3.1. Net3 Network Contamination Scenario
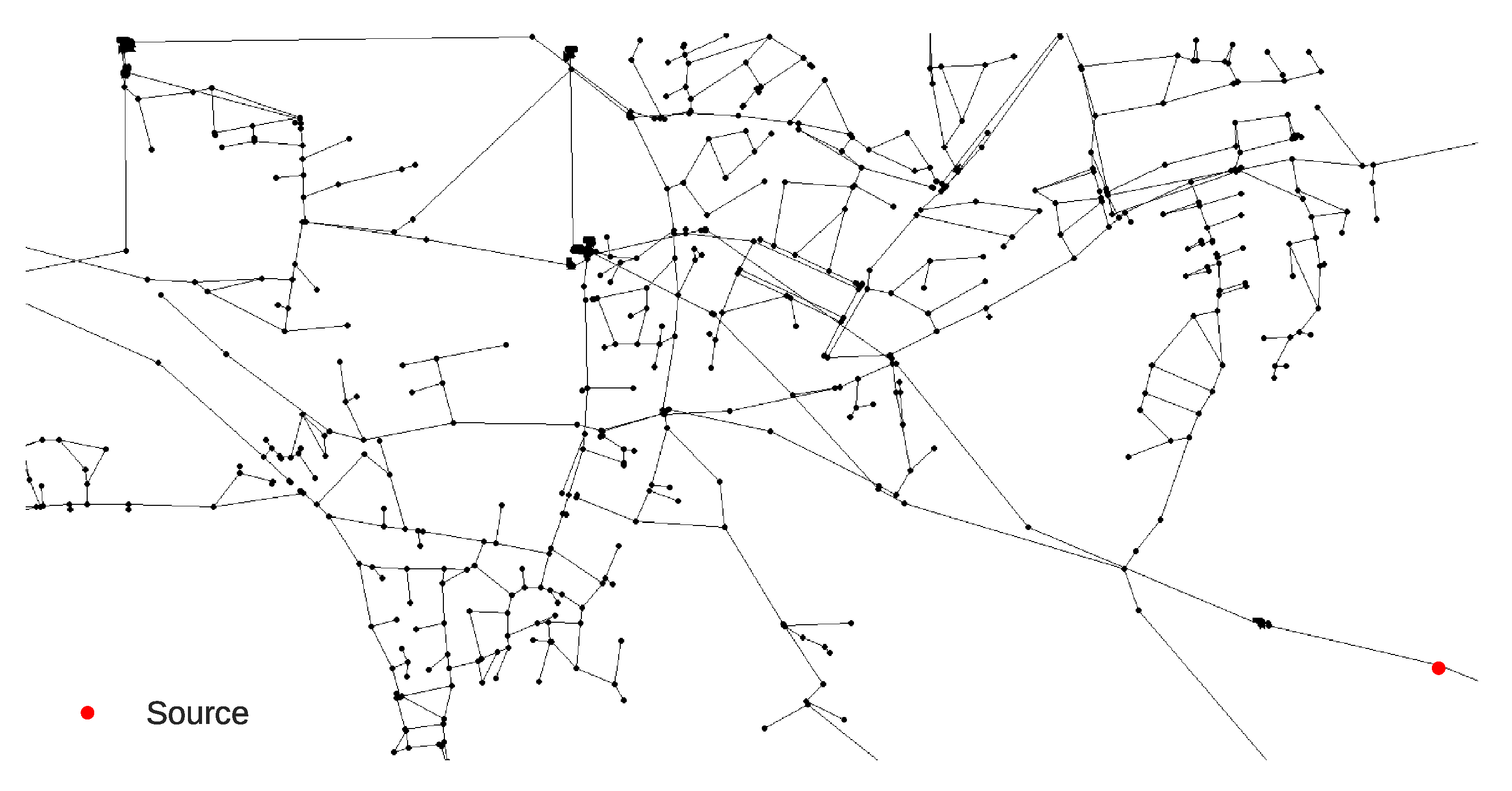
The contamination event scenario for the Net3 benchmark network was chosen to be from the same node (119) as in the one from the work by Preis and Ostfeld [
7] and the location can be seen in
Figure 6. The contamination event characteristics at source node 119 were freely chosen with the event starting at 14:20 h and lasting until 20:20 h with a constant chemical mass inflow of 813.7 mg/L.
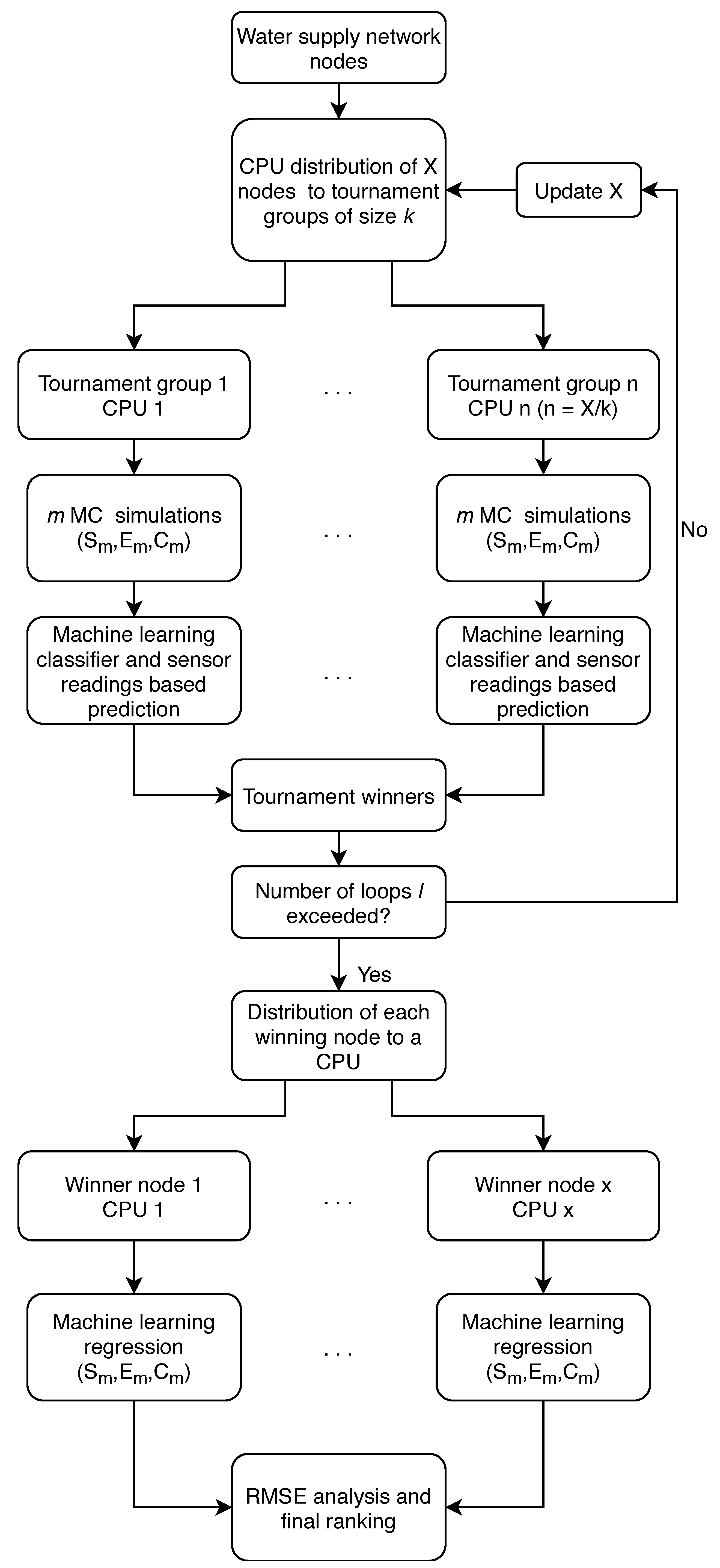
The selected number of algorithm loops l was 3, the number of m (MC simulations for every tournament group) was 200 and the size of a tournament group k was 2, which means that with 92 initial water supply network nodes, the number of used CPUs for every tournament group was 46 and after every loop that number was halved. After three loops, the number of tournament winners was 11, which means that 11 CPUs were used for the RF regression analysis and prediction of other relevant variables.
The contamination source search was repeated 30 times since there the algorithm consists of a stochastic component (MC simulations). In 22 out of 30 runs the true source node was the suspect node with the highest probability and in the remaining eight runs the true source node was a part of the final winners list, which means that the ANN classification can successfully narrow down the search space from 92 to 11 nodes in this case. The average run which includes MC simulations, ANN classification and RF regression lasted for 8 min (even though the RF regression lasted only for 8 s). The algorithm was run (at its initial loop) on 46 Intel Xeon E5 CPUs (two cluster nodes). Out of the other eight runs when the true source node was not ranked first, it was always in the top six of the tournament winners.
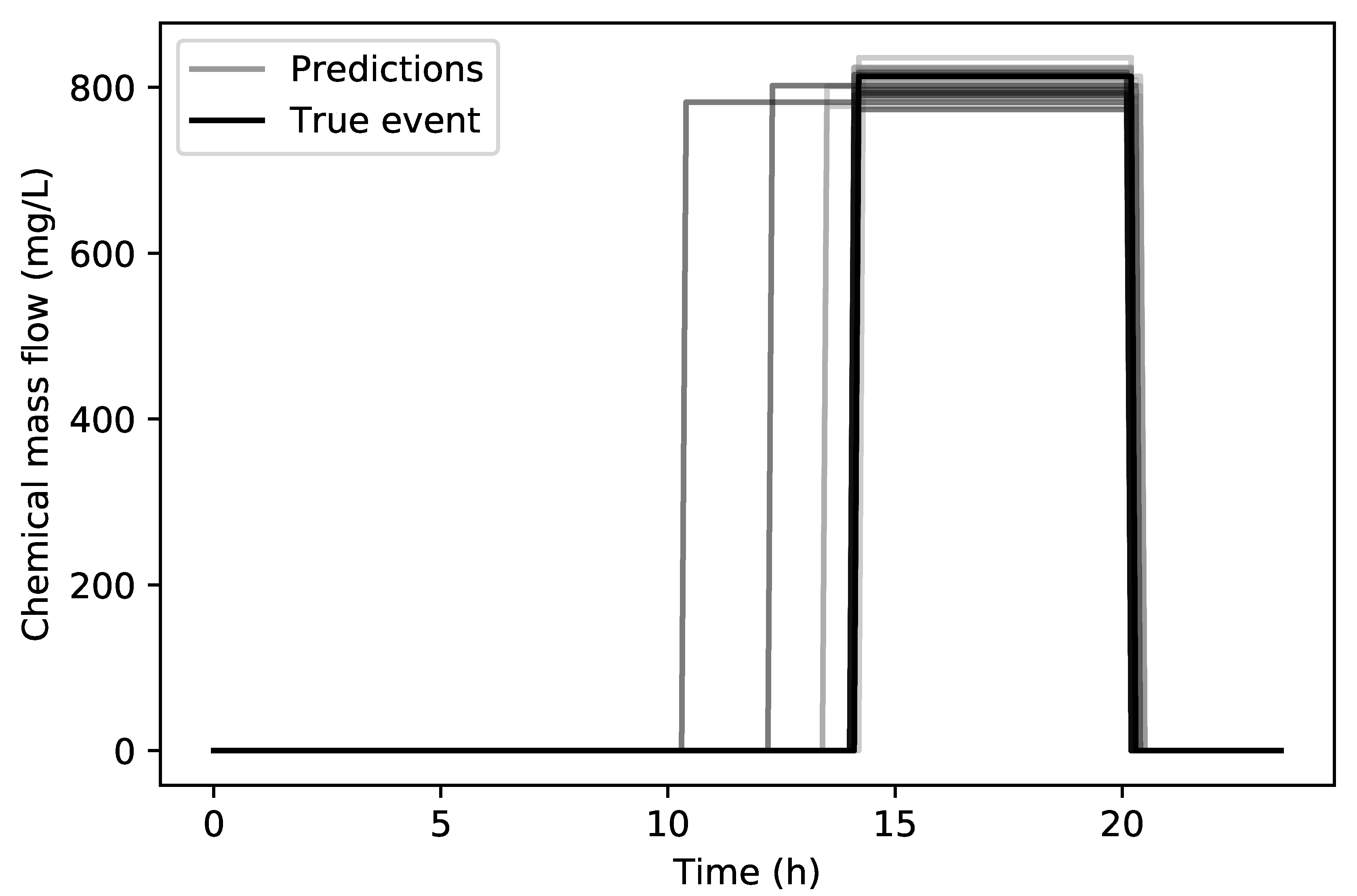
In
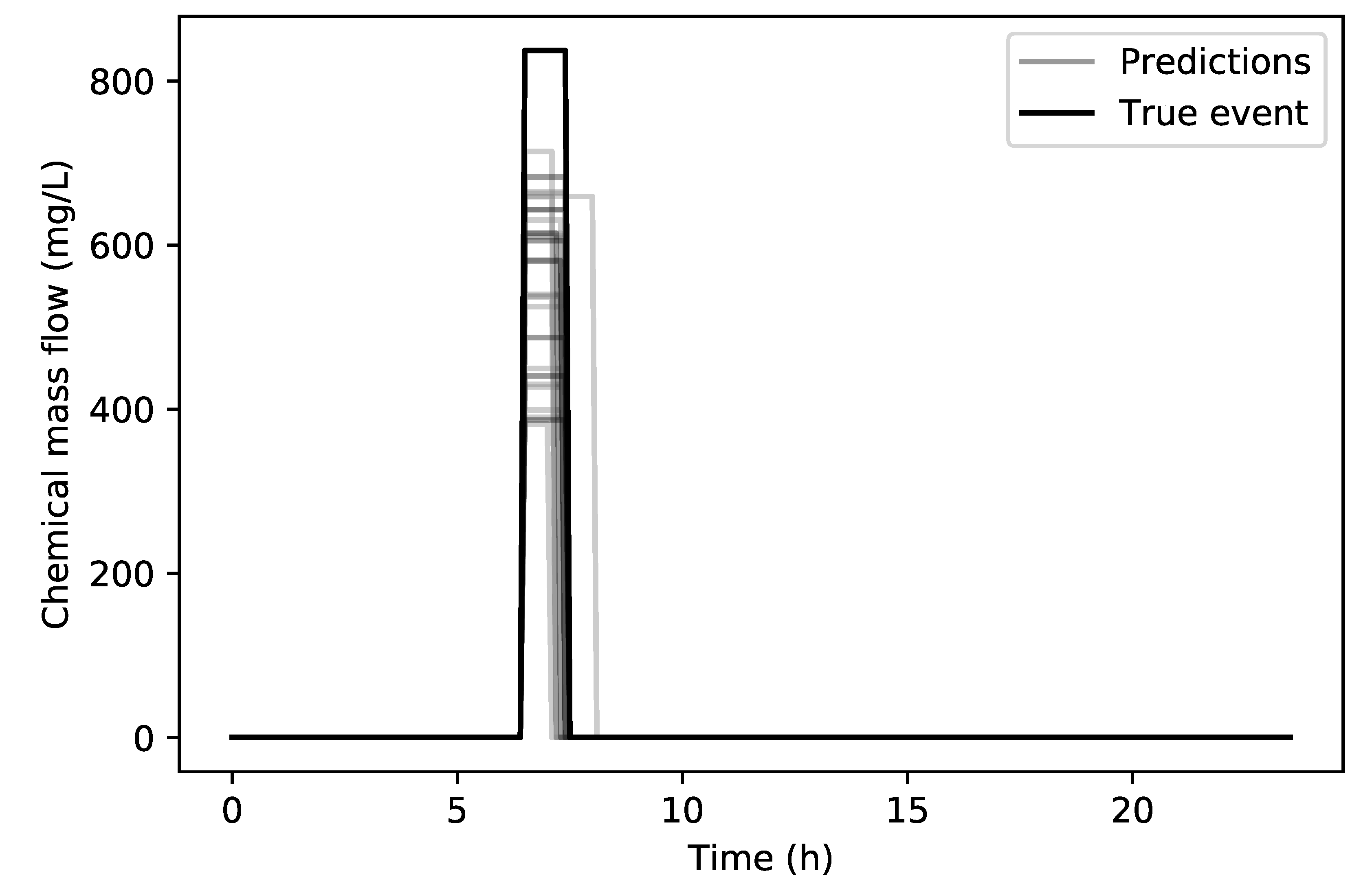
Figure 7 a comparison can be seen between the true contamination event (14:20 h to 20:20 h with 813.7 mg/L) and all of the 30 predicted contamination events for the true source node. It can be seen that the end time prediction of the event is very accurate while the starting time only lacking in accuracy on three runs. The overall RMSE for the starting time for all 30 runs is 48 min, the end time is 4.38 min and the chemical concentration is 18.06 mg/L. The average RMSE For the three of the worst runs with respect to the starting time was 2.47 h. In
Table 1, a summary of all runs can be seen through the RMSE analysis and the successful runs represent how many times of the total of 30 runs the true source node was part of the final tournament. The minimum and maximum errors for
,
and
for all 30 runs are presented in
Table 2.
In
Table 3 the best and worst runs are compared with the true contamination event parameters for
,
and
. The overall best and worst runs are calculated (individual RMSE) by taking into account all of the three variables.
In
Figure 8 the nodes which were ranked first in the 30 runs can be seen along with a corresponding number of times they were ranked first. It can be observed that the nodes are topologically clustered together. This is expected since due to the multimodal nature of the problem.
3.2. Richmond Network Contamination Scenario
The Richmond network contamination event scenario was chosen to start at the same node (153) as in the work by Preis and Ostfeld [
7] and the location can be seen in
Figure 9. The contamination event characteristics at source node 153 were chosen with the event starting at 06:50 h and lasting until 07:40 h with a constant chemical mass inflow of 837 mg/L.
The selected number of algorithm loops l was 1, the number of m (MC simulations for every tournament group) was 2500 and the size of a tournament group k was 4, which means that with 865 initial water supply network nodes, the number of used CPUs for every tournament group was 432. After 1 loop the number of tournament winners was 217, which means that 217 CPUs were used for the RF regression analysis and prediction of other relevant variables.
The contamination source search was repeated 30 times just like for the Net3 contamination search. The true source node was ranked first in seven out of 30 runs and it was in the tournament winners list 29 out of 30 times which means that the true source node was not subjected to the RF regression analysis for only one run. The total average run time of the MC simulations and the ANN classification was 41 min and 75 s for the RF regression analysis. The algorithm was run (at its initial loop) on 432 Intel Xeon E5 CPUs. Even though it was ranked first in only seven runs, that was the most number of times a node was ranked first out of the 30 runs. In the 29/30 runs it was in the winners list (which consisted of 217 nodes) it always finished in the top 10 after RF regression was completed.
In
Figure 10 the comparison between the true contamination event and the predicted contamination events can be seen. The starting and ending times RMSE for the 29 of the 30 total runs are 6.06 min and 12.36 min respectively, while the chemical concentration RMSE is 299.84 mg/L. The starting and ending times of the predictions are in good agreement with the true values but the chemical concentration value is underestimated by the RF regression.
A RMSE analysis summary of all runs with the number of successful runs can be seen in
Table 4. The minimum and maximum errors for all 29 runs for the Richmond network are shown in
Table 5 and in
Table 6, the best and worst runs comparison is shown in terms of all the predicted variables (
,
and
).
3.3. Algorithm Parameters Investigation
In this subsection, an analysis of the influence of algorithm parameters is given. The required number of MC simulations m for each node, the tournament group size k and the number of algorithm loops l are separately explored. The examination of m, k and l was done on the Net3 water supply network with the previously defined contamination event scenario (source at node 119, = 14:20 h, = 20:20 h and = 813.7 mg/L). Each different setup (of m, k and l) was independently run 10 times and a run was considered successful if the node was present in the final ranking after the RF regression and RMSE analysis.
Firstly, the influence of parameter m on the prediction accuracy was explored and a complete summary can be seen in
Table 7. The selected tournament group size k for all runs was 2 and the number of loops l was set as 1 during the exploration of parameter m.
The first column of
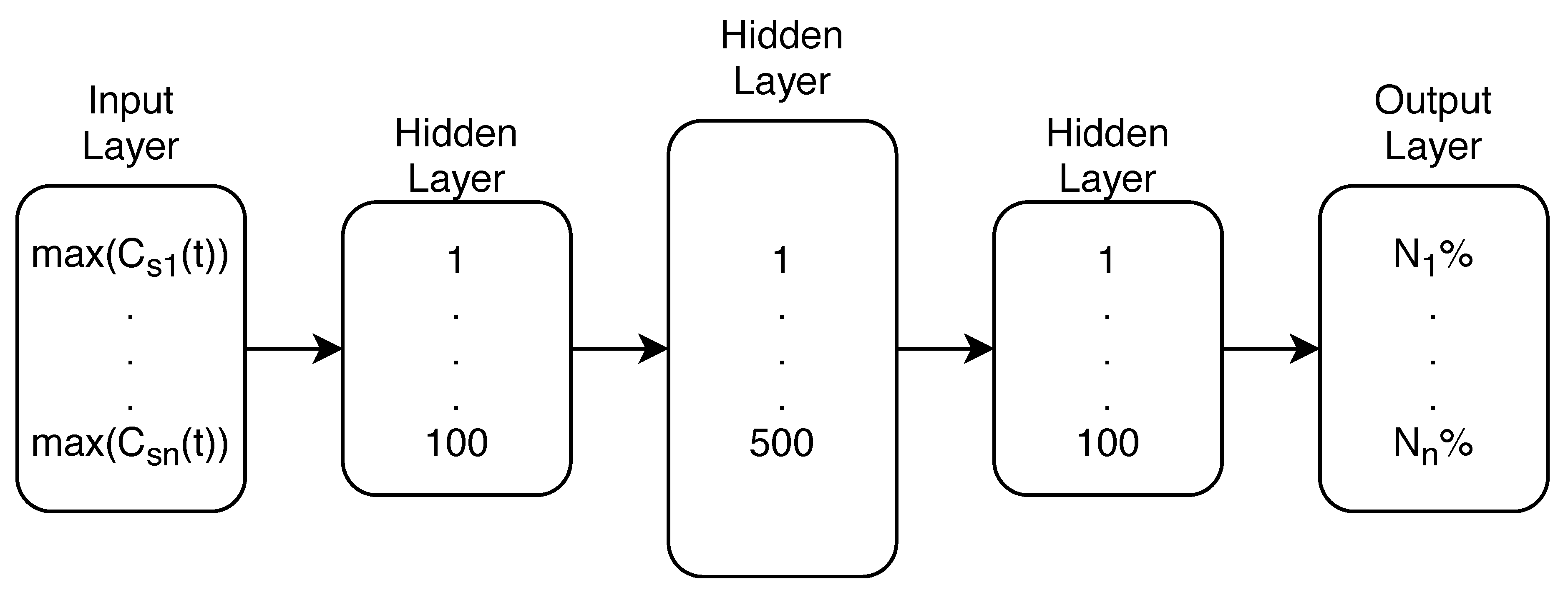
Table 7 represents the total number of MC simulations per tournament group, which means that since the tournament group size was 2 for each run, each node in the tournament group was the source node in m/2 MC simulations. When observing the analysis of the parameter m in
Table 7 it can be seen that the higher the value of the parameter is, both contamination event prediction accuracy (as seen through the decrease
,
and
RMSE) and the average computation time per run (last column) increases. This is expected since more randomly generated data covers more possible scenarios and more input data for the ML model enables a wider and more accurate solution space exploration. Additionally, the best and worst ranks of the true source node are shown and the number of times the true source node won (Times won meaning the rank was 1).
When m was set as 80 the number of successful runs was 10 and the worst possible rank was 6. This means that after 2 min of computation time on average, the search space was reduced from 92 total nodes to 6, which is a reduction of 93.5%. The set of runs when m was 400 could be considered as the first set of runs when the results are acceptable in terms of finding the true source node since it was the winner 50% of the time.
When the value of m is 2000 and above it can be seen that there is not a significant change in prediction accuracy as the RMSE values of and exhibit stability and minor oscillations, while has showed a steady convergence to the same value as the true contamination scenario for all 10 runs.
For further exploration of the tournament group size k, the chosen m was 800 as it exhibited a reasonable computation run time, accuracy in terms of the average RMSE and the number of times the true source node was ranked first. The same scenario was chosen as the one for the investigation of m with the number of tournament loops l set as 1. Five different tournament group sizes k were explored and are summarized in
Table 8.
From the results presented in
Table 8 it can be observed that when the tournament group is larger, both accuracy and prediction reliability decrease. Furthermore, besides tournament group sizes of 2 and 4, a reasonable result in terms of reliability is achieved with k = 10 with a total search space reduction of 94.6% and even a 50% winning rate in the 10 successful runs. The number of used CPUs for each tournament group size is added and with the given as the last column of the
Table 8. Even though a tournament group size of 2 is not that impressive when compared to those of 4 and 10 in the categories of best and worst rank and times won, the achieved overall
,
and
RMSE shows that it is undoubtedly more accurate.
Lastly, the influence of the number of tournament loops l is investigated and a summary of the results is shown in
Table 9. The same scenario was used as for the exploration of previous two parameters with k = 2 and with a total number of MC simulations m = 800. An additional column m/L was added to the
Table 9 which defines the number of MC simulations m (of a tournament group) per every loop l.
It can be observed that increasing the number of loops l up to a certain value increases the accuracy and reliability of the algorithm. Even though the total number of MC simulations is the same for every run and the computational strain in that sense is similar, adding more loops decreases the number of used CPUs after every tournament loop since losing nodes are omitted and that can be considered as a great advantage.
The value of
,
and
RMSE does not differ much for all tested loops l since the total number of MC simulations is preserved. When the number of loops is set to 8, the successful number of runs dropped as the number of MC simulations per loop (m/L) was not high enough and the true source node was not in the final RF analysis ranking for one run. This was also observed for smaller values of m in
Table 7. It can be argued that a higher number of loops positively affects the success of the algorithm in predicting the relevant variables (source node,
,
and
) since there is a higher chance that a main tournament top ranking rival to the true source node is omitted in the process of removing losing nodes after every tournament loop. However, setting l too high could result in unsuccessful runs as well (due to a small m/L) as it can be seen in
Table 9.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}