Hyperspectral Classification of Cyperus esculentus Clones and Morphologically Similar Weeds


Abstract
:1. Introduction
2. Materials and Methods
2.1. Random Forest (RF)
2.2. Regularized Logistic Regression (RLR)
2.3. Partial Least Squares–Discriminant Analysis (PLS–DA)
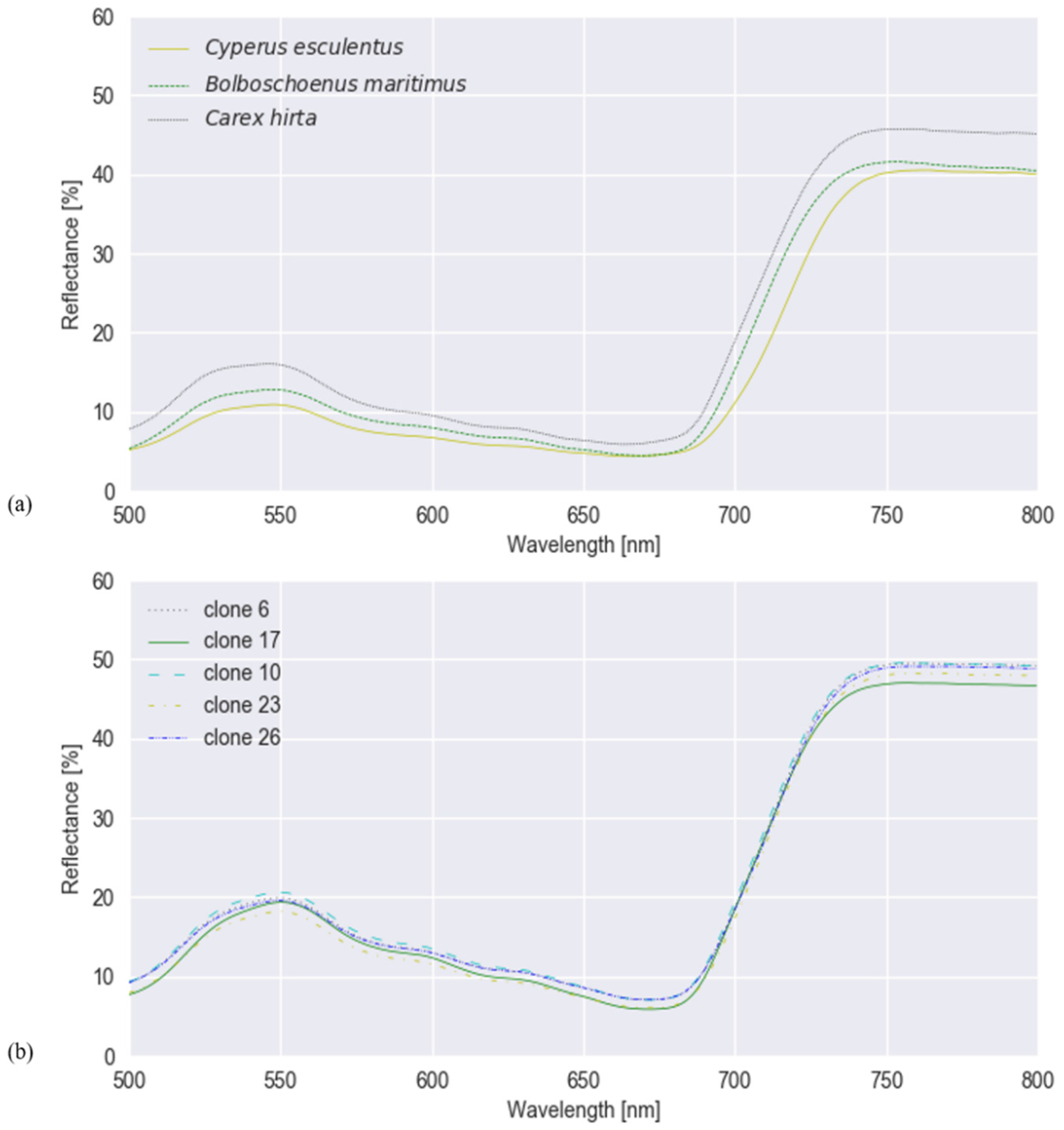
3. Results and Discussion
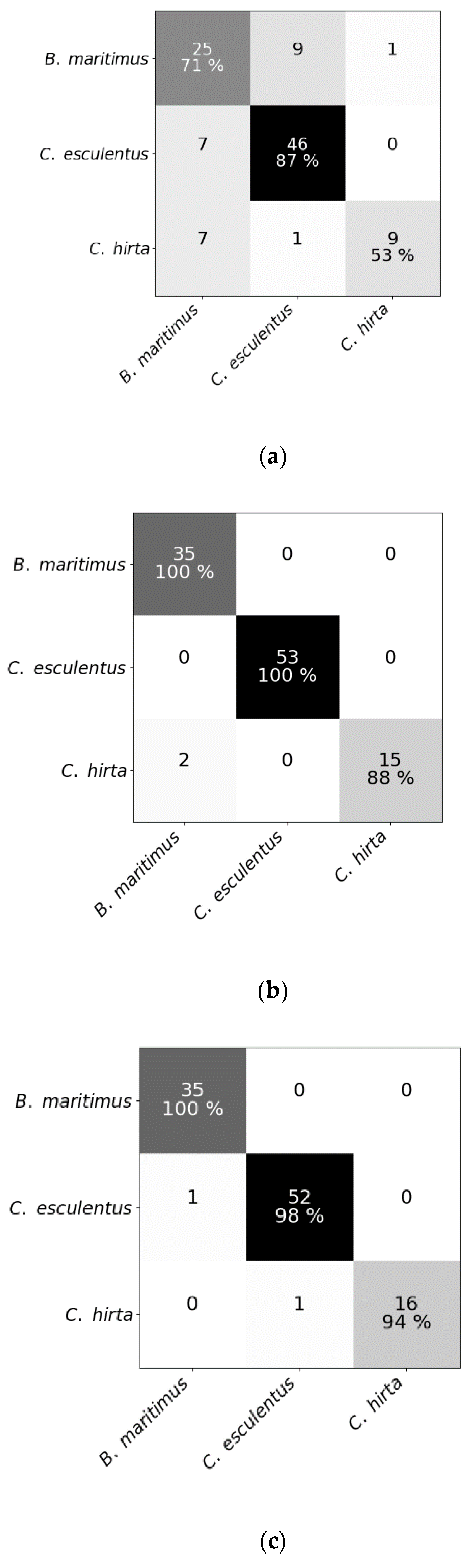
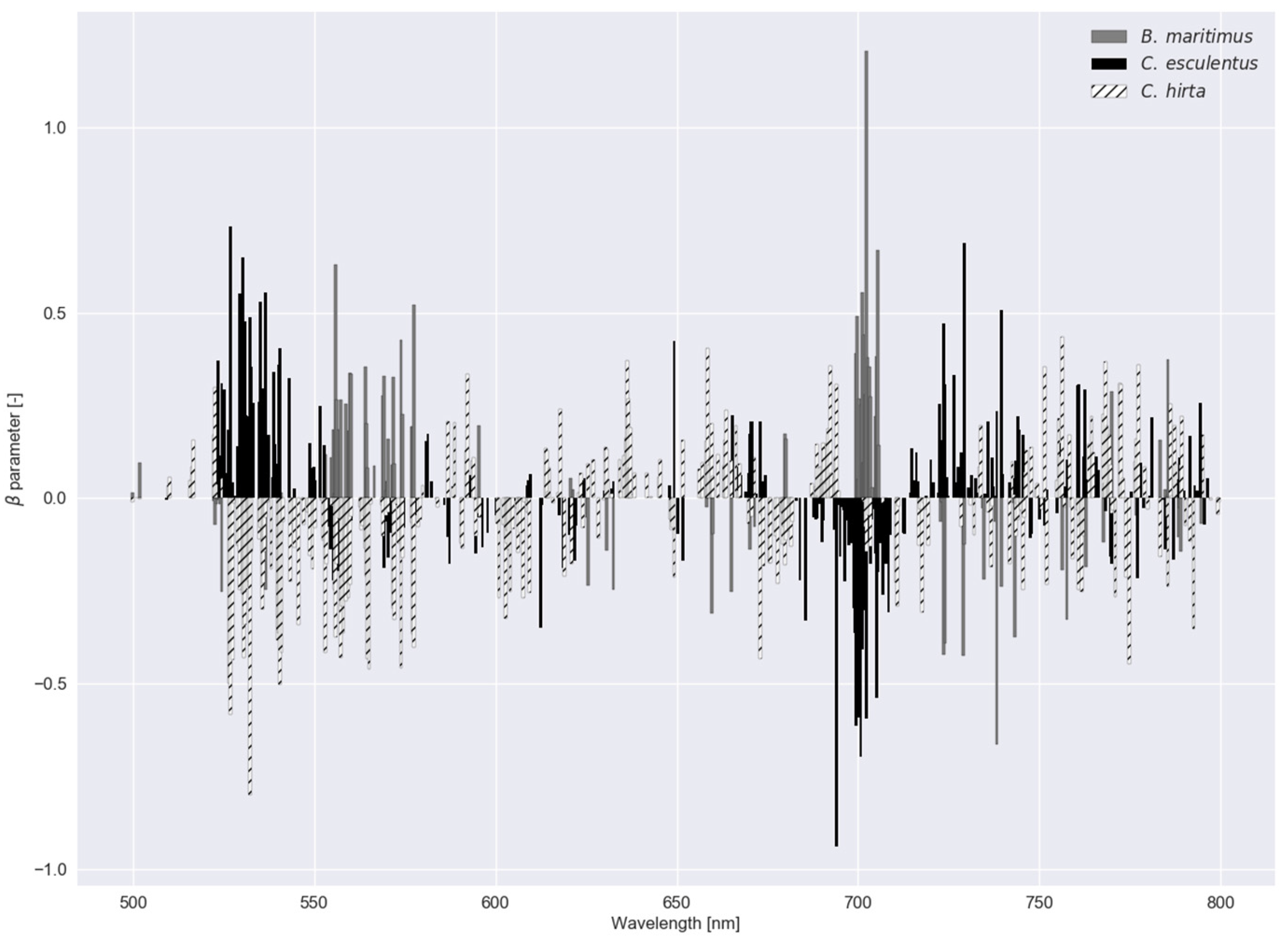
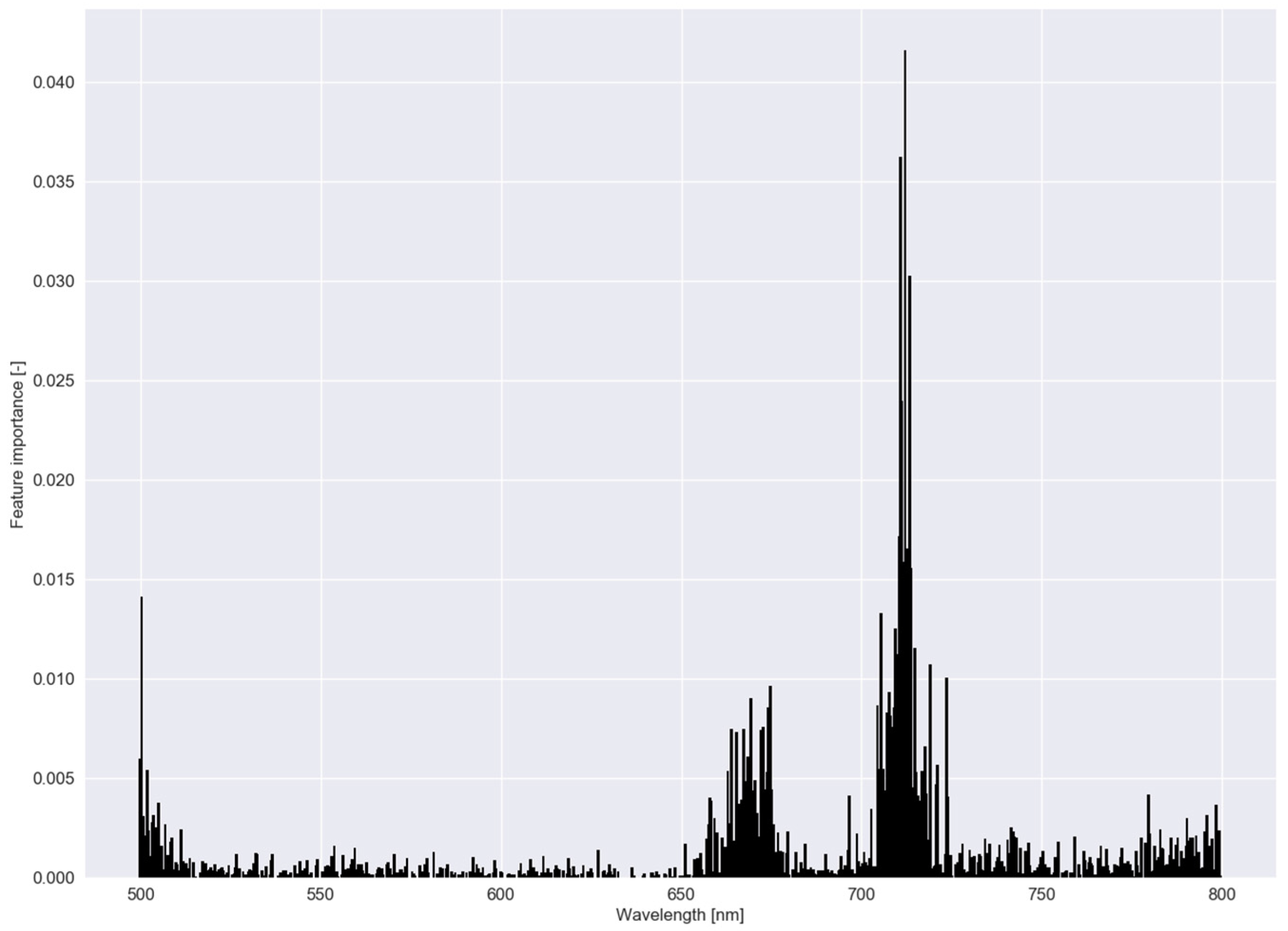
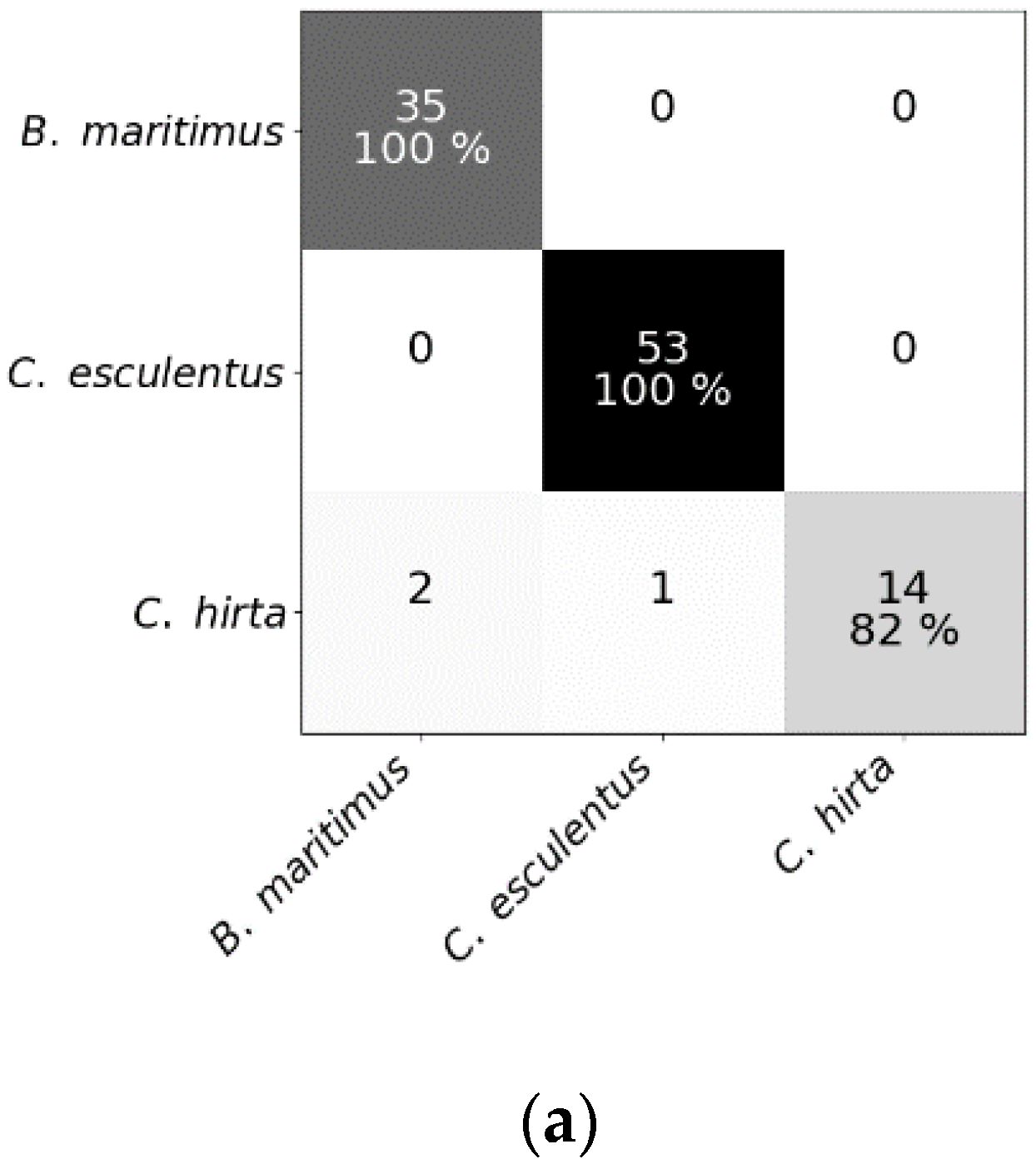
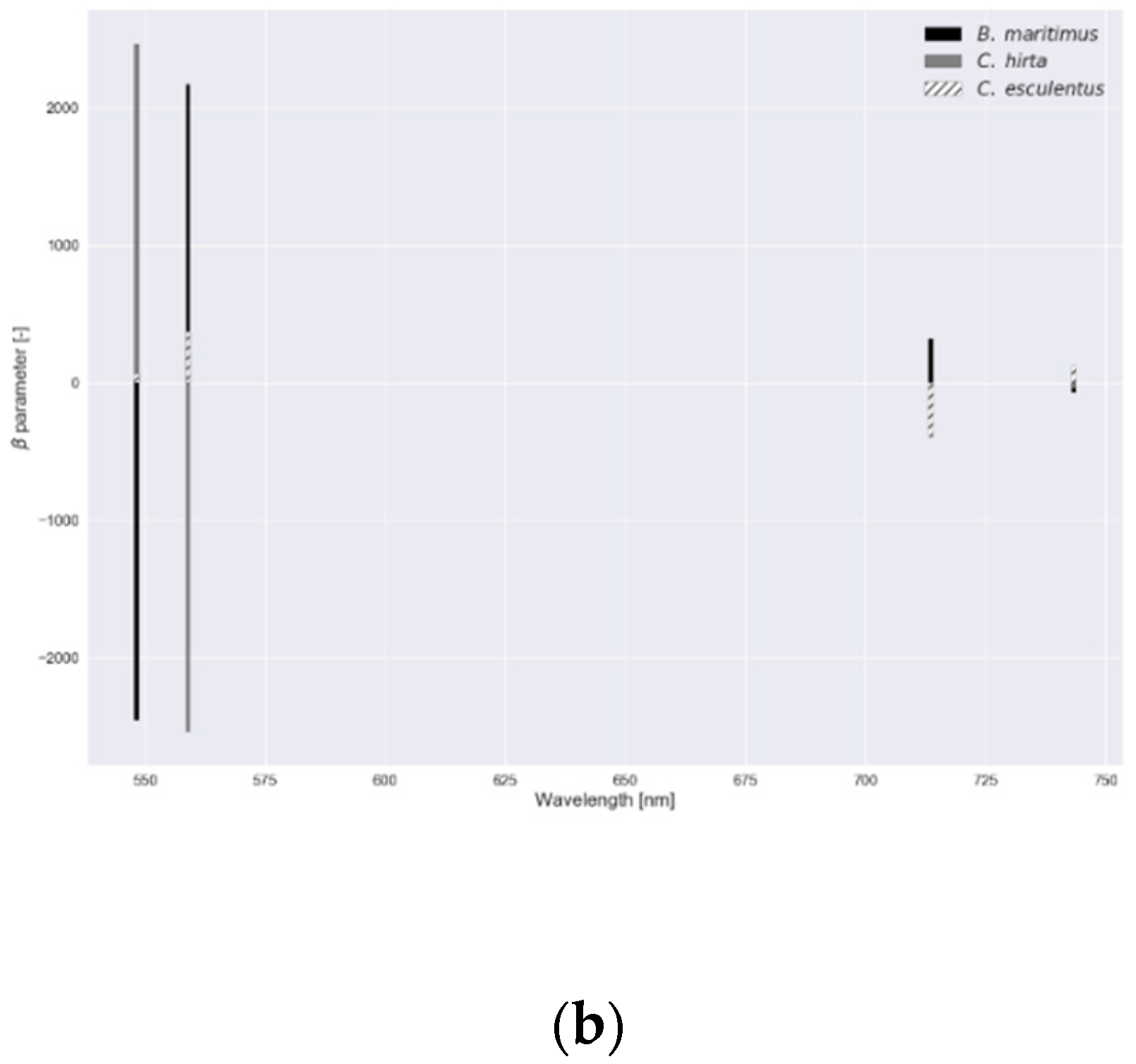
3.1. Classification Results (Experiments I and II)
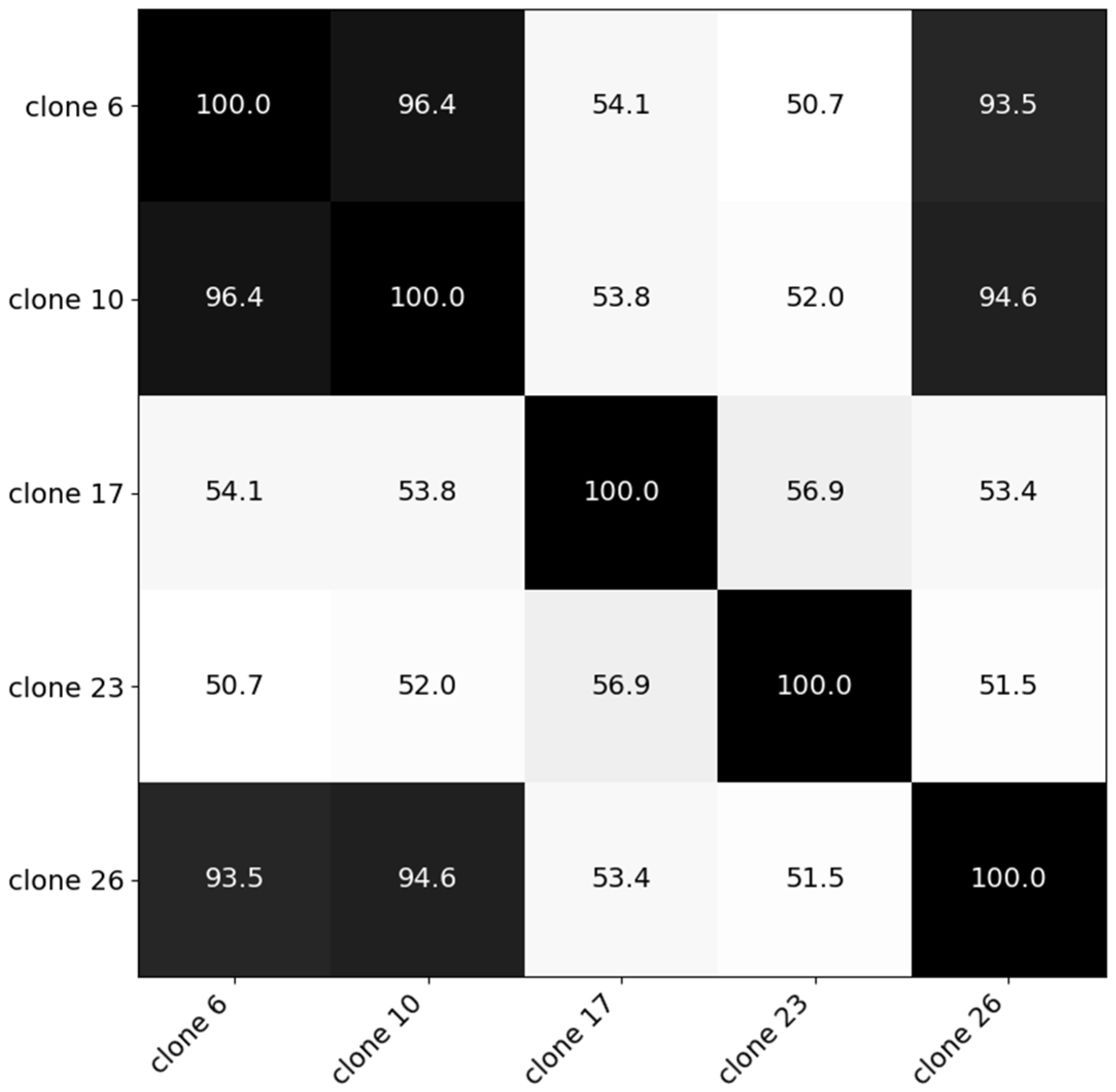
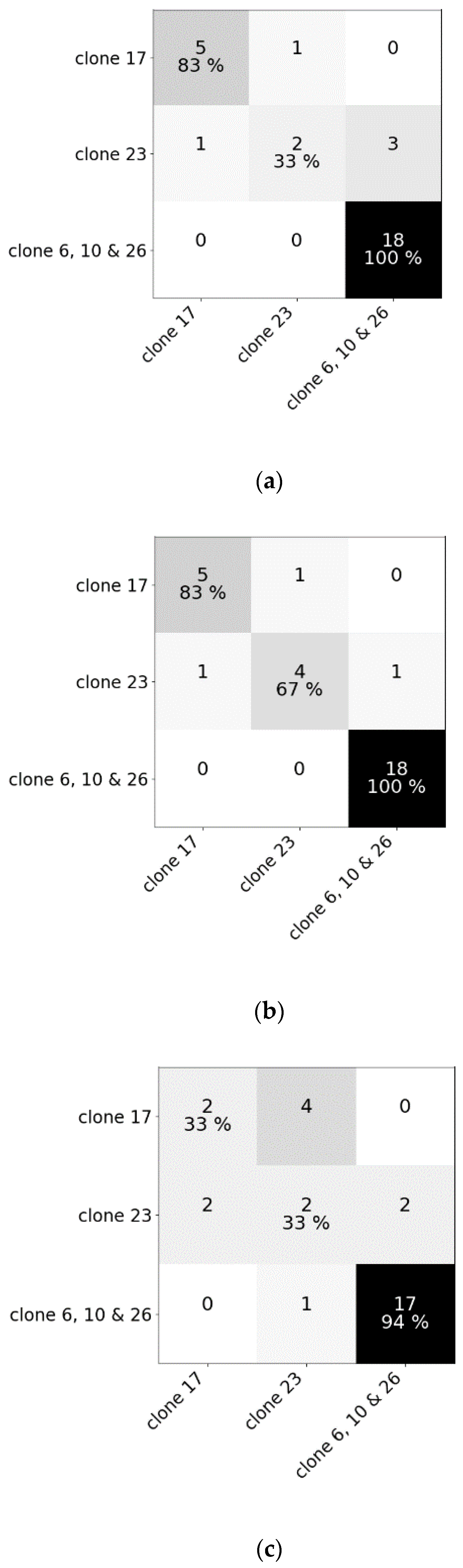
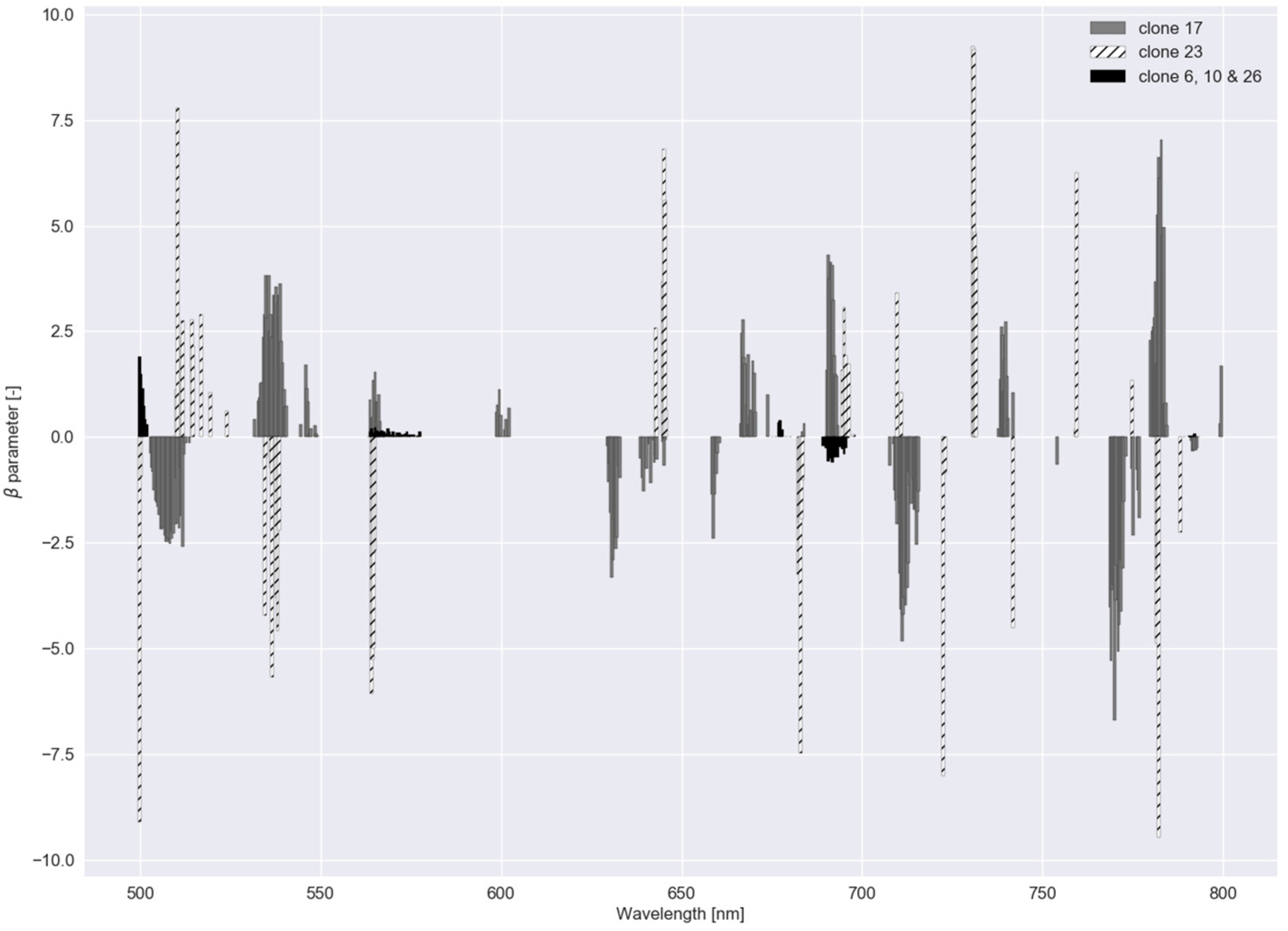
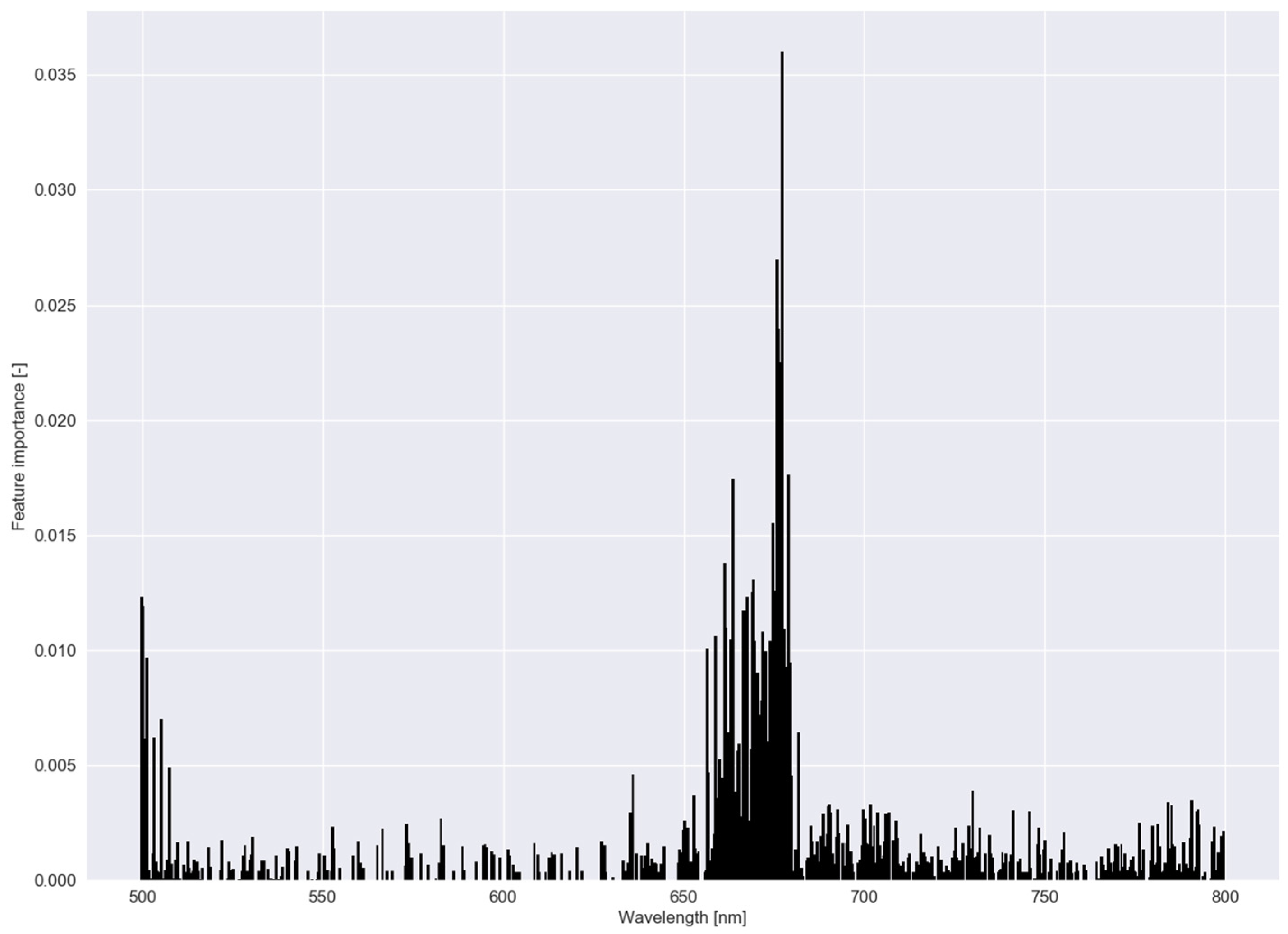
3.2. Robustness of the Models (Experiment III)
3.3. Low-Cost Tool (Experiment IV)
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Holm, L.G.; Plucknett, D.L.; Pancho, J.V.; Herberger, J.P. The world’s worst weeds; University Press: Honolulu, HI, USA, 1977. [Google Scholar]
- Verloove, F. Manual of the Alien Plants of Belgium. Available online: http://alienplantsbelgium.be/ (accessed on 1 October 2019).
- De Cauwer, B.; De Ryck, S.; Claerhout, S.; Biesemans, N.; Reheul, D. Differences in growth and herbicide sensitivity among Cyperus esculentus clones found in Belgian maize fields. Weed Res. 2017, 57, 234–246. [Google Scholar] [CrossRef]
- Follak, S.; Aldrian, U.; Moser, D.; Essl, F. Reconstructing the invasion of Cyperus esculentus in Central Europe. Weed Res. 2015, 55, 289–297. [Google Scholar] [CrossRef]
- Wills, G.D. Description of purple and yellow nutsedge (Cyperus rotundus and C. esculentus). Weed Technol. 1987, 1, 2–9. [Google Scholar] [CrossRef]
- Stoller, E.W.; Sweet, R.D. Biology and life cycle of purple and yellow nutsedges (Cyperus rotundus and C. esculentus). Weed Technol. 1987, 1, 66–73. [Google Scholar] [CrossRef]
- Tumbleson, M.E.; Kommedahl, T. Reproductive potential of Cyperus esculentus by tubers. Weeds 1961, 9, 646–653. [Google Scholar] [CrossRef]
- Stoller, E.W.; Wax, L.M. Yellow nutsedge shoot emergence and tuber longevity. Cambridge Univ. Press behalf Weed Sci. Soc. Am. 1973, 21, 76–81. [Google Scholar] [CrossRef]
- Stoller, E.W.; Nema, D.P.; Bhan, V.M. Yellow nutsedge tuber germination and seedling development. Weed Sci. 1972, 20, 93–97. [Google Scholar] [CrossRef]
- Bohren, C.; Wirth, J. Implementation of control strategies against yellow nutsedge (Cyperus esculentus L.) into practice. Julius Kühn Archiv 2018, 458, 188–196. [Google Scholar]
- Nelson, K.A.; Renner, K.A. Yellow nutsedge (Cyperus esculentus) control and tuber production with glyphosate and ALS-inhibiting herbicides. Weed Technol. 2002, 16, 512–519. [Google Scholar] [CrossRef]
- Pereira, W.; Crabtree, G.; William, R.D. Herbicide action on purple and yellow nutsedge (Cyperus rotundus and C. esculentus). Weed Technol. 1987, 1, 92–98. [Google Scholar] [CrossRef]
- Stoller, E.W.; Wax, L.M.; Slife, F.W. Yellow nutsedge (Cyperus esculentus) competition and control in corn (Zea mays). Weed Sci. 1979, 27, 32–37. [Google Scholar] [CrossRef]
- Felix, J.; Newberry, G. Yellow nutsedge control and reduced tuber production with S-metolachlor, halosulfuron plus dicamba, and glyphosate in furrow-irrigated corn. Weed Technol. 2012, 26, 213–219. [Google Scholar] [CrossRef]
- Edenfield, M.W.; Colvin, D.L.; Brecke, B.J.; Shilling, D.G.; Mclean, H.H. Weed management in peanut (Arachis hypogaea) with pyridate and SAN 582 Systems. Weed Technol. 2001, 15, 13–18. [Google Scholar] [CrossRef]
- Schippers, P.; Ter Borg, S.J.; Bos, J.-J. A Revision of the infraspecific taxonomy of Cyperus esculentus (Yellow Nutsedge) with an experimentally evaluated character set. Syst. Bot. 1995, 20, 461–481. [Google Scholar] [CrossRef] [Green Version]
- Mulligan, A.; Junkins, B.E. The biology of Canadian weeds. 17. Cyperus esculentus L. Can. J. Plant Sci. 1976, 56, 339–350. [Google Scholar] [CrossRef]
- Yu, J.; Boyd, N.S. Weed control with and strawberry tolerance to herbicides applied through drip irrigation. Weed Technol. 2017, 31, 870–876. [Google Scholar] [CrossRef] [Green Version]
- Ransom, C.V.; Rice, C.A.; Shock, C.C. Yellow Nutsedge (Cyperus esculentus) growth and reproduction in response to nitrogen and irrigation. Weed Sci. 2009, 57, 21–25. [Google Scholar] [CrossRef]
- Stoller, E.W.; Wax, L.M.; Matthiesen, R.L. Response of yellow nutsedge and soybeans to bentazon, glyphosate, and perfluidone. Weed Sci. 1975, 23, 215–221. [Google Scholar] [CrossRef]
- Abouziena, H.F.H.; Omar, A.A.M.; Sharma, S.D.; Singh, M. Efficacy comparison of some new natural-product herbicides for weed control at two growth stages. Weed Technol. 2009, 23, 431–437. [Google Scholar] [CrossRef]
- Singh, S.; Singh, M. Effect of growth stage on trifloxysulfuron and glyphosate efficacy in twelve weed species of citrus groves. Weed Technol. 2004, 18, 1031–1036. [Google Scholar] [CrossRef]
- Departement Landbouw en Visserij Praktijkgids Gewasbescherming. Available online: https://lv.vlaanderen.be/nl/plant/gewasbescherming/praktijkgids-gewasbescherming (accessed on 4 November 2019).
- FAVV ADVIES 07-2015: Ontwerp van Koninklijk Besluit tot Opheffing van het Koninklijk Besluit van 12 mei 2011 Betreffende Specifieke Maatregelen om Knolcyperus (Cyperus esculentus L.) te Bestrijden en de Verspreiding Ervan te Voorkomen (dossier SciCom 20). Available online: http://www.afsca.be/wetenschappelijkcomite/adviezen/2015/ (accessed on 1 October 2019).
- Gerhards, R.; Oebel, H. Practical experiences with a system for site-specific weed control in arable crops using real-time image analysis and GPS-controlled patch spraying. Weed Res. 2006, 46, 185–193. [Google Scholar] [CrossRef]
- Borregaard, T.; Nielsen, H.; Nørgaard, L.; Have, H. Crop-weed discrimination by line imaging spectroscopy. J. Agric. Eng. Res. 2000, 75, 389–400. [Google Scholar] [CrossRef]
- Herrmann, I.; Shapira, U.; Kinast, S.; Karnieli, A.; Bonfil, D.J. Ground-level hyperspectral imagery for detecting weeds in wheat fields. Precis. Agric. 2013, 14, 637–659. [Google Scholar] [CrossRef]
- Shapira, U.; Herrmann, I.; Karnieli, A.; Bonfil, D.J. Field spectroscopy for weed detection in wheat and chickpea fields. Int. J. Remote Sens. 2013, 34, 6094–6108. [Google Scholar] [CrossRef] [Green Version]
- Gao, J.; Nuyttens, D.; Lootens, P.; He, Y.; Pieters, J.G. Recognising weeds in a maize crop using a random forest machine-learning algorithm and near-infrared snapshot mosaic hyperspectral imagery. Biosyst. Eng. 2018, 170, 39–50. [Google Scholar] [CrossRef]
- Slaughter, D.C.; Giles, D.K.; Fennimore, S.A.; Smith, R.F. Multispectral machine vision identification of lettuce and weed seedlings for automated weed control. Weed Technol. 2008, 22, 378–384. [Google Scholar] [CrossRef]
- Pérez, A.J.; López, F.; Benlloch, J.V.; Christensen, S. Colour and shape analysis techniques for weed detection in cereal fields. Comput. Electron. Agric. 2000, 25, 197–212. [Google Scholar] [CrossRef]
- Dyrmann, M.; Karstoft, H.; Midtiby, H.S. Plant species classification using deep convolutional neural network. Biosyst. Eng. 2016, 151, 72–80. [Google Scholar] [CrossRef]
- Harrison, D.; Rivard, B.; Sánchez-Azofeifa, A. Classification of tree species based on longwave hyperspectral data from leaves, a case study for a tropical dry forest. Int. J. Appl. Earth Obs. Geoinf. 2018, 66, 93–105. [Google Scholar] [CrossRef]
- Wang, C.; Zhou, B.; Palm, H.L. Detecting invasive sericea lespedeza (Lespedeza cuneata) in Mid-Missouri pastureland using hyperspectral imagery. Environ. Manage. 2008, 41, 853–862. [Google Scholar] [CrossRef]
- Taylor, S.; Kumar, L.; Reid, N.; Lewis, C.R.G. Optimal band selection from hyperspectral data for Lantana camara discrimination. Int. J. Remote Sens. 2012, 33, 5418–5437. [Google Scholar] [CrossRef]
- Fernandes, A.M.; Melo-Pinto, P.; Millan, B.; Tardaguila, J.; Diago, M.P. Automatic discrimination of grapevine (Vitis vinifera L.) clones using leaf hyperspectral imaging and partial least squares. J. Agric. Sci. 2015, 153, 455–465. [Google Scholar] [CrossRef]
- Chivasa, W.; Mutanga, O.; Biradar, C. Phenology-based discrimination of maize (Zea mays L.) varieties using multitemporal hyperspectral data. J. Appl. Remote Sens. 2019, 13, 017504. [Google Scholar] [CrossRef]
- Gratton, E. Method for the automatic correction of scattering in absorption spectra. Biopolym. Orig. Res. Biomol. 1971, 10, 2629–2634. [Google Scholar]
- Dazzi, A.; Deniset-Besseau, A.; Lasch, P. Minimising contributions from scattering in infrared spectra by means of an integrating sphere. Analyst 2013, 138, 4191–4201. [Google Scholar] [CrossRef] [Green Version]
- De Ryck, S. Morfologische Variabiliteit En Herbicidengevoeligheid Van in Vlaanderen Aanwezige Knolcyperus (Cyperus esculentus L.) Klonen; University Gent: Gent, Belgium, 2016. [Google Scholar]
- KMI Klimatologische Overzichten van 2018. Available online: https://www.meteo.be/nl/klimaat/klimatologisch-overzicht/2018/zomer (accessed on 5 November 2019).
- De Ryck, S.; De Riek, J.; Reheul, D.; De Cauwer, B. Morphological and genetic variability of local clonal populations of Cyperus esculentus. Unpublished raw data. 2018. [Google Scholar]
- KMI Klimatologische Overzichten van 2019. Available online: https://www.meteo.be/nl/klimaat/klimatologisch-overzicht/2019/zomer (accessed on 5 November 2019).
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Liaw, A.; Wiener, M. Classification and regression by random forest. R News 2004, 2, 18–22. [Google Scholar]
- Sun, C.; Cao, S.; Sanchez-Azofeifa, G.A. Mapping tropical dry forest age using airborne waveform LiDAR and hyperspectral metrics. Int. J. Appl. Earth Obs. Geoinf. 2019, 83, 101908. [Google Scholar] [CrossRef]
- Naidoo, L.; Cho, M.A.; Mathieu, R.; Asner, G. Classification of savanna tree species, in the Greater Kruger National Park region, by integrating hyperspectral and LiDAR data in a random forest data mining environment. ISPRS J. Photogramm. Remote Sens. 2012, 69, 167–179. [Google Scholar] [CrossRef]
- Adam, E.M.; Mutanga, O.; Rugege, D.; Ismail, R. Discriminating the papyrus vegetation (Cyperus papyrus L.) and its co-existent species using random forest and hyperspectral data resampled to HYMAP. Int. J. Remote Sens. 2012, 33, 552–569. [Google Scholar] [CrossRef]
- Shang, X.; Chisholm, L.A. Classification of Australian native forest species using hyperspectral remote sensing and machine-learning classification algorithms. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2481–2489. [Google Scholar] [CrossRef]
- Erudel, T.; Fabre, S.; Houet, T.; Mazier, F.; Briottet, X. Criteria comparison for classifying peatland vegetation types using in situ hyperspectral measurements. Remote Sens. 2017, 9, 748. [Google Scholar] [CrossRef] [Green Version]
- Dumont, J.; Hirvonen, T.; Heikkinen, V.; Mistretta, M.; Granlund, L.; Himanen, K.; Fauch, L.; Porali, I.; Hiltunen, J.; Keski-Saari, S.; et al. Thermal and hyperspectral imaging for Norway spruce (Picea abies) seeds screening. Comput. Electron. Agric. 2015, 116, 118–124. [Google Scholar] [CrossRef]
- Wold, S.; Sjöström, M.; Eriksson, L. PLS-regression: A basic tool of chemometrics. Chemom. Intell. Lab. Syst. 2001, 58, 109–130. [Google Scholar] [CrossRef]
- Ruiz-Perez, D.; Narasimhan, G. So you think you can PLS-DA? bioRxiv 2018, 207225. [Google Scholar] [CrossRef]
- Fan, R.-E.; Chang, K.-W.; Hsieh, C.-J.; Wang, X.-R.; Lin, C.-J. LIBLINEAR: A library for large linear classification. J. Mach. Learn. Res. 2008, 9, 1871–1874. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn 0.22.1 Documentation. Available online: https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression (accessed on 28 January 2020).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Gutiérrez, S.; Wendel, A.; Underwood, J. Spectral filter design based on in-field hyperspectral imaging and machine learning for mango ripeness estimation. Comput. Electron. Agric. 2019, 164, 104890. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Horler, D.N.H.; Dockray, M.; Barber, J. The red edge of plant leaf reflectance. Int. J. Remote Sens. 1983, 4, 273–288. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Explanation | 2018 (Exp. I) | 2019 (Exp. II) |
|---|---|---|---|
| min_samples_split | Minimum numbers of samples required to split an internal node | 3 | 5 |
| min_samples_leaf | Minimum of samples required to be at a leaf node | 1 | 1 |
| max_features | Number of features to consider when looking for the best split | 77 | 74 |
| Submodel | 2018 (Exp. I) | Submodel | 2019 (Exp. II) |
|---|---|---|---|
| B. maritimus | 8.50 | Clone 17 | 291.51 |
| C. esculentus | 509.41 | Clone 23 | 14.85 |
| C. hirta | 2718.59 | Clone 6, 10 and 26 | 4.86 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lauwers, M.; De Cauwer, B.; Nuyttens, D.; Cool, S.R.; Pieters, J.G. Hyperspectral Classification of Cyperus esculentus Clones and Morphologically Similar Weeds. Sensors 2020, 20, 2504. https://doi.org/10.3390/s20092504
Lauwers M, De Cauwer B, Nuyttens D, Cool SR, Pieters JG. Hyperspectral Classification of Cyperus esculentus Clones and Morphologically Similar Weeds. Sensors. 2020; 20(9):2504. https://doi.org/10.3390/s20092504
Chicago/Turabian StyleLauwers, Marlies, Benny De Cauwer, David Nuyttens, Simon R. Cool, and Jan G. Pieters. 2020. "Hyperspectral Classification of Cyperus esculentus Clones and Morphologically Similar Weeds" Sensors 20, no. 9: 2504. https://doi.org/10.3390/s20092504
APA StyleLauwers, M., De Cauwer, B., Nuyttens, D., Cool, S. R., & Pieters, J. G. (2020). Hyperspectral Classification of Cyperus esculentus Clones and Morphologically Similar Weeds. Sensors, 20(9), 2504. https://doi.org/10.3390/s20092504