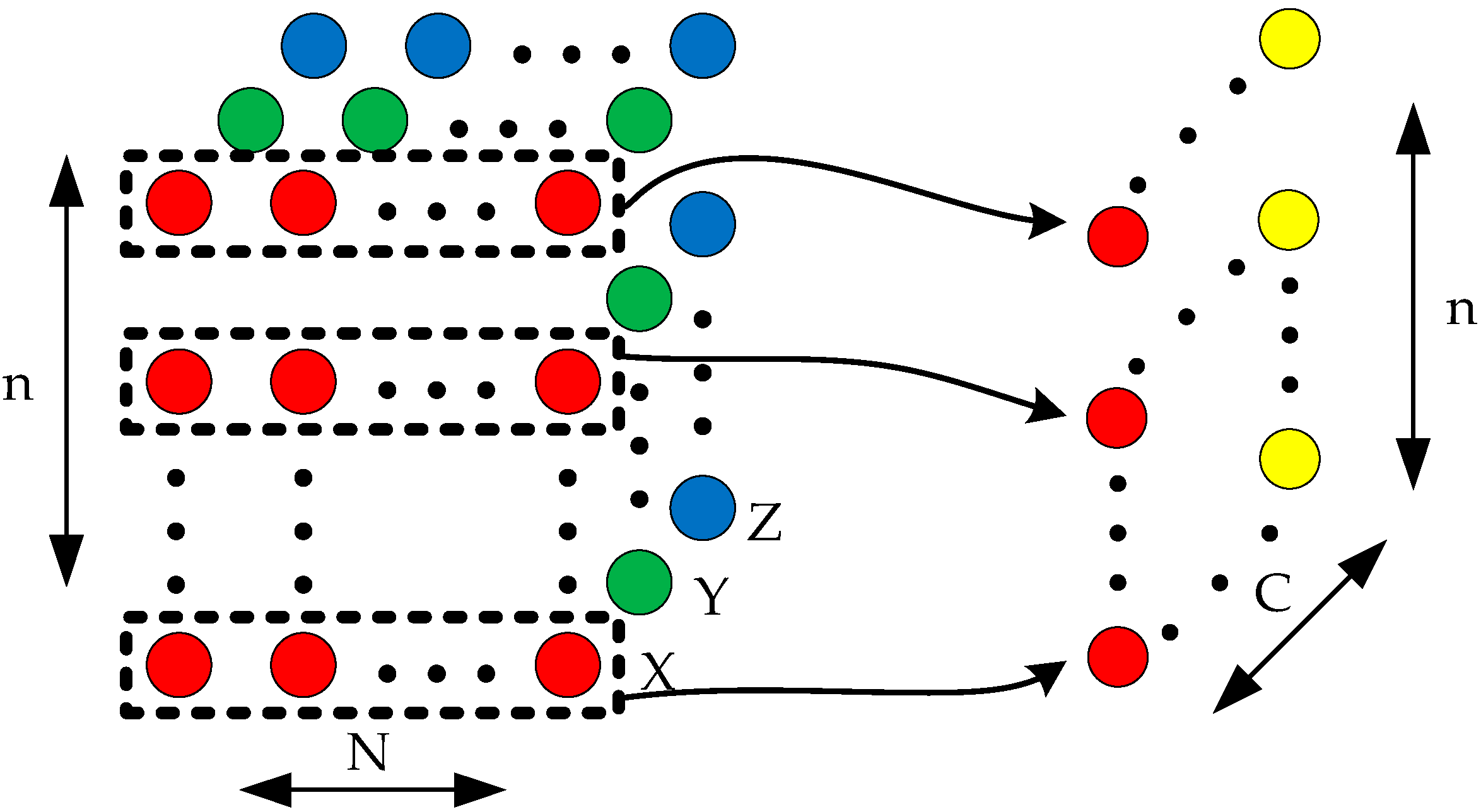
3.2. Generate Feature Representation
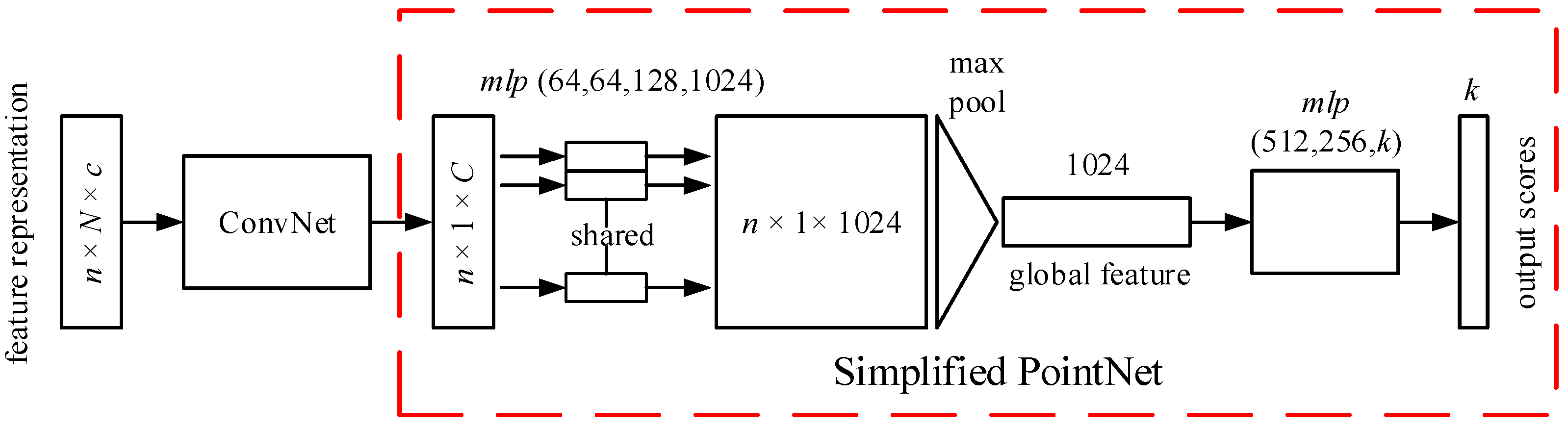
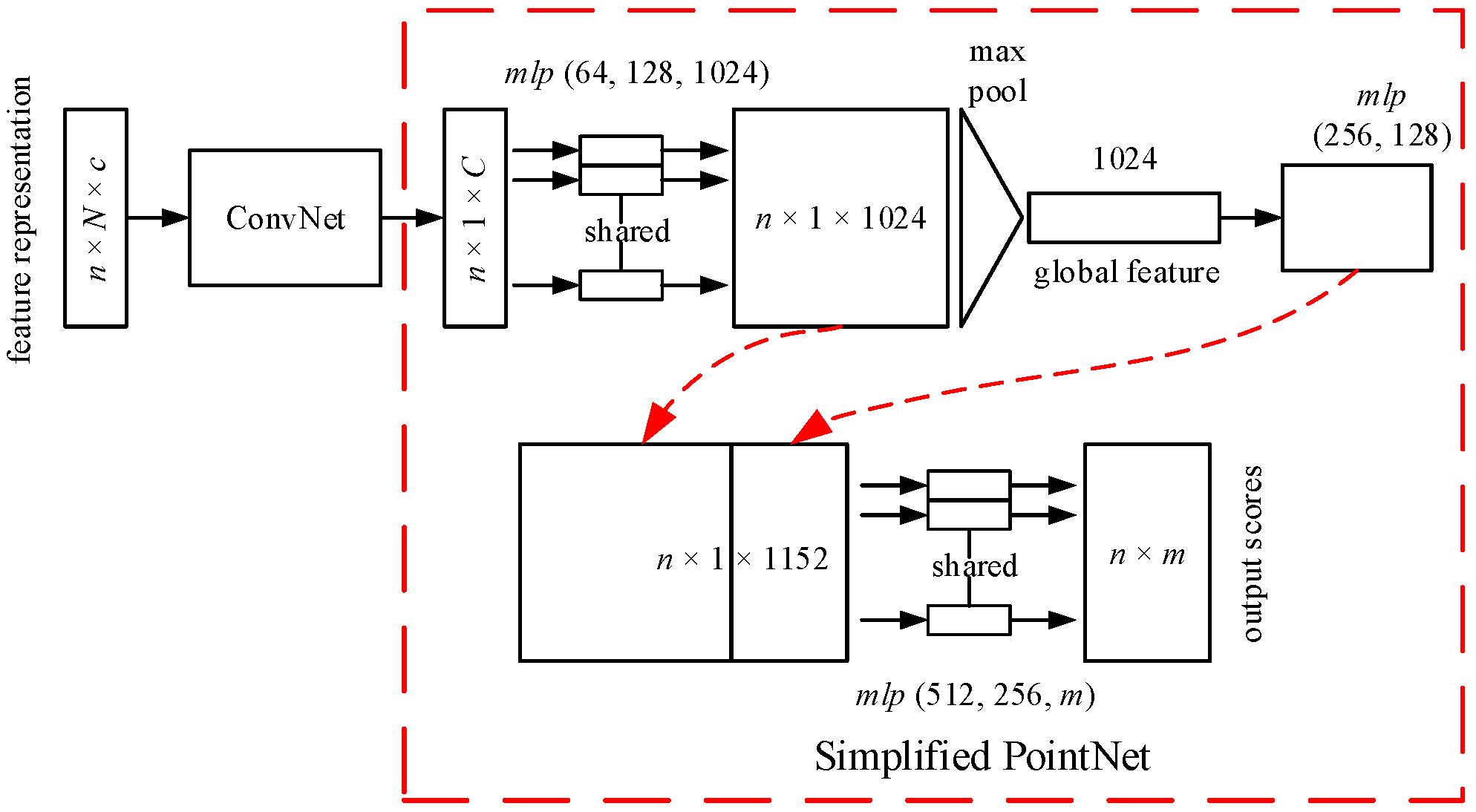
3.3. Deep Learning Architecture for Processing Feature Representation
4. Experimental Studies
4.1. Experimental Setup
4.2. Experiments for 3D Object Classification
4.2.1. Experimental Results for Classification
4.2.2. Classification Details for Each Category
4.3. Experiments for 3D Semantic Segmentation
4.4. Sensitivity Experiments and Analyses
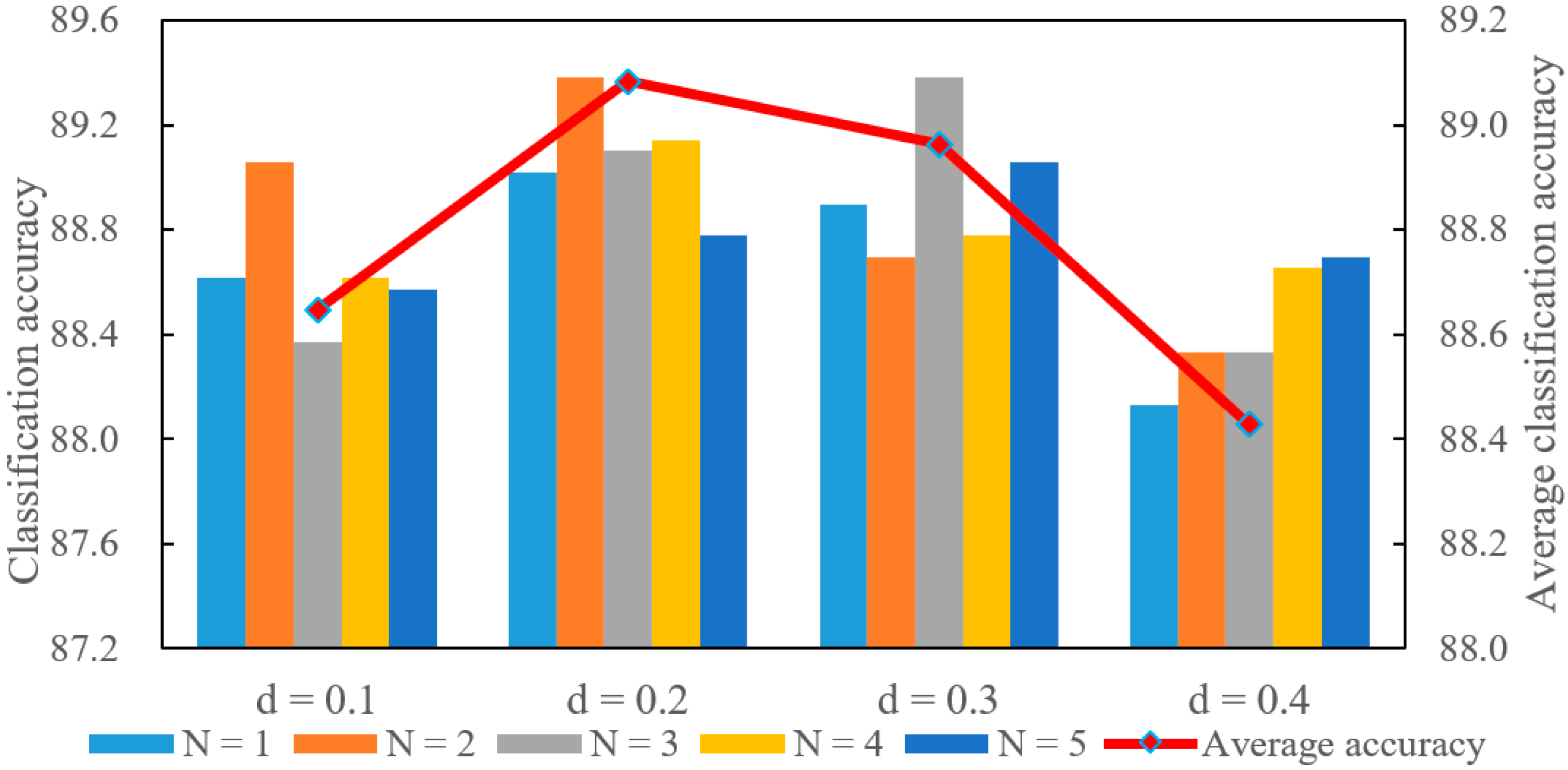
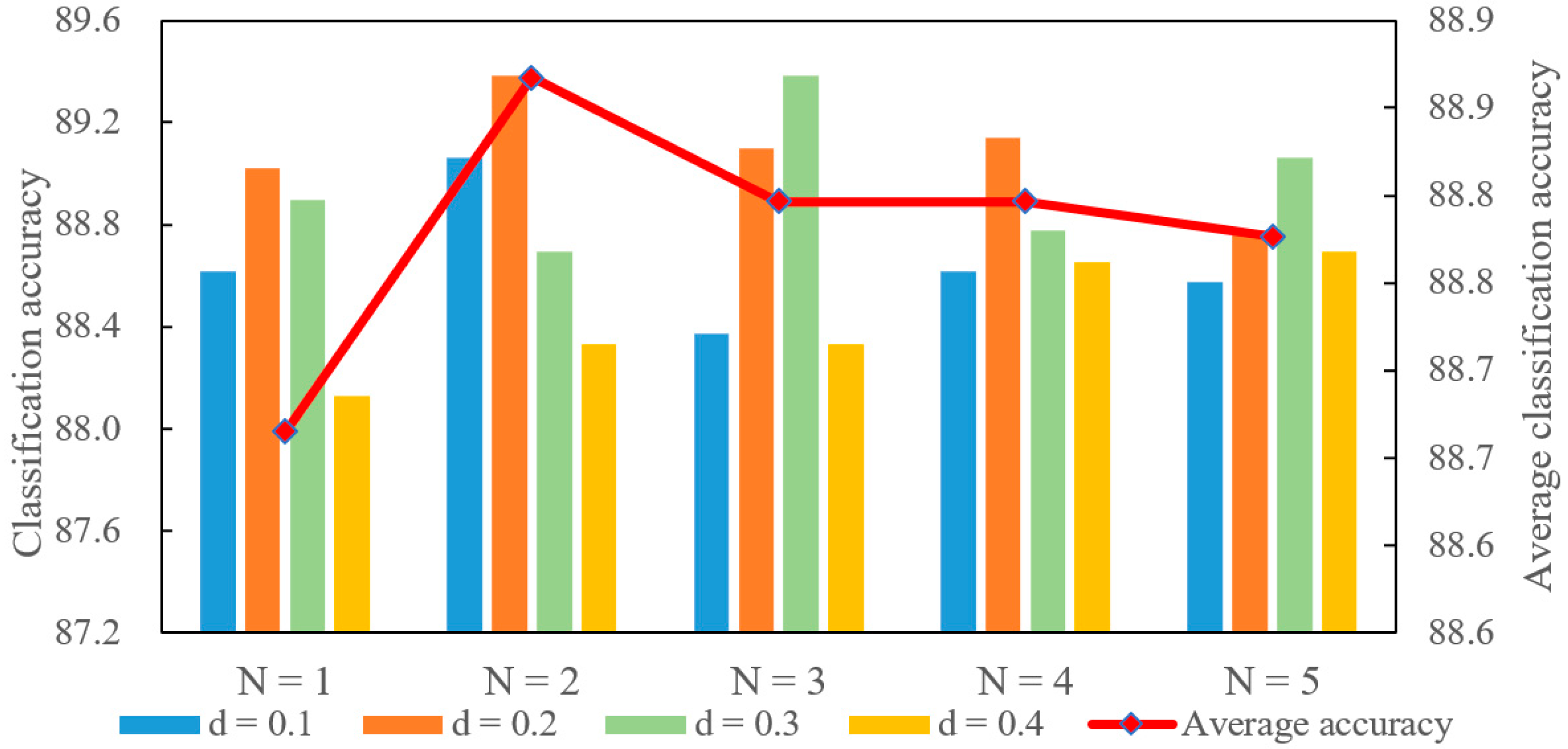
4.4.1. Sensitivity Analyses for 3D Object Classification
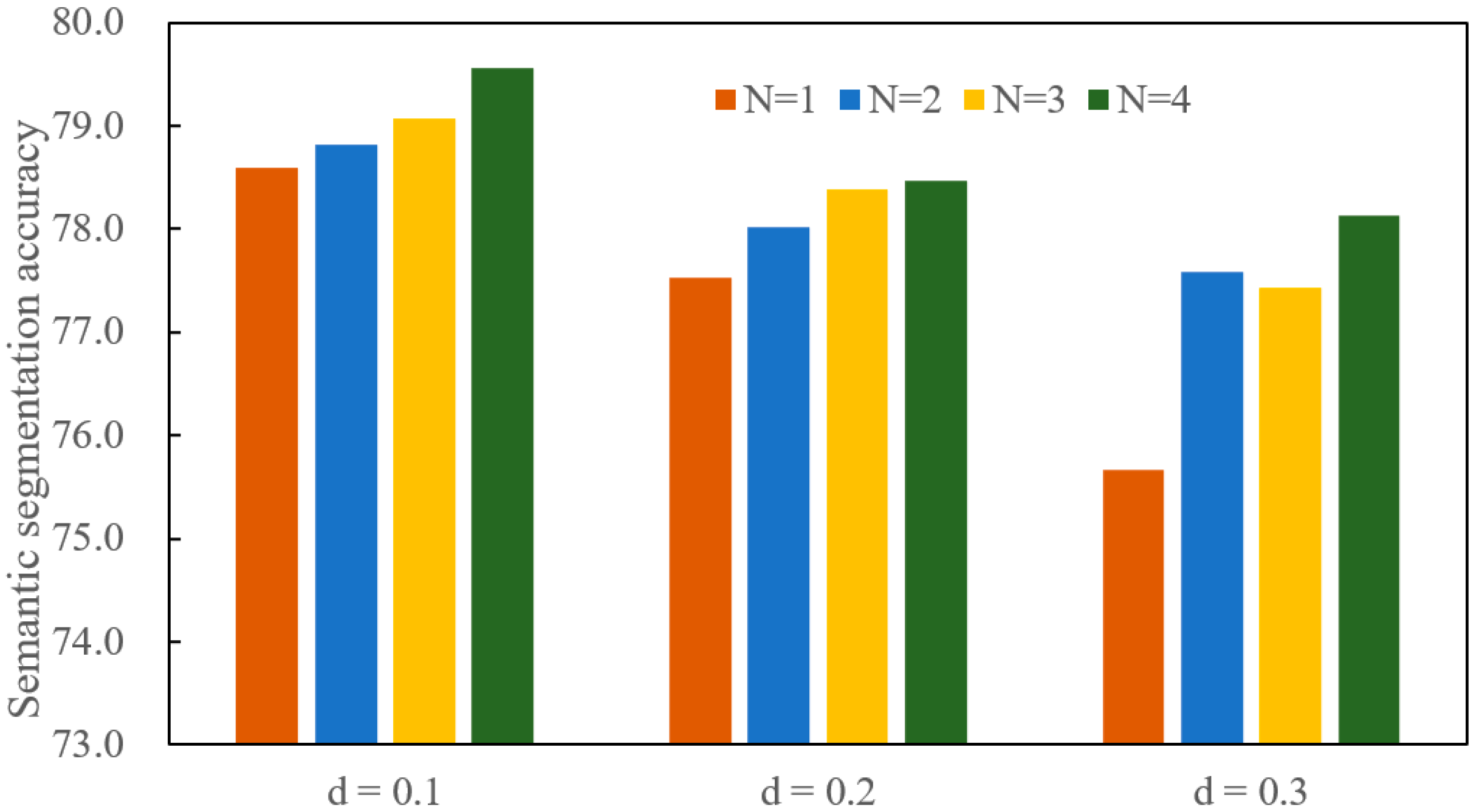
4.4.2. Sensitivity Analyses for Semantic Segmentation
4.5. Discussions
5. Conclusions and Future Work
- The raw point cloud is encoded into the corresponding feature representations with local information. The point cloud encoding method facilitates the deep leaning network to extract more discriminative features.
- The axis-aligned cube that can improve the search speed is used to search for a local region. Partial points in the local region are selected to construct the feature representation of a point with low computation complexity.
- The proposed method reduces the complexity of the network while remaining high in accuracy in classification and segmentation tasks.
Author Contributions
Funding
Conflicts of Interest
References
- Wang, S.J.; Liu, B.; Chen, Z.; Li, H.P.; Jiang, S. The Segmentation Method of Target Point Cloud for Polarization-Modulated 3D Imaging. Sensors 2020, 20, 179. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cai, G.R.; Jiang, Z.N.; Wang, Z.Y.; Huang, S.F.; Chen, K.; Ge, X.Y.; Wu, Y.D. Spatial Aggregation Net: Point Cloud Semantic Segmentation Based on Multi-Directional Convolution. Sensors 2019, 19, 4329. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hu, F.C.; Yang, D.; Li, Y.G. Combined Edge- and Stixel-based Object Detection in 3D Point Cloud. Sensors 2019, 19, 4423. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, J.; Ma, Y.X.; He, S.H.; Zhu, J.H. 3D-GIoU: 3D Generalized Intersection over Union for Object Detection in Point Cloud. Sensors 2019, 19, 4093. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wen, L.; Gao, L.; Li, X.Y. A New Deep Transfer Learning Based on Sparse Auto-Encoder for Fault Diagnosis. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 136–144. [Google Scholar] [CrossRef]
- Zhang, Y.Y.; Li, X.Y.; Gao, L.; Li, P.G. A new subset based deep feature learning method for intelligent fault diagnosis of bearing. Expert Syst. Appl. 2018, 110, 125–142. [Google Scholar] [CrossRef]
- Makkie, M.; Huang, H.; Zhao, Y.; Vasilakos, A.V.; Liu, T.M. Fast and scalable distributed deep convolutional autoencoder for fMRI big data analytics. Neurocomputing 2019, 325, 20–30. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.; Gao, L.; Li, X.; Shen, W. A novel robotic grasp detection method based on region proposal networks. Robot. Comput.-Integr. Manuf. 2020, 65, 101963. [Google Scholar] [CrossRef]
- Maturana, D.; Scherer, S. Voxnet: A 3d convolutional neural network for real-time object recognition. In Proceedings of the International Conference on Intelligent Robots and Systems, Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Zhang, L.; Sun, J.; Zheng, Q. 3D Point Cloud Recognition Based on a Multi-View Convolutional Neural Network. Sensors 2018, 18, 3681. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Charles, R.Q.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Cao, L.; Wang, Y.F.; Zhang, B.; Jin, Q.; Vasilakos, A.V. GCHAR: An efficient Group-based Context-aware human activity recognition on smartphone. J. Parallel Distrib. Comput. 2018, 118, 67–80. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Landrieu, L.; Simonovsky, M. Large-Scale Point Cloud Semantic Segmentation with Superpoint Graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4558–4567. [Google Scholar]
- Li, J.; Chen, B.M.; Hee Lee, G. SO-Net: Self-organizing network for point cloud analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9397–9406. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D ShapeNets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Armeni, I.; Sener, O.; Zamir, A.R.; Jiang, H.; Brilakis, I.; Fischer, M.; Savarese, S. 3D Semantic Parsing of Large-Scale Indoor Spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1534–1543. [Google Scholar]
- Chen, D.Y.; Tian, X.P.; Shen, Y.T.; Ouhyoung, M. On visual similarity based 3D model retrieval. Comput. Graph. Forum 2003, 22, 223–232. [Google Scholar] [CrossRef]
- Kazhdan, M.; Funkhouser, T.; Rusinkiewicz, S. Rotation invariant spherical harmonic representation of 3D shape descriptors. In Proceedings of the Symposium on geometry processing, Aachen, Germany, 23–25 June 2003; pp. 156–164. [Google Scholar]
- Savelonas, M.A.; Pratikakis, I.; Sfikas, K. Fisher encoding of differential fast point feature histograms for partial 3D object retrieval. Pattern Recognit. 2016, 55, 114–124. [Google Scholar] [CrossRef]
- Aubry, M.; Schlickewei, U.; Cremers, D. The wave kernel signature: A quantum mechanical approach to shape analysis. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Barcelona, Spain, 6–13 November 2011; pp. 1626–1633. [Google Scholar]
- Ji, S.W.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dou, Q.; Chen, H.; Yu, L.Q.; Zhao, L.; Qin, J.; Wang, D.F.; Mok, V.C.T.; Shi, L.; Heng, P.A. Automatic Detection of Cerebral Microbleeds From MR Images via 3D Convolutional Neural Networks. IEEE Trans. Med. Imaging 2016, 35, 1182–1195. [Google Scholar] [CrossRef] [PubMed]
- Qi, C.R.; Su, H.; Nießner, M.; Dai, A.; Yan, M.; Guibas, L.J. Volumetric and Multi-view CNNs for Object Classification on 3D Data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5648–5656. [Google Scholar]
- Li, Y.; Pirk, S.; Su, H.; Qi, C.R.; Guibas, L.J. FPNN: Field Probing Neural Networks for 3D Data. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 307–315. [Google Scholar]
- Riegler, G.; Ulusoy, A.O.; Geiger, A. Octnet: Learning deep 3D representations at high resolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3577–3586. [Google Scholar]
- Engelcke, M.; Rao, D.; Wang, D.Z.; Tong, C.H.; Posner, I. Vote3deep: Fast object detection in 3d point clouds using efficient convolutional neural networks. In Proceedings of the IEEE International Conference on Robotics and Automation, Marina Bay, Singapore, 29 May–3 June 2017; pp. 1355–1361. [Google Scholar]
- Pang, G.; Neumann, U. 3d point cloud object detection with multi-view convolutional neural network. In Proceedings of the International Conference on Pattern Recognition, Cancun, Mexico, 4–8 December 2016; pp. 585–590. [Google Scholar]
- Shi, B.; Bai, S.; Zhou, Z.; Bai, X. Deeppano: Deep panoramic representation for 3-D shape recognition. IEEE Signal Process. Lett. 2015, 22, 2339–2343. [Google Scholar] [CrossRef]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3d shape recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 945–953. [Google Scholar]
- Huang, Q.; Wang, W.; Neumann, U. Recurrent Slice Networks for 3D Segmentation of Point Clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2626–2635. [Google Scholar]
- Wang, W.Y.; Yu, R.; Huang, Q.G.; Neumann, U. SGPN: Similarity Group Proposal Network for 3D Point Cloud Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2569–2578. [Google Scholar]
- Meagher, D. Geometric modeling using octree encoding. Comput. Graph. Image Process. 1982, 19, 129–147. [Google Scholar] [CrossRef]
- Xia, Z.H.; Xiong, N.N.; Vasilakos, A.V.; Sun, X.M. EPCBIR: An efficient and privacy-preserving content-based image retrieval scheme in cloud computing. Inf. Sci. 2017, 387, 195–204. [Google Scholar] [CrossRef]
- Song, Y.N.; Pan, Q.K.; Gao, L.; Zhang, B. Improved non-maximum suppression for object detection using harmony search algorithm. Appl. Soft Comput. 2019, 81, 105478. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Kernel Size | Stride | Channel |
|---|---|---|---|
| conv | 1 × 2 | 1 × 1 | 64 |
| Method | Input | Views | Accuracy Avg. Class | Overall Accuracy |
|---|---|---|---|---|
| SPH [19] | mesh | - | 68.2 | - |
| 3DShapeNets [16] | volume | 1 | 77.3 | 84.7 |
| VoxNet [9] | volume | 12 | 83.0 | 85.9 |
| Subvolume [24] | volume | 20 | 86.0 | 89.2 |
| LFD [16] | image | 10 | 75.5 | - |
| PointNet [11] | point | 1 | 86.2 | 89.2 |
| Proposed method | point | 1 | 85.5 | 89.4 |
| Class | Accuracy | Class | Accuracy | Class | Accuracy |
|---|---|---|---|---|---|
| airplane | 100.0 | dresser | 87.2 | range_hood | 93.0 |
| bathtub | 92.0 | flower_pot | 15.0 | sink | 65.0 |
| bed | 99.0 | glass_box | 97.0 | sofa | 97.0 |
| bench | 80.0 | guitar | 96.0 | stairs | 85.0 |
| bookshelf | 97.0 | keyboard | 95.0 | stool | 75.0 |
| bottle | 96.0 | lamp | 85.0 | table | 78.0 |
| bowl | 100.0 | laptop | 100.0 | tent | 95.0 |
| car | 97.0 | mantel | 94.0 | toilet | 98.0 |
| chair | 96.0 | monitor | 95.0 | tv_stand | 88.0 |
| cone | 95.0 | night_stand | 70.9 | vase | 80.0 |
| cup | 65.0 | person | 80.0 | wardrobe | 65.0 |
| curtain | 80.0 | piano | 88.0 | xbox | 85.0 |
| desk | 88.4 | plant | 76.0 | ||
| door | 85.0 | radio | 65.0 |
| Type | Kernel Size | Stride | Channel |
|---|---|---|---|
| conv | 1 × 4 | 1 × 1 | 64 |
| Method | Average IoU | Overall Accuracy |
|---|---|---|
| PointNet [11] | 47.71 | 78.62 |
| Proposed method | 49.04 | 79.57 |
| Feature Dimension | Type | Kernel Size | Stride | Channel |
|---|---|---|---|---|
| 1024 × 1 × 3 | conv | 1 × 1 | 1 × 1 | 64 |
| 1024 × 2 × 3 | conv | 1 × 2 | 1 × 1 | 64 |
| 1024 × 3 × 3 | conv | 1 × 3 | 1 × 1 | 64 |
| 1024 × 4 × 3 | conv | 1 × 3 1 × 2 | 1 × 1 1 × 1 | 64 64 |
| 1024 × 5 × 3 | conv | 1 × 3 1 × 3 | 1 × 1 1 × 1 | 64 64 |
| Feature Dimension | Type | Kernel Size | Stride | Channel |
|---|---|---|---|---|
| 4096 × 1 × 9 | conv | 1 × 1 | 1 × 1 | 64 |
| 4096 × 2 × 9 | conv | 1 × 2 | 1 × 1 | 64 |
| 4096 × 3 × 9 | conv | 1 × 3 | 1 × 1 | 64 |
| 4096 × 4 × 9 | conv | 1 × 4 | 1 × 1 | 64 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, Y.; Gao, L.; Li, X.; Shen, W. A Novel Point Cloud Encoding Method Based on Local Information for 3D Classification and Segmentation. Sensors 2020, 20, 2501. https://doi.org/10.3390/s20092501
Song Y, Gao L, Li X, Shen W. A Novel Point Cloud Encoding Method Based on Local Information for 3D Classification and Segmentation. Sensors. 2020; 20(9):2501. https://doi.org/10.3390/s20092501
Chicago/Turabian StyleSong, Yanan, Liang Gao, Xinyu Li, and Weiming Shen. 2020. "A Novel Point Cloud Encoding Method Based on Local Information for 3D Classification and Segmentation" Sensors 20, no. 9: 2501. https://doi.org/10.3390/s20092501
APA StyleSong, Y., Gao, L., Li, X., & Shen, W. (2020). A Novel Point Cloud Encoding Method Based on Local Information for 3D Classification and Segmentation. Sensors, 20(9), 2501. https://doi.org/10.3390/s20092501